🚀 ������Դ���� 🚀
| ѧϰ·��ָ��(�������) | ֪ʶ��λ | ��Ⱥ��λ |
|---|---|---|
| 🧡 Pythonʵս�Ŷ���С���� 🧡 | ���� | ���γ���python flask+��С������������,����Ŀ�����Ѷ�Ʋ�������,����һ��ȫջ����ϵͳ�� |
| 💛Python��������ʵս💛 | ���ż� | �ְ��ִ������һ������չ������ȫ��Ч�ʸ��ߵ���������ϵͳ |
Ŀ¼* 16.1 ��ƪ����
+ 16.1.1 ��ƪ����
+ 16.1.2 �豸��������
+ 16.1.3 ͼ����������
- 16.2 ͼ����������
- 16.3 ����ϵͳͼ������
- 16.4 GPU����
- 16.5 ͼ������Ӧ��
- 16.6 ��ƪ�ܽ�
- �ر�˵��
- �����
16.1 ��ƪ����
16.1.1 ��ƪ����
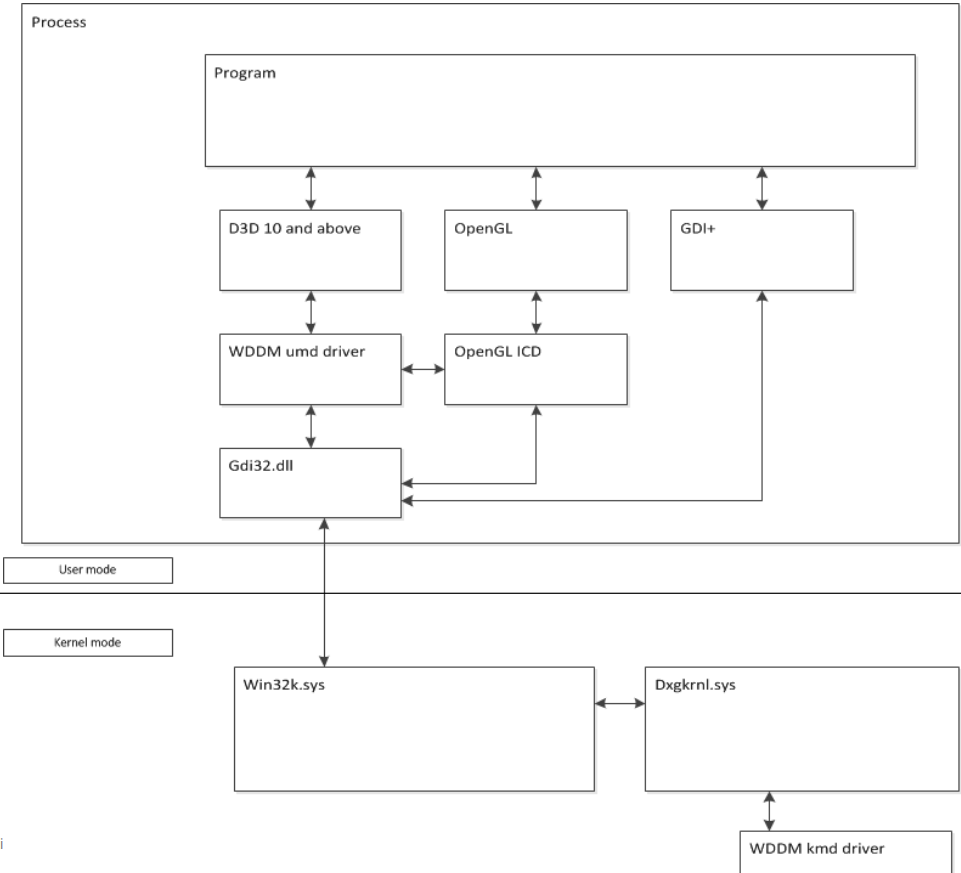
����Ϊֹ,�����ڲ����в��������ݰ���ͼ��API��GPU����Ϸ���桢Shader����Ⱦ�����������Ż��ȵȼ�����������,���ƺ���δ�漰ͼ����������Ļ����ƪ��վ��Ӧ�ò㿪���ߵ��ӽ�,ȥ����ͼ����������ؼ�����Ļ(���������������,��������Ϊ��Ŀ�����),��Ҫ��������������������:
- ͼ�������ļܹ���
- ͼ�������ļ�����Ļ��
- ͼ�������ij���ʵ�֡�
- ��ص�Ӳ��������
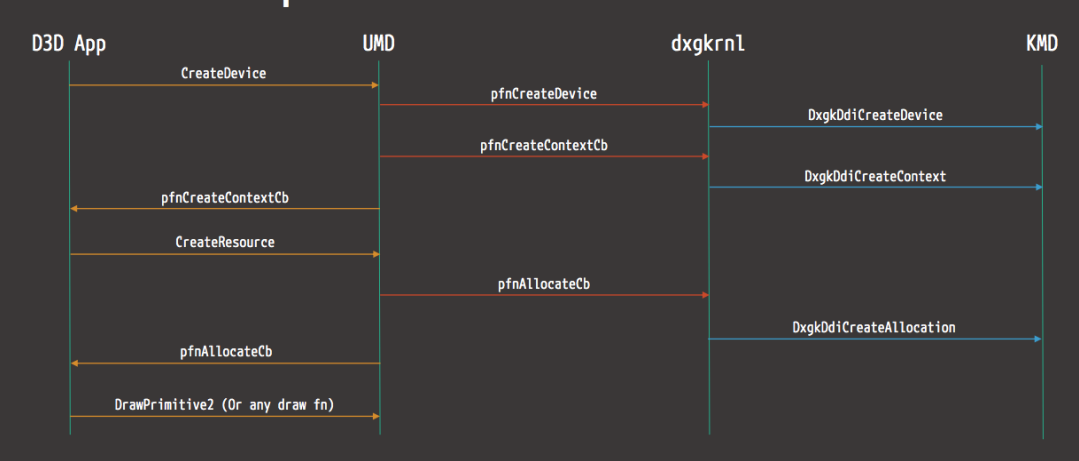
16.1.2 �豸��������
Ҫ����������һ����һ��ȷ�Ķ�����һ����ս����������������Ͻ�,����������һ���������,����������ϵͳ���豸�ͨ�š�����,����Ӧ�ó�����Ҫ���豸��ȡһЩ����,Ӧ�ó�����ò���ϵͳʵ�ֵĺ���,����ϵͳ������������ʵ�ֵĺ�������������������ƺ�������豸��ͬһ�ҹ�˾��д,����֪��������豸Ӳ��ͨ���Ի�ȡ���ݡ�����������豸��ȡ���ݺ�,�����ݷ��ظ�����ϵͳ,����ϵͳ�����ݷ��ظ�Ӧ�ó���
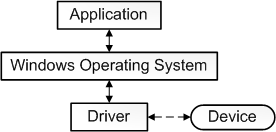
�ڼ������,�豸����������һ�ּ��������,���ڲ�����������ӵ���������Զ������ض����͵��豸����������ΪӲ���豸�ṩ�����ӿ�,ʹ����ϵͳ����������������ܹ�����Ӳ������,������֪����ʹ��Ӳ����ȷ��ϸ�ڡ�
��������ͨ��Ӳ�����ӵļ��������ͨ����ϵͳ���豸ͨ�š������ó���������������е�����ʱ,�����������豸��������(�����豸)��һ���豸�����ݷ��ͻ���������,��������Ϳ��Ե���ԭʼ���ó����е����̡���������������Ӳ�����ض��ڲ���ϵͳ,ͨ���ṩ�κα�Ҫ���첽ʱ�����Ӳ���ӿ�������жϴ�����
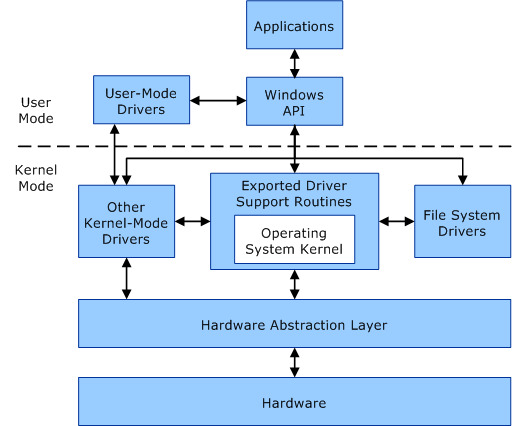
�豸��������,�ر������ִ�Microsoft Windowsƽ̨��,�������ں�ģʽ(x86 CPU�ϵ�ring 0)���û�ģʽ(x86 CPU�ϵ�ring 3)�����С����û�ģʽ�����������������Ҫ�ô���������ȶ���,��Ϊд�ò��õ��û�ģʽ�豸��������ͨ�������ں��ڴ������ϵͳ��������һ����,�û�/�ں�ģʽת��ͨ��������൱������ܿ���,�Ӷ�ʹ�ں�ģʽ���������Ϊ���ӳ��������ѡ��
�û�ģ��ֻ��ͨ��ʹ��ϵͳ�����������ں˿ռ�,�����û�����(��UNIX shell����������GUI��Ӧ�ó���)���û��ռ��һ����,��ЩӦ�ó���ͨ���ں�֧�ֵĺ�����Ӳ��������
�������豸����������������:
- ��ӡ����
- ��Ƶ��������
- ������
- ������
- �������͵ı�������,�ر����������ִ�ϵͳ�Ͽ������ߡ�
- ���ֵʹ�������/�������(������ꡢ���̵ȶ����豸)��
- ������洢�豸,��Ӳ�̡�CD-ROM����������(ATA��SATA��SCSI��SAS)��
- ʵ�ֶԲ�ͬ�ļ�ϵͳ��֧�֡�
- ͼ��ɨ���ǡ�
- ���������
- ���ֵ�����ӵ�г����
- �������߸��˾���������Ƶͨ���շ���������,���ڼ�ͥ�Զ����еĶ̾����������ͨ��(��������������(BLE)���̡߳�ZigBee��Z-Wave)��
- IrDA��������
���ϵĽ��������¼���������ڼ�:
- ����������������������Ƹ��豸�Ĺ�˾��д�������������,�豸�Ǹ����ѷ�����Ӳ������Ƶ�,��ζ���������������Microsoft��д,�����豸����������ṩ��������
- �������������������豸ֱ��ͨ�š����ڸ�����I/O����(����豸��ȡ����),ͨ���ж�����������������,��Щ��������ֲ������������ջ�С����ӻ���ջ�Ĵ�ͳ������,��һ���������ڶ���,���һ���������ڵײ�,����ͼ��ʾ����ջ�е�һЩ�����������ͨ���������һ�ָ�ʽת��Ϊ��һ�ָ�ʽ�����롣��Щ��������ֱ�����豸ͨ��,����ֻ�Dz����������ݸ���ջ�нϵ͵���������
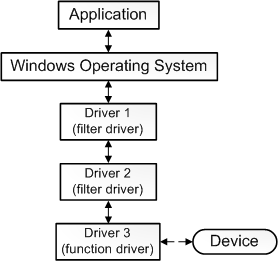
���й������������Ƕ�ջ��ֱ�����豸ͨ�ŵ�һ����������,��������������ִ�и�����������������
- һЩ������������۲첢��¼�й�����/����������Ϣ,��������������Щ��������,ijЩ������������䵱��֤��,��ȷ����ջ�е���������������ȷ����I/O����
����ͨ��˵���������ǹ۲��������ϵͳ���豸֮��ͨ�ŵ��κ������������չ��������Ķ��塣
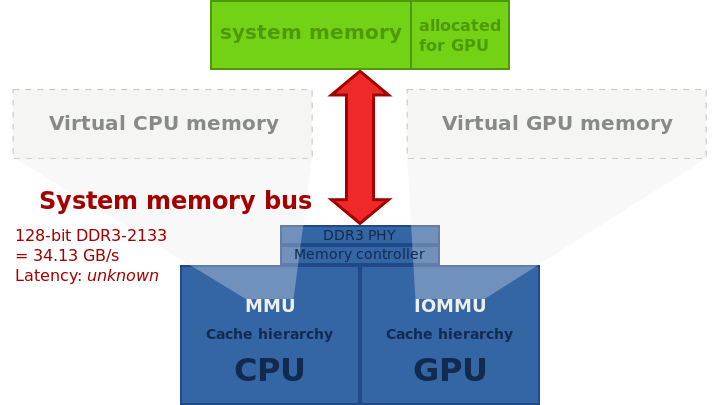
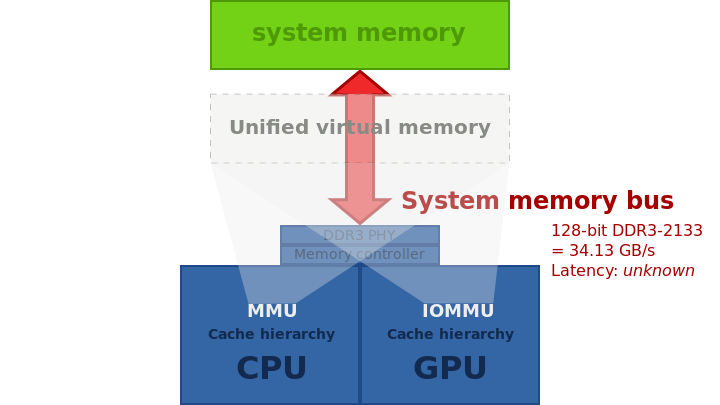
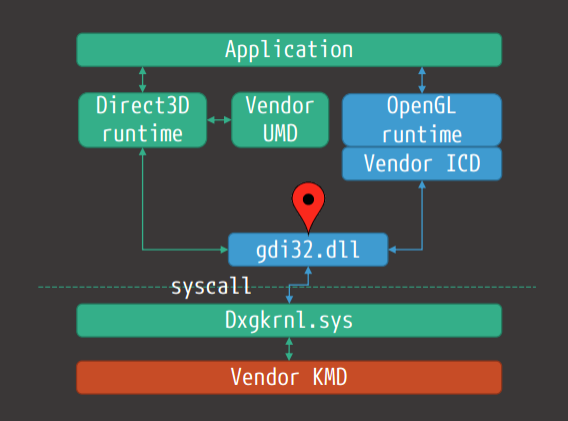
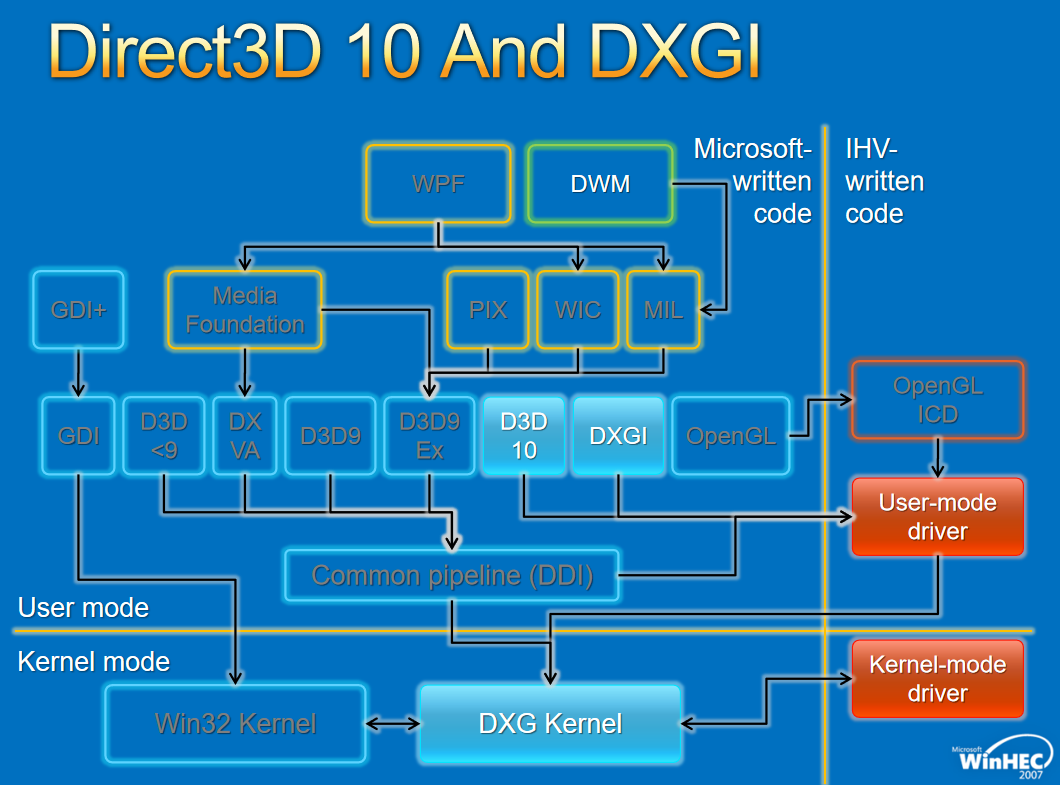
����,��չ�����൱ȷ,����Ȼ������,��ΪһЩ��������������κ�Ӳ���豸��û�й���������,������Ҫ��дһ���ܹ����ʺ��IJ���ϵͳ���ݽṹ�Ĺ���,��ֻ�����ں�ģʽ�����еĴ�����ܷ��ʺ��IJ���ϵͳ���ݽṹ������ͨ�����ù��߲��Ϊ���������ʵ����һ��,��һ��������û�ģʽ���в���ʾ�û�����,�ڶ���������ں�ģʽ����,���Է��ʺ��IJ���ϵͳ���ݡ����û�ģʽ�����е������ΪӦ�ó���,���ں�ģʽ�����е������Ϊ������������,��������������Ӳ���豸����������ͼ˵�������ں�ģʽ������������ͨ�ŵ��û�ģʽӦ�ó���
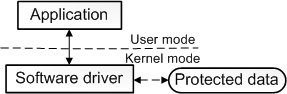
�������������������ں�ģʽ������,��д���������������Ҫԭ����Ϊ�˷��ʽ����ں�ģʽ�¿��õ��ܱ������ݡ�Ȼ��,�豸��������������Ҫ�����ں�ģʽ�����ݺ���Դ�����,һЩ�豸�����������û�ģʽ���С�
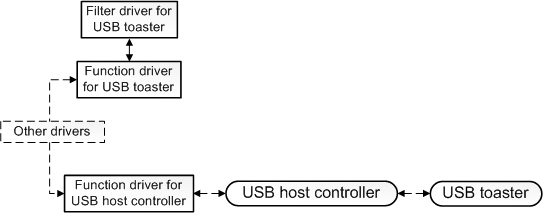
����,�������������ȸ����������(��ͼ)��
16.1.3 ͼ����������
��ʾ������������������ϵͳ��ͼ��Ӳ��һ������������ͼ��Ӳ��������ʾ��,�����Ǽ�����е����俨,Ҳ���������ڼ����������·����(��ʼDZ�����),Ҳ����פ���ڼ�����ⲿ(��Matrox remote graphics units)��ÿ���ͺŵ�ͼ��Ӳ�����Dz�ͬ��,��Ҫһ����ʾ������������ϵͳ�����ಿ�����ӡ����в�ͬ���ԵĽ���ͼ��Ӳ���ͺŲ��Ϸ���,ÿ�����ͺŵĿ��Ʒ�ʽ������ͬ��
����������ϵͳ��������(����)ת��Ϊ�ض��ڸ��豸�ĵ��á�����ͬһ�ͺŵ�ͼ��Ӳ��,ʹ�ò�ͬ�������õ�ÿ������ϵͳҲ��Ҫ��ͬ����ʾ������������,Windows XP��Linux��Ҫ�dz���ͬ����ʾ����������,ͬһ����ϵͳ�IJ�ͬ�汾��ʱ����ʹ����ͬ����ʾ������������,Windows 2000��Windows XP����ʾ��������ͨ������ͬ�ġ�
���δ��װ�ض��ڼ����ͼ��Ӳ������ʾ��������,ͼ��Ӳ������ʹ�û������ޡ�����ض����ͺŵ���ʾ����������,����ϵͳͨ������ʹ�þ��л������ܵ�ͨ����ʾ������������,Windows�ڡ���ȫģʽ����ʹ��ͨ��VGA��SVGA��ʾ�������������������,������ض���ģ�͵Ĺ��ܶ������á�
����ͼ��Ӳ���dz�����,������ʾ��������dz��ض��ڸ�Ӳ��,�����ʾ��������ͨ����Ӳ�������̴�����ά��,��������ϵͳ�а�������ʾ��������Ҳͨ��������������ṩ�������̿�����ȫ�����й�Ӳ������Ϣ,����ȷ������ѷ�ʽʹ����Ӳ������ӵ�мȵ����档
��ʾ���������ϵͳ��Դ���еͼ�(�ں˼�)����Ȩ��,��Ϊ��ʾ����������Ҫֱ����ͼ��Ӳ��ͨ��,���ֵͼ������ʹ����ʾ��������ı��������ϸ�Ϳɿ�����ʾ���������еĴ����Ӧ�ó��������еĴ�����п���ʹ��������ϵͳ��ʱ��ʹ�á�
���˵���,ijЩ��˾����֯(��Matrox)ƾ�����רҵ�û��Ĵ�ͳ��ŵ�Լ����Ʒ�ij��ڲ�Ʒ��������,������ɿ�����ʾ����������������ʢ����������������ζ������ʾ����������Ŀ���������������ʱ��,ʹ������δ����������п��ܵõ����,������ʾ���������ܹ���Ӧ���ϱ仯�������������µIJ���ϵͳ���µ�Ӧ���������ڲ��Ϸ���,ÿһ�ֶ�������Ҫ�µ���������汾�����ּ����Ի��ṩ�µĹ���,���õ�������ʾ������������������⡣���IJ�Ʒ��������Ҳʹ����ʾ����������п��������µ����Ժ���,�������Dz���ϵͳ��Ӧ�ó���������
����Linux�ȿ�Դ����ϵͳ,����������ʱ��ά����ʾ��������,����ϵͳ�Ŀ�Դ����ʹ��Ϊ�������ϵͳ��д�����ø�����(����������)����ȻMatroxΪ����Ŀ��ά���Լ���Linux��ʾ��������,��Matrox Millennium Gϵ�в�Ʒ�ṩ�˻����Ŀ�ԴLinux��ʾ��������,Matrox�������Xi Graphics(һ����Linux/Unix����������10���꾭��Ĺ�˾)ΪMatrox��Ʒ�ṩ��ȫ���ܵ�Linux��ʾ��������
��ʹ������ͬ�IJ���ϵͳ��ͼ��Ӳ���ͺ�,��ʱҲ��ͬʱ�ṩ��ͬ����ʾ��������,�����㲻ͬ������������Matroxͼ��Ӳ��ijЩ�ͺſ��õIJ�ͬ��ʾ���������ժҪ:
- ��HF����������:��������������зḻ�Ľ���,��ҪMicrosoft .NET Framework����,������ϲ���˽���������д˽�����û�,��NET�������������������װ��Windows������������Ҫ����Ӧ�ó����С���HF��������������ijЩ�ͺŵ�Parheliaϵ�в�Ʒ��Millennium Pϵ�в�Ʒ��
- Microsoft .NET Framework:����Microsoft������һ�ֱ�̻����ܹ�,���ڹ���������������û�ʹ�õ�Ӧ�ó���ͷ���.NET����,�����ǵ�HF��������
- ͳһ��������:������������һ��֧�ֶ����ͬ�ͺŵ�Matrox��Ʒ��������Ҫһ��Ϊ���ͬ��Matrox��Ʒ��װ��ʾ��������ϣ����һ�����������а�װ��ϵͳ����Ա�dz�����,���ڲ�ȷ���Լ���ͼ��Ӳ���ͺŵ��û�Ҳ�����á�����ͳһ��������Ľӿڱ���֧�ֲ�ͬ��Ӳ��,Matroxͳһ��������ʹ��֧�ָ��㷺�ġ�SE���ӿڡ�
- XDDM:Windows XP��ʾ��������ģ��,��ʱ����ΪXPDM��XPDDM��
- WDDM:Windows��ʾ��������ģ��(WDDM)��Windows Vista��Server 2008��Windows 7֧�ֵ���ʾ����������ϵ�ṹ��
- ��WDM��(Windows���������ͺ�)���������:��������������������Ҫ��Ƶ�����ʵʱ���Ź��ܵ��û�,��һ����ҪMicrosoft�ķḻ����.NET Framework������֧����Ƶ�Ķ����,��NET�������������������װ��Windows������������Ҫ����Ӧ�ó����С���������ijЩ�ͺŵ�Parheliaϵ�в�Ʒ��
- WHQL��������:��WindowsӲ������ʵ���ҡ������������Microsoft������һϵ�б�����,�������������Ŀɿ��ԡ�Matrox��Ӳ����Ӧ��ִ����Щ����,��������ύ��Microsoft������֤������û���װ����������δͨ��WHQL��֤(��ʹ��������ͨ��������ʽ��֤),��Windows����ϵͳ�����°汾�����û��������档Ϊ�˱�����ྯ���WHQL�����ṩ�Ķ������,ϵͳ����Աͨ����ϲ��ʹ��WHQL��������
- ��֤��������:Matroxͨ�����ȵ�רҵ2D/3D������֤��ʾ��������,��������AEC��MCAD��GIS��P&P(�����������)������,��������ͨ��Ҫ��ܸ�,���㷺ʹ��ͼ��Ӳ�����١�Matrox������֤����Ӧ�ó���,��ȷ������Ŀɿ��ԡ��ò����Ƕ�����Matrox��ʾ������������еij�����ԵIJ��䡣
- ISV��֤��������:ijЩ������������Ӧ�̡�����Ӧ���������Լ�����֤����,��Matrox��֤��������������,��Ϊ�ض�ͼ��Ӳ������ʾ������������ض�Ӧ�ó����н��ж�����ԡ�����,�����������,Matrox��Ӳ������ʾ���������ύ��ISV,ISVִ�в��ԡ���Matrox��֤���,ISV��֤��Ƶ�ʽϵ�,���ǵ�Ӧ�ý��١�
- ������������:��ʱ,����֧�ֻ�������������Ϊ�����桱�������������������Ѿ�������һЩ����,����һ�������������������,������������ɹ���Ҫ���Ի�Ԥ����Ҫ�¹��ܵ��û�ʹ�á�
- ��
�豸���������Dz���ϵͳ�ں˴�����������,Linux�ں����г���500���д���,���һᵼ�����صĸ����ԡ�bug�Ϳ����ɱ���������,������һϵ��ּ����߿ɿ��Ժͼ������������о���Ȼ��,���������о���һС������������֮��,���Ƕ���һ�Ӵ�Ĵ�����Ĺ���֪֮���١�
��ѧ���о�Linux���������Դ����,���˽����������ʵ����;����ǰ���о����Ӧ������Щ���������Լ�δ�����о�����,������,�о���������������������������:
- ����������빦�ܵ�������ʲô,���������о����������������������
- ��������������ںˡ��豸�����߽�����
- �Ƿ���ڿɳ���Ϊ���Լ������������С�����Ե�������?
�����������о���,����USB�����ṩ��һ����Ч�����߽ӿ�,������Ҫ�ı�������ʹ����ȷ���,�dz��ʺϸ���ִ������������,��ͬ���ߺͼ��������������豸����ˮƽ����ܴ�,���������ɱ�������졣
�豸�����������ڲ���ϵͳ��Ӳ���豸֮���ṩ�ӿڵ��������,�����������ú����豸,���������ں˵�����ת��Ϊ��Ӳ���������������������������ӿ�:
- ����������ں�֮��Ľӿ�,����ͨ������ͷ��ʲ���ϵͳ����
- ���������豸֮��Ľӿ�,����ִ�в�����
- ������������֮��Ľӿ�,���ڹ������豸��ͨ�š�
��ͼ��ʾ��Linux���������������ӿڵIJ�νṹ,�ӻ��������������Ϳ�ʼ,��char��block��net,��ȷ��72�����ص�����������𡣴����(52%)��������������ַ���������,�ֲ���41�����С�������������ռ������������25%,��ֻ��6���ࡣ����,��Ƶ��GPU��������������������Ĺ��ܴ�(��9%),������Ϊ���ӵ��豸����ÿ������ı��ָ�,����Щ�豸�����临����,�ںܴ�̶��ϱ����������о������ӡ�
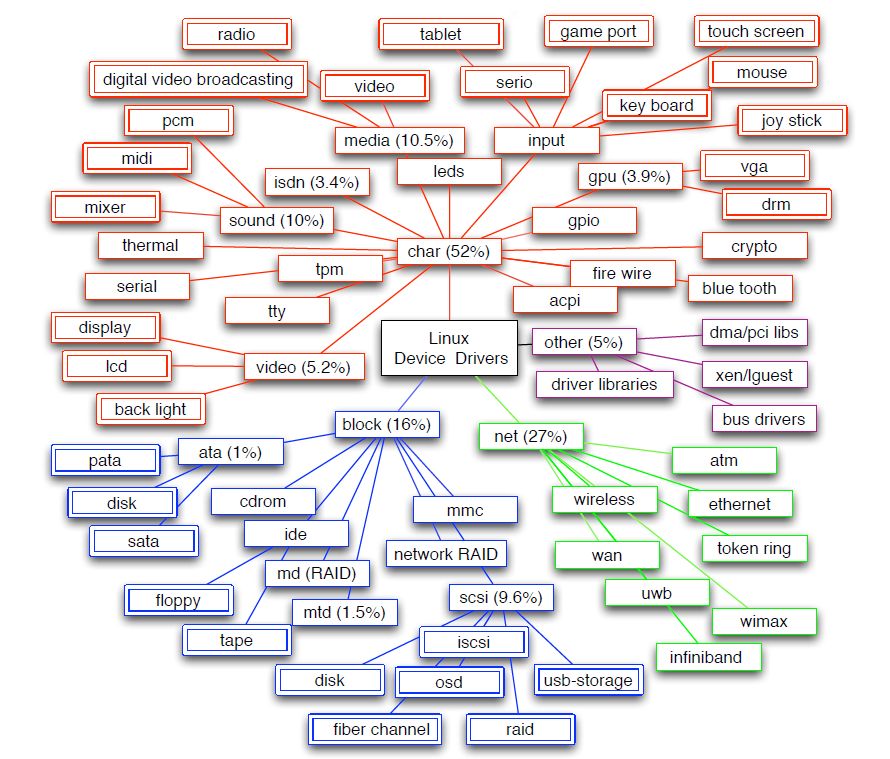
Linux���������ڻ��������������ķ��ࡣ�����ᵽ��5�������Ĵ�С(�Դ����еİٷֱȱ�ʾ)��
ͨ����Ϊ�豸����������Ҫִ������/����������Ʋ���ϵͳ�̿���涨:�豸����������Կ�����ת����,�������ɸ��������,�硰������123���������Ӳ��������ʹ�õĵͼ����ض���Ӳ����ָ�����,Ӳ��������������/����豸���ӵ�ϵͳ�����ಿ�֡�
�����豸����Խ��Խǿ��,��ӵ���Լ��Ĵ�����,����ͨ����Ϊ��������ִ�еĴ�������,ֻ���ڲ���ϵͳ���豸֮�䴫�����ݡ�Ȼ��,�������������Ҫ������CPU����,�������RAID��żУ�顢����У��ͻ���Ƶ����������ʾ����,����뱣������������15%����������������һ��ִ�д����ĺ���,���������������������������е�1%��
�±��Ƚ���PCI��USB��XenBus�����豸���ĸ�����ָ�ꡣͨ���Ƚ�һ����������֧�ֵ�оƬ������������֧�ֶ���豸��Ч��,������֧�����豸�ĸ�����,�Լ���������ij���֧�����Բ�ͬ��Ӧ�̵�����оƬ������������ʾ���и�ˮƽͨ�ù��ܵı����ӿڡ����֮��,֧�ֵ���оƬ�����������Ч�ʽϵ�,��Ϊÿ���豸����Ҫһ����������������

��������(bus)������Ч�ʲ��ܴ�PCI��������֧��ÿ����������7.5��оƬ��,������������ͬһ��Ӧ�̡����֮��,USB���������ƽ��ֵΪ13.2,ͨ���������Ӧ�̡����кܴ�һ���ֲ�������USBЭ��ı���,������PCI�豸�����������ֱ���������,USB�洢�豸ʵ�ֱ��ӿڡ����,��USB�洢������������ںܴ�̶��Ϻܳ���,���������豸�ض�����ĵ��á��˴�������ض����豸�ij�ʼ��������/�ָ�(δ�ṩͨ��USB�洢����Ϊ���ӹ���Ҫ����)��������Ҫ�豸�ض���������̡���ȻUSB�����������˸���ı�������,���Բ�������
�����ִ�����ϵͳ�������������һ���ؼ�Ҫ������Ҫ��·�����豸������,һ�����̿�����������������������Ӧ�ó���ͬʱ��д����,��ʹ��ЩӦ�ó���û��������������һҪ���ʹ����������Ƹ��ӻ�,��Ϊ�������˶Զ�������߳�֮��ͬ������Ҫ���о�����������ο糤�ӳٲ�����·����:�����������̻߳����롢�ڶ�ջ�ϱ���״̬����ֹ�¼�,�����������¼��������롢���ص�ע��ΪUSB���������������̻�PCI�豸���жϴ�������ͼ�ʱ����������������ƶ����ں�֮��,����������ں˽�ʹ��ͨ��ͨ���ͨ��,֧���¼������������ܸ���Ȼ��
��ͼ�б��Ϊ�¼��Ѻ��ͺ��̻߳�������ͼ����ʾ�Ľ������,�̻߳����¼��Ѻ��ʹ���Ļ����������������в���ܴ��ܵ���˵,����������ڲ�ͬ��Ŀ�Ĺ㷺ʹ��������ͬ����������������ʹ���߳�ԭ����ͬ������������豸����,ͬʱ��ʼ��������������������ȫ�����ݽṹ,���¼��Ѻ��ʹ������ں���I/O����
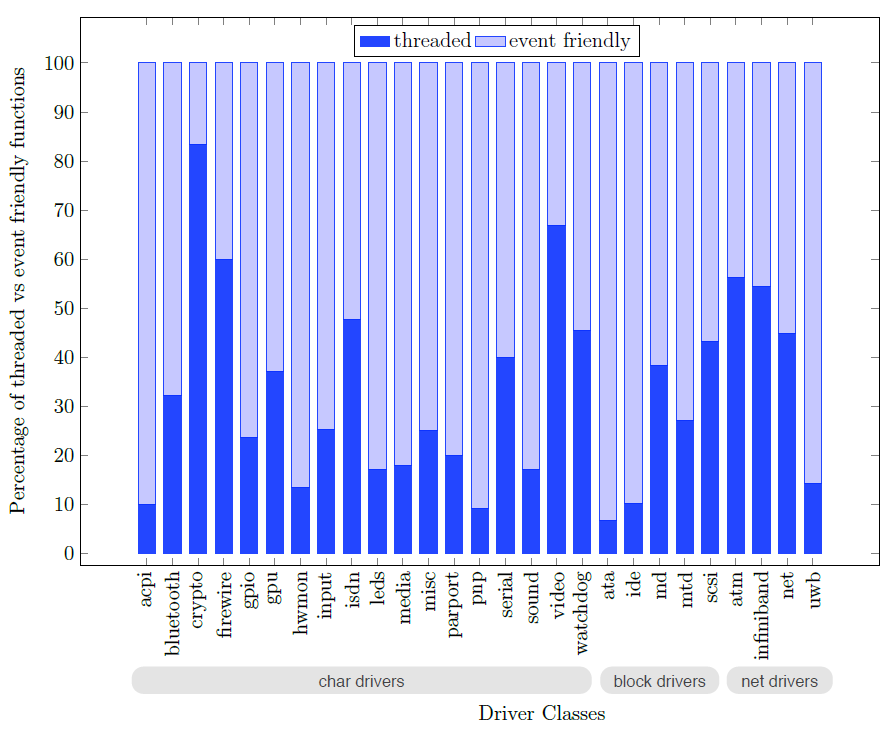
�̻߳����¼��Ѻ���ͬ��ԭ�︲�Ƿ�Χ�ڵ�����������ڵ�İٷֱȡ�
����GPU���ܵ����,��ͼ�����������Ҫ��ҲԽ��Խ�ߡ����õ��û�����ȡ�����ȶ����ɿ�������ջ��
16.2 ͼ����������
16.2.1 Ӳ������
������(��2012��)�ļ����Ӳ���ܹ����ɳ������������:
����һ���Կ��Ľṹ����ͼ,������GPU(ִ�����м���)����Ƶ���(���ӵ���Ļ)���Դ�(�洢������ͨ������)����Դ����(���͵�ѹ,���ڵ���)��������������(��CPU��ͨ��)�Ȳ���:
���,���м�����Ľṹ�������Ƶ�:һ�����봦������������Χ�豸��Ϊ�˽�������,��Щ��Χ�豸ͨ��������,����ͨ�Ŷ�ͨ�����߽��С���ͼ�����˱����������Χ�豸�IJ��֡�
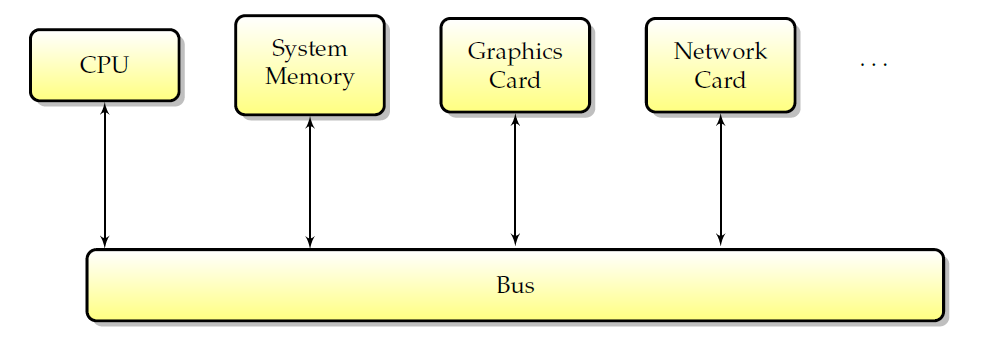
���ͼ�����е���Χ������
���ߵĵ�һ���û���CPU��CPUʹ�����߷���ϵͳ�ڴ��������Χ�豸��Ȼ��,CPU������Ψһ�ܹ�����Χ�豸д��Ͷ�ȡ���ݵ��豸,��Χ�豸����Ҳ����ֱ�ӽ�����Ϣ�������������˵,�ܹ���û��CPU��Ԥ������¶�ȡ��д��洢������Χ�豸����Ϊ����**DMA(ֱ�Ӵ洢������)**����,���Ҵ洢������ͨ������ΪDMA���������͵��������Ȥ,��Ϊ��������������ʹ��GPU������CPU�������ڴ洫�䡣����CPU������Ҫ����������ʵ����Щ����,��������������CPU��GPU֮����õ��첽��,��˿��Ի�ø��õ����ܡ�**DMA�ij�����;������������ϴ�������Ƶ�����ܡ�**���,����ͼ�δ�������������������(��ΪDMA��������),��������������Ƶ�����������������롣
��������ܹ��ڲ��������ڴ�ҳ�б���ʵ��DMA(���������ڴ��в�����ʱ�dz�����),��������DMA��ɢ-�ռ�(scatter-gather)����(��Ϊ�����Խ����ݷ�ɢ����ͬ���ڴ�ҳ,��Ӳ�ͬ���ڴ�ҳ�ռ�����)��
**��ע��,DMA������ijЩ����¿�����һ��ȱ�㡣**����,��ʵʱϵͳ��,��ζ�ŵ�DMA�������ڽ���ʱ,CPU����������,��������DMA�������첽������,���ܵ��´���ʵʱ���Ƚ�ֹʱ�䡣��һ��������С��DMA�ڴ洫��,��������DMA��CPU���������첽����,���´����ٶȱ��������,��ȻDMA�����ܽǶ������кܶ�����,����ijЩ�����Ӧ�ñ��⡣
����,GPU��Ҫ����:
- ������Ļģʽ/�ֱ���(ģʽ����)��
- ���������ͨ�����ߡ�
- ������Դ��������������(����,�Թ���/����������Ӧ),����GPU��Ƶ��/��ѹ�Խ�ʡ��Դ��
- �������ݡ����䴦��������(GPU VM+������ID),�ϴ�����������,����Ҫ����������ִ�е����
16.2.2 ��������
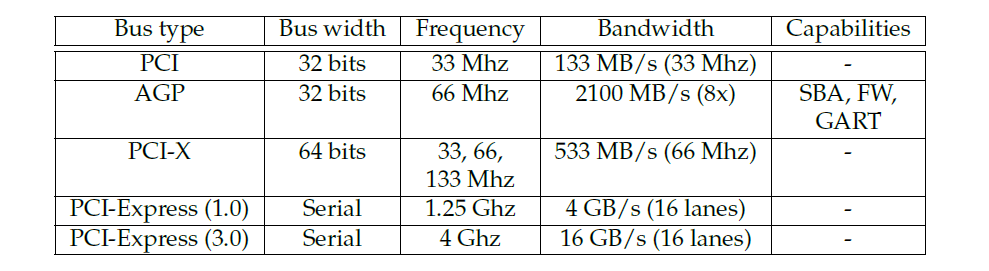
���߽�������Χ�豸������һ��,��ͬ����֮���ÿһ��ͨ�Ŷ�ͨ��(����)һ�����߽��С��ر���,�����Ǵ����ͼ�ο����ӵ���������ಿ�ֵķ�ʽ(һ��������������ijЩǶ��ʽϵͳ,����GPUֱ�����ӵ�CPU)�����±���ʾ,������������ͼ�ε���������:PCI��AGP��PCI-X��PCI express�ȵȡ���С�ڽ���ϸ���ܵ������������Ͷ���PCI�������͵ı���,������һЩ������ԭʼPCI������ж��صĸĽ���
-
PCI (Peripheral Component Interconnect,���貿��������):PCI��Ŀǰ��������ͼ����Χ�豸������������ߡ�����һ���ؼ����Խ������߿���,�˹���������������Χ�豸�ڸ�������������ռ�����߲�ִ������������(��ΪDMA,ֱ���ڴ����)��PCI������һ�µ�,��ζ��������ʽˢ�¼���ʹ�ڴ����豸�䱣��һ�¡�
-
AGP (Accelerated Graphics Port,ͼ�μ��ٶ˿�):AGP��������һ�־����Ľ���PCI����,�������������,�����������Ĺ��ܡ�����Ҫ����,�����ٶȸ���,��Ҫ�����ڸ��ߵ�ʱ���ٶ��Լ���ÿ��ʱ��tick��ÿ��ͨ������2��4��8λ������(�ֱ�������AGP 2x��4x��8x)��AGP�������������ص�:
- ��1��������AGP GART(ͼ�ι�Ȧ��ӳ���),��IOMMU��һ�ּ���ʽ����������ϵͳ�ڴ���ȡ��һ��(��������)�����ڴ�ҳ,�����䱩¶��GPU��Ϊ��������ʹ��,�Ժܵ͵ijɱ�������GPU���õ��ڴ���,��ΪCPU��GPU֮�乲�����ݴ�����һ�����������(AGPͼ�ο������ڸ�������п���DMA,��������GART������һ��ϵͳRAM,���CPU���ʱ�VRAM��ö�)��һ��������ȱ����,GART����һ��,�������һ����ʼ����֮ǰ,��Ҫˢ�¶�GART��д��(�����Ǵ�GPU����CPU)����һ��ȱ����,Ӳ��ֻ����һ��GART����,������������������䡣
- ��2��������AGP�ߴ�Ѱַ(SBA)���ߴ�Ѱַ��������ַ���ߵ�8����������λ���,���·���õ�ַ������֮������ߴ�����ͬ,��AGP����ֻ���������ݡ��˹��ܶ�����������Ա�����ġ�
- ��3��������AGP����д��(FW)������д������ֱ����ͼ�ο���������,������ͼ�ο�����DMA���˹��ܶ�����������ԱҲ�����ġ�ע��,�����������ڸ���Ӳ���϶����ȶ�,ͨ����Ҫ�ض���оƬ���hack������������,��˽��鲻�������ǡ���ʵ��,������AGP���ϳ������Ӳ������ļ�Ϊ������ԭ��
-
PCI-X:PCI-X��Ϊ�������忪����һ�ָ����PCI,���ָ�ʽ��ͼ����Χ�豸����(һЩMatrox G550��)����Ҫ������PCI-Express����,���ߵ�ʹ�÷dz��㷺��
-
PCI-Express (PCI-E):PCI Express����һ��PCI�豸,�ȼĸĽ�PCI�и�����ŵ㡣���,��Ҫע�����,������ϵ�ṹ,CPU-GPUͨ�Ų�����������������,��GPU��CPUλ�ڵ���оƬ�ϵ�Ƕ��ʽϵͳ�����䳣���������������,CPU����ֱ�ӷ���GPU�Ĵ�����
16.2.3 �Դ�ܹ�
��ȻDRAMͨ������Ϊһ����ƽ���ֽ�����,�����ڲ��ṹҪ���ӵöࡣ������GPU�����ĸ�����Ӧ�ó���,�dz��б�Ҫ��������������������ϴ��¿�,VRAM�����²������:
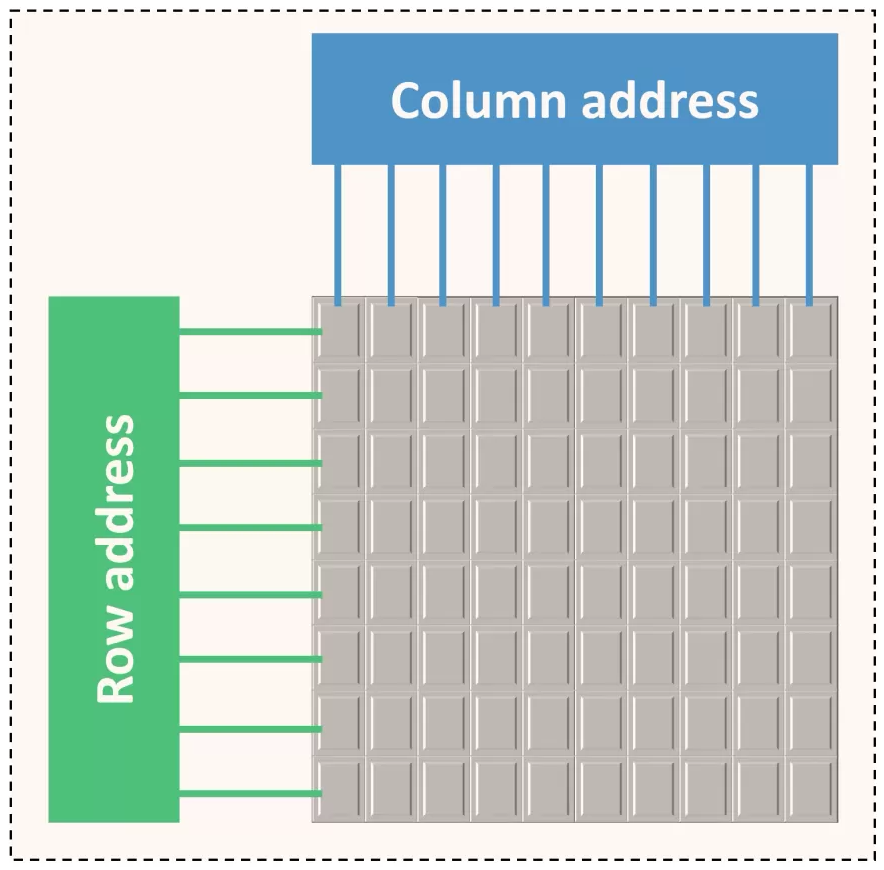
- R�г���C�е��ڴ�ƽ��(memory plane),ÿ����ԪΪһλ��
- ��32��64��128������ʹ�õ��ڴ�ƽ����ɵ��ڴ���(memory bank)������Щƽ��ͨ���ֲ��ڶ��оƬ��,����һ��оƬ����16��32���ڴ�ƽ�档bank�е�����ҳ�涼���ӵ���Ѱַϵͳ(��Ҳ�����),������Щҳ���������źź�ÿ��/�еĵ�ַ���ơ�bank�е��к���Խ��,��ַ����Ҫʹ�õ�λ��Խ�ࡣ

- �����ɸ�[2��4��8]��memory bank������һ���ɵ�ַλѡ����ڴ���(memory rank)���������ڴ�ƽ�������memory bankλ��ͬһоƬ�С�
- ��һ��������������һ����оƬѡ����ѡ���memory rank��ɵ��ڴ��ӷ���(memory subpartition)����rank����Ϊ������bank,�����ؾ���ͳһ�ļ��νṹ,�����ڵ�����оƬ�С�
- ��һ����������������memory subpartition������ڴ����(memory partition)��
- ����VRAM�ɼ���[1-8]��memory partition��ɡ�
������������ͬ��GPU�ܹ��ͼ������ͬ��
DRAM������ĵ�Ԫ���ڴ�ƽ��,���ǰ���ν���к�����֯�Ķ�άλ����:
column
row 0 1 2 3 4 5 6 7
0 X X X X X X X X
1 X X X X X X X X
2 X X X X X X X X
3 X X X X X X X X
4 X X X X X X X X
5 X X X X X X X X
6 X X X X X X X X
7 X X X X X X X X
buf X X X X X X X X
�ڴ�ƽ�����һ��������,�û����������������С����ڲ�,DRAMͨ������������Ϊ��λ���ж�/д������м������:
- �ڶ�ij��λ���в���֮ǰ,���뽫���м��ص���������,�������
- ������һ�к�,��Ҫ����д���ڴ�����,Ҳ������
- ���,�������е��ٶȺ���,����Ѿ���һ�����,�����ٶ�����������
- ��һ�β��ʱ���,���ȹر�һ��ͨ�������á������ֲ�����Ϊprecharging(Ԥ���?)һ��bank��
- ����,���Կ��ٷ���ͬһ���еIJ�ͬ�С�
���ڼ����е�ַ������ʵ�ʷ��ʻ�������е�λ���Ѹ����ʱ��,����DRAM����ͻ����ʽ���ʵ�,���Ի����1-8������λ��һϵ�з��ʡ�ͨ��,ͻ���е�����λ������λ�ڵ��������8λ���С��ڴ�ƽ���е��к��е�����ʼ����2����,��ͨ����ѡ�����ѡ��λ�ļ���������[����/�м�����log2],ͨ����8-10��λ��10-14��λ���ڴ�ƽ�汻��֯��bank��,bank�������ڴ�ƽ�������ɡ��ڴ�ƽ���Dz������ӵ�,������ַ�Ϳ�����,ֻ������/�����������Ƿֿ��ġ�����Ч��ʹ�ڴ�bank��������32λ/64λ/128λ�ڴ浥Ԫ��ɵ��ڴ�ƽ��,�����ǵ���λ����������ƽ������й�����Ȼ������bank,�������ĵ�Ԫ��λ�����洢оƬͨ������16��32���洢ƽ��,���ڵ���bank,��˶��оƬͨ��������һ�����γɸ�����bank��
һ���ڴ�оƬ�������[2��4��8]��bank,ʹ����ͬ��������,��ͨ��bankѡ���߽��ж�·���á���Ȼ��bank֮���л�����һ���е���֮���л�Ҫ��һЩ,��Ҫ����ͬһbank�е���֮���л���öࡣ���,һ���ڴ�bank��(MEMORY_CELL_SIZE / MEMORY_CELL_SIZE_PER_CHIP)�洢��оƬ��ɡ�һ��������ͨ��������(��������)���ӵ��ڴ���,оƬѡ���߳���,�����ڴ��ӷ�������rank֮���л�����bank�е�����֮���л����л�����ͬ�����ܺ��,Ψһ������������ʵ�ֺ�Ϊÿ��rankʹ�ò�ͬ������ѡ��λ�Ŀ�����(�����м������м�������ƥ��)�����ڶ��bank/rank�ĺ��:
- ȷ��һ����ʵ�����Ҫô����ͬһ��,Ҫô���ڲ�ͬ��bank,��һ�����Ҫ(�Ա������л�)��
- �ֿ��ڴ沼�ֵ����ʹ�ֿ���¶�Ӧ��һ��,���ڵķֿ�Ӳ�����һ��bank��
�ڴ��ӷ�����GPU�����Լ���DRAM��������1��2���ӷ�������һ���ڴ����,����һ���൱������ʵ��,�����Լ����ڴ���ʶ��С��Լ���ZROP��CROP��Ԫ,�Լ����߰汾���ϵĶ������档�����ڴ������crossbar��һ����GPU������VRAM��,�����е������ӷ������������ͬ������,GPU�еķ���ͨ��������ͬ,���ڽ��µĿ������DZ���ġ��ӷ���/�������ڵĺ��:
- ��bankһ��,����ʹ�ò�ͬ�ķ���������������ݵ��г�ͻ��
- ��bank��ͬ,���(��)����û�еõ�ͬ������,�����ͻ��ܵ�Ӱ�졣���,����ƽ��dz���Ҫ��
��Ȼ�ڴ�Ѱַ�߶�������GPUϵ��,����������˻����������ڴ��ַ��λ��˳������:
- ʶ���ڴ浥Ԫ�е��ֽ�,��Ϊ������ζ��������������Ԫ��
- �����ѡ��λ,������ͻ��(burst)��
- ����/�ӷ���ѡ��-�Ե�λ����,��ȷ�����õĸ���ƽ��,������̫��,�Ա��ڵ��������б�����Խϴ��tile,������ROP��
- ʣ����ѡ��λ��
- ����/��bankѡ��λ,��ʱ������ѡ��λ,�Ա����ڵ�ַ���ᵼ���г�ͻ��
- ���
- ʣ���bankλ��rankλ,��Ч��������VRAM���Ϊ��������,������һ�����������ɫ������,����һ���������zeta������,��������֮��Ͳ������г�ͻ��
����,���Բ�ͬ��������������ͬ����̬�����ȡ�ڴ�,������������֪��DDR-SDRAM��DDR:

��ank��˫rank�Աȡ�

�����ʡ�˫���ʡ������ʶԱ�ͼ��
��ͼ��CPU��GPU�ڴ�����·��:
GTT/GART��ΪCPU-GPU��������������ͨ��:
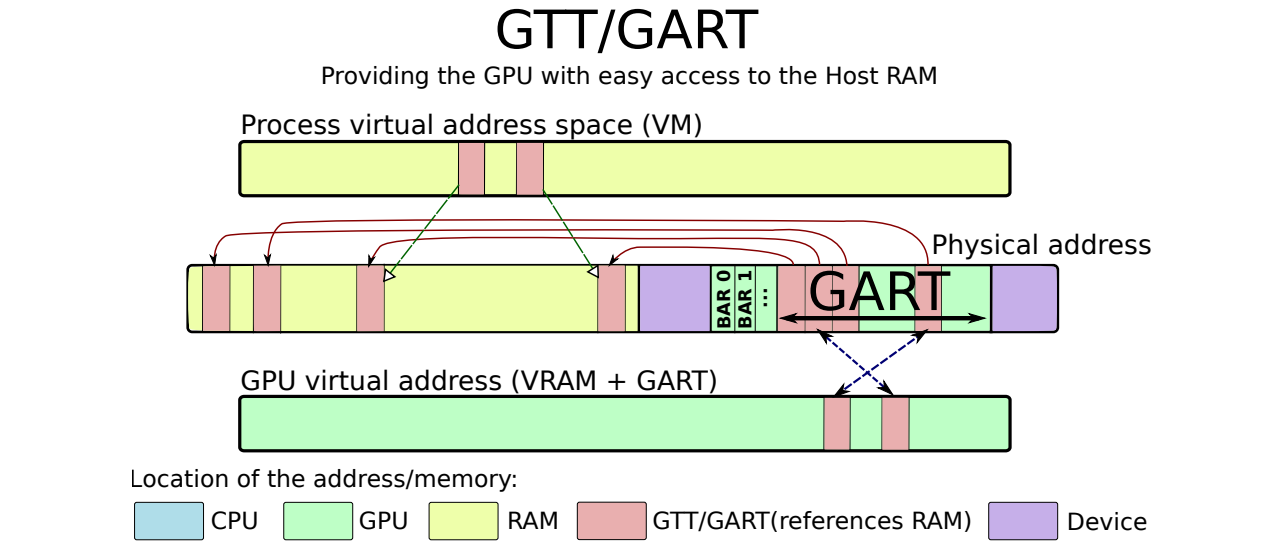
16.2.4 ����������ڴ�
�ڴ���������Ҫ�IJ�ͬ����:
- �����ڴ档�����ڴ�����ʵ��Ӳ���ڴ�,�洢���ڴ�оƬ�С�
- �����ڴ档�����ڴ��������ڴ��ַ��ת��,�����û��ռ�Ӧ�ó���鿴�����Ŀ�,�ͺ���������������,��������оƬ������Ƭ���ͷ�ɢ�ġ�
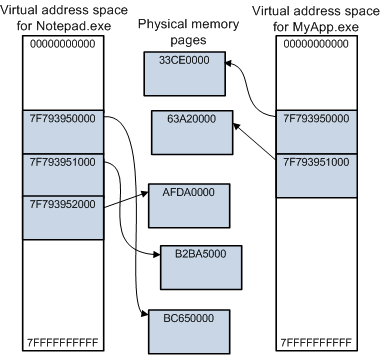
�����ַ�ռ��һЩ�ؼ�����,�Լ������ڴ�������ڴ�Ĺ�ϵ��
һЩ����ϵͳ(��Windows)������**��ҳ�����(paged pool)���Ƿ�ҳ�����(nonpaged pool)**�Ļ��ơ����û��ռ���,���������ڴ�ҳ�涼���Ը�����Ҫ�����������ļ��� ��ϵͳ�ռ���,ijЩ����ҳ����Ե���,����������ҳ�����ܡ� ϵͳ�ռ�������ڶ�̬�����ڴ����������:��ҳ����غͷǷ�ҳ����ء���ҳ������з�����ڴ���Ը�����Ҫ�����������ļ�,�Ƿ�ҳ������з�����ڴ���Զ�������������ļ���
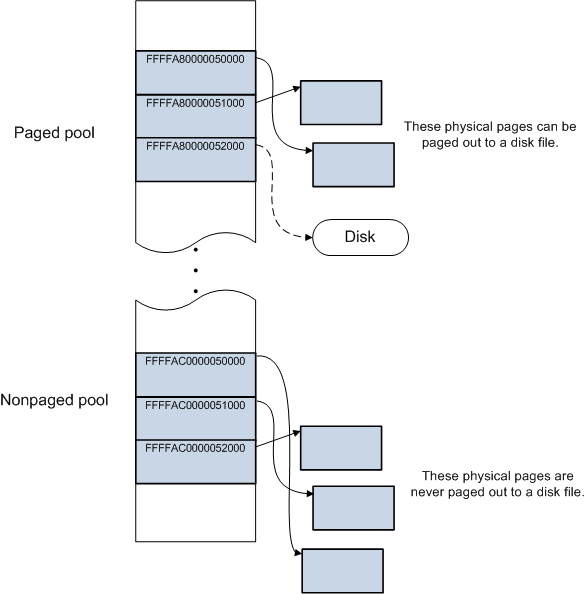
Ϊ�˼��,�����״����������ڴ�������һ��С���������������,������һ��������ڴ�齫��Ҫͬ��������������ڴ�,�������������ڴ���Ƭ����������ʵ�֡����,��Ҫһ�ֻ���������Ӧ�ó���������ڴ�����,ͬʱʹ�÷�ɢ���ڴ�顣
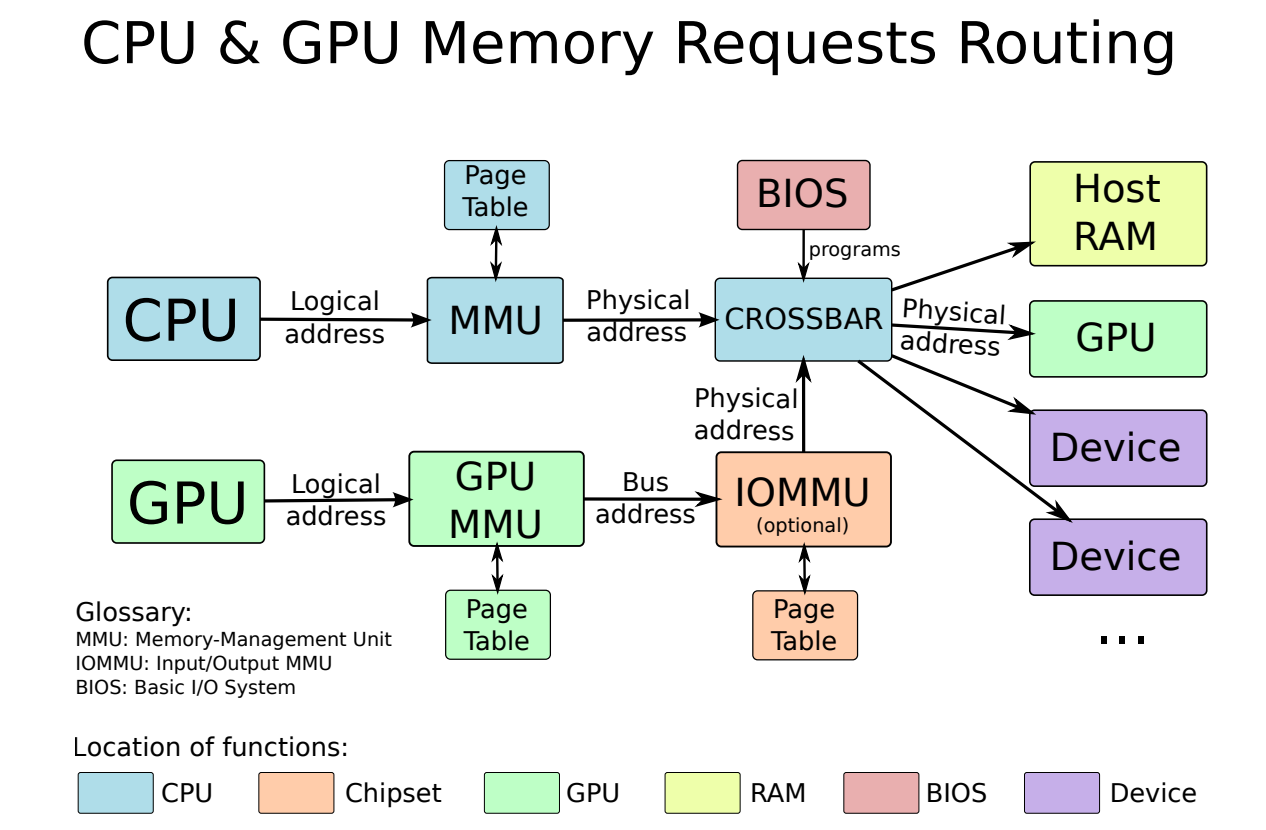
Ϊ��ʵ����һ��,�ڴ汻���Ϊ���ҳ���ͱ��ĵķ�Χ����,����˵�ڴ�ҳ�������ڴ��������ֽڵļ���,�Ա�ʹ��ɢ������ҳ�б�������ռ��п�������������,һ����Ϊ**MMU(�ڴ�ӳ�䵥Ԫ)**��Ӳ��ʹ��ҳ���������ַ(����Ӧ�ó���)ת��Ϊ������ַ(����ʵ�ʷ����ڴ�),����ͼ��ʾ�����ҳ�治����������ռ���(��˲���MMU����),MMU�������䷢���ź�,Ϊ����Բ������ڴ�����ķ����ṩ�˻������ơ��������ֱ�ϵͳ����ʵ�ָ��ڴ���,�罻����̬ҳ��ʵ����������MMU����CPU�����ڴ���Ч,�����ַ��Ӳ����,��Ϊ����������������ַƥ�䡣
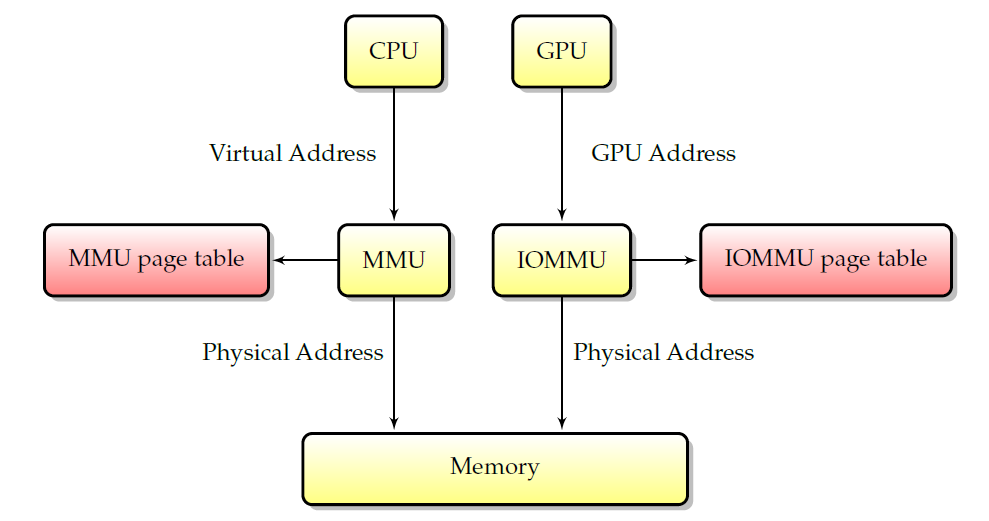
MMU��IOMMU��
��ȻMMUֻ������CPU����,��������Χ�豸��һ���ȼ���:IOMMU������ͼ��ʾ,IOMMU��MMU��ͬ,ֻ�������⻯����Χ�豸�ĵ�ַ�ռ䡣IOMMU����������оƬ��(�����������,����������Χ�豸֮�乲��)��ͼ�ο�����(��ͼ�ο�������,��������ΪAGP GART��PCI GART)�Ͽ������ֻ�����IOMMU�Ĺ����ǽ���Χ�豸���ڴ��ַת��Ϊ������ַ���ر���,����������ƭ���豸����DMA�����ڸ������ڴ淶Χ��,�Ǹ��õİ�ȫ�Ժ�Ӳ�����⻯������ġ�
IOMMU��һ��������Linux swiotlb,��������ʱ����һ�������������ڴ�(ʹ����һ������������������ǿ��е�,��Ϊ��û����Ƭ),����������DMA�������ڴ�����������������,����Ҫҳת��,��˿����ڸ��ڴ淶Χ�ڽ���DMA������,��ζ�Ÿ��ڴ�(Ĭ��Ϊ64MB)��Ԥ�ȷ����,�������������κ���;��
AGP GART��IOMMU����һ������,����AGPͼ�ο�һ��ʹ��,��ͼ�ο���ʾһ���������������������,IOMMU��Ƕ�������ϵ�AGPоƬ���С�AGP GART������Ϊ�����ڴ������������ϵͳ������
IOMMU����һ��������ijЩGPU�ϵ�PCI GART,����������һ��ϵͳ�ڴ档�����������,IOMMU��Ƕ�뵽ͼ�ο���,ͨ��ʹ�õ������ڴ治��Ҫ�������ġ�
��Ȼ,����ô�ͬ���ڴ�����,�����Dz����ȵ�,�������еķ�����϶��ǿ��ٵ�,��Ҫȡ���������Ƿ��漰CPU��GPU�����ߴ��䡣��һ���������ڴ�һ����:���ȷ�����豸���ڴ�һ��,������CPUд������ݿɹ�GPUʹ��(���෴)����������������ص�,��Ϊ�ϸߵ�����ͨ����ζ�Žϵ�ˮƽ���ڴ�������,��֮��Ȼ��
�������ڴ滺���������,�����ַ����������ڴ淶Χ�����û�������:
- MTRR��MTRR(�ڴ����ͷ�Χ�Ĵ���)���������������ڴ淶Χ���ԵļĴ�����ÿ��MTRR����һ����ʼ������ַ��һ����С��һ���������͡�MTRR������ȡ����ϵͳ,���dz����ޡ���Ȼ�����������ڴ淶Χ,��Ч������������Ӧ�������ڴ�ҳ������,����ʹ���ض��Ļ�������ӳ��ҳ�档
- PAT(ҳ�����Ա�)��������ÿҳ�ڴ����ԡ���MTRRһ�����������������ڴ淶Χ��ͬ,������ÿҳ�Ļ�����ָ���������ԡ�����,���ǽ�������x86�������Ͽ��õ���չ��
����֮��,������ijЩ��ϵ�ṹ��ʹ����ʽ����ָ��,������x86��,movntq��һ��δ�����movָ��,clflush����ѡ���Ե�ˢ�»����С�
�����ֻ���ģʽ,��ͨ��MTRR��PATϵͳ�ڴ�ʹ��:
- UC(UnCached)�ڴ�δ���档CPU�Դ�����Ķ�/д��δ�����,ÿ���ڴ�д��ָ��ᴥ��ʵ�ʵļ�ʱ�ڴ�д�롣������ȷ����Ϣ��ʵ��д��,�Ա���CPU/GPU���õ������
- WC(Write Combine)�ڴ�δ����,��CPUд�뱻�����һ����������ܡ�����Ҫδ�����ڴ浫��д���������һ���������Ӱ��������,�dz�������������ܡ�
- WB(Write Back)�ڴ��ѱ����档��Ĭ��ģʽ,���Ի��CPU���ʵ�������ܡ�Ȼ��,������ȷ���ڴ�д��������ʱ����������ڴ档
��ע��,���ϻ���ģʽ��������CPU,GPU���ʲ��ܵ�ǰ����ģʽ��ֱ��Ӱ�졣Ȼ��,��GPU�������֮ǰ��CPU�����ڴ�����ʱ,δ����ģʽ��ȷ��ʵ������ڴ�д��,���Ҳ��������CPU�����С�ʵ����ͬЧ������һ�ַ�����ʹ��ijЩx86������(��cflush)�ϵĻ���ˢ��ָ��,����ʹ�û���ģʽ�Ŀ���ֲ�Բ��һ��(����ֲ��)������ʹ���ڴ�����,������ȷ���ڼ���֮ǰ��������ڴ�д���ύ�����ڴ档
��Ȼ,����ô�ͬ�Ļ���ģʽ,�������з��ʶ�������ͬ������:
- ��CPU����ϵͳ�ڴ�ʱ,δ����ģʽ�ṩ��������,��д�ṩ��õ�����,д����Ͻ�������֮�䡣
- ��CPU����ɢ��������Ƶ�ڴ�ʱ,���з��ʶ��dz���,�����Ƕ�����д,��Ϊÿ�η��ʶ���Ҫ�����ϵ�һ�����ڡ����,������ʹ��CPU���ʴ������VRAM������,��ijЩGPU����Ҫͬ��,������ܻᵼ��GPU����
- ��Ȼ,GPU����VRAM���ٶȷdz��졣
- GPU��ϵͳRAM�ķ��ʲ��ܻ���ģʽ��Ӱ��,������ͨ������,DMA�������������������ڶ����첽������,��CPU�ĽǶ�����,���ǿ��Ա���Ϊ����ѡ�,����ÿ��DMA�����漰�����ɺ��Ե����óɱ��������Ϊʲô�ڴ��������ڴ�ʱ,DMA������������ֱ��CPU���ʡ�
���,�����ڴ�����һ����Ҫ�۵����ڴ����Ϻ�д���˱�(write posting)�ĸ�����ڻ���(д�ϲ���д��)�ڴ�����,�ڴ����Ͽ�ȷ�������д����ʵ�������ύ���ڴ档����,��Ҫ��GPU��ȡ�������ڴ�����֮ǰ,��ʹ�ô�ѡ�����I/O����,����һ�����Ƶij�Ϊд���˱��ļ���:������I/O�����ڽ��������ȡ,��Ϊһ�ָ�����,����ȵ������д����Ч������ɡ�
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-lNEQw0ro-1656218692594)(https://img2022.cnblogs.com/blog/1617944/202206/1617944-20220623135955177-1742403431.svg)]
���������������ϵ�ṹ,��PCI Express�Ͼ��ж��ص�ͼ�ο��������ڴ漼���ĵ��ʹ���ȱ���ڴ��ӳ�,GPU��CPU֮�䲻����ʵ���㿽��,��Ϊ���߶��и��Բ�ͬ�������ڴ�,���ݱ����һ�����Ƶ���һ�����ܹ�����
���������ڴ�ļ���ͼ��:ϵͳ�ڴ��һ����ר�ŷ����GPU,�㿽��������ʵ��,���ݱ���ͨ��ϵͳ�ڴ����ߴ�һ���������Ƶ���һ��������
����ͳһ���洢���ļ���ͼ��,����AMD Kaveri��PlayStation 4(HSA)���ҵ���
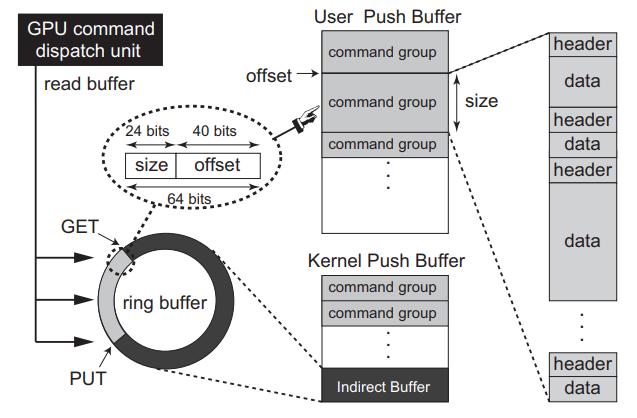
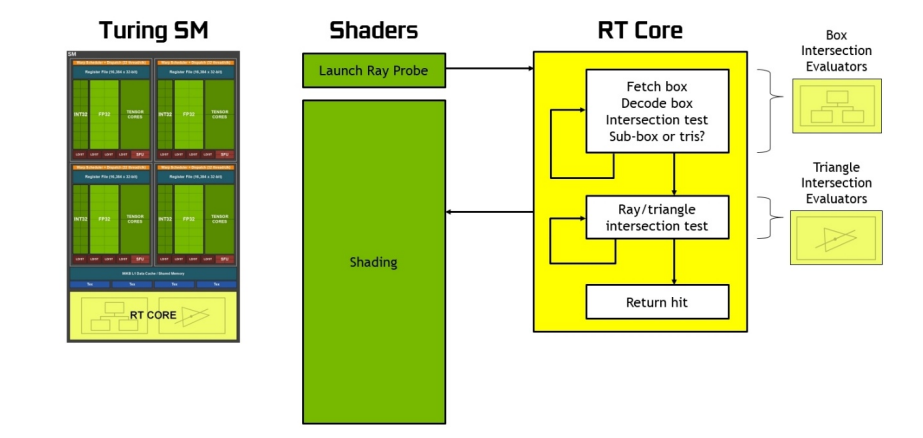
16.2.5 PFIFO
���������������ͨ��һ����ΪPFIFO���������淢�͵�,PFIFOά�������ȫ�������������,��Ϊͨ��(channel)��FIFO,ÿ��ͨ��ͨ����ͨ�������������п���,��������MMIO[GF100֮ǰ]��VRAM[GF100+]������,PFIFO�������н���������ͨ���������ȡ�ж���
PFIFO�ڲ���ͨ��֮����з�ʱ(time-sharing),����Ӧ�ó���������,PFIFO���Ƶ�����Ҳ֪��ͨ��,��Ϊÿ��ͨ��ά�������������ġ�
PFIFO���������л�����ȡ���ڿ��Ĵδ�����NV40,PFIFO�����Ͽ�����ʱ��ͨ��֮���л����ھɿ���,����ȱ�ٻ���ĺ洢,ֻ���ڻ���Ϊ��ʱ�����л���Ȼ��,PFIFO���Ƶ��������л�����Ҫ��ö�:����ֻ��������֮���л�����Ȼ���ַ�ʽ�ھɿ��ϲ���һ��������(��Ϊ���֤������ʱ����ִ��),���������ѭ�����ܵĿɱ����ɫ��,����ͨ��������ʱ�����е���ɫ������Ч�ع�������GPU��
PFIFO���¿ɷ�Ϊ4������:
- PFIFO pusher:�ռ��û��������ע�롣
- PFIFO cache:�ȴ�ִ�еĴ������
- PFIFO puller:ִ������,���䴫�ݸ��ʵ��������������
- PFIFO switcher:���ͨ����ʱ��Ƭ,����PFIFO�Ĵ�����RAMFC�ڴ�֮�䱣��/�ָ�ͨ����״̬��
ͨ�������²������:
- ͨ��ģʽ:PIO[NV1:GF100]��DMA[NV4:GF100]��IB[G80-]��
- PFIFO DMA pusher״̬[����DMA��IBͨ��]��
- PFIFO����״̬:�ѽ��ܵ���δִ�е����
- PFIFO puller״̬��
- RAMFC:��PFIFO�ϵ�ͨ����ǰδ����ʱ,�洢������Ϣ��VRAM����[�û����ɼ�]��
- RAMHT[����GF100֮ǰ�汾]:ͨ������ʹ�õġ�����,����������32λ�����ʶ,������DMA����[�μ�NV3 DMA����NV4:G80 DMA����DMA����]�����������G80֮ǰ�Ŀ���,������ͨ��֮�乲����������
- vspace(��G80+):ҳ���IJ�νṹ,����������ִ��ͨ������ʱ�ɼ��������ڴ�ռ�,���ͨ�����Թ���һ��vspace��
- �����ض�״̬��
ͨ��ģʽ������ͨ���ύ����ķ�ʽ����GF100֮ǰ�Ŀ��Ͽ���ʹ��PIOģʽ,������Ҫ����Щ����ֱ�Ӳ���ͨ���������������ٶ����Ҵ������������ͨ��ͬʱʹ��ʱ,������������,�ʶ����Ƽ�ʹ�á���NV1:NV40��,����ͨ����֧��PIOģʽ����NV40:G80��,ֻ��ǰ32��ͨ��֧��PIOģʽ����G80��:GF100��ͨ��0֧��PIOģʽ��
16.2.6 ͼ�ο�����
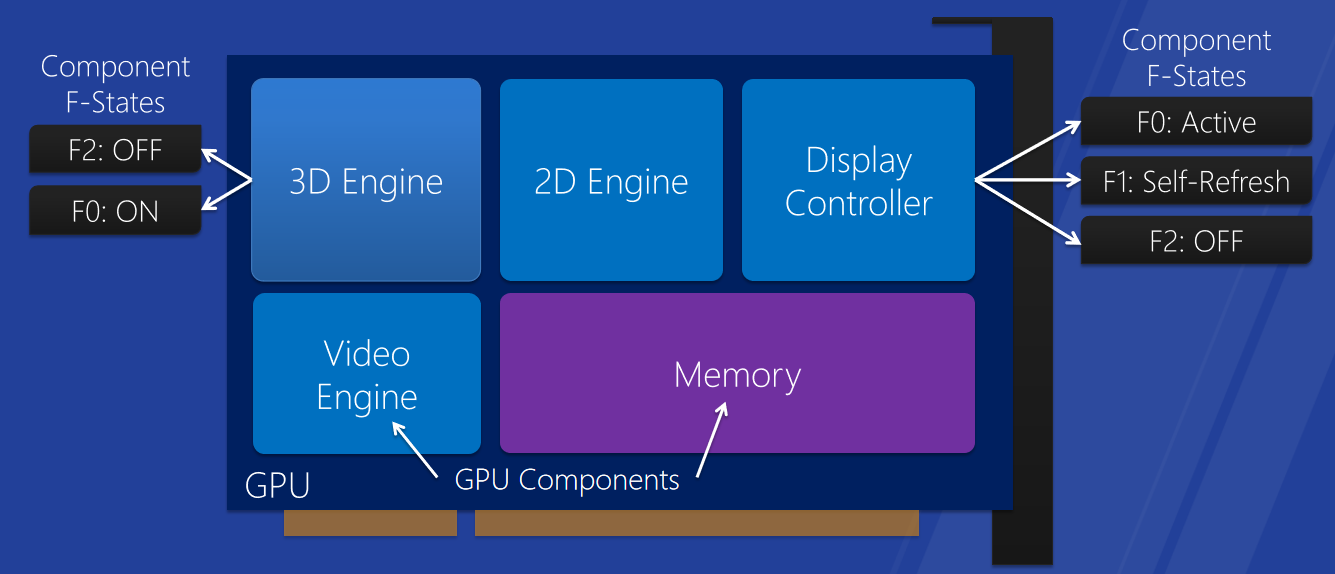
���,ͼ�ο��������Ǽ�����еļ����������һ�����ӵ�Ұ��,��һ�������Ŀ�����һ��ר�ô�����,�����Լ��ļ��㵥Ԫ�����ߺ��ڴ档���ڸ���ͼ�ο�,��������Ԫ�ء�
- Graphics Memory(ͼ���ڴ�)
GPU���ڴ�(��Ƶ�ڴ�),��������ʵ�ġ�ר�õġ������ڴ�(������ɢ��),Ҳ��������CPU�������ڴ�(���ڼ��ɿ�,Ҳ��Ϊ�������ڴ桱����ڴ桱)����ע��,�����ڴ�����������Ȥ�ĺ���,��Ϊ���ʵ�ֵõ�,ϵͳ����Ƶ�ڴ�Ŀ���ʵ��������ѵġ���ר���ڴ�������,��ζ����Ҫ�������ش���,�������ǽ��ܵ������ٶȵ����ơ�
�ִ�GPUҲ��һ����ʽ�������ڴ�,��������ͬ����Դ(ϵͳ�ڴ����ʵ��Ƶ�ڴ�)ӳ�䵽GPU��ַ�ռ�,��CPU�������ڴ�dz�����,��ʹ����ȫ������Ӳ��ʵ�֡�����,�Ͼɵ�Radeon��(ʵ������Rage 128)�����������(Surface),���ǿ��Խ���Щ����ӳ�䵽GPU��ַ�ռ�,ÿ�����涼���������ڴ���Դ(��Ƶram��AGP��PCI)���ɵ�Nvidia��(NV40֮ǰ�����п�)��һ�����Ƶĸ���,�����������ڴ�����Ķ���,Ȼ�������������;���Ժ��ͼ�ο�(��NV50��R800��ʼ)������������ҳ������ַ�ռ�,����������ѡ��ϵͳ��ר����Ƶ�ڴ�ҳ����Щ��CPU�����ַ�ռ�������Էdz�����,��ʵ��,δӳ���ҳ����ʿ���ͨ���ж���ϵͳ�����ź�,������Ƶ�ڴ�ҳ�������������ִ�С�Ȼ��,С�Ĵ�����Щ����,��Ϊ����������Ա���봦������CPU��GPU�Ķ����ַ�ռ�,���Ǿ��б����ԵIJ�ͬ�㡣
- Surface(����)
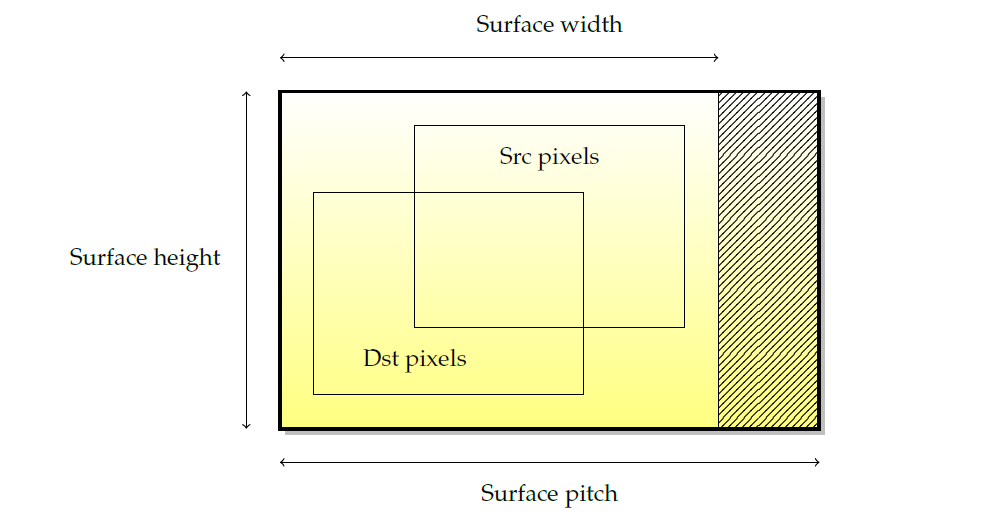
������������Ⱦ�Ļ���Դ��Ŀ�ꡣ�������ǵĽз���������(��������ȾĿ�ꡢ��������)����˼������һ���ġ���ͼ������ͼ�α���IJ��֡�����Ӳ������(ͨ����ijЩ2�η�����һ������),������ȱ��������뵽�������Ƶļ��,��˴���һ��δʹ�õ�����������
ͼ�α��������������:
- ��������ظ�ʽ��������ɫ�����ɫ����ɫ����ɫ�����Լ�������ϲ����ȵ�alpha������ʾ���������ص�λ��ͨ����Ӳ����С��ƥ��(8��16��32λ),���ĸ����֮���λ�����·��䲻����Ӳ����С��ƥ�䡣����ÿ�����ص�λ������Ϊÿ����λ����bpp�����������ظ�ʽ����888 RGBX��8888 RGBA��565 RGB��5551 RGBA��4444 RGBA����ע��,���ڴ����ͼ�ο�������8888��ԭ�������ġ�
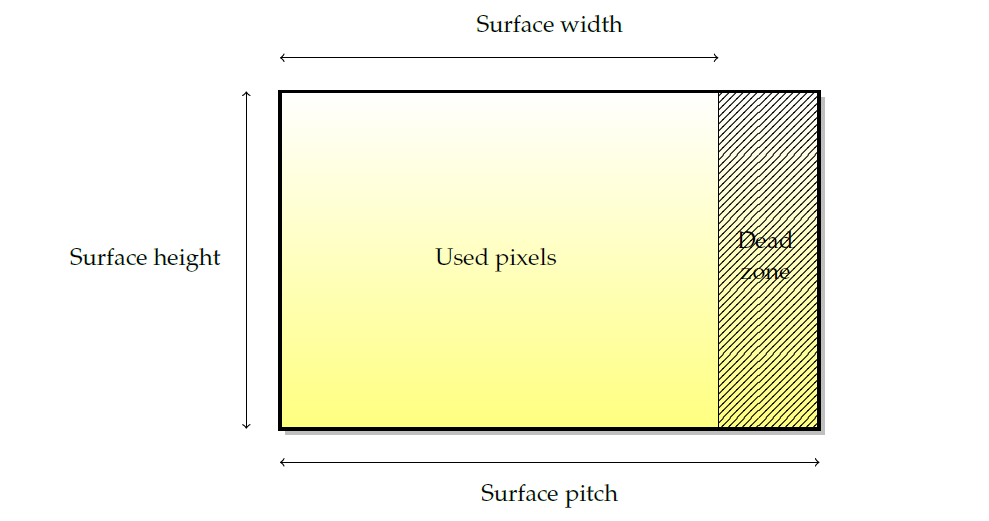
- ���Ⱥ߶��������Ե�����,������Ϊ��λ��
- ��������ֽ�Ϊ��λ�Ŀ���(����������Ϊ��λ!)�����,�����հ�����(dead zone)���ء�pitch���ڼ����ڴ�ʹ����,����,����Ĵ�СӦͨ��
�߶� x pitch�������߶� x ���� x bpp������,�Ա����dead zone��
��ע��,���沢���������Դ洢����Ƶ�ڴ���,��ʵ��,��������ԭ��,����ͨ�����������Դ洢,��Ϊ�������Ը�����Ⱦʱ�ڴ���ʵ�λ�á���������Ϊ�ֿ����(tiled surface),�ֿ����ľ�ȷ���ָ߶�������Ӳ��,��ͨ����һ�ֿռ��������,��Z����(�ֽ�Z-order���ߡ�Morton����,��ͼ)��Hilbert����(����ͼ)��

����,Morton��Hilbert����֧��3D�ռ�ı���:
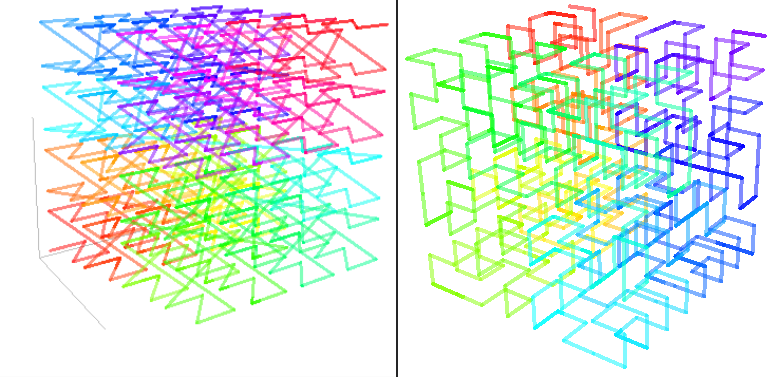
- 2D Engine(2D����)
2D�����blitter������2D���ٵ�Ӳ��,Blitter�������ͼ�μ�����ʽ֮һ,������Ȼ�dz��ձ顣ͨ��,2D�����ܹ�ִ�����²���:
- Blits��BLIT��GPU���ڴ���δ�һ��λ�ø��Ƶ���һ��λ�õĸ���,Դ��Ŀ���������Ƶ��ϵͳ�ڴ档
- ʵ����䡣ʵ������������ɫ�������ڴ�����,Ҳ������alphaͨ����
- Alpha blits��Alpha Blitʹ�����Ա�������ص�Alpha������ʵ�����ȡ�
- ���쿽����
��ͼ��ʾ����������ͬ����֮��ƴ�Ӿ��ε�ʾ�����˲��������²�������:Դ��Ŀ�����ꡢԴ��Ŀ��ھ��Լ�blit���Ⱥ߶ȡ�Ȼ��,������2D����,ͨ������ʹ��blitting��������ӻ�任��
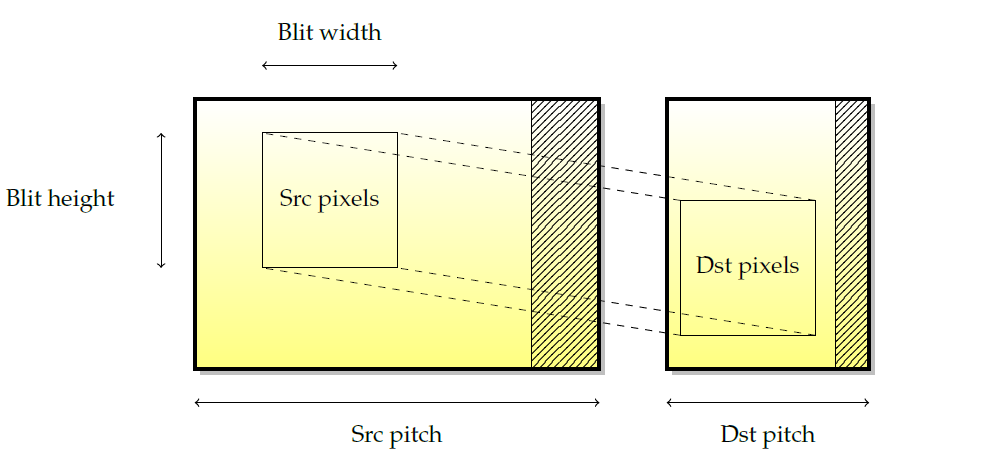
��blit�����������ص���Դ�����Ŀ�����֮��ʱ,���������岢���Ǽ����,�����ǵ�������Ϊblit�����IJ��Ǽľ����ƶ�,�����ں����������ƶ�ʱ������ͼ��ʾ,���һ��һ�еش��ϵ��¸���,һЩԴ���ؽ�����Ϊ�����á����,��������ĸ�����뵽blitter�С������������,Ҫ�����ȷ�ĸ���,��Ҫ���µ��ϵĸ�����һЩ�������ݱ����ص��Զ�ȷ����������(����nvidia GPU),����������,�����������,���������������������Ϊʲô��ЩGPUʵ����֧�ָ���pitch,�Ա����2D������ˡ�
���,���ס,�������е�ǰ��ͼ�μ�����������2D���档����3D�����ڼ�������2D���ٵij���,��˿���ʹ��3D����ʵ��2D���١���ʵ��,һЩ��������ʹ��3D������ʵ��2D,ʹ��GPU�����̿�����ȫ����ר����2D�ľ���ܡ�Ȼ��,����һЩ������ר���ھ����,������GPU�ڲ���3D����֮�϶�2D������������(nv10֮���nVidia����nv50֮ǰ��nVidia�������������,����Radeon R600ϵ��,���Ǿ�����3D֮��ʵ��2D�Ŀ�ѡ�̼�)����ʱ��Ӱ��2D��3D�����Ļ��,��Ϊ�������ڹ���Ӳ����Ԫ��
- 3D Engine(3D����)
3D����Ҳ��Ϊ��դ�����档������һϵ���Թ���(����)��ʽ�������ݵĽ�,�綥��->����->ƬԪ��ͼ��FIFO��DMA�ȡ�Ϊ�˻�ø��õĻ���λ��,�����ͱ���ͨ����ֿ顣�ֿ���ζ�������������Դ洢��GPU�ڴ���,���Ǵ洢���ڴ���,�Ա�ʹ�����ռ��нӽ�������Ҳ���ڴ�ռ��нӽ�,����Z�����ߺ�ϣ���������ߡ�
- ���Dz��Ӳ������(Overlays and hardware sprites)��
ɨ�����:ͼ����ʾ�����һ�����ǽ���Ϣ��ʾ����ʾ�豸����Ļ��,��ʾ�豸��ͼ���������һ��,�������û�չʾͼƬ��
����,����������ģ���źš�hsync��vsync����ͬ�����������ͱ�����(CRTC��TMD��LVDS��DVI-I��DVI-A��DVI-D��VGA)�ȼ���,���ĺ���֮��
16.2.7 ͼ�ο����
ÿ��PCI���������PCI��Դ,lspci-v�г�����Щ��Դ,������������BIOSS��MMIO��Χ����Ƶ�洢��(�������)������PCI����Դ��С����,ͨ��һ�ſ�ֻ�ܽ��䲿����Ƶ�ڴ���Ϊ��Դ����,����ʣ���ڴ��Ψһ������ͨ�������ɷ��������DMA(����������תҳ��ķ�ʽ)��������Ƶ�ڴ��С��������,��PCI��Դ�ռ���Ȼ����,�������Խ��Խ�ձ顣
- MMIO
MMIO�ǿ�����ֱ�ӷ��ʷ�ʽ��һϵ�е�ַ��¶��CPU,ÿ��д������ֱ�ӽ���GPU,ʹ�ô�CPU��GPU������ͨ��������ֱ����ͬ����;д������CPU���,����GPU����������ʽִ��,�ᵼ�µ��ڱ�������,��Ϊÿ�η��ʶ����������ϱ��һ�����ݰ�,����CPU���ύ��������֮ǰ����ȴ���ǰ��GPU������ɡ����,MMIO�����ڵ�����������ķ����ܹؼ�·����
- DMA
ֱ���ڴ����(DMA)��ָ��Χ�豸ʹ�����ߵ��������ع���,����һ������ֱ������һ������Ի�,������CPU�ĸ�Ԥ����ͼ�ο��������,DMA�����������;��:
1��GPU��ϵͳ�ڴ�֮��Ĵ���(���ڶ�ȡ������д�뻺����)��������AGP��PCI��ʵ������,�Լ�Ӳ�����ٵ��������䡣
2��ִ������FIFO������CPU��GPU֮���MMIO��ͬ����,����ͼ������������ʹ�ô�����I/O,�����Ҫ����ķ�ʽ�뿨ͨ�š�����FIFO��ͼ�ο���CPU֮�乲����һ���ڴ�(ϵͳ�ڴ�����������Ƶ�ڴ�),CPU�����з������GPU�Ժ�ִ��,Ȼ��GPUʹ��DMA�첽��ȡFIFO��ִ�������ģ�������첽ִ��CPU��GPU������,�Ӷ�������ܡ�
- Interrupt(�ж�)
�ж�ͨ����Ӳ����Χ�豸,������GPU��CPU�����¼��źŵ�һ�ַ�ʽ���жϵ�ʹ��ʾ����������ͼ��������ɵ��źš�������ֱ�����¼����źš�����GPU����ȵȡ�
����Χ�豸�����ж�ʱ,CPU��ִ��һ����Ϊ�жϴ��������С����(routine),�����̻���ռ������ǰִ�С��жϴ���������һ�����ִ��ʱ��,�������������뱣�ֽ϶̵�ʱ��(����������)��Ϊ��ִ�и���Ĵ���,�����Ľ�������Ǵ��жϴ����������һ��С����(tasklet)��
16.2.8 ͼ��Ӳ������
- ǰ����Ⱦ
ǰ����Ⱦ��(��������Ⱦ��)����Ⱦ��άͼԪ��ֱ�ӵķ���,����GPU����ύͼ��API�Ի��Ƽ�����,���ظ��������,�Ǵ�����ƶ�GPU��ʹ�õķ�����
��������ϵ�ṹ���,NVidiaӲ�����ж��������ԡ���һ���Ƕ�������ĵĿ�����,��ʹ�ö������FIFO(������ijЩ�߶�infiniband�����Ĺ���)���������л�������ʵ����ЩFIFO֮���ת����һ��С�̼�����������֮����������л�,����ͼ�ο�״̬���浽�ڴ��һ���ֲ��ָ���һ�������ġ�ʹ��ѭ���㷨�ĵ���ϵͳ���������ĵ�ѡ��,����ʱ��Ƭ�ǿɱ�̵ġ�
�ڶ���������ͼ�ζ���ĸ��NvidiaӲ����������GPU���ʼ���:��һ����ԭʼ����,�����������л�;�ڶ�����ͼ�ζ���,��ԭʼ������������ʵ�ָ�����(����2D��3D����)��
- �ӳ���Ⱦ
�ӳ���Ⱦ����GPU�IJ�ͬ��ơ�����������洢���ڴ���,����������ȾAPI�ύʱ��Ⱦÿ��3DͼԪ,����ע�֡����ʱ,���ᷢ������Ӳ����������Ⱦ�����������뾭����ϵ�ṹ���,�ӳ���Ⱦ�������ŵ�:
1��ͨ������Ļ���Ϊ�ֿ�(ͨ����16 x 16��32 x 32���ط�Χ��),����ʵ�ָ��õ���Ⱦλ�á�Ȼ��,GPU���Ե�����Щ�ֿ�,�������е�ÿ���ֿ�,�������ڲ�(����)zbuffer�н���ÿ������ȡ���Ⱦ�������ֿ��,���Խ���д����Ƶ�ڴ�,�Ӷ���ʡ����Ĵ��������Ƶ�,���ڿɼ������ڻ�ȡ��������֮ǰȷ����,��˽���ȡ���õ���������(�ٴν�ʡ����),���ҽ��Կɼ�ƬԪִ��ƬԪ��ɫ��(��ʡ�˼�������)��
2���������Ҫ��Ȼ�����ֵ,�����轫��д���ڴ档��Ȼ������ֱ��ʿ�����GPU�ڵ�ÿ���ֿ���ʵ��,������Զ����д����Ƶ�ڴ�,��˿��Խ�ʡ��Ƶ�ڴ�����Ϳռ䡣
��Ȼ,�ֿ���Ⱦ��Ҫ�ڿ�ʼ����֮ǰ�����������洢���ڴ���,���һ��������ӳ�,��Ϊ����������Ҫ�ڿ�ʼ����֮ǰ�ȴ�֡�����������������Ѿ�����Ӧ�ó����ύ��һ֡������ʱ,ͨ����GPU�ϻ��Ƹ���֡���Բ��������ӳ����⡣Ȼ��,��ijЩ�����(�ض��������ͬ��),���������ܹ���������
�ӳ���Ⱦ�����ڴ���ͨ���dz�ϡȱ��Ƕ��ʽƽ̨�ر�����,����Ӧ�ó���dz���,��˶�����ӳٺͷ����������ؽ�Ҫ��SGX���ӳ���ȾGPU��һ��ʾ������ʹ�÷ֿ�ṹ��SGX��ɫ������˻�Ϻ���Ȳ��ԡ��ӳ���Ⱦ������һ��ʾ����Maliϵ��GPU��
��֮,��������ж���ڴ���,���Dz�һ�¡�GPU��һ̨��ȫ�����ļ����,���Լ������ߡ���ַ�ռ�ͼ��㵥Ԫ��CPU��GPU֮���ͨ����ͨ������ʵ�ֵ�,���������ŷdz���Ҫ��Ӱ�졣GPU����ʹ������ģʽ���б��:MMIO������FIFO����ʾ�豸û�б������������
16.3 ����ϵͳͼ������
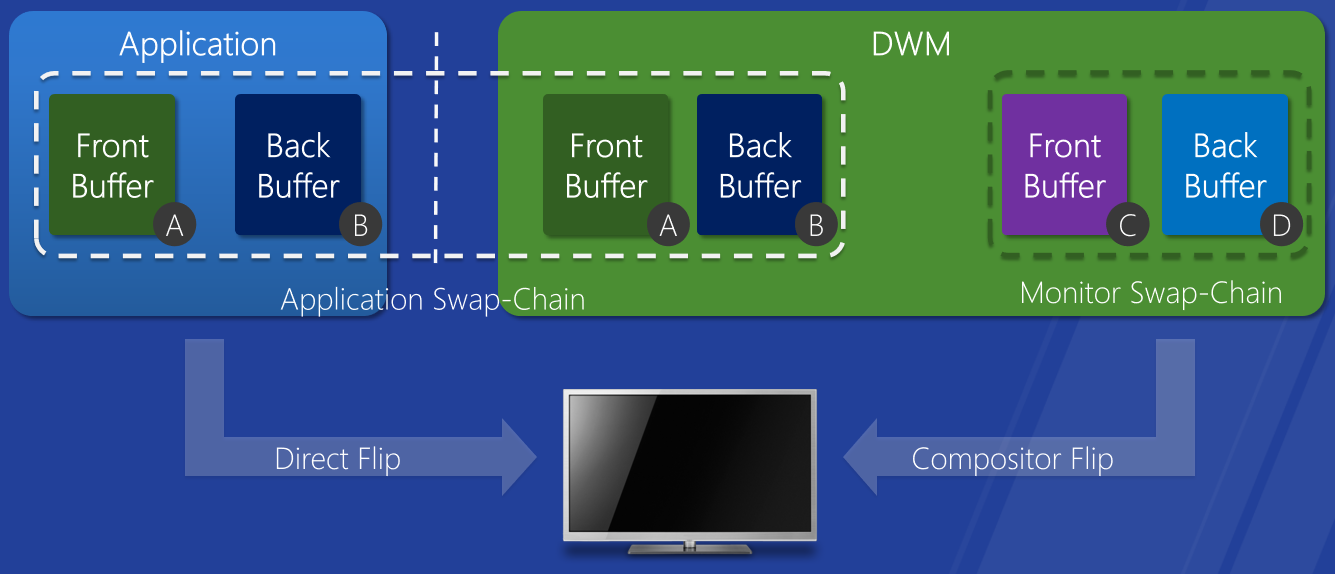
16.3.1 Windowsͼ������
16.3.1.1 WDDM����
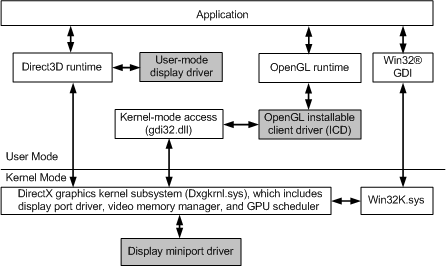
Windowsͼ������������IHV(Ӣ�ض���NVIDIA��AMD����ͨ��PowerVR��VIA��Matrox��)ʵ�ֲ�ά��,�Ƿdz��ḻ����������֧�ֻ�������(������Ⱦ��������ʾ),ʵ������ȵ���������,��֧�����⻯(VMware��Virtual Box��Parallels��������)��Զ�����淽��(XenDesktop��RDP��)��������ʾ(intelligraphics��extramon��)��
WDDM(Windows Display Driver Model)��Ϊ�û�ģʽ���ں�ģʽ,�ƶ����û�ģʽ��Ϊ���ȶ��ԺͿɿ��ԡ�
�û�ģʽ���ں�ģʽ���֮���ͨ�š�
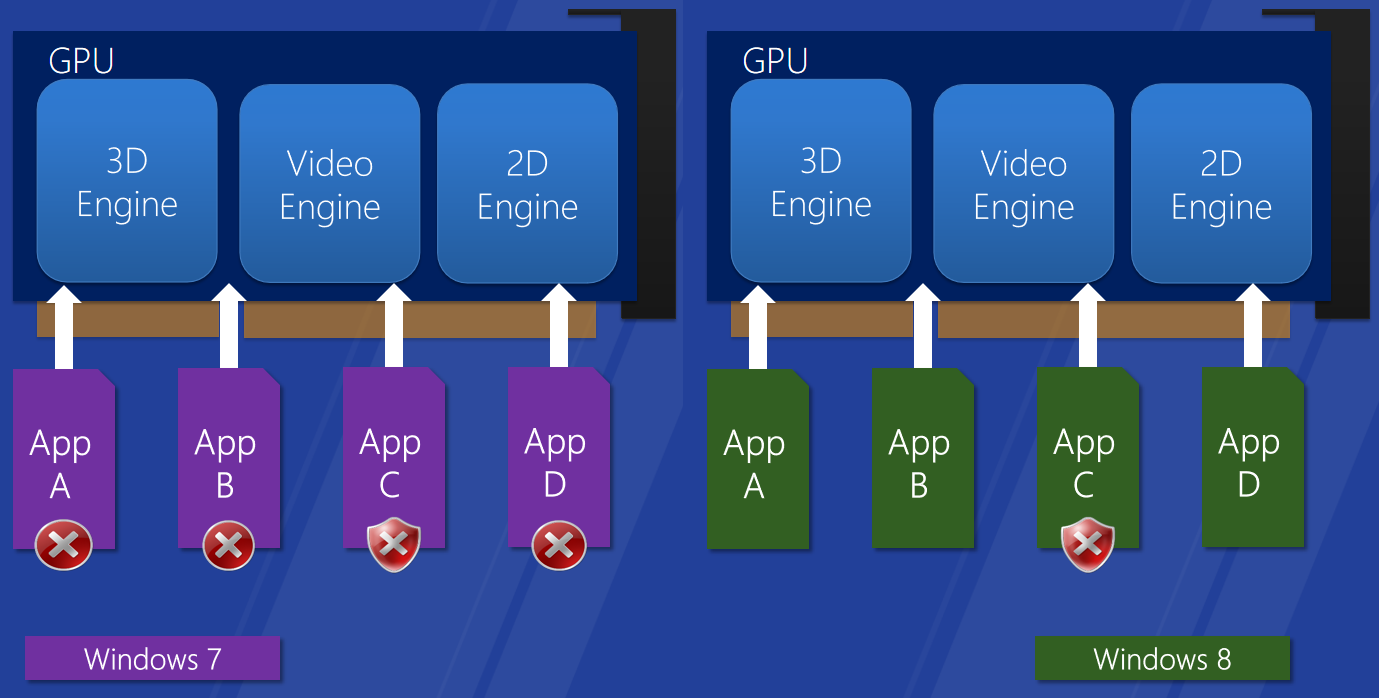
vista֮ǰ�Ĵ�����������ͼ����������(����MSDN):����Windows XP��,�����ӵ���ʾ�������������ϵͳ���ȶ�����Ҫԭ����Щ����������ȫ���ں�ģʽ��ִ��(������ϵͳ����),���,���������е�һ������ͨ������ʹ����ϵͳ����������������Windows XPʱ������ռ��Ĺ��Ϸ�������,��ʾ��������ռ����������20%����
�ڴ����������,�û�ģʽ������Ϊdll��һ��������,��Ȼ���Է��ʱ���(������/��������������ֲ�롢ijЩAPI���ܲ���(����)��¶��Զ�̷��ʱ���(����WebGL)����ͼ��ʾ��֧��WDDM�������ϵ�ṹ��
Windows������ģ���ݱ���ʷ����:
- Windows XP:XPDM��
- Windows Vista:WDDM 1.0��DWM��Aero��
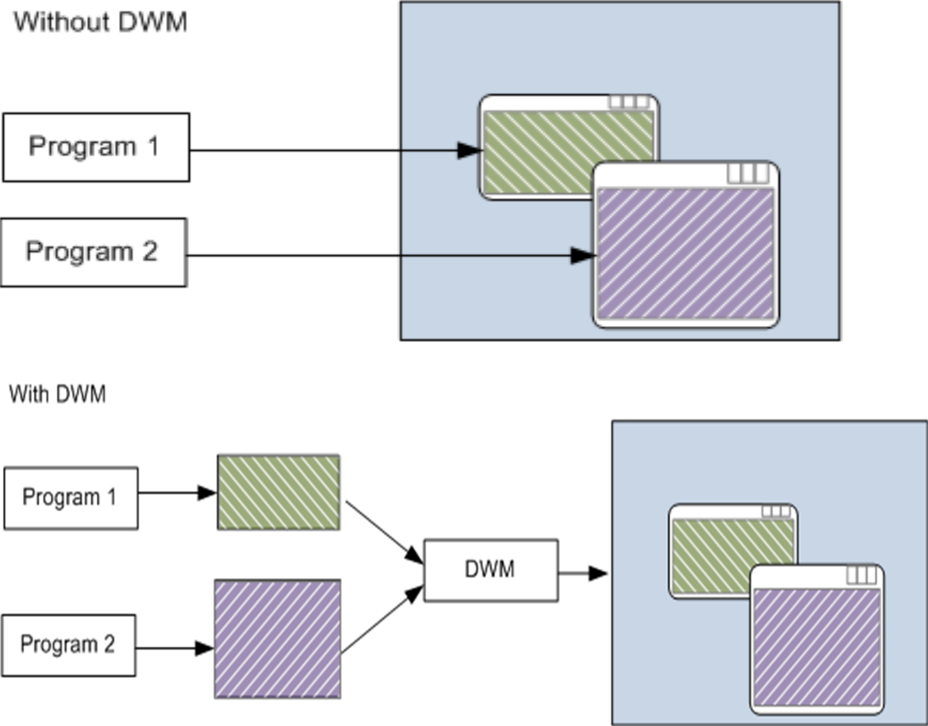
û��DWM����dWM�ĶԱȡ���ΪDWM��������ĺϳ�,���Ե�ÿ������������Լ�����ʾʱ,�¹��ܾͲ�������,�������е�Aero Peek,Aero Glass����������Ĵ��ں�鿴Ӧ�ó���,�ܹ����ɸı䷽��,�����µ�Windows������������DWM,��������������������Ч����
- Windows 7:WDDM 1.1,��չDWM��
- Windows 8:WDDM 1.2,ɾ��XPDM֧�֡�
- Windows 8.1:WDDM 1.3��
- Windows 10:WDDM 2.0��
16.3.1.2 WDDM�ܹ�
���ڵ�Windows�汾(��Vista),ͼ��/��Ϸ/��ý��/���ֶ�ջ�ܹ�����:
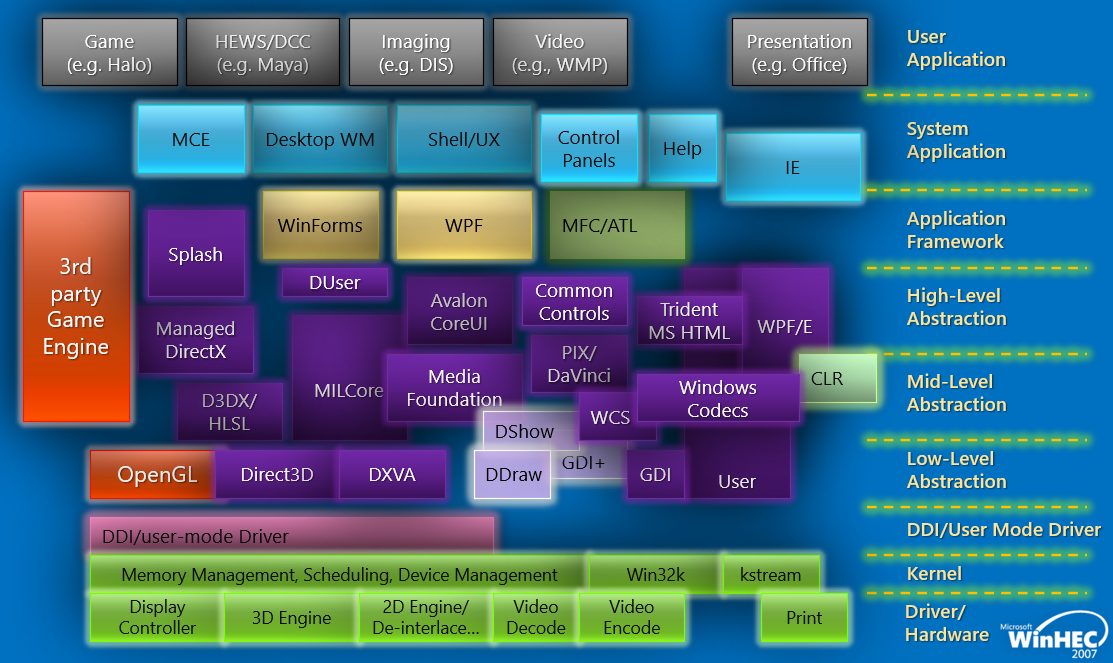
��ļܹ�ͼ����:
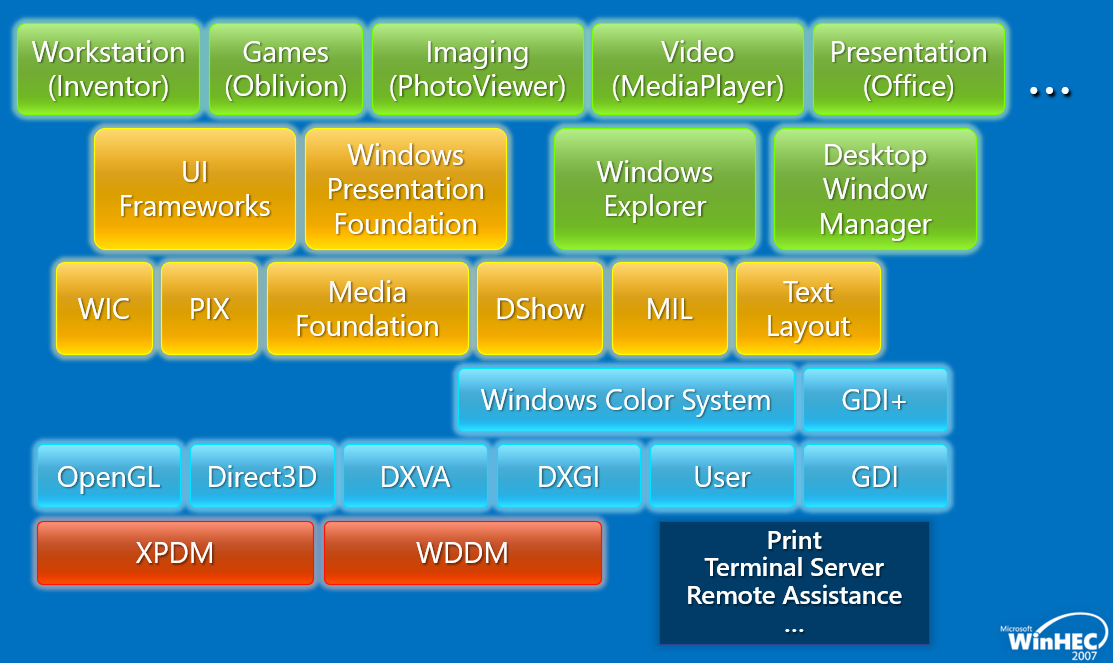
Windows Vista�е�ͼ�κ�������:
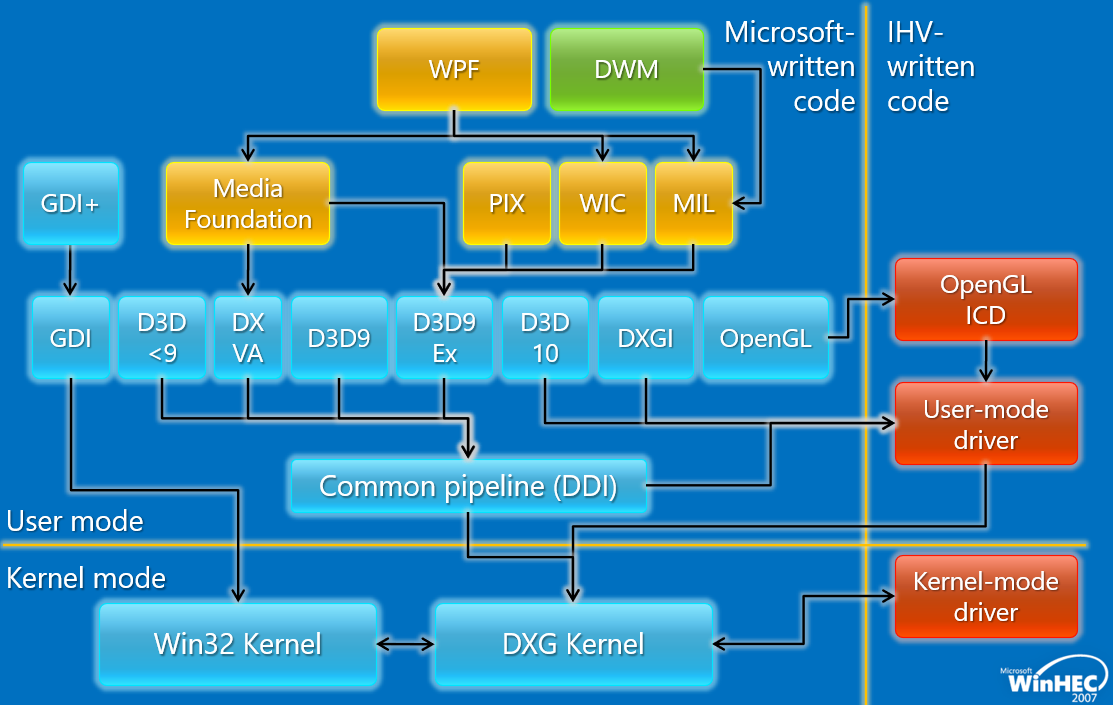
����Windows Display Driver Model(WDDM,Windows��ʾ����ģ��)��ص�ģ������:

WDDM�ǹ�������ͼ�εĻ�ʯ,����ԭ����ͼ�ι�������,���¼ܹ��������������ջ,����10��ķ�չ,�µ���������ģ��,�����ȶ��ԡ���ȫ��������(Ӧ�ó������⻯)�����ܡ�
����ͼ��API,���ڵ�WDDM���ڼ����汾,�ֱ�����:
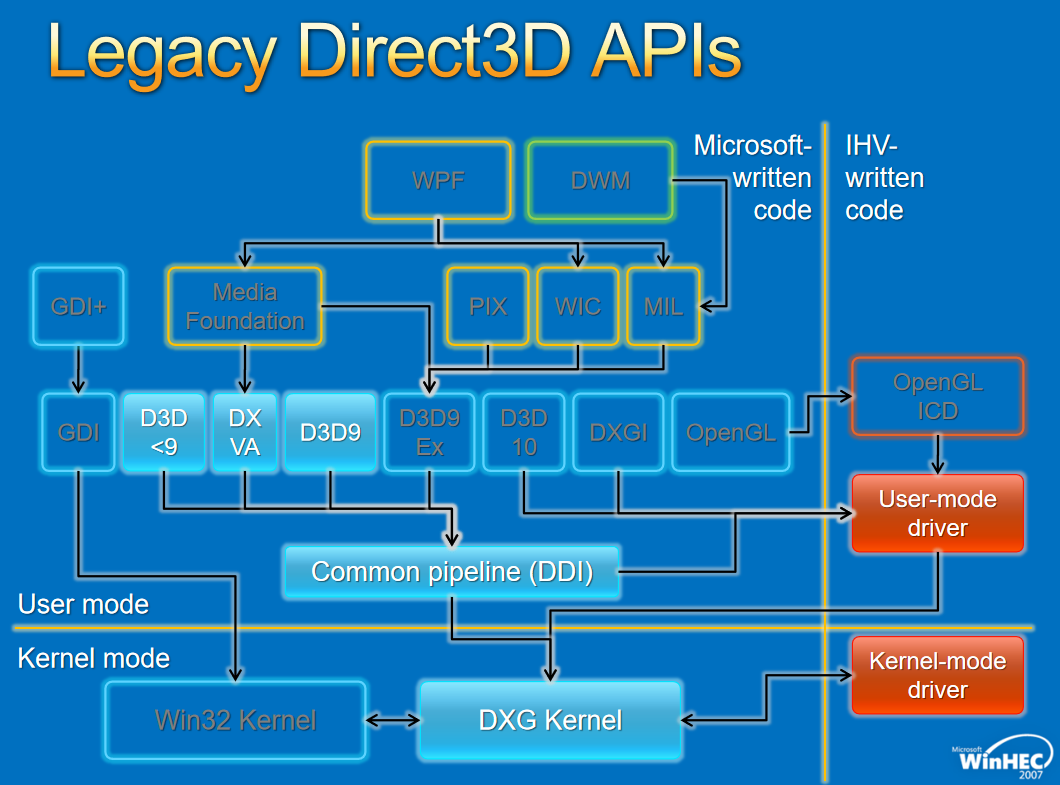
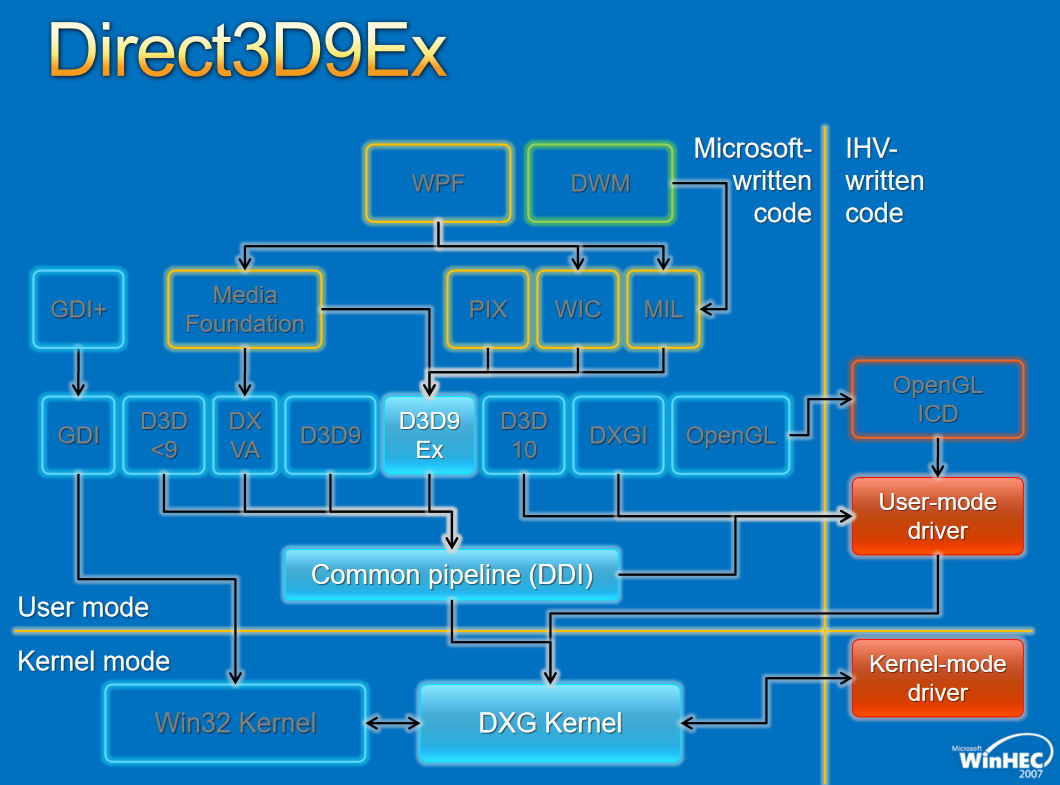
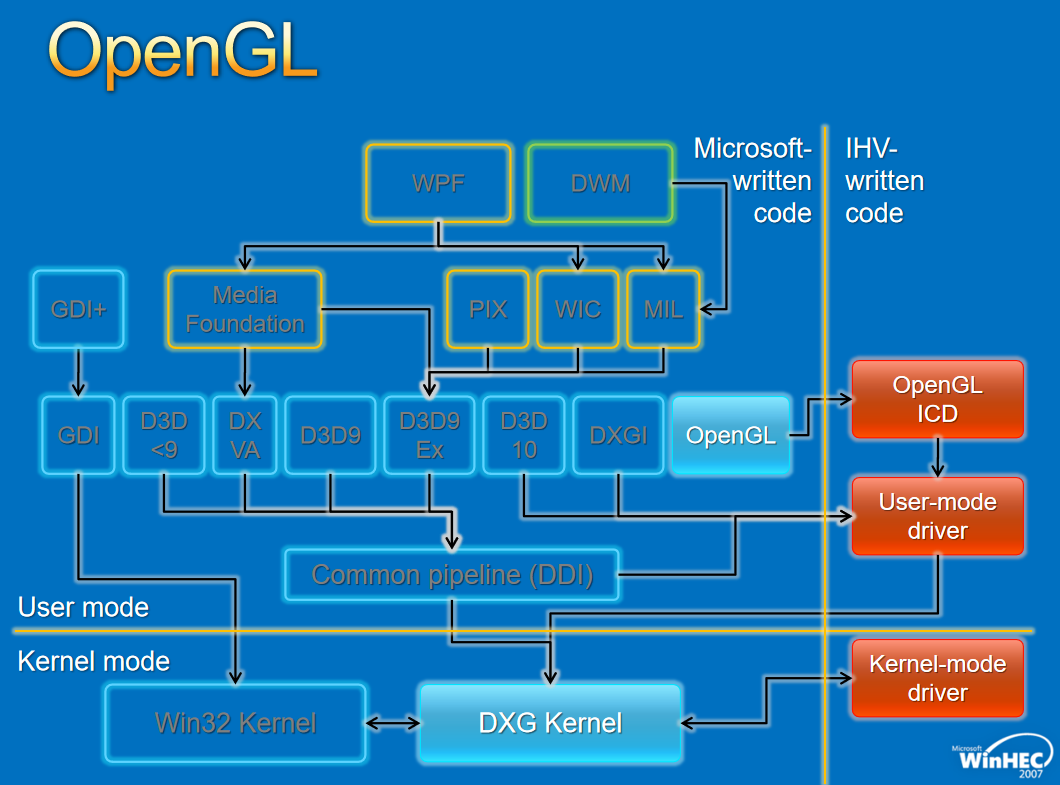
����Window���ڹ���,�ܹ�����:
Windowsͼ����������ģ������������Windows�û��ĵ�һͼ����������ģ��,ͼ������ģ����ǿ�û�����,����ʵ�����µ��Ӿ��ͼ��㳡��,���ܺͿɿ��ԵĸĽ�ʹWindows�ܹ���һϵ����״���ؽ�����չ��������ͼ�ֲ�չʾ��Windows 7��8�ĶԱ�:

WDDM 1.2���ܼ�:
- ��ǿ�û�����:����3D����,ƽ����Ļ��ת,�������ͻָ�,��ʾ������ID��֧�֡�
���������ָ�����������������
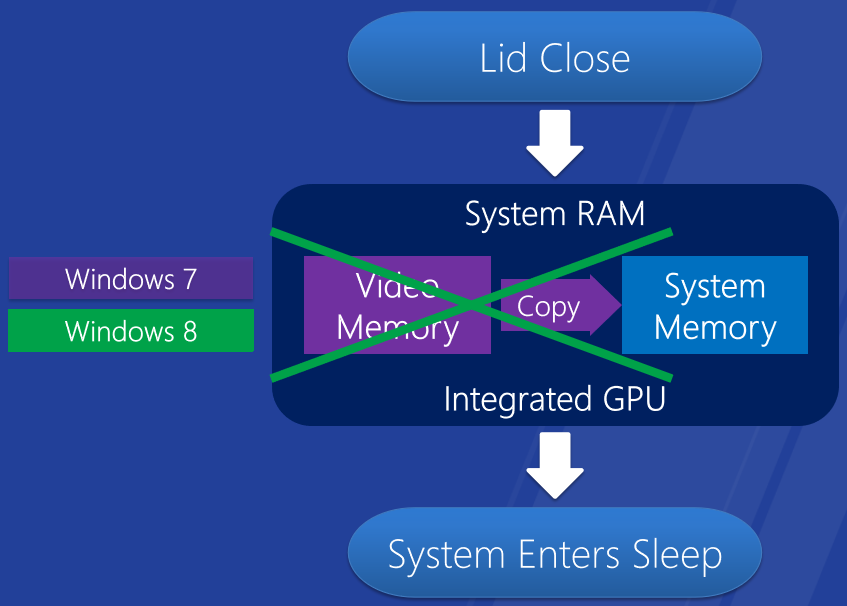
Windows 8�ϸ����˯�ߺͻָ�-����GPU��
- ���õ�����:GPU����Ȩ,˯�ߺͻָ��Ż�,��Ƶ�ڴ��ṩ�ͻ���API��DDI,ϸ�����豸��Դ����,SoC�Ż�,���ڷֿ����Ⱦ�Ż���
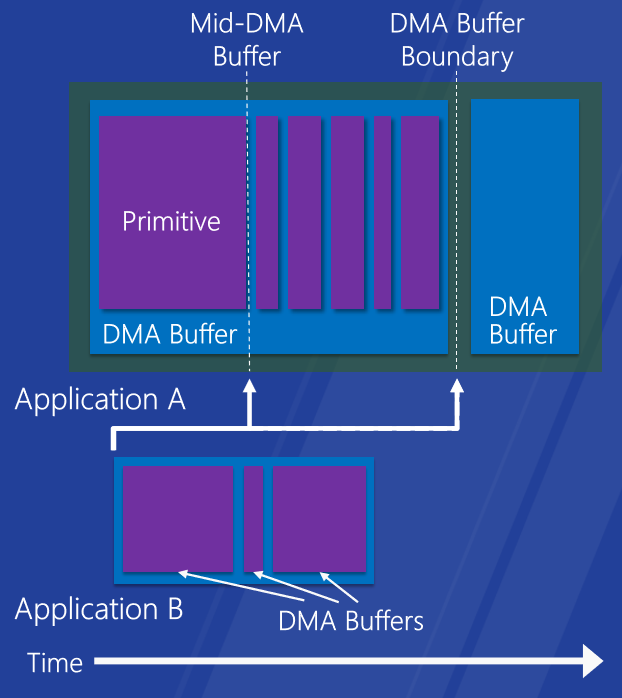
�Ľ�������ʹ�����Ӧ���������������ĵ������ʹ�������,֧��ϸ����GPU��ռ,��ռԽ��ϸ,��Ӧ�ٶ�Խ�졣
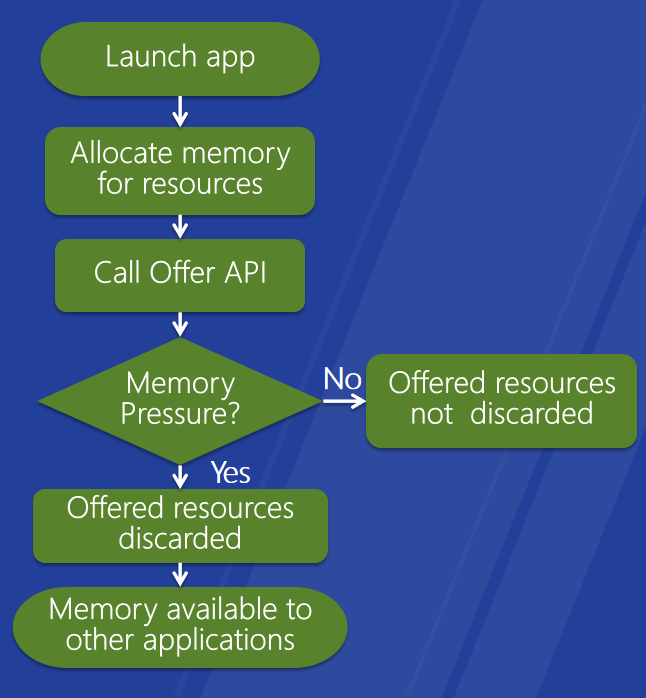
��Ƶ�ڴ��ṩ�ͻ���API���Ľ�����Ƶ�ڴ���䷽��,�ŵ�:���Ӧ�ó������Ƶ�ڴ������,��D3D API��WDDM DDI
:D3DӦ�ó���WDDM 1.2��������
�����Դ������
ֱ�ӷ�ת���Ż���������������Ч,����Ƶ֡�����ڼ��ʡ�ڴ濽����
����ƽ�̵���Ⱦ�Ż���TBR GPU�������ռ�,���TBR�Ż���ͼ�ζ�ջ,��ʡ����,��С���ڴ����ʹ����,�ֿ���١�
- ���ƿɿ���:�Ľ���GPU�ݴ�����,Ϊ������Ա��ϵͳ�������ṩ���õ����,����������������������������������
�Ľ���GPU�ݴ���������:windows 7�ij�ʱ���ͻָ��Ľ�,��ǰ�IJ���ϵͳ,ȫ��TDR,����ͼ��Ӧ�ó������ò�������������:Windows 8��GPU������,��ռ��ʱ,�ܹ�ִ�г�ʱ�����е�����,�������TDR��
��֮,Windows 8��WDDMʵ���Ӿ��Ϸḻ�����ٺ������������û�����,ͨ��������ʽ���ش���ȫ������,�Ż�����,ͬʱ��ʡ��Դ,�������ܹ��ߵ���ͼ����������
���,WDDM�������ܹ�����:
����������D3D����Ⱦ������ʾ��ͼ:
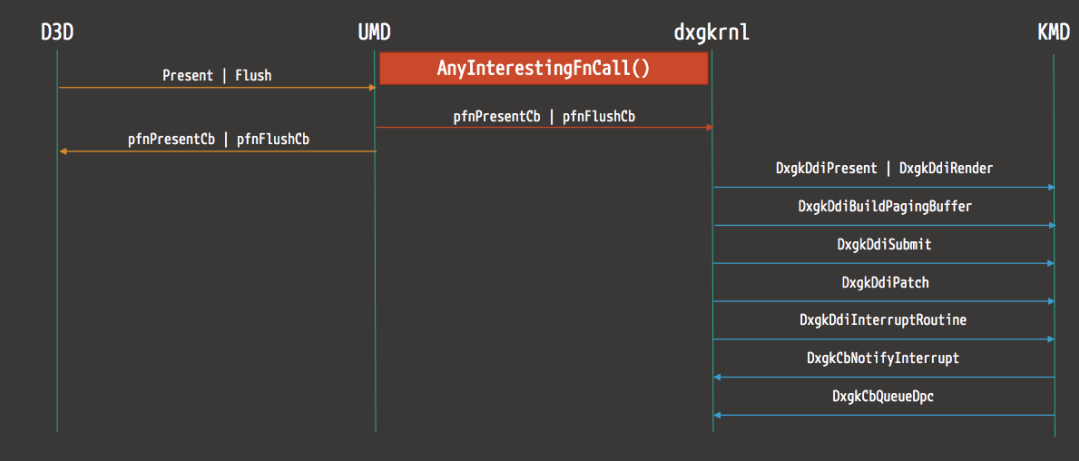
��ͼ��ʾ��WDDM����ʾ�Ͷ˿�����������߳�ͬ��������ʽ:
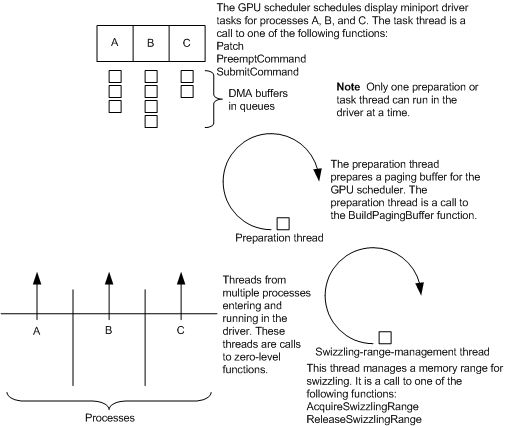
16.3.1.3 WDDM�ӿ�
kmd������WDDM���ں�ģʽ������һ��ģ��,��������������ʾ:
NTSTATUS DriverEntry(IN PDRIVER\_OBJECT DriverObject, IN PUNICODE\_STRING RegistryPath)
{
(...)
DRIVER_INITIALIZATION_DATA DriverInitializationData;
(...)
DriverInitializationData.DxgkDdiEscape = DDIEscape;
(...)
Status = DxgkInitialize(DriverObject, RegistryPath, &DriverInitializationData);
(...)
}
WDDM kmd����������ͬ��ʱ,Ϊ��Щ�ص��ṩ��һ���߳�ģ��,��ģ�ͻ��������ĸ��������(����ÿ���ص���������һ������):
3:ֻ��һ���߳̿��Խ���,GPU���봦�ڿ���״̬,û�����ڴ�����DMA������,��Ƶ�ڴ汻���������CPU�ڴ档
2:��3��ͬ,����Ƶ�ڴ��Ƴ����⡣
1:���ñ�����Ϊ��,ÿ����ֻ����һ���߳�ͬʱ���ûص���
0:��ȫ�����롣
�����������,�����������̲߳�������ͬһ����,��Ѱ��DZ�ڵľ�����������ʱ,��Ҫ������һ�㡣
����WDDM kmd����������ڵ�,�൱�ٵĻص���userland�������Ҫ������:�˳�����Ⱦ�����䡢QueryAdapter,���ҵ�����֮ǰ,������Ҫִ����ȷ�����������ʼ��,Ȼ��鿴�ص����漰�Ľṹ���ӿ�:
// Escape
NTSTATUS D3DKMTEscape(\_In\_ const D3DKMT\_ESCAPE *pData );
typedef struct \_D3DKMT\_ESCAPE
{
D3DKMT_HANDLE hAdapter;
D3DKMT_HANDLE hDevice;
D3DKMT_ESCAPETYPE Type;
D3DDDI_ESCAPEFLAGS Flags;
VOID *pPrivateDriverData;
UINT PrivateDriverDataSize;
D3DKMT_HANDLE hContext;
} D3DKMT_ESCAPE;
// Render
NTSTATUS APIENTRY DxgkDdiRender(\_In\_ const HANDLE hContext, \_Inout\_ DXGKARG\_RENDER *pRender){ ... }
typedef struct \_DXGKARG\_RENDER
{
const VOID CONST *pCommand;
const UINT CommandLength;
VOID *pDmaBuffer;
UINT DmaSize;
VOID *pDmaBufferPrivateData;
UINT DmaBufferPrivateDataSize;
DXGK_ALLOCATIONLIST *pAllocationList;
UINT AllocationListSize;
D3DDDI_PATCHLOCATIONLIST *pPatchLocationListIn;
UINT PatchLocationListInSize;
D3DDDI_PATCHLOCATIONLIST *pPatchLocationListOut;
UINT PatchLocationListOutSize;
UINT MultipassOffset;
UINT DmaBufferSegmentId;
PHYSICAL_ADDRESS DmaBufferPhysicalAddress;
} DXGKARG_RENDER;
// Allocation
NTSTATUS APIENTRY DxgkDdiCreateAllocation(const HANDLE hAdapter, DXGKARG\_CREATEALLOCATION *pCreateAllocation){ ... }
typedef struct
\_DXGKARG\_CREATEALLOCATION
{
const VOID *pPrivateDriverData;
UINT PrivateDriverDataSize;
UINT NumAllocations;
DXGK_ALLOCATIONINFO *pAllocationInfo;
HANDLE hResource;
DXGK_CREATEALLOCATIONFLAGS Flags;
} DXGKARG_CREATEALLOCATION;
// queryadapter
NTSTATUS APIENTRY DxgkDdiQueryAdapterInfo(HANDLE hAdapter, DXGKARG\_QUERYADAPTERINFO *pQueryAdapterInfo ){ ... }
typedef struct \_DXGKARG\_QUERYADAPTERINFO
{
DXGK_QUERYADAPTERINFOTYPE Type;
VOID *pInputData;
UINT InputDataSize;
VOID *pOutputData;
UINT OutputDataSize;
} DXGKARG_QUERYADAPTERINFO;
16.3.2 Linuxͼ������
Linuxͼ�ζ�ջ�ڹ�ȥ�����о����������ݱ䡣���ڵ�Ŀ������ϸ˵�������ʷ,�������������������ı�������ɡ�����,�����Ȼ����ֲ���������ʷ,���ڽ����������ʷ,�Ը��õ��ƶ�Linuxͼ�ζ�ջ�ĵ�ǰ��ơ��������Linuxͼ�������ܹ��漰�ĸ���ģ������:
-
PCI (Peripheral Component Interconnect):�û���Ҫ��ͼ�ο����������ϵ�PCI��ۡ�PCI�淶������������ṩ,�˼�������ߵı����ڵ���PCI���ÿռ�,��ͨ��x86��ϵ�ṹI/O�˿ڵ�ַ�ռ��е�0xCF8��0xCFC I/O�˿ڷ��ʵġ��������˵,0xCF8�ǵ�ַ�˿�,0xCFC�����ݶ˿ڡ�ÿ��PCIʵ��(�����ϵ���С��Ѱַ��Ԫ,���ڴ��е��ֽ�)���Լ������ÿռ䡣ʵ������ÿռ��н���3�����͵���Դ:
-
����/����ڴ档����ʵ�����������ڴ�顣ǩ��/proc/iomem�����ݡ�
-
����/����˿ڡ�����ʵ������I/O�˿ڿռ��е����ݡ�ǩ��/proc/ioports�ļ������ݡ�
-
IRQ(�ж�����)��ǩ��/proc/irqĿ¼�����ݡ�������Դ������ʹ��2��ϵͳ���:
-
PCI PNP(���弴��)�ѹ�ʱ��
-
ACPI(�����ú͵�Դ�ӿ�),Ŀǰʵ�ֵķ���,��һ����OS(����ϵͳ)�ں���ɵ�����
-
-
AGP (Accelerated Graphic Port)��PCI Express card:ϵͳ����������AGP��ۻ�PCI Express��۵�ͼ�ο�,����PCI�豸һ����
-
ACPI (Advanced Configuration and Power Interface):���ļ����ͨ������ACPI����,ACPIȡ��PCI PNP����ʵ������,��Ϊ���������ӵ�Դ�������ദ����sweet���������ݡ���PCI��ͬ,ACPI�淶������ṩ�ġ�ACPI�����ڴ��:�ڼ��������ʱ,����ϵͳ�����������ڴ����ҵ�RSDP(��ϵͳ����ָ��)����x86��ϵ�ṹ��,��Ҫ���ض��������ڴ������в��ҡ�RSD PTR���ַ�����
-
XORG��DDX (Device Dependent X)��DIX (Device Independent X):XORG��X Windowϵͳ�ͻ���libs�ͷ�������һ���֡�������Ŀ�IJο�ʵ��,��Ҫ�˽�X Window����Э�顣���ס,XORG�ж��������,��DMX(�ֲ�ʽ��ͷX)��������kdrive��������������XGL��������DIX��XORG��һ����,�������ͻ��ˡ��������Ⱥ�������Ⱦ��DDX��XORG����Ӳ��(�Լ���һ���̶��ϴ�������ϵͳ)��һ���֡�
-
EXA:EXA��XORG���ٵ�API,xfree86 DDX��Ψһʵ������DDX��ÿ�γ�ʼ����Ļʱ(����,���·��������ɿ�ʼʱ),�����ʼ��EXA����(�������)��
-
DRI (Direct Rendering Infrastructure) ��DRM (Direct Rendering Manager):DRI��DRM��ͼ�ο�Ӳ����̵Ĺܵ�,��Ҫ��mesa(����libre��openglʵ��)ʹ��,�����ڶ�Ӳ���ķ��ʱ���������ͼ�ο�Ӳ���ͻ���֮��ͬ��,xfree86 DDX��Ƶ����ģ����봦����,��Ϊ���������������Ŀͻ��ˡ�Ȼ��,EXA����Ҫִ�м��ٲ���ʱ,������Ӳ������DRI�Ի�����һ������xfree86 DDX�����DRI xfree86 DDXģ��,ϣ��ͨ��DRI��ʽ����Ӳ�����ʡ���ģ�����ص�xfree86 DDX���뽫ʹ��DRM�û����ӿڿ�libdrm��������,δ����DRM�ݽ����������ǰ���XORG��������PCI��̴��롣
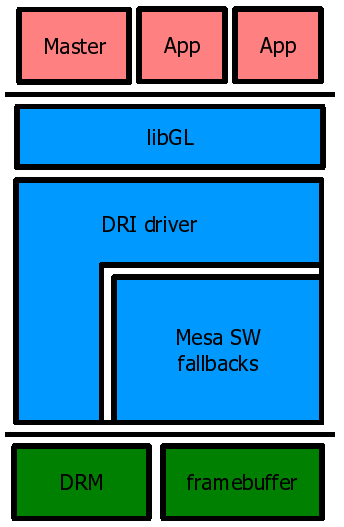
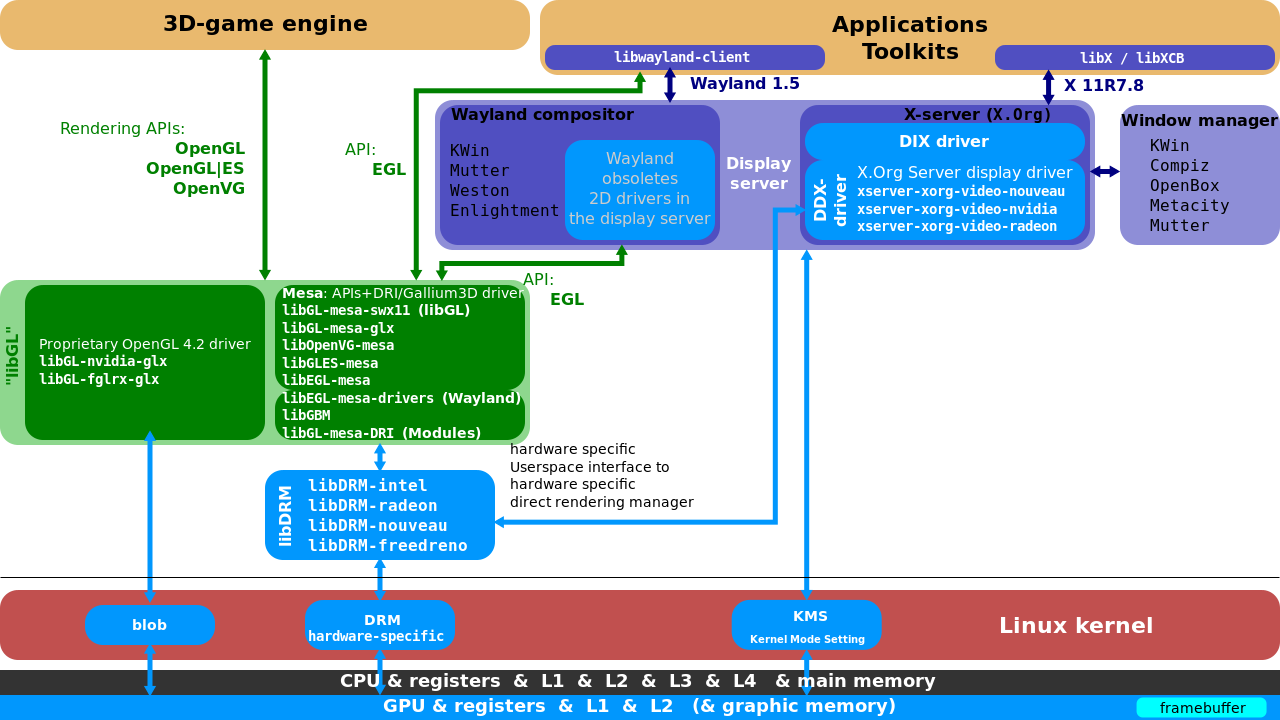
16.3.2.1 X11�����ܹ�
X11�ܹ�ͼ����,����DIX(�豸��X)��DDX(�豸���X)��Xlib�����֡�XЭ�顢X��չ,shm->���ڴ���Ĺ����ڴ�,XCB->�첽�ȡ�
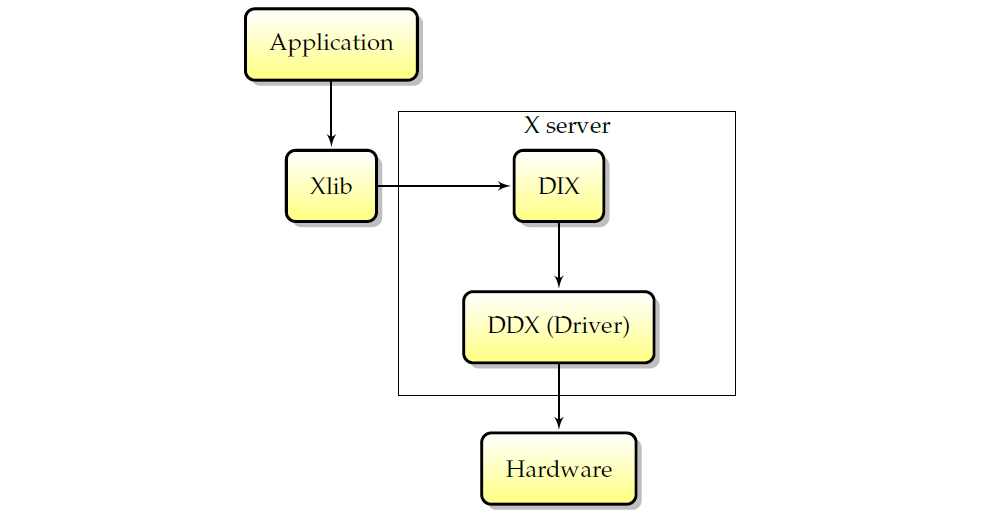
X������ڲ�����ͼ����:
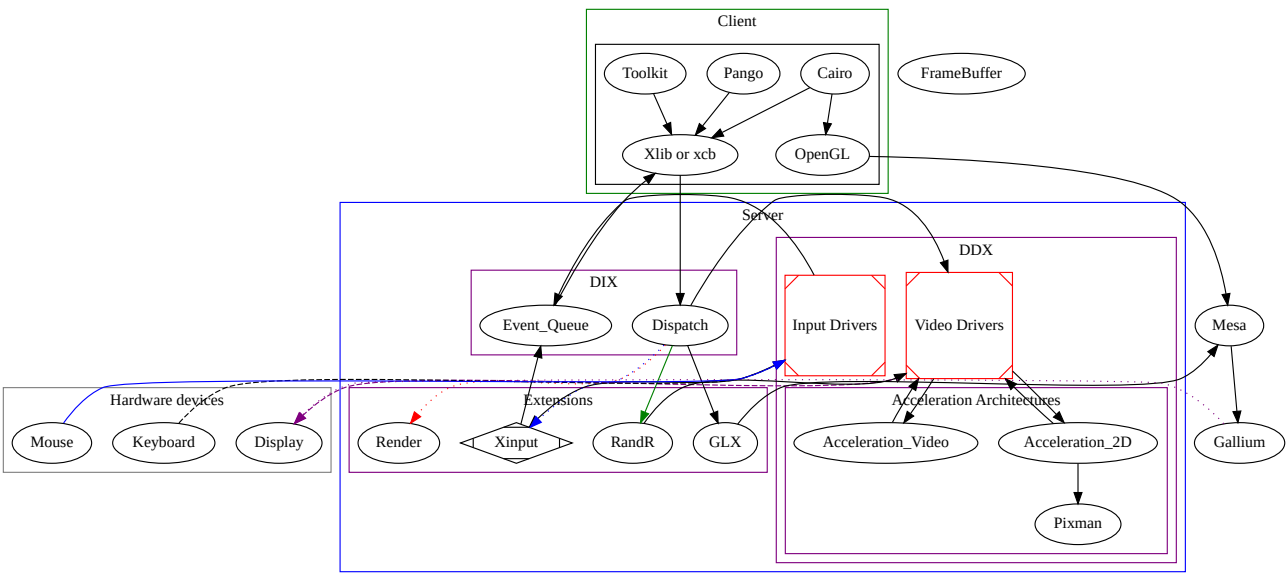
16.3.2.2 DRI/DRM�����ܹ�
ֱ����Ⱦ������(DRM)��Linux�ں˵�һ����ϵͳ,�������ִ���Ƶ����GPU�ӿڡ�DRM������һ��API,�û��ռ�������ʹ�ø�API��GPU�������������,��ִ������������ʾ����ģʽ���õȲ�����DRM�������ΪX Serverֱ����Ⱦ������ʩ�ĺ��Ŀռ����������,������ʱ��,���ѱ�����ͼ�ζ�ջ���Ʒ(��Wayland)ʹ�á�
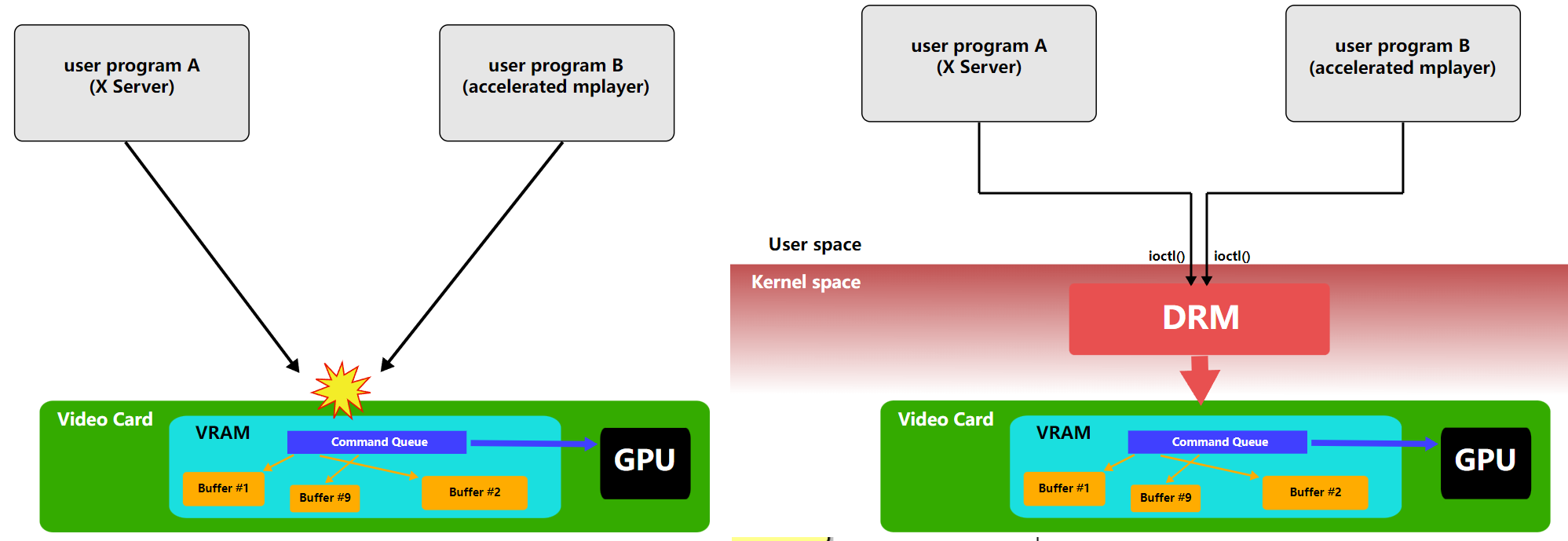
DRM�����������ͬʱ����3D��Ƶ��,�����ͻ��
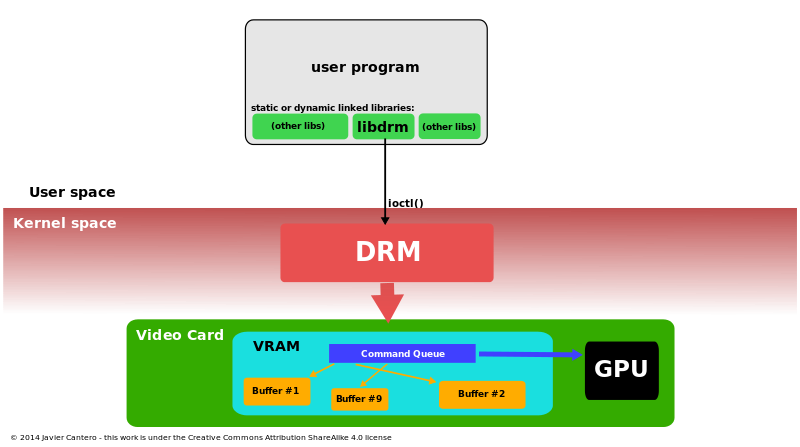
ʹ��Linux�ں˵�ֱ����Ⱦ����������3D����ͼ�ο��Ĺ��̡�
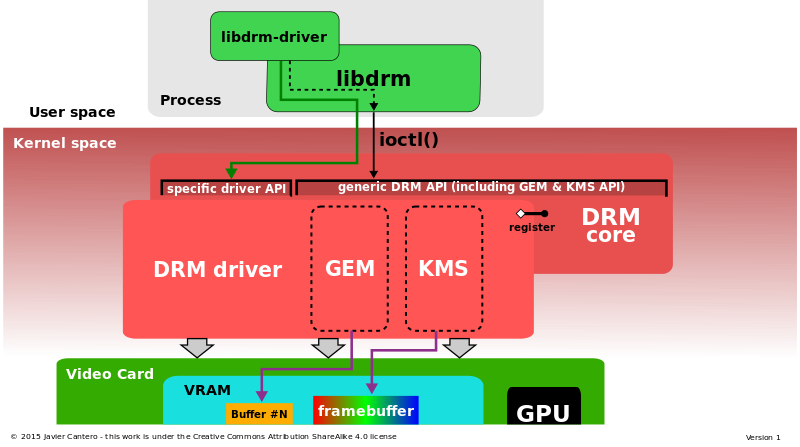
ֱ����Ⱦ��������ϵ�ṹ��ϸ��Ϣ:DRM���ĺ�DRM��������(����GEM��KMS),��libdrm�ӿڡ�
���(��Linux�״�֧��ͼ��Ӳ������ʱ),ֻ��һ�δ������ֱ�ӷ���ͼ�ο�:XFree86���������������:ͨ���Գ����û�Ȩ������,XFree86���������Դ��û��ռ���ʿ�,���Ҳ���Ҫ�ں�֧����ʵ��2D���١�������Ƶ��ŵ��Ǽ�,����XFree86���������Ժ����ش�һ������ϵͳ��ֲ����һ������ϵͳ,��Ϊ������Ҫ�ں������������,������㷺��X���������(����Ҳ�����Ե�����,����XSun,�����ں���ΪһЩ��������ʵ����modesetting)��
����,��һ��������Ӳ����3D�������Utah-GLX������Linux��,Utah-GLX�����ϰ���һ��ʵ��GLX�ĸ����û��ռ�3D��������,����������2D��������ķ�ʽ���û��ռ�ֱ�ӷ���ͼ��Ӳ������3DӲ����2D���Է����ʱ��(��Ϊ2D��3Dʹ�õĹ�����ȫ��ͬ,������Ϊ3D����һ����ȫ�����Ŀ�,��3Dfx),ӵ��һ����ȫ����������������������ġ�����,���û��ռ�ֱ�ӷ���Ӳ������Linux��ʵ��3D���ٵ�����������;����
���ͬʱ,֡��������������Խ��Խ�㷺,�������˿���ͬʱֱ�ӷ���ͼ��Ӳ������һ�������Ϊ�˱���֡��������XFree86��������֮���DZ�ڳ�ͻ,������VT��������,�ں˽���X�����������ź�,�����䱣��ͼ��Ӳ��״̬��Ҫ��ÿ������������VT�������ϱ�����������GPU״̬ʹ����������Ӵ���,����ͻȻ���ٲ�ͬ��������֮�����׳��ִ���Ľ����Ŀ�����Ա��˵,�����ø������ѡ����ס,XFree86�����������������ֿ���(xf86��Ƶvesa�ͱ���XFree86��������)�������ں�֡��������������(vesafb�ͱ���֡��������������),���ÿ��GPU���������ֹ��������������ϡ�
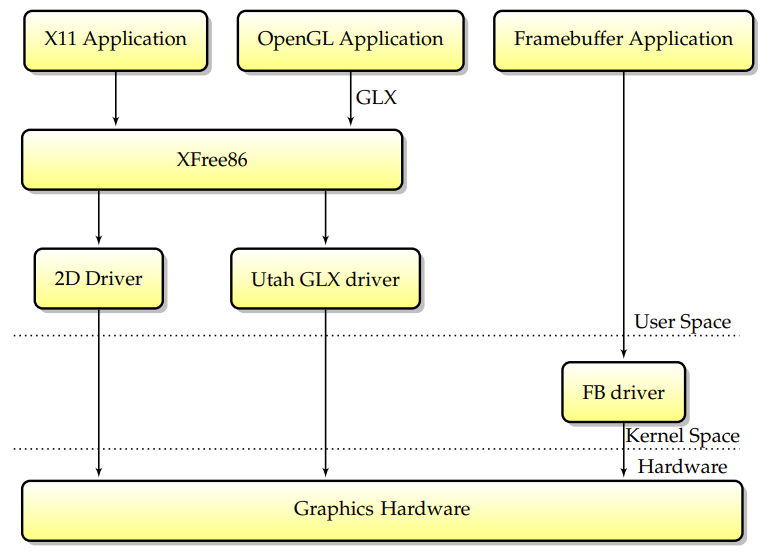
��Ȼ,����ģʽ��ȱ�㡣����,��Ҫ������δ����Ȩ���û��ռ�Ӧ�ó������3Dͼ��Ӳ�������,����ͼ��ʾ,����GL���ٶ�����ͨ��XЭ���ӽ���,�������������ٶ�,�����Ƕ��������ϴ��������ܼ����ܡ���������Խ��Խ����Linux�İ�ȫ�Ժ�����ȱ��,��Ҫ��һ��ģ�͡�
Ϊ�˽��Utah-GLXģ�͵Ŀɿ��ԺͰ�ȫ������,��DRIģ�ͷ���һ��;XFree86��������汾X.Org��ʹ����������ģ��������һ��������ں����,��ְ���ǴӰ�ȫ�Ƕȼ��3D����������ȷ�ԡ����ڵ���Ҫ�仯��,û��Ȩ��OpenGLӦ�ó������ں��ύ�������,�ں˽�������ǵİ�ȫ��,Ȼ�����Ǵ��ݸ�Ӳ��ִ��,������ֱ�ӷ��ʿ�������ģ�͵��ŵ��Dz�����Ҫ�����û��ռ�,��XFree86��2D��������Ȼû��ͨ��DRM,���X��������Ȼ��Ҫ�����û�Ȩ����ֱ��ӳ��GPU�Ĵ�����
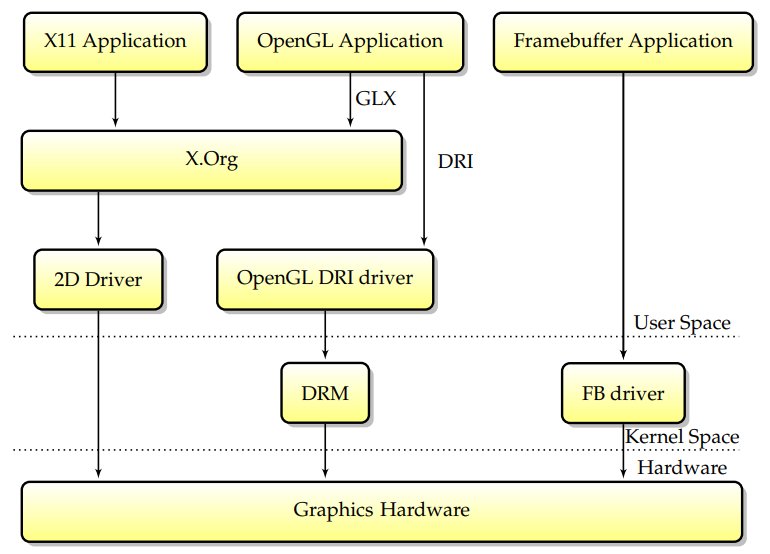
��ǰ��ջ�Ǵ�һ���µ������ݱ�����ġ�����,Ҫ��X���������г����û�Ȩ�����ǻ�������صİ�ȫ���������,����ǰ�������,��ͬ����������Ӵ�����Ӳ��,ͨ���ᵼ�����⡣Ϊ�˽���������,�ؼ�����������:��һ,���ں�֡���������ܺϲ���DRMģ����,�ڶ�,��X.Orgͨ��DRMģ�����ͼ�ο�����Ȩ�����С�����ģ�ͱ���Ϊ�ں�ģʽ����(KMS),�����ģ����,DRMģ�����ڸ�����Ϊ֡���������������X.Org�ṩģʽ���÷���
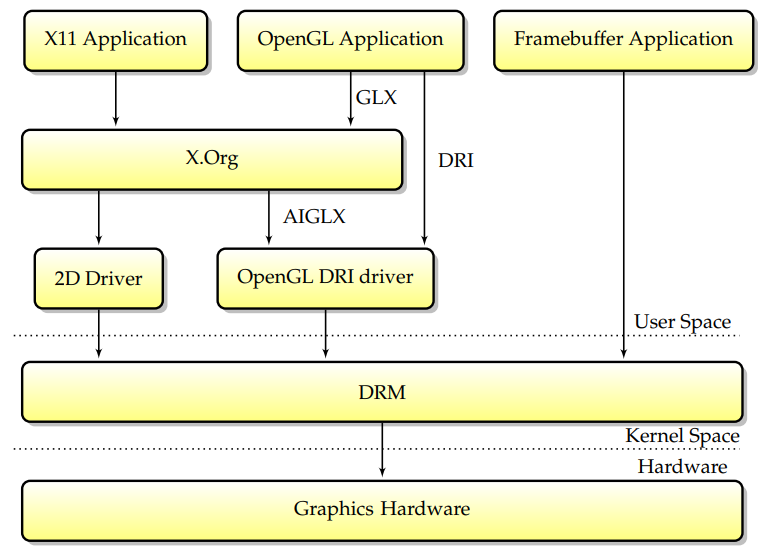
��֮,Ӧ�ó���ͨ����װ��ͼ���õ��ض�����X.Orgͨ��,��ǰ��DRI�������ʱ���������������Ҫ�����в��Ϸ�չ,���ִ���ջ��,����ͼ��Ӳ��������ں�ģ��DRM���ơ�Linux�ܵ�ģ�齻��ͼ����:
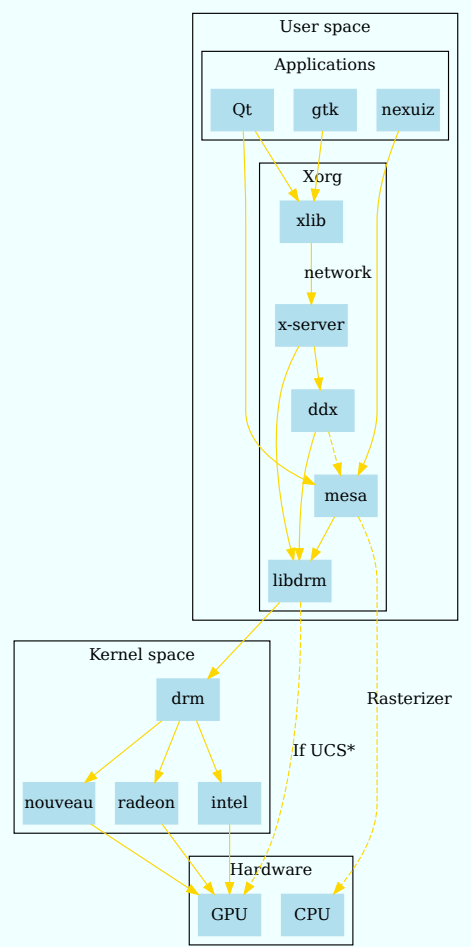
����ϸ�Ľ����ͷֲ�ܹ�����:
16.3.2.3 Framebuffer����
�ں���,֡��������������ʵ�����¹���:
- ģʽ���á�ģʽ���ð���������Ƶģʽ������Ļ�ϻ�ȡͼƬ,����ѡ����Ƶ�ֱ��ʺ�ˢ���ʡ�
- ��ѡ2d���١�֡������������������ṩ���ڼ���linux����̨�Ļ���2D����,������Ƶ�ڴ��еĿ�����ʵ����䡣������ʱͨ���ҹ��ṩ���û��ռ�(Ȼ���û��ռ������ض��ڿ���MMIO�Ĵ������б��,��ҪrootȨ��)��
ͨ��ֻʵ����������,֡����������������Ȼ���������ʵ�linuxͼ������������ʽ��֡�������������������������ض��Ŀ��ͺ�(��nvidia��ATI)������vesa��EFI��Openfirmware֮�ϵ���������,��Щ����������ֱ�ӷ���ͼ��Ӳ��,���ǵ��ù̼�������ʵ��ģʽ���ú�2D���١�
֡����������������linuxͼ����������������ʽ��ֻ����ٵ�ʵ�ֹ���,֡���������������ṩ�˽ϵ͵��ڴ�ռ��,��˶�Ƕ��ʽ�豸�����á�ʵ�ּ����ǿ�ѡ��,��Ϊ�����������˹��ܡ�
16.3.2.4 ֱ����Ⱦ������
�ڸ��ӵ�������,ʹ���ں�ģ����һ��Ҫ���ں�ģ���Ϊֱ����Ⱦ������(DRM),�����ڶ�����;:
- ��ͼ�ο��Ĺؼ���ʼ�������ں���,�������ع̼�������DMA����
- �ڶ���û��ռ����֮�乲����ȾӲ��,���������ʡ�
- ͨ����ֹӦ�ó���������ڴ�����ִ��DMA,�Լ���һ��ط�ֹ���κο��ܵ��°�ȫ©���ķ�ʽ�Կ����б������ǿ��ȫ�ԡ�
- ͨ�����û��ռ��ṩ��Ƶ�ڴ���书�������������ڴ档
- DRM�õ��˸Ľ�,��ʵ��ģʽ����,������ǰDRM��֡������������������ͬһGPU��������෴,��ɾ��֡��������������,����DRM��ʵ��֡������֧�֡�
**�ں�ģ��(DRM)**��ȫ��DRI/DRM�û��ռ�/�ں˷���(��ͼ����libdrm-DRM-��ڵ�-����û��ռ�Ӧ�ó���):
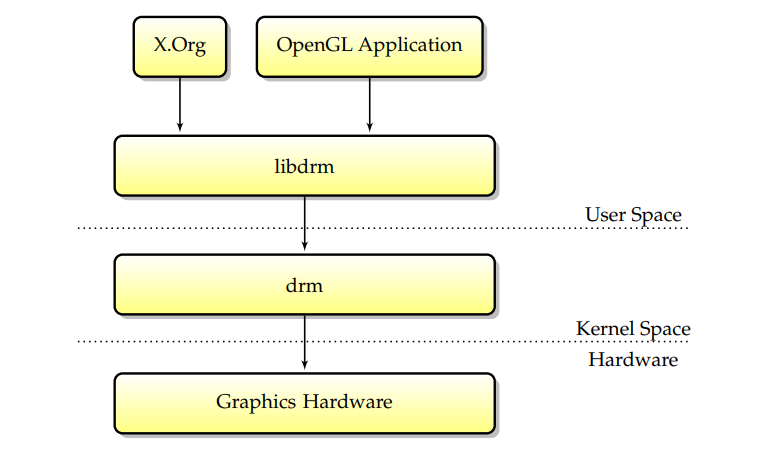
�����һ��Linuxͼ������������ʵ�ֲ������Ǽ�֡������֧��ʱ,����Ҫ������һ��DRM���,Ӧ��������һ�ּȸ�Ч���ܼ�ǿ��ȫ�Ե���ơ�DRI/DRM���������Բ�ͬ�ķ�ʽʵ��,���ҽӿ�ȷʵ��ȫ���ض��ڿ��ġ�
DRM�����������ύģ��:DRM��Ƶĺ�����DRM_GEM_EXECBUFFER ioctl,�����û��ռ�Ӧ�ó������ں��ύһ��������������,Ȼ���ں˽������GPU�ϡ���ioctl������������,�繲��Ӳ���������ڴ��ǿ��ִ���ڴ汣����
DRM��ְ��֮һ���ڶ���û��ռ����֮�临��GPU���������GPU����ͼ��״̬,��ô�����Ӧ�ó���ʹ��ͬһGPUʱ,�ͻ����һ������:���ʲô������,Ӧ�ó���ͻ��ƻ��˴˵�״̬�����ݵ�ǰ��Ӳ��,��Ҫ���������:
1����GPU����Ӳ��״̬���ٹ���ʱ,Ӳ�����������,��Ϊÿ��Ӧ�ó����Է��͵�������������,GPU�����ÿ��Ӧ�ó�������״̬�����ַ��������������Ĺ�����ʽ��
2����GPUû�ж��Ӳ��������ʱ,����Ӳ���ij�����������ÿ��������������������ʱ�����ύ״̬,��intel��radeon���������·����GPU�ķ�ʽ����ע��,�����ύ״̬��ְ����ȫ�������û��ռ䡣����û��ռ�û����ÿ����������������ʼʱ�����ύ״̬,��ô��������DRM���̵�״̬��й©�������ϡ�DRM����ֹͬʱ����ͬһӲ����
�ں��ܹ��ƶ��ڴ������������ڴ�ѹ��������������Ӳ���IJ�ͬ,������ʵ�ַ���:
1�����Ӳ�������������ڴ汣�������⻯,������ڷ����ڴ���Դʱ�����ҳ��GPU��,������ÿ�����̡����,֧��GPU�ڴ���ڴ汣������Ҫ̫�ࡣ
2����Ӳ��û���ڴ汣��ʱ,��Ȼ������ȫ���ں���ʵ��,�û��ռ���ȫ������Ӱ�졣Ϊ���������¶�λ���û��ռ����������,���û��ռ�������������沢��֪������,�����ύioctl��ͨ��������Ӳ��ƫ�����滻����ǰλ������д�ں��е���������������ں�֪�������ڴ滺�����ĵ�ǰλ��,ʹ��ǰ��������Ϊ���ܡ�Ϊ�˷�ֹ��������GPU�ڴ�,�����ύioctl�����Լ����Щƫ�����е�ÿһ���Ƿ�Ϊ���ý�������,�������,��ܾ�������������������,��Ӳ�����ṩ�ù���ʱ,�Ϳ���ʵ���ڴ汣����
DRM�����ִ�linuxͼ�ζ�ջ�е�����ͼ�λ,�Ƕ�ջ��Ψһ�����εIJ���,����ȫ,���,��Ӧ����������������ṩ������ͼ�ι���:ģʽ���á�֡���������������ڴ������
16.3.2.5 Mesa
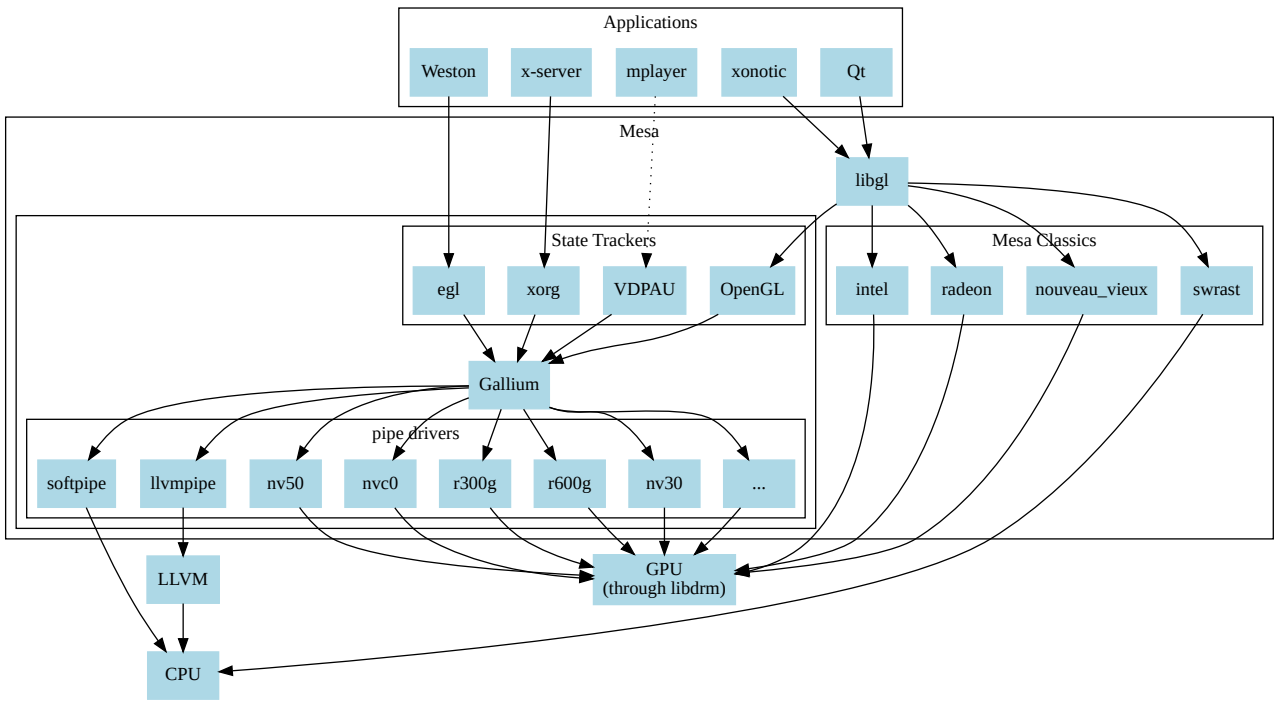
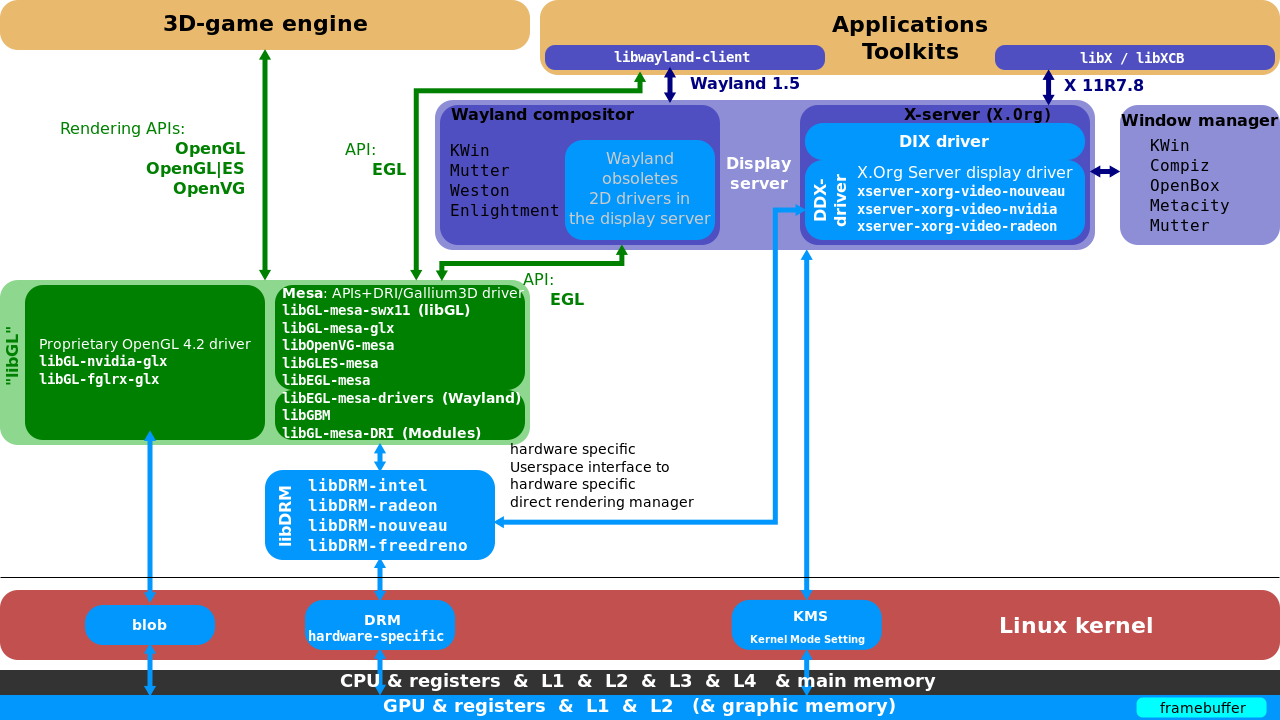
MesaҲ��ΪMesa3D��Mesa3Dͼ�ο�,��OpenGL��Vulkan������ͼ��API�淶�Ŀ�Դ����ʵ�֡�Mesa����Щ�淶ת��Ϊ�ض��ڹ�Ӧ�̵�ͼ��Ӳ����������������Ҫ���û�������ͼ����������,������Ҫ��Intel��AMDΪ���Ե�Ӳ������������(AMD�ڲ��Ƽ���AMD Catalyst���ƹ���Mesa��������Radeon��RadeonSI,Intelֻ֧��Mesa��������)��ר��ͼ����������(��Nvidia GeForce���������Catalyst)ȡ��������Mesa,�ṩ���Լ���ͼ��APIʵ��,������ΪNouveau��Mesa Nvidia��������Ŀ�Դ������Ҫ������������
������Ϸ��3DӦ�ó�����,�ִ���ʾ����(X.org��Glamer��Wayland��Weston)Ҳʹ��OpenGL/EGL;���,����ͼ��ͨ����Ҫʹ��Mesa��Mesa��freedesktop�й�,����Ŀ��1993��8���ɲ�������������Mesa��㷺����,���ڰ�����������ظ��ָ��˺�˾���ڶ��,��������OpenGL�淶��Khronos����ͼ��Ӳ�������̵Ĺ��ס�
Mesa��������Ҫ��;:
1��Mesa��OpenGL������ʵ��,����Ϊ�Dzο�ʵ��,�ڼ��һ����ʱ������,��Ϊ�ٷ���OpenGLһ���Բ��Բ���������
2��MesaΪlinux�µĿ�Դͼ�����������ṩ��OpenGL��ڵ㡣
Mesa��Linux�µIJο�OpenGLʵ��,���п�Դͼ����������ʹ��Mesa for 3D��
��Ƶ��Ϸͨ��OpenGL����Ⱦ����ʵʱ�����GPU,��ɫ��ʹ��OpenGL��ɫ���Ի�SPIR-V��д,����CPU�ϱ���,�����ij�����GPU��ִ�С�(��ͼ)
Linuxͼ�ζ�ջ����ͼ:DRM&libDRM,Mesa 3D,������ʾ�������ڴ���ϵͳ,ֻ������Ϸ���ϲ�Ӧ�á�
Wayland�����ʵ��������EGL��Mesaʵ��,��Ϊlibwayland EGL���������Ϊ֧�ֶ�֡�������ķ��ʶ���д��,EGL 1.5�汾�ѹ�ʱ����GDC 2014��,AMD����̽��ʹ��DRM���������ں���blob��ս�Ա仯��
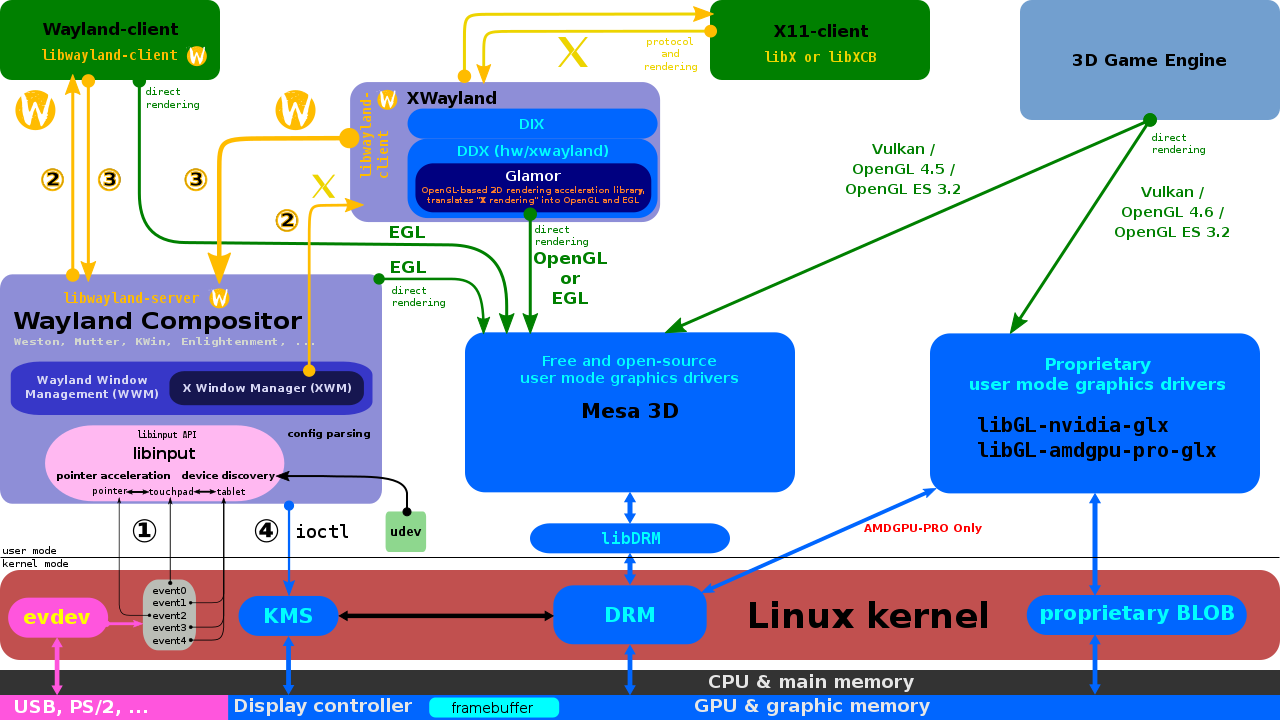
16.3.2.6 Wayland
Waylandּ�ڸ������X,�����ڿ�����ά����Wayland��һ�����ںϳ�������ͻ����Ի���Э��,Ҳ�Ǹ�Э���C��ʵ�֡��ϳ�����������Linux�ں�ģʽ���ú�evdev�����豸�����еĶ�����ʾ��������XӦ�ó����wayland�ͻ��˱������ͻ��˿����Ǵ�ͳӦ�ó���X������(����ȫ��)��������ʾ��������Wayland��Ŀ��һ����Ҳ��Wayland�ϳ�����Weston�ο�ʵ��,Weston������ΪX�ͻ��˻�Linux KMS����,Weston�ϳ�����һ����С�ҿ��ٵĺϳ���,����������Ƕ��ʽ���ƶ�������
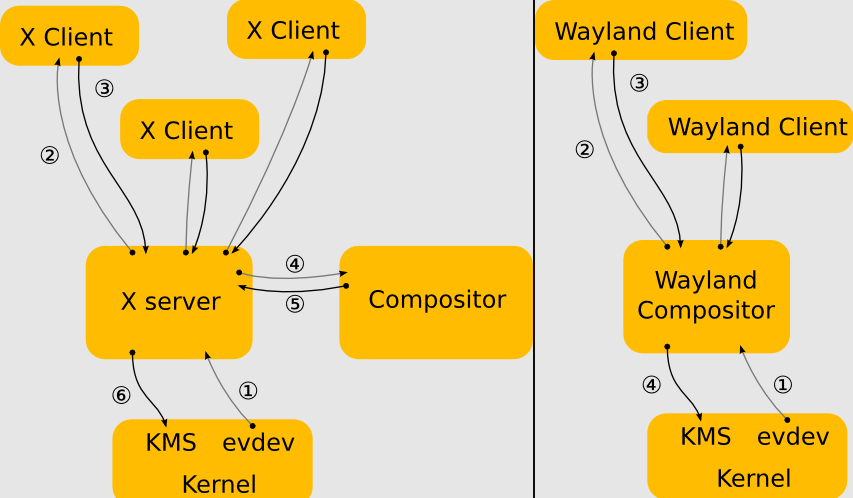
ʹ��X(��)��Wayland(��)�������ܹ��Աȡ�
16.3.3 ���Ȼ���
16.3.3.1 OS And GPU abstraction
����10��ǰ,�����ϴ�ѧ�Ŀ�����Ա��Operating Systems must support GPU abstractions��ָ��,ȱ����GPU����IJ���ϵͳ֧�ִӸ�����������GPU������Ӧ������Ŀ����ԡ�����ϵͳΪ�������Դ(��CPU�������豸���ļ�ϵͳ)�ṩ�������֮��,����ϵͳĿǰ��GPU�����ڱ���ioctl �ӿں���,������ĸ���ת�Ƶ��û��������ʱ�ϡ����,����ϵͳ��ΪGPU�ṩϵͳ��Χ�ı�֤,���繫ƽ�Ժ�����,������Ա�ڹ�������GPU����������ϵͳ������Դ��ϵͳʱ,��������ģ�黯�����ܡ�����������µ��ں˳���,��֧��GPU�������������豸��Ϊһ���ļ�����Դ��
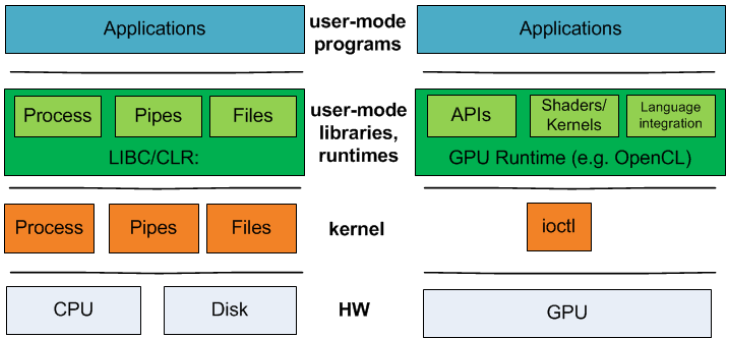
CPU��GPU����ļ�����ջ������GPU����,CPU����IJ���ϵͳ������û�ģʽ����ʱ����֮��û��1��1�Ķ�Ӧ��ϵ��
�����ڶ�GPU�����ֱ�Ӳ���ϵͳ֧��,�������GPU��ɴ˹������ر�Ȼ��Ҫһ���û���GPU��̿�ܺ�����ʱ,��CUDA��OpenCL������Щ�����ʵ��xform��detect������߸������е�������ٶ�,�����ϵͳ(catusb | xform | detect | hidinput)������û��ں˱߽�Ϳ�PCI-e���ߵ�Ӳ���Ĺ��������ƶ�������
�ִ�����ϵͳĿǰ����֤GPU�Ĺ�ƽ�Ժ����ܸ���,��Ҫ����ΪGPU������Ϊ����������Դ(��CPU)������,������ΪI/O�豸������,��ӿڽ�����һС������֪����(��init_module��read��write��ioctl)��������ϵͳ��Ҫʹ��GPU��ʵ���书��ʱ,������ƾͳ�Ϊ��һ�����ص����ơ�ʵ����,NVIDIA GPU Directʵ��������һ������,����Ҫ�����漰���κ�I/O�豸�������������ṩר�ŵ�֧�֡��Լ�����(����,Windows 7��Aero�û�����һ��)���ڵ�ǰ���ƶ���,ʱ��ָ�ͳ�ʱ����ȷ����Ļˢ���ʱ��ֲ���,����ִ�й�ƽ�Ժ�ϵͳ����ƽ��ʱ,����ϵͳ�ںܴ�̶���ȡ����GPU��������
�µ���ϵ�ṹ���ܻ�ı��GPU��CPU�ڴ���������ݵ�����Ѷ�,������������������Ҫ����,�ڿ�Ԥ����δ��,�Ż������ƶ���Ȼ����Ҫ��AMD��Fusion��CPU��GPU���ɵ�һ��оƬ��,Ȼ��,����CPU��GPU�ڴ������Intel��Sandy Bridge(��һ��CPU/GPU���)����,δ�����꽫���ָ�����ʽ�ļ���CPU/GPUӲ�����С��µĻ��ϵͳ,����NVIDIA Optimus,��оƬ��������ɢͼ�ο��϶�������Ч,��ʹʹ����ϵ�CPU/GPUоƬ,���ݹ���Ҳ������ȷ������ʹ��һ����ȫ���ɵ������ڴ�ϵͳ,Ҳ��Ҫϵͳ֧������С�����ݿ�����
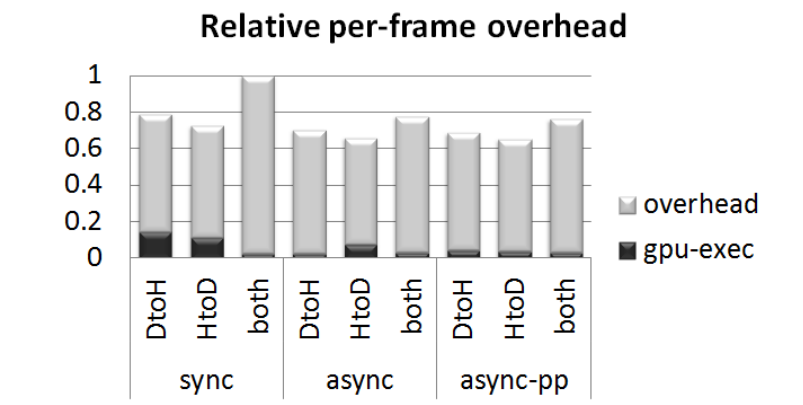
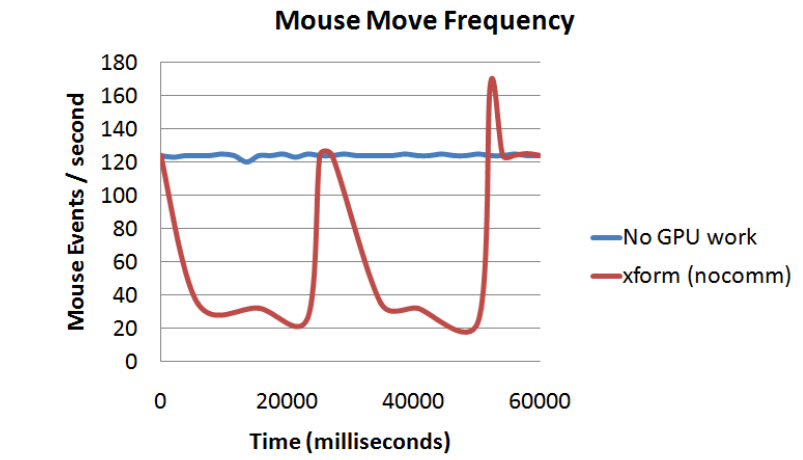
ԭ��ϵͳ�л���CUDA��xform����ʵ�ֵ����GPUִ��ʱ��Ϳ���(Խ��Խ��)��syncʹ��CPU��GPU֮��Ļ�����ͬ��ͨ��,asyncʹ���첽ͨ��,async ppͬʱʹ���첽��ƹ�һ���������һ�������ӳ١�����ͼ��Ϊ��GPU��ִ�е�ʱ���ϵͳ������DtoH��ʾ�豸������֮����ÿ��֡�Ͻ���ͨ�ŵ�ʵ��,��֮��Ȼ,�������߶���ʾÿ��֡��˫��ͨ�š������ִ��ʱ����ͬ����˫�����(ͬ������)��ء�
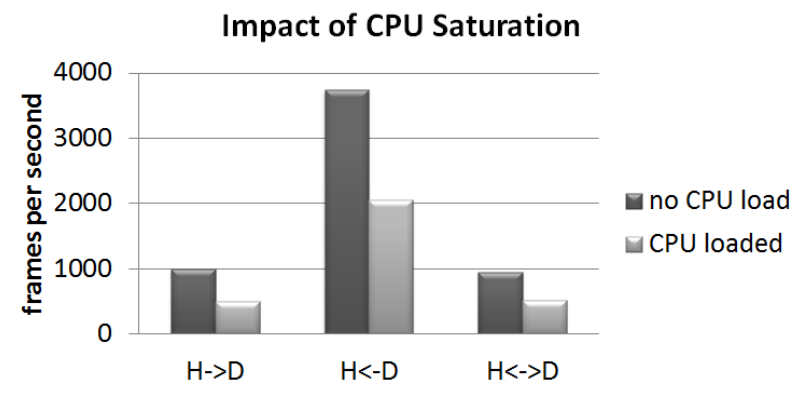
CPU�ܼ�������GPU�ܼ������Ӱ�졣��ϵͳ�д��ڲ���GPU��CPU����ʱ,��ǰ�IJ���ϵͳ���������˲���ϵͳ�ṩ���ܸ����������H��D��һ��CUDA��������,�����д�������GPU�豸��ͨ��,��H��D���д�GPU��������ͨ��,H?D����˫��ͨ�š�
 g)
g)
GPU�ܼ�������CPU�ܼ������Ӱ�졣��Щͼ��ʾ�˲���ϵͳ�ܹ��ڳ������ʹ��GPU��60���ڴ�������ƶ��¼���Ƶ��(��HzΪ��λ)���ڴ��ڼ��ƽ��CPU�����ʵ���25%��
��������������µIJ���ϵͳ����,����ʹGPU�����ڸ��㷺��Ӧ�ó�������Щ���������������ʾΪ����ͼ,�Ӷ�ʵ�ָ�Ч�������ƶ���Ч����ƽ�ĵ��ȡ�
- PTask��PTask�����ڴ�ͳ��OS���̳���,��PTask��������GPU�����С�PTask��Ҫ����OS��һЩ������Э����ִ��,������Ҫ�û�ģʽ�������̡�PTask��һ�������˿ڵ�����������Դ�б�(������POSIX stdin��stdout��stderr�ļ�������)��
- Port��Port���ں������ռ��е�һ������,����PTask����������Դ��һ��Port��һ������Դ�������,�ṩ��һ�ַ���������GPU�����е����ݺͲ���,��Щ���ݺͲ������붯̬��,���ҿ�����GPU��CPU�ڴ��еĻ�������䡣
- Channel��Channel������POSIX�ܵ�:�����˿����ӵ������˿�,�����ӵ�ϵͳ�е���������Դ�ͽ�����,��I/O���ߡ��ļ��ȡ�Channel����������GraphInputChannel��GraphOutChannel��GraphInternalChannel��
- Graph��Graph��PTask�ڵ�ļ���,�����������˿�ͨ��ͨ�����ӡ����Զ���������ִ�ж��ͼ,PTask����ʱ����ƽ�ص������ǡ�
�ڲ���ϵͳ�ӿ���֧����Щ�µij�����Ҫ�µ�ϵͳ��������������ptask���˿ں�ͨ��,�����ϵͳ����������POSIX�еĽ���API�����̼�ͨ��API�͵�������ʾAPI��
��GPUЭ������ϵͳ���ȵ�������Ҫ�ô���:
- Ч��������ָptask����������GPU�ϵ���֮��ĵ��ӳ�,�Լ���GPU�ϵ����㹻��ptask�����Գ����������������
- **��ƽ�ԡ�**��ָ����ϵͳ��������GPU�����ʺ��û�������Ӧ��֮��ȡ��ƽ�⡣����,��GPU������PTAK���ܻ�����������ĺ����ݶ��������PTASK����������Щ����Ҫ��,����͵�CUDA�����ĵ��ӳٵ��ȡ�
��֮,�������Ŷ��ں˳�����и����Ե�����,�Թ�������ʽ�����ģ�����豸���ں˱��������Ҫֻ�����㹻��Ӳ��ϸ��,��ʹ����Ա�ܹ�ʵ�����õ����ܺ͵��ӳ�,ͬʱ�ṩ���ݻ������˽��з�װ��ר�Ż���ͨ�ų���GPU��һ��ͨ�õĹ���������Դ,�����ɲ���ϵͳ���й���,���ṩ��ƽ�Ժ����ԡ�
16.3.3.2 Halide Pipeline
Schedule Synthesis for Halide Pipelines on GPUs��ʾ��Halide DSL�ͱ�����ͨ�������㷨�������Ż�����,ʵ��������칹��ϵ�ṹ��ͼ�����ܵ��ĸ����ܴ������ɡ�Ȼ��,�Զ���������Ŀǰ�������ڶ��CPU��ϵ�ṹ�����,��Ϊ����GPU���ܵ�ƽ̨�����Ż�ʱ,��Ȼ��Ҫר�Ҽ�֪ʶ������ʹ���µ��Ż�������չ�˵�ǰ��Halide�Զ����ȳ���,�Ը�Ч�����ɻ���CUDA��GPU��ϵ�ṹ�ĵ��ȡ�ʵ��������,�õ���ƽ�����ֶ����ȿ�10%,����ǰ���Զ����ȿ�2�����ϡ�
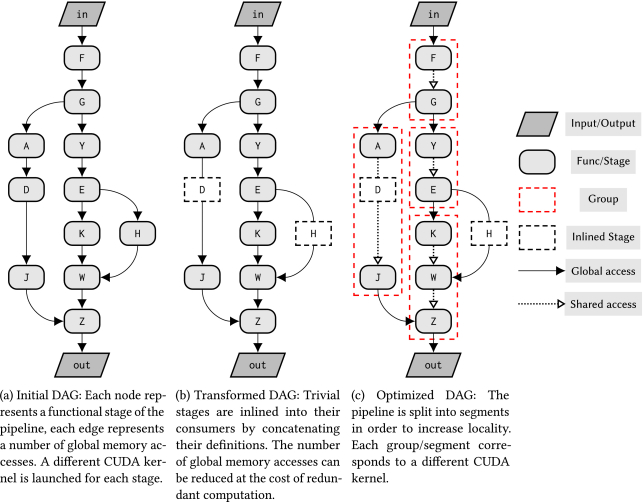
ͨ�ùܵ�ʾ��:�ڽ��ܵ����Ϊ�������Ż��ƻ��Ľ�С����֮ǰ,����ͨ����������ʹ�����С�

��ʵ�ֻ��ڲ�ͬ��CUDA�ں�����ȫ����ÿ����,�����������ݴ洢��ȫ���ڴ��С�

�ص��ֿ�ʱ�������һ�ηֿ��ڵ���(���߳̿�)�������������,������洢�ڹ����ڴ��С�
���Ļ���������Halide master�Զ����ȳ�����ʵ�ֵ����Ż�����,��������Ի���CUDA��GPU�ܹ����Ż����ȡ�����ѭһ�������ڵ�ǰ�Ż����̵Ĺ���,��������(�������)�����ȱ�����������������,Ȼ��ʹ��Halide master��ʵ�ֵ�̰���㷨���з��顣��ͼ��ʾ��autoschedulerʹ�õ��Ż����ĸ�����
������������:��������Ҫѭ���߽�����Լ��û�������Ŀ��淶����,�����ɸ����ܵ����Ż����ȡ��������еĴ�������趼����չ,��֧���Զ�GPU���ȡ�
16.3.3.3 Hardware Accelerated GPU Scheduling
Hardware Accelerated GPU Scheduling������WDDM��2020��5�������һ�ֻ���Ӳ�����ٵ�GPU���Ȼ��ơ�
�Դ�Windows��ʾ��������Model 1.0(WDDM)���Ƴ��Լ�GPU������Windows�е�����,�Ѿ���ȥ�˽���14�ꡣ�������˻�ǵ�WDDM֮ǰ������,������,Ӧ�ó���ֻ����GPU�ύ������Ҫ�Ĺ������ɡ������ύ��һ��ȫ�ֶ���,�����������ϸ�ġ����ύ,��ִ�С���ʽִ�С��ڴ����GPUӦ�ó�����ȫ����Ϸ��ʱ��,��Щ������ĵ��ȷ����ǿ��е�,һ������һ����
������ʹ��GPUʵ�ָ��ḻͼ�κͶ����Ĺ㷺Ӧ�ó���Ĺ���,��ƽ̨��Ҫ���õ�ȷ��GPU���������ȼ�,��ȷ����Ӧ���û����顣���,WDDM GPU���ȳ������ˡ�
����ʱ�������,Windows������ǿ��WDDM���ĵ�GPU���ȳ���,֧��ÿ����WDDM�汾���������ܺͳ�����Ȼ��,��������չ������,��������һ������û�иı䡣����һֱ��CPU������һ�������ȼ��߳�,���̸߳���Э������������Ͱ��Ÿ���Ӧ�ó����ύ�Ĺ�����
���ֵ���GPU�ķ������ύ�����Լ���������GPU���ӳٷ�����һЩ����������,��Щ�����ֱ���ͳ��Ӧ�ó����д��ʽ���ڸǡ�����,Ӧ�ó���ͨ�����ڵ�N֡��ִ��GPU����,����CPU��ǰ����,Ϊ��N+1֡��GPU�������GPU�����������������Ӧ�ó���ÿֻ֡�ύ����,�Ӷ�����ȵؽ��͵��ȳɱ�,��ȷ�����õ�CPU-GPUִ�в����ԡ�
CPU��GPU֮�仺���һ�����и�������,�û����鵽���ӳٻ�������CPU�ڡ���N+1֡���ڼ�ʰȡ�û�����,��GPUֱ����һ֡����Ⱦ�û�����,�ӳټ��ٺ��ύ/���ȿ���֮����ڸ����Ľ��Ź�ϵ��Ӧ�ó�����Ը�Ƶ�����ύ,��С������ʽ�ύ�Լ����ӳ�,���߿����ύ���������Ĺ����Լ����ύ�͵��ȿ�����
����Windows 2020��5��10�յĸ���,������һ���µ�GPU���ȳ�����Ϊ�û�ѡ�����,��Ĭ�Ϲر�ѡ����������ȷ��Ӳ������������,Windows���ڿ��Խ���GPU����ж�ص�����GPU��ר�õ��ȴ������ϡ�Windowsϵͳ����ͨ��Windows���� -> ϵͳ -> ��ʾ -> ͼ��������������ҳ��,�Ա㿪����ر�Ӳ�����ٵ�GPU���ȡ�

Windows�����������ȼ�,��������ЩӦ�ó������������о������ȼ������ǽ���Ƶ����ж�ص�GPU���ȴ�����,��������GPU��������ӹ������������л����µ�GPU���ȳ����Ƕ���������ģ�͵��ش�����Ը���,���ĵ��ȳ������������Ծ�ס�ڷ����е�������ؽ����ݵĻ�����
��Ȼ�µĵ�����������GPU���ȵĿ���,�������Ӧ�ó������Ϊͨ�����������ص��ȳɱ���Ӳ������GPU���ȵ�һ�ε�Ŀ����ʹͼ����ϵͳ��һ������֧���ִ���,��Ϊ������������������
��Ŀǰ����,��������������,��������ܶԲ���3A��Ϸ����ʵ�ʵ�֡��������
16.3.3.4 TimeGraph
GPU���ڳ�����ͼ�κ����ݲ��м��㡣����Խ��Խ���Ӧ�ó����������ڶ������е�GPU�ϼ���,���ж������ͬʱ����GPU,����ϵͳ������GPU��Դ�������ṩ���ȼ����빦��,�ر�����ʵʱ�����С���ǰ������GPU������������:
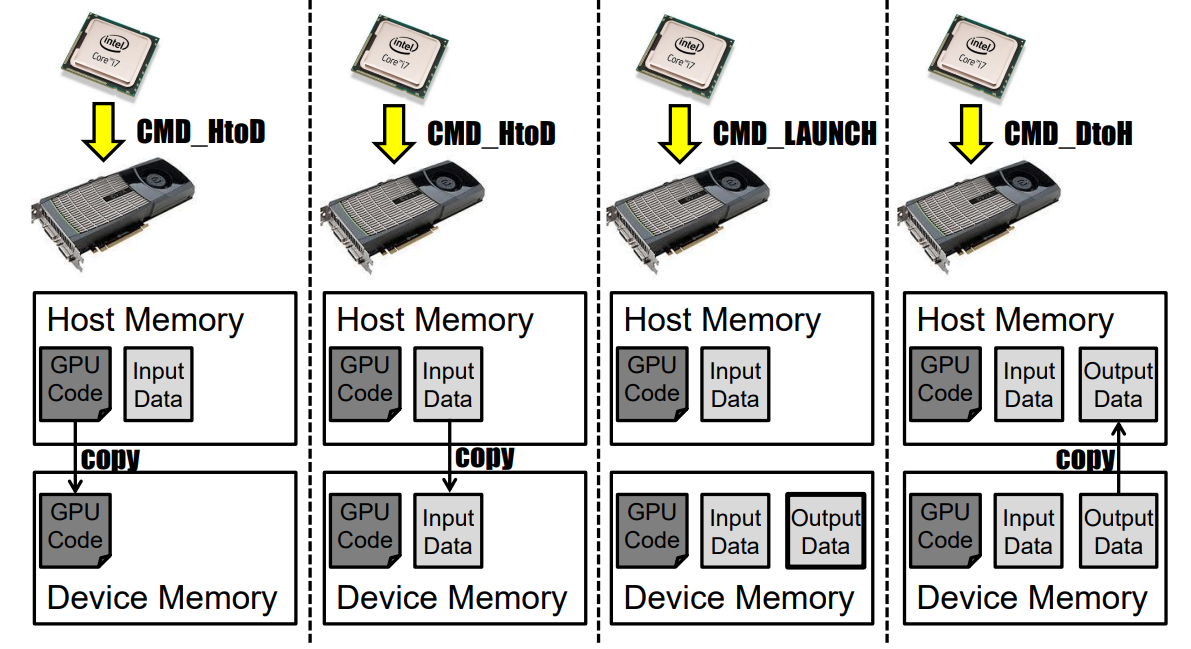
������ij���������CPU�����ᵼ��GPU����:
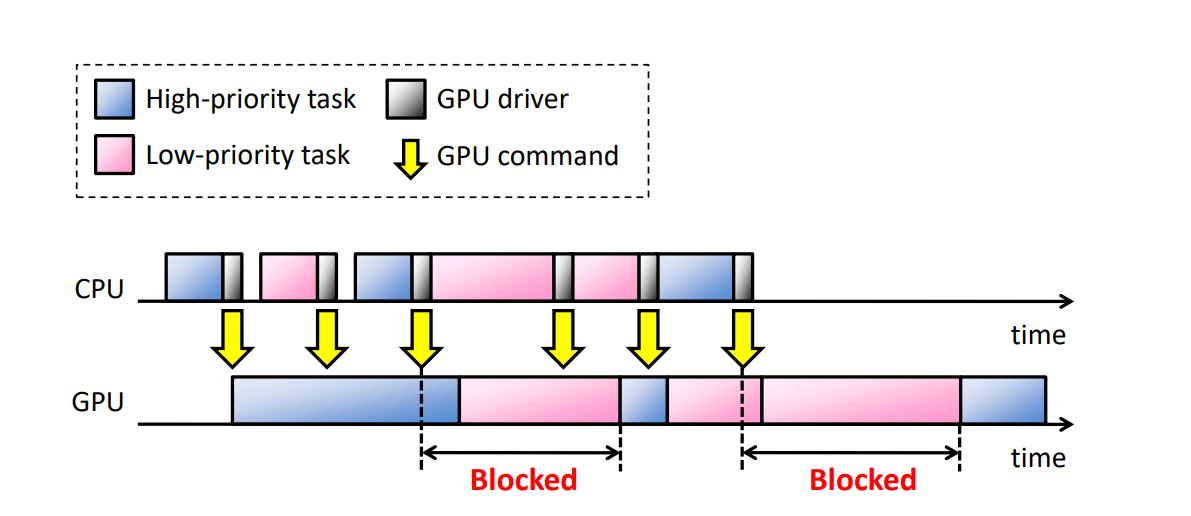
TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments������TimeGraph����һ���豸���������ʵʱGPU������,���ڱ�����Ҫ��GPU���������������ܸ��š�
TimeGraph������һ���µ��¼�����ģ��,��ģ�ͽ�GPU��CPUͬ��,�Լ�ش��û��ռ䷢����GPU����,������Ӧ��ʽ����GPU��Դ��ʹ�á�TimeGraph֧�����ֻ������ȼ��ĵ��Ȳ���,�Խ��GPU�������첽�Ժͷ���ռ�Դ�������Ӧʱ���������֮���Ȩ�����⡣��Դ�������ƻ�����˵����ǿ��ִ��GPU��Դʹ��,�Ӷ���ֹ��Ϊ���˵�����ľ�GPU��Դ����һ���ṩGPU����ִ�гɱ���Ԥ��,����ǿ���롣
����ʹ��OpenGLͼ�λ����е�ʵ�����,��ʹ��Լ��˵�GPU��������,TimeGraphҲ�ܽ���ҪGPU�����֡���ʱ����������ˮƽ,�����û��TimeGraph֧��,��Щ����û����Ӧ���������,ʩ����ʱ��ͼ�ϵ����ܿ�������������4-10%,���¼������������������������е�tick���������������Լ30����
���ļ���ϵͳ��ͨ�ö��CPU�Ͱ���GPU���,�������κ�GPU�ڲ���Ԫ,���GPU�������ύ��GPU�ᱻ��ռ��TimeGraph�����ڿ⡢������������ʱ����,���,ʱ��ͼ��ԭ�������ڲ�ͬ��GPU�ܹ�(��NVIDIA Fermi/Tesla��ATI Stream)�ͱ�̿��(��OpenGL��OpenCL��CUDA��HMPP)��Ŀǰ,TimeGraph��ΪGallium3D OpenGL����ջ�е�Nouveau��ƺ�ʵ�ֵ�,������ջҲ�ƻ�֧��OpenCL������,TimeGraph����ֲ�������PathScale ENZO���е�PSCNV��Դ��������,����֧��CUDA��HMPP��Ȼ��,����Ŀǰ���õ�һ�鿪Դ�������:Nouveau��Gallium3D,������Ҫ��עOpenGL�������ء�
TimeGraph���豸���������һ����,�����û��ռ������GPU�ύGPU����Ľӿڡ������豸���������ǻ��ڴ������UNIX����ϵͳ�в��õ�ֱ����Ⱦ������ʩ(DRI)ģ����Ƶ�,��ΪX Windowϵͳ��һ���֡���DRIģʽ��,�û��ռ�������ֱ�ӷ���GPU����Ⱦ֡,������ʹ�ô���Э��,ͬʱ�Կ���ʹ�ô��ڷ���������Ⱦ֡blit����Ļ�ϡ�GPGPU��ܲ���Ҫ�����Ĵ��ڹ���,������ǵ�ģ���Ӽ�
Ϊ����GPU�ύGPU����,����Ϊ�û��ռ�������GPUͨ��,��Щͨ���ڸ����ϱ�ʾGPU�ϵĵ�����ַ�ռ䡣����,NVIDIA Fermi��Tesla�ܹ�֧��128��ͨ��,ÿ��ͨ����GPU�����ύģ������ͼ��ʾ��
GPU�����ύģ�͡�
ÿ��ͨ��ʹ���������͵��ں˿ռ仺����:�û����ͻ��������ں����ͻ��������û����ͻ�����ӳ�䵽��Ӧ����ĵ�ַ�ռ�,����GPU������û��ռ����͡�GPU����ͨ������Ϊ����ռ����,��ƥ���û��ռ�ԭ���Լ��衣ͬʱ,�ں����ͻ����������ں�ԭ��,�������豸ͬ����GPU��ʼ����GPUģʽ���á�
���û��ռ����GPU�������͵��û����ͻ�����ʱ,���ǻ������ݰ�д���ں����ͻ��������ض����λ���������,��Ϊ��ӻ�����,ÿ�����ݰ�����һ��(��С�͵�ַ)Ԫ��,���ڶ�λij��GPU�����顣��������GPU�ϵ�������ȵ�Ԫ����Ϊ��ȡ���������ύ�Ļ�����,������λ�������GET��PUTָ�����,ָ���ͬһ���ط���ʼ��ÿ�����ݰ�д�뻺����ʱ,�������ὫPUTָ���ƶ������ݰ���β��,����GPU������ȵ�Ԫ�����ź�,������λ��GET��PUTָ��֮������ݰ����ڵ�GPU�����顣Ȼ��,GETָ����Զ����µ���PUTָ����ͬ��λ�á�һ����ЩGPU�������ύ��GPU,���������ٹ�������,�������ύ��һ��GPU������(�����)�����,�����ӻ�����������������еĽ�ɫ��
ÿ��GPU��������������GPU����,ÿ��GPU����ɱ�ͷ(header)���������,��ͷ�������������ݴ�С,�����ݰ������ݸ�������ֵ��������ʾGPUָ��,����һЩָ���ڼ����ͼ��֮�乲��,��һЩ�����ÿ��ָ����Ǽ���,һ��GPU������ж�ص�GPU��,�豸����������ռ���ǡ���ͬһGPUͨ����,GPU����ִ��˳�����GPUͨ����GPU�����Զ��л���
������������ģ�ͻ���ֱ����Ⱦ������(DRM),�������NVIDIA Fermi��Tesla�ܹ�,��Ҳ�������������ܹ�,ֻ���Լ��ġ�
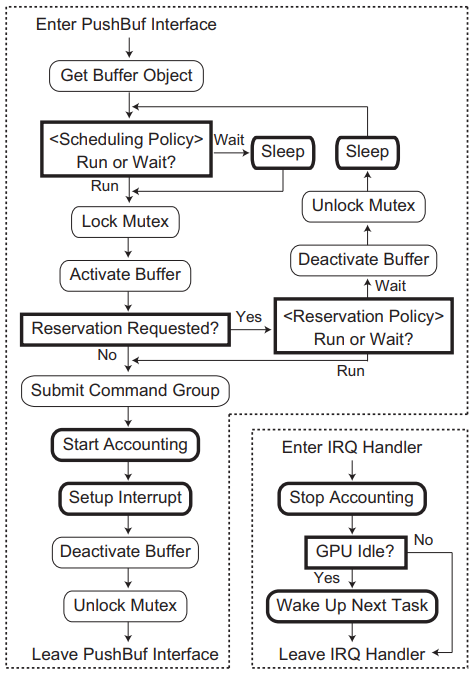
TimeGraph����ϵ�ṹ������������ջ���ಿ�ֵĽ�������ͼ��ʾ���û��ռ����������,GPU���������ͨ����������������ɡ�Ȼ��,TimeGraph��Ҫ���豸��������ռ�����ΪPushBuf���ض��ӿڽ���ͨ��,PushBuf�ӿ������û��ռ��ύ�洢���û����ͻ������е�GPU�����顣TimeGraphʹ�ô�PushBuf�ӿڽ�GPU�������Ŷ�,����ʹ��ΪGPU��CPU�ж�����IRQ����������������һ�����õ�GPU�����顣
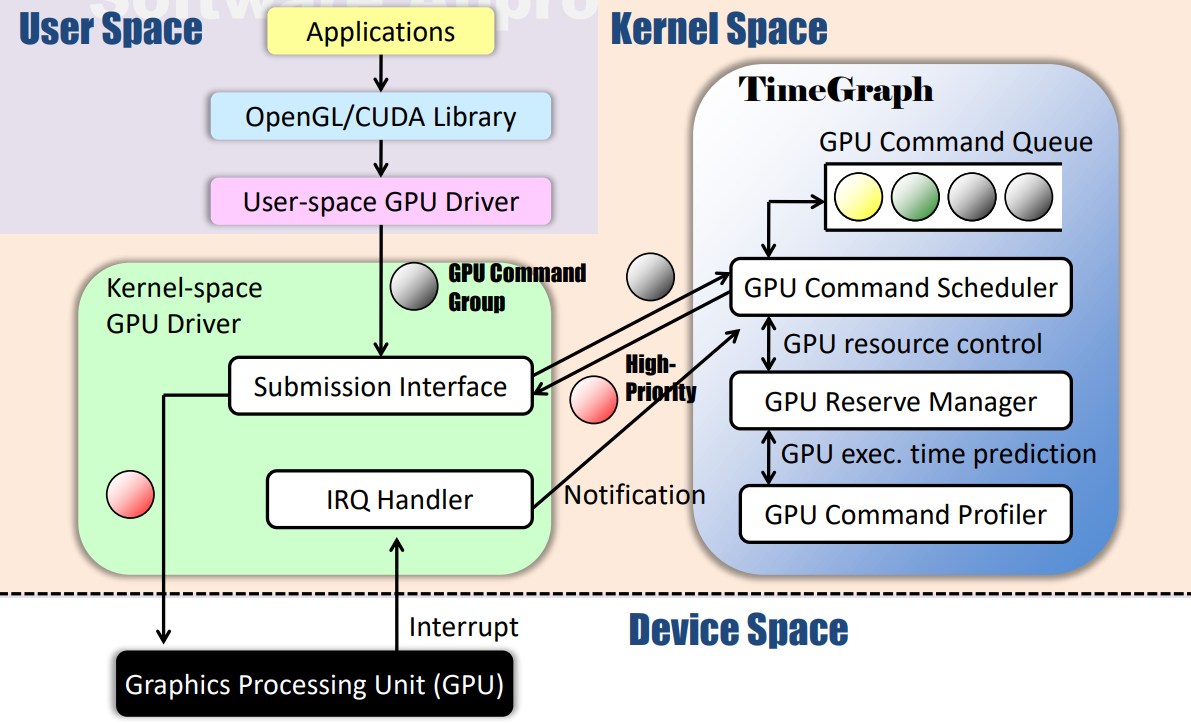
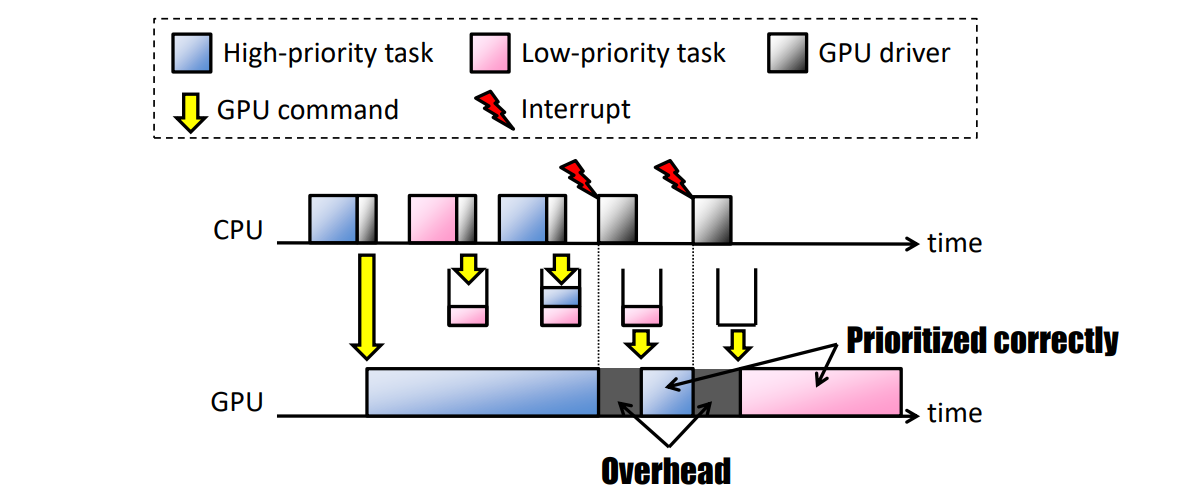
TimeGraph��GPU�����������GPU������������GPU����̽������ɡ�GPU��������������������ȼ���GPU����������ŶӺ͵���,������GPU����������Э��,�Լ����ǿ��ִ�������GPUִ��ʱ�䡣GPU����̽����֧��Ԥ��GPU����ִ�гɱ�,�Ա��ⳬ��������Χ��֧�����ֵ��Ȳ����������Ӧʱ���������֮���Ȩ������:
- ��Ԥ����Ӧʱ��(PRT):�˲�������ȵؼ���GPU�ϵ����ȼ���ת,�Ը������ȼ��ṩ��Ԥ�����Ӧʱ�䡣��GPU������ʱ,GPU�����Ŷ�;��GPU����ʱ,GPU�������:
- ��������(HT):�˲���������������,������������ȼ���ת����GPU������ʱ,ֻ�е����ȼ����ڵ�ǰGPU������ʱ,GPU����Ż��Ŷ�;��GPU����ʱ,�����GPU����:
 ng)
ng)
����֧������GPU��������,�Խ�������������֮���Ȩ������:
- ����ǿ��(PE):�˲�����GPU��������ɺ�ǿ��GPU��Դʹ��,�����������������Ż�GPU��Դʹ��,ָ��ÿ�����������(C)������(P)(/proc/GPU/$����):
- ����ǿ��(AE):�˲������ύGPU������֮ǰ,ʹ��GPUִ�гɱ�Ԥ��ǿ��GPU��Դʹ��,�������Ӷ���Ŀ�����ָ��ÿ�����������(C)������(P)(/proc/GPU/$����):
Ϊ�˽��������ͳһ��һ��������,TimeGraph���������ṩ�˹�������ģʽ���ر���,TimeGraph�ڼ���ʱʹ��PE���Դ���һ������Ĺ�������ʵ��(��ΪBackground,��Ϊ�������κ��ض�����������GPUAccessed�����ṩ����)����ͼ��ʾ��PushBuf�ӿں�IRQ��������ĸ�ͼ,����TimeGraph��������Դ�����ͻ����ʾ����ͼ����Nouveauʵ��,�������GPU��������Ӧ�þ������ƵĿ�������
PushBuf�ӿں�IRQ����������ʱ��ͼ�����Ĺ�ϵͼ��
GPU�����������Ŀ���Ǹ����������ȼ��Է���ռʽGPU����������ŶӺ͵��ȡ�Ϊ��,TimeGraph����һ����ͣ����ĵȴ�����,��������GPU�����б�,��ָ��ǰ��GPU��ִ�е�GPU�������ָ���б���
��GPU���������PushBuf����ʱ,GPU�����б����ڼ�鵱ǰ�Ƿ�������ִ�е�GPU�����顣����б�Ϊ��,����Ӧ�������������,����GPU�������ύ��GPU������,�����뵽Ҫ���ȵĵȴ������С�
GPU�����б��Ĺ�����Ҫ�й�GPU�������ʱ��ɵ���Ϣ��TimeGraph�����¼�����ģ��,��ģ��ʹ��GPU��CPU�ж���֪ͨÿ��GPU����������,��������ǰ�����в��õ�tick����ģ�͡�ÿ���ж�ʱ,��Ӧ��GPU�����齫��GPU�����б���ɾ����
TimeGraph֧������GPU���Ȳ��ԡ�**��Ԥ����Ӧʱ��(PRT)**���Թ������������ڲ�Ӱ����Ҫ���������¼�ʱִ�С��˲�����ij���������ǿ�Ԥ���,GPU�������ǻ����������ȼ����е��ȵ�,��ʹ�����ȼ�������GPU����Ӧ����һ����,**��������(HT)**����������Ӧ�þ����ܿ��ִ�е�������һ��Ȩ��,��PRT����������������Ϊ���۷�ֹ�����ܵ�����,��HT����ʵ����һ������ĸ�������,�����ܻ���ֹ������������,����С������������������Ƶ������������Ҫʹ��PRT����,����ά��Ϸ�ͽ���ʽ��ά�ӿ��������ʹ��HT���ԡ�
PRT����ǿ���κ�GPU������ȴ�ǰ���GPU������(�����)��ɡ��������,���GPU�����б�Ϊ��,���豸�����������GPU��������������ύ��GPU������,��Ӧ����������ڵȴ����������ߡ��ȴ������е�������ȼ�����(�����)��GPU��ÿ���ж�ʱ�����ѡ�
��ͼ(a)��ʾ����PRT�����������GPU�ϵ��Ⱦ��в�ͬ���ȼ�����������,�������ȼ��������ȼ�(MP)�͵����ȼ�(LP)����MP����ʱ,��GPU�����������GPU��ִ��,��Ϊû��GPU����������ִ�С����GPU��CPU�첽����,��MP�������������һ��GPU������ִ��ʱ�ٴε������,����PRT����,����GPUû�п���,MP������ν��Ŷӡ�����ͬ����ԭ��,������һ��HP����Ҳ���Ŷ�,��Ϊ�������ȼ���������ܺܿ�ͻᵽ�TimeGraph������ÿ��GPU������ĩβ���ض�GPU�������CPU����һ���ж�,����Ӧ�ص���TimeGraph���ȳ����Ի��ѵȴ������е�������ȼ��������,������ѡ����GPU��ִ��HP����,������MP��������,LP�������һ��ʵ����HP����ĵڶ���ʵ�������������ȼ����е��ȡ�
����GPU������ĵ���ʱ��δ֪,��ÿ��GPU�����鶼�Ƿ���ռ��,������ΪPRT�������ṩ��Ԥ����Ӧʱ�����ѷ�����Ȼ��,��ÿ��GPU������߽���е��Ⱦ��߲��ɱ���ػ��������,����ͼ(a)��ʾ��
HT���Լ��������ֵ��ȿ���,�������˿�Ԥ�����Ӧʱ�䡣���(i)��ǰ����ִ�е�GPU����������ͬһ�����ύ��,����(ii)�ȴ�������û�и������ȼ�������,������������GPU�������ύ��GPU������,���DZ�������PRT������ͬ�ķ�ʽ��ͣ�����ж�ʱ,ֻ�е�GPU�����б�Ϊ��(GPU����)ʱ,�ȴ����������ȼ���ߵ�����Żᱻ���ѡ�
��ͼ(b)��������HT��������ε�����ͼ(a)��ʹ�õ�ͬһ��GPU�����顣��PRT���Բ�ͬ,MP����ĵڶ���ʵ�����������ύ��GPU������,��Ϊ��ǰ����ִ�е�GPU���������������������ġ�MP�����������GPU�������������ִ��,�������������ʱ��,HP���������GPU������Ҳ����ˡ����,HT���Ը�����������������������,��HP����MP��������������ʱ�䡣����һ��Ȩ��,������ȼ���ת������Ҫ,��PRT���Ը����ʡ�
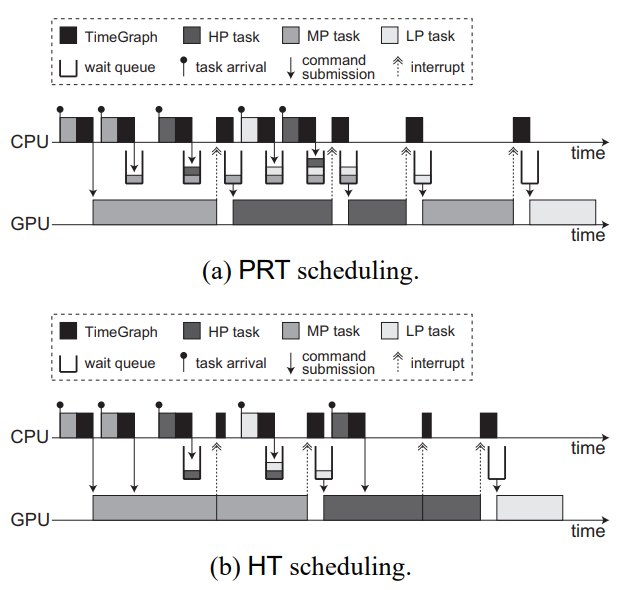
TimeGraph��GPU���ȵ�ʾ����
TimeGraph֧��GPUִ��ʱ��Ԥ��,ʹ�û�����ʷ�ķ������������봫��GPU��������ƥ�����ǰGPU�������еļ�¼,�����ڶ�ά,����Ҫ������ά�ͼ��㡣
TimeGraph������,�ڸ����������Ӱ������:
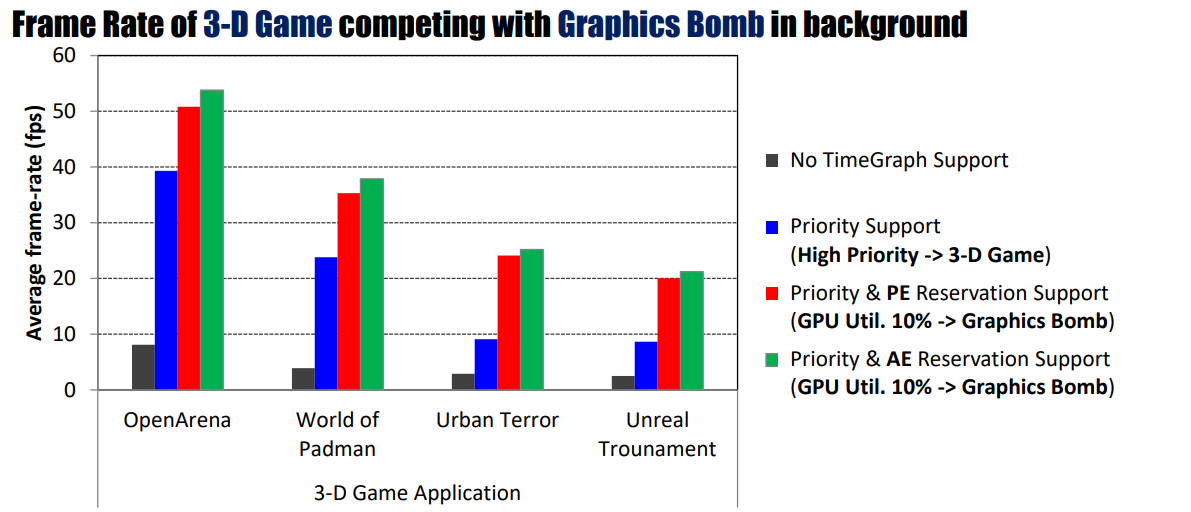
�ں�̨����ͼ��Bomb��������ά��Ϸ֡���ʡ�
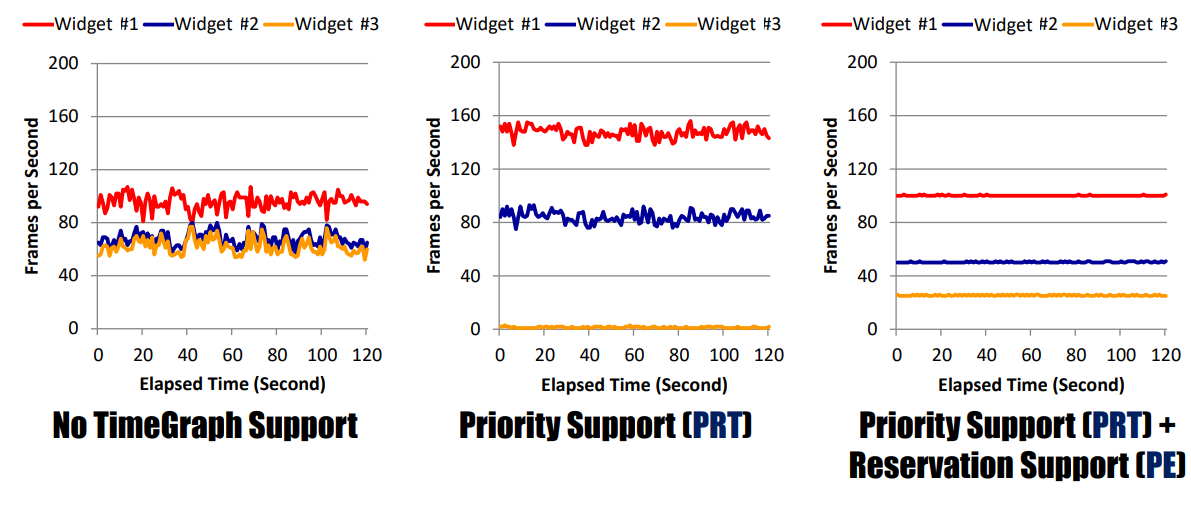
����ʱ�䡣

