����Ŀ¼

0. ժҪ
���,�Ѿ������һ�����ɱ���Զ������� (variational autoencoder, VAE) ����������ǿ�Զ�����ͳ�ƽ��н�ģ��Ȼ��,���ַ���ֻ��ѵ����ʹ�øɾ�������,ʹ�ù��ƶ������Ĵ����ر�����,�������ڵ������ (SNR) ������¡�Ϊ����� VAE ��³����,���Ľ�����ѵ���μ���������Ϣ,�ò��Կ�ͨ��ʹ��(noisy-clean pairs)ѵ����noise-aware encoderʵ�֡�����ʹ��������ͬ���������ݼ��������ǶԲ�ͬ������������ѧ��������ʵ��¼�ķ�����ʵ�����,���������������֪ VAE ������ʧ�淽�����ڱ� VAE,����������ģ�Ͳ�����������ͬʱ,����֤�������ǵ�ģ���ܹ����мලǰ����������� (DNN) ���õط���������������������������,����չʾ��ģ�����ܶԼ���ѵ�����ݹ�ģ�����³���ԡ�
1. Introduction
������ǿͨ����Ҫ�������������Ĺ������ܶ�(PSD)����ͳ�ƹ���,�Ǹ�����ֽ�(Non-negative matrix factorization, NMF)��PSD���Ƶij��÷�����Ȼ��,�ڶԸ��ӵĸ�ά���ݽ�ģʱ,���Լ�������������NMF���������ܡ� ���֮��,���ڷ��������������(DNN)��������ǿ���ֳ����õĽ�ģ������ �����ķ����������Լල��ʽ�ƶ�ʱƵ���� [7]�� Ȼ��,Ϊ���ƹ㵽����������������,DNN��Ҫ������������ݽ���ѵ����
���ɱ���Ա�����(generative VAE)��һ�ָ���ģ��,�㷺����ѧϰ���ʷֲ���DZ�ڱ�ʾ��VAE�����뾭���Ա��������ƵĽṹ,Ϊencoder��decoder�ܹ�,����VAE��DZ�ڿռ䲻ͬ,����Ҫ����������,���������˹�ֲ�������,VAE������Ӧ���ڵ�ͨ���Ͷ�ͨ��������ǿ������[14-16]����Щ�������Դ�������Ƶ����ѵ��,�Դ���������ͳ�ƽ��н�ģ��Ȼ��,������ѵ����ȱ��������Ϣ,��VAE��encoder������������,�ڵ�����������,�������������Իᵼ�¶�DZ�ڱ����Ĵ������,�Ӷ����²�ǡ������������ϵ�����������ܡ�
[14] Y. Bando, M. Mimura, K. Itoyama, K. Yoshii, and T. Kawahara, ��Statistical speech enhancement based on probabilistic integration of variational autoencoder and non-negative matrix factorization,�� in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 716�C720.
[15] S. Leglaive, L. Girin, and R. Horaud, ��A variance modeling framework based on variational autoencoders for speech enhancement,�� in International Workshop on Machine Learning for Signal Processing (MLSP), 2018, pp. 1�C6.
[16] S. Leglaive, L. Girin, and R. Horaud, ��Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization,�� in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2019, pp. 101�C105.
��conditional VAE ������ͼ��ָ�Ӧ���е�����,Ϊ���������³����,���������������֪�������滻 VAE �ı�����������ʹ�øɾ�����Ƶ��ѵ��VAE,֮��ʹ�ô�����������ѵ��,���мල�ķ�ʽ����ѵ��,ʹ��DZ�ڿռ��ʾ�����ܽӽ���ʹ�ô�������ѵ����encoder�����ķ�����VAE-NMF��������ǿ���Ϊ����,��ģ�Ϳ����,NMF���ڶ�������PSD���н�ģ��ʵ��������,���ķ������������ڸ���³��,�����ڲ�����ģ�Ͳ�������������¸Ľ����������ơ� �÷�����ͨ���������Բ�ͬ�������ݼ�����ʵ��¼,��ʾ���Կ�����������������³���ԡ� ���,����˵��ʹ������noisy-clean���������ݿ��Ը�������ʧ�档
2. Problem Formulation
2.1 Mixture model
���Ŀ��Ǽ�������ģ��,��STFT�任���ʾΪ:

�����������������Ǿ������ֵ��������ĸ���˹�ֲ�����ʾΪ
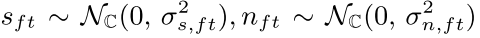
�źŵ� �������ܶ�(PSD)�ɾֲ�ƽ�ȼ����µIJ������������
����,Ϊ�����Ӷ���Ƶ������ȵ�³����,��������ʱ���Ƶ���ص����� gt�����,(1)�еļ��Ի��ģ�Ϳ���Ϊ
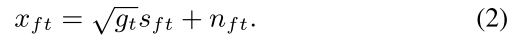
�����������Ӹ���˹�ֲ�,�ɱ�ʾΪ:
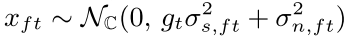
2.2 Speech model
���ڻ��� VAE ������ģ��,��������֡�� D άDZ�ڱ��� z t �� R D z_t \in R^D zt?��RD,�������������Ȼ�ֲ� p �� ( s t �O z t ) p_{\theta}(s_t|z_t) p��?(st?�Ozt?)�в��� F ά����֡ s t s_t st?���������ͨ��VAE��decoderʵ��,Ҳ��Ϊ����ģ�͡����� �� \theta ����ʾdecoder����IJ���, �� ^ s 2 \hat{\sigma}^2_s ��^s2?��ʾ�����Ժ�����
VAE������ѭ��Ҷ˹���,����ѧϰDZ�ڱ���������ģ��,��Ҫ�ƽ����Դ�������ʵ����ֲ�
p
(
z
t
�O
s
t
)
p(z_t|s_t)
p(zt?�Ost?)����VAE��,encoder�ֳ�Ϊ����ģ��,���ڽ�����ʵ����ֲ�,��ʾΪ
q
?
(
z
t
�O
s
t
)
q_{\phi}(z_t|s_t)
q??(zt?�Ost?)��������ݶ��½���,����ģ�͵IJ��� �� ������ģ�͵IJ��� �� ͨ���������������Ż�,����ʽ����
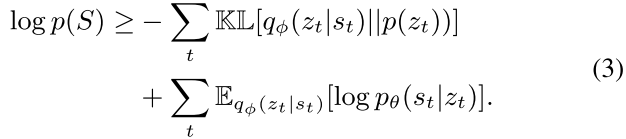
p
(
z
t
)
p(z_t)
p(zt?)��ʾDά����
z
t
z_t
zt?������ֲ�,KL ��ʾ Kullback-Leibler ɢ�ȡ�DZ�ڱ��������鶨��Ϊһ�����ֵ����ͬ�Զ�Ԫ��˹ zt��N(0, I),Ŀ�꺯��(3)�еĵ�һ����ָDZ�ڿռ��е��������,��ȷ���������DZ�ڱ���,�ڶ������ؽ���

2.3 Noise model
NMF ��ͼͨ��������ϵ�������Ȩ�Ļ��������ֵ�������ҵ�����������ѽ���ֵ����������NMF������������н�ģ,��������ͨ���ֵ����
W
��
R
F
��
K
W \in R^{F \times K}
W��RF��K��ϵ������
H
��
R
K
��
T
H \in R^{K \times T}
H��RK��T��˵Ľ�����н���:
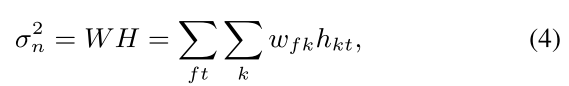
K��ʾ����ģ�͵���,��k������
w
f
k
��
h
k
t
w_{fk}��h_{kt}
wfk?��hkt?�ֱ��ʾW��H��Ԫ�ء�
2.4 Clean speech inference
ͨ��ʹ��VAE��NMF�ֱ���������������н�ģ,���������ķֲ����Ա�ʾΪ:
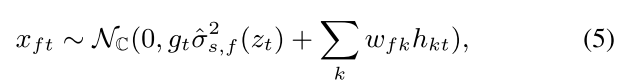
����
��
^
s
,
f
2
\hat{\sigma}^2_{s, f}
��^s,f2?��ʾ�Ե�f��Ƶ��ķ����Ժ���
��
^
s
2
\hat{\sigma}^2_s
��^s2?���������������Ϊ�۲�ֵ,���ؿ���������� (MCEM) �㷨���ڹ��� NMF ��������������,�������Ի���Metropolis-Hastings�㷨��ͨ������ά���˲�
m
^
f
t
\hat{m}_{ft}
m^ft?,���ԴӴ�����������ȡ�������źš�
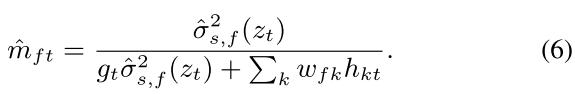
3. Noise-Aware VAE
�������һ��������֪������,������߱��������������ڵ�³���ԡ��������ɹ���,���������������Ƶ���DZ�ڱ�����Ŀ��֮������ӳ�䡣 Ȼ��,������Ϊ,ʹ��������Ϲ��Ƶ�DZ�ڱ��������ܽӽ�����Ӧ�Ĵ����������ƶϳ���DZ�ڱ�����������صġ�

�������������ѧϰ����,ѧϰ�Ӵ����źŵ�DZ�ڱ���֮��ķ�����ӳ��,��DZ�ڱ�����ʾ�˴���������ͳ�ơ������������ù�ʽ��ѵ��VAE,�Ӷ�ѧϰ�ɾ������ź��ϵ�����DZ�ڱ�ʾ��Ȼ��,noise-aware encoder�����ڴ���������
x
t
x_t
xt?��������,�ƽ�DάDZ�ڱ���
z
t
��
��
R
D
z'_t \in R^D
zt��?��RD����ĸ���
q
��
(
z
t
��
�O
x
t
)
q_{\gamma}(z'_t|x_t)
q��?(zt��?�Oxt?),��������������
q
��
q_{\gamma}
q��?���ӱ���˹�ֲ�������
��
\gamma
����ʾencoder�IJ��������,�Ӵ��������õ���
z
t
��
z'_t
zt��?����Ӧ�Ĵ��������ƶϵõ���DZ�ڱ���
z
t
z_t
zt?�ľ������Kullback-Leiblerɢ����С��,��ͼ2(a)��ʾ,��Ӧ��ʽ����:

��
~
d
��
��
~
d
2
\tilde{\mu}_d��\tilde{\sigma}_d^2
��~?d?����~d2?��ʾ������Ա���
z
t
��
z'_t
zt��?�����˹�ֲ��ľ�ֵ�ͷ���ķ�����ӳ�䡣ͨ��ʹ������ݶ��½��㷨��С���ɱ��������Ż�������ģ�� �� �IJ����� ͨ�����ַ�ʽ,���ǽ���� VAE �������������ලѧϰ��ʹ������-�ɾ������źŶԵļලѧϰ��
��ͼ 2 (b) ��ʾ,ͨ����DZ�ڿռ�����������ɱ�����,��������� xt ���Ƶ�DZ�ڱ��� zt ���������Ӧ�ĸɾ����� st ���Ƶ� zt�� ��������߱�ʾ���źſռ䵽DZ�ڿռ�ķ�����ӳ��,��ͬ����ɫ��ʾ����ӳ��ԡ� ��������,������֪����ģ������������Ļ��������ı�����,VAE �Ľ��������ֲ��䡣
4. ʵ����֤
�������� WSJ0
�������ݼ�:QUT-NOISE �� DEMAND������QUT-NOISE���ڹ���ѵ�����ϲ��Լ�,DEMAND���ڹ���unseen��֤����
�źŲ�����Ϊ16kHz, STFT�任ʱʹ�ô���1024,hop_lengthΪ25%������ Kullback-Leibler ɢ����߶����,��˲���ȫ�ֹ�һ��Ϊ���ֵ�͵�λ������ѵ��������֪��������NMF����ѡ��K=8,W��H�����ʼ����MCEM�����IJ���������[15]��ͬ��
VAE��encoder��decoder��������128��Ԫ��ǰ�����ز�,���ز�ʹ��˫�����м����,DZ�ڿռ�L��ά������Ϊ16��
����ָ��ΪSI-SDR��
5. Result and Discussions
5.1 Performance evaluation


5.2 Analysis of the amount of training data


