1. urllib库的作用 :解析网页
| URL模块 | 代码 |
|---|---|
| 请求模块 | urllib.request |
| 异常处理模块 | urllib.error |
| 解析模块 | urllib.parse |
2. 请求模块
举个例子:访问百度
import urllib.request
#解析一个网址 获取get请求
response = urllib.request.urlopen("http://www.baidu.com") #把访问的网站的源码封装到一个对象当中(response)
print(response.read().decode('utf-8')) #读取并解码成中文界面
运行结果:
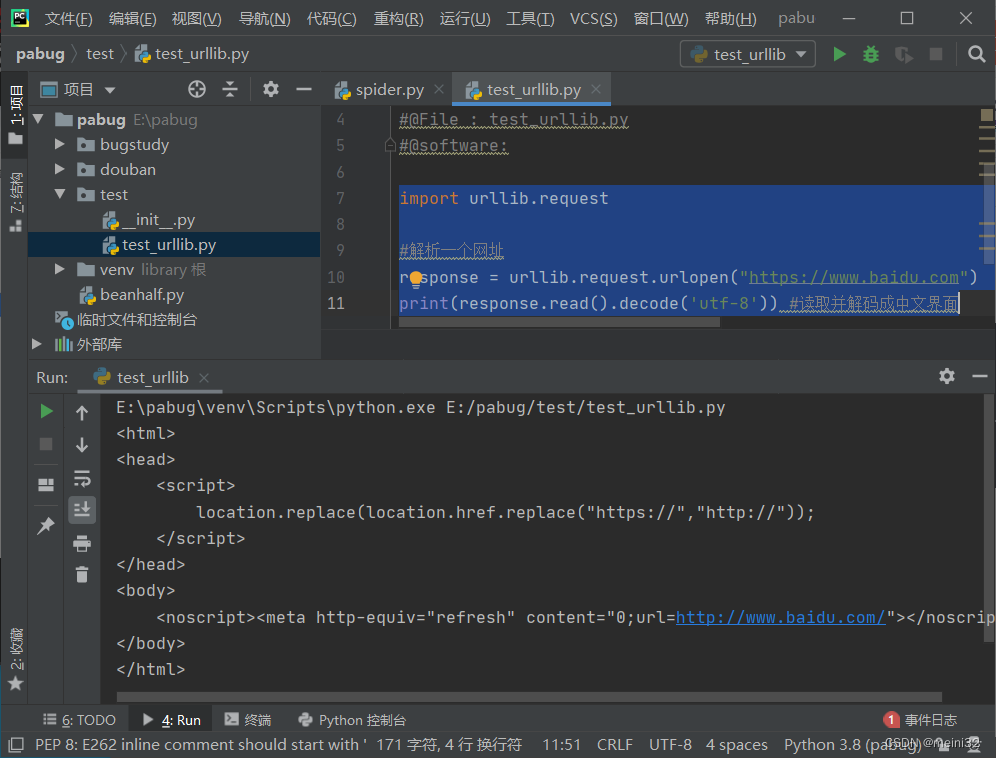
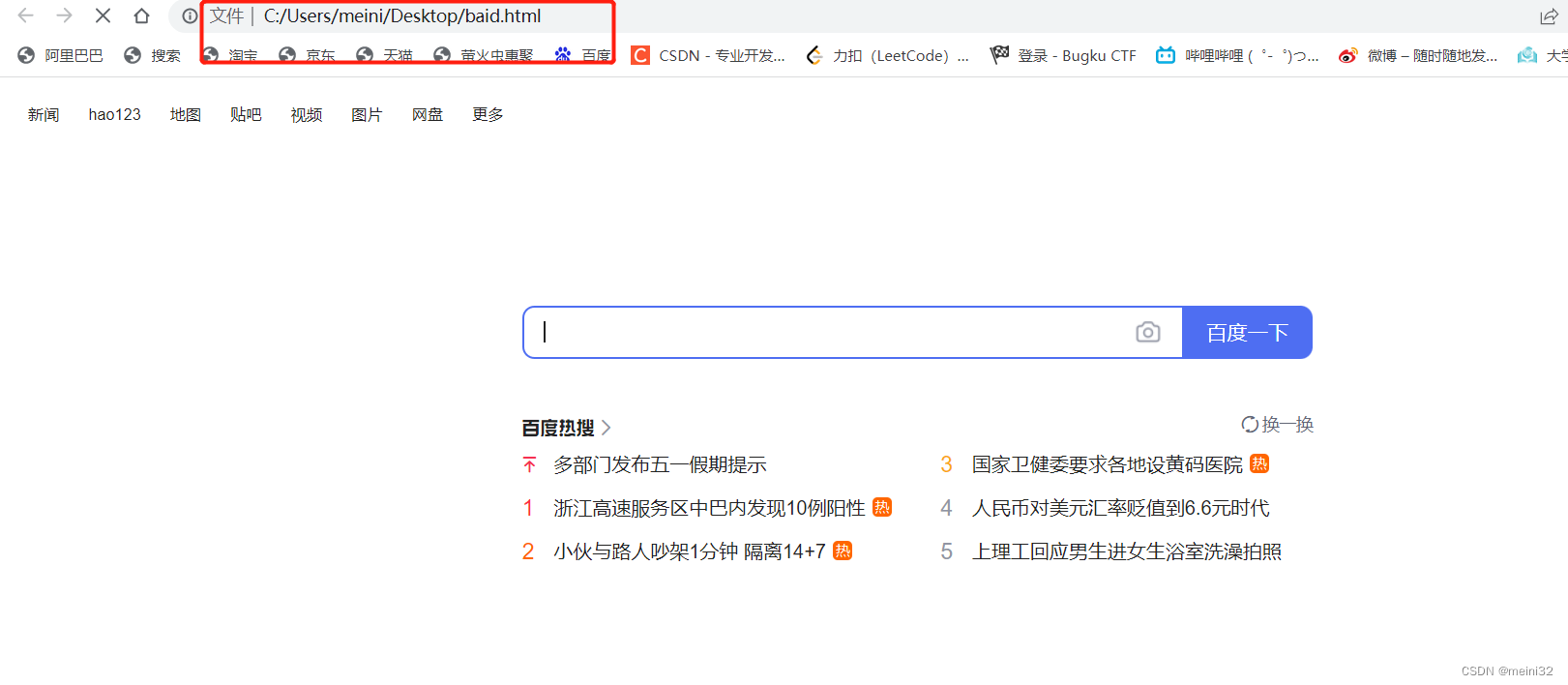
将结果复制到文本文件改后缀名为html打开:

3.解析模块
一个专门用于响应http或https的网页:http://httpbin.org/
#一个post请求(模拟用户真实登录)
import urllib.request #请求
import urllib.parse #解析
#获取一个post请求
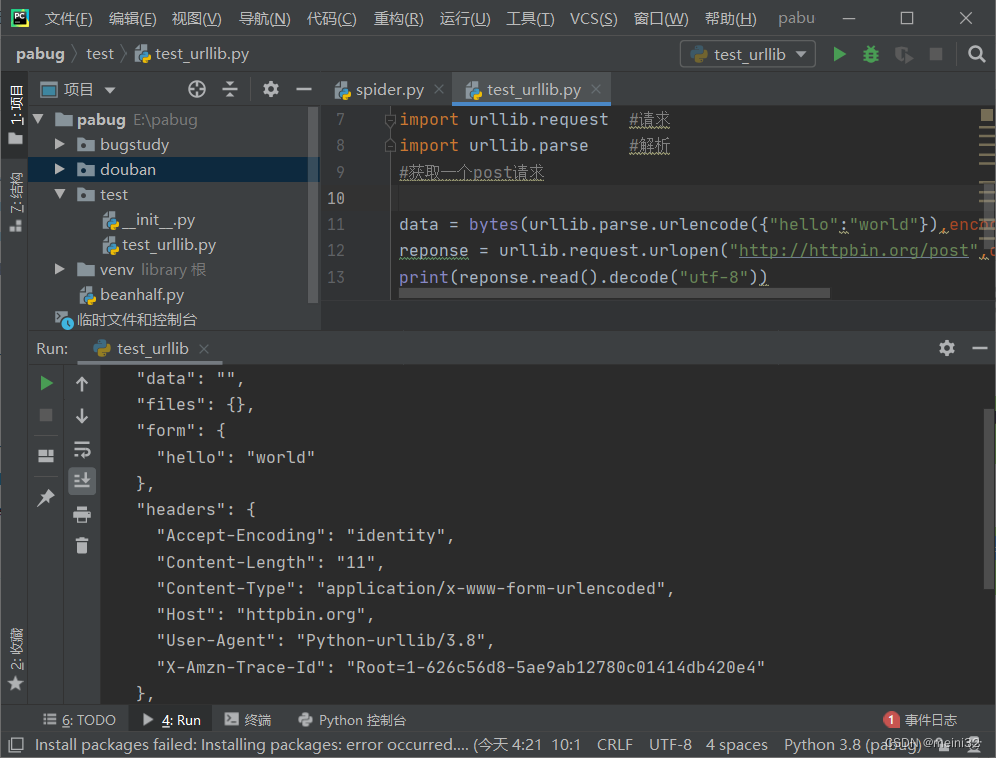
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding = "utf-8")
