目录
压缩算法原理可看我上一篇文章:数据压缩算法原理
算法实现
Deflate
一个基于LZ77算法和Huffman编码实现的压缩算法。
/**
* 压缩字符串
*
* @param unZipStr 需要压缩的字符串
* @return 压缩之后的字符串
*/
public static String deflateCompress(String unZipStr) {
? ?if (isEmpty(unZipStr)) {
? ? ? ?return null;
? }
? ?//使用指定的压缩级别创建一个新的压缩器。
? ?Deflater deflater = new Deflater(Deflater.BEST_COMPRESSION);
? ?//设置需要压缩的数据
? ?deflater.setInput(unZipStr.getBytes(StandardCharsets.UTF_8));
? ?//当被调用时,表示压缩应该以输入缓冲区的当前内容结束。
? ?deflater.finish();
?
? ?final byte[] bytes = new byte[256];
? ?ByteArrayOutputStream outputStream = new ByteArrayOutputStream(256);
? ?while (!deflater.finished()) {
? ? ? ?//压缩输入数据并用压缩数据填充指定的缓冲区。
? ? ? ?int len = deflater.deflate(bytes);
? ? ? ?outputStream.write(bytes, 0, len);
? }
? ?//关闭压缩器并丢弃任何未处理的输入
? ?deflater.end();
? ?return Base64.getEncoder().encodeToString(outputStream.toByteArray());
}
?
/**
* 解压字符串
*
* @param zipString 待解压字符串
* @return 解压之后的字符串
*/
public static String deflateUnCompress(String zipString) {
? ?if (isEmpty(zipString)) {
? ? ? ?return null;
? }
? ?byte[] decode = Base64.getDecoder().decode(zipString);
? ?//创建一个解压器
? ?Inflater inflater = new Inflater();
? ?//设置解压缩的输入数据
? ?inflater.setInput(decode);
? ?final byte[] bytes = new byte[256];
? ?ByteArrayOutputStream outputStream = new ByteArrayOutputStream(256);
? ?try {
? ? ? ?while (!inflater.finished()) {
? ? ? ? ? ?//将字节解压缩到指定的缓冲区中
? ? ? ? ? ?int len = inflater.inflate(bytes);
? ? ? ? ? ?outputStream.write(bytes, 0, len);
? ? ? }
? } catch (DataFormatException e) {
? ? ? ?log.error("数据格式异常,返回原数据");
? ? ? ?return zipString;
? }
? ?return outputStream.toString();
}GZIP
一个压缩比高的慢速算法,压缩后的数据适合长期使用。 JDK中的java.util.zip.GZIPInputStream / GZIPOutputStream便是这个算法的实现。
/**
* 将字符串进行gzip压缩
*
* @param unZipStr 待压缩字符串
* @return 压缩之后的字符串
*/
public static String gzipCompress(String unZipStr) {
? ?if (isEmpty(unZipStr)) {
? ? ? ?return null;
? }
? ?ByteArrayOutputStream out = new ByteArrayOutputStream();
? ?try (GZIPOutputStream gzip = new GZIPOutputStream(out)) {
? ? ? ?gzip.write(unZipStr.getBytes(StandardCharsets.UTF_8));
? } catch (IOException e) {
? ? ? ?log.error("gzip压缩字符串出错:", e);
? ? ? ?return unZipStr;
? }
? ?return Base64.getEncoder().encodeToString(out.toByteArray());
}
?
