ѧϰĿ��:
ѧϰʹ��JobSystem
ѧϰ����:
JobSystem�Ļ������� �̵߳�֪ʶ JobSystem��ʹ��ѧϰʱ��:
2022.1.25
ѧϰ����:
����һ���ٷ��ĵ������,�������ݼ���һЩ�Լ�����ͽ����Լ��״������,�����ܽ�Ϊѧϰ�ʼ�
�����кܶ�����ʹ��JobSystem�������Ŀ�,�Լ�ԭ��
ϣ�����������ǿ�������
1.ʲô��JobSystem?����ΪʲôҪѧϰ��?
Unity C# Job System �����û���д�� Unity �����ಿ�����ý����Ķ��̴߳���,���Ҹ����ױ�д��ȷ�Ĵ��롣
��д���̴߳�������ṩ���������ơ����а���֡���ʵ�������ߡ��� Burst �������� C#
��ҵһ��ʹ�ÿ�����ߴ�����������,��Ҳ�������ż����ƶ��豸�ϵĵ�����ġ�
C# Job System ��һ����Ҫ���������� Unity �ڲ�ʹ�õ�(Unity �ı�����ҵϵͳ)���ɡ��û���д�Ĵ���� Unity
���������̡߳����ֺ��������˴������̶߳���CPU �ں�,�Ӷ����� CPU ��Դ�����á�
Ĭ�������,�ű��м������е�ִ����䶼��Main thread��ִ�С�����һ��ͨ��CPU�����·��,����Խ�������Ϊ���ٹ�·

ͬ����,���ǿ��Խ��������ٹ�·�ϵĹ�������,����������ĸ��ٹ�·��Ҳ���Ǵ���Job���ֵ�����Mainthread���������,��������ѹ�������ǿ��Խ��Ķ���ʱ�ļ������������߳�����,�������̵߳�ѹ������Ҳ������ʹ��JobSystem����Ҫԭ��

Jobsystem����������:
- ����Job
- ʵ����Job
- ִ��Job
- ���Job

2.ʲô�Ƕ��߳�?
�ڵ��̼߳���ϵͳ��,һ������һ��ָ��,һ�����һ����������غ���ɳ����ʱ��ȡ��������Ҫ CPU ��ɵĹ�������
���߳���һ������ CPU �����ں�ͬʱ��������̵߳������ı�����͡����Dz���һ����һ����ִ�������ָ��,����ͬʱ���С�
Ĭ�������,һ���߳��ڳ���ʼʱ���С����ǡ����ߡ������̴߳������߳�������������Щ���̱߳˴˲�������,����ͨ������ɺ����������߳�ͬ����
�������һЩ��Ҫ��ʱ�����е�����,���ֶ��̷߳��������Ч��Ȼ��,��Ϸ��������ͨ����������Ҫһ��ִ�е�Сָ������Ϊÿ���̴߳���һ���߳�,�����ջ�õ������߳�,ÿ���̵߳��������ڶ��̡ܶ�����ܻ�ͻ��CPU �Ͳ���ϵͳ�Ĵ����������ޡ�
����ͨ��ӵ��һ���̳߳��������߳��������ڵ����⡣����,��ʹ��ʹ���̳߳�,��Ҳ�ܿ���ͬʱ�д����̴߳��ڻ״̬���̶߳��� CPU �ں˻ᵼ���߳������ CPU��Դ,�Ӷ�����Ƶ�����������л����������л�����ִ�й����б����߳�״̬�Ĺ���,Ȼ������һ���߳��Ϲ���,Ȼ���ؽ���һ���߳�,�Ժ�������������������л�����Դ�ܼ��͵�,�����Ӧ�þ����ܱ���ʹ������
3.ʲô��JobSystem?
JobSystemͨ��������ҵ�������߳����������̴߳��롣
JobSystem����һ������ں˵Ĺ����̡߳���ͨ��ÿ���� CPU
������һ�������߳�,�Ա����������л�(����������Ϊ����ϵͳ������ר��Ӧ�ó�����һЩ����)��
JobSystem����ҵ������ҵ������ִ�С���ҵϵͳ�еĹ����̴߳���ҵ�����л�ȡ��Ŀ��ִ�����ǡ���ҵϵͳ����������ϵ
��ȷ����ҵ���ʵ���˳��ִ�С�
ʲô��Job?
