一. 性能测试
1.0 为什么要进行性能测试?
- 评估当前系统的能力
- 寻找性能瓶颈,优化系统性能
- 评估软件是否满足未来的需要
- 招聘需要
1.1 什么是性能
时间:系统处理用户请求的响应时间
资源:系统运行过程中,系统资源的消耗情况
1.2. 性能测试是什么
1.2.1 广义定义
基于协议模拟用户发出请求,对服务器形成一定负载,来测试服务器的性能指标是否满足要求性能指标关注点:时间性能、空间性能性能测试与页面无关
1.2.1 狭义定义
指通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。
1.3 功能和性能测试
- 不同
功能测试验证系统的功能需求规格,聚焦功能。
性能测试验证系统的业务性需求场景,聚焦时间和资源。 - 关系
一般项目中,先功能测试通过后,后进行性能测试。
1.4 性能测试的分类
1.4.1 基准测试
狭义:单用户测试
广义:建立基准线,当系统软硬件环境发生变化之后再进行一次基准测试以确定变化对性能的影响。
1.4.2 负载测试
- 概念
通过逐步增加系统负载,确定在满足性能指标的情况下,找出系统所能承受最大负载量的测试。 - 作用
系统最大负载量达到用户要求时,系统才能正式上线使用。 - 案例
电梯行业规范:电梯从1楼到5楼的运行时间不超过24s1人 20s 7人 20s 13人 20s 达到最大负载 16人 25s 19人 28s 21人 断绳子 - 注意
通过负载测试,可以确定系统的最大负载量和极限负载量
系统对外宣称的最大负载量
负载测试的时间一般为1-2小时
1.4.3 稳定性测试
- 概念:在服务器稳定运行(用户正常业务负载下)的情况进行长时间测试(1天-一周等),并最终保证服务器能满足线上业务需求。
- 系统在用户需求的业务负载下运行达到规定的时间时,系统才能正式上线使用。
1.4.4 压力测试
- 概念:在强负载下的测试,查看系统在峰值下是否功能隐患、系统是否具有良好的容错能力和可恢复的能力。
- 测试场景
高负载下的长时间稳定性压力测试 (如:B-C区间内进行24/3*24小时长时间测试)
极限负载下的破坏性压力测试(如:C-D区间内进行测试)
1.4.5 并发测试
- 概念:在极短时间内,发送多个请求,来验证服务器对并发的处理能力。
- 应用场景
特定的活动场景:抢红包、秒杀、抢购等。 - 与负载测试对比:
负载测试:主要目的是测试高负载情况下,对系统资源的消耗,是否会耗尽的问题(双11活动)
并发测试:主要目的是测试极短时间内,并发请求时,系统资源争抢的问题(抢红包、秒杀)
1.5 性能测试的指标
1.5.1 响应时间
- 指从客户端发起请求开始,到客户端接收到结果的总时间
- 包括:服务器处理时间 + 网络传输时间
1.5.2 并发用户数
某一时刻同时向服务器发送请求的用户数
1.5.3 吞吐量(Throughout)
1.概念:单位时间内处理客户端的请求数量,直接体现软件系统能能承载能力。
- 吞吐量单位分类
1.5.4 QPS
QPS(Query Per Second)每秒查询数,即控制服务器每秒处理的指定请求的数量。
1.5.5 TPS
TPS(Transaction Per Second)每秒事务数,即控制服务器每秒处理事务请求的数量。
如:支付请求事务=查询用户余额请求+校验支付安全请求+发送支付请求
每秒处理查询用户余额15请求,每秒处理校验支付安全15个请求,每秒处理发送支付15个请求
支付tsp为15
1.5.6 点击数
所有的页面元素(如:图片、链接、框架等)的请求总数量
- 注意:
- 点击数是请求数,不是页面上的一次点击
1.5.7 错误率
- 指系统在负载情况下,失败业务的概率
- 注意:
- 错误率是性能指标,是高负载下的失败业务的概率
-随机bug是功能bug,先解决随机bug才能进行性能测试
1.5.8 资源利用率
- 概念:系统各种资源的使用情况,率=资源使用量/总资源可用量x100%
- 常见资源指标
CPU使用率:不高于75%-85%
内存大小使用率:不高于80%
磁盘IO(速率):不高于90%
网路(速率):不高于80%
1.6 性能测试工具
 ?
?
二. Jmeter简介
2.1. 我们为什么使用Jmeter
开源,免费,基于Java编写,可集成到其他系统可拓展各个功能插件
支持接口测试,压力(负载和压力)测试等多种功能,支持录制回放,
入门简单相较于自己编写框架活其他开源工具,有较为完善的UI界面,便于接口调试
多平台支持,可在Linux,Windows,Mac上运行,支持多协议
2.2. Jmeter的作用
- 接口测试 面试说postman,因为方便好用。
- 性能测试 jmeter,也可以用postman(runner),但是没有性能指标
- 数据库测试
2.3. Jmeter怎么用
Windows下Jmeter下载安装,登录 http://jmeter.apache.org/download_jmeter.cgi ,根据自己平台,下载对应文件
2.4. 安装JAVA环境
安装JDK,配置环境变量(具体步骤不做介绍)
 ?
