title: DMLNet
date: 2022-05-03 20:07
Tag:
- ���ѧϰ
- �쳣�ָ�
- ����ѧϰ
������������ָ�
- ��������ָ�ģ��
- �ռ�����ָ���ģ��
- �쳣�ָ���ģ��
- ����С����ѧϰģ��
���Ƕ�С����������ժҪ(??????) ?
CODE
multiscale ���Լ��趨���� cfg.DATASET.imgSizes = (300, 375, 450, 525, 600)
Seg ת��Ϊlong Tensor��Ŀ����ʲô
colors��������ʲô
������������������:
Normalization(x):
x
?
m
i
n
(
x
)
m
a
x
(
x
)
?
m
i
n
(
x
)
\dfrac{x - min(x)}{max(x) - min(x)}
max(x)?min(x)x?min(x)?
Coefficient_map(x, thre):
1
1
+
e
x
p
(
50
?
(
x
?
t
h
r
e
)
)
\dfrac{1}{1 + exp(50*(x - thre))}
1+exp(50?(x?thre))1?
normfun(x, mu, sigma):
e
x
p
(
?
(
x
?
m
u
)
2
2
?
��
2
)
��
?
2
?
��
\dfrac{exp(-\frac{(x - mu)^2}{2 * \sigma^2})}{\sigma * \sqrt{2*\pi}}
��?2?��?exp(?2?��2(x?mu)2?)?
�����Ķ�
����
Classical close-set semantic segmentation networks have limited ability to detect out-of-distribution (OOD) objects, which is important for safety-critical applications such as autonomous driving. Incrementally learning these OOD objects with few annotations is an ideal way to enlarge the knowledge base of the deep learning models. In this paper, we propose an open world semantic segmenta- tion system that includes two modules:
(1) an open-set semantic segmentation module to detect both in-distribution and OOD objects.
(2) an incremental few-shot learning module to gradually incorporate those OOD objects into its existing knowledge base.
This open world semantic segmentation system behaves like a human being, which is able to identify OOD objects and gradually learn them with corresponding supervision.
We adopt the Deep Metric Learning Network (DMLNet) with contrastive clustering to implement open-set semantic segmentation. Compared to other open-set semantic segmentation methods, our DMLNet achieves state-of-the-art performance on three challenging open-set semantic segmentation datasets without using additional data or generative models.
On this basis, two incremental few-shot learning methods are fur- ther proposed to progressively improve the DMLNet with the annotations of OOD objects
����ıռ�����ָ�������ֲ��� (OOD) �������������,������Զ���ʻ�Ȱ�ȫ�ؼ���Ӧ�ú���Ҫ�� ����ѧϰ��Щ��������ע�͵� OOD �������������ѧϰģ��֪ʶ������뷽���� �ڱ�����,���������һ��������������ָ�ϵͳ,��������ģ��:
(1) һ�����ż�����ָ�ģ��,���ڼ���ڷֲ���OOD����
(2) һ��������С����ѧϰģ��,����Щ OOD �������������е�֪ʶ�⡣
����������������ָ�ϵͳ����һ����,�ܹ�ʶ��OOD��������Ӧ�ļල����ѧϰ���ǡ�
���Dz��þ���==�ԱȾ������ȶ���ѧϰ����(DMLNet)==��ʵ�ֿ��ż�����ָ ���������ż�����ָ�����,���ǵ� DMLNet ������������ս�ԵĿ��ż�����ָ����ݼ���ʵ�������Ƚ�������,������ʹ�ö�������ݻ�����ģ�͡�
�ڴ˻�����,��һ���������������������ѧϰ����,ͨ�� OOD �����ע���Ľ� DMLNet
6. Conclusion
We introduce an open world semantic segmentation system which incorporates two modules:
- an open-set segmentation module
- an incremental few-shot learning module.
Our proposed open-set segmentation module is based on the deep metric learning network, and it uses the Euclidean distance sum criterion to achieve state-of-the-art performance.
Two incremental few-shot learning methods are proposed to broaden the perception knowledge of the network. Both modules of the open world semantic segmentation system can be further studied to improve the performance. We hope our work can draw more researchers to contribute to this practically valuable research direction.
