��Ӳ�ˡ�����һ����,Cisco���繤��ʦ֪ʶ���ܽ�
����Ԥ��,��������һ����ǰ�Ϳ�ʼд��,�������ݻ�dz���,��ȻҲ�dz�Ӳ��,��ʵ��,������,���Բ�д�������ڡ�
������90%�Ķ��߶�����һ���������,��Ϊʵ��̫����,����������15���mbp���ֱ༭���ǿ���,������ϣ������պ��뿴Cisco���繤��ʦ����������ǰ��Ҫ�˽�����ѻ�ͷ��һ�¾���,����д������µ�����Ҳ�����ˡ�
Ҳ����BB,ֱ�ӿ�����
һ��OSIģ��
���²���Ϊ�ϲ�����
7# Ӧ�ò�:���ڶ˵��˵�ͨѶ(��������֮�� QQ ͨѶ,����֮���ϵͳ��һ��,��˶����ݵļӽ��ܷ�ʽҲ��һ��,�����Ҫ��������ӽ��ܵķ�ʽ,ʹ�ò�ͬϵͳ��Ӧ�ó���֮���ܹ��ͨѶ)��
6# ��ʾ��:�������ݵı�ʾ,�����ݽ��м��ܵȴ���(Ҫ�����Ự������Ҫ���ӹ�ϵ,����ûỰ�㽨���������ӹ�ϵ)��
5# �Ự��:��֤��ͬӦ�ü����ݵ�����,��������������ֹ�Ự(message �������ӵ�ʱ�����Ƚ���������ŵ�,��֤��ͬ�ĻỰ�ܹ������,Ȼ�����֮���ŵ����,��������ݽϴ�,��������Ƭ,Ȼ����)��
4# �����:�ṩ�ɿ��ɿ��Ķ˵��˱��ĵĴ���Ͳ������(TCP,UDP)
(segment ��ô���͵ı��ı���Ƭ��,��ô֪����ԭ�������������������,�����ҷ��͵���:hi,��������һ��ȥ�Է����Զ��յ�֮����Ҫ��Ϣ����ԭ���Ļػ���ԭ,��Ҫһ��Э�鶨��,��˶����ݽ��з�װ, �ҵ����Ӧ��Ӧ�ò�ij���,��װ֮�����dz�Ϊ PDU(protocol data unite Э�����ݵ�Ԫ):���ǰ������ڶԵȲ�֮�佻������Ϣ��Ϊ PDU)��
3# �����:�������Դ���͵�Ŀ�Ķ�,�ṩ·������������Ѱַ (IP ��ַ)
( A ��ô֪����Ҫ�����ݴ��ݵ�����,Ҳ��������ô֪�� B ������,���������ԭ���İ�ͷ�Ϸ�װ IP ��ַ(Դ,Ŀ IP
��ַ),�����������п������ظ��� IP ��ַ(�ھ�����������ͬ������))��
��β鿴���Ե� MAC ��ַ:ipconfig /all
2# ������·��:�����ݷ�װ��֡,�ṩ�ڵ㵽�ڵ�Ĵ���(Frame ����һ�� 2 ���֡ͷ,������ԴĿ�� MAC ��ַ,�������ܽ�Լ�����������Ŀ�����,MAC ��ַ:��ַ�� 48 λ��,ʮ�����Ʊ�ʾ,ǰ24 λ��OUI �������ͬ��tf��,�� 24 λtf���Լ�����
���� A-----Router-----Router---- B, A �Ҳ��� B �ľ���λ��,��ô��Ҫ����ȷ�ĵ�ַ������ A �ҵ� B, Ҳ���dz�Ϊ MAC ��ַ,Ҳ���൱��������ֲ�����Ψһ,��������֤������Ψһ�� ,A ���Ƚ�Դ,Ŀ��IP ��ַ��װ,Ȼ���ٽ�Դ,Ŀ�� MAC ��ַ��װ,A ��·�������� ARP ��ѯ��,·�����鿴�Լ���·�ɱ�, Ȼ�������������֪����ôȥ, Ȼ����� A �������ݽ�����,�ҿ�������ȥ��Ŀ�� IP,���� A ����·������·�ɱ��в鿴����һ����ַ�� MAC ��ַ��װ��Ŀ�� MAC ��ַ,Ȼ��������·���·���� 2 �����鿴�Լ���·�ɱ�,Ȼ���ٲ鿴�Լ���·�ɱ�,���װ������֮������� MAC ��ַ�������Լ��� MAC ��ַ,�������װ,Ȼ����� IP ��ַ���ڵ��������Լ�ֱ��������,Ȼ��鿴·�ɱ�֮���Լ���һ�� IP ��ַ�� MAC ��ַ��װ,Ȼ�����·���,B �յ�֮�����װ,Ȼ��ƥ���Լ� MAC ��ַ,������ɴ��䡣
1# ������:�豸�䷢�ͺͽ��ձ�����(bit)�����������豸֮��ĵĴ���һ�㶼�������ź�, ��˽�����֡ת���� bit( 1byte=8bit), Ҳ���� 010101 �������ź���ͨ�����ʴ�����ء�
v.35 ������ǹ�����
���ߵĽӷ�:
T568A ��:����,��,�׳�,��,����,��,����,��
T568B ��:�׳�,��,����,��,����,��,����,��
����R&S ��Ҫ�����˽�OSI ��,����
����ÿ���Ӧ���������ͷ�װ�ͽ��װ
������̨ PC ֮�����ݵĴ��ݹ���
һ��������
�豸:���������м���(�Ŵ��ź�)������-���������������������(��ͬ����֮���ͨ��)���е��豸��ͬһ����ͻ��(��ͻ�ͳ�ͻ��ĸ���)
�㲥��:�㲥֡��������緶Χ��������������ͬһ���㲥���,��Ҫ��·����������㲥 ��,��������һ���ӿ���һ����ͻ��,�ӵ� hub ��,���䵽������,�����ͻ��ĸ���CSMA/CD(�ز�������·����)����,ȫ˫��,��˫��,����ͨ�š�
���ʲ���
| 10base2 | 10M ���� | �������� | �������Ϊ 185M | ϸ��ͬ����� |
|---|---|---|---|---|
| 10base5 | 10M ���� | �������� | �������Ϊ 500M | �ֵ�ͬ����� |
| 10baseT | 10M ���� | �������� | �������Ϊ 100M | ������˫���� |
| 10baseTX | 10M ���� | �������� | �������Ϊ 100M | ��ǿ�͵�˫���� (��֧�ֳ� 5 ��� 6 ��) |
| 10base-F | 10M ���� | �������� | �������Ϊ 2000M | ���� |
����������·��
��װԴĿ�� MAC ��ַ,���� A B C ����������һ̨��������,A ���ȥ�� C ��,ͨ�� MAC Ѱַ��ѯ MAC ��ַ��,���ʱ�� 300S��
��̫��֡��ʽ���ֶ���:
| 802.3 : | ǰ���� | Ŀ�� MAC ��ַ | Դ MAC ��ַ | ���� | ���� | FCS |
|---|---|---|---|---|---|---|
| Byte | 8 | 6 | 6 | 2 | �ɱ䳤(46-1500) | 4 |
| EthernetII: | ǰ���� | Ŀ�� MAC ��ַ | Դ MAC ��ַ | ���� | ���� | FCS |
| Byte | 8 | 6 | 6 | 2 | �ɱ䳤(46-1500) | 4 |
ǰ����:����Ӧ���շ��Ǹ�֡,������������Ϣ��
����:�������ݰ��ij����Dz������� MTU(Maximum Transmission Unit ����䵥Ԫ)�ı�
MTU:�����������ݰ��ij���(����䵥Ԫ������ 1500byte)��
FCS: У���(У��֡ͷ��������,md5 �㷨�������֡ͷ�Dz��Ǹ����ڽ��յĵ�ƥ��)
����:���������װ��Э�� IPv4 0x0800 �����ֶ� IPv6 0x86dd �����ֶ�
��̫����֡��ԭ��:(֡�Ĵ�С��Χ:64~~1518 �ֽ�,��trunk ��֡���� 1518 �ֽڲ��ᱻ������)
1# ֡С�� 64 �ֽڡ�
2# ֡���� 1518 �ֽڡ�
3# �����
������������:(��������ÿ���ӿ���һ����ͻ��,������һ���㲥��)
1# ѧϰ MAC ��ַ��
2# ת��,��������֡��
3# ��ֹ��·��
���������
IPv4 ��ַ:32 λ���ʮ���Ʊ�ʾ,���Ķ�,������ź���������ɡ���ͬһ��������Ҫ��ͬһ������,�鿴�Լ����Ե� IP ��ַ
ʹ������綨����λ������λ
1 ����ƥ������λ,0 ����ƥ������λ��
PS:IP ��ַ������λ����Ϊȫ 0 ����ȫ 1 �Dz����õ�(����ȫ 0 ���������,ȫ 1 ���������εĹ㲥��ַ)
192.168.1.0 192.168.1.255 ���� IP ��ַΪ 254 ��
������ͬ������֮���ͨ�� PC1----router----PC2 pc1 ��PC2 �ͨ��,�����ҵ����ء�
·�����ϴ�ŵ���·�ɱ���(·�ɱ�:��ŵ���Ŀ�����ε����·�ɡ�)
�ġ������:(TCP UDP ����Э��)
TCP_�������Э��:(�ɿ��Ĵ���Э��)
TCP ���������ӵĴ���Э��,ͨ���������ֽ�������,ͨѶ���ʱҪ�������,���� TCP ���������ӵ�����ֻ�����ڶ˵��˵�ͨѶ,TCP �ṩ����һ�ֿɿ�������������,���á����ش��Ŀ϶�ȷ�ϡ�������ʵ�ִ���Ŀɿ��ԡ�TCP ������һ�ֳ�Ϊ���������ڡ��ķ�ʽ������������,��ν����ʵ�ʱ�ʾ��������,�������Ʒ��ͷ��ķ����ٶȡ�
UDP_�û����ݱ�Э��:(���ɿ��Ĵ���Э��)
UDP �����������Ӿ�����Ϊ�Ĵ���Э��,UDP ���ݰ���Ŀ�Ķ˿ںź�Դ�˿ں���Ϣ,����ͨѶ����Ҫ����, ���Կ���ʵ�ֹ㲥����,UDP ͨѶʱ����Ҫ���շ�ȷ��,���ڲ��ɿ��Ĵ���,���ܻ���ֶ�������,ʵ��Ӧ����Ҫ�����Ա�����֤��
IP_������:
IP ������ɸ��Ͳ㷢�������ݰ�,���Ѹ����ݰ����͵����߲�(TCP,UDP),�෴ͬ����IP ���ݰ��Dz��ɿ���,��Ϊ IP ��û�����κ�������ȷ�����ݰ��Ƿ�˳���͵Ļ�����û�б��ƻ�,IP ���ݰ��к��з������������ĵ�ַ(Դ��ַ)�ͽ������������ĵ�ַ(Ŀ�ĵ�ַ)��
TCP/IP:
�ŵ�:ģ�黯�Ľṹ����ͬʱ��������������,ά��������
ȱ��:���㹦�ܷ��䲻��,���ܺͷ����帴��,���Ѳ�Ʒ����
1# OSI ���ֲο�ģ��,һ��������ѧ�Ϳ���ʹ��,���ֹ��ʻ����������
2# ʹ�ý϶���� TCP/IP ģ��,�����������������ġ�
���� TCP/IP ���IJ�ģ��:
| application | Ӧ�ò�: | ���������������Э�鹦��,������������Ӧ�ó����Э�顣 |
|---|---|---|
| transport | �����: | ������������ |
| network | ����� | |
| database link physical | ����ӿڲ� |
TCP/IP ���������ֹ���:
1# A �� B �� SYN(ͬ������)
2# B �ظ� SYN+ACK(ͬ������Ӧ��,��ȷ��)
3# A �ظ� ACK ȷ����Ϣ,TCP ��������
�塢Ӧ�ò��Э��:
| HTTP(���ı�����Э��) | ���� TCP 80 | ���������ҳ |
|---|---|---|
| HTTPS(��ȫ���ı�����Э��) | ���� TCP 443 | Ҳ�����������ҳֻ�Ǽ�����,�Ƚϰ�ȫ |
| TFTP (���ļ�����Э��) | ���� UDP 69 | ����С�������ļ�һ�����ڹ����豸�� |
| IOS ����ϵͳ�Լ������ļ� | ||
| DHCP(��̬��������Э��) | ���� UDP 68 | �� PC���������Լ������豸�Զ���õ�ַ������������� |
| FTP (�ļ�����Э��) | ���� TCP 20 21 | �ϴ������ش��������ļ���һ�� 20 ������ͨһ����������ŵ�,�������֮��,ͨ�� 21 �˿ڷ����������� |
| SMTP(���ʼ�����Э��) | ���� TCP 25 | �������ʼ� |
| POP3 | ���� TCP 110 | ���ڷ��ʼ� |
| DNS (������������) | ���� UDP 53 | ���һ̨�������� WWW.baidu.com һ����Ӧһ�� IP ��ַ,������ DNS ������ѯ��www.baidu.com �ĵ�ַ��ʲô,Ȼ��ͨ��������ַ,��� WWW �ĵ�ַ�� |
| Telnet (Զ�̵�¼) | ���� TCP 23 | Զ�̹��������豸 |
| SNMP(���������Э��) | ���� UDP 161 | ͬʱ������̨�豸 |
| SSH (��ȫ���) | ���� TCP 22 | ���ܵ�Զ�̹��� |
������������:
���� TCP ���� UDP ��ͷ,TCP(��С 20byte)�� UDP(��С 8byte)�����ݰ�����,���ڻ���(TCP �д��ڵĴ�Сֻ���� 2 �� N �η�),�������֮������ IP ��ͷ��
IP ���ݰ��ĸ�ʽ:
1# �汾(4 bit):0100 ��ʶ IPv4 0110 ��ʶ IPv6
2# ͷ������(4 bit):���� IP ��ͷ�ij���,����ֶο����� 32 �ֽڵ���ȡ�
3# ��������(TOS)ʵ�� QOS ��������(8 bit):�������������ȼ�(FIFO Ĭ��)��
4# ��ʶλ(16 bit):��ʾ��ͬ������,���ش����ݳ��� MTU(1500byte)��Ҫ�ֶδ��䡣
5# ����ֶ�(3 bit)(Flag):�ڶ�λΪ 1 ʱ,��ʾ·�������ܶ����ݰ����зֶΡ�Ҳ�����ڼ�� MTU ֵ��
6# �ֶ�ƫ��(13 bit):�����ǵڼ�����ƫ����,Ҳ��˵�����ʱ���ƫ����,Ȼ����ԭ(���ݲ�ͬ���ݰ��İ���ԭ����˳��ԭ)��
7# ����ʱ��(TTL)(8 bit):��ֵΪ 255,ÿ����һ��·���� TTL ֵ�� 1,ֱ��Ϊ 0,�Ͷ���,��ֹ����������������ֹ�Ĵ��䡣
8# Э��(8 bit):��ʾ��װ����Э�顣Э���:ICMP:1 IGMP:2 TCP:6 PIM: 13 TCP:6 UDP:17 EIGRP:88 OSPF:89
9# ��ͷУ���:(16 bit)16 λȫΪ 1,��ʾ���ݰ��ڴ�����û�з�������
10# Դ��ַ:32 bit
11# Ŀ���ַ:32 bit
11# Ŀ���ַ:32 bit
ICMP(���������ϢЭ��): echo request(��������)�� echo replay (����ظ�)
PING(ͨ�� ICMP Э��): ��ȥ�л�,���ڼ������Ŀɴ��ԡ�
ARP ��ַ����: MAC �� IP �Ľ������� IP ��ַ������ MAC ��ַ
RARP �����ַ���� �ӻ������ҵ� MAC ��ַ��Ӧ�� IP ��ַ
VLSM �ɱ䳤��������
ARP �����ϻ�ʱ���� 4 Сʱ
���ϻ�ʱ��Ϊ 1800s
int f0/0
arp timeout 1800
clear arp cache //���� arp �����ж�̬����
IP ��ַ����:IP ��ַ���õ��ʮ���Ʊ�,�ֳ� 4 ��,ÿ�� 8 λ��
IP ��ַ = ����� + ������
ȫ 1 ��ʾ�����,ȫ 0 ��ʾ������
8.8.8.8 �ȸ����ŵ���������������
218.2.131.5 �Ͼ� DNS �������� IP ��ַ����:������ȫ 1 ��������ȫ 0��
IP ��ַ������������ 1 ƥ�������λ,0 ƥ���Ϊ����λ��
�����=IP ��ַ��������������
192.168.1.2 255.255.255.0
| 192 | 168 | 1 | 2 |
|---|---|---|---|
| 11000000 | 10101000 | 00000001 | 00000010 |
| 11111111 | 11111111 | 11111111 | 00000000 |
��������ó�
192.168.1.0 �����
���εı�ʾ 192.168.1.0/24
PS:IP ��ַ������λ����Ϊȫ 0 ����ȫ 1 �Dz����õ�
����ȫ 0 �������籾��,ȫ 1 ���������εĹ㲥��ַ,����IP ��ַΪ 254 �� ��
IP ��ַ�ķ���:
| A: ��λ�̶�Ϊ 0 | 1-126 | ����Ϊ 8 λ |
|---|---|---|
| B: ǰ��λ�̶�Ϊ 10 | 128-191 | ����Ϊ 16 λ |
| C: ����λ�̶�Ϊ110 | 172-223 | ����Ϊ 24 λ |
| D: �鲥,ǰ��λ 1110 | 224-239 | |
| E: ������(����) |
����� IP ��ַ:
1��127 ����,���ڱ��ز��� 127.0.0.1
���Լ������ϲ��� 127.0.0.1 ���ڱ��ػػ�����
2��ȫ���㲥��ַ,255.255.255.255
3���������籾��:0.0.0.0
4��RFC 1918 �����˽�� IP ��ַ:��� IP ��ַ�����õ�����(���ھ�������)
| A ��: | 10.0.0.0 | 10.255.255.255 | 10.0.0.0/8 |
|---|---|---|---|
| B ��: | 172.16.0.0 | 172.31.255.255 | 172.16.0.0/12 |
| C ��: | 192.168.0.0 | 192.168.255.255 | 192.168.0.0/16 |
RFC (һϵ���Ա���Ŷ����ļ�)������Ż������ı���
����ʹ�� IP ��ַ,�����������ֵĸ���:
�������硢�������硢С������ÿ������������ź��������������һ��,�����Ҫ���ֲ� ͬ������ź����������������� ip ��ַ��
tracert www.cae.com ��ȥ��Ŀ�� IP ��վ�㡣
172.16.0.0/16 �ɻ��ֳ� 4 ������:
172.16.0.0/18 172.16.64.0/18 172.16.128.0/18 172.16.192.0/18 ��� 4 ��������
VLSM(�ɱ䳤��������):����λ������λ��λ
CIDR (�������·��):����λ������λ��λ,���� A B C ��Ľ綨,ǰ��ͬ��Ϊͬһ���γ�Ϊ����
��������������
172.16.0.0/16 ����Ϊ��������,һ���������� 60 ̨����,һ���������� 280 ̨����,��λ���(�Ȼ��ִ�ķ�Χ,�ٻ���С�ķ�Χ):
280<512=2^9 �� ô �� �� �� �� λ 9 �� �� λ 23 Ҳ �� �� �� �� �� �� Χ : 172.16.0000000
0.0��172.16.0000000 1.255
172.16.0.0/23 ����Ϊ 510 �� IP ��ַ,�� 1 ֮��Ҳ�����¸����εĵ�һ����ַΪ 172.16.2.0 ��
60<64=2^6 ��ô��������λ 6 ����λ 26 Ҳ�������η�Χ:172.16.00000010.00 000000------
172.16.00000010.00 111111 172.16.2.0/26 ����Ϊ 62 �� IP ��ַ��
��ϰ:
202.101.12.98/26 �������,��ַ�ռ�Ϳ��� IP ��ַ��Χ,������仮�ֳɿ���������ͬ�������� 2 ����,��λ���
202.101.12.64 202.101.12.64/26 202.101.12.64--------202.101.12.127
��Ϊ���ֳ� 2 ������,Ҳ������Ҫ������λ�� 1,ȷ������Ϊ/27 ��
010 00000 64 202.101.12.64/27 �����һ����ַ���� 202.101.12.96 010 111111
011 00000 95 202.101.12.96/27 �����һ����ַ���� 202.101.12.127 011 111111
����:202.101.12.64/27 202.101 12.96/27
CISCO �豸�IJ���
��������ʾ��
( > �û�ģʽ���豸�IJ鿴
������Ȩģʽ enable
( # ��Ȩģʽ���豸������ϸ�IJ鿴
�����û�ģʽ disable
����д,���ʺ�,�� tab ��ȫ
����:��������ģʽ
�鿴:������Ȩģʽ
Router> //�û�ģʽ
Router# //��Ȩģʽ
�Ƚ��뵼��ģʽ,Ȼ�����ʾһϵ�еĶ���
Continue with configuration dialog? [yes/no]: no
//Ȼ���ٽ����Լ�����ģʽ,Ȼ���������롣
Router#configure terminal // ��������ģʽ
Router(configure)# // ����ģʽ
Router(config)#enable password CISCO ����������ʾRouter(config)#enable secret CCIE ����������ʾ
PS:������������ͬʱ���ڵ�ʱ����ܵ����ȼ��ϸ�
RAM:�ϵ�֮����
ROM:�ϵ�֮��
·�������������¼��ֲ�ͬ���͵��ڴ�,ÿ���ڴ��Բ�ͬ��ʽЭ��·����������
1.ֻ���洢��(ROM)
ֻ���ڴ�(ROM)�� Cisco ·�����еĹ����������е� ROM ����,��Ҫ����ϵͳ��ʼ���ȹ��ܡ�
ROM ����Ҫ����:
(1)ϵͳ�ӵ��Լ����(POST),���ڼ��·�����и�Ӳ�������Ƿ����;
(2)ϵͳ����������(BootStrap),��������·���������� IOS ����ϵͳ;
(3)���ݵ� IOS ����ϵͳ,�Ա���ԭ�� IOS ����ϵͳ��ɾ�����ƻ�ʱʹ�á�
ͨ��,��� IOS �������� IOS �İ汾��һЩ,��ȴ����ʹ·������������,ROM ��ֻ���洢��,���������д�ŵĴ��롣��Ҫ��������,��Ҫ�滻 ROM оƬ��
2.����(Flash)
����(Flash)�ǿɶ���д�Ĵ洢��,��ϵͳ����������ػ�֮�����ܱ������ݡ�Flash �д���ŵ�ǰʹ���е� IOS����ʵ��,��� Flash �����㹻��,�������Դ�Ŷ������ϵͳ, ���ڽ��� IOS ����ʱʮ�����á�����֪���°� IOS �Ƿ��ȶ�ʱ,�����������Ա����ɰ� IOS, ����������ʱ��Ѹ���˻ص��ɰ����ϵͳ,�Ӷ����ⳤʱ�����·���ϡ�
3.����ʧ�� RAM(NVRAM)
����ʧ�� RAM(Nonvolatile RAM)�ǿɶ���д�Ĵ洢��,��ϵͳ����������ػ�֮�����ܱ������ݡ����� NVRAM �����ڱ������������ļ�(Startup-Config),����������С,ͨ����·������ֻ���� 32KB~128KB ��С�� NVRAM��
ͬʱ,NVRAM ���ٶȽϿ�,�ɱ�Ҳ�Ƚϸߡ�
4.����洢��(RAM)
RAM Ҳ�ǿɶ���д�Ĵ洢��,�����洢��������ϵͳ������ػ���������ͼ�����е�RAM һ��,Cisco ·�����е� RAM Ҳ�������ڼ���ʱ��Ų���ϵͳ�����ݵĴ洢��,��·������Ѹ�ٷ�����Щ��Ϣ��RAM �Ĵ�ȡ�ٶ�����ǰ�����ᵽ�� 3 ���ڴ�Ĵ�ȡ�ٶȡ������ڼ�, RAM �а���·�ɱ���Ŀ��ARP ������Ŀ����־��Ŀ�Ͷ������Ŷӵȴ����͵ķ��顣����֮��, ���������������ļ�(Running-config)������ִ�еĴ��롢IOS ����ϵͳ�����һЩ��ʱ������Ϣ��
running-config �����ڴ�����
startup-config ·���� nvram ����
write=copy running-config startup-config //����ǰ�����ñ����� NVRAM
Router> // �û�ģʽ ���û�ģʽ������Ȩģʽ Router>enable
Router# //��Ȩģʽ ���û���Ȩ��������ģʽ Router#conf terminal �Ƚ��뵼��ģʽ,Ȼ�����ʾһϵ�еĶ���
Continue with configuration dialog? [yes/no]: no //Ȼ���ٽ�������ģʽ ,Ȼ����������
Router#configure terminal // ��������ģʽ
Router(configure)# // ����ģʽ
Router(config)#enable password CISCO // ����������ʾ
Router(config)#enable secret CCIE // ����������ʾPS:������������ͬʱ���ڵ�ʱ����ܵ����ȼ��ϸ�
ʵ��:
һ:·�������������úͻָ�
��һ��:��������
Router(config)#enable secret
�ڶ���:�ϵ�����
ctrl+break ��������������� romon ģʽ���� ctrl+C ��
������:�ļĴ���ֵ
rommon 1 > confreg 0x2142
0x2102 ���������� (Ĭ�ϼĴ�����ֵ)
0x2142 ������������
���IJ�:����
rommon 2 > boot �Կ���������
���岽:������Ȩģʽ
�鿴��ǰ������
show running ֮�����ǿյ�,Ȼ����ԭ��������
Router#copy startup-config
running-config Ȼ��鿴��ǰ������,�鵽���롣
������:Ȼ��ɾ��ԭ��������
Router(config)#no enable password ���� no enable secret
���߲�:�Ļ�ԭ���ļĴ���ֵ
Router(config)#config-register 0X2102
PS: ���Բ鿴��ǰ�Ĵ�����ֵ(show version) �� ʾ :Configuration register is 0x2142 (will be 0x2102 at next reload)
reload ������
show version �鿴��ǰ�İ汾Configuration register is 0x2102
����IOS ���ѻָ�
��һ��:ģ���
Router#delete flash:c2600-ipbasek9-mz.124-8.bin //������ϵͳ�ļ�ɾ��
�ڶ���:����·����
Router#reload ���� ROMMON ģʽ
������: �����������õ�ַ,tftpdnld
rommon 3 > tftpdnld
���IJ�:�� TFPF ���������� IOS �ļ�,���ñ�·������ز���
rommon 4 > IP_ADDRESS=192.168.1.1 //���ñ�·���� F0/0 �ӿڵ� IP ��ַ
rommon 5 > IP_SUBNET_MASK=255.255.255.0 // ������������
rommon 6 > DEFAULT_GATEWAY=192.168.1.200 //������������(ȱʡ�����������)
rommon 7 > TFTP_SERVER=192.168.1.2 //���� TFTP �������� IP ��ַ
rommon 8 > TFTP_FILE=c2600-ipbasek9-mz.124-8.bin//��Ҫ�� TFTP �����������ص� IOS �ļ���
���IJ�:�ٴ����� tftpdnld ��ʼ����������� IOS �ļ� (�ɴ��ʺŲ鿴)
rommon 8 > SET ///���ղŵ���������
���岽: ����
rommon 20 > boot / reset
������:�鿴��ǰ�� VERSION(�汾) Router>show version
Ӱ����������ܵ������������������ߵij�ͻ������Ĺ㲥,���ֶΡ�������ָ�ɽ�С�ĶΡ�
������:
����:1����ַ��ѧϰ 2��֡��ת��/���� 3����ֹ��·
1# ��ַ��ѧϰ:�鿴 ARP ����(ARP -a)
�������ʱ MAC ��ַ���ǿյ�
��� mac ��ַ���ɴ� 1024 ��,һ����ַ����, �ͻ�鷺���е��� MAC ��ַ��֡,ֱ���ִ��ַ��Ŀ�ϻ�Ϊֹ��
Mac ��ַ����ĿĬ���ϻ�ʱ���� 300 ��,��������ɸı��ϻ�ʱ��:
switch(config)#mac-address-table aging-time ? <10-1000000>
2# ֡��ת��/����,�������γ� MAC ��ַ��
������ A ��������֡��������
�ڵ�ַ������Ŀ������,����֡���᷺���ֱ��ת����
3# �� · �� �� ֹ , �� �� �� Э �� STP
VLAN:(����ľ����� virtual LAN)
һ�� VLAN = һ���㲥�� = ������ (����)
VLAN ʵ�����������Ч�ֶ�,������ǿ������İ�ȫ�Ժ�����ԡ�ÿ������ VLAN ����һ�������������š�
�������ϵ�ÿһ���˿ڶ����Է������ͬ�� VLAN��
Ĭ�ϵ������,���еĶ˿ڶ����� VLAN1(Cisco ����)��
���ֲ�ͬ�� VLAN,ʹ�ò�ͬ�� VLAN �䲻��ͨ�š�
Switch#show vlan brief //�鿴 VLAN ��Ϣ
ʵ��1: VLAN�Ĵ����ڻ���

�� �� VLAN :
����һ:
Switch(config)#vlan 10 //���� VLAN
Switch(config-vlan)#name CCNP //����Ϊ CCNP
Switch(config)#exit
������:
Switch#vlan database //���� VLAN database ģʽ
Switch(vlan)#vlan 30 name CCIE //���� VLAN ������Ϊ CCIE Switch(vlan)#exit //�˳�����
���ӿڻ�����Ӧ�� VLAN :
Switch(config)#int f0/1
Switch(config-if)#switchport mode access //���ӿ�ģʽ��Ϊ����ģʽSwitch(config-if)#switchport access vlan 10 //���ӿڻ��� VLAN 10
һ��ÿ������VLAN ����һ��������������
1# ͬһ�� VLAN ���Կ�Խ���������
2# ��ͬ�Ĵ�¥֮����ͬ�� VLAN ��Ҫʵ��ͨѶ,ʹ�� TRUNK
3# ���ɹ���֧�ֶ�� VLAN ������
4# ����ʹ��������ķ�װ��ʽ֧�ֲ�ͬ�� VLAN
5# ֻ�п�����̫���˿ڿ�������Ϊ���ɶ˿�
����TRUNK :���Գ��ض��VLAN ��Ϣ����·
��������֡���� VLAN ���������Э��:ISL(Cisco ˽��)�� 802.1Q(����)
ISL:��ԭʼ��̫��֡��ͷ������ 26 �ֽڵ� ISL ͷ��,β�������� 4 �ֽڵ� CRC ��,û���ƻ�ԭʼ֡.���֧�� 1024 �� vlan��
802.1Q:��ԭʼ֡Դ MAC ����(�м仹������)�� 4 ���ֽ� TAG ���λ,�� VLAN ���б��,�ƻ���ԭʼ֡.���֧�� 4094 �� VLAN��
TAG �ֶθ�ʽ:4 �ֽ�=32 ����
| ��̫���� | ���ȼ�(priority) | flag(���ƻ���ʶ) | VLAN ID |
|---|---|---|---|
| 16bit | 3 ���� | 1 ���� | 12 ����(�����VLAN ) |
ʵ��2:VLAN�����ڻ���2
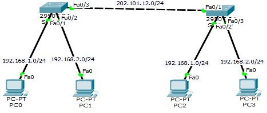
��һ��:���� PC �� IP ��ַ(��ͼ)
�ڶ���:�������ϴ��� VLAN
Vlan 10
Vlan 20
������:���ӿڻ�����Ӧ�� VLAN Interface f0/1
SW MO ac
Sw ac Vlan 10 Interface f0/2
SW mo ac
Sw ac vlan 20
���IJ�:�������������Ľӿ�ģʽ��Ϊ TRUNK Int f0/3
sw mo tr
show interface trunk //�鿴��װ��ʽ
����ʵ�ֲ�ͬ VLAN ��ͨ��
·����ʵ�ֲ�ͬ VLAN ���ͨ��,����㲥��
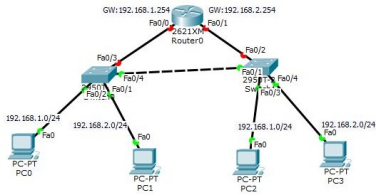
Ҫ��ʵ�ֲ�ͬ VLAN ֮���ͨ��,����·������ʵ�֡�
���岽:���������ϵĽӿڻ�����Ӧ�� VLAN
SW1: F0/3 �ӿ������� VLAN 10
SW2: F0/2 �ӿ����� VLAN 20
������:����·�����ӿ� IP ��ַ
interface FastEthernet0/0
ip address 192.168.1.254 255.255.255.0
no shutdown
interface FastEthernet0/1
ip address 192.168.2.254 255.255.255.0
no shutdown
ʵ��3:����·��
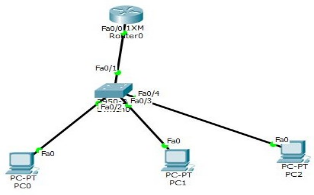
��һ��:���� PC �� IP ��ַ
�ڶ���:�������ϻ��� VLAN
Switch(config)#vlan 10
Switch(config-vlan)#vl 20
Switch(config-vlan)#vl 30
������:�ѽӿڻ�����Ӧ�� VLAN (�������� int rang f0/0-1) Switch(config)#int f0/4
Switch(config-if)#sw mo access
Switch(config-if)#sw ac vl 30
Show vlan brief //�鿴�ӿ�
���IJ�:·�����ͽ����������Ľӿ���Ҫ���ض�� VLAN, Switch(config)#int f0/1
Switch(config-if)#sw mo trunk
���岽:·�����������ӽӿ�
Router(config)#int f0/0
Router(config-if)#no shutdown
Router(config-if)#int f0/0.10
Router(config-subif)#encapsulation dot1Q 10 //���� 802.1Q ����ı�ǩ��ʽ,���ӽӿڴ��ϱ�ǩ,���ں� vlan 10 ���û�ͨ��
Router(config-subif)#ip add 192.168.1.10 255.255.255.0 ���岽:�����������ͨ��
ʵ��4:ʹ�����㽻����(����·�ɹ���)ʵ�� VLAN ��ͨ��
�������㽻�����������ӿ�����ip ��ַ,����ر����Ķ���ӿ�,������ӿڡ�
int f0/4
no switchport Ip address
�ӿڷ�װ����ѡ���װЭ��,���� trunk ģʽ
sw trunk encapsulation dot1q
sw mo trunk
**��һ�������� pc �� ip ��ַ
�ڶ��������� VLAN
�� �� �� �� �� �� �� �� VLAN**
Switch(config)#int f0/1
Switch(config-if)#sw mo ac
Switch(config-if)#sw ac vlan 10
Switch(config-if)#int f0/2
Switch(config-if)#sw mo ac
Switch(config-if)#sw ac vlan 20
���IJ��������㽻��������������Ľ����ӿڵ�ַ,�ֱ���ΪVLAN 10 �� VLAN 20 ������
Switch(config)#interface vlan 10
Switch(config-if)#ip add 192.168.1.254 255.255.255.0
Switch(config-if)#int vlan 20
Switch(config-if)#ip add 192.168.2.254 255.255.255.0
���岽���������㽻������·�ɹ���
Switch(config)#ip routing
ʵ��5:VTP(VLAN Trunking Protocol)����:ͬ��
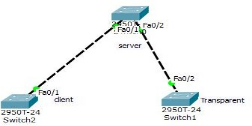
VLAN:
��һ��:�������������Ľӿڸ�Ϊ trunk ģʽ
CLI(config)#int rang f0/1-2
CLI(config-if-range)#switchport mo trunk
�ڶ���:���� vtp Э��
CLI(config)#vtp domain CCIE // ����VTP ������PS:���������û����������,����Զ�ͬ���������Ľ�����������
CLI(config)#vtp mode client / CLI(config)#vtp mode server //����VTP ��ģʽ �ͻ�ģʽ/����ģʽ
CLI(config)#vtp password cisco //����vtp ������
Devicemode already VTP SERVER //vtp ģʽĬ��Ϊserver ģʽ
������:�� server �˴��� VLAN(client �˲��ܴ��� vlan) SER(config)#vlan 10
SER(config)#vlan 20
SER(config)#vlan 30
CLI#show vtp status //�鿴��ǰ���������е�vtp ����ϢVTP
Version : 2
Configuration Revision : 3 //ÿ�� VLAN ���в���һ��,revision ������һ
Maximum VLANs supported locally :255
Number of existing VLANs : 8 //��ǰ���������ڵ� VLAN ����
VTP Operating Mode : Server // VTP ��ģʽVTP Domain Name : CCIE VTP ����
���IJ�:Transparent ����ͬ�� server �˵� vlan,ֻ�� client �˲Ż�ͬ��
Showvlan brief //�鿴��ǰ�������� vlan ��
ͬ������:
С�����ŵĽ�������ͬ�����Ŵ�ĵĽ������� vlan
��������ķ���
1.�� vtp ��ģʽ�ij���ģʽ
2.�� vtp ������
3.�������
·��Э��
·��Э��:����ѧϰ��Դ��Ŀ�������·����
��·��Э��:�������ݰ���·��Э��ѧϰ��������·�ɽ�����ת����ȥ(IP Э��)��
·�ɱ�:·����ת�����ݰ���Ҫ������·�ɱ�(ÿ��·�����ж�������һ��·�ɱ�,����ÿ��·���
ָ�����ݰ���ij������ij����Ӧͨ��·�������ĸ������˿ڷ���,Ȼ��Ϳɵ����·������һ��·����, ���߲��پ������·���������͵�ֱ�������������е�Ŀ������)��
·��:��Դ��Ŀ���һ��·��
Ҫʵ��·��,·��������֪��:Ŀ�ĵ�ַ,Դ��ַ,���п��ܵ�·��·��,���·��·��,����·����
Ϣ��
·�ɱ��е�·����Ϣ����Դ:
ֱ��·��:
·���������Զ�ʶ���Լ��ӿ������õ� IP ��ַ���ڵ����ΰ�װ���Լ���·�ɱ���,�γ�һ��·�ɡ�
��̬·��:
��Ҫ����Ա���õ�·��,ָ��ȥ��Ŀ��������ô�ߡ�
��̬·��:
ͨ����̬·��ѧϰ��
����ʸ��·��Э��:RIP(routing information protocol)(120)
��·״̬·��Э��:OSPF(110) ��ISIS
���ľ���ʸ��·��Э��:EIGRP(90)
�߽�·��Э��:BGP
��������:��Ҫ���ڲ�ͬ·��Э��֮��Ŀ��Ŷ�(·�����ȼ�)
(���Ŷȵķ�Χ��:0 �� 255 ֮��,����ʾһ��·��ѡ����ϢԴ�Ŀ�����ֵ.��ֵԽС,���Ŷ�Խ��. ���ֵΪ 0 Ϊ������, ���ֵΪ 255 Ϊ����μ�û�д�������·��û���κ�����ͨ��)
ֱ���Ĺ���·��(Connected):0 ��̬·��(Static):1
EIGRP �ڲ�:90 RIP:120
EIGRP �ⲿ:170
��̬·����ȱ��
�ŵ�:
1.��·���� CPU û�й����Կ���
2.��·������û�д���ռ��
3.���Ӱ�ȫ��
ȱ��:
1.���������˽�����
2.���������������÷���
3.���ڴ������繤������
Ĭ�ϵľ�̬·��,ȱʡ��·��:��û���ҵ��κ�ƥ����Ŀ�������ʹ��·�������ʽ:
IP route 0.0.0.0 0.0.0.0 ���ڽӿ�/��һ�� IP ��ַ //һ��������ҵ����·����
��̬·��Э��
1# ����ʸ��·��Э��:RIP(routing information protocol)
���ж�̬·��Э�� RIP
·������·����֮�䴫�����·����Ϣ,·���ǰ��մ������ġ�
2# ��·״̬·��Э��:OSPF
·������·����֮�䴫�������·״̬,�����е�·����֪��������������ˡ�·�������Լ�ΪԴ��,�����һ��ȥ��Ŀ���������ŵ�·����װ���Լ���·�ɱ���
RIP �ķ���:
����ʱ��(convergence time):���������˷����仯,����������������·������֪������仯��ʱ��,�ͽ�����ʱ�䡣
ˮƽ�ָ�:�ӿڲ�����յ������������ȥ��·����Ϣ��
������ת:·��������մ���������ȥ��·����Ϣ,���DZ�Ǹ�·�ɲ��ɴ
����ʧЧ��ʱ��:����ʵЧ��ʱ��(Ĭ�� 180s)
��������һ����· down ��,���� 180s ������ʱ�䡣������ʱ�������������:
1,ԭ������·�ָ�,��ָ�ԭ����·��,���°�װ��·�ɱ�
2,�յ�һ����ԭ��·�����ŵ�·��,��װ��·�ɱ�
3,�յ�һ����ԭ��·����һ���·��,���� 180s �ڱ����ȶ�,���� 180s ֮��,����װ��·�ɱ�
��������:��·������·�ɱ������仯��ʱ��,��������Ϣ
�������:ָ�������������ֹ��·��
RIP Э��ָ����·�ɵ������ﵽ 16 ��,����Ϊ���ɴ�(��� 15 ��)��
RIP ������:
r1(config)#router rip //���� rip ·��Э��
r1(config-router)#version 2 //ʹ��rip �İ汾�� 2
r1(config-router)#no auto-sunmmary //�ر��Զ�����
r1(config-router)#network 192.168.1.0
RIPv2 �Ļ�������:
Ӧ�ò�Э��,ʹ�� UDP Э�鴫�����ݰ���
1.rip ��������Ϊ����ֵ(metric),���Ϊ 15 ����2.rip �� 30s ʱ�����ھӷ���·�ɸ�����Ϣ��
3.rip ·��Э�����֧����� 6 �����ؾ��⡣
4.rip ·��Э����� UDP 520 ��װ��
5.rip ��������Ϣ:
������Ϣ(request):����ս���,����������Ϣ,�����ھӵ�·�ɵĸ���.
Ӧ����Ϣ(response):��Ӧ������Ϣ,����·����Ϣ(ÿ 30s ���ڷ���).
6.RIP ��ʱ��:
1# ���¼�ʱ��(update timer):�����Եķ���·�ɸ�����Ϣ(Ĭ�� 30 ��) �첽����:Ϊ�˱���˲��������߷�,���� 15%�������(25.5~30s)
2# ��Ч��ʱ��(invaild timer):·�����ж�·�ɳ�ΪʧЧ·�ɵĵȴ�ʱ��(Ĭ�� 180s) 3# ����ʧЧ��ʱ��(holdtime timer)(180s):
��������һ����· down ��,���� 180s ������ʱ�䡣������ʱ�������������:
1# ԭ������·�ָ�,��ָ�ԭ����·��,���°�װ��·�ɱ���
2# �յ�һ����ԭ��·�����ŵ�·��,��װ��·�ɱ���
3# �յ�һ����ԭ��·����һ���·��,���� 180s �ڱ����ȶ�,���� 180s ֮��,����װ��·�ɱ� ��
4# ˢ�¼�ʱ��(flush timer):·��������Ч·�ɲ���·�ɱ�ɾ����ʱ����(240s)��
show ip protocols //�鿴��ǰ·����
hostname newname //�ĵ�����
��:tracert www.baidu.com �� TCP/IP Э��ջ��,Routed Protocol(IP Э��)�����������,�� Routing Protocol �����ڴ�������Ӧ�ò�,����֮��Ĺ�ϵΪ:Routing Protocol����ѧϰ��Դ��Ŀ������·�� Routed Protocol �������·���������ϲ����Ϣ��װ��IP ���ﴫ��?
·�ɱ�:·����ת�����ݰ��Ĺؼ���·�ɱ���
·�ɱ�����Ϣ����Դ:
ֱ��·�� :·���������Զ�ʶ���Լ��ӿ������� IP ��ַ���ڵ�����,���������ΰ�װ���Լ���·�ɱ���,�γ�һ��·�ɡ�
��̬·�� :�ֹ����õ���Ŀ�� IP ��ַ��·��
��̬·�� :ͨ����̬·��Э��ѧϰ
����ʸ��(distancevector)��Ҫ��:
RIP(routing information protocol)
IGRP ��·״̬(linkstate)
OSPF(�������·������) IS-IS
EIGRP(���ľ���ʸ��·��Э��)
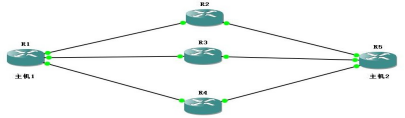
���� 1 ȥ������ 2,�ж��ֲ�ͬ��·��, ���ݹ�������ѡ��ȥ��Ŀ��������������: Administrative Distances(AD ֵ)����������Ҫ���ڲ�ͬ·��Э��֮��Ŀ��Ŷȡ� ���Ŷȵķ�Χ��:0 �� 255 ֮��,����ʾһ��·��ѡ����ϢԴ�Ŀ�����ֵ.��ֵԽС,���Ŷ�Խ�ߡ� 0 Ϊ������,255 Ϊ����μ�û�д�������·��û���κ�����ͨ����
·��Э��Ĺ�������:
1# ֱ������:0
2# ��̬·��:1
3# EIGRP:90(�ڲ�)
4# IGRP:100
5# OSPF:110
6# RIP:120
7# EIGRP:170(�ⲿ)
ע:RIPv1 �� RIPv2 ������:
1.RIPv1 ������·��Э��,RIPv2 ������·��Э�顣
2.RIPv1 ����֧�� VLSM,RIPv2 ����֧�� VLSM��
3.RIPv1 û����֤�Ĺ���,RIPv2 ����֧����֤,���������ĺ� MD5 ������֤��
4.RIPv1 û���ֹ����ܵĹ���,RIPv2 �����ڹر��Զ����ܵ�ǰ����,�����ֹ����ܡ�
5.RIPv1 �ǹ㲥����,RIPv2 ���鲥���¡�
6.RIPv1 ��·��û�б�ǵĹ���,RIPv2 ���Զ�·�ɴ���(tag),���ڹ��˺������ԡ�
7.RIPv1 ���͵� updata ������Я�� 25 ��·����Ŀ,RIPv2 ������֤����������ֻ��Я�� 24 ��·�ɡ�
8.RIPv1 ���͵� updata ������û�� next-hop ����,RIPv2 �� next-hop ����,��������·�ɸ��µ��ض���
ע:����·��������·�ɵ�����:
1������·��Э�鷢��·�ɸ��°���ʱ��Я���Լ����������롣
2������·��Э�鷢��·�ɸ��°���ʱ��Я��·����Ŀ���������롣
��̬·�ɵ����÷���
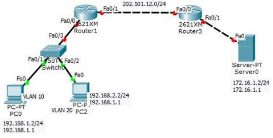
ʵ�ֲ�ͬ����֮����ͨѶ
��һ��:���� PC �ͷ������� IP ��ַ������
PC0:IP ��ַ:192.168.1.1 255.255.255.0
����:192.168.1.1(�������ⶨ�� ���DZ���Ҫ�͵�ַ��ͬһ����)
PC1:IP ��ַ:192.168.2.2255.255.255.0
����:192.168.2.1(�������ⶨ�� ���DZ���Ҫ�͵�ַ��ͬһ����)
server:IP ��ַ:172.16.1.2255.255.255.0 ����: 172.16.1.1
�� �� �� : �� �� �� �� �� �� VLAN
Switch(config)#hostname Sw1 //������������Ϊ SW1
����һ:
Sw1(config)#vlan 10
Sw1(config-vlan)#name VLAN10 //�� VLAN10 ������VLAN10��
������
Switch#vlandatabase
Switch(config-vlan)#vlan 10 name VLAN10 //���� VLAN 10,���� VLAN10 ������VLAN10��
Sw1(config)#vlan 20
Sw1(config-vlan)#name VLAN20
������:�ѽӿڻ�����Ӧ�� VLAN
Switch(config)#int f0/1
Switch(config-if)#sw mo access
Switch(config-if)#sw ac vl 10
Switch(config)#int f0/2
Switch(config-if)#sw mo access
Switch(config-if)#sw ac vl 20
Show vlanbrief //�鿴�ӿ������ĸ� VLAN
���IJ�:·�����ͽ����������Ľӿ���Ҫ���ض�� VLAN. Switch(config)#int f0/0
Switch(config-if)#sw mo trunk
���岽:·�����������ӽӿ�,��Ϊ��ͬ������
IP Router(config)#int f0/0
Router(config-if)#no shutdown
Router(config-if)#int f0/0.10
Router(config-subif)#encapsulation dot1Q 10 //���ϱ�ǩ 10
Router(config-subif)#ip add 192.168.1.1 255.255.255.0 //�����ӽӿڵ� IP ��ַ
Router(config-if)#int f0/0.20
Router(config-subif)#encapsulationdot1Q 10//���ϱ�ǩ 10
Router(config-subif)#ip add 192.168.2.1 255.255.255.0 //���ýӿڵ� IP ��ַ
���岽:�����������ͨ��
PC0:ping192.168.2.1
������:����·���� IP ��ַ
Router(config)#hostname R1 //��·��������Ϊ R1
R1(config)#intf0/1 //���� F0/1 �ӿ�
R1(config-if)#no sh //�����ӿ�(·�����Ͻӿ���Ĭ�Ϲرյ�,��Ҫ�ֶ�����)
R1(config-if)#ipadd 202.101.12.1 255.255.255.0 //���ýӿڵ� IP ��ַR2(config)#intf0/0 //���� F0/0 �ӿ�
R2(config-if)#nosh //�����ӿ�(��Ϊ·�����Ͻӿ���Ĭ�Ϲرյ�,��Ҫ�ֶ�����)
R2(config-if)#ipadd 202.101.12.2 255.255.255.0 //���ýӿڵ� IP ��ַ
���߲�:�鿴·������·�ɱ�:
Show IP route
�ڰ˲�:����·�����ľ�̬·��
R1:IP router 172.16.1.0 255.255.255.0 202.101.12.2 //������һ��(��·����ֱ����·�����Ľӿ� IP ��ַ)
R2: ip route 192.168.1.0255.255.255.0 f0/0 //���ڱ�·�����ij��ӿ�
R2: ip route 192.168.2.0255.255.255.0 202.101.12.1 //���ڱ�·������һ��
�ھŲ�:�鿴·�ɱ�,·�ɱ����д� S ��ǵ�·��,��ʾͨ����̬ѧϰ����·�ɡ�
��ʮ��:������ ping ����,ʵ�ֲ�ͬ����֮���ͨ�š�
PC0 :
ping 172.16.1.2
ping :192.168.2.2
Server:
Ping:192.168.1.2 Ping:192.168.2.2
��̬·�ɵ����������ʽ:
ip route a.a.a.a b.b.b.b c.c.c.c
a.a.a.a ����Ҫ���͵���Զ������� ip,
b.b.b.b ��Զ���������������,
c.c.c.c ����һ��·�����ӿڵ�ַ
ʵ�� ACL���Ʒ����б�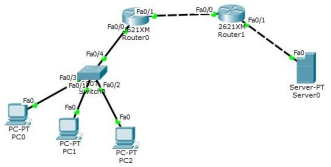
(һ)�� ACL(1-99 1300-1999)���Դ IP ��ַ,ͨ���������߾ܾ�����Э�顣
����һ:������ 192.168.5.0 ���η��ʷ�����
R2:
access-list 1 deny 192.168.5.0 0.0.0.255 //ץȡ 192.168.5.0
access-list 1 permit any //Ĭ�Ͼܾ�����,���г��� 192.168.5.0 ������
interface f0/1
iP access-group 1 out //�� F0/1 �ӿ��µ���,���ݰ���ȥ�ķ�����á�
����
interface f0/0
ip access-group 1 in //�� F0/0 �ӿ��µ���,���ݰ����ķ�����á�
(��)��չ ACL(100-199 2000-2699)���ԴĿ IP ��ַ,�ɾܾ���������Э��Ķ˿ںš�
������:������ 192.168.6.2 ���ʷ������� www ����
R2:
access-list 101 deny tcp host 192.168.6.2 host 172.16.1.2 eq www(80)
access-list 101 permit ip any any //��������(��Ϊ�IJ��Э����Ҫ���������ܴ���)��
interface f0/0
ip access-grup 101 in //�� F0/0 �ӿ��µ���,���ݰ��Ľ��ӿڷ�����á�
������:Ϊ�˱���������,Ҫ��������û������� ping ͨ������,������������ ping ������
R2:
access-list 101 deny icmp any host 172.16.1.2 echo(ping ����:��Դ��Ŀ��)echo-replay(ping �ذ�ʹ��:��Ŀ�굽Դ)
access-list 101 permit ip any any interface f0/0
IP access-group 101 in
�����ַ���� NAT (network address translation)
˽�� ip ��ַ�� 3 ��:
a;10.0.0.0 - 10.255.255.255 10.0.0.0/8 b;172.16.0.0 - 172.31.255.255 172.16.0.0/12 c;192.168.0.0 - 192.168.255.255 192.168.0.0/16
����:���ڲ������в��Ϸ��� IP ��ַת��Ϊ�Ϸ��� ip ��ַ���ӵ�������
NAT �ļ�������:
�ڲ����ص�ַ:˽�� IP,����ֱ�����ڻ�������(NAT ת��֮ǰ�� IP ��ַ)
�ڲ�ȫ�ֵ�ַ:���������ڲ����� IP ��ַ��,�������ڻ������ϵĺϷ��ĵ� IP ��ַ��(NATת��֮��� IP ��ַ)
NAT ����
1# �ڲ���ַת��
2# �����ڲ���ȫ�ֵ�ַ
3# TCP ���ؾ���
4# ��������ַ�ص�
��̬ NAT:
ʵ��:
��һ��:����� ping ͨ
�ڶ���:�������� ip ��ַ,��������ͨ
������:����������·��������һ��ȥ�������ĵľ�̬Ĭ��·��
r1:ip route 0.0.0.0 0.0.0.0 202.101.12.2
���IJ�:����ַ����
����:���� IP ��ַΪ 192.168.2.2 �ķ����� ip ת��Ϊ 200.2.2.2 Ϊ�������û��ṩ�������ַ����:r1(config)#ip nat inside source static 192.168.2.2 200.2.2.2
�����ʽ:
ip nat inside source static �ڲ����ص�ַ�ڲ�ȫ�ֵ�ַ�����ڲ��ӿں��ⲿ�ӿ�
r1(config)#int f0/0.10
r1(config-subif)#ip nat inside
r1(config-subif)#int f0/0.20
r1(config-subif)#ip nat inside //�� f0/0.10 f0/0.20 ����Ϊ�ڲ��ӿ�(�ڲ��ӿڻ����ⲿ�ӿ�����,ֻ�������� ip ��ַ�Ľӿ�����)
r1(config)#Int f0/1
r1(config-if)# ip nat outside //�� f0/1 ����Ϊ�ⲿ�ӿ�
�� r2 ��ָһ���ذ�·��
r2:
ip route 200.2.2.0 255.255.255.0 202.101.12.1
ʵ�鲽��:
����һ:
��һ��: ����� ping ͨ
�ڶ���: �������� IP ��ַ,��������ͨ
������: ����������·����������һ��ȥ�������ľ�̬Ĭ��·��R1 :
ip route 0.0.0.0 0.0.0.0 202.101.12.2
���IJ�: ����ַ����
����:������ IP ��ַΪ 192.168.2.2 �ķ�����IP ת��Ϊ 200.2.2.2 Ϊ�����е��û��ṩ����1�������ַ����
R1(config)#ip nat inside source static 192.168.2.2 200.2.2.2 �����ʽ;ip nat inside source static �ڲ����ص�ַ �ڲ�ȫ�ֵ�ַ2�������ڲ��ӿں��ⲿ�ӿ�
R1(config-subif)#int f0/0.20
R1(config-subif)#ip nat inside //f0/0.20 ����Ϊ�ڲ��ӿ�(�ڲ��ӿڻ����ⲿ�ӿ����� ֻ�������� IP ��ַ�Ľӿ�����)
R1(config)#int f0/1
R1(config-if)#ip nat outside //�� f0/1 ������ⲿ�ӿ�
���岽:�� R2 ��ָһ���ذ�·��R2:
ip route 200.2.2.0 255.255.255.0 202.101.12.1
������:
��һ��:�ڲ�������ֻ�����ṩ tcp 80 ����
R1(config)#ip nat inside source static tcp 192.168.2.2 80 200.2.2.2 8888
�ڶ���:�� NAT ���ڲ��ӿں��ⲿ�ӿ�
r1(config-subif)#int f0/0.20
r2(config-subif)#ip nat inside
r1(config)#int f0/1
r1(config-if)#ip nat outside
��̬ NAT ���ڲ��� IP ��ַ���õ�ӳ����ⲿ�����еĺϷ� ip ��ַ,�����ڷ�����(�ڲ������еķ�������Ҫ�������ṩ����,Ϊ�˰�ȫ���,ʹ�þ�̬ NAT ֻ������������IJ��ֶ˿�)
PAT(Port Address Translation)��̬��ַת��:
���Խ��ڲ������е� ip ��ַӳ�䵽������һ�� ip ��ַ�IJ�ͬ�˿ڡ���һ��:
ץȡ������ 192.168.1.0/24 �� 192.168.2.0/24 ����������������R1(config)#access 1 permit 192.168.1.0 0.0.0.255
R1(config)#access 1 permit 192.168.2.0 0.0.0.255
�ڶ���:
���� NAT ת��
�� ACL 1 ��������� IP ������·�����ӿ� f0/1 ȥ����������
r1(config)#ip nat inside source list 1 interfacef0/1 overload //����˿ڿ���
������:
�����ڲ����ⲿ�ͽӿ�
r1(config)#int f0/0.10
r1(config-subif)#ip nat inside
r1(config)#int f0/0.20
r1(config-subif)#ip nat inside
�鿴����:
r1#show ip nat translations //�鿴 nat ��ӳ���б���
r1#clear ip nat translations //�� nat ��ӳ���
HDLC �� PPP ������·��װЭ��
������·��������Ĵ�����·��װЭ��,Cisco Ĭ�ϵĴ��еķ�װ��ʽΪ HDLC,����Ϊ�˺��������̼���,������·���õ� PPP Э�顣
һ�������� ppp �ػ����̰����Ľ�: 1# ��·������
2# ȷ����·������
3# �����������
4# ��·��ֹ��
PPP �� CHAP �� PAP ��֤:
1# PAP ��֤
����������,����Զ�����Ľڵ������ĵķ�ʽ�����Լ����û���������,Ȼ��,���Ľ� ����ұ��ش�ŵ��û���������,����û���������һ�¿��Խ�������,�����һ��,�� �ܽ������ӡ�
����������֮��,Զ�˻�ϵ������Ľڵ㷢���Լ����û��������롣
��һ��:r1 �� r2 �����Լ����豸��:
r1:ho r1
r2:ho r2
�ڶ���:
r1 �� r2 ��װ ppp ���� ip ��ַ:
r1:
int s1/0 en ppp
ip add 202.101.12.1 255.255.255.0
no sh
r2:
int s1/0 en ppp
