���ֲ���,�������,�������,ֻ��ת��ע������:
https://blog.csdn.net/newchenxf/article/details/119803489
GPU ��Ⱦ��������ɫ�� ����ܽ� ---- һƪ��
1 ǰ��
��ͼ��ͼ��,��Ҫ��GPU;
Ҫ��GPU,����Ҫ�Ƕ���Ⱦ����(���߽���ˮ��);
����Ⱦ����,����Ҫ�Ļ��ھ���shader,����ɫ����
���Ա��ij����ܽ�GPU����Ⱦ���̺�shader,����Ϊͼ�������Ž̡̳�
2 ��Ⱦ����
����,�ֳ���ˮ�ߡ�
ʲô����ˮ����?
��ˮ����ָ���ظ�ִ��һ������ʱ,����ϸ�ֳɺܶ�С����,����ЩС�����ص�ִ��,��������������Ч�ʡ�
�ٸ�����:
ж�����˹�,3���˴ӳ��ϰᵽ���3���˷ֱ���A, B, C��
A��B,B��C,C�����
A����Ҫ��C�ŵ�����,�ٿ�ʼ��һ�εİ���,����C�ڰ�Ĺ�����,�Ϳ��Կ�ʼ��ڶ��������ˡ�
CPU�Ĵ���,��ʵҲ������ˮ����,����һ��ָ���ִ��,��ֳ��������:ȡָ����롢ȡ����,�����д�����Ȼ�����̸�����İ��˹���ࡣ
����Ⱦ����,���Ǹ���һ����ά�����еĶ��㡢��������Ϣ,ת����һ�Ŷ�άͼ�����������CPU + GPU ��ͬ��ɡ�
ͨ����һ����Ⱦ���̷�3����:
(1) Ӧ�ý�
(2) ���ν�
(3) ��դ����
Ӧ�ý���CPU���,���ν� �� ��դ���� ��GPU��ɡ�
��Ȼ��,��Ȼ����ˮ��,��ζ��3���ε�ִ�����첽�ġ�Ҳ����,CPUִ������,����ҪGPUִ����ſ�ʼ��һ�ε��á�
����,GPUִ�еļ��νκ�դ����,Ҳϸ����������,Ҳ��ʹ����ˮ�ߵļ�����
2.1 CPU��GPU����β��й�����?
�𰸾�������������������������һ��������С�CPU��������,GPU��ȡ���
��CPU��Ҫ��ȾһЩ����ʱ,�������������������;��CPU���һ����Ⱦ�����,���Դӻ���������ȡ�����ִ�С�
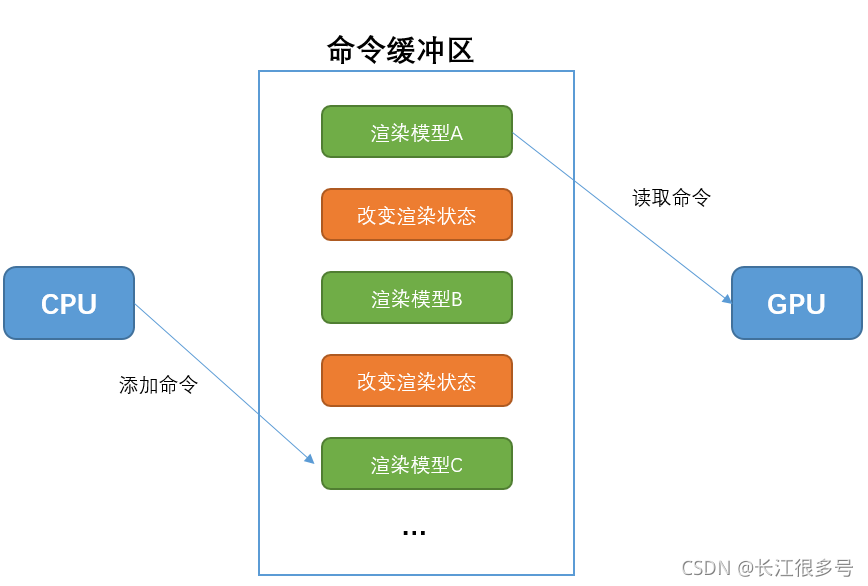
��ɫ�ġ���Ⱦģ�͡�,��������˵��Draw Call��
�ٸ�һ��openGL������:
GLES20.glDrawArrays(GLES20.GL_TRIANGLE_STRIP, 0, 4);
��ɫ�ġ��ı���Ⱦ״̬��,���Ǽ�������,�ı���ɫ��,�л�����ɶ��,�ٸ�openGL������:
GLES20.glUseProgram(program);
GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, textureId);
3 CPU���� ---- Ӧ�ý�
��Ҫ����:
(1) �����ݼ��ص��Դ�(GPU���ڴ�)
(2) ������Ⱦ״̬
(3) ����Draw Call
3.1 �����ݼ��ص��Դ�
GPUһ�㲻��ֱ�ӷ����ڴ�,�����Լ����˸��ڴ�,���Դ�(�Կ��ڴ�)��CPU��һЩ��Ⱦ�������ݴ�Ӳ�̻�������ص��ڴ�,Ȼ���͵��Դ档
��������Ҫ������,ģ������(��������+��������)������ͼ������������������С,�編�߷����ص��Դ��,��CPU���ڴ��е�����,����ɾ��,������bitmap����һ������,���ص�GPU��Ϳ��Ի����ˡ�
3.1.1 ����ģ����������
������һ��android��Ƶ������Ⱦ������,��˵����μ���ģ�����ݡ�
��Ƶ����һ����ά�ľ��ο�����ʾ,����ֻ��Ҫ4����������,�Լ���Ӧ��4���������ꡣ�����õ�����Ƶ������ͼ��
//��������
private float[] vertexData = {
-1f, -1f,
1f, -1f,
-1f, 1f,
1f, 1f
};
//������������
private float[] fragmentData = {
0f, 0f,
1f, 0,
0f, 1f,
1f, 1f
};
public void onCreate() {
//��������������JVM���ڴ�,���Ƶ�ϵͳ�ڴ�
vertexBuffer = ByteBuffer.allocateDirect(vertexData.length * 4)
.order(ByteOrder.nativeOrder())
.asFloatBuffer()
.put(vertexData);
vertexBuffer.position(0);
//��������������JVM���ڴ�,���Ƶ�ϵͳ�ڴ�
fragmentBuffer = ByteBuffer.allocateDirect(fragmentData.length * 4)
.order(ByteOrder.nativeOrder())
.asFloatBuffer()
.put(fragmentData);
//VBOȫ�����㻺�����(Vertex Buffer Object),����Ҫ�����þ��ǿ���һ���Եķ���һ�����������ݵ��Կ���
int [] vbos = new int[1];
GLES20.glGenBuffers(1, vbos, 0);
vboId = vbos[0];
//�����ľ����,���ڴ�����ݸ��Ƶ��Դ���
GLES20.glBindBuffer(GLES20.GL_ARRAY_BUFFER, vboId);
GLES20.glBufferData(GLES20.GL_ARRAY_BUFFER, vertexData.length * 4 + fragmentData.length * 4, null, GLES20. GL_STATIC_DRAW);
GLES20.glBufferSubData(GLES20.GL_ARRAY_BUFFER, 0, vertexData.length * 4, vertexBuffer);
GLES20.glBufferSubData(GLES20.GL_ARRAY_BUFFER, vertexData.length * 4, fragmentData.length * 4, fragmentBuffer);
}
�������Ѿ�����ע��,�������ﻹ�ǿ�����˵��һ�¡�
vertexData �Ͼ���java����ı���,ʹ�õ�JAVA��������ڴ�,������ϵͳ�ڴ�,û�취ֱ�Ӹ�GPU�ġ�����,����ByteBuffer,��vertexData������ϵͳ�ڴ档
����,����һ�����㻺�����(Vertex Buffer Object),����Ҫ�����þ��ǿ���һ���Եķ���һ�����������ݵ��Կ��ϡ�Ȼ��,����glBufferData,�����ݿ������Կ��ڴ���!��������GPU��ʼ����ʱ,�Ϳ��Կ��ٷ����ˡ�
3.1.2 ��������������
��������һ��android app��������ͼ�������:
public static int createTexture(Bitmap bitmap){
int[] texture=new int[1];
//��������
GLES20.glGenTextures(1,texture,0);
//��������
GLES20.glBindTexture(GLES20.GL_TEXTURE_2D,texture[0]);
//������С����Ϊʹ��������������ӽ���һ�����ص���ɫ��Ϊ��Ҫ���Ƶ�������ɫ
GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_MIN_FILTER,GLES20.GL_NEAREST);
//���÷Ŵ����Ϊʹ��������������ӽ������ɸ���ɫ,ͨ����Ȩƽ���㷨�õ���Ҫ���Ƶ�������ɫ
GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D,GLES20.GL_TEXTURE_MAG_FILTER,GLES20.GL_LINEAR);
//���û��Ʒ���S,��ȡ�������굽[1/2n,1-1/2n]����������Զ������border�ں�
GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_S,GLES20.GL_CLAMP_TO_EDGE);
//���û��Ʒ���T,��ȡ�������굽[1/2n,1-1/2n]����������Զ������border�ں�
GLES20.glTexParameterf(GLES20.GL_TEXTURE_2D, GLES20.GL_TEXTURE_WRAP_T,GLES20.GL_CLAMP_TO_EDGE);
if(bitmap!=null&&!bitmap.isRecycled()){
//��������ָ���IJ���,����һ��2D����,�ϴ���GPU
GLUtils.texImage2D(GLES20.GL_TEXTURE_2D, 0, bitmap, 0);
}
return texture[0];
}
����glGenTextures����һ������id����ʱ��,��û�д���ʵ�����ݡ�
����,����һ������������,Ȼ��,����texImage2D,����ȴ���һ������buffer,Ȼ���bitmap������buffer�ϡ�Ȼ�����¡�����ĺ���������,bitmap�����ݾͿ�����GPU��,���Ը�����Ҫ���ա�
��Ҫǿ������,�����Ǽ��ض��㻹������,��ֻ��Ҫ�ڳ�ʼ��ʱ,һ�������,����Ҫÿ��onDraw������,�����û�������ˡ�
3.2 ������Ⱦ״̬
����������������(ģ��)��α���Ⱦ,�������ĸ�vertex shader/fragment shader,��Դ����,����(����)�ȡ�������Ʋ�ͬ������ʱû���л���Ⱦ״̬,��ôǰ�������,��ʹ��ͬһ����Ⱦ״̬��
3.3 ����Draw Call
ǰ���Ѿ��ᵽ��DrawCall,�������Ѿ�������,��ʵ����һ������,������CPU,���շ���GPU��
��һ��Draw Call����ʱ,GPU�ͻ������Ⱦ״̬(����,����,��ɫ��)�����еĶ������ݽ��м���,GPU��ˮ�߿�ʼ��ת��
�ٴ�ǿ��,
3.4 ��
��һ��ֻ��Ҫ1�μ��ؾ���,����ÿ�λ��ƶ����ء� �ڶ��͵���,��Ҫÿ��onDrawʱ���á�
����Ҳ�û�����Ƶ��ͼƬ��onDraw����,���ٸ�����:
public void onDraw(int textureId)
{
GLES20.glClear(GLES20.GL_COLOR_BUFFER_BIT);
GLES20.glClearColor(1f,0f, 0f, 1f);
//������Ⱦ״̬: program���ݾ����shader����,�������ָ�����ĸ�shader
GLES20.glUseProgram(program);
//������Ⱦ״̬:ָ������
GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, textureId);
//������Ⱦ״̬:��VBO
GLES20.glBindBuffer(GLES20.GL_ARRAY_BUFFER, vboId);
//������Ⱦ״̬:ָ������������VBO�Ĵ�0��ʼ,8������
GLES20.glEnableVertexAttribArray(vPosition);
GLES20.glVertexAttribPointer(vPosition, 2, GLES20.GL_FLOAT, false, 8,
0);
//������Ⱦ״̬:ָ������������VBO�Ĵ�8*4(float��4���ֽ�)��ʼ,8������
GLES20.glEnableVertexAttribArray(fPosition);
GLES20.glVertexAttribPointer(fPosition, 2, GLES20.GL_FLOAT, false, 8,
vertexData.length * 4);
//����Draw Call, GPU ���߿�ʼ����
GLES20.glDrawArrays(GLES20.GL_TRIANGLE_STRIP, 0, 4);
//�������,�ָ��ֳ�
GLES20.glBindTexture(GLES20.GL_TEXTURE_2D, 0);
GLES20.glBindBuffer(GLES20.GL_ARRAY_BUFFER, 0);
}
4 GPU���� ----���ν�
���Ѽ��νκ�դ���η���һ��,��һ��ͼ��
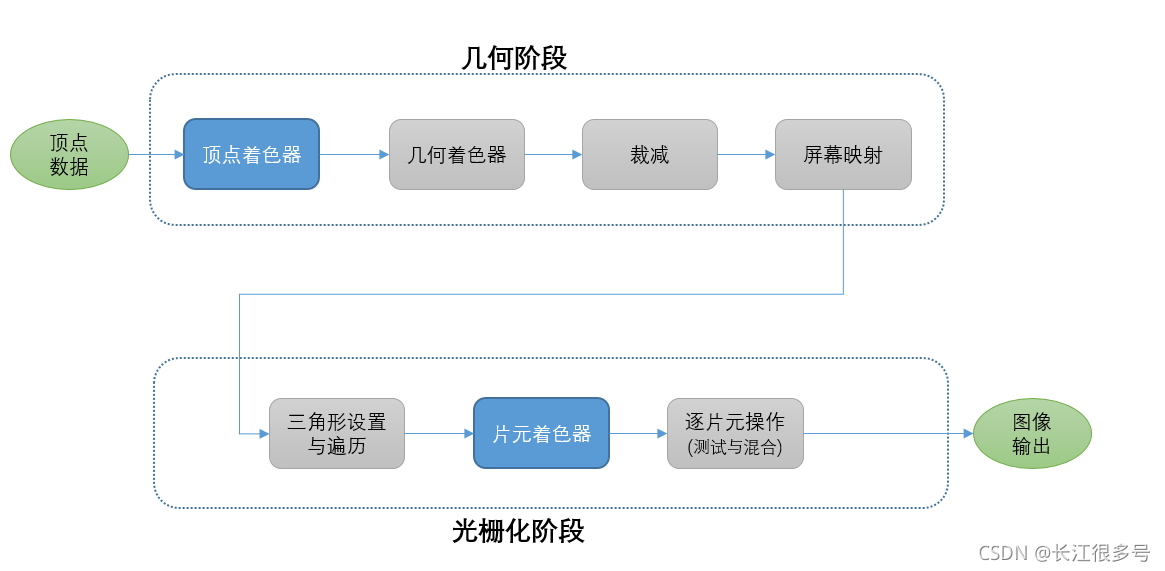
��Ȼ��,��ͼ���ܲ�ȫ,�м���ܻ���Щ��ѡ�IJ���,��ֻ�ǰ�����Ҫ���г�����
����,��ɫ���ֵĶ�����ɫ��,��ƬԪ��ɫ��,�ǿ�������ȫ���Զ����̵�,Ҳ�Ǵ�ͼ��ͬѧ��Ҫ���ĵ�2�����衣
4.1 ����������ʲô