���ǽ�����һ��������������ָ�ϵͳ,����������ģ��:һ�����ż��ָ�ģ���һ������С����ѧϰģ�顣
��������Ŀ��ż��ָ�ģ�������ȶ���ѧϰ����,��ʹ��ŷ����¾���ͱ���ʵ�����Ƚ������ܡ�
�������������������ѧϰ�������ؿ�����ĸ�֪֪ʶ�� ������������ָ�ϵͳ������ģ�鶼���Խ�һ���о���������ܡ� ����ϣ�����ǵĹ����ܹ�����������о���ԱΪ�������ʵ�ʼ�ֵ���о�������������
1. ����
�����ڸ����������ݼ� [3,4,5],��Ⱦ�������������ָ����� [1, 2] ��ȡ���˾�ɹ��� ��Щ����ָ�����������Ӧ���б�������֪ϵͳ,���Զ���ʻ[6]��ҽ�����[7]�ȡ�Ȼ��,��Щ��֪ϵͳ�еĴ�������DZռ��;�̬�ġ� �ռ�����ָ��������е�������Ѿ���ѵ���ڼ����,���ڿ����������Dz���ȷ�ġ� ����ռ�ϵͳ����ؽ��ַ��б�ǩ����� OOD ���� [8],�����ܻ��ڰ�ȫ�ؼ���Ӧ�ó���(���Զ���ʻ)����������Ժ���� ͬʱ,��̬��֪ϵͳ�������������ݸ�����֪ʶ��,���,���������ض�����,��Ҫ��һ��ʱ�������ѵ���� Ϊ�˽����Щ����,���������һ�ֿ��ż��Ķ�̬��֪ϵͳ,��Ϊ������������ָ�ϵͳ�� ����������ģ��:
(1)һ�����ż�����ָ�ģ��,���ڼ��OOD������ȷ�ı�ǩ������ֲ��еĶ���
(2) һ��������С����ѧϰģ��,����Щδ֪�����ϲ��������е�֪ʶ���С�
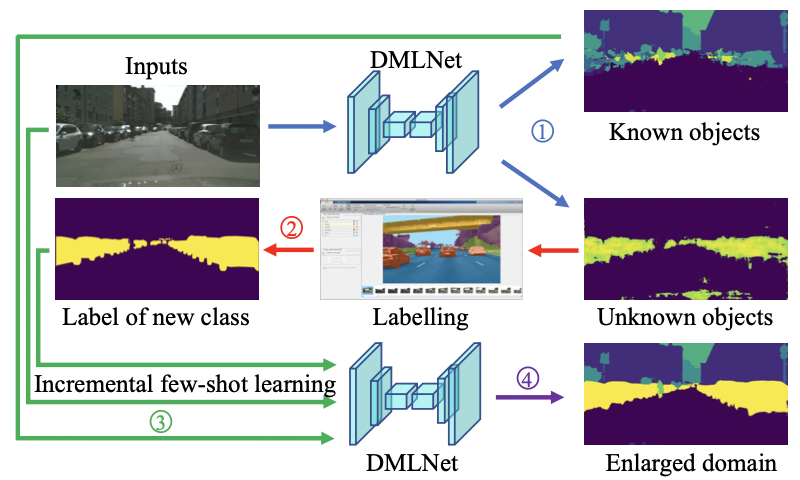
��������Ŀ�����������ָ�ϵͳ������������ͼ 1 ��ʾ
���ż�����ָ������С����ѧϰ��û�еõ��ܺõĽ����
���ڿ�������ָ�,����Ҫ�IJ�������һ��ͼ�������������ʶ��OOD����,��Ϊ�쳣�ָ �쳣�ָ�ĵ��ͷ����ǽ�ͼ�Ŀ��������Ӧ�������ؼ��Ŀ������ࡣ
��Щ�����������ڲ�ȷ���Թ��Ƶķ��� [9, 10, 11, 12] �ͻ����Զ��������ķ��� [13, 14]�� Ȼ��,�����ַ����ѱ�֤���ڼ�ʻ��������Ч,��Ϊ���ڲ�ȷ���Թ��Ƶķ������������������쳣ֵ��� [15] �����Զ����������������ɸ��ӵij��г��� [16]�� ���,�������ɶԿ�����(���� GAN)�ķ��� [16, 17] �ѱ�֤������Ч��,������Զ��������,��Ϊ������Ҫ�ڹܵ���ʹ�ö��������硣
��������������ѧϰ,���Dz���Ҫ��������ѧϰ����ս,��������������[18],��Ҫ����������ѧϰ����ս,������������������ȡ����������[19]
�ڱ�����,���ǽ���ʹ�� DMLNet �����������������ָ����⡣ ԭ������:
(1) DMLNet�ķ���ԭ���ǻ����ԱȾ���,������Чʶ���쳣����,��ͼ2��ʾ
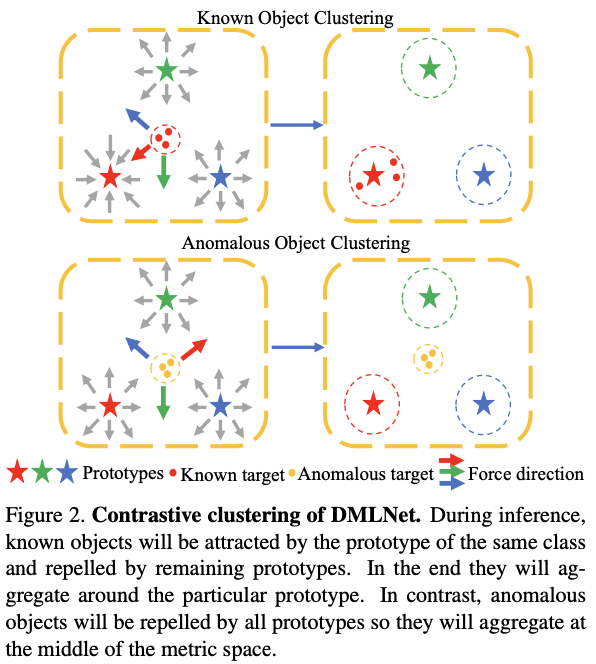
����ѧϰ:��������ѧϰһ�ֶ������ݶ�������ķ�������Ŀ����ʹ����ѧ�õľ��������,���ƶ����ľ���С,�����ƶ����ľ����
��ͳ�Ķ���ѧϰ����ֻ��ѧϰ����������,��Ȼ��һЩ�ܹ���ȡ�����������ĺ˷��������,����ѧϰЧ��Ҳû����������
��ȶ���ѧϰ:���ѧϰ�ļ����ѧϰ��������������������,���ѧϰ�����ܹ��Զ��ش�ԭʼ������ѧ����������������������ѧϰ������ṹ�봫ͳ�Ķ���ѧϰ���������ܹ����������Ч����
(2) DMLNet���ԭ�ͷdz��ʺ�few-shot ����[19]��
(3) DMLNet ������ѧϰ����ͨ�������µ�ԭ����ʵ��,����һ����Ȼ�����õķ��� [20]��
���� DMLNet �ܹ�,����Ϊ���ż�����ָ�ģ�鿪��������δ֪ʶ���,Ϊ����������ѧϰģ�鿪�������ַ�����
�������ǵ�ʵ��,������ģ�鶼����֤Ϊ��Ч���������ġ� �ܶ���֮,���ǵĹ�������:
- ���������Ƴ�������������ָ�ϵͳ,��ʵ��Ӧ���и����Ƚ�ʵ�á�
- ��������Ļ��� DMLNet �Ŀ��ż�����ָ�ģ��������������ս�Ե����ݼ���ʵ�������Ƚ������ܡ�
- ���������few-shot ����ѧϰģ�鷽���ںܴ�̶��ϻ������������������⡣
- ͨ�������������Ŀ��ż�����ָ�ģ�������������ѧϰģ��,ʵ����һ��������������ָ�ϵͳ��
2. Related Work
2.1 �쳣����ָ�
�쳣����ָ�ķ������Է�Ϊ��������: ���ڲ�ȷ���Թ��Ƶķ����ͻ�������ģ�͵ķ�����
��ȷ���Թ��ƵĻ��������softmax����(MSP),��������[9]������� Dan ����û��ʹ�� softmax ���ʡ� [11]���ʹ�����logit(MaxLogit)��ȡ�ø��õ��쳣�ָ����ܡ� ��Ҷ˹����������ѧϰ����ĸ��ʹ۵�,�������ǵ�Ȩ�غ�����Ǹ��ʷֲ��������ض������� [21, 22]�� ��ʵ����,Dropout [10] �� [12] ͨ�����ڽ��Ʊ�Ҷ˹������
�Զ�������(AE)[23, 13] �� RBM [14] �ǵ��͵����ɷ���,���� OOD ͼ����ؽ������ڷֲ���ͼ��
���,��һ�ֻ��� GAN �ٺϳɵ�����ģ�ͱ�֤�����Ի�����ɿ��ĸ߷ֱ������ص�����ת�����ʵ�����Ƚ������ܡ� SynthCP [17] �� DUIR [16] �ǻ��� GAN �ٺϳɵ����ַ����� ���ҵ���,����������������Զ,��Ϊ��������ʹ������������������������ OOD ��⡣
���������,����֤���˻��ڶԱȾ���� DMLNet ���и��õ��쳣�ָ�����,��ֻ��Ҫ����һ��
2.2 ��ȶ���ѧϰ����
DMLNets �����ڶ���Ӧ��,������Ƶ���� [24] ����Ա����ʶ�� [25]�� DMLNet ʹ��ŷ����á����Ͼ���� Matusita ���� [26] ����������ת��Ϊ��������ռ��е�Ƕ���������ƶȡ�
����ԭ������� DMLNets ͨ��һ�����ڽ���ض�����,������ͼ�� OOD ���� [27��28��29] ����������ָ��С����ѧϰ [19��30��31]�� ����Ҳ����������Ϲ����˵�һ�����ڿ�����������ָ�� DMLNet
2.3 �����������ͼ��
����������������� [32] ���������������������쳣ֵ (NNO) �㷨,���㷨���������Ӷ�����𡢼���쳣ֵ�������ſռ���շ���dz���Ч��
���Լɪ����ˡ� [33]�����һ�ֻ��ڶԱȾ��ࡢδ֪��֪��������ͻ���������δ֪ʶ����Ŀ������������ϵͳ�� ���ǵĿ�����������ָ�ϵͳ�Ĺܵ������ǵ�����,����������Ҫ������ʹ���ǵ����������ս��:(1)�����ǵĿ��ż����ģ����,����������������������(RPN)�� ���֪,���Ҳ���Լ�δ��ǵ�DZ�� OOD ���� ����,OOD��������Ϣ����ѵ������Ч�ġ� ����,����רע������ָ�,����ѵ����ʹ�õ�ÿ�����ض���������һ���ֲ��ڱ�ǩ,������ܽ� OOD �������ӵ�ѵ������ (2) ������ѧϰģ����,����ʹ����������б������,������רע����Ȼ�����ѵ������������� �������о�����������С����ѧϰ��,���а������ڷ��������С����ѧϰ[34]��������[35]������ָ�[36]
3. ������������ָ�
�ڱ�����,���Ǹ����˿�����������ָ�ϵͳ�Ĺ������̡� ��ϵͳ��һ�����ż�����ָ�ģ���һ������С����ѧϰģ����ɡ� ���� C i n = { C i n , 1 , C i n , 2 , . . . , C i n , N } \mathcal{C}_{in} = \{\mathcal{C}_{in,1}, \mathcal{C}_{in,2},...,\mathcal{C}_{in,N} \} Cin?={Cin,1?,Cin,2?,...,Cin,N?} �� N ���ֲ��ڵ���,���Ƕ���ѵ�����ݼ��н�����ע��,���� C o u t = { C o u t , 1 , C o u t , 2 , . . . , C o u t , M } \mathcal{C}_{out} = \{\mathcal{C}_{out,1},\mathcal{C}_{out,2},...,\mathcal{C}_{out,M} \} Cout?={Cout,1?,Cout,2?,...,Cout,M?} ��ѵ�����ݼ���û�������� M �� OOD ��
��������ָ�ģ���ַ�Ϊ������ģ��:�ռ�����ָ���ģ����쳣�ָ���ģ����
- Y ^ c l o s e \hat{Y}^{close} Y^close �DZռ�����ָ���ģ������ͼ,����ÿ�����ص���� Y ^ i , j c l o s e �� C i n \hat{Y}^{close}_{i,j} �� C_{in} Y^i,jclose?��Cin?��
- �쳣�ָ���ģ��Ĺ�����ʶ��OOD����,�������Ϊ�쳣����ͼ: P ^ �� [ 1 , 0 ] H �� W \hat{P} \in [1,0]^{H \times W} P^��[1,0]H��W,���� H H H �� W W W ��ʾ����ͼ��ĸ߶ȺͿ��ȡ�
����
Y
^
c
l
o
s
e
\hat{Y}_{close}
Y^close? ��
P
^
\hat{P}
P^,��������ָ�ͼ
Y
^
o
p
e
n
\hat{Y}^{open}
Y^open ����Ϊ:
Y
^
i
,
j
o
p
e
n
=
{
C
a
n
o
m
a
l
y
?
P
^
i
,
j
>
��
o
u
t
Y
^
i
,
j
c
l
o
s
e
P
^
i
,
j
��
��
o
u
t
(1)
\hat{Y}^{open}_{i,j} = \begin{cases} \mathcal{C}_{anomaly} \quad \ \hat{P}_{i,j} > \lambda_{out} \\ \hat{Y}_{i,j}^{close} \quad \quad \hat{P}_{i,j} \le \lambda_{out} \end{cases} \tag{1}
Y^i,jopen?={Canomaly??P^i,j?>��out?Y^i,jclose?P^i,j?����out??(1)
C
a
n
o
m
a
l
y
\mathcal{C}_{anomaly}
Canomaly? :��ʾ OOD ���
��
o
u
t
��_{out}
��out? :ȷ�� OOD ���ص���ֵ��
���,openset����ָ�ģ��Ӧ��ʶ��OOD���ز�������ȷ�ķֲ���ǩ��Ȼ�� Yopen ����ת�������Դ� C o u t C_{out} Cout? ��ʶ�� C a n o m a l y C_{anomaly} Canomaly? �������������Ӧע�͵ı�ע�� ����������ѧϰģ�����������±�ǩʱ�������ָ���ģ���֪ʶ��� C i n C_{in} Cin? һ��һ������Ϊ C i n + M C_{in+M} Cin+M?,���� C i n + t = C i n �� { C o u t , 1 , C o u t , 2 , . . . , C o u t , t } , t �� 1 , 2 , . . . , M C_{in+t} = Cin \cup \{C_{out,1},C_{out,2},...,C_{out,t}\},t ��{1,2,...,M} Cin+t?=Cin��{Cout,1?,Cout,2?,...,Cout,t?},t��1,2,...,M�� ͼ 1 ��ʾ�˿�����������ָ�ϵͳ��ѭ��������ˮ��
ͼ 1. ������������ָ�ϵͳ�� �� 1 ��:ʶ����֪��δ֪����(��ɫ��ͷ)�� �� 2 ��:ע��δ֪����(��ɫ��ͷ)�� �� 3 ��:Ӧ������������ѧϰ����������ķ��Χ(��ɫ��ͷ)�� �� 4 ��:������������ѧϰ֮��,DMLNet �����ڸ��������������(��ɫ��ͷ)��
4. ����
���Dz��� DMLNet ��Ϊ���ǵ�������ȡ��,���� 4.1 �����ۼܹ�����ʧ������ ���ż��ָ�ģ�������������ѧϰģ���� 4.2 �� 4.3 ���н�����˵��
4.1 ��ȶ���ѧϰ����
Classical CNN-based semantic segmentation networks can be disentangled into two parts:
- a feature extractor f ( X ; �� f ) f(X;��_f) f(X;��f?) for obtaining the embedding vector of each pixel
- a classifier g ( f ( X ; �� f ) ; �� g ) g(f(X;��_f);��_g) g(f(X;��f?);��g?) for generating the decision boundary,
where X X X, �� f ��_f ��f? and �� g ��_g ��g? denote the input image, parameters of the feature extractor and classifier respectively.
This learnable classifier is not suitable for OOD detection because it assigns all feature space to known classes and leaves no space for OOD classes.
��ͳCNN-based����ָ�����:
- f ( X ; �� f ) f(X;\theta_f) f(X;��f?) ������ȡ��:��ȡÿ�����ص�Ƕ������
- g ( f ( X ; �� f ) ; �� g ) g(f(X;\theta_f);\theta_g) g(f(X;��f?);��g?) ������:���ɾ��߽߱�
������ѧϰ�ķ������������� OOD ���,��Ϊ�������������ռ�������֪��,����û��Ϊ OOD �����¿ռ䡣
In contrast, the classifier is replaced by the Euclidean distance representation with all prototypes M i n = { m t �� R 1 �� N �O t �� { 1 , 2 , . . . , N } } \mathcal{M}_{in} = \{ m_t \in \mathbb{R}^{1 \times N}|t \in \{1,2,...,N\} \} Min?={mt?��R1��N�Ot��{1,2,...,N}} in DMLNet, where m t m_t mt? refers to the prototype of class C i n , t \mathcal{C}_{in,t} Cin,t?. The feature extractor f ( X ; �� f ) f(X;��_f) f(X;��f?) learns to map the input X X X to the feature vector which has the same length as the prototype in metric space. For the close-set segmentation task, the probability of one pixel X i , j X_{i,j} Xi,j? belonging to the class C i n , t \mathcal{C}_{in,t} Cin,t? is formulated as:
DMLNet ��, ����ԭ�͵�ŷ����þ�����ʾ�����˴�ͳ�Ŀ�ѧϰ������
- m t m_t mt? ָ���� C i n , t \mathcal{C}_{in,t} Cin,t? ���ԭ�͡�
������ȡ�� f ( X ; �� f ) f(X;��_f) f(X;��f?)ѧϰ������ X ӳ�䵽������ռ��е�ԭ�ͳ�����ͬ������������
���ڱռ��ָ�����,һ������
X
i
,
j
X_{i,j}
Xi,j? ������
C
i
n
,
t
\mathcal{C}_{in,t}
Cin,t? �ĸ��ʹ�ʽΪ:
p
t
(
X
i
,
j
)
=
e
x
p
(
?
�O
�O
f
(
X
;
��
f
)
i
,
j
?
m
t
�O
�O
2
)
��
t
��
=
1
N
e
x
p
(
?