reponse = urllib.request.urlopen("http://httpbin.org/post",data = data)
print(reponse.read().decode("utf-8"))
显示结果:
4.异常处理模块-超时处理
import urllib.request #请求
import urllib.parse #解析
try:
reponse = urllib.request.urlopen("http://httpbin.org/get",timeout = 0.1)#设置响应时间为0.1秒
print(reponse.read().decode("utf-8"))
except urllib.error.URLError as result:
print("超时")
运行结果:

5.状态码
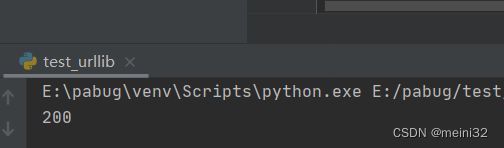
reponse = urllib.request.urlopen("http://httpbin.org/get")
print(reponse.status) #显示状态码
运行结果:
6.响应头
import urllib.request #请求
import urllib.parse #解析
reponse = urllib.request.urlopen("http://www.baidu.com")
print(reponse.getheaders()) #响应头
运行结果:

[(‘Bdpagetype’, ‘1’), (‘Bdqid’, ‘0xbe9c7f2f000fe988’), (‘Cache-Control’, ‘private’), (‘Content-Type’, ‘text/html;charset=utf-8’), (‘Date’, ‘Fri, 29 Apr 2022 21:38:21 GMT’), (‘Expires’, ‘Fri, 29 Apr 2022 21:38:03 GMT’), (‘P3p’, ‘CP=" OTI DSP COR IVA OUR IND COM "’), (‘P3p’, ‘CP=" OTI DSP COR IVA OUR IND COM "’), (‘Server’, ‘BWS/1.1’), (‘Set-Cookie’, ‘BAIDUID=AB8EC72EAFA93C6D3740E013FF09A2F9:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com’), (‘Set-Cookie’, ‘BIDUPSID=AB8EC72EAFA93C6D3740E013FF09A2F9; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com’), (‘Set-Cookie