以下内容来源于AutoSar官网的AUTOSAR_PRS_SOMEIPProtocol文档
SOME/IP Payload
SOME/IP Payload由事件的数据元素或方法的参数组成,大小取决于所使用的传输层协议,对于UDP,payload介于0到1400个字节之间,而由于TCP支持payload分段,所以支持更大的长度
SOME/IP payload应以网络字节顺序编码,也就是大端规则传输
数据结构的序列化
将结构化的数据按照一定规则转换成byte字节流,然后封装到SOME/IP的payload里,发送到网络上,这就是数据结构的序列化
结构化的数据是并行的,而payload数据是串行的
数据结构的序列化就是把并行的结构化数据序列化成串行数据
更进一步地说,结构化数据里的元素的数据类型有可能是字符串,数字,布尔值等等,而payload数据只可能是byte数组
那么怎样才能把包含不同数据类型的结构化数据序列化成byte数组呢,不同的项目有不同的规则
之前遇到的项目,是把结构化数据按照ASN.1的格式进行定义的,那么序列化时也是按ASN.1的规则编码成byte数组
Payload数据序列化基于接口规范定义的参数列表,接口规范定义了PDU中所有数据结构的确切位置,并且必须考虑内存对齐
所以SOME/IP payload数据一要根据项目规范,二还要考虑内存对齐
什么是内存对齐,之前在学习capl中的结构体时涉及过
计算机系统为了简化处理器与内存之间的传输,以及提升读取数据的速度,对数据在内存中的存储的位置进行了限制,要求是某个数k的倍数,这就是所谓的内存对齐
结构体中的元素由于大小不一,就需要设置这个k值,每个元素的长度必须是这个k值的倍数,如果不满足,就需要填充一定的内存空间以满足k值的倍数
设置对齐方式,并不意味着结构体的长度/大小发生了变化
而对于payload里的数据结构,如果某个元素大小可变,且不是序列化数据流中的最后一个元素,则应通过在可变元素数据后插入填充位来实现数据对齐

固定长度数据元素后不应该有填充,如果非要填充,必须在规范中明确
可变长度元素后面的数据对齐应为1、2、4、8、16、32个byte
支持的数据类型
基本数据类型

- 布尔类型
- 无符号整数,包括8、16、32、64位
- 有符号整数,包括8、16、32、64位
- 浮点数,包括32位和64位
结构化数据类型(结构体)
结构体应按顺序序列化,还需考虑内存对齐
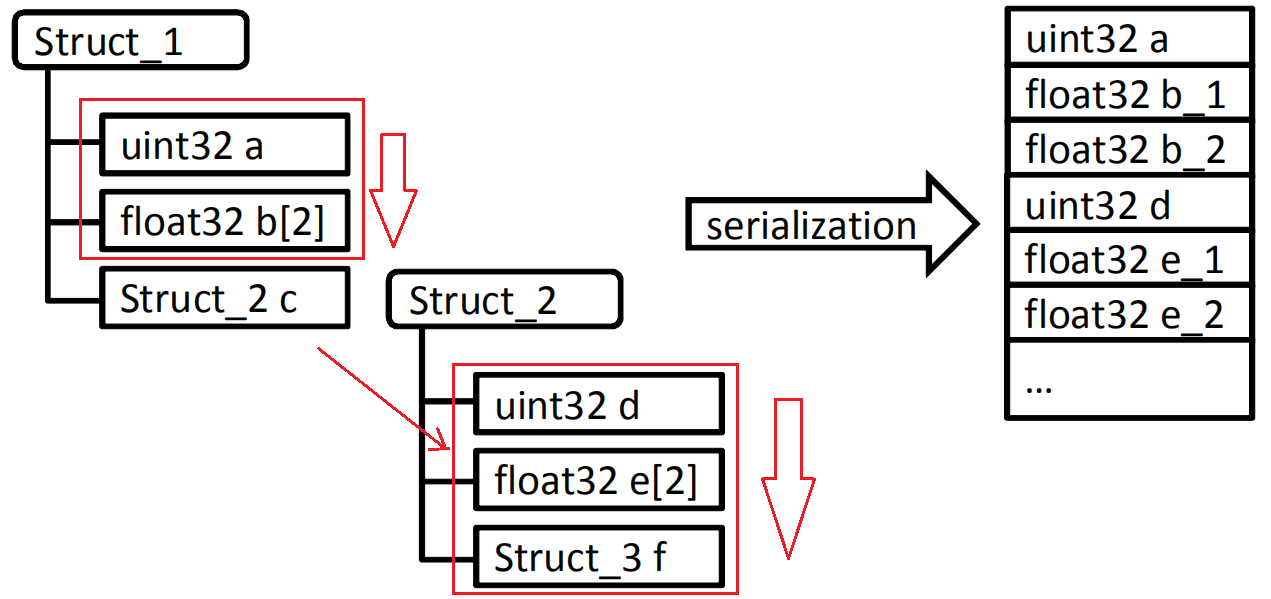
SOME/IP不能自动插入虚拟或填充数据
根据配置情况,可以在结构体前插入长度字段,以表示这个结构体数据在SOME/IP传输时的长度,长度字段的大小为8、16或32位
如果长度字段大小大于结构体长度,则仅反序列化指定的字节,并根据长度字段跳过其他字节,如果长度字段大小小于结构体长度,且接收方无法在本地提供数据来替换,则中止反序列化,并将SOME/IP消息视为格式错误
反序列化是对序列化的反向操作,接收方根据收到的SOME/IP payload进行的解析
带有标识符和可选成员的结构化数据类型和参数
为了兼容之前或之后的版本,可以为结构成员或方法参数添加数据ID,有了这个ID,接收方才会反序列化,这样就可以设置可选成功,同时可以在任意位置添加新的成员
每个数据ID在结构中是唯一的,不能重复,在不同的结构或方法中不需要唯一
结构中同一层级的成员,要么全部定义数据ID,要么全部都不定义,方法中所有参数要么全部定义数据ID,要么全部都不定义

通过上图,可以看到结构体中一个元素的组成
- Wire Type
第一个byte的6-4位,它的值表示后面数据的类型

Wire Type 4时长度字段是静态配置的,而5、6、7是忽略静态配置,忽略长度字段的大小,根据Wire Type选择长度字段的大小,5是1个byte,6是2个byte,7是4个byte,可以看上图
- Data ID
第一个byte的3-0位,和第二个byte的8位,共12位
如果结构的元素或方法的参数配置了Data ID,则应该在序列化字节流中插入tag,也就是下面这个东西
还有Strings、Arrays等数据类型
SOME/IP协议规范
SOME/IP支持TCP和UDP传输消息,选择哪种传输协议,后续会讲到
如果服务器和多个客户端进行同一个服务的SOME/IP通信,它会运行同一服务的不同实例,这些实例的消息是通过传输层协议端口映射到该实例上的
也就是说为了辨别不同的实例,就需要用实例的消息的传输层端口来区分
传输层payload里允许有多个SOME/IP消息,根据长度字段确定每个SOME/IP消息
每个SOME/IP payload都应该有自己的SOME/IP首部
一个服务实例可以用以下方式来进行所有方法、事件和通知的通信
- 最多一个TCP连接
- 最多一个UDP单播
- 最多一个UDP多播
UDP绑定
SOME/IP的UDP绑定通过UDP包传输SOME/IP消息来实现
SOME/IP协议不应限制UDP分片的使用
UDP payload里是SOME/IP消息,如果payload太大,在网络层会进行分片,而SOME/IP协议不能限制它的分片功能
对于配置为使用UDP单播通信的服务实例的所有方法、事件和通知,客户端和服务器应使用单个UDP单播连接
这句话的意思是一个单播UDP能实现所有配置为UDP单播通信的方法、事件和通知
一个多播UDP能实现所有配置为UDP多播通信的事件和通知
TCP绑定
SOME/IP的TCP绑定通过TCP报文传输SOME/IP消息来实现
一个单播TCP能实现所有配置为TCP单播通信的方法、事件和通知
这里有几个注意点
- 客户端在SOME/IP通信前首先需要建立TCP连接
- 客户端负责在失败时重新建立TCP连接
- 当需要断开连接时,由客户端发起断开连接请求
- 当使用TCP连接的所有服务不再可用(停止或超时)时,客户端应关闭TCP连接
- 服务器在停止所有服务时不应停止TCP连接,给客户端足够的时间来处理控制数据以关闭TCP连接本身
- 如果客户端没有主动关闭TCP连接,而服务器关闭TCP连接,那么客户端会尝试重新建立连接
上面讲的TCP连接与断开的逻辑只针对SOME/IP的TCP协议而言,并不是标准TCP协议的规范
SOME/IP-TP
记得在前面看到SOME/IP-TP时并不了解其含义,这里就涉及到了
通过UDP传输长度很长的SOME/IP消息
SOME/IP的UDP绑定只能传输直接适合IP数据包的SOME/IP消息
什么意思
就是SOME/IP消息的大小最好能在IP层不需要分片直接传输
如果需要通过UDP传输更大的SOME/IP消息,则应使用SOME/IP-TP
就是说如果SOME/IP消息太大,就要用SOME/IP-TP协议,相当于在SOME/IP层对SOME/IP消息进行分片,这时候的SOME/IP Header就变成了SOME/IP-TP Header
SOME/IP消息太大而不能用UDP绑定直接传输的,称为“原始”SOME/IP消息
在SOME/IP-TP消息中传输的原始SOME/IP消息payload的“片段”称为segments
所有的SOME/IP-TP段必须携带原始消息的Session ID,因此,它们都具有相同的Session-ID
SOME/IP-TP segments应将消息类型的TP-Flag设置为1
就是其中有一位要设置为1,可以回顾下前面的文章
举例
原始SOME/IP消息为

如何分片
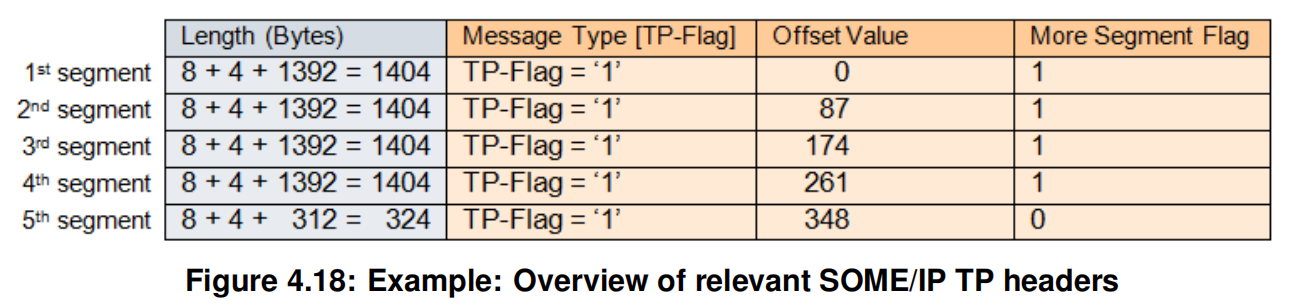
SOME/IP-TP消息
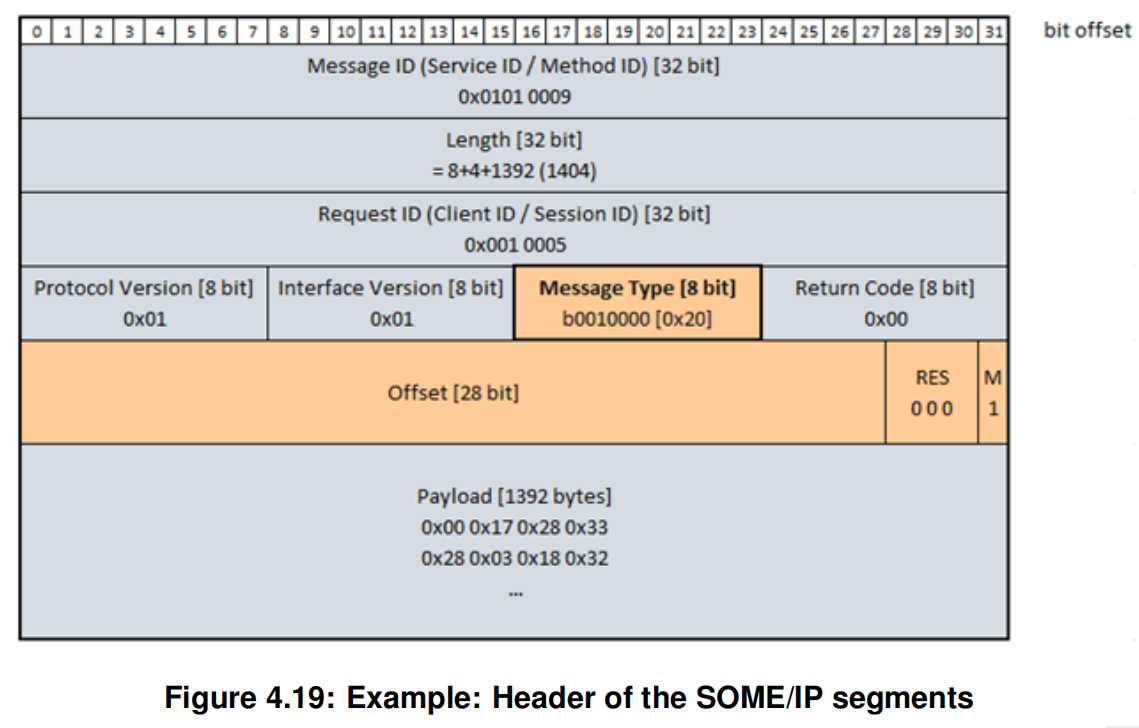
最后一条SOME/IP-TP消息
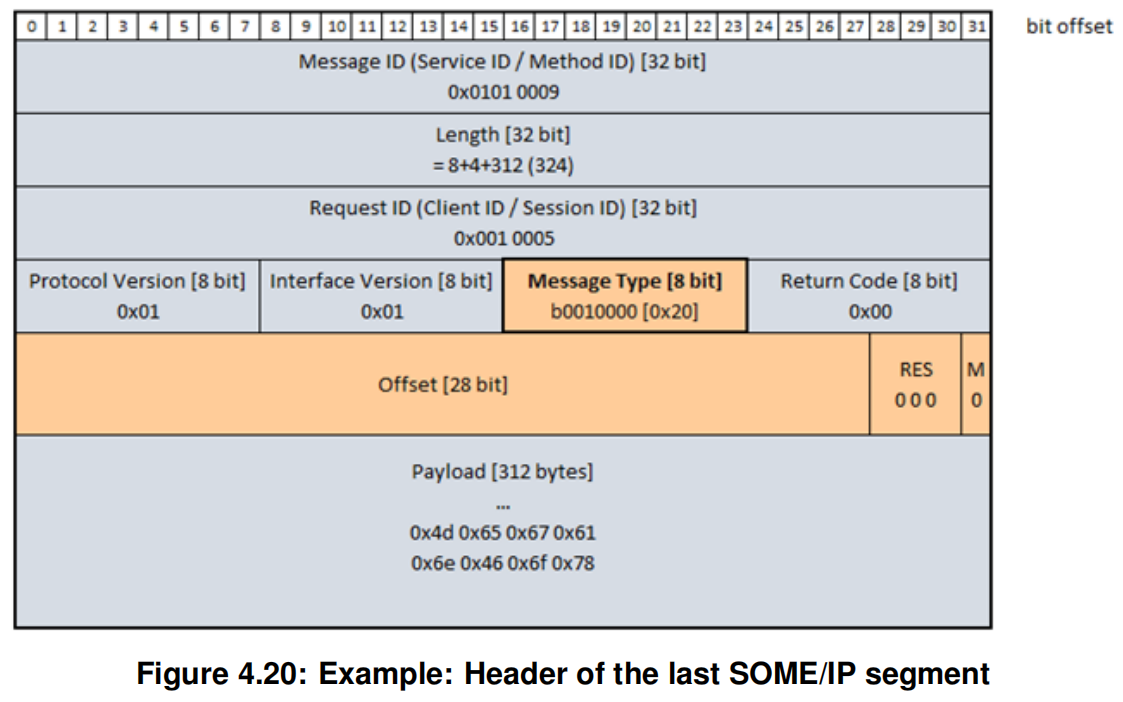
可以看出,SOME/IP-TP其实是对SOME/IP长消息的分片,SOME/IP-TP的首部相比较SOME/IP的首部,有两个不同点
- Message Type字段的TP-Flag标志位要设置为1
- 多了4个字节的字段,用来表示offset、Res和M
发送方行为
发送方应仅对配置为分段的消息进行分段,且按顺序发送
发送方应把More Segment Flag设置为1的所有段都分片成相同的大小,也就是说除了最后一片,其他的分片大小都要相同,都是1392个byte
发送方不得发送重复的分片报文
接收方行为
接收方应根据配置的Message-ID、Protocol-Version、Interface-Version和Message-Type(w/o TP Flag)进行重组
Session ID用于检测下一个要重组的原始消息
这句话说明了什么
说明同一原始SOME/IP消息分片的Segment的Session ID相同,同时它还是接收方重组新的分片的标志
如果接收到具有不同Session-ID的Segment,则接收方应开始新的重组(并可能丢弃未成功重组的旧段)
这句话说明如果收到新的Session ID,而之前的重组还未完成,接收方需要开始新的重组,这时候就会导致之前的还未完成的重组的消息被丢弃
这种情况通常发生在新的消息的分片跑到了旧消息的分片的前面,被接收方收到
只有正确重组的消息才能传递给应用程序
消息的每个分片都有Return Code,只有最后一片的Return Code在重组时被使用
当检测到有丢失的分片时,应该取消之前的重组,这意味着不支持重新排序
接收方还支持覆盖重复的分片以正确重组消息