HTTPгыHTTPS
HTTPавщ
ЮвУЧдкЪфШывЛИіURLЪБ,ЯдЪОГіИїжжИїбљЕФWebвГУц,етаЉвГУцДгКЮЖјРД,гжЪЧОЙ§СЫЪВУДВйзїГЪЯждкЮвУЧУцЧАЕФ?
Web НчУцЕБШЛВЛЛсЦОПеГіРД,ИљОн Web фЏРРЦїЕижЗРИжажИЖЈЕФ URL,Web ЪЙгУвЛжжУћЮЊ HTTP ЕФавщзїЮЊЙцЗЖ,ЭъГЩДгПЭЛЇЖЫЕНЗўЮёЖЫЕФвЛаЉСїГЬЁЃПЩвдЫЕ,Web ЪЧНЈСЂдк HTTP авщЩЯНјааЭЈаХЕФЁЃ
ЪВУДЪЧHTTP
HTTP:ГЌЮФБОДЋЪфавщ(HyperText Transport Protocol)ЪЧЕБНёЛЅСЊЭјгІгУзюЙуЗКЕФвЛжжЭјТчавщ,ЫљгаЕФЭђЮЌЭј(WWW)ЮФМўЖМБиаызёЪиетИіавщ,КЭTCP/IPавщзхЕФЦфЫћавщвЛбљ,HTTPгУгкПЭЛЇЖЫКЭЗўЮёЖЫжЎМфЕФЖіЭЈаХЁЃ
ЖрАцБОЕФHTTP(0.9,1.0,1.1,2.0)
0.9АцБОКЭ1.0АцБОгЩгквбОКмЩйЪЙгУ,ОЭВЛЖрУшЪіСЫ,жївЊзмНсКѓСНжж
HTTP/1.1:1997 ФъЙЋВМЕФ HTTP 1.1 ЪЧФПЧАжїСїЕФ HTTP авщАцБОЁЃЕБФъЕФ HTTP авщЕФГіЯжжївЊЪЧЮЊСЫНтОіЮФБОДЋЪфЕФФбЬт,ЯждкЕФ HTTP дчвбГЌГіСЫ Web етИіПђМмЕФОжЯо,БЛдЫгУЕНСЫИїжжГЁОАРяЁЃ
аТЬиад
- аТв§ШыConnectionзжЖЮ,ПЩвдЩшжУГЄСЌНг(keep-alive)БЃГжСЌНгзДЬЌ,ВЛгУЯёжЎЧАвЛбљвЛИіЧыЧѓНЈСЂвЛДЮСЌНг
- ЙмЕРЛЏЁЊЁЊЛљгкГЄСЌНгЕФЛљДЁ,ПЩвдВЛЕШД§ЯьгІЕНДяОЭМЬајЗЂЫЭЧыЧѓ,ЕЋЪЧЯьгІЕФЫГађЛЙЪЧАДееЧыЧѓЕФЯШКѓЫГађХХађ
- ЛКДцДІРэ
- ЖЯЕуДЋЪф
HTTP/2.0:2.0АцБОЕФHTTPавщЪЧЖд1.xАцБОЕФавщНјааСЫЩ§МЖгХЛЏ,ВЂВЛЪЧЭъШЋЕФИФЭЗЛЛУцСЫЁЃ
аТЬиад
- ЖўНјжЦЗжжЁ
- ЖрТЗИДгУЁЊдкЙВЯэTCPСЌНгЕФЛљДЁЩЯЭЌЪБЗЂЫЭЧыЧѓКЭЯьгІ(ОЭЪЧЫЕЮвУЧдкЗЂЫЭЧыЧѓЕФЭЌЪБвВПЩвдвЛВЂАбЯьгІвВЗЂЫЭЙ§ШЅ)
- ЭЗВПбЙЫѕЁЊhttp1.xЕФЭЗДјгаДѓСПаХЯЂ,ЖјЧвУПДЮЖМвЊжиИДЗЂЫЭЁЃhttp/2ЪЙгУencoderРДМѕЩйашвЊДЋЪфЕФheaderДѓаЁЁЃ
- ЗўЮёЦїЭЦЫЭЁЊЗўЮёЦїПЩвдЖюЭтЕФЯђПЭЛЇЖЫЭЦЫЭзЪдД,ЖјЮоашПЭЛЇЖЫУїШЗЕФЧыЧѓ
ЧјЗжURLКЭURI
ЮвУЧдкDNSавщжаЬсЕНЙ§URLЦфЪЕОЭЪЧЗўЮёЦїзЪдДЕФзМШЗТЗОЖ,гжНазіЭјжЗ,БШШч http://baidu.comЁЃ
ЖјURIЪЧUniform Resource IdentifierЕФЫѕаД,жаЮФОЭЪЧЭГвЛзЪдДБъЪЖЗћ,ЖјURLЪЧUniform Resource LocationЕФЫѕаД,жаЮФЪЧЭГвЛзЪдДЖЈЮЛЗћ
- Uniform-гУЭГвЛЕФЙцИёДІРэВЛЭЌаЮЪНЕФзЪдД
- Resource-зЪдДЕФЖЈвхЪЧПЩБъЪЖЕФШЮвтЖЋЮї,ВЛвЛЖЈЪЧЕЅвЛЕФ,вВПЩвдЪЧвЛИіМЏКЯ
- Identifier-зЪдДЖРвЛЮоЖўЕФБъЪЖ,ОЭКУБШШЫЕФЩэЗнжЄ,етРяНазіБъЪЖЗћЁЃ
змНсРДЫЕ:URIгУРДБъЪЖФГВПЗжЭјТчЕФзЪдД,ЖјURLгУРДЖЈЮЛзЪдДЕФЕиЕу,URLЪЧURIЕФзгМЏ
ЮвУЧжЊЕРдкгІгУВуЕФЪ§ОнИёЪНЪЧHTTPЧыЧѓБЈЮФКЭЯьгІБЈЮФ,ФЧУДетаЉЪ§ОнРяЕНЕзАќКЌСЫЪВУДаХЯЂКЭЪ§ОнФи?
HTTP авщЙцЖЈ:дкСНЬЈМЦЫуЛњжЎМфЪЙгУ HTTP авщНјааЭЈаХЪБ,дквЛЬѕЭЈаХЯпТЗЩЯБиЖЈгавЛЖЫЪЧПЭЛЇЖЫ,СэвЛЖЫдђЪЧЗўЮёЖЫЁЃПЭЛЇЖЫвЊЯШЗЂЦ№HTTPЧыЧѓ,ЗўЮёЦїЪеЕНКѓдйЗЕЛиЯьгІБЈЮФ,ЫљвдЫЕ,вЛЖЈЪЧгЩПЭЛЇЖЫПЊЪМНЈСЂЭЈаХЕФЁЃ
HTTPЧыЧѓБЈЮФ
HTTP ЧыЧѓБЈЮФгЩ 3 ДѓВПЗжзщГЩ:
1)ЧыЧѓаа(Биаыдк HTTP ЧыЧѓБЈЮФЕФЕквЛаа)
2)ЧыЧѓЭЗ(ДгЕкЖўааПЊЪМ,ЕНЕквЛИіПеааНсЪјЁЃЧыЧѓЭЗКЭЧыЧѓЬхжЎМфДцдквЛИіПеаа)
3)ЧыЧѓЬх(ЭЈГЃвдМќжЕЖд {key:value}ЗНЪНДЋЕнЪ§Он)(ПЩвдУЛга)

HTTPЧыЧѓаажаЕФЧыЧѓЗНЗЈ
ЧыЧѓаажаЕФЗНЗЈзїгУдкгкПЩвджИЖЈЗўЮёЦїжаЕФзЪдДАДЦкЭћзіГіФГжжааЮЊ,ОЭЪЧПЭЛЇЖЫЪЙгУЧыЧѓЗНЗЈИјЗўЮёЦїЯТВйзїУќСю
ГЃгУЕФЗНЗЈга(1.0жЎКѓ):GET(0.9ЮЈвЛжЇГж),POST,PUT,HEAD,DELETE,OPTIONS,TRACEЕШЕШ,ЕБШЛзюГЃгУЕФЛЙЪЧЧАУцЫФИіЗНЗЈЁЃ
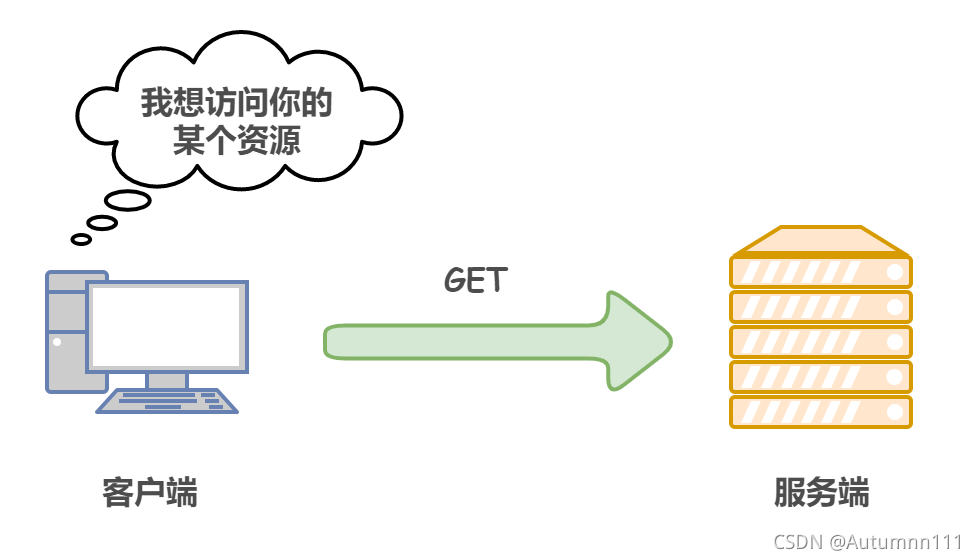
1)GETЛёШЁзЪдД
GETЗНЗЈгУРДЛёШЁвбОБЛURIБъЪЖЕФзЪдД,ЗўЮёЦїЪеЕНЧыЧѓКѓЗЕЛиЖдгІЕФНтЮіФкШн
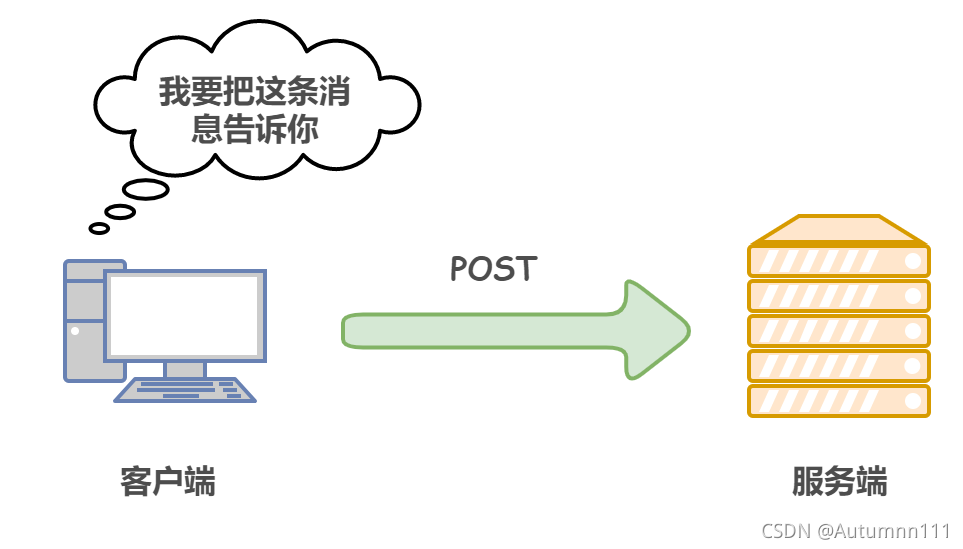
2)POSTДЋЪфЪЕЬхжїЬх
POSTжївЊгУРДДЋЪфЪ§Он,ЗўЮёЦїЪеЕНЧыЧѓКѓЛсЗЕЛиетДЮЧыЧѓЕФДІРэНсЙћ
3)PUTДЋЪфЮФМў
PUTЗНЗЈгУРДДЋЪфЮФМў,ШЮКЮШЫЖМПЩвдЪЙгУ,ЫљвдАВШЋадВЛИп,вЛАуВЛЪЙгУ
4)HEADЛёШЁБЈЮФЪзВП
КЭGETЗНЗЈРрЫЦ,ЕЋЪЧЗЕЛиЕФВЛЪЧеце§ЕФБЈЮФЪзВП,ЯьгІБЈЮФРяАќКЌЕФЪЧБЈЮФЪзВПРяЕФОпЬхаХЯЂ,БШШчURIЕФгааЇадКЭзЪдДЕФИќаТШеЦкЕШЕШЁЃ
5)DELETEЩОГ§ЮФМў
КЭPUTЙІФмЯрЗД,вВВЛДјгабщжЄЛњжЦ,ШЮКЮШЫЖМПЩвдвРееURIЩОГ§ЖдгІЮФМў
6)OPTIONSВщбЏжЇГжЕФЧыЧѓЗНЗЈ
гУгкВщбЏЕБЧАURIБъЪЖзЪдДжЇГжЕФЧыЧѓЗНЗЈ,ЯьгІБЈЮФЕФЯьгІЭЗжаЛсАќКЌвЛИіAllowзжЖЮ,valueОЭЪЧЖдгІЕФЗНЗЈЁЊЁЊGET,POSTЕШЕШ


7)TRACEЛиЯдЗўЮёЦїЪеЕНЕФЗНЗЈжИСю,гУгкВтЪд
HTTPЧыЧѓЭЗ
ЧыЧѓЭЗгУгкВЙГфЧыЧѓЕФИНМгаХЯЂ,БШШчЫЕПЭЛЇЖЫаХЯЂ,ЖдЯьгІФкШнЯрЙиЕФгХЯШМЖЕШФкШнЁЃвдЯТСаГіГЃМћЧыЧѓЭЗ:
1)Referer:ИцжЊЗўЮёЦїетИіЧыЧѓЪЧДгФФИіURIЬјзЊЙ§РДЕФ(ОЭКУЯёСДТЗВуЕФТЗгЩвЛбљ),ШчЙћЪЧжБНгДгПЭЛЇЖЫЗЂЦ№ЕФЧыЧѓОЭВЛЛсАќКЌетИізжЖЮЁЃ

**2)Accept:**ИцЫпЗўЮёЖЫ,етИіЧыЧѓжЇГжЕФЯьгІЪ§ОнРраЭ,ОЭБШШчЫЕЮвЗЂЦ№вЛИіЧыЧѓБЈЮФжЇГжЭМЦЌЗЕЛи,ЗўЮёЖЫШчЙћЯьгІЕФЪЧЪгЦЕРраЭОЭВЛааЁЃ
(ЯьгІБЈЮФЭЗРявВАќКЌвЛИізжЖЮContent-Type,БэЪОЯьгІЕФЪ§ОнРраЭ,ШчЙћContent-TypeКЭAcceptРяЕФжЕВЛЖдгІ,ОЭЛсБЈДэ)
**3)Host:**ИцжЊЗўЮёЦїзЪдДЫљДІЕФЛЅСЊЭјжїЛњЕижЗКЭЖЫПкКХ,етбљЗўЮёЦїОЭжЊЕРШЅФФРяеветИізЪдДСЫЁЃетИізжЖЮдкHTTP1.1АцБОжаЙцЖЈЪЧБиаыАќКЌЕФ
**4)Cookie:**ПЭЛЇЖЫЕФCookieОЭЪЧЭЈЙ§етИізжЖЮДЋИјЗўЮёЦїЕФ,cookieОЭЯрЕБгкЗўЮёЦїИјПЭЛЇЖЫЕФвЛИіЦОжЄ,ЗўЮёЦївРППетИізжЖЮГжгаПЭЛЇЖЫзДЬЌ
Cookie: JSESSIONID=15982C27F7507C7FDAF0F97161F634B5