’, ‘PSTM=1651268301; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com’), (‘Set-Cookie’, ‘BAIDUID=AB8EC72EAFA93C6D69D6BF837EFD6605:FG=1; max-age=31536000; expires=Sat, 29-Apr-23 21:38:21 GMT; domain=.baidu.com; path=/; version=1; comment=bd’), (‘Set-Cookie’, ‘BDSVRTM=0; path=/’), (‘Set-Cookie’, ‘BD_HOME=1; path=/’), (‘Set-Cookie’, ‘H_PS_PSSID=36309_31254_35915_36165_34584_35978_35863_36232_26350_36301_36313_36061; path=/; domain=.baidu.com’), (‘Traceid’, ‘1651268301354531149813734992803414403464’), (‘Vary’, ‘Accept-Encoding’), (‘Vary’, ‘Accept-Encoding’), (‘X-Frame-Options’, ‘sameorigin’), (‘X-Ua-Compatible’, ‘IE=Edge,chrome=1’), (‘Connection’, ‘close’), (‘Transfer-Encoding’, ‘chunked’)]
对应的网页头部信息:
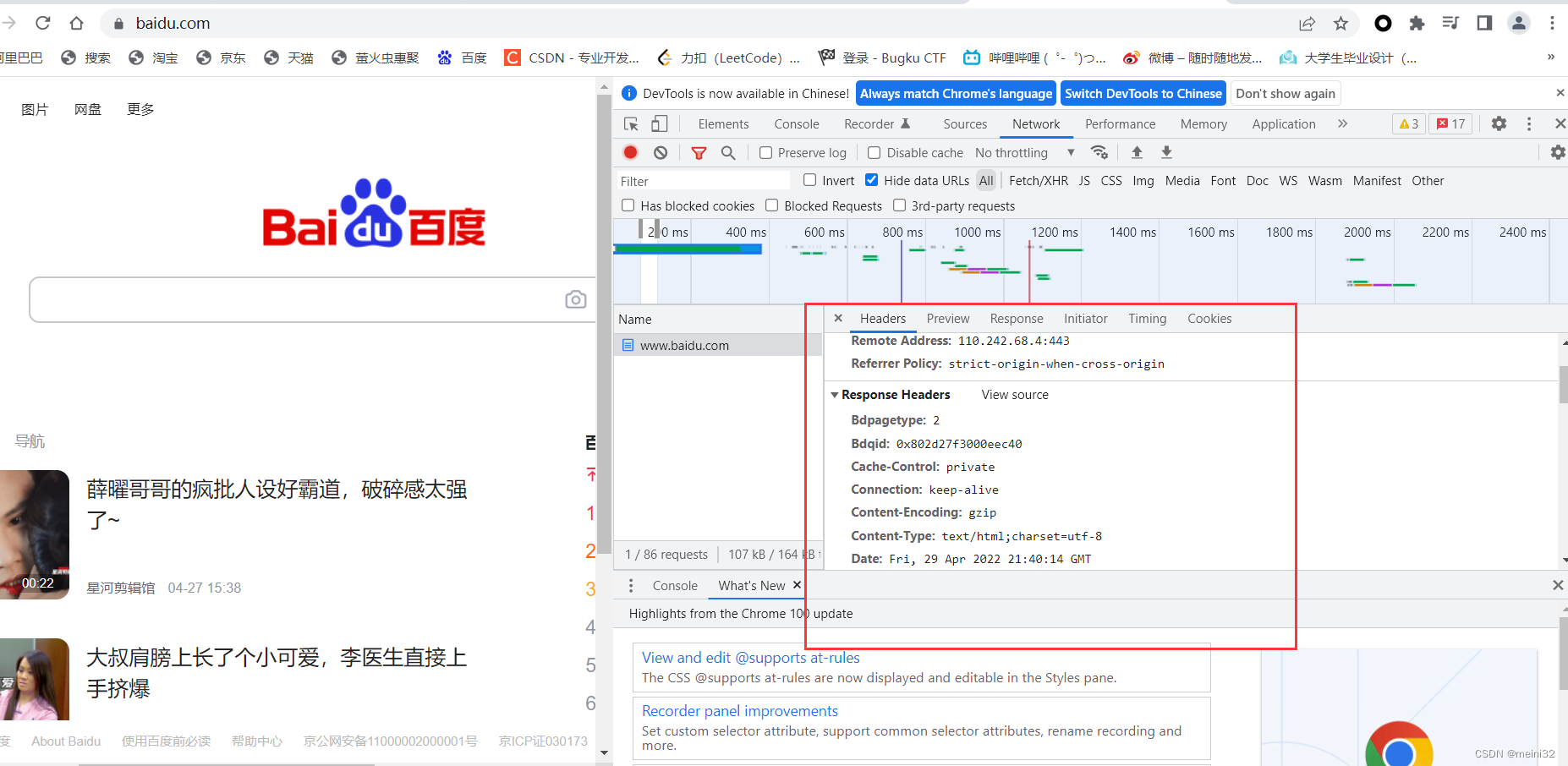
7.伪装
请求头部信息伪装:
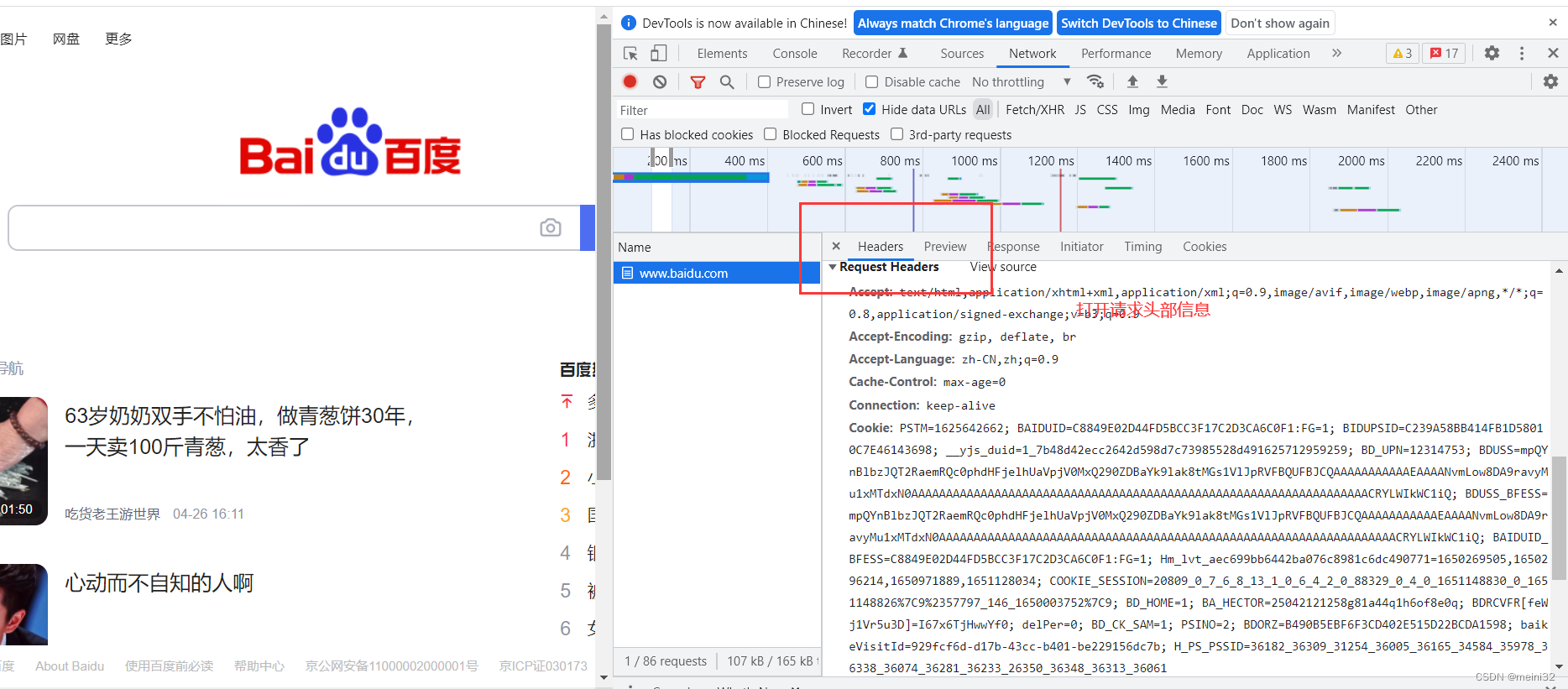
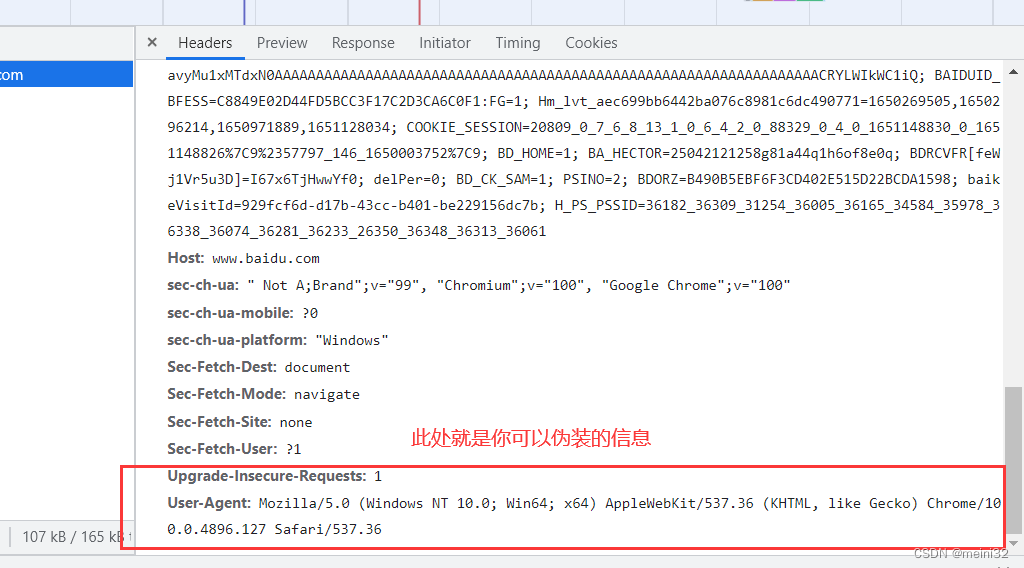
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/100.0.4896.127 Safari/537.36
import urllib.request #请求
import urllib.parse #解析
url ="https://www.dpuban.com"
headers = { #伪装自己
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/100.0.4896.127 Safari/537.36"
} #字典类型
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
python爬虫 原文章地址:
视频学习地址:https://www.bilibili.com/video/BV12E411A7ZQ?p=18&spm_id_from=pageDriver

