�ڱ�����,�ҽ�����һ����ΪLocust�����ܲ��Թ��ߡ��ҽ���Locust�Ĺ������Գ���,���ʵ����Locust��ʹ�÷������н��ܡ�
����
Locust��Ҫ�����µĹ�������:
-
��Locust���Կ����,���Գ����Dz��ô�Python�ű����������ġ�����Ҫ���ص�UI��ӷ��XML
-
���������
http(s)Э���ϵͳ,Locust����Python��requests��Ϊ�ͻ���,ʹ�ýű���д��������http(s)Э���ϵͳ֮��,Locust��֧�ֲ�������ϵͳ��Э��,ֻ��Ҫ����Ϊ���Ե����ݱ�дһ���ͻ��˾Ϳ����ˡ� -
��ģ�Ⲣ������,
Locust�ǻ����¼�����,ʹ��gevent�ṩ�ķ�����IO��coroutine��ʵ�������IJ�������,ʹ�õ������̴���ǧ�������û����ټ���Locust֧�ֲַ�ʽ,ʹ��֧����ʮ���û������Ρ� -
Locust��һ���ɾ���Web����,����ʵʱ��ʾ���Խ��ȡ��ڲ��������ڼ�,������ʱ���ĸ��ء�����������û��UI�����������,��������CI/CD���ԡ�
���Ƕ�֪����������ܲ��Թ�������ĵIJ�����ѹ��������,��ѹ���������ĺ���Ҫ��������:һ����ʵģ���û�����,����ģ����Ч������
- ��� LoadRunner��Jmeter ����ѹ���(ͨ���̶߳�Ӧһ���û�/�����ķ�ʽ��������)����,Locust�ܹ��ԱȽϵ͵ijɱ���������(LoadRunner һ�� Vuser ռ���ڴ���M������ʮMB,�� Jmeter ��߲����������� JVM ��С)��
- ֧��BDD(��Ϊ��������)��д�����Լ�ִ������,�ܹ����õ�ģ���û���ʵ�IJ������̡�
�ű��ṹ����
����ͨ��һ���İ���ѧϰһ��locust�Ļ���ʹ��:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time:2022/3/26 9:38 ����
# @Author:boyizhang
from locust import TaskSet, HttpUser, task, run_single_user
class BaiduTaskSet(TaskSet):
"""
����
"""
@task
def search_by_key(self):
self.client.get('/')
class BaiduUser(HttpUser):
"""
- ����������û�ʵ��
- �������û�ʵ�������ݹ���ȥִ������
"""
# ���������
tasks = [BaiduTaskSet,]
host = 'http://www.baidu.com'
if __name__ == '__main__':
# debug:���������Ƿ������ͨ
run_single_user(BaiduUser)
�ӽű��п��Կ���,�ű���Ҫ����������:BaiduTaskSet��BaiduUser,BaiduTaskSet�̳�TaskSet,BaiduUser�̳�HttpUser(HttpUser�̳�User)��
BaiduTaskSet�Ƕ����û�ִ�е�����ϸ��,��BaiduUser(User)���Ǹ��������û�ʵ��ȥִ����Щ����
User��ͺñ���һȺ�ȳ�,��ÿһֻ�ȳ����һ�����ʵ������Ӧ��,TaskSet��ͺñ��ǻȳ�Ĵ���,�����Żȳ�ľ�����Ϊ,��ʵ��ҵ�����Զ�Ӧ������
HttpUser(User)
��User����,����һ��client����,����Ӧ�������û���Ϊ�ͻ������߱�������������
- ͨ�������,���Dz���ֱ��ʹ��
User��,��Ϊ��client����û�а��κη����� - ��ʹ��
User��ʱ,��Ҫ�ȼ̳�User��,Ȼ���ڼ̳������е�client�����аͻ��˵�ʵ���ࡣ
���ڳ�����HTTP(S)Э��,���ǿ��Լ̳�HttpUser�ࡣHttpUser ����õ��û��ࡣ��������һ��client����,���ڷ��� HTTP ����
- ��
client������HttpSession��,��HttpSession�ּ̳���requests.Session������ڲ���HTTP(S)��Locust�ű���,���ǿ���ͨ��client������ʹ��Python requests������з���,���÷�ʽҲ��requests��ȫһ�¡� - ����
requests.Session��ʹ��,���client�ķ�������֮����Զ�������״̬����Ĺ��ܡ������ij�������,�ڵ�¼ϵͳ�����ά�ֵ�¼״̬��Session,�Ӷ�����HTTP����������ܴ��ϵ�¼̬��
������HTTP(S)�����Э��,����ͬ������ʹ��Locust���в���,
- ��ȻLocust �������˶� HTTP/HTTPS ��֧��,����������չ�����Լ����κ�ϵͳ��ֻ��Ҫ����
User��ʵ��client���ɡ� - ���ǿ���ʹ��locust-plugins,����ǵ�����ά���Ŀ�,֧��
Kafka��mqtt,webdriver�Ȳ��ԡ�
TaskSet
����
TaskSet��ʵ�����û�ʵ����ִ������ĵ����㷨,�����滮����ִ��˳����ѡ��һ������ִ���������ߵȴ����жϿ��Ƶȡ��ڴ˻�����,���ǾͿ�����TaskSet�����в��÷dz����ķ�ʽ������ҵ����Գ���,��������Ϊ(����)������֯������,�����ԶԲ�ͬ�����Ȩ�ؽ������á�
��TaskSet�����ж���������Ϣʱ,���Բ�ȡ���ַ�ʽ,@taskװ������tasks���ԡ�
- ����
@taskװ����
from locust import TaskSet, task, constant
class MyTaskSet(TaskSet):
def on_start(self):
"""
�û���ʼִ�д�����ʱ����
:return:
"""
print("task is running")
def on_stop(self):
"""
�û�ִֹͣ�д�����ʱ����
:return:
"""
print(("task is stopped"))
@task(2)
def task1(self):
print("User instance (%r) executing my_task1" % self)
@task
def task2(self):
print("User instance (%r) executing my_task2" % self)
- ����tasks����
����ʹ��list,Ҳ����ʹ��dict�����ʹ��list,��Ȩ��Ϊ1:1
from locust import User, task, constant
class MyTaskSet(TaskSet):
def on_start(self):
"""
�û���ʼִ�д�����ʱ����
:return:
"""
print("task is running")
def on_stop(self):
"""
�û�ִֹͣ�д�����ʱ����
:return:
"""
print(("task is stopped"))
def task1(self):
print("User instance (%r) executing my_task1" % self)
def task2(self):
print("User instance (%r) executing my_task2" % self)
tasks = {task1:2, task2:1}
# ������б�����ʽ,��ִ�������Ȩ��Ϊ1:1
# tasks = [task1, task2]
���������ֶ���������Ϣ�ķ�ʽ��,��������Ȩ������,��ִ��task1��Ƶ����task2������������ָ��ִ�������Ȩ��,���൱�ڱ���Ϊ1:1��
on_start()��on_stop()����,�ֱ���д�����TaskSet��on_start()��on_stop()���ֱ����û���ʼ��ִֹͣ�д�����ʱ������
TaskSet Ƕ��-��ʵģ���û�����
TaskSet ���������������� TaskSet ��,��������Ƕ�����������ļ�����ʹ�����ܹ��Ը���ʵ�ķ�ʽ����ģ���û�����Ϊ��
class NestTaskSet(TaskSet):
@task(3)
def get_index_page(self):
print("get_Index_page")
@task(7)
class get_forum_page(TaskSet):
@task(3)
def get_view_detail(self):
print('get_view_detail')
@task(1)
def create_forum(self):
print('create_forum')
@task(1)
def stop(self):
print('exit forum page')
self.interrupt()
@task(1)
def get_info(self):
print('get info')
from locust import HttpUser, TaskSet, task, between
class ForumThread(TaskSet):
pass
class ForumPage(TaskSet):
# wait_time can be overridden for individual TaskSets
wait_time = between(10, 300)
# TaskSets can be nested multiple levels
tasks = {
ForumThread:3
}
@task(3)
def forum_index(self):
pass
@task(1)
def stop(self):
self.interrupt()
class AboutPage(TaskSet):
pass
class WebsiteUser(HttpUser):
wait_time = between(5, 15)
# We can specify sub TaskSets using the tasks dict
tasks = {
ForumPage: 20,
AboutPage: 10,
}
# We can use the @task decorator as well as the
# tasks dict in the same Locust/TaskSet
@task(10)
def index(self):
pass
���� TaskSet ��Ҫ�ر�ע�����,������Զ����ִֹͣ��������,��Ҫ�ֶ����ø�TaskSet.interrupt()������ִֹͣ�С�
������İ���һ��,���û��stop����,��ôһ���û�������get_forum_page֮��,�����Ӵ�������������,ֻ��ִ��get_forum_page�µ�task��
�ű���д
����1:
�ٶ����������Ƚϴ�,��������ٶȵ������ӿڽ���ѹ��,���дѹ��ű���?