�O
�O
f
(
X
;
��
f
)
i
,
j
?
m
t
��
�O
�O
2
)
(2)
p_t(X_{i,j}) = \frac{exp(-||f(X;\theta_f)_{i,j} - m_t||^2)}{\sum^N_{t'=1} exp(-||f(X;\theta_f)_{i,j} - m_{t'}||^2)} \tag{2}
pt?(Xi,j?)=��t��=1N?exp(?�O�Of(X;��f?)i,j??mt��?�O�O2)exp(?�O�Of(X;��f?)i,j??mt?�O�O2)?(2)
�������ֻ���ŷ����¾���ĸ���,�б��� (DCE) ��ʧ����
L
D
C
E
(
X
i
,
j
,
Y
i
,
j
;
��
f
,
M
i
n
)
\mathcal{L}_{DCE}(X_{i,j},Y_{i,j};��_f,M_{in})
LDCE?(Xi,j?,Yi,j?;��f?,Min?) [27] ����Ϊ:
L
D
C
E
=
��
i
,
j
?
l
o
g
(
e
x
p
(
?
�O
�O
f
(
X
;
��
f
)
i
,
j
?
m
Y
i
,
j
�O
�O
2
)
��
k
=
1
N
e
x
p
(
?
�O
�O
f
(
X
;
��
f
)
i
,
j
?
m
k
�O
�O
2
)
(3)
\mathcal{L}_{DCE} = \sum_{i,j} -log (\frac{exp(-||f(X;\theta_f)_{i,j} - m_{Y_{i,j}}||^2)}{\sum^N_{k=1} exp(-||f(X;\theta_f)_{i,j} - m_{k}||^2)} \tag{3}
LDCE?=i,j��??log(��k=1N?exp(?�O�Of(X;��f?)i,j??mk?�O�O2)exp(?�O�Of(X;��f?)i,j??mYi,j??�O�O2)?(3)
Y
Y
Y:����ͼ��
X
X
X �ı�ǩ
L
D
C
E
\mathcal{L}_{DCE}
LDCE? �ķ��Ӻͷ�ĸ�ֱ�ָͼ2�е����������ų�����
�ų�������Ҫ��ȥ������������,�������ԭ����?
ͼ 2. DMLNet �ĶԱȾ��ࡣ ������������,��֪����ͬһ���ԭ��������,����ʣ���ԭ�����ų⡣ ���,���ǽ�Χ���ض���ԭ�ͽ��оۺϡ� �෴,�쳣��������ԭ���ų�,������ǽ��ۼ��ڶ����ռ���м䡣

�����ƶ�����һ����ʧ����,��Ϊ������ʧ (VL) ����
L
V
L
(
X
i
,
j
,
Y
i
,
j
;
��
f
,
M
i
n
)
\mathcal{L}_{VL}(X_{i,j},Y_{i,j};��_f,M_{in})
LVL?(Xi,j?,Yi,j?;��f?,Min?),�䶨��Ϊ:
L
V
L
=
��
i
,
j
�O
�O
f
(
X
;
��
f
)
i
,
j
?
m
Y
i
,
j
�O
�O
2
(4)
\mathcal{L}_{VL} = \sum_{i,j} ||f(X;\theta_f)_{i,j} - m_{Y_{i,j}}||^2 \tag{4}
LVL?=i,j��?�O�Of(X;��f?)i,j??mYi,j??�O�O2(4)
L
V
L
\mathcal{L}_{VL}
LVL? ֻ������������,û���ų������á�
ʹ�� DCE �� VL,�����ʧ����Ϊ: L = L D C E + �� V L L V L \mathcal{L}= \mathcal{L}_{DCE} + ��_{VL}\mathcal{L}_{VL} L=LDCE?+��VL?LVL?,���� �� V L ��_{VL} ��VL? ��Ȩ�ز���
4.2 ��������ָ�ģ��
��������ָ�ģ���ɱռ�����ָ���ģ����쳣�ָ���ģ����ɡ� ���ż�����ָ�ģ��������� ͼ3 ��ʾ��
ͼ3.�ռ��ָ���ģ���������ɫ���߿���,�쳣�ָ���ģ������ں�ɫ���߿��ڡ� �����ָ�ͼ����������ģ�����ɵĽ������ϡ� �ڿ��ż��ָ�ͼ��Ԥ��ֲ������ OOD �ࡣ EDS map �� MMSP map �Ķ�����ο� 4.2 �ڡ�
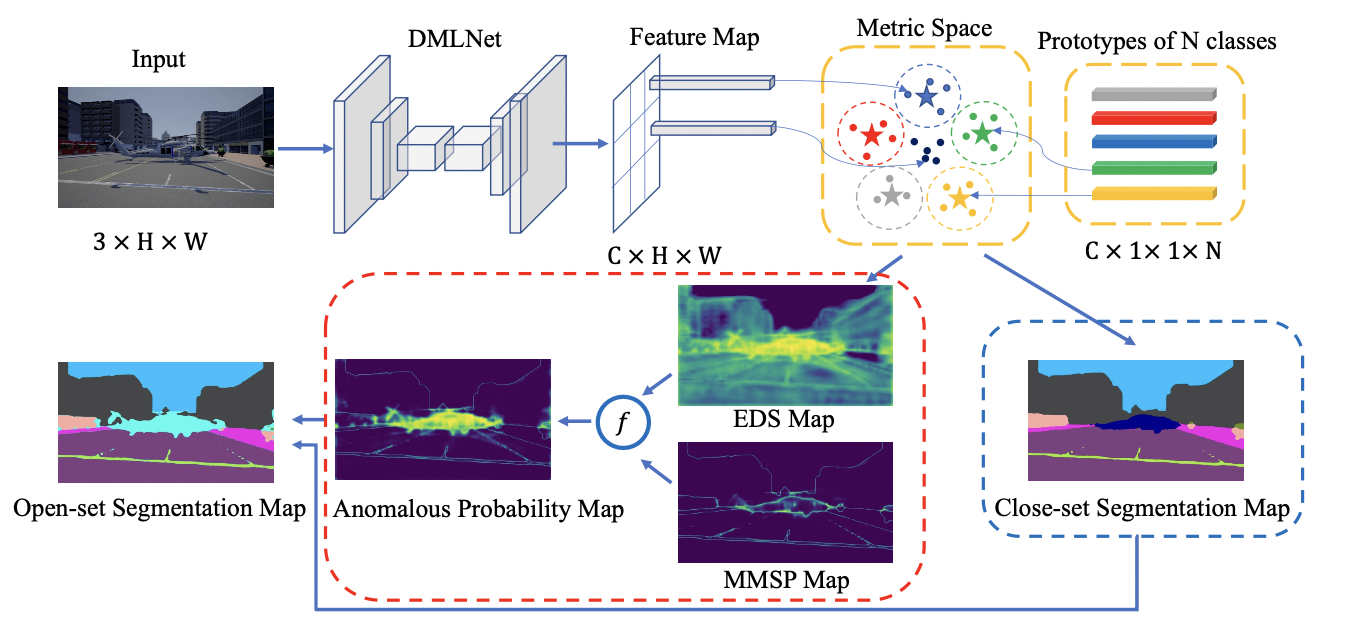
-
�ռ�����ָ���ģ��Ϊһ��ͼ����������ط���ֲ���ǩ�� ����һ������ X i , j X_{i,j} Xi,j? ������ C i n , t \mathcal{C}_{in,t} Cin,t? �ĸ������ù�ʽ 2 ��ʾ,�ռ��ָ�ͼΪ:
Y ^ i , j c l o s e = a r g m a x t ? p t ( X i , j ) (5) \hat{Y}_{i,j}^{close} = argmax_t \ p_t(X_{i,j}) \tag{5} Y^i,jclose?=argmaxt??pt?(Xi,j?)(5) -
�쳣�ָ���ģ�����OOD���ء� �������������δ֪��ʶ����������쳣����,����_���ڶ��������softmax����(MMSP)��_ŷ����þ����(EDS)��
-
�����ǻ��� MMSP ���쳣����:
P ^ i , j M M S P = 1 ? m a x ? p t ( X i , j ) , ? t �� { 1 , 2 , 3... , N } (6) \hat{P}^{MMSP}_{i,j} = 1 - max \ p_t(X_{i,j}),\ t \in \{ 1,2,3...,N \} \tag{6} P^i,jMMSP?=1?max?pt?(Xi,j?),?t��{1,2,3...,N}(6) -
EDS �Ǹ������·��������:�������λ�� OOD ���ؾۼ��Ķ����ռ������,��������ԭ�͵�ŷ����þ����С,���쳣��ŷ����þ����С�� EDS ����Ϊ:
S ( X i , j ) = �� t = 1 N �O �O f ( X ; �� f ) i , j ? m t �O �O 2 (7) S(X_{i,j}) = \sum_{t=1}^N ||f(X;\theta_f)_{i,j} - m_t||^2 \tag{7} S(Xi,j?)=t=1��N?�O�Of(X;��f?)i,j??mt?�O�O2(7)
���� EDS ���쳣���ʼ�������:
P ^ i , j E D S = 1 ? S ( X i , j ) m a x S ( X ) (8) \hat{P}^{EDS}_{i,j} = 1- \frac{S(X_{i,j})}{maxS(X)} \tag{8} P^i,jEDS?=1?maxS(X)S(Xi,j?)?(8)
-
EDS ���������,����������ԭ��Ӧ�þ��ȷֲ��ڶ����ռ���,������ѵ���ڼ䲻�ƶ��� ��ѧϰ��ԭ�ͻ���ѵ���ڼ䵼�²��ȶ�,���ҶԸ��õ�����û�й��� [37]�� ���,������ one-hot ������ʽ����ԭ��:ֻ�� m t m_t mt? �ĵ� t ��Ԫ���� T T T,������Ԫ�ر���Ϊ��,���� t �� {1,2,��,N}
PAnS��ʲô���?
EDS ���������������֮���������͵ı���,��ʹͼ����û�� OOD ����,���쳣��������϶�������ÿ��ͼ���С� ����,ÿ���ֲ������ľ����ܺͷֲ��˴����в�ͬ,��ͼ4��ʾ��
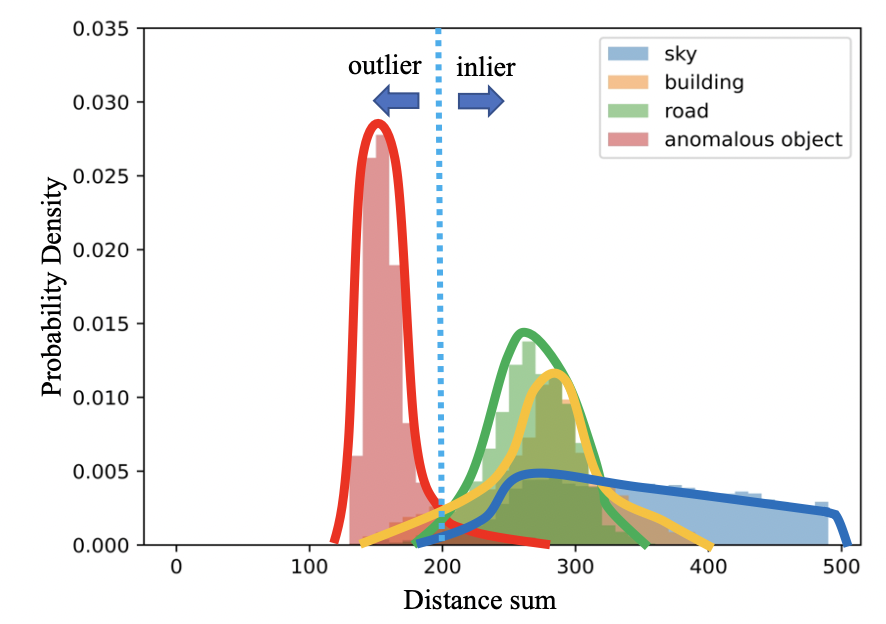
��MMSP��EDS����,��������Щʵ���ϴ��ڷֲ�״̬�ľ����м���Ӧ�����ء�
��Ϻ���Ϊ:
P
^
=
��
P
^
E
D
S
+
(
1
?