Job�����һ���ض������һС���ֹ�������ҵ���ղ����������ݽ��в���,�����ڷ������õ���Ϊ��ʽ��Job������������,Ҳ������������Job����ɲ������С�
ʲô�ǹ�������( job dependencies)?
�ڸ��ӵ�ϵͳ��,������Ϸ���������ϵͳ,������ÿ���������Ƕ����ġ�һ���ͨ����Ϊ��һ��������ݡ�Jobs
֪����֧�����������������������jobA������jobB,����ҵϵͳȷ�������jobA֮ǰ���Ὺʼִ��jobB��
4.C#��ҵϵͳ�еİ�ȫϵͳ
Race conditions(��������)
��д���̴߳���ʱ,���Ǵ��ھ��������ķ��ա���һ�����������ȡ������һ����������ƵĽ��̵�ʱ��ʱ,�ͻ���־���������
���������������Ǵ���,�����Dz�ȷ����Ϊ����Դ������������ȷʵ���´���ʱ,���ܺ����ҵ�����ĸ�Դ,��Ϊ��ȡ����ʱ��,�����ֻ���ڼ�������������´������⡣���������ܻᵼ��������ʧ,��Ϊ�ϵ����־��¼���Ըı䵥���̵߳�ʱ�䡣���������ڱ�д���̴߳���ʱ���������ش����ս��
��ȫϵͳ Ϊ�˸����ɵر�д���̴߳���,Unity C# Job System �������DZ�ڵľ����������������������ǿ��ܵ��µĴ����Ӱ�졣
����:��� C#
��ҵϵͳ�����߳��еĴ�������ҵ���Ͷ����ݵ�����,��������֤���߳��Ƿ�����ҵ����д�����ݵ�ͬʱ���ڶ�ȡ���ݡ�����������������������
C# ��ҵϵͳͨ����ÿ����ҵ��������Ҫ���������ݵĸ���(Ҳ����NativeContainer)������������,�����Ƕ����߳��е����ݵ����á��˸�������������,�Ӷ������˾���������
�̷߳��������Ǹ���ͷ�۵�����,��Ҳ��ΪʲôJobSystem��������ȥ�������̡߳�
����˵,���߳���һ������m,ֵΪ5
������Job,һ��Job������m++,һ��Job������m�C,��ô���m�����߳��������ݵ�ȷ�Ծͺ��ѱ�����,���ܱ�Job��ʱ��,����һϵ������
����ִ����ɺ�,Job�������κ�ֵ,���ܱ���һ��Job��,Ҳ���ܱ��ڶ���Job��,����Ȼ����������Ҫ�Ľ�������ݵİ�ȫ���Ǹ�����Ҫ������,��Ҳ������ΪʲôҪ���þ�̬������ԭ��̬�������κεط����ܷ��ʺ��ĵ�,���Ժ�Σ�ա�
����Ҳ����ͨ���ӡ�����������,������̫��,Ҳ���ṩ��̵��ѶȺͳ���ĸ��Ӷ�
�ҵ�GitHub�ֿ������ж�C#�̵߳�ʹ�ý�ѧ,�Լ�һЩ��ѧϰC#���İ����ͱʼǡ�
����,��JobSystem����,���ܴ����ⲿ����,Ҳ�������ⲿ����,Ҳ���ܸ������̡߳�ֻ�ܵ��ú��ľ�̬����,����ʹ���Զ����NativeArrayȥ���úͼ�������,���������̴߳���NativeArrayΪ�丳ֵ,Ȼ���Jobȥ����,��������֮��,�����߳̽�NativeArray��ֵ�ó�����
�����ж������ϸ����
5.ԭ������(NativeContainer)
��ȫϵͳ�������ݹ��̵�ȱ�������������ÿ�������е���ҵ�����Ϊ�˿˷��������,����Ҫ������洢��һ�ֳ�ΪNativeContainer�Ĺ����ڴ��С�
ANativeContainer��һ���й�ֵ����,��Ϊ�����ڴ��ṩ��ȫ�� C# ��װ����������һ��ָ����йܷ����ָ�롣���� Unity C# ��ҵϵͳһ��ʹ��ʱ,aNativeContainer������ҵ���������̹߳���������,������ʹ�ø�����
NativeContainer ������ Unity ������һ��NativeContainer��ΪNativeArray����������ʹ��NativeSlice ���� aNativeArray�Ի�ȡ��NativeArray�ض�λ�õ��ض����ȵ��Ӽ���
ע��:ʵ�����ϵͳ(ECS) ����չ��Unity.Collections�����ռ�������������NativeContainer:
NativeList- �ɵ�����С��NativeArray. NativeHashMap - ��ֵ�ԡ� NativeMultiHashMap - ÿ�����ж��ֵ�� NativeQueue- �Ƚ��ȳ� ( FIFO ) ���С� NativeContainer �Ͱ�ȫϵͳ ��ȫϵͳ����������NativeContainer�����С��������κ����ڶ�ȡ��д�������NativeContainer��
ע��:�������͵İ�ȫ���NativeContainer(����Խ���顢�ͷż��;����������)���� Unity�༭���Ͳ���ģʽ�п��á�
�ð�ȫϵͳ��һ������DisposeSentinel��AtomicSafetyHandle��DisposeSentinel�����û����ȷ�ͷ��ڴ�,�������ڴ�й©������һ���������ڴ�й©��������й©�����ܾ�֮��
ʹ��AtomicSafetyHandleת��NativeContainer�����е�����Ȩ������,��������ƻ�����ҵ����д��ͬһ��NativeArray,��ȫϵͳ���׳��쳣,��������ȷ�Ĵ�����Ϣ,����Ϊʲô�Լ���ν�����⡣�����������������ҵʱ,��ȫϵͳ���������쳣��
�����������,������ʹ�� ���� .��һ����ҵ����д��NativeContainer,һ�������ִ��,��һ����ҵ�Ϳ���ȫ�ض�ȡ��д����ͬNativeContainer�� . �������̷߳�������ʱ,��ȡ��д������Ҳ���á���ȫϵͳȷʵ���������ҵ���ж�ȡ��ͬ�����ݡ�
Ĭ�������,����ҵ���Է��� aNativeContainerʱ,��ͬʱ���ж�ȡ��д�����Ȩ�ޡ������ÿ��ܻή�����ܡ�C#��ҵϵͳ������������һ���� a ����д����Ȩ��NativeContainer��ҵ����һ������д��������ҵͬʱ���С�
�����ҵ����Ҫд�� a NativeContainer,��NativeContainerʹ��[ReadOnly]���Ա�� ,������ʾ:
[ReadOnly] public NativeArray<int> input;
�������ʾ����,������������Ҳ�Ե�һ������ֻ������Ȩ����ҵͬʱִ�и���ҵNativeArray��
ע��:û�з�ֹ����ҵ�з��ʾ�̬���ݵı�����ʩ�����ʾ�̬���ݻ��ƹ����а�ȫϵͳ,�����ܵ��� Unity �������й���ϸ��Ϣ,�����C#��ҵϵͳ��ʾ�����ų���
NativeContainer ������ ���� ʱNativeContainer,������ָ��������ڴ�������͡���������ȡ������ҵ���е�ʱ�䳤�ȡ�ͨ�����ַ�ʽ,�����Ե�����������ÿ������»��������ܡ�
�ڴ������ͷŹ������ַ��������͡�NativeContainerʵ���� a ʱ����ָ���ʵ���NativeContainer��
Allocator.Temp�ķ����ٶ���졣����������������Ϊһ֡����ٵķ��䡣����,������ʹ��Temp��NativeContainer���䴫�ݸ���ҵ��
Allocator.TempJob�ķ���Temp�ٶȱ�Persistent.
Allocator.Persistent�������ķ���,�����Գ���������Ҫ��ʱ��,����б�Ҫ,������Ӧ�ó�����������������ڳ���ʹ�á�����ֱ�ӵ���malloc�İ�װ�����ϳ�����ҵ����ʹ�ô�NativeContainer�������͡���ҪPersistent������������Ҫ�ĵط�ʹ�á�
����:
NativeArray<float> result = new NativeArray<float>(1,Allocator.TempJob); ע��:�����е����� 1 ��ʾNativeArray.
