ЮФеТФПТМ
зЫЬЌЧЈвЦМђНщ
ФПЧАAR,VR,дЊгюжцЖМБШНЯЛ№,ашвЊЪЕМЪГЁОАКЭащФтжаНјааНЛЛЅЕФЧщПі,вђДЫбаОПСЫЭЈЙ§ЩуЯёЭЗЛёШЁЭМЯёНјааЪЖБ№,БОЮФжївЊИХЪіСЫдкШЫЬхЩэЬхзЫЪЦЪЖБ№ИњзйЗНУцЕФвЛаЉЕїбаКЭГЂЪдЁЃ
ЭЈЙ§ИїИіЗНАИ,ЮвУЧПЩвдДгRGBЪгЦЕжЁжаЭЦЖЯГіећИіЩэЬхЕФЙиМќЬиеїЕу,ДгЖјИљОнетаЉЙиМќЬиеїЕуШЅзіРЉеЙ,БШШчЧЈвЦЕНunityФЃаЭжаЕШЁЃ
ДгЪЖБ№НЧЖШРДЫЕ,ЮвУЧПЩвдЗжГЩСНИіДѓЗНЯђ,вЛЪЧШЫЬхЩэЬхЙиМќЬиеїЕуЪЖБ№,етРяЬиеїЕуЗжЮЊ2dЬиеїЕуКЭ3dЬиеїЕу,ВПЗжЗНАИжЛжЇГж2dЬиеїЕу;ЖўЪЧШЫЬхЖЏзїЪЖБ№,БШШчгУЛЇдкзіЪВУДЖЏзї,ОйвЛИіКмМђЕЅЕФР§зг,ЮвУЧПЩвдЭЈЙ§mediapipeЪЖБ№ГігУЛЇдкзіИЉЮдГХЛђепЩюЖзЕШЁЃ
ДггУЛЇЬхбщНЧЖШРДЫЕ,ЮвУЧПЩвдЗжГЩЪЕЪБЩуЯёЭЗДЋЪфКЭЖдЪгЦЕНјааДІРэСНИіЗНЯђЁЃЩуЯёЭЗЪЕЪБДЋЪфЕФЛАОЭБиаывЊзіЕНЖдЪгЦЕУПвЛжЁRGBЭМЯёзіЕНМДЪБДІРэ,етРяОЭЧЃГЖЕНгХЛЏаЇТЪЮЪЬтЁЃЖдЪгЦЕНјааДІРэЕФЛАПЩвдВЩгУЖдЪгЦЕКѓЦкДІРэЕФаЮЪНШЅДІРэ,вЛАуЖЏВЖЗНАИЖМЪЧетУДзіЕФЁЃ
ЗНАИЯъНт
Mediapipe
GoogleГіЦЗ,ПЩвдЪЕЯжШЫСГМьВтЁЂзЫЬЌЪЖБ№,ЪжЪЦЪЖБ№ЕШКмЖраЇЙћ,ВЂЧвПЩвддкЖрЦНЬЈИпаЇЕФЪфГіЁЃетРяЧПЕїЯТMediapipeМьВтГіРДЕФЬиеїЕуЪ§ОнОљЮЊ3d,гаПеМфИаЁЃ
MediapipeМьВтЪЧЛљгкBlazeFaceФЃаЭ,УїШЗЕидЄВтСЫСНИіЖюЭтЕФащФтЙиМќЕу,етаЉащФтЙиМќЕуНЋШЫЬхжааФЁЂа§зЊКЭЫѕЗХРЮЙЬЕиУшЪіЮЊвЛИідВШІЁЃЪмРГАКФЩЖрЕФЮЌЬиТГЭўШЫЕФЦєЗЂ,ЮвУЧдЄВтСЫвЛИіШЫЭЮВПЕФжаЕу,ЭтНгећИіШЫЕФдВЕФАыОЖ,вдМАСЌНгМчВПКЭЭЮВПжаЕуЕФЯпЕФЧуаБНЧЁЃ
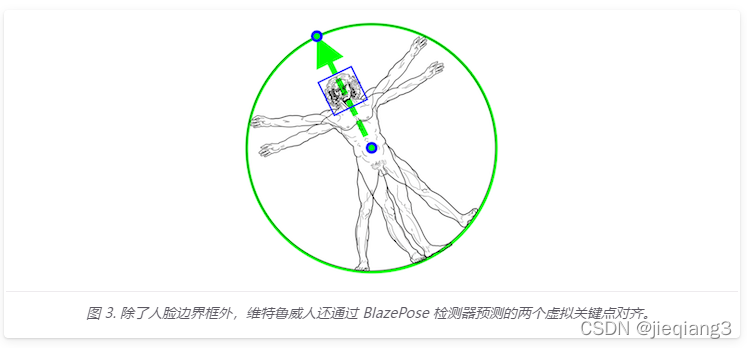
MediapipeЪ§ОнЛёШЁ
ДгMediapipeЩЯЛёШЁЕФЩэЬхЕФ33ИіЬиеїЕу,ОпЬхШчЯТЭМ,ЖдДЫ33ИіЬиеїЕуНјааХаЖЯЁЃ
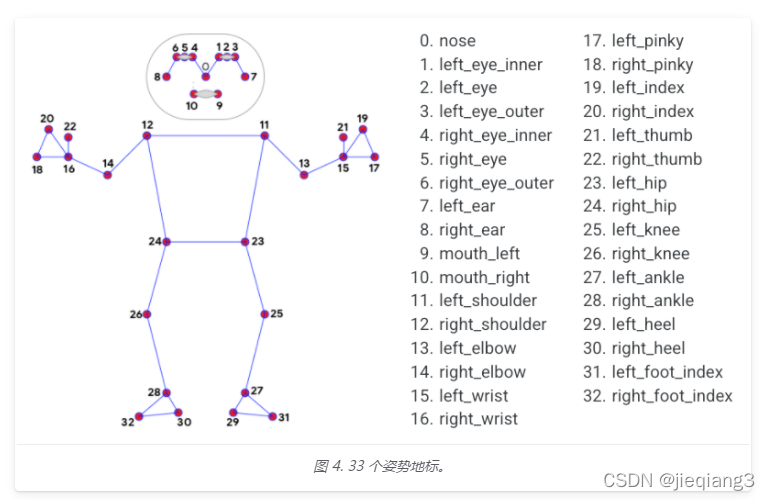
жївЊЭЈЙ§НЧЖШРДХаЖЯ:
float Angle(NormalizedLandmark ver1, NormalizedLandmark ver2, NormalizedLandmark ver3, NormalizedLandmark ver4)
{
return Vector3.Angle(new Vector3(ver1.X, ver1.Y, ver1.Z) - new Vector3(ver2.X, ver2.Y, ver2.Z),
new Vector3(ver3.X, ver3.Y, ver3.Z) - new Vector3(ver4.X, ver4.Y, ver4.Z));
}
ЖрШЫзЫЬЌЪЖБ№ЗНЯђЬНЫї
Mediapipe дкШЫСГЩЯЪЧжЇГжЖрШЫЕФ,ЕЋЪЧдкзЫЬЌЪЖБ№ЩЯФПЧАжЛжЇГжЕЅШЫЁЃдкЪЕбщСЫЭјЩЯФмЫбЕНЕФИїжжЗНАИжЎКѓ,гавЛжжЗНАИФПЧАЪЧПЩааЕФ,ЕЋЪЧдкадФмЩЯЛсБШНЯПЈЖйЁЃ
МШШЛMediapipeжЇГжЕЅШЫ,ФЧЮвУЧАбЪгЦЕЛУцжаЕФЖрШЫЛУцВ№ЗжГЩЖрИіЕЅШЫОЭааСЫЁЃ
етРяЮвВЩгУЕФЪЧOpenVINOжаЕФааШЫМьВтФЃаЭЁЃ(ЮвГЂЪдСЫЖржжЗНАИ,YOLO-unityЁЂBarracuda-Image-ClassificationКЭOpenVINOКѓЗЂЯжOpenVINOаЇЙћзюМб)OpenVINO ToolKitЪЧгЂЬиЖћЗЂВМЕФвЛЬзЩюЖШбЇЯАЭЦЖЯв§Чц,жЇГжИїжжЭјТчПђМмЁЃЖдДЫВЛЪьЯЄЕФЭЌбЇПЩвдВЮПМOpenVINOПЊЗЂЯЕСаЮФеТЛузмНјааНЯЮЊЯЕЭГЕФбЇЯАЁЃ

ОпЬхЫМТЗОЭЪЧЭЈЙ§OpenVINOЪЖБ№ГіШЫЮяЗЖЮЇПђ,ШЛКѓЪЙгУOpencvНјааЭМЯёЗжИю,ЕЅШЫЭМЯёДЋЕнИјMediapipe sdkШЅзіЕЅШЫзЫЬЌЪЖБ№,ШЛКѓНјааЛузмЁЃФПЧАИУЗНАИдквЦЖЏЖЫВтЪдаЇЙћНЯЮЊПЈЖй,ВЛЪЧКмРэЯыЁЃ
PoseNet
PoseNetЪЧTensorFlowКЭЙШИшДДвтЪЕбщЪвКЯзїЗЂВМЕФзЈУХгУгкзЫЬЌЙРМЦЕФвЛжжММЪѕЗНАИЁЃPoseNetПЩгУгкЙРМЦЕЅИізЫЪЦЛђЖрИізЫЪЦ,ИУЫуЗЈгавЛИіАцБОПЩвдНіМьВтЭМЯё/ЪгЦЕжаЕФвЛИіШЫ,СэвЛИіАцБОПЩвдМьВтЭМЯё/ЪгЦЕжаЕФЖрИіШЫЁЃ
СїГЬжївЊгаСНИіНзЖЮ:
- ЪфШыRGB ЭМЯёЭЈЙ§ОэЛ§ЩёОЭјТчРЁЫЭЁЃ
- ЕЅзЫЪЦЛђЖрзЫЪЦНтТыЫуЗЈгУгкНтТыРДздФЃаЭЪфГіЕФзЫЪЦЁЂзЫЪЦжУаХЖШЗжЪ§ЁЂЙиМќЕуЮЛжУ КЭЙиМќЕужУаХЖШЗжЪ§ЁЃ
ЭЌMediapipeвЛбљ,ЮвУЧРДПДПДPoseNetИјЕНЮвУЧЕФЙиМќзЫЪЦЕуЁЃPoseNetЬсЙЉСЫ17ИіЙиМќЕу,ВЛЭЌгкMediapipeЬсЙЉЕФ3dЪ§ОнЕу,PoseNetЬсЙЉЕФЪЧЙиМќЕуЕФ2dзјБъ,xКЭyЁЃвдМАЙиМќЕуПЩаХЖШЗжЪ§,ЪЙгУепПЩвдИљОнЪЕМЪЧщПіШЅзіХаЖЯ,ЗЖЮЇдк0.0-1.0жЎМф,дННгНќ1.0БэЪОЪЖБ№ГіРДЕФЕудНе§ШЗЁЃ
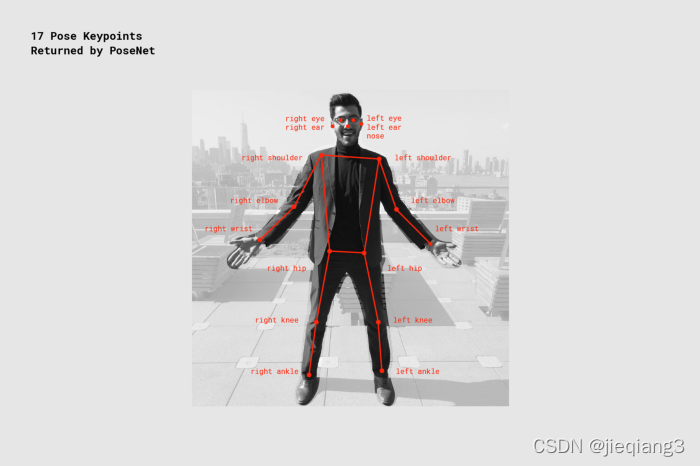
