rpc框架项目实现细节
概述:
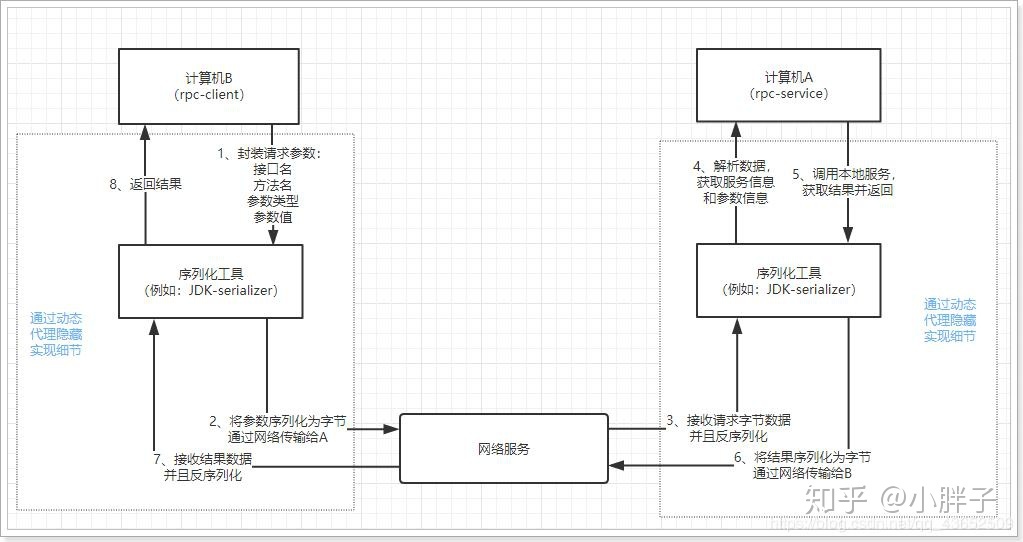
参考相关博客和dubbo的文档书籍,编写一个简易的rpc框架。学习远程服务调用的基本原理,像dubbo一样,只需要引用一个接口就可以调用远程服务,如:通过传输代理(Proxy)对象获取相应的代理方法,然后服务端接受到传过来的对象以后进行本地的反射调用。需要自定义传输协议(一个对象)来封装传输的内容,比如:接口名字,待调用方法的名称,一些方法的参数,参数类型等等。其中可能出现的一些问题,需要利用序列化机制,把传输的对象序列化成二进制流进行传输,其中对不同序列化器的选取也会造成不同的问题。
-
-
要实现远程调用,肯定是通过网络传输数据。A程序提供服务,B程序通过网络将请求参数传递给A,A本地执行后得到结果,再将结果返回给B程序。这里需要关注的有两点:
-
-
1)采用何种网络通讯协议?
-
- 现在比较流行的RPC框架,都会采用TCP作为底层传输协议
-
-
-
-
-
2)数据传输的格式怎样?
-
- 两个程序进行通讯,必须约定好数据传输格式。就好比两个人聊天,要用同一种语言,否则无法沟通。所以,我们必须定义好请求和响应的格式。另外,数据在网路中传输需要进行序列化,所以还需要约定统一的序列化的方式。
-
-
-
像调用本地服务一样调用远程服务
-
- 如果仅仅是远程调用,还不算是RPC,因为RPC强调的是过程调用,调用的过程对用户而言是应该是透明的,用户不应该关心调用的细节,可以像调用本地服务一样调用远程服务。所以RPC一定要对调用的过程进行封装
序列化出现的问题
之前使用JSON序列化器,本质是基于JSON字符串类型的序列化,因为JSON的序列化器反序列化时,需要通过一个Object 数组来接受反序列化的结果,而Object 是一个模糊的类型,而JSON序列化器本身不记录对象的类型信息,所以会出现反序列化失败的情况,无法保证传入参数的类型还是原类型,所以在定义传输协议的时候,需要额外再传递参数类型,重新判断
后面改用Kryo序列化器,他是基于字节的序列化,网络传输可以减小体积,序列化时记录属性对象的类型信息,反序列化的时候不会出问题
过程:先创建Output 对象,使用writeObject写入Output,调用toByte()获取对象字节数组,反序列化从input对象中readObject只需要传入对象的类型,无需传入每一个属性的类型信息
序列化工具还有Protobuf:
支持java python,该技术是基于二进制流进行传输,速度更快而且更灵活,但支持的数据类型比较少,不支持常量类型。
可靠传输的另外一个问题:粘包?
需要重新设计传输协议,魔数进行分割处理,以及传输实际数据的长度。
一开始的思路是,只要拆包或粘包,一律丢弃重发。但是这样的效率太低。
另一种思路:实现netty的定长编码器和解码器,不同长度的包通过字符或空格补齐长度。
改进:
解析消息头的时候,先查看表头的信息是否有传送到,表头包涵:魔数,消息体实际长度等信息,如果没有,则重发。
再来查看消息体长度与实际消息体长度是否相等。如果相等,则继续传输后面的数据。如果不相等,则判断是否是拆包,即消息长度小于实际数据的长度,就记录这段消息到一个buffer,并且记录他的下一个包过来开始读的指针,循环的等待下一个包的发送,接受后开始读,直到读到的消息长度等于实际数据的长度退出循环。如果是粘包,当前的消息体包涵了完整的协议栈,和下一个消息的部分数据,则截取完整的协议栈先解码,然后剩下的部分按拆包的来处理。
为什么用Netty?
