联邦持续学习的目的
联邦持续学习意在将联邦学习和持续学习相结合,以解决 “每个客户端从私有本地数据流中学习一系列任务,不同客户端之间也可以互相借鉴彼此已有的知识以增强自身的学习效果” 的场景,目前这方面的研究还很少。
联邦持续学习的挑战
和持续学习类似的,联邦持续学习也面临“灾难性遗忘”;此外,由于不同客户端训练的任务可能存在很大的差别,联邦持续学习训练过程中每个客户端还面临“来自其他客户端的干扰”;再者,由于每个客户端都希望能从其他客户端的相似任务中获得共识知识,“通信代价”也成为了一个不可忽视的问题。
FedWeIT
ICLR 2021有一篇文章――《Federated Continual Learning with Weighted Inter-client Transfer》提出了一种联邦持续学习的方法:Federated Weighted Inter-client Transfer(FedWeIT)。该算法的目的是最小化不同性质的任务之间的互相干扰,最大化相似任务之间共识知识的传递。
具体来讲,将每个客户端的网络参数分解为 global federated parameters 和 sparse task-specific parameters,以减少不同任务之间的干扰。而且,每个客户端可以选择性地使用其他客户端的 task-specific parameters,具体是通过服务端获得其他客户端的 task-specific parameters,再对这些参数进行加权聚合得到 selective knowledge,从而最大化相似任务之间共识知识的传递。
FedWeIT的思想其实跟 ADP 这种持续学习方法很像,ADP 这一方法具体可以看我之前的这篇文章:《持续学习――Continual Learning With Additive Parameter Decomposition》。看懂了 Additive Parameter Decomposition (ADP) 这一方法就能很容易地理解 FedWeIT 了。
根据上述概念,下面从公式的角度理解 FedWeIT
具体任务的模型定义
- 全局参数 ( θ G θ_G θG?) 用于捕获所有客户的全局共识知识
- local base parameters (B) 用于捕获每个客户自身所有任务的共识知识(这个参数相当于 ADP 中的 task-shared parameter)
- task-adaptive parameters (A) 用于捕获每个客户的特定任务的知识。
客户端
c
c
c_c
cc? 训练任务 t 时的模型参数
θ
c
(
t
)
θ_c^{(t)}
θc(t)? 定义如下,其中
m
c
(
t
)
m_c^{(t)}
mc(t)?为 masking variable, 其作用与 ADP 中的
M
t
M_t
Mt? 一样,在这里就是引导学习者只关注与当前任务相关的部分。
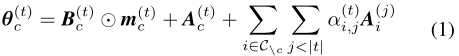
如果理解了 ADP 的话,模型参数
θ
c
(
t
)
θ_c^{(t)}
θc(t)? 的意义也就很明显了,为了帮助大家理解,我还是把原文的解释贴上来。
The first term allows selective utilization of the global knowledge. We want the base parameter
B
c
(
t
)
B^{(t)}_c
Bc(t)? at each client to capture generic knowledge across all tasks across all clients. In Figure 3 (a), we initialize it at each round t with the global parameter from the previous iteration,
θ
G
(
t
?
1
)
θ^{(t?1)}_G
θG(t?1)? which aggregates the parameters sent from the client. This allows
B
c
(
t
)
B^{(t)}_c
Bc(t)? to also benefit from the global knowledge about all the tasks. However, since
θ
G
(
t
?
1
)
θ^{(t?1)}_G
θG(t?1)? also contains knowledge irrelevant to the current task, instead of using it as is, we learn the sparse mask
m
c
(
t
)
m^{(t)}_c
mc(t)? to select only the relevant parameters for the given task. This sparse parameter selection helpsminimize inter-client interference, and also allows for efficient communication. The second term is the task-adaptive parameters
A
c
(
t
)
A^{(t)}_c
Ac(t)?. Since we additively decompose the parameters, this will learn to capture knowledge about the task that is not captured by the first term, and thus will capture specific knowledge about the task
T
c
(
t
)
T^{(t)}_c
Tc(t)?. The final term describes weighted inter-client knowledge transfer. We have a set of parameters that are transmitted from the server, which contain all task-adaptive parameters from all the clients. To selectively utilizes these indirect experiences from other clients, we further allocate attention
α
c
(
t
)
α^{(t)}_c
αc(t)? on these parameters, to take a weighted combination of them. By learning this attention, each client can select only the relevant task-adaptive parameters that help learn the given task. Although we design
A
i
(
j
)
A^{(j)}_i
Ai(j)? to be highly sparse, using about 2 ? 3% of memory of full parameter in practice, sending all task knowledge is not desirable. Thus we transmit the randomly sampled task-adaptive parameters across all time steps from knowledge base, which we empirically find to achieve good results in practice.
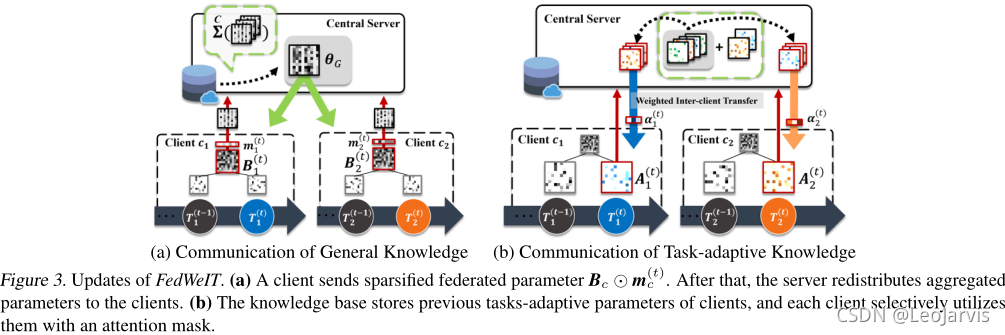
模型训练
目标函数如下:
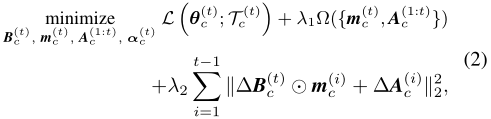
其中,L 为损失函数,Ω(・) 为所有 task-adaptive parameters 和 masking variable 的稀疏诱导正则化项(这里为
L
1
L_1
L1? 正则化”),使它们变得稀疏以降低通信代价、提升计算效率。第二个正则化项用于追溯更新之前的 task-adaptive parameters。其中,
?
B
c
(
t
)
?B^{(t)}_c
?Bc(t)? =
B
c
(
t
)
B^{(t)}_c
Bc(t)? ?
B
c
(
t
?
1
)
B^{(t-1)}_c
Bc(t?1)? 为基础参数在当前时间步与上一时间步的差值,
?
A
(
i
)
?A^{(i)}
?A(i) 为任务 i 在当前时间步与上一时间步的 task-adaptive parameters 的差值。这种正则化对于防止 “灾难性遗忘” 至关重要。λ1 和 λ2 是控制这两个正则化效果的超参数。
伪代码