ok,ЮвУЧРДПДЯТЮвАбposenetетвЛЬзЭЈЙ§tf-liteМгдиЕФаЮЪНдкunityЩЯЕФГЪЯжаЇЙћЁЃ

MoveNet
MoveNetЪЧвЛжжГЌПьЫйЧвзМШЗЕФФЃаЭ,ПЩМьВтЩэЬхЕФ 17 ИіЙиМќЕуЁЃИУФЃаЭдкTF HubЩЯЬсЙЉ,гаСНжжБфЬх,ГЦЮЊ Lightning КЭ ThunderЁЃLightning ЪЪгУгкбгГйЙиМќЕФгІгУГЬађ,Жј Thunder ЪЪгУгкашвЊИпОЋЖШЕФгІгУГЬађЁЃдкДѓЖрЪ§ЯжДњЬЈЪНЛњЁЂБЪМЧБОЕчФдКЭЪжЛњЩЯ,етСНжжФЃаЭЕФдЫааЫйЖШЖМБШЪЕЪБ (30+ FPS) Пь,етЖдгкЯжГЁНЁЩэЁЂНЁПЕКЭБЃНЁгІгУжСЙиживЊЁЃ
ЮвУЧПЩвдПДЕНmovenetЕФЪЖБ№ГіРДЕФЕуЕФаЇЙћШчЯТ:

ЙйЗНДгtf hub МгдиФЃаЭДњТы:
model_name = "movenet_lightning"
if "tflite" in model_name:
if "movenet_lightning_f16" in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/lightning/tflite/float16/4?lite-format=tflite
input_size = 192
elif "movenet_thunder_f16" in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/thunder/tflite/float16/4?lite-format=tflite
input_size = 256
elif "movenet_lightning_int8" in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/lightning/tflite/int8/4?lite-format=tflite
input_size = 192
elif "movenet_thunder_int8" in model_name:
!wget -q -O model.tflite https://tfhub.dev/google/lite-model/movenet/singlepose/thunder/tflite/int8/4?lite-format=tflite
input_size = 256
else:
raise ValueError("Unsupported model name: %s" % model_name)
# Initialize the TFLite interpreter
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
def movenet(input_image):
"""Runs detection on an input image.
Args:
input_image: A [1, height, width, 3] tensor represents the input image
pixels. Note that the height/width should already be resized and match the
expected input resolution of the model before passing into this function.
Returns:
A [1, 1, 17, 3] float numpy array representing the predicted keypoint
coordinates and scores.
"""
# TF Lite format expects tensor type of uint8.
input_image = tf.cast(input_image, dtype=tf.uint8)
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
interpreter.set_tensor(input_details[0]['index'], input_image.numpy())
# Invoke inference.
interpreter.invoke()
# Get the model prediction.
keypoints_with_scores = interpreter.get_tensor(output_details[0]['index'])
return keypoints_with_scores
else:
if "movenet_lightning" in model_name:
module = hub.load("https://tfhub.dev/google/movenet/singlepose/lightning/4")
input_size = 192
elif "movenet_thunder" in model_name:
module = hub.load("https://tfhub.dev/google/movenet/singlepose/thunder/4")
input_size = 256
else:
raise ValueError("Unsupported model name: %s" % model_name)
def movenet(input_image):
"""Runs detection on an input image.
Args:
input_image: A [1, height, width, 3] tensor represents the input image
pixels. Note that the height/width should already be resized and match the
expected input resolution of the model before passing into this function.
Returns:
A [1, 1, 17, 3] float numpy array representing the predicted keypoint
coordinates and scores.
"""
model = module.signatures['serving_default']
# SavedModel format expects tensor type of int32.
input_image = tf.cast(input_image, dtype=tf.int32)
# Run model inference.
outputs = model(input_image)
# Output is a [1, 1, 17, 3] tensor.
keypoints_with_scores = outputs['output_0'].numpy()
return keypoints_with_scores
ЪЕМЪЩњВњЙ§ГЬжа,movenetжївЊЭЈЙ§tf-liteШЅМгдиМЦЫу,ПЩвдЗжЮЊЕЅШЫКЭЖрШЫЁЃtf-hubЕижЗШчЯТ:ЕижЗЁЃВтЪдЗЂЯж,ДгжЁТЪКЭаЇЙћЩЯРДЫЕ,movenetБШmediapipeаЇЙћвЊКУвЛЕуЁЃ
ЕЋЪЧдкunityЪЙгУжа,ЮвЗЂЯжmovenetЕФtf-liteФЃаЭдкunityжагіЕНСЫunity barracudaВхМўзЊЛЛЕФЮЪЬт,ЕЅШЫЕФtf-liteПЩгУ,ЕЋЪЧЖрШЫЮоЗЈзЊЛЛЁЃвбжЊЪЧunity barracudaВхМўЮЪЬт,вбЬсНЛissues,ЕЋФПЧАЛЙУЛзпЭЈЁЃ
ВЛЪьЯЄunity barracudaЕФЭЌбЇПЩвдвЦВНетРя
жївЊгУгкдкuntiyжаМЏГЩЩёОЭјТчЫуЗЈЁЃ
OpenPose
OpenPoseЪЧЮвдкgithubЩЯЫбЕНЕФвЛИіШЫЬхзЫЬЌЪЖБ№ЕФвЛИіЫуЗЈЗНАИЁЃ
жївЊЙІФм:
- 2DЪЕЪБЖрШЫЙиМќЕуМьВт:15ЁЂ18 Лђ25 ЙиМќЕуЩэЬх/зуВПЙиМќЕуЙРМЦ,АќРЈ6 ИізуВПЙиМќЕуЁЃдЫааЪБВЛЪмМьВтЕНЕФШЫЪ§ЕФгАЯьЁЃ2x21-keypoint ЪжВПЙиМќЕуЙРМЦЁЃдЫааЪБМфШЁОігкМьВтЕНЕФШЫЪ§ЁЃ70ИіЙиМќЕуШЫСГЙиМќЕуЙРМЦЁЃдЫааЪБМфШЁОігкМьВтЕНЕФШЫЪ§ЁЃ
- 3DЪЕЪБЕЅШЫЙиМќЕуМьВт
ЦфЪЕПЩвдРэНтГЩдкаЇЙћВњГіКЭзЫЬЌЪЖБ№НЧЖШРДЫЕ,ЪЧmediapipeКЭposenetЕФзлКЯЬхЁЃ
аЇЙћШчЯТ:

OpenMMD
OpenMMDЪЧвЛИіПЩвджБНгЗжЮіЯжГЩЪгЦЕ(ИїжжMP4, AVIЕШЪгЦЕИёЪН),здЖЏЩњГЩvmdЖЏзїЮФМўЕФЙЄОпЁЃ
етИіЗНАИЮоЗЈзіЕНЪЕЪБзЊЛЛ,МДЪЙФуЕФЪфШыдДЪЧЩуЯёЭЗЕФЛА,вВБиаыТМЭъвдКѓЩњГЩЖЏВЖЮФМў,ШЛКѓдйАбЖЏВЖЮФМўАѓЖЈЕНФЃаЭЩЯВХПЩвдЭъГЩЁЃ
OpenMMDОпЬхЪЙгУНЬГЬдкbеОЩЯгавЛИіДѓРазмНсЕФКмЧхГўСЫ,ЕЋгавЛИіЮЪЬт,ЫћжЛФмАѓЖЈдкmmdФЃаЭЩЯ,mmdФЃаЭдкгЮЯЗРяЕФЭЈгУадВЂВЛДѓ,ЪєгкБШНЯаЁЗЖЮЇЕФгІгУЁЃГЂЪдСЫМИжжФЃаЭжЎМфЛЅзЊЕФЗНАИ,BlenderЕШ,ЕЋЮоЙћ,зЊЛЛЦ№РДУЛФЧУДМђЕЅЁЃ
етЪЧЮвЧЈвЦКѓЕФаЇЙћ,зѓБпЪЧmmdФЃаЭ,ГЩЙІХмЭЈЁЃ

змНс
вдЩЯЮхжжЗНАИ,МђЕЅзмНсШчЯТ:

ВЮПМСДНг
ИіШЫЮЂаХЙЋЙВеЫКХвбЩЯЯп,ЛЖгЙизЂ:
