ps:经历过毕业论文的洗礼之后,写这种小博文就觉得不需要太用心了!反正,都是给自己看的!所以,就这样吧!
函数 CheckCompound2 根据开发的两个关键规则确定关系查询是否是复合的。在等式中的规则9和10分别适用于基于Wh和非Wh(non-Wh)的查询。在等式中的规则11适用于包含该模式的非关系性查询,模式:JSS->CC->JJS->N,即是一个形容词最高级形式后面跟着一个连词后面再加一个形容词最高级后面跟着一个名词(例如,Which is the longest and shortest river in America)

一个复合句被分成两个简单句s1和s2,在规则12中有表述。

在一个复合句当中,使用规则9和10识别出如下句子:

当由规则11识别简单句时,如下:

考虑用户查询语句S=What is the population and area of the most populated state ?
则依赖关系图如下:

应用规则10,如下:

因为这个句子是复合的,Break2(S)函数(规则12)应用后,生成如下两个简单句子s1,s2:


最后,user triples用户三元组通过GenerateTriples2函数生成。为了识别三元组,GenerateTripes2将会识别如下内容:

解释:首先是介词,比如Tom的父亲和德国的山脉;其次是最终的结构,比如Tom的父亲。这可能是前面介绍过的例子,过了太久了,我也忘记是什么了!
介词“of”表示给定名词具有特殊性质,比如,在What is the area of the most populated state问句中,名词state有属性area。介词(preposition)是一个给定的对象属于一个名词的信号,例如,What is the highest mountain in Germany描述了一个给定的mountain属于Germany。因此,基于所使用的介词的类型,GenerateTriples2函数使用两个规则秘钥集(key set of rules)从用户提交的查询中提取三元组triple。当使用一个介词提取三元组的时候,在基于查询的非关系(non-relation)的一般语法约束中为N->IN->(A*)->N的形式,即是一个名词后跟着一个介词后面再跟着一个名词。有时一个行列式/定子(determinant)和存在的形容词被描述为A*。
方程13中的规则适用于其中使用of介词的查询。规则13a和13b分别应用于Wh查询和non-Wh查询。

应用GenerateTriples2中的13a,则s1与s2为:




一个应用介词in时候的案例,规则14a与14b分别适用于Wh和non-Wh的情况。

考虑用户查询语句:Which is the highest mountain in Germany。应用规则15a。

规则如下:

提取用户三元组user triple为:{Germany ?k Mountain} {Mountain ?k Germany}
我们试图抢占底层本体(underlying ontology)中所有可能的概念安排(类似于概念的排列组合吧?)。术语Germany在本体中可能会占据主语地位(subject)例如在三元组{Germany :hasMountain Adelegg},当然也可能在谓语的位置例如在三元组{Adelegg :belongTo Germany}。由词典(lexicon)决定要选择的确切的三元组。当涉及到属格的补充时,应用了公式15中的规则,语法约束为:N->POS->N,即是它包含两个名词,头部和依赖名词或者是编辑名词(modifier noun),比如German’s flag。依赖名词通过表达头部的某些属性来修饰头部。规则15a适用于non-Wh查询,而规则15b适用于基于Wh的查询。
考虑查询语句:What is Angela’s birth name?
依赖图如下:
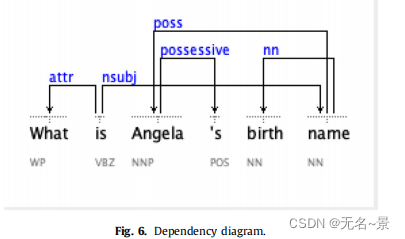
应用规则15b后为:(图是原文的,我觉得应该是由于粗心写错了!)

PS:应该为nsubj(is,name)^poss(name,Angela)^possessive(Angela,'s)=>Triple(Angela,?k,name)∨Triple(name,?k,Angela)
生成三元组为:

PS:应该为{Angela,?k,name}∨{name,?k,Angela}
现在翻译到第7页了!觉得没啥意思了!不过心理学家不是说,人总是有一种,如果开始就一定要结果的欲望嘛!大概还有这一点支撑着我写到现在!
结果,写着写着,突然,担心起了我的毕业论文来!求过!求过!念在我这么闲的份儿上,让我过吧!我的工作岗位在等着我呢!社会需要劳动力!谢谢,大佬们!!!