python+selenium����ȫ�������
selenium+python������
�ý̳��������ݻ��ڸ��˾���,����������Щ���ﻯ
���д���ĵط��鷳��ʱָ��(�����ۻ���˽��)
selenium���Խű�
seleniumʵ������web�Զ������Թ���,�ܹ�ͨ��������ȫģ����ʹ��������Զ�����Ŀ��վ�㲢����������web���ԡ�
python+selenium
ͨ��python+selenium�����ʵ������ʮ�����
������ģ���˵ĵ��������,����ʵ���ϱ������ĸ��ʽ���͡�
selenium�ܹ�ִ��ҳ���ϵ�js,����js��Ⱦ�����ݺ�ģ���½���������dz����ס�
�ü���Ҳ���Ժ���������������������ʽ,bs4,request,ip�صȡ�
��Ȼ�����ڻ�ȡҳ��Ĺ����лᷢ�ͺܶ�����,����Ч�ʽϵ�,��ȡ�ٶȻ������,��������С��ģ������ȡ��
selenium��װ,ֱ��ͨ��pip��װ����
pip3 install selenium
�����
from selenium import webdriver
ģ�������----��chromeΪ��
�����������װ
����: https://registry.npmmirror.com/binary.html?path=chromedriver/
����ֻ��Ҫ���������������ض�Ӧ�汾��������,���ŵ�python��װ·����scriptsĿ¼�м��ɡ�
������汾�������èC����Chrome�п���
 ��Ȼ���������ʱ�����Զ�����,����Ҳ�ǵ�ʹ��ǰҪ�������Ӧ������
��Ȼ���������ʱ�����Զ�����,����Ҳ�ǵ�ʹ��ǰҪ�������Ӧ������
�����ģ���������
browser = webdriver.Chrome() # �������
driver.maximize_window() # �����
browser.minimize_window() # ��������
url='https://www.bilibili.com/v/popular/rank/all'#�Ը�����Ϊ��
browser.get(url)#�������Ӧ����
browser.close#�ر������
��ȡ���ݨCweb��λ
����֪ʶ��ҪһЩweb���֪ʶΪǰ��
�����Cbվ���а�
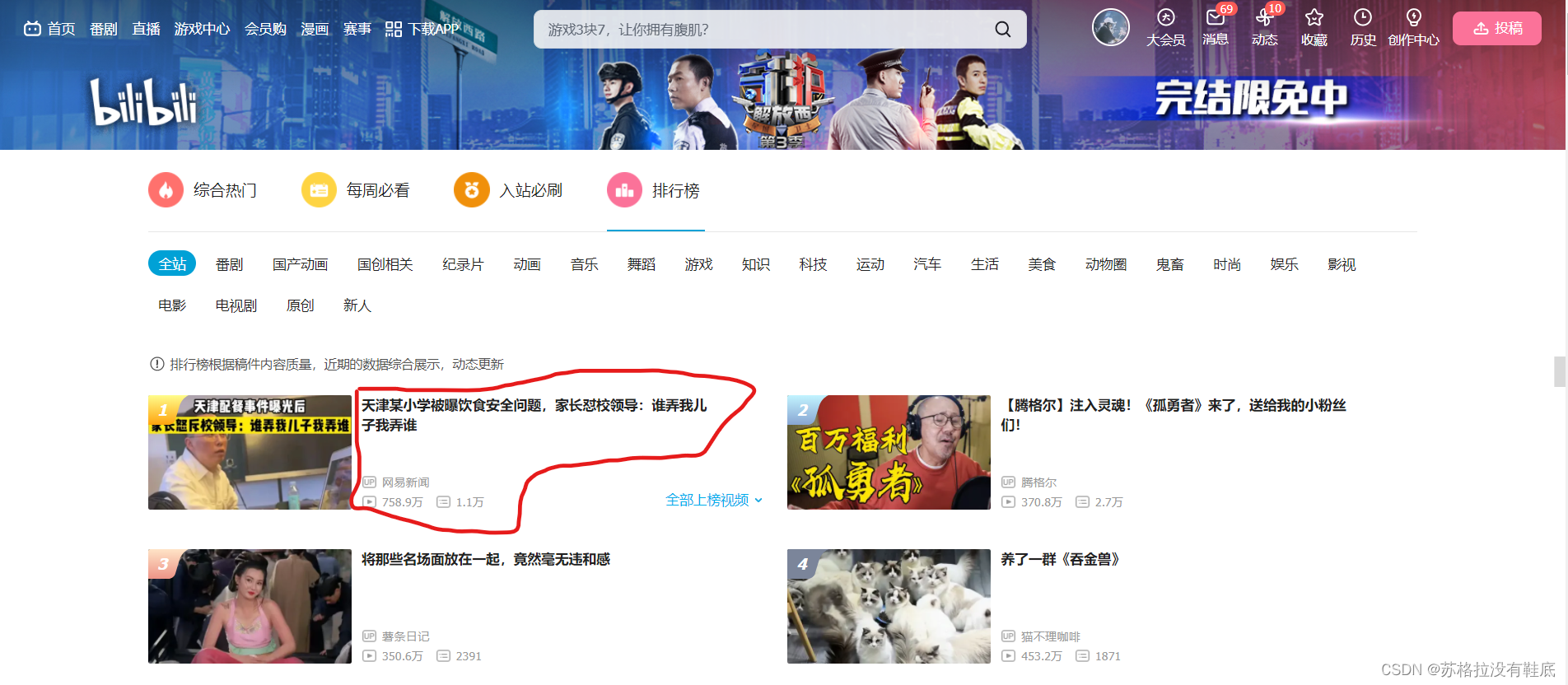
����������Ҫ��ȡ��ͼ��Ȧ�е��ı�����,��ô������Ҫ��λ���õط��ĵ�λ
��λ�����Լ�ʵ��
��λ������ѡ����Ҫ����Ŀ����ҳ���������
#find_elements_by_xxx����ʽ�Dz��ҵ����Ԫ��(��ǰ��λ������λԪ�ز�Ψһ)
