ФПТМ
1ЁЂЪзЯШДДНЈвЛИіЯюФП,УќУћЫцвт,ЕМШыSeleniumЕФpomвРРЕ
3)ЩшЖЈЫЏУпЪБМф(ПЩИљОнЭјТчЫйЖШЪЕМЪЕїећ)
вЛЁЂSeleniumМђНщ?
SeleniumЪЧвЛИігУгкWebгІгУГЬађздЖЏЛЏВтЪдЙЄОпЁЃSeleniumВтЪджБНгдЫаадкфЏРРЦїжа,ОЭЯёеце§ЕФгУЛЇдкВйзївЛбљЁЃжЇГжЕФфЏРРЦїАќРЈIE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,OperaЕШЁЃ
ЪЪгУгкздЖЏЛЏВтЪд,jsЖЏЬЌХРГц(ЦЦНтЗДХРГц)ЕШСьгђ
ЖўЁЂSeleniumзщГЩ
1)Selenium IDE:ЧЖШыЕНFirefoxфЏРРЦїжаЕФвЛИіВхМў,ЪЕЯжМђЕЅЕФфЏРРЦїВйзїТМжЦгыЛиЗХЙІ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? Фм,жївЊгУгкПьЫйДДНЈBUGМАжиЯжНХБО,ПЩзЊЛЏЮЊЖржжгябд
2)Selenium RC: КЫаФзщМў,жЇГжЖржжВЛЭЌгябдБраДздЖЏЛЏВтЪдНХБО,ЭЈЙ§ЦфЗўЮёЦїзїЮЊДњРэ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ЗўЮёЦїШЅЗУЮЪгІгУ,ДяЕНВтЪдЕФФПЕФ
3)Selenium WebDriver(жиЕу):вЛИіфЏРРЦїздЖЏЛЏПђМм,ЫќНгЪмУќСюВЂНЋЫќУЧЗЂЫЭЕНфЏРРЦї? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?ЫќЪЧЭЈЙ§ЬиЖЈгкфЏРРЦїЕФЧ§ЖЏГЬађЪЕЯжЕФЁЃЫќжБНггыфЏРРЦїЭЈ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?аХВЂЖдЦфНјааПижЦЁЃSelenium?WebDriverжЇГжИїжжБрГЬгя? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?бд,ШчJavaЁЂC# ЁЂPHPЁЂPythonЁЂPerlЁЂRuby
4)Selenium grid:ВтЪдИЈжњЙЄОп,гУгкзіЗжВМЪНВтЪд,ПЩвдВЂаажДааЖрИіВтЪдШЮЮё,ЬсЩ§ВтЪдаЇТЪ
Ш§ЁЂSeleniumЬиЕу
? ? ?1)ПЊдДЁЂУтЗб
? ? ?2)ЖрфЏРРЦїжЇГж:FireFoxЁЂChromeЁЂIEЁЂOperaЁЂEdge;
? ? ?3)ЖрЦНЬЈжЇГж:LinuxЁЂWindowsЁЂMAC;
? ? ?4)ЖргябджЇГж:JavaЁЂPythonЁЂRubyЁЂC#ЁЂJavaScriptЁЂC++;
? ? ?5)ЖдWebвГУцгаСМКУЕФжЇГж;
? ? ?6)МђЕЅ(API МђЕЅ)ЁЂСщЛю(гУПЊЗЂгябдЧ§ЖЏ);
?????7)жЇГжЗжВМЪНВтЪдгУР§жДаа
ЫФЁЂАИР§бнЪО
1ЁЂЪзЯШДДНЈвЛИіЯюФП,УќУћЫцвт,ЕМШыSeleniumЕФpomвРРЕ
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>2ЁЂЯТдиЧ§ЖЏАќ
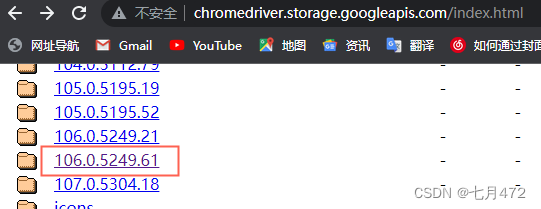
ЯТдиЭјжЗ:http://chromedriver.storage.googleapis.com/index.html
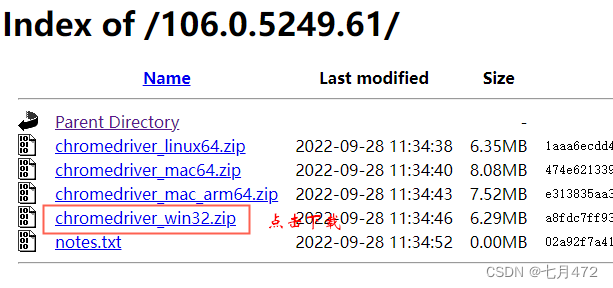
аЁБрЪЙгУЙШИшЗУЮЪSelenium,ЯТдиЧ§ЖЏАќЧАЯШВщПДвЛЯТФуЕФЙШИшЪЧФФИіАцБОЕФКѓдкЯТдиЭјжЗжаевЕНЖдгІЕФАцБОЯТди
?