ip add 202.101.12.1 255.255.255.0
no sh
������:r2 �� r1 ����֤
r1:user r2 pass 222 //���屻��֤�����û���������
int s1/0
ppp authentication pap//�ӿ��¿��� pap ��֤
r2:
Int s1/0
ppp pap sent-username r2 password 222
���IJ�:
r1 pass 111
int s1/0
ppp authentication pap
r1:
int s1/0
ppp pap sent-username r1 password 111
R1:
username R2 password 222
interface Serial1/0
ipaddress202.101.12.1255.255.255.0
encapsulation ppp
ppp authentication pap
ppp pap sent-username R1 password 111
clock rate 2000000 //�ڴ��нӿڵ� DCE �� ����Ҫ��ʼ��Ƶ�ʵĶ���,����豸�Զ�������Ҫ�ֶ�����
R2:
username R1 password 111
interface Serial1/0
ip address 202.101.12.2 255.255.255.0
encapsulation ppp
ppp authentication pap
ppp pap sent-username R2 password 0 222
2# chap �� ֤
����������Ҫ��������
1# ��֤������֤������ʱ�䡣
2# ����֤������֤��ѯ��
3# ���ܻ��߾ܾ�����(������֤�������Ǽ��ܵ�)
һ��chap ˫��� chap ��֤
r1: //���� chap ��֤(��֤˫�������붨��Ҫһ��)
hostname r1 //�����豸��
username r2 password cisco //�����û���������
int s1/0
encapsulation ppp //�ӿڷ�װ ppp
ppp authentication chap //�ӿ���ʹ����֤
r2:
hostname r2
username r1 password cisco
int s1/0
encapsulation ppp
ppp authentication chap
2��chap �ĵ�����֤:r2 �� r1 ȥ��֤:
r1:
hostname r1
username r2 pass cisco
int s1/0
encapsulation ppp
ppp authentication chap callin
r2:
hostname r2 int s1/0
encapsulation ppp
ppp chap hostname r2
ppp chap password cisco
DHCP(��̬��������Э��)��ԭ��:
�ĸ���Ϣ:1# Discovery 2# Offer 3# Request 4# Ack
1.�������͵�ַ������Ϣ discovery(˭���Ը��ҵ�ַ)
2.�������յ���ַ������Ϣ,��Ӧ����,�ظ� offer ��Ϣ (���е�ַ���Է���)
3.�����յ��ķ����� offer ��Ϣ,���� request ��Ϣ�� (�Զ���������������� ip ��ַѡ��,Ȼ���������Լ�ѡ�е� ip ��ַ)
4.�������յ���������������Ϣ��������Ϣ,���� ack ��ȷ��,���ҷ��͵�ַ���õ�ʱ������Ϣ��
DHCP �Զ���ȡ IP ��ַ
R1(config)#ip dhcp pool ccna //���� DHCP ��ַ�ص�����Ϊccna
R1(dhcp-config)#network 192.168.1.0 255.255.255.0 //�����·��������Ϊ192.168.1.0/24
R1(dhcp-config)#default-router 192.168.1.1 //���������ص�ַ
R1(dhcp-config)#dns-server 218.2.135.1 //DNS �������� IP ��ַ
R1(config)#ip dhcp excluded-address 192.168.1.1 //���� 192.168.1.1 ��������
R1(config)#ip dhcp excluded-address 192.168.1.1 192.168.1.5 //���� 1.1- 1.5 ��������
R5(config)#int f0/0
R5(config-if)#ip address dhcp //R5 ���� IP ��ַ
DHCP �м�:·�����Ľӿڻ����㲥��Ϣ,��Ҫ�м��� DHCP ���������� ip ��ַ
����:
r1:
int f0/0
ip helper-address 202.101.12.2 //ip ��ַ�� DHCP �������ĵ�ַ
DHCP ���䲿��

��ͨ�Ļ�ȡ��ַ:
R2(config)#ip dhcp pool QLB
R2(dhcp-config)#network 202.101.12.0 255.255.255.0
R2(dhcp-config)#dns-server 202.101.12.2
R1(config)#int f0/0 R1(config-if)#no shutdown R1(config-if)#ip address dhcp
R1 ͨ�� DHCP ���Ψһ�� ip ��ַ:
R2:
int f0/0
ip add 202.101.12.1 255.255.255.0
no sh
ip dhcp pool bhb
host 202.101.12.100 255.255.255.0 //������Ҫ�·ŵ� ip ��ַclient-identifier 01.cc.0018.b800.00 //���� ip ��ַ������ mac ��ַ01.aaaa.bbbb.cccc
·������ȡ IP ��ַ:
R1(config)#int f0/0
R1(config-if)#ip address dhcp client-id f0/0
��ǿ���ڲ�����·��Э��( EnhancedInteriorGatewayRoutingProtocol) cisco ˽��Э��
���:88
�鲥��ַ:224.0.0.10
EIGRP �ڲ���������Ϊ 90,�ⲿ�������� 170��
Router # show running-config | section router // ��ѯ��ǰ·���������е�����Э��
Ϊʲô˵ EIGRP �Ǹ���·��Э�顣
1# EIGRP �е����ű�
2# EIGRP ��һ������·��Э��,֧�� VLSM �� CIDR,����������ڵ����ֹ�·�ɻ���
3# һ������� EIGRP ���Ա�֤�ٷְ���·
4# �� EIGRP ������,��·�ɸı�ʱ,EIGRP �õĴ������¡��������µķ�ʽ,ʹ·����������
5# EIGRP ʹ���������ڴ��������·���㷨��DUAL �㷨��,�����ڶ�̨·����֮��ͨ��һ�����еķ�ʽִ��·�ɵļ���
6# EIGRP ������������Э���ģ��(PDM),ʹ EIGRP ����֧�ָ�����������
7# EIGRP ʹ���˿ɿ�����Э��(RTP),��֤�ڽ���·��ʱ������
һ��EIGRP �� 11 ������:
1.���ľ���ʸ��·��Э��
2.��������
EIGRP ���е��㷨 DUAL(��ɢ�����㷨)
3.�����������
֧�� VLSM(�ɱ䳤��������)
�������е��κ�һ���ڵ�(�൱��һ��·����)����
4.�鲥��������㲥����
�鲥��ַΪ 224.0.0.10(TTL Ϊ 2)
(RIP �汾һ,�㲥���� IP ��ַ 255.255.255.255)
(RIP �汾��,�鲥���� IP ��ַ 224.0.0.9)
5.100%��·:�� DUAL �㷨������
6.֧�� VLSM �Ͳ���������(·�ɸ������ݰ���Я������)��
7.���ü�
8.��������κεط�֧���ֹ����ܡ�
9.���ڸ���(�� DUAL �㷨����)��
10.֧�ֶ��������Э��(�� ip,ipx,apple talk)��
11.����֧�ֵȼۺͲ��ȼ۵ĸ��ؾ��⡣(EIGRP ��ĿǰΨһ֧�ַǵȼ۵ĸ��ؾ����·��Э��)
����EIGRP �����ű�:
1# �ھӱ�:
�����Щ��·��������Щ·���������� EIGRP �ھ�
�ھӽӿڵ� IP ��ַ�ͱ�·�����Ľӿ�,Ψһȷ��һ���ھӡ�
�鿴�ھӱ� show ip eigrp neighbors
2# ���˱�
��ű�·���յ���·��,����Щ�ھ�·����������
�鿴���˱� show ip eigrp topology
3# ·�ɱ�
��Ŵ�Դ��Ŀ������·��
�鿴·�ɱ� show ip route
����EIGRP ���ĸ��ؼ�����
1# ������Э��ģ��(PDM ����·��Э��)
����֧�ֶ��������Э��(IP , IPX , apple talk)�����ж����� EIGRP ģ�鸺����Ӧ��·��ѡ��
2#�ɿ��ش���Э��(RTP)
EIGRP ���ݰ�������пɿ��Ժ������ԡ�
3# �ھӷ��ֺͻָ�
hello ���������Եķ���,���Է��ֺͻָ��ھӹ�ϵ�����ڴ������� t1(1.544M)����· hello ʱ��Ϊ 5s
���ڴ���С�ڵ��� t1(1.544M)����· hello ʱ��Ϊ 60s
Holdtime(�ȴ�ʱ��)�� 3 ���� hello ʱ��,(15 ��,180 ��)�������ھӵĻָ�����·������ 3 ����ʱ����û���յ��ھӷ�������hello ���ݰ�,��Ͼ��ھӹ�ϵ,����� 3 ��hello ʱ���������յ� hello ���ݰ�,�ڲ��Ͼ��ھӹ�ϵ��
4#��ɢ�����㷨 DUAL
���·����ʧЧ�����ھӲ�ѯ��û�п��к��·����,�������װ��·�ɱ�,���û���� ���ھ�ȥ��ѯ��
�ġ�DUAL(��ɢ�����㷨)�㷨���������:
1# FD(feasible distance)���о���ֵ:�ӱ�·����ȥ��Ŀ�����ε����ž���Ϊ���о��롣
2# AD(advised distance)ͨ�����ֵ:��·�������ھ�ͨ���·����,���Լ�ȥ��Ŀ�����εľ��롣
3# FC(feasible condition)����������:��·�����ھ�ͨ��ĵ���Ŀ�����εľ����Ƿ�С�ڱ�·����ȥ����ͬĿ�����εľ���,���ж� ad ֵ�Ƿ�С�� fd ֵ�����С�����������������,�����С��,�����������������
4# FS (feasible successor)�����Ժ��·����:����������������ھ�·����,��Ϊ�����Ժ��·������
5# successor ���·����:ӵ�����ž����·�ɽ���Ž�·�ɱ�,��ͨ����������·�ɵ��ھ�·�����������·������
DUAL ��һ������״̬��,����ѡ����Щ��Ϣ�洢�����˱���·��ѡ����С�
DUAL �㷨��·�������� query ���ĺ�,�ᴦ�� active ״̬,�����ʱ�䲻���յ��ھӻظ��� reply ��Ϣ,��Ῠ�� active ״̬��(query ��ѯ active ���)
SIA(stack in active)��ʱ��,ȥ�����ʱ���ղ��� reply ��Ϣ�����⡣(reply �ش�)
�塢SIA(stack in active)��ʱ��:
�ϵ� SIA ��ʱ��:
·�����ڷ��� query ����֮��� 3 ������û���յ��ھӵ� reply ��Ϣ,����������ǵ��ھӹ�ϵ��
�µ� SIA ��ʱ��:
·�����ڷ��� query ���ĺ�� 1.5 ������û���յ��ھӷ������� reply ��Ϣ,����SIA-query ��Ϣ,ÿ�� 1.5 ���ӷ���һ��,һ����������,����� 3 �η��ͽ���֮��û���յ� reply �������ھӹ�ϵ��(6 ���Ӻ������ھӹ�ϵ)��
���´��� SIA ״̬��ԭ��:
1# ��ѯ��Χ����
2# ·����̫æ��Ӧ��
3# ·��֮�����·��������,���²�ѯ���Ķ�ʧ��
4# ijЩ������·ʧЧ��
����EIGRP �� 5 �����ݰ�:
1# hello �����ھӵķ��ֺͻָ��Ĺ���,hello ����ʹ���鲥��ʽ����,����ʹ�ò��ɿ��ķ�ʽ���͡�
2# updata (·�ɸ��±���)
���ڴ���·�ɸ�����Ϣ,���ݰ��ǰ��跢�͡��������鲥����ʽ���͵�,�ǿɿ������ݰ��� ��Ҫ ack ȷ�ϡ�
3# query (��ѯ����)
���� DUAL �㷨��,��û���ҵ����к�̵�·�����������,���ھӷ��Ͳ�ѯ����,ѯ���Ƿ�ǰ��Ŀ�����ο��к��·����,�Ե������鲥����ʽ����,�ǿɿ��ġ�
4# reply �� DUAL �㷨��ȥ��Ӧ��ѯ����,�Ե����ɿ����͡�
5# ack ����ȷ�ϸ���,��ѯ,Ӧ��,�Ե�����ʽ����(�Dz����κ����ݵ� hello ��,ֻ����һ����Ϊ���ȷ�Ϻ�)��(ack ȷ��)
������Ҫȷ�ϵ����ݱ���,���û���յ���Ӧ��ȷ�����ش� 16 ��,16 ��֮�������ھӹ�ϵ���� RTO(���ʱ��)�����ش����ݰ�֮��ļ��ʱ�䡣
�ߡ�EIGRP �����ھӵĹ���
1# A ���� hello ���ĸ� B��
2# B ���� hello ���ĸ� A,ͬʱ�����Լ���·�ɸ�����Ϣ�� A��
3# A �ظ� ACK ���Ķ� B �� UPdata ����ȷ��,����·����Ϣ��Ž��Լ������˱���
4# A �����Լ���·�ɸ�����Ϣ�� B��
5# B ���� ACK ���Ķ� A �� UPdata ����ȷ��,����·����Ϣ��Ž��Լ������˱���
�鿴����:
R1#show ip eigrp neighbors //�鿴�ھӱ�
R1#show ip eigrp topology //�鿴eigrp���˱�
R1#show ip eigrp topology-all-links //�鿴�������˽ṹ
R1#show ip eigrp interfaces //�鿴��·������Щ�ӿ�����eigrp
�ˡ�EIGRP �����ھӵ��ĸ���Ҫ����
1# as ��Ҫһ�¡�
2# k ֵҪһ������show ip protocols,Ĭ������� k1 �� k3 ���� 1
3# ��֤ͨ��(��֤������:ȷ��·�ɴӺϷ����ھ�ѧ����)
4# ��ͬһ������
�š�EIGRP �����������:
1# ���� 2# ʱ�� 3# �ɿ��� 4# ���� 5# mtu
EIGRP ʵ��

R1(config)#int e0/1
R1(config-if)#ip add 202.101.12.1 255.255.255.0
R3(config-if)#no sh R1(config)#int loopback 0
R1(config-if)#ip add 1.1.1.1 255.255.255.0
R2(config)#int e0/2
R2(config-if)#ip add 202.101.12.2 255.255.255.0
R3(config-if)#no sh R2(config)#int loopback 0
R2(config-if)#ip add 2.2.2.2 255.255.255.0
R3(config)#int e0/1
R3(config-if)#ip add 202.101.23.3 255.255.255.0
R3(config-if)#no sh R3(config)#int loopback 0
R3(config-if)#ip add 3.3.3.3 255.255.255.0
���� EIGRP ��
R1(config)#router eigrp 100 //���� EIGRP Э�鶨�� as ��Ϊ 100 R1(config-router)#no auto-summary //�ر��Զ�����
R1(config-router)#network 202.101.12.1 0.0.0.0 //·�����ӿ� IP �ľ�ȷ����
R1(config-router)#network 1.1.1.1 0.0.0.0 //·�����ӿ� IP �ľ�ȷ����
R2(config)#router eigrp 100 R2(config-router)#no auto-summary
R2(config-router)#net 202.101.12.2 0.0.0.0
R2(config-router)#net 202. 101.23.2 0.0.0.0
R2(config-router)#net 2.2.2.2 0.0.0.0
R3(config)#router eigrp 100 R3(config-router)#no auto-summary
R3(config-router)#net 202.101.23.3 0.0.0.0
R3(config-router)#net 3.3.3.3 0.0.0.0
show ip interface brief //�鿴���ж˿ڵ�״̬��Ϣshow int f1/0 //��ʾ�˿���Ϣ
FD �Ķ�����(metric)=(10^7/��С����+��ʱ��/10)*256 kbps usec
R1 ѧ�� 5.5.5.0/24 �Ķ���ֵΪ 161280
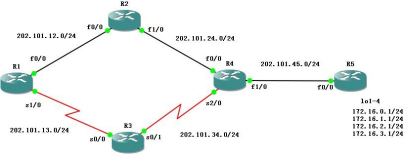
EIGRP �ĵȼ۸��ؾ���:
EIGRP Ĭ��֧�� 4 �����ؾ���,���֧�� 16 ����
offset-list(ƫ���б�),����Ծ���·��,�������Ķ���ֵ�� �� r1 ����� 5.5.5.0/24 ��·��ʵ�ֵȼ۸��ؾ���:
1,ץȡ 5.5.5.0/24 ��·��
access 1 per 5.5.5.0
2.�� eigrp ������ʹ�� offset-list ��·�ɴ� r2 �������ĽӿڼӴ����ֵ
router eigrp 100
offset-list 1 in 2651136 f0/0 //�ڽӿ�f0/0 �Ľ��������·�� 5.5.5.0 �Ӵ����ֵ 2651136
ƫ���б�ֻ����һ����������һ��
R1#show run | section ei ɸѡ eigrp ������
EIGRP �ķǵȼ۸��ؾ����:
ʵ�ַǵȼ۸��ؾ��������
1.����븺�ؾ����·������Ŀ���ܳ��������,Ĭ�� 4 ��
2.��μӸ��ؾ����·���� ad ֵ����С������ fd ֵ
variance ��������;����һ��·��������·������̶�Ĭ��ֵΪ 1.