5)Connection:БэЪОДЫДЮСЌНгРраЭ,keep-aliveБэЪОГЄСЌНг,closeЪЧСЌНгЙиБе
6)Content-Length:ЧыЧѓЬхЕФГЄЖШ
7)Range:ЖдзЪдДЕФЗЖЮЇЧыЧѓ,БШШчЫЕгавЛИі1GДѓаЁЕФзЪдД,ЮвжЛашвЊ128M,ОЭПЩвддкRangeзжЖЮжажИЖЈЁЃ
(КѓУцЛЙгавЛаЉУцЪдВЛГЃЮЪ,гааЫШЄПЩвдздМКСЫНт)
HTTPЯьгІБЈЮФ
HTTPЯьгІБЈЮФКЭЧыЧѓБЈЮФвЛбљ,вВЪЧЗжГЩШ§ИіВПЗж:
1.ЯьгІаа
2.ЯьгІЭЗ
3.ЯьгІЬх

ЮвУЧПЩвдПДЕНЯьгІааКЭЧыЧѓааЕФзжЖЮЪЧгаВювьЕФ
ЧыЧѓаа=ЧыЧѓЗНЗЈ(GET)+зЪдДБъЪЖЗћ(URI)+авщАцБО(HTTP1.1)
ЯьгІаа=авщАцБО(HTTP1.1)+зДЬЌТы(200)+двђЖЬгя(OK)
ЯьгІааЕФзДЬЌТыКЭдвђЖЬгяЪЧЯьгІБЈЮФЕФКЫаФ,вВЪЧБОеТНкЕФжиЕу
HTTPЧыЧѓааЕФзДЬЌТы
HTTPзДЬЌТыБэЪОЗўЮёЦїдкНгЪеПЭЛЇЖЫЧыЧѓКѓЕФЗЕЛиНсЙћ,ЗўЮёЖЫДІРэНсЙћЪЧЗёе§ГЃ,ЭЈжЊДэЮѓГіЯжЕШЧщПі,гыШеГЃПЊЗЂЯЂЯЂЯрЙиЁЃ
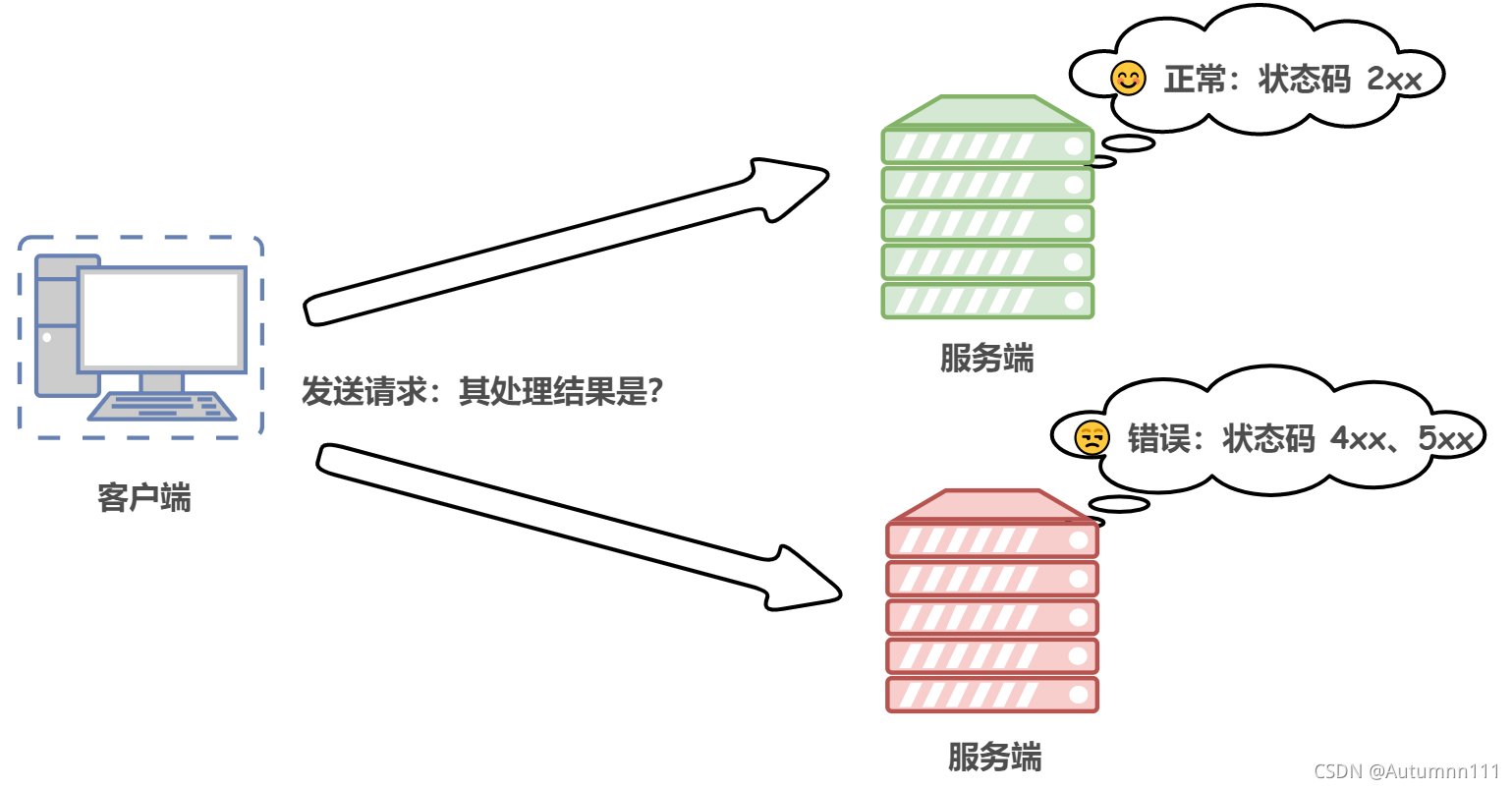
зДЬЌТыгЩ3ЮЛЪ§зжзщГЩ,ПЊЭЗЕФЕквЛИіЪ§зжЖЈвхСЫЯьгІЕФРрБ№
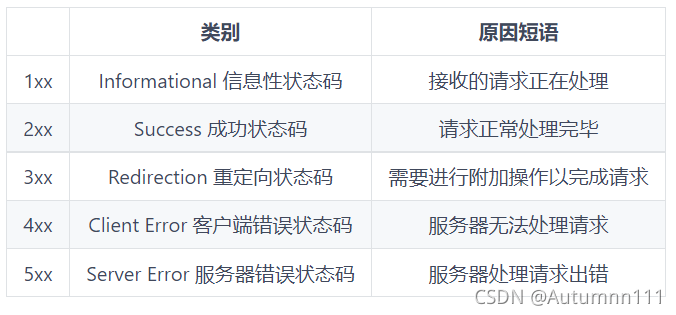
1xx:НгЪеЕФЧыЧѓе§дкДІРэ
2xx:НгЪеЕФЧыЧѓе§ГЃДІРэЭъБЯ
3xx:зЪдДжиЖЈЯђ,ШдашИНМгВйзї
4xx:ЗўЮёЦїЮоЗЈДІРэЧыЧѓ
5xx:ЗўЮёЦїДІРэЧыЧѓГіДэ
(1xxРраЭЕФзДЬЌТывЛАуКмЩйГіЯж,ДѓИХжЊЕРЪВУДвтЫММДПЩ)