 ? ?НтбЙ-->? ?
? ?НтбЙ-->? ? ? НтбЙКѓНЋЫќПНБДЕНвЛИіЗЧжаЮФФПТМЯТ,РћгУЧ§ЖЏГЬађШЅЧ§ЖЏфЏРРЦї
? НтбЙКѓНЋЫќПНБДЕНвЛИіЗЧжаЮФФПТМЯТ,РћгУЧ§ЖЏГЬађШЅЧ§ЖЏфЏРРЦї
?
ЙЬЖЈДњТы:
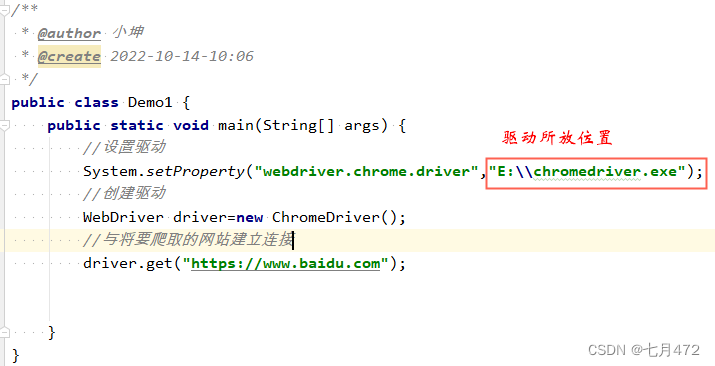
//ЩшжУЧ§ЖЏ
System.setProperty("webdriver.chrome.driver","E:\\chromedriver.exe");
//ДДНЈЧ§ЖЏ
WebDriver driver=new ChromeDriver();
//гыНЋвЊХРШЁЕФЭјеОНЈСЂСЌНг
driver.get("https://www.baidu.com");
дЫаавЛЯТ,ВтЪдАйЖШЭјеО?

1)ClassбЁдё:driver.findElement(By.className("s_ipt"));
// ЭЈЙ§РрбЁдёЦїФУЕНБЛПижЦЕФвГУцЕФАДХЅдЊЫи
WebElement s_btn = driver.findElement(By.className("s_btn"));
System.out.println(s_btn.getAttribute("id"));
System.out.println(s_btn.getAttribute("value"));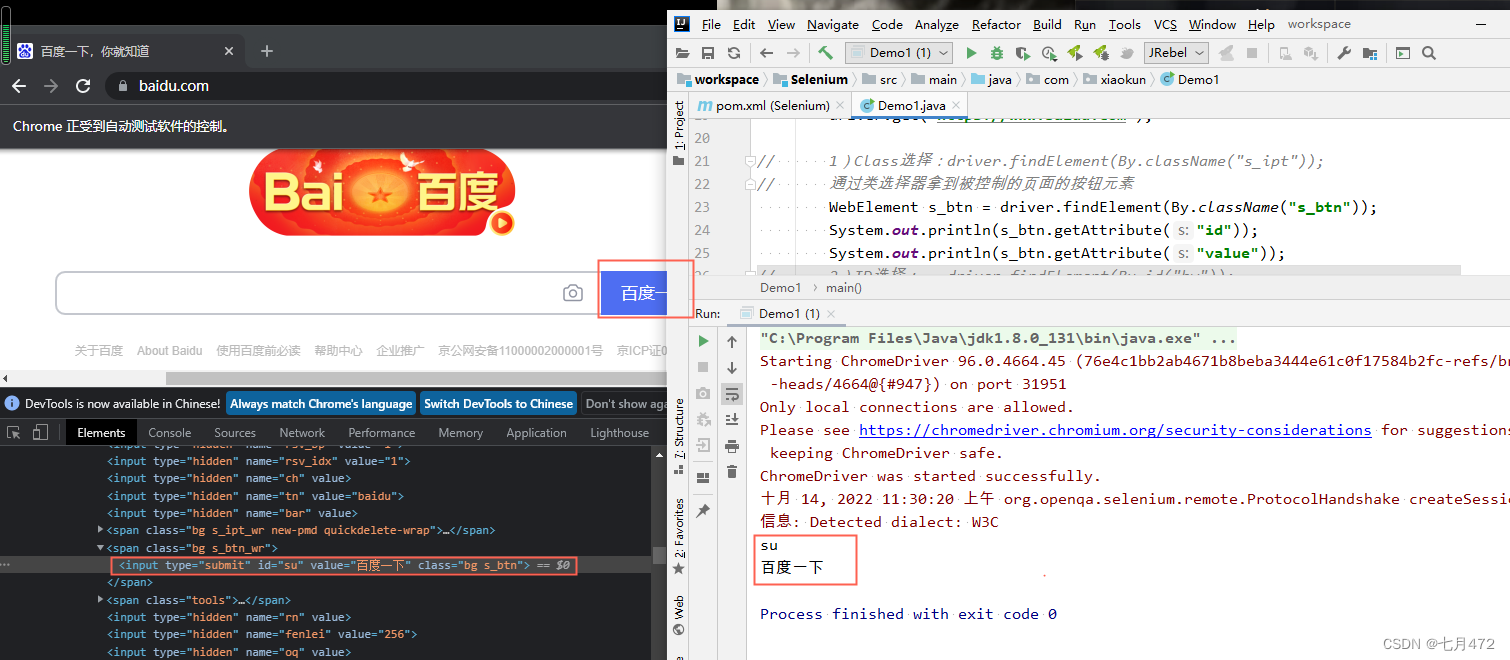
2)IDбЁдё: driver.findElement(By.id("kw"));
// ЭЈЙ§idбЁдёЦїФУЕНвГУцжаЕФдЊЫи
WebElement su = driver.findElement(By.id("su"));
System.out.println(su.getAttribute("class"));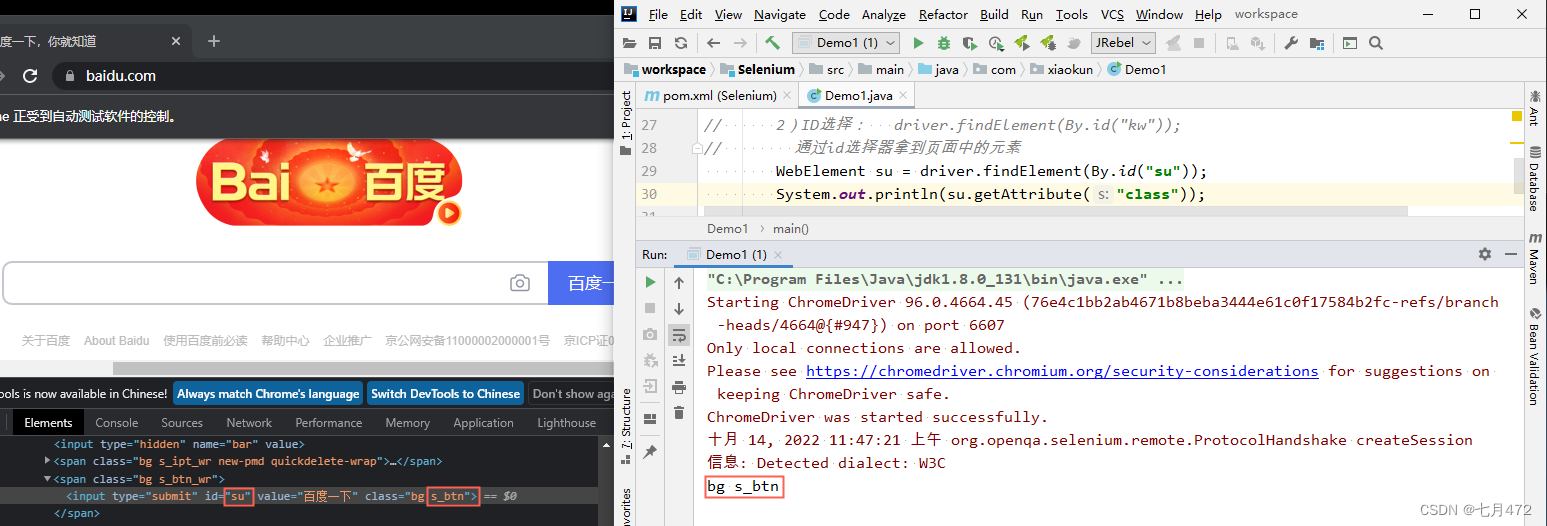