/**
* 将字符串进行gzip解压缩
*
* @param zipStr 待解压字符串
* @return 解压之后的字符串
*/
public static String gzipUnCompress(String zipStr) {
? ?if (isEmpty(zipStr)) {
? ? ? ?return null;
? }
? ?byte[] decode = Base64.getDecoder().decode(zipStr);
? ?ByteArrayOutputStream out = new ByteArrayOutputStream();
? ?ByteArrayInputStream in = new ByteArrayInputStream(decode);
? ?try (GZIPInputStream gzip = new GZIPInputStream(in)) {
? ? ? ?byte[] buffer = new byte[256];
? ? ? ?int len;
? ? ? ?while ((len = gzip.read(buffer)) != -1) {
? ? ? ? ? ?out.write(buffer, 0, len);
? ? ? }
? } catch (IOException e) {
? ? ? ?log.error("gzip解压缩字符串出错:", e);
? ? ? ?return zipStr;
? }
? ?return out.toString();
}LZO
-
底层也是使用的LZ77算法
-
LZO是块压缩算法,它压缩和解压一个块数据。压缩和解压的块大小必须一样。
-
LZO将块数据压缩成匹配数据(滑动字典)和非匹配的文字序列。LZO对于长匹配和长文字序列有专门的处理,这样对于高冗余的数据能够获得很好的效果,这样对于不可压缩的数据,也能得到较好的效果。
需要导lzo-core包,最近一次更新是2018年10月,maven仓库上提示依赖有漏洞,所以要使用它最好对其进行漏洞修复再使用。
<!-- https://mvnrepository.com/artifact/org.anarres.lzo/lzo-core -->
<dependency>
? ?<groupId>org.anarres.lzo</groupId>
? ?<artifactId>lzo-core</artifactId>
? ?<version>1.0.6</version>
</dependency>/**
* lzo压缩
* @param str 待压缩字符串
* @return 压缩之后的字符串
*/
public static String lzoCompress(String str){
? ?LzoCompressor compressor = LzoLibrary.getInstance().newCompressor(
? ? ? ? ? ?LzoAlgorithm.LZO1X, null);
? ?ByteArrayOutputStream os = new ByteArrayOutputStream();
? ?LzoOutputStream louts = new LzoOutputStream(os, compressor);
? ?try{
? ? ? ?louts.write(str.getBytes(StandardCharsets.UTF_8));
? ? ? ?louts.close();
? ? ? ?return Base64.getEncoder().encodeToString(os.toByteArray());
? }catch (Exception e){
? ? ? ?throw new RuntimeException("LzoCompressError", e);
? }
}
/**
* lzo解压缩
* @param str 待解压缩字符串
* @return 解压缩之后的字符串
*/
public static String lzoUnCompress(String str){
? ?LzoDecompressor decompressor = LzoLibrary.getInstance()
? ? ? ? ? .newDecompressor(LzoAlgorithm.LZO1X, null);
? ?try{
? ? ? ?ByteArrayOutputStream os = new ByteArrayOutputStream();
? ? ? ?ByteArrayInputStream is = new ByteArrayInputStream(Base64.getDecoder().decode(str.getBytes(StandardCharsets.UTF_8)));
? ? ? ?LzoInputStream lis = new LzoInputStream(is, decompressor);
? ? ? ?int count;
? ? ? ?byte[] buffer = new byte[256];
? ? ? ?while((count = lis.read(buffer)) != -1){
? ? ? ? ? ?os.write(buffer, 0, count);
? ? ? }
? ? ? ?return os.toString();
? }catch (Exception e){
? ? ? ?throw new RuntimeException("lzoUnCompressError", e);
? }
}LZ4
一个用16k大小哈希表储存字典并简化检索的LZ77,压缩比较差。
需要导lz4包,最近一次更新是2014年11月.
<!-- https://mvnrepository.com/artifact/net.jpountz.lz4/lz4 -->
<dependency>
? ?<groupId>net.jpountz.lz4</groupId>
? ?<artifactId>lz4</artifactId>
? ?<version>1.3.0</version>
</dependency>/**
* lz4压缩
* @param str 待压缩字符串
* @return 压缩之后的字符串
*/
public static String lz4Compress(String str){
? ?LZ4Factory factory = LZ4Factory.fastestInstance();
? ?ByteArrayOutputStream byteOutput = new ByteArrayOutputStream();
? ?LZ4Compressor compressor = factory.fastCompressor();
? ?try{
? ? ? ?LZ4BlockOutputStream compressedOutput = new LZ4BlockOutputStream(
? ? ? ? ? ? ? ?byteOutput, 2048, compressor);
? ? ? ?compressedOutput.write(str.getBytes(StandardCharsets.UTF_8));
? ? ? ?compressedOutput.close();
? ? ? ?return Base64.getEncoder().encodeToString(byteOutput.toByteArray());
? }catch (Exception e){
? ? ? ?throw new RuntimeException("lz4CompressError", e);
? }
}
?
/**
* lz4解压缩
* @param str 待解压缩字符串
* @return 解压缩之后的字符串
*/
public static String lz4UnCompress(String str){
? ?byte[] decode = Base64.getDecoder().decode(str.getBytes());
? ?ByteArrayOutputStream baos = new ByteArrayOutputStream();
? ?try{
? ? ? ?LZ4BlockInputStream lzis = new LZ4BlockInputStream(
? ? ? ? ? ? ? ?new ByteArrayInputStream(decode));
? ? ? ?int count;
? ? ? ?byte[] buffer = new byte[2048];
? ? ? ?while ((count = lzis.read(buffer)) != -1) {
? ? ? ? ? ?baos.write(buffer, 0, count);
? ? ? }
? ? ? ?lzis.close();
? ? ? ?return baos.toString("utf-8");
? }catch (Exception e){
? ? ? ?throw new RuntimeException("lz4UnCompressError", e);
? }
}Snappy
snappy是google基于LZ77的思路编写的快速数据压缩与解压程序库。它的目标并非最大压缩率或与其他压缩程序库的兼容性,而是非常高的速度和合理的压缩率。snappy的压缩解压性能是非常优秀的,压缩比也较好。
需要导lz4包,最近一次更新是2021年1月.
<!-- https://mvnrepository.com/artifact/org.xerial.snappy/snappy-java -->
<dependency>
? <groupId>org.xerial.snappy</groupId>
? <artifactId>snappy-java</artifactId>
? <version>1.1.8.4</version>
</dependency>/**
* snappy压缩
* @param str 待压缩字符串
* @return 压缩之后的字符串
*/
public static String snappyCompress(String str){
? ?try{
? ? ? ?byte[] compress = Snappy.compress(str);
? ? ? ?return Base64.getEncoder().encodeToString(compress);
? }catch (Exception e){
? ? ? ?throw new RuntimeException("snappyCompressError", e);
? }
}
/**
* snappy解压缩
* @param str 待解压缩字符串
* @return 解压缩之后的字符串
*/
public static String snappyUnCompress(String str){
? ?ByteArrayOutputStream baos = new ByteArrayOutputStream();
? ?try{
? ? ? ?byte[] decode = Base64.getDecoder().decode(str.getBytes());
? ? ? ?baos.write(Snappy.uncompress(decode));
? ? ? ?return baos.toString();
? }catch (Exception e){
? ? ? ?throw new RuntimeException("snappyUnCompressError", e);
? }
}数据压缩算法性能测试
使用jmh做性能测试
准备工作
1.准备两个json文件,放在项目的file目录下:
-
json-min.txt:大小514KB
-
json-max.txt:大小7147KB ~=7M
2.使用maven生成jmh工程:
$ mvn archetype:generate \
-DinteractiveMode=false \
-DarchetypeGroupId=org.openjdk.jmh \
-DarchetypeArtifactId=jmh-java-benchmark-archetype \
-DgroupId=org.sample \
-DartifactId=data-compress \
-Dversion=1.03.将上述算法实现封装好放入jmh工程,相关maven依赖也添加进去
4.编写测试基准类
/*
* Copyright (c) 2005, 2013, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
?
package org.sample;
?
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Fork;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Warmup;
?
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.concurrent.TimeUnit;
?
?