?
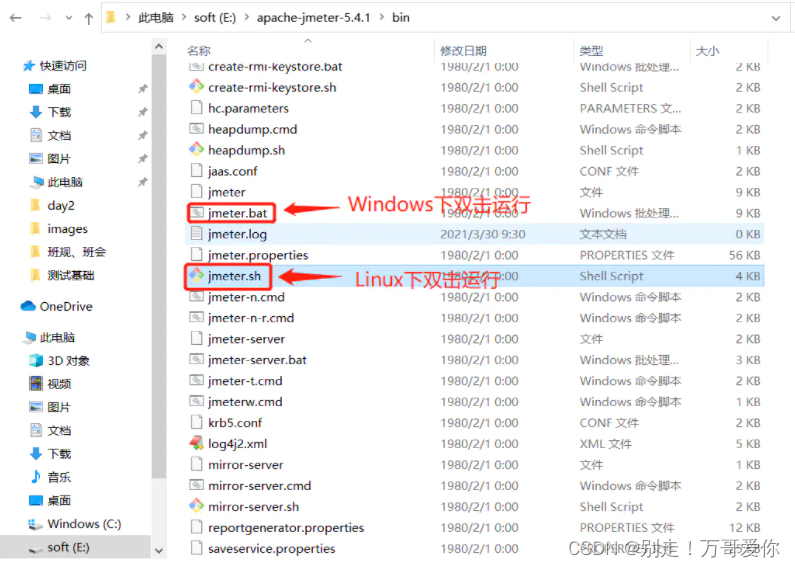
将下载Jmeter文件解压,打开/bin/jmeter.bat
 ??
??
2.5. Jmeter的目录结构
 ?
?
/bin 目录常用文件介绍:
examples:目录下包含Jmeter使用实例
ApacheJMeter.jar:JMeter源码包
jmeter.bat:windows下启动文件
jmeter.sh:Linux下启动文件
jmeter.log:Jmeter运行日志文件
jmeter.properties:Jmeter配置文件
jmeter-server.bat:windows下启动负载生成器服务文件
jmeter-server:Linux下启动负载生成器文件
/docs目录――Jmeter帮助文档
/extras目录――提供了对Ant的支持文件,可也用于持续集成
/lib目录――存放Jmeter依赖的jar包,同时安装插件也放于此目录
/licenses目录――软件许可文件,不用管
/printable_docs目录――Jmeter用户手册
三. 使用Jmeter测试快速入门
3.1. 线程组是什么
进程: 一个正在执行的程序对应一个进程
线程: 一个进程有多个执行线程
线程组: 按照线程性质对线程分组。查看任务管理器(爱奇艺有多个)
三者关系: 一个进程有多个线程组,一个线程组有多个线程
测试计划―线程组―线程组属性中的线程数
并发执行:多个线程同时执行,特点:执行结束的顺序与开始的顺序不一致
顺序执行:按照线程的启动顺序挨个执行
默认情况下,线程组中的线程是并发执行
每一个线程都要执行组内的http请求
设置线程组顺序执行:勾选测试计划中的(独立运行每个线程组)
线程组用来模拟用户的并发访问
3.1.1. 创建线程组
 ?
?
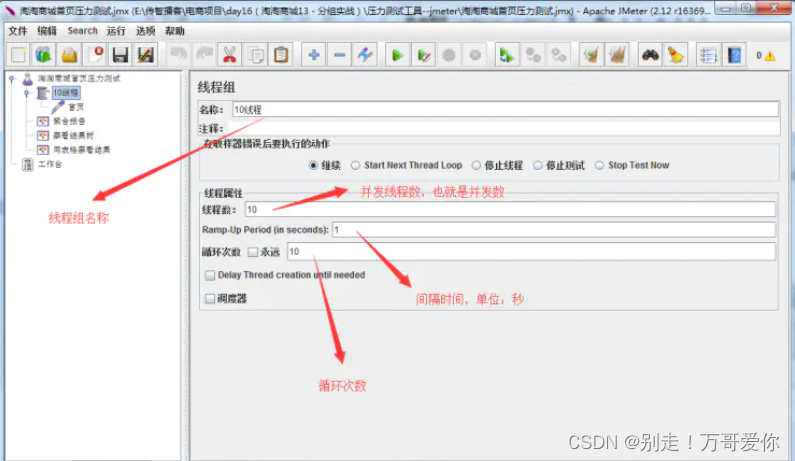
3.1.2. 线程组主要包含三个参数:
线程数、准备时长(Ramp-Up Period(in seconds))、循环次数。
3.1.3. 线程数:
虚拟用户数。一个虚拟用户占用一个线程。设置多少虚拟用户数在这里也就是设置多少个线程数。
3.1.4. 准备时长(秒):
设置的虚拟用户数需要多长时间全部启动。如果线程数为20 ,准备时长为10 ,那么需要10秒钟启动20个线程。也就是每秒钟启动2个线程。
3.1.5. 循环次数:
每个线程发送请求的次数。如果线程数为20 ,循环次数为100 ,那么每个线程发送100次请求。总请求数为20*100=2000 。如果勾选了“永远”,那么所有线程会一直发送请求,一直到选择停止运行脚本。
3.1.6. 调度器
设置线程组启动的开始时间和结束时间(配置调度器时,需要勾选循环次数为永远)
3.1.7. 持续时间(秒)
测试持续时间,会覆盖结束时间
3.1.8. 启动延迟(秒)
测试延迟启动时间,会覆盖启动时间
3.1.9. 启动时间
测试启动时间,启动延迟会覆盖它。当启动时间已过,手动只需测试时当前时间也会覆盖它。
3.1.10. 结束时间
测试结束时间,持续时间会覆盖它。
3.2. 创建http请求
 ?
