这篇文章主要解决以下问题
1数据库连接池的整合
2何为连接池?(内存中一块存储“可重用连接对象的空间”)
3为什么使用连接池(提高其性能-反复创建和销毁连接会带来很大的性能损耗)
4为什么说创建连接和销毁连接会有很大性能损耗(底层建立连接使用的是TCP/IP协议,基于此协议创建连接需要三次握手,释放连接需要四次握手)
在C/S架构,提高服务端响应的数据速度降低响应时间影响因素可能有以下几点
1请求数据的传输时间 (数据量,带宽)
2请求数据的处理时间(架构,算法,CPU,磁盘,内存)
3响应数据的传输时间?(数据量,带宽,缓冲)
4响应数据的渲染时间? ?(html,css,js,images)如果js在head里js文件较大则先执行js再展现数据 如果再body里把数据放在js前面则数据先渲染再执行js
数据库连接池代码设计:
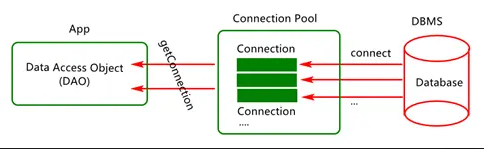
?在系统初始化的时候,在内存中开辟一片空间,将一定数量的数据库连接作为对象存储在对象池里,并对外提供数据库连接的获取和归还方法。用户访问数据库时,并不是建立一个新的连接,而是从数据库连接池中取出一个已有的空闲连接对象;使用完毕归还后的连接也不会马上关闭,而是由数据库连接池统一管理回收,为下一次借用做好准备。如果由于高并发请求导致数据库连接池中的连接被借用完毕,其他线程就会等待,直到有连接被归还。整个过程中,连接并不会关闭,而是源源不断地循环使用,有借有还。数据库连接池还可以通过设置其参数来控制连接池中的初始连接数、连接的上下限数,以及每个连接的最大使用次数、最大空闲时间等,也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。 私否上看到的很好的总结
?代码设计:
第一步添加依赖
<dependency>
<!--当前添加data-jdbc依赖时会自动下载HikariCPy依赖-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<!--连接数据库的驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>第二步配置
#spring datasource
spring.datasource.url=jdbc:mysql:///dbgoods?serverTimezone=GMT%2b8&characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=root
第三步根据此图进行编码测试
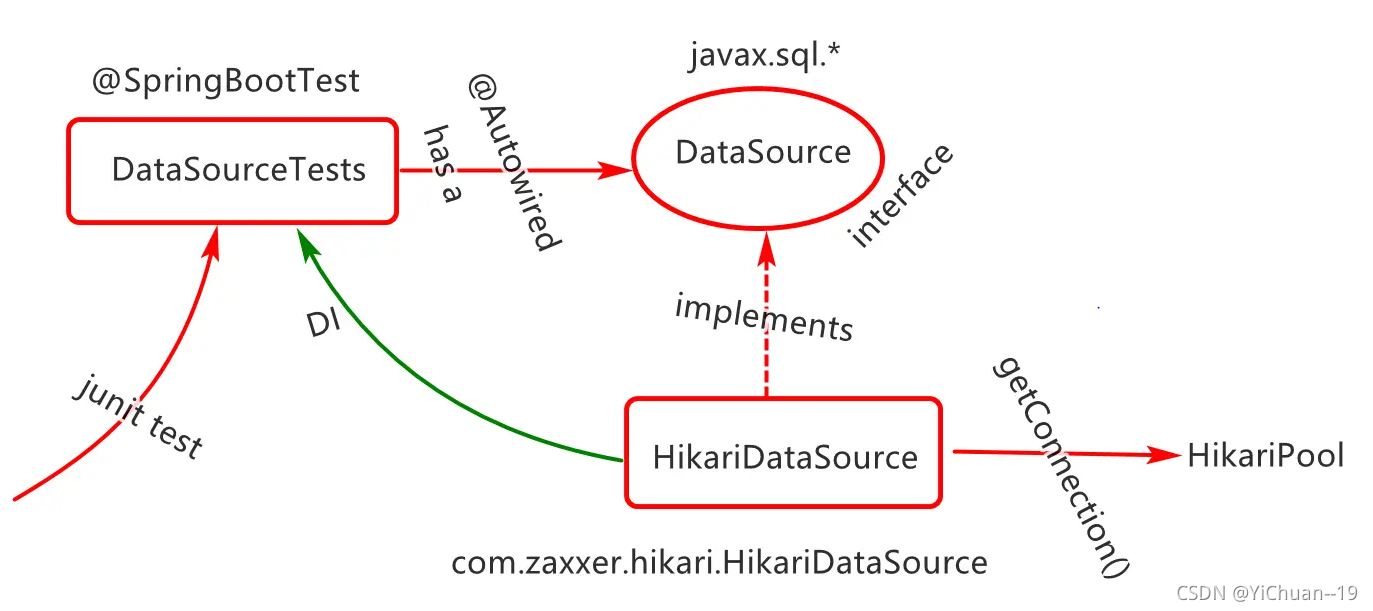
package com.cy.datasouire;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.sql.DataSource;
import java.sql.SQLException;
/**
* 从数据库连接池中获取一个链接,并输出链接信息
* 1获取连接池(java中所有的连接池必须实现一个规范java.sql.DataSource)
* 在程序中需要提高DataSource接口的具体实现就是添加连接池规范
* 2那到连接注入测试类
*/
@SpringBootTest
public class DataSourTest {
//运行时dataSource指向的对象是HikariDataSource
@Autowired
private DataSource dataSource;
@Test