����������˵��:GPU��ʶ������,ֻ�е�,��,�����Ρ�
���Ӧ1������,2������,3�����㡣�������ֳ�ΪͼԪ�������һ����2D����ʹ��,��3D����,��������N���������,��ƴ�ӳ�һ������ģ�͡�
��ͼ��һ������ģ�͵�����:

�Ŵ�һЩϸ��,���ֶ�����������϶��ɡ��������εĶ���,��������˵�Ķ������ꡣ

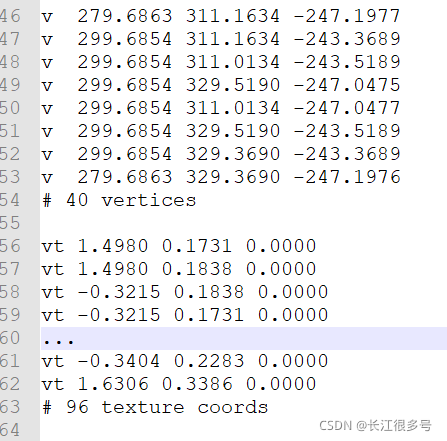
���е����������϶�άͼƬ������,����һ��������ͼ��:

����˵,��������,һ�������������� + �������ꡣ
һ��ģ���ļ�,һ��������������,��������,��������(���������ж���)�ȡ��ٸ�����,��3D max��obj����ģ���ļ�,�Ϳ��Կ��������ı�����:
4.2 ������ɫ��
������ɫ����GPU�ڲ���ˮ�ߵĵ�һ����
���Ĵ�����λ�Ƕ���,Ҳ����ÿ������,�������һ�ζ�����ɫ����
������Ҫ����:����ת���������,�Լ���������(��ƬԪ��ɫ��)�����ݡ�
����ת��,���Ѷ��������ģ������ռ�ת������β�������ռ䡣
�����һ��Unity��shader����,Unity�Ѷ�����ɫ����ƬԪ��ɫ���Ĵ���,�ŵ���һ���ļ���,����Unity���������ļ�,ת��2����ɫ�������,���ݸ�GPU��
Shader "Unlit/SimpleUnlitTexturedShader"
{
Properties
{
// ������ɾ��������ƽ��/ƫ�Ƶ�֧��,
// ����������Dz�Ҫ��ʾ�ڲ��ʼ��������
[NoScaleOffset] _MainTex ("Texture", 2D) = "white" {}
}
SubShader
{
Pass
{
CGPROGRAM
// ʹ�� "vert" ������Ϊ������ɫ��
#pragma vertex vert
// ʹ�� "frag" ������Ϊ����(ƬԪ)��ɫ��
#pragma fragment frag
// ������ɫ������
struct appdata
{
float4 vertex : POSITION; // �����
float2 uv : TEXCOORD0; // ��������
};
// ������ɫ�����("���㵽ƬԪ")
struct v2f
{
float2 uv : TEXCOORD0; // ��������
float4 vertex : SV_POSITION; // �ü��ռ�λ��
};
// ������ɫ��
v2f vert (appdata v)
{
v2f o;
// ��λ��ת��Ϊ�ü��ռ�
//(����ģ��*��ͼ*ͶӰ����)
o.vertex = mul(UNITY_MATRIX_MVP, v.vertex);
// ��������������
o.uv = v.uv;
return o;
}
// ���ǽ����в���������
sampler2D _MainTex;
// ������ɫ��;���ص;���("fixed4" ����)
// ��ɫ("SV_Target" ����)
fixed4 frag (v2f i) : SV_Target
{
// ���������в��������䷵��
fixed4 col = tex2D(_MainTex, i.uv);
return col;
}
ENDCG
}
}
}
�����Ѿ�����������ע�͡�
appdata���Ƕ�����ɫ��������,��������������������ꡣ
ͨ��,������ɫ��ֻ������������,���пռ�ת���� ��������,һ������ƬԪ��ɫ����
�ռ�ת�����뾹Ȼ�����,�����������һ��MVP����!
������,���Ǿͻ���MVP����,��չ��˵һ�¿ռ�ת���ĸ��
4.3 ����ռ�
ʲô������ռ���?��ʵ�������������д������ڡ�����,�������Լ���ڲ���ݴ�����ת100�״�����,��ʱ��,��˵��λ��,��һ���Բ���ݵĴ���Ϊԭ��Ŀռ䡣��������ռ�,��һ����Եĸ��
����Ϸ������Ҳһ����
���ݲ�ͬ�IJ�����,���Է�Ϊģ�Ϳռ�-����ռ�-�۲�ռ�-�ü��ռ�-��Ļ�ռ䡣
��3D������,����������3������,��(x, y, z),��Ϊ�˷�����ƽ��/��ת/���ŵ�ת��,��Ҫ����һ��w��������(x, y, z, w),�����4ά������,��Ϊ������ꡣ��Щ֪ʶ,������ڵ���¼֪ʶ��
������,����������������Щ�ռ䡣
4.3.1 ģ�Ϳռ�
����3D max������һ������ģ��,��ģ�Ϳ��Էŵ��������������䡣 ��ģ���ڲ���˵,��һ������ԭ��,����������ദ,�����������λ���������,����һ������ֵ;
ÿ��ģ�Ͷ���,�����Լ�����������ռ䡣����Ҳ���Գ�Ϊ����ռ����ֲ��ռ���
4.3.2 ����ռ�
������Ϸ�е�һ����ͼ,��Ϊһ��СС������,��ͼ������,������Ϊ����ԭ�㡣����ģ����Ϊһ������,�ŵ���ͼ��,��������Ե�ͼ���ĵ�һ������ֵ�����������ռ䡣
��ģ�Ϳռ������,ת��������ռ������,����ͨ����������õ�����������Model Matrix��
��ʵ��,һ��ģ�ͷŵ���ͼ��,���ܻ�������,Ȼ����ת����ƽ�ơ���3�߶��ж�Ӧ�ľ���,�������¼��
����֮,����������������ڵ�ͼ�е�����,��ת,ƽ�Ʋ��������ġ�
�����Ŀ��,���ǵõ������ij������,�ڵ�ͼ���Ǹ�ʲô����λ�á�
4.3.3 �۲�ռ�
Ҳ���Գ�Ϊ������ռ����۲�ռ�ָ����,��Ϸ��ͼ��ô��,����ֻ�ܿ���һ�������ݡ���������Ϸ��ͼ��,����һ��Camera,��Ҳ��������ռ��С�camera���൱�����ǵ��۾�,camera�յ�����,����������ǿ����Ļ��档
��3D��Ϸ��,�����Ͱ�Camera���û���ɫ����һ�𡣽�ɫ�����ߵ���,Camera������ƶ�����,Ч������,�ߵ���,�Ϳ�������ķ羰!
���Ե�ͼ�е��κ�����,�����Camera��Ϊ����ԭ��,Ҳ��һ�������Camera������ֵ����CameraΪԭ��Ŀռ�,���ǹ۲�ռ��ˡ�
������ռ������,���㵽�۲�ռ�,Ҳ����ͨ����������õ�����������View Matrix��
�����������ʲô������?
����,���������Ҳλ����������ϵ��,�������������������,����ʵ���Ǻܼ�ƽ�ƾ���
��,�����A���������(-3, 0, 0), ����������Ǵ�����ԭ��Oƽ��(-3, 0, 0)�Ľ����������������������Ϊ�µ�ԭ��,��ԭ��������ԭ��O,�൱�ڴ������ƽ��(3, 0, 0)�Ľ����������������ϵ��ת������,������һ��ƽ�ƾ���
��Ȼ��,ʵ����������г���,�Լ��۾������濴,���ǵ���������֪��ɶ�ǵ�����?����ͼ

�������������������������Ӱ�졣
��,һ�������������,���Ǹ��ӵļ�����̡�
glm::mat4 CameraMatrix = glm::LookAt(
cameraPosition, // the position of your camera, in world space
cameraTarget, // where you want to look at, in world space
upVector // probably glm::vec3(0,1,0), but (0,-1,0) would make you looking upside-down, which can be great too
);
4.3.4 �ü��ռ�
�ü��ռ����������ܿ�����������������Ϊ������
����6��ƽ�����,��Щƽ��Ҳ��Ϊ�ü�ƽ������������������,�漰����ͶӰ��ʽ��һ������ͶӰ,һ��������ͶӰ��
��ȫλ�����ռ��ͼԪ,�ᱻ����;
��ȫλ�ڿռ�֮���ͼԪ,��ȫ����;
�Ϳռ�߽��ཻ��ͼԪ,�ᱻ�ü���
��ͼ��һ����ͶӰ��ʾ��ͼ��������ȫ��������,�������½ǵ�Сͼ,�������û�������2D�������ӡ�
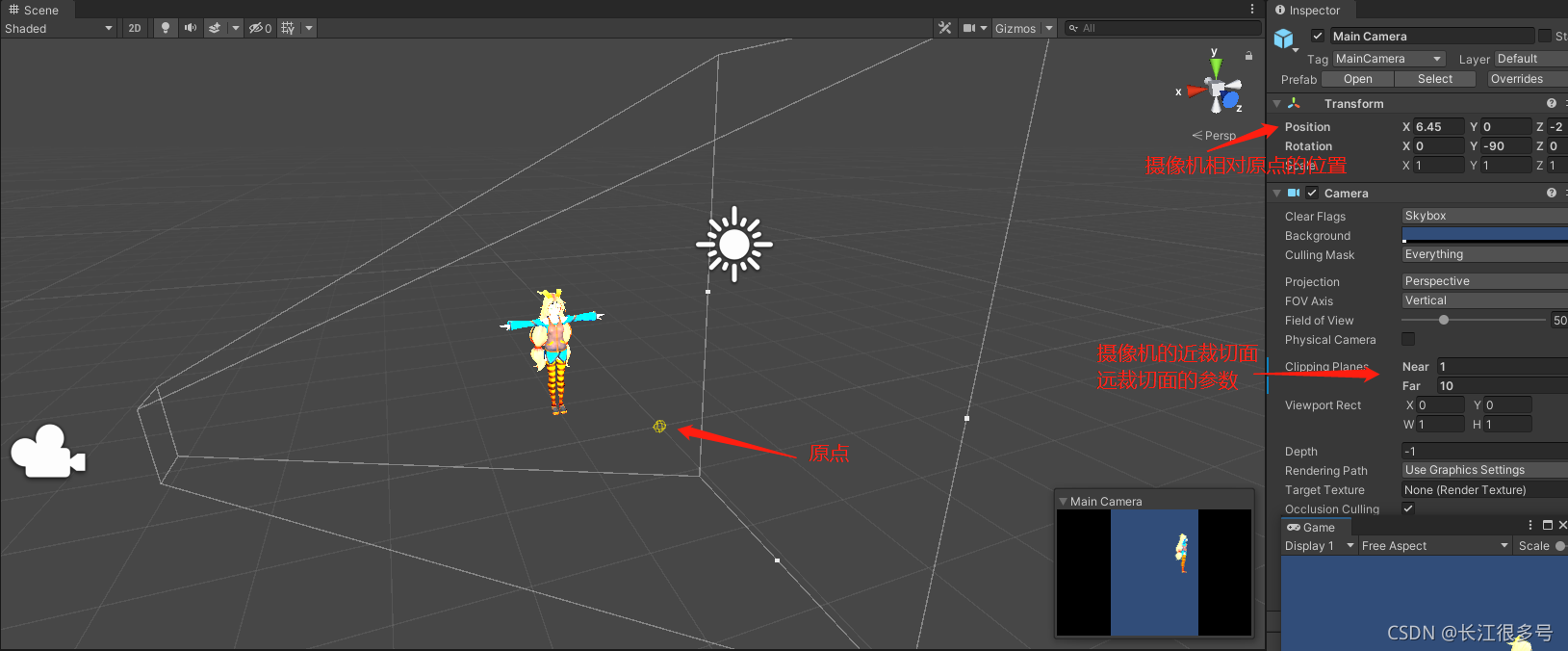
��Ȼ��,ͼ�е�Near ��Far,����Ϊ����ʾ����,�����˱Ƚ�С��ֵ��ʵ����Ϸ��,Near��Far���ܴ�,����Near = 0.1, Far = 1000��������ۿɿ��ķ�Χ�Dz���,�������۾��Ķ���������,�dz�Զ�Ķ���,Ҳ��������
��ô,����ж�һ������������������?
����ͨ��һ��ͶӰ����,�Ѷ���ת����һ���ü��ռ䡣
�������,��������������IJ���������
����ʾ��ͼ����:
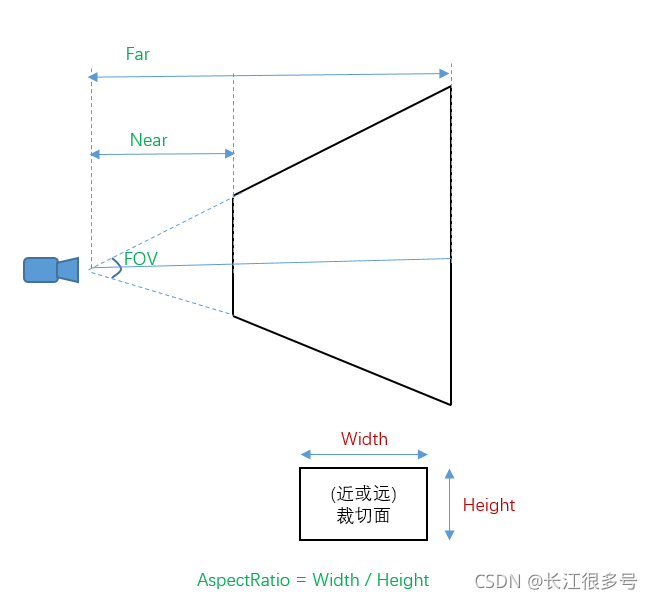
FOV�����ӽǵĶ���(Field of View);
Near��Far�������ԭ��,���������ľ���;
AspectRatio�Dz�����Ŀ��߱�;
�ӹ۲�ռ䵽�ü��ռ�ı仯����,�۳�ΪProjection Matrix��
���������һ������������:
// Generates a really hard-to-read matrix, but a normal, standard 4x4 matrix nonetheless
glm::mat4 projectionMatrix = glm::perspective(
glm::radians(FoV), // The vertical Field of View, in radians: the amount of "zoom". Think "camera lens". Usually between 90° (extra wide) and 30° (quite zoomed in)
AspectRatio, // Aspect Ratio. Depends on the size of your window. such as 4/3 == 800/600 == 1280/960, sounds familiar
Near, // Near clipping plane. Keep as big as possible, or you'll get precision issues.
Far // Far clipping plane. Keep as little as possible.
);
���幫ʽ����ԭ��,����Ͳ�չ����,��������google���߿�����:https://zhuanlan.zhihu.com/p/104768669��
ͶӰ������Ȼ��ͶӰ������,����û����������ͶӰ����������ͶӰ���������� ͶӰҪ����һ��,����Ļ�ռ��ת��,��ʹ�á�
����ͶӰ���������,����˵,���˲ü��ռ��,wֵ�Ͳ�һ����0��1��,������ĺ��塣�������,���һ��������������,��ô���任�������,��������:
-w <= x <= w
-w <= y <= w
-w <= z <= w
������Ҫ���,Ҫô��,Ҫô�ü���
�ٸ�����:
һ������ģ�͵��ֵ�һ����������,���۲�ռ��������
��9, 8.81, -27.31, 1��
�������㵽�ü��ռ�,ֵ��
��11.691, 15.311, 23.69, 27.3��
��ô,�ö������ڲü��ռ���,���Ա���ʾ��
ǰ�涼������ͶӰ��˵���ġ���ô,����ͶӰ����ͶӰɶ������?
��ͶӰ:ԽԶ�Ķ���,��������Ļ��ԽС; ����ͶӰ,Զ�ͽ���ͬ����С����,��������Ļ��һ������
��һ�����ֻ��Ƶ�ͼ,���֪���ҵ���˼��!
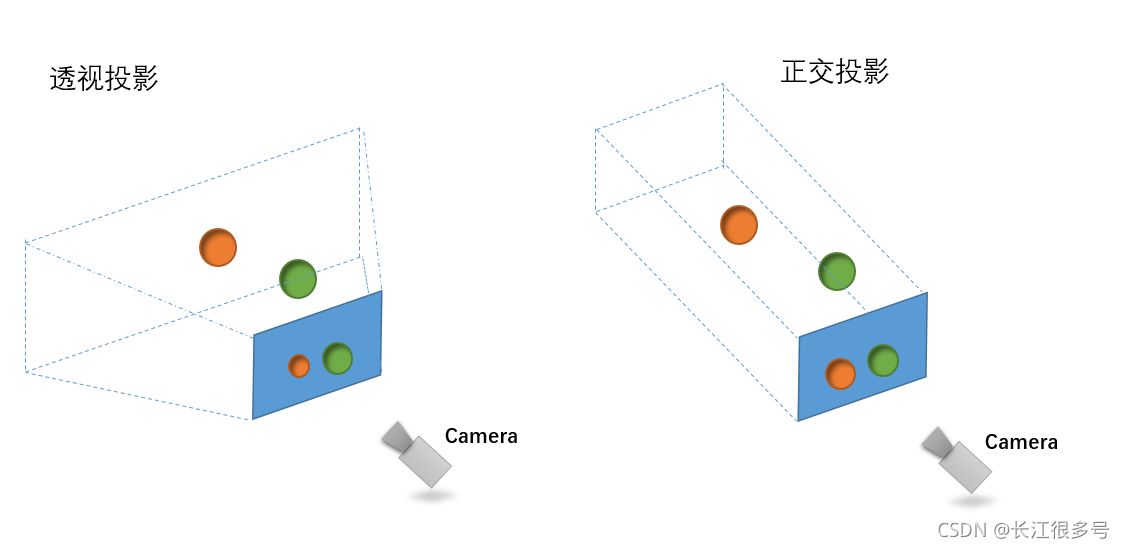
�������֪,��ͶӰ����3DЧ��,��������û��,�Ƚ��ʺ�2D��Ϸ��
4.3.5 ��Ļ�ռ�
��Ļ�ռ���һ����ά�ռ��ˡ�Ҳ�����ǽ�Ҫ�����Ļ���,Ҳ�����һ����Ҫ֪���Ŀռ���(�Dz��dz���һ����,����)
Ҫ�Ѷ���Ӳü��ռ�ת������Ļ�ռ�,��ά���ά��,��������ͶӰ��
���ͶӰ��Ҫ��������:
��һ,��Ҫ������γ�������Ҫ���ø���,��ʵ������w����ȥ����x, y, z��������Open GL��,����һ���õ�������,������һ�����豸����(Normalized Device Coordinates, NDC)��
NDC��x, y, z����Чֵ��Χ,������1��1�������ֵ֮���,���DZ����ĵ㡣
�ڶ�,��Ҫӳ�䵽��Ļ,�õ���Ļ���ꡣ��openGL��,��Ļ�����½ǵ�����������(0, 0),���Ͻ���(pixelWidth, pixelHeight)��
�����һ��������(x, y),��Ļ������(w,h),��ô,��Ļ������
Sx = x*w + w/2
Sy = y*h + h/2
���Dz�����˵,NDC��z������Ҫ��?
�����, z����Ҳ�кܴ�ļ�ֵ,����Ϊ��Ȼ��塣����,���֮����2������,��Ļ���궼һ��,�Ҷ�����,�ǾͿ���Ȼ�����,˭������ͷ��,˭����ʾ��
��Ҫǿ������,�Ӳü��ռ䵽��Ļ�ռ��ת��,���ɵײ��������ɵ�,����Ҫ����ʵ�֡�
������ɫ��,ֻ��Ҫ�Ѷ���,��ģ�Ϳռ�ת�����ü��ռ伴����
��ƬԪ��ɫ��,���Եõ���ƬԪ����Ļ�ռ��λ�á�
4.4 ��������任�ܽ�
�ص�4.2��,����˵��һ��MVP����,��������֪����,��������һ�����Ѷ����ģ�Ϳռ�ת�����ü��ռ�ľ���!
�������,������ ģ�;��� * �۲���� * ͶӰ������˵õ���!
��һ��ͼ��˵��һ��:
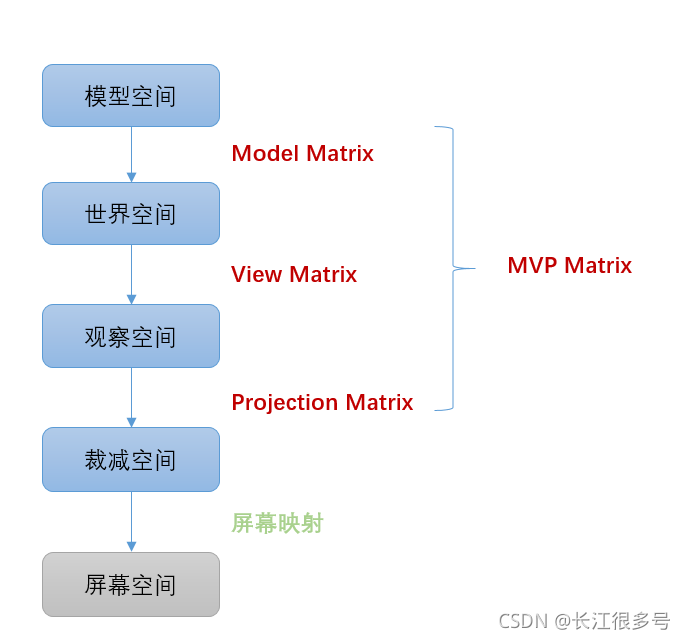
���4.2�ڵ���δ���,���ڶ�����:
o.vertex = mul(UNITY_MATRIX_MVP, v.vertex);
�����UNITY_MATRIX_MVP,����ͼ�е�MVP����
����ȷ����ģ��λ��/��ת/����,������Model Matrix����ȷ���������λ��,����,������View Matrix����ȷ�����������FOV�ӽ�,��Զ������ľ����,������Projection Matrix��
���߶�ȷ����,���,MVP MatrixҲ��ȷ���ˡ�
���Զ�����ɫ���dz��ļ�,����һ���̶�MVP�����OK��!
���������ؿ�3.1��,����һ����Ƶ���ŵ�����,������������:
private float[] vertexData = {
-1f, -1f,
1f, -1f,
-1f, 1f,
1f, 1f
};
Ϊʲô��ô��?��Ϊ����������Ƶ����,�����Ǿ��Ρ�ֻ��Ҫ4������,����������Ƕ�ά�ġ�
����,����Ķ���,ֱ��д���˲ü��ռ��µ�ֵ(zûдĬ��Ϊ0)��
���������,MVP������һ����λ����
����һ��3.1�ڶ�Ӧ�Ķ�����ɫ������,Ҳ�Ǽ����˷�ָ:
attribute vec4 v_Position;
attribute vec4 f_Position;
varying vec2 textureCoordinate;
void main()
{
gl_Position = v_Position;
textureCoordinate = f_Position.xy;
}
ע��,�����4.2�ڲ�̫һ��,��һ���Ѿ��ǿ���ֱ�Ӹ�openGL�����shader,4.2����unity��װ�Ĵ�����ʽ,���Unity������,Ҳ�ᷭ�����������Ĵ���,��main������
v_Position���ⲿ����Ķ�������,gl_Position��ȫ���ڽ�����,��������ڲü��ռ��µ����ꡣ
��������shader��ҪдMVP,Ҳ�ǿ��Ե�,ֻ����,���MVP��һ����λ����
��
gl_Position = mvpMatrix * v_Position;
5 GPU���� ---- ��դ����
��դ������Ҫ����:����ÿ��ͼԪ����������Щ����,Ȼ�����Щ������ɫ��
5.1 ���������������
����������:
���ǹ�դ����ˮ�ߵĵ�һ���Ρ�
����λ�����դ��һ�����������������Ϣ��
�������,��һ���������,��������Ļ�ϵĶ�ά����������Ķ��㡣�����ǵõ�������������ÿ���ߵ������˵㡣�����Ҫ�õ�����������������صĸ������,���Ǿͱ������ÿ�����ϵ��������ꡣΪ���ܹ�����߽����ص�������Ϣ,���Ǿ���Ҫ�õ������α߽�ı�ʾ��ʽ������һ���������������ʾ���ݵĹ��̾ͽ������������á����������Ϊ�˸���һ����������
�������:
�����α�ν�����ÿ�������Ƿ�һ���������������ǡ���������ǵĻ�,�ͻ�����һ��ƬԪ,������һ���ҵ���Щ���ر��������ǵĹ��̾��������α����������α����λ������һ���εļ��������ж�һ��������������Щ����,��ʹ����������3������Ķ�����Ϣ������������������ؽ�����ֵ����ͼչʾ�������α����εļ�����̡�
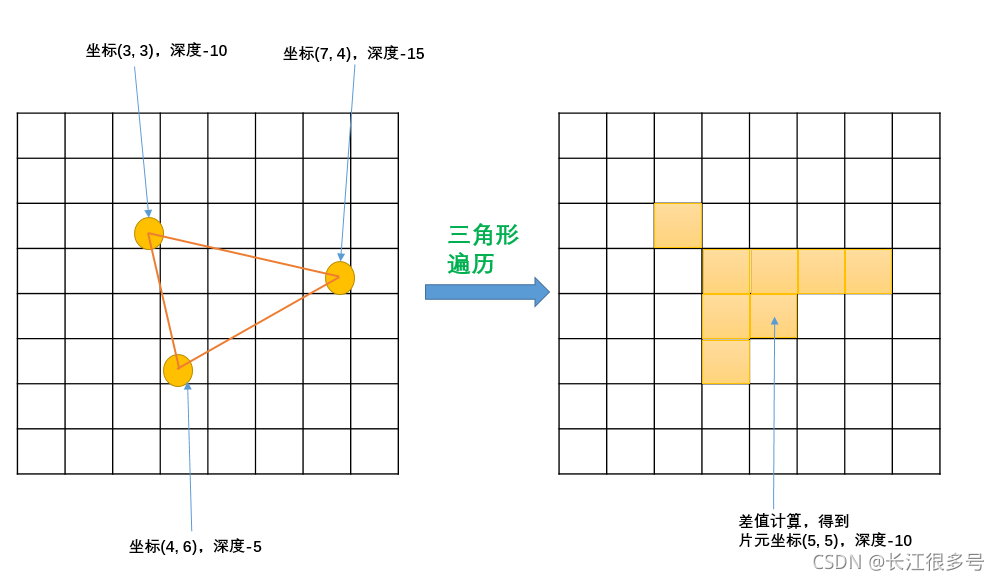
���ݼ��ν�����Ķ�����Ϣ,�õ��������ǵ�����λ�á���Ӧ�����ػ�����һ��ƬԪ,ƬԪ�е�״̬,�������εĶ�����Ϣ,���в�ֵ����õ���
����ͼ����������,��������8��ƬԪ��
��һ����֪��,����һ֡,�����������ƬԪ?
������ô˵,��������Ķ�άʹ��,������Ƶ����,�������ξ�4������,��������Ļ��4������,û���κ����,��ʱƬԪ����������Ļ�Ŀ�*��,��Ӧ�ú���������,����ͼ��
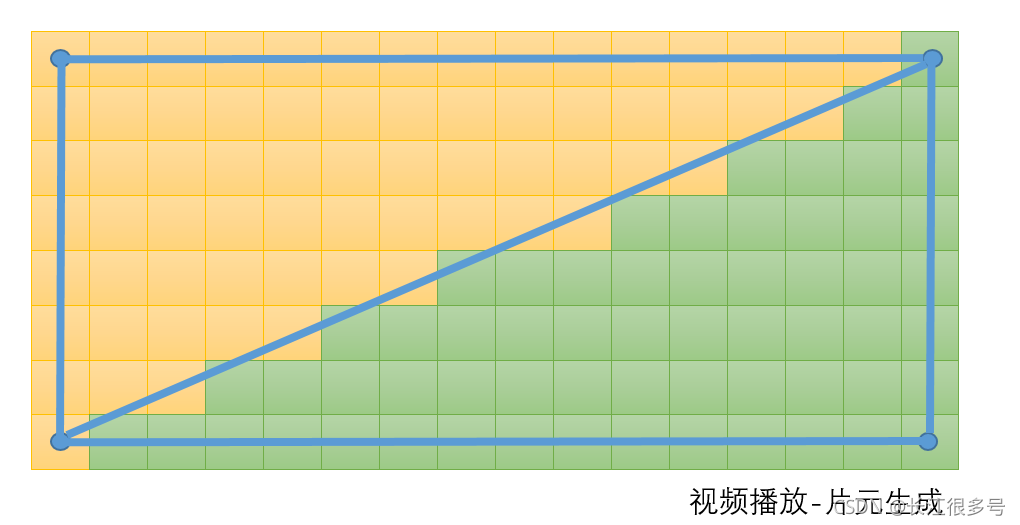
�ܹ���2��������,��ȶ�һ��,Ҳ����û���ص���������,����
�������3D��Ϸ,�Ͳ�һ���ˡ�

������Ϸ�����ֳ���,�кü�������ģ��,ģ�����ص�������ʯͷ�����и����ӡ�
����һ֡,�ж��ģ����Ҫ����,ÿ��ģ�Ϳ��ܶ�Ҫ����һ��Draw Call��һ��Draw Call,���ܾ�Ҫ����һЩƬԪ��
�������嶼���ƵĻ�,������������Ļ��������,�������ǵ�,����ijЩ����������,�����ص���ƬԪ��
����,ʯͷ�ļ�ͷ��������,����Ӧ������������,�����ӵ�����������,��������ƬԪ,���ߵ�x, yһ��,�������z��һ�����ѡ�
����,3D��Ϸ����,ƬԪ���� >= ��Ļ�� * ��
5.2 ƬԪ��ɫ��
ƬԪ��ɫ��Ҳ�ǿ����Զ���Ĵ���,��Ҫ�Ǹ�ƬԪ��ɫ��
����һ��������Ƶ������Ⱦ����ɫ������:
varying highp vec2 textureCoordinate;// ƬԪ��Ӧ����������,�ֶ�����ɫ����varying�����ᴫ�ݵ�����
uniform sampler2D sTexture; // �ⲿ�����ͼƬ���� ����������ͼƬ������
void main()
{
gl_FragColor = texture2D(sTexture, textureCoordinate); // ��������,�ҵ�����ΪtextureCoordinate����ɫ,��ֵ��gl_FragColor
}
�Dz��Ƿ��ֺܼ�?!���Ǹ�����������,����һ����ɫ,��ֵ��gl_FragColor�Ϳ���,��Ϊ��ƬԪ�������ɫ!
����ζ��,������ɫ��ȫ������Ʒ�Χ��,���ںܶ���Ƶ��Ч����,���������ƬԪ��ɫ���������¡�
�ٸ�����,������Ҫ��һ����Ƶ����,�������Ǻڰ�续��:
#extension GL_OES_EGL_image_external : require
precision mediump float;
varying vec2 vCoordinate;
uniform samplerExternalOES uTexture;
void main() {
vec4 color = texture2D(uTexture, vCoordinate);
float gray = (color.r + color.g + color.b)/3.0;
gl_FragColor = vec4(gray, gray, gray, 1.0);
}
��rgb����һ���ľ�ֵ,Ȼ��������ɫ,rgb����һ��(��ζ���ǰ�ɫ����ɫ֮��,grayΪ0��ɫ,grayΪ255,��ɫ,grayΪ����֮��,��ɫ),�Ϳ��Եõ�һ���ڰ���ɫ��Ȼ��ֵ��ƬԪ,һ���ĺڰ��˾�������ˡ�
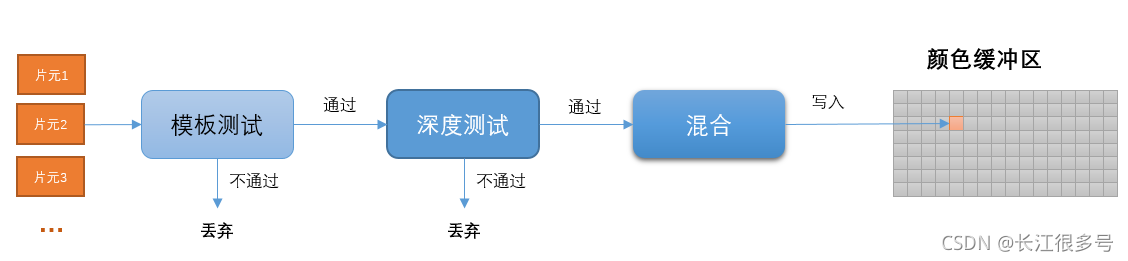
5.3 ��ƬԪ����
��ƬԪ����(PerFragment Operations)��openGL��˵��,��DirectX��,��Ϊ����ϲ���ϽΡ�
����ε���Ҫ����:
(1) ��ģ�����,��Ȳ��Եȹ���,������ÿ��ƬԪ�Ŀɼ���!
(2)ƬԪͨ������,�����ƬԪ����ɫֵ���Ѿ��洢����ɫ����������ɫ,���߽������
5.3.1 ģ�����
����ǿ�ѡ�ġ�ģ�����ݷ���ģ�建��(Stencil Buffer)��
ģ��ɶ��˼��?�ܼ�,���粻�ܳ�����λ���,��ֻ�뿴����Ļ��һ���м�Բ������,���������ɼ���
�ٸ�ģ������:

ƬԪ����������ڿɼ�������,��ֱ�Ӷ�����
6 ��������
6.1 ����ƿ��������
��˵����:һ����CPU��,�ύ����ĺ�ʱ��Draw Call����Խ��,Խ��������������⡣
��ÿ�ε���Draw Call֮ǰ,CPU��Ҫ��GPU���ͺܶ�����,��������,״̬,����ȡ�CPU�����������,�ύ������,GPU�ſ��Կ�ʼ������GPU��Ⱦ������ǿ,��Ⱦ100�������������10000������������,��������,GPU��Ⱦ�ٶ���������CPU�ύ������ٶ����ܶ�ʱ��,����GPU���������������,���еȴ�,CPU����������������!
��ñ���,�����кܶ�txt�ļ�,����1000��,���1000����������һ���ļ���,�ͺ�����������������һ��tar��,���²�ѹ��,һ�ο�������һ���ļ���,��Ҳ�ȽϿ졣
Ϊɶ��?��Ϊcpy�����ܿ�,��ʱ��Ҫ��ÿ��cpy֮ǰ,��Ҫ�����ڴ�,����Ԫ����,�ļ�������ɶ��!
�����ͼ����N������ģ��,��Ⱦһ֡����ͼ��,���ܾ�Ҫ����N��Draw Call,��ÿһ�εĵ���,CPU����Ҫ���ܶ�ǰ�ù���(�ı���Ⱦ״̬),��ôCPU��Ȼ�����ظ���������Ҫ������Ե������Ż���
6.2 ��������Ż�
������������Draw Call��CPU�����Ĵ����һ��ʲô�������:
NVIDIA �� GDC �����,25K batchs/sec ����� 1GHz �� CPU,100%��ʹ���ʡ�
��ʽ:
DrawCall_Num = 25K * CPU_Frame * CPU_Percentage / FPS
DrawCall_Num : DrawCall����(���֧��)
CPU_Frame : CPU ����Ƶ��(GHZ��λ)
CPU_Percentage:CPU ������drawcall��������ϵ�ʱ���� (�ٷֱ�) ?
FPS:ϣ������Ϸ֡��
����˵����ʹ��һ����ͨ820,����Ƶ����2GHz��,����10%��CPUʱ���drawcall��,��������Ҫ��60֡,��ôһ֡�������83��drawcall(25000210%/60 = 83.33), ���������20%��CPUʱ��,�Ǿ��Ǵ��167��
���Զ�drawcall���Ż�,��Ҫ����Ϊ�˾������CPU�ڵ���ͼ�νӿ��ϵĿ��������drawcall������Ҫ��˼·����ÿ�����御��������Ⱦ����,����������һ����Ⱦ,���߽�,������(batching)��
ʲô�������������������?
����ʹ��ͬһ�ֲ��ʵ�������
ͬһ�����ʵ�����,��ζ��,ֻ�ж������ݲ�һ��,����ʹ�õ�����,������ɫ��,ƬԪ��ɫ���Ĵ���,��һ��!
�������ǿ�����Щ����Ķ������ݺϲ���һ��,�ٷ���GPU,�ٵ���һ��DrawCall��
Unity����֧��������������ʽ:��̬������ ����̬��������������Ϸ����Ĵ�����ʽ,������������
6.2.1 Unity��̬������
��̬������,������ģ�͵Ķ�������,��ֻ�����п�ʼ��,��ֻ���˶���ʼ��,�ϲ�һ��ģ�͡���Ҫ����Щ�������ܱ��ƶ�!
�ŵ���,�ϲ�����һ��,������Ⱦ���úϲ�,��Լ���ܡ�
ȱ����,����ռ�ý϶��ڴ档����,û�þ�̬����,һЩ���干��������,�����ͼ��100����ľ,����һ��ģ�͡��������Щ��ɾ�̬������,��Ҫ100���Ķ��������ڴ档
6.2.2 Unity��̬������
��̬������,��ÿһ֡��Ⱦ,����Ҫ�ϲ�һ��ģ������
�ŵ���,��Щ������Ա��ƶ���
ȱ����,��Ϊÿ��Ҫ�ϲ�,��Ҫ��һЩ����,����,������Ŀ���ܳ���300(��ͬUnity�汾��һ��)��
7 ��¼֪ʶ
7.1 ʲô���������
������������N+1ά������Nά���ꡣ
����ѿ�������ϵ������(x, y, z),��(x, y, z, w)����ʾ����������ǵ�,��������
Ŀ��:
�����������ߵ㡣���� ƽ��T����תR������S��3������ķ���任
�����ݵ�:
��������ʾ�Ǽ����ͼ��ѧ����Ҫ�ֶ�֮һ,�����ܹ�������ȷ���������͵�,ͬʱҲ�������ڽ��з��伸�α任��
���� F.S. Hill, JR �������ͼ��ѧ (OpenGL ��)������
�������������͵�,ָ����:
(1) ����ͨ����ת�����������ʱ
���(x,y,z)�Ǹ���,���Ϊ(x,y,z,1);
���(x,y,z)�Ǹ�����,���Ϊ(x,y,z,0)
(2) ���������ת������ͨ����ʱ
�����(x,y,z,1),��֪�����Ǹ���,���(x,y,z);
�����(x,y,z,0),��֪�����Ǹ�����,��Ȼ���(x,y,z)
����ƽ��,��ת,����,������������
7.2 ƽ�ƾ���
ƽ�ƾ�������ı任����ƽ�ƾ�����������:
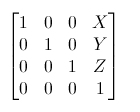
����,X��Y��Z�ǵ��λ��������
����,���������(10, 10, 10, 1)��X�᷽��ƽ��10����λ,�ɵ�:
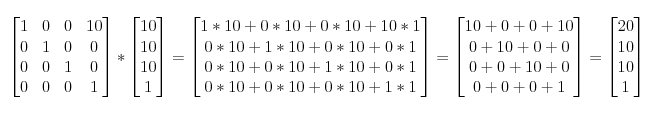
����û,���ƽ��Ҫ�þ���������,���������4x4��,�ǵ�(10, 10, 10)ֻ������һάw,���ܱ�����(����˷���Ҫ��,mn�ľ���,ֻ�ܳ���nt �ľ���)��
7.3 ���ž���
����Ҳ�ܼ�
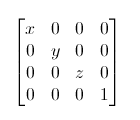
�����һ������(�����Կ�)�ظ�����Ŵ�2��:
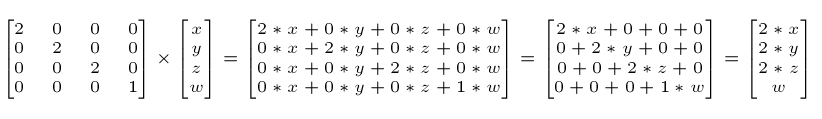
7.4 ��ת����
���������һЩ,����X, Y, Z�����ת��һ��,���������һ���������ﲻ�ٵ���չ��������Ȥ���Բο�:
7.5 ��ϱ任
�����������ת��ƽ�ƺ����ŵ����㷽��������Щ������˾��ܽ������������,����:
TransformedVector = TranslationMatrix * RotationMatrix * ScaleMatrix * OriginalVector;
ע��,����ִ������,������ת,������ƽ�ơ�����Ǿ���˷��Ĺ�����ʽ,Ҳ�����Ƕ�3Dģ�ͷŵ���ͼ�еij��ò�����ʽ��
3���������,����һ������,�������ϱ任�ľ���,�������Ҳ����д��:
TransformedVector = TRSMatrix * OriginalVector;
�ο�
Android OpenGL ES 1.��������
��������ԭ���CGPU
�������Щ��(8)����ͼ��ͼ����Ⱦԭ��
opengl-tutorial
Unity�ĵ�
��դ��������
����Drawcall