?
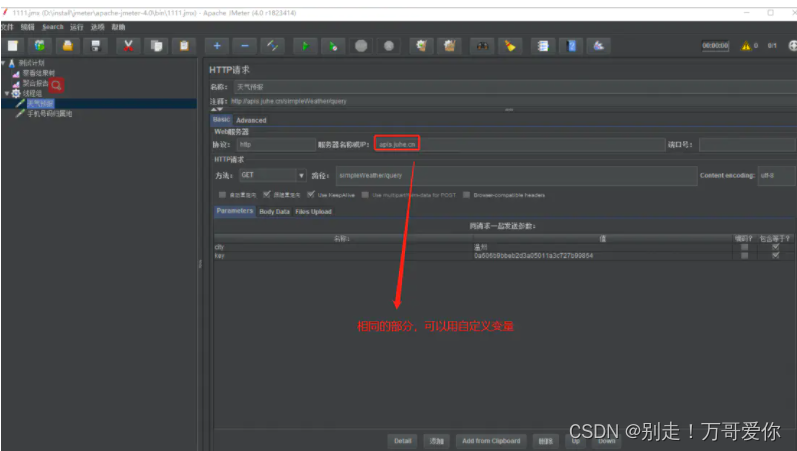
3.3. 指定请求域名,请求路径
 ?
?
| 一个HTTP请求有着许多的配置参数,下面将详细介绍: |
|---|
| 名称:本属性用于标识一个取样器,建议使用一个有意义的名称。 |
| 注释:对于测试没有任何作用,仅用户记录用户可读的注释信息。 |
| 服务器名称或IP :HTTP请求发送的目标服务器名称或IP地址。 |
| 端口号:目标服务器的端口号。 |
| 方法:发送HTTP请求的方法,可用方法包括GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE等。 |
| Content encoding :内容的编码方式,默认值为iso8859 |
| 路径:目标URL路径(不包括服务器地址和端口) |
点击run测试,很麻烦,我们使用postman测试更简单,使用postman操作。
可以使用刚才的接口文档中的,聚合接口中演示一个。
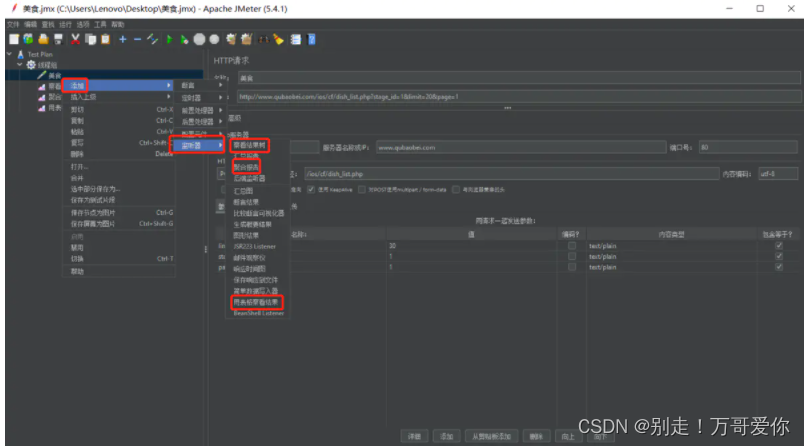
3.4. 设置对应的查看内容
?
注意:如果监听器中有jp@gc开头的,都是第三方插件
3.5. 查看表格信息
 ?
?
| Sample:每个请求的序号 |
|---|
| Start Time:每个请求开始时间 |
| Thread Name:每个线程的名称 |
| Label:Http请求名称 |
| Sample Time:每个请求所花时间,单位毫秒 |
| Status:请求状态,如果为勾则表示成功,如果为叉表示失败。 |
| Bytes:请求的字节数 |
| 样本数目:也就是上面所说的请求个数,成功的情况下等于你设定的并发数目乘以循环次数 |
| 平均:每个线程请求的平均时间 |
| 最新样本:表示服务器响应最后一个请求的时间 |
| 偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布。 |
3.6. 查看结果树
-
请求的数据展示(请求头信息,请求参数,,)
 ?
? -
响应的数据展示(响应码,响应头,,)
?