#���Ϊ�б�
browser.find_element_by_id('')# ͨ����ǩid���Խ��ж�λ
browser.find_element_by_name("")# ͨ����ǩname���Խ��ж�λ
browser.find_elements_by_class_name("")# ͨ��class���ƽ��ж�λ
browser.find_element_by_tag_name("")# ͨ����ǩ���ƽ��ж�λ
browser.find_element_by_css_selector('')# ͨ��CSS���ҷ�ʽ���ж�λ
browser.find_element_by_xpath('')# ͨ��xpath��ʽ��λ
#��chrome�п���ͨ��Դ����Ŀ��Ԫ���Ҽ�--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# ͨ������ ҳ���� ���ӽ��ж�λ
browser.find_element_by_partial_link_text("")# ͨ������ ҳ���� ���ӽ��ж�λ ,����֧��ģ��ƥ��
�ڰ�����վ�����Ǹ���class��������ȡ,��ǩ��class=��info��
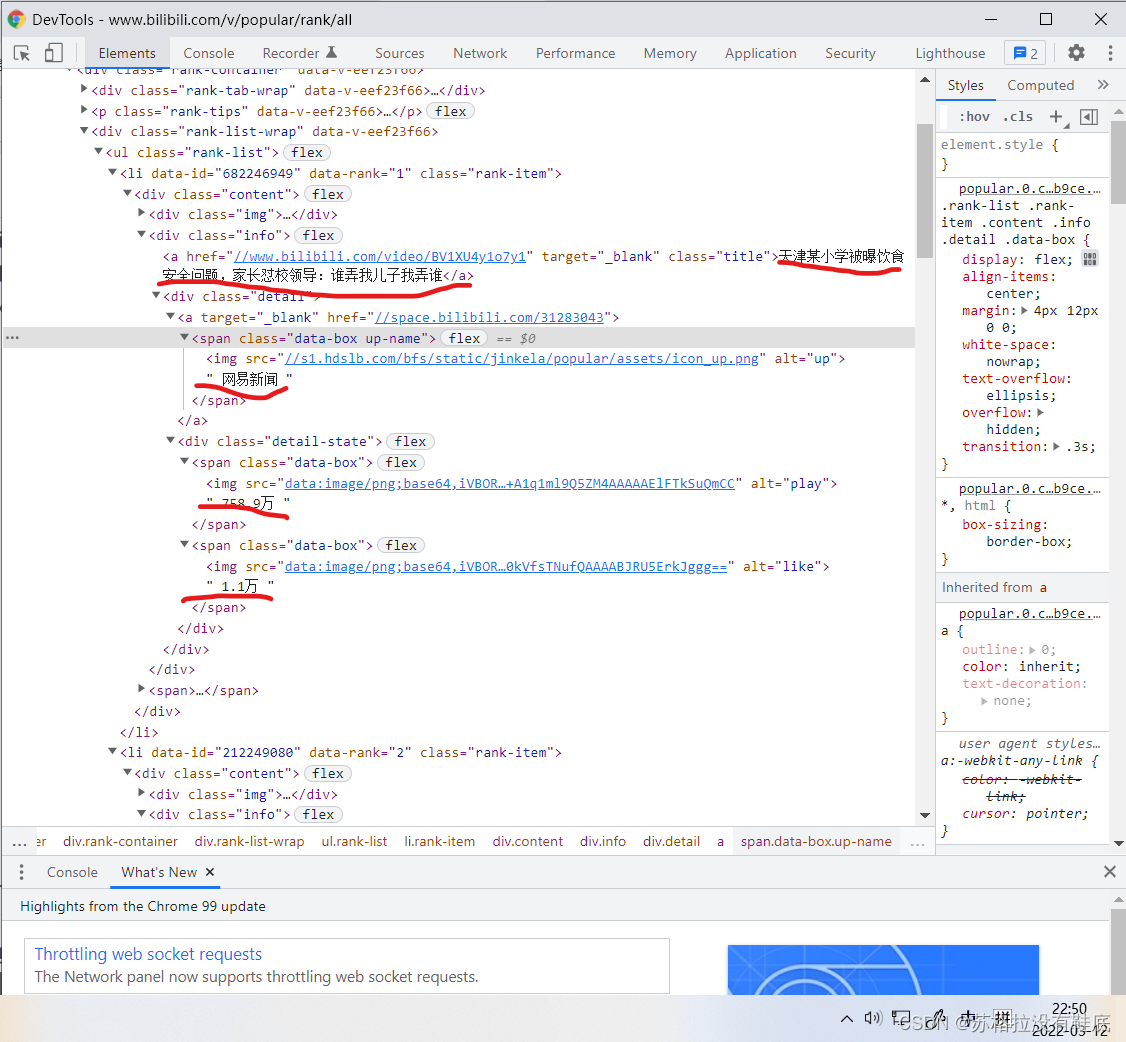
from selenium import webdriver
browser = webdriver.Chrome()
# browser.minimize_window() # ��������
url='https://www.bilibili.com/v/popular/rank/all'
browser.get(url)
info=browser.find_elements_by_class_name('info')
#��Ŀ����վ����վ�б���class���ƶ�Ϊ"info",������elements
for i in info:
print(i.text)
#.textΪ��λԪ�ص��µ������ı�,��Ȼ����Ҳ���Ի�ȡ��ǩ��Ķ���(����������),����Ƶ����:
# print(i.find_elements_by_tag_name('a')[0].get_attribute('href'))
���
���ֿ��ܻ��õ��ķ���(��������/���ͷ���)
�ӿ���ҳ�����ٶ�(������js,images��)
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values': {
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
}
}
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
�쳣��
from selenium.common.exceptions import NoSuchElementException
��ҳ�ȴ�����
�������ٵ������,�������ַ��ҳ�滹û���س�����Ҫ�ȴ�
selenium�Դ��ļ��ط�ʽ
from selenium.webdriver.support.wait import WebDriverWait #�ȴ�ҳ�����
wait=WebDriverWait(browser,10) #��ʽ�ȴ�:ָ���ȴ�ij����ǩ�������
wait1=browser.implicitly_wait(10) #��ʽ�ȴ�:�ȴ����б�ǩ�������
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
��time�ȴ�ʱ��
import time
time.sleep(2)
�����������������
ele = driver.find_element_by_id("kw") # �ҵ�idΪkw�Ľڵ�
ele.send_keys("����") # ��input�������������
#Ҳ����driver.find_element_by_id("kw").send_keys("����")
��ҳ���(������һҳ,���ߵ������)
ele = driver.find_element_by_id("kw") # �ҵ�idΪkw�Ľڵ�
ele.send_keys("��ѧ") # ��input�������������
ele = driver.find_element_by_id('su') # �ҵ�idΪsu�Ľڵ�(�ٶ�һ��)
ele.click() # ģ����
��ӡ��ҳ��Ϣ
print(driver.page_source) # ��ӡ��ҳ��Դ��
print(driver.get_cookies()) # ��ӡ����ҳ��cookie
print(driver.current_url) # ��ӡ����ǰ��ҳ��url
�л�iframe
��ʱ���������ҳ��iframe����Ϊ�ĵ����
driver.switch_to.frame("iframe��id")
��ҳ����(��������)
# 1.��������ҳ�ײ�
js = "document.documentElement.scrollTop=800"
# ִ��js
driver.execute_script(js)
# ����������
js = "document.documentElement.scrollTop=0"
driver.execute_script(js) # ִ��js
����ȴ������ٲ���(��������)
import time
import random
time.sleep(random.randint(0,2))
�������
python+selenium���漼���Ի��кܶ����д,�ý̳̽����漰һ��,���Ӧ�ø���ʵ��������е���,����������
�����ʵ��,��ٶ�,�ܽ���Բ�ͬ��ҳ������߲�ͬ��������ľ���,�������Dz��ܲ��ϳɳ���
ʵ���Ǽ���������Ψһ����
��л��λ�Ķ�,Ҳϣ����λ�������ջ