����Ŀ¼
- �� 1 �� ����������������
- �� 2 �� Ӧ�ò�
- ������ �����
- ������ �����
- �����¡���·��
�� 1 �� ����������������
1.1 ʲô��������
���ǿ��Դ������Ƕ����ش��������:һ�����������������Ӳ��;��һ���ǽ�����ΪΪ�ֲ�ʽӦ���ṩ���������������ʩ����������ʵ,��һ�ֽǶ�,�Ǵ��������������,�ڶ��ֽǶ��Ǵ����Ĺ�����������
1.1.1 �����������
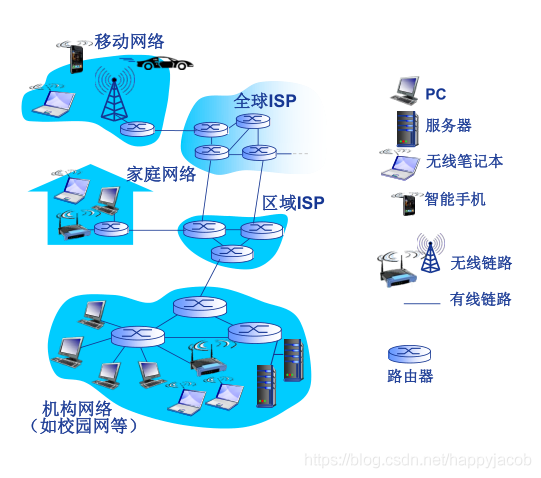
��������һ�����緶Χ�ļ��������,����ζ���������������ڼƵļ����豸(�������Ǽ����Ŷ);��Щ�豸�����������ڴ�ͳPC������վ�Լ���ν�ķ������������и�����豸���뵽��������,�����Яʽ����������ӻ����������������ȡ�����������������˵,�����������������豸�������������߶�ϵͳ��
�������ص��һЩ����:��ϵͳͨ��ͨ����·�����齻�������ӵ�һ��
��ϵͳ֮�䷢������ʱ,���Ͷ�ϵͳ�������ݷֳ�һ��һ��,Ȼ����ϱ�Ҫ����Ϣ���γ�һ���������ݰ�,������ݰ���������˵�������������Ƿ���==�û�����+��Ҫ��Ϣ����·ϵͳ���������������ġ����鵽����ն�ϵͳ��,���ն�ϵͳ�����ݱ�Ҫ��Ϣ����ȡ�û�����;
���齻����������һ������·���շ���,����ѡ��һ������·������ת����ȥ;���齻����Ҳ�кܶ�����,��Ϊ��������·��������·�㽻����;���ߵĵIJ�֮ͬ������,��·�㽻������Ҫ���ڽ�������,·������Ҫ�������������
��ϵͳͨ�������������ṩ��(Internet Service Provider,���ISP)����������;
��������Э����:TCP(Transport Control Protocol,�������Э��)�� IP(Internet Protocol,����Э��);��ΪЭ���������Ϣ�Ĵ���,���Զ�Э����һ�¾ͺ���Ҫ,������Ҫһ�������淶Э��,�Ա㴴�����Эͬ������ϵͳ�Ͳ�Ʒ
���Խ����������ṹ����Ϊ���������:
- �����Ե:������,����Ӧ��
- ��������,��������:����������ͨ����·
- �������(��������):�绥����·����(�����ת���豸)
1.1.2 ��������
��
1.1.3 ��
- ���������
- ������
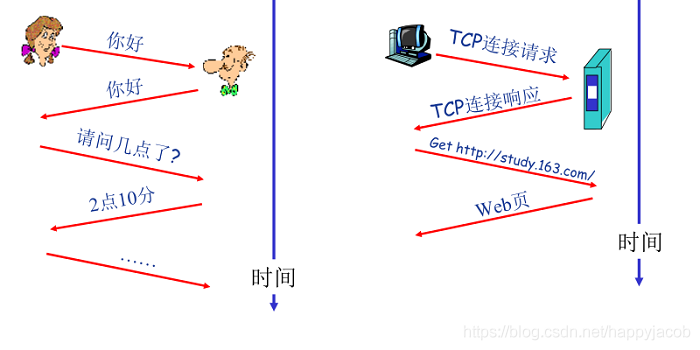
ǰ���ᵽ�˷�����һ����,����==�û�����+��Ҫ����;��Щ��Ҫ����Ϊ��������������û������ṩ����,��Э��������ʹ�ñ�Ҫ���������û����ݵķ������߹���;��������߽��յ����鲢����Э�������û����ݺ�,��Ӧ�öԴ���Ϣ������Ӧ,�����������ӦҲ��Э��淶��һ����(����ӦҲ��һ�ַ�ӦŶ)
Э��:����������������ͨ��ʵ��֮�佻���ı��ĸ�ʽ�ʹ���,�Լ����ķ��ͺ�/�����һ�����Ļ������¼�����ȡ�Ķ�����
����ͨ��ʵ������л��Ҫ�ܵ�Э���Լ��������,Ӳ��ʵ�ֵĿ���Э���������������֮��ı�����;�ڶ�ϵͳ��,ӵ������Э������˷��ͷ��ͽ��շ�֮�䴫�����ݵ����ʵ�
1.2 ����ı�Ե
��ϵͳ:�������������ļ�����������豸,������������ı�Ե
��ϵͳ����:�ͻ��ͷ�����
1.2.1 ������
������:��ָ����ϵͳ���뵽��Ե·������������·
��Ե·����:��ָ��ϵͳ���κ�����Զ�̶�ϵͳ·���ϵĵ�һ̨·����
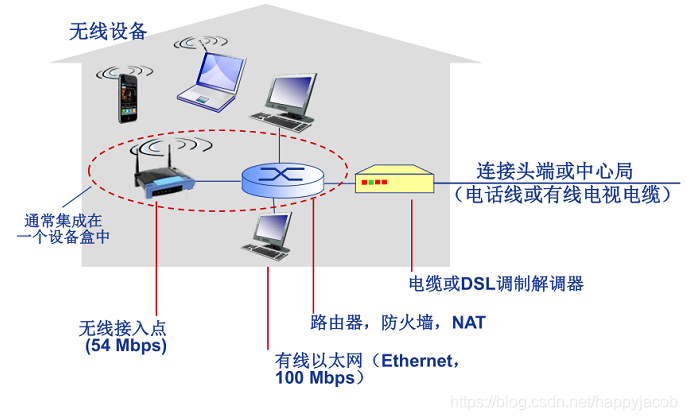
- �����û���(Digital Subscribe Line,DSL)
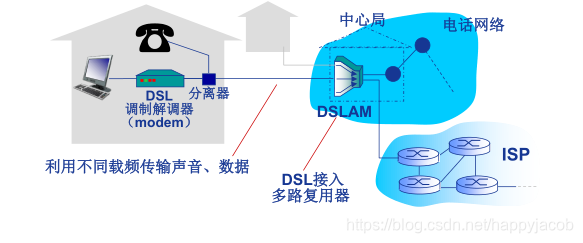
����һ�ֿ���סլ����ķ���,�����е��绰���������ľֵ� DSLAM,����ͨ��ͨ�� DSL �绰�߽��� Internet,����(�绰)ͨ��DSL�绰�߽���绰����ʹ�õ�ͨ����·����������Ϊ�绰��,��һ��˫���ߡ�
�û�ʹ�� DSL ���ƽ����ͨ���绰���� ISP �е������û��߽��븴����(DSLAM)����������;��ͥ DSL ���ƽ��������������ת��Ϊ��Ƶ����ͨ���绰�ߴ��䵽 ISP ����,����ͨ�� DSL ������� DSLAM ��������ģ���ź�תΪ�����ź�;
- ��������������(Cable Internet Access,CIC)
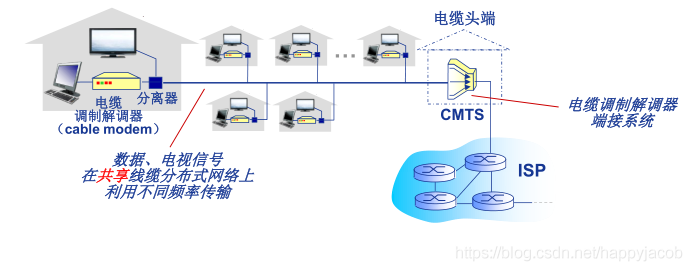
������һ�ֿ���סլ���뷽��,���� ISP �����ߵ��ӹ�˾����ʹ�õ�ͨ����·�����������й��˺�ͬ�����,Ҳ����Ϊ��Ϲ���ͬ��(Hybrid Fiber Coax HFC);
�û�ʹ�õ��µ��ƽ����ͨ��ͬ���������˽������,���˽��ͨ�����������ͷ������,������ͷ�˽��������������ڵ���ͷ��,���µ��ƽ�����˽�ϵͳ(Cable Modem Termination System)�� DSLAM ������,��ʵ��ģ���źź������źŵ�ת��;
- ���˵���(Fiber TO The Home,FTTH)
������Ҫ��ָʹ�ù�����Ϊͨ����·�IJ���,�����־����ԵĹ��˷ֲ�����,һ����������������(Active Optical Network),��һ���DZ�����������(Passive Optical Network).����Ҫ��������,�Ƿ��ڴ�������ʱ�������ˡ�
- ��̫����WIFI
��̫��������һ���ڹ�˾����ѧ����ͥ������еĽ��뷽ʽ;�û�ʹ��˫��������̫������������,�Ӷ�����������;������̫�����������ٶȿɴ� 100Mbps;
�����߾�������,�����û���һ������㷢�ͺͽ�������,���ý��������ҵ������,��ҵ�����ս���������;������ LAN ��,�û���Ҫ��һ�������ļ�ʮ��Χ֮��;
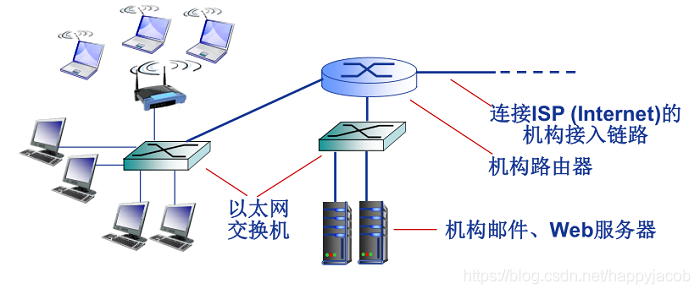
- �������߽���
���ƶ��豸��,ͨ���������ṩ����Ӫ�Ļ�վ�����ͺͽ��շ���,�� WIFI ��ͬ����,�û�����Ҫλ�ڻ�վ��������Χ֮�ڼ���;
1.2.2 ����ý��
����ý���ǹ���ͨ����·����Ҫ����,����ý��ͨ�����Է�Ϊ������ý��ͷǵ�����ý��;���ڵ�����ý��,�粨���Ź���ý��ǰ��,����¡�˫����ͬ����¡����ڷǵ�����ý��,�粨�ڿ��������ռ��д�����
ֵ��ע�����,���贫��ý��������ɱ�ҪԶԶ�����������ϵijɱ�
- ˫����
����˵������Դ���ý��,��������������Ƶ�ͭ����ɡ�Ŀǰ�������е�˫�������ݴ���������10Mbps��10Gbps֮��,���ܴﵽ�����ݴ�������ȡ�����ߵĴ�ϸ�Լ��������;˫����ʵ�����Ѿ���Ϊ���پ�������������Ҫ��ʽ;��Ϊ�ִ���˫���������ʺʹ�����붼�Ǻܲ�����;
- ͬ�����
Ҳ������ͭ���幹��,����������ͬ�ĵ�,���Dz��е�;��������Ľṹ�;�Ե��,ͬ����¿ɵõ��ϸߵ����ݴ�������;�ڵ���ϵͳ��Ӧ�ù㷺;ͬ����¿ɱ����������ԵĹ���ý��;
- ����
һ�ֿ��������������ý��
- ½�����ߵ��ŵ�
���ߵ��ŵ����ص��Ƶ���е��ź�,����Ҫ������·,�ṩ���ƶ��û��������Լ�����������źŵķ�ʽ;��һ������������ý��;
- �������ߵ��ŵ�
ͨ�������������������ڵ����ϵ������䷽(Ҳ����Ϊ����վ),��������һ��Ƶ���Ͻ����ź�,����һ��Ƶ���Ϸ����ź�;������ͬ�����Ǻͽ��ع������;
1.3 �������
������ļ�Ϊ�ɻ�����ϵͳ�ķ��齻��������·���ɵ���״����, ������ĵĹؼ�����: ·��+ת��
ͨ��������·�ͽ������ƶ����������ֻ�������:��·�����ͷ��齻��

1.3.1 ���齻��
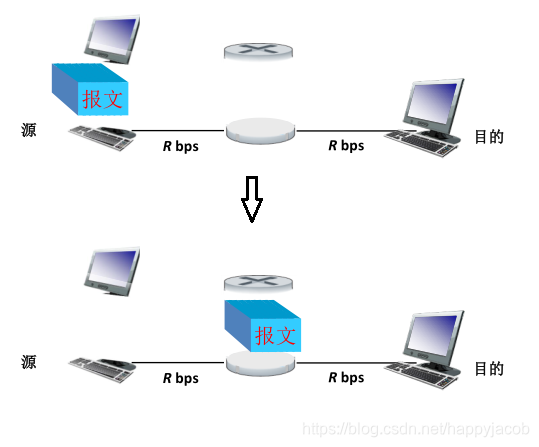
������ͨ����·���Ե��ڸ���·����������ʴ���ͨ��ͨ����·��������ij����·�����������ΪR,���鳤��ΪL,�����·����÷����ʱ��ΪL/R;���ʱ��Ҳ����Ϊ����ʱ��;���齻���ij�����ʽ�Ǵ洢ת������;
����:���ķֲ������һϵ����Խ�С�����ݰ�,���齻����Ҫ���ĵIJ��������,����������
- �洢ת��
��������齻�������ô洢ת��������ת������;��ν�洢ת����ָ���������յ�һ����ɵķ���,�Ż�����·���ת������,����ͽ��յ��IJ��ַ��黺������;��Ϊ����ȴ�һ�������ȫ�����ݶ����µ�ʱ�俪������Ϊ�洢ת��ʱ��
- �Ŷ�ʱ������鶪ʧ
��Ϊ��Ҫ�������,���Դ�ʱ���齻������Ҫһ�����������������;������еĿռ������Ծ��п��ܵ��·��齻�����������������(��Ϊ��·��ռ�û��߷��黹ûȫ����λ)��ʹ������齻���������ݰ����ȶ���;��͵����˷��鲻���е��˴���ʱ��,���е��˶���ʱ�ӡ�
- ת������·��ѡ��Э��
ʵ����,���齻����֮�����ܹ�֪������ȥ����Ϊ���ڲ���һ��ת����,�����ά����һ��IP��ַ����·�Ķ�Ӧ��ϵ,���Դ�������Ϊ:
- ͨ������ı�Ҫ��Ϣ,���Ŀ�Ķ�ϵͳ��IP��ַ
- ͨ��IP��ַ����ת����,�Ӷ�ȷ�������·