2xx:ЧыЧѓе§ГЃДІРэЭъБЯ
-
200 OK:ПЭЛЇЖЫЧыЧѓДІРэГЩЙІ!

-
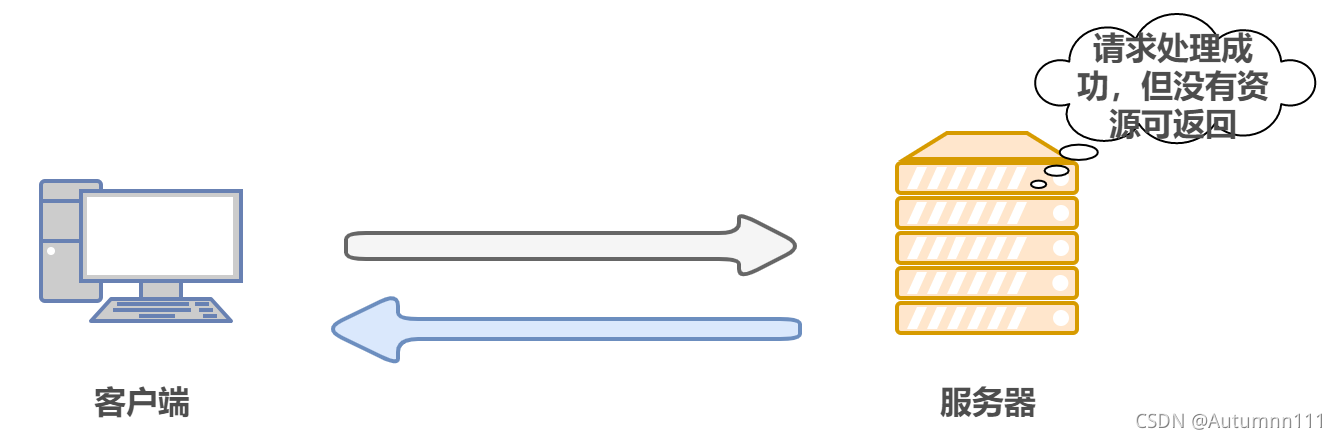
204 No Content:ЗўЮёЦїГЩЙІДІРэЧыЧѓ,ЮоФкШнЗЕЛиЁЃЭЈГЃЪЧПЭЛЇЖЫЯђЗўЮёЦїЗЂЫЭаХЯЂЕФГЁОА
-
206 Partial Content:ЗўЮёЦїЭъГЩСЫВПЗжGETЧыЧѓ(ЧыЧѓБЈЮФжаАќКЌRangeзжЖЮ),ЗЕЛивЛВПЗжзЪдД(ЯьгІБЈЮФжаАќКЌContent-Range)

3xx:зЪдДжиЖЈЯђзДЬЌТы(ашвЊИНМгВйзї) -
301 Move Permanently:гРОУжиЖЈЯђ,ЧыЧѓзЪдДвбОгРОУХВГ§,ВЛдкетИіЗўЮёЦїЩЯСЫ
-
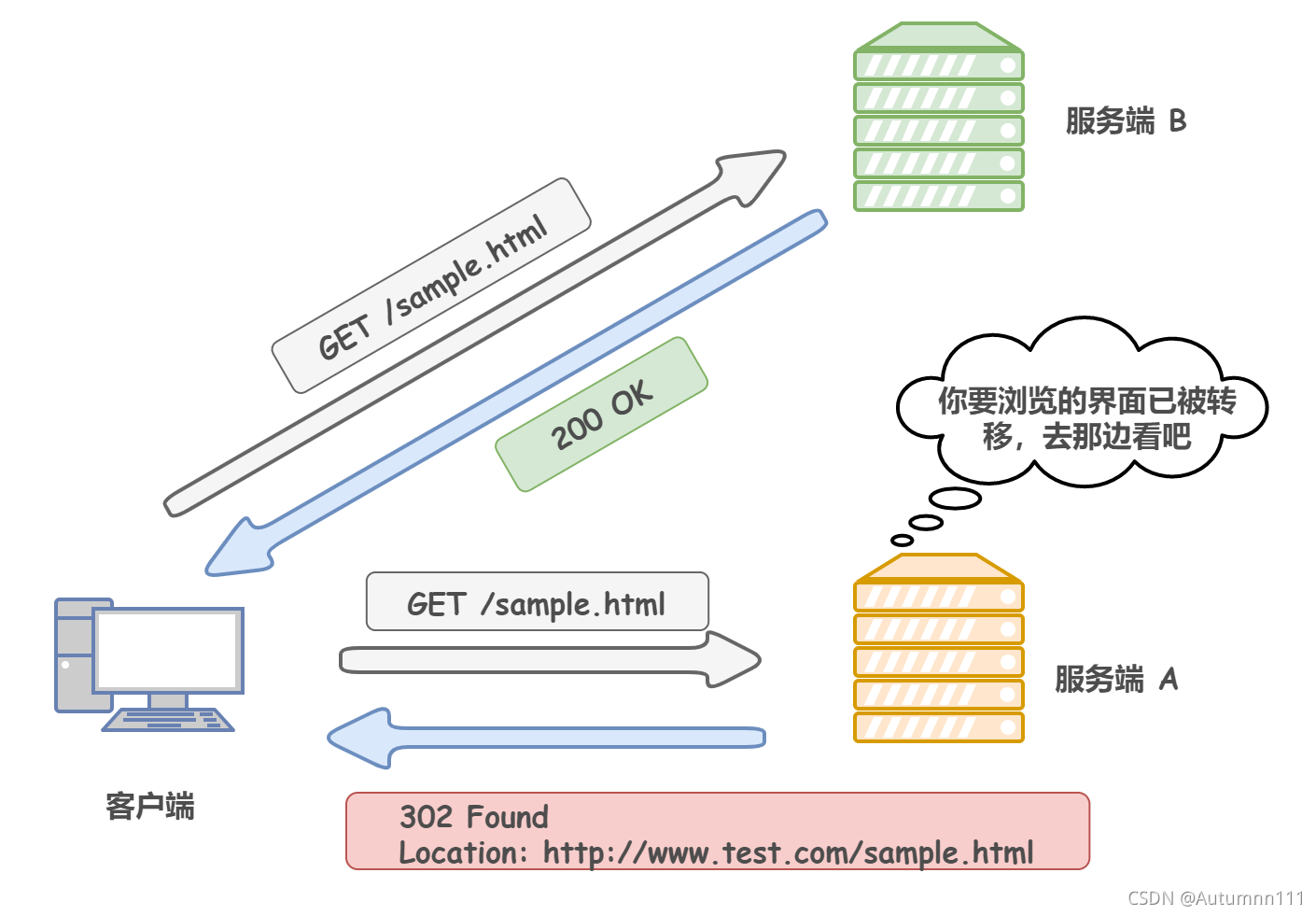
302 Found:СйЪБжиЖЈЯђ,ЧыЧѓЕФзЪдДднЪБХВЕНСЫЦфЫћЕиЗН
-
303 See Other:вВЪЧСйЪБжиЖЈЯђ,КЭ302ЕФЮЈвЛЧјБ№дкгкЯьгІБЈЮФжаЛсУїШЗИцжЊПЭЛЇЖЫгІИУЪЙгУGETЗНЗЈЧыЧѓзЪдД
-
304 Not Modified(ЬиЪт):ЕБПЭЛЇЖЫЧыЧѓБЈЮФжаАќКЌЕФИНМгЬѕМўЮоЗЈТњзуЪБ(ЧыЧѓЭЗжаКЌгаifгяОф)ЛсЗЕЛиетИізДЬЌТы,КЭжиЖЈЯђвЛЗжЧЎЙиЯЕЖМФЊЕУ
-
307 Temporary Redirect:СйЪБжиЖЈЯђ,КЭ302вЛбљ,ВЛЯё303ЛсАбPOSTБфГЩGET
4xx:ПЭЛЇЖЫЧыЧѓГіДэ
- 400 Bad Request:ПЭЛЇЖЫЧыЧѓгагяЗЈДэЮѓ,ЗўЮёЖЫЮоЗЈРэНт
- 401 Unauthorized:ЧыЧѓЮДОЪкШЈ,етИіДњТыБиаыКЭWWW-AuthorizedХфКЯЪЙгУ
- 403 Forbidden:ЗўЮёЖЫОмОјДІРэЧыЧѓ
- 404 Not Found:ЧыЧѓзЪдДУЛгаевЕН,етЪБКђгІИУВщПДURIЪЧЗёаДДэСЫ
- 415 Unsupported media type:ВЛжЇГжЕФУНЬхРраЭ
5xx:ЗўЮёЖЫГіДэ,ЮДФмДІРэКЯЗЈЕФЧыЧѓ
- 500 Internal Server Error:ЗўЮёЖЫЗЂЩњВЛПЩдЄжЊЕФДэЮѓ(ЪЎЗжПжВР)
- 503 Server Unavailable:ЗўЮёЦїЯждкПЩФмГЌдиЛђепе§дкЮЌЛЄ,днЪБЮоЗЈДІРэЧыЧѓ,ПЩвдЙ§ЖЮЪБМфОЭЛжИДе§ГЃЁЃ
HTTPЯьгІЭЗ
ЯьгІЭЗАќКЌвЛаЉИНМгаХЯЂ,ЗўЮёЖЫаХЯЂ,вдМАЖдПЭЛЇЖЫЕФИНМгЧыЧѓЕШ
