?���в��͵�ѧϰ��ַ
���Խ���֪ʶϵ�� - Python+Seleniumϵ�� - ��ʷ��� - С���ܲ��Աʼ� - ����
һ��selenium��������������������
1����װ�������������driver
��chrome������chromedriver ���ص�ַ:
https://code.google.com/p/chromedriver/downloads/list
?��IE������IEdriver ���ص�ַ:
��Firefox������geckodriver
selenium 3.0�汾����firefox��ʱ��Ҫ��geckodriver.exe,selenium2���������������ص�ַ:
��������������� :
selenium��֧�� Android(AndroidDriver)�� iPhone(IPhoneDriver) ���ƶ�Ӧ�ò��ԡ�
2��selenium ����ie �� chrome ��Firefox�������ַ�ʽ:
selenium����ie,chrome ��ʱ����Ҫ�������� IEDriverServer��Chromedriver��geckodriver
�ٰ� ie������chrome����������Ӧ�ļ���,�ڳ���������·������:
Chrome:
System.setProperty(��webdriver.chrome.driver��,��D:\Chromedriver.exe��);
WebDriver driver = new ChromeDriver();IE:
System.setProperty(��webdriver.ie.bin��,��D:\IEDriverServer.exe��);
WebDriver driver = new InternetExplorerDriver();
��ֱ�Ӱ� ie������chrome��������Python��Ŀ¼������Ŀ¼��(ֻҪ��Ŀ¼���ӵ���ϵͳ��������path���漴��),Ȼ��ֱ������
�۽��������ڸ���������İ�װĿ¼��,�������û���������
��chromedriver.exe ����chrome�������װĿ¼��(ͬʱ�����û���������path:C:\Users\xxxxxx\AppData\Local\Google\Chrome\Application;)
��IEDriverServer.exe ����ie�������װĿ¼��(ͬʱ�����û���������path:C:\Program Files\Internet Explorer )
����ie�����ʱ,Ҫע�ⰲȫ��������(internetѡ��C����ȫ ȥ�������ñ���ģʽ���Ĺ�ѡ)
����selenium ���������
��web�Զ�����ϰ��վ:
Sahi Tests
�ڵ���chrome�����
from selenium import webdriver
driver=webdriver.Chrome() #����chrome�����
driver.get('https://www.baidu.com')
print (driver.title)
driver.quit()
�۵���IE�����
from selenium import webdriver
driver=webdriver.Ie() #����IE�����
driver.get('https://www.baidu.com')
print (driver.title)
driver.quit()
�ܵ���firefox�����
from selenium import webdriver
import time
driver=webdriver.Firefox() #����chrome�����
driver.get('https://www.baidu.com')
driver.find_element_by_id("kw").send_keys("Selenium2")
driver.find_element_by_id("su").click()
time.sleep(3) # ǿ�Ƶȴ�3����ִ����һ��, ǿ�Ƶȴ�,������������Ƿ��������
driver.quit()
����Selenium�Ļ���ʹ��
selenium�°���2����,common��webdriver��
common�½���һ��exceptions��selenium.common.exceptions����selenium�п��ܷ������쳣��
�������������ܶ���webdriver�¡�webdriver�����common ��support ,����Ķ��Ƕ�Ӧ������ķ���/���Եȡ�
1�����������
Selenium֧�ֺܶ����������chrome��Firefox��Edge��Safari��,���������ʼ������:
from selenium import webdriver
#browser=webdriver.Firefox()
browser=webdriver.Chrome()
#browser=webdriver.Edge()
#browser=webdriver.Safari()
print(type(browser))
#���ص���һ��WebDriver����
<class 'selenium.webdriver.chrome.webdriver.WebDriver'>
WebDriver����ķ���������:(browser=webdriver.Chrome()��browser�ķ���������)
back(): ���������ʷ��¼�к���һ��
forward(): ���������ʷ��ǰ��һ��
close(): �رյ�ǰ����
quit():�˳��������ر�ÿ�������Ĵ���
refresh():ˢ�µ�ǰҳ��
name:���ش�ʵ���Ļ��������������
title:���ص�ǰҳ��ı���
current_url:��ȡ��ǰҳ���URL
add_cookie(cookie_dict):Ϊ��ǰ�Ự����һ��cookie,Ϊ�ֵ�����
delete_all_cookies():ɾ���Ự��Χ�ڵ�����cookie delete_cookie(name): ɾ�����и������Ƶĵ���cookie
get_cookie(name):�����ƻ�ȡ����cookie get_cookies():����һ���ֵ��cookies