一个高性能、异步事件驱动的 NIO 框架,它提供了对 TCP、UDP 和文件传输的支持
使用更高效的 socket 底层,对 epoll 空轮询引起的 cpu 占用飙升在内部进行了处理,避免
了直接使用 NIO 的陷阱,简化了 NIO 的处理方式。
采用多种 decoder/encoder 支持,对 TCP 粘包/分包进行自动化处理
可使用接受/处理线程池,提高连接效率,对重连、心跳检测的简单支持
该项目通过decoder/encoder来将字节序列还原成对象,并校验一些字段和字节数组的长度
为什么需要注册中心?
服务端的地址如果固化再代码中,对于一个客户端,他只会寻找那么一个服务提供者,需要有一个公共的容器来管理这些服务,可以避免某一个服务挂了或者换地址,客户端的调用失败。
zookeeper 和nacos 有什么区别?
https://www.jianshu.com/p/a9ffa4df2bbe
基于注解服务注册?
通过在服务的对象上添加注解,解决服务手动注册到注册中心,而是启动服务类的时候,自动将注解标注的接口注册到服务中心。
注解的函数ReflectUtil,中实现了这些:
@Service标识这个类提供一个服务,@ServiceScan 放在启动服务类上,标识服务的扫描的根包的范围
Service 值定义为该服务的名称,ServiceScan定义为扫描范围的根包,默认为入口类所在的包
如何知道启动类是哪个?通过调用栈new Throwable.getStackTrace()[stack.length-1].getClassName
方法调用的栈底,就是main方法,然后迭代遍历目录(@ServiceScan 的值),逐个判断是否有注解,如果有就反射Class.forName()该对象,然后注册到注册中心
对于普通得类文件,就查看当前得类文件是否有@Service ,标注,但是对于jar包文件,可以获取jar包下面的枚举类,枚举包下面的类和目录, 可以是目录 和一些jar包里的其他文件 如META-INF等文件。对于类文件可以通过得到类所实现的接口名,然后将类实例化,将实例和接口名放到一个concurrenthashmap中,作为一个服务的映射表。消费者通过路由和接口名找到了服务提供者的这个concurrenthashmap,就可以在服务提供者这里通过反射机制调用服务了。
此处可以引出Class.forName()或者classloader的选取区别,可能会用classloader比较好,因为只有等创建类的时候才会进行初始化,执行static 方法,更加干净一些
负载均衡和重试?
并未压测负载均衡算法,后续会改进
引入了一致性哈希和随机负载均衡,从Zk获取服务的信息表,然后在客户端用这俩算法,选取服务调用。
一致性哈希的实现主要用到了FNV的哈希算法保证哈希分布的均匀性,和java 中的TreeMap(排序map)对计算的哈希值进行排序。我们已经知道virtualInvokers是一个TreeMap,TreeMap的底层实现是红黑树。对于TreeMap的方法ceilingEntry(hash),它的作用是用来获取比传入值大的第一个元素。先对给定服务器的节点先计算哈希的键,然后根据键获取到哈希圈的位置,再将对应的请求(ip+port)计算哈希,分散到就近的服务器结点对应的哈希键的位置。
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,例如系统中只有两台服务器,其环分布如下:

此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现。
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
主要工作是对负载均衡算法的学习和理解
Rpc 与Http有什么异同?
Rpc和http底层都是通过socket进行数据的传输,但是Rpc从效率和速度上会比http要更好,因为http的封装比rpc要更加臃肿需要解析和识别的东西比较多,但是Rpc的支持语言比较有限,实现更加复杂。而http得通用性则更好。
Http3.0 的QUIC
QUIC 一个连接上的多个 stream 之间没有依赖。这样假如 stream2 丢了一个 udp packet,也只会影响 stream2 的处理。不会影响 stream2 之前及之后的 stream 的处理。
这也就在很大程度上缓解甚至消除了队头阻塞的影响。
QUIC协议是基于UDP协议实现的,在一条链接上可以有多个流,流与流之间是互不影响的,当一个流出现丢包影响范围非常小,从而解决队头阻塞问题
QUIC协议 存在的意义在于解决 TCP 协议的一些无法解决的痛点
1 多次握手:TCP 协议需要三次握手建立连接,而如果需要 TLS 证书的交换,那么则需要更多次的握手才能建立可靠连接,这在如今长肥网络的趋势下是一个巨大的痛点
2 队头阻塞:TCP 协议下,如果出现丢包,则一条连接将一直被阻塞等待该包的重传,即使后来的数据包可以被缓存,但也无法被递交给应用层去处理。
3 无法判断一个 ACK 是重传包的 ACK 还是原本包的 ACK:比如 一个包 seq=1, 超时重传的包同样是 seq=1,这样在收到一个 ack=1 之后,我们无法判断这个 ack 是对之前的包的 ack 还是对重传包的 ack,这会导致我们对 RTT 的估计出现误差,无法提供更准确的拥塞控制
4 无法进行连接迁移:一条连接由一个四元组标识,在当今移动互联网的时代,如果一台手机从一个 wifi 环境切换到另一个 wifi 环境,ip 发生变化,那么连接必须重新建立,inflight 的包全部丢失。
改进思路
系统地压测分析
心跳机制,调用地重试机制
接由一个四元组标识,在当今移动互联网的时代,如果一台手机从一个 wifi 环境切换到另一个 wifi 环境,ip 发生变化,那么连接必须重新建立,inflight 的包全部丢失。
改进思路
系统地压测分析
心跳机制,调用地重试机制
admin 监控角色运维,查看服务端口连接列表,跟踪服务调用情况,调用本地服务和服务健康状况