通过察看结果树,我们可以看到每个请求的结果,其中红色的是出错的请求,绿色的为通过。
Thread Name:线程组名称
Sample Start: 启动开始时间
Load time:加载时长
Latency:等待时长
Size in bytes:发送的数据总大小
Headers size in bytes:发送数据的其余部分大小
Sample Count:发送统计
Error Count:交互错误统计
Response code:返回码
Response message:返回信息
Response headers:返回的头部信息
3.7. 聚合报告参数说明
 ?
?
| lable:对应每一个http请求,显示的是http请求的Name,如百度http请求name为baidu |
|---|
| #Samples:表示这一次的测试中一共发出了多少请求,如上图所示,sougou和baidu的http请求每个都发出30个请求 |
| Average:平均响应时间,指的是所有的请求的平均响应时间,如上图的30个请求的总的响应时间除以30得出的平均响应时间,默认的情况下是单个请求的平均响应时间,但当使用了“事务控制器”时,则以事物为单位显示平均响应时间 |
| Median:中位数,也就是50%用户的响应时间 |
| 90%Line:90%用户的响应时间 |
| Min:最小响应时间 |
| Max:最大的响应时间 |
| Error%:本次测试中出现错误的请求的数量/请求的总数,如上图所示,本次的测试中,sougou的http请求66.6%的请求出错,而baidu的请求则没有出错的请求 |
| Throughput:吞吐量,默认情况下表示每秒完成的请求数,如上图所示,每秒完成的请求数分别为6.6个每秒,6.2个每秒 |
| Recived KB/Sec:每秒从服务器端接收到的数据量,以kb为计算的单位 |
掌握:平均时间、错误率、吞吐量。
3.8. 图形结果
作用:通过图形展示出本次性能测试数据的分布。 图形结果一般作为聚合报告的分析辅佐
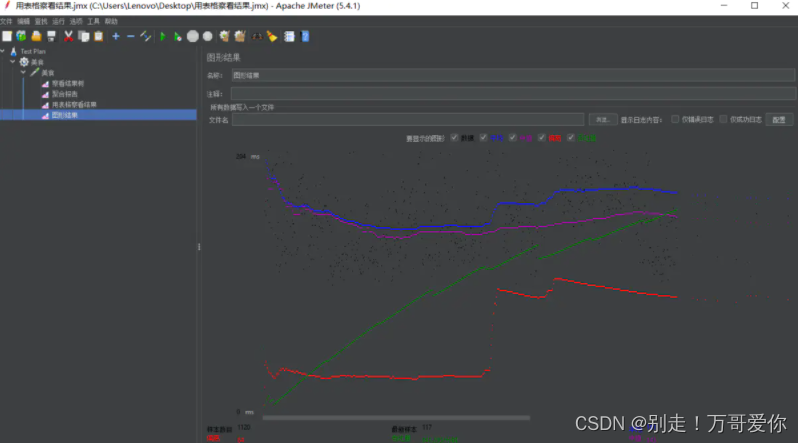
样本数目:总共发送到服务器的请求数。
最新样本:代表时间的数字,是服务器响应最后一个请求的时间。
吞吐量:服务器每分钟处理的请求数。
平均值:总运行时间除以发送到服务器的请求数。
中间值:有一半的服务器响应时间低于该值而另一半高于该值。
偏离:表示服务器响应时间变化、离散程度测量值的大小。
四. Jmeter主要组件介绍
- 测试计划:使用 JMeter 进行测试的起点,它是其它 JMeter 测试元件的容器。
- 线程组:代表一定数量的并发用户,它可以用来模拟并发用户发送请求。实际的请求内容在Sampler中定义,它被线程组包含。可以在“测试计划->添加->线程组”来建立它,然后在线程组面板里有几个输入栏:线程数、Ramp-Up Period(in seconds)、循环次数,其中Ramp-Up Period(in seconds)表示在这时间内创建完所有的线程。如有8个线程,Ramp-Up = 200秒,那么线程的启动时间间隔为200/8=25秒,这样的好处是:一开始不会对服务器有太大的负载。线程组是为模拟并发负载而设计。
- 取样器(Sampler):模拟各种请求。所有实际的测试任务都由取样器承担,存在很多种请求。如:HTTP 、ftp请求等等。
- 监听器:负责收集测试结果,同时也被告知了结果显示的方式。功能是对取样器的请求结果显示、统计一些数据(吞吐量、KB/S……)等。
- 断言:用于来判断请求响应的结果是否如用户所期望,是否正确。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
- 逻辑控制器:允许自定义JMeter发送请求的行为逻辑,它与Sampler结合使用可以模拟复杂的请求序列。
- 定时器:负责定义请求(线程)之间的延迟间隔,模拟对服务器的连续请求。
- 配置元件维护Sampler需要的配置信息,并根据实际的需要会修改请求的内容。
- 前置处理器和后置处理器负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。
4.1. 测试计划
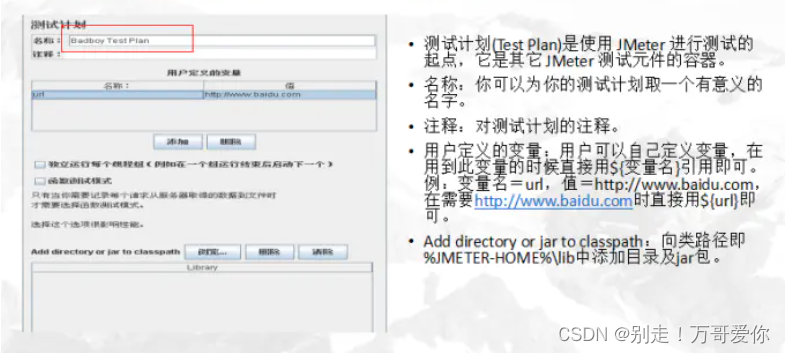
1.测试计划就是一个完整的场景
2.“独立运行每个线程组” :勾选以后所有的线程组都是顺序执行的了。一般不勾选,让所有 的线程组并发启动。
3.“函数测试模式” :勾选后会有详细的请求记录,消耗资源,影响客户端性能。一般不勾选。
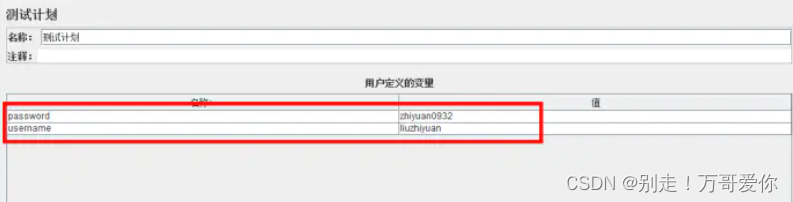
4.用户定义的变量:全局变量,测试计划上可以添加用户定义的变量。一般添加一些系统常用的配置。如果测试过程中想切换环境,切换配置,一般不建议在测试计划上添加变量
?
4.2. 线程组
 ?
?
(1)thread group(线程组)
这个就是我们通常添加运行的线程。通俗的讲一个线程组,可以看做一个虚拟用户组,线程组中的每个线程都可以理解为一个虚拟用户。
(2)setup thread group
一种特殊类型的ThreadGroup的,可用于执行预测试操作。这些线程的行为完全像一个正常的线程组元件。不同的是,这些类型的线程执行测试前进行定期线程组的执行;类似LoadRunner的init,测试开始时进行初始化的工作。
(3)teardown thread group
一种特殊类型的ThreadGroup的,可用于执行测试后动作。这些线程的行为完全像一个正常的线程组元件。不同的是,这些类型的线程执行测试结束后执行定期的线程组;类似LoadRunnner的end,测试结束时进行回收工作。
 ?
?
4.3. 取样器(Http请求)
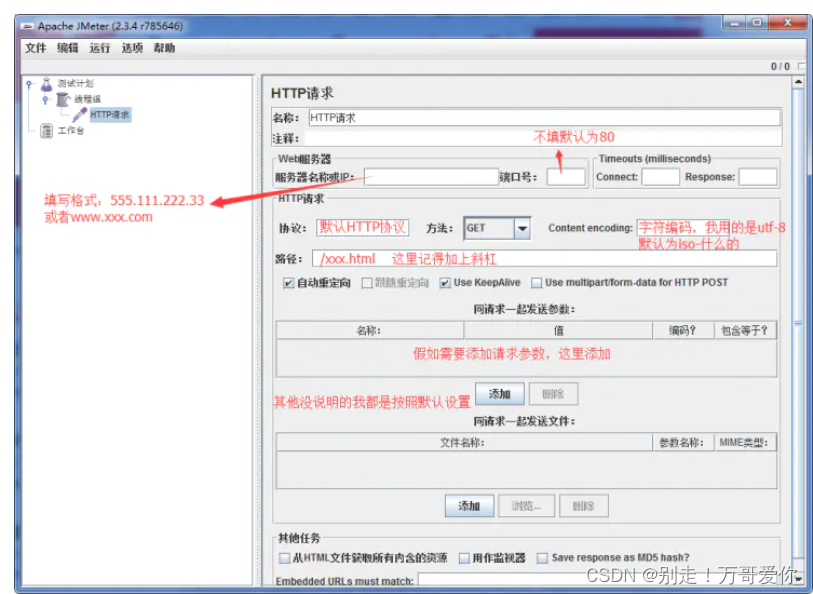
?
关于http请求的的属性参数说明:
1)名称:用于标识一个sample。建议使用一个有意义的名称
2)注释:对于测试没任何影响,仅用来记录用户可读的注释信息
3)服务器名称或IP:http请求发送的目标服务器名称或者IP地址,比如http://www.baidu.com
4)端口号:目标服务器的端口号,默认值为80,可不填
5)协议:向目标服务器发送http请求时的协议,http/https,大小写不敏感,默认http
6)方法:发送http请求的方法(链接:http://www.cnblogs.com/imyalost/p/5630940.html)
7)Content encoding:内容的编码方式(Content-Type=application/json;charset=utf-8)
8)路径:目标的URL路径(不包括服务器地址和端口)
9)自动重定向:如果选中该项,发出的http请求得到响应是301/302,jmeter会重定向到新的界面
10)Use keep Alive:jmeter 和目标服务器之间使用 Keep-Alive方式进行HTTP通信(默认选中)
11)Use multipart/from-data for HTTP POST :当发送HTTP POST 请求时,使用
12)Parameters、Body Data以及Files Upload的区别:
1. parameter是指函数定义中参数,而argument指的是函数调用时的实际参数
2. 简略描述为:parameter=形参(formal parameter), argument=实参(actual parameter)
3.在不很严格的情况下,现在二者可以混用,一般用argument,而parameter则比较少用
While defining method, variables passed in the method are called parameters.
当定义方法时,传递到方法中的变量称为参数.
While using those methods, values passed to those variables are called arguments.
当调用方法时,传给变量的值称为引数.(有时argument被翻译为“引数“)
4、Body Data指的是实体数据,就是请求报文里面主体实体的内容,一般我们向服务器发送请求,携带的实体主体参数,可以写入这里
5、Files Upload指的是:从HTML文件获取所有有内含的资源:被选中时,发出HTTP请求并获得响应的HTML文件内容后还对该HTML
进行Parse 并获取HTML中包含的所有资源(图片、flash等):(默认不选中)
如果用户只希望获取特定资源,可以在下方的Embedded URLs must match 文本框中填入需要下载的特定资源表达式,只有能匹配指定正则表达式的URL指向资源会被下载
4.4. 监听器
监听器(Listener)负责收集测试结果,同时也被告知了结果显示的方式。我们常用的包括:聚合报告、查看结果树、用表格查看结果,都支持将结果数据写入文件。其他的添加上去看看就行。聚合报告前面我们介绍过,后面是查看结果树和用表格查看结果的截图。
?
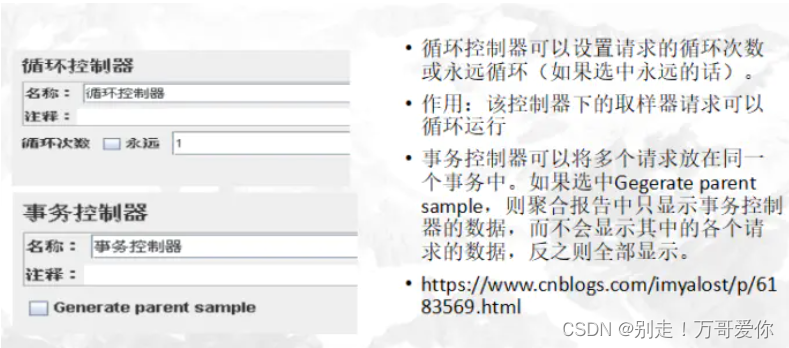
4.5. 循环控制器
 ?
?
 ?
?
?
4.6. 事务控制器
作用: 事务控制器会生产一个额外的采样器,用来统计该控制器子结点的所有时间。
在线程组下创建事务控制器
参数:
・ Generate parent sample:(选中这个参数结果展示如下图红框,否则显示为下图蓝框)
・ Include duration of timer and pre-post processors in generated sample:选中这一项会统计定时器(timer)的时间,否则只统计采样器(sample)的时间
 ?
?
创建sample 访问首页和注册页面
?
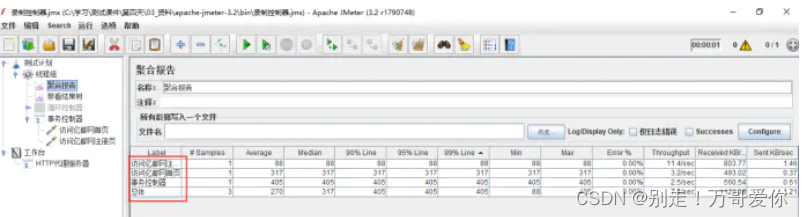
生成聚合报告
?
勾选
 ?
?
聚合报告中只有一项事务报告
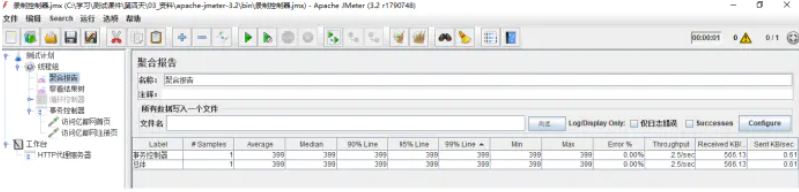
?
4.7. 断言---检查点
断言(Assertions)可以用来判断请求响应的结果是否如用户所期望的。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
两个重要断言:响应断言和JSONAssertion
响应断言:
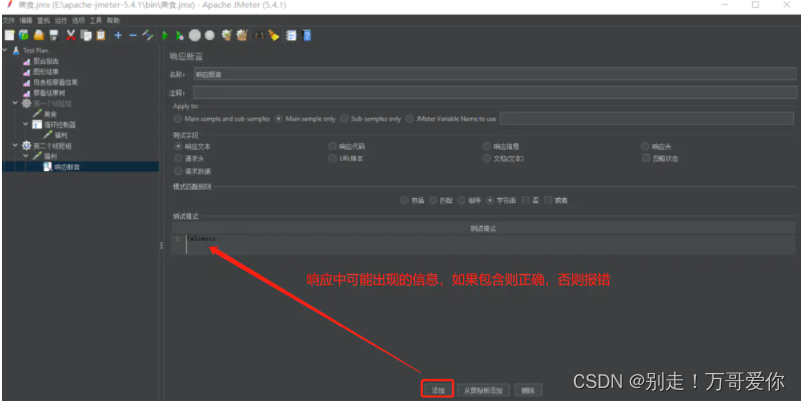
?
JSON断言:
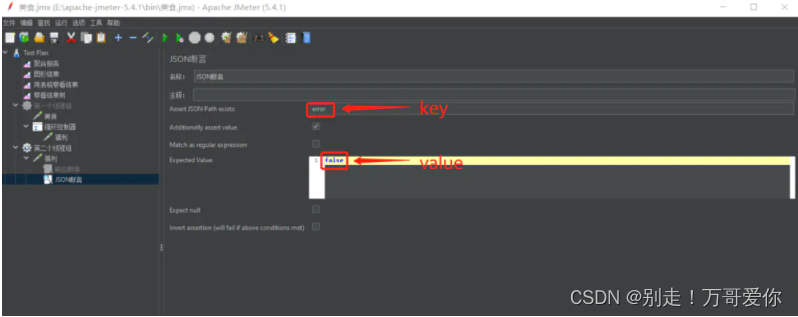
?
4.8. 前置处理器和后置处理器
 ?
?
前置处理器(Pre Processors)和后置处理器(Post Processors)负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。我们主要在动态关联中用到后置处理器的正则表达式提取器。
https://www.cnblogs.com/fengpingfan/p/4755411.html
4.9. 定时器
定时器(Timer)负责定义请求之间的延迟间隔
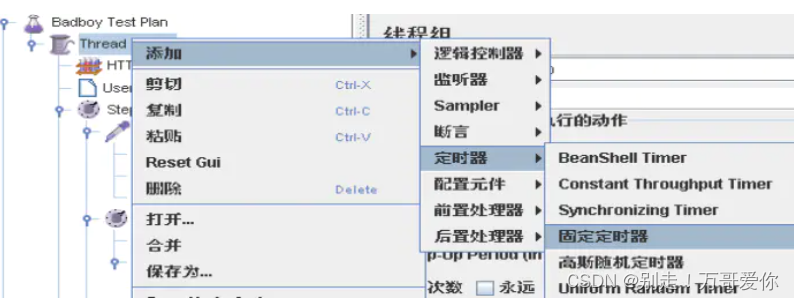
 ??
??
五. Jmeter组件参数化
5.1. 参数化是什么
动态的获取并设置数据
5.2. 为什么使用参数化
执行批量操作,批量添加批量删除,人工效率太低
运用程序代替人工获取并设置数据,安全高效
比如:对被测系统的用户名和密码进行参数化,来模拟多个用户同时登录系统
5.3. 参数化实现之用户自定义变量
通过这个功能,能实现多接口共享数据,修改一条即可修改全部
 ?
?
 ?
?
 ??
??
Filename:所需数据文件的路径。如和脚本同一路径,可直接填写文件名
File encoding:编码和文件保持一致即可,默认为ANSI。如有中文,建议为UTF-8
Variable Names:引用变量时的变量名,对应数据文件中的每一列,以逗号分隔。如不填写,文件的第一行数据将被读取为变量名
Delimiter:在.txt、.dat文件中,可以用逗号(,)或者Tab键(\t)来区分列与列
Allow quote data:选项选为“true”的时候对全角字符的处理出现乱码
Recycle on EOF:到数据文件结尾时是否循环读取。设置为True时,线程数过多,数据文件读取到最后一行时,会再次从第一行开始读取。设置为False,到达文件结尾时如继续读取,则值会默认为<EOF>,可通过设置jmeter属性csvdataset.eofstring来改变该值。
Stop thread on EOF:Recycle on EOF设置为False,Stop thread on EOF设置为True,则读取数据文件最后一行后,停止测试,不管还有多少线程组未执行。
Sharing mode:共享模式。默认在所有线程组中使用,可选择每个线程组单独打开
相同的部分使用用户自定义变量
只需要修改一次接口
效果展示
5.4. 参数化实现之CSV Data Set Config
添加CSV Data Set Config:
 ?
?
添加界面:
 ?
?
通过这个组件可以动态获取并设置数据,实现批量添加操作
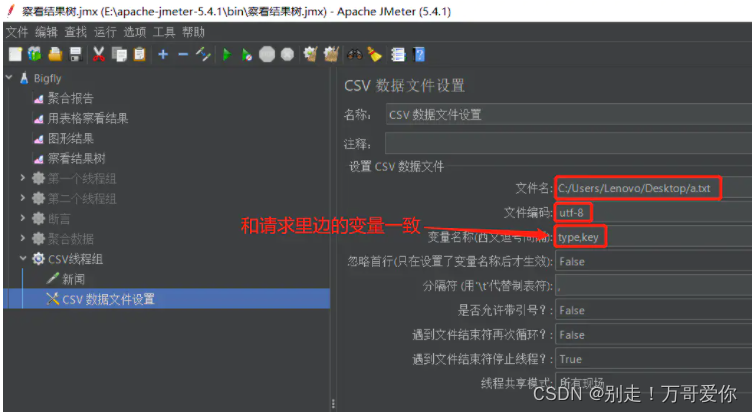
名词解释:
Filename:所需数据文件的路径。如和脚本同一路径,可直接填写文件名
File encoding:编码和文件保持一致即可,默认为ANSI。如有中文,建议为UTF-8
Variable Names:引用变量时的变量名,对应数据文件中的每一列,以逗号分隔。Delimiter:在.txt、.dat文件中,可以用逗号(,)或者Tab键(\t)来区分列与列
Allow quote data:选项选为“true”的时候对全角字符的处理出现乱码
Recycle on EOF:到数据文件结尾时是否循环读取。设置为True时,线程数过多,数据文件读取到最后一行时,会再次从第一行开始读取。设置为False,到达文件结尾时如继续读取,则值会默认为<EOF>,可通过设置jmeter属性csvdataset.eofstring来改变该值。
Stop thread on EOF:Recycle on EOF设置为False,Stop thread on EOF设置为True,则读取数据文件最后一行后,停止测试,不管还有多少线程组未执行。
Sharing mode:共享模式。默认在所有线程组中使用,可选择每个线程组单独打开
添加引用文件:

?
引用:
在jmeter中添加
 ??
??
线程数改为某个值
查看结果树:
 ?
?
其他:
- 线程组线程数改为大于文件中数据的处理:
遇到结束符在循环
遇到结束符停止线程 - 如果数据来自数据库
数据库导出txt文件
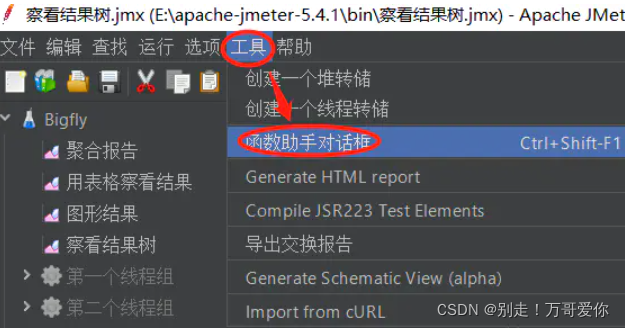
5.5. 使用Jmeter函数助手(文件中不要出现中文):
1、点击 选项-->函数助手 调出函数助手对话框
2、选择 _CSVRead 函数(下图第一个框)
3、函数参数:
1)第一个参数:填写文件路径。
2)第二个参数:文件列号是从0开始的,第一列0、第二列1、第三列2、依次类推,然后点击【生成】按钮,则会自动生成我们需要的参数化函数。
3) 复制生成的参数化函数, copy过程需要使用的地方即可。
4) _Random函数是从某数据段随机读取数据替换参数,当需要添加多条数据记录且某些字段需要唯一性时使用。
 ?
?
 ??
??
六. Jmeter正则表达式提取
6.1. 使用正则提取
运用Jmeter正则提取器,可以从请求的响应结果中取到需要的内容,从而实现关联。关联是请求与请求之间存在数据依赖关系,需要从上一个请求获取下一个请求需要回传回去的数据
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。 |
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。 |
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式提取的相关设置
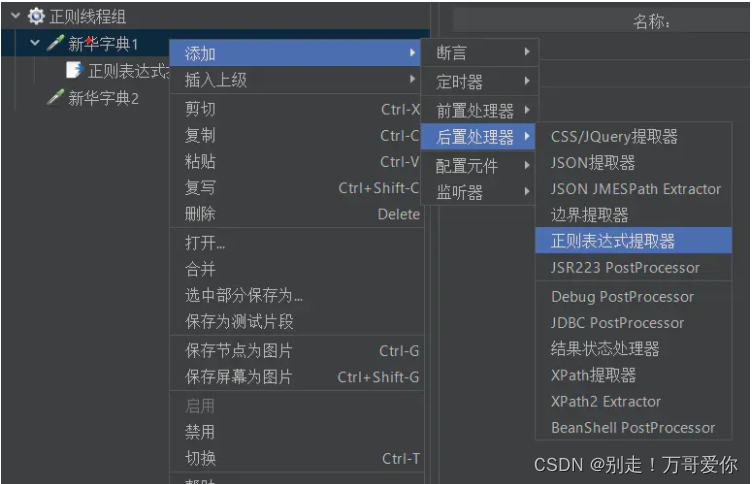
说明:
 ?
?
?
(1)引用名称:下一个请求要引用的参数名称,如填写title,则可用${title}引用它。
(2)正则表达式:
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
?