�����������,��ֻ��һ������Ԫ��,��Ϊ��ֻ�洢��һ������result��
6.Create a Job
Ҫ�� Unity �д�����ҵ,����Ҫʵ��IJob�ӿڡ�IJob�������������������е��κ�������ҵ�������еĵ�����ҵ��
ע��:����ҵ���� Unity ��ʵ��IJob�ӿڵ��κνṹ��ͳ�ơ�
Ҫ��������,����Ҫ:
����һ��ʵ��IJob. ������ҵʹ�õij�Ա����(blittable ���ͻ�NativeContainer����)��
�����Ľṹ�д���һ����ΪExecute�ķ���,���а�����ҵ��ʵ�֡�
ִ����ҵʱ,��Execute�����ڵ�������������һ�Ρ�
ע��:����ƹ���ʱ,���ס���Ƕ����ݸ������в���,����NativeContainer.
���,�����߳��е���ҵ�������ݵ�Ψһ������д��NativeContainer.
����ҵ�����ʾ��
// Job adding two floating point values together
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
7.����JobSystem
Ҫ�����߳��а�����ҵ,������:
ʵ������ҵ�� �����ҵ�����ݡ� ���õ��ȷ�����
����Schedule����ҵ������ҵ������,�Ա����ʵ���ʱ��ִ�С�һ�����ź�,���Ͳ����ж���ҵ��
ע��:��ֻ��Schedule�����̵߳��á�
������ҵ��ʾ��
// Create a native array of a single float to store the result. This example waits for the job to complete for illustration purposes
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// Set up the job data
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// Schedule the job
JobHandle handle = jobData.Schedule();
// Wait for the job to complete
handle.Complete();
// All copies of the NativeArray point to the same memory, you can access the result in "your" copy of the NativeArray
float aPlusB = result[0];
// Free the memory allocated by the result array
result.Dispose();
8.JobHandle ��������
����������ҵ��Schedule����ʱ,���᷵��JobHandle��������JobHandle�ڴ�����ʹ�� a ��Ϊ����
�����������������һ����ҵ��������һ����ҵ�Ľ��,�����Խ���һ����ҵJobHandle��Ϊ�������ݸ��ڶ�����ҵ��Schedule����,������ʾ:
JobHandle firstJobHandle = firstJob.Schedule();
secondJob.Schedule(firstJobHandle);
�������
���һ����ҵ�кܶ�����,�����ʹ��JobHandle.CombineDependencies�������ϲ����ǡ�CombineDependencies�����������Ǵ��ݸ�Schedule������
NativeArray<JobHandle> handles = new NativeArray<JobHandle>(numJobs, Allocator.TempJob);
// Populate `handles` with `JobHandles` from multiple scheduled jobs...
JobHandle jh = JobHandle.CombineDependencies(handles);
�����߳��еȴ���ҵ
����JobHandleǿ�����Ĵ��������߳��еȴ�������ҵ���ִ�С�Ϊ��,����JobHandle. ��ʱ,��֪�����߳̿���ȫ�ط�����ҵ����ʹ�õ�NativeContainer��
ע��:������������ʱ,��ҵ���Ὺʼִ�С�������������߳��еȴ���ҵ,��������Ҫ������ҵ����ʹ�õ� NativeContainer
����,����Ե��÷���JobHandle.Complete���˷������ڴ滺����ˢ����ҵ����ʼִ�й��̡�����CompleteaJobHandle������ҵ���͵�����Ȩ����NativeContainer�����̡߳�����Ҫ����Completea���ٴδ����߳�JobHandle��ȫ�ط�����Щ���͡�NativeContainerҲ����ͨ������������ҵ������Complete��
a��������Ȩ���ظ����̡߳�JobHandle����,�����Ե���Completeon jobA,���������Ե���which depends
Completeon �����߶�����jobBjobANativeContainerjobA�ڵ���Complete.
����,���������Ҫ��������,����Ҫ��ʽˢ����������Ϊ��,����þ�̬����JobHandle.ScheduleBatchedJobs����ע��,���ô˷���������ܲ�������Ӱ�졣
�����ҵ���������ʾ��
��������:
// Job adding two floating point values together
public struct MyJob : IJob
{
public float a;
public float b;
public NativeArray<float> result;
public void Execute()
{
result[0] = a + b;
}
}
// Job adding one to a value
public struct AddOneJob : IJob
{
public NativeArray<float> result;
public void Execute()
{
result[0] = result[0] + 1;
}
}
���̴߳���:
// Create a native array of a single float to store the result in. This example waits for the job to complete
NativeArray<float> result = new NativeArray<float>(1, Allocator.TempJob);
// Setup the data for job #1
MyJob jobData = new MyJob();
jobData.a = 10;
jobData.b = 10;
jobData.result = result;
// Schedule job #1
JobHandle firstHandle = jobData.Schedule();
// Setup the data for job #2
AddOneJob incJobData = new AddOneJob();
incJobData.result = result;
// Schedule job #2
JobHandle secondHandle = incJobData.Schedule(firstHandle);
// Wait for job #2 to complete
secondHandle.Complete();
// All copies of the NativeArray point to the same memory, you can access the result in "your" copy of the NativeArray
float aPlusB = result[0];
// Free the memory allocated by the result array
result.Dispose();
������ʾ,AddOneJob����MyJobִ������֮��Ż�ִ��
9.һ�ֿ��Կ���ѭ��ִ�е�Job-ParallelFor jobs
�ڵ�����ҵʱ,ֻ����һ����ҵִ��һ����������Ϸ��,ͨ��ϣ���Դ�������ִ����ͬ�IJ�������һ����ΪIJobParallelFor �ĵ�����ҵ���������������⡣
ע��:"ParallelFor"��ҵ�� Unity ��ʵ�ֽӿڵ��κνṹ��ͳ�ơ�IJobParallelFor
ParallelFor ��ҵʹ��NativeArray������Ϊ������Դ��ParallelFor ��ҵ�����ں����С�ÿ��������һ����ҵ,ÿ����ҵ�����������ص�һ���Ӽ��� ��Ϊ������ ,�����ǵ���Execute����,����������Դ�е�ÿ������ø÷���һ�Ρ���������һ���������������������ڷ�����ҵʵ��������Դ�ĵ���Ԫ�ز�������в�����IJobParallelForIJobExecuteExecute
ParallelFor ��ҵ�����ʾ��:
struct IncrementByDeltaTimeJob: IJobParallelFor
{
public NativeArray<float> values;
public float deltaTime;
public void Execute (int index)
{
float temp = values[index];
temp += deltaTime;
values[index] = temp;
}
}
�ƻ����ж�����ҵ
�ڼƻ� ParallelFor ��ҵʱ,����ָ��Ҫ��ֵ�����Դ�ij��ȡ�����ṹ���ж������Դ,Unity C# ��ҵϵͳ����֪��Ҫ���ĸ���������Դ�����Ȼ����� C# ��ҵϵͳ��Ҫ�����ַ�����NativeArrayNativeArrayExecute
����
,�� ParallelFor ��ҵ�ĵ��ȸ��Ӹ��ӡ��ڼƻ� ParallelFor ��ҵʱ,C# ��ҵϵͳ�Ὣ��������Ϊ������,�Ա����ں�֮��ַ���ÿ�����ζ�����һ�������Ӽ���Ȼ��,C# ��ҵϵͳ��ÿ�� CPU �ں����� Unity �ı�����ҵϵͳ����ల��һ����ҵ,�����ñ�����ҵ����һЩ��������ɡ�
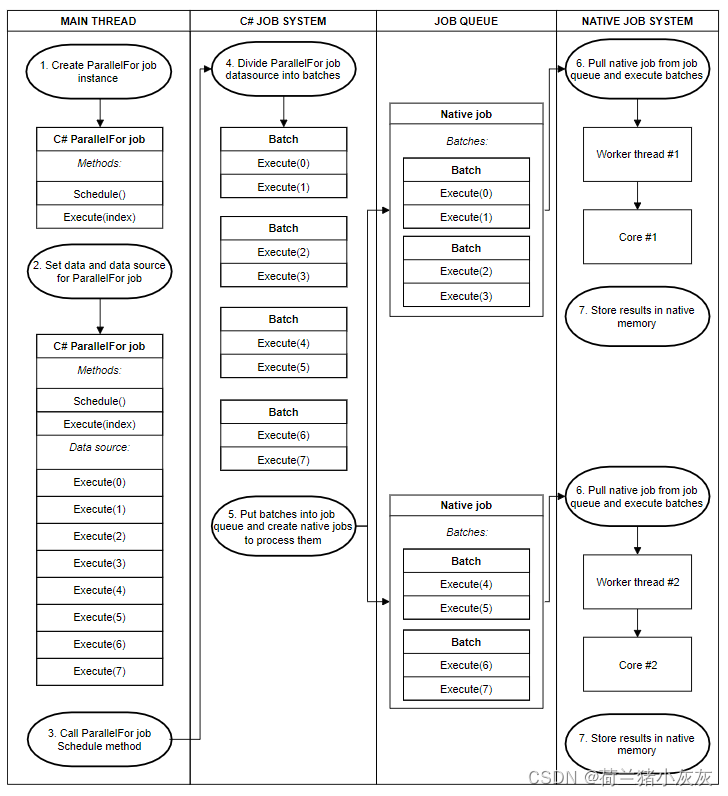
�������ڿ��ں˻�������������ҵ
��������ҵ����������ҵ�����������ʱ,���������������ҵ����ȡʣ�������������һ��ֻ��ȡ������ҵʣ�����ε�һ��,��ȷ������ֲ��ԡ�
Ҫ�Ż�����,����Ҫָ�����μ�����������������������õ���ҵ��,�Լ��߳�֮�乤�����·����ϸ���ȡ����нϵ͵�������(�� 1)�����߳�֮������ȵط��乤������ȷʵ�����һЩ����,�����ʱ����������μ������� 1 ��ʼ������������,ֱ�������������Ժ��Բ���,����һ����Ч�IJ��ԡ�
�ƻ� ParallelFor ��ҵ��ʾ��
ְλ����:
// Job adding two floating point values together
public struct MyParallelJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<float> a;
[ReadOnly]
public NativeArray<float> b;
public NativeArray<float> result;
public void Execute(int i)
{
result[i] = a[i] + b[i];
}
}
���̴߳���:
NativeArray<float> a = new NativeArray<float>(2, Allocator.TempJob);
NativeArray<float> b = new NativeArray<float>(2, Allocator.TempJob);
NativeArray<float> result = new NativeArray<float>(2, Allocator.TempJob);
a[0] = 1.1;
b[0] = 2.2;
a[1] = 3.3;
b[1] = 4.4;
MyParallelJob jobData = new MyParallelJob();
jobData.a = a;
jobData.b = b;
jobData.result = result;
// Schedule the job with one Execute per index in the results array and only 1 item per processing batch
JobHandle handle = jobData.Schedule(result.Length, 1);
// Wait for the job to complete
handle.Complete();
// Free the memory allocated by the arrays
a.Dispose();
b.Dispose();
result.Dispose();
���ǿ��Կ���,����ͨ��Job���������Schedule��ʱ��,������Ҫ����������Ҫѭ���Ĵ�����
��Ҳ�����˸�Job�ĺ����������ڶԴ�������ִ����ͬ�IJ���
10.ʹ����ʾ
1.���ܽ�NativeContainer���������ͷ���NativeContainer
��������
NativeHashMap<int, NativeList<float3>> DicP = new NativeHashMap<int, NativeList<float3>>(FrameCount, Allocator.TempJob);
�����

2.ֻ��ָ������������,����float,byte������ָ�����ӵ���������,����Vector3����Object֮���
3.����ֻ��ͨ��NativeContainer�õ�����,Ҳ����ͨ����ȫ����ȥ������
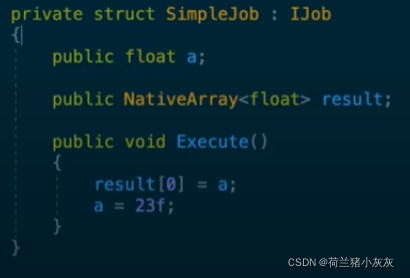
��ͼ��ʾ,������ǵȴ�Jobָ������֮��,����ȥDebug��a��ֵ,���ǻᷢ��,a���ᱻ��

����һ��,���ͺ������
JobSystemֻ����NativeContainer���������,������Job������Public ��float����a,�Dz���Ч��
��Ҳ��JobSystemΪ�˰�ȫ�Կ�������������,ֻ����NativeContainer���������
4.����ֻ����Job���֮��,����ȥ����Job�����NativeContainer����
���Jobû�����,���Ǿ�ȥ������������,�ͻᱨ������Ϊ���Dz���֪����ʱJob��������,���ܸ�job��û��ʼִ��,�������ݲ�û�б�����

5.����CPU�Ὺ��һ��������ȥ�����ͷַ�����,Ȼ��ȡ�����ݡ�
����Job���˹���
6.������JobSystem���治�ܶ�IO���в���,��������һЩֻ�������߳̽��еIJ���
��Ȼ,��Ҳ��Unity�İ�ȫϵͳ��ǰΪ���ǿ��Ǻõ�����