��
)
P
^
M
M
S
P
(9)
\hat{P} = \alpha \hat{P}^{EDS} + (1-\alpha)\hat{P}^{MMSP} \tag{9}
P^=��P^EDS+(1?��)P^MMSP(9)
-
�� :
�� = 1 1 + e x p ( ? �� ( P ^ E D S ? �� ) ) (10) \alpha = \frac{1}{1 + exp(-\beta(\hat{P}^{EDS} - \gamma))} \tag{10} ��=1+exp(?��(P^EDS?��))1?(10)- �� �� �� �ǿ�������Ч������ֵ�ij�������
ͨ������ 9 �õ��쳣����ͼ�ͷ��� 5 �õ��ռ��ָ�ͼ��,����Ӧ�÷��� 1 �������յĿ����ָ�ͼ
5. ʵ��
Our experiments are divided into three parts.
- We first evaluate our open-set semantic segmentation approach in Section 5.1.
Then we demonstrate our incremental few-shot learning results in Section 5.2.Based on the open-set semantic segmentation module and incremental few-show learning module, the whole open world semantic segmentation is realized in Section 5.3.
5.1 ��������ָ�
���ݼ��� �������ݼ����� StreetHazards [11]��Lost and Found [38] �� Road Anomaly [16] ����֤�����ǻ��� DMLNet �Ŀ��ż�����ָ�����Ƚ��Ժ���Ч�ԡ�
- StreetHazards �Ĵ�����쳣�����Ǵ���ϡ���������,����ֱ�������ɻ�����������
- Lost and Found ������С���쳣��Ʒ,������ߺͺ��ӡ�
- Road Anomaly ���ݼ��������Ƴ��г����еij���,��������ׯ��ɽ����ͼ��
ָ���� ���ż�����ָ��Ƿ�ռ��ָ���쳣�ָ�����,�� 4.2 ��������
- ���ڱռ�����ָ�����,����ʹ�� mIoU ���������ܡ�
- �����쳣�ָ�����,���� [11] ʹ������ָ��,���� ROC ���������(AUROC)��95% �ٻص�����(FPR95)�;�ȷ�ٻ����������(AUPR)��
ʵʩϸ����
-
���� StreetHazards,������ѭ�� [11] ��ͬ��ѵ������,�� StreetHazards ��ѵ������ѵ�� PSPNet [2]��
[11]: Scaling out-of-distribution detection for real-world settings.
-
����Lost and Found�� Road Anomaly,���ǰ��� [16] ʹ�� BDD-100k [39] ��ѵ�� PSPNet�� ��ע��,PSPNet ��������ȡ������ 4.1 �������۵�����(���ÿ�����ص�Ƕ������)�� �����ʧ�� �� V L ��_{VL} ��VL? Ϊ 0.01�� ����ԭ���з���Ԫ�� T T T Ϊ 3����ʽ 10 �е� �� �� �� �ֱ�Ϊ 20 �� 0.8��
[16]: Detecting the unexpected via image resynthesis
������
- StreetHazards: MSP [9]��Dropout [10]��AE [13]��MaxLogit [11] �� SynthCP [17]��
- Lost and Found �� Road Anomaly: MSP��MaxLogit��Ensemble [12]��RBM [14] �� DUIR [16]��
�����
StreetHazards �Ľ����� 1 ��ʾ��
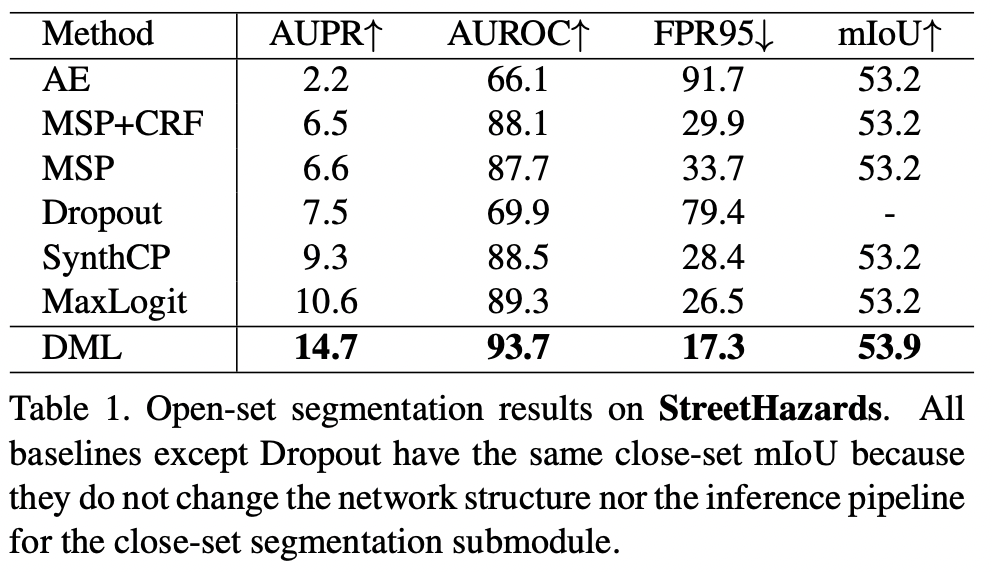
���� Lost and Found �� Road Anomaly,mIoU ����Ч��,��Ϊ����ֻ�ṩ OOD ���ǩ,��û���ض��ķֲ������ǩ�� ����ڱ� 2 �С�
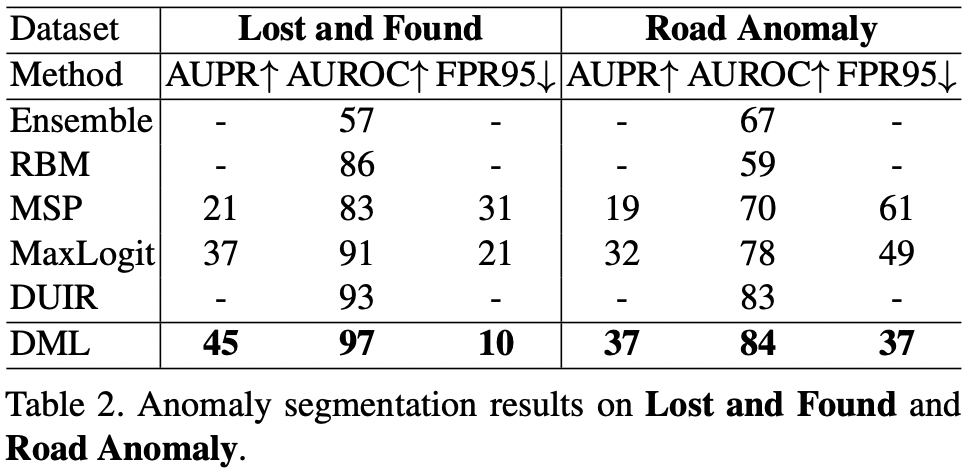
���ǵ�ʵ�����:
- ���� DMLNet �ķ��������������쳣�ָ����ָ���ж��ﵽ�����Ƚ������ܡ�
- ���������Ļ��� GAN �ķ���(���� DUIR �� SynthCP)���,���ǵķ������쳣�ָ�����������������,�ṹ��������,��Ϊ������������������Ҫ�������������������,������ֻ��Ҫ����һ�Ρ�
- StreetHazards �бռ��ָ�� mIoU ֵ�������ǵķ����Առ��ָ�û��Σ����
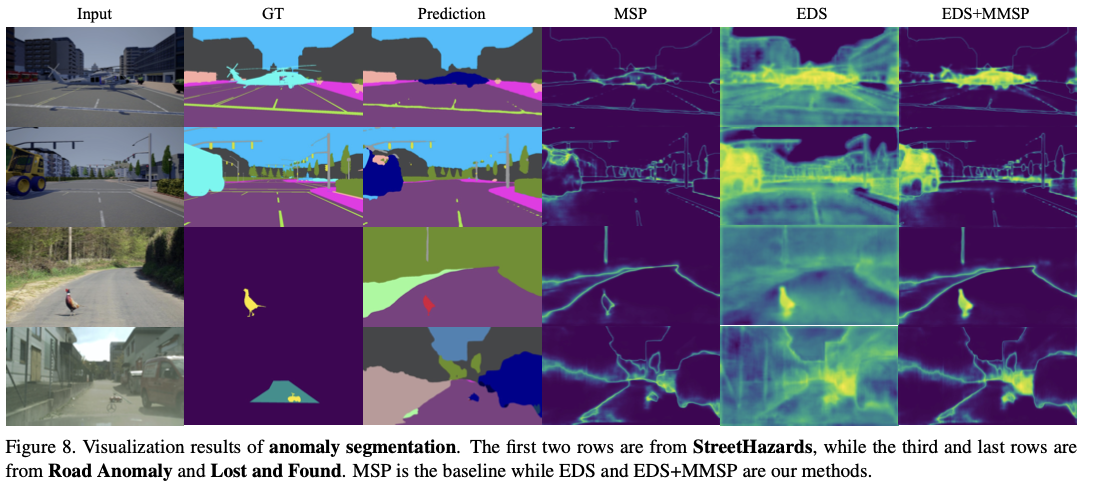
һЩ���Խ����ͼ 8 ��ʾ
�����о��� ������ϸ����������ʵ��,�о��˲�ͬ��ʧ����(VL �� DCE)���쳣�жϱ�(EDS �� MMSP)��Ӱ��,��� 3 ��ʾ��
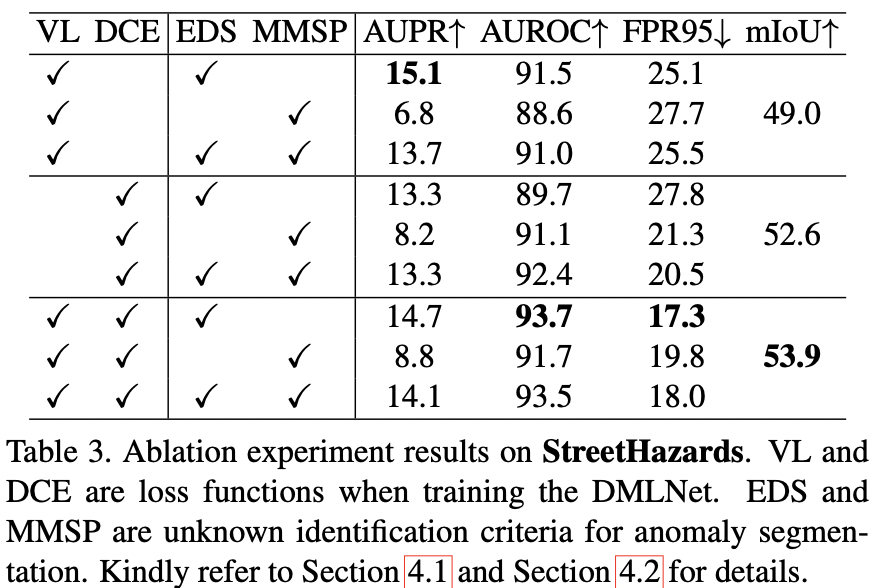
- DCE �� mIoU �ϵ��������� VL ����ʵ������ �ų�����
- EDS ��������ʧ�¶����� MMSP ����,����ζ�������صı����ʺ����쳣�ָ�����

