阅读目标:
- 了解解决异构性问题的角度
- 了解解决异构性问题的方法
阅读结束回答:
- 标签、特征、量
- FedAvg、FedProx等,并不是我想要的解决复杂异构性的方法
动机:隐私保护和数据条例的出现,导致多个“数据孤岛”分散数据库的形成;而这些分散数据库的关键挑战就是数据分布的异构性;联邦学习中出现很多应对这种non-iid的方法,但很少有实证研究来系统的梳理这些方法的优点和缺点
工作:1)提出了覆盖大多数non-iid情形的全面数据分区策略 2)设计了扩展实验来评估最先进的FL算法 3)结论是,没有任何一个最先进的算法能在所有情形下超越其他算法(也就是说没有一个完全意义上的最优算法)4)为”数据孤岛“的未来研究的挑战提供见解
也就是说,首先会介绍数据分区策略,然后介绍应对这些non-iid情形的算法,最后对这些算法进行评估(原本想模拟分布、评估分布,最后解决分布差异,这应该不是唯一的办法),然后给出未来发展方向,这些其实都是我想知道的嘿嘿
贡献:1)提出6个non-IID数据分区策略,考虑了标签分布倾斜、特征分布倾斜和量倾斜情况,其中有两个是比较popular的其他工作的贡献,其他四个是本论文提出的 2)定义了联邦学习中的关键挑战是non-IID数据分布,并为non-IID数据上的联邦学习开发了一个benchmark(不太懂这个benchmark是干啥的) 3)对FedAvg、FedProx、SCAFFOLD和FedNova四种方法进行了扩展实验,并提供了有远见的发现和未来方向
那么首先看non-iid数据的模拟
对于如何模拟,1)要考虑是使用真实世界的数据还是合成的数据,作者选择了后者 2)要考虑如何模拟,包括1.标签分布倾斜、2.特征分布倾斜和3.量倾斜三种,2.可以使用t-SNE方法对特征进行提取
下面对这三种倾斜的模拟分别进行介绍
标签分布倾斜:a)基于数量的标签不平衡,最早在FedAvg文章中提出,一个通用的模拟分区方法是,假设每个客户端分到的标签数量是 k k k,首先为每个客户端随机地分配 k k k个标签,然后对每个标签的样本,随机均等地将他们分配给拥有这个标签的客户端,作者用KaTeX parse error: Expected 'EOF', got '#' at position 1: #?C=k来表示这种分区策略 b)基于分布的标签不平衡,根据 p k p_k pk? ~ D i r N ( β ) Dir_N(\beta) DirN?(β)进行采样,客户端 j j j分配到类别 k k k的 p k , j p_{k,j} pk,j?比例的样本,其中 D i r ( ? ) Dir(・) Dir(?)表示Dirichlet分布, β \beta β表示专注度的超参数,这种分区的优势是可以灵活地改变不平衡级别,用 p k p_k pk? ~ D i r ( β ) Dir(\beta) Dir(β)表示这种分区方式
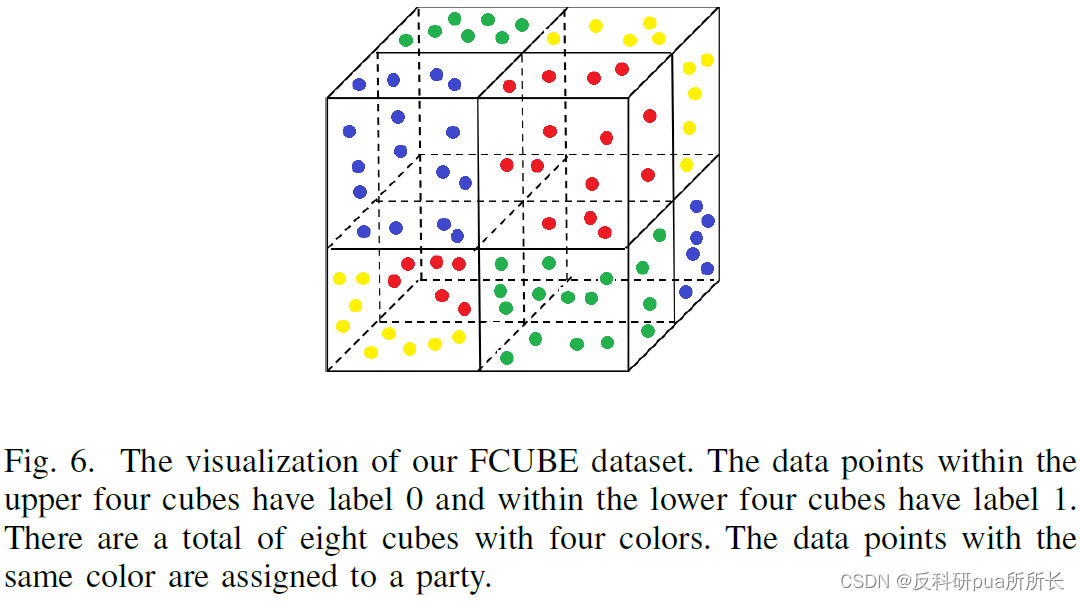
特征分布倾斜:包括基于噪声的特征不平衡、合成特征不平衡和真实世界特征不平衡;a)基于噪声的特征不平衡,对每个客户端,为每个本地数据集增加不同级别的高斯噪声,获得不同的特征分布(有点疑惑,不同的特征分布是自己增加的吗?不是本来就存在的不同吗);给定用户(就是我们研究者)定义的噪声级别 σ \sigma σ,为客户端 i i i增加噪声 x ^ \hat{x} x^ ~ G a u ( σ ? i / N ) Gau(\sigma・i/N) Gau(σ?i/N),其中 G a u ( σ ? i / N ) Gau(\sigma・i/N) Gau(σ?i/N)表示以 0 0 0为均值以 σ ? i / N \sigma・i/N σ?i/N为方差的高斯分布,用户可以通过改变 σ \sigma σ来提升客户端之间的特征差异,用 x ^ \hat{x} x^ ~ G a u ( σ ) Gau(\sigma) Gau(σ)来表示这种基于噪声的特征不平衡 b)合成特征不平衡,生成一个合成特征不平衡联邦数据集,称为FCUBE,假设数据点的分布是一个三维立方体(三个维度分别是 x 1 , x 2 , x 3 x_1, x_2, x_3 x1?,x2?,x3?,那么根据 x 1 = 0 x_1=0 x1?=0, x 2 = 0 x_2=0 x2?=0和 x 3 = 0 x_3=0 x3?=0可以将整个空间分为八个立方体,上面四个立方体的标签是0,下面四个立方体的标签是1,同标签的不同立方体分配给不同的颜色,按照颜色分给不同的客户端(这个立方体的例子,是不是只有在标签是0/1,只有四个客户端的情况下才能用啊,感觉标签数和客户端数变化之后,就不是立方体了) c)真实世界的特征不平衡,比如说手写字符中,不同writer写出来的字符是有一个固定特征的,可以直接将同一个writer的字符随机均匀地分给不同客户端
量倾斜:也是使用Dirichlet分布,只是分配给客户端的时候不考虑类别了