**1)Allow:**КЭЧыЧѓЭЗжаЕФOPTIONSХфКЯ,ЗЕЛиЗўЮёЦїжЇГжЕФЧыЧѓЗНЗЈ
**2)Content-Type:**КЭЧыЧѓЭЗжаЕФAcceptХфКЯ,ЗЕЛиЯьгІАќКЌЕФЪ§ОнРраЭ
3)Last Modified:зЪдДзюКѓвЛДЮИФЖЏЪБМф
4)Location:ИцжЊПЭЛЇЖЫгІИУШЅФФРябАевзЪдД,ЛсЗЕЛи302зДЬЌТы
5)Set-Cookie:ЩшжУКЭвГУцЙиСЊЕФCookie,ЯТДЮПЭЛЇЖЫЗЂЦ№ЧыЧѓКѓОЭЛсДјЩЯетИіCookieЕБзіЦОжЄЁЃ
HTTPСЌНгРраЭ
ЖЬСЌНг
дк1.0АцБОМАвдЧА,ЪЙгУЕФЖМЪЧЖЬСЌНг,МДУПЗЂЦ№вЛИіЧыЧѓ,ОЭНЈСЂвЛДЮTCPСЌНг,ЗЕЛиЯьгІКѓгжЖЯПЊСЌНгЁЃетбљЕФБзЖЫОЭЪЧаЇТЪЪЎЗжЕЭЯТ,УПИіЧыЧѓЖМАщЫцзХвЛДЮTCPШ§ДЮЮеЪжКЭЫФДЮЛгЪж
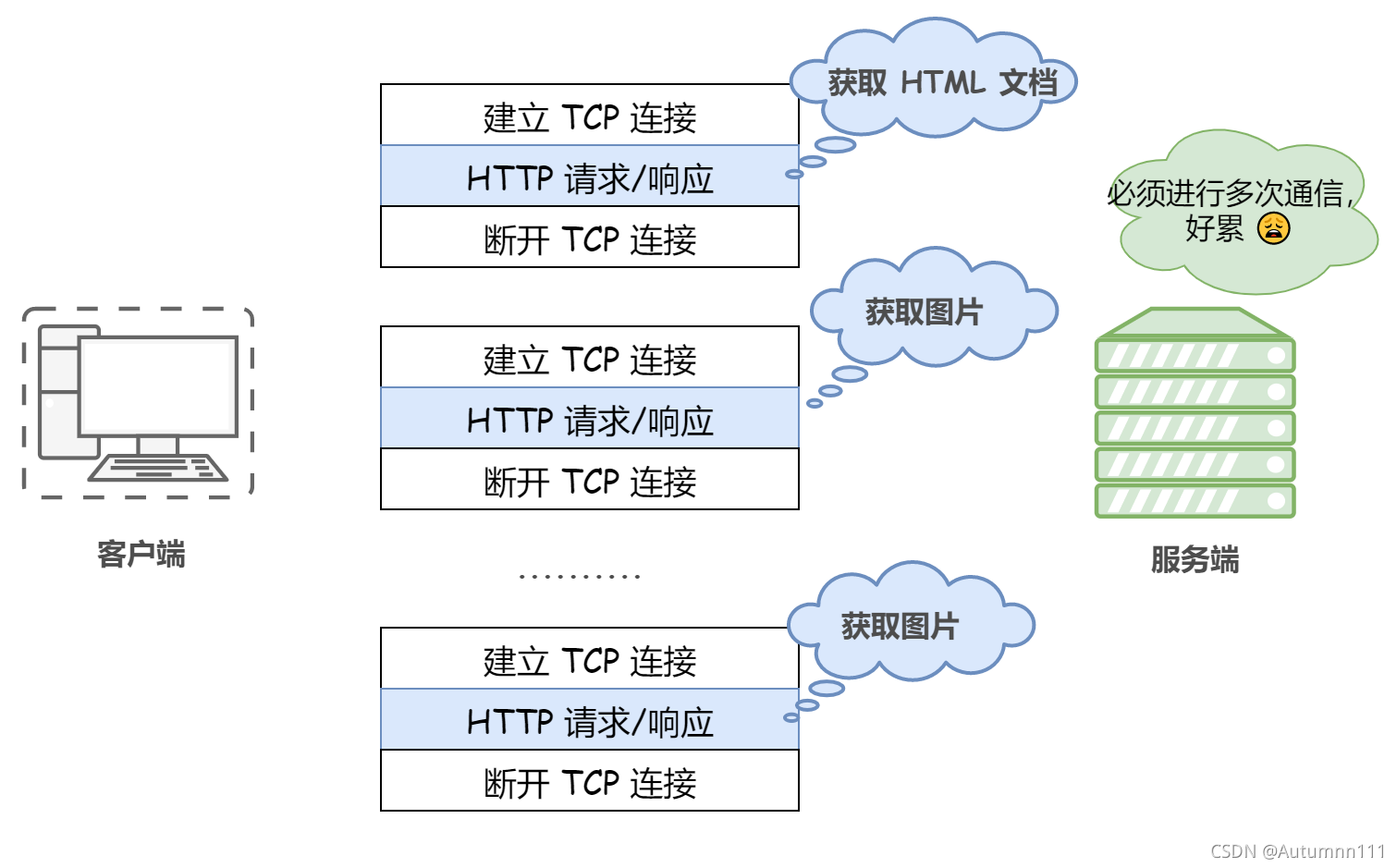
ЮЊСЫНтОіетИіЮЪЬт,ГЄСЌНгГіЯжСЫЁЊЁЊKeep-Alive
ГЄСЌНг
Дг1.1АцБОПЊЪМСЌНгЗНЪНОЭБфГЩСЫГЄСЌНг,ЪЙгУГЄСЌНгЕФHTTPавщ,ЛсдкЧыЧѓЭЗМгЩЯConnection:keep-aliveзжЖЮ
