在典型的联邦学习中,不同设备之间的数据分布差异很大。为了缓解这种统计异质性的不利影响,《Federated learning with personalization layers》这篇文章给出了一个新的思路:将模型分为基础层和个性化层,提出了名为 FedPer 的架构。与联邦迁移学习(即首先对所有层进行全局训练,然后对所有或个别层进行局部数据再训练)不同,FedPer 先在全局数据上训练基础层,再在本地数据上训练个性化层,避免了联邦迁移学习需要重训练的问题。
《Exploiting Shared Representations for Personalized Federated Learning》所提出的 FedRep 算法就类似于 Base + Personalization Layers 的形式。但它基于“数据间通常存在一个 global feature representation,而 client 或 task 之间的统计异质性主要集中在 labels 上”这一直觉,提出用基础层来学习数据间的 global feature representation 的降维表示,以缓解 Non-IID 对模型训练的影响,用个性化层作为每个 client 唯一的 local head 实现个性化。
那废话不多说,我们直接看这个算法长什么样。下图就是FedRep的图示结构
- global representation φ : R d → R k φ : R^d → R^k φ:Rd→Rk,将从本地数据中学到的global feature representation由高维空间map到低维空间中;
- local head h : R k → y h : R^k → y h:Rk→y,根据低维representation输出结果;
训练过程中,每个client共同训练 global representation:φ, 再用各自的数据训练自己的 local head:h
值得注意的是,k<<d,也就是说local head:h需要训练的参数量很少,这也就意味着local head:h可以在较小的计算代价下进行多轮训练。
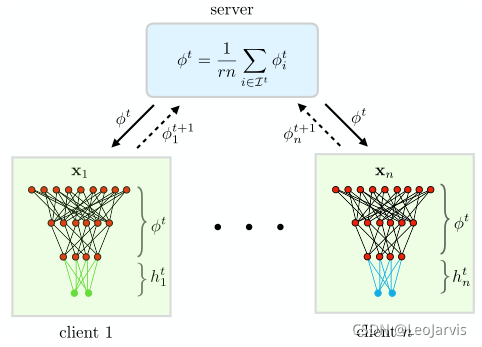
FedRep算法流程
目标函数为
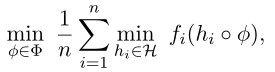
伪代码如下:

每个client的本地更新都需要分成两步,需要注意的是,这两步更新用的是同一批样本。
即先更新local head:h,由于h的参数量很小,所以可以进行多轮更新。
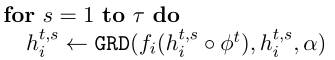
再基于更新后的 h 更新 global representation:φ,由于φ的参数量较大,所以一般只更新一次。
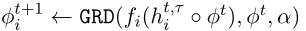
其中 GRD(f, h a) 表示学习率为a,用SGD等方式计算 f 的梯度以更新 h。
本文还解释了为什么要用个性化 FL 而不能用传统意义的 FedAvg 聚合全局模型:
对于传统 FL ,其目标函数是 :
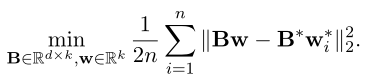
而个性化 FL 的目标函数是 :
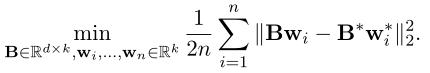
其中
B
?
w
i
?
B^*w_i^*
B?wi??是指 ground-truth 的模型表示。
由两者的目标函数可以看出,传统FL的目标是让全局模型去逼近 ground-truth,而个性化 FL 是让每个 client 的本地模型去逼近 ground-truth ,显然,肯定是个性化 FL 的结果会更好,每个client都能有一个很好的个性化模型,而不是共享一个折中的模型。
对于新加入的 client,要怎么初始化模型呢?
global representation:φ 可直接用于 new client,也就是说,new client 仅需训练 local head:h,且由于 h 的参数量较小,可以很快为 new client 的训练出一个个性化模型。