原文地址:Multi-object representation learning with iterative variational inference

提出一种名为“IODINE”的方法,实现对多目标图像的解耦。
 ?
?
?摘要翻译:
人类的感知是围绕着物体进行的,它构成了我们高层次认知和令人印象深刻的系统概括能力的基础。然而,大多数关于表征学习的工作都集中在特征学习上,甚至没有考虑多个物体,或者将分割作为一个(通常是监督的)预处理步骤。相反,我们论证了学习分割和表示对象的重要性。我们证明,从一个场景由多个实体组成的简单假设出发,有可能学习将图像分割成具有分离表征的可解释对象。
我们的方法在没有监督的情况下,学会了对被遮挡的部分进行涂抹,并推断出有更多物体的场景和有新特征组合的未见过的物体。我们还表明,由于使用了迭代变异推理,我们的系统能够为模糊的输入学习多模式后验,并自然地扩展到序列中。
Introduction(节选):
本文认为在场景中物体的发现(discovery)应视作 Representation Learning的重要部分,而不是视作一个单独的问题。
从空间混合模型(Spatial mixture model)角度来处理该问题,并在variational framework(变分框架?)中使用潜在对象表征的摊销迭代细化(amoritized iterative refinement)。
将关于对象存在的基本直觉(basic intuition)编码进模型中,这同时有利于对象的发现和实现完全由数据驱动的无监督方式的有效表示。
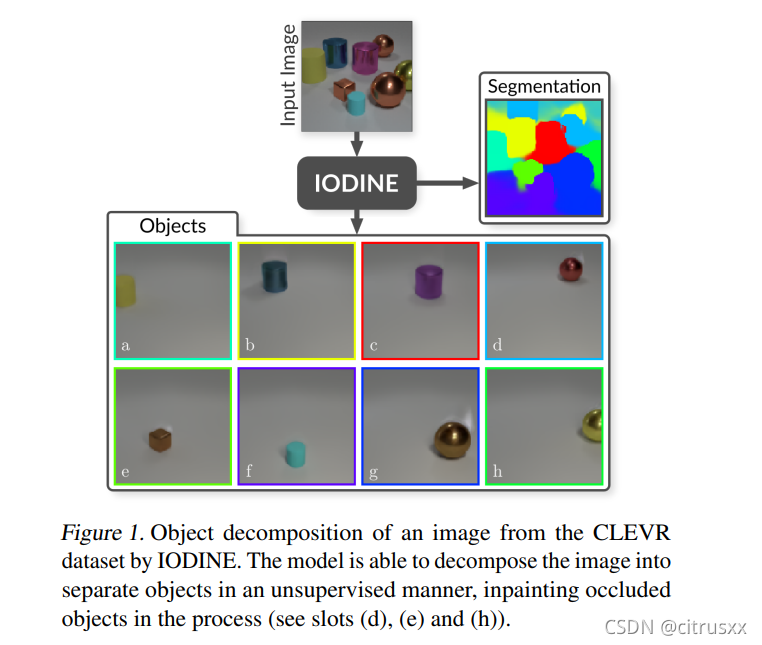
IODINE可对数据集CLEVR, Objects Room (Burgess et al., 2019), and Tetris (see Appendix B) 进行复杂场景的分割,并无监督的学习解耦物体特征。
?
方法:
由三部分组成:
- 在生成框架(Generative modelling)内表达多目标表征学习。
- 基于成功的VAE框架,使用变分推断(Variational inference)联合学习生成和推理模型。讨论多对象时的特殊挑战,并使用迭代摊销解决该问题。
- 整合所有元素并展示完整的系统如何进行端到端的训练。
1.??在生成框架(Generative modelling)内表达多目标表征学习。
标准VAE使用的方法不适用组合对象结构。为了实现系统概括(Systematic generalization),提出使用 multi-slot 表征, 其中给每个slot共享基本的表征格式,且可描述独立部分。
例如结构上看,Figure1中场景由八个对象组成,每个有自己的属性如形状,大小,颜色,位置和材料。为了分离对象,标准VAE会使用单独的特征维度来表示每个物体,但事实是这些物体是拥有共同属性的可互换对象。
生成模型:
使用K个潜在物体表征,来表示每个场景。由此生成输入图像
。
假设是独立的,且共享生成机制,这样无论任何排序都可生成相同图像。
图像使用空间高斯混合模型(Spatial Gaussian Mixture Model)建模?,每个slot对应一个单独的对象。
即每个对象变量被解码为一个像素级的平均值
(物体的外观)和一个图像级的Assignment
?(Segmentation Mask)。 假设像素
是独立与
, 似然估计为:
?
对所有对象使用一个全局固定方差。
解码器结构:
由图2(d)可知,每一物体的潜在被分别解码为像素级别的平均值
和Mask-logits
,然后用一个横跨各slot的softmax操作进行归一化,使得每个像素的mask
和为1。
和
?一起完成了参数化空间混合分布。
使用Broadcast decoder,在空间上复制潜在变量,并复制两个坐标向量(水平,垂直,-1~1),再应用一系列的 size-preserving卷积层。该结构可以将整个图像的位置与其他变量(颜色,纹理等)分离开,并大体上支持解耦。为了保持共同的格式,所有的slot?
共享权重,独立解码,直至mask归一化。
2. 推论
与VAE相似,使用摊销变分推断(amortized variational inference)获取近似的后验,参数为高斯
。
但存在其他问题:
- 作为空间混合模型,需要推断对象(如物体外观)和混合(如物体的segmentation)。传统上一般使用迭代过程解决,因为缺乏有效的直接解决方案。
- 每个slot在原理上可以解释任何像素。当一个像素由其中一个slot解释后,其他的slot将不再关注它。在解释关系上的强耦合将推断复杂化。还会导致多模态后验(Multimodal posterior)。
因此使用一个更有效的推断方法。
迭代推理:
从对后验参数 λ 的任意猜测开始,然后使用来自当前后验估计的输入和样本迭代细化。
?使用一个与训练的细化网络,但与原作不同,此时仅考虑对后验的加法更新,并使用几个突出的辅助输入到细化网络。独立且平行地更新K个slot的后验。Slot仅在输入层交互。
 ?
?
?对于细化网络,使用卷积网络和LSTM。与常见的VAE编码器不同,该细化网络可以被认为是梯度后验的摊销。后验和似然估计的交替更新可以被视为信息传递。
 ?
?
该算法的伪代码如下:
 ?
?
输入:
对于每个Slot?,均向细化网络
![]() 提供一组辅助输入
提供一组辅助输入并用其计算后验概率
![]() 的更新。输入还包括关于ELBO的梯度信息。该信息提供了哪些信息尚未被其他slots解释。
的更新。输入还包括关于ELBO的梯度信息。该信息提供了哪些信息尚未被其他slots解释。
输入的为:图像
, 均值
,mask
,mask-logits?
,均值梯度
,mask梯度
, 后验梯度
, 后验mask
, 像素级别似然估计
,leave-one-out似然估计
, 和decoder中两个坐标通道。
?3. 训练
使用通过unrolled iterations 的梯度下降训练如下参数:decoder(![]() ),细化网络(
),细化网络(![]() ),初始后验(
),初始后验(![]() )。?
)。?
?原则上只需要最小化最后的负ELBO![]() 即可,但使用包含早期条件的加权和更有效。公式如下:
即可,但使用包含早期条件的加权和更有效。公式如下:

每一步细化都使用梯度信息优化后验。但通过该过程的反向传播会导致数值不稳定。
停止梯度通过梯度梯度输入,
,
的反向传播可解决这个问题。
结果:
 ?IODINE成功地学习了分离的表征,因为它能够首先分解场景,然后表示单个物体(图6右)。在?图6 中,我们展示了标准VAE与IODINE的最重要特征(由KL选择)的遍历。虽然标准的VAE明显地将许多属性纠缠在一起,甚至跨越多个物体,但IODINE能够整齐地将它们分开。
?IODINE成功地学习了分离的表征,因为它能够首先分解场景,然后表示单个物体(图6右)。在?图6 中,我们展示了标准VAE与IODINE的最重要特征(由KL选择)的遍历。虽然标准的VAE明显地将许多属性纠缠在一起,甚至跨越多个物体,但IODINE能够整齐地将它们分开。
 ?
?
另外,重要的两个超参数分别是迭代次数和Slot数量。
- 迭代次数:
推理在最初的3-5次迭代中迅速收敛,之后,分割和重建都没有什么变化。第二个重要的发现是,该系统在比它所训练的迭代次数长得多的时间里都非常稳定。当模型运行更多的迭代时,它甚至进一步改善了分割和重建,尽管在大约两到三倍的训练迭代次数后,它最终开始发散。
 ?
?
- ?Slot数量:
Slot数量控制了系统可以分离的最大对象数量。如果模型在训练时有足够多的Slots来适应所有的物体(K=7,K=9),那么测试时会生成很好的test-time behavior。
如果该模型的训练Slots 过少(K=3和K=5),其性能就会受到很大影响。发生这种情况是因为,在这里,在训练期间重建整个场景的唯一方法是在每个Slot中持续地表示多个物体。而这导致了模型学习低效和entangled的表征。
 ?
?