void testGetConnection() throws SQLException {
//此链接从池中获取
System.out.println(dataSource.getConnection());
}
}
?从连接池中获取链接并进行查询
代码结构图
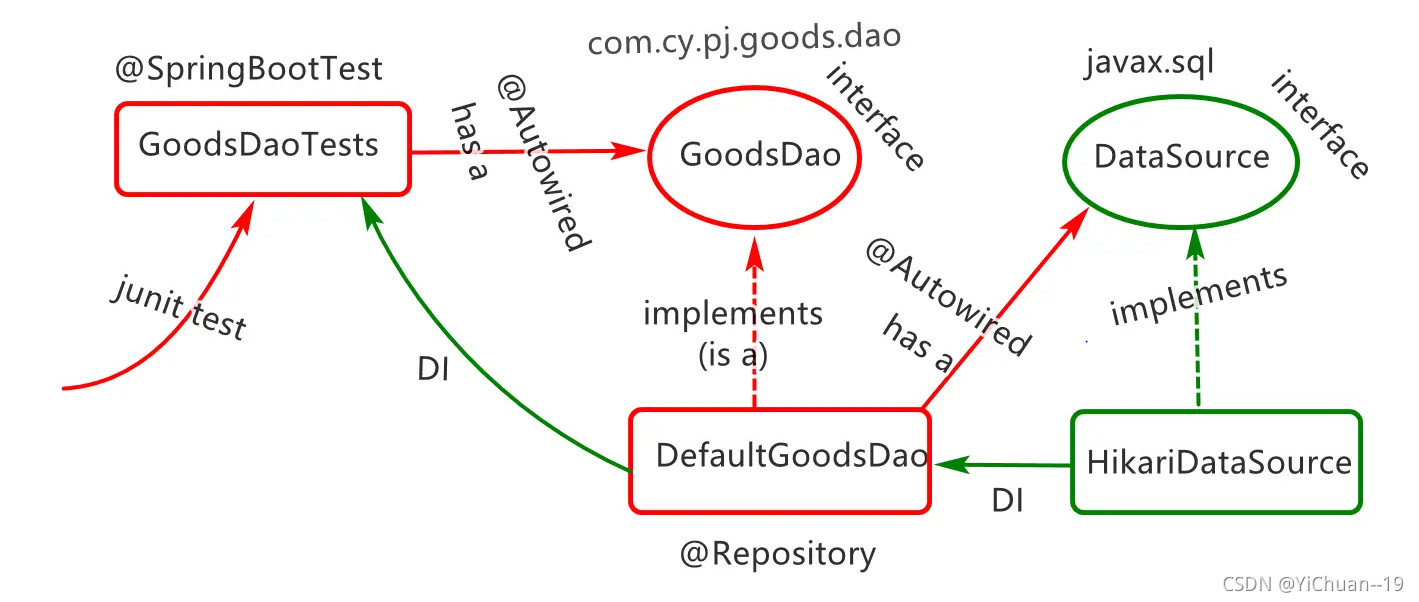
?代码如下:定义接口
package com.cy.pj.goods.dao;
import java.util.List;
import java.util.Map;
public interface GoodsDao {
List<Map<String,Object>> findGoods() throws Exception;
}
接口实现类的编写
package com.cy.pj.goods.dao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import javax.sql.DataSource;
import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @Repository 是spring框架中定义一个描述数据层bean对象的注解
*/
@Repository//是一个特殊的Component对象
public class DefaultGoodsDao implements GoodsDao {
@Autowired
private DataSource dataSource;
Map<String,Object> rowMap(ResultSetMetaData remd,ResultSet rs) throws Exception {
Map<String,Object> map=new HashMap<>();
for (int i=1;i<=remd.getColumnCount();i++){//循环去除所有字段的值
map.put(remd.getColumnName(i), rs.getObject(remd.getColumnName(i)));
}
return map;
}
void close( Connection conn,Statement stmt,ResultSet rs){
if (rs != null) try {
rs.close();
} catch (SQLException e) {
}
if (stmt != null) try {
stmt.close();
} catch (SQLException e2) {
}
if (conn != null) try {
conn.close();
} catch (SQLException e3) {
}
}
@Override
public List<Map<String, Object>> findGoods() throws Exception {
Connection conn = null;
Statement stmt = null;
String sql = "select * from tb_goods;";
ResultSet rs = null;
//获取连接
try {
conn = dataSource.getConnection();
//创建传输器
stmt = conn.createStatement();
//发送sql
rs = stmt.executeQuery(sql);
//处理结果
List<Map<String, Object>> list = new ArrayList<>();