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time:2022/3/27 5:15 ����
# @Author:boyizhang
import random
from locust import TaskSet, task, FastHttpUser, HttpUser,run_single_user
from locust.clients import ResponseContextManager
from locust.runners import logger
class BaiduTask(TaskSet):
@task
def search_by_baidu(self):
wd = random.choice(self.user.share_data)
path = f"/s?wd={wd}"
with self.client.get(path,catch_response=True) as res:
# �����ͬһ�ӿڲ�ͬ��������ͬһ��,�����������ַ�ʽ
# with self.client.get(path,catch_response=True,name="/s?wd=[wd]") as res:
res: ResponseContextManager
# ���������,����Ϊfailure
if res.status_code != 200:
res.failure(res.text)
def on_start(self):
logger.info('hello')
def on_stop(self):
logger.info('goodbye')
class Baidu(HttpUser):
host = 'https://www.baidu.com'
tasks = [BaiduTask,]
share_data = ['��С��','boxiaoyi','���ܲ���','locust']
if __name__ == '__main__':
run_single_user(Baidu)
�ڰ�������,ͨ����HttpUser�������ж���һ���б�share_data,��ִ������ʱ,�������ѡȡ�б�share_data�е�һ��Ԫ����Ϊ�ӿ���Ρ�
�ű�ִ��
�ҿ���Locust�ĵ�һ�����ص���ɴ��:�ű��ṹ����,���������ϰ�������Locust��ִ�С�
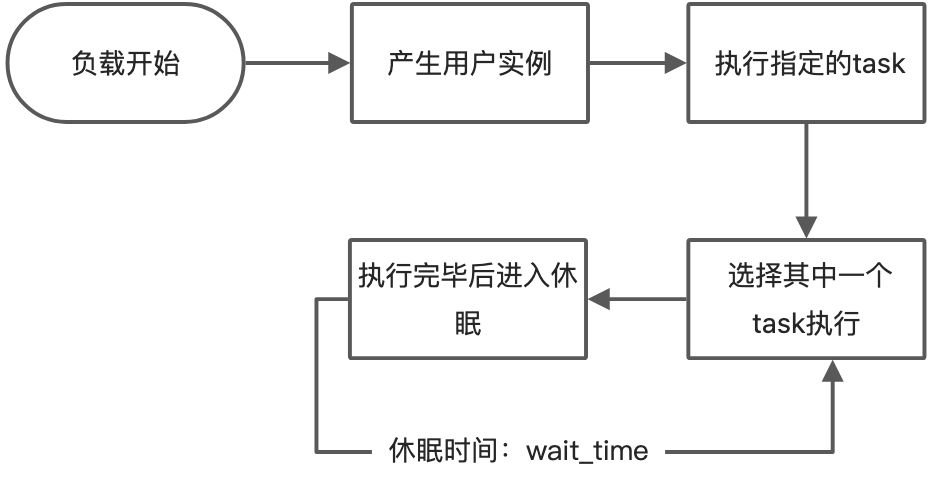
���ز�������ʱ,�ᰴ���û������Number of users�Լ�Spawn rate�����û�ʵ����
- �û�ʵ��ִ��ָ����TaskSet
- �û�ʵ����ѡ��
TaskSet������֮һȥִ�� - ִ�����֮���߳�ʹ�û��������߲�����ָ��ʱ��(�û������
wait_time) - ���߽���֮��,�ٴ�
TaskSet��������ѡ��һ��������ִ�� - �ٴεȴ�,�������ơ�
���Ͼ���Locust���µ�ִ�����̡�
ִ�з�ʽ
������ִ��
����ͨ��locust -h�鿴Locust�������в�����Ҳ����ͨ���鿴:Locust�����в������� ��ȡ�����÷���
$ locust -f example.py --headless --users 10 --spawn-rate 1 -H http://www.boxiaoyi.com -t 300s
- -f: ָ��ִ�е�Locust�ű�
- �Cheadless:���� Web ����(ʹ���ն�)),��������ʼ���ԡ�ʹ�� -u �� -t �����û���������ʱ��
- -u/�Cusers:���� Locust �û��ķ�ֵ��������Ҫ
--headless��--autostartһ��ʹ�á������ڲ����ڼ�ͨ���������� w��W(���� 1��10 ���û�)�� s��S(ֹͣ 1��10 ���û�)������ - -r/�Cspawn-rate:��(ÿ���û���)�����û������ʡ���Ҫ��
-�Cheadless��-�Cautostartһ��ʹ�� - -t/�Crun_time:��ָ����ʱ���ֹͣ,����(300s��20m��3h��1h30m ��)������
--headless��--autostartһ��ʹ�á�Ĭ����Զ���С� - �Cautostart: ������ʼ����(������ Web UI)��ʹ�� -u �� -t �����û���������ʱ�䡣��ͬʱʹ���ն��Լ�web uiҳ��۲�
����������ִ�е�֧��,���ϲ�����֧��,���Խ��м��ɵ�CI/CD�����̵���,������һ����Ҫע�����,��Ҫָ��--run_time,�������Զ��˳������̡�
web ui����ִ��
$ locust -f example.py
���� Locust ��,�������������ָ�� http://localhost:8089����չʾ����ҳ��:
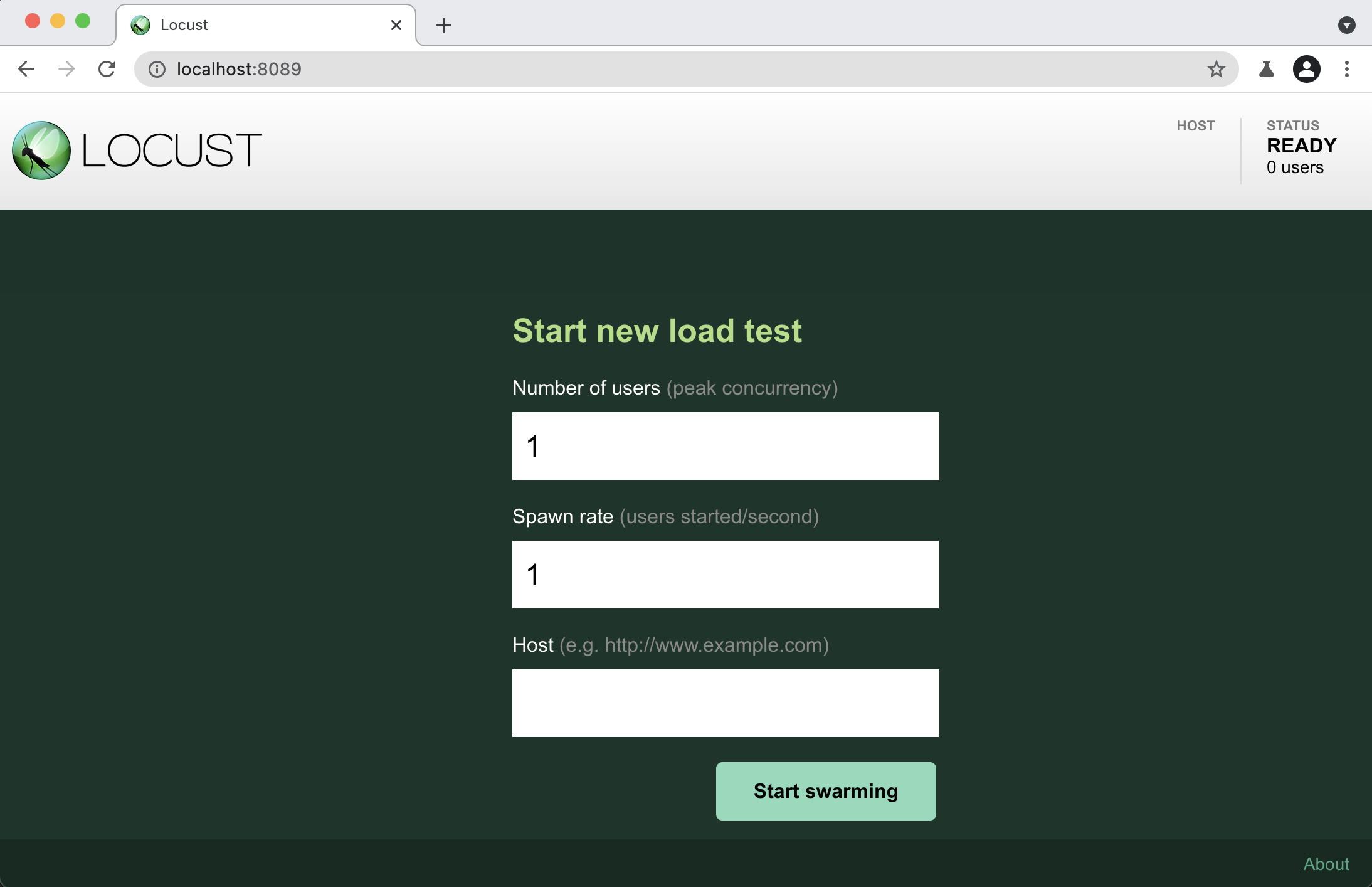
���start swarming,���ɿ�ʼ���ز��ԡ�
ִ�в���
����ִ��
����ִ��,��ִ�е�ʱ���Ӧһ��Locust���̡��ɲο����������
�ֲ�ʽִ��
���� Locust �ĵ������̿���ģ���൱�ߵ�������������һ���IJ��Լƻ�,��Ӧ���ܹ�ÿ�뷢�����ٸ�����,���ʹ��FastHttpUser����ǧ�������������IJ��Լƻ��ܸ��ӻ����������и���ĸ���,�����Ҫ��չ���������,���������Ƕ�̨������
���ǿ���ʹ��--master��־Master����һ��Locustʵ��,��ʹ��--worker��־Worker�����������ʵ����
- ���worker������master������ͬһ̨������,����worker��������Ҫ����������CPU������һ������,��ѹЧ�����ܲ���������
- ���worker������master���̲���ͬһ̨������,����ʹ��
--master-host������ָ������master���̵Ļ�����IP/�������� - ��Locust��ִ�зֲ�ʽʱ,master��worker����ʵ����һ��Ҫ��locusfile�ĸ�����
- masterʵ������Locust��Web����,������workers��ʱ����/ֹͣ�û���worker�����û�����ͳ�����ݷ��ͻ�masterʵ����masterʵ�������������κ��û���
ע���
- ��ΪPython������ȫ����ÿ������һ�����ϵ��ں�(�μ�GIL),����ͨ��Ӧ����Worker������Ϊÿ���������ں�����һ��Workerʵ��,�Ա��������ǵ����м���������
- ����ÿ��Workerʵ���������е��û���������û�����ơ�ֻҪ�û�����������/RPS��̫��,Locust/gevent�Ϳ�����ÿ��������������ǧ����������û���
- ���Locust�����ľ�CPU��Դ,������¼һ�����档
���ʹ�÷ֲ�ʽ?
- ����Masterʵ��:
locust -f my_locustfile.py --master
- Ȼ����ÿ��Worker��(xxxΪmasterʵ����IP,�����������Worker�����������ͬһ̨�������,����ȫʡ�Ըò���):
locust -f my_locustfile.py --worker --master-host=xxx
��������:
- �Cmaster:�� locust ����Ϊ master ģʽ��Web ���潫�ڴ˽ڵ������С�
- �Cworker:���ȳ�����Ϊworkerģʽ��
- �Cmaster-host=X.X.X.X:��ѡ����Cworker����master�ڵ��������/IP һ��ʹ��(Ĭ��Ϊ 127.0.0.1)
- �Cmaster-port=5557:��ѡ����Cworker����master�ڵ�Ķ˿ں�һ��ʹ��(Ĭ��Ϊ 5557)��
- �Cmaster-bind-host=X.X.X.X:��ѡ����Cmaster. ȷ��master�ڵ㽫��������ӿڡ�Ĭ��Ϊ *(���п��ýӿ�)��
- �Cmaster-bind-port=5557:��ѡ����Cmaster. ȷ��master�ڵ㽫����������˿ڡ�Ĭ��Ϊ 5557��
- �Cexpect-workers=X:��ʹ�� �������ڵ�ʱʹ�èCheadless��Ȼ��,���ڵ㽫�ȴ� X ��worker�ڵ�����,Ȼ���ٿ�ʼ���ԡ�
ʹ��dockerִ�зֲ�ʽ
version: '3'
services:
master:
image: locustio/locust
ports:
- 8089:8089
- 5557:5557
volumes:
- ./:/myexample
command: -f /myexample/locustfile.py WebsiteUser --master -H http://www.baidu.com
worker:
image: locustio/locust
links:
- master
volumes:
- ./:/myexample
command: -f /myexample/locustfile.py WebsiteUser --worker --master-port=5557
����
$ docker-compose -d -f myexample/run_locust_by_docker.yml up --scale worker=3
�������
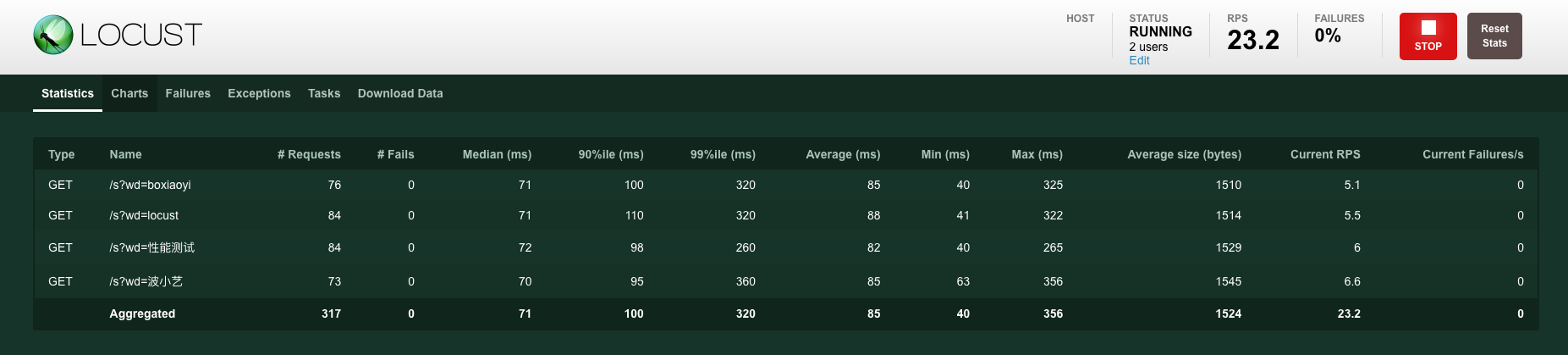
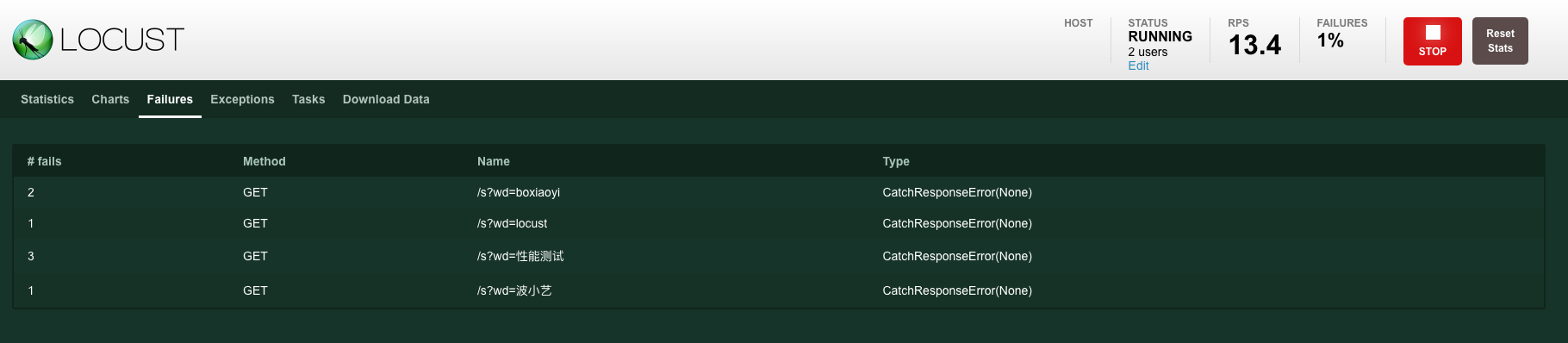
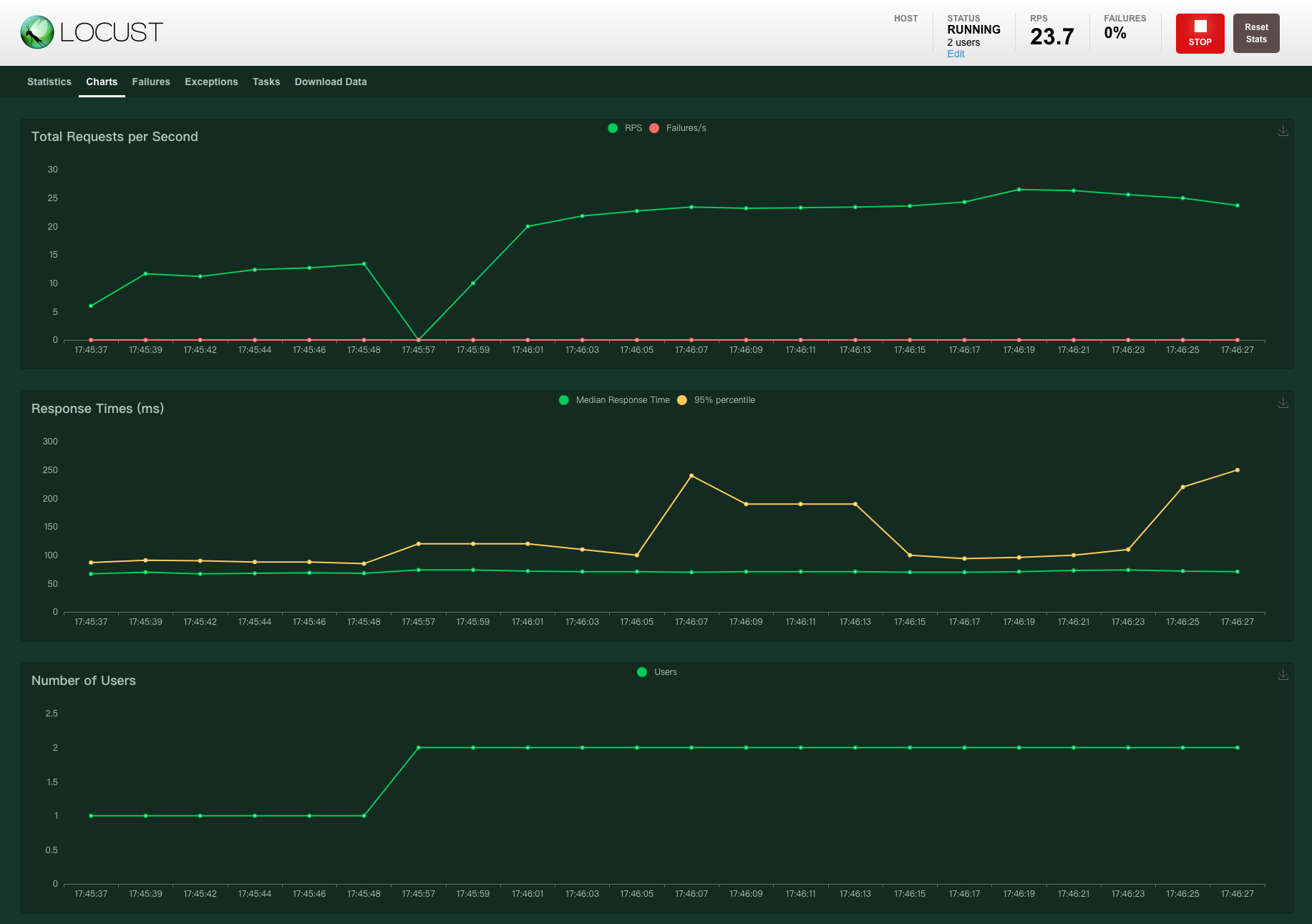
Locust��ִ�в��ԵĹ�����,���ǿ�����web������ʵʱ�ؿ�����������������Ҫչʾ������ָ��:��������RPS��ʧ���ʡ���Ӧʱ�� latency,���չʾ�˲���ָ�������ͼ,�簸��1-ͼ3��
ִ������1:locust -f locustfile.py,ͨ��Webҳ��,���Կ������½��: