��.iOS������-----���߳����֮NSOperation��NSOperationQueue��NSThread+runloopʵ�ֳ�פ�̡߳�����
һ��NSOperationQueue���ŵ�
NSOperation��NSOperationQueue ��ƻ���ṩ�����ǵ�һ���߳̽��������ʵ���� NSOperation��NSOperationQueue �ǻ��� GCD ����һ��ķ�װ,��ȫ��������DZ� GCD �������á�����ɶ���Ҳ���ߡ�
-
1������������������,�������ִ��˳��
-
2�������趨����ִ�е����ȼ�
-
3������ִ��״̬����:isReady,isExecuting,isFinished,isCancelled
���ֻ����дNSOperation��main����,�ɵײ���Ʊ������ִ�м����״̬,�Լ������˳�
�����д��NSOperation��start����,���п�������״̬
ϵͳͨ��KVO�ķ�ʽ�Ƴ�isFinished==YES��NSOperation
����NSOperation��NSOperationQueue
ִ�в�������˼,���仰˵���������߳���ִ�е��Ƕδ��롣
�� GCD ���Ƿ��� block �еġ��� NSOperation ��,ʹ�� NSOperation ���� NSInvocationOperation��NSBlockOperation,�����Զ�����������װ������
����Ķ���ָ��������,��������Ų����Ķ��С���ͬ�� GCD �еĵ��ȶ��� FIFO(�Ƚ��ȳ�)��ԭ��NSOperationQueue �������ӵ������еIJ���,���Ƚ�����������״̬(����״̬ȡ���ڲ���֮���������ϵ),Ȼ��������״̬�IJ����Ŀ�ʼִ��˳��(�ǽ���ִ��˳��)�ɲ���֮����Ե����ȼ�����(���ȼ��Dz�����������������)��
��������ͨ���������������(maxConcurrentOperationCount)�����Ʋ��������С�
NSOperationQueue Ϊ�����ṩ�����ֲ�ͬ���͵Ķ���:�����к��Զ�����С����������������߳�֮��,���Զ�������ں�ִ̨�С�
iOS ���߳�:��NSOperation��NSOperationQueue���꾡�ܽ� - ����
����NSThread+runloopʵ�ֳ�פ�߳�
NSThread��ʵ�ʿ����бȽϳ��õ��ij�������ȥʵ�ֳ�פ�̡߳�
- ����ÿ�ο������̶߳�������cpu,����ҪƵ��ʹ�����̵߳������,Ƶ���������̻߳����Ĵ�����cpu,���Ҵ����̶߳�������ִ�����֮��Ҳ���ͷ���,�����ٴ�����,��ô��δ���һ���߳̿������������ٴι�����?Ҳ���Ǵ���һ����פ�̡߳�
���ȳ�פ�̼߳�Ȼ�dz�פ,��ô���ǿ�����GCDʵ��һ������������NSThread
+ (NSThread *)shareThread {
static NSThread *shareThread = nil;
static dispatch_once_t oncePredicate;
dispatch_once(&oncePredicate, ^{
shareThread = [[NSThread alloc] initWithTarget:self selector:@selector(threadTest) object:nil];
[shareThread setName:@"threadTest"];
[shareThread start];
});
return shareThread;
}
����������thread�Ͳ�����������?
[self performSelector:@selector(test) onThread:[ViewController shareThread] withObject:nil waitUntilDone:NO];
- (void)test
{
NSLog(@"test:%@", [NSThread currentThread]);
}
��û�д�ӡ,˵��test����û�б����á�
��ô������runloop�����̳߳�פ
+ (NSThread *)shareThread {
static NSThread *shareThread = nil;
static dispatch_once_t oncePredicate;
dispatch_once(&oncePredicate, ^{
shareThread = [[NSThread alloc] initWithTarget:self selector:@selector(threadTest2) object:nil];
[shareThread setName:@"threadTest"];
[shareThread start];
});
return shareThread;
}
+ (void)threadTest
{
@autoreleasepool {
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
[runLoop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
[runLoop run];
}
}
��ʱ����ȥ����performSelector���д�ӡ�ˡ�
�ġ��������뻥����
������:
��һ�����ڱ������̹߳�����Դ����,��һ�㻥����(mutex)��֮ͬ�����ڵ����������Ի�ȡ��ʱ��æ�ȴ�(busy waiting)����ʽ���ϵ�ѭ��������Ƿ���á�����һ���̵߳�����û��ִ����ϵ�ʱ��(����ס),��ô��һ���̻߳�һֱ�ȴ�(����˯��),����һ���̵߳�����ִ�����,��һ���̻߳�����ִ�С�
�ڶ�CPU�Ļ�����,�Գ������϶̵ij�����˵,ʹ������������һ��Ļ����������ܹ���߳�������ܡ�
������:
����һ���̵߳�����û��ִ����ϵ�ʱ��(����ס),��ô��һ���̻߳����˯��״̬�ȴ�����ִ�����,����һ���̵߳�����ִ�����,��һ���̻߳��Զ�����Ȼ��ִ������
�ܽ�:
��������æ��: ��νæ��,���ڷ��ʱ�����Դʱ,�������̲߳�������,���Dz�ͣѭ��������,ֱ��������Դ�ͷ�����
����������������: ��ν����,���ڷ��ʱ�����Դʱ,�������̻߳�����,��ʱcpu���Ե��������̹߳�����ֱ��������Դ�ͷ�������ʱ�ỽ�������̡߳�
��ȱ��:
���������ŵ�����,��Ϊ�������������������˯��,���Բ�������̵߳���,CPUʱ��Ƭ��ת�Ⱥ�ʱ����������������ں̵ܶ�ʱ���ڻ����,��������Ч��Զ���ڻ�������
����ȱ������,������һֱռ��CPU,����δ������������,һֱ����--����,����ռ����CPU,��������ں̵ܶ�ʱ ���ڻ����,�����ɻ�ʹCPUЧ�ʽ��͡�����������ʵ�ֵݹ���á�
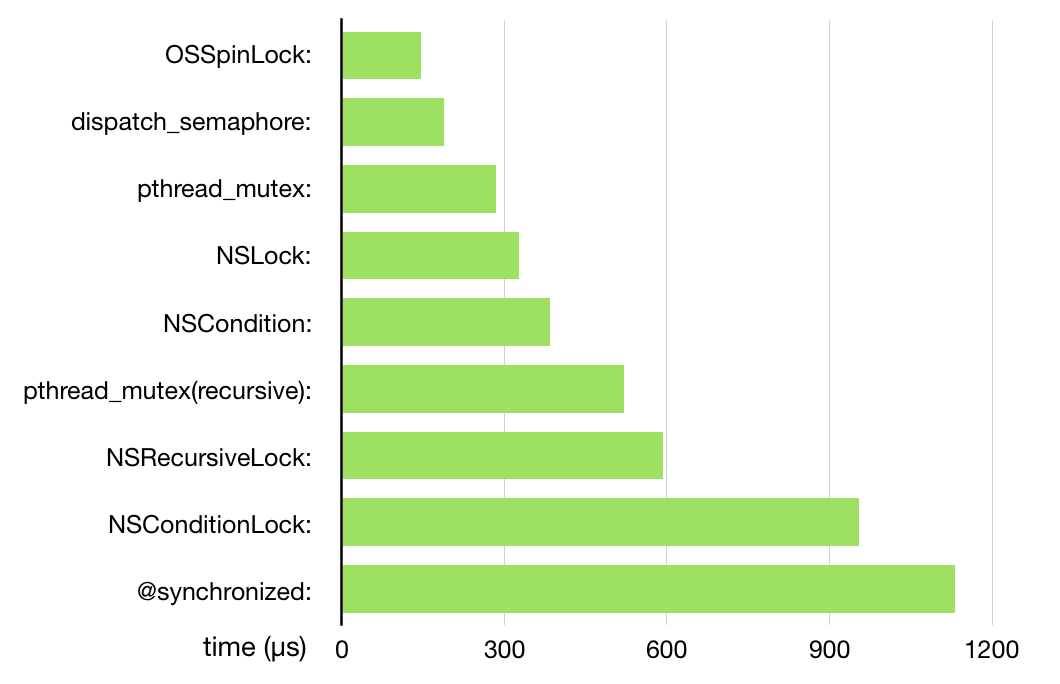
������:atomic��OSSpinLock��dispatch_semaphore_t
������:pthread_mutex��@ synchronized��NSLock��NSConditionLock ��NSCondition��NSRecursiveLock
ʮ.RunLoop���ݽṹ��RunLoop��ʵ�ֻ��ơ�RunLoop��Mode��RunLoop��NSTimer���߳�
RunLoop����
RunLoop�����ݽṹ
RunLoop��Mode
RunLoop��ʵ�ֻ���
RunLoop��NSTimer
RunLoop���߳�
һ��RunLoop����
RunLoop��ͨ���ڲ�ά�����¼�ѭ��(Event Loop)�����¼�/��Ϣ���й�����һ������
1��û����Ϣ����ʱ,�����ѱ�����Դռ��,���û�̬�л����ں�̬(CPU-�ں�̬���û�̬)
2������Ϣ��Ҫ����ʱ,���̱�����,���ں�̬�л����û�̬
Ϊʲômain���������˳�?
int main(int argc, char * argv[]) {
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class]));
}
}
UIApplicationMain�ڲ�Ĭ�Ͽ��������̵߳�RunLoop,��ִ����һ������ѭ���Ĵ���(���Ǽ�forѭ����whileѭ��)
//����ѭ������ģʽ(α����)
int main(int argc, char * argv[]) {
BOOL running = YES;
do {
// ִ�и�������,���������¼�
// ......
} while (running);
return 0;
}
UIApplicationMain����һֱû�з���,���Dz��ϵؽ��մ�����Ϣ�Լ��ȴ�����,�������г���֮��ᱣ�ֳ�������״̬��
����RunLoop�����ݽṹ
NSRunLoop(Foundation)��CFRunLoop(CoreFoundation)�ķ�װ,�ṩ����������API
RunLoop ��ص���Ҫ�漰�����:
CFRunLoop:RunLoop����
CFRunLoopMode:����ģʽ
CFRunLoopSource:����Դ/�¼�Դ
CFRunLoopTimer:��ʱԴ
CFRunLoopObserver:�۲���
1��CFRunLoop
��pthread(�̶߳���,˵��RunLoop���߳���һһ��Ӧ��)��currentMode(��ǰ����������ģʽ)��modes(�������ģʽ�ļ���)��commonModes(ģʽ�����ַ�������)��commonModelItems(Observer,Timer,Source����)����
2��CFRunLoopMode
��name��source0��source1��observers��timers����
3��CFRunLoopSource
��Ϊsource0��source1����
source0:
���ǻ���port��,Ҳ�����û��������¼�����Ҫ�ֶ������߳�,����ǰ�̴߳��ں�̬�л����û�̬source1:
����port��,����һ�� mach_port ��һ���ص�,�ɼ���ϵͳ�˿ں�ͨ���ں˺������̷߳��͵���Ϣ,����������RunLoop,���շַ�ϵͳ�¼���
�߱������̵߳�����
4��CFRunLoopTimer
����ʱ��Ĵ�����,������˵�ľ���NSTimer����Ԥ���ʱ��㻽��RunLoopִ�лص�����Ϊ���ǻ���RunLoop��,���������ʵʱ��(����NSTimer �Dz�ȷ�ġ� ��ΪRunLoopֻ����ַ�Դ����Ϣ������̵߳�ǰ���ڴ������ص�����,���п��ܵ���Timer������ʱ,������ִ��һ��)��
5��CFRunLoopObserver
��������ʱ���:CFRunLoopActivity
kCFRunLoopEntry
RunLoop������kCFRunLoopBeforeTimers
RunLoop��Ҫ����һЩTimer����¼�kCFRunLoopBeforeSources
RunLoop��Ҫ����һЩSource�¼�kCFRunLoopBeforeWaiting
RunLoop��Ҫ��������״̬,�������û�̬�л����ں�̬kCFRunLoopAfterWaiting
RunLoop������,�����ں�̬�л����û�̬��kCFRunLoopExit
RunLoop�˳�kCFRunLoopAllActivities
��������״̬
6�������ݽṹ֮�����ϵ
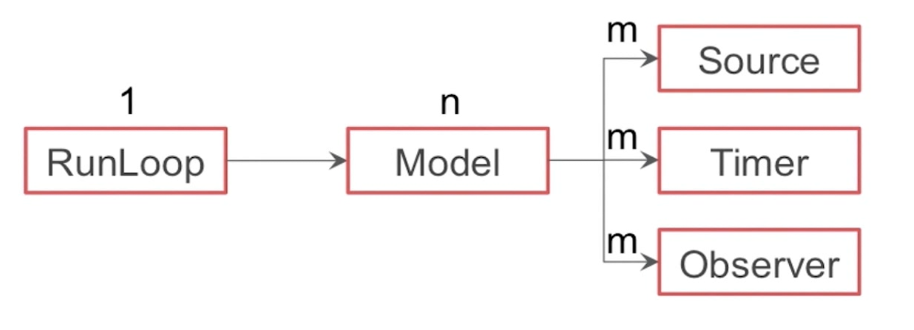
�̺߳�RunLoopһһ��Ӧ, RunLoop��Mode��һ�Զ��,Mode��source��timer��observerҲ��һ�Զ��
����RunLoop��Mode
����Mode����Ҫ֪��һ��RunLoop �����п��ܰ������Mode,��ÿ�ε��� RunLoop ��������ʱ,ֻ��ָ������һ�� Mode(CurrentMode)���л� Mode,��Ҫ����ָ��һ�� Mode ����Ҫ��Ϊ�˷ָ�����ͬ�� Source��Timer��Observer,������֮�以��Ӱ�졣
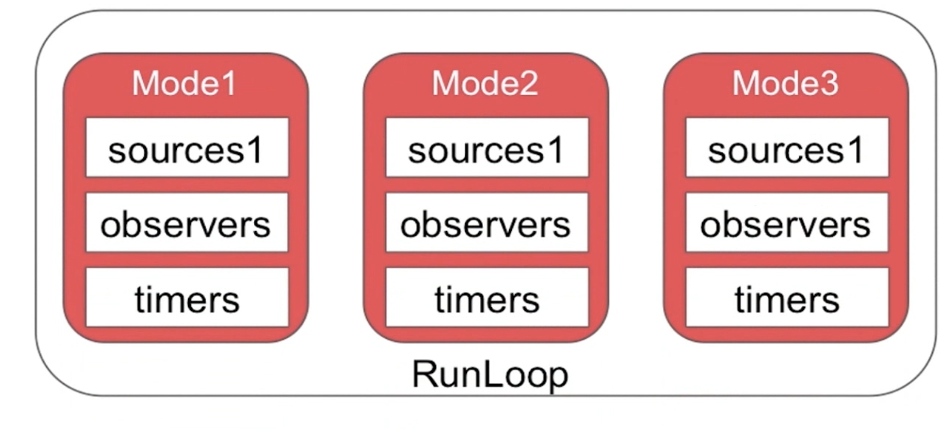
��RunLoop������Mode1��ʱ,�������ܴ���Mode2��Mode3�ϵ�Source��Timer��Observer�¼���
�ܹ���������CFRunLoopMode:
-
kCFRunLoopDefaultMode:Ĭ��ģʽ,���߳������������ģʽ������ -
UITrackingRunLoopMode:�����û������¼�(���� ScrollView �ٴ�������,��֤���滬��ʱ��������ModeӰ��) -
UIInitializationRunLoopMode:�ڸ�����Appʱ�ڽ���ĵ�һ�� Mode,������ɺ�Ͳ���ʹ�� -
GSEventReceiveRunLoopMode:����ϵͳ�ڲ��¼�,ͨ���ò��� -
kCFRunLoopCommonModes:αģʽ,����һ������������ģʽ,��ͬ��Source/Timer/Observer�����Mode�е�һ�ֽ������
�ġ�RunLoop��ʵ�ֻ���
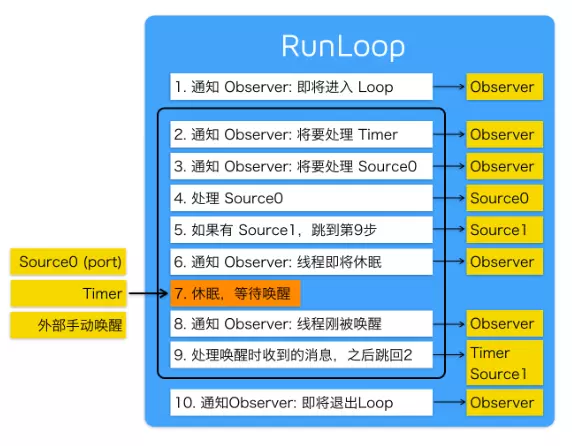
����ͼ�����������ȽϹ㡣
����RunLoop��������ĵ�������DZ�֤�߳���û����Ϣ��ʱ������,������Ϣʱ����,����߳������ܡ�RunLoop�������������ϵͳ�ں�����ɵ�(ƻ������ϵͳ�������Darwin�е�Mach)��
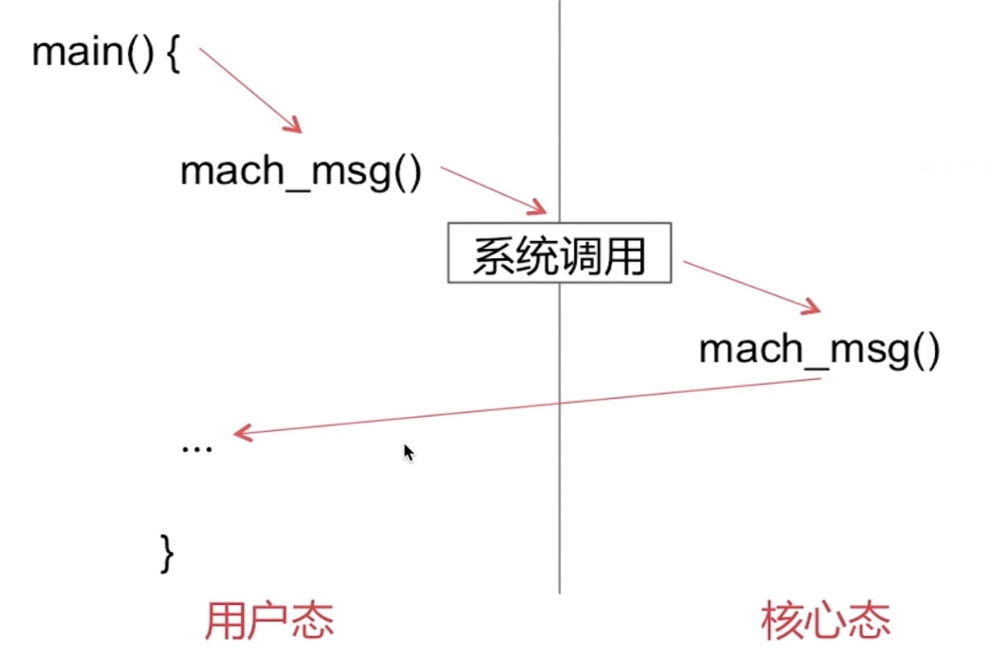
RunLoopͨ��mach_msg()�������ա�������Ϣ�����ı����ǵ��ú���mach_msg_trap(),�൱����һ��ϵͳ����,�ᴥ���ں�״̬�л������û�̬���� mach_msg_trap()ʱ���л����ں�̬;�ں�̬���ں�ʵ�ֵ�mach_msg()���������ʵ�ʵĹ�����
������port��source1,�����˿�,�˿�����Ϣ�ͻᴥ���ص�;��source0,Ҫ�ֶ����Ϊ���������ֶ�����RunLoop
Mach��Ϣ���ͻ���
������Ϊ:
1��֪ͨ�۲��� RunLoop ����������
2��֪ͨ�۲�����Ҫ����Timer�¼���
3��֪ͨ�۲�����Ҫ����source0�¼���
4������source0�¼���
5��������ڶ˿ڵ�Դ(Source1)���ò����ڵȴ�״̬,���벽��9��
6��֪ͨ�۲����̼߳�����������״̬��
7�����߳���������״̬,���û�̬�л����ں�̬,ֱ���������һ�¼������Ż����̡߳�
- һ������ port ��Source1 ���¼�(ͼ��Ӧ����source0)��
- һ�� Timer ��ʱ���ˡ�
- RunLoop �����ij�ʱʱ�䵽�ˡ�
- �������������ֶ����ѡ�
8��֪ͨ�۲����߳̽������ѡ�
9����������ʱ�յ����¼���
- ����û�����Ķ�ʱ������,������ʱ���¼�������RunLoop�����벽��2��
- �������Դ����,������Ӧ����Ϣ��
- ���RunLoop����ʾ���Ѷ���ʱ�仹û��ʱ,����RunLoop�����벽��2
10��֪ͨ�۲���RunLoop������
�塢RunLoop��NSTimer
һ���Ƚϳ���������:����tableViewʱ,��ʱ��������Ч��?
Ĭ�������RunLoop������kCFRunLoopDefaultMode��,��������tableViewʱ,RunLoop�л���UITrackingRunLoopMode,��Timer����kCFRunLoopDefaultMode�µ�,�������ܴ���Timer���¼���
��ôȥ������������?��Timer���ӵ�UITrackingRunLoopMode�ϲ����ܽ������,��Ϊ������Ĭ������¾������ܶ�ʱ���¼��ˡ�
����������Ҫ��Timerͬʱ���ӵ�UITrackingRunLoopMode��kCFRunLoopDefaultMode�ϡ�
��ô��ΰ�timerͬʱ���ӵ����mode����?��Ҫ�õ�NSRunLoopCommonModes��
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
Timer�ͱ����ӵ����mode��,������ʹRunLoop��kCFRunLoopDefaultMode�л���UITrackingRunLoopMode��,Ҳ����Ӱ�����Timer�¼�
����RunLoop���߳�
- �̺߳�RunLoop��һһ��Ӧ��,��ӳ���ϵ�DZ�����һ��ȫ�ֵ� Dictionary ��
- �Լ��������߳�Ĭ����û�п���RunLoop��
1����ô����һ����פ�߳�?
1��Ϊ��ǰ�߳̿���һ��RunLoop(��һ�ε��� [NSRunLoop currentRunLoop]����ʱʵ���ǻ���ȥ����һ��RunLoop)
1����ǰRunLoop������һ��Port/Source��ά��RunLoop���¼�ѭ��(���RunLoop��mode��һ��item��û��,RunLoop���˳�)
2��������RunLoop
@autoreleasepool {
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
[[NSRunLoop currentRunLoop] addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
[runLoop run];
}
2������±ߴ����ִ��˳��
NSLog(@"1");
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"2");
[self performSelector:@selector(test) withObject:nil afterDelay:10];
NSLog(@"3");
});
NSLog(@"4");
- (void)test
{
NSLog(@"5");
}
����1423,test����������ִ�С�
ԭ��������Ǵ�afterDelay����ʱ����,�����ڲ�����һ�� NSTimer,Ȼ�����ӵ���ǰ�̵߳�RunLoop�С�Ҳ���������ǰ�߳�û�п���RunLoop,�÷�����ʧЧ��
��ô���Ǹij�:
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"2");
[[NSRunLoop currentRunLoop] run];
[self performSelector:@selector(test) withObject:nil afterDelay:10];
NSLog(@"3");
});
Ȼ��test������Ȼ��ִ�С�
ԭ�������RunLoop��mode��һ��item��û��,RunLoop���˳������ڵ���RunLoop��run������,������mode��û�������κ�itemȥά��RunLoop��ʱ��ѭ��,RunLoop�漴���ǻ��˳���
���������Լ�����RunLoop,һ��Ҫ������item��
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@"2");
[self performSelector:@selector(test) withObject:nil afterDelay:10];
[[NSRunLoop currentRunLoop] run];
NSLog(@"3");
});
3��������֤���߳����ݻ�������UI��ʱ����û��Ļ�������?
�����������������ݵ�ͬʱ���������ǰҳ��,�����������ɹ�Ҫ�л����̸߳���UI,��ô�ͻ�Ӱ�쵱ǰ���ڻ��������顣
���ǾͿ��Խ�����UI�¼��������̵߳�NSDefaultRunLoopMode��ִ�м���,�����ͻ���û����ٻ���ҳ��,���߳�RunLoop��UITrackingRunLoopMode�л���NSDefaultRunLoopModeʱ��ȥ����UI
[self performSelectorOnMainThread:@selector(reloadData) withObject:nil waitUntilDone:NO modes:@[NSDefaultRunLoopMode]];
ʮһ. iOS������-----�������֮HTTPЭ��
HTTPЭ��:���ı�����Э��
��һ����ϸ�涨�����������ά��(WWW = World Wide Web)������֮�以��ͨ�ŵĹ���,ͨ��������������ά���ĵ������ݴ���Э�顣
HTTP�ǻ���TCP��Ӧ�ò�Э��
(OSI�����߲�Э����ϵ��·ֱ��� Ӧ�ò�����ʾ�����Ự�� �������������� ��������·����������)
- ����/��Ӧ����
- ���ӽ�������
- HTTP���ص�
һ�������ĺ���Ӧ����
1��������
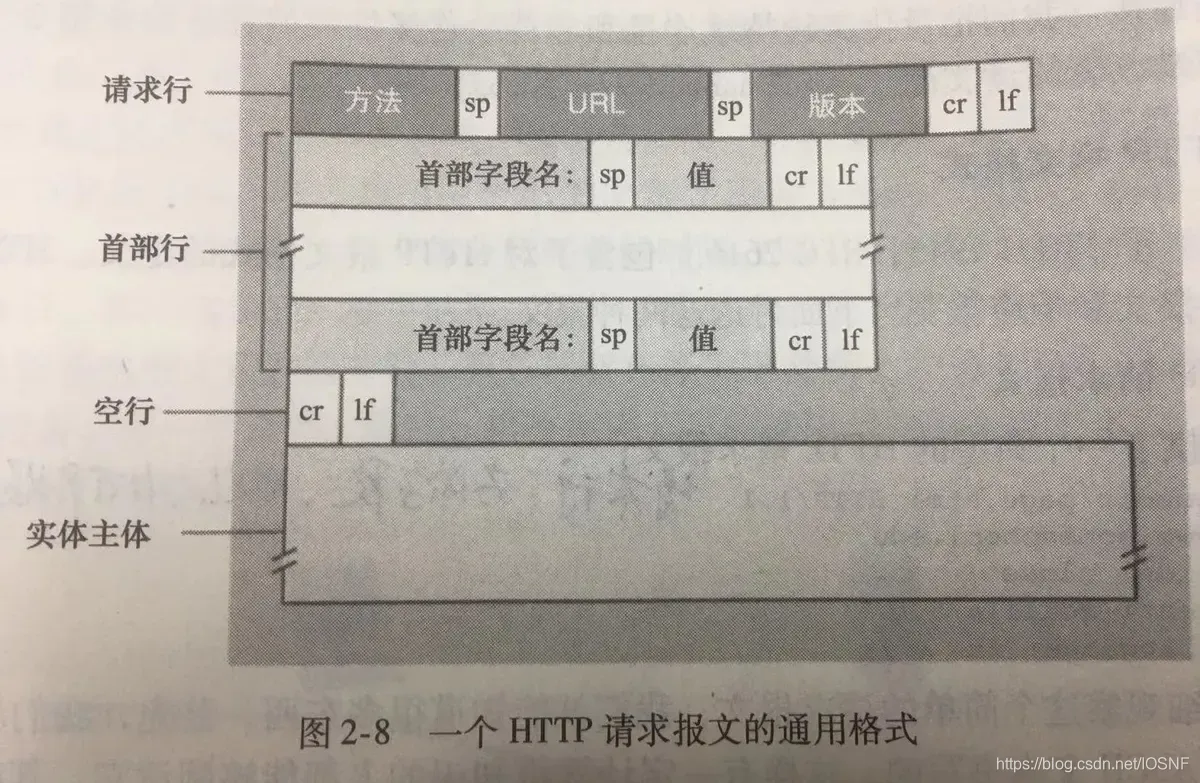
����:
POST /somedir/page.html HTTP/1.1
//������������:�����ֶΡ�URL�ֶκ�HTTP�汾�ֶ�
Host: www.user.com
Content-Type: application/x-www-form-urlencoded
Connection: Keep-Alive
User-agent: Mozilla/5.0.
Accept-lauguage: fr
//�������ײ���
(�˴�������һ����) //���зָ�header����������
name=world ������
Host:ָ���˸ö������ڵ�����
Connection:Keep-Alive�ײ���������������������߷�����ʹ�ó�������
Content-Type: x-www-form-urlencoded�ײ����������� HTTP�Ὣ���������key1=val1&key2=val2�ķ�ʽ������֯,���ŵ�����ʵ������
User-agent:�ײ�������ָ���û�����,���������������������������
Accept-lauguage:�ײ��б�ʾ�û���õ��ö���ķ���汾(������������������Ķ���Ļ�),����,������Ӧ��������Ĭ�ϰ汾
2����Ӧ����
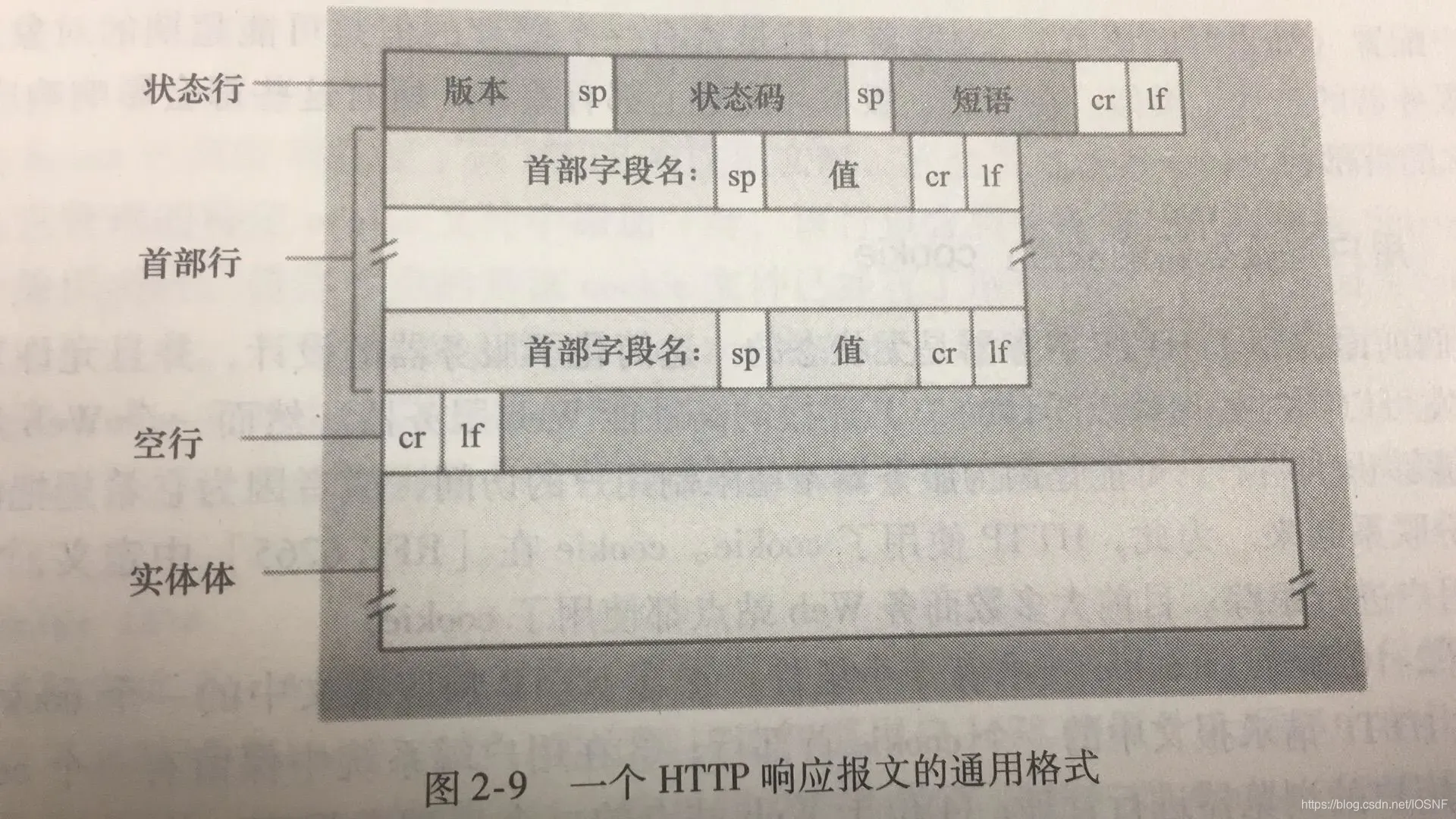
����:
HTTP/1.1 200 OK
//������״̬��:Э��汾�ֶΡ�״̬�롢��Ӧ״̬��Ϣ
Connection:close
Server:Apache/2.2.3(CentOS)
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html
Content-Length: 122
//�������ײ���
(�˴�������һ����) //���зָ�header��ʵ������
(data data data data)//��Ӧʵ������
״̬�뼰����Ӧ�Ķ���ָʾ������Ľ����
һЩ������״̬��Ͷ�Ӧ�Ķ���:
- 200 OK:����ɹ�,��Ϣ�ڷ��ص���Ӧ������
- 301 Moved Permanently:����Ķ����Ѿ�������ת����,�µ�URL��������Ӧ�����е�Location:�ײ����С��ͻ��������Զ���ȡ�µ�URL
- 400 Bad Request:һ��ͨ�ò������,ָʾ�������ܱ�����������
- 404 Not Found:��������ļ����ڷ�������
- 505 HTTP Version Not Supported:��������֧��������ʹ�õ�HTTPЭ��汾
<4��ͷ��״̬��ͨ���ǿͻ��˵�����,5��ͷ����ͨ���Ƿ���˵�����>
Connection:close�ײ��и��߿ͻ�,�����걨�ĺر�TCP���ӡ�
Date:ָ�IJ��Ƕ���������ĵ�ʱ��,���Ƿ��������ļ�ϵͳ�м������ö���,���뵽��Ӧ����,��������Ӧ���ĵ�ʱ�䡣
Server: �ײ���ָʾ�ñ�������һ̨Apache Web������������,������HTTP���������User-agent
Content-Length:�ײ���ָʾ�˱����Ͷ����е��ֽ���
Content-Type:�ײ���ָʾ��ʵ�����еĶ�����HTML�ı�
����HTTP������ʽ
GET��POST��PUT��DELETE��HEAD��OPTIONS
1��GET��POST��ʽ������
����Ƕ�����,��ֱ�۵��������
- GET���������һ����
?�ָ�ƴ�ӵ�URL����,POST���������Body���� - GET������������Ϊ2048���ַ�,POSTһ����û���Ƶ�
- GET�������ڲ�����¶��URL��, �Dz���ȫ��,POST�����������ȫ
֮����˵�����ȫ,����Ϊ,���POST��Ȼ����������,�������ץ��,GET��POSTһ�����Dz���ȫ�ġ�(HTTPS���û��ǵ���)
��������ĽǶ�����:
GET:��ȡ��Դ�� ��ȫ��,�ݵȵ�(ֻ����,�����), �ɻ����
POST:��ȡ��Դ�� �ǰ�ȫ��,���ݵȵ�,���ɻ����
- �����
��ȫ��ָ��Ӧ����Server�˵��κ�״̬�仯
GET��������ǻ�ȡ����,�Dz��������������״̬�仯��,���ǰ�ȫ�ġ�(HEAD,OPTIONSҲ�ǰ�ȫ��)
��POST���������ύ����,�ǿ��ܻ����������״̬�仯��,���Dz���ȫ�� �ݵ�:ͬһ������ִ�ж�κ�ִ��һ�ε�Ч����ȫ��ͬ
��ȻGET�������ݵ���POST���������ݵ��ġ�
�������ݵ�����GET������,��ΪGET��ֹ��ִ�ж�κ�ִ��һ�ε�Ч����ȫ��ͬ,������ִ��һ�κ�ִ����ε�Ч��Ҳ����ȫ��ͬ�ġ��ɻ����
�����Ƿ���Ա����档
GET�������������Cache
��������,���Dz���,������ΪGET���ݵȵ�ֻ����,��GET������˷������ݲ���������������,����GET������ȫ��,�Ӷ�����ֱ����CDN����,������������ĸ���,Ҳ�����ɻ������
��POST�����ݵȵ�,�����˷������ݻ���������������,����POST������ȫ��,���뽻��web����������,���� ���ɻ����
GET��POST�����Ͼ���TCP����,����𡣵�������HTTP�Ĺ涨�������/������������,����������Ӧ�ù��������ֳ�һЩ��ͬ��
����Ӧʱ,GET����һ��TCP���ݰ�;POST��������TCP���ݰ�:
����GET��ʽ������,��������Header��ʵ������һ�����ͳ�ȥ,��������Ӧ200(��������);
������POST,������ȷ���Header,��������Ӧ100 Continue,������ٷ���ʵ������,��������Ӧ200 OK(��������)��
2��GET ��� POST ��������ʲô?
1���������ƾ��Ƿ��㡣GET ��URL����ֱ������,�Ӷ�GET�����е�URL���Ա�������ǩ��,������ʷ��¼��
2�����Ա�����,������������ĸ���
���Դ���������,������GET�ȽϺá�
����HTTP���ص�
�������� ��״̬
HTTP�ij־����ӡ�Cookie/Session
1��HTTP����״̬
��Э�����������û�м���������
ÿ�ε������Ƕ�����,����ִ������ͽ����ǰ��������֮�������ʱ��ֱ�ӹ�ϵ��,��������ǰ�������Ӧ�����ֱ��Ӱ��,Ҳ����ֱ��Ӱ����������Ӧ�����
Ҳ����˵��������û�б���ͻ��˵�״̬,�ͻ��˱���ÿ�δ����Լ���״̬ȥ���������
����HTTPЭ��ָ���Dz�����cookies,session,application��HTTPЭ��
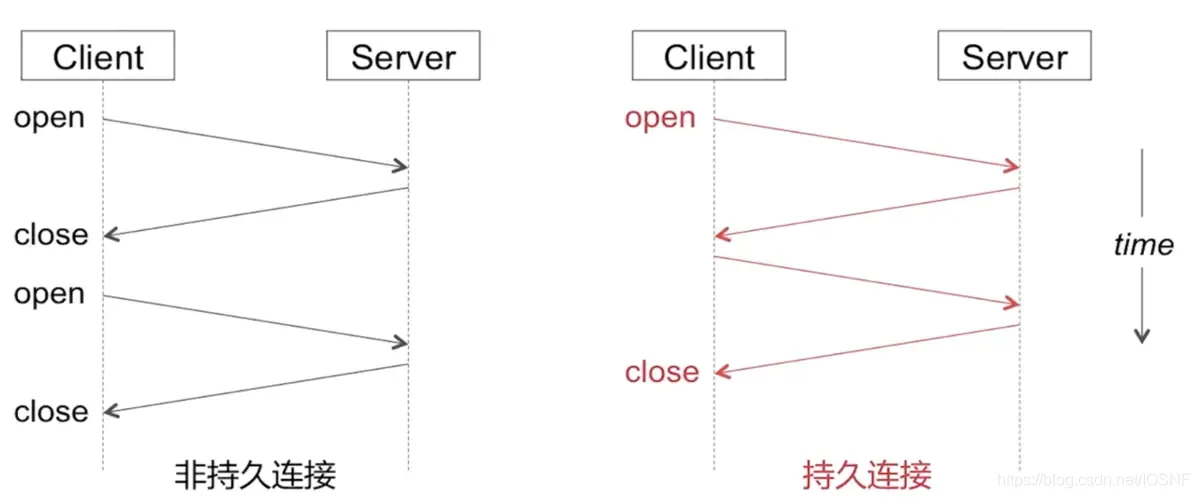
2��HTTP�ij־�����
-
�dz־�����:ÿ�����Ӵ���һ������-��Ӧ����
-
�־�����:ÿ�����ӿ��Դ����������-��Ӧ����
�־����������,������������Ӧ����TCP���Ӽ������š�ͬһ�Կͻ�/������֮��ĺ����������Ӧ����ͨ��������ӷ��͡�
HTTP/1.0 ʹ�÷dz־����ӡ� HTTP/1.1 Ĭ��ʹ�ó־����� <keep-alive>��
�dz־����ӵ�ÿ������,TCP���ڿͻ��˺ͷ���˷���TCP������,��ά��TCP����,���������ӷ���������������ÿ��������2��RTT(Round Trip Time,Ҳ����һ�����ݰ��ӷ���ȥ��������ʱ��)���ӳ�,����TCP��ӵ�����Ʒ���,ÿ����������TCP������,��Ϊÿ��TCP���Ӷ���ʼ�ڻ�������
HTTP�־�������ô�ж�һ�������Ƿ������?
Content-length:�����������ֽ����Ƿ�ﵽContent-lengthֵchunked(�ֿ鴫��):Transfer-Encoding����ѡ��ֿ鴫��ʱ,��Ӧͷ�п��Բ�����Content-Length,���������Ȼظ�һ���������ݵı���(ֻ����Ӧ�к���Ӧͷ��\r\n),Ȼ��ʼ�������ɸ����ݿ顣�����������ɸ����ݿ��,��Ҫ�ٴ���һ���յ����ݿ�,���ͻ����յ��յ����ݿ�ʱ,��ͻ���֪�����ݽ�����ϡ�
ʮ��.iOS������-----�������֮HTTPS���ԳƼ��ܡ��ǶԳƼ���
һ��HTTPS��HTTP������
HTTPS�� = HTTP�� + SSL/TLS��
SSL��ȫ����Secure Sockets Layer,����ȫ�Ӳ�Э��,��Ϊ����ͨ���ṩ��ȫ�����������Ե�һ�ְ�ȫЭ�顣TLS��ȫ����Transport Layer Security,����ȫ�����Э�顣
��HTTPS�ǰ�ȫ��HTTP��
����HTTPS�����ӽ�������
HTTPSΪ�˼�˰�ȫ��Ч��,ͬʱʹ���˶ԳƼ��ܺͷǶԳƼ��ܡ��ڴ���Ĺ����л��漰��������Կ:
-
�������˵Ĺ�Կ��˽Կ,��������
�ǶԳƼ��� -
�ͻ������ɵ������Կ,��������
�ԳƼ���
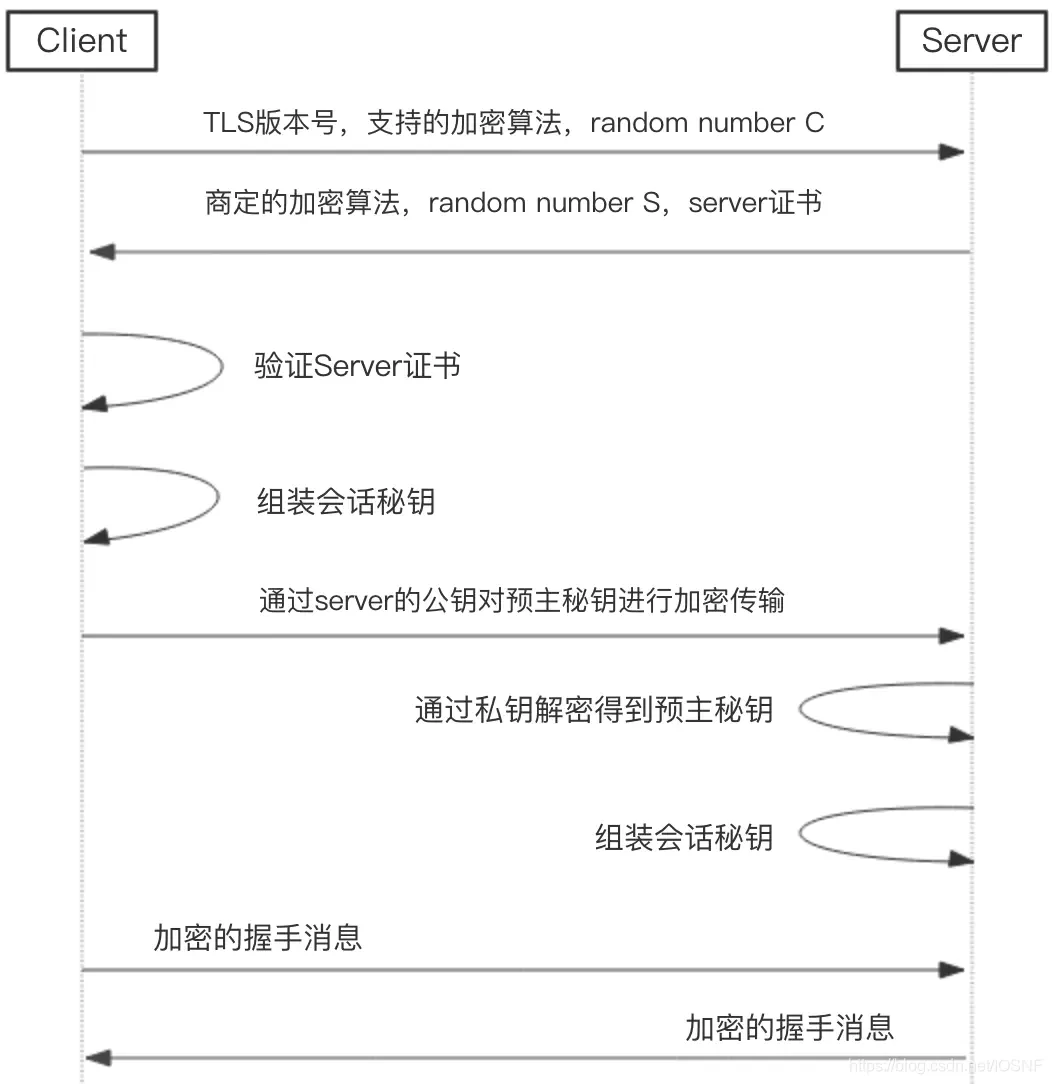
����ͼ,HTTPS���ӹ��̴��¿ɷ�Ϊ�˲�:
1���ͻ��˷���HTTPS���ӡ�
�ͻ��˻����ȫЭ��汾�����ͻ���֧�ֵļ����㷨�б��������C��������ˡ�
2������˷���֤����ͻ���
����˽�����Կ�㷨�����,����Լ�֧�ֵļ����㷨�б����бȶ�,���������,��Ͽ����ӡ�����,����˻��ڸ��㷨�б���,ѡ��һ�ֶԳ��㷨(��AES)��һ�ֹ�Կ�㷨(������ض���Կ���ȵ�RSA)��һ��MAC�㷨�����ͻ��ˡ�
����������һ����Կ��,����Կ��˽Կ,�����������ǶԳƼ���ʹ�õ�,�������˱�����˽Կ,���ܽ���й¶,��Կ���Է����κ��ˡ�
�ڷ��ͼ����㷨��ͬʱ���������֤���������S�����ͻ���
3���ͻ�����֤server֤��
���server��Կ���м��,��֤��Ϸ���,������ַ��ֹ�Կ������,��ôHTTPS�������������
4���ͻ�����װ�Ự��Կ
�����Կ�ϸ�,��ô�ͻ��˻��÷�������Կ������һ��ǰ����Կ(Pre-Master Secret,PMS),��ͨ����ǰ����Կ�������C��S����װ���Ự��Կ
5���ͻ��˽�ǰ����Կ���ܷ��������
��ͨ������˵Ĺ�Կ����ǰ����Կ�����ǶԳƼ���,���������
6�������ͨ��˽Կ���ܵõ�ǰ����Կ
����˽��յ�������Ϣ��,��˽Կ���ܵõ�����Կ��
7���������װ�Ự��Կ
�����ͨ��ǰ����Կ�������C��S����װ�Ự��Կ��
����,����˺Ϳͻ��˶��Ѿ�֪�������ڴ˴λỰ������Կ��
8�����ݴ���
�ͻ����յ�������������������,�ÿͻ�����Կ������жԳƽ���,�õ����������͵����ݡ�
ͬ��,������յ��ͻ��˷�����������,�÷������Կ������жԳƽ���,�õ��ͻ��˷��͵����ݡ�
�ܽ�:
�Ự��Կ = random S + random C + ǰ����Կ
-
HTTPS���ӽ�������ʹ��
�ǶԳƼ���,���ǶԳƼ����Ǻܺ�ʱ��һ�ּ��ܷ�ʽ -
����ͨ�Ź���ʹ��
�ԳƼ���,���ٺ�ʱ��������������� -
����,
�ԳƼ������ܵ���ʵ�ʵ�����,�ǶԳƼ������ܵ��ǶԳƼ�������Ҫ�Ŀͻ��˵���Կ��
�����ԳƼ��ܺͷǶԳƼ���
1���ԳƼ���
��ͬһ����Կ�����м��ܽ��ܡ�
�ԳƼ���ͨ���� DES,IDEA,3DES �����㷨��
2���ǶԳƼ���
�ù�Կ��˽Կ���ӽ��ܵ��㷨��
��Կ(Public Key)��˽Կ(Private Key)��ͨ��һ���㷨�õ���һ����Կ��(��һ����Կ��һ��˽Կ),��Կ����Կ���й����IJ���,˽Կ���Ƿǹ����IJ���,˽Կͨ���DZ����ڱ��ء�
-
��
��Կ���м���,��Ҫ��˽Կ���н���;��֮,��˽Կ����,��Ҫ����Կ���н���(����ǩ��)�� -
����˽Կ�DZ����ڱ��ص�,����
�ǶԳƼ���������ԳƼ����ǰ�ȫ�ġ�
���ǶԳƼ������ԳƼ�����ʱ(100������),����ͨ��Ҫ����ԳƼ�����ʹ�á�
�����ķǶԳƼ����㷨��:RSA��ECC(�ƶ��豸��)��Diffie-Hellman��El Gamal��DSA(����ǩ����)
��Ϊ��ȷ���ͻ����ܹ�ȷ�Ϲ�Կ������Ҫ���ʵ���վ�Ĺ�Կ,����������֤��ĸ���,����֤�����һ��һ����ǩ������,���Ծͳ�����֤����,��֤�����еĶ��˵ľ��Ǹ�CA��
ʮ��.iOS����-----һ������UDP�ļ�����Demo(��C���ԡ�python��GCDAsyncUdpSocket��ʵ��UDPͨ��)
һ���ֱ���C���ԡ�python��GCDAsyncUdpSocket��ʵ��UDPͨ��
1��C���Է�ʽ
- ���ȳ�ʼ��
socket����,UdpҪ��SOCK_DGRAM - Ȼ���ʼ��
sockaddr_in����ͨ�Ŷ���,�����Ϊ�����Ҫ��socket������ͨ������,��������Ϣ - Ȼ����һ��ѭ��,ѭ������
recvfrom��������Ϣ - �յ���Ϣ��,�����·���Ϣ����ĵ�ַ,�Ա�֮��ظ���Ϣ
- (void)initCSocket
{
char receiveBuffer[1024];
__uint32_t nSize = sizeof(struct sockaddr);
if ((_listenfd = socket(AF_INET, SOCK_DGRAM, 0)) == -1)
{
perror("socket() error. Failed to initiate a socket");
}
bzero(&_addr, sizeof(_addr));
_addr.sin_family = AF_INET;
_addr.sin_port = htons(_destPort);
if(bind(_listenfd, (struct sockaddr *)&_addr, sizeof(_addr)) == -1)
{
perror("Bind() error.");
}
_addr.sin_addr.s_addr = inet_addr([_destHost UTF8String]);//ip�����DZ���������ip,Ҳ�����ú�INADDR_ANY����,����0.0.0.0,�������е�ַ
while(true){
long strLen = recvfrom(_listenfd, receiveBuffer, sizeof(receiveBuffer), 0, (struct sockaddr *)&_addr, &nSize);
NSString * message = [[NSString alloc] initWithBytes:receiveBuffer length:strLen encoding:NSUTF8StringEncoding];
_destPort = ntohs(_addr.sin_port);
_destHost = [[NSString alloc] initWithUTF8String:inet_ntoa(_addr.sin_addr)];
NSLog(@"����%@---%zd:%@",_destHost,_destPort,message);
}
}
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[self initCSocket];
});
- ����
sendto������������Ϣ
- (void)sendMessage:(NSString *)message
{
NSData *sendData = [message dataUsingEncoding:NSUTF8StringEncoding];
sendto(_listenfd, [sendData bytes], [sendData length], 0, (struct sockaddr *)&_addr, sizeof(struct sockaddr));
}
2��GCDAsyncUdpSocket��ʽ
-
GCDAsyncUdpSocket��ַ
-
���ȳ�ʼ��
Socket���� -
�˿�,����
beginReceiving:������������Ϣ
- (void)initGCDSocket
{
_receiveSocket = [[GCDAsyncUdpSocket alloc] initWithDelegate:self
delegateQueue:dispatch_get_global_queue(0, 0)];
NSError *error;
// ��һ���˿�(��ѡ),������˿�, ��ô�ͻ��������һ�������Ψһ�Ķ˿�
// �˿����ַ�Χ(1024,2^16-1)
[_receiveSocket bindToPort:test_port error:&error];
if (error) {
NSLog(@"��������ʧ��");
}
// ��ʼ���նԷ���������Ϣ
[_receiveSocket beginReceiving:nil];
}
- �ڴ����������ȡ���Է�����������Ϣ,��¼�������Ͷ˿�,�Ա�֮��ظ���Ϣ
#pragma mark - GCDAsyncUdpSocketDelegate
- (void)udpSocket:(GCDAsyncUdpSocket *)sock didReceiveData:(NSData *)data fromAddress:(NSData *)address withFilterContext:(id)filterContext {
NSString *message = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
_destPort = [GCDAsyncUdpSocket portFromAddress:address];
_destHost = [GCDAsyncUdpSocket hostFromAddress:address];
NSLog(@"����%@---%zd:%@",_destHost,_destPort,message);
}
- ����
sendData:(NSData *)data toHost:(NSString *)host port:(uint16_t)port withTimeout:(NSTimeInterval)timeout tag:(long)tag������������Ϣ
- (void)sendMessage:(NSString *)message
{
NSData *sendData = [message dataUsingEncoding:NSUTF8StringEncoding];
[_receiveSocket sendData:sendData toHost:_destHost port:_destPort withTimeout:60 tag:500];
}
3��python��ʽ
python��ʽ�ͱȽϼ���
- ��ʼ��socket,�˿�
socket = socket(AF_INET, SOCK_DGRAM)
socket.bind(('', port))
- ѭ��������Ϣ
while True:
message, address = socket.recvfrom(2048)
print address,message
- ������Ϣ
socket.sendto(message, address)
��������pythonʵ��Udpͨ��demo
-
��������python�ļ�,�ֱ���Ϊ�ͻ��˺ͷ����,Ȼ��ͬʱ����
-
�ͻ���
from socket import *
host = '127.0.0.1'
port = 12000
socket = socket(AF_INET, SOCK_DGRAM)
while True:
message = raw_input('input message ,print 0 to close :\n')
socket.sendto(message, (host, port))
if message == '0':
socket.close()
break
receiveMessage, serverAddress = socket.recvfrom(2048)
print receiveMessage,serverAddress
- �����
from socket import *
port = 12000
socket = socket(AF_INET, SOCK_DGRAM)
socket.bind(('', port))
print 'server is ready to receive'
count = 0
while True:
message, address = socket.recvfrom(2048)
print address,message
count = count + 1
if message == '0':
socket.close()
break
else:
message = raw_input('input message ,print 0 to close :\n')
socket.sendto(message, address)
- �ͻ��˴�ӡ
/usr/local/bin/python2.7 /Users/wangyong/Desktop/other/python/UDPClient.py
input message ,print 0 to close :
hello,�����
hello,�ͻ��� ('10.208.61.53', 12000)
input message ,print 0 to close :
����ͨ�Ű�����
�õ� ('10.208.61.53', 12000)
input message ,print 0 to close :
0
Process finished with exit code 0
- ����˴�ӡ
/usr/local/bin/python2.7 /Users/wangyong/Desktop/other/python/UDPServer.py
server is ready to receive
('10.208.61.53', 53500) hello,�����
input message ,print 0 to close :
hello,�ͻ���
('10.208.61.53', 53500) ����ͨ�Ű�����
input message ,print 0 to close :
�õ�
('10.208.61.53', 53500) 0
Process finished with exit code 0
����iOS�˻���UDP�ļ�������demo
1��UdpManager
Udpͨ����C�����GCDAsyncUdpSocket������,��װ��UdpManager��
initSocketWithReceiveHandle:(dispatch_block_t)receiveHandle:��ʼ��socket���,receiveHandle�ǽ��յ���Ϣ��Ļص�sendMessage:(NSString *)message:������ϢmessageArray:��Ϣ�б�,�������յ��ĺͷ��ͳ�ȥ����Ϣ
+ (void)initSocketWithReceiveHandle:(dispatch_block_t)receiveHandle;
+ (void)sendMessage:(NSString *)message;
+ (NSMutableArray *)messageArray;
��Ϣ������MessageModel,����role������Ϣ���Ͷ���,Ϊ0���ǽ��յ�����Ϣ,1Ϊ�Լ����͵���Ϣ
@interface MessageModel:NSObject
@property (nonatomic, copy) NSString *message;
@property(nonatomic,assign) NSInteger role;
@end
2��ViewController
�����������UdpManager��ʼ��socket
[UdpManager initSocketWithReceiveHandle:^{
dispatch_async(dispatch_get_main_queue(), ^{
self.title = [NSString stringWithFormat:@"%@---%@",[[UdpManager shareManager] valueForKey:@"_destHost"],[[UdpManager shareManager] valueForKey:@"_destPort"]];
[self reloadData];
});
}];
�ڴ�������textFieldShouldReturn��������̵ķ��Ͱ�ťʱ���ͱ༭�õ���Ϣ
#pragma mark - UITextFieldDelegate
- (BOOL)textFieldShouldReturn:(UITextField *)textField
{
if (self.textField.text.length == 0) return YES;
[UdpManager sendMessage:self.textField.text];
[self reloadData];
self.textField.text = nil;
return YES;
}
���ͻ��߽��յ�����Ϣ�Ὣ��Ϣ���ӵ�messageArray��,��ˢ��ҳ��
- (void)sendMessage:(NSString *)message
{
NSData *sendData = [message dataUsingEncoding:NSUTF8StringEncoding];
[self.messageArray addObject:[[MessageModel alloc] initWithMessage:message role:1]];
#ifdef UseGCDUdpSocket
// �ú���ֻ������һ�η��� ���������������ݵķ���, �����ú�̨���߳������ķ��� Ҳ����˵�������������ɺ�,���ݲ�û�����̷���,�첽����
[_receiveSocket sendData:sendData toHost:_destHost port:_destPort withTimeout:60 tag:500];
#else
sendto(_listenfd, [sendData bytes], [sendData length], 0, (struct sockaddr *)&_addr, sizeof(struct sockaddr));
#endif
}
UI�Ͳ�����������,��������ֻ��һ����ʾ���պͷ�����Ϣ�����б���tableView��һ���༭��Ϣ�������textField����ž���Щ����,ֻ�Ǹ�����demo,ֻʵ���˽��շ���������Ϣ�Ĺ���,��û���������Ż�
3������
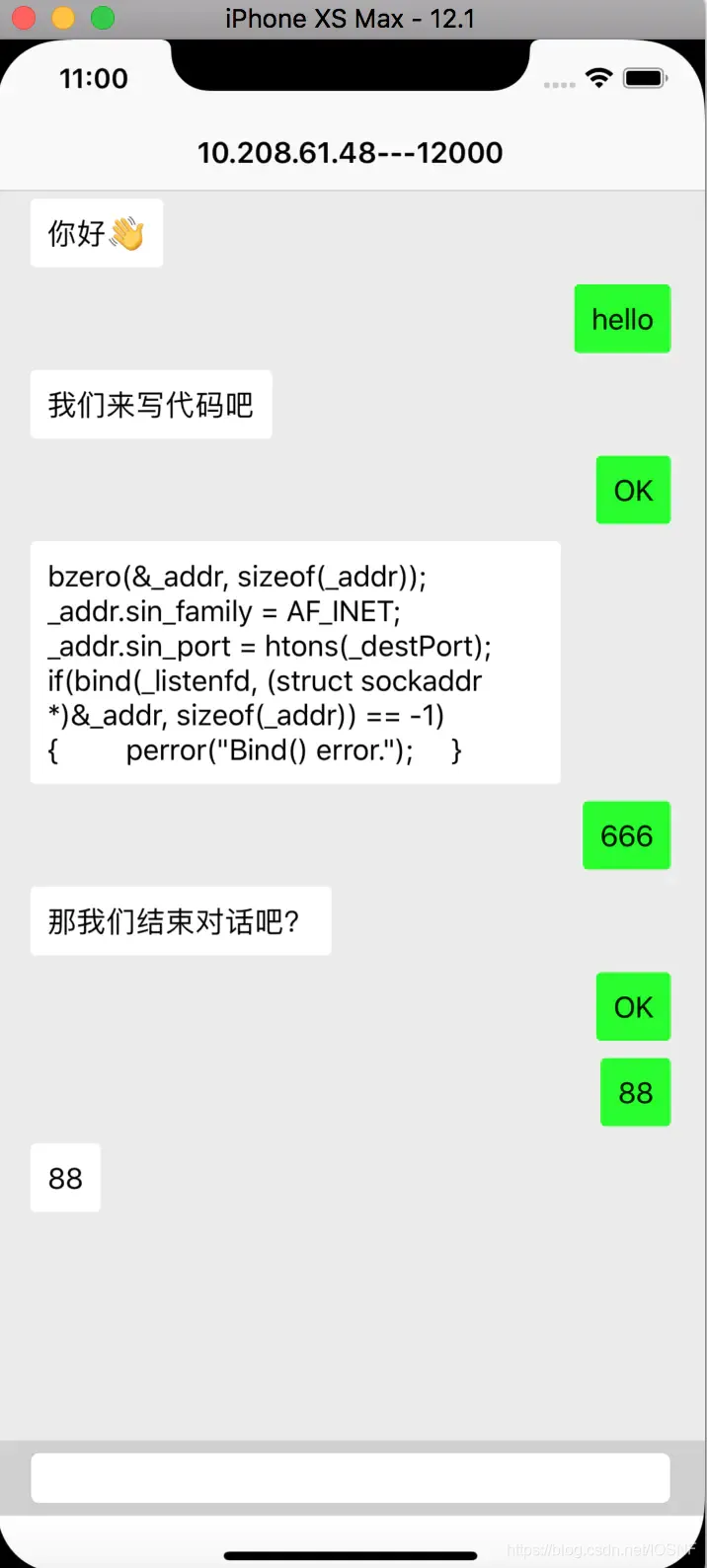
�ֱ���ģ�������������,���߿�����ϸղŵ�python�������.
test_host��ֱ���õ���ip����

- Ȼ���ֻ��ȷ�����Ϣ��ģ������,ģ�����Ϳ��Ը��ݼ�¼�µ��ֻ��������Ͷ˿ڻظ���Ϣ�ˡ������ֻ�������Ҳ�ǿ��Ե�
- Ч��ͼ����
ʮ��.iOS������-----�������֮UDP���ص㡢UDP�ı��Ľṹ��������
TCP(Transmission Control Protocol �������Э��)��UDP(User Datagram Protocol �û����ݱ�Э��)ͬ�������Э��
һ��UDP���ص�
UDP������������ӵ�Э��,�������ݲ���Ҫ�ͷ���������,ֻ��Ҫ֪��ip�ͼ����˿�,����Ҫ����û��Ŀ�ĵ�socket,ֻ�ǽ����ݱ�Ͷ�ݳ�ȥ,���ܽ��շ��Ƿ�ɹ����յ�,��һ�ֲ��ɿ��Ĵ��䡣
��ȻUDP�Dz��ɿ����ݴ���Э��,��Ϊʲô��ô��Ӧ��ȥѡ��UDP��?
1�����ں�ʱ������ʲô���ݵ�Ӧ�ò���Ƹ��Ӿ�ϸ
- ֻҪӦ�ý����ݴ��ݸ�UDP,UDP�ͻὫ�����ݴ����UDP���Ķβ����̽��䴫�ݸ�����㡣
- ��TCP�����и�ӵ�����ƻ���,��ȷ�������ܹ���ȫ����,�����ܿɿ�����ɹ���Ҫ�ö���ʱ�䡣
- ������ЩʵʱӦ��,��������Ƶ���������Ǹ�ϣ�������ܹ���ʱ����,Ϊ�˿�������һ�������ݶ�ʧ,�Ƚ��ʺ���UDP
2���������ӽ���
- ������֪,TCP�����ݴ���ǰ��Ҫ������������,UDPȴ����Ҫ���κε������ɽ������ݴ���,���UDP�������뽨�����ӵ�ʱ�ӡ�
- ��Ҳ��DNS������UDP������TCP�ϵ���Ҫԭ��
- ��HTTPЭ��֮����ʹ��TCP,����Ϊ����HTTPЭ����˵,�ɿ�����������Ҫ�ġ�
3��������״̬
- TCP��Ҫά������״̬��������״̬�������պͷ��ͻ��桢ӵ�����Ʋ����Լ������ȷ�ϺŵIJ�����(���������ʱ��,����ϸ˵��TCP��ӵ�����Ʒ���,�Ը÷�����˵,��Щ״̬��Ϣ���DZ�Ҫ��)
- ��UDP����Ҫά������״̬,Ҳ���ø�����Щ����
4�������ײ�����С
ÿ��TCP���Ķζ���20�ֽڵ��ײ�����,��UDP����8�ֽڵĿ���
����,��DZ�Ҫ,��������ʼ�,Զ���ն˷���,web,�Լ��ļ�����,��Ҫ�ɿ������ݴ���,��ȥ����TCP������������Ƕ�ʵʱ��Ҫ��ߵ�Ӧ��,����ʵʱ��Ƶ����,����绰,һ�㶼��ѡ��UDP
����UDP�ı��Ľṹ
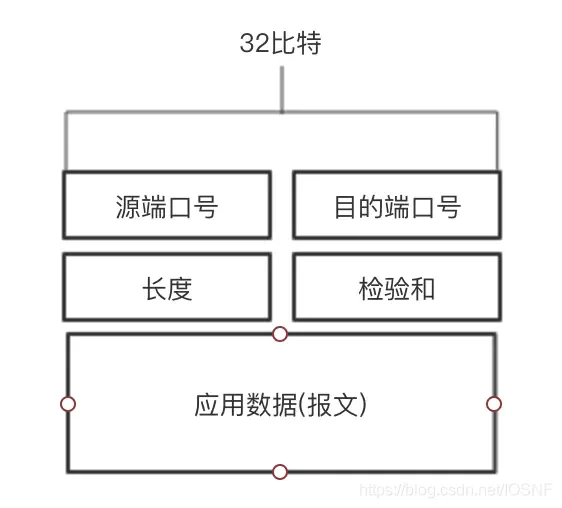
Ӧ�ò�����ռ��UDP���Ķε������ֶΡ�UDP�ײ�ֻ��4���ֶ�,ÿ���ֶ���2���ֽ����,��UDP�ײ�����8�ֽڡ�
- �˿ں�:����ʹĿ��������Ӧ�����ݽ���������Ŀ�Ķ�ϵͳ�ж���Ӧ����,ִ�з��ù��ܡ�
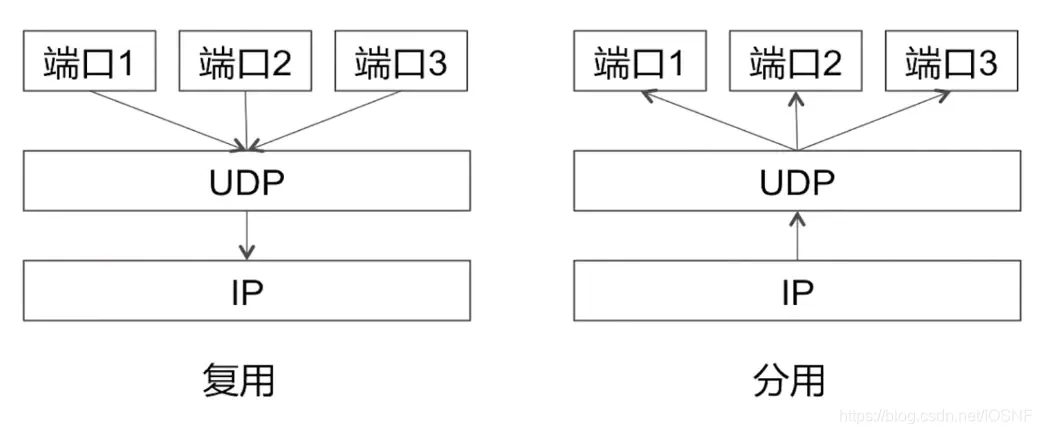
-
����:���ֶ�ָʾ����UDP���Ķ��е��ֽ���(�ײ�+����)
-
�����:���շ�ʹ�ü����������ڸñ��Ķ����Ƿ�����˲��,�������⡣
����UDP������
UDP������ṩ�����������ܡ�
������൱������ȷ����UDP���Ķδ�Դ����Ŀ�ĵ��ƶ�ʱ,���еı����Ƿ����˸ı�(����,������·�е��������Ż�洢��·������ʱ����������)��
���ͷ���UDP�Ա��Ķ��е�����16�����ֶԺͽ�����������,���ʱ�������κ���������ؾ����õ��Ľ��������UDP���Ķ��е�������ֶΡ�
����,�ٶ�����������16���ص���:
0110011001100000
0101010101010101
1000111100001100
��Щ16�����ֵ�ǰ����֮����:
1011101110110101
�ٽ��ú��������16���������,�ó�:
10100101011000001
���������,�ú;�Ҫ���ؾ�,������λ��1�ӵ����һλȥ,�ó�:
0100101011000010
Ȼ�������з�������,��ν��������,���ǽ����е�1����0,0����1
1011010100111101
����ǵó��ļ���͡����ڽ��շ�,ȫ����4��16������(���������)����һ�����������û��������,��Ȼ�ڽ��մ��úͽ���1111111111111111���������Щ����֮һ��0,�����Ǿ�֪���÷����г����˲����
UDP���˵��˻�������������ṩ������,�������ϵͳ����б����̵��˵���ԭ��
��UDP��Ȼ�ṩ������,�����Բ���ָ�����Ϊ���������Ҫ�õ��ɿ����ݴ���CTCP��
ʮ��.iOS������-----�������֮TCP���������֡��Ĵλ��֡�����ʵ��
һ��TCP���ص�ͱ��Ľṹ
1���������ӡ��ɿ����䡢�����ֽ�����ȫ˫������
2��TCP�ı��Ľṹ
TCP���Ķ���***�ײ��ֶ�***��һ��***�����ֶ�***��ɡ�
�����ֶΰ���һ��Ӧ�����ݡ�����ij���MSS(Maximum Segment Size)�����˱��Ķ������ֶε���ȡ�MSSѡ��������TCP���ӽ���ʱ,�շ�˫��Э��ͨ��ʱÿһ�����Ķ����ܳ��ص�������ݳ��ȡ�
���Ե�TCP����һ�����ļ�(����һ�Ÿ���ͼƬ)ʱ,ͨ���ǽ����ļ�����ΪMSS���ȵ����ɿ�(���һ�����,ͨ����С��MSS)����ʵ�ʽ���ʽӦ��ͨ�����ͳ���С��MSS�����ݿ顣
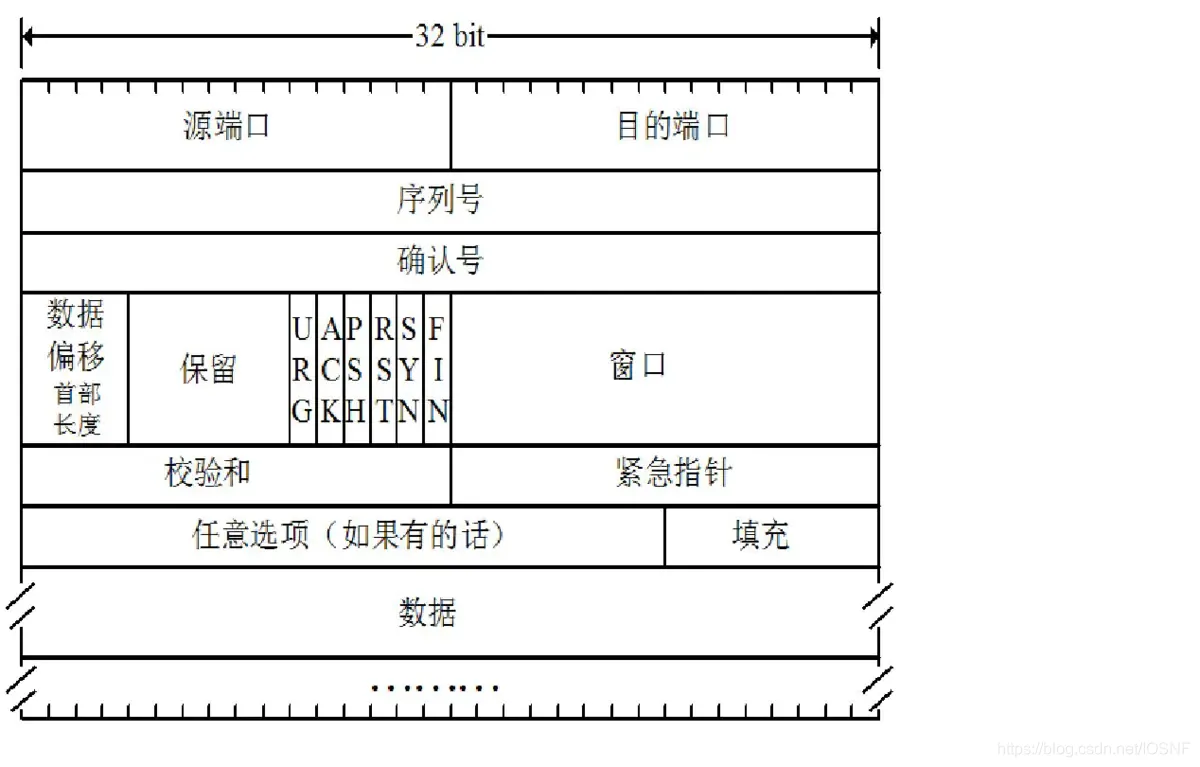
��ͼ,��UDPһ��,�ײ�����***Դ�˿ں�***��***Ŀ�Ķ˿ں�***,���ڶ�·����/�ֽ������ϲ���͵��ϲ�Ӧ�õ����ݡ�TCP�ײ�Ҳͬ������***������ֶ�***
TCP�ײ������������ֶ�:
- 32���ص�***����ֶ�Seq(sequence number field)��32���ص�***ȷ�Ϻ��ֶ�Ack(acknowledge number field)
- 16���ص�***���մ����ֶ�RW(receive window field)***,���ֶ�������������,����ָʾ���շ�Ը����յ��ֽ�������
- 4���ص�***�ײ������ֶ�(header length field)***,���ֶ�ָʾ����32���ص���Ϊ��λ��TCP�ײ����ȡ�����TCPѡ���ֶε�ԭ��,TCP�ײ������ǿɱ�ġ�(ͨ��,ѡ���ֶ�Ϊ��,����TCP�ײ��ĵ��ͳ��Ⱦ���20�ֽ�)
- ��ѡ�ͱ䳤��***ѡ���ֶ�(option field)***,���ֶ����ڷ��ͷ��ͽ��շ�Э������Ķγ���(MSS)ʱ,���������ڵ�������ʱʹ�á�
- 6���ص�***��־�ֶ�(flag field)***��***ACK***��������ָʾȷ���ֶ��е�ֵ����Ч��,���ñ��Ķΰ���һ�����ѱ����ձ��Ķε�ȷ�ϡ�RST��SYN��***FIN***�����������ӽ����Ͳ����
***PSH***����ָʾ���շ�Ӧ���������ݽ����ϲ㡣***URG***��������ָʾ���Ķ�������ű����Ͷ˵��ϲ�ʵ����Ϊ�������������ݡ��������ݵ����һ���ֽ���16���صĽ�������ָ���ֶ�ָ�������������ݴ��ڲ�����ָ���������β��ָ���ʱ��,TCP����֪ͨ���ն˵��ϲ�ʵ�塣��ʵ����,PSH��URG�ͽ�������ָ�벢û��ʹ�á�
3������ֶ�Seq��ȷ�Ϻ��ֶ�Ack
- ��TCPͨѶ��,�����ǽ�������,���ݴ���,�ѺöϿ�,ǿ�ƶϿ�,���벻��Seqֵ��Ackֵ,������TCP����Ŀɿ���֤��
���Seq:
TCP�����ݿ���һ���ṹ�ġ�������ֽ�����һ��***���Ķε����***����Ǹñ��Ķε����ֽڵ��ֽ�����š�
������������һ������100000�ֽڵ��ļ����,��MSS��1000�ֽ�,�����������ֽڱ����0����TCP��Ϊ������������100�����ĶΡ�����һ�����Ķη������0,�ڶ�������1000,��������2000,�Դ����ơ�ÿһ����ű����뵽��ӦTCP���Ķ��ײ�������ֶ��С�
ȷ�Ϻ�Ack:
TCP��ȫ˫�������,�������A��������B�������ݵ�ͬʱ,Ҳ��Ҳ�ڽ�������B�����ݡ�
����A�������Ķε�ȷ�Ϻ�������A����������B�յ�����һ���ֽڵ���š�
���ϸ�������,���������Ѿ����հ����ֽ�0-999�ı��ĶκͰ����ֽ�2000-2999�ı��Ķ�,������ij��ԭ��,��δ�յ������ֽ�1000-1999�ı��Ķ�,��ô���Ի�ȴ��ֽ�1000(�������ֽ�)����˷���˷����ͻ��˵���һ�����Ķν���***ȷ�Ϻ�Ack***�ֶ��а���1000��
��ΪTCPֻȷ�ϸ���������һ����ʧ�ֽ�Ϊֹ���ֽ�,����TCP����Ϊ***�ۻ�ȷ��***��
������������
-���ݿ�ʼ����ǰ,��Ҫͨ�� ������������������
��ʵ������Ϊ,����ƺ���������(three-way handshake)�Ÿ�����Щ
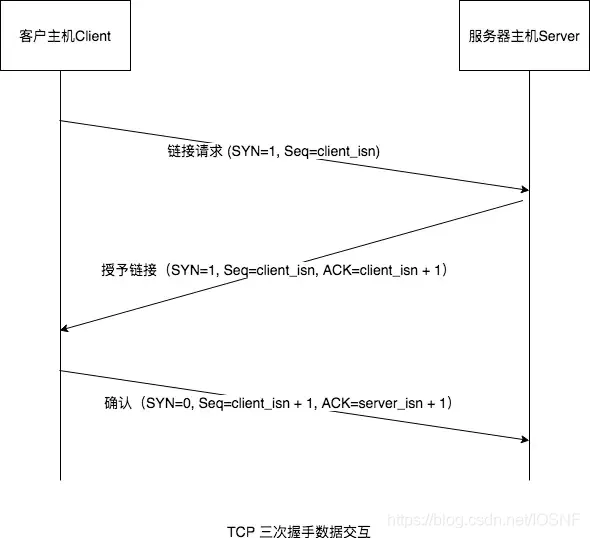
��һ��:
- �ͻ��˵�TCP���������˵�TCP����һ�������TCP���ĶΡ��ñ��Ķβ�����Ӧ�ò�����,�ñ��Ķ��ײ��е�һ��
��־λ(SYN����)����Ϊ1,���Ըñ��Ķα���Ϊ***SYN���Ķ�***������,�ͻ������ѡ��һ����ʼ���client_isn,��������ŷ����ڸ���ʼ��TCPSYN���Ķε�����ֶ��С� - �ͻ��˺ͷ�����ʼ������
CLOSED״̬,������SYN���Ķκ�,�ͻ���TCP����SYN_SENT״̬,�ȴ������ȷ�ϲ���SYN������Ϊ1�ı��ĶΡ�
�ڶ���:
- �յ�SYN���Ķκ�,����˻�Ϊ��TCP���ӷ���TCP����ͱ���,�����TCP�����
SYN_RCVD״̬,�ȴ��ͻ���TCP����ȷ�ϱ��ĶΡ� - ����ÿͻ���TCP�����������ӵı��Ķ�,�ñ��Ķ�ͬ��������Ӧ�ò����ݡ��ñ��Ķ��ײ���
SYN���ر���Ϊ1,ȷ�Ϻ��ֶα���Ϊclient_isn+1������˻���ѡ���Լ��ij�ʼ���server_isn,�ŵ����Ķ��ײ�����Ŷ��С������ӱ���Ϊ***SYNACK���Ķ�***��
������:
- �յ�SYNACK���Ķκ�,�ͻ���ҲҪΪ��TCP���ӷ��仺��ͱ���,�ͻ���TCP����
ESTABLISHED״̬,�ڴ�״̬,�ͻ��˾��ܷ��ͺͽ��հ�����Ч�غ����ݵı��Ķ��ˡ� - ��������TCP����һ�����Ķ�:�����һ�����ĶζԷ���˵��������ӵı��ı�ʾ��ȷ��(��
server_isn+ 1�ŵ����Ķ��ײ���ȷ���ֶ���)����Ϊ�����Ѿ�������,���Ը�SYN���ر���Ϊ0�������,�����ڱ��Ķθ�����Я��Ӧ�ò����ݡ� - �յ��ͻ��˸ñ��Ķκ�,�����TCPҲ�����
ESTABLISHED״̬,���Է��ͺͽ��հ�����Ч�غ����ݵı��ĶΡ�
�����Ĵλ���
����TCP���ӵ����������е��κ�һ��������ֹ������,�����ӽ�����,�����е���Դ(����ͱ���)�ᱻ�ͷš�
�ϱ�˵��,SYN��FIN��־λ�ֱ��Ӧ��TCP���ӵĽ����Ͳ����
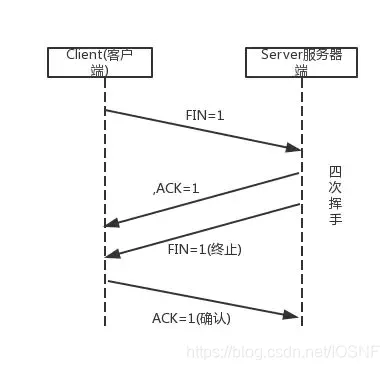
��ͼ,
��һ��:
- �ͻ�Ӧ�ý��̷���һ���ر����ӵ�ָ�������ͻ���TCP�����˷���һ�������TCP���ĶΡ��ñ��Ķμ��ǽ��ײ���һ����־λ
FIN������Ϊ1�� - ͬʱ,�ͻ��˽���
FIN_WAIT_1״̬,�ȴ�����˵Ĵ���ȷ�ϵ�TCP���ĶΡ�
�ڶ���:
- �յ��ñ��Ķκ����ͻ��˷���һ��ȷ�ϱ��ĶΡ�
- �����TCP����
CLOSE_WAIT״̬,��Ӧ�ͻ��˵�TIME_WAIT,��ʾ�����رա� - �ͻ����յ��ñ��Ķκ�,����
FIN_WAIT_2״̬,�ȴ�����˵�FIN������Ϊ1�ı��ĶΡ�
������:
- ����˷����Լ�����ֹ���Ķ�,ͬ���ǰѱ��Ķ��ײ��ı�־λ
FIN������Ϊ1�� - �����TCP����
LAST_ACK״̬,�ȴ����������ȷ�ϱ��ĶΡ�
���IJ�:
- �ͻ����յ�����˵���ֹ���Ķκ�,�����˷���һ��ȷ�ϱ��ĶΡ�ͬʱ,�ͻ��˽���
TIME_WAIT״̬�� - ����ACK��ʧ,
TIME_WAIT״̬ʹTCP�ͻ��ش�����ȷ�ϱ���,TIME_WAITͨ����ȴ�2MSL(Maximum Segment Lifetime ����Ķ�����)�������ȴ���,���Ӿ���ʽ�ر�,���½���CLOSED״̬,�ͻ���������Դ�����ͷš� - ������յ��ñ��Ķκ�,ͬ��Ҳ��ر�,���½���
CLOSED״̬,�ͷ����з����TCP��Դ��
�ġ�һЩ����
1����:Ϊʲô��������ֻ����������,���Ͽ�����ȴҪ�Ĵλ���?