ResultSetMetaData rsmd= rs.getMetaData();//源数据描述数据的数据的对象
while (rs.next()) {//循环一次取一次
// Map<String, Object> map = new HashMap<>();
// map.put("id", rs.getInt("id"));
// map.put("name", rs.getString("name"));
// map.put("remark", rs.getString("remark"));
// map.put("createdTime", rs.getTimestamp("createdTime"));
// list.add(map);
//映射翻案2由于重用性很差所以又rowMap方法修改
list.add(rowMap(rsmd ,rs));
}
return list;
} catch (SQLException e) {
e.printStackTrace();
return null;
}
finally {
close(conn,stmt,rs);
}
}}
测试代码
package com.cy.datasouire;
import com.cy.pj.goods.dao.GoodsDao;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Map;
@SpringBootTest
public class GoodDaoTest {
@Autowired
private GoodsDao goodsDao;
@Test
void aa() throws Exception {
List<Map<String,Object>> list =goodsDao.findGoods();
for (Map<String,Object> map:list){
System.out.println(map);
}
}
}
连接池的连接数配置?spring.datasource.hikari,maximum-pool-size=2*cpu核数+磁盘数量
当我们设计一个池需要考虑的问题
1池的存储结构 (数组链表)
2从池中取用什么方法算法换
3池的操作的线程安全(如何在保证线程安全的情况下还要很好的性能)
3.1如何保证对象的线程安全以及导致线程不安全的因素
多线程不安全的因素有多线程并发 多线程有共享数据集 多线程在共享数据集上的操作不是原子操作(一个线程在没有完成当前操作时,不能有其他线程介入)多线程在共享数据集上有读写操作并且不是原子操作
解决方案 取消并发 取消数据共享(列如java中不能多线程同时共享一个Connection对象) 保证多线程在共享数据集上的操作为原子操作(列如加锁,CAS算法)
HikariCP底层储存链接使用的是数组结构 借和还都是随机 线程安全应用到CAS算法
在HikariPool这个类中有一个对象 ConcurrentBag对象这个对象就是并发口袋中文意思
ConcurrentBag对象中又有个对象CopyOnWriteArrayList对象 此对象底层存储是一个ArrayList
先更新在写入 因为要保证线程安全 不能直接加锁不然影响并发? CAS则是基于cpu内核实现的
java中连接池规范是 java.sql.DataSource 使用规范可以让代码更严谨 其可维护性也会更好 可以通过此接口获取具体连接池对象
java是Driver和连接池建立连接
连接池用到了享元设计模式:主要用于减少创建对象的数量,以减少内存占用和提高性能 几乎所有的池都会用到此模式