/**
* 基准测试后对代码预热总计5秒(迭代5次,每次1秒)。预热对于压测来说非常非常重要,如果没有预热过程,压测结果会很不准确。
* # Warmup Iteration ? 1: 164.260 ms/op
* # Warmup Iteration ? 2: 168.476 ms/op
* # Warmup Iteration ? 3: 156.233 ms/op
* # Warmup Iteration ? 4: 121.852 ms/op
* # Warmup Iteration ? 5: 125.359 ms/op
*
*/
@Warmup(iterations = 5, time = 1)
/**
* 循环运行5次,每次迭代时间为1秒,总计10秒时间。
*/
@Measurement(iterations = 10, time = 1)
/**
* 表示fork多少个线程运行基准测试,如果@Fork(1),那么就是一个线程,这时候就是同步模式。
*/
@Fork(1)
/**
* 基准测试模式,@BenchmarkMode(Mode.AverageTime)搭配@OutputTimeUnit(TimeUnit.MILLISECONDS)
* 表示每次操作需要的平均时间,而OutputTimeUnit申明为毫秒,所以基准测试单位是ms/op,即每次操作的毫秒单位平均时间
*/
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class MyBenchmark {
?
?
? ?/**
? ? * 被拷贝的源对象,预加载需要压缩的json字符串
? ? */
? ?@State(Scope.Benchmark)
? ?public static class CommonState {
? ? ? ?String resourceString;
? ? ? ?String deflateResourceString;
? ? ? ?String gzipResourceString;
? ? ? ?String lzoResourceString;
? ? ? ?String lz4ResourceString;
? ? ? ?String snappyResourceString;
?
? ? ? ?@Setup(Level.Trial)
? ? ? ?public void prepare() throws IOException {
? ? ? ? ? ?byte[] resourceBytes = Files.readAllBytes(Paths.get("./file/json-min.txt"));
? ? ? ? ? ?resourceString = new String(resourceBytes);
// ? ? ? ? ? byte[] deflateResourceBytes = Files.readAllBytes(Paths.get("./file/json-min-deflate.txt"));
// ? ? ? ? ? deflateResourceString = new String(deflateResourceBytes);
// ? ? ? ? ? byte[] gzipResourceBytes = Files.readAllBytes(Paths.get("./file/json-min-gzip.txt"));
// ? ? ? ? ? gzipResourceString = new String(gzipResourceBytes);
// ? ? ? ? ? byte[] lzoResourceBytes = Files.readAllBytes(Paths.get("./file/json-min-lzo.txt"));
// ? ? ? ? ? lzoResourceString = new String(lzoResourceBytes);
// ? ? ? ? ? byte[] lz4ResourceBytes = Files.readAllBytes(Paths.get("./file/json-min-lz4.txt"));
// ? ? ? ? ? lz4ResourceString = new String(lz4ResourceBytes);
// ? ? ? ? ? byte[] snappyResourceBytes = Files.readAllBytes(Paths.get("./file/json-min-snappy.txt"));
// ? ? ? ? ? snappyResourceString = new String(snappyResourceBytes);
? ? ? }
? }
?
// ========================================压缩测试=========================================//
? ?@GenerateMicroBenchmark
? ?public void testDeflateCompress(MyBenchmark.CommonState commonState) throws IOException {
? ? ? ?// place your benchmarked code here
? ? ? ?String compress = ZipUtils.deflateCompress(commonState.resourceString);
? ? ? ?Files.write(Paths.get("./file/json-min-deflate.txt"),compress.getBytes());
? }
?
? ?@GenerateMicroBenchmark
? ?public void testGzipCompress(MyBenchmark.CommonState commonState) throws IOException {
? ? ? ?// place your benchmarked code here
? ? ? ?String compress = ZipUtils.gzipCompress(commonState.resourceString);
? ? ? ?Files.write(Paths.get("./file/json-min-gzip.txt"),compress.getBytes());
? }
?
? ?@GenerateMicroBenchmark
? ?public void testLzoCompress(MyBenchmark.CommonState commonState) throws IOException {
? ? ? ?// place your benchmarked code here
? ? ? ?String compress = ZipUtils.lzoCompress(commonState.resourceString);
? ? ? ?Files.write(Paths.get("./file/json-min-lzo.txt"),compress.getBytes());
? }
?