3.������·����������һ�� variance,��μӷǵȼ۸��ؾ����·���� fd ����С�����ŵ� fd
���� variance ��ֵ(��μ� fd <���� fd*variance)
�� R1 ���ҵ��п��к��·������·��,ʵ�ַǵȼ۸��ؾ���ǵȼ۸��ؾ���
R1(config)#router ei 100
R1(config-router)#variance 2 //���������ij� 2
R1#show ip rout 202.101.34.0 255.255.255.0 //�����鿴·����Ϣ
��� SIA ��ѯ��Χ����: 1# �������Ʋ�ѯ��ΧR5(config)#int lo1
R5(config-if)#ip address 172.16.0.1 255.255.255.0 R5(config-if)#exit
R5(config)#int lo2
R5(config-if)#ip address 172.16.1.1 255.255.255.0 R5(config-if)#exit
R5(config)#int lo3
R5(config-if)#ip address 172.16.2.1 255.255.255.0 R5(config-if)#exit
R5(config)#int lo4
R5(config-if)#ip address 172.16.3.1 255.255.255.0 R5(config-if)#exit
R5(config)#router eigrp 100
R5(config-router)#net 172.16.0.1 0.0.0.0
R5(config-router)#net 172.16.1.1 0.0.0.0
R5(config-router)#network 172.16.2.1 0.0.0.0
R5(config-router)#network 172.16.3.1 0.0.0.0 R5(config-router)#exit
EIGRP ������ܺ�,���ڱ�·��������һ��ָ�� null0 �Ļ���·��,��������Ϊ 5������:
int f0/0
ip summary-address eigrp 100 172.16.0.0 255.255.252.0 5 int s0/0
ip summary-address eigrp 100 172.16.0.0 255.255.252.0 5
2# ĩ��·�������Ʋ�ѯ��Χ�� eigrp ·������Ϊĩ��·����R4(config)#router eigrp 100
R4(config-router)#eigrp stub //R4 ֻ�����ھ�ͨ�汾�ر���ֱ�����κ��ڱ��ػ��ܵ�·��
EIGRP ����֤:
EIGRP ֻ֧��������֤,ȷ��·�ɴӺϷ����ھ�ѧ������
1.���� key
R1(config)#key chain ccnp //���� key-chain ��Ϊ ccnp
R1(config-keychain)#key 1 //����Կ����
R1(config-keychain-key)#key-string cisco //������ԿΪ cisco
�ڽӿ����� EIGRP ��������֤,���� key chain
R1(config-if)#ip authentication mode eigrp 100 md5 //����������֤R1(config-if)#ip authentication key-chain eigrp 100 ccnp //����������֤
R2(config)#key chain ccnp //���� key-chain ��Ϊ ccnp
R2(config-keychain)#key 1 //����Կ����
R2(config-keychain-key)#key-string cisco //������ԿΪ cisco R2(config)#int f0/0
R2config-if)#ip authentication mode eigrp 100 md5 R2(config-if)#ip authentication key-chain eigrp 100 ccnp
����豸����������ܵķ���,����������ʹ������Cshow key chian //��ȡ���������Կ
EIGRP �·�Ĭ��·��:
1.�طַ���̬·��
��һ��:
����һ����̬��Ĭ��·��(���ڳ��ӿ�)
ip route 0.0.0.0 0.0.0.0 f0/0
�ڶ���:
�� eigrp �����г�ַַ���Ĭ��·��
router reigrp 100
redistribute static //�طַ���̬·��
2.ʹ�� network 0.0.0.0
��һ��:
����һ����̬��Ĭ��·��(���ڳ��ӿڵ�)
ip route 0.0.0.0 0.0.0.0 f0/0
�ڶ���:
�� eigrp ������������ 0.0.0.0 router eigrp 100
network 0.0.0.0 3.default-network
��һ��:
����һ��Ĭ�ϵ���������
ip default-network 100.0.0.0(a ��)
�ڶ���:
����һ��������Ļ��ڳ��ӿھ�̬·��ip route 100.0.0.0 255.0.0.0 f0/0
������:���������� eigrp ����������router eigrp 100
network 100.0.0.0
4.�ӿ���ȫ 0 ����·��
int f0/0
ip summary-address ei 100 0.0.0.0 0.0.0.0
�� �� �� �� · �� �� �� OSPF(open shortest pathfirst) (����Э��)
OSPF ������� 89
��������Ϊ 110
��·״̬·��Э��TTL=1
������:
������Ӧ����仯
������仯ʱ���ʹ�������
�Խϵ͵�Ƶ�ʷ��Ͷ��ڸ��³�����·״̬ˢ��
OSPF ������:
�Ǹ�����:���� 0
�ǹǸ�����:�� 0 ��(�ǹǸ�����ͨ�ű�������� 0 ����)
OSPF ����������:
1.����·�ɱ�����Ŀ
2.�������ڵ����˱仯��Ӱ�������ڱ���
3.�� LSA(link- state -advanced ��·״̬ͨ��)1# 2# 3# 4# 5# 7#��չ������������4.Ҫȥ��ȡ����������
OSPF ·����������:
ABR(area border router)����߽�·��:��һ���ӿ��������� 0,������������ 0 �����������·������
ASBR(autonomous system border router)����ϵͳ�߽�·��Э��:�������� ospf ���������·
��Э���·������
�Ǹ�·����:����һ���ӿ���Ǹ�����������·������ �ڲ�·����:·���������нӿ�����ͬһ������
LSA(��·״̬�㲥):LSA ������״̬Э��ʹ�õ�һ������,�������й��ھӺ�ͨ���ɱ�����Ϣ��
OSPF �� 5 �����ݰ�:
hello ����:���ڷ���,�������������ھ�,Э�̲���,����(keeplive)�ھ�,ȷ��˫��ͨ��,�ڹ㲥��ǹ㲥������ѡ�� DR �� BDR��
DBD(database description ���ݿ���������):Я�� LSA ��ͷ����Ϣ��
LSR(link-state request ��·״̬������):ȥ���������Լ�����·���ݿ�û�е� LSA��LSU(link-state update ��·״̬���±���):������Ӧ LSR ����(һ�� LSU ������ֻ��Я��һ�� LSA)��
LSACK(link-state Acknowledgment ��·״̬ȷ����Ϣ):����ȷ��·�����յ��� LSA��
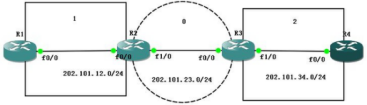
R1(config)#router ospf 1 //���� ospf Э��,������̺�Ϊ 1
R1(config-router)#router-id 1.1.1.1 //���� ospf �� router-id Ϊ 1.1.1.1
R1(config-router)#net 202.101.12.1 0.0.0.0 area 1
R1(config-router)#net 1.1.1.1 0.0.0.0 area 1
- ���̺��DZ�����Ч,�������ֱ�·�����IJ�ͬ OSPF ����
- router-id ����Ψһ��ʶ��·����,�� IP ��ַ��ʽ��д��
OSPF �� router-id ѡ�ٹ���:
A:��������� router-id ��ʹ�ö���� router-id:
B:���û�ж��� router-id,��ʹ�ñ�·�����Ļ��ؽӿ� IP ��ַ���� Ip,��Ϊ��·������ router-id:
C:���û�л��ؽӿ�,��ʹ�ñ�·���������ӿ� ip ��ַ���� ip,��Ϊ��·������router-id��
R2(config)#router os 1
R2(config-router)#router-id 2.2.2.2
R2(config-router)#network 202.101.12.2 0.0.0.0 a 1 //�� 12.2 ����� ospf ���� 1
R2(config-router)#net 202.101.23.2 0.0.0.0 a 0 //�� 23.2 ����� ospf ���� 0
R2(config-router)#net 2.2.2.2 0.0.0.0 a 0
�鿴����:
show ip os int b //���Բ鿴·��������Щ�ӿ������� ospf,�Լ����̺�,����ź� cost ֵ�ȡ�
OSPF �����ű�:
1.OSPF �ھӱ�
show ip ospf neighbor //�鿴 OSPF �ھӱ�
�ھӵ� ip ��ַ�ͱ�·�����Ľӿڿ���Ψһȷ��һ�� ospf ���ھ�
2.OSPF ���˱�(���ݿ��)
��show ip ospf database //�鿴��·��������·���ݿ�
3.OSPF ·�ɱ�
�Cshow ip route //���ǰ��Ŀ�����ε�����·�ɡ�
OSPF �����ھӵı�Ҫ����
1# �����һ��
2# hello ʱ��Ҫһ���� ospf �� hello ʱ��int f0/0
ip ospf hello-interval 30 //�� hello ʱ����Ϊ 30s
show run int f0/0 //�����鿴�ӿ�����
3# ��֤Ҫͨ��
4# ĩ�ڱ�ʶҪһ��
(OSPF ·��Э�鶨�廻�ؽӿ�Ϊ�����ĩ������ͨ��·�ɵ�ʱ����32 λ����·�ɵ���ʽͨ��)
5# MTU(����䵥Ԫ)Ҫһ��(MTU ��һ�»Ῠ�� exstart ״̬)
�� mtu(Ĭ�� 1500)ֵR4(config)#int s1/0 R4(config-if)#mtu 1400
O ��������·�� intra �ڲ�
OIA �������·�� inter ֮��
Hello ���ݰ��еļ����ֶ�:
Router id
Hello and deal interval * �� hello ʱ��� 4 ��neighbors
Area id * �����
Router priority ���ȼ�(Ĭ������ӿ����ȼ�Ϊ 1) DR ip address
BDR ip address Authtication password * Stub area flag *
DR �� BDR(ָ��·�����ͱ���ָ��·����)
�ڶ�·������,·����ֻ�� DR �� BDR �����ھӹ�ϵ���� DR �� BDR ·������ DRother
DRother �� DRother ֮����ھӹ�ϵ״̬Ϊ 2-way
DR �� BDR ��ѡ�ٹ���(�������̿�������ѡ�� DR,BDR)
1# �ھ�֮����ͨ������ hello ���ݰ�ѡ�� DR �� BDR��
2# ���ȼ��ߵ�Ϊ DR,�θ���Ϊ BDR,Ĭ�Ͻӿ�����Ϊ 1;������ȼ�һ��,��ͨ�� router-id ��ѡ��,router-id ���Ϊ DR,�θ���Ϊ BDR��������ȼ�Ϊ 0,��������μ� DR �� BDR ��ѡ�١�
3# DR �� BDR ѡ�ٳ������ȶ���,��ʹ�����������ȵĸ��ߵ�·��������Ҳ������ռ
DR �� BDR �ĵ�λ��
����һ:
�� r3 ��Ϊ BR,r2 �� r4 ������ DR �� BDR ��ѡ�١�
R2:
R2(config)#int f1/0
R2(config-if)#ip ospf priority 0
R2#cle ip os process //���� ospf ����,�� ospf ��������������
R4:
R4(config)#int f0/0 R4(config-if)#ip os priority 0
R4#cle ip os process //���� ospf ����,�� ospf ��������������
R3#cle ip os process //���� ospf ����,�� ospf ��������������
OSPF �������鲥��ַ:
�ڹ㲥�����ǹ㲥��·������������:
1# DRother ʹ�� 224.0.0.6 �� DR,BDR �������ݰ���
2# DR,BDR ʹ�� 224.0.0.5 �� DRther �������ݰ���
OSPF �� 7 ���ھ�״̬:
OSPF �����ھӹ�ϵ 4 ������
1�� OSPF �����ڽ�:
1# Down:A �� B �˴�û���յ��Զ˵� hello �ı��ġ�
2# init :A �� B ���� hello ��,���а��� A �� router-id,B �յ� A �� hello ����,���� A�� router-id,�� A ���ھ�״̬��Ϊ init��
3# 2-way:B �� A ���� hello ����,���а��� B �Լ��� router-id �� A �� router-id,A �յ� B
�� hello ����,�����Լ��� router-id,���ھ�״̬��Ϊ 2-way��(�γ�˫���ڽӹ�ϵ)
2��������Ϣ(DBD ����):
4# Exstart:A ��B ����˫��ͨ��֮��,�������Ϳյ� DBD ����,����Э������(master/slane)��ϵ,���յ��յ� DBD ���ĺ�,���ھ�״̬��Ϊ Exstart��(MTU ���߲�ƥ��,��ͣ�� Exstart ״̬)
5# Exchange:A �� B ���� DBD ����,ͬ�����ݿ�,���յ��Զ˷ǿյ� DBD ���ĺ�,���ھ���Ϊ Exchange ״̬��
3����������·״̬���ݿ�(LSR LSU LSACK)
6# Loading:A �� B ֮��� LSA ���ڲ���,��Զ������� LSR,�Զ��յ� LSR ֮��,�ھ�״̬��Ϊ loading��
4����ȫ�ڽ�(���ڷ��� hello ����)
7# Full:A �� B �����ݿ���ȫͬ��֮��,���ھ�״̬��Ϊ full(��ȫ�ڽӹ�ϵ)��
OSPF �ھӹ�ϵ:�ھ�·����֮����Խ���˫���ͨ�������ھӹ�ϵ��
OSPF �ڽӹ�ϵ:OSPF �ھ�֮����� LSA ��ͬ��֮��,��־�ڽӹ�ϵ������
OSPF ����������:
show ip os int f0/0 // �鿴�ӿ� f0/0 ����Ϣ
�ڽӿ�ģʽ����,ͨ������:
ip ospf hello-interval
1# BROADCAST �㲥������
Ĭ����̫���� OSPF ��������Ϊ broadcast��
Hello ʱ��Ϊ 10s,deadtime Ϊ 40s,��Ҫѡ�ٳ� DR �� BDR�������Զ������ھ�
�鲥��ַ������ 224.0.0.5 �� 224.0.0.6��
2# point-to-point ��Ե���������
Ĭ������´�����· PPP �� HDLC ����������Ϊ��Ե㡣
Hello ʱ��Ĭ�� 10s,deadtime Ϊ 40s,����Ҫѡ�ٳ� DR �� BDR,�����Զ������ھӡ��鲥��ַֻ��һ�� 224.0.0.5��
(��Ե��������ͺ� broadcast �������Ϳ��Խ�����ȫ�ڽӹ�ϵ,��(�������Ͳ�ƥ��)�˴˲��ܴ���·����Ϣ)��
3# NBMA �ǹ㲥��·����Ĭ��֡�м̵���������Ϊ NBMA��
Hello ʱ��Ϊ 30s,deadtime Ϊ 120s,��Ҫѡ�� DR �� BDR���������Զ������ھ�,��Ҫ�ֶ�ָ�ھӡ�
R2(config)#int f1/0
R2(config-if)#ip os network non-broadcast R3(config)#int f0/0
R3(config-if)#ip os network non-broadcast R4(config)#int f0/0
R4(config-if)#ip os network non-broadcast
R2,R3,R4:�������Զ�ָ�ھ�,��Ҫ�ֶ�ָ�ھӡ�
R2(config)#router os 1
R2(config-router)#neighbor 202.101.234.3 //�ֶ�ָ�Զ�����˿ڵ� ip ��ַ
R2(config-router)#neighbor 202.101.234.4
R3(config)#router os 1
R3(config-router)#neighbor 202.101.234.2
R3(config-router)#neighbor 202.101.234.4
R4(config)#router os 1
R4(config-router)#nei 202.101.234.2
R4(config-router)#nei 202.101.234.3
attempt (����)�ھ�״̬:���������� NBMA ����,��һ̨·�������г�Ϊ DR �� BDR ���ʸ��ʱ��,���Խ��ھӵ�״̬ת��Ϊ attempt,���� down �� init ֮�䡣
4# point-to-multipoint �㵽�������������Զ���
Hello ʱ�� 30s,deadtime 120s
�����Զ������ھ��鲥��ַ 224.0.0.5
ģ��㵽������������ R1,R2 ��
R1:
R1(config)#int f0/0
R1(config-if)#ip os net point-to-multipoint R2:
R2(config)#int f0/0
R2(config-if)#ip os net point-to-multipoint
5# point-to-multipoint noboardcast ��Զ��ǹ㲥�Զ���
Hello ʱ��Ϊ 30s deadtime ʱ��Ϊ 120s������Ҫѡ�� DR �� BDR
��Ҫ�ֶ�ָ�ھӡ�
NBMA �͵㵽���(point-to-multipoint )�� RFC ����,������������Ϊ Cisco ���塣
OSPF ����ֵ�ļ���
Metric=sum(cost) //·�ɽ��ӿڵ� cost ֵ�ۼ�
�� show ip os int //���Կ��� cost ֵ
Cost=(10^8 / ���� BW(bps) �� cost ֵ����:
int s1/0
ip ospf cost 1 //���ӿڵ� cost ֻ��Ϊ 1
OSPF �ӿ���֤����: ������֤:
R1:
int f0/0
ip os authentication message-digest //����������֤
ip os authentication-key 1 MD5 cisco //������ܵ�����key-id Ϊ 1,��ԿΪ cisco
R2:
int f0/0
ip os authentication message-digest //����������֤
ip os authentication-key 1 MD5 cisco //������ܵ����� key-id Ϊ 1,��ԿΪ cisco
sh cdp nei //���Կ�����·�����ӿڽӵ��Զ��Ǹ��ӿ�
������֤:
R4(config)#int s1/0
R4(config-if)#ip os authentication-key cisco R5(config)#int s0/0
R5(config-if)#ip os authentication-key cisco
����֤:
ip os authentication null
OSPF ������֤:
�����¿���������֤
R3(config)#router os 1
R3(config-router)#area 0 authentication message-digest R3(config-router)#exit
R3(config)#int f0/0
R3(config-if)#ip ospf message-digest-key 1 md5 cisco R4(config)#router os 1
R4(config-router)#area 0 authentication message-digest R4(config-router)#exit
R4(config)#int f0/0
R4(config-if)#ip os me 1 Md5 cisco
OSPF �ļ��� LSA
����(Flooding):������������ʹ�õ�һ�����������ݼ���,��ij���ӿ��յ����������ӳ��ýӿ�֮������нӿڷ��ͳ�ȥ��
1# router LSA(·����·״̬�㲥)
show ip os database router
˭������:�����ڵ�ÿ̨·������
����:ֱ����·���б��Լ� cost ֵ,ÿ����·�� IP ǰ����ʶÿ����·�������߱�ʶ:router id
���鷶Χ:�ڸ������ڷ���,�ᴩԽ ABR,����������·�����Ƿ�Ϊ ABR ���� ASBR��
2# network LSA(������·״̬�㲥)
show ip os database network
˭������:�ڹ㲥��������� NBMA �����е� DR ������
����:���ӵ������ӵ�һ��·�����б�,��������·���������롣 ���鷶Χ:�����ڷ���,���ᴩԽ ABR��
3# summary LSA(�ܽ���·״̬�㲥)
sh ip os database summary
˭������:ABR ����
����:��·�������,��������,metric ֵ
���鷶Χ:���鵽���� OSPF ������,ÿ����һ̨ ABR,Advertising Router(ͨ����)�����仯��
4# asbr-summary LSA(����ϵͳ�߽�·������·״̬�㲥)
show ip os da asbr-summary
˭������:ABR �����ġ�
����:��������������˭�� ASBR,���� ASBR �� router-id
���鷶Χ:���� OSPF ����ÿ����һ̨ ABR,Advertising Route(ͨ����)r �ᷢ���仯��
5# external LSA(�ⲿ��·״̬�㲥)
show ip os database external
˭������:ASBR ������
����:������ OSPF �����ⲿ������·�ɡ�
���鷶Χ:���� OSPF ����,Advertising Router(ͨ����)ÿ���� ABR ���ᷢ���仯��
7# NSSA-LSA(��ĩ��������·״̬�㲥)
sh ip os database nssa-external
˭������:ASBR ������
����:NSSA ���������·ǰ�����롣
���鷶Χ:�ڱ��������� 7#LSA ����ʽ����,���� ABR ֮��,�� 7#LSA ת���� 5#LSA,����ͨ���߷����仯;֮�� ABR,Advertising Router(ͨ���߲��䡣
OSPF �� 4 ����������
1# ĩ������(stub ����)
ĩ���������� ASBR(��������ĩ�������طַ�) ĩ����������Ҫ��һ�� ABRĩ���������Զ�����һ��Ĭ��·��,ָ�� ABR(ĩ������������� 4#,5# LSA,�Զ�����һ�� 3#��Ĭ��·��)��
������ 1 ��Ϊ stub ����
R1,R2:
Router os 1
area 1 stub
2# ��ȫ��ĩ������(totally-stub ����)
��ȫĩ����������� 3#,4#,5# �� LSA,���ǻ�����ȫĩ�������·�һ�� 3#��Ĭ��·��·�ɱ��в������ OIA ����ϸ·�ɺ� OE1 �� OE2 ·��)�����ڵ�����·������������Ϊĩ������,ABR ���ó���ȫĩ�����ԡ������� 1 ��Ϊ��ȫĩ������
R2:
router os 1
area 1 stub no-summary //�� ABR ������
R1:
router os 1
area 1 stub
3# NSSA(not so stub area)
NSSA �������� ASBR��
NSSA �����ڵ�ÿһ̨·���������� NSSA ���Բ����Զ�����һ��Ĭ��·�ɡ�
������ 4#,5# LSA,���ǻ���� 7#LSA
Ϊ�˽�� NSSA ����·��������ȥ�����������طַ�������·��,��Ҫ�� ABR ���ֶ������·�Ĭ��·�ɡ�
R2:
Router os 1
area 1 nssa default-information-originate
������ 1 ��Ϊ nssa ����
R1,R2
R1:
int lo0
ip address 172.16.1.1 255.255.255.0
Router os 1
redistribute connected subnets
4# ��ȫ�� NSSA ����(totally-nssa)
��ȫ�� NSSA �����ڵ�·��������Ϊ NSSA ����,ABR ���ó���ȫNSSA ���ԡ���ȫ�� NSSA ��������� 4#,5#,3# LSA,ABR ����� 3#��Ĭ�� LSA��
������ 1 ��Ϊ��ȫ�� NSSA ����
R2:
Router os 1
area 1 nssa no-summary
OSPF �Ļ���
1# OSFP �������(���� 5# LSA): �� ABR �� �� �� �� �� �� �� �� : R4(config)#router os 1
R4(config-router)#summary-address 192.168.0.0 255.255.248.0
2# OSFP ���ڻ���(���� 3# LSA):
ģ��:
R3(config)#int lo1
R3(config-if)#ip address 10.1.8.1 255.255.255.0 R3(config-if)#exit
R3(config)#int lo2
R3(config-if)#ip address 10.1.9.1 255.255.255.0 R3(config-if)#exit
R3(config)#int lo3
R3(config-if)#ip address 10.1.10.1 255.255.255.0
R3(config-if)#exit R3(config)#int lo4
R3(config-if)#ip address 10.1.11.1 255.255.255.0 R3(config-if)#exit
R3(config)#router os 1
R3(config-router)#router-id 3.3.3.3
R3(config-router)#net 10.1.8.1 0.0.0.0 area 2
R3(config-router)#net 10.1.9.1 0.0.0.0 area 2
R3(config-router)#net 10.1.10.1 0.0.0.0 area 2
R3(config-router)#net 10.1.11.1 0.0.0.0 area 2 R3(config-router)#exit
�� ABR ���������ڵĻ�:
R2(config)#router os 1
R2(config-router)#area 2 range 10.1.8.0 255.255.252.0
OSPF ����·
ͨ������·�� LSA �����ϻ�,hello �������ھ�֮��,hello ��������,������ hello ��������ʱ�䡣
1# ����µ�����,������������
R2:
R2(config)#router os 1
R2(config-router)#area 1 virtual-link 3.3.3.3 R3:
R3(config)#router os 1
R3(config-router)#area 1 virtual-link 2.2.2.2
2# ������� 0 ���ָ������
����:ospf �����г������������� 0,�˴�֮������� 3#LSA,ʹ������·������� 0 ���ָ�����⡣
R2:
R2(config)#router os 1
R2(config-router)#area 1 virtual-link 3.3.3.3 R3:
R3(config)#router os 1
R3(config-router)#area 1 virtual-link 2.2.2.2
R3(config)#do sh ip os nei //���Կ������һ������·��
OSPF �·�Ĭ��·��
����һ:
R3(config)#ip route 0.0.0.0 0.0.0.0 lo10 //ָһ���� ASBR ���ⲿ����ľ�̬·�ɡ�
R3(config)#router os 1
R3(config-router)#default-information originate
������:
R3(config)#router os 1
R3(config-router)#default-information originate always
·���طַ�
��һ��Э���·�ɿ���һ�ݴ�����һ��Э�顣
���Ӷ���ֵ:
RIP:����(infinity)���� 15 ���,16 Ϊ���ɴ
IGRP/EIGRP:(infinity)���� ʱ�� �ɿ��� ���� MTU
OSPF:20(���� BGP Ϊ 1) Cost ֵ������й�
IS-IS:0
BGP:��·�ɷַ������� IGP Э��Ķ���ֵ������

1# �� eigrp �طַ���
rip router rip
redistribute eigrp 100 metric 2
2# �� rip �� �� �� �� eigrp
router eigrp 100
redistribute rip metric 1000 100 255 1 1500 ���� ʱ�� �ɿ��� ���� mtu
3# �� Ospf �طַ��� eigrp
router eigrp 100
redistribute ospf 1 metric 1000 100 255 1 1500
4# �� eigrp �طַ��� ospf
router os 1
redistribute eigrp 100 subnets
subnets ����:����طַ���ʱ�� subnets ��������������벻ƥ���·��,���ܱ��طַ��� ospf ·��Э�顣
����Э���طַ��� OSPF �����Ӷ���ֵΪ 20,����Ϊ OE2��
router ospf 1
redistribute eigrp 100 subnets metric-type 1 metric 60 //�طַ��� OSPF ��ʱ������
Ϊ OE1 ����ֵ��Ϊ 60.
5# �� ospf �طַ��� rip��
Router rip
redistribute ospf 1 metric x(1<x<16)
6# �� rip �طַ��� ospf��
Router ospf
redistribute rip subnets 7# �� Ospf �طַ��� BGP router bgp 2
redistribute ospf 1 match external internal
R1#ping 172.16.1.1 source 192.168.1.1 // �� Դ ping
R1#ping 192.168.1.1 repeat 1000 // ���� ping 1000 ��
OSPF ·��Э��� OE1 �� OE2 ������
OE1:����Э���طַ��� OSPF Э���,Cost �ۼӡ�
OE2:����Э���طַ��� OSPF Э���,Cost ���ۼӡ�
OSPF ·�ɵ����ȼ����μ�С�� O > OIA > OE1 > OE2
Ϊ���� ospf �Ļ��ؽӿ�����ͨ������ʵ������,���ӿ��������ij� point-to-point
R1(config-if)#int lo0
R1(config-if)#ip os net point-to-point
·�ɵĹ���:
1# distribute-list �ַ��б�
����һ:
Ҫ���� R3 ��·�ɱ���ֻ�ܿ��� 192.168.1.0/24 ��·�ɡ�
��һ��:ץȡ·�� 192.168.1.0/24
R3(config)#access-list 1 permit 192.168.1.0
�ڶ���:�� EIGRP ������ʹ�÷ַ��б�
R3(config)#router eigrp 100
R3(config-router)#distribute-list 1 in //�ַ��б����� acl �����·�ɺͶ���IJ�����
������:
Ҫ�� r3 ������ 192.168.1.0/24 �� 192.168.3.0/24 ��·��
R3:
��һ��:���� ACL ץȡ·��
access-list 1 deny 192.168.1.0
access-list 1 deny 192.168.3.0 access-list 1 permit any
�ڶ���:
�ڽ�����ʹ�÷ַ��б�����
router eigrp 100
distribute-list 1 in
*�� ACL �IJ���
R3(config)#ip access-list standard 1 // ����������б� 1,�ڽ������ӻ�ɾ��������
*�ַ��б�ֻ����һ���������һ�Ρ�(in / out)
2# prefix-list ǰ�б�
����һ:
Ҫ�� r3 ��ֻ�ܿ��� 192.168.1.0/24 ��·��(������ֱ��)��
��һ��:ʹ��ǰ�б�ץȡ·�� 192.168.1.0/24
R3(config)#ip prefix-list wscn permit 192.168.1.0/24
�ڶ���:
�� eigrp �����µ��� prefix-list
R3(config-router)#distribute-list prefix wscn in //ʹ�÷ַ��б����� prefix-list ����Ķ�·�ɵIJ������ԡ�
������:
Ҫ�� R3 �Ͽ����� 192.168.1.0/24 192.168.2.0/24 192.168.3.0/24 ��·�ɡ�
����һ:
��һ��:����·�ɲ���(prefix-list)
R3(config)#ip prefix-list nscn deny 192.168.1.0/24
R3(config)#ip prefix-list nscn deny 192.168.2.0/24
R3(config)#ip prefix-list nscn deny 192.168.3.0/24
R3(config)#ip prefix-list nscn permit 0.0.0.0/0 le 32 //��������·��
ǰ�б��������ʽ:ip prefix name deny|premit ǰ/ƥ�����λ ge ������ڵ���,le ����С�ڵ��ڡ�
�ڶ���:����
R3(config)#router eigrp 100
R3(config-router)#distribute-list prefix nscn in
������:
ʹ��һ������ܾ� 192.168.1.0-3.0 ����Ϊ 24 λ��·�ɡ�
��һ��:
����ǰ�б�
ip prefix-list abc seq 5 deny 192.168.0.0/22 ge 24 le 24 //ƥ�� 192.168.0.0 ��ǰ 22 λ,��
����ڵ��� 24 ������С�ڵ��� 24 ��·��(������Ϊ 24 λ)��
ip prefix-list abc seq 10 permit 0.0.0.0/0 le 32
�ڶ���:
�� eigrp �����µ���
Router eigrp 100 distribute-list prefix abc in
��ǰ�б��ֱ��ʾ�����е� A ��,B ��,C ��·�ɡ�
R3(config)#ip prefix-list a permit 1.0.0.0/1 ge 8 le 8
R3(config)#ip prefix-list b permit 128.0.0.0/2 ge 16 le 16
R3(config)#ip prefix-list c permit 192.0.0.0/3 ge 24 le 24
������:
Ҫ���� R2 �Ͽ����� 192.168.1.0/24 ��·��ʹ�� ACL ���������
��һ��:���� ACL��
R2(config)#access-list 1 deny 192.168.1.0
R2(config)#access-list 1 permit any
�ڶ���:����
R2(config)#router ospf 1
R2(config-router)#distribute-list 1 in
Ҫ���� R2 �Ͽ����� 172.16.1.0-172.16.4.0/24 ��·��,Ҫ��ʹ��ǰ�б�������ԡ�
R2(config)#ip prefix-list bca deny 172.16.0.0/21 ge 24 le 24 R2(config)#ip prefix-list bca permit 0.0.0.0/0 le 32
R2(config)#router eigrp 100
R2(config-router)#distribute-list bca in
·��ӳ�� Route-map:
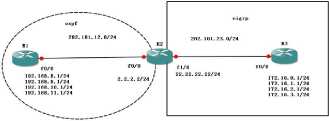
Ҫ��:
1# �� r2 �Ͻ��� eigrp �طַ��� ospf,�� ospf ����,������ 172.16.*.0/24(*��Ϊż����·����Ŀ);
2# 172.16.1.0/24 ��·������Ϊ OE1;
3# 172.16.3.0/24 �Ķ���ֵΪ 88;
4# ʣ������ eigrp ·��Я����ǩ 90;
��һ��:ץȡ����
ץ 172.19.*.0/24 ��ż��·��
access-list 1 permit 172.16.0.0 0.0.254.0
access-list 2 permit 172.16.1.0
access-list 3 permit 172.16.3.0
�ڶ���:ʹ�� route-map �����Ŀ��Ҫ��
R2(config)#route-map 66 deny 10
R2(config-route-map)#match ip address 1 //���� route-map 66 �ܾ� ACL 1 ���������·�ɡ�
R2(config)#route-map 66 permit 20
R2(config-route-map)#match ip address 2
R2(config-route-map)#set metric-type type-1 //���� ACL 2 �������·�ɷ���,���ҽ����Ķ�����Ϊ����һ��
R2(config)#route-map 66 permit 30 R2(config-route-map)#match ip address 3
R2(config-route-map)#set metric 88 //�� ACL 3 �������·�ɷ���,���ҽ����Ķ���ֵ��Ϊ 88��
R2(config)#route-map 66 per 40
R2(config-route-map)#set tag 90 //��������û��ƥ�䵽������·�ɴ��� TAG 90,���ҷ���**route-map �� ACL һ��Ĭ�Ϻ���ܾ����С�
�طַ���ʱ�����route-map
R2(config)#router os 1
R2(config-router)#redistribute eigrp 100 subnets route-map 66 //�� EIGRP ·��Э���طַ��� ospf Э���ʱ����� route-map��
sh ip rou 22.22.22.0 //�鿴·�� 22.22.22.0 ��ϸ·����Ϣ��
������:
�� ospf �طַ��� eigrp ��ʱ�������²���:
1# �� eigrp ���ڵ�·��,������ 192.168.*.0/24 ��·��,*��������;
2# ʹ 192.168.8.0/24 ��·��Я����ǩΪ 666;
3# ������·��Я����ǩ 888;
4# �� R3 ��·�ɱ��в��������ֱ�ǩΪ 666 ��·�ɡ�
��һ��:
ץȡ·��:
access-list 10 permit 192.168.1.0 0.0.254.0
access-list 11 permit 192.168.8.0
�ڶ���:
1# route-map 66 deny 10 match ip add 10
2# route-map 66 deny 20 match ip add 11
set tag 666
3# route-map 66 permit 30
set tag 888
������:
�� OSPF �طַ� EIGRP ��ʱ����á�
router eigrp 100
redistribute ospf 1 metric 1000 100 255 1 1500 route-map 66
���IJ�:
�� R3 ��·�ɱ��в��������ֱ�ǩΪ 666 ��·�ɡ�
R3(config)#route-map xvh deny 10 R3(config-route-map)#match tag 666
R3(config-route-map)#route-map xvh permit 20 R3(config)#router eigrp 100
R3(config-router)#distribute-list route-map xvh in
�����ӿ� passive-interface
���� EIGRP �� OSPF Э��,����Ϊ passive-interface ������Ҳ������Э�����ݰ������� RIP Э��ֻ����,������Э�����ݰ���
���÷�ʽ:
R1(config)#Router os 1
R1(config-router)#passive-interface lo0
R1(config-router)#passive-interface lo1
R1(config-router)#passive-interface lo2
R1(config-router)#passive-interface lo3 ����
R3(config)#router ei 100
R3(config-router)#passive-interface default //�����нӿڶ���ɱ����ӿ�
R3(config-router)#no passive-interface f0/0 //���������ӿ�
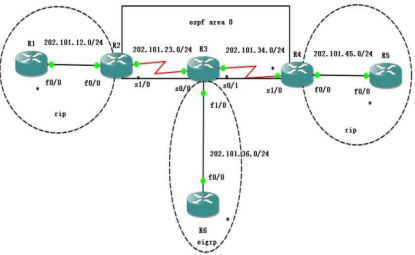
OSPF ��������� filter-list
Ҫ�� ospf ���� 0 �� 192.168.8.0-11.0 �����Գ��������� ospf ����
��һ��:ʹ��ǰ�б� prefix -list ץȡ·��
R2(config)#ip prefix-list abc deny 192.168.8.0/22 ge 24 le 24 R2(config)#ip prefix-list abc permit 0.0.0.0/0 le 32
�ڶ���:�� ospf �����¹���R2(config)#router os 1
R2(config-router)#area 0 filter-list prefix abc out //������ 0 �ij���������
·��Э���˫���طַ�
����һ��RIP Э���·����ֻ�ܿ��� RIP Э���·��
��һ��:RIP_L �طַ��� OSPF,���ǩ 120��
R2(config)#route-map 233 permit 10
R2(config-route-map)#set tag 120
R2(config)#router os 1
R2(config-router)#redistribute rip subnets route-map 233
�ڶ���:ospf �طַ��� RIP_R ֻƥ���ǩΪ 120 ��·�ɡ�
R4(config)#route-map 233 permit 10
R4(config-route-map)#match tag 120 R4(config)#router rip
R4(config-router)#redistribute os 1 metric 2 route-map 233 // ���طַ���ʱ�����route-map
������:RIP_R �طַ��� OSPF ��ǩΪ 210 ��·��
R4(config)#route-map 999 permit 10
R4(config-route-map)#set tag 210
R4(config)#router os 1
R4(config-router)#redistribute rip subnets route-map 999
���IJ�:OSPF �طַ��� RIP_L ֻƥ���ǩΪ 210 ��·�ɽ���
R2(config)#route-map 999 permit 10
R2(config-route-map)#match tag 210 R2(config)#router rip
R2(config-router)#redistribute os 1 metric 2 route-map 999
�������EIGRP Э���ڵ�·���������� RIP Э�鴫������·��
��������Ҫ�� EIGRP Э���ڵ�·�������� OSPF Э�鴫������·��Я����ǩ 666
R3:
��һ��:���� route-map
OSPF �طַ��� EIGRP �ܾ�Я����ǩ 210 �� 120 ��·��
route-map 888 deny 10
match tag 210
match tag 120
OSPF Э���·��Я����ǩ 666
route-map 888 per 20
set tag 666
�ڶ���:�� OSPF �طַ��� EIGRP ��ʱ����� route-map 888 router ei 100
redistribute os 1 metric 1000 100 255 1 1500 route-map 888
������:�� EIGRP �طַ��� OSPF route os 1
redistribute ei 100 sub
sh ip ospf int lo0 //�鿴 lo0 ������״̬��
IGP( interiorgatewayprotocol) �ڲ�����Э��
As ������ϵͳ(Autonomous System)
RIP ���� (15)����ʸ��·��Э��
�鲥��ַ 224.0.0.9 ���� UDP520 TTL = 2
Eigrp ���� ��ʱ �ɿ��� ���� mtu ���ľ���ʸ��·��Э��
�鲥��ַ 224.0.0.10
Э��� 88 Ĭ������ 100
TTL = 2
Ospf cast(bw) ��·״̬·��Э��
�鲥��ַ 224.0.0.5
224.0.0.6
��� 89
TTL = 1 ������ 1w ��·��ISIS ������ 2w ��·��
BGP( bordergatewayprotocol) �߽�����Э��
���Գ��� 10w ·������
���� TCP �� 179 �˿ڿ�����
TTL ֵ(EBGP=1 ,IBGP=255(���ؽӿ�)) AS ��(1-65535 ����,64512-65531 ����)
����:
1# �ɿ���
���� TCP��
ͨ�� keepalive ���Ʊ������ӡ�·����Ϣ���͵ľ�ȷ��
2# �ȶ���
ֻ���������˷����仯����Ա仯�ҵ�����Сͨ��ʱ������ͨ�档
EBGP ͨ��ʱ������ 30s,IBGP ͨ������ 5s ��
���� NSF(���ж�ת��),������������������֧���豸����(CCIE)��
3# ����չ��
�ɴ���·�ɳ��� 10 ����,֤����չ�Ժ�ǿ��������չ�ԡ�
ӵ�зḻ�����Կ��ԶԲ�ͬ·��ִ�в�ͬ����,��������ֳ����Ϳͻ�����,����ѡ·��
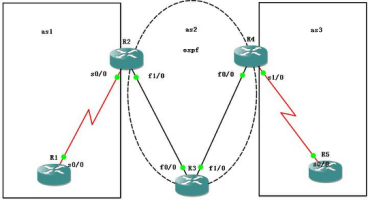
R1 �� R2 ֮������ EBGP
R1:
router bgp 1 //���� BGP Э��,AS ��Ϊ 1
no synchronization //Ĭ���Ѿ��ر���ͬ��
bgp router-id 11.11.11.11 //���� BGP �� router-id
neighbor 202.101.12.2 remote-as 2 //ָ�ھ�,EBGP ʹ�öԶ˵������ӿ�,�Զ˵� AS ��Ϊ 2
no auto-summary //ϵͳĬ�Ϲر��Զ�����
R2:
router bgp 2
no synchronization
bgp router-id 22.22.22.22
neighbor 202.101.12.1 remote-as 1
R2 �� R4 ���� IBGP ��ϵ
R2 �Ļ��ؽӿں� R4 �Ļ��ؽӿڿ���� ping ͨ R2
R2:
router bgp 2
neighbor 4.4.4.4 remote-as 2 //�� R4 ���� IBGP ��ϵ��neighbor 4.4.4.4 update-source lo0 //ʹ�û��� 0 ����Ϊ��Ч����Դ��
R4:
router bgp 2
bgp router-id 44.44.44.44
neighbor 2.2.2.2 remote-as 2
neighbor 2.2.2.2 update-source Loopback0
R4 �� R5 ֮������ EBGP
R4(config)#router bgp 2
R4(config-router)#nei 202.101.45.5 remote-as 3
R5(config)#router bgp 3
R5(config-router)#bgp router-id 55.55.55.55
R5(config-router)#nei 202.101.45.4 remote-as 2
R5(config-router)#network 5.5.5.0 mask 255.255.255.0
��Ϊ as �ı߽�·����,���������Լ� IGP ·�ɱ��е��κ�·��,����һ��Ҫ�� IGP ·�ɱ��е�·����ƥ�䡣
R2(config)#router bgp 2
R2(config-router)#net 3.3.3.3 mask 255.255.255.255
BGP �����ű�
1# �ھӱ�
----- sh ip bgp su //�鿴�ھӱ�
ע��:State/PfxRcd ��������ִ������ھӴ����·����Ŀ
2# BGP ת�����ݿ�
---- sh ip bgp
���ھӴ��������������������������Ķ���·������ bgp ·���Ķ�������
3# ip ·�ɱ�
----- show ip route
��ŵ�����������·��
Bgp ����Ч����Դ
����:��·��ѡ�������ʹ�øõ�ַ��ΪԴ��ַ�� Ĭ�������,��Ч����Դ�����ǵ������ӿ� ip ��ַ��
�ڽ��� IBGP �ھӹ�ϵ��ʱ��һ��ʹ�û��ؽӿ���Ϊ��Ч����Դ(���ؽӿڱȽ��ȶ�)�����˵ĸ���Դ��ַ�ͶԶ� neighbors ����ĵ�ַҪ����һ�¡�
BGP ���ĸ����ݱ���:
1# open
�����汾��,AS ��,router-id ����ʱ��(180s)��
2# keepalive
�����Ϣ,����ȷ�� bgp �Ե����ϵ�Ľ���,Ĭ�� 60s ����һ��,��� hold time Ϊ 0,���� keepalive��
3# updata
����һ��·����Ϣ,����·����Ϣ��Ҫ��� updata ����,���������·�����ԡ�
4# notification
����������,�����������Ϣ,���̹ر� bgp ���ӡ�
BGP ������ھ�״̬
1# idle(����)
·��������·�ɱ�,����·���Ƿ�ɴ
2# connect(����)
·�������ҵ�·��,����� TCP ���������֡�
3# open sent(���� open ��Ϣ) ���� BGP ֮������Ӳ�����
4# open confirm(open ȷ �� ) ·���������Ӳ���һ����ȷ�ϡ�5# established (�ѽ�����)
�����ھӹ�ϵ�Ѿ�������
BGP �ھ�״̬���� Active ��ԭ��
1# û���ھӵĻذ�·��
2# �ھӵĶԵ����ַ���
3# �Զ�û��ָ�ھ�
4# ����� as ��
����bgp ���̵�����
Cle ip bgp* //�ϵ���·�������� BGP �Ե����ϵ,����������
Cle ip bgp * soft //�öԵ������·��� updata ���ġ�
Cle ip bgp 202.101.45.5 //��� 202.101.45.5 ���½��� BGP �Ե����ϵ��
ʵ��:
R1 �� R2 ֮��ʹ�û��ؽӿڽ��� EBGP �Ե����ϵ
R1:
router bgp 1
nei 2.2.2.2 remot
2 nei 2.2.2.2 up
lo0
R2:
router bgp 2
nei 1.1.1.1 remot
1 nei 1.1.1.1 up
lo0
��ʱ�����Խ����Ե����ϵ
ԭ��:�����Ե����ϵ�� ip ��ַ���ɴ���:
R1:
ip route 2.2.2.0 255.255.255.0 202.101.12.2 R2:
ip route 1.1.1.0 255.255.255.0 202.101.12.1
��ʱ��Ȼ�����Խ����Ե����ϵ
ԭ��:EBGP �� TTL ֵΪ 1��
IBGP �� TTL ֵΪ 255(���ؽӿ�)��
�������:
�� TTL ֵ��Ϊ����
R1:
Router bgp 1
neighbor 2.2.2.2 ebgp-multihop 255 //�� TTL ֵ��Ϊ 255
R2:
Router bgp 1
Neighbor 1.1.1.1 ebgp-multihop 255 //�� TTL ֵ��Ϊ 255
BGP �ķ���,IBGP ����һ������:
IBGP ��һ������:
���� IBGP �Ե��崫��·�ɵ�ʱ��������һ�����ɴ������,������ָ IBGP �Ե����ʱ�����һ����Ϊ�Լ�:
R2(config)#router bgp 2
R2(config-router)#neighbor 4.4.4.4 next-hop-self
R4(config)#router bgp 2
R4(config-router)#neighbor 2.2.2.2 next-hop-self
EBGP ��һ���ı�:
IBGP �ķ���:IBGP �Ե���ѧ����·�ɲ��ᱻͨ��������� IBGP �Ե���(ˮƽ�ָ�)��
BGP ��ͬ��:
Bgp �������� ibgp �Ե���ѧϰ��·��ֱ�ӷ��͵� ebgp �Ե���,������Щ·���Ѿ��� IGP ѧ����
Ĭ�������ͬ���DZ��رյ�
BGP ����ڶ�����
1# ��ͬ��(����Ԥ���ڶ��IJ���)��
2# �� BGP �طַ��� IGP(����ȡ,BGP ·�ɱ���Ŀ�Ӵ�)
3# IBGP ȫ������(����ȡ)��
4# ʹ�� MPLS ���(��Э���ǩת��) ����:
R2(config)#int f1/0
R2(config-if)#mpls ip
R3(config)#int f0/0
R3(config-if)#mpls ip
R3(config)#int f1/0
R3(config-if)#mpls ip
R4(config)#int f0/0
R4(config-if)#mpls ip
BGP ·������
1# ���ϱ�ѡ:·�ɸ�����Ϣ�б���Я��������,�������� BGP ���豸����ʶ������
Origin (��Դ):��������·�ɸ�����Ϣ����Դ,i > e > ? ��//? ������ IGP �طַ��� BGP��·����Ŀ(incomplete)
As-path :�� AS ����¼·�ɴ����·��,ֻ���� EBGP �Ե���֮��ͨ��·�ɵ�ʱ��,AS �ŲŻḽ�ӵ� as-path �С�
Next-hop :����������Ŀ�����ε���һ�� IP ��ַ��
2# ������ѡ:·�ɸ�����Ϣ�п���ѡ��Я��������,�������� BGP ���豸ʶ������ԡ�
Local_preference (�������ȼ�):���� BGP ��·�����յ�ȥ��ͬһ��Ŀ�ĵصĶ���·��,����ʹ�ñ������ȼ����������ȼ�Ĭ��Ϊ 100,ֻ���ڱ� AS ��Ч,���ᴫ�� EBGP�Ե���,������ѡ����(�������ȼ�Խ��Խ����)��
Atomic_aggregate ԭ�Ӿۺ�(����)
3# ��ѡ������������:BGP �豸��Ҫ��һ��֧�ָ�����,��һ̨·�����յ������Ե� BGP ·��,��ʹ��ʶ��Ҳ�Ὣ�����Դ��͵��Զˡ�
Community �Ŷ�����
aggregator �ۺ�����
4# ��ѡ�ǿ�����������:BGP �豸��һ��Ҫ�������,��һ̨·�����յ������Ե� BGP ·��,���Ը�·��,���Ҳ�����Զ˴��͡�
MED ����Ӱ�����ݽ��뱾 as,�� Local_preference �෴,med ֵֻ���� ebgp �ھ�,MED ֵԽСԽ���ȡ�
Originator_id
Cluster_list
Weight(Ȩ��ֵ)(Cisco ˽��)ֻ��·������Ч,ֵԽ��Խ����,���ز�����·�� weight
ֵΪ 32768,���ھӴ�������Ϊ 0 ��
BGP 13 ��ѡ·ԭ��
1# ��ѡ��ߵ� weight ,������Ч,Ĭ�� 32768,�ھӹ�����Ϊ 0�� Cisco ˽��
R3:
1.1.1.0 r1
2.2.2.0 r2
����·��
1.1 1.0 r2
2.2.2.0 r1
��һ��:ץȡ·��
access 1 per 1.1.1.0
access 2 per 2.2.2.0
�ڶ���:���·����
weight ֵroute-map m1 permit 10
macth ip address 1 // ƥ��·�� 1.1.1.0
Set weight 1 //�� weight ֵ��Ϊ 1
route-map m1 permit 20 //����ʣ������·��
route-map m2 permit 10
macth ip address 2 //ƥ��·�� 2.2.2.0
set weight 100 //�� weight ��Ϊ 100
route-map m1 permit 20 //����ʣ�����е�·��
������:
���� route-map router bgp 65345
neighbor 202.101.13.1 route-map m2 in //�� r1 �� r3 ��·�� 2.2.2.0 �� weight ֵ��Ϊ 100
neighbor 202.101.23.2 route-map m1 in //�� r2 �� r3 ��·�� 1.1.1.0 �� weight ֵ��Ϊ 1
2# ��ѡ��ߵ� local-preference,Ĭ���� 100,�ڱ� AS �ڿɴ��ݡ�
1.1.1.0 �C r1
2.2.2.0 �C r2
����·��
1.1.1.0 �C r2
2.2.2.0 �C r1
��һ��:ץȡ·��
access list 1 permit 1.1.1.0
access list 2 permit 2.2.2.0
�ڶ���:�����·���ı������ȼ�
R3(config)#route-map m1 permit 10
R3(config-route-map)#match ip address 1
R3(config-route-map)#set local-preference 200 //�����·�� 1.1.1.0 ������
���ȼ���Ϊ 200
R3(config-route-map)#exit
R3(config)#route-map m2 permit 10
R3(config-route-map)#match ip address 2
R3(config-route-map)#set local-preference 300 //�����·�� 2.2.2.0 ������
���ȼ���Ϊ 300
R3(config-route-map)#exit
R3(config)#route-map m2 permit 20
�� �� �� : �� �� route-map
R3(config)#router bgp 65345
R3(config-router)#neighbor 202.101.13.1 route-map m2 in //��R1 ��·��2.2.2.0 ����R3 �Ľ�����,���������ȼ���Ϊ 300��
R3(config-router)#neighbor 202.101.23.2 route-map m1 in //��R2 ��·��1.1.1.0 ����R3 �Ľ�����,���������ȼ���Ϊ 200��
3# Originate ��Դ����:network(����)>redistribute(�طַ�)>aggregate-address(�ۺϵ�ַ)
4# ��ѡ��̵� AS_PATH ,����ʹ�� bgp bestpath as-path ignore ���������������һ����
1.1.1.0�Cr1
2.2.2.0 --r2
����·��
1.1.1.0�Cr2
2.2.2.0�Cr1
��һ��:ץȡ·��
�ڶ���:���� route-map ��·�ɵ� as-path route-map M1 permit 10
match ip address 1
set as-path prepend 65001 //���·�� 1.1.1.0 �� as �� 65001
route-map M1 permit 20
route-map M2 permit 10 match ip address 2
set as-path prepend 65002 //���·�� 2.2.2.0 �� as �� 65002
route-map M2 permit 20 ������:���� route-map router bgp 65345
neighbor 202.101.13.1 route-map m1 in //��r1 ��·�� 1.1.1.0 ��r3 ��ʱ���as �� 65001
neighbor 202.101.23.2 route-map m2 in //��r2 ��·�� 2.2.2.0 ��r3 ��ʱ���as �� 65002
5# ��С�� origin code (Դ����)(IGP(0)>EGP(1)>incomplete(2))
1.1.1.0�Cr1
2.2.2.0 --r2
����·��
1.1.1.0�Cr2
2.2.2.0�Cr1
��һ��:ץȡ·��
�ڶ���:���� route-map �� origin code route-map M1 permit 10
match ip address 1
set origin egp 65012 //����� 1.1.1.0 ����Դ�����Ϊ e
route-map M2 permit 20
route-map M2 permit 10 match ip address 2
set origin incomplete //����� 2.2.2.0 ����Դ������Ϊ?
route-map M2 permit 20
������:���� route-map��R3(config)#router bgp 65345
R3(config-router)#neighbor 202.101.13.1 route-map m1 in R3(config-router)#neighbor 202.101.23.2 route-map m2 in
6# ��ѡ��С�� MED(metric ֵ) (AS ֮�佻��).
route-map M1 permit 10
match ip address 1
set metric 200000
route-map M1 permit
20 route-map M2
permit 10 match
ip address 2
set metric 300000
route-map M2 permit 20
router bgp 65345
neighbor 202.101.13.1 route-map M1
in neighbor 202.101.23.2 route-map M2 in
7# EBGP ���� IBGP (��ѡ�������,�����ڲ����ⲿû����)��
8# BGP ����ѡ�� BGP ��һ���� IGP ·����͵�·����
9# ��������� maximum-paths n (n �� 2-16),���ؾ��⡣
10# ��ѡ���ϵ� EBGP ·��,�������������
�������� bgp bestpath compare-routerid��
�ڶ���·��������ͬ�� router-id,��Ϊ���Ǵ�ͬһ·�����յ���
�۵�ǰû�����·��,ͨ�����·����·����ʧЧ��
11# ��ѡ��͵� BGP router_ID ��·����
12# �������·����ʼ��·���� ID �� router_id ��ͬ,ѡ cluster_list ������̵ġ�
13# ��ѡ��͵��ھӵ�ַ��·����
BGP ����
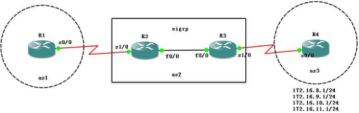
BGP �� �� �� :
R3(config)#router bgp 2
R3(config-router)#aggregate-address 172.16.8.0 255.255.252.0
//��ϸ·�ֲ��ᱻ���ơ�
R3(config-router)#aggregate-address 172.16.8.0 255.255.252.0 summary-only
//ֻ����ͨ��ۺ�·��,����������ϸ·�ɡ�
R3(config-router)#aggregate-address 172.16.8.0 255.255.252.0 as-set summary-only
//as-set �þۺ�·��Я���ۺ���������,�����Ա�������·���ھۺ�ǰ������ as��
show ip bgp 172.16.8.0 255.255.252.0 //�鿴�ۺ�������
Ebgp �ķ���
ʹ�� as_path �� as-path �б��г��ֱ� as ��ʱ,���ܸ�·�ɸ��¡�
BGP �·�Ĭ��·��
R4(config)#router bgp 3
R4(config-router)#neighbor 202.101.34.3 default-originate //�� R3 �·�Ĭ��·�ɡ�
BGP �Ĺ��˻���
���� 1:
R2 �� R1 ����·�ɵ�ʱ��֮������Դ�� AS3 ��·�ɵ�һ��:�����б�
R2(config)#ip as-path access-list 1 permit ^3$
�ڶ���:����
R2(config)#router bgp 2
R2(config-router)#neighbor 202.101.12.1 filter-list 1 out
���� 2:
��һ��:�����б�
R2(config)#ip as-path access-list 10 deny ^3$ //�ܾ���Դ�� as3 ��·�ɡ�
R2(config)#ip as-path access-list 10 permit .* //�������ʣ�����е�.*���ڶ���:����
R2(config)#router bgp 2
R2(config-router)#neighbor 202.101.12.1 filter-list 10 out
���� 3:
R4 �Ͼܾ�����Դ�ڱ� as ��·�ɴ������� as����һ��:�����б�
R4(config)#ip as-path access-list 10 deny ^$ //�ܾ���Դ�ڱ� as ��·�ɡ�
R4(config)#ip as-path access-list 10 permit .* //����ʣ�µ����С�
�ڶ���:����
R4(config)#router bgp 3
R4(config-router)#nei 202.101.34.3 filter-list 10 out
���� 4:
R2 �� R1 ֻ���� 172.16.8.0/22 ��·��,�����ľܾ�����һ��:ץȡ·��
R2(config)#ip prefix-list 233 permit 172.16.8.0/22 �ڶ���:����
R2(config)#router bgp 2
R2(config-router)#neighbor 202.101.12.1 prefix-list 233 out
������·��( ����)
��̫��֡��ʽ���ֶ���:
802.3:
| ǰ���� | Ŀ��MAC ��ַ | ԴMAC ��ַ | ���� | ���� | FCS У����) |
|---|---|---|---|---|---|
| byte 8 | 6 | 6 | 2 | �ɱ䳤(46-1500) | 4 |
| Ethernet II: | |||||
| ǰ���� | Ŀ��MAC ��ַ | ԴMAC ��ַ | ���� | ���� | FCS У����) |
| Byte 8 | 6 | 6 | 2 | �ɱ䳤(46-1500) | 4 |
һ�� VLAN = һ���㲥�� = һ��������
vlan:����ľ�����,������ǿ���������ԺͰ�ȫ��,���Զ����������Ч�ķֶΡ�
TRUNK :���Գ��ض�� VLAN ��Ϣ����·��
����������������:
1# ��ַѧϰ
2# ֡ת������
3# ��·��ֹ
��������֡���� VLAN ���������Э��:
ISL(Cisco ˽��)�� 802.1Q(����)
ISL:��ԭʼ��̫��֡��ͷ������ 26 �ֽڵ� ISL ͷ��,β�������� 4 �ֽڵ� CRC ��,û���ƻ�ԭʼ֡.���֧�� 1024 �� vlan��
802.1Q:��ԭʼ֡Դ MAC ����(�м仹������)�� 4 ���ֽ� TAG ���λ,�� VLAN ���б��{ǰ�����ֽڱ������̫��������(3bit �������ȼ�,1bit �������ƻ����,12bit ��vlan_id)},����Э��,�ƻ���ԭʼ֡.���֧�� 4094 �� VLAN��
У��������ܹ�
1# access(�����)
2# distribution(��۲�)
3# core(���IJ�)
VLAN ID �ķ�Χ:(0-4095)
1# 0,4095 ϵͳ�������ܱ�ʹ�á�
2# Vlan 1 ����ʹ��,Ĭ�����н������ vlan 1(������ɾ��)��
3# 2-1001 ����ʹ��,������̫��,���������ġ�
4# 1002-1005 ����ʹ��,Ĭ������ FDDI �����ƻ�����,����ɾ����
5# 1006-1024 ����,ϵͳʹ�á�
6# 1025-4094 ��չ,������̫��,�����ġ�
7# 2-1001.1025-4094 ��������ʹ�á�
1������vlan (Native VLAN)
���� vlan �� trunk �����в����ǩ�ı��� vlan ������
int f0/3
switch trunk native vlan 99 //�ı��� vlan Ϊ 99.
Trunk ��·�����˱��� vlan Ҫһ�¡�
2��DTP Э��(��̬�м�Э�� dynamic trunking protocol)
����:���ڽӿ�Э�� trunk(�������Զ�Э��ָ��������֮�����·�Ƿ��γ� trunk) DTP ������ 5 �ֽӿ�ģʽ:
1# Access // �������� pc,��Զ���ܳ�Ϊ trunk
2# On // ��������Ϊ trunk
3# Dynamic desirable // ���Է��� DTP Э��,Ը���Ϊ trunk
4# Dynamic auto // ���Խ��� DTP Э��,Ը���Ϊ trunk
5# Nonegotiate // �Ѿ���Ϊ trunk,�������� DTP ��Ϣ
3��һ�����ֱ�ӽ��������Ľӿ�ģʽ��Ϊtrunk,�ر�DTP Э��
int f0/3
switchport nonegotiate
4����trunk ��·������ vlan �Ĵ���
int f0/3
switch trunk allowed vlan 1,20,99 //trunk ֻ���� vlan1 20,99 ������show int trunk //�鿴 trunk �ӿ�
STP(spanning-tree)��������
������Ϊ�˽������·����,�ڽ������������������豸�� ��������֮�����׳�����������:
1���㲥�籩(�������Թ㲥���ݰ��Ƿ��鴦��)
2���ظ�������֡
3��Mac ��ַ�����ȶ�
һ����������ѡ�ٹ���:
1# ѡ��һ�����š�(�������� ID ��С��Ϊ����)�� ID(8Byte)=�����ȼ�(2Byte)+��mac(6Byte))
sh spanning-tree //�鿴������������
���ȼ�:32768 ����:
Mac ��ַ:0000.0CC8.432B
sw2#sh spanning-tree Address 0001.63D6.026A
Sw3#sh spanning-tree Address 0000.0CC8.432B
2# ��ÿ���Ǹ�������ѡ�ٳ����˿�(���˿ڵ����Ż�����С)
(������ͬ��������ɷ����ߵĸ��˿ں��� ID ����) ���˿������� BPDU �ġ�
·������(IEEE ��):
�������� ����
10Gbps 2
1Gbps 4
100Mbps 19
10Mbps 100
�˿� ID = �˿����ȼ� + �˿ں�
3# ��ÿ����ѡ�ٳ�һ��ָ���˿�(��ѡ������ ID С��,��ѡ���Ͷ˿� ID С��,�����ϵĶ˿�ÿ������ָ���˿�,������Ǹ��ŷ��� BPDU)
4# ��ָ���˿ڻ�Ǹ��˿ڱ�������(block)
����BPDU(bridge protocol data unit)����Э�����ݵ�Ԫ
BPDU ÿ 2s ����һ��
Switch(config)#spanning-tree vlan 1 priority 0 //�� vlan1 �����ȼ���Ϊ 0
1# 802.1D ����� stp,���� vlan ʹ��һ��������Э�� (RFC ����)
2# PVST ��ÿ vlan ��һ�� stp(cisco ����)
Cisco �豸���ȼ� 4bit 12bit 48bit
���ȼ� sys-id-ext(VLAN ID) MAC ��ַ
Cisco �豸�������ȼ������� 4096 �ı���
��������������������,����ͨ���������ȼ���
����:�� SW3 ��Ϊ VLAN1 �ĸ���(Cisco ��Ĭ�����ȼ��� 32768 + VLAN ID)
����һ:
spanning-tree vlan 1 root priority 0 (1-10 ���Ե��� 1-10)
//�� vlan1,vlan2 ���ȼ���Ϊ 0��
������:
spanning-tree vlan 1 root secondary //�������������ȼ���Ϊ 28672��spanning-tree vlan 1,2 root primary(������ 4096 �ı���)//��Ĭ�����ȼ� 32768 �Ļ����ϼ����� 2 ���� 4096,���� primary �����ȼ�Ϊ����,���Լ��ĺ����㡣
�ġ�STP Э��Ľ������� 5 �ֶ˿�״̬
Disable:����,������������,����ȥת�����ݡ�
Blocking:����״̬,����������,������֡ת��,�ܼ�������� BPDU,����ѧϰ mac ��ַ��
Listening:���Ծ�������,ѡ����˿�,ָ���˿ںͷ�ָ���˿ڡ�������֡��ת��,�ܼ� �� BPDU,�ܾ���������,����ѧϰ MAC ��ַ��
Learning:ѧϰ״̬,������֡��ת��,�ܹ�ѧϰ MAC ��ַ,�����ܲ���֡��ת����
Forwarding:����ת������֡,�ܹ�ѧϰ MAC ��ַ��
�塢�������˿ڴ�BLK �� FWD ��ת��ʱ��
ֱ�ӹ���:�� BLK �� FWD ��ת��ʱ��Ϊ 30s(15s+15s) ���� BPDU(������)
��ӹ���:�� BLK �� FWD ��ת��ʱ��Ϊ 50s(20s+15s+15s) ���� BPDU(�����ŷ����仯�� BPDU)
��ǿ�͵�STP(PVST+)
1# �Ż� portfast //����ڽ��������� pc ���߷������Ľӿ�,�����Ż� 30s ת����ʱ,���� Forwarding ״̬��
����һ:
int f0/3(����ģʽ�Ķ˿�) spanning-tree portfast
������:
����ģʽ��,�����нӿ�ģʽΪ access �Ķ˿ڱ�Ϊ����ת���˿ڡ�
spanning-tree portfast default
2# uplinkfast
���ڽ��ֱ�ӹ���,�� blocking �� forwarding ״̬�� 30s ������ʱ�䱻�Ż���
���������� RP(���˿�)Сʱ������ѡ�� RP,��Ҫ 30s ʱ��uplinkfast �����Ż� 30s ��ʱ�䡣
����ģʽ:
Spanning-tree uplinkfast
3# backbonefast
���ڽ����ӹ���,�� blocking �� forwarding ״̬50s(20S+15S+15S)�����Ż�ǰ��� 20s
ʱ�䡣
����ģʽ:
Spanning tree backbonefast
RSTP(rapid-stp)����������
802.1W ���� RSTP
Cisco rapid-pvst(���ٵ� VLAN ������)
1# �����������Ķ˿ڽ�ɫ:
STP �Ķ˿ڽ�ɫ:
���˿�(RP),ָ���˿�(DP),��ָ���˿�,ֻ�и��˿ں�ָ���˿ڲ��ܳ��� forwarding״̬��
RSTP �Ķ˿ڽ�ɫ:
1# Root port ���˿� forwarding
2# designated port ָ���˿� forwarding
3# backup port ���ݶ˿� ����ָ���˿�,���ݶ˿ڳ����ڡ��Ի�����,�� DP ��ʧ֮��,���Խ�ʡ 30s ʱ��,������� DP��
4# Alternate port ����˿� (����ĸ��˿�)�����˿���ʧ��,������Ϊ���˿�,�� ʡ 30s ʱ�䡣
5# Edge port �߽�˿�(�������� pc �������)���Խ�ʡ 30s ��ʱ��,���Ƕ������ǵĿ�������������Ҫָ����Ե�˿ڡ�
����ģʽ:
spanning tree portfast edge default //�����Ե�˿�Ϊ����ת���˿�
2# �����������Ķ˿�״̬
Discard (disable blocking listening,����ѧϰ mac ��ַ)
Learnning(����ѧϰ mac ��ַ,����ת������)
Forwarding (����ѧϰ mac ��ַ,��ת������)
���˿�,ָ���˿�,��Ե�˿�,״̬���� forwarding ״̬������˿�,���ݶ˿ڴ��� discard ״̬��
3# ����������ģʽΪ����������
����ģʽ:Spanning tree mode rapid-pvst
һ��Rstp ����·����(rstp link type):
1# p2p ��Ե�(�������뽻������������·)
2# shared ������(�������뼯������������·)
����������������ԭ��
1# �������������˱��ݶ˿�,����˿�,��Ե�˿ڡ�
2# �������������˷����仯��ʱ��� STP �����졣
3# ������������ P/A ����,����������·���ܹ����ٵ�ѡ�ٳ����˿ں�ָ���˿ڡ�
����������������P/A ����
1# ����·�в�����һ���µ���·,��ѡ�� DP �Ķ˿�,����Զ˷��� proposal ��λ�� BPDU
2# ���յ� proposal ��λ�� BPDU,�����Ž��Լ������еĶ˿���λ SYN(ͬ��)
*Edge �˿����� SYN
*֮ǰ�� block �Ķ˿�Ҳ���� SYN
*֮ǰ���� dp ���� rp �Ķ˿� block,���� SYN ״̬
3# �����еĶ˿ڴ��� SYN ״̬֮��,���������ν��������� proposal �Ľ���������
agreement bpdu,�˿������ı��Լ���״̬�����Կ��ٵ��� DP/RP ���� AP,BP �õ����ٵ�ȷ�ϡ�
MSTP(multiple spanning-tree protocol)����������
802.1s ����
Mstp �ǽ���� vlan ����һ��ʵ��(instance),ÿ��ʵ��ά��һ����Mstp �����ȼ���֮ǰ�� VLAN_ID ��Ϊʵ����.
Bridge ID= ���ȼ� + instance number + mac address
1# MSTP ����:
CST:�������� MST ����,��ά��һ��������������,���������ܰ����Ų������κ������ 802.1d �Ľ�������
IST:mst �����ڵ�������,ά���ͼ���� mst ������ڵ� stp,����� IST Ϊʵ�� 0,�� IST Ϊ������� MST �������֡�
Ĭ�ϵ����е� vlan ������ʵ�� 0.
2# MSTP ������:
Spanning-tree mode mst //��������ģʽ��Ϊ MST Spanning-tree mst configuration //���� MST ����������Name QLB //�������� QLB
Revision 2 //��������Ϊ 2
Instance 1 vlan 1-500 //�� vlan1-500 ����ʵ�� 1
Instance 2 vlan 501-1000 //�� vlan501-1000 ����ʵ�� 2
3# ��Э���������������ȼ�:
Spanning tree mst 0-1 root primary //���ý���������Ϊʵ�� 0,1 ��������Spanning tree mst 2 root secondary //������������Ϊʵ�� 2 �ı��ݸ�����
Spanning-tree mst 0-1 priority 0 //��ʵ�� 0 1 �����ȼ�����Ϊ 0
spanning-tree mst 2 priority 4096 //��ʵ�� 2 �����ȼ�����Ϊ 4096
��·�ۺ�:
1# LACP
IEEE 802.3ad �������·�ۺ�Э��������֧�� 16 ����·������Lacp ������·����ɹ������Active �� active
Active �� passive Sw1:
Int rang f0/1-3 Sw tr en dot Sw mo tr
Channel-protocol lacp
Channel-group 12 mode active / passive Sw2:
int rang f0/1-3 Sw tr en dot Sw mo tr
Channel-protocol lacp Channel-group 21 mode active
�鿴����:Show etherchannel summary // �鿴��·��״̬
2# PAPG(cisco ˽��)
Pagp ��·����ɹ��ĵ����:���֧�� 8 ����·����desirable �� auto
desirable �� desirable Sw1:
int rang f0/1-3 Channel protocol pagp
Channel-group 12 mode desirable / auto Sw2:
int rang f0/1-3 Channel protocol pagp
Channel-group 21 mode desirable
3# �Զ�������̫��·
Sw1:
int rang f0/1-3
Channel-group 12 mode on Sw2:
int rang f0/1-3
Channel-group 21 mode on
��̫��·����ɹ��ĵ�����(����ʵ�ָ��ؾ��������):
1# ��������Ҫһ��,��˫��������ƥ��
2# �����װ�� trunk,��װЭ��Ҫһ��(802.1Q �� ISL)
3# ���û�з�װ trunk Ҫ��ͬһ�� vlan
4# ��װ�Ķ˿�Ҫ����
5# Lacp �� pagp ������
·�ɵĵ�һ������
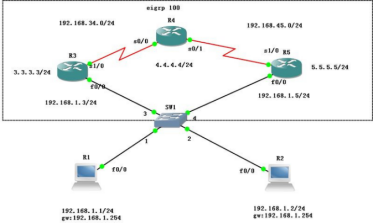
һ��HSRP (hot standby rouer protocol �ȱ���·��Э��) --Cisco ˽��
���� UDP 1985 �˿��鲥��ַ 224.0.0.2
R3 R5 ģ�����������·��
1# ����� mac ��ַΪ:0000.0c07.ac + group ID 2# ��������ά���� IP Ҫһ��
3# ��ռĬ���ǹرյ�
4# �ȶ���״̬Ϊ active �� standby 5# ���� active ��״̬��·������ת��
6# ������������̫�ӿں� SVI(Switch Virtual Interface)
�� �� :
R3(config)#int f0/0
R3(config-if)#standby 1 ip 192.168.1.254 R5(config)#int f0/0
R5(config-if)#standby 1 ip 192.168.1.254
HSRP �� 6 ��״̬:
1# Initial ��ʼ��
2# Learn ѧϰ
3# Listen ����
4# Speak ����
5# Standby ����
6# active �
active ״̬��ѡ��ԭ��:
�ȱȽ����ȼ�,���ȼ�������ȳ�Ϊ active(Ĭ�����ȼ� 100) ������ȼ�һ��,�ȽϽӿڵ� ip ��ַ,ip ��ַ��ij�Ϊ active��
�� R3 �����ȼ������� R5 ��:
R3:
int f0/0
Standby 1 priority 110 //�����ȼ�����Ϊ 110,��ʱ��Ȼ�� R5 ת����
���� R3 ����ռ: R3(config)#int f0/0
R3(config-if)#standby 1 preempt //������ռ
R3(config)#int f0/0
R3(config-if)#standby 1 track s1/0 //���� s1/0 �ӿڵ�״̬
��(track)4.4.4.0/24 �Ƿ�ɴ�:
R3(config)#track 100 ip route 4.4.4.4 255.255.255.0 reachability(�ɴ���) R3(config)#int f0/0
R3(config-if)#standby 1 track 100 //��·�� 4.4.4.0/24 ·�ɵĿɴ���,����������ȼ�Ĭ�ϼ� 10��
R3:
Access 1 deny 4.4.4.0 Access 1 permit any Router eigrp 100
Distribution 1 in //���� 4.4.4.0/24 ·�ɵĿɴ���, ������ɴ����ȼ�Ĭ�ϼ� 10.
����VRRP(Virtual router redundancy portocol ����·������Э��)�C����Э��
1# Э����鲥��ַ 224.0.0.18
2# ��� 112
3# ����� MAC ��ַΪ:0000.5e00.01+group id
4# ��ռĬ�Ͽ���
5# Ĭ�����ȼ�Ϊ 100
6# �ȶ���״̬:master backup(master ת����,backup ����)
VRRP ������״̬
Initialize ��ʼ��
Backup �� ��
Master ת �� ��
VRRP ������
sh run int f0/0 //�鿴�ӿ��µ�����
R5:
ip address 192.168.1.5 255.255.255.0
vrrp 1 ip 192.168.1.254
vrrp 1 authentication md5 key-string cisco R3:
ip address 192.168.1.3 255.255.255.0
vrrp 1 ip 192.168.1.254
vrrp 1 priority 101
vrrp 1 authentication md5 key-string cisco
vrrp 1 track 100 //������ٺ�
����GLBP(gateway load balancing protocol ���ظ��ؾ���Э��)-- ����Э��
clear arp-cache //ARP �����������
��ռ��Ĭ�Ϲرյ�,���ȼ�Ϊ 100(����ѡ�� AVG)
�������ַ����ĸ��ؾ���:
1> host-dependent:���ݲ�ͬ������Դ MAC ��ַ����ƽ��;
2> round-roin:��ѯ��ʽ,��ÿ��Ӧһ�� ARP ����,�ֻ�һ����ַ,Ĭ�ϼ�Ϊ���ַ�ʽ;
3> weighted:����·������Ȩ�ط���,Ȩ�ظߵı�����Ŀ����Դ�; 1# AVG(active virtual gateway)���������
Avg ��ÿ����Ա�������� MAC ��ַ
����Ӧ�� ARP ����,��ÿ���������䲻ͬ�� MAC ��ַ,�ﵽ���ؾ���
2# AVF(active virtual forwarder)��Ծ����ת���߸���ת���û�������
�鲥��ַ 224.0.0.102
���� UDP 3222 �˿ڡ�
R3:
int f0/0
glbp 1 ip 192.168.11.254
R3(config-if)#glbp 1 load-balancing //���ַ������ؾ���
R3(config-if)#glbp 1 weighting ** //����Ȩ��ֵ
R5:
int f0/0
glbp 1 ip 192.168.11.254
���
��������,Cisco���緽������ݾͲ����,��ҳ�հ�֪ʶ,ʵ�鹮��һ��,�����һ��,��������һ��˼·��ϵ��ѧϰ,����֮�����Թ��������а�����
��߶��߶
��Һ�,��������,��л�˲��ǵ�����,�ղ�������,�����ټ���!