// 3)nameбЁдё: driver.findElement(By.name("wd"));
// ????????System.out.println(driver.findElement(By.name("rqlang")).getAttribute("value"));
// 4)tagбЁдё: driver.findElements(By.tagName("input"));
// ЛёШЁЕНАйЖШЪзвГЫљгаЕуЛїбЁдё
List<WebElement> eles = driver.findElements(By.tagName("a"));
for (WebElement ele : eles) {
//eleжИЕФЪЧЕЅИіaБъЧЉ
String text = ele.getText();
if (text != null && !"".equals(text.trim())){
System.out.println(text);
}
}

?
5)linkбЁдё: driver.findElement(By.linkText("ЕиЭМ")); // ЭЈЙ§СДНгЮФБОЛёШЁСДНгдЊЫи,ФЃФтЕуЛїИУСДНг // driver.findElement(By.linkText("ЕиЭМ")).click(); // 6)Partial linkбЁдё(aБъЧЉЮФБОФкШнФЃК§ЦЅХф)driver.findElement(By.partialLinkText("ЪЙгУАй")); // ЭЈЙ§СДНгЕФЕижЗФЃК§ЦЅХф List<WebElement> eles = driver.findElements(By.partialLinkText("3")); for (WebElement ele : eles) { System.out.println(ele.getText()); }
?
?
7)cssбЁдёЦї:driver.findElement(By.cssSelector("#kw")); //ЭЈЙ§CSSбЁдёЦїЛёШЁвГУцдЊЫи // WebElement ele = driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(1)")); // System.out.println(ele.getText());

?
8)xpathбЁдё:driver.findElement(By.xpath("//*[@id=\"kw\"]")); // /students/student/... WebElement ele = driver.findElement(By.xpath("//*[@id=\"hotsearch-content-wrapper\"]/li[1]")); System.out.println(ele.getText());
 ?
?
ЮхЁЂ?SeleniumХРШЁЩЬЦЗаХЯЂ
?1)ГѕЪМЛЏ
//НЋЧ§ЖЏМгдиЕНJavaЕФJVMащФтЛњжа
System.setProperty("webdriver.chrome.driver","E:\\chromedriver.exe");
/***********************************ЗНЪНвЛ:ВЛДђПЊфЏРРЦї**************************///ЖЈвхфЏРРЦїВЮЪ§
ChromeOptions chromeOptions = new ChromeOptions();
//ЩшжУВЛДђПЊфЏРРЦїchromeOptions.addArguments("--headless");
//ГѕЪМЛЏЧ§ЖЏdriver=new ChromeDriver(chromeOptions);
/***********************************ЗНЪНЖў:ДђПЊфЏРРЦї**************************///ГѕЪМЛЏЧ§ЖЏ
WebDriver driver=new ChromeDriver();
?
2)ЕуПЊЭјжЗВЂжИЖЈЙиМќзжЫбЫї?