1.3.2 ��·����
�ڵ�·����������,�ڶ�ϵͳͨ�ŻỰ�ڼ�,��������Ԥ����ϵͳ��ͨ��·���ϵ������Դ(����,��·��������),���Ƚ�������,Ȼ��ͨ��,��ռ��Դ;���ڷ��齻��������,��Щ��Դû�б�Ԥ��;Ҳ����˵,�ڶ�ϵͳ����ͨ��ʱ,������Ҫ����Դ�DZ����ֵ�,����ͨ������ʹ����һ������Դ��;Ҳ��˵,��ϵͳ������������һ�������ӡ�;����һ����,�õ绰�����ﱻ��Ϊ����·������ͳ�ĵ绰������ǵ�·������������ӡ�
- ��·���������еĸ���
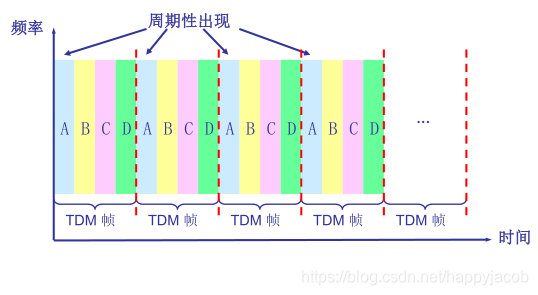
ʱ�ָ���(Time-Division Multiplexing TDM):��ָ��ʱ�仮��Ϊ�̶������֡,ÿ��֡���ֱ�����Ϊ�̶�������ʱ����϶;��������Ҫ����һ������ʱ,���罫��ÿ��֡��Ϊ������ָ��һ��ʱ϶;�ڸ�ʱ϶��,��·������������ӵ�����;
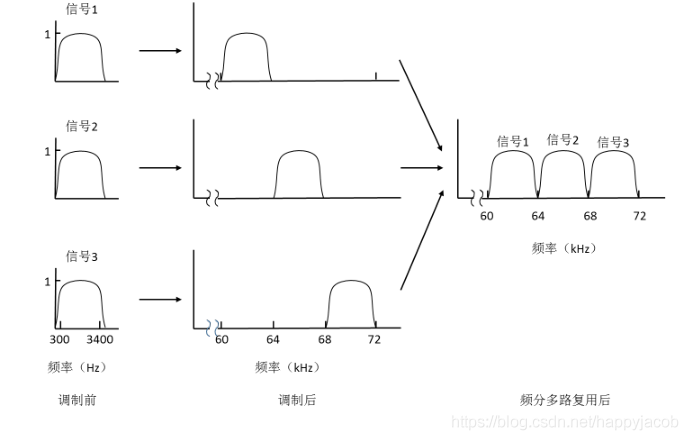
Ƶ�ָ���(Frequency-Division Multiplexing):��Ƶ����ΪƵ��,Ȼ��Ƶ�η��������;��Ƶ�α�����ר�Ŵ������ӵ����ݡ���Ƶ�εĿ��ȳ�Ϊ������
����֮��,��·���ü����������ֶ�·����(Wavelength division multiplexing-WDM)�ͺ���ֶ�·����( Code division multiplexing-CDM),���ָ��þ��ǹ��Ƶ�ָ���
���ݽ������˵�·�����ͷ��齻��,����һ������δ���ܵ����Ľ���,����:Դ(Ӧ��)������Ϣ����,����һ���ļ�,��Ϊ������з��͡�
���Ľ�������齻�������ô洢-ת��������ʽ,����:
- ���Ľ����������������С��洢-ת����
- ���齻������С�ķ������С��洢-ת����
1.3.3 ���齻���͵�·�����ĶԱ�
���齻�����ŵ�:
- ���ṩ�˱ȵ�·�������õĴ�������;
- ���ȵ�·������������Ч��ʵ�ֳɱ�����;
���齻����ȱ��:
- ���齻�����ʺ�ʵʱ����,��Ϊ�˵��˵�ʱ���ǿɱ䡢����Ԥ���,������������������;
��·�������ŵ�:
- �ṩ�˶˶Զ˴������ݵ����ʱ�֤;
��·������ȱ��:
- ��·�������ھ�Ĭ��,����ָר�õ�·����ʱ,��ռ�õ���Դ��û�еõ���ֵ�����;
- �������ӵĹ��̱Ƚϸ���;
��������˵,���齻��������Ҫ���ڵ�·����������,���Dz�ͬ���͵ķ��齻����ʽ�в�ͬ��Ӧ�ó���;����һЩ��������������ϸ�Ҫ���Ӧ��,����ʵʱ�����,Ϊ�˻�����ʱ�֤,���������Ч��Ҳ�ǿ��Խ��ܵġ��������ŷ��齻����չ
1.3.4 ���������
���ò�˵,��������һ���Ӵ�����ӵ�ϵͳ,����������Ȼ�а취������(���Dz����Ѿ���ô��������?),����������Ҫһ��ģ�����̻��������Ľṹ;����ʲô���Ľṹ���̻���������?����,���ձ��˵������:����������������硣������һ˵���㹻������ͬʱҲ������ȷ������Ҫ����,���ǿ���ѡ�����ȷ�ķ������̻�������;����ͨ��5��ģ�Ͳ��Ϲ��ɵ�����ģ��,��ʵ���ɵĹ��̾ͽṹ���Ϻ��������ӷ�ʽ������ȷ�Ĺ��̡�
������ʲô�������� һ���н���ISP,��ϵͳ��ͨ��ISP������������,Ϊ��ʵ�ֶ�ϵͳ�Ļ���,ISPҲ���뻥��,��ʵ����ģ�;�����������ISP�Ͷ�ϵͳ�Լ�ISP֮��Ľṹ�ij���;
����ṹ1:����Ψһ��ȫ�����ISP�������еĽ���ISP,����ָ,ȫ��ISP��һ����·������ͨ����·���ɵ�����,�������Խȫ��,���������Ľ���ISP�����ٺ�һ������·��������;
����ṹ2:���ڶ��ȫ�����ISP,���Ƿֱ���һ���ֵĽ���ISP����;Ϊ��ʵ�ֶ�ϵͳ�Ļ���,����ȫ��ISPҲ���뻥��;����ṹ��һ������ṹ,����ȫ�����ISPλ�ڶ���,����ISP���ڵײ�;
����ṹ3:����ȫ�����ISP�������Ѿ�����,���ǽ���ISP���ڻ��ܻ���,����,����ֱ��ͬ����ISP����;������ṹ3��,����ISPҲ�Ƿֲ��:��С�����е�ISP����ϴ������ISP,������ֱ���붥��ISP����;Ϊʲô����������Ľṹ��?������Ϊ,�����ֱ��ͬ����ISP����,��ô����ͬһ��С������,������ͬISP�Ķ�ϵͳ֮��ͨ�ŵ�����Ҳ�ᵽ����ISP����ȥһ��,������Dz���ֱ�ӽ��붥��ISP,���ǽ�����һ���ϴ������ISP,��ô����֮���ͨ�����ݾͲ���ȥ����ISP������,��Ϊ����ͨ���ϴ������ISP�Ѿ�ʵ���˻���,����ͨ���ٶȿ϶�����ȥ�ˡ�
����ṹ4:��������ṹ3�Ļ�����,�����������ص���γɵĽṹ:���ڵ�(Point of Presence,PoP)�����ޡ��Եȡ�������������(Internet exchange point,IXP)��
PoP�����ڵȼ��ṹ�����в��,���ǵײ�ISP����;һ��PoP��ISP�����е�һ̨���߶�̨·����Ⱥ��,���пͻ�ISP�ܹ�ͨ���������ṩ�ĸ�����·ֱ�ӽ�����·������Ӧ�̵�PoP����,�Ӷ�ʵ�����ṩ��ISP���ӡ����������ٶȺ����Ծ�����ˡ�
����(multi-home)��ָ,�κ�ISP(����һ��ISP)���������������߶���ṩ��ISP����,�ⱻ��Ϊ����;��������Ŀɿ��Ծ������
�Ե�(peer) ��ָ,λ����ͬ�ȼ��ṹ��ε�һ���ڽ�ISP�ܹ�ֱ�ӽ����ǵ��������ӵ�һ��,ʹ����֮��������ֱ�����Ӷ����Ǿ������ε��м�ISP����,�����Ȳ��ø���,�ٶ�Ҳ���ܻ��һЩ;
��������������Ϊ��ʵ�ֶ��ISP���ԶԵȶ������ġ�
����ṹ5:����ṹ5��������ṹ4�Ļ����������������ṩ����������ɡ������ṩ�̹����Լ�������,����ͨ����ϵͲ�ISP�Եȶ����ƹ����ϸ߲�������ISP,���������ṩ�̶Զ��û�Ҳ���˸���Ŀ��ơ�
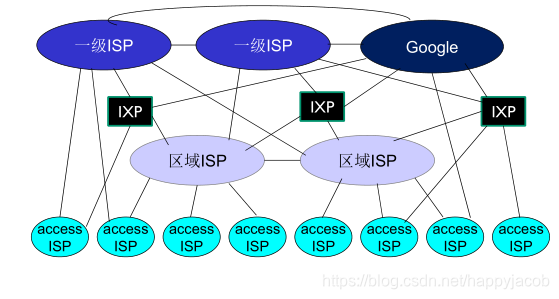
������˵,�������������һ������������硱,��ṹ����,��ʮ�������ISP����ʮ����ϵͲ�ISP���ɡ�������,��Ҫ�������ṩ�̴����Լ�������,ֱ���ڿ��ܵĵط���ϵͲ�ISP����
1.4 ���齻���е�ʱ�ӡ�������������
�������ܹ�������һ�������ڶ�ϵͳ�ϵķֲ�ʽӦ���ṩ����Ļ�����ʩ
���������ض�ҪҪ�����ڶ�ϵͳ֮���������,���ڶ�ϵͳ֮�����ʱ�ӡ�����;
1.4.1 ���齻�����е�ʱ�Ӹ���
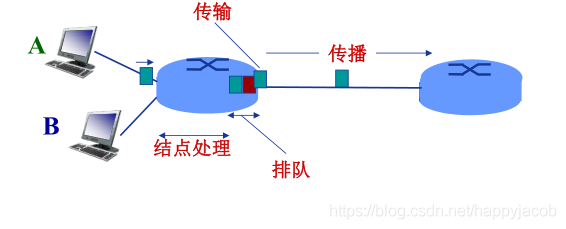
һ����������;ÿ���ڵ���ܲ�ͬ���͵�ʱ��,��Щʱ������Ϊ��Ҫ����:��㴦��ʱ�ӡ��Ŷ�ʱ�ӡ�����ʱ�Ӻʹ���ʱ��.��Щʱ�������ۼ������ǽ����ʱ��
ʱ�ӵ�����
(1)����ʱ��(nodal processing delay
����ʱ������Ϊ�ڵ���Ҫ��������ı�Ҫ��ϢȻ����������·(����ת�����Ȳ���)��������,ͨ��������߸���������;
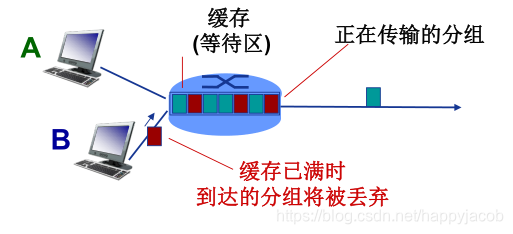
(2)�Ŷ�ʱ��(queueing delay)
�Ŷ�ʱ������Ϊ��������Ӧ�ij���·ǰ���������������ڴ���,���Է�����Ҫ����·�Ļ��������ȴ��������鴫����϶�������;һ����˵,�Ŷ�ʱ���ǵ���ö��е�����ǿ�Ⱥ����ʵĺ���,ͨ�����Դﵽ���뼶���뼶;
(3)����ʱ��(transmission delay)
����ʱ���ǽ����з���ı���������·������Ҫ��ʱ��,ʵ�ʵĴ���ʱ��ͨ���ں��뵽������������L��ʾ����ij���,��Rbps��ʾ��·����A��B����·�������ʡ�����ʱ����L/R��
dtrans = L/R,���� L �Ƿ��鳤��(bits),R ����·���� (bps)
(4)����ʱ��(propagation delay)
����ʱ����ָ���ؽ�����·��,�Ӹ���·����㵽��һ��������õ�ʱ��;һ�������е����һ�����ص���·��������ζ�Ÿ÷�������б��ض��ѵ���·����;��������,����ʱ��һ���Ǻ��뼶�ġ�����ʱ����d/s��d��·����A��B�ľ��롣s����·�Ĵ������ʡ�
dprop = d/s,���� d ��������·����,s ���źŴ����ٶ� (~2��10 8m/sec)
����ʱ�Ӻʹ���ʱ�ӵĶԱ�
�������ȷ��Ļ�,����ʱ�Ӿ��Ǵ������շ�վ��ʱ�������ʱ����dz��ڸ��ٹ�·����ʻ��ʱ�䡣����ʱ���Ƿ��鳤�Ⱥ���·�������ʵĺ���������ʱ������̨·���������ĺ���
1.4.2 �Ŷ�ʱ�ӺͶ���
����:����ķ��鷢��һ�����Ķ��С�����û�еط��洢�������,·�����������÷���,�÷��齫�ᶪʧ
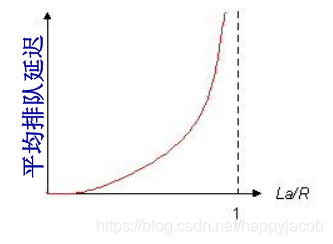
�Ŷ�ʱ�ӺͶ����������״���ͽ��Ļ���ռ��С�������ٶ����;������鵽����ٶȸ��ڽ��Ĵ����ٶ�,��ô����ͻ��ڻ���������Ŷӵȴ���������ռ������,������е��ķ���,��ô�÷��齫���ȶ���
Ϊ����������״��,��������������ǿ����һ����:����ǿ��=���鵽����ٶ�/���Ĵ����ٶ�;����������һ��������ɾ���:���ϵͳʱ����ǿ�Ȳ��ܴ���1;
������ǿ����������1ʱ,�ͽ����ֶ�������
1.4.3 �˵���ʱ��
dend-end = N(dproc + dtrans + dprop)
dproc:ÿ̨·������Դ�����ϵĴ���ʱ��
dtrans = L/R,R���������,L�Ƿ��鳤��
dpgp:��·�Ĵ���ʱ��
1.4.4 ����������������
����������������ʵ������һ���ٶ�ָ��,�������˱��ؾ���ij���ڵ���ٶȡ�����ij��·���ϵĽ����˵,�ý���йص��ٶ�������:�������ݵ��ٶȺͷ������ݵ��ٶ�,���ý������������������ٶ��н�С��һ��;����ij��·����˵,��·�����������������нڵ������������Сֵ;��������������Ժ������������.
�κ�ʱ���˲ʱ������������B���ܵ����ļ�������
������ļ���F�������,����B���ܵ����б�����ȥTs,���ļ���ƽ��������ΪF/Tbps
���������Խ���ΪԴ��Ŀ�ĵ�֮��·������С�������ʡ���С�������ʵ���·Ϊƿ����·��
�ڽ���,�������������ʵ���������ͨ���ǽ�������
1.5 Э���μ������ģ��
��������һ����Ϊ���ӵ�ϵͳ,��ϵͳ������Ŵ�����Ӧ�ó����Э�顢�������͵Ķ�ϵͳ�����齻�����������͵���·��ý�塣������ͬʱҲ�����������ṹ��,��������ǰ����������� һ�ڽ��ܵ�,�������ܹ������Ľṹģ��
1.5.1 �ֲ���ϵ�ṹ
�����������÷ֲ����ϵ�ṹ,�ֲ�����ϵ�ṹ��Ϊ�ṩģ�黯�����кܸߵļ�ֵ,ͬʱҲ���ڷ���ʵ�ֵĶ�����:ijһ�������һ���ṩ����,ͬʱ������������һ���ṩ�ķ���ֻҪ�����ṩ�ķ���Ͷ������õķ���û�б仯,����ڲ���ʵ�ֲ������ϵͳ�ṹ����Ӱ��;���ڴ����������Ҫ���ϸ��µ�ϵͳ��˵,�ı�����ʵ�ֶ���Ӱ��ϵͳ��������Ƿֲ�ģʽ����һ����Ҫ�ŵ�
Ϊ�˸�����Э�������ṩһ���ṹ,����������Էֲ�ķ�ʽ��֯Э���Լ�ʵ����ЩЭ�����Ӳ��
һ��Э������ʹ����Ӳ��ʵ��,ͬʱij��Э���IJ�ͬ���ֳ���λ����������ĸ����֡�Э��ֲ���и���ͽṹ�����ŵ㡣ģ�黯ʹ�ø���ϵͳ�����Ϊ���ס����Ƿֲ�Ҳ����ȱ��,���ǹ����ϵ�����,��������Э��ջ�����·�Ͷ˵�������������ṩ�˲���ָ����ܡ��ڶ���DZ�ڵ�ȱ�����ij��Ĺ��ܿ�����Ҫ����������ų��ֵ���Ϣ
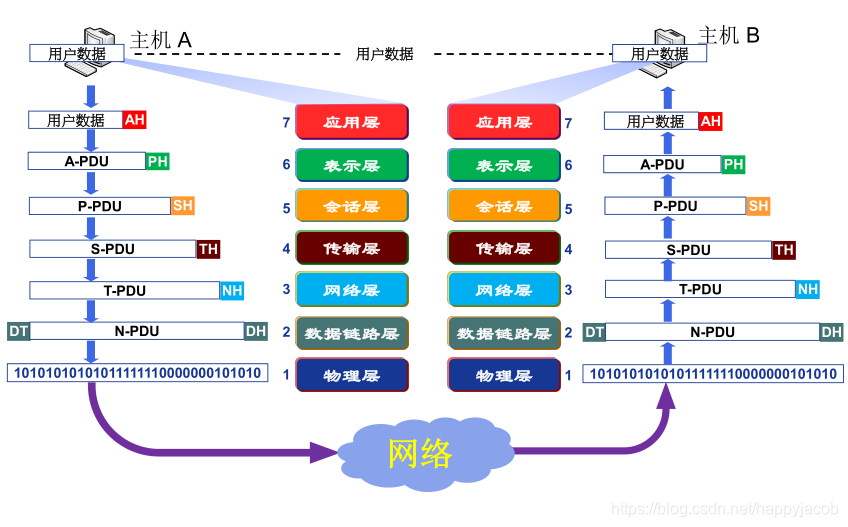
������˵,�����������Э���������,��ΪЭ��ջ����������Э��ջ��5��������:�����㡢��·�㡢����ɡ�����㡢Ӧ�ò�
- Ӧ�ò�:֧�ָ�������Ӧ��,�� FTP, SMTP, HTTP
- �����:����-���̵����ݴ���,�� TCP, UDP
- �����:Դ������Ŀ�����������ݷ���·����ת��,�� IP Э�顢·��Э���
- ��·��:��������Ԫ��(��������������·������)�����ݴ���,����̫��(Ethernet)��802.11 (WiFi)��PPP
- ������:���ش���
- OSIģ��
��������Э��ջ������ǰ,OSIģ����ISO��֯�з��ļ��������ṹģ�͡�OSI��ģ��һ����7��,���µ�������Ϊ:������,��·��,�����,�����,�Ự��,��ʾ��,Ӧ�ò㡣�����������ϵ�ṹ,OSI�������㡣
������������Ĺ��������˿���������ʵ�֡�
1.5.2 ��װ
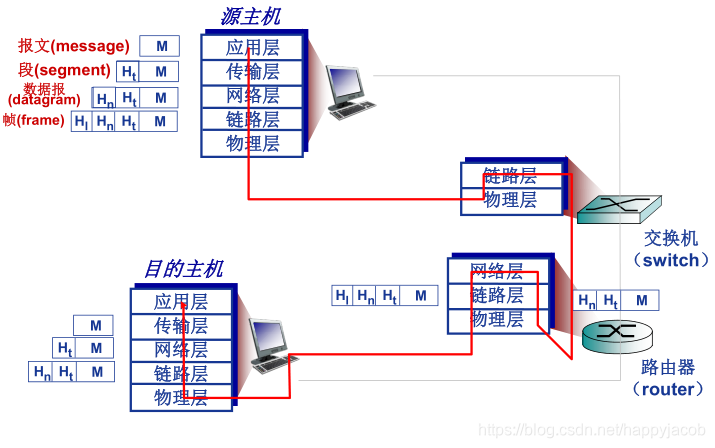
һ������,�ڲ�ͬ�IJ���в�ͬ�ij�ν,����Ϊ���Ǿ���ÿһ���ʱ��ͱ��ò��װ�������ڸò�������Ϣ,Ҳ����ǰ���ᵽ�ı�Ҫ��Ϣ;����,ÿһ�ֲ�ķ������������͵��ֶ�:�ײ��ֶκ���Ч����;������Ч���ؼ�Ϊ������һ��ķ�������,���ײ��ֶξ��Ǹò���ϵı�Ҫ��Ϣ;���鲻�ϱ���װ��ʵ�ָ���Э��涨����ع���
��װ����������Ϣ,����Э�����ݵ�Ԫ (PDU);������Ϣ��Ҫ����:��ַ,���������(Error-detecting code),Э�����(Protocol control),Э�����ʵ��Э�鹦�ܵĸ�����Ϣ,��: ���ȼ�(priority)����������(QoS)�� �Ͱ�ȫ���Ƶ�
�� 2 �� Ӧ�ò�
2.1 Ӧ�ò�Э��ԭ��
�з�����Ӧ�õĺ�����д���ܹ������ڲ�ͬ��ϵͳ��ͨ������˴�ͨ�ŵij���;ֵ��ע�����,���Dz���Ҫд����������豸��·����������·�㽻���������е�����,������Ʒ�ʽ����Ӧ�ó��������ڶ�ϵͳ�ķ���,�ٽ��˴�������Ӧ�ó����Ѹ���з��Ͳ���
2.1.1 ����Ӧ�ó�����ϵ�ṹ
Ӧ�ó������ϵ�ṹ��ͬ���������ϵ�ṹ����Ӧ�ó����з��ߵĽǶ�����,������ϵ�ṹ�ǹ̶���,��ΪӦ�ó����ṩ�ض��ķ���;����֮,Ӧ�ó�����ϵ�ṹʹ��Ӧ�ó�����Ƶ�,���涨���ڶ�ϵͳ�������֯Ӧ�ó������ֳ������ִ�����Ӧ�ó��������õ���ϵ�ṹΪ:�ͻ�-��������ϵ���Ե���ϵ�ṹ
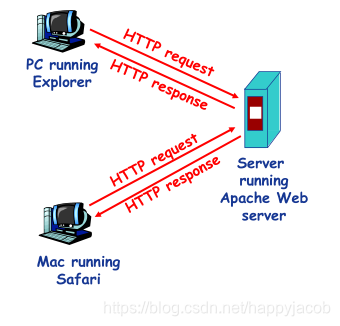
- �ͻ�-��������ϵ�ṹ
�ڸ���ϵ�ṹ��,��һ�����Ǵ�����,��������,�����պͷ��������������౻��Ϊ�ͻ�����������;ֵ��ע�����,�ڸ���ϵ�ṹ��,�ͻ�֮���Dz�ֱ��ͨ����;�÷��������й̶��ġ���֪�ĵ�ַ��
�ͻ�-��������ϵ�ṹ������Ӧ����:Web��FTP��Telnet�͵����ʼ���
ͨ��,�������һ̨�������������е�����,��ô������ϵͳ���ܿ��ò����ظ�,Ϊ��,�䱸�����������������ij������ڴ���ǿ�������ķ�����,һ���������Ŀ�������ʮ��̨������,������Ҫ�����ά��,ͬʱ�����ṩ�̻���Ҫ֧�����ϳ��ֵĻ����ʹ�������,�Լ����ͺͽ��յ���/�����������ĵ�����;
- P2P ��ϵ�ṹ
��P2P��ϵ�ṹ��,��λ���������ĵ�ר�÷�����������С(����û��)������Ӧ�ó����ڼ�����ӵ�������֮��ʹ��ֱ��ͨ��,��Щ��������Ϊ�Եȷ����Եȷ�����Ϊ�����ṩ����ӵ��,��Ϊ���ֶԵȷ�ͨ�Ų���Ҫͨ��ר�ŵķ�����,���Ը���ϵ�ṹҲ����Ϊ�Եȷ����Եȷ��ṹ
Ŀǰ,�����ܼ���Ӧ�ö���P2P��ϵ�ṹ�ġ���ЩӦ�ð����ļ�����(���� BitTorrent)��Э������(����Ѹ��)���������绰(���� Skype)�� IPTV (����Ѹ����)��
ֵ��ע�����,ijЩӦ�þ��л�ϵ���ϵ�ṹ,���ǽ���˿ͻ�-��������P2P��������ϵ���,��������ļ�ʱͨѶ����,���������������û�IP��ַ,�����û�֮���ͨ����ʹ��ֱ�ӷ���
P2P ��ϵ�ṹ��������ʤ������֮һ�������ǵ�����չ�����������ļ�����Ӧ����,�Եȷ�����ͨ�����ļ���ԭʼӵ���߷������������������,���ǶԵȷ�Ҳ�п���ͨ��Ϊ�����Եȷ������ļ���Ϊԭʼӵ���߷ֵ�ѹ��;P2P��ϵ�ṹҲ�dzɱ���Ч��,��Ϊ��ͨ������Ҫ�Ӵ�ķ�����������ʩ�ͷ��������
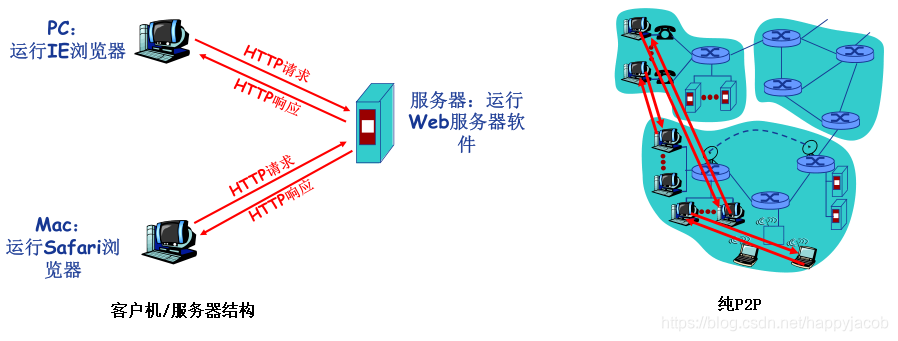
���� P2P Ҳ������������������:
- ISP �Ѻá������סլ ISP �����ڷǶԳƴ���Ӧ��,Ҳ�������ر��ϴ�Ҫ��öࡣ���� P2P ��Ƶ���ļ��ַ�Ӧ�øı��˴ӷ�������סլISP����������,����� ISP ����ѹ��;
- ��ȫ�ԡ���Ϊ��߶ȵķֲ��Ϳ���ʽ,P2PӦ��Ҳ���ܸ���ȫ������ս;
- ���������˵���û���Դ��Ӧ���ṩ�������洢�ͼ�����Դ?����һ������;
2.1.2 ����ͨ��
�ڲ���ϵͳ��,ʵ�ʽ���ͨ�ŵ��ǽ��̶�����Ӧ�ó���;������������ͬһ����ϵͳ��ʱ,����ʹ�ý��̼�ͨ�Ż����ͨ��;�����̼�ͨ�ŵĹ������ɶ�ϵͳ�ϵIJ���ϵͳȷ���ġ������������ڲ�ͬ�Ķ�ϵͳ��ʱ,����ͨ����Խ���������ı����ͨ��;���ͽ��̲������IJ����������з���,���ս��̽��ձ��IJ��Դ�������Ӧ(����ӦҲ��һ����Ӧ)��
- �ͻ����̺ͷ���������
����û��ͨ�Ž���,����ͨ��������������֮һ��ʶΪ�ͻ�,����һ�����̱�ʶΪ��������
��Ҫע�����,��ijЩP2PӦ����,һ�����̿��ܼ��ǿͻ�Ҳ�Ƿ�����,��Ϊ��һ���ļ�����Ӧ����,һ�����̵�ȷ���������ļ�Ҳ�ܷ����ļ������Դӽ��������ݵĽ�ɫ�������ǿͻ����̻��Ƿ��������̲�����ȷ,�������Ǵӷ���ͨ�ŵ�˳������������:�ڸ�����һ�Խ���֮��,���ȷ���ͨ�ŵĽ��̱����Ϊ�ͻ�����,�ڻỰ��ʼʱ�ȴ���ϵ�Ľ��̱���Ϊ���������̡�
- ��������������֮��Ľӿ�
����Ӧ�ó�������ͨ�Ž��̶���ɵ�,�����ڲ�ͬ��ϵͳ�ϵĽ��̶�֮��ͨ�������������ʵ��ͨ�š�����,��Ӧ�ó�����̺ͼ��������֮�����һ���ӿ�,�ýӿڱ���Ϊ��������Ϊȷ��˵,������ͬһ̨������Ӧ�ò�������֮��Ľӿڡ����ڸ������ǽ�������Ӧ�ó���Ŀɱ�̽ӿ�,�������Ҳ����ΪӦ�ó��������֮���Ӧ�ñ�̽ӿ�(Application Programming Interface).
Ӧ�ó����߿��Կ���������Ӧ�ò��һ������,���Ƕ�����������ز���,����û�п���Ȩ,����������:�� ѡ�����Э��,���趨������������,�������������㱨�ij���
- ����Ѱַ
Ϊ�����ض�Ŀ�Ľ��̷��ͱ���,���ͻ�������Ҫ֪�����ս���(��Ϊȷ��˵��,���ս��̶�Ӧ������)�ı�ǡ��ñ�������������:�ٽ��ս������ڵ�������ַ,�ڽ��ս����ڸ������еı��;����������,������IP��ַ���,����IP��ַ��һ��32λ(IPV4)���;�����ս���(����˵�����Ӧ������)ʹ�ö˿ںű��;һЩ���õ�Ӧ�ó������Ź̶����˿ں�,����Web������ʹ��80�˿ڡ��ʼ�������(����SMTPЭ��)ʹ��25�˿ڵ�
2.1.3 �ɹ�Ӧ�ó���ʹ�õ��������
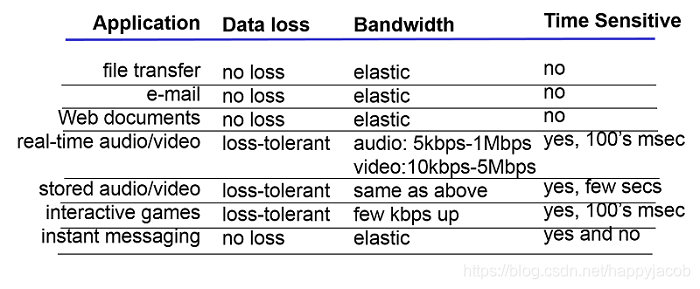
�����Э����ص���¿��Դ��������ĸ����濼��:�ɿ����ݴ��䡢����������ʱ�Ͱ�ȫ��
- �ɿ����ݴ���
��ͬ�ڵ�һ���н��ܵ�,�����ڴ�������п��ܻᶪʧ������,������Ϊ·�����еĻ�����������������߷����ڴ���Ĺ����з����������;��ЩӦ���Dz��������ݷ�����ʧ��,��������ʼ����ļ����䡢Զ���������ʡ�Web�ĵ������Լ�����Ӧ�õȡ�Ϊ��֧����ЩӦ��,������һЩ������ȷ��Ӧ�ó���һ�η��͵�������ȷ����ȫ�ؽ������������ݵĽ��̡����һ��Э���ṩ��������ȷ�����ݽ����ķ���,����Ϊ��Э�ṩ�˿ɿ����ݴ��䡣��Ӧ�ó���ʹ�ÿɿ����ݴ���Ĵ����Э��ʱ,ֻҪ��Ҫ���͵����ݴ�������־Ϳ�����ȫ���Ÿ����ݿ�����������ص�����շ�;
��һ�������Э�鲻�ṩ�ɿ����ݴ���ʱ,�ɷ��ͷ����͵����ݾͿ��ܲ��ܹ�������ս��̡���ЩӦ�����������������������,��ЩӦ�ñ���Ϊ��ʧ������Ӧ�á�����Ӧ�ó�������:��̸ʽ��Ƶ����Ƶ�������ܹ��е���ʧһ������������ʧ,����ЩӦ����,�����ʧ�������ݽ�����С����,���Dz����������������,��ЩӦ��Ϊ���̶�ʧ��Ӧ����
- ������
��һ������·���ϵ���������֮���ͨ�ŻỰ��,��������������ָ�ܹ�����ս��̽������ص����ʡ���Ϊ���������Ự�����������·���Ĵ���,������Ϊ��Щ�Ự�ĵ������뿪,�����������������仯;��͵�����һ����Ȼ�ķ���,�������Э���ܹ��ṩȷ�еĿ�����������ʹ�����ַ���ʱ,Ӧ�ó����������ȷ���ٶȽ�������,���������Ӧ����֤����������������������Ϊ���ٶ�;
������������ȷҪ���Ӧ�ó���Ϊ�������е�Ӧ���������ý��Ӧ���Ǵ������е�(����ijЩ��ý��Ӧ�ó�����ܲ�������Ӧ���뼼����������Ƶ����Ƶ���뵱ǰ���ô�����ƥ����ٶȼӽ��롣),�����������绰��������Ӧ�����������û���ϸ��Ҫ������Ӧ�ð���:�����ʼ����ļ������Լ�web���͵ȡ�ֵ��ע�����,��������Ȼ��Խ��Խ���ˡ�
- ��ʱ
��ʱ�����������ǹ����ٶȵġ�һ���ṩ��ʱ�����������:���ͷ�ע�������е�ÿ�����ص�����շ������ֲ�����100ms��Ҳ����˵,��ʱ�Ƕ����ݴӷ��͵���������ʱ���Ҫ��,���������Ƕ����ݽ����ٶȵ�Ҫ����ȷ�,��������ָһ��Сʱ�ھ���ij���շ�վ��������Ŀ,����ʱ���ǵ�һ�����ӳ����������շ�վ��ʱ�䡣��ЩӦ��Ϊ�˷������Ч�Զ������ݵ���ʱ�����ϸ��Ҫ��,������Ӧ����:�������绰���������Ϸ��;
- ��ȫ��
���������ṩһЩ��ȫ����,�Է�ֹ�����������ij�ַ�ʽ������������֮�䱻���������Щ��ȫ�������:���ݵļӽ��ܡ����ݵ������ԺͶ˵����ȡ�
2.1.4 �������ṩ�Ĵ�������
������(��һ�����TCP/IP����)ΪӦ�ó����ṩ���������Э��,��UDP��TCP��ÿ��Э���Ӧ�ó����ṩ�˲�ͬ�������ϡ�����Ϊ������������Ӧ�õ��ص�:
- TCP����
TCP����ģ�Ͱ������������ӵķ���Ϳɿ����ݴ������
�������ӵķ���:��Ӧ�ò����ݱ��Ŀ�ʼ����֮ǰ,TCP���ڿͻ��˺ͷ����������������������Ϣ��������ֹ��̽���ʾ�ͻ��˺ͷ�������,������Ϊ���������Ĵ�������������;���ֽν��պ���һ��TCP���ӡ�����������ȫ˫����,������˫��ʹ�ø������ӿ���ͬʱ���б��ĵ��շ����������ӽ���ͨѶ��������;
�ɿ������ݴ���:Ӧ�ó���ʹ��TCPЭ���ʵ����������ʵ�˳�����з��͵�����,û���ֽڵĶ�ʧ������;
TCP�����ṩ��ӵ���������ơ��û��Ʋ�һ�����ͨ��˫�������ô�,���ǻ�������������ô�;�����ͷ��ͽ��շ�֮����������ӵ��ʱ,TCP��ʹ��ӵ�����ƻ�����ʹ����ָ�����
- UDP����
UDP������һ�ֲ��ṩ����Ҫ���������������Э�顣�����ṩ��С����UDP�������ӵ�Ҳ����˵ͨ��֮ǰû������;UDP���ṩ���ݵĿɿ�����;UDPҲû��ӵ�����ƻ��ơ���ЩӦ�ó�����,UDPЭ�齫��������ı�����Ч��,����DNS��һЩ�������绰����(Ϊ�˱���ӵ������Э��Ŀ��ƶ�ʹ��UDP)
- ��������ṩ�ķ���
�ӿɿ����ݴ��䡢����������ʱ����ȫ�Ե��ĸ��Ƕ�����������ṩ�ķ���,���Ƿ���,����������������Ͷ�ʱ������֤������,������������ܹ�Ϊʱ�����е�Ӧ���ṩ����ķ���,�����������ṩ�κζ�ʱ���ߴ�����֤;
2.1.5 Ӧ�ò�Э��
Ӧ�ò�Э�鶨�������ڲ�ͬ��ϵͳ�ϵ�Ӧ�ó����������������Ϣ���漰�����ݰ���:�����ı�������(���������Ӧ)�������а�����Щ�ֶΡ��ֶ���α����͡�һ�����̺�ʱ�շ����IJ���ζԱ��Ľ�����Ӧ������
��Ҫע�����,Ӧ�ò�Э��������Ӧ�õ�һ����
2.1.6 �������漰������Ӧ��
�������ܵ�Ӧ�ð���:Web���ļ����䡢�����ʼ���Ŀ¼�����P2P��Web���ֽ�����HTTPЭ��,���Ƚϼ���������;FTP���HTTP�γ��˶���;�����ʼ��DZ�Web��Ϊ���ӵ�Ӧ��,��Ϊ��ʹ���˶��Ӧ�ò�Э��;������û�����ֱ�Ӻ�DNS�Ӵ�,����DNS�ܺõ�˵����һ�ֺ��ĵ����繦���������Ӧ�ò�ʵ�ֵġ�������P2PӦ�õļ����ˡ�
2.2 WEB��HTTP
2.2.1 HTTP����
HTTP(HyperText Transfer Protocol)��WEB��Ӧ�ò�Э��,����Web�ĺ���;HTTP��������ʵ��,һ���ͻ��˳���һ������������;HTTP�����˿ͻ��ͷ��������б��Ľ����ķ���;
Webҳ�����ɶ�����ɵ�,һ��������һ���ļ�,����ͨ��һ��URL��ַ����Ѱַ���ͻ��ͷ����������ĺ���˼���ǿͻ�ͨ��HTTP����Է�����������Webҳ���������,�������յ��ñ��ĺ��ذ����ö����HTTP��Ӧ���ġ�URL��ַ�����������:��Ŷ���ķ������������Ͷ����·����
HTTPʹ��TCP��Ϊ���Ĵ����Э��;HTTP�ͻ����ȷ���һ�����������TCP����,��Ҫע�����,��������������������Ӧ,���Dz��洢�κι��ڸÿͻ���״̬��Ϣ;Ҳ����Ϊ����,HTTP����Ϊ��״̬Э����ͬʱ,Webʹ���˿ͻ���-��������Ӧ����ϵ�ṹ;����web���������ǿ��ŵ�
2.2.2 �������Ӻͷdz�������
��������Ӧ�ó�����,�ͻ��˺ͷ��������ںܳ���ʱ�䷶Χ��ͨ��;Ӧ�ó������������ص�,ѡ���Թ���ļ���������Է�������Ҳ���Լ����һ������������ͨ����ʹ��TCPЭ��ʱ,����������Ҫ����һ������:��Щ������ʹ��һ��TCP������ɻ���ͨ��������TCP������ɡ������ȡǰһ������,���Ӧ�ó���ʹ����������,���ʹ�ú�һ�ַ�ʽ,���Ϊ�dz���������
HTTP�ȿ�ʹ�ó�������Ҳ����ʹ�÷dz������ӡ�����HTTP�ھ�Ĭ�����ʹ�ó�������
- ���÷dz������ӵ�HTTP
ʹ�÷dz�������ʱ,ÿ��TCP�����ڷ���������һ�������ͻ�ر�,Ҳ����ÿ��TCPֻ����һ�������ĺ���Ӧ����;
Ϊ�������������Ӻͷdz������ӵ��ص�,������������ʱ��(Round-Trip Time,RTT)��RTTָ����,һ���̷���ӿͻ��˵�������,Ȼ���ٷ��ؿͻ������õ�ʱ�䡣RTT��������Ĵ���ʱ�ӡ��Ŷ�ʱ�ӡ�����ʱ��(��Ϊ�Ƕ̷���,�����䴫��ʱ�ӿɲ���);��Ϊ�ͻ��˺ͷ���������TCP���ӵ�ʱ��,��ͨ��һ���������ֵĹ������������������Ϣ���������ֵ�ǰ����ռ����һ��RTT,�ͻ���ϵ���������ͨ�л�ͨ�������ӷ���һ��HTTP������,һ���÷��鵽�������,�������㿪ʼʹ��TCP����HTML�������,���Ե�˵,��Ӧʱ��������RTT���ϴ���HTML��ʱ��(���Ǵ���)��

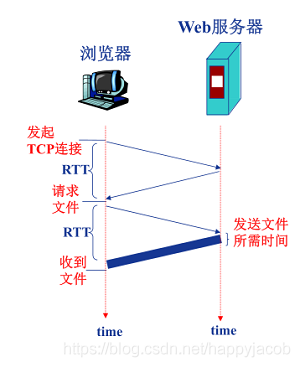
- ���ó������ӵ�HTTP
�dz�������ȱ��:��һ�� ����Ϊÿһ������Ķ�������ά��һ��ȫ�µ�����,��ÿ��TCP���ӽ�ռ��ϵͳ��Դ,�����������ͱ�����,�����������ĸ����ͺ����ˡ� �ڶ�,ÿһ������������ RTT �Ľ���ʱ�ӡ�
���ʹ�ó�������,һ��������Webҳ�� ( �����е� HTML �����ļ�����10��ͼ�� ) �����õ������� TCP ���ӽ��д��͡���������,ͬһ̨�������ϵĶ��ҳ��Ҳ����ͨ��ͬһ�����ӷ��͡��Զ������Щ�������һ����һ���ط���,�����صȴ���δ������Ļش�
- ����ˮ(pipelining)�ij־�������:�ͻ���ֻ���յ�ǰһ����Ӧ��ŷ����µ�����,ÿ�������õĶ����ʱ1��RTT
- ������ˮ���Ƶij־�������:HTTP 1.1��Ĭ��ѡ��,�ͻ���ֻҪ����һ�����ö���;��췢������,���������,�յ����е����ö���ֻ���ʱԼ1��RTT
һ����˵,���һ��������һ����ʱ������û��ʹ�õĻ�,�ͻᱻ�رա�HTTPĬ��ʹ�õ��Ǵ���ˮ�ߵij������ӡ�
2.2.3 HTTP���ĸ�ʽ
- ������

һ�������ľ�������һ�е����ݡ������ĵĵ�һ�г�Ϊ������(request line),���̵ĸ��б���Ϊ�ײ���(header lines)�������а�����������:�����ֶΡ�URL�ֶΡ�HTTP�汾;���з����ֶο�Ϊ:GET��POST��PUT��DELETE��HEAD�ȡ�URL�ֶ�����Դ����������ı�־;
�ײ��� Host : www. someschool. edu ָ���˶������ڵ�������Connection : close ��������߷�����ʹ�÷dz�������;������汾�� Mozilla/5.0,�� Firefox �����; Accept-language �ײ��б�ʾ�û���õ��ö���ķ���汾��
���ײ���֮��һ������,֮���������ġ�ʵ���塱����ʵ���������POST�����ﴫ��Form�������ݻ��ߴ�������һЩ�����������ݵȡ�ֵ��ע�����,����Ҳ��һ������ʹ��POST���������ʹ��get,ʵ����Ϊ��,����ʾ��url�С�
Head������get����,������һ��http���Ľ�����Ӧ,���Dz������������,�����������Ը��١�put���������û��ϴ�����ָ����Web��������ָ����·����Delete���������û���Ӧ�ó���ɾ��Web�������ϵĶ���
- HTTP��Ӧ���ĸ�ʽ

��Ӧ����������Ҳ����������,��һ������״̬��(status line),����HTTP�汾��״̬�Լ�״̬��Ϣ������;�ڶ��������ײ���(header lines),�����������ڡ����������͡���һ����������Դ��ʱ�䡢���ݵ����͵����ݡ�����������ʵ����(entity body),ʵ������������������
�����Date�Ǵ��ļ�ϵͳ�м������ö���,���뵽��Ӧ����,��������Ӧ���ĵ�ʱ�䡣
����״̬��
- 200:����ɹ� ������ʽ:�����Ӧ������,���д���
- 301:������Դ�������һ�����õ�URL,�����Ϳ����ڽ���ͨ����URL�����ʴ���Դ ������ʽ:�ض������URL
- 400:�Ƿ����� ������ʽ:����
- 404:û���ҵ� ������ʽ:����
- 505:��������֧��������ʹ�õ�http�汾��
2.2.4 �û���������Ľ���:Cookie
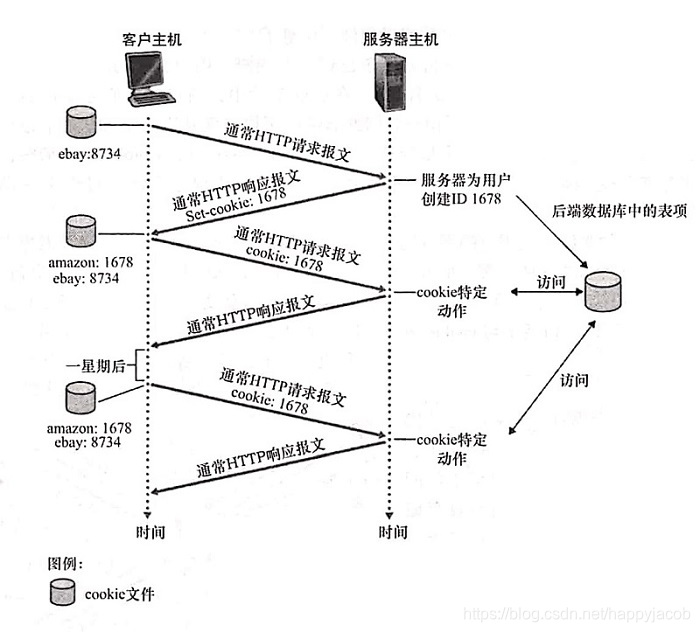
ǰ���ᵽ,HTTP����״̬Э��,����Webվ��Ϊ��ʶ���û����ݻ��������û����ʵ�ʱ����߽��û����ʵ�����ͬ�û����������,Webվ�����ʹ��Cookie����;
Cookie��������4�����
- HTTP��Ӧ����������һ������Cookie���ײ���;
- HTTP������������һ������Cookie���ײ���;
- �û���ϵͳ����һ��Cookie�ļ�,�����������ά��;
- Webվ�㽨��Cookie���û����ݵĹ���;
cookie �������ڱ�ʶһ���û����û��״η���һ��վ��ʱ,������Ҫ�ṩһ���û���ʶ(����������)�� �ں�̻Ự��,����������������һ�� cookie �ײ�,�Ӷ���÷�������ʶ���û���
��Ȼ,Cookie��ʹ�÷������û�Ҳ�����˷����,��������ʹ�ô�������,��Ϊʹ��Cookie����Ϊ�Ƕ��û���˽��һ���ַ�,��ΪWebվ�����ͨ��Cookie�õ��ܶ��û�����Ϣ,���п��ܽ��ⲿ����Ϣ������������
2.2.5 Web����
Web������( Web cache)Ҳ����Ϊ����������,��������ʼweb������������HTTP���������Լ��Ĵ洢�ռ�,���ڴ洢�ռ��ﱣ�������������Ķ���ĸ���;����ͨ�����������,������ָ���ʼ����������������ָ�������������
�������������յ�һ��HTTP�����,������鱾���Ƿ���ö���,�������������ڻ�����,���淵�ض���,����,�����������ԭʼ����������HTTP����,��ȡ����,Ȼ�ظ��ͻ��˲�����ö�����ȳ䵱�ͻ���,Ҳ�䵱������
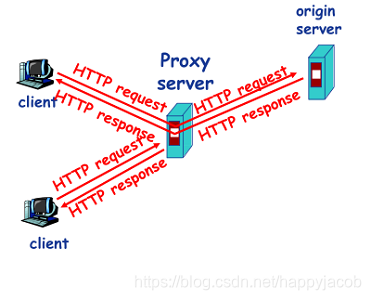
ͨ��,������������ͻ��˵�ͨ���ٶ�Ҫ���ڳ�ʼ��������ͻ��˵������ٶȡ�Web�������������Դ������ٶԿͻ��������Ӧʱ��;�ܹ�������һ�������Ľ�����·����������ͨ����������,Web �������ܴ������ϴ������������ϵ� Web Ӧ�ò�����, �Ӷ�����������Ӧ�õ����ܡ�
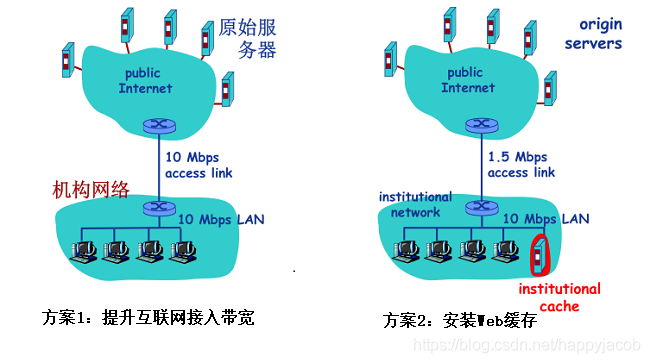
Web ����ʾ��
�ٶ�:
- �����ƽ����С=100,000����
- ���������е������ƽ��ÿ����15����ԭʼ������������
- �ӻ���·������ԭʼ�������������ӳ�=2��
�������ܷ���:
- ������(LAN)��������=15%
- ���뻥��������·��������=100%
- �ܵ��ӳ�=�������ϵ��ӳ�+�����ӳ�+������
�ӳ�=2��+������+����

�������1:
- �����������������=10Mbps
�������ܷ���:
- ������(LAN)��������=15%
- ���뻥��������·��������=15%
- �ܵ��ӳ�=�������ϵ��ӳ�+�����ӳ�+������
�ӳ�=2��+����+��������:�ɱ�̫��
�������2:
- ��װWeb����
- �ٶ�������������0.4
�������ܷ���:
- 40%���������̵õ�����,60%������ͨ��ԭʼ����������
- ���뻥��������·���������½���60%,�Ӷ����ӳٿ��Ժ��Բ���,����10��
- �ܵ�ƽ���ӳ�=�������ϵ��ӳ�+�����ӳ�+�������ӳ�
=0.6��2.01��+0.4��n��<1.4��
2.2.6 ����GET����
���ٻ�������ʹ��,�����ܶ�ô�,������һ��������Ǵ����������Ի������Ĺ���:���ȷ��������Ķ��������µ�?��ʵHTTP�ṩ��һ�ֻ���,����������֤ʵ��ʹ�õĶ��������µ�,���ֻ��ƾ�������GET(conditional GET)������ʹ������GET����ֻ����ʹ��GET������ʱ��,����һ��If-Modified-Since�ײ���,���Ӧ��������һ��ʱ��,������������Դ��ָ�����ں�����,��ô�������������µĶ���,���������������һ��������ʵ����ı��ġ����������������Ϳ���ȷ�ϻ����Ƿ�����ˡ�
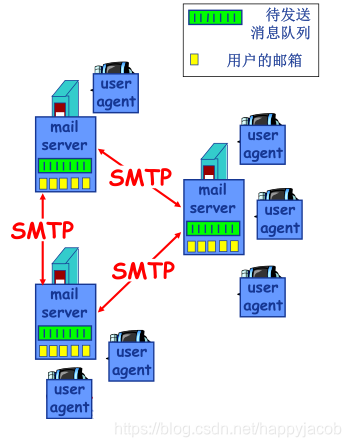
2.3 �������еĵ����ʼ�
�����������ʼ�ϵͳ�������������:�û�����(user agent)�� �ʼ������� (mail server)�����ʼ�����Э��(Simple Mail Transfer Protocol,SMTP)
ÿ���շ������ʼ���������ӵ��һ������;һ�����͵��ʼ���������:�ӷ��ͷ����û�������ʼ,���䵽���ͷ����ʼ�������,�ٴ��䵽���շ����ʼ�������,Ȼ�������ﱻ�ַ������շ��������С�
SMTP���������е����ʼ�����ҪӦ�ò�Э��,��ʹ��TCP�ɿ����ݴ���ӷ��ͷ����ʼ�����������շ����ʼ������������ʼ�;��ÿ̨�ʼ���������ͬʱ����SMTP��������SMTP�ͻ��ˡ����ʼ����������������ʼ����������ʼ�ʱ,������ΪSMTP������,���ʼ��������������ʼ������������ʼ�ʱ,����ΪSMTP�ͻ��ˡ�
������Ͷ˲��ܽ��ʼ��������ܶ˵ķ�����,���Ͷ˵��ʼ�����������һ�����Ķ����б��ָñ��IJ����Ժ����ٴη��͡�
2.3.1 SMTP
�����������:�������������ر�������
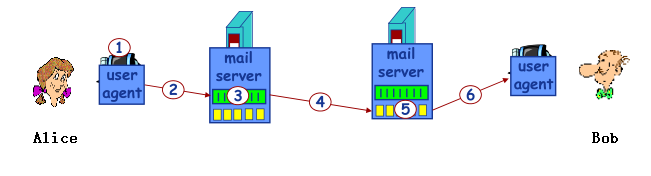
��һ��ʾ��:���� Alice ��� Bob ����һ��� ASCII ���� ��
- Alice ���������ʼ����������ṩ Bob ���ʼ���ַ,д����, Ȼ��ָʾ�û��������ñ��� ��
- Alice ���û������ѱ��ķ��������ʼ�������,�ñ��ı����ڱ��Ķ����С�
- ������ Alice ���ʼ��������ϵ� SMTP �ͻ��˷����˱��Ķ����е��������,����һ���������� Bob ���ʼ��������ϵ� SMTP �������� TCP ���ӡ�
- �ھ���һЩ��ʼ SMTP ���ֺ� , SMTP �ͻ����� Alice �ı��ġ�
- �� Bob ���ʼ���������,SMTP �ķ������˽��ոñ��ġ�Bob ���ʼ�������Ȼ�ñ��ķ��� Bob �������С�
- �� Bob �����ʱ�� , �������û������Ķ��ñ��ġ�
ֵ��ע�����,SMTP����һ����ʹ���м��ʼ����������ͱ���,Ҳ�����ʼ��������м�ij���ʼ�����������;��SMTP���ֽ�,SMTP�ͻ��˽����ܷ��ͷ��ͽ��շ��������ַ;һ��������Ϻ�,SMTP�ͻ��˽���ʼ���ͱ��ġ�
SMTP ʹ��25�Ŷ˿ڡ�SMTP�dz������ӵġ�SMTP�����ʼ����ĵ����в���ֻ��ʹ��7���ص�ASCII��ʾ,��͵��¶����ƶ�ý���ļ���Ҫ����ΪASCII,�����ڷ��ͷ���Ҫ����,���շ�����Ҫ���롣
SMTP ����ʾ������:
S: 220 hamburger.edu
C: HELO crepes.fr
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: <alice@crepes.fr>
S: 250 alice@crepes.fr... Sender ok
C: RCPT TO: <bob@hamburger.edu>
S: 250 bob@hamburger.edu ... Recipient ok
C: DATA
S: 354 Enter mail, end with "." on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger.edu closing connection
�ͻ������� 5 ������:HELO(�� HELLO ����д)��MAIL FROM��RCPTTO��DATA �Լ� QUIT,�����Խ��͵ġ�
��������:��Do you like ketchup? How about pickles?��
�ͻ�����һ��ֻ����һ��������,�������ָʾ�ñ��Ľ����ˡ�
ʹ�� Telnet ��һ�� SMTP ����������һ��ֱ�ӶԻ�,����Ȥ�Ŀ��Բο����� telnet ������� SMTP ����
2.3.2 ��HTTP�Ա�
HTTP��SMTP������TCPЭ��;������HTTP��SMTP�����ó�������;��������Ҳ������
- ����HTTP�����Ϊһ��PullЭ���SMTP�����Ϊһ��PushЭ�顣���û�ͨ��HTTP�������������������,��SMTP���ǿͻ������������������;
- �ڶ����������HTTP��������ݲ�һ������ASCII�ַ�,����SMTP��ֻ��ʹ��ASCII�ַ�;
- ��������Ҫ�������,HTTP��ÿ�������װ���Լ�����Ӧ������,��SMTP�����еı��Ķ���ŵ�һ������֮��;
2.3.3 �ʼ����ĸ�ʽ
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life.
���������������:һ������������Ϣ���ײ���һ�������ʼ����ݵı�����;�ײ��ͱ�����֮��ʹ�ÿ��зֿ�;�ײ��еĸ�ʽΪ�ؼ��ָ�ð�ż���ֵ;ÿ���ײ��������һ��From��To�ײ��С��ײ�Ҳ������������Ϣ,����Subject�ȡ�����2.3.1�нӴ���SMTP���ͬ,�ǽ��е�����������Э���һ����;�������о����������ʼ�����������һ����
2.3.4 �ʼ�����Э��
��Ҫע�����,SMTP���ʼ�������֮�䷢���ʼ�������Э��,�������û�ͨ���������ʼ�������֮��ͨ�ŵ�Э��;�û�����ʹ���ʼ�����Э�������ʼ��������ϻ�ȡ�ʼ���Ϣ;Ŀǰ���õ��ʼ�����Э������������ʾ�Э��(Post Office Protocol��Version 3,POP3)���������ʼ�����Э��(Internet Mail Access Protocol,IMAP)�Լ� HTTP��
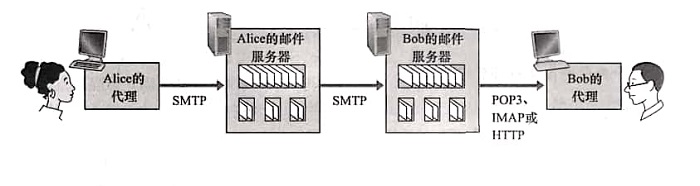
- POP3
POP3��һ���dz���Э��,��Ϊ��,���Թ�������;POP3ʹ�ö˿�110������TCP����(SMTPʹ�ö˿�25);POP3���������ν��й���:������������������;��������,�û���������������û���,�������ݼ���;�ڶ���,�û�����ȡ�ر���,ͬʱ��������ɾ����ȡ��ɾ���ȱ�ǻ���ͳ���ʼ���Ϣ;�������������û��˳���,POP3�����Ự,ɾ������ǵ��ʼ�;
һ����Ҫע�����,POP3�û���������ʹ������������ģʽ:һ�������ز�ɾ��,��һ�������ر���;���ز�ɾ���ķ������ڵ�������,����û���һ̨�豸�ϲ鿴���ʼ�(�������ʼ�)��,�ʼ�����ɾ��,��ô�������豸�Ͻ����鿴�ʼ�;����û�����һ���IJ��㡣ʹ�����ر��淽ʽ,���û������ʼ���,�ʼ����ڷ������ϡ�
- IMAP
POP3Э����Ϊ�û��ṩ�ʼ���������Ĺ���,��Ȼ�û�����ͨ�����ʼ����ص�����,Ȼ�����û������������������,���Ǵ����Ľ������ͬ���������鿴�豸�ϵġ�Ϊ�˽����һ����,IMAP�����ˡ�IMAP��һ���ʼ�����Э��,��POP3Ҫ���ӵĶ�,��ȻҲ���и������ɫ�ˡ�
IMAP��ÿһ���ʼ���һ���ļ�����ϵ����,�����ĵ�һ�ε��������ʱ,�����ռ��˵�INBOX��������ռ��˿��Խ��ʼ��Ƶ��´������ļ���,�Ķ��ʼ�,ɾ���ʼ��ȡ�IMAP�����û��ڲ�ͬ�ļ������ƶ��ʼ����Ҳ�ѯ�ʼ���ֵ��ע�����,IMAP������ά����IMAP�Ự���û�״̬��Ϣ,����POP3����;IMAPЭ�黹�����û�������ȡ������������DZ������塣
- ����Web�ĵ����ʼ�
���ַ�ʽ��Ҫ��ָ,�û�ʹ��HTTPЭ����ʼ�������ͨ�š��û�����������ͨ�������,����,�ʼ�������֮�仹��ʹ��SMTPЭ��ġ�
2.4 DNS:��������Ŀ¼����
2.4.1 DNS�ṩ�ķ���
����:������IP��ַ֮�����ӳ��?
�������������һ��Ӧ��ר���ṩ�����ķ���,����������ϵͳ(Domain Name System,DNS)��DNS��:��һ���ɷֲ��DNS������(DNS serve)��ɵķֲ�ʽ���ݿ�;��һ��ʹ���������Բ�ѯ�ֲ�ʽ���ݿ��Ӧ�ò�Э�����;
DNSͨ��������Ӧ�ò�Э��ʹ��,����:HTTP��SMTP��FTP�ȡ���ЩЭ������ʽ������ǰ,��������DNS�ṩ�ķ���,��������ת��ΪIP��ַ,���Է��ֵ���,DNSΪ�û����������ͬʱ,ҲΪ����Ӧ�ô��������ʱ�ӡ�����ѯDNS��������ʱ�ӡ���Ҫע�����,������Ϊһ���������,�ر��Dz�ѯ���ܵ��ֶ�,��DNS��ͬ�����á�
DNS������UDP֮��,ʹ��53�Ŷ˿ڡ�
�����ṩ��������IP��ַ��ת����,DNS���ṩ������Ҫ����:
- ��������:��Ȼ,����������IP��ַ�üǶ���,������ʱ�����ǵ���������Ȼ�ܳ�,�ܲ��ü���,����������ҪΪ����������һ������,�������������,DNS�����ṩ��������IP��ַ��ת������,���ṩ������������������ת��;��ʱ����������Ϊ�淶������;
- �ʼ�����������:DNSͬ��Ҳ�ṩ�ʼ��������������ͱ�����ת������,ʵ����,��˾���ʼ���������Web����������ʹ����ͬ������������
- ���ط���:DNSҲ����������ķ�����֮����为�ء�ÿ�����������Ų�ͬ��IP��ַ,�������Ƕ���ͬһ�������������,Ҳ����һ��IP��ַ����ͬһ���淶����������ϵ;��ij��DNS�������յ�DNS����ʱ,�÷�������ʹ��IP��ַ������������Ϊ��Ӧ,������ÿ��Ӧ����,ѭ����Щ��ַ�Ĵ�����Ϊ�ͻ���ͨ������ʹ��IP��ַ���ϵ���Ԫ��,����DNS���������Web������֮������˸��ء�ͬ��,����ʼ����������Ծ�����ͬ�ı�����
2.4.2 DNS������������
����,DNSʹ��UDP��Ϊ�䴫���Э��;DNS����ʹ��53�˿�;�������ϵ�DNS�ͻ����յ�һ��ת������ʱ,�ͻ��˽������緢��һ��DNS��ѯ����,Ȼ��ͻ��˽��յ�һ�����������Ϣ��DNS�ش���,����������пͻ�����Ҫ������,֮��DNS�ͻ��˽�IP��ַ���ظ������������ɡ���ʹ��DNS���������������,DNS����һ�����ṩֱ��ת������ĺں��ӡ�
DNS���÷ֲ�ʽ����Ʒ���,ʵ����,DNS��һ����������ʵ�ֲַ�ʽ���ݿ�ľ��ʷ���!��֮����������,����Ϊ,��һ��DNS�����������������������֤ͨ�������������ٽ����еIJ�ѯ������ά������������
- �ֲ�ʽ��ε����ݿ�
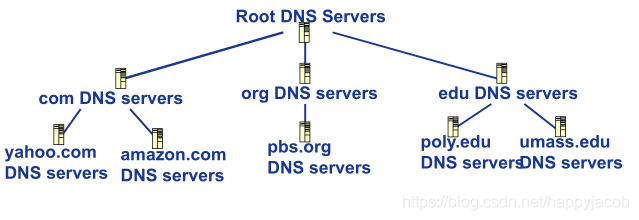
Ϊ�˴�����չ������,DNS���������ò��ʽ��֯,���ҷֲ���ȫ���緶Χ��;������˵,��������DNS������:��DNS��������������(Top Level Domain, TLD)DNS��������Ȩ��DNS������������˵��,�ٶ�һ�� DNS �ͻ�Ҫ��ȡ������ www.amazon.com �� IP ��ַ���ͻ��������������֮һ��ϵ,�������ض������� com �� TLD �������� IP��ַ�� �ÿͻ�����Щ TLD ������֮һ��ϵ,����Ϊ amazon.com ����Ȩ���������� IP ��ַ�����,�ͻ���amazon.com Ȩ��������֮һ��ϵ,������ IP ��ַ��
- ��DNS������:����������13����DNS������,�ֲַ��ڱ����ޡ�
- ������DNS������:��������,��com,org,net,edu,gov�Լ��������ҵĶ���������ת����
- Ȩ��DNS������:��֯����������������,�ṩ��֯�ڲ��������Ľ�������
������������DNS������,����һ�ֲ���DNS��νṹ֮��,���Ǻ���Ҫ��DNS,������DNS������������DNS������ͨ���ڽ��������������������������������DNS����ʱ,������������DNS������,�����Ŵ���������,��������ת����DNS��������νṹ�С�
DNS��ѯ������,һ�����ݹ��ѯһ����������ѯ;ʵ����,��ѯͨ������������ģʽ:����������������DNS�������IJ�ѯ�ǵݹ��,�����ѯ�ǵ�������
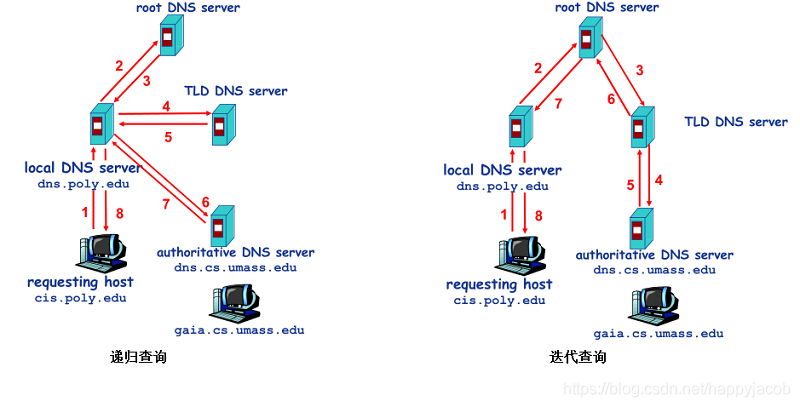
- DNS����
DNS����ʵ������Ϊ�˸���ʱ�����ܲ��Ҽ������������ϴ����DNS��������������ġ�DNS����ԭ��ʮ�ּ�,ÿ��DNS����������������յ��ش�ʱ,�ͽ��ش�����ݻ��������Լ��������ռ��ϡ�����,�������ͬ������ʱ,�Ͳ���Ҫ��ȥ��������,ֱ��ʹ�û��漴��;��Ϊ���˻���,����DNS�Ϳ���ֱ���ṩһЩ���������ʵ�����������Ӧ��IP��ַ,������Ҫѯ�ʸ�DNS�������ˡ���Ҫע�����,���治�ɱ����һ������:��Чʱ�䡣��������ʱ��δ�õ�����,��ô�ͻᵼ��һЩ����ʧ�ܡ�
2.4.3 DNS��¼�ͱ���
��ͬʵ�ֲַ�ʽ���ݿ������DNS�������洢����Դ��¼(Resource Record)����RR�ṩ����������IP��ַ��ӳ����Ϣ;һ��RR�Ǿ���һ���ֶε�4Ԫ��:(name, value, type, TTL);����TTL��ָ�ü�¼������ʱ��,�������˸�����¼��ʱ��ɾ����
| type | name | value | ���� |
|---|---|---|---|
| A | �������� | ��Ӧ��IP��ַ | (Tayl.bar.foo.com, 145.37.93.126, A) |
| NS | �� | ����Ȩ�������������������������� | (fgcom, cins.foo.com, NS) |
| CNAME | �������� | �淶������ | (foo.com, relay1.bar.foo.com, CNAME) |
| MX | �������� | �ʼ��������Ĺ淶������ | (foo.com, mail.bar.foo.com, MX) |
������˵,����һ̨ edu TLD �������������� gaia.cs.umass.edu ��Ȩ�� DNS ������,��÷�����������һ���������� cs.umass.edu �����¼,��(umass.edu,dns.umass.edu,NS);�� edu TLD ��������������һ������ A ��¼,��(dns.umass.edu,128.19.40.111,A),�ü�¼������ dns. umass. edu ӳ��Ϊһ�� IP ��ַ��
- DNS����

DNS����������,����ѯ�������ش���,�������ֱ���������ͬ�Ľṹ:
- ǰ12�ֽ�Ϊ�ײ�����ʶ����һ��������Ǹò�ѯ��16���������ñ�־���ᱻ���Ƶ���Ӧ�Ļش�����,�Ա�ƥ������ͻش�;
- ��־�ֶ������ɱ�־,����ָ�����ĵ�����(��������Ӧ)����ѯ����(�ݹ黹�ǵ���)���Ƿ������������ֵ�Ȩ��DNS���������Լ�4���й��������ֶ�,����ָʾ4������������ֵ�����;
- ����������������ڽ��еIJ�ѯ��Ϣ,���������ֶΡ���ѯ����;
- �ش���������˶������������ֵ���Դ��¼,�ش��ĵĻش��������������RR,���һ�����������ж��IP��ַ;
- Ȩ���������������Ȩ������������Ϣ;
- ������������������а����ļ�¼,�����ڶ���һ��MX���͵�����ش�����,�ش�������ָ�����ʼ��������Ĺ淶������,��������������п��ܰ���һ������ΪA�Ĺ��ڸù淶�������ĵ�IP��ַ;
- ��DNS���ݿ��в�������
��Ҫ��ע��Ǽǻ��������һ����,����ע��һ������ʱ,��Ҫ��û����ṩ��Ļ�������DNS�����������ֺ�IP��ַ;��ע�������ȷ��һ������ΪNS������ΪA�ļ�¼�����Ӧ�Ķ�������������;����������˲������ݡ�
2.5 P2PӦ��
- P2P ��ϵ�ṹ����չ��
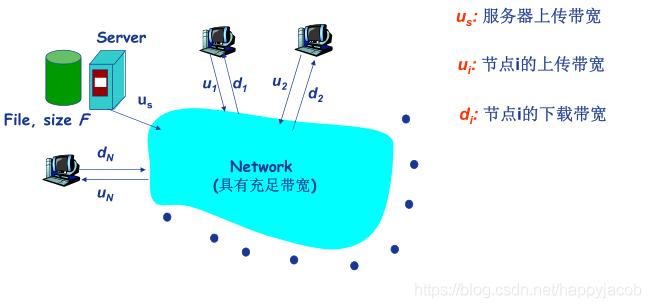
���� : ��һ����������N���ڵ�ַ�һ���ļ���Ҫ�ʱ��?����Աȿͻ���/������ �� P2P �ļ��ַ�ʱ�䡣
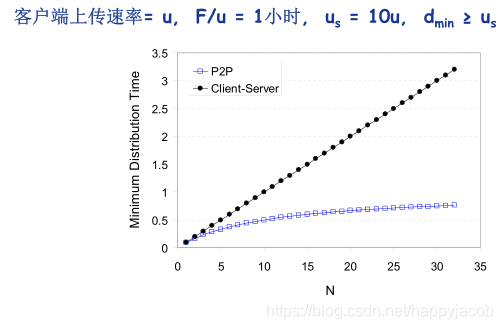
���ڿͻ���/������ģʽ�µ��ļ��ַ�:���������еط���N������,��ʱ NF/us,�ͻ��� i ��Ҫ F/di ʱ�����ء�����С�ķַ�ʱ�� dcs = max{NF/us,F/min(di)}
���� P2P ģʽ���ļ��ַ�:���������뷢��һ������,�û� F/us,�ͻ��� i ��ҪF/di ʱ������,�ܹ���Ҫ���� NF ����,���Ŀ����ϴ�����Ϊ us + ui������С���ļ��ַ�ʱ�� dP2P = max { F/us,F/min(di),NF/(us + ui)}
- BitTorrent
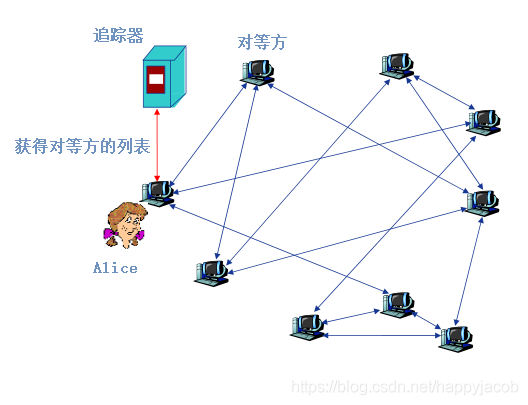
BitTorrent ��һ�������ļ��ַ�������P2PЭ��;��BitTorrent��������˵,����һ���ض��ļ��ַ������жԵȷ��ļ��ϱ���Ϊһ������(torrent);��һ�������еĶԵȷ��˴����صȳ��ȵ��ļ���;��һ���Եȷ������ļ����ʱ��,Ҳ�������Եȷ������˶����;һ��ij�Եȷ�����������ļ�,�Ϳ�����˽���뿪�������ߴ���˽�������������������Եȷ������ļ���
ÿ����������һ������(tracker),��һ���Եȷ�����ij����ʱ,��������ע���Լ�,�������Ե�֪ͨ���������ڸú����С������ַ�ʽ,�������ٲ����ں����еĶԵȷ���
����˵��:Alice����ij����ʱ,�������������ע��,������֪ͨ���������ں����С����dz�������Alice�ɹ��Ĵ�����һ��TCP���ӵĶԵȷ���Ϊ�ڽ��Եȷ�����������Ӳ���Եȷ��Ľ����ѡ��һ���Ӽ�,�����ǵ�IP��ַ����Alice,Aliceά�����ŶԵȷ��б�,��ͼ�����жԵȷ��������е�TCP���ӡ�Alice����ѯ��ÿ���ڽ��Եȷ�(���ϵ�)�����е��ļ����б�,����ʱ֪���ھ�����Щ�ļ��顣
�ھ���������Щ��Ĺ����� , Alice ʹ��һ�ֳ�Ϊ��ϡȱ����(rarest Erst)�ļ��������ּ�����˼·��,�����û�еĿ��������ھ��о�����ϡȱ�Ŀ�(�������ٵĿ�),������������Щ��ϡȱ�Ŀ顣����,��ϡȱ��õ���ΪѸ�ٵ����·ַ�,��Ŀ���Ǿ���ÿ�����ں����еĸ���������
Alice���ȴ�������ʱ�ٶ������ھ�(4��,ÿ10s��һ��)�����ȡ�ļ��顣ÿ��30s,AliceҲҪ���ѡ������һ���Եȷ�Bob,�������Ϳ顣��Alice��Bob����ǰ�Ŀ�,BobҲ��Alice��ǰ4��,��Bob��Alice��������ݡ�ÿ��30s��һ���µĶ���,���ཻ������(һ����һ��),Ϊ��ʹ�Եȷ��ܹ��ҵ��˴�Э���������ϴ���
2.7 ���ֱ��
��
������ �����
3.1 ��������������
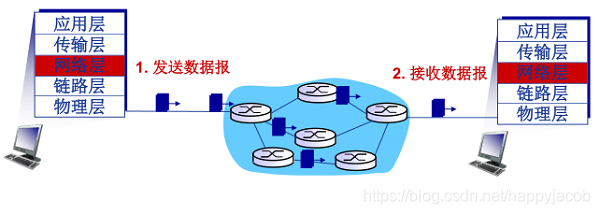
�����Э��Ϊ�����ڲ�ͬ��ϵͳ�ϵ�Ӧ�ý���֮���ṩ��ͨ������;Ӧ�ò����ʹ�ô�����ṩ����ͨ�Ź��ܶ����迼��ʵ��ͨ�ŵ�����������ʩ��ϸ��;
ֵ��ע�����,�����Э��������ϵͳ��ʵ�ֵĶ�������·������ʵ�ֵġ����ͷ���Ӧ�õݽ�����Ϣ�ֳ�һ�������� Segment,�����´��������;���շ������յ���segment��װ����Ϣ,�����Ͻ���Ӧ�ò㡣
����Ӧ�ÿ���ʹ�ö��ִ����Э��,�����������ִ����Э��,��TCP��UDP,��ͬ�Ĵ����Э���ṩ��ͬ����������
3.1.1 �����������Ĺ�ϵ
- ������ṩ����֮�����ͨ�Ż���
- ������ṩӦ�ý���֮�����ͨ�Ż���,λ�������֮��,��������������,�������������(���ܵ�)��ǿ
3.1.2 �������������
������ΪӦ�ò��ṩ�˽�Ȼ��ͬ�����ִ����Э��:UDP(�û����ݱ�Э��)���ṩһ�����ɿ����������ķ���;��һ����TCP,���ṩ�ɿ���,���������ķ���,��ӵ������,�������ƻ��ƺ����ӽ�������; ���ǽ����������Ϊ���Ķ� ( segment) ��
���˽�һ���������������,�����Э����һ�����ּ�IP,������Э�顣IPΪ�������ṩ��ͨ��,IP�ķ���ģ��Ϊ������Ϊ��������(best-effort delivery service)��������֤���ĶεĽ���������֤���Ķΰ���������֤���Ķ������ݵ�������;��IP�ṩһ�ֲ��ɿ��ķ���;ÿ̨��������Ҫ��һ��������ַ,��IP��ַ��
�������佻����չ�����̼佻������Ϊ��������·����(transport-layer multiplexing)����·�ֽ�(demultiplexing)
3.2 ��·���úͶ�·�ֽ�
������㱨�Ķ��е����ݽ�������ȷ�����ֵĹ�����Ϊ��·�ֽ� ( demultiplexing)����Դ�����Ӳ�ͬ�������ռ����ݿ�,��Ϊÿ�����ݿ��װ���ײ���Ϣ(�⽫���Ժ����ڷֽ�)�Ӷ����ɱ��Ķ�,Ȼ���Ķδ��ݵ������,������Щ������Ϊ��·���� ( nmhiplexing) ��
ʵ����,ÿ�����ֶ���һ��Ψһ��ID,����Ϊ�˿ں�;���ڴ������յ�����Ӧ�ó���ķ��鲢ͨ�����Ӵ�����ײ����γɱ��ĶεĹ�����,�ö˿ںű�д��;�˿ںŴ�С��0-65535֮��,����0-1023������֪�˿ں�,����Ϊ�ض���Socket��ӵ�С�
- �����ӵĶ�·�������·�ֽ�
��Ҫע�����,�ڴ���Socket��ʱ��,���ɴ����Ϊ֮����˿ں�;һ��UDP�����ɶ�Ԫ���־:(Ŀ��IP��ַ,Ŀ�Ķ˿ں�);�������UDP���Ķ��в�ͬ��ԴIP��ַ����Դ�˿ں�,��������ͬ��Ŀ��IP��Ŀ�Ķ˿ںŵĻ�,���ǽ�ͨ��ͬһ��Socket����ͬһ��Ӧ�ó���
- �������ӵĶ�·�������·����
TCPЭ���е�Socket��ͨ��һ����Ԫ������ǵ�:(ԴIP��ַ,Դ�˿ں�,Ŀ��IP��ַ,Ŀ�Ķ˿ں�);�������в�ͬԴIP��ַ����Դ�˿ں�,������ͬ��Ŀ��IP��ַ��Ŀ�Ķ˿ںŵ�TCP���Ķν�ͨ��������ͬ��Socket����ͬһӦ�ý���;��Ҳ��ʾ,һ��Ӧ�ý��̿��Թ������Socket,��һ��Socket��ֻ����һ��Ӧ�ý���;����,�����Ķ�Ӧ��ϵ��ͨ���߳���ʵ�ֵ�:һ�������ж���߳�,��ÿ���̹߳�����һ��Socket;������������߷�����������
ʵ����,�������Ǹ�����Щ��Ϣ��ʵ�ֶ�·�ֽ��;����Щ��Ϣ���ڶ�·���õ�ʱ�����ڱ��Ķ��е�
3.3 ����������:UDP
UDP����ʵ���˸���/���ù��ܺͼĴ���У����,����û�ж� IP ���ӱ�Ķ���;UDP �ṩ������Ϊ�����������,UDP�ο��ܶ�ʧ���ǰ���;UDP�������ӵ�,���ͷ��ͽ��շ�֮�䲻��Ҫ����,ÿ��UDP�εĴ��������������Ρ�
TCP�ṩ�ɿ����ݴ����ӵ������,Ϊʲô����ҪUDP��?UDP�����ºô�:
- Ӧ�ÿɸ��õؿ��Ʒ���ʱ�������
- ���轨������ (�����ӳټ����ӳ�)����Ҳ������DNSʹ��UDP������TCP����Ҫԭ��,���ʹ��TCP�Ļ�,DNS�������ܶࡣ
- ����ά������״̬:TCPΪ��ʵ�ֿɿ����ݴ����ӵ��������Ҫ�ڶ�ϵͳ��ά��һЩ����,��Щ��������:���պͷ��͵Ļ��桢ӵ�����Ʋ�����ȷ�Ϻź����;��Щ������Ϣ���DZ����;��UDP��Ϊ����������,������ȻҲ�Ͳ���Ҫά����Щ״̬,��ͼ�����ʱ�տ���;
- �����ײ���С:TCP��20�ֽڵ��ײ�����,��UDPֻ��8�ֽ�;
UDP��������ý��Ӧ��,���̶�ʧ,��������,UDP������DNS��SNMP��
| Ӧ�� | Ӧ�ò�Э�� | �����Э�� |
|---|---|---|
| �����ʼ� | SMTP | TCP |
| Զ���ն˷��� | Telnet | TCP |
| Web | HTTP | TCP |
| �ļ����� | FTP | TCP |
| Զ���ļ������� | NFS | UDP |
| ��ʽ��ý�� | ͨ��ר�� | UDP��TCP |
| �������绰 | ͨ��ר�� | UDP��TCP |
| ������� | SNMP | UDP |
| ·��ѡ��Э�� | RIP | UDP |
| ����ת�� | DNS | UDP |
��Ҫע�����,ʹ��UDP��Ȼ����ʵ�ֿɿ����ݴ���,ֻ������һ���ֹ�����Ҫ��Ӧ�ó�������������;���ɿ���ֱ�ӹ�����Ӧ�ó�����,��ʹ��ȿ��Կɿ��ش��������ֿ��Ա���������TCP��ӵ������(�������ʵĿ���)
3.3.1 UDP���Ľṹ
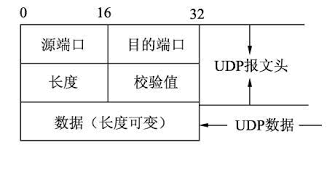
UDP�ײ�ֻ��4���ֶ�,ÿ���ֶ�ռ�������ֽ�,�ֱ���:Դ�˿ں���Ŀ�Ķ˿ں���������У���;�����ֶ�ָʾ���� UDP ���Ķ��е��ֽ���(�ײ�������)�����շ�ʹ�ü����������ڸñ��Ķ����Ƿ�����˲����
3.3.2 UDP �����
���Ŀ��:���UDP���ڴ������Ƿ�������(��λ��ת)
���ͷ�
- ���ε�������Ϊ16-bit����
- У��ͼ���:�������������ĺ�,��λ���ں͵ĺ���,���õ���ֵ��λ��,�õ�У���
- ���ͷ���У��ͷ���У����ֶ�
���շ�
- �������յ��ε�У���
- ������У����ֶν��жԱ�,����Ⱦ��Ǽ�������,��Ⱦ���û�м�������(�������д���)
У��ͼ���ʾ��,ע��:���λ��λ���뱻�ӽ�ȥ

3.4 �ɿ����ݴ���ԭ��
�ɿ����ݴ���Ϊ�ϲ�ʵ���ṩ�ķ��������:���ݿ���ͨ��һ�ɿ����ŵ����д���,�����ڿɿ��ŵ�,�������ݾͲ����ܵ����߶�ʧ;�����������ݶ��������䷢��˳����н�������������TCP���������Ӧ�����ṩ�ķ���ģ�͡�
ʵ�����ֳ�������ǿɿ����ݴ��������,������Ϊ�ɿ����ݴ���ĵײ�Э������Dz��ɿ���,��������������һ������;
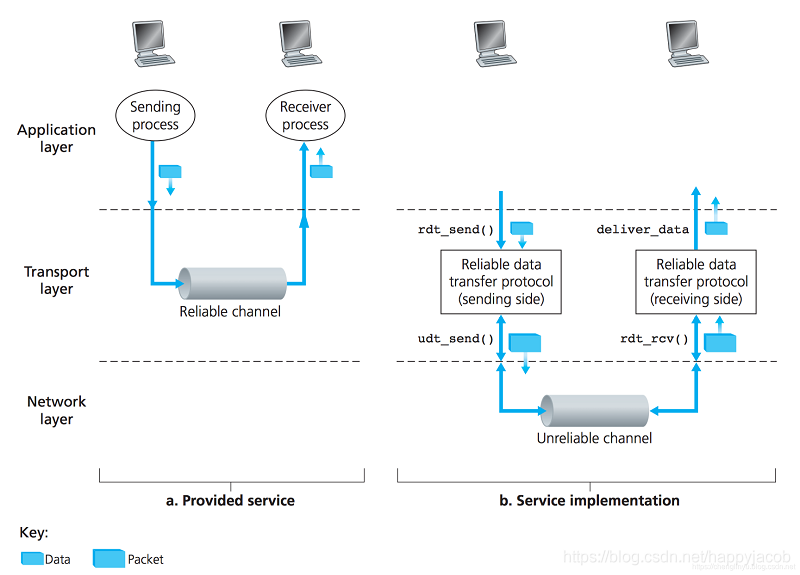
3.4.1 ����ɿ��ŵ��Ŀɿ����ݴ���
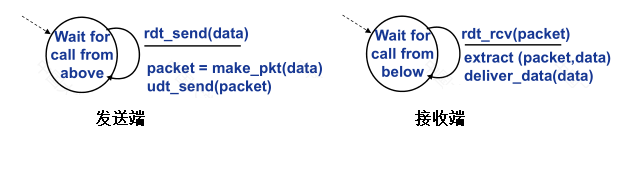
- 1. ����ȫ�ɿ��ŵ��Ŀɿ����ݴ���:rdt 1.0
����������,���ײ��ŵ�����ȫ�ɿ��ġ����dzƸ�Э��Ϊ rdt 1.0
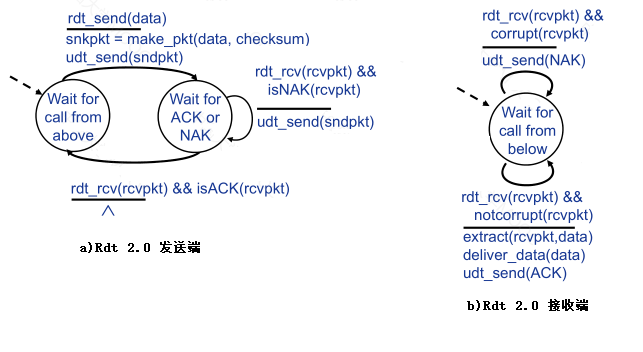
- 2. �����б��ز���ŵ��Ŀɿ����ݴ���:rdt 2.0
Rdt 2.0 ��������»���
- ������:����У������λ����
- ���շ�����������Ϣ:ACK/NAK,ȷ�ϻ���(Acknowledgements, ACK)���շ���ʽ�ظ�֪���ͷ���������ȷ���� ���շ���ʽ�ظ�֪���ͷ���������ȷ����;NAK:���շ���ʽ�ظ�֪���ͷ������д���
- �ش�:���ͷ��յ�NAK��,�ش�
���ֻ����ش����ƵĿɿ����ݴ���Э���Ϊ�Զ��ش�����(Automatic Repeat reQuest,AR)Э����
rdt2.0�ķ��Ͷ�ÿ����һ��������Ҫ�ȴ����ն˵�ȷ���ź�,����Э�鱻��Ϊͣ��( stop-and-wait)Э�顣
- 3. rdt 2.1:Ӧ��ACK/NAK �ƻ�
rdt 2.0 ����һ��������ȱ��,����û�п��ǵ� ACK �� NAK ��������Ŀ����ԡ�������ѵ�����,���һ�� ACK �� NAK ��������,���ͷ���֪�����շ��Ƿ���ȷ��������һ�鷢�͵����� ��
����ACK��NAK����ĸ���������:
- �����㹻��У��ͱ���
- �����ܵ�ģ�������ACK��NAK����ʱ,ֻ��Ҫ�ش���ǰ���ݷ��顣���������������
�������ĸ����������ڽ��շ���֪�����ϴ������͵�ACK��NAK�Ƿ��ͷ���ȷ���յ��������������֪�����յ��ķ������µĻ���һ���ش���
�������������һ���ķ������Ƿ��ͷ���ÿ�������������к�,���շ������ظ����顣
��Rdt 2.0���,Rdt 2.1�仯����:
���ͷ�:
- Ϊÿ���������������к�,��Ϊ��ͣ��Э��,�������к�(0, 1)����
- ��У��ACK/NAK��Ϣ�Ƿ�������
- ״̬��������:״̬���롰��ס������ǰ���ķ������к�
���շ�
- ���жϷ����Ƿ����ظ�,��ǰ����״̬�ṩ�������յ���������к�
- ע��:���շ���֪��ACK/NAK�Ƿ��ͷ���ȷ�յ�
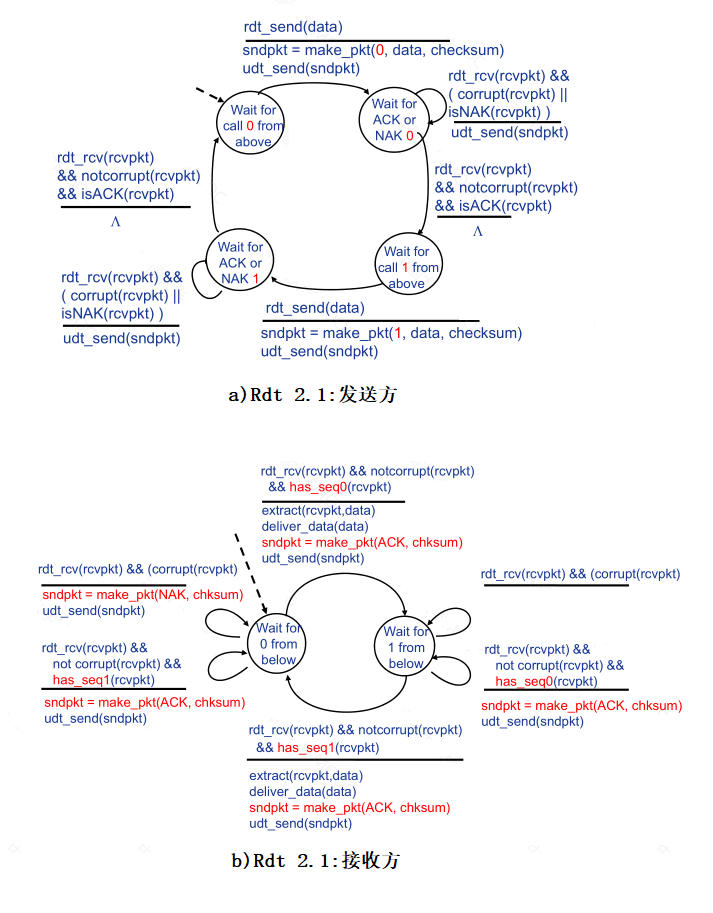
- 4. rdt 2.2: ��NAK��ϢЭ��
���������Ҫ����ȷ����Ϣ(ACK + NAK)��?��rdt2.1������ͬ,����ֻʹ��ACK,���ʵ����?
- ���շ�ͨ��ACK��֪���һ������ȷ���յķ���,��ACK��Ϣ����ʽ�ؼ��뱻ȷ�Ϸ�������к�
- ���ͷ��յ��ظ�ACK ֮��,�ش���ǰ����
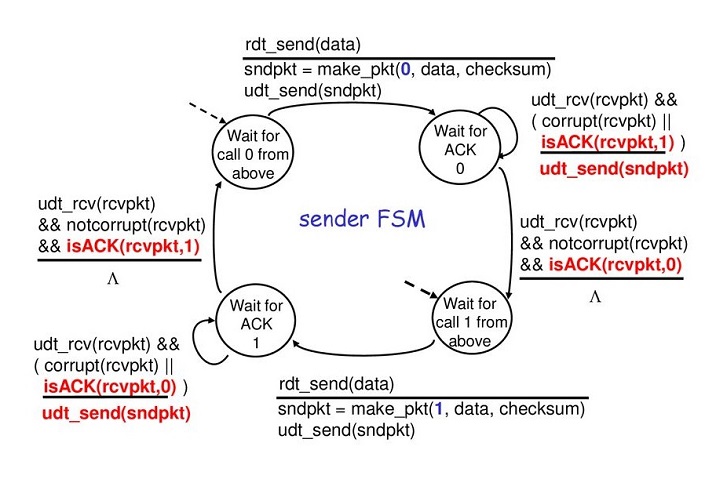
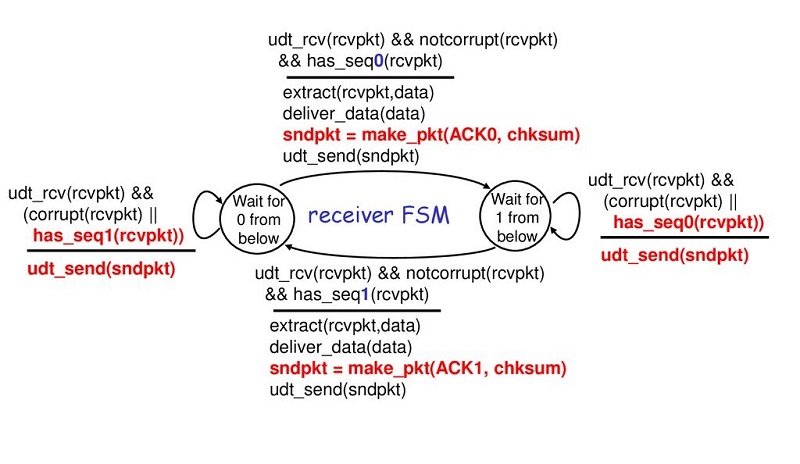
- 5. �����б��ز���Ķ����ŵ��Ŀɿ����ݴ���:rdt3.0
����ŵ��ȿ��ܷ�������,Ҳ���ܶ�ʧ����,��У��� + ���к� + ACK + �ش����Ͳ�����
����:���ͷ��ȴ���������ʱ��
- ��Ҫ��ʱ��
- ���û�յ�ACK,�ش�
- ��������ACKֻ���ӳٶ����Ƕ���,�ش�������ظ�,���кŻ����ܹ�����,���շ�����ACK����ʽ��֪��ȷ�ϵķ���

�� rdt 3.0 ��,�����������÷��ͷ�����������Ƿ��͵ķ��鶪ʧ,���ǽ��շ����ص�ȷ�Ϸ��鶪ʧ,ֻҪ�ھ���һ����ʱ�Ӻ�,�÷��ͷ��ط��÷��鼴�ɡ�
�ɴ˲����� �������ݷ��� ���ɽ��շ�ͨ����Ŵ�����Ϊ��ʵ�ֻ���ʱ����ش�����,��Ҫһ������ʱ��ʱ��
��Ϊ��������� 0 �� 1 ֮�佻��,��� rdt 3.0 ��ʱ����Ϊ ���ؽ���Э�顣

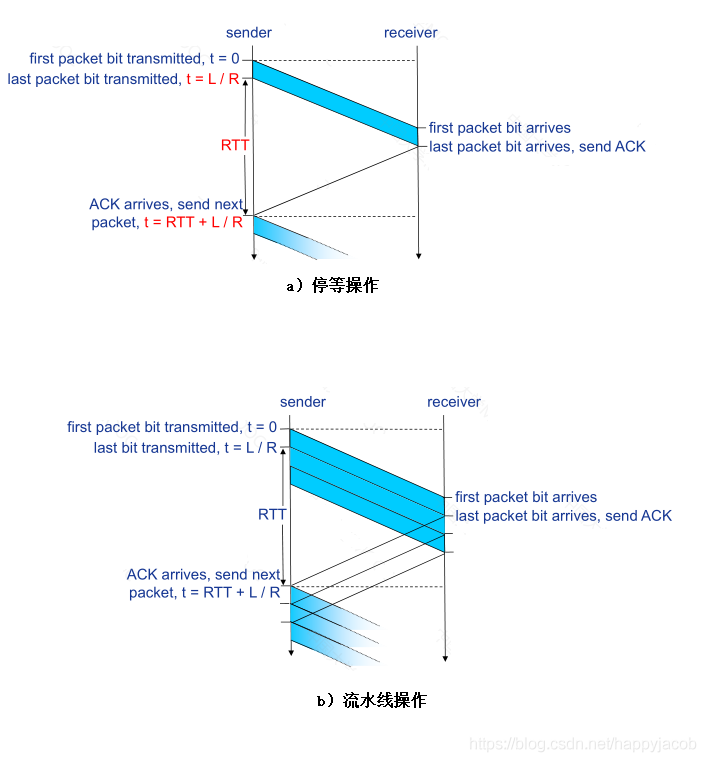
3.4.2 ��ˮ�߿ɿ����ݴ���Э��
rdt 3.0�ĺ���������������һ��ͣ��Э��
��ˮ��Э��
rdt 3.0 ��һ��������ȷ��Э��,������������һ��ͣ��Э��,�ֵ�ʱ�䶼�˷��ڵȴ�ȷ������,�������ܲ��á���������������������һ���ķ�����:��ʹ��ͣ�ȷ�ʽ����,�������ͷ����Ͷ�����������ȴ�ȷ�ϡ����ּ�������Ϊ ��ˮ�ߡ�
Ҫʹ����ˮ����,����:
- ������ŷ�Χ����ΪҪ���Ͷ������,��ÿ�������еķ��������һ����������š�
- Э��ķ��ͷ��ͽ��շ����˱����ܻ��������顣���ͷ����ٵ��ܻ�����Щ�ѷ��͵�δȷ�ϵķ���,�����շ�����Ҳ��Ҫ������Щ�Ѿ���ȷ���յķ��顣
- ������ŵķ�Χ�ͶԻ����Ҫ��ȡ�������ݴ���Э����δ�����ʧ������ʱ����ķ��顣
��ˮ�ߵIJ���ָ������ֻ�������:
- ���� N ��(Go-Back-N,GBN))
- ѡ���ش�(Selective Repeat,SR)
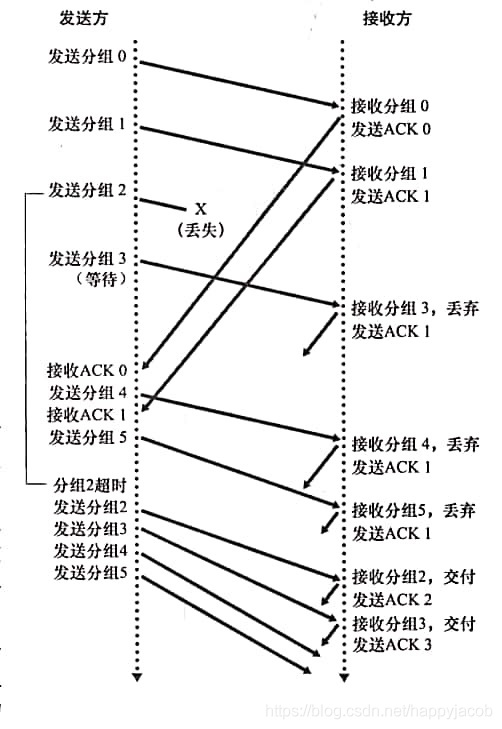
3.4.3 ����N��(GBN)
����ͷ������ k-bit ���к�
- [0,base - 1] ��Ӧ�Ѿ����Ͳ���ȷ�ϵķ���
- [base,nextseqnum - 1]��Ӧ�Ѿ����͵�δ��ȷ�ϵķ���
- [nextseqnum,base + N - 1] ��ӦҪ���������͵ķ���
- ���ڻ���� base + N ������Dz���ʹ�õ�
N ����Ϊ���ڳ���(window size),GBN Э��Ҳ������Ϊ��������Э��(sliding-window protocol)