�����豸�����ܡ�
��֮,TimeGraph֧���ڶ������ж�GPUӦ�ó���������ȼ��������:
- �豸��������������:�����û��ռ䡣
- GPU����ĵ��ȡ�
- ����GPU��Դʹ�á�
16.3.3.5 GPU Scheduling
Ҫ��ʼ�����ڶ������Ӧ�ó���֮�乲������GPU�ĺ��������,�������ȱ����˽�GPUͨ����δ�������Ӧ�ó����������ȡ������ǿ�ʱ��Ϳռ�ά�ȿ��ǵ�,����������Ӧ���ں�ʱ�ε�ִ�С�ʱ�����������FCFS�㷨ȷ��;��������е�ͷ��ʱ,�����õ�����(������㹻����Դ����)�����ֵ���Ҳ�Ƿ���ռ�Եġ���һ����һ������ȵ��豸,�Ͳ���Ϊ��һ������ռִ�С�����,���ַ���ռҲ���������𡣿ռ���ȸ���������Դ�����SMX�ϵ���Դ�����Ե�˫�ؿ���,ȷ���������ִ�е�SMX��Ԫ��
��Ӳ�����ȼ���,��С�Ŀɵ��ȵ�Ԫ���߳̿�,��ζ���豸�ϵ�ijЩSMX�����ܹ��������������Դ����,�Ա㽫�����ִ�С�����,һ���ں˵������߳̿鶼����һ�δ���,���������ִ�в��ĸ��������ǽ��������Ϊһ��˲ʱ����,��ôÿ��wave������ݿ�������豸��Դ��������������������Ŀ�����һ��������wave,����ʣ��Ŀ鶼��������ִ�ж�����,ֱ���豸�ϵ�����ִ�����,�Ӷ��ͷ���Դ��
���������ؾ������ж��ٿ�������һ��������ִ��wave���ں��߳̿��������һ����Ҫ����,��Ϊ������������ÿ����Դ����������һ���ؼ����������Ƕ�ÿ��SMX������פ���߳̿�����������Լ��������ע������Լ��,��Ϊ�ڴﵽ���פ������֮ǰ,������Դͨ�����ܲ�����ȫ�ľ�,���ɾ��в�ͬ���ú���Դ������ں���ɵIJ���ִ�г�����������ܡ��±��г��˶��NVIDIA GPU��ÿ��SMX����Դ���ơ�
| Compute Capability | 3.5 | 5.2 | 6.0 | 7.0 |
|---|---|---|---|---|
| Maximum Threads / SMX | 2048 | 2048 | 2048 | 2048 |
| Maximum Thread Blocks / SMX | 16 | 32 | 32 | 32 |
| Maximum Threads per Block | 1024 | 1024 | 1024 | 1024 |
| Maximum Registers / SMX | 65536 | 65536 | 65536 | 65536 |
| Shared Memory per SMX | 48 KB | 96 KB | 64 KB | 96 KB |
����,�߳̿�������SMX��Ԫ�еķֲ�ȷ����ijЩ����(���繦��ѡͨ)���ɿ���Ӧ������߹���Ч�ʡ����,�ռ���ȷ����ᵼ�²�ȷ����ģʽ,�Ӷ�������ͨ����ijЩ��ӳ�䵽�ض�SMX����������ʺ�/��Ч�ʵĿ��ܷ��������,�ڲ���������,�����ں˵IJ�ͬ��Դ������SMX��Ԫ���������ʲ��Գơ�
���������Ȳ���Ӧ���ڶ������Ӧ�ó�����GPU�豸�ij���,��Ҫ������Դ��ͻ��ȷ��ijЩ����,���繫ƽ�ԡ���GPU������ʵ����һ���һ�ַ�����ͨ����������
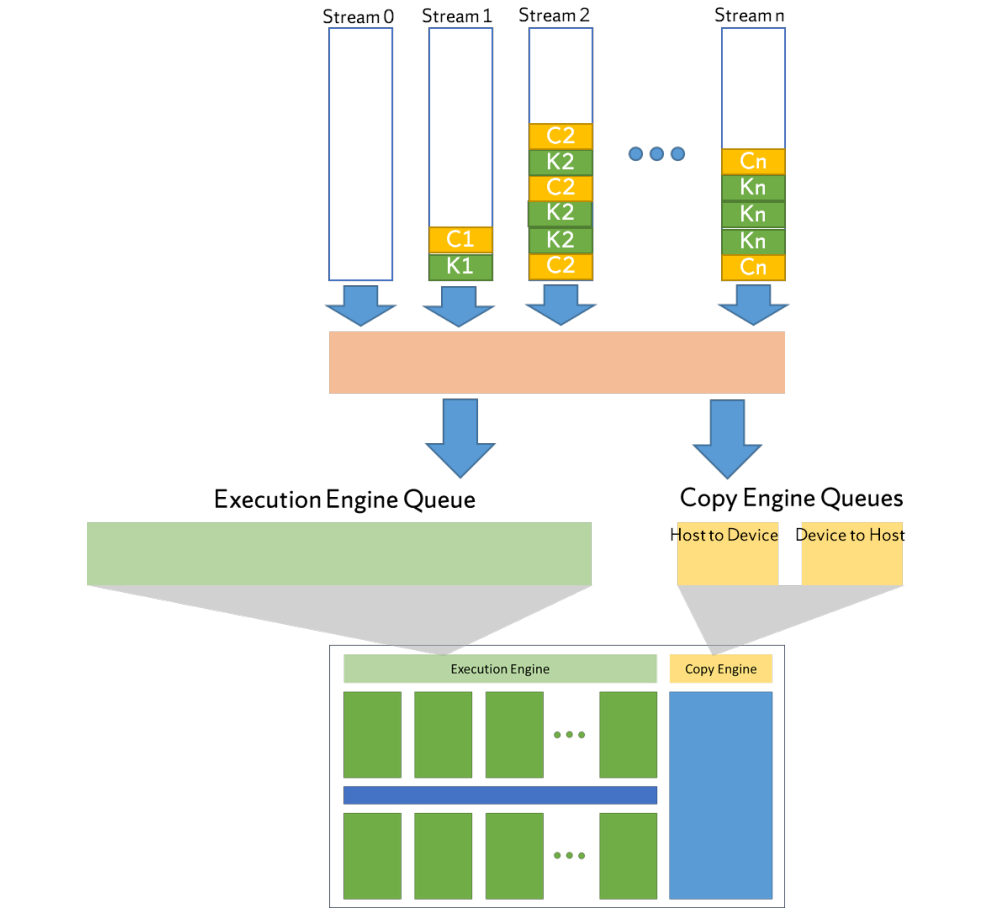
GPU����ʾCPU��GPU֮��Ķ���ִ����,������CPU�̡߳�������,����������˳��(��FCF)˳��ִ�С��ڲ�ͬ����֮��,������Դ�Ŀ�����,���Բ��л�ִ�в�������ͼ��ʾ�˶��������ij����ʾ,���еIJ��������ȵ���������������,ֻ�е��������������е�ǰ��ʱ,�ŻὫ����ȵ���һ���豸��������
���ں˵��Ȳ�νṹ��
��һ����������ʾִ�ж���(�����ں�)���ƶ���(�����ڴ洫��)��ͬ��,��Щ�����еIJ�������FCFS��ʽ���ȵ�,������ijЩ�豸״��,�����һЩ���档�±���һЩGPU���ȹ���(�����NVIDIA Jetson TX2��ϵ�ṹ���ݾ���ó���һ����ȹ���,�������������NVIDIA��ϵ�ṹ��������֤)��
| ��ʶ�� | ���� |
|---|---|
| G1 | �����ù�����CUDA API����(�ڴ洫����ں�����)ʱ,���Ʋ������ں������������������Ŷӡ� |
| G2 | ���ں˵����������е�ͷ��ʱ,����������EE���С� |
| G3 | EE����ͷ�����ں�һ����ȫ����,�ͻ�Ӹö������˳����С� |
| G4 | һ���ں˵����п����ִ��,�ں˾ͻ�������������˳����С� |
| X1 | ֻ��λ��EE����ͷ�����ں˿�����ʸ���䡣 |
| R1 | ֻ����������ԴԼ���������,λ��EE����ͷ�����ں˿�����ʸ��䡣 |
| R2 | ֻ����ijЩSM�����㹻�Ŀ����߳���Դʱ,λ��EE����ͷ�����ں˿�����ʸ��䡣 |
| R3 | ֻ����ijЩSM�����㹻�Ĺ����ڴ���Դ����ʱ,λ��EE����ͷ�����ں˿�����ʸ��䡣 |
| C1 | ���Ʋ��������������е�ͷ��ʱ,����CE�������Ŷӡ� |
| C2 | CE����ͷ���ĸ��Ʋ������ʸ�����CE�� |
| C3 | һ�������������GPU�ϵ�CE,CE����ͷ���Ŀ�����������CE�������˳��� |
| C4 | CE��ɸ��ƺ�,���Ʋ������������������˳����С� |
| N1 | ������ÿ������������,Ҫô����Ϊ��,Ҫô��ͷ�����ں���Kk֮������ʱ,λ�ڿ�������ͷ�����ں�Kk���Ŷӵ�EE�����ϡ� |
| N2 | �ǿ�������ͷ�����ں�Kk������EE�������Ŷ�,���ǿ�������Ϊ�ջ���ͷ�����ں�����Kk֮�������ġ� |
| A1 | �ں�ֻ�������������ȼ�ƥ���EE�������Ŷӡ� |
| A2 | ֻ�е����и����ȼ�EE����(���ȼ��߹����ȼ���)Ϊ��ʱ,�κ�EE����ͷ�����ں˿�����ʸ���䡣 |
������Щ���ȹ������ʵ�������Դ�����ʺ�ϵͳ������������Ҫ����Щ����ͬ˵��,һ���ں˵Ŀ鿪ʼ���ȵ�GPU(ͨ��X1),�ڵ������һ���ں˵����п�֮ǰ,�����������ں�(G3)������һ���ں����ڲ���������һ����Դ����(R1-R3)����ִ�ж�������ͣʱ,���п��ܳ������������Ȼ��,ִ�ж����к����ں˵�������ȫ����������Щ��Դ�������,����ʧ����豸�����ʵĻ���,�Ӷ���Ҫ����ϸ��ִ�ж��е��ȷ������ڲ��������ƽ��͵������,�������Ƹ��ƶ���Ҳ������Щ��������,�����Ҫ��������Ȳ��Խ������Ƶļ�顣
��ǰ���о�Ϊ��һ������GPU��Դ����������ṩ�˶���,��ʵ�ָ����ܺ���Ч��Hong��Kim�������������������Ӧ�ó�������˷���,������Լ����Ӧ�ó�����ڴ�Լ����Ӧ�ó���,���������ܡ������ʺ���Ч֮��Ĺ�ϵ���������ء��ܼ������Ƶ�Ӧ�ó������ǿ�����ԡ����ڹ̶��������С,�����Ӧ�ó������Ĵ����ں�,������ʾ���ں������ɱ����ļ���(���ڸ��̵�ʱ���������ͬ�����Ĺ���)����һ����,�ڴ�����Ӧ�ó�������������ԡ������������,�����ܵ��̶������С������,��������С����������(������ͬʱ������ɸ����),�����Ӹ��ദ����ֻ��������ܡ�
Hong��Kimչʾ����Щ�������������GPU�ں˵����ܺ���֮��Ĺ�ϵ,�Եó���Ӧ�ó�����ʹ�õ�����ں��������ַ������Ƶĺô���,����Ӧ������,�ڲ�ͬ���������¿���ʵ����ѵ���Ч�������ܼ������Ƶ�Ӧ�ó���,��ѵ��dz��������,���������ڴ����Ƶ�Ӧ�ó���,��ѵ��ǵ��ڴ�ֵ���Զ����Ľ�����,����Ӧ�ó�����Ҫ��ȫ����GPU��Դ��ʵ��������ܡ�����,�������з�����Ŀ���ǿ���һ��ģ��,��ȷ�������ں˵�����ں�����,���ɹ�֤��������Ч�ʵ���ߡ�Ȼ��,�÷���û�н������ִ�г���,Ҳû�����һ������δ������õ�GPU��ԴDZ���ķ�����
��ͼ��ʾ�ļ���,�����,չʾ�˵����ں�ִ�еĸ����(�������ں�֮��û���豸����)�Լ��ɴ˲��������ܺ������ʡ��ر��Ǹ��豸�������ʽ�Ϊ62.5%,�ƻ��ں˵��������ʱ��Ϊ4��ʱ�䵥λ��Ȼ��,�����Dz���ִ��ʱ,����ͼ����ʾ,���������ӵ�83.3%,����깤ʱ����ٵ�3��ʱ�䵥λ����Ȼ��ʾ�����ǶԸ��ӵ�������Ĺ��ȼ�,�ر��ǿ��ǵ��������۵ĵ��ȹ����Լ��,�����ṩ�˷����Ϳ����¼���������ȵ�����GPU����ܹ����������������
����(��)�Ͳ���(��)ִ�е����ܺ������ʱȽϡ�
�ڿ��ǵ���GPU�豸�Ĺ�������ʱ,��һ����֤�����ò����Ժ�����豸�����ʵĺô�����������,������ѭ�����ѭ���ķ�ʽ������豸�ϵ�SMX��Ԫ�����,�����豸��ִ���ڼ�ͨ��,����ѡͨ�Ȳ���ͨ�������á���Ȼ,�ж������ؾ����ں�Ӧ�ó���ķ�ֵ����,�����̲߳������ڴ���ʵ�,�����ǹ۲쵽,��ֵͨ���������õ����豸��Դ������ٷֱ��ء���ͼ˵��������һ��ʾ����
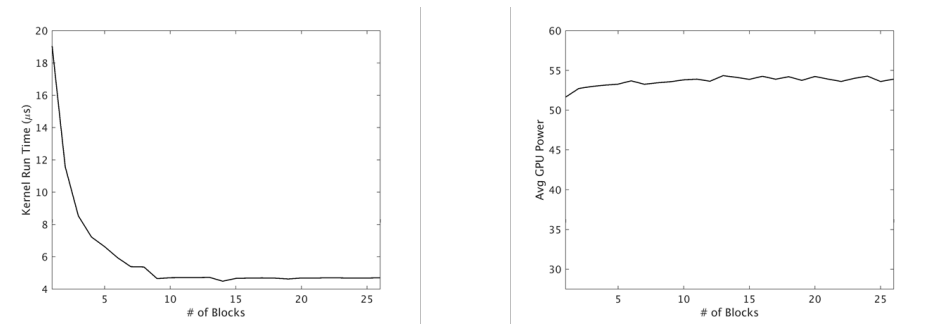
�ں�����ʱ��(��)��GPU����(��),�������ӿ������豸�����ʡ�
�ڱ�����,�ں˵������������GPU�����ʲ���������ʵ�ֵġ����Ƶ�,��ֵ���Ĵ����������ˮƽ�����ܵ��������������Լ5%,�������Ժ��Բ��ơ��������ڴӾ�������֤�еĹ۲���,�����������������������:���ϵͳ�������ķ���,���ڽ϶�ʱ������ɸ�������,����ϵͳ��Ч��������Ӱ��,�����������κ���ȷ�������ĵļ�����������Щ����,�о�����Ҫ�ص��Ƕ���GPU������Ż�����,�����ϵͳ����������Դ�����ʡ�����������Ч��,���ַ����ĺô�������ͨ��ƽ��������תʱ�����������Ƹ��Ե�����Ч��
OS��GPU���ȿɴ��û��ռ����ں˿ռ�����,���Ǹ���4�ֵ��ȷ�ʽ��
���ȿ����û��ռ���GPU��������������ϵ�ṹ,��ͼ�����˼�����ϵ�ṹ��
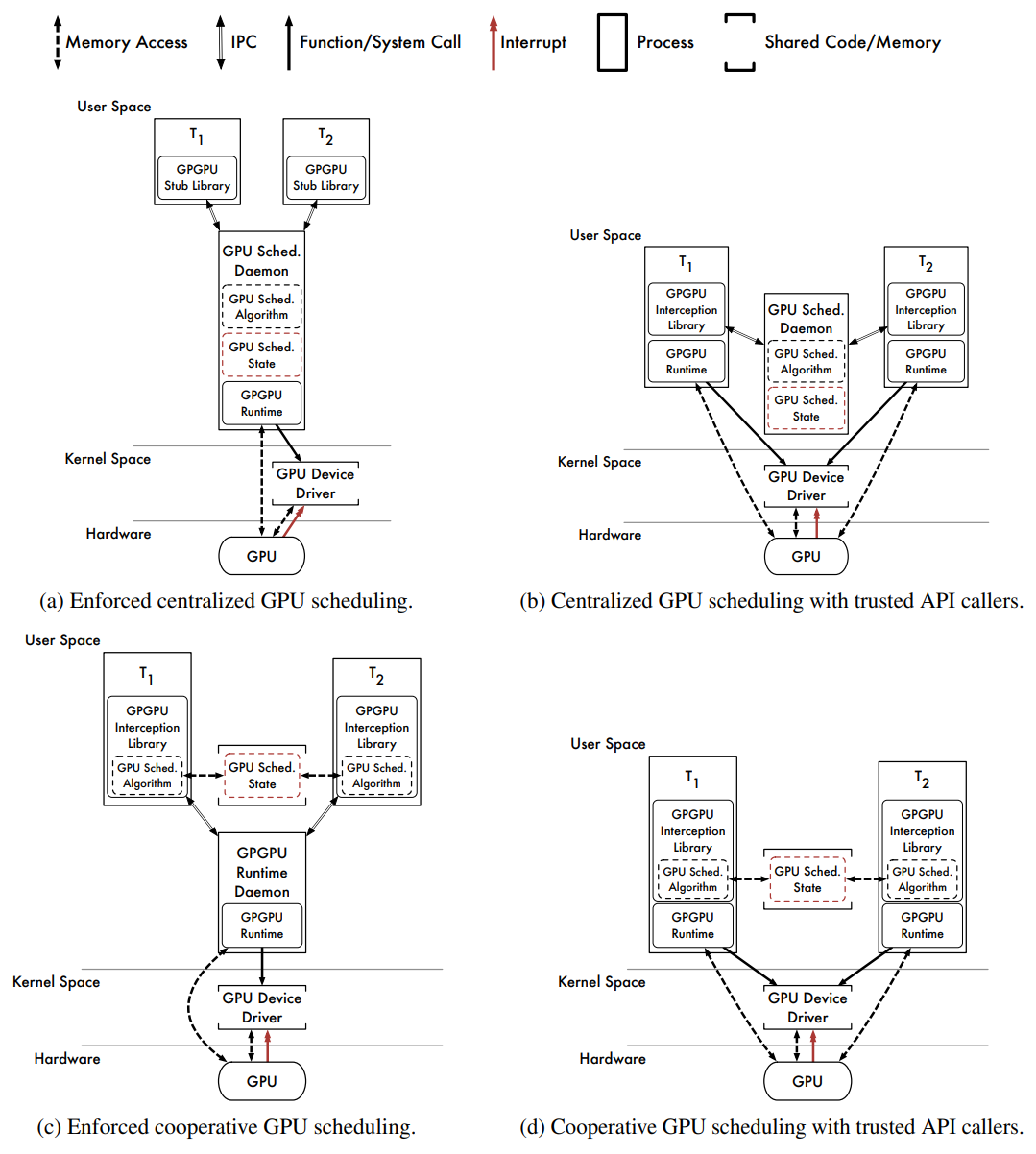
���û��ռ���ʵ�ֵ�API������GPU���ȳ���ļ���������ϵ�ṹ��
- Centralized Scheduling With Enforcement(���е�����ʵʩ)
��ͼ(a)�������û��ռ���GPU���ȵ�ͨ��������ϵ�ṹ��GPGPU API���ñ�������ÿ�������е�GPGPU�����,�����ͨ��IPCͨ��(����UNIX�����֡�TCP/IP���ֵ�)��API�����ض���GPGPU�����ػ�����,���ػ�������ݼ���ʽ���Ȳ���Ϊ�����ṩ�����ػ���������ִ������API����,ǿ��ִ�����е��Ⱦ��ߡ�
�ô�:
1�����ھ�����,���Ȳ�������ʵʩ��
2�����ڼƻ���API������GPGPU�����ػ�������ִ��,���ִ�е��Ⱦ��ߡ�
ȱ��:
1���ػ����̱���������ܹ�������������GPU�ں˴��롣������ڱ����ػ�����ʱ��ɡ�GPU�ں˴���Ķ�̬����Ҳ�ǿ��ܵ�,��ʵ������������
2������������ػ�����֮�����Ϣ����,IPC�����˿�����
3������ʹ���κ��ڴ���ӳ�似��,GPU�ں����ݱ���ͨ��IPCͨ�����䡣�����ܼ���GPGPUӦ�ó���(����,��������ṩ���ݵ����˼��Ӧ�ó���)�����ܽϲ
4��������ػ����̱������е��ȡ�����������ĵ��ȳ�����������,����RTOS�ṩһ�ֻ���,ʹ�ػ����̿��Դ�����ɲ��ּ̳����ȼ�����,�ɵ����Է�������ֱ���˵��ġ�����ͨ������ػ���������ȼ�(��Ӱ��ɵ����Է���)���ƹ�������,���߿���Ϊ�ػ�����ר�ű���һ��CPU(�ᵼ������������ʧһ��CPU)�������ַ���������ȡ��
GViM��gVirtuS��vCUDA��rCUDA��MPS�����������е���ϵ�ṹ��Ȼ��,��Щ��û��ʵ��ʵʱGPU���Ȳ��ԡ�ͨ��IPCͨ������GPU�ں����ݵĿ������ܻᵼ�����������Ӧ�ó��������ܵ����ܡ�
- Centralized Scheduling Without Enforcement(���е���,����ǿ��ִ��)
��ͼ(b)��������һ�������ػ����̵ĵ�������GPGPU API���ñ�����Ŀ�ػ�,����ÿ������,�ⶼ��ͨ��IPCͨ����GPU�����ػ�������ӦGPU���������ȴ�ÿ����������,�ػ�������ݼ���ʽ���Ȳ�����������,һ�������˱�Ҫ����Դ,����Ŀ�ͻὫ�ػ��API���ô��ݸ�ԭʼGPGPU����ʱ��
�ô�:
1������ʵ��,��Ϊ���Ⱦ����Ǽ��е�,GPU�ں˴������ÿ����������DZ��صġ�
2��GPU�ں����ݲ���ͨ��IPCͨ�����ơ������ܼ���GPGPUӦ�ó����������á�
ȱ��:
1����ִ��GPU���Ⱦ��ߡ���Ϊ����������������ܻ��ƹ�����Ⲣֱ�ӷ���GPGPU����ʱ��
2��IPC��������Ϣ���ݿ�����
3�����밲���ػ���������
����GPU�ں������������ݲ�����IPCͨ��,������ϵ�ṹ�����˵��Ⱦ��ߵ�ִ��,��ʵ�������ܼ���Ӧ�ó�����������ơ�����,����8��GPU������ϵ�ṹ��������ʵ�ֵ�,�ǻ���Windows 7��PTaskԭ�������õ���ϵ�ṹ,PTask��һ�ַ�ʵʱGPU���ȳ���RGEMҲ��һ��ʵʱGPU������,��Ҳ������������ϵ�ṹ��
- Cooperative Scheduling With Enforcement(��ִ�е�Э������)
��ͼ(c)������Э��GPU��������GPGPU����ʱ�ػ������������ϵ�ṹ������Ŀ�����API����,ÿ�������п��ÿ��ʵ��������ͬ��GPU�����㷨,���㷨Ƕ���ڲ���Ŀ��С�GPU���ȳ���״̬�ĵ���ʵ���洢�ڹ����ڴ���,����Ŀ⽫API���ô��ݸ��ػ�������ʵ��ִ�С�
�ô�:
1��GPU�����Ǹ�Ч��,��Ϊÿ��������ֱ�ӷ���GPU���ȳ���״̬��
2�����Ⱦ���ִ������������GPGPU����ʱ�ػ��������˶�GPU�����з���,����Ϊ����������������ܻ��ƹ�Э��GPU���ȳ���ֱ�����ػ�����������
ȱ��:
1���Թ���GPU���ȳ���״̬�ķ��ʱ���������֮�����Э��(��ͬ��)������ʹ�õ�ͬ������,���������Ҫ��ִ�е����㷨ʱ����ռ��ִ��(�Ա�������)������ҪRTO��֧�ֻ������ʱ������ռ����ȨCPUָ�
2����Ϊ����������������ܻ���GPU���ȳ���״̬,��Ϊ�����ܻḲ�ǹ����ڴ��е��κ����ݡ��Ӵ�������лָ����ܺ����ѡ�
3����Ϊ������������������ƹ�GPU���ȳ���,ֱ����GPGPU����ʱ�ػ���������,�����ػ����������֤����Ļ��ơ�
4��IPC��������Ϣ���ݿ�����
5��GPU�ں����ݱ���ͨ��IPCͨ�����䡣
6�����밲���ػ���������
����ϵ�ṹ����IPC��صĿ���������Э�����ȵ��κ�DZ�ںô�������,���ڿ����ƹ�GPU������,ִ�е��Ⱦ��ߵ�������������������ϵ�ṹ�뼯��ʽ����(��ͼa)���û�����Ե����ơ�
- Cooperative Scheduling Without Enforcement(��ǿ�Ƶ�Эͬ����)
��ͼ(d)������Э��GPU���ȳ����������ϵ�ṹ,����ʹ���ػ�������Ŀ�����API����,��֮ǰһ��,����Эִͬ����ͬ��GPU�����㷨,������ͬ�Ĺ������ȳ���״̬�����С��ػ��API�����ڼƻ�ʱ���ݸ�ԭʼGPGPU����ʱ��
�ô�:
1��û��IPC�������á������ܼ���GPGPUӦ�ó����������á�
2��û��Ҫ���ȵ��ػ����������ʵʱ����,�������˶�RTO��֧�֡�
3����Ч��GPU���ȡ�
����:
1������Э����GPU���ȳ���״̬�ķ��ʡ�
2��GPU���ȳ���״̬������
3����ִ��GPU���Ⱦ��ߡ�
�����о�������Ч���û��ռ���ϵ�ṹ��������������IPC����,�������ػ����̴��������п����ͷ������⡣Ȼ��,��Ҳ������8����ϵ�ṹ���������,������������:��Ҫ�ƹ�GPU���ȳ���Ͳ���GPU���ȳ���״̬��
������̽���ں˿ռ���GPU���ȡ�
�û��ռ��е�GPU�����м������㡣һ��ȱ����,���ǿ�������ֱ���GPU���ȳ������ݽṹ��Э�����ȷ��������������,����GPU���ȳ���״̬���ܻᱻ��Ϊ�������������ƻ���Ȼ��,�û��ռ���ȵ������������������ײ�RTO���ܼ���,���ܻ�����������κγ̶ȵ�����ʵ����ȷ��ʵʱϵͳ��RTOS�����ṩһЩ����,����ʵʱ����ͨ���û��ռ����Ӱ����������ĵ������ȼ�(����,�������ȼ��Ľ��Ȼ��Ƶ�ʵʱ����Э��,�Լ�ֱ�Ӳ������ȼ���ϵͳ����)������������ЩΪ�û��ռ�GPU����������һЩʵʱȷ���ԡ�Ȼ��,��Щ���ƿ��ܲ�������С��,����Ҫ����,����GPU��ص����ȼ���ת��
���ǽ���ܶ�����������ܵ��û��ռ���������ơ�ͨ����GPU��������CPU��������RTOS�ں��е���������ϵͳ���(���жϴ�������)���ܼ���,������õؽ����Щ���⡣��Щ�����ʹ���ǿ����ں˿ռ�GPU����������ͼ�������ں˿ռ�GPU�������ļ��ָ�������ϵ�ṹ���������з�������������RTO���ܼ��ɵ�������
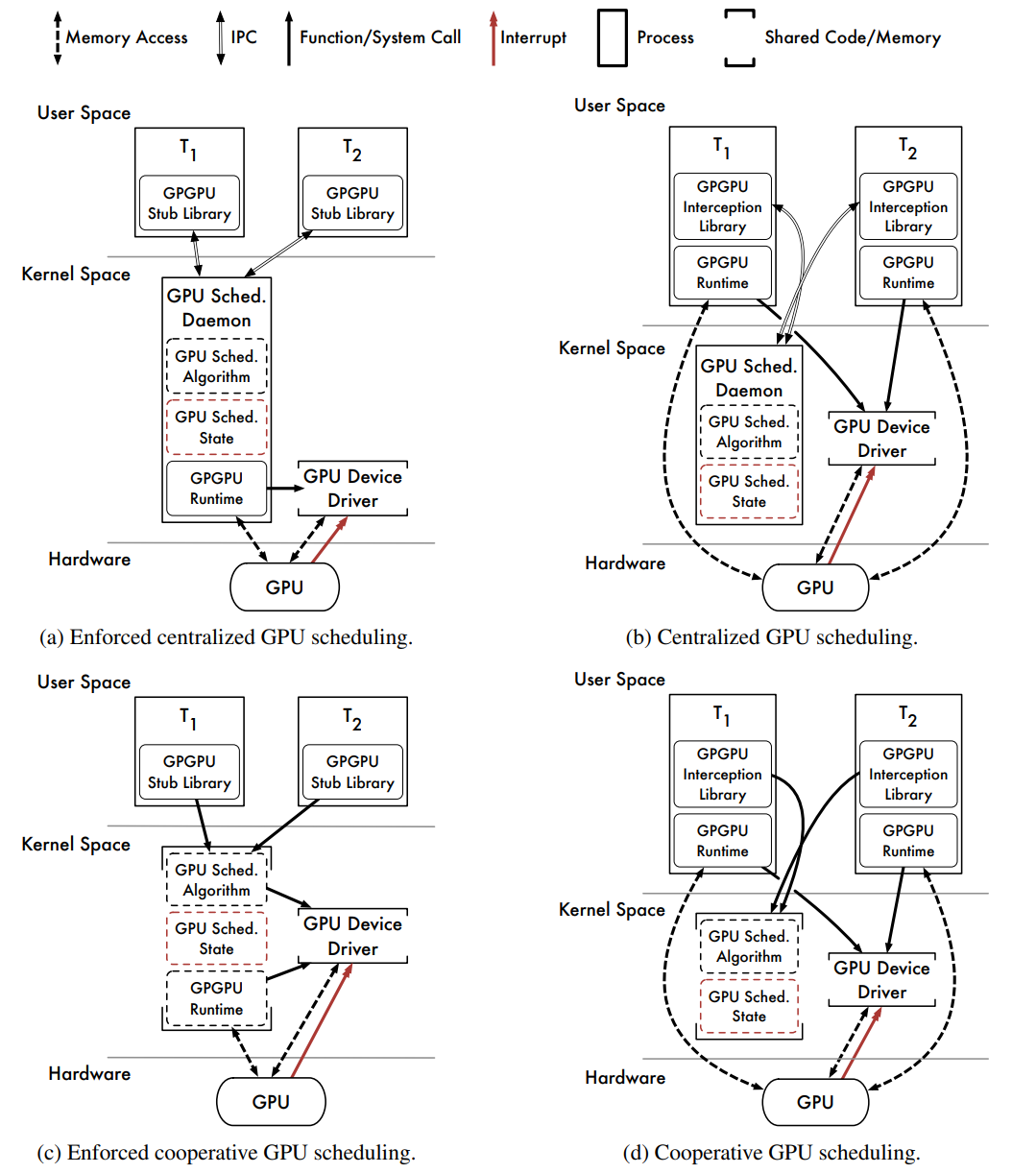
- Centralized Scheduling With Enforcement(���е�����ʵʩ)
��ͼ(a)�����˾��м���ʽ���ȳ����ػ������������ϵ�ṹ������ϵ�ṹ��ͼ3.1(a)����ʾ����ϵ�ṹ�dz�����,�书�ܴ�����ͬ��Ȼ��,GPU�����ػ��������ڴ��ں˿ռ����С�
�ô�:
1��GPU�ں����ݲ���ͨ��IPCͨ�����ơ����ǿ��ܵ�,��ΪGPU�����ػ��������ֱ�ӷ��������������û��ռ��ڴ档�����ܼ���GPGPUӦ�ó����������á�
2�����Ȳ����Ǽ��еġ�
3��ִ�мƻ����ߡ�
ȱ��:
1���ں˿ռ�GPGPU����ʱ���ܲ����á������������ṩ��GPGPU����ʱ�����û��ռ������С�
2��������ػ����̱������е��ȡ�����������ϵͳ����,Ȼ��,���ں˿ռ�����,���Ը����ض��ػ����̽����ʵ������ȼ�����,��ȷ��ʵʱȷ���ԡ�
3���ػ����̱���������ܹ�������������GPU�ں˴��롣
4��IPC��������Ϣ���ݿ�����
������ϵ�ṹ������ǿ�Ƶļ���ʽ����,������IPCͨ���ϴ���GPU�ں������������ݡ�������Ϣ����,���ַ�����Ȼ������һЩIPCͨ��������Ȼ��,���ַ�������ȱ����ʵ����:�ں˿ռ�GPGPU����ʱͨ�������á�����Gdev(������ͼa��d�Ļ�ϼܹ�)��ʾ,�䲻��һ�����˷�����ս,�������ѡ�
- Centralized Scheduling Without Enforcement(���е���,����ǿ��ִ��)
��ͼ(b)��������һ������GPU�����ػ������������ϵ�ṹ,��ܹ����û��ռ��(b)�еļܹ���ƥ��,ֻ���ػ������������ں˿ռ������С�
�ô�:
1��ʹ��ͨ���û��ռ�GPGPU����ʱ��
2�����Ȳ����Ǽ��еġ�
3��GPU�ں�����δͨ��IPCͨ�����ơ�
�ô�:
1����ִ��GPU���Ⱦ��ߡ�
2��IPC��������Ϣ���ݿ�����
3����������ػ���������
����ϵ�ṹ���ں˿ռ伯��ʽ���Ⱥ�ʵ��Լ��֮��������Э�����Ⱦ��������ں˿ռ���������,���ɾ����û��ռ�GPGPU����ʱ�ĵ�������ִ�С����,��ϵ�ṹ��ǿ��ִ������Ⱦ���,�ǻ���Linux��PTaskԭ�������õ���ϵ�ṹ,PTask��һ����ʵʱGPU��������
- Cooperative Scheduling With Enforcement(��ִ�е�Э������)
��ͼ(c)������Э��GPU��������������ϵ�ṹ��GPGPU API���ñ�·�ɵ������,�����ͨ��OSϵͳ���õ����ں˿ռ�GPU���ȳ���GPU���ȳ���״̬������������,���洢���ں˿ռ����ݽṹ�С��ƻ���API�������ں˿ռ�GPGPU����ʱʹ�õ�������ij����߳�ִ�С�
�ô�:
1��GPU���ȳ���״̬�ܱ�������Э���û��ռ��������ͬ,GPU������״̬���ں˿ռ����ܵ�����,��������Ϊ�����������û��ռ��������
2�����ں˿ռ���,��GPU���ȳ���״̬��ͬ��������������ġ��ڸ���GPU���ȳ������ݽṹʱ,��������Ȩ���Է���ռ��ʽִ�С�
3��GPU��������Ч�ġ�
4��ִ�мƻ����ߡ�
�ô�:
1����Ҫ�ں˿ռ�GPGPU����ʱ��
���Ǵ����ܽǶ��о���8����ϵ�ṹ����ǿ��һ��,Э�����Ⱦ����Ǹ�Ч��,��RTOִ�С�GPGPU����ʱ��ʹ�õ�������ij����ջ���ں˿ռ���ִ�е�,�����ǵ������ȵ��ػ�����,û��IPC����,Ψһ�����Ƕ��ں˿ռ�GPGPU����ʱ��������
- Cooperative Scheduling Without Enforcement(��ǿ�Ƶ�Эͬ����)
��ͼ(d)������Э��GPU����������һ��������ϵ�ṹ������Ŀ�����API����,��ͨ��ϵͳ���õ����ں˿ռ�GPU����������֮ǰһ��,GPU���ȳ���״̬������������,�������䲻����Ϊ�����Ͷ��������Ӱ�졣Ҫ�ƻ�API����,GPU���ȳ�����Ȩ���ص�����Ŀ⡣����Ŀ�ʹ���û��ռ�GPGPU����ʱִ�мƻ���API���á�
�ô�:
1��ʹ��ͨ���û��ռ�GPGPU����ʱ��
2��GPU���ȳ���״̬�ܱ�����
3������GPU���ȳ���״̬������ͬ����
4��GPU��������Ч�ġ�
����:
1����ִ��GPU���Ⱦ��ߡ�
Ϊ��֧���û��ռ�GPGPU����ʱ,����ϵ�ṹ������ǿ�ƹ���,ͨ��ֱ�ӷ���GPGPU����ʱ,���������ƹ�����Ŀ⡣�����д�����,�������ܽǶ�����,����Ȼ��һ��ǿ�����ϵ�ṹ����ǰ��ķ���һ��,���Ⱦ�������Ч�ġ�����,û����IPC���ػ�������صĿ���������Ը��ʵ�ֲ���ϵͳ��������о���Ա����Ա��˵,������ϵ�ṹ����ʵ�õĸ�����ѡ�
����������GPU������ص��������
��ͼ����ΪvHybrid��CPU-GPU���ȼܹ�:
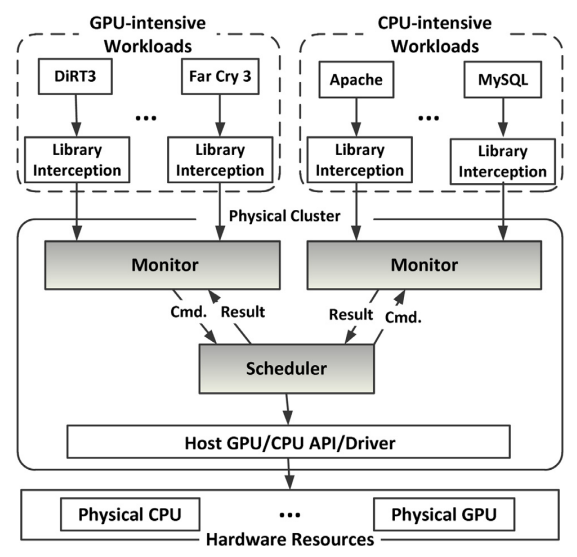
��ͼ��ʹ��klmirqd��GPU�̵߳��Ȼ����ܹ�:
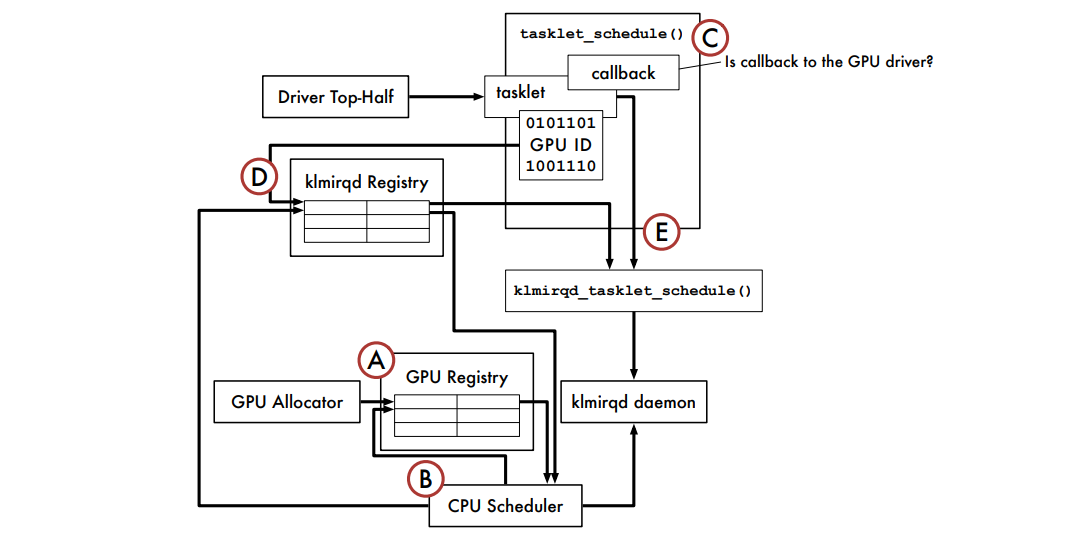
ʹ��GPUSync������ĸ���ִ��������ʾ��:
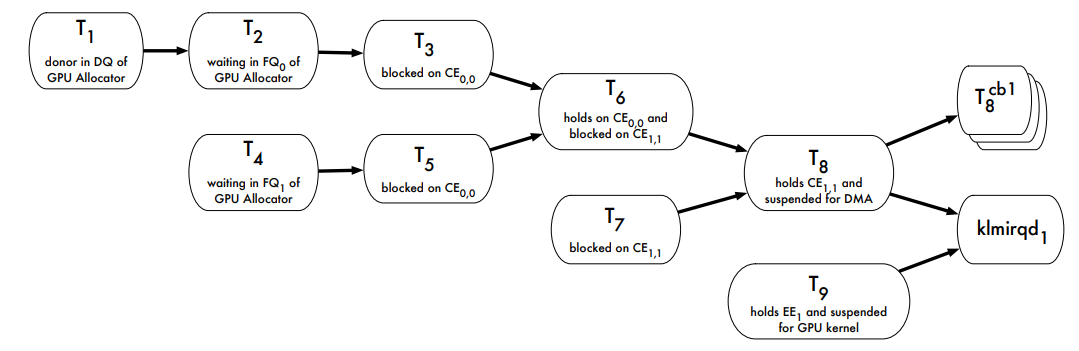
���ƽ̨����:
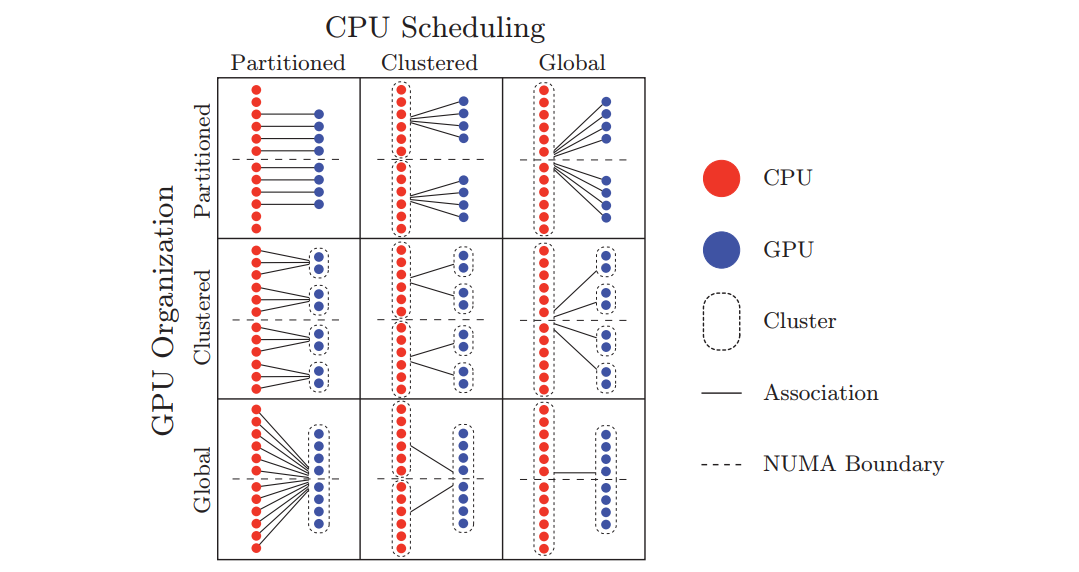
�°벿�ֿ��������ĸ���ͼ:
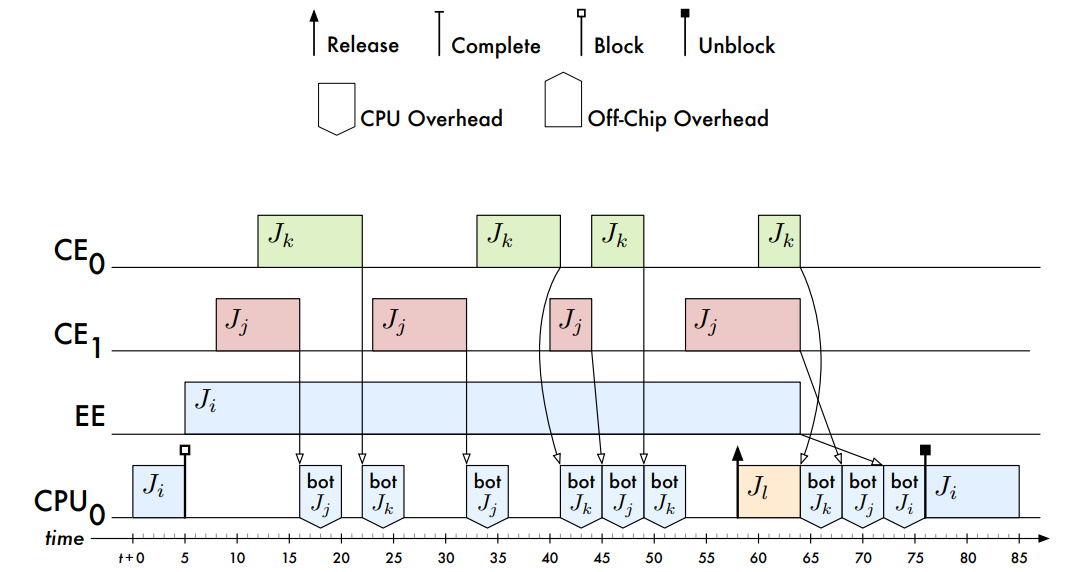
��ӿ������������ٽ������ȵ����:
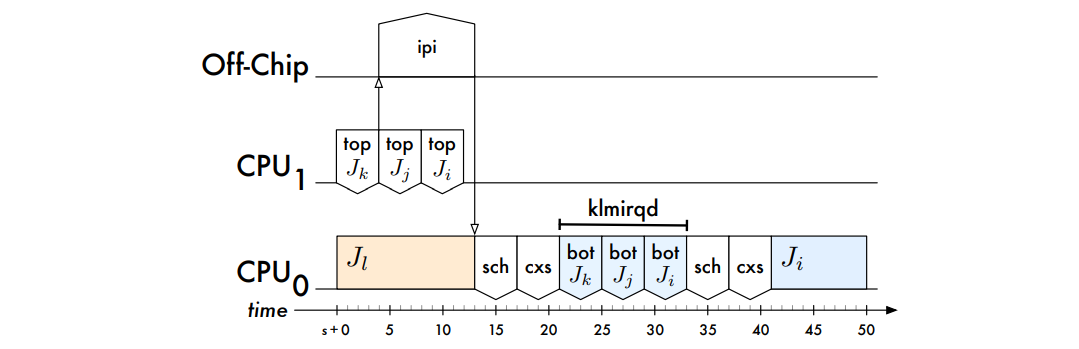
�����ص������ĵ���:
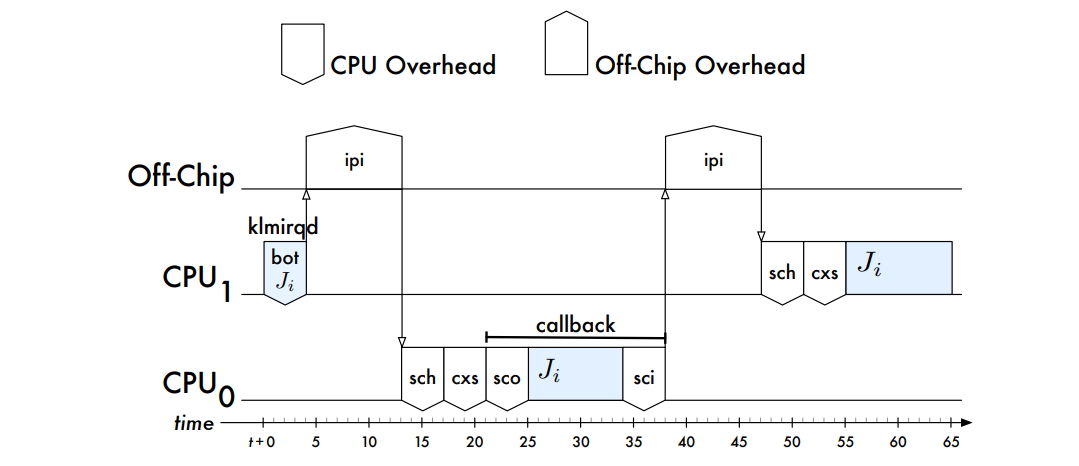
�������鿴����:
- REAL-TIME SCHEDULING FOR GPUS WITH APPLICATIONS IN ADVANCED AUTOMOTIVE SYSTEMS
- GPU Resource Optimization and Scheduling for Shared Execution Environments
16.4 GPU����
16.4.1 NVIDIA
16.4.1.1 Turing�ܹ�
Turing������ʮ���������ļܹ���Ծ,���ṩ��һ���µĺ���GPU�ܹ�,ʹPC��Ϸ��רҵͼ��Ӧ�ó�������ѧϰ�ƶ���Ч�ʺ����ܷ���ȡ�����ش������
ʹ���µĻ���Ӳ���ļ������ͻ����Ⱦ����,Turing�ں��˹�դ����ʵʱ���߸��١�AI��ģ��,��ʵ��PC��Ϸ���������ŵ���ʵ�С�������֧�ֵľ�����Ч������Ӱ�����Ľ�������,�Լ�����������3Dģ��ʱ�����彻����
�ں�����ϵ�ṹ��,Turing��������ͼ�����ܵĹؼ��ٳ������Ǿ��иĽ���ɫ��ִ��Ч�ʵ���GPU������(��ʽ�ദ����SM)��ϵ�ṹ,�Լ�����֧������GDDR6�ڴ漼�������ڴ�ϵͳ��ϵ�ṹ��
ͼ����Ӧ�ó���(��ImageNet Challenge)�����ѧϰ�������ɹ�����֮һ,���AI��DZ�����������Ҫ��ͼ������Ҳ�Ͳ���Ϊ���ˡ�Turing��Tensor CoresΪһ���µĻ������ѧϰ�������ṩ����,����Ϊ�����Ƶ�ϵͳ�ṩ����AI�ƶ���,��Ϊ��Ϸ��רҵͼ���ṩ���˵�ͼ��Ч����

Turing�ĸ����������ԡ�
NVIDIA Turing�����������Ƚ���GPU��ϵ�ṹ,�߶�TU102 GPU������̨����12����FFN(FinFET NVIDIA)���������칤���������186�ڸ�����ܡ�GeForce RTX 2080 Ti Founders Edition GPU������������ļ�������:
- 14.2��ֵ������(FP32)���ܵ�TFLOPS��
- 28.5��ֵ�뾫��(FP16)���ܵ�TFLOPS��
- 14.2 TIPS1ͨ������������ִ�е�Ԫ��FP������
- 113.8 Tensor TFLOPS��
- 10 Giga����/�롣
- 78 Tera RTX-OPS��
Quadro RTX 6000�ṩ��רΪרҵ��������Ƶ�Խ��������:
- 16.3��ֵ������(FP32)���ܵ�TFLOPS��
- 32.6��ֵ�뾫��(FP16)���ܵ�TFLOPS��
- 16.3 TIPSͨ������������ִ�е�Ԫ��FP������
- 130.5����TFLOPS��
- 10 Giga����/�롣
- 84 Tera RTX-OPS��
����,�µ����Ի����µ�Streaming Multiprocessor (SM)��Turing Tensor Core��ʵʱ�����١��µ���ɫ�Ľ�(Mesh Shading��Variable Rate Shading��Texture-Space Shading ��Multi-View Rendering)��Deep Learning��GDDR6�ȵȡ�

Turing�ܹ���TU102 GPU��
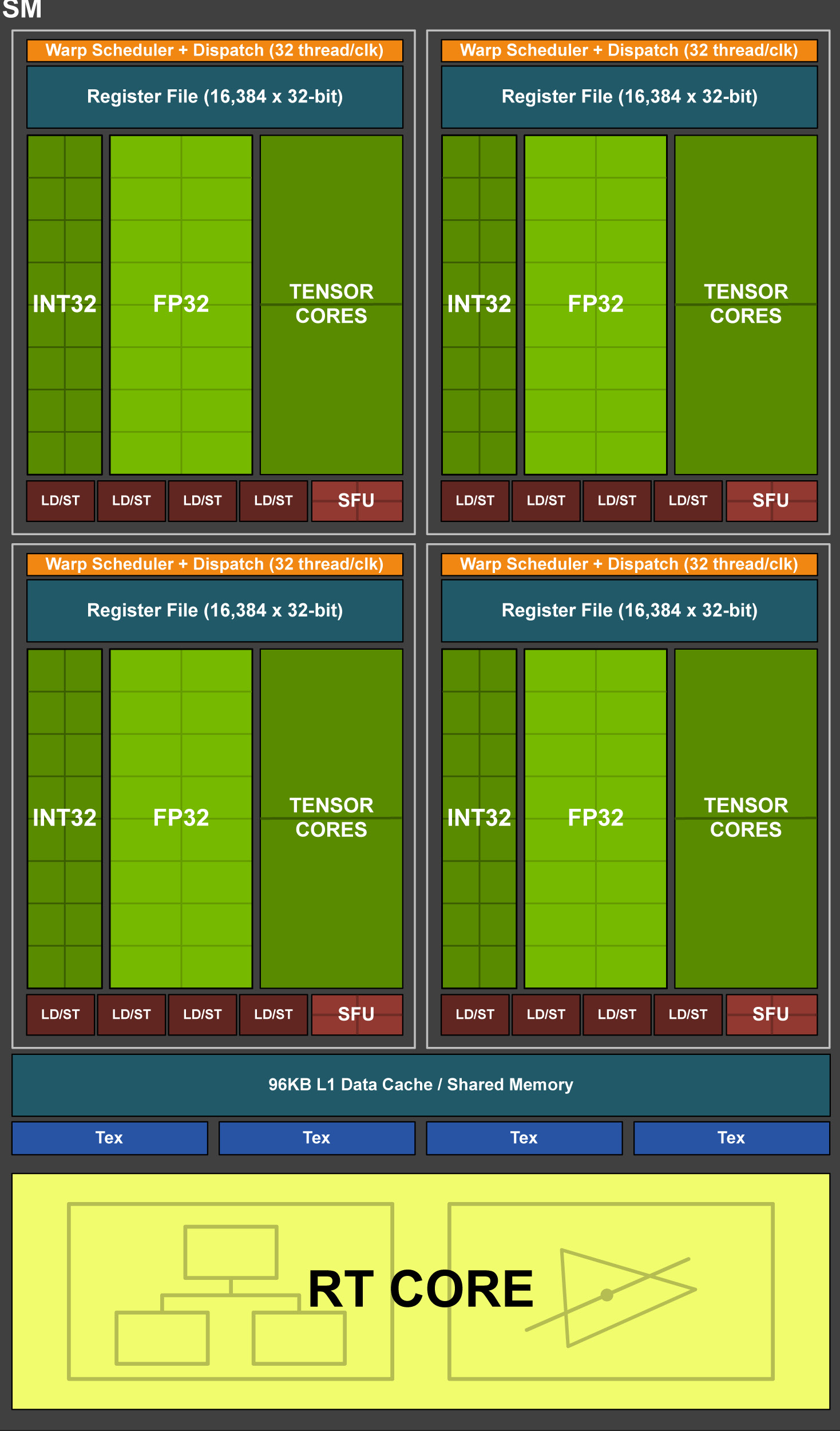
Turing TU102/TU104/TU106 Streaming Multiprocessor (SM)��
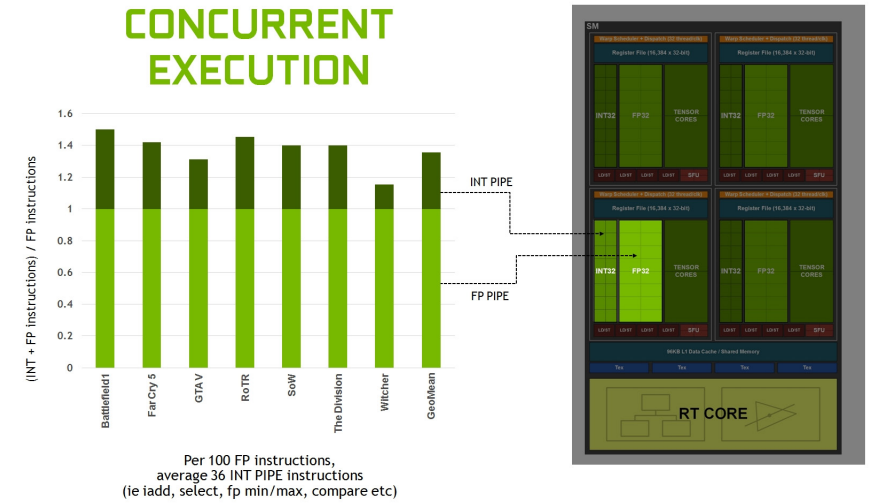
���������������ʾ,ƽ��ÿ100�����������36������������
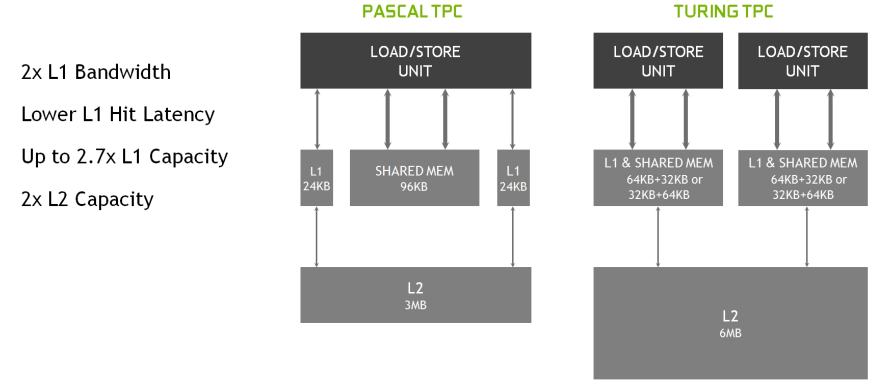
�µĹ����ڴ���ϵ�ṹ��
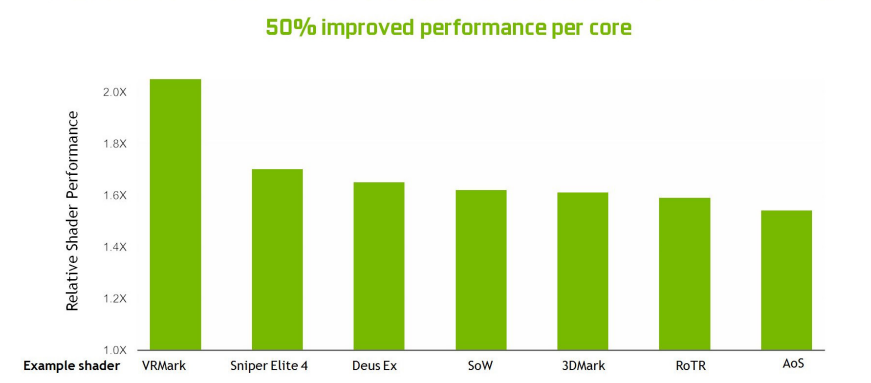
��Pascal���,Turing Shading�����ͬ���������µ����ܼ��ٱȡ�
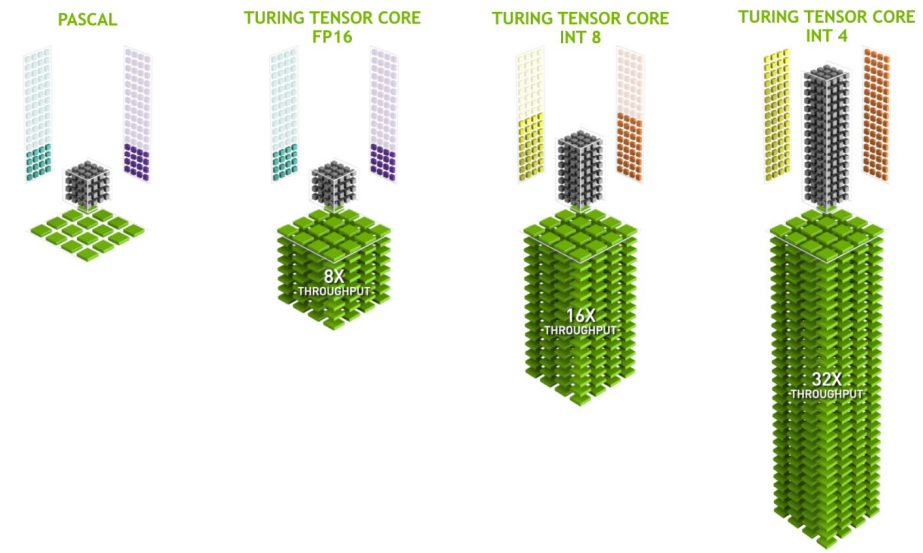
�µ�Turing Tensor CoreΪ�˹����������ṩ�˶ྫ�ȡ�
Turing GDDR6��
ͼ��GPU�����µ�GDDR6�ڴ���ϵͳ֮��,�������˸�����Ķ������档TU102 GPU����6 MB��������,��TITAN Xp��ʹ�õ���һ��GP102 GPU�ṩ��3 MB���������������TU102���ṩ�˱�GP102�ߵö�Ķ����������������һ��NVIDIA GPUһ��,ͼ���е�ÿ��ROP���������˸�ROP��Ԫ,ÿ����Ԫ���Դ���һ����ɫ������������TU102оƬ����12��ROP����,�ܹ�96��ROP��
NVIDIA GPU���ü��������ڴ�ѹ����������������д��֡����洢��ʱ���ڴ��������GPU��ѹ�������и��ֲ�ͬ���㷨,��Щ�㷨�������ݵ�����ȷ��ѹ�����ݵ�����Ч��ʽ,������д���ڴ�ʹ��ڴ洫�䵽���������������,�������˿ͻ���(��������Ԫ)��֡������֮�䴫�����������ͼ���һ���Ľ���Pascal���Ƚ����ڴ�ѹ���㷨,��GDDR6ԭʼ���ݴ����������ӵĻ�����,��һ����������Ч����������ͼ��ʾ,ԭʼ���������Ӻ�ͨ�����ļ�����ζ����Pascal���,Turing�ϵ���Ч����������50%,���ڱ�����ϵ�ṹƽ���֧����Turing SM��ϵ�ṹ�ṩ������������Ҫ��
�����Pascal GP102��1080 Ti���,����Turing TU102��RTX 2080 Ti���ڴ���ϵͳ��ѹ��(��������)�Ľ��ṩ�˴�Լ50%����Ч�����Ľ���
����,Turing�������Ե�������ʵʱ�����ٵ�֧��,�����˻�Ϲ���:

Turing GPU���Լ�������������Ⱦ�ͷ���Ⱦ������ʹ�õĹ��߸��ټ���:
- ��������䡣
- ��Ӱ�ͻ������ڵ���
- ȫ��������
- ��ʱ���߹�����ͼ�決��
- ��������Ƭ��������Ԥ����
- ����ע�ӵ�VR��Ⱦ�������ߡ�
- �ڵ�����
- ��������ײ��⡢����ģ�⡣
- ��Ƶģ��(����,NVIDIA VRWorks��Ƶ������OptiX API֮��)��
- AI�ɼ��Բ�ѯ��
- ������·������(��ʵʱ)���ɲο���Ļ��ͼ,���ڵ���ʵʱ��Ⱦ������ȥ���������ʺϳɺͳ���������
��û��Ӳ�����ٵ������,���߸�����Ҫÿ��������ǧ������ָ���,�Ա���BVH�ṹ���������Խ�С�İ�Χ��,ֱ����������������Ϊֹ������һ�������ܼ��͵Ĺ���,���û�л���Ӳ���Ĺ��߸��ټ���,�Ͳ�������GPU��ʵʱ���(����ͼ)��
��ͼ˵���˴�ͳ�Ĺ�դ������ɫ����,3D��������դ����ת��Ϊ��Ļ�ռ��е�����,�����ؽ��пɼ��Բ��ԡ������ɫ���Ժ���Ȳ��ԡ����в�������������ͬ����Ļ�ռ�����������,����ͬ�������ϡ�
ʹ�������ռ���ɫ(Texture Space Shading,TSS),�ɼ��Բ���(��դ����z����)����۲���(��ɫ)��������Ҫ�������Խ���,���Բ�ͬ�����ʡ��ڲ�ͬ�IJ��������ϡ������ڲ�ͬ��ʱ������ִ�С���ɫ���̲���ֱ�Ӱ���Ļ�ռ�����,���Ƿ����������ռ��С�����ͼ��,�������Ա���դ����������Ļ�ռ�����,�ɼ��Բ���������Ļ�ռ��н��С�Ȼ��,��������Ļ�ռ�����ɫ,���Ƿ�����Ҫ����������ص����������仰˵,��Ļ�ռ����ص��㼣ӳ�䵽�����������ռ���,���������ռ��жԹ�����texel������ɫ��ӳ�䵽�����ռ���һ�ֱ�������ӳ�����,��LOD�������Թ��˵Ⱦ�����ͬ�Ŀ��ơ�Ϊ���������յ���Ļ�ռ�����,���Ǵ���ɫ�����в����������Ǹ���ʾ�������贴����,��Ϊ���õ���������ֵ��
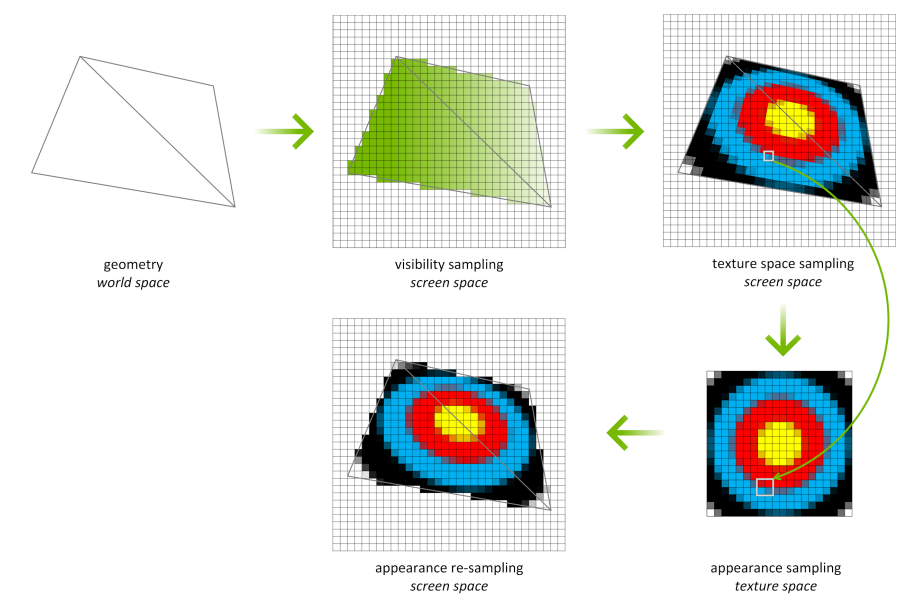
TSS��һ��ʾ�����������VR��Ⱦ��Ч��,��ͼ��ʾ��VR��Ⱦ��TSS��һ��ʾ����������VR��,��Ⱦһ������ͼ��,���ۿɼ��ļ�������Ԫ��Ҳ��ʾ��������ͼ�С�ʹ��TSS,���ǿ��Զ�����������ͼ������ɫ,Ȼ��ͨ������ɵ�������ͼ��������Ⱦ������ͼ��������ͼֻ����δ�ҵ���Ч����������¶�������������ɫ(����,�����۽Ƕȿ�,������������ͼ�б��ڵ�,�����ۿɼ�)��

**����ͼ��Ⱦ(MVR)**����������Ա�Ӷ���ӵ��Ч�ػ��Ƴ���,�����Բ�ͬ���ƻ��ƽ�ɫ�Ķ��ʵ��,������Щ����һ��ͨ������ɡ�TuringӲ��ÿ���������֧���ĸ���ͼ,��API�������֧��32����ͼ��ͨ��ֻ��ȡһ�μ����岢������ɫ,Turing��������Ⱦ����汾ʱ����ѷ�ʽ���������μ�������Ķ������ԡ���ͨ��D3D12��ͼʵ����API����ʱ,������Աֻ��ʹ�ñ���SV_ViewID��������ͬ�ı任�������ò�ͬ�Ļ��Ȩ�ػ��������ϲ�����κ���ɫ����Ϊ,��Щ��Ϊȡ�����������ڴ�������ͼ��
��ͼ��ʾ��200�� FOV HMD������,����ʹ����������б���,��ҪMVR����ı�������MVR�������Ҳ������֧�ֱ�����VR��ʾ���ĸ���ȷУ,���뵥���û����沿���롣��������Ⱦ��,�۾�ֻ����X�������ƫ�Ƶļ��貢����ȫ��ȷ,ʵ���ϻ���һЩ����IJ��Գ�,��Ҫ����ͶӰ���ܻ����ߵı���ȶ��롣

200��FOV HMD,����ʹ��������б���,��������MVR��

MVR��ͨ��������Ӱ��ͼ��Ⱦ��
16.4.1.2 Ampere�ܹ�
NVIDIA Ampere��ϵ�ܹ�GPUϵ�е����³�ԱGA102��GA104,GA102��GA104����Ӣΰ�GA10x����Ampere�ܹ�GPU��һ����,GA10x GPU���ڸ����Ե�NVIDIA Turing GPU�ܹ���
GeForce RTX 3090��GeForce RTXϵ����������ߵ�GPU,רΪ8K HDR��Ϸ��ơ�ƾ��10496��CUDA�ںˡ�24GB GDDR6X�ڴ���µ�DLSS 8Kģʽ,��������8K@60fps��GeForce RTX 3080��������GeForce RTX 2080������,ʵ����GPU��ʷ��������һ����Ծ,GeForce RTX 3070�����ܿ���NVIDIA��һ���콢GPU GeForce RTX 2080 Ti������,GA10x GPU��������HDMI 2.1��AV1���빦�������û�ʹ��HDR��8K���ٶȴ������ݡ�
NVIDIA A40 GPU���������������ܺͶ���������������һ�θ����Է�Ծ,����һ����רҵͼ����ǿ��ļ����AI��������,��Ӧ�Ե������ơ�����Ϳ�ѧ��ս��A40������RTX A6000��ͬ���ں��������ڴ��С,��Ϊ��һ�������վ�ͻ��ڷ������Ĺ��������ṩ������NVIDIA A40����Ч����һ���߳�2��,��Ϊרҵ��ʿ�����˹��߸�����Ⱦ��ģ�⡢�������������Ƚ��Ĺ��ܡ�

Ampere GA10x��ϵ�ṹ���о�ķ�Ծ��
GA102�Ĺؼ�������2��FP32�������ڶ���RT Core��������Tensor Core��GDDR6X��GDDR6�ڴ桢PCIe Gen 4�ȡ�
��֮ǰ��NVIDIA GPUһ��,GA102��ͼ�δ�����Ⱥ(Graphics Processing Cluster,GPC)������������Ⱥ(Texture Processing Cluster,TPC)����ʽ�ദ����(Streaming Multiprocessor,SM)����դ������(Raster Operator,ROP)���ڴ��������ɡ�������GA102 GPU����7��GPC��42��TPC��84��SM��
GPC����Ҫ�ĸ�Ӳ����,���йؼ�ͼ�δ�����Ԫ��λ��GPC�ڲ���ÿ��GPC������һ��ר�õĹ�դ����,���ڻ���������ROP����(ÿ�����������˸�ROP��Ԫ),��NVIDIA Ampere Architecture GA10x GPU��һ���¹��ܡ�GPC��������TPC,ÿ��TPC��������SM��һ��PolyMorph���档
GA102 GPU������168��FP64��Ԫ(ÿ��SM����),FP64 TFLOP������FP32����TFLOP���ʵ�1/64������������FP64Ӳ����Ԫ,��ȷ���κδ���FP64����ij�������ȷ����,����FP64 Tensor Core���롣
GA10x GPU�е�ÿ��SM����128��CUDA�ˡ��ĸ�������Tensor�ˡ�һ��256 KB�ļĴ����ļ����ĸ�������Ԫ��һ���ڶ������߸��ٺ˺�128 KB��L1/�����ڴ�,��Щ�ڴ���Ը��ݼ����ͼ�ι������ص���Ҫ����Ϊ��ͬ��������GA102���ڴ���ϵͳ��12��32λ�ڴ���������(��384λ),512 KB�Ķ���������ÿ��32λ�ڴ���������,��������GA102 GPU��������Ϊ6144 KB��
Ampere�ܹ�����ROPִ�����Ż�������ǰ��NVIDIA GPU��,ROP���ڴ�������Ͷ������档��GA10x GPU��ʼ,ROP��GPC��һ����,ͨ������ROP������������ɨ��ת��ǰ�˺�դ�������֮�����������ƥ������߹�դ���������ܡ�ÿ��GPC��7��GPC��16��ROP��Ԫ,������GA102 GPU��112��ROP���,��������ǰ��384λ�ڴ�ӿ�GPU(��ǰһ��TU102)�п��õ�96��ROP���˷����ɸĽ����������ݡ���������ʺͻ�����ܡ�
��SM�ܹ�����,ͼ��SM��NVIDIA�ĵ�һ��SM��ϵ�ṹ,�������ڹ��߸��ٲ�����ר���ںˡ�Volta GPU������������,Turing������ǿ�ĵڶ��������ˡ�Turing��Volta SMs֧�ֵ���һ����Dz���ִ��FP32��INT32������GA10x SM�Ľ����������й���,ͬʱ������������ǿ����¹��ܡ�����ǰ��GPUһ��,GA10x SM������Ϊ�ĸ�������(�����),ÿ�������鶼��һ��64 KB�ļĴ����ļ���һ��L0ָ��桢һ��warp���ȳ���һ�����ȵ�Ԫ�Լ�һ����ѧ��������Ԫ�����ĸ���������һ��128 KB��һ�����ݻ���/�����ڴ���ϵͳ����ÿ���������������ڶ��������ˡ��ܹ��˸������˵�TU102 SM��ͬ,�µ�GA10x SMÿ����������һ��������������,�ܹ��ĸ�������,ÿ��GA10x�����˵Ĺ�����ͼ�������˵���������Turing���,GA10x SM��һ�����ݻ�������ڴ���������Ҫ��33%������ͼ�ι�������,�������������ͼ�������,��32KB���ӵ�64KB��

GA10x Streaming Multiprocessor (SM) ��
GA10x SM����֧��ͼ��֧�ֵ�˫��FP16(HFMA)��������TU102��TU104��TU106ͼ��GPU����,��FP16������GA10x GPU�е������˴�����FP32�������ıȽ�X�������±�:
| Turing | GA10x | |
|---|---|---|
| FP32 | 1X | 2X |
| FP16 | 2X | 2X |
��ǰ����,��ǰһ��ͼ����ϵ�ṹһ��,GA10x�������ڹ����ڴ桢һ�����ݻ�������������ͳһ��ϵ�ṹ������ͳһ��ƿ��Ը��ݹ������ؽ�����������,�Ա������ҪΪL1�����ڴ��������ڴ档һ�����ݻ������������ӵ�ÿ��SM 128 KB���ڼ���ģʽ��,GA10x SM��֧����������:
- 128 KB L1 + 0 KB Shared Memory
- 120 KB L1 + 8 KB Shared Memory
- 112 KB L1 + 16 KB Shared Memory
- 96 KB L1 + 32 KB Shared Memory
- 64 KB L1 + 64 KB Shared Memory
- 28 KB L1 + 100 KB Shared Memory
Ampere�ܹ���RT Core��Turing��RT Core������/�������ཻ�����ٶ������һ��:
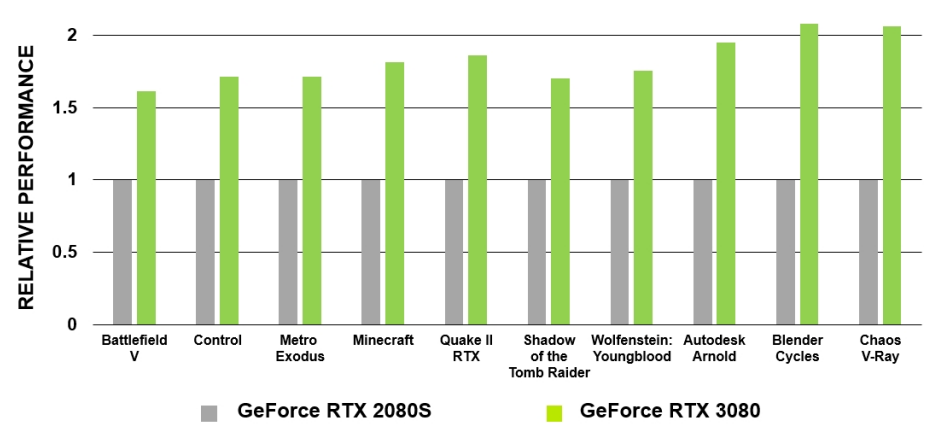
GA10x GPUͨ��һ���¹�����ǿ����ǰNVIDIA GPU���첽���㹦��,�ù���������ÿ��GA10x GPU SM��ͬʱ����RT Core��ͼ�λ�RT Core�ͼ��㹤�����ء�GA10x SM����ͬʱ�����������㹤������,���Ҳ�����ǰ��GPU������������ͬʱ�����ͼ��,�������ڼ���Ľ����㷨�ȳ��������RT Core�Ĺ��߸��ٹ���ͬʱ���С�

���Turing�ܹ�,NVIDIA Ampere��ϵ�ṹ����Ⱦͬһ��Ϸ�е�ͬһ֡ʱ,�ɴ���������:
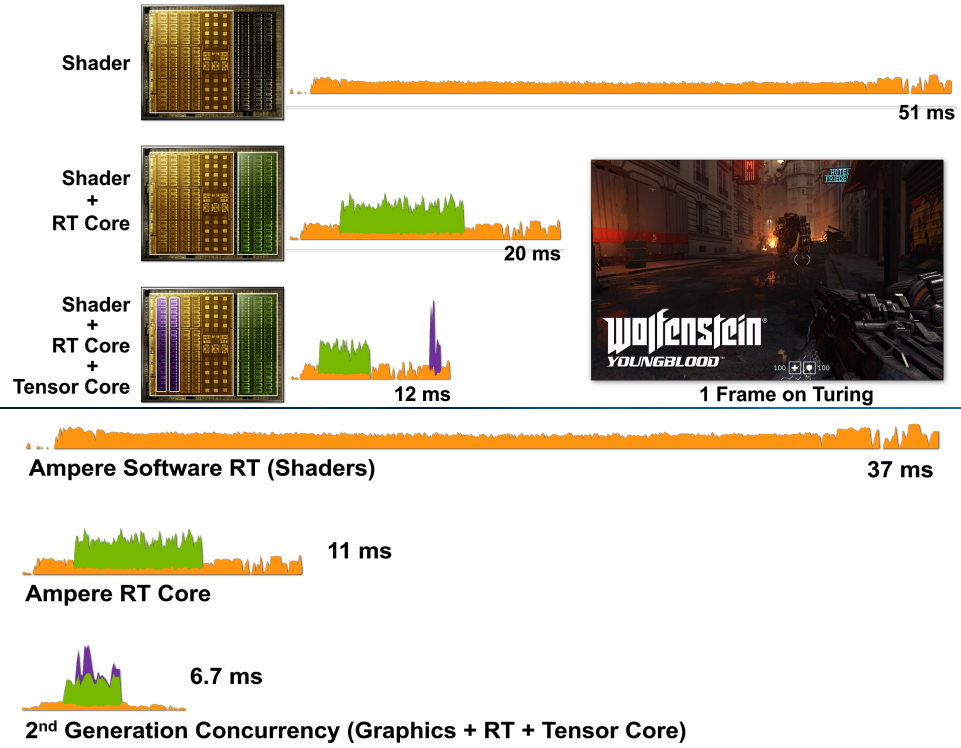
��:����ͼ���RTX 2080����GPU��ȾWolfenstein��һ֡:��ʹ����ɫ������(CUDA����)����ɫ������+RT���ĺ���ɫ������+RT����+�������ĵ�Youngblood����ע��,�����Ӳ�ͬ��RTX�����ں�ʱ,֡ʱ�����١�
��:���ڰ�����ϵ�ṹ��RTX 3080 GPU��Ⱦһ֡Wolfenstein:Youngblood��ʹ����ɫ������(CUDA����)����ɫ������+RT���ĺ���ɫ������+RT����+�������ġ�
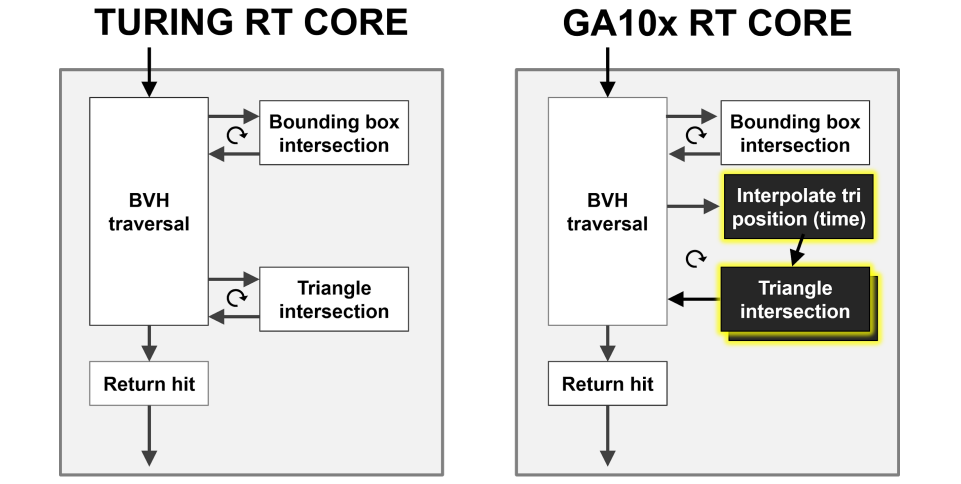
GA10x RT Coreʹ����/�������ཻ�������ʱ�Turing RT Core�����һ��,��������һ���µIJ�ֵ������λ�ü��ٵ�Ԫ,��Э�����߸����˶�ģ��������
������ϡ���Ե������,GeForce RTX 3080�ṩ��FP16 Tensor��о������ֵ��������GeForce RTX 2080 Super��2.7��,���߾����ܼ���Tensor��о����:
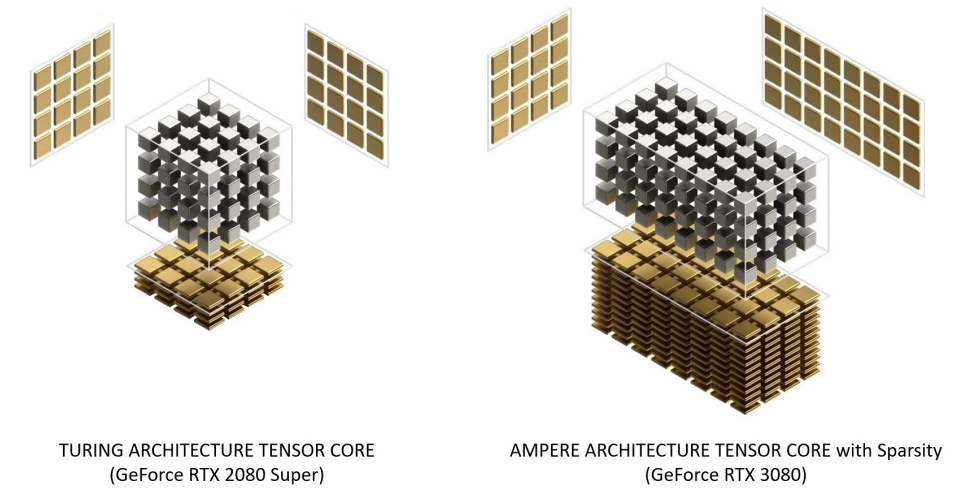
ϸ���Ƚṹ��ϡ����ʹ����ȡ������ģʽ��ѵ��Ȩ��,Ȼ����������Ȩ�صļ�ͨ�÷�������Ȩ�ؽ���ѹ��,ʹ����ռ�úʹ�������2��,ϡ���������IJ���ͨ��������ʹ��ѧ�������ӱ���(��ͼ)
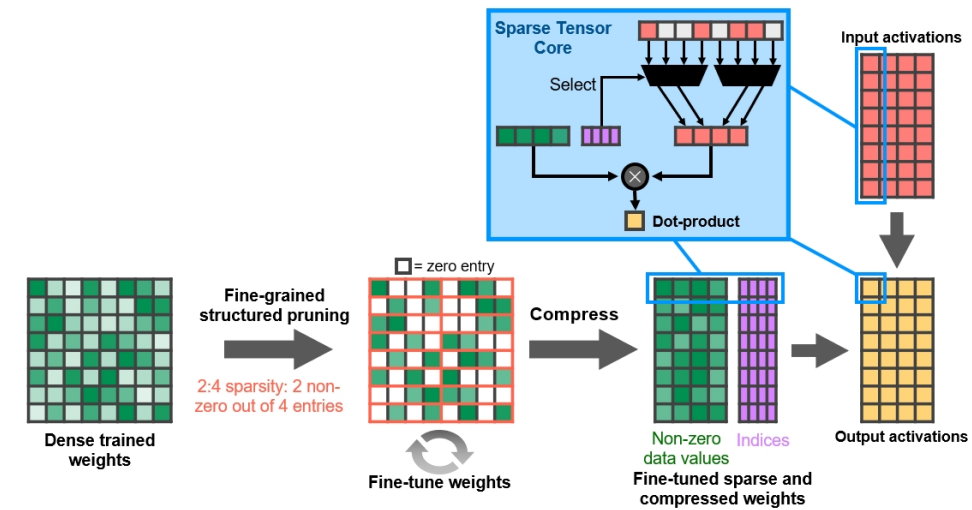
��ͼ��ʾ��GDDR6(��)��GDDR6X(��)֮���������(data eye)�Ƚ�,ͨ��GDDR6X�ӿڿ�����GDDR6��һ��Ƶ�ʴ�����ͬ����������,����,�ڸ����Ĺ���Ƶ����,GDDR6X����ʹ��Ч������GDDR6����һ����
GDDR6Xʹ��PAM4������������ܺ�Ч�ʡ�
Ϊ�˽��PAM4����������������ս,������һ����ΪMTA(���������,����ͼ)���±��뷽��,�����Ƹ����źŵ�ת�ơ�MTA�ɷ�ֹ�źŴ���ߵ�ƽת������͵�ƽ,��֮��Ȼ,�Ӷ���߽ӿ�����ȡ�����ͨ���ڱ���ܽ��ϴ�����ֽ���Ϊÿ���ܽŷ���һ��������ͻ��(ʱ�佻��),Ȼ��ʹ������ѡ������ֽ�����ͻ����ʣ�ಿ��ӳ�䵽û�����ת����������ʵ�ֵġ�����,���������µĽӿ���ѵ������Ӧ�;��ⷽ�������,��װ��PCB�����Ҫ��ϸ�滮��ȫ����źź͵�Դ�����Է���,��ʵ�ָ��ߵ��������ʡ�

�ڴ�ͳ�Ĵ洢ģ����,��Ϸ���ݴ�Ӳ�̶�ȡ,Ȼ���ϵͳ�ڴ��CPU����,Ȼ���ٴ��䵽GPU,ʹ��IO������Ϊ��Ϸ������ƿ��:
ʹ�ô�ͳ�Ĵ洢ģ��,��Ϸ��ѹ����������Threadripper CPU�ϵ�����24���ںˡ��ִ���Ϸ�����Ѿ������˴�ͳ�洢API����������Ҫ��һ��������/�����ϵ�ṹ�����ݴ�������Ϊ��ɫ��,����CPU�ں�Ϊ��ɫ/��ɫ�顣��Ҫѹ������,��CPU������:
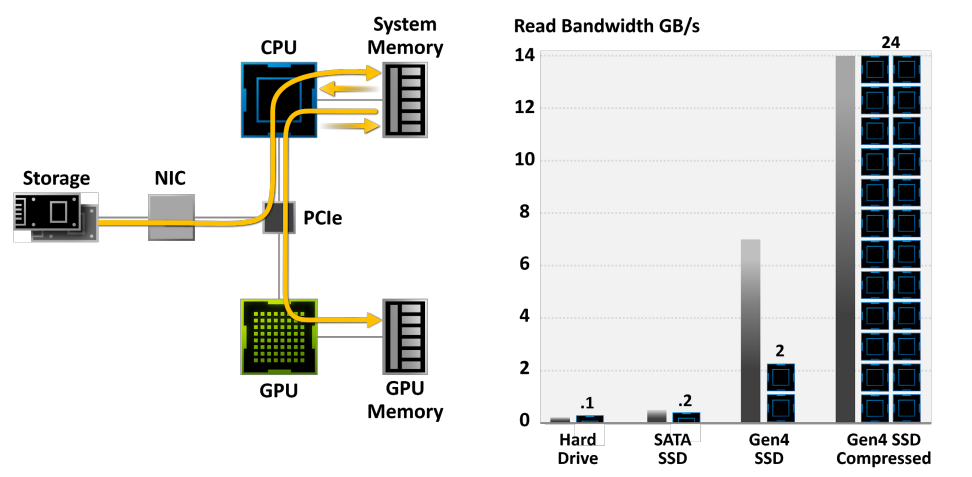
NVIDIA RTX IO����Microsoft�����Ƴ���DirectStorage API,����һ����һ���洢��ϵ�ṹ,רΪ�䱸���Ƚ�NVMe SSD����ϷPC���ִ���Ϸ����ĸ��ӹ������ض���ơ���֮,ר��Ϊ��Ϸ���Ƶ������ͺͲ��л�API������������IO����,������ȵ���ߴ�NVMe SSD��֧��RTX IO��GPU������/�������������,NVIDIA RTX IO�����˻���GPU�������ѹ��,����ͨ��DirectStorage���еĶ�ȡ����ѹ��,�����͵�GPU���н�ѹ�����˼���������CPU�ĸ���,�Ը���Ч����ѹ������ʽ�����ݴӴ洢���ƶ���GPU,����I/O���������������
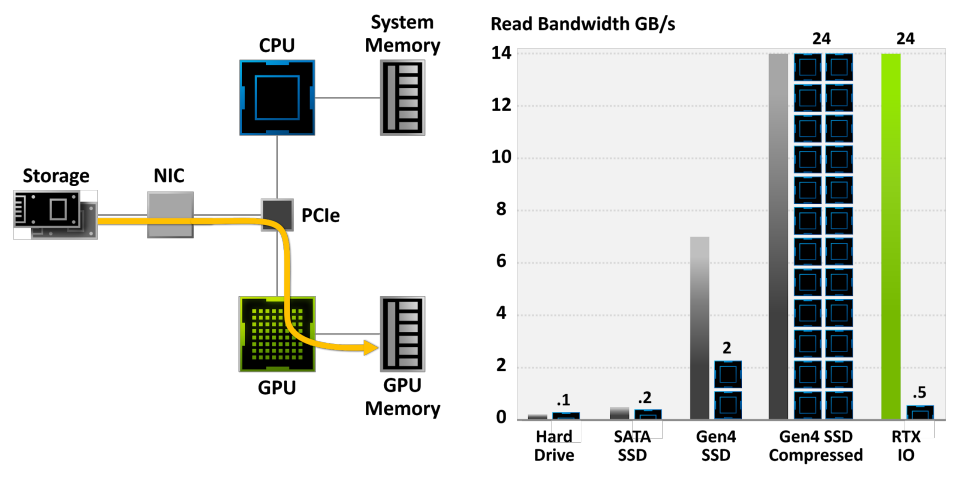
RTX IO�ṩ100����������,20����CPU�����ʡ����ݴ�������Ϊ��ɫ����ɫ��,����CPU�ں�Ϊ��ɫ/��ɫ�顣
�ؿ�����ʱ��Ƚϡ����ز�����24��Threadripper 3960xƽ̨������,ԭ��Gen4 NVMe m.2 SSD,alpha������
16.4.1.3 Nouveau
��Nouveau���Ƿ����С�new������˼��Nouveau��Ŀּ��ΪnVidia�����������������/���ɵ�������������,Nouveau��Linux�ں�KMS��������(Nouveau)��Mesa�е�Gallium3D���������Xorg DDX(xf86 video Nouveau)���,�ں����Ҳ����ֲ��NetBSD��������https://nouveau.freedesktop.org/index.html��
����GPU��֧��2D/3D����(GA10x����),�����pre-Maxwell��֧����Ƶ�������,��GM10x Maxwell��Kepler��Tesla G94-GT218 GPU��֧���ֶ����ܼ���ѡ��GM20x���µ�GPU����������ϣ����ã,��Ϊ���̼���ҪNVIDIAǩ����ܻ�ñ�Ҫ�ķ���Ȩ�ޡ�����ĸ�����2021��1��:Linux 5.11�кϲ���GA10x�ں�ģʽ����֧�֡�
Nouveau���ʹ��Mesa 3D��ֱ����Ⱦ������ʩ(DRI)��Ⱦ3D�����ͼ��,����ֱ�Ӵ�3DӦ�ó���ʹ��ͼ�δ�����Ԫ(GPU)����3D����;����2008��2��,DRI֧�ַ���Ĺ���ֹͣ��,��ת�Ƶ����µ�Gallium3D��2013��9��23��Nvidia��������,���ǽ�����һЩ������GPU���ĵ�,ּ�ڽ��Ӱ��Nvidia GPU��nouveau���ֳɿ����Ե�����2016��7��9��,Red HatԱ��Ben Skeggs�ύ��һ������,�ò�������GeForce GTX 1070��GeForce GTX 1080Ʒ��ͼ�ο��ϻ���Pascal��GP104оƬ��֧�����ӵ�Linux�ں��С�XDC2016������2016�����״��δ���Ĺ���,FOSDEM����ʾ��OpenCL���¹���״̬��2019��,NVidia�ṩ��һЩ�йؿ����ա����˹Τ����˹�����ֶ���оƬ����ĵ���
����Nouveau,֧��NVIDIA�Կ�����������pscnv��DirectFB nVidia driver��BeOS/Haiku nVidia driver��Utah-GLX��xfree 3.3.3 nvidia driver�ȡ�2022��5��,NVIDIA�ͷ���֧������NV GPU��Linux�ں�����ģ��,Դ����:NVIDIA Linux Open GPU Kernel Module Source��
16.4.2 AMD
AMD Radeon������һ�����ڸ�Micro Devicesͼ�ο���APU���豸���������ʵ������������ͼ���û�������Electron����,����64λWindows��Linux���а���ݡ�
��������ǰ��ΪAMD Radeon Settings��AMD Catalyst��ATI Catalyst��AMD Radeon����ּ��֧��GPU��APUоƬ�ϵ����й��ܿ�,����������Ⱦ��ָ�������,��������ʾ����������������Ƶ����(ͳһ��Ƶ������(UVD))����Ƶ����(��Ƶ��������(VCE))��SIP�顣�豸��������֧��AMD TrueAudio,��һ������ִ��������ؼ����SIP�顣
Radeon���������Ĺ���:��Ϸ�����ļ���������Ƶ�ͽ�Ƶ�����ܼ�ء�¼�ƺ���ý�塢�������Ƶ����Ļ��ͼ��������������֪ͨ������advisor�ȡ����֧�ֶ���ʾ������Ƶ���١���Ƶ���١�������ʡ��GPGPU���ȹ���,��֧��D3D��Mantle��OpenGL��Vulkan��OpenCL��ͼ��API��
GCNͨ�����Ӳ������������֧��,�뻺��һ����һ�������������ڴ档�����ڴ��������ڴ�����������ս�Եķ���,���ṩ���µĹ��ܡ�AMD�ڸ�����ͼ�κ�����������Ķ���ר����������,��ΪGCN�������ڴ�ģ���ѱ���ϸ����Ϊ��x86���ݡ��˾ټ��˳�ʼ��Ʒ��CPU����ɢGPU֮��������ƶ�,����Ҫ����,��ΪCPU��GPU�칲���ĵ�����ַ�ռ���ƽ�˵�·���������Ǹ������ݶ������ܺ���Ч������Ҫ,Ҳ��AMD���ٴ�����Ԫ(APU)���칹ϵͳ�еĹؼ�Ԫ�ء�
GCN����������������������ո�API����,������ӳ�䵽��ͬ�Ĵ����ܵ���GCN��������Ҫ�ܵ����첽��������(ACE)�������������ɫ��,��ͼ�������������ͼ����ɫ���̶�����Ӳ����ÿ��ACE�����Դ������е���������ͼ�������������Ϊÿ����ɫ�������ṩ������������,�Ӷ����������Ĺ���������GCN�Ķ�����
AMD GCN�ܹ��Ļ����νṹ��
16.4.3 Intel
��ͼ��ʾ��Intelͼ��ƽ̨�������Ĺ���ջ����ijɷ�,�Լ�ÿ������ļ�Ҫ˵����
- Intel Graphics Controller:�����ڵ�7��Intel Core�����������°汾�е�ͼ������Ӳ��,���ڽ���ͳ���HDR���ݡ�����ʾ����ͨ��HDMI��DisplayPort���½�HDR�źŴ��䵽HDR��ʾ����
- Intel Graphics Driver:��������Ӧ��Ӳ����,����Ҫ�ض�����������汾,ʼ�ս����ȡintel.com��PC OEM��վ��ͨ��Windows Update�Ϸ���������ͼ����������
- Operating System:Windows 10����ϵͳ���ʵ��汾,Windows 10 Fall Creators Update(RS3)���κν��°汾�����õ���Ͳ���ϵͳ�汾��
- LSPCON:Ҫ�ڵ�7��Intel Core��������ͨ��HDMIʵ��HDR����,�����ϱ�����һ����ΪLSPCON(��ƽ��λ����Э��ת����)�Ķ���Ӳ�����,��һ�ֱ�����PC�����̰�װ�����,�����û������ӡ�ע��,LSPCON��������HDMI,����������DisplayPort����ʹ�õ�9��Intel Core����������߰汾HDMI2�Ľ���ƽ̨��,ԭ��֧��2.0,��˲���ҪLSPCON֧�֡�
- LSPCON FW:LSPCON����Ҫ��ȷ�汾��FW��
- System BIOS:�ر��Ƕ��ڳ��������ⲥ��,ϵͳBIOS������ȷ������֧��Intel Software Guard Extensions(SGX)��
- Intel CSME FW:��ҪIntel Management Engine(ME)�̼��汾����ʵ�ֱ�Ҫ��HW-DRM֧�ֺ�HDCP2.2��HDR��Ƶ������Ҫ��·����,ͨ��������ϵͳ������ӵ�е�ϵͳBIOS�С�
- Intel MEI Driver:���밲װ����������,�Ա�����������ME FWͨ�š�
- Application:����HDR������Ҫ�ض���Ӧ�ó����internet�����(��Microsoft Edge)��
- Content:HDR��Ƶ�ļ����Բ�ͬ����Դ,Ҫ��ijЩ��ý���ṩ��(��Netflix)����HDR����,��������ʵ��ļƻ�/�ʻ����͡�
- HDR display:�����豸��������ʾ�����ṩ�˳�Ϊ��չ��̬��Χ(EDR)�IJ���HDR����,���ʼDZ����Ժ�ƽ����Ե�������ʾ������ʵ��������HDR���š�
- Display connector:���������ӵ�HDR��ʾ����������ʾ�ӿ�(�ӿ�)������HDMI��DisplayPort��mini DisplayPort��USB Type-C��Ѱ��HDCP2.2֧�ֺ���Ҫ,�ɽ������ݴ��䵽��ʾ������ġ�
- Cable/ dongle:����֧�ֱ���HDMI��DP��������PC,����ֱ��ʹ���ʵ��ĵ������ӵ���ʾ�������PC����USB Type-C�˿�(֧��Thunderbolt 3��DP Altģʽ),����Ҫ����������ܹ���USB Type-Cת��ΪHDMI2.0��DisplayPort,�Լ�֧��HDCP2,miniDP������Ҳ��Ҫ���Ƶ�������,�����������ɴӵ�������Ӧ�̴����,��Club3D��BelkinUptab�ȡ�
����,**Intel Graphics Media Accelerator(GMA)**��Intel��2004���Ƴ���һϵ�м���ͼ�δ�����,ȡ�������ڵ�Intel Extreme Graphicsϵ��,����Intel HD��Iris Graphicsϵ��ȡ��,��ϵ������ͳɱ�ͼ�ν�������г�����ϵ�в�Ʒ������������,ͼ�δ�����������,��ʹ�ü���������ڴ������ר����Ƶ�ڴ���д洢������ͨ�����������������ͼ۱ʼDZ����Ժ�̨ʽ������,�Լ�����Ҫ��ˮƽͼ�ι��ܵ���������ϡ���2007���,��Լ90%��PC���嶼��һ������GPU��
16.4.4 Qualcomm
Freedreno��һ����Դ��������Ŀ,Ϊ��ͨ��˾��Adrenoͼ��Ӳ��ʵ����һ����ȫ��Դ����������Freedreno��MSM DRM��������xf86��ƵFreedreno DDX��Mesa�ڲ���Freedreno Gallium3D����������ɡ�Դ���ַ��https://github.com/freedreno/freedreno��
�û��ռ��������������ģʽ������,Ҫôʹ��msm drm/kms�ں���������,Ҫôʹ������msm android���е�msm fbdev+kgsl������������������ҪĿ����ʹ��android�豸��ʹ��freedreno��������,�ر�����Ϊmsm drm/kms����������δ���ֻ�/ƽ������ϵ�LCD��ʾ���ṩ������DSI���֧�֡�(��ʹDSI֧����msm drm/kms�о�λ,��Ȼ��ҪΪÿ����ͬ�ͺŵ�LCD����д�����������)
ʹ��drm/kms��������ʱ,ͼ�ζ�ջ���������κ�������Դ������������(nouveau��radeon��)��ͼ�ζ�ջһ��:
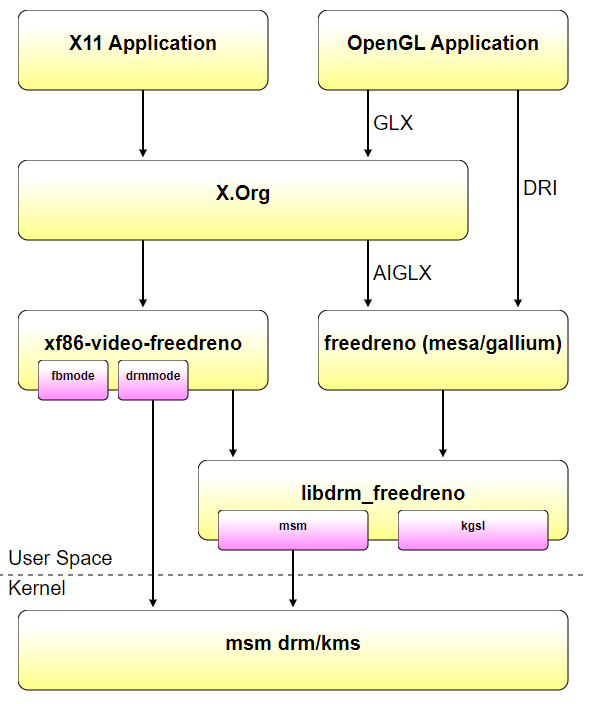
ʹ��android fbdev/kgsl��������ʱ,��ջ������ͬ,ֻ��xf86 video freedreno�е�fbmode_displayģʽ���ô����libdrm_freedreno�е�kgsl��˱���������drmmode_display��msm��ˡ��������±����κ��û��ռ����,xf86 video freedreno��libdrm_freedreno����ȷ��������ʱʹ��ʲô��
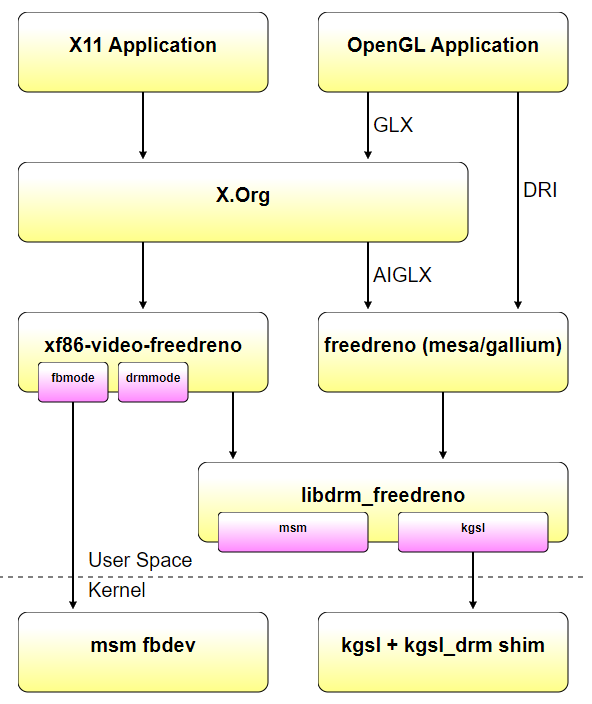
Command Processor (CP)�Ǵ�ringbuffer(PM4������)��ȡһϵ����Ⱦ����Ŀ�,����������һЩ�Ĵ���ֵ��һЩ��Ⱦ����,��Ҫ��Type-0(PKT0)��Type-3(PKT3)������ɡ�Type-0 (PKT0)��BASE_INDEXָ���ļĴ�����ʼ,��N������(32λ)DWORDд��N���Ĵ���(��ͼ��),Type-3(PKT3)ִ��IT_OPCODE������ָ���IJ���(��ͼ��)��
������Ƕ��ʽ/SoC GPUһ��,Adreno��һ�ֻ���Tile����ϵ�ܹ�,Ȼ��,��ʵ�ַ�ʽҪ��һЩ��������ֿ�����ȾС(32x32��/��64x64)�ֿ�,Ӳ����ij�ַ�ʽ��ÿ���ֿ�ļ������������,ͨ�����Ը����ֿ�IJ��ɼ����档��һ����,Adreno��һ��(���)����ں�(GMEM)��Ƭ��(OCMEM)�ֿ黺����,��С��256KB��1MB���ȡ�������Ⱦ�Ļ�������Ϊ��tile����bin��,��ɫ��������(�������)���/ģ�建���������ڷֿ黺���������ɡ�����������ȫ����ÿ��tile/bin�Ļ���,�Լ��ָ�(�����ݴ�ϵͳ�ڴ��ƶ���GMEM)�ͽ���(�����ݴ�GMEM�ƶ���ϵͳ�ڴ�)����ע��,�����������ͨ�����ͨ�����ڶ�����������
��ķ����ǽ���CMD������״̬��ִ�����/����,����tile,Ȼ���ڶ���������������(�ύ���ں˵�����)��,ִ��(��ѡ)��ÿ��tile���á�IB(��֧)����Ϊ���/��������,Ȼ�����:
- ÿ��tile�ڵ���ȾЧ���봫ͳIMR���ơ�
- ��tile����:
- �ָ�������ѡ�����ݴ�ϵͳ�ڴ洫�䵽tile��������
- ���ô���ƫ�ƺ���Ļ���С�
- IB���/������Ⱦ���
- ����������tile���������䵽ϵͳ�ڴ档
- ע��:������������˳����GPUִ�е�˳��ͬ,���һָ�/����Ҳ�����/������ʹ�õ�һЩGPU״̬�Ĵ���,�����������������Ҫע���ڵ�һ�����/����֮ǰ��ijЩ״̬������Ϊ�ࡣ
������gallium3D����������ʵ�ֵ�����,�����������������/�����۵Ķ�����ɫ��ʱ,��һ����һ�����ȱ�㡣
�����Ĵ��Եķ�����һ��ȱ��,��������ɫ�����ÿ��bin��ÿ����������,����ʵ���Է�Ϊ���������Լ��ٿ������ڵ�һ��pass(��װ�䡱����)��,���㱻���Ϊÿ���ֿ���,����Ϣ�ڵڶ���pass����������Ϊÿ�����Ӵ����Ķ��㡣����Ҫ������������ʹ����ͬ�Ķ�����ɫ��,װ����̿���ʹ�ü���ɫ��,����ɫ��������gl_Position / gl_PointSize��
ע:����ע��������a3xx,��a2xxӦ�������ơ�
blob��������Ϊÿ��tile����һ��VSC_PIPE,���а˸�����,����Ϊһ�����߷�����tile,������ʹ���ĸ�����������4x4��tile,������ʾ:
# X, Y = upper-left tile coord of group of tiles mapped to pipe
# W, H = size of group in tiles, so below each pipe is mapped to
# a 2x2 group of tiles
VSC_PIPE[0].CONFIG: { X = 0 | Y = 0 | W = 2 | H = 2 }
VSC_PIPE[0x1].CONFIG: { X = 0 | Y = 2 | W = 2 | H = 2 }
VSC_PIPE[0x2].CONFIG: { X = 2 | Y = 0 | W = 2 | H = 2 }
VSC_PIPE[0x3].CONFIG: { X = 2 | Y = 2 | W = 2 | H = 2 }
����ÿ������,�����������ù���������ַ/��С( VSC_PIPE[p].DATA_ADDRESS��VSC_PIPE[p].DATA_LENGTH),Ϊgpu�ṩ�˴洢�ɼ��������ݵ�λ�á���С������(VSC_SIZE_ADDRESS),һ��4�ֽ� x 8�����ߵĻ�����,GPU�����д洢д��ÿ������������������,��װ����������ڿ��ƽ���Щ����洢���ĸ����ߡ�����Ⱦ������,��ÿ��tile�Ŀ�ʼ��,��������GPU����Ϊͨ��CP_SET_BIN_DATA���ݰ�ʹ�����Թ���p������(���ʵ��Ļ�������С/��ַ):
OUT_PKT3(ring, CP_SET_BIN_DATA, 2);
OUT_RELOC(ring, pipe[p].bo, 0); /* same value as VSC\_PIPE[p].DATA\_ADDRESS */
OUT_RELOC(ring, size_addr_bo, (p * 4)); /* same value as VSC\_SIZE\_ADDRESS + (p * 4) */
OUT_PKT0(ring, REG_A3XX_PC_VSTREAM_CONTROL, 1);
OUT_RING(ring, A3XX_PC_VSTREAM_CONTROL_SIZE(pipe[p].config.w * pipe[p].config.h) |
A3XX_PC_VSTREAM_CONTROL_N(n)); /* N is 0..(SIZE-1) */
OUT_PKT3(ring, CP_SET_BIN, 3);
OUT_RING(ring, 0x00000000);
OUT_RING(ring, CP_SET_BIN_1_X1(x1) | CP_SET_BIN_1_Y1(y1));
OUT_RING(ring, CP_SET_BIN_2_X2(x2) | CP_SET_BIN_2_Y2(y2));
**������/���зֿ���һ��,�л���ȾĿ����۸߰�,�ᴥ��ˢ�¡�**����,���ٶ���freedreno gallium3D��������,���ֻ��Ⱦ��������һ����,�����ȥ�������в��ᱻtouch(����д)�IJ��֡�gallium�����������ʹ�ô���Ϣ����tile�߽�/��С,���ⲻ��Ҫ�Ļָ�(�����ݴ�ϵͳ�ڴ�����GMEM)�����(��GMEMд��ϵͳ�ڴ�)��
����ָ���ϵ�ṹ(Instruction Set Architecture,ISA),��a2xx��ɫ��ISA��ͬ,a3xxʹ�á�������ָ�,����һЩ���ɡ���������Ҫ�����˽���Ⱥ�����һЩԼ����ÿ��ָ��Ϊ64λ(qword),��7�ֻ���ָ���������(��ijЩ������ж���ӱ���)����a2xxһ��,û�е�����CF vs FETCH/ALU����ijЩ����ָ�����첽���е�,��Ҫ�����ͬ���������ȶ���д(���ȶ���д)����a2xx��ͬ����,�����������Ͱ�(16λ)�Ĵ���,���Ƕ�û���ص���ָ�����Ը���,�����������7��ָ�������������:
-
���0(cat0):ͨ�������������������ָ��(��ʱ����Ƕ�볣��),����:
nop��jump��branch�� -
���1(cat1):�ƶ�/ת���ı���(����Դ�Ĵ���),����ָ��û�в�����,������ɫ�����Ƿ���src��Ŀ�����Ͷ��졣���src��Ŀ��������ͬ,���Ϊ�ƶ�:
mov.f16f16 Rdst, Rsrc- ��ͬһ����src��dst�ƶ���cov.f32u16 Rdst, Rsrc- ��f32 src�ƶ�/ת����u16 dst��mova- ��mov.f16f16Ѱַ���Ĵ���(a0)��(�����������,src�Ĵ�����������const)
-
���2(cat2):��ͨALUָ��,ͨ������2��src�Ĵ���,�������������,��2��src����ᱻ����:
add.f Rdst, Rsrc0, Rsrc1and.b Rdst, Rsrc0, Rsrc1floor.f Rdst, Rsrc0- an example of cat2 which ignores the 2nd src.
-
���3(cat3):����src�Ĵ�������,����:
mad.f16- src0 * src1 + src2sel.f32- src1 ? src0 : src2
-
���4(cat4):��cat1-cat3���,���ӵĵ�src������Ҫ���������(������Ԥ�������)��/����첽:
rcp Rdst, Rsrclog2 Rdst, Rsrc��cat4ָ��д��ļĴ�����ȡ��������cat4ָ����뽫(ss)λ����Ϊ�븴��alu����ͬ����
-
���5(cat5):һ�������������˵��:
sam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0isam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0samgq (f32)(xyzw)Rdst, Rsrc0, Rsrc1, s#0, t#0isam (f32)(xyzw)Rdst, Rsrc0, Rsrc1, Rsrc2
-
���6(cat6):��ָ�����/�洢��ר��/����/ȫ���ڴ桢ԭ������/����/������,�Լ���������ָ���opencl�����á�
��**����(Scheduling)**��,������������ǰһ��ָ���Ŀ��Ĵ���������֮ǰ����(ָ�����)������������cat1-cat3ָ��,Ŀ��Ĵ���������ָ��֮�����,�����Ҫ,�������������nopָ�������cat4��cat5ָ��д���Ŀ��Ĵ���,(ss)��(sy)λ��������Ϊͬ��,��Ϊ��cat1-cat3��ͬ,���������������Dz���Ԥ��ġ��ر��Ƕ���cat3ָ��,ֱ���ڶ������ڲ���Ҫ������src�Ĵ���,���,����DP4(���)ָ�����ʵ��Ϊ:
; DP4 r0.x, r2.xyzw, r3.xyzw:
mul.f r0.x, r2.x, r3.x
nop
mad.f32 r0.x, r2.y, r3.y, r0.x
nop
mad.f32 r0.x, r2.z, r3.z, r0.x
nop
mad.f32 r0.x, r2.w, r3.w, r0.x
��������Ҫ����nop���ܻ��ǰһ��ָ��Ľ��,�������,��������Ȼ��������Щnop����е��Ȳ���ص�ָ�д��Ĵ�����ָ����ǰ����������ָ���src(WAR hazard),��Ҫ(ss)λ����
ͨ��,��if/else���콫��չ��,ִ�з�֧�����з�֧,Ȼ��ʹ��selָ����������д�ش������ƽǶȡ���ȡ���ķ�֧�Ľ����amonst�̵߳ķ�ɢ������ͨ���ܰ���(��,Ӳ�����ձ������߳�����һ��ִ��һ���߳�),��˱�����ͨ���ᾡ���������������(Ŀǰ,if/else����gallium���������еķ�֧ʵ�ֵ�,��������Ϊ��������������,��֪����ν���չ����)����Ҫ��֧ʱ,����ʹ��cat0ָ����ʵ������,����,����ͨ�����·�ʽʵ��if/else:
cmps.f.eq p0.x, hr1.x, hc2.x
br p0.x, #6
mov.f16f16 hr1.x, hc2.x
mov.f16f16 hr1.y, hc2.y
mov.f16f16 hr1.z, hc2.x
mov.f16f16 hr1.w, hc2.y
jump #6
(jp)nop
mov.f16f16 hr1.x, hc2.y
mov.f16f16 hr1.y, hc2.x
mov.f16f16 hr1.z, hc2.x
mov.f16f16 hr1.w, hc2.y
(jp)nop
��ע��,��֧Ŀ��ָ����������(jp)(��תĿ��)��־,�����������̵߳������ҳ�DZ�ڵľۺϵ�,��תĿ�겻����nop����֧��������ǰ(��)�����(��)����ƫ�ơ�
����ͨ��������,û�и���Ҫ�����ɾ����ָ������ͨ����������������б�������Ľڵ㿪ʼ����ÿ��������,�ݹ�س�����ÿ��ָ���Դָ������ӳٲ�֮�����ÿ��ָ��,������Ҫ����NOP��
��ָ����ʹ��const src������һЩ����,��ijЩ�����,��������Ҫ��const�ƶ���GPR�С���֪�����ư���:
- cat2������ʹ��һ������src(������������λ��)��
- cat3���ܽ�����src��Ϊ�ڶ�������(src1)��
- cat4���ܽ��ܳ���src��
16.4.5 ����
����,��������ƽ̨������:
- Vidix:��һ����������Unix����ϵͳ�ı�Яʽ��̽ӿ�,���������û��ռ������е���Ƶ����������ͨ��X Windowϵͳ��ֱ��ͼ�η�����չֱ�ӷ���֡��������
- MPLAB:MPLAB Harmony Graphics Suite��MPLAB��̬ϵͳ����չ,����Ϊ32λоƬ�豸����Ƕ��ʽͼ�ι̼����������
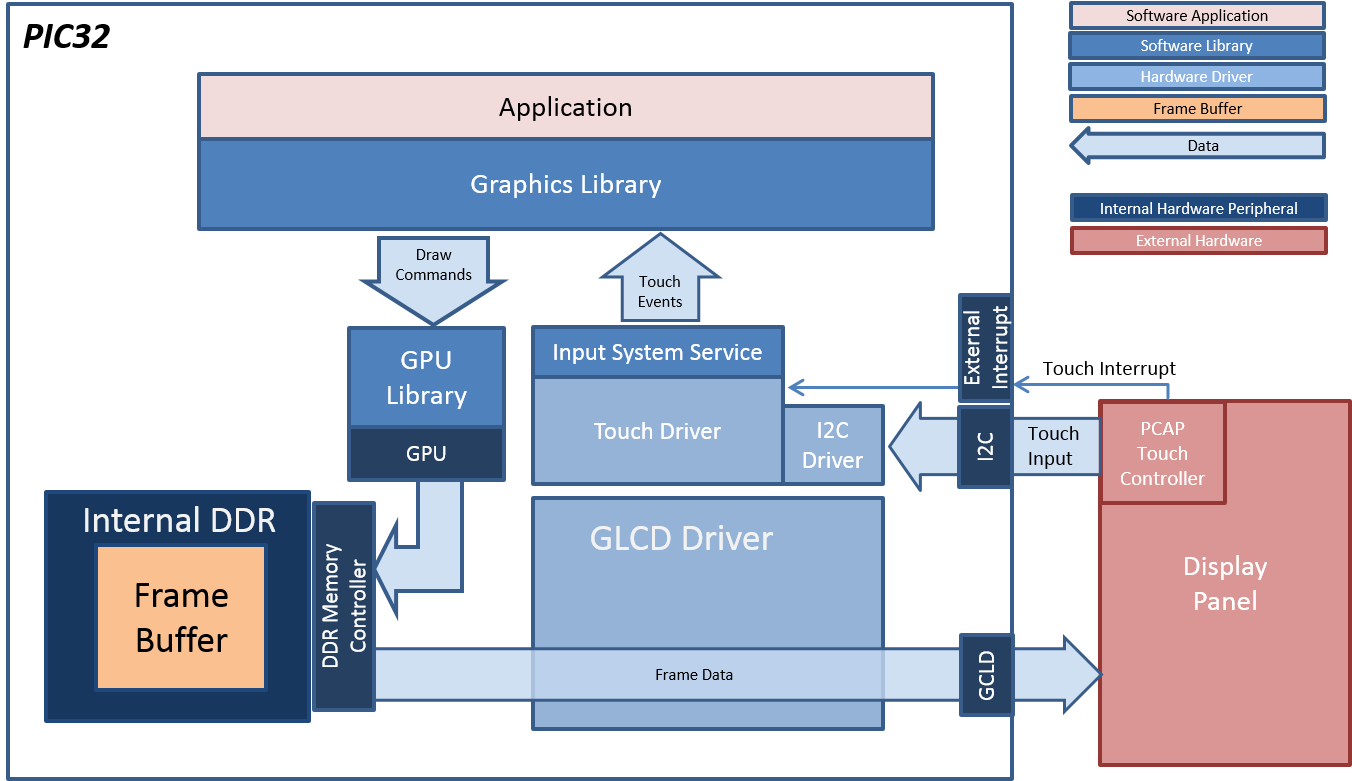
- MiniGLX:��һ��Ӧ�ó����̽ӿڹ淶,��������û�д���ϵͳ��ϵͳ�Ͻ���OpenGL��Ⱦ,����,û��X����ϵͳ��Linux��û�д���ϵͳ��Ƕ��ʽϵͳ���ýӿ���GLX�ӿڵ��Ӽ�,����һ����С��Xlib�ຯ����
16.5 ͼ������Ӧ��
16.5.1 ��Ƶ��ϳ�
������GFX/��Ƶ��������(Ӧ�ó������Ƶ������)ʱ,�鿴Ӱ��Ӣ�ض���ϵ�ṹ��UI������ض��ȶ�������,��Ϊ�Ƕ���һ��UI,Ȼ����һ������,Ȼ����ϵͳ��������(��Ȼ����һ�������ʱ����֮��)��
���3D�ͻ���Ӧ�ó�����GPU,��GPU���̿��ܻᱻ��ֹ,Ȼ��GPU����ȫ���á����ڸ��ӵ�����,����Ƶ����,����֡/����ǰ��������״̬,�����ֹGPU���̲�����GPU�ᵼ�²��ܻ�ӭ��Ч����
����Ľ������:��ʱ���ͻָ�(Timeout Detection & Recovery,TDR)��Intel GPU���¹���(����Ϊwip),����Ӧ�ó����ڵ��������������������ù�����,�Ӷ�����ȶ��Ժ�³���ԡ���ʱ���ͻָ�(TDR)������������GPU�еIJ�ͬ����(��������ȫ����GPU)��һ����˵,��Щʵ����i915����������������һ���µ�IRQ��������,�Լ���gpu�Ļ��λ������з�����������������������ָ��֮ǰ��֮�������������µ�gpu����ָ�TDR�IJ�������:
����Ľ������:
1��UMDý�����������ڷ�������������������ʱ����
2����ʱ�����ں�,��ý�����洦�ڹ���״̬��
3��GPU���������������Ӱ���ý�����档
4������UMDý����������֪���ύ�������ε�ʱ��,��˿�����ý����������������лָ���ʱ���ڲ�ȡ��ʩ��
��������ͨ��������ֵ����,����ֵ����ͨ��ioctl��Ӧ�ó������á�����ֵ����̫��,��������̫����
**�ϳ���(compositor)**�������?�����ͼ���Իش�:
1���ϳ����Ļ�������������֡��
2����ȥ,�����Ǽ�GPU����ʱ,�ϳ����ָ�(��Ļ���ᡢ��ɫ���ɫ��Ļ��ϵͳ��������)Ϊʱ������
3����Ƶ�ͻ���Ӧ�ó������ڿ�������ȷ���������Ƿ���ý���������,�����,����ϳ����������ʾ��ǰ֡,ͬʱý������������з��ء�
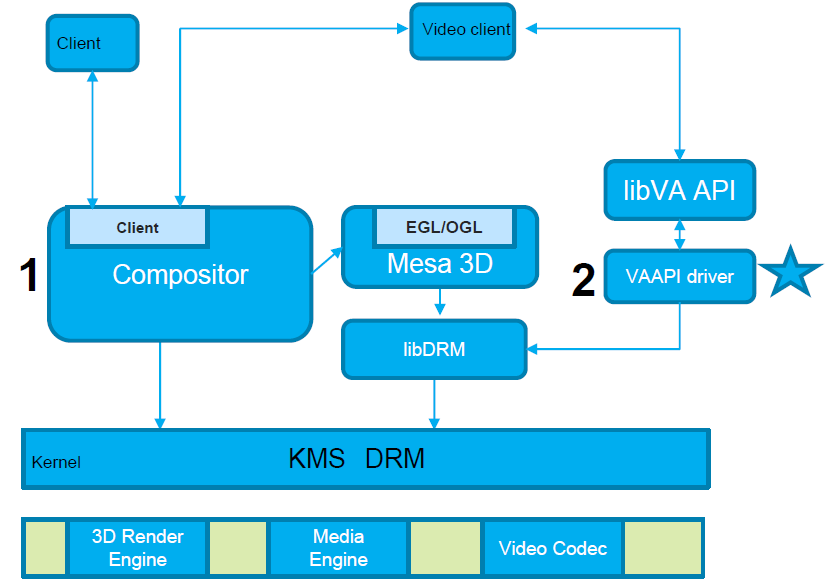
16.5.2 Rocksolid
Rocksolid�����GPU����Ʒ������,������չ��Ϊһ�������IJ�Ʒ�����˿ͻ�����֮��,�ÿ�����Ȼ�������������ء���������Ⱦ/����������Ҫ��Է���Ϸ��;,��С��Ƕ��ʽϵͳ��չ���ִ����漶Ӳ����������һ���������Ϸ����,�����Ŀ����ȴ����ִ���Ϸ����͵ö�,Ҳ��������,���ȶ�,���ҿ���ͨ����ð�ȫ��֤����ͼ��Rocksolid����ļܹ�ͼ,�ɴ˿�֪,������ֱ�ӷ����豸����,�Ӷ��������ܡ�
ͼ�ι�����һ�ַdz��õ����з�ʽ,����ͼ��������������Ӳ����,���������Ȼӳ�䵽ȫ����դ������,������Ϊͼ�ιܵ������Ǽ���ܵ����л���졣��һ����ҵ�ͻ�������,Rocksolid�������ṩGPU���ٵ�ͼ�����ܵ�����ԭʼOpenCL�汾���,Ŀ��Ӳ�����ٶȿ��˺ü�����
��OpenGL��,Rocksolid����ֻ�����������������м�¼�Ľڵ������б�����Vulkan��,ÿ��ʹ�õ�������ж���һ���ύ�̡߳�Ŀǰ,Ĭ������ֻ��һ���������,����ֻ��һ���ύ�̡߳��ύ�߳��������С����ύ�߳�������������ʱ,��������ಿ�ֿ�������һ֡��Vulkan��CPU�ɼ���Դ�ɼ�ѭ��Χ��ϵͳ������
16.5.3 I/O����
��Ӧ�ó��������/�������ת��Ϊ�豸�ĵͼ�����,�����䷢���豸������,��ȡ����/����豸����Ӧ�����䷢�͵�Ӧ�ó���
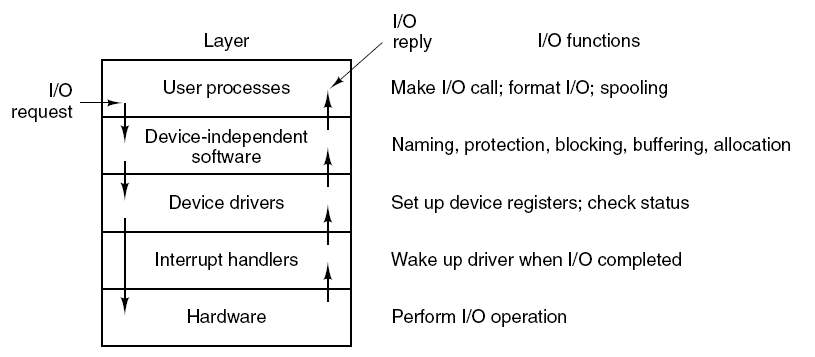
����/���ϵͳ�ĸ����Լ��������Ҫ���ܡ�
�����Ӳ���з���IO��?��������:
- ����ϵͳ��Ҫ���豸����������/��������Ϳ������������/�����
- �豸��������һ���������ڿ��ƺ����ݵļĴ�����
- ������ͨ����/д��Щ�Ĵ����������ͨ�š�
- ���Ѱַ��Щ�Ĵ���?
- �����ڴ��I/O��
- ���ڶ˿ڵ�����/�����
- �������/�����
�ڴ�ӳ��/���ڶ˿�/��ϵ�IO�ķ�ʽ����ͼ:
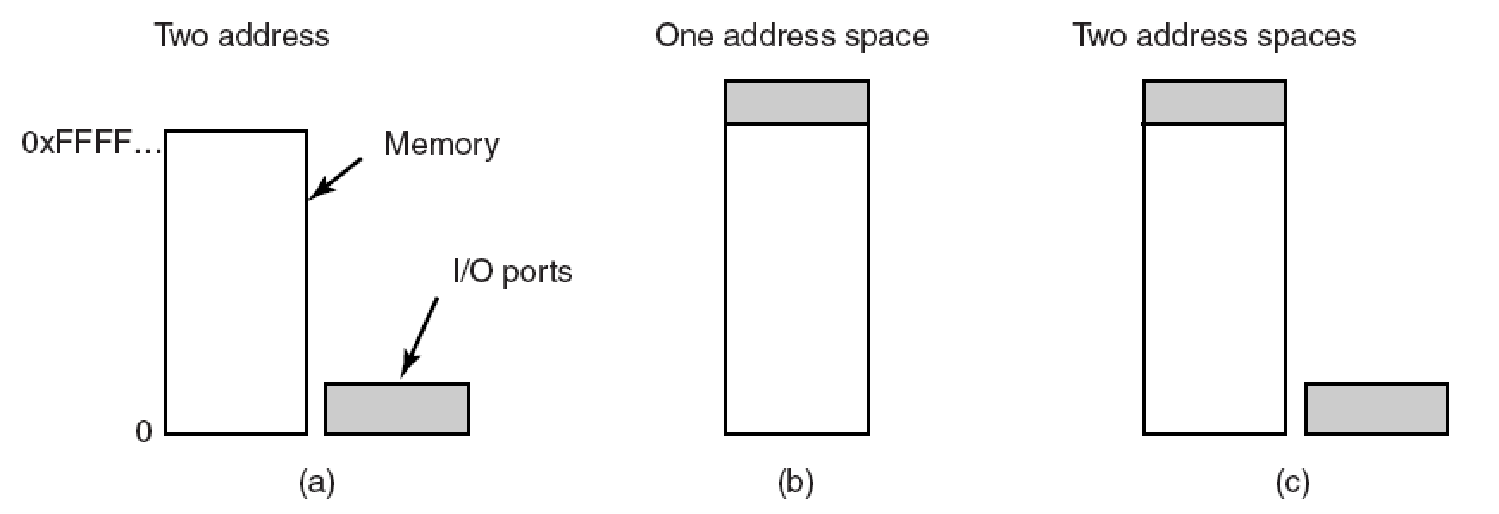
(a)����CPUָ��(����/���)��(b)�ڴ�ӳ��:ΪӲ������/����Ĵ��������ڴ������ڴ�ָ���������ǡ�(c)���:һЩ������ӳ�䵽�ڴ�,һЩʹ��I/Oָ�
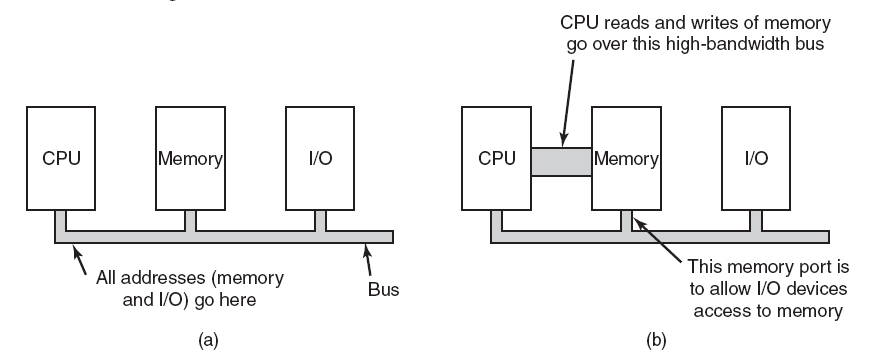
�����ߺ�˫����IO��(a)�ڴ�ӳ��I/Oֻ��һ����ַ�ռ�,�ڴ�ӳ��I/O������ʵ�ֺ�ʹ�á�֡�������������豸���ʺ����ڴ�ӳ���I/O��(b)���ڶ˿ڵ�I/O��������ַ�ռ�:һ�������ڴ�,һ�����ڶ˿ڡ�˫�����������ж�/д���ݺ��豸��
�����ߺ�˫���߸���ϸ�ĶԱ�ͼ����:
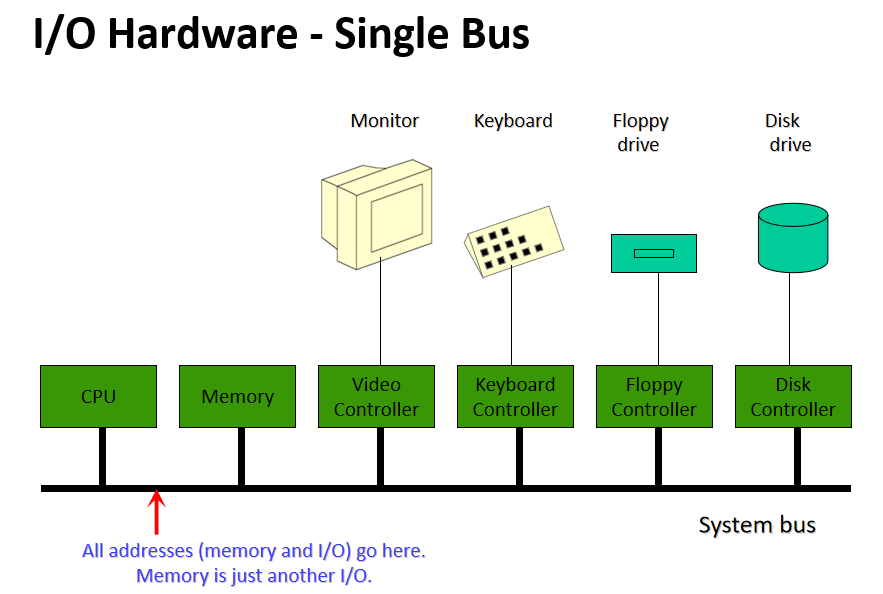
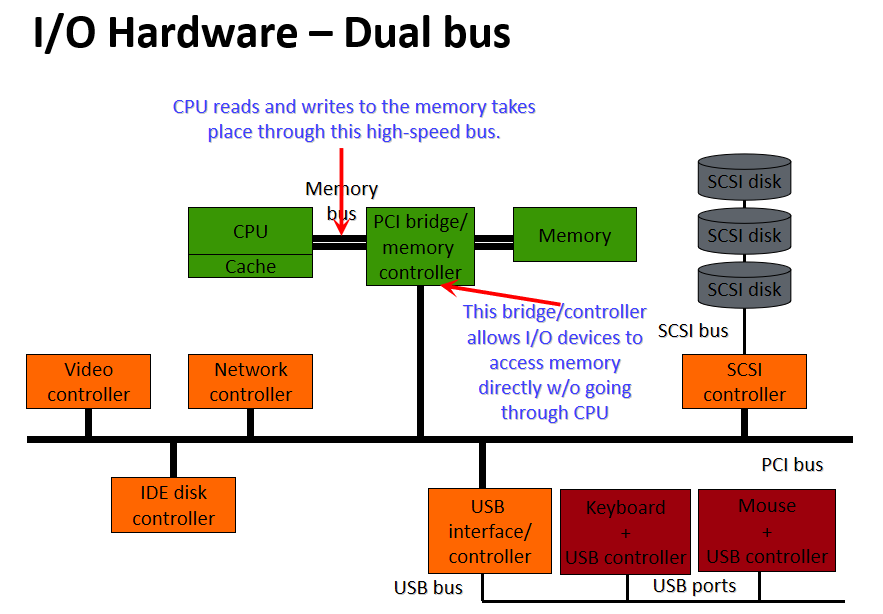
����:���(����CPU)֮��Ļ���,�������Ӷ���豸:
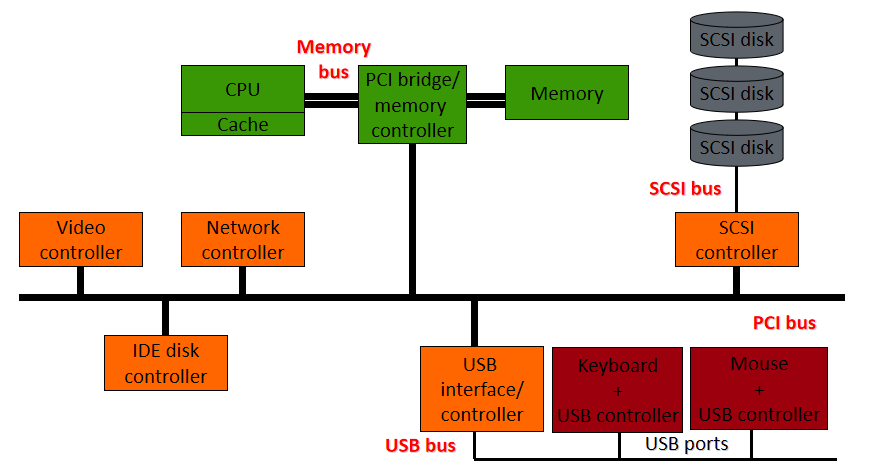
�˿�:������һ������/����豸�Ľӿ�:
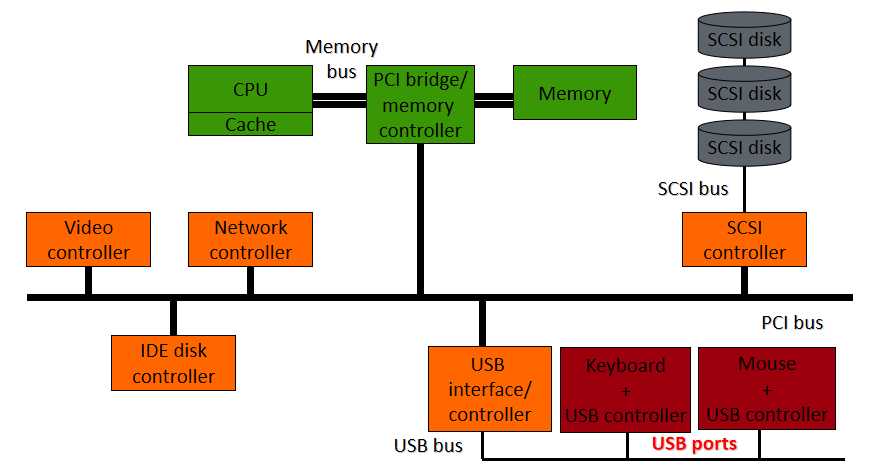
�豸������:�������豸���ӵ�ϵͳ����/�˿�:
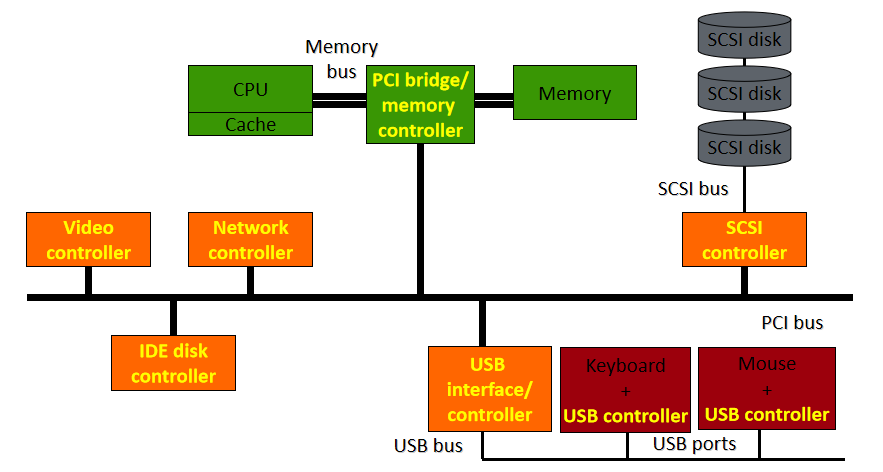
ÿ���豸����һ���豸��������һ���豸���������������ϵͳͨ��,�豸���������ǿ��Բ������ϵͳ�Դ����ض��豸������ģ��,�豸�����������豸���豸��������֮��Ľӿ�,�豸���������Դ�������豸����Ϊһ���ӿ�,������Ҫ�����ǽ�����λ��ת��Ϊ�ֽڿ�,��������Ҫִ�о�����
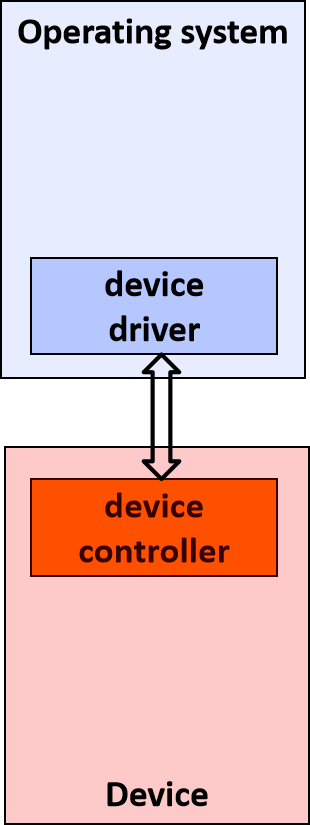
IO�˿ڼĴ�����״̬�Ĵ���(��host��ȡ)������Ĵ���(��hostд��)���Ĵ����е�����(��host��ȡ�Ի�ȡ����)����������Ĵ���(��hostд���Է������)��
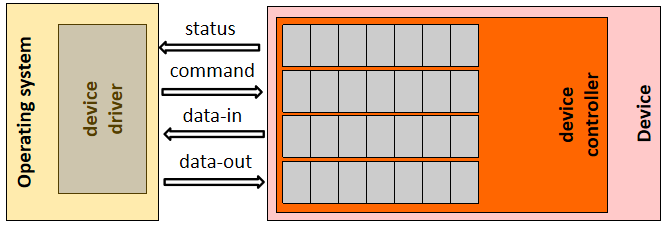
ֱ���ڴ����(Direct Memory Access,DMA):���ڽ��д��ʹ�����豸,�����������,ʹ�ð����ͨ�ô�����������״̬λ��������һ������1�ֽڵĿ������Ĵ���,�ƺ���һ���˷ѡ�����һ���̳�Ϊ�������/����������жϵ�I/O����һ�ֲ��ȷ���,��Ϊÿ���ֽڶ��ᴴ��һ�����жϴ����������̵������Ŀ��ء��ڻ�����ѯ�ͻ����жϵ�I/O��,�����ֽڶ���Ҫͨ��CPU,��������/����豸<->CPU<->�ڴ��кܶ����������ǿ��Խ����ƽ��������ж�ص�һ��������;�Ĵ�������,�ô��������Խ����ݴ�����/����豸ֱ���ƶ����ڴ���,�Ǿ�̫����!�����ֱ���ڴ����(DMA)��������
Ҫ����DMA����,host��DMA�����д���ڴ档ָ����Դ��ָ��,ָ����Ŀ���ָ��,�Լ�Ҫ������ֽ����ļ�����CPU���������ĵ�ַд��DMA������,Ȼ���������������DMA����������ֱ�Ӳ����ڴ�����,�������Ϸ��õ�ַ��ִ�д���,��������CPU�İ�������DMA��������PC�еı����,PC��������������/�����ͨ�������Լ��ĸ���DMAӲ����ʹ��DMA��IOʾ��:
/* Code executed when the print system call is made */
copyFromUser(buffer, p, count);
setupDMAController();
scheduler();
/* Interrupt Service Routine Procedure for the printer */
acknowledgeInterrupt();
unblockUser();
returnFromInterrupt();
��ע��,�ж���ÿ��I/O��������һ��,������ÿ���ֽ�����һ��(�ڻ����жϵ�I/O�����)��
IOӲ���ӿ�:�豸��������֪���������ݴ��䵽��ַX���Ļ�����,�豸����������ߴ��̿�������C�ֽڴӴ��̴��䵽��ַX���Ļ�����,���̿���������DMA����,���̿�������ÿ���ֽڷ��͵�DMA������,DMA���������ֽڴ��䵽������X,�����ڴ��ַ,�ݼ�Cֱ��0,��C==0ʱ,DMA�ж�CPU������źŴ��䡣
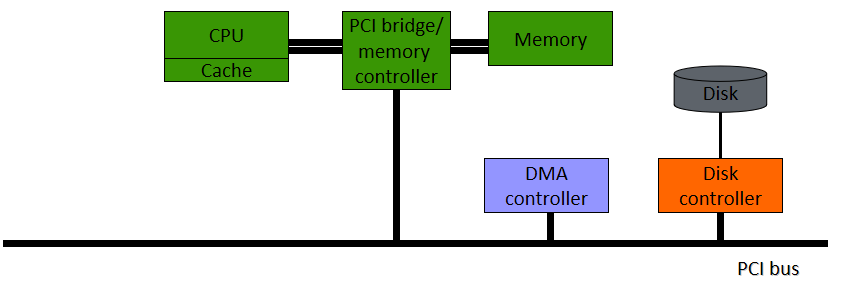
Ӧ�ó���IO�ӿ�����ͼ��ʾ:
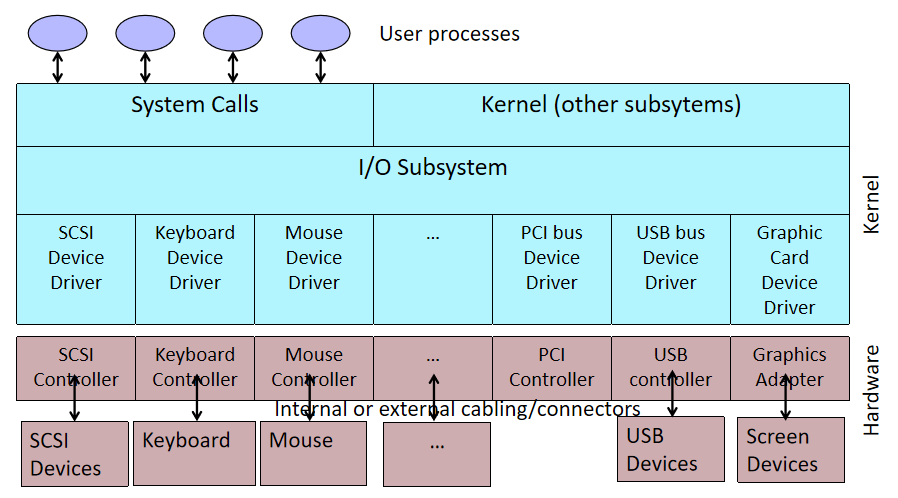
���ӵ��������ÿ������/����豸����ҪһЩ�ض����豸�Ĵ��������������豸�����̱�д,ÿ������ϵͳ����Ҫ�Լ����豸��������,ÿ���豸��������֧���ض����ͻ���������/����豸����������������֧�ֲ�ͬ���͵����,������������������ͷ������ϵͳ��������������Ĺ����Լ�����������ϵͳ�����ಿ�ֽ������豸����������ж������,Ҫ�����������Ϸ��������豸�������ij����д����,��ȷ��ִ����Щ����,�豸��ʼ��,����is��Դ�������־�¼���
Microsoft Windowsʹ���ļ�ϵͳ�ϵ��豸��ݷ�ʽ��Ѱַ�豸,�豸����APIΪӦ�ó������Ա�ṩ��һ���ӿ�,�Լ���豸����֮����,Windows�豸���Ϊ�豸���������ṩ���û����ں˽��档����/�������(����ϵͳ�ӽ�)��:
- �ַ����Ϳ顣
- ˳�������������ʡ��豸�����������������豸�е�ƫ������
- ͬ�����첽���豸���������ϵ�I/O�������豸�������ϵ�I/O���ͬ��,�첽I/O���緵��,�Ժ�ɹ�/ʧ�ܡ�
- �����ֱ�ӡ�����IJ�������ڻ��������豸����������ɡ�
- ������ר�á�ÿ���豸ʵ���ϵ�I/O�ǻ���ġ�(����ӡ��)
- ֻ����ֻд����д��
�ں��ṩ��������I/O��صķ���:���ȡ����塢���桢�ػ����豸������������,����Ӳ�����豸������������ܹ�������
IO������������һ��I/O����,��ζ��ȷ��ִ�����ǵ�����˳����ϵͳ������Աͨ��ά��ÿ���豸�����������ʵ�ֵ���,��Ӧ�ó�������I/Oϵͳ����ʱ,���������ڸ��豸�Ķ����С�I/O�������������ж��е�˳��,���������ϵͳЧ�ʺ�Ӧ�ó����ƽ����Ӧʱ�䡣����/���ͨ������,һЩ�豸������������Ҫ�Ż�,����Ӳ�̡����ɴ�ͷ�ƶ�����ת����Ļ�еװ�ú��ӳ١������FIFO������ִ������/���,��е֮�����˶����ܻ�������/���������I/O���Ȼ�ȡ�豸�ϵ�һ��I/O����,��ȷ�����豸��ִ����������˳���ʱ�䡣�����������Ҫ������I/O����ʱ,���ȱ�ø��ӡ�
���豸�����������ڴ�ͷ�ҳ�������,һЩ֡����ҳ�滺��,�������豸�����ݱ�����ϵͳ�С����豸�е�����/���:�������Ƿ�����ҳ������(�����ڴ���):����ҵ�����֡�Ķ�/д������,����,����һ��֡,���豸���ȡ��֡��,��֡���Ϊ�����豸��ԴӴ�֡��ȡ/д�뻺��������ҳ����д����豸,�����ӿ�I/O����,�������ļ�ϵͳԪ���ݲ�����
ҳ�滺��˼�뻹���ڴ�ӳ���I/O����,mmap()�ļ��������ƵĻ��ơ����̵������ڴ�ӳ����Ϊ�ļ�(�����ǿ��豸)���ݵ�ҳ,���Ļ����ڴ��ϸ���,�����֡�ᶨ���ڴ�����ǿ��ִ�С�VMϵͳ����ҳ����ļ������Լ�����(��פ�����)ҳ���֡,VMϵͳ����ϵͳ���ڴ�״̬�����ļ����豸����Ĵ�С��
���������������豸֮����豸��Ӧ�ó���֮�䴫������ʱ�洢���ݵĴ洢�����л���������ԭ��:
- �����������������ߺ�������֮����ٶȲ�ƥ�䡣ͨ�������������ļ��Դ洢��Ӳ���ϡ�
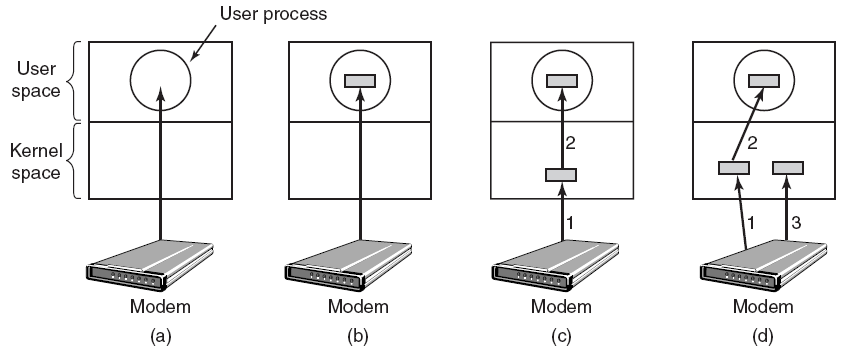
(a) �������롣(b) �û��ռ��еĻ��塣(c)���ں��н��л���,Ȼ���Ƶ��û��ռ䡣(d) �ں��е�˫���塣
- �ھ��в�ͬ���ݴ����С���豸֮����е���������:��Ϣͨ���ڷ��ͺͽ��չ����б��ָ
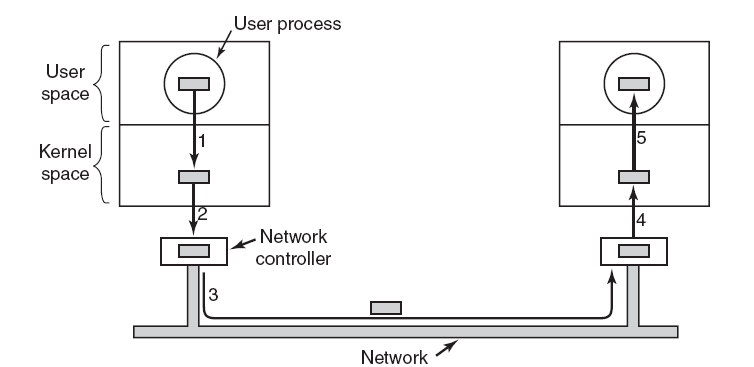
���������漰һ�����ݰ��Ķ��������
- ֧��Ӧ�ó���I/O�ĸ������塣Ӧ�ó������write()ϵͳ����,�ṩָ������ָ���ָ��Ҫд����ֽ�����������ϵͳ���÷��غ�,���Ӧ�ó�����Ļ�����������,�ᷢ��ʲô���?�ڴ���write()ϵͳ����ʱ,����ϵͳ�ὫӦ�ó������ݸ��Ƶ��ں˻�����,Ȼ���ٽ�����Ȩ���ظ�Ӧ�ó�����д���Ǵ��ں˻�����ִ�е�,��˶�Ӧ�ó������ĺ������IJ�������κ�Ӱ�졣
������I/O�������,�����I/OЧ�ʡ��������ͻ���֮�����������,����������ֻ��������������и���,��������ݶ���,ֻ����λ������λ�õ���ĸ���洢�ϵĸ���������ͻ����Dz�ͬ�Ĺ���,����ʱһ���ڴ������������������Ŀ�ġ�����,Ϊ�˱����������岢ʵ�ִ���I/O�ĸ�Ч����,����ϵͳʹ�������еĻ�����������������ݡ�
����/�������ͨ����Ϊ�IJ�,ÿ���㶼��һ���������õĽӿڡ�
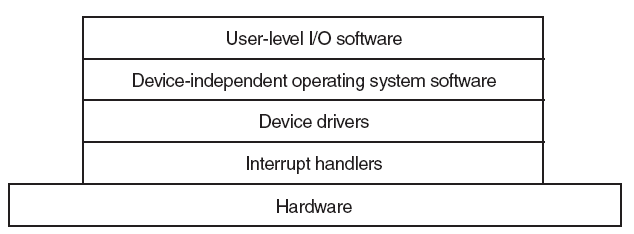
��������(��)��(��)�������ӿڵĶԱ�ͼ:
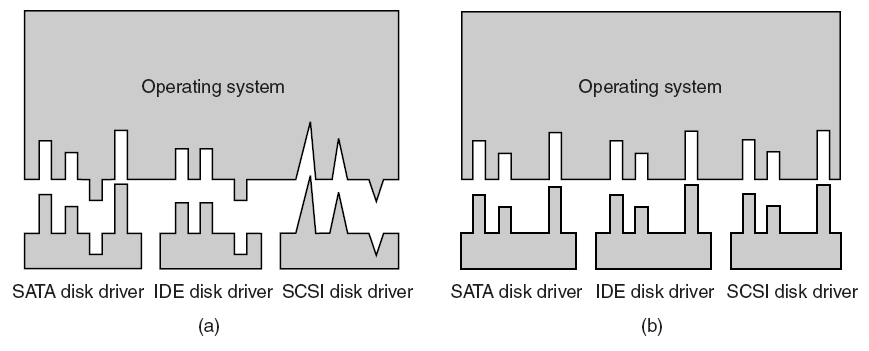
16.5.4 UEͼ������
��Ȼԭ����Ӧ�ò㲻Ӧ�ù����������GPU��ϸ��,����������ԸΥ,�ڶ��GPU��ϵͳ��ͼ��API���汾������ڶ����������汾,����֮����ܴ���һЩ����ֵֹ�����,�������������źܳ��Ĺ�Ӧ��·,����������������Ƚ���������ΪӦ�ó�����,�϶��������Դ���,������������ܡ�UE�ṩ�����Ľӿں�����,Ϊ�����ṩ��һЩ��Ϣ,�Ӷ����Զ�ȡGPU����������Ϣ����ص���Ҫ�ӿ�:
// GenericPlatformDriver.h
// ��Ƶ����ϸ��
struct FGPUDriverInfo
{
uint32 VendorId; // DirectX��Ӧ��ID,0���δ����,��ʹ�����º�������/��ȡ
FString DeviceDescription; // e.g. "NVIDIA GeForce GTX 680" or "AMD Radeon R9 200 / HD 7900 Series"
FString ProviderName; // e.g. "NVIDIA" or "Advanced Micro Devices, Inc."
FString InternalDriverVersion; // e.g. "15.200.1062.1004"(AMD), "9.18.13.4788"(NVIDIA)
FString UserDriverVersion; // e.g. "Catalyst 15.7.1"(AMD) or "Crimson 15.7.1"(AMD) or "347.88"(NVIDIA)
FString DriverDate; // e.g. 3-13-2015
FString RHIName; // e.g. D3D11, D3D12
FGPUDriverInfo();
bool IsValid() const;
FString GetUnifiedDriverVersion() const;
bool IsAMD() const { return VendorId == 0x1002; }
bool IsIntel() const { return VendorId == 0x8086; }
bool IsNVIDIA() const { return VendorId == 0x10DE; }
(...)
};
// GPUӲ����Ϣ
struct FGPUHardware
{
// ������Ϣ
const FGPUDriverInfo DriverInfo;
FGPUHardware(const FGPUDriverInfo InDriverInfo);
FString GetSuggestedDriverVersion(const FString& InRHIName) const;
FBlackListEntry FindDriverBlacklistEntry() const;
bool IsLatestBlacklisted() const;
const TCHAR* GetVendorSectionName() const;
(...)
};
// GenericPlatformMisc.h
struct CORE\_API FGenericPlatformMisc
{
// ��ȡGPU������Ϣ
static struct FGPUDriverInfo GetGPUDriverInfo(const FString& DeviceDescription);
(...)
};
�������Ͻӿ�,�Ϳ��Է��������Ⱦ�㡢��Ϸ�����ȡ������Ϣ��ִ������ԵIJ�����
����GPU����,�����Է���ͼ��API������,�������ڸ���ͼ��API��RHIʵ����,����Android Vulkan:
// AndroidPlatformMisc.cpp
bool FAndroidMisc::HasVulkanDriverSupport()
{
(...)
// this version does not check for VulkanRHI or disabled by cvars!
if (VulkanSupport == EDeviceVulkanSupportStatus::Uninitialized)
{
// assume no
VulkanSupport = EDeviceVulkanSupportStatus::NotSupported;
VulkanVersionString = TEXT("0.0.0");
// check for libvulkan.so
void* VulkanLib = dlopen("libvulkan.so", RTLD_NOW | RTLD_LOCAL);
if (VulkanLib != nullptr)
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan library detected, checking for available driver"));
// if Nougat, we can check the Vulkan version
if (FAndroidMisc::GetAndroidBuildVersion() >= 24)
{
extern int32 AndroidThunkCpp\_GetMetaDataInt(const FString& Key);
int32 VulkanVersion = AndroidThunkCpp_GetMetaDataInt(TEXT("android.hardware.vulkan.version"));
if (VulkanVersion >= UE_VK_API_VERSION)
{
// final check, try initializing the instance
VulkanSupport = AttemptVulkanInit(VulkanLib);
}
}
else
{
// otherwise, we need to try initializing the instance
VulkanSupport = AttemptVulkanInit(VulkanLib);
}
dlclose(VulkanLib);
if (VulkanSupport == EDeviceVulkanSupportStatus::Supported)
{
UE_LOG(LogAndroid, Log, TEXT("VulkanRHI is available, Vulkan capable device detected."));
return true;
}
else
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan driver NOT available."));
}
}
else
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan library NOT detected."));
}
}
return VulkanSupport == EDeviceVulkanSupportStatus::Supported;
}
16.6 ��ƪ�ܽ�
��ƪ��Ҫ������ͼ����Ⱦ��ϵ����������,�������ĸ���������ܹ������ƺ���ص�Ӳ��������
��PC��,�����߿���Ҫ���û���������������,������������ס����ƶ��豸��,������Ҫ�ڶ���λ����֤,��Ӳ����Ӧ�̵��ͻ��������ܳ�,�������Ȱ����ֻ���,���������¹��ܿ�����Ҫ����ʱ��,��ζ��bug��������Ҫ�ܳ�ʱ����ܽ����û������С��ڽϾ�/�Ͷ��豸��,���ǿ�����Զ���ᵽ����Ŀǰ����Ŭ���Ľ���һ��,��������������������,��ҵ��ҵ�������������һ������ں�ת(�����̻���)��
˵����������bug,���ƶ��豸���о�Vulkan����������Ŷ�ͨ��û����PC����ô��,�кܶ�GPU��Ƕ��ʽ������Ҫ���ԡ���ζ�����������������е�����ټ��Ϸ�����������ӳ�,�������Ƿ���Ч��������������,��������������Ϊһ������Ͳ���Ϊ���ˡ�����һ���Բ��ԵĸĽ�,��������IJ��Ա�ø���,Khronos��Ӳ����Ӧ�̷dz��������һ���߶����������Ҫ��ҵ��ҵ������Э��������һ��(CTS)��
�����ִ�ͼ��API�ĵ���,�������ٽ�����ʽ���Ż�,��Ԥ��������ǿ�Ԥ��ĵ�!ʹ����API��������Ŀ�Ŀ�����Ա��������(��ͼ),�µ�ͼ��API������������װȺ�����˸�������⡣������Ⱦ��,�Ա�����ȷ��˳�����������Ϣ,�ڿ�ʼʱҪ�ȸ�װ���öࡣ����Ҫ����,���Ը��ݾɵ�APIִ�е����������Ż�����д����,�Ի�����õ����ܡ�����,����������Աӵ���˿���Ȩ,ʹ�����ܿ���Ԥ��,��ȷ��Ӧ������ȷ���Ż�,��Ҳȷʵ��ζ���ɿ�����Ա��ȷ����Щ�Ż����ڡ�
DirectX11��������(��)��DirectX12Ӧ�ó���(��)ִ�еĹ����Ա�ͼ��
�ر�˵��
- ��л���вο���������,����ͼƬ���Բο���������,��ɾ��
- ��ϵ������Ϊ����ԭ��,ֻ�����ڲ�����,��ӭ������������,��δ��ͬ��,������ת��!
- ϵ������,δ�����,����Ŀ¼������ݸ�Ŀ��
- ϵ������,δ�����,����Ŀ¼������ݸ�Ŀ��
- ϵ������,δ�����,����Ŀ¼������ݸ�Ŀ��
�����
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Understanding Modern Device Drivers
- AMD GRAPHICS CORES NEXT (GCN) ARCHITECTURE
- I/O systems
- A low latency GPU engine based reset mechanism for a more robust UI experience
- Graphics Driver Quality - AMD
- High Dynamic Range(HDR)on Intel Graphics
- Understanding the Windows 8 graphics driver model
- Linux Graphics Drivers: an Introduction
- Linux GPU Driver Developer��s Guide
- Matrox Display Driver Guide
- nouveau Development
- envytools
- Mobile Graphics 101 - Arm Community
- Understanding Citrix HDX Graphics
- Windows Kernel Graphics Driver Attack Surface
- Vulkan in Rocksolid
- Windows Graphics Architecture
- Anatomy of RAM
- Memory structure
- FIFO overview
- NVIDIA TURING GPU ARCHITECTURE
- NVIDIA AMPERE GA102 GPU ARCHITECTURE
- ����GPUӲ���ܹ������л���
- Graphic Stack Overview
- The State of Linux Graphics
- A deeper look into GPUs and the Linux Graphics Stack
- Device driver
- Free and open-source graphics device driver
- Mesa (computer graphics)
- nouveau (software)
- AMD Radeon Software
- Freedreno in freedesktop
- Freedreno Architecture Overview
- Freedreno in Mesa3d
- Freedreno in Phoronix
- Freedreno in GitHub
- Adreno tiling
- Vidix
- Graphics card
- NVIDIA Linux Open GPU Kernel Module Source
- MPLAB? Harmony Graphics Suite Applications
- What is a driver?
- WDDM Architecture
- Low-Level GPU Documentation
- MiniGLX
- Intel GMA
- Game Architecture and Game Engine
- Z-order curve
- Hilbert curve
- Direct Rendering Manager
- Direct X �C Direct way to Microsoft Windows Kernel
- User mode and kernel mode
- Virtual address spaces
- Thread Synchronization and TDR
- Wayland
- Wayland Architecture
- Operating Systems must support GPU abstractions
- Schedule Synthesis for Halide Pipelines on GPUs
- Hardware Accelerated GPU Scheduling
- Windows 10 Hardware-Accelerated GPU Scheduling Benchmarks (Frametimes, FPS)
- TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
- TimeGraph: GPU Scheduling for Real-Time Multi-Tasking Environments
- REAL-TIME SCHEDULING FOR GPUS WITH APPLICATIONS IN ADVANCED AUTOMOTIVE SYSTEMS
- GPU Resource Optimization and Scheduling for Shared Execution Environments
- An Integrated GPU Power and Performance Model
- A user mode CPU�CGPU scheduling framework for hybrid workloads
- Balancing Energy Efficiency and Real-Time Performance in GPU Scheduling