execute(driver_command,params=None): ����commandִ�е�����
execute_async_script(script,*args):�첽ִ�е�ǰ���ڻ����е�JavaScript,�������������߳�ִ��
execute_script(script,*args):ͬ��ִ�е�ǰ���ڻ����е�JavaScript,����ִ��js������������߳�ִ��,ֱ��js����ִ�����
get(url):�ڵ�ǰ������Ự�м�����ҳ,һ��Ҫ����ȫ������,������http://��,��������Ҳ���
get_log(log_type):��ȡ������־���͵���־
get_screenshot_as_base64():��ȡ��ǰ���ڵ���Ļ��ͼ,��Ϊbase64������ַ���
get_screenshot_as_file(filename):����ǰ�����еĽ�������Ϊpngͼ��
save_screenshot(filename):����ǰ���ڵ���Ļ��ͼ����ΪPNGͼ���ļ�
get_screenshot_as_png():��ȡ��ǰ���ڵ���Ļ��ͼ��Ϊ����������
get_window_position(windowhandle=��current��):��ȡ��ǰ���ڵ�x,yλ��
get_window_rect():��ȡ���ڵ�x,y�����Լ���ǰ���ڵĸ߶ȺͿ���
get_window_size():��ȡ��ǰ���ڵĸ߶ȺͿ���
maximize_window():���webdriver����ʹ�õĵ�ǰ����
minimize_window():��С����ǰwebdricerʹ�ô���
fullscreen_window():���ô��ڹ������ض���ȫ������
set_window_rect(x=None,y=None,width=None,height=None):���ô��ڵ�x,y�����Լ���ǰ���ڵĸ߶ȺͿ���
set_window_size(width,height,windowHandle=��current��):���õ�ǰ���ڵĸ߶ȺͿ���
set_window_position(x,y,windowHandle=��current��):���õ�ǰ���ڵ�x,yλ��
current_window_handle:���ص�ǰ���ڵľ��
window_handles:���ص�ǰ�Ự�����д��ڵľ��
create_web_element(element_id): ʹ��ָ����id����WebԪ��
set_page_load_timeout(time_to_wait):���õȴ�ҳ�������ɵ�ʱ��
set_script_timeout(time_to_wait):���ýű���ִ���ڼ�ȴ���ʱ��
desired_capabilities:������������ǰʹ�õ����蹦��
log_types:��ȡ������־���͵��б�
page_source:��ȡ��ǰҳ���Դ��
switch_to �������л�������ѡ��Ķ�����
switch_to.alert �����������Alert����,�ɶ������alert��confirm��prompt�����
switch_to.default_content() �е����ĵ�
switch_to.frame(frame_reference) �е�ij��frame
switch_to.parent_frame() �е���frame,�ж��frame��ʱ�������
switch_to.window(window_name) �е�ij�����������
switch_to.active_element ���ص�ǰ�����WebElement����,��ҳ�ϵ�ǰ�����Ķ���(Ҳ��������ҳ�Ϲ���λ��),���������������һ��input��,����������input����������Ϣ,��ʱ���input���㡣
?ʵ��JavaScript:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.execute_script("alert('are you sure');") #����������ʵ��JavaScript�����й���
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('http://selenium-python.readthedocs.io')
browser.execute_script('window.open("https://www.baidu.com");') #�ڱ�ǩҳ��URL
browser.execute_script('window.open("https://www.taobao.com");')
browser.back() #���˵�ǰһ��ҳ��
browser.set_page_load_timeout(5)
browser.forward() #ǰ������һ��ҳ��
print(browser.name)
print(browser.title)
print(browser.current_url)
print(browser.current_window_handle)
print(browser.get_cookies())
print(type(browser))
��ȡҳ���ͼ:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.python.org')
driver.save_screenshot('screenshot.png') #����ҳ���ͼ����ǰ·��
driver.quit()
��ҳ��������ײ�:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.python.org')
#ͨ��js�е�window�����scrollTo����,������λ�ù�����ָ��λ��,document.body.scrollHeight��������body�ĸ߶�,����ҳ�潫������ҳ��ײ�
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
cookies����:
driver.get_cookies()���Ի�ȡ����ǰ��վ������cookie��Ϣ
driver.get_cookie(name),��ȡָ����cookie,name������Ҫ��ȡ��cookie�����ơ���:driver.get_cookie(name="PHPSESSID")
driver.add_cookie(str),����cookie��¼,str�������ֵ����ϸ�ʽ
#!/usr/bin/ python3
# -*- coding: utf-8 -*-
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('https://www.baidu.com')
print(driver.get_cookies()) #��ȡ����cookies
driver.add_cookie({'name':'name','domain':'www.baidu.com','value':'germey'}) #����cookie
print(driver.get_cookies())
driver.delete_all_cookies()
print(driver.get_cookies())
2����λԪ��
webdriver �ṩ�˰���Ԫ�ض�λ����:
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
- find_element_by_id(id����,����Ψһ��λ)
- find_element_by_name (name����,����Ψһ��λ)
- find_element_by_xpath (�����,����)
- find_element_by_link_text (��λ�������Ӻ���)
- find_element_by_partial_link_text (��λ�������Ӻ���)
- find_element_by_tag_name (ÿ��Ԫ�ض�����tag��ǩ,�����)
- find_element_by_class_name (class���Զ�λԪ��)
- find_element_by_css_selector (cssѡ������λ)
��ʱ����Ҫ������Ԫ����һ����������,��ô���ǿ���ͨ��link text ��partial link text ����Ԫ�ض�λ��Ҳ����a��ǩ
����,��λ�ٶ���ҳ���Ͻǵġ����š�,��hao123��,���������ȵ���Щ�������ӡ��Ϳ���ʹ��link text��partail link text��λ��ʽ
ͨ��linx text��λ:
find_element_by_link_text("����")
find_element_by_link_text("����")
ͨ��partail link text��λ:
find_element_by_link_text("��")
find_element_by_link_text("��")
Ҫ���Ҷ��Ԫ��(��Щ����������һ���б�):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
from selenium import webdriver
from selenium.webdriver.common.by import By
driver=webdriver.Chrome()
driver.get('http://selenium-python.readthedocs.io/locating-elements.html#locating-elements')
data=driver.find_elements(By.CLASS_NAME,'simple') #��ȡ���
data=driver.find_element(By.CLASS_NAME,'simple') #��ȡһ��
driver.find_element(By.ID,'IDname') #��ȡID��ǩ��λԪ��
driver.find_element(By.CSS_SELECTOR,'cssname')#CSSѡ������λԪ��
driver.find_element(By.LINK_TEXT,'linktext') #�����ı���λԪ��
driver.find_element(By.PARTIAL_LINK_TEXT,'linktext') #���������ļ���λԪ��
driver.find_element(By.NAME,'name') #��������λԪ��
driver.find_element(By.TAG_NAME,'tagname') #��ǩ����λԪ��
print(data.text) #��ӡԪ���ı�����
ͨ��Id��λ:
����֪��Ԫ�ص�id����ʱʹ�ô�ѡ�ʹ�ô˲���,������id����ֵ���λ��ƥ��ĵ�һ��Ԫ��,��ʹ��find_elements_by_id�����ض��ƥ���Ԫ�ء����û��Ԫ�ؾ���ƥ���id ����,NoSuchElementException��ᴥ��
driver.find_element_by_id('kw1')
driver.find_elements_by_id('kw1')
�����ƶ�λ:
����֪��Ԫ�ص�name����ʱ,��ʹ�ô�ѡ�ʹ�ô˲���,��������������ֵ��λ��ƥ��ĵ�һ��Ԫ��,��ʹ��find_elements_by_name�����ض��ƥ���Ԫ�ء����û��Ԫ�ؾ���ƥ���name ����,NoSuchElementException����
driver.find_element_by_name('wd')
driver.find_elements_by_name('wd')
����ǩ���ƶ�λԪ��:
���Ҫ����ǩ���Ʋ���Ԫ��,��ʹ�ô�ѡ�ʹ�ô˲���,�����ؾ��и���������Ƶĵ�һ��Ԫ�ء����û��Ԫ�ؾ���ƥ��ı������������NoSuchElementException�쳣��tag name ��ȡ���DZ�ǩ������,��һ��ҳ�����������кܶ��ǩ����ͬ��Ԫ��,�Ⲣ����˵ tag name �����ͺ�������֮��,�ڶ�λһ��Ԫ�ص�ʱ������������Ҫ tag name ��������æ��
driver.find_element_by_tag_name('input')
��������λԪ��:
���Ҫ�����������ƶ�λԪ��,��ʹ�ô�ѡ�ʹ�ô˲���,�����ؾ���ƥ�����������Ƶĵ�һ��Ԫ�ء����û��Ԫ�ؾ���ƥ�������������,NoSuchElementException������
driver.find_element_by_class_name('s_ipt')
ͨ�������ı����ҳ�����:
��������Ԫ����һ����������, ��ô���ǿ���ͨ��link text �� partial link text ����Ԫ�ض�λ�������������ı�ֵ��λ��ƥ��ĵ�һ��Ԫ�ء����û��Ԫ�ؾ���ƥ��������ı�����,NoSuchElementException����������һ���������Ӻܳ�ʱ,���ǿ���ֻȡ���е�һ����,ֻҪȡ�IJ��ֿ���Ψһ��ʶԪ�ء�һ��һ��ҳ���ϲ��������ͬ���ļ�����,ͨ��������������λԪ��Ҳ��һ�ּ���Ч�Ķ�λ��ʽ��
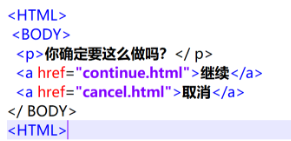
driver.find_element_by_link_text('����) #ͨ�������ı���λ��Ԫ��
driver.find_element_by_partial_link_text('����) #ͨ�������ı���λ��Ԫ��
?ͨ��XPath��λ:
XPath��������XML�ĵ��ж�λ�ڵ�����ԡ�����HTML������XML��ʵ��,��˿�������XPath����λ��WebӦ�ó����е�Ԫ�ء�XPath��չ��ͨ��id��name���Զ�λ�ķ���,�����˸����µĿ�����,������ҳ���ϲ��ҵ�������ѡ��ʹ��XPath����Ҫԭ��֮һ�ǵ���û���ʺ���Ҫ���ҵ�Ԫ�ص�id��name����ʱ��������ʹ��XPath�Ծ������������ھ���id��name���Ե�Ԫ������λԪ�ء�XPath��λ��Ҳ��������ͨ��id��name֮�������ָ��Ԫ�ء�

����·����λ(��λ���һ��Ԫ��):
find_element_by_xpath("/html/body/div[2]/form/span/input")
���·����λ(��λ���һ��Ԫ��):
#ͨ�������� id ���Զ�λ
find_element_by_xpath("//input[@id=��input��]")
#ͨ����һ��Ŀ¼�� id ���Զ�λ
find_element_by_xpath("//span[@id=��input-container��]/input")
#ͨ��������Ŀ¼�� id ���Զ�λ
find_element_by_xpath("//div[@id=��hd��]/form/span/input")
#ͨ��������Ŀ¼�� name���Զ�λ
find_element_by_xpath("//div[@name=��q��]/form/span/input")
��������Ҫ��λ��Ԫ�غ����ҵ����ʵķ�ʽʱ,����ͨ���־���·���ķ�ʽλ,ȱ���ǵ�Ԫ���ںܶ༶Ŀ¼��ʱ,���Dz��ò�Ҫд�ܳ���·��,�������ַ�ʽ�����Ķ���ά���� XPath �Ķ�λ��ʽ�dz�����ǿ���,���� XPath ����������������,����://div[@id=��hd�� or @name=��q��]��
driver.find_element_by_xpath("//from[1]") #�鿴��һ������Ԫ��
driver.find_element_by_xpath("//from[@id='loginform']") #����idΪloinform�ı���Ԫ��
xpath��λ��ȱ��:
1�����ܲ�,��λԪ�ص�����Ҫ�������������ʽ��;
2��������׳,XPath ������ҳ��Ԫ�ز��ֵĸı���ı�;
3�������Բ���,�ڲ�ͬ��������¶� XPath ��ʵ���Dz�һ���ġ�
ͨ��CSSѡ������λԪ��:
CSS���������� HTML �� XML �ĵ��ı��֡�CSS ʹ��ѡ������Ϊҳ��Ԫ�ذ����ԡ���Щѡ�������Ա� selenium ������λ�������ؾ���ƥ���CSSѡ�����ĵ�һ��Ԫ�ء�CSS ���ԱȽ����ѡ��ؼ�����������,һ������¶�λ�ٶ�Ҫ�� XPath ��,�����ڳ�ѧ����˵�Ƚ�����ѧϰʹ�á����û��Ԫ�ؾ���ƥ���CSSѡ����,NoSuchElementException�������
driver.find_element_by_css_selector('p.content')
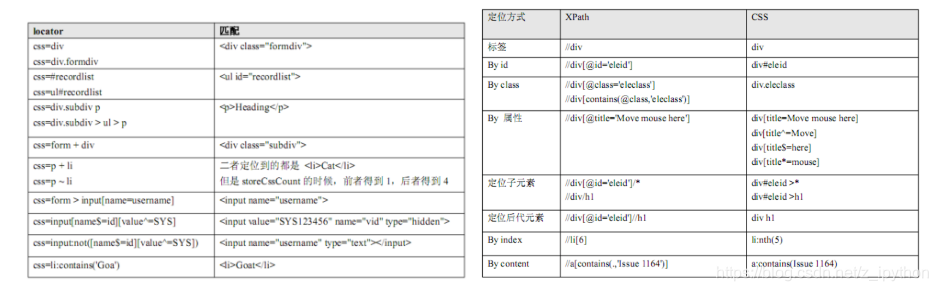
?XPath��CSS��λ�ٲ��:
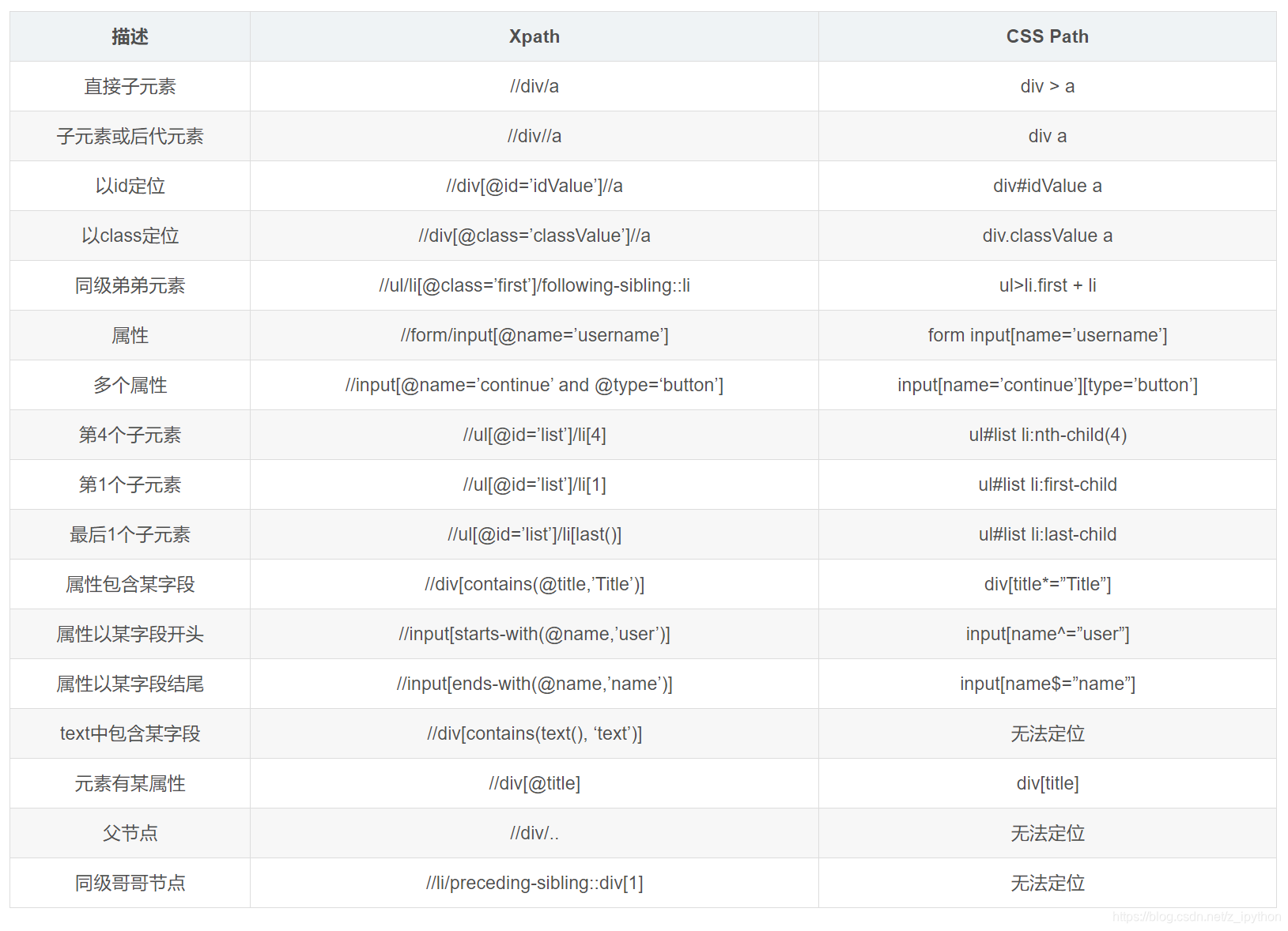
?CSS��λ��� XPath ��Ϊ���,��λ��ʽ����������;������ CSS ��������Ҫ�� XPath����;�������Ǵ����ܻ��Ƕ�λ�����ӵ�Ԫ����,CSS ����XPath,���Ը��Ƽ�ʹ�� CSS��λҳ��Ԫ�ء�
3��Ԫ�ض���(element)
������ͨ������ �ķ�����λ��Ԫ�غصĶ����ΪwebԪ�ض���,���ǿ��Զ�Ԫ�ض����ٽ��н�����������ҵȲ���
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# ʵ���������ѡ��
opt=Options()
# ���Ӳ���,�����������
opt.add_argument('headless')
# ѡ��Ӧ�õ����������������
driver=webdriver.Chrome(chrome_options=opt)
driver.get('http://selenium-python.readthedocs.io/api.html')
element=driver.find_element_by_id('remote-webdriver-webelement')
print(element)
print(type(element))
element�ķ�����������:
- clear() :����ı�Ԫ��
- click() :����Ԫ�ذ�ť
- get_attribute(name) :��ȡԪ�صĸ������Ե�����ֵ
- get_property(name) :��ȡԪ�صĸ�������
- is_displayed() :�ж�Ԫ���Ƿ����
- is_enable() :�ж�Ԫ���Ƿ�����
- is_selected() :����Ԫ���Ƿ�ѡ��
- screenshot(filename) :����ǰԪ�ص���Ļ��ͼ���浽�ļ�
- send_keys() #����Ԫ��ֵ,�����ȡ�����ؿ��������������������
- submit() :�ύ����
- value_of_css_property() :CSS���Ե�ֵ
- id :seleniumʹ�õ��ڲ�ID
- location :Ԫ���ڿ���Ⱦ�����е�λ��
- location_once_scrolled_into_view :����Ԫ������Ļ��ͼ�е�λ��
- rect :���ذ���Ԫ�ش�С��λ�õ��ֵ�
- screenshot_as_base64 :��ȡ��ǰԪ�صĽ���,��Ϊbase64������ַ���
- size :��ȡԪ�صĴ�С
- tag_name :��ȡԪ�ص�tagName����
- text :��ȡԪ�ص��ı�
��ҳ�潻��,ʵ������ı���������,����ӡ�������Դ��:
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
element=driver.find_element_by_id('xx') #��ȡ�����Ԫ��
element.send_keys('python') #����Ԫ��
button=driver.find_element_by_id('btnZzk') #��ȡ������ť
button.click() #������������
data=driver.page_source
print(driver.current_url) #��ӡURL
print(data)
print(type(element))
driver.close()
4��������
selenium.webdriver.common.action_chains.ActionChains(driver)
�������ʵ����������Ե���ij���ڵ�Ԫ�صIJ���,���Ҫ��û���ض�Ԫ�صĶ�������������ק�����̰�����,��Щ�����ͳ�Ϊ������,seleniumʹ��ActionChains()����ʵ������ƶ�,��갴ť����,���������������IJ˵�����,��ͣ���Ϸŵ�
- click(on_element=None) ��������������
- click_and_hold(on_element=None) �������������,���ɿ�
- context_click(on_element=None) �����������Ҽ�
- double_click(on_element=None) ����˫��������
- drag_and_drop(source, target) ������ק��ij��Ԫ��Ȼ���ɿ�
- drag_and_drop_by_offset(source, xoffset, yoffset) ������ק��ij������Ȼ���ɿ�
- key_down(value, element=None) ��������ij�������ϵļ�
- key_up(value, element=None) �����ɿ�ij����
- move_by_offset(xoffset, yoffset) �������ӵ�ǰλ���ƶ���ij������
- move_to_element(to_element) ��������ƶ���ij��Ԫ��
- move_to_element_with_offset(to_element, xoffset, yoffset) �����ƶ�����ij��Ԫ��(���Ͻ�����)���پ����λ��
- perform() ����ִ�����е����ж���
- release(on_element=None) ������ij��Ԫ��λ���ɿ�������
- send_keys(*keys_to_send) ��������ij��������ǰ�����Ԫ��
- send_keys_to_element(element, *keys_to_send) ��������ij������ָ��Ԫ��
��Ԫ����ק��Ŀ��λ��:
from selenium.webdriver import ActionChains
element = driver.find_element_by_name("source")
target = driver.find_element_by_name("target")
action = ActionChains(driver)
action.drag_and_drop(element, target).perform()
ִ��������������:
from selenium.webdriver import ActionChains
menu = driver.find_element_by_css_selector(".nav") #��ȡelement����
submenu = driver.find_element_by_css_selector(".nav #submenu1") #��ȡ�������
actions = ActionChains(driver) #����������
actions.move_to_element(menu) #�ƶ���굽����
actions.click(submenu) #�������
actions.perform() #ִ�в���
(5)�����Ի���
����������alert��window��αװ�Ի���:
alert,�����������,һ��������ȷ��ijЩ�����������text���û����������,����������IJ�ͬ,���������ʽҲ��һ��,�������Ǻܼ�һ��С����firebug��������ȡ���ÿ��Ԫ�ص�,Ҳ����˵alert�Dz�������ҳDOM���ġ�����ͼ��ʾ:
window,���������,���һ������֮����ܻ��һ���µ����������,��֮ǰ�Ĵ�����ƽ�й�ϵ(alert�������Ǹ��ӹ�ϵ,���߽д�����ϵ,alert����������ijһ������),���Լ��ĵ�ַ���������С����ť�ȡ���������ֱ档
divαװ�Ի���,��ͨ����ҳԪ��αװ�ɶԻ���,���ֶԻ���һ��Ƚϻ���,���ݱȽ϶�,���Ҹ������һ���Ͳ���һ��,����ҳ����firebug�ܹ���ȡ�����Ԫ��,����ͼ:
?Alert����֧�ִ��������Ի���ķ���:
- accept() :ȷ�ϵ���,�÷�:Alert(driver).appept()
- authenticate(username,password) :���û��������뷢�͵�authenticated�Ի���,�������ȷ��,�÷�driver.switch_to.alert.authenticate(��username��,��password��)
- dismiss() :ȡ��ȷ��
- send_keys(keysToSend) :����Կ���͵�����,keysToSendΪҪ���͵��ı�
- text :��ȡAlert���ı�
import time
from selenium import webdriver
from selenium.webdriver.common.alert import Alert
driver=webdriver.Chrome()
driver.get('https://www.baidu.com')
driver.execute_script("alert('ȷ��');") #��������
time.sleep(2)
print(driver.switch_to.alert.text) #���alert�ı�
alert=Alert(driver).accept() #�Զ����ȷ������
window����
window������alert,������ԭwindow��ƽ�е�,����ֻ��Ҫ�л����µ�window�ϱ���Բ�����window��Ԫ�ء�driver.switch_to.window(window_handle)
��window��ͨ��window���handle����λ�ġ���selenium�ṩ���������Է�������ѯwindow���:driver.current_window_handle ��driver.window_handles
�������������Ի�ȡ����ǰ�����Լ����д��ڵľ��,�Ϳ����л���������window�ˡ�
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.alert import Alert
driver = webdriver.Firefox()
driver.maximize_window()
driver.get('http://sahitest.com/demo/index.htm')
current_window = driver.current_window_handle # ��ȡ��ǰ����handle name
driver.find_element_by_link_text('Window Open Test With Title').click()
all_windows = driver.window_handles # ��ȡ���д���handle name
# �л�window,���window���ǵ�ǰwindow,���л�����window
for window in all_windows:
if window != current_window:
driver.switch_to.window(window)
print driver.title # ��ӡ��ҳ��title
driver.close()
driver.switch_to.window(current_window) # �ر��´��ں��л�ԭ����,�����ﲻ�л�ԭ����,��������ԭ����Ԫ�ص�,��ʹ��ر����´���
print driver.title # ��ӡԭҳ��title
driver.quit()
div��Ի���
div��Ի�������ͨ����ҳԪ��,ͨ��������find_element�Ϳ��Զ�λ�����в����������������������ע������һ���ĵȴ�ʱ��,���δ���س����������һ������,���NoSuchElementException������
6�����̲���
selenium.webdriver.common.keys.Keys
selenium�ṩһ��keys����ģ�����еİ�������,������һЩ���õİ�������:
- �س���:Keys.ENTER
- ɾ����:Keys.BACK_SPACE
- �ո��:Keys.SPACE
- �Ʊ���:Keys.TAB
- ���˼�:Keys.ESCAPE
- ˢ�¼�:Keys.F5
- ȫѡ(ctrl+A):send_keys(Keys.CONTROL,��a��) #��ϼ���Ҫ��send_keys��������
- ����(ctrl+C):send_keys(Keys.CONTROL,��c��)
- ����(ctrl+X):send_keys(Keys.CONTROL,��x��)
- ճ��(ctrl+V):send_keys(Keys.CONTROL,��v��)
import requests
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
driver=webdriver.Chrome()
driver.get('https://pypi.org/')
element=driver.find_element_by_id('search') #��ȡ�����
element.send_keys('selenium') #����selenium��
element.send_keys(Keys.ENTER) #���س���
#element_a=driver.find_element_by_link_text('selenium') #��λselenium������
element_a = driver.find_element_by_xpath('//*[@id="content"]/section/div/div[2]/form/section[2]/ul/li[1]/a/h3/span[1]')#��λselenium������
ActionChains(driver).move_to_element(element_a).click(element_a).perform() #������������ִ��
element_down=driver.find_element_by_link_text('Download files') #���������
ActionChains(driver).move_to_element(element_down).click(element_down).perform() #������������
element_selenium=driver.find_element_by_link_text('selenium-3.13.0.tar.gz') #��λԪ��selenium���ذ�����
data=element_selenium.get_attribute('href') #��ȡ���ӵ�ַ
with open('selenium-3.13.0.tar.gz','wb') as f:
source=requests.get(data).content #�����������ӵ�ַ��ȡ�����ư�����
f.write(source) #�����
f.close()
driver.quit()
7����ʱ�ȴ�
Ŀǰ�����WebӦ�ó�����ʹ��AJAX�����������������ҳ��ʱ,��ҳ���е�Ԫ�ؿ����Բ�ͬ��ʱ�������ء���ʹ��λԪ�ر������:���DOM����δ����Ԫ��,��locate����������ElementNotVisibleException�쳣��ʹ�õȴ�,���ǿ��Խ��������⡣Selenium Webdriver�ṩ�������͵ĵȴ�: ��ʽ����ʽ��
��ʽ�ȴ�ʹWebDriver�ȴ�ij����������,Ȼ���ټ���ִ�С���ʽ�ȴ��ڳ��Բ���Ԫ��ʱ,��ʹWebDriver��ѯDOMһ��ʱ�䡣
��ʾ�ȴ�:
���Եȴ�WebDriverWait,��ϸ����until()��until_not()����,���ܹ������ж��������������صȴ��ˡ�����Ҫ����˼����:����ÿ��xx�뿴һ��,�������������,��ִ����һ��,��������ȴ�,ֱ���������õ��ʱ��,Ȼ���׳�TimeoutException��
until
method: �ڵȴ��ڼ�,ÿ��һ��ʱ��(__init__�е�poll_frequency)�����������ķ���,ֱ������ֵ����False
message: �����ʱ,�׳�TimeoutException,��message�����쳣
until_not
��until�෴,until�ǵ�ijԪ�س��ֻ�ʲô�������������ִ��,
until_not�ǵ�ijԪ����ʧ��ʲô���������������ִ��,����Ҳ��ͬ,��������
���õȴ�����:
- title_is :������ij����
- title_contains :�������ij����
- presence_of_element_located :�ڵ���س���,���붨λԪ��,��(By.ID, ��p��)
- presence_of_all_elements_located :���нڵ���س���
- visibility_of_element_located :�ڵ�ɼ�,���붨λԪ��
- visibility_of :�ɼ�,����ڵ����
- text_to_be_present_in_element :ij���ڵ��ı�����ij����
- text_to_be_present_in_element_value :ij���ڵ�ֵ����ij����
- invisibility_of_element_located :�ڵ㲻�ɼ�
- frame_to_be_available_and_switch_to_it :���ز��л�
- element_to_be_clickable :�ڵ�ɵ��
- staleness_of :�ж�һ���ڵ��Ƿ�����DOM,���ж�ҳ���Ƿ��Ѿ�ˢ��
- element_to_be_selected :�ڵ��ѡ��,���ڵ����
- element_located_to_be_selected :�ڵ��ѡ��,���붨λԪ��
-element_selection_state_to_be :����ڵ�����Լ�״̬,��ȷ���True,����False- element_located_selection_state_to_be :���붨λԪ���Լ�״̬,��ȷ���True,����False
- alert_is_present :�Ƿ���־���
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver=webdriver.Chrome()
driver.get('https://www.taobao.com/')
wait=WebDriverWait(driver,3) #���ü���driver�ȴ�ʱ��3��
input=wait.until(EC.presence_of_element_located((By.ID,'q'))) #���õȴ�����ΪidΪq��Ԫ�ؼ������
button=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search'))) #���õȴ�����Ϊclass��Ϊbtn-search��Ԫ�ؼ������
print(input,button)
��ʽ�ȴ�:
Selenium��DOM��û���ҵ��ڵ�,���ʹ������ʽ�ȴ�,Selenium������еȴ�,�������趨ʱ���,���׳��Ҳ����ڵ���쳣������Ҫ���ҵĽڵ�û���������ֵ�ʱ��,��ʽ�ȴ����ȴ�һ��ʱ���ٲ���DOM,Ĭ�ϵ�ʱ����0������driver��implicitly_wait()����ʵ����ʽ�ȴ�:
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) #��ʽ�ȴ����õȴ�ʱ��Ϊ10s
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
8���쳣����
����webdriver�����з������쳣:
- selenium.common.exceptions.WebDriverException :webdriver�����쳣
- selenium.common.exceptions.UnknownMethodException :�����������URLƥ�䵫��URL������ƥ��
- selenium.common.exceptions.UnexpectedTagNameException :��֧����û�л��Ԥ�ڵ�WebԪ��ʱ�׳�
- selenium.common.exceptions.UnexpectedAlertPresentException :�������⾯��ʱ�׳�,ͨ����Ԥ��ģʽ��ֹwebdriver����ִ���κθ�������ʱ����
- selenium.common.exceptions.UnableToSetCookieException :����������������cookieʱ�׳�
- selenium.common.exceptions.TimeoutException :������û�����㹻��ʱ�������ʱ�׳�
- selenium.common.exceptions.StaleElementReferenceException :����Ԫ�ص��������ڡ��¾ɡ�ʱ�׳�,�¾���ζ�Ÿ�Ԫ�ز��ٳ�����ҳ���DOM��
- selenium.common.exceptions.SessionNotCreatedException :�������»Ự
- selenium.common.exceptions.ScreenshotException :��Ļ��ͼ�����쳣
- selenium.common.exceptions.NoSuchWindowException :��������Ҫ�л��Ĵ���Ŀ��ʱ�׳�
- selenium.common.exceptions.NoSuchElementException :���ҵ�Ԫ��ʱ�׳�
- selenium.common.exceptions.NoSuchCookieException :�ڵ�ǰ��������ĵĻ�ĵ��Ĺ���cookie���Ҳ��������·����ƥ���cookie
- selenium.common.exceptions.NoSuchAttributeException :���ҵ�Ԫ�ص�����ʱ�׳�
- selenium.common.exceptions.JavascriptException :ִ���û��ṩ��JavaScriptʱ��������
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
driver=webdriver.Chrome()
driver.get('https://www.baidu.com')
try:
element=driver.find_element_by_id('test')
print(element)
except NoSuchElementException as e:
print('Ԫ�ز�����:',e)
9��ʵ��:ץȡ�Ա�ҳ����Ʒ��Ϣ
import re
import pymongo
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from urllib.parse import quote
from selenium.common.exceptions import WebDriverException
from pyquery import PyQuery as pq
#����mongodb���ݿ�
client=pymongo.MongoClient(host='localhost',port=27017)
db=client['taobao']
#������ͷchrome
opt=webdriver.ChromeOptions()
opt.add_argument('--headless')
driver=webdriver.Chrome(chrome_options=opt)
#����ҳ��ȴ�ʱ��
wait=WebDriverWait(driver,10)
#����������Ʒ��
uname='iPad'
#������Ʒ
def search():
try:
url = 'https://s.taobao.com/search?q=' + quote(uname)
driver.get(url)
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
except TimeoutException:
return search()
return total.text
#ʵ�ַ�ҳ��Ʒ
def next_page(page):
print('����ץȡ��{}'.format(page))
try:
if page >= 1:
input=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > input')))
submit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
input.clear()
input.send_keys(page)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page)))
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .items .item')))
get_products()
except TimeoutException:
next_page(page)
except WebDriverException as e:
print('index_page:',e)
#������Ʒ��Ϣ
def get_products():
#print('��ʼ����ҳ��...')
html = driver.page_source
doc = pq(html, parser='html')
items = doc('#mainsrp-itemlist .items .item').items()
for i in items:
product = {
'image': 'https:' + i.find('.pic .img').attr('data-src'),
'price': i.find('.price').text(),
'deal': i.find('.deal-cnt').text(),
'title': i.find('.title').text(),
'shop': i.find('.shop').text(),
'location': i.find('.location').text()
}
#print(product)
save_to_mongo(product)
#���浽mongodb
def save_to_mongo(result):
try:
if db['collection_taobao'].insert(result):
print('���浽mongodb�ɹ�!',result)
except Exception:
print('���浽mongodbʧ��',result)
#����������
def main():
try:
total=search()
total=int(re.compile('(\d+)').search(total).group(1))
for i in range(1,total+1):
next_page(i)
finally:
driver.quit()
#ִ�к������
if __name__ == '__main__':
main()