//гыНЋвЊХРШЁЕФЭјеОНЈСЂСЌНг
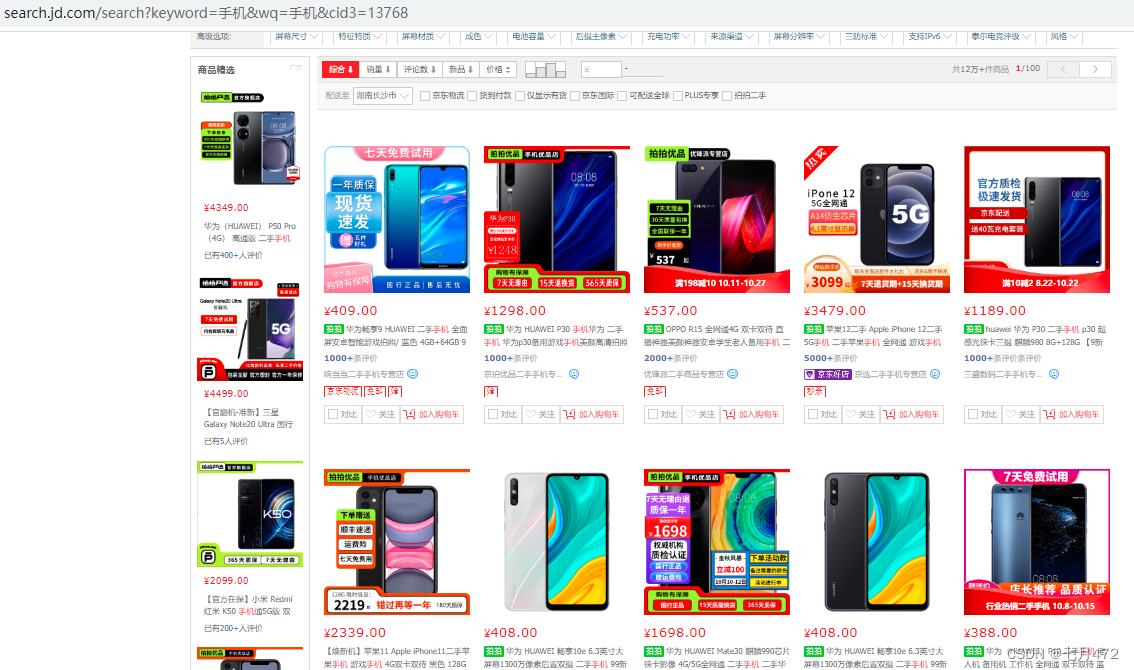
driver.get("https://search.jd.com/search?keyword=%E6%89%8B%E6%9C%BA&wq=%E6%89%8B%E6%9C%BA&cid3=13768");
//ЪфШыЙиМќзж? driver.findElement(By.id("key")).sendKeys("вТЗў");
//ЕуЛїЫбЫїАДХЅ
? driver.findElement(By.cssSelector("button.button")).click();
3)ЩшЖЈЫЏУпЪБМф(ПЩИљОнЭјТчЫйЖШЪЕМЪЕїећ)
Thread.sleep(i * 1000);
4)ВщевЩЬЦЗСаБэВЂЛёШЁЯрЙиаХЯЂ
//1.ЛёШЁЕН АќКЌ ЪжЛњ ЫљгааХЯЂ ЕФвГУцдЊЫи div
List<WebElement> divs = driver.findElements(By.className("gl-i-wrap"));
System.out.println(divs.size());for (WebElement div : divs) {
? ? //2.ЭЈЙ§ div ЛёШЁ ОпЬхЕФХРШЁаХЯЂ аХЯЂ МлИё ЭМЦЌ
? ? System.out.println(div.findElement(By.cssSelector("div.p-name > a > em")).getText());
? ? System.out.println(div.findElement(By.cssSelector("div.p-price > strong > i")).getText());
? ? WebElement img = div.findElement(By.cssSelector("div.p-img > a > img"));
? ? System.out.println(img.getAttribute("src"));
}
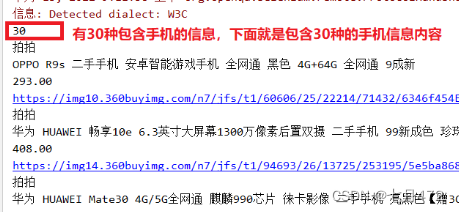
?СљЁЂSeleniumХРШЁЭМЦЌ
1)БЃДцЭМЦЌ?
URL url=new URL(img); //ДДНЈЪфШыСї InputStream is=url.openStream(); //ДДНЈЪфГіСї OutputStream out=new FileOutputStream(new File(ТЗОЖ));
package com.xiaokun.demo;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URL;
import java.util.List;
import java.util.UUID;
/**
*
* ФПБъ:ЪжЛњаХЯЂЁЂМлИёЁЂЭМЦЌ
* ВНжш:
* 1.ЛёШЁЕН АќКЌ ЪжЛњ ЫљгааХЯЂ ЕФвГУцдЊЫи div
* 2.ЭЈЙ§ div ЛёШЁ ОпЬхЕФХРШЁаХЯЂ
* аХЯЂ
* МлИё
* ЭМЦЌ
* 3.еыЖдЭМЦЌзіеыЖдЕФДІРэЁЊЁЊ>ДгЭјЩЯНЋЭМЦЌЯТдиЯТРД
* 3.1 НЋ дДЭЗЭМЦЌ ЖЈвх ЪфШыСї
* 3.2 ЖЈвх зюжеЭМЦЌЯТдиЖЉжЦ,ЖЈвх ЪфГіСї
* 3.3 БпЖСБпаД
* 3.4 ЪЭЗХзЪдД
*/
public class Demo2 {
public static void main(String[] args) throws Exception {
//ЩшжУЧ§ЖЏ
System.setProperty("webdriver.chrome.driver","E:\\chromedriver.exe");
//ДДНЈЧ§ЖЏ
WebDriver driver=new ChromeDriver();
//гыНЋвЊХРШЁЕФЭјеОНЈСЂСЌНг
driver.get("https://search.jd.com/search?keyword=%E6%89%8B%E6%9C%BA&wq=%E6%89%8B%E6%9C%BA&cid3=13768");
//1.ЛёШЁЕН АќКЌ ЪжЛњ ЫљгааХЯЂ ЕФвГУцдЊЫи div
List<WebElement> divs = driver.findElements(By.className("gl-i-wrap"));
System.out.println(divs.size());
for (WebElement div : divs) {
//2.ЭЈЙ§ div ЛёШЁ ОпЬхЕФХРШЁаХЯЂ аХЯЂ МлИё ЭМЦЌ
System.out.println(div.findElement(By.cssSelector("div.p-name > a > em")).getText());
System.out.println(div.findElement(By.cssSelector("div.p-price > strong > i")).getText());
WebElement img = div.findElement(By.cssSelector("div.p-img > a > img"));
System.out.println(img.getAttribute("src"));
//3.еыЖдЭМЦЌзіеыЖдадЕФДІРэ--->ДгЭјЩЯНЋЭМЦЌЯТдиЯТРД
downloadImg(img.getAttribute("src"));
System.out.println("===========ДѓМвЖМдкЗЂ===КйКй ПраІ пкбР ЧПбеЛЖаІ КЉаІ=====");
}
//ЙиБефЏРРЦї
driver.close();
//ЪЭЗХзЪдД
driver.quit();
}
private static void downloadImg(String src) throws Exception{
if(null == src || "".equals(src))
return;
//3.1 НЋдДЭЗЭМЦЌ ЖЈвх ЪфШыСї
URL url = new URL(src);
InputStream in = url.openStream();
//3.2 ЖЈвх зюжеЭМЦЌЯТдиЖЈжЦ,ЖЈвх ЪфГіСї
OutputStream out = new FileOutputStream(new File("E:\\temp\\"+ UUID.randomUUID().toString()+".jpg"));
//3.3 БпЖСБпаД
int len = 0;//вЛДЮЖСЖрЩйзжНк
byte[] bytes = new byte[1024];//ФЌШЯвЛДЮЖС1k
while ((len = in.read(bytes))!=-1){
out.write(bytes,0,len);
}
//3.4 ЪЭЗХзЪдД
in.close();
out.close();
}
}
БОЕиТЗОЖПЩвдПДЕНЯТдиКѓЕФЭМ
 ?
?
?
ЧГЧГСЫНтПДетЦЊЙЛСЫ,Б№Им👀👀👀