? ?@GenerateMicroBenchmark
? ?public void testLz4Compress(MyBenchmark.CommonState commonState) throws IOException {
? ? ? ?// place your benchmarked code here
? ? ? ?String compress = ZipUtils.lz4Compress(commonState.resourceString);
? ? ? ?Files.write(Paths.get("./file/json-min-lz4.txt"),compress.getBytes());
? }
?
? ?@GenerateMicroBenchmark
? ?public void testSnappyCompress(MyBenchmark.CommonState commonState) throws IOException {
? ? ? ?// place your benchmarked code here
? ? ? ?String compress = ZipUtils.snappyCompress(commonState.resourceString);
? ? ? ?Files.write(Paths.get("./file/json-min-snappy.txt"),compress.getBytes());
? }
?
// ======================================解压缩测试=======================================//
// ? @GenerateMicroBenchmark
// ? public String testDeflateUnCompress(MyBenchmark.CommonState commonState) throws IOException {
// ? ? ? // place your benchmarked code here
// ? ? ? return ZipUtils.deflateUnCompress(commonState.deflateResourceString);
// ? }
//
// ? @GenerateMicroBenchmark
// ? public String testGzipUnCompress(MyBenchmark.CommonState commonState) throws IOException {
// ? ? ? // place your benchmarked code here
// ? ? ? return ZipUtils.gzipUnCompress(commonState.gzipResourceString);
// ? }
//
// ? @GenerateMicroBenchmark
// ? public String testLzoUnCompress(MyBenchmark.CommonState commonState) throws IOException {
// ? ? ? // place your benchmarked code here
// ? ? ? return ZipUtils.lzoUnCompress(commonState.lzoResourceString);
// ? }
//
// ? @GenerateMicroBenchmark
// ? public String testLz4UnCompress(MyBenchmark.CommonState commonState) throws IOException {
// ? ? ? // place your benchmarked code here
// ? ? ? return ZipUtils.lz4UnCompress(commonState.lz4ResourceString);
// ? }
//
// ? @GenerateMicroBenchmark
// ? public String testSnappyUnCompress(MyBenchmark.CommonState commonState) throws IOException {
// ? ? ? // place your benchmarked code here
// ? ? ? return ZipUtils.snappyUnCompress(commonState.snappyResourceString);
// ? }
?
}测试
-
打包,cmd进入项目目录(data-compress),执行
mvn clean package -
运行基准测试:
java -jar .\target\microbenchmarks.jar
json-min.txt压缩结果
Benchmark ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? Mode ? Samples ? ? ? ? Mean ? Mean error ? Units o.s.MyBenchmark.testDeflateCompress ? ? avgt ? ? ? 10 ? ? ? 12.100 ? ? ? 0.498 ? ms/op o.s.MyBenchmark.testGzipCompress ? ? ? avgt ? ? ? 10 ? ? ? 7.434 ? ? ? 4.398 ? ms/op o.s.MyBenchmark.testLz4Compress ? ? ? ? avgt ? ? ? 10 ? ? ? 3.310 ? ? ? 1.096 ? ms/op o.s.MyBenchmark.testLzoCompress ? ? ? ? avgt ? ? ? 10 ? ? ? 3.255 ? ? ? 1.014 ? ms/op o.s.MyBenchmark.testSnappyCompress ? ? avgt ? ? ? 10 ? ? ? 1.971 ? ? ? 0.209 ? ms/op
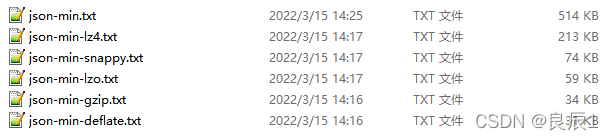
可以得到如下结论:
-
压缩率(越小越好):deflate(6.0%) < gzip(6.6%) < lzo(11.4%) < snappy(14.3%) < lz4(41.4%) 。
-
压缩耗时:snappy < lzo < lz4 < gzip < deflate
-
综合来看lz4压缩率比较差
将MyBenchmark类里面min文件改为max文件,再次执行打包和运行基准测试。
json-max.txt压缩结果
Benchmark ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? Mode ? Samples ? ? ? ? Mean ? Mean error ? Units o.s.MyBenchmark.testDeflateCompress ? ? avgt ? ? ? 10 ? ? 124.612 ? ? ? 6.494 ? ms/op o.s.MyBenchmark.testGzipCompress ? ? ? avgt ? ? ? 10 ? ? ? 60.421 ? ? ? 6.102 ? ms/op o.s.MyBenchmark.testLz4Compress ? ? ? ? avgt ? ? ? 10 ? ? ? 39.454 ? ? ? 2.442 ? ms/op o.s.MyBenchmark.testLzoCompress ? ? ? ? avgt ? ? ? 10 ? ? 149.784 ? ? ? 19.208 ? ms/op o.s.MyBenchmark.testSnappyCompress ? ? avgt ? ? ? 10 ? ? ? 18.322 ? ? ? 0.406 ? ms/op
?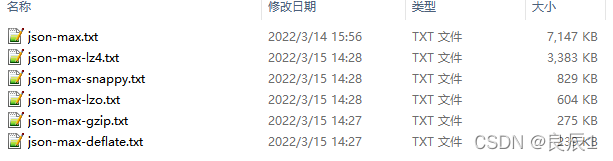
?可以得到如下结论:
-
压缩率(越小越好):deflate(3.3%) < gzip(3.8%) < lzo(8.4%) < snappy(11.5%) < lz4(47.3%) 。
-
压缩耗时:snappy < lz4 < gzip < deflate < lzo , 该结论和上面压缩小串有所区别,lzo的操作时间直线下滑,成为最慢。
-
综合来看lz4和lzo压缩性能都比较差,不推荐使用,其余3个可根据需要选择
将MyBenchmark类里面max文件改为min文件,注释调压缩的测试方法,放开解压的测试方法,再次执行打包和运行基准测试。
json-min-**.txt解缩结果
Benchmark ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? Mode ? Samples ? ? ? ? Mean ? Mean error ? Units o.s.MyBenchmark.testDeflateUnCompress ? ? avgt ? ? ? 10 ? ? ? 2.318 ? ? ? 0.080 ? ms/op o.s.MyBenchmark.testGzipUnCompress ? ? ? avgt ? ? ? 10 ? ? ? 2.266 ? ? ? 0.063 ? ms/op o.s.MyBenchmark.testLz4UnCompress ? ? ? ? avgt ? ? ? 10 ? ? ? 2.087 ? ? ? 0.050 ? ms/op o.s.MyBenchmark.testLzoUnCompress ? ? ? ? avgt ? ? ? 10 ? ? ? 1.604 ? ? ? 0.085 ? ms/op o.s.MyBenchmark.testSnappyUnCompress ? ? avgt ? ? ? 10 ? ? ? 1.467 ? ? ? 0.067 ? ms/op
将MyBenchmark类里面min文件改为max文件,再次执行打包和运行基准测试。
json-max-**.txt解缩结果
Benchmark ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? Mode ? Samples ? ? ? ? Mean ? Mean error ? Units o.s.MyBenchmark.testDeflateUnCompress ? ? avgt ? ? ? 10 ? ? ? 31.372 ? ? ? 1.124 ? ms/op o.s.MyBenchmark.testGzipUnCompress ? ? ? avgt ? ? ? 10 ? ? ? 31.198 ? ? ? 0.687 ? ms/op o.s.MyBenchmark.testLz4UnCompress ? ? ? ? avgt ? ? ? 10 ? ? ? 34.771 ? ? ? 0.716 ? ms/op o.s.MyBenchmark.testLzoUnCompress ? ? ? ? avgt ? ? ? 10 ? ? ? 23.342 ? ? ? 0.749 ? ms/op o.s.MyBenchmark.testSnappyUnCompress ? ? avgt ? ? ? 10 ? ? ? 22.764 ? ? ? 0.502 ? ms/op
由上述解压结果可看出解压速度都很快,相差不大,所以可以主要看压缩率和压缩时间来选择压缩算法。