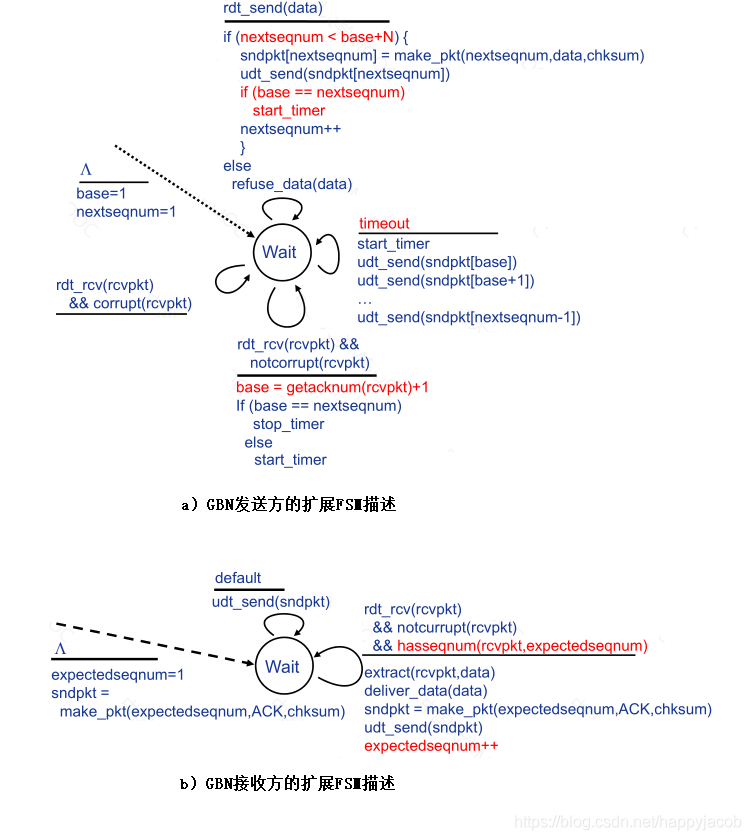
���ͷ���Ҫ��Ӧ���¼���:�ϲ���á��յ�ACK����ʱ�¼�;
- �ϲ����:���next Sequence�Ƿ��ڴ���֮��,�����,��˵�����ͷ����з�������,����;
- �յ�ACK:����N�����Զ����Ϊn�ķ����ȡ�ۻ�ȷ���ķ�ʽ,�����յ����Ϊn��ACKʱ,�������С�ڵ���n�ķ���ȫ����λ;
- ��ʱ�¼�:���������ʱ�¼�,��ô���ͷ����ط������ѷ��͵���δȷ�ϵķ���,���������base��next sequence-1֮������з���;��Ҳ��Ϊʲô�С�����N����,����յ�һ��ACK,��ʱ������������;���û�д�ȷ�ϵķ���,��ʱ��������ֹ;
�ڽ��շ�,ֻ��Ҫ��סΨһ��expectedseqnum����������������Ϊn�Ҹ÷����ǰ���,��ô����ACK,��͵��·��ͷ��ƶ�����;
������ǰ���,���շ�û�л���,��������ʧ�����,����ȷ�����к����ġ�����ķ���,����һ����ȷ���յ�ʧ�������ܻᵼ�¸�����ش���
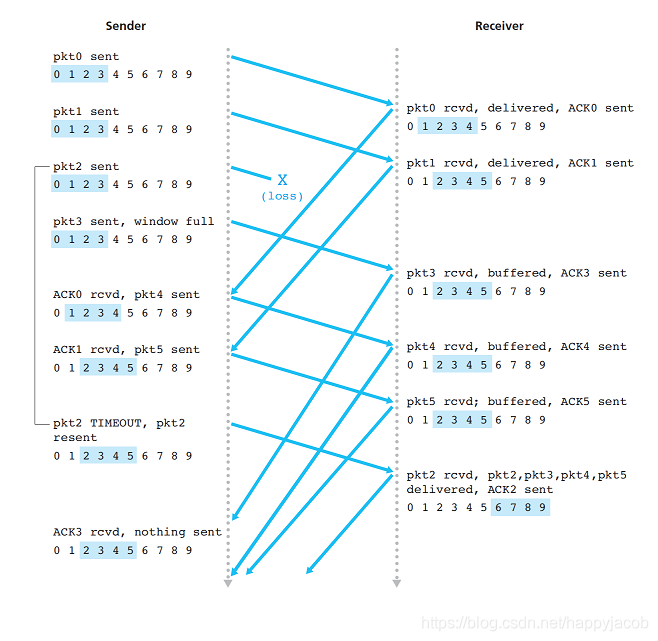
3.4.4 ѡ���ش�(SR)
GBN ��ȱ��:��������IJ�����ܹ����� GBN �ش���������,����������û�б�Ҫ�ش��� ѡ���ش�(SR)Э��ͨ���÷��ͷ����ش���Щ�������ڽ��շ�����(����ʧ������)�ķ���������˲���Ҫ���ش���
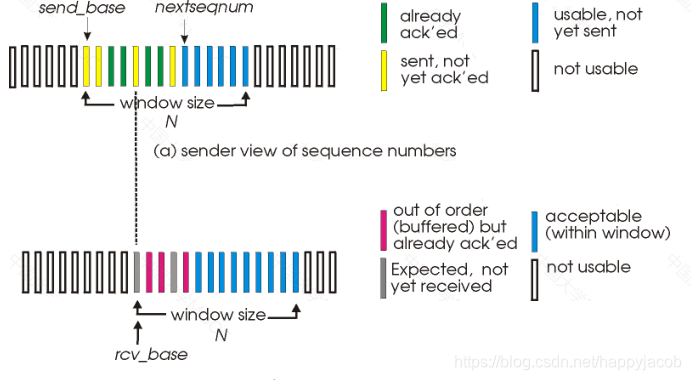
SR ���ͷ����¼��Ͷ���:
- ���ϲ��������:�����һ�������ڸ÷�������,���ڷ��ͷ��Ĵ�����,�����ݴ�����͡�
- ��ʱ:��ʱ���ٴ�������ֹ��ʧ���顣��������ÿ�����������е����Ķ�ʱ����
- �յ� ACK:�����÷�������ڴ�����,�� SR ���ͷ����Ǹ���ȷ�ϵķ�����Ϊ�ѽ��ա�����÷������ŵ���send_base,�ڻ������ǰ�ƶ���������С��ŵ�δȷ�Ϸ��鴦��
SR ���շ����¼��ڶ���:
- ����� [rcv_base,rcv_base + N -1] �ڵķ��鱻��ȷ���ա��ڴ������,�յ��ķ������ڽ��շ��Ĵ�����,һ��ѡ�� ACK ���������ͷ�������÷�����ǰû�յ���,��÷��顣����÷������ŵ��ڽ��մ��ڵĻ����,��÷��鼰��ǰ�������������ķ��齻�����ϲ㡣
- ����� [rcv_base - N,rcv_base - 1] �ڵķ��鱻��ȷ���ա�����һ�� ACK,��ʹ�÷����ǽ��շ���ǰ��ȷ�Ϲ��ķ��顣
- �������:���Ը÷��顣

Ҫ�����������,���кſռ��С�봰�ڳߴ����������¹�ϵ,NS +NR <=2k
3.5 �������ӵ�TCP
3.5.1 TCP����
TCPЭ�����������ӵ�Э�顣TCPֻ�����ڶ�ϵͳ֮��,����һ��״̬�����������ġ�ʵ�ʵ����ӡ�TCP�ṩȫ˫������,��������Ե���,TCPЭ�����ṩ���ಥ������,һ��TCP����ֻ����һ�����ͷ��ͽ��շ�;
TCP�������̳�Ϊ������������,ǰ���α��Ķβ����ء���Ч���ء�,���������ֱ��Ķ��ǿ���װ�ء���Ч���ء���

��TCP���ӽ�����,����Ӧ�ý��̾Ϳ��Է��������ˡ�Ӧ�ó���Ҫ���͵�����ͨ��Socket���ݸ�TCP,TCP�����������������ӵķ��ͻ���,���ͻ����С�����������ֵĹ�����ȷ����;֮��TCP��ʱ��ʱ�Ӹû������ó����ݽ��з���,һ����Ȥ��������,TCP�淶��û�й涨TCPӦ���ں�ʱ���ͻ����������,����Ϊ��TCPӦ�����������ʱ���Ա��Ķε���ʽ�������ݡ�;TCPÿ�ο��Դӻ����з��͵�������ݳ��ȳ�Ϊ������Ķγ���(Maximum Segment Size,MSS)��һ����˵,MSS+TCP/IP�ײ��ij���ҪС�ڵ�����·������䵥Ԫ(Maximum Transmission Unit,MTU)������̫����PPP��MTU������1500�ֽ�,TCP/IP���ײ�ͨ��Ϊ40�ֽ�,����MSSһ����˵Ϊ1460�ֽڡ�
TCP���ӵ�ÿһ�˶��з��ͺͽ��ջ��档
3.5.2 TCP���Ķνṹ
TCP���Ķνṹ,����������˵���ײ�+�����ֶ����;���������ֶ�����Ӧ�ò�,�䳤�Ȳ��ܴ���MSS;�ײ��ij��泤��Ϊ20�ֽ�,����ֵ��ע�����,TCP�ײ��ǿɱ䳤��;TCP�ײ�����32����Ϊ��λ��֯��,��ṹ�������ͼ:
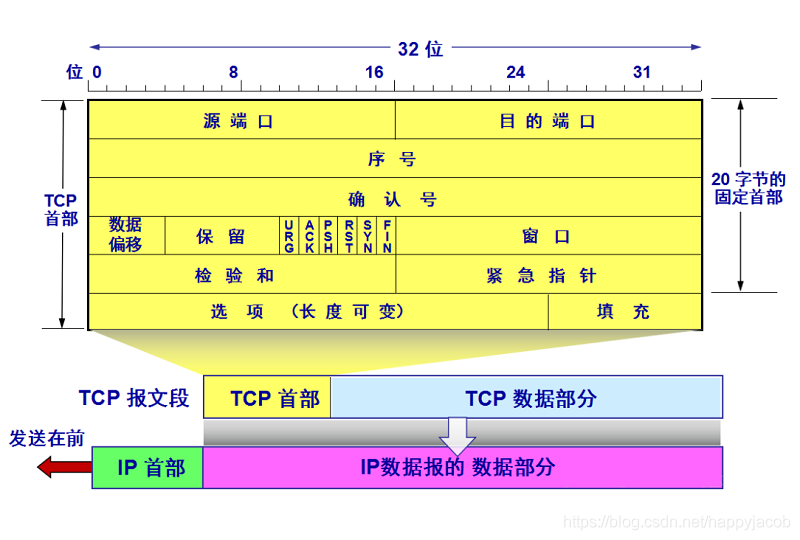
- Դ�˿ںź�Ŀ�Ķ˿ں�:��������������TCP�Ķ�·���úͶ�·�ֽ�;�ֱ�Ϊ16λ;
- ���:���к�ָ����segment�е�һ���ֽڵı��,�������е�һ���ֽڵı�š�����TCP����ʱ,˫�����ѡ�����к�;
- ȷ�Ϻ�:TCP����Ϊ�ṩ�ۻ�ȷ��,ȷ�Ϻű�ʾ�����յ�����һ�ֽڵ���š�
- �ײ�����:��32���ص���Ϊ��λ��TCP�ײ����ȡ�
- ѡ���ֶ�:���ֶ������ڷ��ͷ��ͽ��շ�֮��Э��MSS�Ĵ�С,�ڸ������绷����,Ҳ�����ڵ��ڴ��ڴ�С;
- ����ֶ�
1)ACKλ��ʾȷ�Ϻ��ֶε����ֵ�Ƿ���Ч,���ACK����λ,��ô�ñ��ĶξͶ�ȷ�Ϻ���ָʾ�ı��Ķν�����ȷ��;
2)RST��SYN��FINλ����TCP�����ӺͲ��;
3)PSH����λʱ,ָʾ���շ�Ӧ�����������ݽ����ϲ�;
4)URG����λʱ��ʾ���Ķ�������ŷ��Ͷ˵��ϲ�ʵ����Ϊ����������;�������ݵ����һ���ֽ���16λ����ָ��ָ�������������ݴ��ڲ��Ҹ�����ָ���������βָ��ʱ,TCP����֪ͨ���ն˵��ϲ�ʵ��;
ʵ����,PSH��URG�ͽ�������ָ����ʵ���в�û�б�ʹ��;����ֶ�һ��6����;
3.5.3 ����ʱ��Ĺ����볬ʱ
- 1. ��������ʱ��
TCPʹ��һ��Sample RTT�ķ���������RTT��Sample RTT���Ǵ�ij���Ķη������յ��Ըñ��Ķε�ȷ��֮���ʱ�����������TCP��ʵ������ij��ʱ����һ��Sample RTT���ԡ�TCP����Ϊ�Ѿ��ط��ı��Ķ���Sample RTT����,��ֻΪ����һ�εı��Ķβ���Sample RTT��
TCP ά��һ�� SampleRTT ��ֵ(��ΪEstimatedRTT),һ�����һ����SampleRTTʱ,TCP �ͻ�������й�ʽ������ Estimated RTT,���ַ���Ҳ����Ϊָ����Ȩ�ƶ�ƽ��:Estimated RTT=(1-a)Estimated RTT+a*Sample
����RTT�ı仯Ҳ���м�ֵ�ġ�DevRTT���ڹ���SampleRTTƫ��EstimatedRTT�ij̶ȡ�DevRTT =(1-b)DevRTT+b*|Sample RTT-Estimated RTT|
����b���Ƽ�ֵΪ0.25;��Sample RTT�仯�ϴ��ʱ��,DevRTT��ֵ�ϴ�,��Sample RTT�仯��С��ʱ��,DevRTT�ͽ�С;
- 2. ���ú����ش���ʱ���
TCP����ο��dz�ʱʱ�����?��ʱ�����Դ��ڲ�����RTT,��С��������Ҫ���ش�,����ʱ������ڱ��Ķζ�ʧ����ķ�Ӧ�ͻ����;���TCP���������¼��㷽ʽ:Timeout Interval=Estimated RTT+4*Dev RTT
�����ֳ�ʱ��,TimeOutInteval ֵ���ӱ���һ�����Ķ��յ�������Estimated RTT��,TimeInteval ��������ֵ�����ˡ�
3.5.4 �ɿ����ݴ���
TCPʹ����ʱ�ش�������ȷ��������������ʱ����ʧ�����;ʹ��ȷ�Ϻ�������ȼ�������֤����;ʹ��У����������Ƿ��Ķ��ڴ���������Ƿ����˴���;
TCP ���ͷ��������뷢�ͺ��ش��йص��¼�:
- ���ϲ�Ӧ�ó����������
- ��ʱ��
- �յ� ACK
- 1. ��ʱʱ��ӱ�
�ڴ����TCPʵ����,��������ʱ�¼�ʱ,ֱ�ӽ���ʱʱ������Ϊԭ��������;Ȼ��,ÿ����ʱ�����������¼�(�յ�ACK�ͽ��յ��ϲ�Ӧ������)����ʱ,�µij�ʱʱ�佫�� Estimated RTT�� Dev RTT ����ֵ���������
- 2. �����ش�
һ���յ� 3 ������ ACK,TCP ��ִ�������ش�(fast retransmit)��������ͷ��յ�����ACK,˵���ж�����Ķε����˽��ն�,�����ǽ��ն��������ġ�������ζ��,���п��ܷ����˶�ʧ�����Է��ͷ������ڶ�ʱ����ʱ֮ǰ�����ش�����ʧ�ı��ĶΡ�
- �ǻ���N������ѡ���ش�
TCP ȷ�����ۻ�ʽ��,TCP ���ͷ�����ά���ѷ�����δ��ȷ�ϵ��ֽڵ���С���(SendBase)����һ��Ҫ���͵��ֽڵ����(NextSeqNum)��������������,TCP ����������һ�� GBN ����Э�顣���� TCP �� GBN Э��֮������һЩ�������������� TCP ʵ�ֻὫ��ȷ���յ�ʧ��ı��Ķλ���������
��TCP�����һ�����������ν��ѡ��ȷ�ϡ��������շ���ʧ��ķ���Ҳ��ȷ��,���û��ƺ��ش���������ʹ��TCP����ѡ���ش�,����TCP�IJ���ָ�Э����ñ�����ΪGBN��SRЭ��Ļ���塣
3.5.5 ��������
����������һ���ٶ�ƥ�����:TCP���ӵķ��ͷ��ͽ��շ�������ά��һ������,������ߵ����ݽ���Ӧ����һ���������ٶȷ�Χ��:���öԷ������������;TCPΪ����Ӧ�ó����ṩ�����ַ���:�������Ʒ�������Ȼ�������ƺ�ӵ����������ȡ�Ķ����dz�����,�������ǵ�Ŀ�ĺ����Բ���ͬ���ڽ�������������,���ǽ�����TCP������ʵ�ֵ�,��TCP���շ�����ʧ��ı��Ķ�
��TCP�ײ�����һ�����մ����ֶ�,TCP���ӵ�˫��ͨ�����ֶ�����Է������Լ��Ĵ��ڴ�С,������ռ�Ĵ�С;ͬ��,��TCP���ӵ�����,����ά������صı���:last Sent��last Acked;�ڷ��ͷ�,����������֮��ķ�������Ѿ����͵�����δȷ�ϵķ���;���ڽ��շ�,last Read��ʾӦ�ý�����һ�ζ�ȡ������,last Revd��ʾ������뻺��ı��Ķα��(ע��,�������۵�ǰ����TCP�Ὣʧ��ı��Ķζ���);ͨ����Щ�����Լ����Ķ��ײ��д��ڴ�С�ֶ�,���ǾͿ��ԶԷ����ٶ���һЩ����:�ڷ��ͷ�last Sent-last AckedӦ��С�ڵ��ڽ��շ��Ĵ��ڴ�С;�ڽ��ն�A=last Received-last Read�����Ѿ�ʹ�õĿռ��С,���Դ��ڴ�С=buffer-A;
�����յ����ڴ�СΪ0�ı��Ķκ�,���ͷ�������շ��������ֻ��һ���ֽڵ����ݡ�
3.5.6 TCP���ӹ���
1. TCP��������
һ��ʼ,�ͻ��˺ͷ���˶����� CLOSED ״̬�����Ƿ������������ij���˿�,���� LISTEN ״̬
��һ�����ġ���SYN ����
�ͻ��˻������ʼ�����(client_isn),����������� TCP �ײ���"���"�ֶ���,�� SYN ��־λ��Ϊ 1 ,��ʾ SYN ���ġ���SYN���ķ�������˱�ʾ�����˷�������,֮��ͻ��˴��� SYN-SENT ״̬��
�ڶ������ġ���SYN + ACK ����
������յ��ͻ��˵� SYN ���ĺ�,���ȷ����Ҳ�����ʼ���Լ������(server_isn),����������� TCP �ײ���"���"�ֶ���,��ΰ� TCP �ײ���"ȷ�Ϻ�"�ֶ����� client_isn + 1,�� SYN �� ACK ��־λ��Ϊ 1,�����ͻ���,����˴��� SYN-RCVD ״̬��
���������� ���� ACK ����
�ͻ��˻�Ҫ��Ӧһ��Ӧ����,Ӧ���� TCP �ײ� ACK ��־λ��Ϊ 1 ,��Ρ�ȷ�Ϻš��ֶ����� server_isn + 1 ���������,�ͻ��˴��� ESTABLISHED ״̬��
�������յ��ͻ��˵�Ӧ���ĺ�,Ҳ���� ESTABLISHED ״̬��
���������ֿ���Я������,ǰ�������ֲ�����Я������
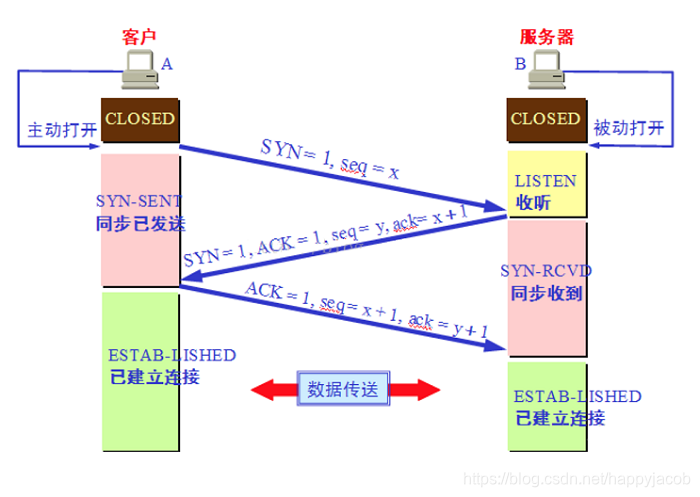
Ϊʲô���ӽ�����Ҫ��������,��������������?
- ��ֹʧЧ�����������Ķα�����˽���,�Ӷ���������(��Ҫԭ��)
- ͬ��˫���ij�ʼ���к�
- ������Դ�˷�
ԭ��1:��ֹʧЧ�����������Ķα�����˽���,�Ӷ���������
client A����ȥ�ĵ�һ�����������IJ�û�ж�ʧ,������ΪijЩδ֪��ԭ����ij������ڵ��Ϸ�������,�����ӳٵ������ͷ��Ժ��ij��ʱ��ŵ�����һ��(server)B����������һ������ʧЧ�ı��Ķ�,����B�յ���ʧЧ�ı���֮��,������Ϊ��A�ٴη�����һ���µ���������,����B�˾���A�ַ���ȷ�ϱ���,��ʾͬ�⽨�����ӡ���������á��������֡�,��ôֻҪB�˷���ȷ�ϱ��ľͻ���Ϊ�µ������Ѿ�������,����A�˲�û�з����������ӵ�����,��˲���ȥ��B�˷�������,B��û���յ����ݾͻ�һֱ�ȴ�,����B�˾ͻ�װ��˷ѵ��ܶ���Դ��
ԭ��3:������Դ�˷�
����ͻ��˵� SYN ������,�ظ����Ͷ�� SYN ����,��ô���������յ������ͻὨ������������Ч����,��ɲ���Ҫ����Դ�˷ѡ�
2. TCP�Ĵλ���
��ͨ����ɺ�,A��B�����������Ͽ����ӡ�
- A,B������ESTAB-LISHED��������״̬����A���������ݺ�,��Ҫ�Ͽ�����,��B����FIN=1(1��������Ͽ�����)seq=u,���ͺ�,A����FIN-WAIT-1 ��ֹ�ȴ�1״̬��
- ��B�յ�A�������,�ظ�ACK=1(ȷ���յ�)seq=v,ack=u+1(������һ�����͵İ�Ϊu+1),��B���ͺ�,����CLOSE-WAIT�رյȴ�״̬
- A�յ�B�Ļظ���,����FIN-WAIT-2��ֹ�ȴ�2״̬,��ΪB�����ǻظ���,���յ���ĶϿ�������,����Bû˵�Ƿ�ͬ��Ͽ�,����A�����ȴ���
- ������B�ٴη���FIN=1(�����ж�����,��ͬ���ж�),ACK=1(ȷ���յ�)seq=w,ack=u+1,��B���ͺ����LIST-ACK���ȷ��״̬��
- ��A�յ�B���ж������,���ͻظ�,ACK=1(ȷ���յ�)seq=u+1,ack=w+,,�������A����TIME-WAITʱ��ȴ�״̬,��Ϊ�����п��ܻ��������ڴ���,����AҪ�ȴ�һ��ʱ��,ȷ����Щ���ݷ��ͳɹ���
- ��B�յ�A��ȷ�Ϻ�,����CLOSED�ر�״̬,�Ͽ���A����,Ȼ���Ѹ�ٽ���LISTEN����״̬,����������һ���ͻ��˵��������ӡ���A�ȴ�2MSL(TCP���Ķ��������е��������ʱ��,RFC 1122���Ľ���ֵ��2min),����CLOSED�ر�״̬,�Ͽ��������B���ӡ�
ΪʲôAҪ�Ƚ���TIME-WAIT״̬,�ȴ�ʱ���Ž���CLOSED״̬?
Ϊ�˱�֤B���յ�A��ȷ��Ӧ����A����ȷ��Ӧ���ֱ�ӽ���CLOSED״̬,��ô�����Ӧ��ʧ,B�ȴ���ʱ��ͻ����·��������ͷ�����,����ʱA�Ѿ��ر���,���������κ���Ӧ,���B��Զ�������رա�

3.6 ӵ������ԭ��
3.6.1 ӵ��ԭ�������
ӵ��(Congestion)����ʽ����:��̫�������������̫�����ݻ��߷����ٶ�̫��
,������������������������Ϊ���鶪ʧ(·�����������)�������ӳٹ���(��·�����������Ŷ�)
ӵ���ij���ʹ���:����1
����senders,����receivers,һ��·����,������,û���ش�
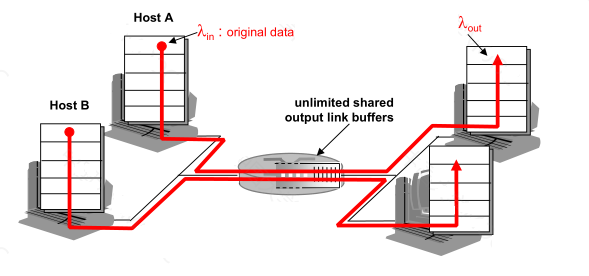
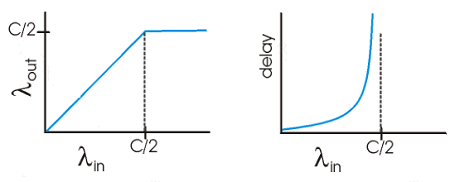
ӵ��ʱ�����ӳ�̫��,�ﵽ���throughput
ӵ���ij���ʹ���:����2
һ��·����, ����buffers,Sender�ش�����
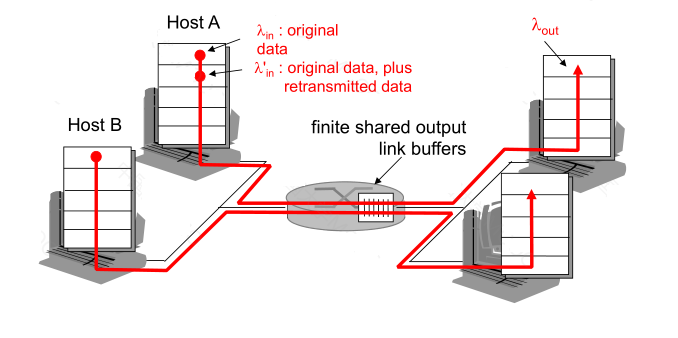
���a: Sender�ܹ�ͨ��ij�ֻ��ƻ�֪·����buffer��Ϣ,�п��вŷ���in == ��out(goodput)
���b: ��ʧ����ط�:��in�� > ��out
���c:���鶪ʧ�Ͷ�ʱ����ʱ���ط�, ��in�� ��ø���
ӵ���Ĵ���:�Ը����ġ�goodput��,Ҫ������Ĺ��� (�ش�),�����Դ���˷�
ӵ���ij���ʹ���:����3
�ĸ����ͷ�,����,��ʱ/�ش�
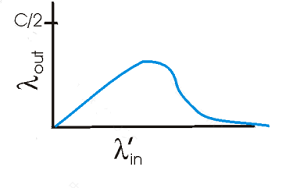
ӵ������һ������:�����鱻dropʱ,�κ����ڸ÷���ġ����Ρ���������ȫ�����˷ѵ�
3.6.2 ӵ�����Ʒ���
ӵ������:ӵ�������������������,���Ƿ�ֹ���������ע�뵽������,����������縺�ع�������;
��������:���������������ڽ����ߵ�,���ǿ��Ʒ����ߵķ����ٶȴӶ�ʹ���������ü����ա�
�˵���ӵ������:����㲻��Ҫ��ʽ���ṩ֧��,��ϵͳͨ���۲�loss,delay��������Ϊ�ж��Ƿ���ӵ��,TCP��ȡ���ַ���
���縨����ӵ������:·�������ͷ���ʽ�ط�������ӵ����Ϣ,��ӵ��ָʾ(1bit):SNA,DECbit,TCP/IP ECN,ATM,ָʾ���ͷ�Ӧ�ò�ȡ��������
3.7 TCPӵ������ԭ��
���ǽ�TCP���ͷ��Ķ����¼�����Ϊ:Ҫô��ʱ,Ҫô�յ����շ���3������ACK;
TCPӵ�������㷨����������Ҫ����:��������ӵ�����������ٻָ�;��������ӵ��������TCP��ǿ�Ʋ���;���ߵIJ������ڶ��յ���ACK������Ӧʱ����ӵ������(cwnd)���ȵķ�ʽ;���ٻָ����Ƽ�����,����TCP���ͷ������DZ����
1.������
TCP�����ڿ�ʼ��ʱ��,��cwnd������Ϊһ��MSS,Ȼ����������״̬ÿ�յ�һ��ACK,cwnd������һ��MSS;�����Ļ�,����������,����������ָ�����ӵ�(1,2,4,8��)
��ʱ��������ָ������?���������:�����˳�ʱ������������ACK�Լ�cwnd�ﵽssthresh(��������ֵ���ټ�)������������,��������˳�ʱ�¼�,��ôssthresh�ͱ�����Ϊ��ǰcwnd��һ��,Ȼ��cwnd��Ϊ1;��cwnd�����ӵ�ssthreshʱ,TCP����������,����ӵ������ģʽ����ӵ������ģʽ��,TCP��������������cwnd;����յ�����ACK,��ôTCP����һ�ο����ش�,Ȼ�������ٻָ���;
2.ӵ������
һ������ӵ������״̬,cwnd��ֵ��Լ���ϴ�����ӵ��ʱ��һ��,����TCP��ÿ��RTT��,ֻ��cwnd����һ��1��MSS��С;Ҳ����˵��ӵ�������,cwnd���������ӵ�;
�����ֳ�ʱʱ,TCP��cwnd����Ϊ1,Ȼ��ssthresh����Ϊcwnd��һ��;���յ�����ACKʱ,TCP��cwnd����,Ȼ��ssthresh��Ϊcwndֵ��һ��,���ҽ�����ٻָ�״̬;
3.���ٻָ�
3���ظ�ACKs:cwnd�е�һ��,Ȼ����������,
Timeout�¼�:cwndֱ����Ϊ1��MSS,Ȼ��ָ������,�ﵽssthresh��, ����������
3���ظ�ACKs��ʾ����,���ܹ�����һЩ segments,timeout�¼�����ӵ����Ϊ����
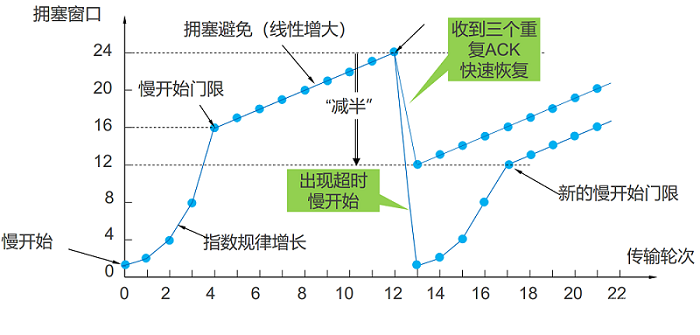
3.7.1 ��ƽ��
- ���n�������TCP������ƿ������,��ÿ�����ջ��C / n,���ǹ�ƽ��
- ���TCP + UDP������·,UDP��ռ�ø������,���Dz���ƽ��!
- ����û�ʹ�ö����������(��Web�����),��ʹ�ڴ�������,Ҳ�Dz���ƽ��!
������ �����
4.1 ����
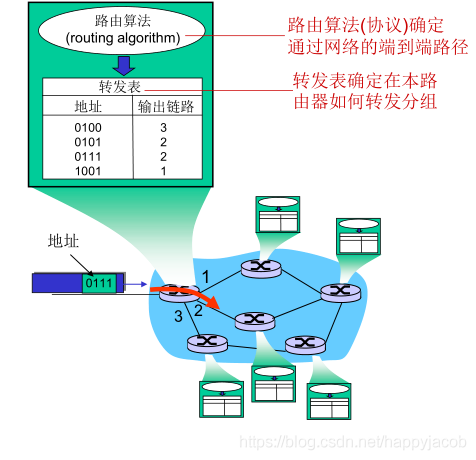
4.1.1 ת����·��ѡ��
����������:�������һ̨���������ƶ���һ̨������������Ҫ���ֹ���:
- ת��(forwarding):�������·����������˿�ת�Ƶ����ʵ�����˿�
- ·��(routing):ȷ�������Դ��Ŀ�ľ�����·��
ÿ̨·�ɶ���һ��ת������·�����������ײ��ֶ�ֵ(������Ŀ�ĵ�ַ����������,�������Э��)��ת������,ʹ�ø�ֵ��ת����������ѯ����ֵָ���˸÷��齫��ת����·���������·�ӿ�
·��ѡ���㷨�����˲���·����ת�����е�ֵ��·��������·��ѡ��Э�鱨��,������ת�������������㷨:����ʽ�ͷֲ�ʽ
���齻����:ָһ̨ͨ�÷��齻���豸,���ݷ����ײ��ֶ�ֵ��������·�ӿ�ת�Ʒ��鵽�����·�ӿڡ�
��·�㽻����:������·��֡�е��ֶ�ֵ����ת������,����·��(��2��)�豸��
·����:������������ݱ��е��ײ��ֶ�ֵ����ת������,�������(��3��)�豸��
����������봫������ӵĶԱ�:
- ���������:��������֮�� (·���ϵ�·�����������豸��������)
- ���������:����Ӧ�ý���֮��(���м������豸��)
4.1.2 �������ģ��
�������������IPЭ���ṩ��һ����,��Ϊ������Ϊ����,������֤,������֤,��˳��֤,����ʱ,��ӵ��ָʾ��
��:���·�����ݱ�����
��������ģ��:
- �����ӷ���(connection-less service):������Ϊϵ�з���Ĵ���ȷ������·��,ÿ���������ȷ������·��,��ͬ������ܴ���·����ͬ,�������ݱ�����(datagram network )
- ���ӷ���(connection service):����Ϊϵ�з���Ĵ���ȷ����Դ��Ŀ�ľ�����·��(��������),Ȼ���ظ�·��(����)����ϵ�з���,ϵ�з��鴫��·����ͬ,���������������,�������·����(virtual-circuit network )
���·����
���·:һ����Դ������Ŀ������,�����ڵ�·��·��(������),���÷��齻��,ÿ������Ĵ���������·��ȫ������,Դ��Ŀ��·��������������豸��ͬ������·����
ͨ�Ź���:���н���(call setup)�����ݴ�����������
ÿ�����·����:
- ��Դ������Ŀ��������һ��·��
- ���·��(VC ID),��·��ÿ����·һ������,����һ�����·�ķ����ײ���VC��
- ��·ÿ��������豸(��·����),����ת������¼������ÿ�����·
һ�����·ÿ����·�Ͽ����в�ͬVC��,ÿ̨·����������һ���µ�VC�Ÿ���ÿ�������VC��,����һ�����龭��һ̨·����,�ײ�VC�ſ��ܾͱ���,ԭ��:
- ����·����ú�������˷����ײ�VC�ֶγ���
- �������·���������Ҫ��һ��VC��,�������·ʱ·������Ҫ����������
���·�����е�·��������Ϊ�����е�����ά������״̬��Ϣ������һ������,ת������һ��,�ͷ�һ������,ת����ɾһ�����Ϣ��VC��������ӿں���ϵ��������ʹû��VC��ת��,���б�Ҫά��״̬��Ϣ,����Ϣ��VC�ź�����ӿں���ϵ������
���ݱ�����
�����������,ÿ������Я��Ŀ�ĵ�ַ,·�������ݷ����Ŀ�ĵ�ַת������,����·��Э��/�㷨����ת����,����ת����,ÿ���������ѡ·��
ÿ��·������ת����,��Ŀ�ĵ�ַӳ�䵽�����·�ӿڡ�IP��ַ̫��,������ÿ��IP��ַ��һ������,���,Ŀ�ĵ�ַ��ʹ�õ�ַ��Χƥ�䡣���ж��ƥ��ʱ,ʹ���ǰƥ�������
���ݰ�������·������ά������״̬��Ϣ,����ά����ת��״̬��Ϣ��ʵ����ÿ1-5����,·��ѡ���㷨����һ��ת������
��Ϊ�����ݰ������е�ת���������κ�ʱ����,��һ����ϵͳ����һ����ϵͳ����һϵ�з��������ͨ������ʱ�߲�ͬ��·��,���������
���·�����ݱ�����Ա�
���·�����ɵ绰�����ݻ�����,����ҵ����ʵʱ�Ի�,���ϸ��ʱ�䡢�ɿ�����
��,��Ҫ�б��ϵķ���,һ�����ڵ绰��������������·��������Ե��,��������
���ݱ��������ڼ����֮������ݽ���,�ǡ����ԡ�����,û���ϸ�ʱ������;��·�����ڶ�,�ص㡢���ܸ���;ͳһ��������;һ�����ڡ����ܡ���ϵͳ (�����),��������Ӧ�����ܿ��ơ�����ָ������ݱ�����������,���ӡ���Ե��
4.2 ·��������ԭ��
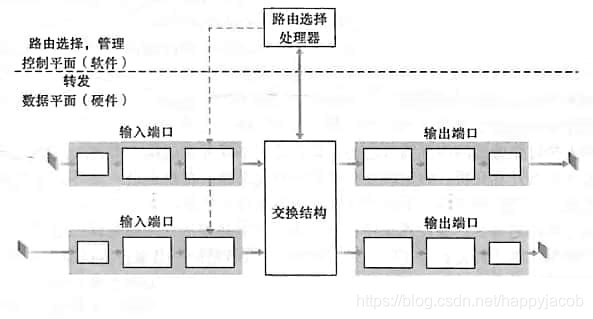
·��������ɲ���
- ����˿�:
(1)ִ�н�һ�������������·��·���������ӵ������㹦��
(2)ִ����λ������·Զ�˵�������·�㽻����������·�㹦��
(3)���ҹ���,��ѯת��������·����������˿�- �����ṹ
(1)��·����������˿�������˿�����
(2)����ͨ�������ṹת��������˿�- ����˿�
(1)�洢�ӽ����ṹ���յķ���,ִ�б�Ҫ����·��������㹦����������·�ϴ�����Щ���顣
(2)����·��˫���ʱ,����˿�������˿���ͬһ��·���ɶԳ���- ·��ѡ������
(1)ִ��·��ѡ��Э��
(2)ά��·��ѡ��������ӵ���·״̬��Ϣ,Ϊ·��������ת����
- ·��ת��ƽ��:һ̨·����������˿ڡ�����˿ںͽ����ṹ��ͬʵ����ת������,������Ӳ��ʵ��(����̫��,��������ʱ��߶�����)
- ·�ɿ���ƽ��:·�����Ŀ��ƹ���(ִ��·��ѡ��Э�顢��������������·������Ӧ����������),�ں���ʱ��߶�������,������ʵ�ֲ���ѡ��������ִ��(һ��cpu)
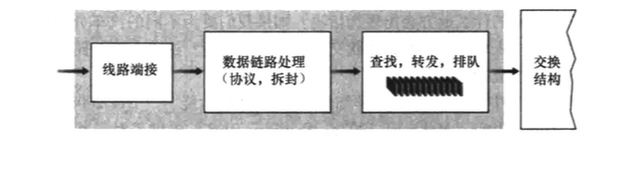
4.2.1 ����˿ڴ����ͻ���Ŀ�ĵ�ת��
����:ͨ��ʹ��ת��������������˿ڡ�
Ӱ�Ӹ���:ת������·��ѡ�����������������߸��Ƶ���·��,��ΪӰ�Ӹ�����ʹ����ÿ������˿ڵ�Ӱ�Ӹ���,ת����������ÿ������˿ڱ�������,�������ÿ��������ü���ʽ·��ѡ������,��˱����˼���ʽ������ƿ��
�Ŷ�:����ȷ����ij��������˿�,������ܷ��ͽ��뽻���ṹ��һ���������ķ������������˿ڴ��Ŷӡ�
���ܲ���������˿ڿ���˵����Ϊ��Ҫ��,�������ȡ������������:(1)��������������������·�㴦��;(2)����������İ汾�š�����ͺ������ֶΡ��������ֶα�����д;(3)�������������������ļ�����
4.2.2 ����
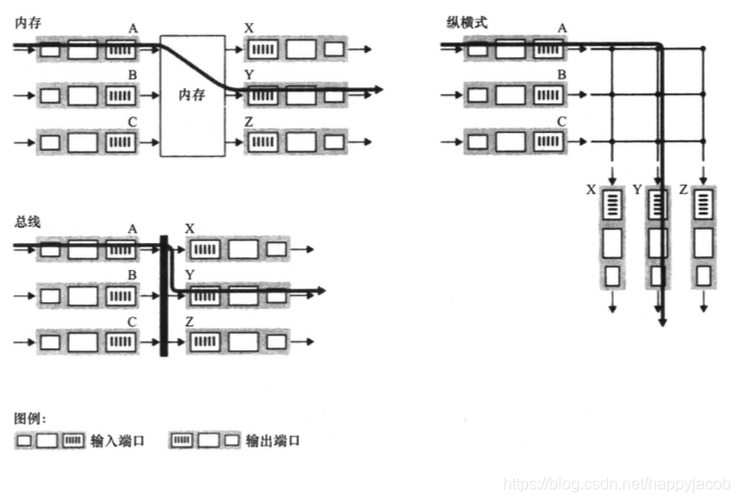
���ֽ�����ʽ:
- ���ڴ潻��
һ�����鵽������˿�ʱ,�ö˿ڻ���ͨ���жϷ�ʽ��·��ѡ�����������źš�����,�÷��������˿ڴ������Ƶ��������ڴ���,·��ѡ������������ײ�����ȡĿ�ĵ�ַ,��ת�������ҳ��ʵ�������˿�,�����÷��鸴�Ƶ�����˿ڵĻ����С� - �����߽���
����˿ھ�һ���������߽�����ֱ�Ӵ��͵�����˿�,����Ҫ·��ѡ�������ĸ�Ԥ - ���������罻��
�ݺ�ʽ������,2N�������������,����N������˿ں�N������˿�;ÿ����ֱ��������ÿ��ˮƽ�����߽���,�����ͨ�������ṹ�����������պ�;ij���鵽��˿�A,��Ҫת����Y,�������������պ�����A��Y�Ľ����,A���������Ϸ��ͷ���,����Y����;ͬʱBҲ�ܷ����鵽X,��Ϊû�й������ߡ��ݺ�ʽ�����ܲ���ת��������顣�������������ͬ����˿ڵ����������Ŀ����ͬһ������˿ڡ���һ���������������˵ȴ���
4.2.3 ����˿ڴ���

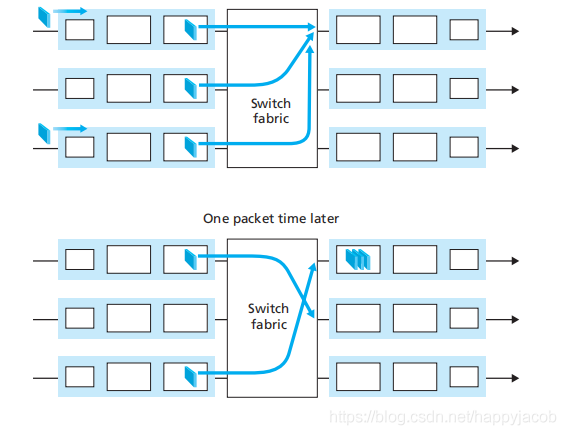
4.2.4 �δ������Ŷ�
����˿ں�����˿ڶ����γɷ������,Ҳ�����Ŷ������Ŷӵ�λ�úͳ̶Ƚ�ȡ�����������ء������ṹ��������ʡ���·���ʡ�����ŶӶ��й���,������·�����洢�ռ����Ĵ���,��ʱ������ֶ�����
1. �����Ŷ�
����ķ�����Ҫ���뵽����˿ڶ�����,�Եȴ�ͨ�������ṹ���䵽����˿ڡ����λ�� 2 ���������ǰ�˵� 2 ������ʱ������ͬ������е�,������һ������������,��Ҫ����������еȴ������������֮Ϊ�����Ŷӽ������е���·ǰ��(Head-Of-the-Line, HOL)����,����һ������������Ŷӵķ������ȴ�ͨ�������ṹ���� ( ��ʹ����˿��ǿ��е�),��Ϊ����λ����·ǰ������һ�������������������������,�������������ӵ�����ʱ,������ִ���������

2. ����Ŷ�
����������Ŀ�ĵ�����ͬ������˿�,�����ͻ�������˿���ɶѻ�,��ʱҲ������Ŷ��������ڴ洢�ռ�������,���Ծͻ���ɶ���,��ʱ���Բ�����β����,�����µ���ķ���,����ɾ��һ�������Ѿ��ڶ����еķ������ڳ��ռ䡣�ȽϺõ��������ڴ洢�ռ�ľ�ǰ����һ������,�����ӱ��,��ʾ��������ӵ����ϸ,������������й����㷨��
4.2.5 �������
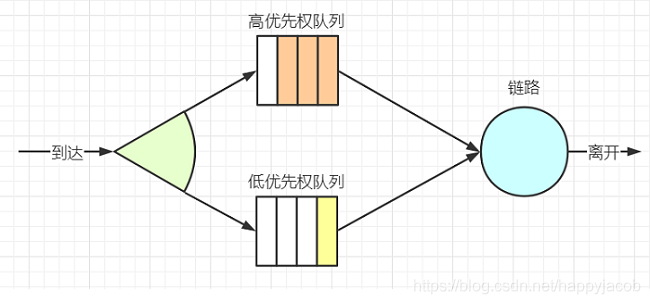
������˿ڳ����Ŷ�ʱ,���Ǿ�ҪΪ������н��з������,��ʱ��ѡ��һ��������д��䡣ѡ��ķ�ʽ�кܶ�,������������ 3 �֡�
1. �Ƚ��ȳ�
FIFO,Ҳ���������ȷ���,�õ��ȹ�����ǰ��շ��鵽�������·���е���ͬ����,��ѡ���������·�ϴ��䡣
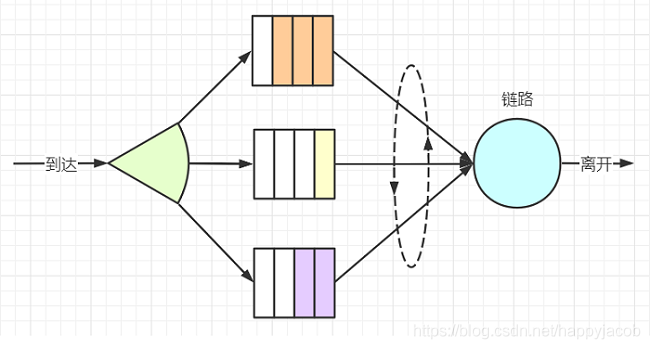
2. ����Ȩ�Ŷ�
�ù�������������������е�����Ȩ��,ÿ������Ȩ��ͨ�����Լ��Ķ��С���ѡ��һ�����鴫��ʱ,���Ӷ��зǿյ��������Ȩ����ѡ����һ�����顣
3. ѭ����Ȩ��ƽ�Ŷ�
���ȷ���Ҳ�ȷ��������������е�����Ȩ��,Ȼ��������֮�䲻�����ϸ�����ȷ���Ȩ,����ѭ������������Щ��֮�������ṩ����ʱ����ѭ���ֹ����Ŷӹ���,�����з���ȴ�����ʱ,��������·���ֿ���,�ڷ���һ���յ���ʱ,������ȥ������һ���ࡣ������·�����е��Ǽ�Ȩ��ƽ�Ŷ�(WFQ) ����,���ǰ������ԭ��ʵ�ֵġ�
4.3 ����Э��:IPv4��Ѱַ��IPv6 ������
4.3.1 IPv4 ���ݱ���ʽ

- �汾��:4λ,IPЭ��İ汾�š�eg:4��IPv4,6��IPv6
- �ײ�����:4λ,IP�����ײ�����,��4�ֽ�Ϊ��λ��eg:5��IP�ײ�����Ϊ20(5��4)�ֽ�
- ��������(TOS):8λ,ָʾ��������������͵ķ���,1998 ������ֶθ���Ϊ���ַ���,ֻ���������ṩ���ַ���(DiffServ)ʱʹ��,һ������²�ʹ��,ͨ��IP����ĸ��ֶ�(��2�ֽ�)��ֵΪ00H
- �ܳ���:16λ:IP��������ֽ���(�ײ�+����),���IP������ܳ���Ϊ65535B,��С��IP�����ײ�Ϊ20B,����IP������Է�װ���������Ϊ65535-20=65515B
- ����ʱ��(TTL):8λ,IP�����������п���ͨ����·������(��������),·����ת��һ�η���,TTL��1,���TTL=0,·����������IP����
- Э��:8λ,ָʾIP�����װ�����ĸ�Э������ݰ�,6ΪTCP,17ΪUDP
- �ײ�У���:16λ,ʵ�ֶ�IP�����ײ��IJ�����,��ÿ̨·�����ϱ������¼������Ͳ��ٴδ�ŵ�ԭ��,��ΪTTL�ֶ��Լ����ܵ�ѡ���ֶλ�ı䡣
- ԴIP��ַ��Ŀ��IP��ַ:��ռ32λ,�ֱ��ʶ���ͷ����Դ����/·����(����ӿ�)�ͽ��շ����Ŀ������/·����(����ӿ�)��IP��ַ
- ѡ��:���ȿɱ�,��Χ��1~40B֮��,Я����ȫ��Դѡ·����ʱ�����·�ɼ�¼������,ʵ���Ϻ��ٱ�ʹ��
- ���:���ȿɱ�,��Χ��0~3B֮��,Ŀ���Dz��������ײ�,��֤�ײ�������4�ֽڵı���
4.3.2 IPv4 ���ݱ���Ƭ
һ����·��֡�ܳ��ص������������������䵥Ԫ(Maximum Transmission Unit,MTU)��
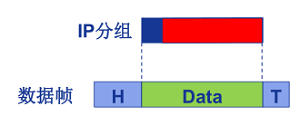
�����IP�������СMTU��·ת��ʱ,���Ա�����Ƭ��(fragmented),1��IP�����Ϊ��ƬIP����,IP��Ƭ����Ŀ����������С����顱(reassembled)��ע��,IPv4�����ݱ���������װ���ڶ�ϵͳ��,������·�����С�
IP�ײ�����ʶ����־λ��Ƭƫ���ֶ����ڱ�ʶ��Ƭ�Լ�ȷ����Ƭ�����˳��
- ��ʶ�ֶ�:16λ,��ʶһ��IP����,IPЭ������һ��������,ÿ����IP�����������1,��Ϊ��IP����ı�ʶ
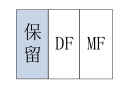
- ��־λ�ֶ�ռ3λ:
- DF =1:��ֹ��Ƭ
- DF =0:������Ƭ
- MF =1:�����һƬ
- MF =0:���һƬ(��δ��Ƭ)
- Ƭƫ��:13λ,һ��IP�����Ƭ��װԭIP�������ݵ����ƫ����,Ƭƫ���ֶ���8�ֽ�Ϊ��λ
���ݱ�����Ч�غɽ�����IP������ȫ�ع�Ϊ��ʼIP���ݱ�ʱ,�Żᴫ�ݸ�Ŀ�ĵش���㡣���һ������Ƭû�е���Ŀ�ĵ�,��ò����������ݱ�����ʧ��
4.3.3 IPv4 ��ַ
������������·�ı߽���ӿ�(interface),һ̨·�����ж���ӿ�, һ�� IP��ַ��һ���ӿ������,������������ýӿڵ�������·�����������ͨ�������ʮ���ƼǷ���д��
IP��ַ����������,�����(NetID) ��������(HostID),������ͬ����ŵ��豸�ӿ��������,���Ա˴�������ͨ,����Խ·����(���������ϲ������豸)IP��ַΪ�����������һ����ַ:223.1.1.0/24,/24�Ƿ���Ϊ�������롣

����IP��ַ
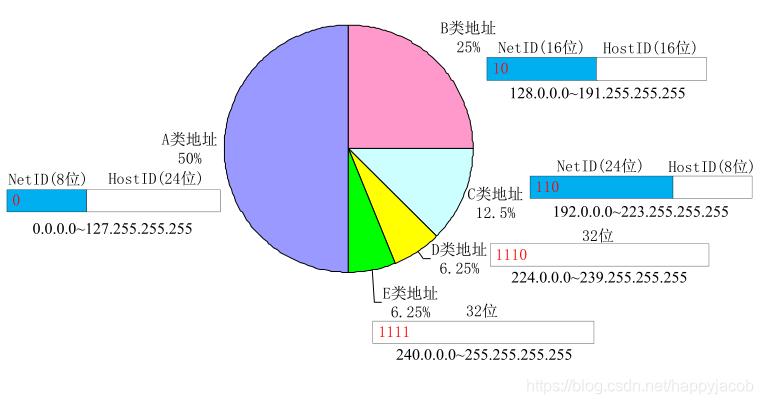
| NetID | HostuD | ��ΪIP����Դ��ַ | ��ΪIP����Ŀ�ĵ�ַ | ��; |
|---|---|---|---|---|
| ȫ0 | ȫ0 | ���� | ������ | �ڱ�����Χ�ڱ�ʾ����;��·�ɱ������ڱ�ʾĬ��·��(�൱�ڱ�ʾ��Internet ����) |
| ȫ0 | �ض�ֵ | ������ | ���� | ��ʾ������ij���ض����� |
| ȫ1 | ȫ1 | ������ | ���� | �����㲥��ַ(·������ת��) |
| �ض�ֵ | ȫ0 | ������ | ������ | �����ַ,��ʾһ������ |
| �ض�ֵ | ȫ1 | ������ | ���� | ֱ�ӹ㲥��ַ,���ض������ϵ������������й㲥 |
| 127 | ��ȫ0���ȫ1���κ��� | ���� | ���� | ���ڱ����������ز���,��Ϊ���ص�ַ |
˽��(Private )IP��ַ
| Class | NetIDs | Blocks |
|---|---|---|
| A | 10 | 1 |
| B | 172.16 to 172.31 | 16 |
| C | 192.168.0 to 192.168.255 | 256 |
��������ַ�������:��������·��ѡ�� (Classless Interdomain Routing,CIDR) ,a.b.c.d/x�ĵ�ַ��x��߱��ع���IP��ַ�����粿��,��Ϊ�õ�ַ��ǰ,һ����֯ͨ��������һ�������ĵ�ַ,��������ͬǰ��һ�ε�ַ��
��ַ�ۺ�(·�ɾۺ�):ʹ�õ�������ǰͨ�������������
1. ��ȡһ���ַ
������ȡIP��ַ:��ISP��������ַ�з���
ISP��ȡIP��ַ:IP��ַ�����������ֺͱ�ŷ������ICANN����(Ҳ����DNS����������AS��ʶ��)��ICANN��������������ע����������ַ,�����������ڵĵ�ַ����/������
2. ��ȡ������ַ:��̬��������Э��
��̬��������Э��(Dynamic Host Configuration,DHCP)���������Զ���ȡ(������)һ�� IP ��ַ���������Ա�ܹ����� DHCP,��ʹij��������ÿ������������ʱ�ܵõ�һ����ͬ�� IP ��ַ,����ij������������һ����ʱ�� IP ��ַ(tempomry IP address ),ÿ������������ʱ�õ�ַҲ���Dz�ͬ�ġ� �������� IP ��ַ������,DHCP ������һ̨������֪������Ϣ,���������������롢���ĵ�һ��·������ַ(����ΪĬ������)�����ı���DNS �������ĵ�ַ��
DHCP���弴��Э��,DHCP��һ���ͻ�-������Э�顣
����������ʱ,DHCPЭ����ĸ�����
-
DHCP����������
�µ��Ŀͻ�ͨ���㲥DHCP���ֱ���,����һ��Ҫ���佻����DHCP���������ͻ���UDP��������˿�67���÷��ֱ���,��ʱ�����ù㲥��ַ255.255.255.255,Դ��ַ��0.0.0.0 -
DHCP�������ṩ
DHCP�յ�DHCP���ֱ��ĺ�,��Ӧһ��DHCP�ṩ����,��Ȼʹ�ù㲥��ַ,��Ϊ��ʱ�¿ͻ���û��IP��ַ��
�����ж�̨DHCP������,ÿ̨�������ṩ�ı�����,����ͻ������Ƽ���IP��ַ�����������Լ�IP��ַ������(һ�㼸���Сʱ) -
DHCP����
�ͻ����ṩ��ѡһ��,��ѡ�еķ������ṩһ��DHCP�����Ľ�����Ӧ,�������ò��� -
DHCP ACK
�յ�DHCP�����ĺ�,��DHCPACK���Ķ��������Ӧ,֤ʵ��������
�ͻ��յ�ACK��,�������,��������ʹ��DHCP�����IP��ַ����Ϊ�ͻ������ڸ������ڳ�ʱ��ϣ��ʹ�������ַ,����DHCP���ṩ��һ�ֻ����������ͻ���������һ��IP��ַ�����á�
4.3.4 �����ַת��
�����ַת��(Network Address Translation,NAT)�����������(WAN)����,��һ�ֽ�˽��(����)��ַת��Ϊ�Ϸ�IP��ַ��ת��������
�����㷺Ӧ���ڸ�������Internet���뷽ʽ�������͵������С�ԭ��ܼ�,NAT���������ؽ����lP��ַ���������,���һ��ܹ���Ч�ر������������ⲿ�Ĺ���,���ز����������ڲ��ļ������NAT·���������������һ�����е�һIP��ַ�ĵ�һ�豸��
�滻
����(NAT IP��ַ,�¶˿ں�)�滻ÿ�����IP���ݱ���(ԴIP��ַ,Դ�˿ں�)
��¼
��ÿ��(NAT IP��ַ,�¶˿ں�)��(ԴIP��ַ,Դ�˿ں�)���滻��Ϣ�洢��NATת������
�滻
����NATת����,����(ԴIP��ַ,Դ�˿ں�)�滻ÿ����������IP���ݱ���(Ŀ��IP��ַ,Ŀ�Ķ˿ں�),��(NATIP��ַ,�¶˿ں�)
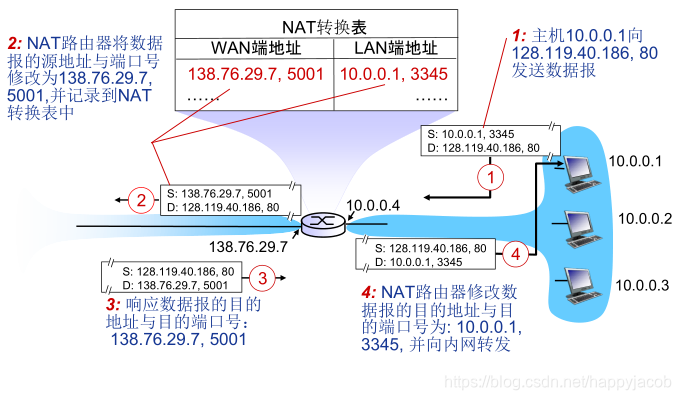
NAT��Ҫ����:
- ·����Ӧ��ֻ������3�㹦��
- Υ���˵���ͨ��ԭ��,Ӧ�ÿ����߱��뿼�ǵ�NAT�Ĵ���,e.g:P2PӦ��
- ��ַ��ȱ����Ӧ����IPv6�����
4.3.5 IPV6
1. IPv6 ���ݱ���ʽ
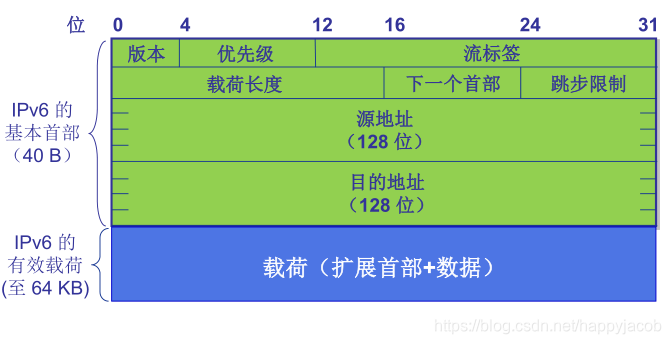
IPv4��ַ�ľ�,Ҳ������ǿ��IPv4ijЩ����
IPv6�ֶ�
- �汾��(version):IPv6 �����ֶ�ֵ��Ϊ 6
- ��������:ռ8λ,��IPv4�ķ�����������,���ֲ�ͬ�����ݱ�
- ����ǩ:ռ20λ,������ʶһ�����ݱ�����,�ܹ���һ�����е�ijЩ���ݱ���������Ȩ��
- ��Ч�غɳ���(payloadlength):ռ16λ,������IPv6���ݱ��������ײ�������ֽ���
- ��һ���ײ�:ռ8λ,��IPv6���ݱ�û����չ�ײ�ʱ,ָ������Ӧ����������һ���ϲ�Э��;��������չ�ײ�ʱ,��ʶ�����һ����չ�ײ�������
- ��������:ռ8λ,���ֶ�������IPv4�е�TTL,ÿ��ת��������1,���ֶδﵽ0ʱ�����ᱻ����
- Դ��ַ��Ŀ�ĵ�ַ(Address) ��ռ128λ,��ʶ�ñ��ĵ���Դ��Ŀ�ĵ�
IPv6�������Ҫ�仯
- ����ĵ�ַ����,32bit��>128bit,
- ��Ч��40�ֽ��ײ�,��Ҳ��˵���� IPv4 �ĺܶ��ײ�ͳͳ��������,����·�������ܸ���ش��� IP ���ݱ���
- ����ǩ�����ȼ�������Ƶ������Ƶ���������ȼ��û����ص�����
�����IPv4�Ѿ�ɾ�����ֶ�
- ��Ƭ/������װ,IPv6 ���ݱ���������·�����Ϸ�Ƭ,�������ֻ����Դ��Ŀ��ִ�С�����м�������·�� MTU ��С��ô��?���ʱ��·������ֱ�Ӷ���,Ȼ�����ͷ���һ��������̫�� ICMP ����,Ȼ��Դ�����������,�����ݱ��ֳɸ�С�ļ������ش�����������Ǻ�����,��Ϊ·�����ķ�Ƭ�Ǻ�ʱ�IJ���,���������� IP ���ݱ�ת�����ٶ���ߡ�
- �ײ�У���:��Ϊ�ڴ���㡢������·��Э����,�кܶ�Э�鶼�о߱�������Ĺ���,���ײ�У�����Ϊ�� TTL �Ȳ����仯,����Ŀ����ܴ���˰�����ֶ�ȥ��֮��,Ҳ�������� IP ���ݱ�ת�����ٶȡ�
- ѡ��,���Ĺ��ܱ��鲢����һ���ײ��ֶ����ˡ����ָĶ�����ʹ�� IP ���ݱ����ײ�����Ϊ����,Ҳ���� 40 �ֽڡ�
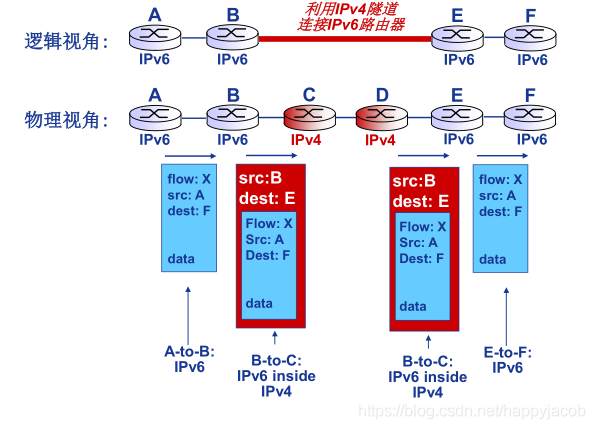
2. �� IPv4 �� IPv6 ��Ǩ��
����(tunneling):IPv6���ݱ���ΪIPv4���ݱ����غɽ��з�װ,��ԽIPv4����
4.5 ·��ѡ���㷨
·��ѡ���㷨Ŀ���Ǵӷ��ͷ������շ��Ĺ�����ȷ��һ��ͨ��·��������ĺõ�·��
����ͨ��ֱ����һ̨·��������,��·������Ϊ��������Ĭ��·�������һ��·����Դ����Ĭ��·������ΪԴ·����,Ŀ������Ĭ��·������ΪĿ��·������
·��ѡ���㷨��һ�ַ����:
- ����ʽ·��ѡ���㷨:��������ȫ���Ե�������Ϣ��������·��(��ͷ���·��) ����ȫ��״̬��Ϣ���㷨����������·״̬(Link State,LS)�㷨
- ��ɢʽ·��ѡ���㷨:�������ֲ�ʽ�ķ�ʽ�������·��û�н��ӵ�й���������·��������Ϣ,ÿ������������ֱ��������·����Ϣ���ɹ���,ͨ���������㲢�����ڽ�㽻����Ϣ,�������ͷ���·��,������������(Distance-Vector,DV)�㷨
�ڶ��ַ����:
- ��̬·��ѡ���㷨:�仯����,ͨ���˹���Ԥ
- ��̬·��ѡ���㷨:·�ɸ��¿�,���ڸ���,��ʱ��Ӧ��·���û��������˱仯
�����ַ����:
- ���������㷨:��·���ö�̬�仯����ӳ��·ӵ��ˮƽ
- ���سٶ��㷨:��·������ӵ����,����������·��ѡ���㷨�������dzٶ۵�
4.5.1 ��·״̬·��ѡ���㷨
����Dijkstra�㷨,ͨ������·״̬�㲥��,���н��(·����)�����������˺���·����,���н��ӵ����ͬ��Ϣ��Dijkstra�㷨�����һ�����(��Դ��)�������������������·����øý���ת����,k�ε�����,�õ�����k��Ŀ�Ľ������·����
�㷨������:O(n2) nΪ�������
����:�����Ŀ���
�����ķ���:��ÿ̨·����������·ͨ���ʱ�������
4.5.2 ��������·��ѡ���㷨
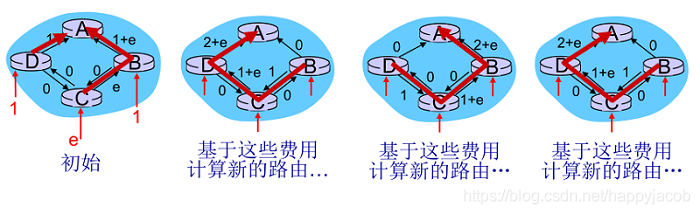
��������(Distance-Vector,DV)�㷨��һ�������ġ��첽�ĺ��ֲ�ʽ���㷨
- �ֲ�ʽ:ÿ�����Ҫ��һ������ֱ�������ھӽ���ijЩ��Ϣ,����,�������������ھ�
- ����:���̳������ھ�֮��������Ϣ����
- �첽:��Ҫ�����нڵ������һ�²���
Bellman-Ford����(��̬�滮)
dx(y) = min {c(x,v) + dv(y) }
dx(y):��x��y���·���ķ���(����)
c(x,v):x���ھ�v�ķ���
dv(y):���ھ�v����Ŀ��y�ķ���(����)
min:��x�������ھ�v��ȡ��Сֵ
Bellman-Ford ����
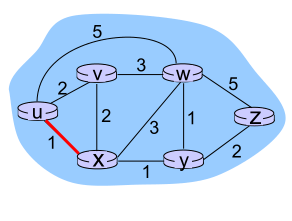
��֪:dv(z)=5,dx(z)=3,dw(z)=3
du(z) = min{c(u,v)+dv(z),c(u,x)+dx(z),c(u,w)+dw(z)}
=min{2+5,1+3,5+3}=4
Dx(y) = �ӽ��x�����y����С���ù���,���x��֪����ÿ���ھӵķ���c(x,v),ά���������ھӵľ������� Dv=[Dv(y):y?N]
����˼��:ÿ����㲻��ʱ�ؽ���������DV���Ʒ������ھ�,��x���յ��ھӵ��µ�DV����ʱ,������B-F�����������ľ�����������,Dx(y)������������ʵ�ʵ���С����dx(y)
Dx(y)��minv{c(x,v)+Dv(y)} for each node y?N
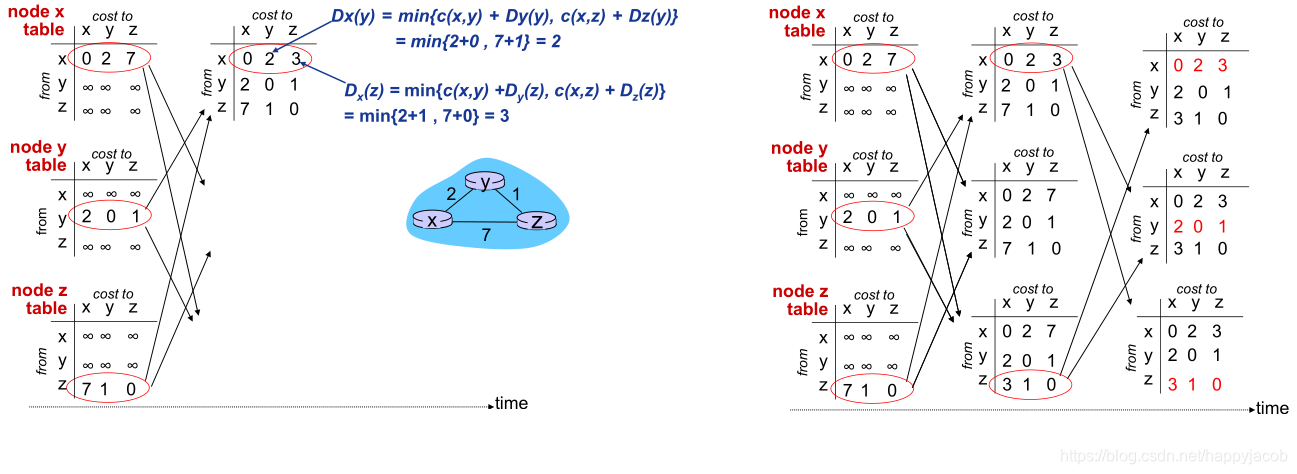
1. ���������㷨:��·�����ı�����·����
����ֻ��ע��y��z��Ŀ�ĵ�x�ľ���
ͼʾ�˴�y��x����·������4��Ϊ1�������
- t0:y����·���øı�,����DV,ͨ�����ھ�
- t1:z�յ�y�ĵ�DV����,���������������,���㵽��x��������С����,������DV,�������������ھ�
- t2:y�յ�z��DV����,���������������,���¼���y�ĵ�DV,δ�����ı�,������z����DV
����:����Ϣ������!
ͼʾ�˴�y��x����·������4��Ϊ60�������
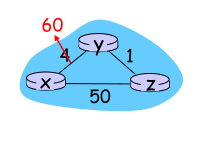
- t0:y����·���øı�,����DV,��ʱz��x����Ϊ5,y����Ϊ�ȵ�z�ٵ�x,����Ϊ6
- t1:z�յ�y�ĵ�DV����,���������������,�ȵ�y�ٵ�z,����Ϊ7
- t2:y�յ�z��DV����,�ٴθ���,�ȵ�z�ٵ�x,����Ϊ8
��
����:����Ϣ������!���ڡ��������������!
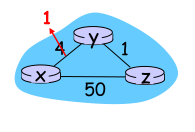
2. ���������㷨:���Ӷ�����ת
��� z ͨ�� y ·��ѡ��Ŀ�ĵ� x,�� z ��ͨ�� y,���� x �ľ����������,Ҳ���� z ���� y ͨ��Dz(x) = ��
- t0 ʱ��(x,y)������4��Ϊ60,y�������Dy(x)=60
- t1ʱ��,z �յ����º�,�л���(z,x)��
- t2ʱ��,��Ϊ����һ���µĵ�x����Ϳ���·��,�Ҳ�����y,z֪ͨy,Dz(x) = 5,y�յ�����z�ĸ��º�,����Dy(x) = 51
������ת�������ֱ�����������������,�����㻷·�������
3. LS �� DV ·��ѡ���㷨�ıȽ�
- ���ĸ�����:��ȻLS���ӵö�,ÿ����·���øı䶼Ҫ֪ͨ���н��
- �����ٶ�:DV�㷨��������,�һ�����·��ѡ��·�������������
- ��׳��:·������������,LS���������Լ���ת����,�ṩ��һ����׳��,DV�㷨һ������ȷ�Ľ�����ɢ����������
4.5.3 ���·��ѡ��
�������ģ�������Ϊһ��ͼ����·��-�������뻯,��ʵ������(�����Ǵ��ģ����)�в�����,ԭ������:
- ��ģ����·������Ŀ��úܴ�,�㷨�����ߵIJ���ʵ��,��LS������·����
- �������Ρ�һ����֯Ӧ�õ����Լ�Ը�����й���������
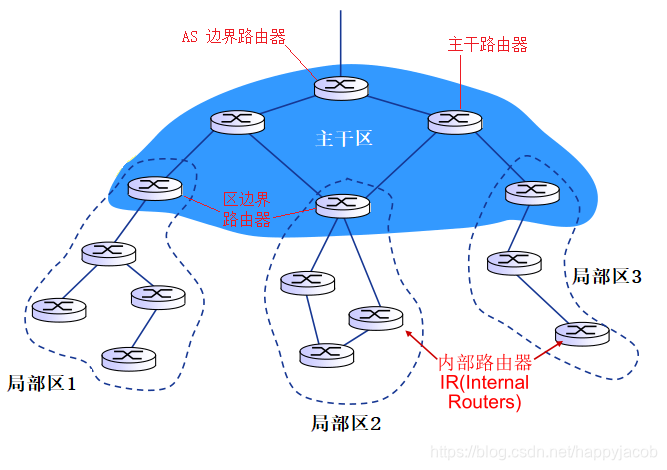
�������:��·������֯������ϵͳ(AutonomousSystem,AS)
ͬһAS�ڵ�·����������ͬ��·��Э��,��������ϵͳ�ڲ�·��Э��,��ͬ����ϵͳ�ڵ�·�����������в�ͬ��AS�ڲ�·��Э�顣
����·����(gateway router)λ��AS����Ե��,ͨ����·��������AS������·����
ת������AS�ڲ�·���㷨��AS��·���㷨��ͬ����,AS�ڲ�·���㷨����AS�ڲ�Ŀ������·�����,AS�ڲ�·���㷨��AS��·���㷨��ͬ����AS�ⲿĿ������·�����
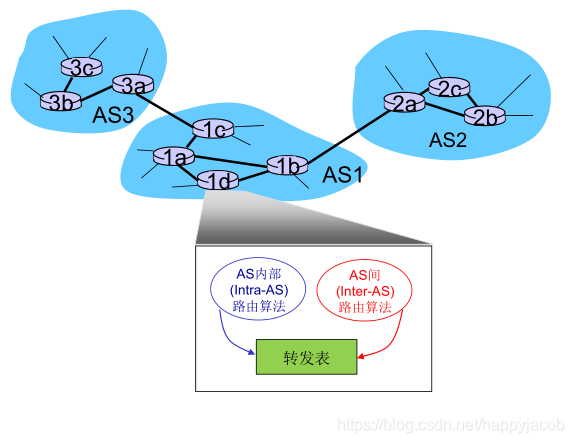
����ϵͳ��·������!
-
��:·����1d ��ת��������
����AS1ѧϰ��(ͨ��AS��·��Э��):����x����ͨ��AS3 (���� 1c)����,������ͨ��AS2����,AS��·��Э���������ڲ�·���������ÿɴ�����Ϣ,·����1d ����AS�ڲ�·����Ϣ,ȷ���䵽��1c����С����·���ӿ�I,��ת�������������(x, I) -
����:�ڶ�AS��ѡ��
����AS1ͨ��AS��·��Э��ѧϰ��,����xͨ��AS3��AS2���ɵ���,Ϊ������ת����,·����1d����ȷ��Ӧ�ý�ȥ������x�����ݱ�ת�����ĸ�����?�������Ҳ����AS��·��Э�����!
ʹ��������·��:�����鷢�����������·������

ʹ��������·��ѡ��(�����п��ܵ�·����)ѡ���·�ɵ���ʼ��·�ɵ�NEXT-HOP ·����������С������
������·��ѡ�����ݵ�˼����:����·����lb,�����ܿ�ؽ������ͳ���AS(����ȷ��˵,�ÿ��ܵ���Ϳ���),����������AS�ⲿ��Ŀ�ĵص����²��ֵĿ������͡�������·��ѡ�����ƶ���,���鱻���Ϊ���ֵ�����������Ϊ������,��Ҫ�����ܿ�ؽ���������һ����(��һ��AS)��
4.6 �������е�·��ѡ��
AS�ڲ�·��Э��Ҳ��Ϊ�ڲ�����Э��(interior gateway protocols,IGP)
�����AS�ڲ�·��Э��:
- ·����ϢЭ��:RIP(Routing Information Protocol)
- �������·������:OSPF(Open Shortest Path First)
- �ڲ�����·��Э��:IGRP(Interior Gateway Routing Protocol)
- Cisco˽��Э��
4.6.1 RIP(DV˼��)
RIPЭ�������ȵõ��㷺ʹ�õ�һ��·��Э��,���ü���һ�ֻ��ھ���ʸ���㷨��Э��,��ʹ��������Ϊ��������������Ŀ������ľ��롣RIPͨ��UDP���Ľ���·����Ϣ�Ľ���,ʹ�õĶ˿ں�Ϊ520��
RIPЭ��Ҫ��������ÿһ̨·������Ҫά����������ÿһ�������·����Ϣ��RIPЭ��ʹ�����������������ġ����롱:��һ̨·��������ֱ���������������Ϊ1;��һ̨·���������ֱ������ľ��붨��Ϊ:ÿ����һ��·����������1�������롱Ҳ��Ϊ����,RIP�������������Ϊ15,�����쵽16ʱ,����Ϊ���ɴ�������RIPһ��ֻ������С�����硣
1. RIP�Ĺ���ԭ��
RIPЭ������ʱ�ij�ʼ·�ɱ����������豸��һЩֱ���ӿ�·�ɡ�ͨ�������豸����ѧϰ·�ɱ���,����ʵ�ָ�����·�ɻ�ͨ����·��������ֱ�����緢������ʱ,�����Ͻ�·�ɱ����µ���Ϣ��1���ľ���ת������������·�ɽڵ㡣����·�������յ�������Ϣ��,�Լ�1���ľ������������·����ת����ÿ��·�����յ�������Ϣ,�������һ��������·�ɱ���Ϣ��ÿ��·����ƽ��ÿ��30s�ʹ�ÿ��������RIPЭ��Ľӿڷ���·�ɸ�����Ϣ��
RIPЭ����ȫ������������Ϊ��,���������,R1ͨ��R3��ʱ��,����2��·���Ĵ����ٶ�ԶԶ����1��·��,RIPЭ����Ȼ��ѡ������10kbps��·�������д��䡣���������·��������Ҫ,�����ֶ�����RIP��·��ѡ��,����·���Ķ���ֵ������ѡ������·����
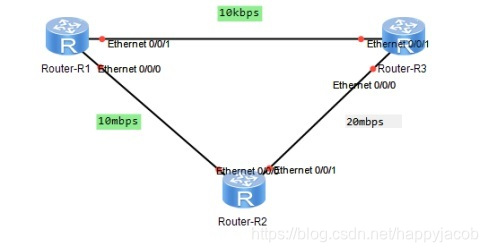
RIPЭ��֮���Խ�·����֮��������������15���ϲ��ɵ���,��Ϊ�˽��RIP·�ɻ�·����,Ҳ��������ǰ��˵�Ļ���Ϣ������������,�������������:
- ˮƽ�ָ:RIP��ij���ӿ�ѧ����·��,����Ӹýӿ��ٷ��ظ��ھ�·�������������������˴�������,�����Է�ֹ·�ɻ�·��
- ���Է�ת��:RIP��ij���ӿ�ѧ��·�ɺ�,��ԭ�ӿڷ����ھ�·����,������·�ɵĿ�������Ϊ16(��ָ����·�ɲ��ɴ�)���������ַ�ʽ,��������Է�·�ɱ��е�����·�ɡ�
4.6.2 ������������ϵͳ�ڲ���·��ѡ��:OSPF(LS˼��)
OSPF�����ֵ�IS-ISͨ���������ϲ�ISP��,RIP���²�ISP����ҵ���С�
OSPF��һ����·״̬Э��,��ʹ�ú鷺��·״̬��Ϣ��Dijkstra��Ϳ���·���㷨��ʹ��OSPF,��̨·����������һ��������������ϵͳ����������ͼ
ʹ��OSPFʱ,·����������ϵͳ����������·�����㲥·��ѡ����Ϣ,ÿ��һ����·��״̬�����仯ʱ(�翪���ı仯������/�ж�״̬�ı仯),·�����ͻ�㲥��·״̬��Ϣ����ʹ��·״̬δ�����仯,��ҲҪ�����Ե�(����ÿ��30min-��)�㲥��·״̬��
OSPF �ŵ�(RIP)
- ��ȫ:����OSPF���Ŀ��Ա���֤(Ԥ����������)
- ����ʹ�ö�����ͬ���õ�·�� (RIPֻ��ѡһ��)
- �Ե�����ಥ·��ѡ����ۺ�֧��
- ֧���ڵ��� AS �еIJ�νṹ:һ��OSPF AS�������óɶ������,ÿ�����������Լ���OSPF LS�㷨,��·״̬ͨ��ֻ��������,ÿ��·������������������ϸ���ˡ�����߽�·��������Ϊ�������������ķ����ṩ·��ѡ��,AS��ֻ��һ��OSPF�������ó���������,Ϊ��������֮��������ṩ·��ѡ�����ɰ���AS����������߽�·����,Ҳ���ܰ���һЩ�DZ߽�·������AS �߽�·������������AS��
4.6.3 ISP ֮���·��ѡ��:BGP
BGPЭ������������ϵͳAS֮��Ķ�̬·��Э�顣BGP��һ���ⲿ����Э��,��OSPF��RIP���ڲ�����Э�鲻ͬ,�����۵㲻���ڷ��ֺͼ���·��,������������AS֮�����·�ɵ�ת����ѡ�����·�ɡ�BGP��Internet ��ճ�ϡ�Ϊһ�����塣
��Խ����AS��BGP���ӳ�Ϊ�ⲿBGP(eBGP)����,������ͬAS�е���̨·����֮���BGP�Ự��Ϊ�ڲ�BGP(iBGP)���ӡ�
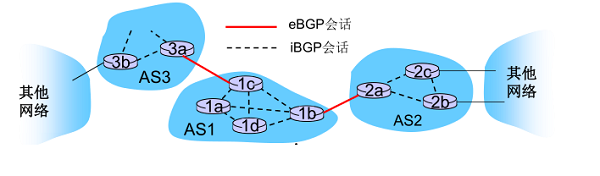
BGP�Ự(session):����BGP·��������BGP����,ͨ��ȥ����ͬĿ��ǰ(prefix)��·��(��·������(path vector)��Э��),���Ľ������ڰ����õ�TCP����
BGP����:
- OPEN:��peer����TCP����,����֤���ͷ�
- UPDATE:ͨ����·��(����ԭ·��)
- KEEPALIVE:����UPDATEʱ,��������;Ҳ���ڶ�OPEN�����ȷ��
- NOTIFICATION:������ǰ���ĵIJ��;Ҳ�����ڹر�����
����ͼ��ʾ,��AS3ͨ��һ��ǰ��AS1ʱ,��3a��1c֮��,AS3����eBGP�Ự��AS1����ǰ�ɴ�����Ϣ.
- 1c���������iBGP��AS1�ڵ�����·�����ַ��µ�ǰ�ɴ�����Ϣ
- 1b����(Ҳ���ܲ�)��һ��ͨ��1b-��-2a��eBGP�Ự,��AS2ͨ���µĿɴ�����Ϣ
- ��·��������µ�ǰ�ɴ���ʱ,������ת���������ӹ��ڸ�ǰ�����(·����).
·��=ǰ+����
������Ҫ����:
- AS-PATH(AS·��):����ǰͨ����������AS���С�e.g:AS67,AS17
- NEXT-HOP(��һ��):��һ��ָ������һ��AS��IP,����ָ·��
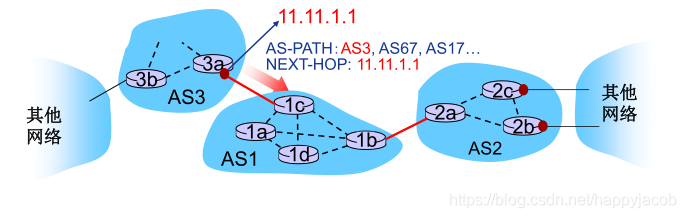
·�������ܻ�֪����ijĿ��AS�Ķ���·��,����������ѡ��:
- ����ƫ��(preference)ֵ����: ���Ծ���(policy decision)
- ���AS-PATH
- ���NEXT-HOP·����: ������·��(hot potato routing)
- ������
BGP·��ѡ�����
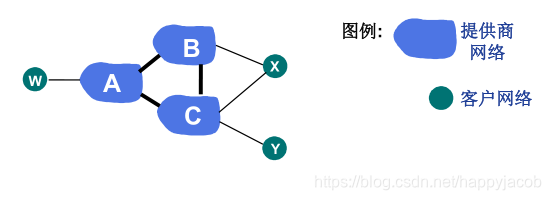
A,B,C���ṩ������
X,W,Y�ǿͻ�����
W,Y������:ֻ��һ������AS����
X��˫������:������������AS
A��Bͨ��һ��·��:AW
B��Xͨ��·��:BAW
B�Ǿ���Ӧ����Cͨ��·��BAW,��ΪW��C������B�Ŀͻ�,B·��CBAW������û���κΡ����桱,B����ǿ��Cͨ��A��W·������,B����ֻ·��ȥ��/������ͻ�������!
����: �κδ�Խij ISP ��������������������Դ��Ŀ��( ������ ) λ�ڸ� ISP ��ij���ͻ�������
4.7 �㲥�Ͷಥ·��ѡ��
�����¡���·��
5.1 ��·�����
������·��Э����κ��豸����Ϊ���,����ͨ��·���������ڽ���ͨ���ŵ���Ϊ��·��ͨ���ض���·ʱ,�����㽫���ݱ���װ����·��֡��,����֡������·��
5.1.1��·���ṩ�ķ���
- ��֡
��װ���ݱ���������֡,���ײ���β��,֡�Ľṹ����·��Э��涨�� - ��·����
ý����ʿ���MACЭ��,�涨֡����·�ϴ���Ĺ���,Э���������֡���䡣֡�ײ��еġ�MAC����ַ,���ڱ�ʶ֡��Դ��Ŀ��,����ͬ��IP��ַ! - �ɿ�����
��֤�������·���ƶ�ÿ����������ݱ�,���ư���ȷ�Ϻ��ش�,����TCP
ͨ�����ڸ߲������·,��������·;�ڵ������ʵ�������·�Ϻ��ٲ��� (�����,ijЩ˫���ߵ�)
��·��ɿ��������ܻᱻ��Ϊ��һ�ֲ���Ҫ�Ŀ������������ԭ��,�������ߵ���·��Э�鲻�ṩ�ɿ��������� - ������;���(Ӳ��)
��żУ��,�����,ѭ��������
5.1.2 ��·���ںδ�ʵ��
��·������岿����������������(networkadapter)��ʵ�ֵ�,������������ʱҲ��Ϊ����ӿڿ�(Network Interface Card,NIC)��
��·����Ӳ���������Ľ����,��Э��ջ��������Ӳ�����ӵĵط���

������ͨ��
- ���Ͷ�:�����ݱ���װ��֡,���Ӳ��������,ʵ�ֿɿ����ݴ�����������Ƶ�.
- ���ն�:�����,ʵ�ֿɿ����ݴ�����������Ƶ�,��ȡ���ݱ�,�����ϲ�Э��ʵ��
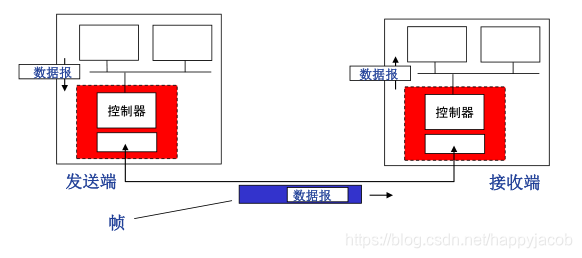
5.2 ������;�������
����������ԭ��:D��DR ,����RΪ���������������(�������)
������벻�ܱ�֤100%�ɿ���

�������ļ������
�������ɷ�Ϊ�������������
��������:���ڶ����ƴ�a��b��˵,�����������aXORb��1����Ŀ
-
���ڼ����,������뼯�ĺ������� ds=r+1,��ò��������Լ�� r λ�IJ��
����,���뼯 {0000,0101,1010,1111} �ĺ�������ds=2,����100%���1���ز��,����1���ؾ�������ˡ� -
���ھ�����,������뼯�ĺ�������ds=2r+1,��ò��������Ծ��� r λ�IJ��
����,���뼯 {000000,010101,101010,111111} �ĺ�������ds=3,���Ծ���1���ز��,����1���ؾ���������,��100010����Ϊ101010�����ִ�������������������������ַ�����
5.2.1 ��żУ��
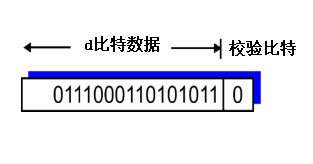
��żУ�鷽����,���ͷ�����һ������,ʹ����d+1������1��������ż����
������У�鷽��,���ͷ�����һ������,ʹ����d+1������1��������������
- 1 ����У��λ
���������
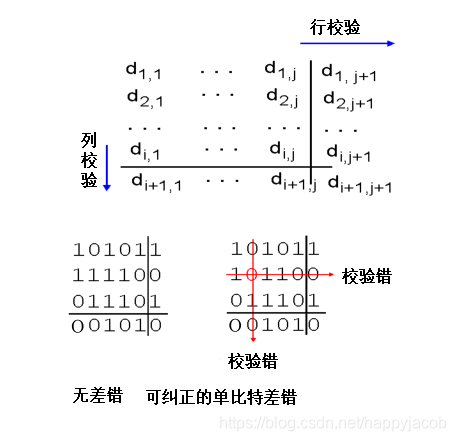
��ά��żУ��:
- �������λ���������ż��λ���
- ����ͬһ��/�е�����λ��
5.2.2 ����ͷ���
��У��ͷ�����,���ݱ��г�k���ص�����,��Щ����ȫ�����֮��ȡ�������У��͡����շ��յ�����֮��,���������ݼ�����(����У���)���ý���Ƿ�ȫΪ1����Ϊ�ж������Ƿ�����ı���
��CRC���,У����ṩ�����ı���,Ϊʲô�����ʹ��У��Ͷ���·��ʹ��CRC��?
- �����ʹ������ʵ��,���ü��ٵķ����DZ����(У���)
- ��·���CRC��Ӳ��ʵ��,�ܹ�����ִ��CRC����.
5.2.3 ѭ��������
ѭ��������(CyclicRedundancy Check,CRC)����Ҳ��Ϊ����ʽ������CRC����Ĺؼ�˼����ͼ��ʾ������һ�����������ݶ�D,���ͷ�Ҫѡ�� r �����ӱ���R,�������Ǹ��ӵ� D ��,ʹ�õõ��� d+r ����ģʽ(������Ϊһ����������)��ģ2����ǡ���ܱ�G����(��û������)��
��CRC���в�����Ĺ�����˺ܼ�:���շ���Gȥ�����յ��� d+r ���ء��������Ϊ����,���շ�֪�������˲��;������Ϊ������ȷ�������ա�
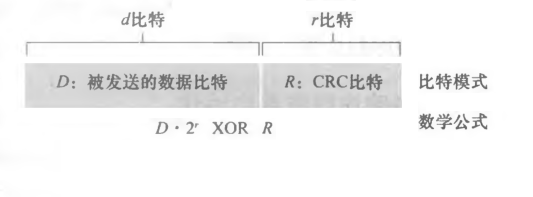
ƴ�Ӻ��d+r�����൱��d��������rλ�ٺ�R�����,���ΪG�ı�����
D?2r XOR R = nG
���߶��� R ��õ�
D?2r = nG XOR R
���߳���G, ����ֵ�պ���R,�����Ϳ��Եõ�R��
R= remainder(D?2r /G)
5.3 ��·������·��Э��
������·
- ��Ե���·:����·һ�˵ĵ������ͷ�����·��һ�˵ĵ������շ���ɡ����Ե�Э��PPP,��������·����Э��HDLC
- �㲥��·(��������):������ͺͽ��սڵ㶼���ӵ���ͬ�ġ���һ�ġ������Ĺ㲥�ŵ���,����̫�������߾�����
��·��������
(1)���Э��������ͺͽ��ս���һ�������㲥�ŵ��ķ���
(2)���������������Ͻ��ͬʱ�����������,���ͬʱ���յ��������߶���źŻᵼ�½���ʧ��!
MAC �����
- �ŵ�����MACЭ��:���ö�·���ü���,��TDMA��FDMA��CDMA��WDMA��
- �������MACЭ��:�ŵ�������,������ͻ,���ó�ͻ���ָ�������
- ��תMACЭ��:�������ʹ���ŵ�
5.3.1 �ŵ�����Э��
ʱ�ֶ�·����(time division multiple access,TDM)
TDM��ʱ�仮��Ϊʱ��֡,����һ����ʱ��֡����ΪN��ʱ϶(slot)��Ȼ���ÿ��ʱ϶�ָ�N���ڵ��е�һ�������ۺ�ʱij���ڵ����з�����Ҫ���͵�ʱ��,����ѭ����TDM֡��ָ�ɸ�����ʱ϶�ڴ��������ء�ʱ϶����һ��Ӧ��һ��ʱ϶���ܴ���һ�����顣
TDM��ȱ��
- �������ֻ�ܴﵽR/N bps ,��ʹֻ��һ����ʹ���ŵ�
- �ڵ���������Ҫ�ȴ�����ʱ϶,���ܻ�Ի�������ѹ��
- ��������ײ��ʮ�ֹ�ƽ
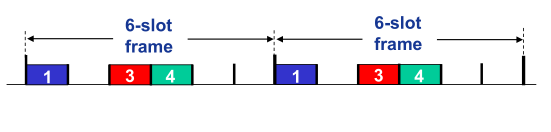
Ƶ�ֶ�·����(frequency division multiple access,FDMA)
FDM��Rbps���ŵ�����Ϊ��ͬ��Ƶ��(ÿ��Ƶ�ξ���R/N����),����ÿ��Ƶ�ηָ�N������е�һ�������FDM��N���ϴ���ŵ��д�����N����С��R/N�ŵ���
FDM��ȱ���TDM��ͬ,������ÿ�����ֻ��ʹ��R/N������

��ֶ�ַ(Code Division Multiple Access,CDMA)
TDM��FDM�ֱ�Ϊ������ʱ϶��Ƶ��,CDMA��ÿ�������䲻ͬ�ı���
ÿ���������Ψһ����Է������ݽ��б���,ʹ�ò�ͬ�����ͬʱ����,���շ�������ȷ�����ա�������,���ھ���ϵͳ,���÷��ѵ绰��
5.3.2 ���������
�������������ŵ�ȫ������R bps���з��͡������������ͬʱ����,����ײʱ,�漰��ײ��ÿ���ڵ㷴���ط�����֡(�ȴ�һ�����ʱ��),ֱ����֡����ײ��ͨ���������������Э��:ʱ϶(sloted)ALOHA,ALOHA,CSMA��CSMA/CD��CSMA/CA
1. ʱ϶ALOHAЭ��
����֡��С��ͬ,ʱ�䱻����Ϊ�ȳ���ʱ϶(ÿ��ʱ϶���Դ���1��֡),���ֻ����ʱ϶��ʼʱ�̷���֡,����ʱ��ͬ��,���2����2�����Ͻ����
ͬһʱ϶����֡,��㼴����ͻ��
��������µ�֡ʱ,����һ��ʱ϶(slot)����,�����ͻ,�ý���������һ��ʱ϶���������µ�֡,�����ͻ,�ý������һ��ʱ϶�Ը���p�ش���֡,ֱ���ɹ���
Ч��:һ�������Ľ��ɹ����͵ĸ�����p(1-p){n-1}, ��Ϊ��N�����,����һ�����ɹ����͵ĸ�����Np(1-p){n-1}������Ծ����������������ʱ,���Ч��1/e,��37%��
2. ALOHA ��
��ʱ϶(��)Aloha���Ӽ�,����ͬ��,�����µ�֡����ʱ��������,��ͻ����������
��t0ʱ�̷���֡,������[t0-1,t0+1]�ڼ�������㷢�͵�֡��ͻ
P(�������ɹ�����֡) = P(�ý�㷢��) * P(�����������[t0-1,t0]�ڼ䷢��֡) * P(�����������[t0,t0+1]�ڼ䷢��֡)
= p * (1-p)N-1 * (1-p)N-1
= p * (1-p)2(N-1)
= 1/(2e) = 0.18(ѡȡ���ŵ�p,����n)
3. �ز�������·����CSMA
�ز�������·����Э��carrier sense multiple access,CSMA)
��ʱ϶�ʹ�ALOHA��,һ����㴫��ľ����������������,�������Լ�����ʱ�����Dz����ڴ��䡣CSMA����֮֡ǰ,�����ŵ�(�ز�):
- �ŵ�����:��������֡
- �ŵ�æ:�Ƴٷ���,1-���CSMA,�Ǽ��CSMA,P-���CSMA
�����źŴ����ӳٳ�ͻ������Ȼ����,�������ͳ�ͻ֡�����˷��ŵ���Դ,����ͼ��ʾ����ʱ��t0,�ڵ�B�������ŵ��ǿ��е�,�ڵ�B��ʼ����,���Ź㲥ý�������������ϴ�������ʱ��t1,�ڵ�D��һ��֡Ҫ����,����B����ı��ػ�û�е���D,���D��w�������ŵ�����,�Ӷ�D��ʼ��������֡���ŵ�����ʱ�������ͻ��
4.������ײ�����ز�������·����CSMA/CD
��ʱ���ڿ��Լ���ͻ,��ͻ������ֹ,�����ŵ��˷ѡ�
5.3.3 ������
��ѯЭ��
ָ��һ�������,��ѭ���ķ�ʽ��ѯÿ�����;�������������A����һ������,��֪A�ܴ���֡���������,A�������������B�ܴ�֡���������,���ѭ��
ȱ��:����ѯʱ��;��������,�����ŵ���GG
���ƴ���Э��
û�������,һ��������token������֡�ڽ��֮���Թ̶�����,��1����2,2����3,N����1,�����������˽ṹ�еĻ�״��������,��һ������յ�����ʱ,��֡����,�������������֡,Ȼ��ת������;û֡����,ֱ�Ӱ�����ת����
ȱ��:������ϡ�
DOCISIS
���ڵ����������������·��Э��
5.4 ����������
5.4.1 ��·��Ѱַ��ARP
1. MAC��ַ
������������·����������·���ַ,�������ǵ�������(����ӿ�)������·���ַ�����ж������ӿڵ�������·����Ҳ�ж����·���ַ,������Ҳ�ж��IP��ַһ����
MAC��ַ(���LAN��ַ,������ַ,��̫����ַ) ���ھ������ڱ�ʶһ��֡���ĸ��ӿڷ���,�����ĸ����������������ӿڡ�
MAC��ַ48λ,ͨ����ʮ�����Ʊ�ʾ��,��1A-2F-BB-76-09-AD��MAC��ַ�̻���������ROM��,��ʱҲ�����������á�
û����������������ͬ��MAC��ַ,MAC��ַ�ռ���IEEE����,IEEE����˾�̶�ǰ24������,����24�������ù�˾�Լ�ȥ���ɡ�
MAC��ַ���б�ƽ�ӿڡ��������802.11�ӿڵ��ֻ���������ͬmac��ַ,���������ƶ�ʱ,IP��ַ��ı�(IP��ַ�Dz�νṹ)��MAC��ַ������֤��,������Ϊλ�øı䷨���ı�;IP��ַ��������ַ,��ı�
2. ��ַ����Э��ARP(���弴�õ�)
����:ʵ��IP��ַ��MAC��ַ��ת��
DNSΪ���������κεط�����������������,��ARPֻΪ��ͬһ�������ϵ�������·�����ӿڽ���IP��ַ��ÿ̨������·�������ڴ�����һ��ARP��,
�洢ijЩLAN����IP/MAC��ַӳ���ϵ:< IP��ַ; MAC��ַ; TTL>
TTLΪ����ʱ��(����ֵΪ20����)
- A�㲥ARP��ѯ����,���а���B��IP��ַ,
Ŀ��MAC��ַ = FF-FF-FF-FF-FF-FF,LAN�����н�㶼�����ARP��ѯ - B����ARP��ѯ����,IP��ַƥ��ɹ�,���õ���֡��AӦ��B��MAC��ַ
- A����ARP����,����B��IP-MAC��ַ��,ֱ����ʱ
ARP�ǡ����弴�á�Э��,�����������ARP��,�����Ԥ
3. �������ݱ�����������
�����е�ij����Ҫ������֮��(Ҳ���ǿ�Խ·��������һ������)������������������ݱ���
ͨ�Ź���:Aͨ��·����R��B�������ݱ�
- ����1:
A����IP���ݱ�,����ԴIP��ַ��A��IP��ַ,Ŀ��IP��ַ��B��IP��ַ
A������·��֡,����ԴMAC��ַ����A��MAC��ַ,Ŀ��MAC��R(��)�ӿڵ�MAC��ַװ,��װA��B��IP���ݱ��� - ����2
֡��A������R,R����֡,��ȡIP���ݱ�,���ݸ��ϲ�IP - ����3
Rת��IP���ݱ�(Դ��Ŀ��IP��ַ����!)
R������·��֡,����ԴMAC��ַ��R(��)�ӿڵ�MAC��ַ,Ŀ��MAC��ַ��B��MAC��ַ,��װA��B��IP���ݱ���
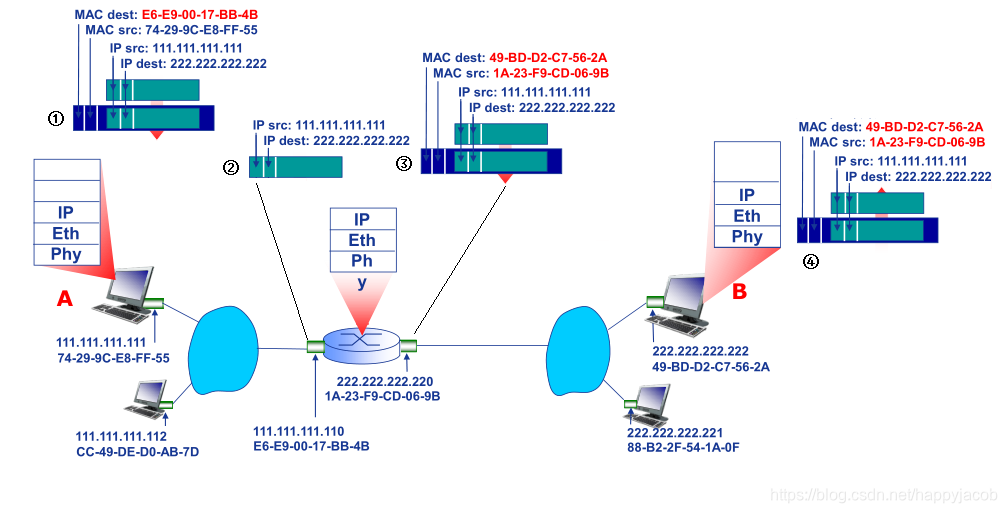
5.4.2 ��̫��
��̫��ռ�������е����߾������г�,����������֮��ȫ�������ĵ�λ
��̫����������:
- ����(bus):���н����ͬһ��ͻ��,���ܱ˴˳�ͻ
- ����(star):Ŀǰ������������,ʹ�����Ľ�����,ÿ�����һ��������ͻ��,����˴˲���ͻ
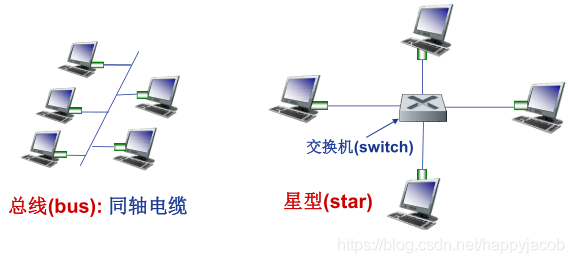
1. ��̫��֡�ṹ
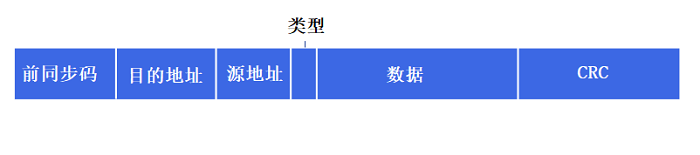
- ǰ����(8�ֽ�):���ڷ��Ͷ�����ն˵�ʱ��ͬ��
- Ŀ��MAC��ַ��ԴMAC��ַ(��6�ֽ�):���������MAC��ַ���յ���֡��Ŀ��MAC��ַƥ��,����֡��Ŀ��MAC��ַΪ�㲥��ַ(FF-FF-FF-FF-FF-FF),���������ո�֡,�������װ���������齻����Ӧ�������Э�顣����,����������֡��
- ����(2�ֽ�):ָʾ֡�з�װ�������ָ߲�Э��ķ���(��IP���ݱ�)
- ����(46-1500�ֽ�):ָ�ϲ�Э���غɡ�
- CRC(�ֽ�):ѭ������У����,�������֡
��̫��������������ṩ���ɿ��������ӷ�����֡�����������֡��������û�С����֡�����;û��ͨ��CRCУ��ֻ�Ƕ���,�ɿ�����Ҫ�����ϲ�TCPЭ�顣
5.4.3 ��·�㽻����
������������:��������·��֡,ת��������·
�����������������е�������·����������,������֪�����������Ĵ���
����������ӿ����л���
�������Ǽ��弴���豸,����Ա��������
��������˫����,�κν������ӿ���ͬʱ���ͺͽ���
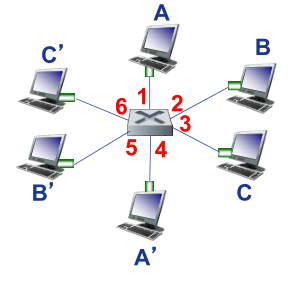
- �������ö�����·ֱ�����ӽ�����
- ����������֡
- ��������ÿ����·������CSMA/CD�շ�֡,����ͻ,�ҿ���ȫ˫��
ÿ����·һ�������ij�ͻ�� - ����:A-A����B-B���Ĵ������ͬʱ����,û�г�ͻ
1. ������ת������
�ٶ�Ŀ�ĵ�ַΪDD-DD-DD-DD-DD-DD��֡�ӽ������ӿ�x����,�������ø�MAC��ַ������������,�����ֿ���:
- ����û�иõ�ַ,�������㲥��֡
- �����б���õ�ַ��ӿ�x��ϵ����,ֱ�Ӷ�������Ϊ��֡�Ѿ��ڰ���Ŀ�ĵصľ��������ι㲥����
- ����Ŀ���б��õ�ַ��ӿ�y��x��ϵ����,��֡��Ҫ��ת������ӿ�y�����ľ�������,�ŵ��ӿ�yǰ���������,���ת������
2. ��ѧϰ
������ͨ����ѧϰ,��֪���������Ľӿ���Ϣ
- ���յ�֡ʱ,��������ѧϰ��������֡������(ͨ��֡��ԴMAC��ַ),λ���յ���֡�Ľӿ������ӵ�LAN����
- ����������MAC��ַ/�ӿ���Ϣ��¼����������
������������д洢:��֡ԴMAC��ַ,֡����Ľӿ�,��ǰʱ��
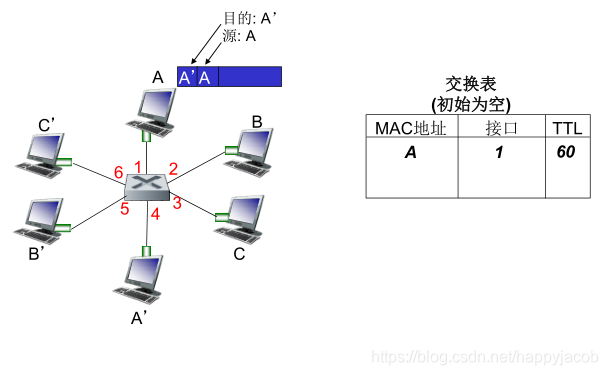
3. ��·�㽻����������
- ������ײ
����������֡���Ҳ�����������ͬʱ�������һ��֡,�������ṩ�˱ȹ㲥��·�������ߵĶ�����ܸ��� - ���ʵ���·
����������·�˴˸���,��˾������еIJ�ͬ��·�ܹ��Բ�ͬ��������,�ڲ�ͬý�������� - �������
�����Ͽ��쳣������
�ռ�����ʹ�õ�ͳ�����ݡ���ײ�ʺ���������,��Щ��Ϣ�������Խ������
4. ��������·�����Ƚ�
���߾�Ϊ�洢-ת���豸:
- ·����:������豸 (������������ײ�)
- ������:��·���豸 (�����·��֡���ײ�)
���߾�ʹ��ת����:
- ·����: ����·���㷨(·��Э��)����(����),����IP��ַ
- ������: ������ѧϰ�����鹹��ת����,����MAC��ַ
5.4.4 ���������
���������(Virtual Local Area Network):֧��VLAN ���ֵĽ�����,������һ������LAN �ܹ������� ��������VLAN��

���ڶ˿ڵ�VLAN
- ��������(traffic isolation):ȥ��/���Զ˿�1-8��ֻ֡����˿�1-8
- Ҳ���Ի���MAC��ַ����VLAN,�����ǽ����˿�
- ��̬��Ա:�˿ڿ��Զ�̬�������ͬVLAN
��VLAN��ת��:ͨ��·��(�����ڶ����Ľ�����֮��),ʵ����,���һὫ��������·������������һ��
��Խ�ཻ������VLAN,���β�ͬVLAN�������ϵĶ˿���λ��һ��VLAN��,�����ô������?
һ�ָ�����չ�Ի���VLAN�������ķ�����ΪVLAN�������ӡ�ÿ̨�������ϵ�һ������˿�(��ཻ�����ϵĶ˿�16,�Ҳཻ�����ϵĶ˿�1)������Ϊ���߶˿�,�Ի�������̨VLAN���������ø��߶˿���������VLAN,���͵��κ�VLAN��֡����������·ת����������������
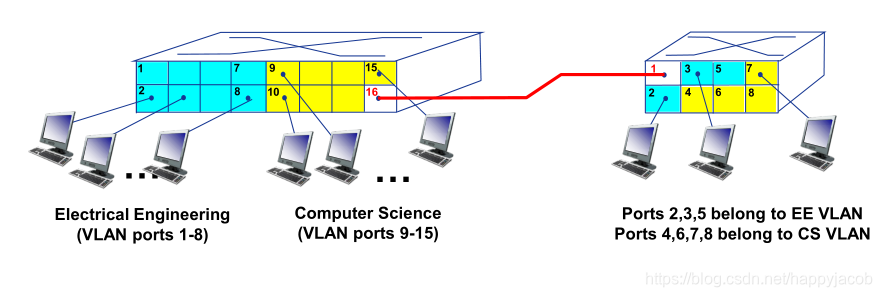
�ο�:
1�����������(�Զ����·���)ѧϰ�ʼ�,����:ͷͺ��Ů����Ա
2�����������(�Զ����·���)
3�����������(��������ҵ��ѧ)