- ����,���ͻ��������ѷ������,��֪�������Ҳȫ�����յ���ʱ,�ͻ�ȥ�Ͽ����Ӽ������˷���FIN
- ����˽��յ��ͻ��˵�FIN,Ϊ�˱�ʾ���յ���,�ͻ���ͻ��˷���ACK
- ����ʱ,����˿��ܻ��ڷ�������,��û�йر�TCP���ڵ���˼,���Է���˵�FIN��ACK������ͬ������,ֻ�е����ݷ�������,�Żᷢ��FIN
-
��:����˵�FIN��ACK��Ҫ�ֿ���,����������������������,SYN���Ժ�ACKͬ����,���Ծ���Ҫ�Ĵλ���
2�����Ĵλ�����,�ͻ���Ϊʲô��TIME_WAIT�����ȴ�2MSLʱ����?
���ACK���Ķ��п��ܶ�ʧ,���ʹ����LAST_ACK�˵ķ�����ղ������ѷ��͵�FIN���Ķε�ACK���Ķ�,�Ӷ�����˻�ȥ�����ش�FIN���ĶΡ�
���ͻ��˾�����2MSLʱ�����յ��ش���FIN���ĶΡ����ſͻ����ش�һ��ȷ��,��������2MSL��ʱ����ֱ��������յ���,�ͻ��˺ͷ���˾Ͷ������CLOSED״̬,�ر�TCP���ӡ�
������ͻ��˲��ȴ�2MSLʱ��,�����ڷ�����ACKȷ�Ϻ������ͷ���Դ,�ر�����,��ô�����յ�������ش���FIN���Ķ�,���Ҳ�����ٷ���һ��ACKȷ�ϱ��Ķ�,����,����˾�����������CLOSED״̬,��Դ��һֱ���ͷ��ˡ�
3��TCP�ڴ�������ʱ,Ϊʲô��Ҫ�������ֶ��������λ��Ĵ�?
һ��������:
��������:
��ι,�����õ���?��
�������õ�ѽ,�����õ�����?��
������������,����balabala��������������:
��ι,�����õ���?��
�������õ�ѽ,�����õ�����?��
��ι,�����õ���?��
������˭��˵��?��
��ι,�����õ���?��
���������Ĵ�����:
��ι,�����õ���?��
�������õ�ѽ����������������?��
�����������ɵ��˵����
֮���Բ����Ĵ�������ԭ�����������,�����˷���Դ,����˵�SYN��ACK����һ��,��ȫû��Ҫ�ֿ����Ρ�
���������������:
�ͻ��˷����ĵ�һ����������SYN���Ķβ�û�ж�ʧ,������ij�������㳤ʱ���������,�������������ͷ��Ժ��ij��ʱ��ŵ������ˡ���������һ������ʧЧ�ı��ĶΡ���������յ���ʧЧ����������SYN���Ķκ�,������Ϊ�ǿͻ����ٴη�����һ���µ���������SYN���ĶΡ����Ǿ���ͻ��˷���ACKȷ�ϱ��Ķ�,ͬ�⽨�����ӡ����費������������,��ôֻҪ����˷���ȷ��,�µ����Ӿͽ����ˡ�
�������ڿͻ��˲�û�з����������ӵ�SYN����,��˲������Ƿ���˵�ȷ��,Ҳ���������˷������ݡ��������ȴ��Ϊ�µ����������Ѿ�����,��һֱ�ȴ��ͻ��˷������ݡ�����,����˵ĺܶ���Դ�Ͱװ��˷ѵ��ˡ�
��ʵ��:TCP�������ݵ�TCP���Ķα���ȷ�ϵ�ԭ��,����,�ͻ��˶Է���˵�SYN���Ķα���ظ�һ��ACK���Ķα�ʾȷ�ϡ�����,TCP����Ϊû�����ݵ�ACK��ʱ�ش�,��ô�������û�յ��ͻ��˵�ACKȷ�ϱ��Ķ�ʱ,�ᳬʱ�ش��Լ���SYN���Ķ�,һֱ���յ��ͻ��˵�ACKΪֹ��
�塢����ʵ��
2019 iOS����-----һ������UDP�ļ�����Demo(��C���ԡ�python��GCDAsyncUdpSocket��ʵ��UDPͨ��)
�ο�UDP�Ĵ���,��ʵTCP�ڴ���ʵ����Ҳ������,���ȡ�socket����ʼ��ʱ�����á�SOCK_DGRAM��,�����á�SOCK_STREAM��
fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
TCP�����Ҫ����һ���������������ӵĹ���:
int listen_ret = listen(fd,5);
int listen_socket = accept(_fd,(sockaddr *)&addr,&addr_len);
UDP���Ƕ���һ�����ӵĹ���:
int ret = connect(_fd, (struct sockaddr *) &addr, sizeof(addr));
Ȼ������ڽ��պͷ�������ʱ,�����ٴ������Ͷ˿��ˡ�����recvfrom��sendto��Ϊrecv��send��
send(_fd, [buffer bytes], [buffer length], 0);
recv(_fd, receiveBuffer, sizeof(receiveBuffer), 0);
python�Ŀͻ��˴�������:
from socket import *
serverName = '127.0.0.1'
serverPort = 12000
clientSocket = socket(AF_INET,SOCK_STREAM)
clientSocket.connect((serverName,serverPort))
sentence = raw_input('Input lowercase:\n')
clientSocket.send(sentence)
modifiedSentence = clientSocket.recv(1029)
print 'From server:\n',modifiedSentence
clientSocket.close()
����˴���:
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET,SOCK_STREAM)
serverSocket.bind(('',serverPort))
serverSocket.listen(1)
print 'server is ready to receive'
connectionSocket,addr = serverSocket.accept()
sentence = connectionSocket.recv(1029)
capitalizeSentence = sentence.upper()
print capitalizeSentence
connectionSocket.send(capitalizeSentence)
connectionSocket.close()
ʮ��.iOS������-----�������֮TCP����:�ɿ����ݴ��䡢��������(��������)��ӵ������
һ���ɿ����ݴ���
��������(IP����)�Dz��ɿ��ġ�IP����֤���ݱ��Ľ���,����֤���ݱ��İ���,Ҳ����֤���ݱ������ݵ������ԡ�
TCP������IP�����ϴ�����һ���ɿ����ݴ������
TCP���ɿ����ݴ������ȷ��һ�����̴�����ջ����ж���������������������������ࡢ������������������ֽ��������ӵ���һ�˷������ֽ�������ȫ��ͬ�ġ�
��ΪTCP���շ�,�������뷢�ͺ��ش��йص���Ҫ�¼�
1�����ϲ�Ӧ�����ݽ�������
�����ݷ�װ��һ�����Ķ���,���ѱ��Ķν�����IP��ÿ�����Ķζ�����һ�����Seq,���ñ��Ķε�һ�������ֽڵ��ֽ�����š������ʱ����û��Ϊ�������Ķζ�����,��������ʱ��(������ÿ�����Ķζ�������һ����ʱ��,����һ��ֻ����һ����ʱ��),��ʱ���Ĺ��ڼ����TimeoutInterval
����EstimatedRTT��DevRTT���������:TCP������ʱ��Ĺ����볬ʱ
2����ʱ
TCPͨ���ش�����ʱ�ı��Ķ�����Ӧ��ʱ�¼�,Ȼ��������ʱ����
�����Ͷ˳�ʱ���������:�������ݳ�ʱ,���ն˷���ACK��ʱ��������������ᵼ�·��Ͷ���TimeoutInterval�ڽ��ղ���ACKȷ�ϱ��ĶΡ�
- 1������Ƿ������ݳ�ʱ,ֱ���ش����ɡ�
- 2��������ǽ��ն˷���ACK��ʱ,����������ն�ʵ�����Ѿ����յ����Ͷ˵������ˡ���ô�����Ͷ˳�ʱ�ش�ʱ,���ն˻ᶪ���ش�������,ͬʱ�ٴη���ACK��
�������TimeoutInterval����յ���ACK,������ACK,�������κδ���
- TCP����Ϊû�����ݵ�ACK��ʱ�ش�
�����������:
- 1������ڷ���������������ݱ��Ķζ���ʱ,��ôֻ���ش������С���Ǹ�,��������ʱ����ֻҪ���౨�Ķε�ACK���������Ķ�ʱ����ʱǰ����,�Ͳ����ش���
- 2������������Ϊ
100��120���������ݱ��Ķ�,���100��ACK��ʧ,���յ������120��ACK,�����ۻ�ȷ�ϻ���,���Եó����շ��Ѿ����յ������100�ı��Ķ�,�������Ҳ����ȥ�ش���
3�����յ�ACK
��TCP״̬����SendBaseָ����δ��ȷ�ϵ��ֽڵ���š���SendBase - 1 ָ���շ�����ȷ������յ������ݵ����һ���ֽڵ���š�
���յ�ACKȷ�ϱ��Ķκ�,�ὫACK��ֵY��SendBase�Ƚϡ�TCP�����ۼ�ȷ���ķ���,����Yȷ�����ֽڱ����Y֮ǰ�������ֽڶ��Ѿ��յ������Y��SendBaseС,��������;�����Y��SendBase��,���ACK����ȷ��һ��������ǰδ��ȷ�ϵı��Ķ�,���Ҫ����SendBase����,�����ǰ����δ��ȷ�ϵı��Ķ�,TCP��Ҫ������ʱ����
ͨ����ʱ�ش�,�ܱ�֤���յ��������������������������,�������ܱ�֤����
��ͨ��TCP��������,�ܹ���Ч��֤������������
������������
TCP���ӵ�˫����������Ϊ��TCP���ӷ��仺��ͱ���������TCP�����յ���ȷ��������ֽں�,�ͽ����ݷ������ջ������ϲ��Ӧ�ý��̻�Ӹû����ж�ȡ����,������������һ�����������ȡ,��Ϊ��ʱӦ�ó���������������������Ӧ�ò��ȡ������Ի���,�����ͷ����͵�̫�ࡢ̫��,���͵����ݾͻ������ʹ�����ӵ����ջ��������
����,TCPΪӦ�ó����ṩ���������Ʒ���(flow-control service),���������ͷ�ʹ���շ���������Ŀ����ԡ�
����������һ���ٶ�ƥ�����,�����ͷ��ķ�����������շ�Ӧ�ó���Ķ�ȡ������ƥ�䡣
��Ϊȫ˫��Э��,TCP�Ự��˫��������ά��һ�����ʹ�����һ�����մ���(receive window)�ı������ṩ�������ơ������ʹ����Ĵ�С���ɶԷ����մ�����������,���մ������ڸ����ͷ�һ��ָʾ�C�ý��շ����ж��ٿ��õĻ���ռ䡣
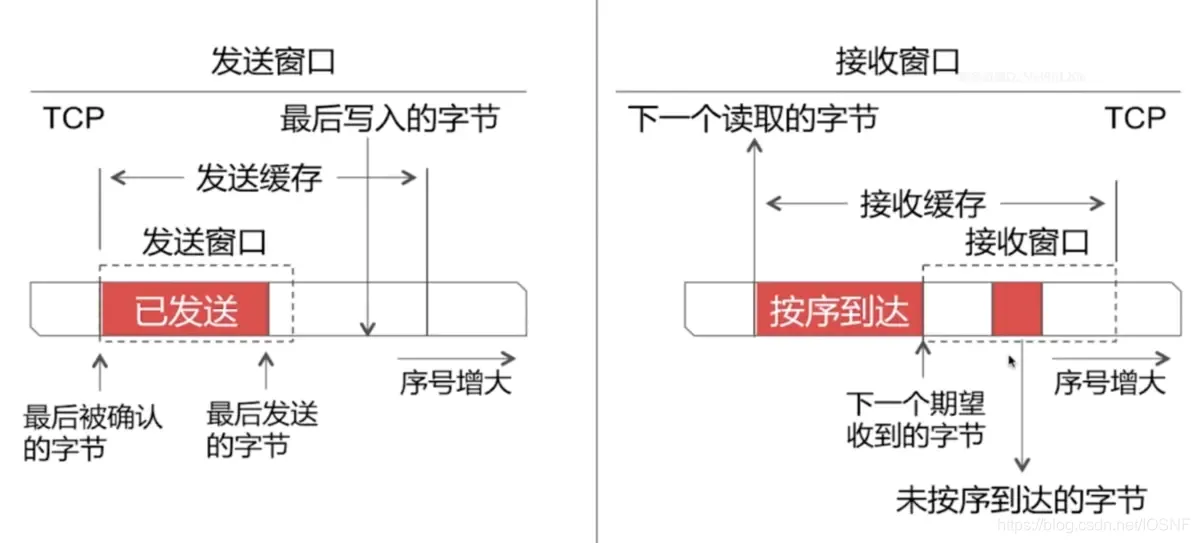
1�����ʹ���
���ͷ��ķ��ͻ����ڵ����ݶ����Ա���Ϊ4��:
- �ѷ���,���յ�ACK
- �ѷ���,δ�յ�ACK
- ���,����������
- ���,������������
��2��3�������ʹ���
���ʹ���ֻ���յ����ʹ������ֽڵ�ACKȷ��,�Ż��ƶ����ʹ��ڵ���߽�
2�����մ���
���շ��Ļ������ݷ�Ϊ3��:
1.�ѽ���
2.δ���յ�������
3.δ���ն��Ҳ�������
��2 �������մ���(����Ľ���ָ�������ݲ�ȷ��)
���մ���ֻ����ǰ�����еı��Ķζ�ȷ�ϵ�����²Ż��ƶ���߽硣����ǰ�滹���ֽ�δ���յ��յ������ֽڵ������,���Ƚ�������,���մ��������ƶ�,�����Ժ����ֽڷ���ACKȷ�ϱ���,�Դ�ȷ�����Ͷ˻����Щ�����ش���
���Ƕ������±���:
LastByteRead:���շ�Ӧ�ó����ȡ�������������һ���ֽڱ�š����Ե�֪,�������ջ��������LastByteRcvd:�������е���IJ����ѷ������ջ����е������������һ���Լ��ĵı�š�
���Ե�֪:LastByteRcvd - LastByteRead <= RcvBuffer(���ջ����С)
��ô���մ���rwnd =RcvBuffer - (LastByteRcvd - LastByteRead)
rwnd����ʱ�䶯̬�仯��,���rwndΪ0,����ζ�Ž��ջ����Ѿ����ˡ�
���ն��ڻظ������Ͷ˵�ACK�л������rwnd,���Ͷ�������ACK�еĽ��մ��ڵ�ֵ�����Ʒ��ʹ��ڡ�
��һ������,���������rwndΪ0��ACK��,���Ͷ�ֹͣ�������ݡ��ȴ�һ��ʱ���,���շ�Ӧ�ó����ȡ��һ��������,���ն˿��Լ�����������,���Ǹ����Ͷ˷��ͱ��ĸ��߷��Ͷ������մ�����С,��������IJ��Ҷ�ʧ��,����֪��,�������ݵ�ACK�Dz��ᳬʱ�ش���,���Ǿͳ��ַ��Ͷ˵ȴ����ն˵�ACK֪ͨ||���ն˵ȴ����Ͷ˷������ݵ�����״̬��
Ϊ�˴�����������,TCP������������ʱ��(Persistence timer),�����Ͷ��յ��Է���rwnd=0��ACK֪ͨʱ,�����øü�ʱ��,ʱ�䵽����һ��1�ֽڵ�̽�ⱨ��,�Է����ڴ�ʱ��Ӧ���������մ�����С,��������δ0,�����������ʱ��,�����ȴ���
����ӵ������
TCP�����ɿ����������,��һ���ؼ����־���ӵ��������
TCP��ÿһ�����ͷ���������֪��������ӵ���̶����������������ӷ������������ʡ�
��������������:
1��TCP���ͷ���θ�֪����ӵ��?
2��TCP���ͷ���������������ӷ�������������?
3�����ͷ���֪������ӵ��ʱ,���ú����㷨���ı��䷢������?
�����TCP��ӵ�����ƻ�����
ǰ��˵��,TCP���ӵ�ÿһ�˶�����һ�����ջ��桢һ�����ͻ���ͼ�������(LastByteRead��LastByteRcvd��rwnd��)��ɡ��������ڷ��ͷ���TCPӵ�����ƻ��ƻ����һ������ı���,��ӵ������cwnd(congestion window)������һ��TCP���ͷ����������з������������ʽ��������ơ�
���ͷ���δ��ȷ�ϵ����������ᳬ��cwnd��rwnd����Сֵ:min(rwnd,cwnd)
1��TCP���ͷ���θ�֪����ӵ��?
����ACK(duplicate ACK):�����ٴ�ȷ��ij�����Ķε�ACK,�����ͷ���ǰ�Ѿ��յ��Ըñ��Ķε�ȷ�ϡ�
����ACK�IJ���ԭ��:
- 1.�����ն˽��յ�
ʧ���Ķ�ʱ,���ñ��Ķ���Ŵ�����һ�������ġ�����ı��Ķ�,���������еļ��,���ɱ��Ķζ�ʧ,������Ըñ��Ķ�ȷ�ϡ�TCP��ʹ����ȷ��,���Բ������ͷ�������ʽ�ķ�ȷ��,Ϊ��ʹ���շ���֪��һ����,�����һ�������ֽ����ݽ����ظ�ȷ��,��Ҳ�Ͳ�����һ������ACK�� - 2.��Ϊ���ͷ��������ʹ����ı��Ķ�,�������һ�����Ķζ�ʧ,�����ڶ�ʱ������ǰ,�ͻ��յ�������
����ACK��һ���յ�3������ACK(3�����ºܿ�������·������������,���账��),˵��������ѱ�ȷ��3�εı��Ķ�֮��ı��Ķ��Ѿ���ʧ,TCP�ͻ�ִ�������ش�,���ڸñ��ĶεĶ�ʱ������֮ǰ�ش���ʧ�ı��ĶΡ�
��TCP���ͷ��������¼�����Ϊ:Ҫô���ֳ�ʱ,Ҫô�յ����Խ��շ���3������ACK��
�����ֹ��ȵ�ӵ��ʱ,·�����Ļ�������,����һ�����ݱ������������������ݱ����Ż������ͷ��������¼�����ô��ʱ,���ͷ�����Ϊ�ڷ��ͷ������շ���·���ϳ���������ӵ����
2��TCP���ͷ���������������ӷ�������������?
3�����ͷ���֪������ӵ��ʱ,���ú����㷨���ı��䷢������?
��TCPӵ�������㷨(TCP congestion control algorithm)
����������Ҫ����:��������ӵ�����⡢���ٻָ�,���п��ٻָ������Ƿ��ͷ������,��������ӵ����������TCPǿ��Ҫ���
- 1��������
��һ��TCP���ӿ�ʼʱ,ӵ������cwnd��ֵͨ����Ϊһ��MSS�Ľ�Сֵ,���ʹ��ʼ�������ʴ�ԼΪMSS/RTT(RTT:����ʱ��,���Ķδӷ������Ըñ��Ķε�ȷ�ϱ�����֮���ʱ����)��
����TCP���ͷ���˵,���ô������ܱ�MSS/RTT��ö�,TCP���ͷ�ϣ��Ѹ���ҵ����ô��������������,��������״̬,cwnd��һ��MSS��ֵ��ʼ����ÿ���յ�һ��������ACK������һ��MSS��
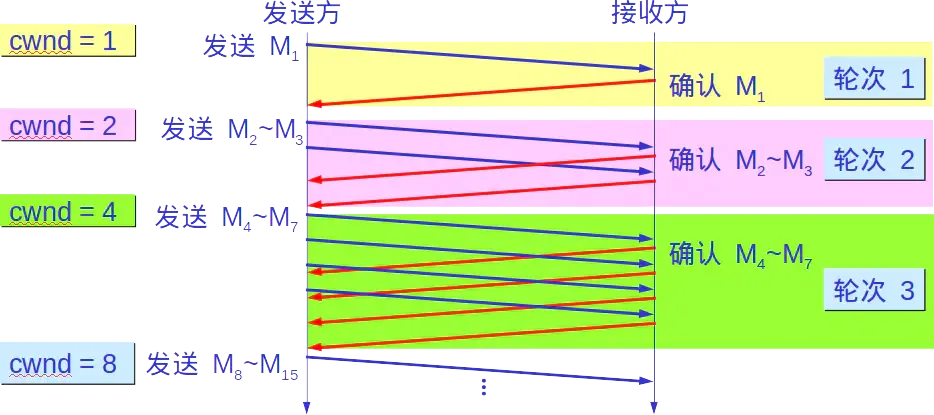
��ͼ,���cwndֵΪ1MSS,����һ�����Ķ�M1���յ�M1��ȷ�Ϻ�,cwnd����Ϊ2MSS,��ʱ���Է����������Ķ�M2,M3���յ����������Ķε�ȷ�Ϻ�,cwnd������Ϊ4MSS,���Է����ĸ����Ķ�,�Դ����ơ�
���,TCP��Ȼ����������ʼ��,��������������ָ��������
����ָ����������Ȼ���������Ƶ�,��ô��ʱ������?
������ֶ����¼�,TCP���ͷ���ssthresh(��������ֵ)����Ϊcwnd/2
-
�����ɳ�ʱ����Ķ����¼�,����
cwnd����Ϊ1MSS,���������� -
��TCP���ͷ���
cwndֵ�ﵽ��ssthresh,�ټ���������Ȼ�����ʡ���ʱ������������ת�Ƶ�ӵ������ģʽ�� -
TCP���ͷ���3������ACK,�����������,��
�����ش�,���ڸñ��ĶεĶ�ʱ������֮ǰ�ش���ʧ�ı��ĶΡ��ҽ�����ٻָ�״̬�� -
2��ӵ������
һ������ӵ������״̬,cwnd��ֵ��Լ���ϴ�����ӵ��ʱ��ֵ��һ��,������ӵ������ңԶ�����,TCP��ÿ��һ��RTT�ͽ�cwnd����������ÿ��RTTֻ����1MSS,��ÿ�յ�һ��������ACK,�ͽ�cwnd����1/cwnd���������ʱcwndΪ10MSS,��ÿ�յ�һ��������ACK,cwnd������1/10MSS,��10�����Ķζ��յ�ȷ�Ϻ�,ӵ�����ڵ�ֵ��������1MSS��
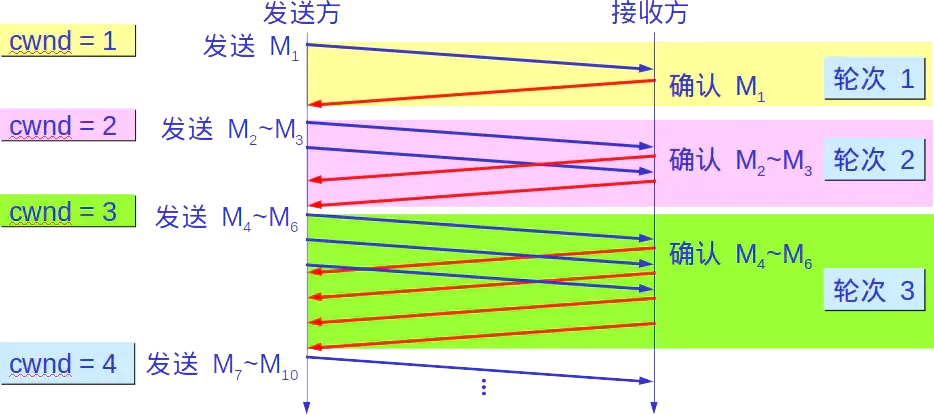
��ô��ʱ����ӵ���������������(ÿRTT 1MSS)��?
��������һ��,������ֶ����¼�,TCP���ͷ���`ssthresh`(��������ֵ)����Ϊ`cwnd/2`(�ӷ�����, �˷���С)
-
�����ɳ�ʱ����Ķ����¼�,ӵ������������������ķ�ʽ��ͬ����TCP���ͷ���
ssthresh(��������ֵ)����Ϊcwnd/2,����cwnd����Ϊ1MSS,���������� -
TCP���ͷ���3������ACK,
cwndΪԭ����һ�����3MSS,������ٻָ�״̬��
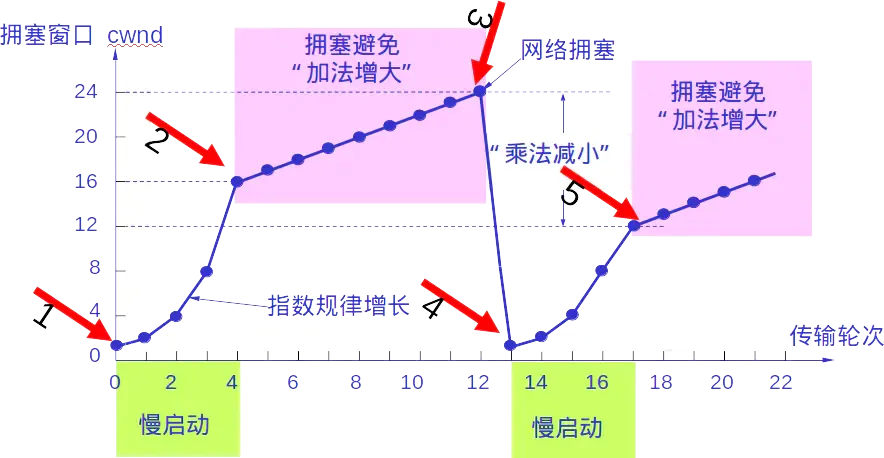
- 3�����ٻָ�
���ٻָ�����3������ACK����ġ�
�ڿ��ٻָ���,������TCP������ٻָ�״̬��ȱʧ���Ķ�,���յ���ÿ������ACK,cwnd����1��MSS������,���Զ�ʧ���Ķε�һ��ACK����ʱ,TCP�ڽ���cwnd�����ӵ������״̬��
������ֳ�ʱ,��֮ǰһ��,��TCP���ͷ���ssthresh(��������ֵ)����Ϊcwnd/2,����cwnd����Ϊ1MSS,����������
���ٻָ������DZ���ġ�
TCP��ӵ��������:ÿ��RTT��cwnd����(������)����1MSS,Ȼ�����3������ACK�¼�ʱcwnd����(���Լ�),���TCPӵ�����Ƴ�����Ϊ������,���Լ�ӵ�����Ʒ�ʽ��
ʮ��.iOS������-----�������֮Cookie��Session
һ��Cookie
������˵��,HTTPЭ������״̬��,��������û�б���ͻ��˵�״̬,�ͻ��˱���ÿ�δ����Լ���״̬ȥ���������
����HTTP�����ص�,�Ͳ�����cookie/session
1���û���������Ľ���:Cookie
cookie��Ҫ��������¼�û�״̬,�����û�,״̬�����ڿͻ�����
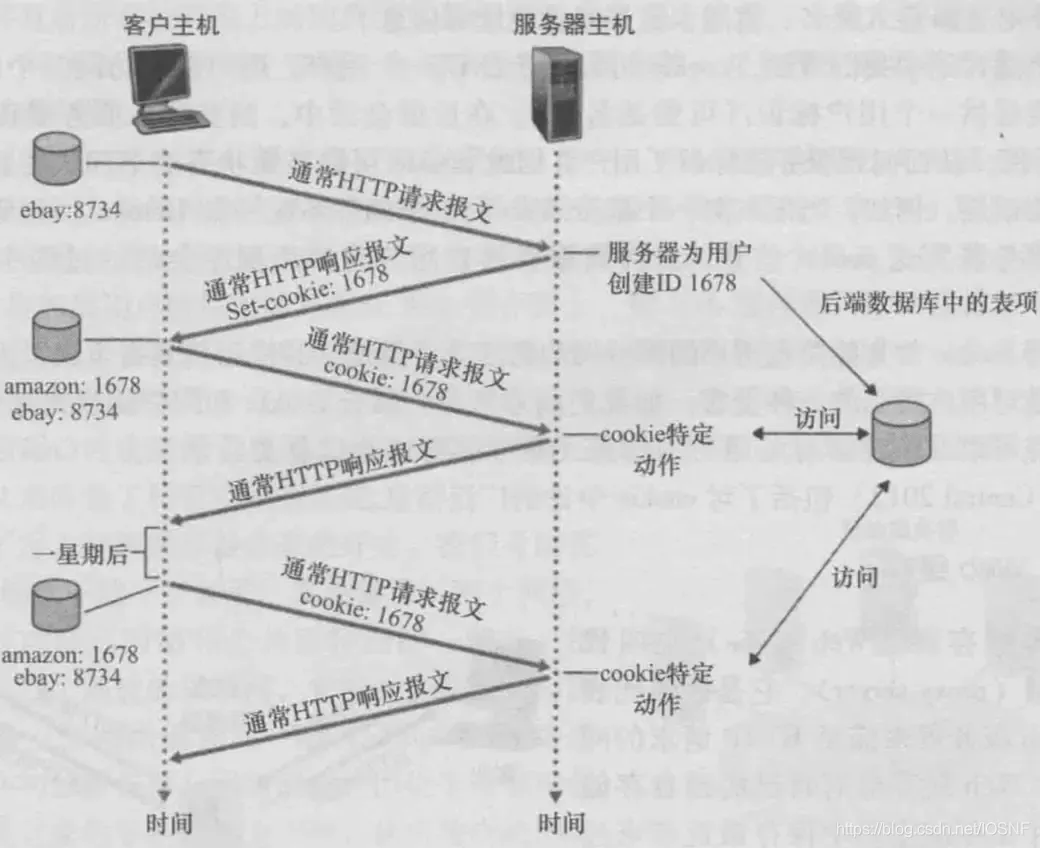
- 1.�״η���
amazonʱ,�ͻ��˷���һ��HTTP���������� ���������˷���һ��HTTP��Ӧ���ͻ���,���а���Set-Cookieͷ�� - 2.�ͻ��˷���һ��HTTP����������,���а���
Cookieͷ�����������˷���һ��HTTP��Ӧ���ͻ��� - 3.����ʱ����ȥ����ʱ,�ͻ��˻�ֱ�ӷ�����
Cookieͷ����HTTP���������˷���һ��HTTP��Ӧ���ͻ���
��ͼ��֪,cookie������4�����:
- 1.��HTTP��Ӧ�����е�һ��
cookie�ײ��� - 2.��HTTP�������е�һ��
cookie�ײ��� - 3.���û���ϵͳ�б���һ��
cookie�ļ�,�����û�����������й��� - 4.λ��Webվ���һ��������ݿ�
Ҳ����˵,cookie������Ҫ�������֧�֡�����������֧��cookie(����ֻ��е������)���߰�cookie������,cookie���ܾͻ�ʧЧ��
2��cookie���ĺ�ɾ��
����cookie��ʱ��,ֻ��Ҫ��cookie���Ǿ�cookie����,�ڸ��ǵ�ʱ��,����Cookie���в��ɿ�������,ע��name��path��domain����ԭcookieһ��
ɾ��cookieҲһ��,����cookie�Ĺ���ʱ��expiresΪ��ȥ��һ��ʱ���,����maxAge = 0(Cookie����Ч��,��λΪ��)����
3��cookie�İ�ȫ
��ʵ��,cookie��ʹ�ô�������,��Ϊ������Ϊ�Ƕ��û���˽��һ���ֺ�,����cookie������ȫ
HTTPЭ�鲻������״̬��,����������ȫ�ġ�ʹ��HTTPЭ������ݲ������κμ��ܾ�ֱ���������ϴ���,�б��ػ�Ŀ��ܡ�ʹ��HTTPЭ�鴫��ܻ��ܵ�������һ��������
- �����ϣ��
Cookie��HTTP�ȷǰ�ȫЭ���д���,��������Cookie��secure����Ϊtrue�������ֻ����HTTPS��SSL�Ȱ�ȫЭ���д������Cookie�� - ����,
secure���Բ����ܶ�Cookie���ݼ���,������ܱ�֤���Եİ�ȫ�ԡ������Ҫ�߰�ȫ��,��Ҫ�ڳ����ж�Cookie���ݼ��ܡ�����,�Է�й�ܡ� - Ҳ��������
cookieΪHttpOnly,�����cookie��������HttpOnly����,��ôͨ��js�ű�������ȡ��cookie��Ϣ,��������Ч�ķ�ֹ**XSS(��վ�ű�����)**����
����Session
����ʹ��Cookie,WebӦ�ó����л�����ʹ��Session����¼�ͻ���״̬��Session�Ƿ�������ʹ�õ�һ�ּ�¼�ͻ���״̬�Ļ���,ʹ���ϱ�Cookie��һЩ,��Ӧ��Ҳ�����˷������Ĵ洢ѹ����
Session����һ�ּ�¼�ͻ�״̬�Ļ���,��ͬ����Cookie�����ڿͻ����������,��Session�����ڷ���������
�ͻ�����������ʷ�������ʱ��,�������ѿͻ�����Ϣ��ij����ʽ��¼�ڷ������ϡ������Session���ͻ���������ٴη���ʱֻ��Ҫ�Ӹ�Session�в��Ҹÿͻ���״̬�Ϳ����ˡ�
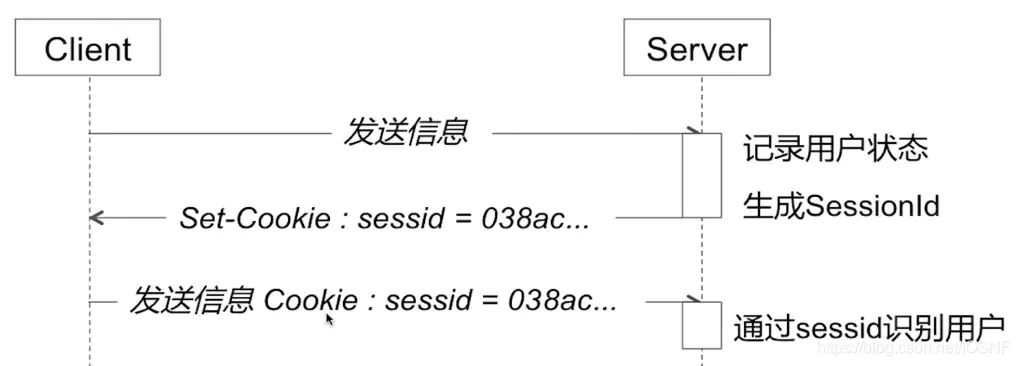
��ͼ:
- ��������ҪΪij���ͻ��˵�����һ��
sessionʱ,���������ȼ������ͻ��˵��������Ƿ��Ѱ�����һ��session��ʶ(��ΪSessionId) - ����Ѱ�����˵����ǰ�Ѿ�Ϊ�˿ͻ��˴�����
session,�������Ͱ���SessionId�����session��������,ʹ��(��������,���½�һ��) - ����ͻ���������
SessionId,��Ϊ�˿ͻ��˴���һ��session��������һ�����session�������SessionId,SessionId��ֵӦ����һ���Ȳ����ظ�,�ֲ����ױ��ҵ������Է�����ַ���,���SessionId�����ڱ�����Ӧ�з��ظ��ͻ��˱��档 - �������
SessionId�ķ�ʽ���Բ���cookie,�����ڽ�������������������Զ��İ��չ���������ʶ��������������cookie���Ա���Ϊ�Ľ�ֹ,����������������Ա���cookie����ֹʱ��Ȼ�ܹ���SessionId���ݻط�������
����Cookie ��Session ������:
1��cookie���ݴ���ڿͻ����������,session���ݷ��ڷ������ϡ�
2��cookie���session���Ǻܰ�ȫ,���˿��Է�������ڱ��ص�cookie������cookie��ƭ,���ǵ���ȫӦ��ʹ��session��
3��session����һ��ʱ���ڱ����ڷ������ϡ�����������,��Ƚ�ռ���������������,���ǵ�������������ܷ���,Ӧ��ʹ��cookie��
4������cookie��������ݲ��ܳ���4K,�ܶ������������һ��վ����ౣ��20��cookie����session�洢�ڷ����,�����������洢
5������:����¼��Ϣ����Ҫ��Ϣ���Ϊsession;������Ϣ�����Ҫ����,���Է���cookie��
ʮ��.iOS������-----�������֮IPЭ�顢IP���ݱ���Ƭ��IPv4��ַ�������ַת��(NAT)
֮ǰ��˵��OSI�߲�Э���е�Ӧ�ò�(HTTPЭ��)�������(TCPЭ�顢UDPЭ��),�ڴ����֮�Ͼ��������,����㸺��IP���ݱ��IJ����Լ�IP���ݰ����������ϵ�·��ת��,������Ϊ�������:
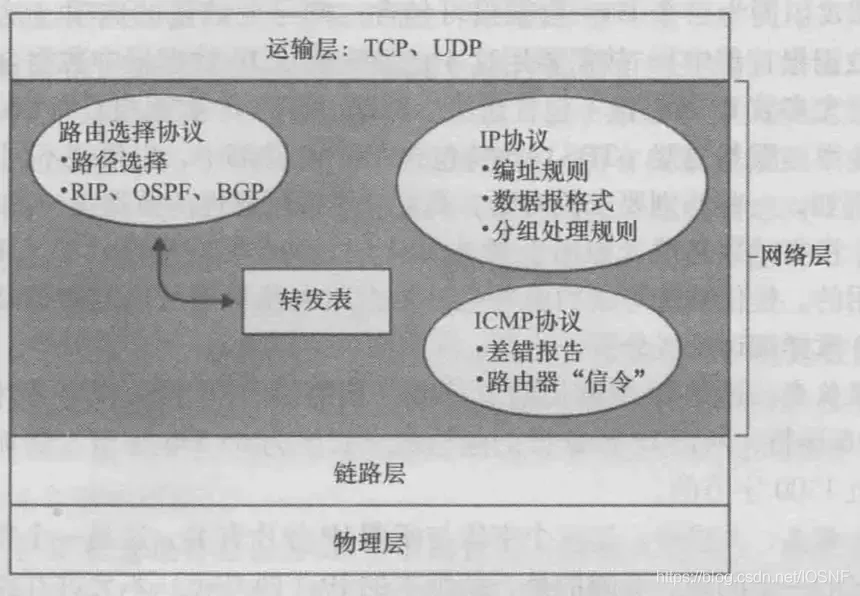
-
1��IP��
-
2��·��ѡ��Э��,�����������ݱ���Դ��Ŀ�ĵ���������·��
-
3��ICMPЭ�� (Internet Control Message Protocol, ���������Ʊ���Э��),�������ݱ��еIJ���Ͷ�ijЩ��·����Ϣ���������Ӧ����ʩ��
�����ʹ���������
- �����ֻ�Ǹ��������ַ��Դ��㷢�������ݰ����͵�Ŀ�Ľ��(�㵽��),����Ҫ������:ͨ��·��ѡ���㷨,Ϊ���Ļ����ͨ��ͨ������ѡ�����ʵ���·�����ò����������·���봫���֮�����Ϣת��,������ά�ֺ���ֹ��������ӡ������˵,������·�����������һ�㱻ת��Ϊ���ݰ�,Ȼ��ͨ��·��ѡ�ֶ���ϡ�˳��/��·�ɵȿ���,����Ϣ��һ�������豸���͵���һ�������豸��
��������ṩ������֮�����ͨ��
- ��������������ݿɿ��ش��͵���Ӧ�Ķ˿�(�˵���),������ṩ������Ӧ�ó������֮��Ķ˵��˵ķ����������������ṩ�ķ���,��ͨ��������ַ�ṩ���߲��û��������ݵ�ͨ�Ŷ˿�,ʹ�߲��û�������ֻ������������ʵ����һ���˵��˵ġ������û����ƺ��趨�ġ��ɿ�������ͨ·��
�������Ϊ�����ڲ�ͬ�����ϵĽ���֮���ṩ����ͨ��
һ��IPЭ��
IPЭ����TCP/IP����Э�顣
1��IPЭ������ݱ���ʽ(IPv4)

�汾��
�涨�����ݱ���IPЭ��汾(IPv4����IPv6)����ͬ��IP�汾ʹ�ò�ͬ�����ݱ���ʽ ,��ͼ��IPv4�����ݱ���ʽ�ײ�����
�����IP���ݱ�������ѡ��,����һ��IP���ݱ�����20�ֽڵ��ײ�����������
ʹ��ͬ���͵�IP���ݱ���������������ݱ�����
����IP���ݱ��ij���,�����ײ����Ⱥ��ܳ��ȾͿ��������IP���ݱ����������ݵ���ʼ��ַ�����ֶγ���Ϊ16����,����IP���ݱ���ɴ�2^16=65535�ֽ�,����ʵ��,���ݱ������г���1500�ֽڵ���ʶ����־��Ƭƫ���ֶ�
�������ֶ���IP��Ƭ�йء�����,IPv6��������·�����϶Է����Ƭ����ʱ��TTL
����ȷ�����ݱ�������Զ��������ѭ�������ø����ݱ����Ծ���������·��������ָ�������ݱ�������ʱ��,����һ��·����,����ֵ�ͼ�1,�����ֶ�Ϊ0ʱ,���ݱ��ͱ�����Э��
���ֶ�ֻ����һ��IP���ݱ�������Ŀ�ĵز����á����ֶ�ֵָʾ��IP���ݱ������ݲ���Ӧ�����ĸ��ض��Ĵ����Э��,����,ֵΪ6����Ҫ����TCP,��ֵΪ17�����Ҫ����UDP�ײ������
��UDP/TCP�ļ���Ͳ�ͬ,����ֶ�ֻ�������ݱ����ײ�,���������ݲ��֡�ѡ���ֶ�
��һ���ɱ䳤�ֶ�,ѡ���ֶ�һֱ��4�ֽ���Ϊ���ޡ������Ϳ��Ա�֤�ײ�ʼ����4�ֽڵ������������ٱ��õ�ԴIP��Ŀ��IP
��¼ԴIP��ַ,Ŀ��IP��ַ
- ����
����IP���ݱ���Ƭ
һ����·��֡�ܳ��ص������������������͵�Ԫ(Maximun Transmission Unit,MTU),����·���MTU������IP���ݱ��ij��ȡ�
�������ڲ�ͬ����·��,����ʹ�ò�ͬ����·��Э��,��ÿ��Э����ܾ��в�ͬ��MTU��
�ٶ���ij����·���յ�һ��IP���ݱ�,ͨ�����ת����ȷ������·,�ҳ���·��MTU�ȸ�IP���ݱ��ij���ҪС,��ν���������IP���ݱ�ѹ������·��֡����Ч�غ��ֶ���?
�������������Ƭ:��IP���ݱ��е����ݷ�ƬΪ������������С��IP���ݱ�,�õ�������·��֡��װ��Щ��С��IP���ݱ�,Ȼ�������·�Ϸ�����Щ֡,ÿ����Щ��С�����ݶ���ΪƬ(fragment)��
Ƭ�ڵ���Ŀ�ĵش����ǰ��Ҫ������װ��
ʵ����,TCP��UDP��ϣ������������յ�������δ��Ƭ�ı��ġ�IPv4�����ݱ����鹤�����ڶ�ϵͳ��,������������·�����С�
��һ̨Ŀ����������ͬԴ�յ�һϵ������ʱ,��Ҫȷ����Щ���ݱ��е�ijЩ�Ƿ���һЩԭ���ϴ�����ݱ��е�Ƭ���������Ƭ�Ļ�,��Ҫ��һ��ȷ����ʱ�յ����һƬ,������ν���ЩƬƴ�ӵ�һ�����γɳ�ʼ�����ݱ����Ӷ����õ���ǰ��˵����IPv4���ݱ��ײ��е�***��ʶ����־��Ƭƫ��*** �ֶΡ�
- 1��������һ�����ݱ�ʱ,����������Ϊ�����ݱ�����
Դ��Ŀ�ĵ�ַ��ͬʱ��������ʶ��,��������ͨ����Ϊ�����͵�ÿ�����ݱ���ʶ����1- 2����ij·������Ҫ��һ�����ݱ���Ƭʱ,�γɵ�ÿ�����ݱ�(��Ƭ)���г�ʼ���ݱ���
Դ��ַ��Ŀ�ĵ�ַ����ʶ��- 3����Ŀ�ĵش�ͬһ���������յ�һϵ�����ݱ�ʱ,���ܹ�������ݱ���
��ʶ����ȷ����Щ���ݱ�ʵ������ͬһ�ϴ����ݱ���Ƭ- 4������IPЭ���Dz��ɿ�����,һ�����߶��Ƭ������Զ���ﲻ��Ŀ�ĵء�Ϊ����Ŀ�������������������յ���ʼ���ݱ������һ��Ƭ,���һ��Ƭ��
��־��������Ϊ0,���౻��Ϊ1- 5��Ϊ����Ŀ������ȷ���Ƿ�ʧ��һ��Ƭ,�����ܰ�����ȷ��˳��������װƬ,ʹ��
ƫ���ֶ�ָ����ƬӦ���ڳ�ʼIP���ݱ����ĸ�λ��>
����,�����һ��Ƭ���߶��Ƭδ�ܵ���,��ò����������ݱ����ᱻ�����Ҳ��ύ������㡣������������ʹ����TCP,��TCP��ͨ����Դ�Գ�ʼ�������ش����ݡ���ΪIP��û�г�ʱ�ش�����,���Ի��ش��������ݱ�,������ij��Ƭ
����IPv4��ַ
1��IP��ַ
һ̨����ͨ��ֻ��һ����·���ӵ�����,�������ϵ�IP�뷢��һ�����ݱ�ʱ,���ڸ���·�Ϸ��͡�������������·֮��ı߽�����ӿ�(interface)��
��·�����������Ǵ���·�Ͻ������ݱ�����ijЩ������·ת����ȥ,·���������������������·��������,·��������������һ����·֮��ı߽�Ҳ�����ӿ�����һ̨·�������ж���ӿ�,ÿ���ӿ�������·��
��Ϊÿ̨������·�������ܷ��ͺͽ���IP���ݱ�,IPҪ��ÿ̨������·�����ӿ������Լ���IP��ַ�����,һ��IP��ַ����������һ���ӿ��������,������������ýӿڵ�������·����������ġ�
2������
ÿ��IP��ַ(IPv4)����Ϊ32����(4�ֽ�),�����ʮ���ƼǷ���д,����ַ�е�ÿ���ֽڶ�������ʮ������ʽ��д,���ֽڼ��Ե�.����,����193.32.122.30
���������ϵ�ÿ̨������·�����ϵ�ÿ���ӿ�,������һ��ȫ��Ψһ��IP��ַ(NAT��Ľӿڳ���)����Щ��ַ��������ѡ��,һ���ӿڵ�IP��ַ��һ������Ҫ�������ӵ�������������
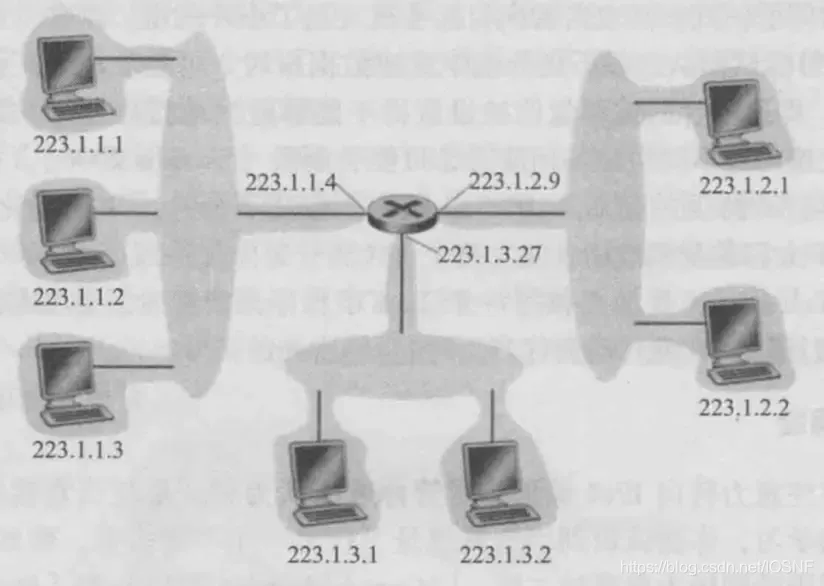
��ͼ,һ̨·�����������ӿ�,����7̨������������̨�����Լ��������ǵ�·�����Ľӿ�,����һ������223.1.1.x��IP��ַ���������ǵ�IP��ַ��,������24��������ͬ�ġ�
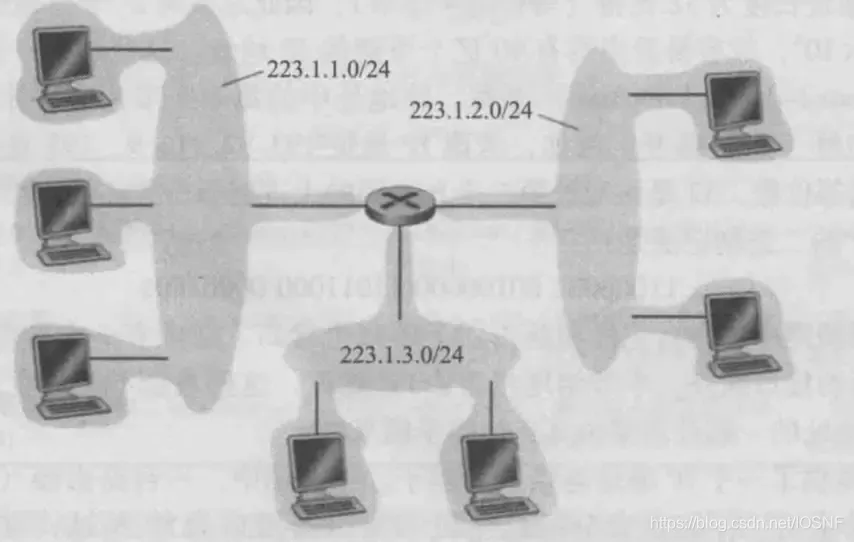
������������������ӿ���1��·�����ӿڵ������γ�1������(subnet)(Ҳ����ΪIP�����ֱ�ӳ�Ϊ����)��IP��ַΪ�����������һ����ַ:223.1.1.0/24,���е�/24�Ƿ�,��ʱ��Ϊ��������(network mask),ָʾ��32�����е������24���ض�����������ַ���κ����ӵ���������������Ҫ�����ַ����223.1.1.x����ʽ��ͬ��ͼ���²���Ҳ�Ҳ������,�ֱ�Ϊ223.1.3.0/24��223.1.2.0/24
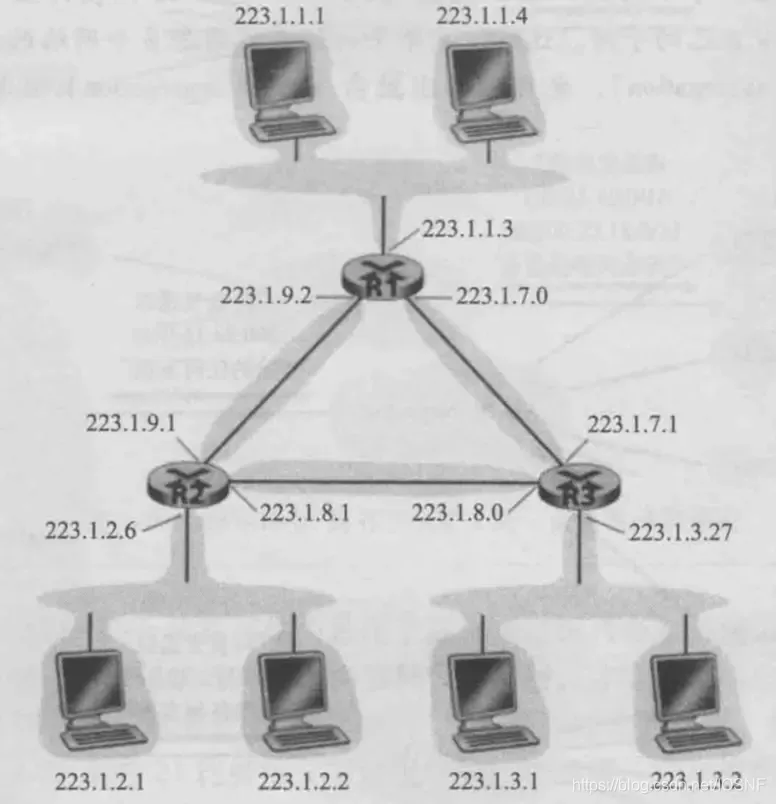
��ͼ��ʾ��3̨ͨ����Ե���·�˴˻�����·����,���������6��������
һ�����ж����̫���κ͵�Ե���·����֯�����ж������,�ڸ��������ϵ������豸��������ͬ��������ַ��
��Ȼ����������˵,��ͬ������������ȫ��ͬ��������ַ������ͼ���Կ���,��6��������ǰ16��������һ�µ�,����223.1
3����������·��ѡ��(CIDR)
�������ĵ�ַ������Ա���Ϊ��������·��ѡ��(CIDR)(Ҳ����Ϊ�����ַ,�������������ַ)����������Ѱַ,32���ص�IP��ַ����Ϊ������,Ҳ�ǵ��ʮ��������ʽa.b.c.d/x,����xָʾ�˵�ַ�ĵ�һ�����еı�����,�ֱ���Ϊ�õ�ַ��ǰ(prefix)��
һ����֯ͨ��������һ�������ĵ�ַ,��������ͬǰ�ĵ�ַ���ڸ���֯��ĵ�·����������ǰ���ǰ����x,���൱��ؼ���������Щ·������ת�����ij���,��ʽΪa.b.c.d/x��һ�������Խ����ݱ�ת��������֯�ڵ��κ�Ŀ�ĵء�
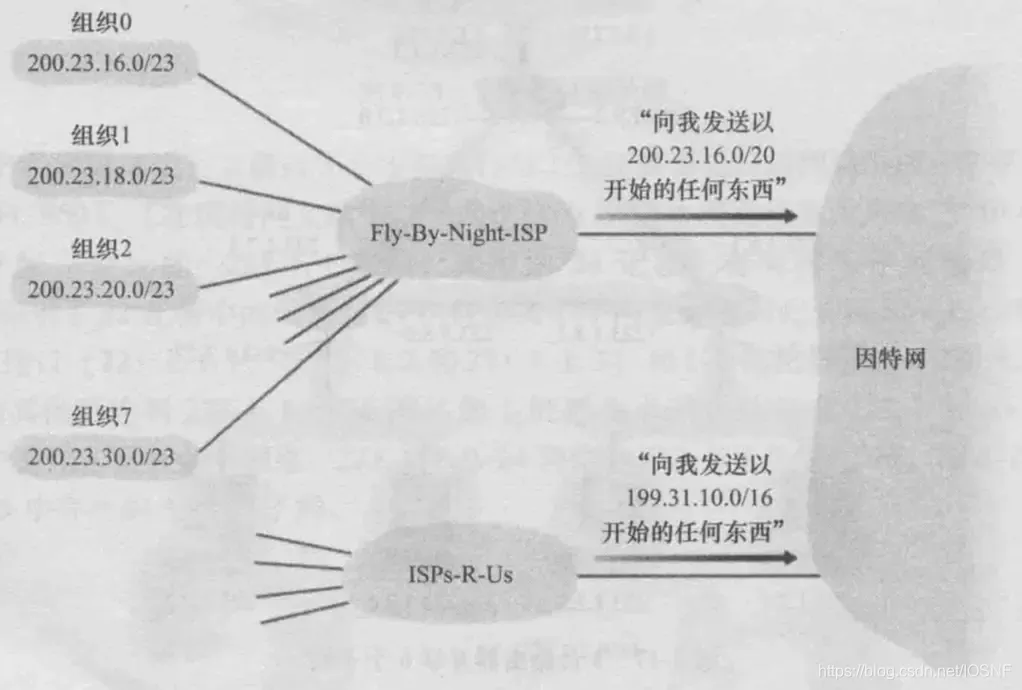
��ͼ,200.23.16.0/20����8����֯,�ֱ���200.23.16.0/23��200.23.30.0/23,ÿ����֯���Լ�������������粻��Ҫ֪����8����֯������ʹ�õ�������ǰͨ�������������ͨ����Ϊ��ַ�ۺ�,Ҳ��Ϊ·�ɾۺ���·��ժҪ
4�������ַ
��CIDR������֮ǰ,IP��ַ�����粿�ֱ����Ƴ���Ϊ8��16��24����,Ҳ���������ַ(classful addressing)������8��16��24����������ַ����������ΪA��B��C�����硣
һ��C��(/24)������������***2[ͼƬ�ϴ�ʧ�ܡ�(image-448ab4-1627110540448)]
-
2 = 254***̨����(����������ַԤ������������;),����ںܶ���֯��˵��̫С�ˡ�
��һ��B��(/16)������֧�ֶ��***2[ͼƬ�ϴ�ʧ�ܡ�(image-8feac9-1627110540448)] -
2 = 65534̨����,��̫���ˡ�
�ڷ����ַ������,һ����2000̨��������֯ͨ�����ָ�һ��B��(/16)��ַ,��ôʣ�µ�6������ַ���˷ѵ��ˡ���ͻᵼ��B���ַ�ռ��Ѹ������Լ�������ĵ�ַ�ռ�������ʵ�*��
����,255.255.255.255��IP�㲥��ַ,��һ̨��������һ��Ŀ�ĵ�ַΪ�õ�ַ�����ݱ�ʱ,�ñ��Ļύ����ͬһ�������е�����������
5����ȡ������ַ
ij��֯һ�������һ���ַ,���Ϳ�Ϊ����֯�ڵ�������·������һ����IP��ַ��ϵͳ����Աͨ���ֹ�����·�����е�IP��ַ��������ַҲ���ֶ�����,������ʹ�õ�����̬��������Э��(DHCP)��DHCP���������Զ���ȡIP��ַ���������Ա��������DHCP,��ʹij��������ÿ������������ʱ�ܵõ�һ����ͬ��IP��ַ,����ij������������һ����ʱ��IP��ַ,�õ�ַ��ÿ������������ʱҲ���Dz�ͬ�ġ�
6�������ַת��
ÿ��IP��ַ(IPv4)����Ϊ32����(4�ֽ�),����ܹ���2[ͼƬ�ϴ�ʧ�ܡ�(image-c49012-1627110540449)]
�����ܵ�IP��ַ,ԼΪ40�ڸ����ڻ�����Խ��Խ�ռ��ĵ���,���˼�����������ֻ���Խ��Խ��,��ЩIP��ַ��Ȼ���������ǵ�����
Ϊ�˽��IP��ַ���������,���Ǿ����������ַת��(Network Address Translation, NAT),����˼����Ǹ�һ�������������һ��IP��ַ����,������������ڵ�����,�����˽�е�ַ,��Щ˽�е�ַ�����Dz��ɼ���,���Ƕ����ͨ�Ŷ�Ҫ�����Ǹ�Ψһ�����IP��ַ��
����ӹ���������NAT·�������������ݱ�������ͬ��Ŀ��IP��ַ,��ô��·�������֪���Ƿ����ĸ��ڲ���������?��ԭ������ʹ����NAT·�����ϵ�һ��NATת����,���ڸñ��ڰ����˶˿ںż���IP��ַ��
����һ̨�������������������,
NAT·�����յ������ݱ�,��Ϊ�����ݱ�����һ���µĶ˿ں��滻��Դ�˿ں�,����ԴIP�滻Ϊ�������һ��ӿڵ�IP��ַ��������һ���µ�Դ�˿ں�ʱ,�ö˿ںſ���������һ����ǰδ��NATת�����е�Դ�˿ں�(�˿ں��ֶ���16����,��ζ��NATЭ������֧�ֳ���60000������ʹ��·����������һ��IP��ַ������),·�����е�NATҲ����NATת����������һ�����
NAT·�����յ����������ص�����ʱ,·����ʹ��Ŀ��IP��ַ��Ŀ�Ķ˿ںŴ�NATת�����м�����������ʹ�õ�IP��ַ��Ŀ�Ķ˿ں�,��д�����ݱ���Ŀ��IP��ַ��Ŀ�Ķ˿ں�,���������ת�������ݱ�
NAT��Ȼ�ڽ�����õ��˺ܹ㷺��Ӧ��,��Ҳ���ܶ��˷��ԡ�
��Ҫ��:
- 1���˿ں����������̱�ַ��,������������ַ��(NATЭ������ NAT·�������ü�ͥ������������������̴���,��ͨ��NATת����Ϊ�����˿ں�)
- 2��·����ͨ����Ӧ�������ߴ������ķ���
- 3��Υ���˵���ԭ��,�������˴�֮��Ӧ���ֱ�ӶԻ�,��㲻Ӧ��������IP��ַ��˿ںš�
- 4��Ӧ����IPv6�����IP��ַ��ȱ����
�����ܷ������,NAT�վ��ѳ�Ϊ������������һ����Ҫ���
ʮ��.iOS������-----�������֮IPv6����IPv4��IPv6��Ǩ��
�����µ�������IP����Ծ��˵�������������������,��������Ψһ��IP��ַ,32���ص�IPv4��ַ�ռ伴���þ�,Ϊ�˽����һ����,IPv6ҲӦ�˶���������ʵ����20����ǰ,����������������Ϳ�ʼ�����ڿ���һ�����IPv4��Э��,��IPv6
һ��IPv6���ݱ���ʽ
1��IPv6���ݱ���ʽ

�汾(4����)
���ֶ����ڱ�ʶIP�汾��,IPv6�����ֶ�ֵ��Ϊ6������������ֶ���Ϊ4�����ܴ���һ���Ϸ���IPv4���ݱ���������(8����)
������IPv4���ݱ��еķ�������(TOS)����ǩ(20����)
����ǩ�ֶ���IPv6���ݱ���������һ���ֶ�,������ʶһ�����ݱ���������,�Ա�����������ֲ�ͬ�ı��ġ���Ч�غɳ���(16����)
IPv6���ݱ�����40�����ֽ����ݱ��ײ�����ֽ�����,������IPv6�����ݱ��ײ�������������ֵ��ܳ���
��һ���ײ�(8����)
��IPv6û����չ��ͷʱ,���ֶε����ú�IPv4��Э���ֶ�һ������������չ��ͷʱ,���ֶε�ֵ��Ϊ��һ����չ��ͷ������������(8����)
��IPv4�����е�TTL�ֶ�����,ת�����ݱ���ÿ̨·�������Ը��ֶε����ݼ�1.��������Ƽ�������0,������ݱ���������Դ��ַ��Ŀ�ĵ�ַ(��128����)
��¼ԴIP��ַ,Ŀ��IP��ַ����
���Կ���,��IPv4���ݱ��г��ֵļ����ֶ���IPv6���ݱ����Ѳ�������:
- ��Ƭ/������װ
IPv6���������м�·�����Ͻ��з�Ƭ��������װ�����ֲ���ֻ����Դ��Ŀ�ĵ���ִ�С����·�����յ���IPv6���ݱ���̫����ת������·�ϵĻ�,·�����ᶪ�������ݱ�,����һ��������̫��ICMP�������- �ײ������
��Ϊ������������·��Э��ִ���˼������,�������������û�б�Ҫ��,�Ӷ������ٴ���IP����- ѡ��
ѡ���ֶβ����DZ�IP�ײ���һ�����ˡ�����û����ʧ,���ǿ��ܳ�����IPv6�ײ����ɡ���һ���ײ���ָ����λ���ϡ�������TCP��UDPЭ���ײ��ܹ���IP�����еġ���һ���ײ���,ѡ���ֶ�Ҳ���ǡ���һ���ײ���
IPv6���IPv4����Ҫ�ı仯����:
����ĵ�ַ����
IPv6��IP��ַ������32�������ӵ�128����,��ʹ�����ۿɴ��ڵ�IP��ַ���ӵ�2[ͼƬ�ϴ�ʧ�ܡ�(image-65d1a1-1627111022615)]��,Լ
340������������,����һ���dz��������,ȷ��ȫ������Ҳ�����þ�IP��ַ,��������Ϊ������ÿһ��ɳ�Ӷ�����һ��Ψһ��IP��ַ
���˵����Ͷಥ��ַ��,IPv6û�й㲥��һ˵��,����������һ�ֳ�Ϊ�β���ַ�����͵�ַ,���ֵ�ַ����ʹ���ݱ�������һ�������е�����һ����Ч��40�ֽ��ײ�
��ȥ��32�ֽڵ�Դ��ַ��Ŀ���ַ��,�ײ������ֶ�ֻռ��8�ֽ�����ǩ�����ȼ�
�������������ķ�����ϱ�ǩ,��Щ�������Ƿ��ͷ�Ҫ��������������,��һ�ַ�Ĭ�Ϸ�����������Ҫʵʱ�������
2��IPv6��д�ͱ��﷽ʽ
��������дʱ,�ѳ���Ϊ128���ص�IPv6��ַ�ֳ�8��16λ�Ķ����ƶΡ�ÿһ��16λ�Ķ����ƶ���4λ��16��������ʾ,�μ��á�:��(ð��)����(����д������IPv4��ʮ�������ӡ�.����ͬ)��
����:1000:0000:0000:0000:000A:000B:000C:000D����ÿһ��16λ�Ķ��������Ķ���4λ16�������Ķ�����ʾ���μ��á�:��(ð��)������һ��IPv6��ַ;����:����4λ16�������Ķ��еĸ�λ0����ʡ��;���,�����IPv6��ַҲ������д��:1000:0:0:0:A:B:C:D��
Ϊ�˸���һ����,IPv6�ĵ�ַ�淶�л��涨,������һ��IPv6��ַ��**���ʹ��һ��˫ð��(::)**��ȡ��IPv6��ַ�н��������Ķ��ȫ0��16�������Ķ�(��Ϊ���������һ��IPv6��ַ��ʹ��һ�����ϵ�˫ð��ʱ�����ж�IPv6��ַ�ij���,����IPv6�ĵ�ַ�淶�вŹ涨:��һ��IPv6��ַ�����ֻ��ʹ��һ��˫ð��),���������IPv6��ַ��������д��:1000::A:B:C:D��
˫ð��ʹ�õĵص������IPv6��ַ��ǰ�桢����������м�;����:����1000:0:0:0:A:B:0:0������һ��IPv6��ַ,����д��1000::A:B:0:0,Ҳ����д��1000:0:0:0:A:B::;���Dz���д��1000::A:B::��
���ж˿ںŵ�IPV6��ַ�ַ�����ʽ,��ַ����Ӧ���á�[]��������,�ں�����š�:�����϶˿ں�,�� [A01F::0]:8000
������IPv4��IPv6��Ǩ��
����IPv4�Ĺ������������Ǩ�Ƶ�IPv6��?���Ǹ��dz���ʵ������
��ȻIPv6ʹ��ϵͳ������������,���ܽ��ա����ͺ�·��IPv4���ݱ�,���Ѳ����IPv4ʹ��ϵͳȴ���ܴ���IPv6���ݱ�
1��˫Э��ջ
����IPv6ʹ�ܽ�����ֱ�ӷ�ʽ��˫ջ����,��ʹ�ø÷�����IPv6�������������IPv4ʵ��,��IPv6/IPv4���,���н��պͷ���IPv4��IPv6�������ݱ���������
����IPv4���������ʱ,IPv6/IPv4�����ʹ��IPv4���ݱ�;����IPv6���������ʱ,IPv6/IPv4����ֿ�ʹ��IPv6���ݱ���
IPv6/IPv4���������IPv6��IPv4���ֵ�ַ������,���ǻ�������ȷ����һ������Ƿ���IPv6ʹ�ܵĻ��IPv4ʹ�ܵġ�
����ʹ��DNS�����,��Ҫ�����Ľ��������IPv6ʹ�ܵ�,��DNS�᷵��һ��IPv6��ַ,����һ��IPv4��ַ���������DNS����Ľ���ǽ�IPv4ʹ�ܵ�,��ֻ����һ��IPv4��ַ��
����IPv6ʹ�ܵĽ�㲻Ӧ�����IPv4���ݱ�,��������ͷ�����շ�����һ����ΪIPv4ʹ�ܵ�,�����ʹ��IPv4���ݱ���
�����ͻ��������������:
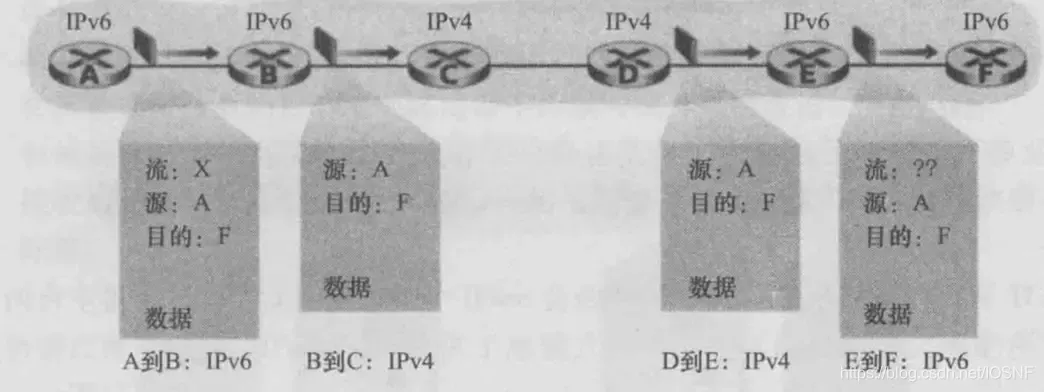
��ͼ,������A��B��E��F����IPv6ʹ�ܵĽ��,�����C��D�ǽ�IPv4ʹ�ܵĽ��,��ô����
A->B->C->D->E->F˳�������ݱ�ʱ,AB֮��ᷢIPv6���ݱ�,BC�ᷢIPV4���ݱ�, ����IPv6���ݱ��ض����ֶ���IPv4���ݱ�����Ӧ�IJ���,��Щ�ֶν��ᶪʧ�����,��ʹE��F֮���ܷ�IPv6���ݱ�,��D����E��IPv4���ݱ���δ���д�A�����ij�ʼIPv6���ݱ��е������ֶΡ�
2������
����������һ��˫ջ����,�÷����ܽ���������⡣
�ٶ�����IPv6���Ҫʹ��IPv6���ݱ����н���,���������Ǿ����м�IPv4·���������ġ�����̨IPv6·�����м��IPv4·�����ļ��ϳ�Ϊһ������,��B->C->D->E��
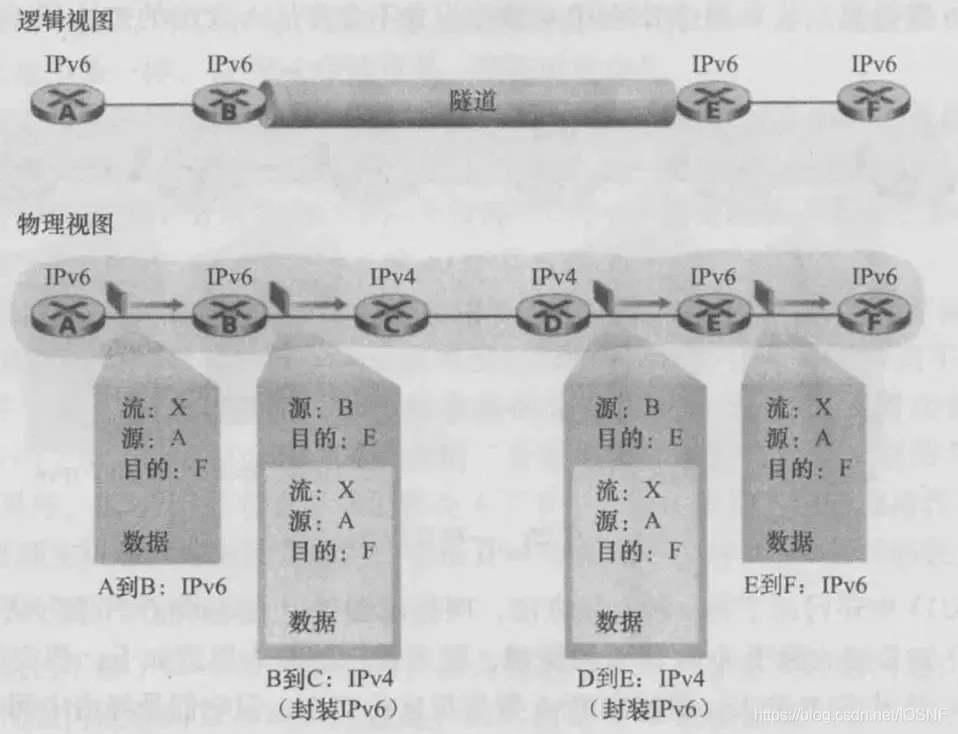
��ͼ,����������,���������Ͷ˵�
IPv6����ɽ�����IPv6���ݱ��ŵ�һ��IPv4���ݱ��������ֶ��С�����,��IPv4���ݱ��ĵ�ַ��Ϊָ���������ն˵�IPv6���,�ٷ��������еĵ�һ����㡣�������е�IPv4·����������֮��Ϊ�����ݱ��ṩ·��,����Դ�����IPv4���ݱ�һ��,��ȫ��֪�������ݱ������ͺ���һ��������IPv6���ݱ������������ն˵�IPv6��������յ���IPv4���ݱ�,��ȷ����IPv4���ݱ��к���һ��IPv6���ݱ�,������ȡ����IPv6���ݱ�,Ȼ����Ϊ��IPv6���ݱ��ṩ·��
3��NAT-PT
����˫ջ������������,����һ��NAT-PT(Network Address Translator - Protocol Translator)����Э��ת�����������ַת��������
������:
iOS�������ϴ�ȫ)