ЪЙгУГЄСЌНгЕФПЭЛЇЖЫКЭЗўЮёЦї,дкЭъГЩвЛДЮЧыЧѓЯьгІКѓВЂВЛЛсТэЩЯЖЯПЊСЌНг,ЖјЪЧЛсБЃГжСЌНгзДЬЌ,ЕБШЛетИіСЌНгВЛЛсгРОУБЃГж,ЮвУЧПЩвддкВЛЭЌЕФЗўЮёЦїШэМў(ШчApache)жаздМКЩшжУ,ЪЕЯжГЄСЌНгашвЊПЭЛЇЖЫКЭЗўЮёЦїЖМжЇГжЁЃ
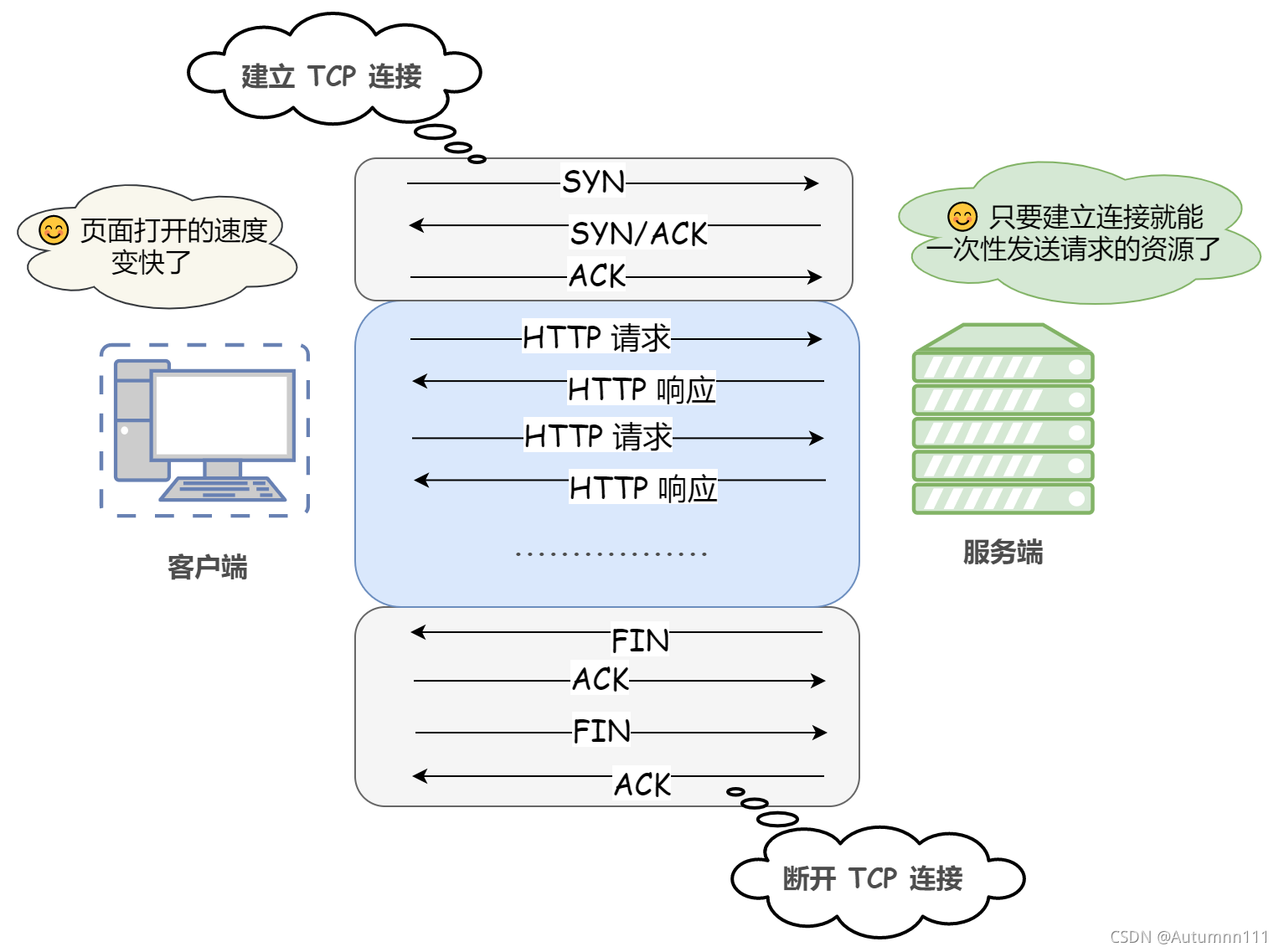
(HTTPавщЕФГЄСЌНг,ЪЕжЪОЭЪЧTCPавщЕФГЄСЌНг)
ЕЋЪЧГЄСЌНгвВВЂВЛЪЧЭъУРЕФ,МДЪЧЫЕУПЗЂЦ№вЛИіЧыЧѓ,БиаыЕШД§ЯьгІВХФмМЬајЗЂЫЭЯТвЛИіЧыЧѓ,ФЧМйЩшФГИіЯьгІЪБМфЙ§ГЄ,етбљЪБМфВЛОЭАзАзРЫЗбСЫ?
ЮЊСЫНтОіетИіЮЪЬт,СїЫЎЯпЛњжЦБЛв§ШыСЫЁЃ
СїЫЎЯп/ЙмЕР(Pipeline)
СїЫЎЯпЦфЪЕвВЪЧЛљгкГЄСЌНгЕФЛљДЁЩЯЪЕЯжЕФ,МДдкЭЌвЛЬѕГЄСЌНгЯпТЗЩЯЗЂЫЭЧыЧѓ,ЮоашЕШД§ЯьгІОЭПЩвдМЬајЗЂЫЭЯТвЛИіЧыЧѓ,етбљОЭПЩвдзіЕНВЂааЗЂЫЭЖрИіЧыЧѓ,ДѓДѓЬсИпСЫаЇТЪЁЃ
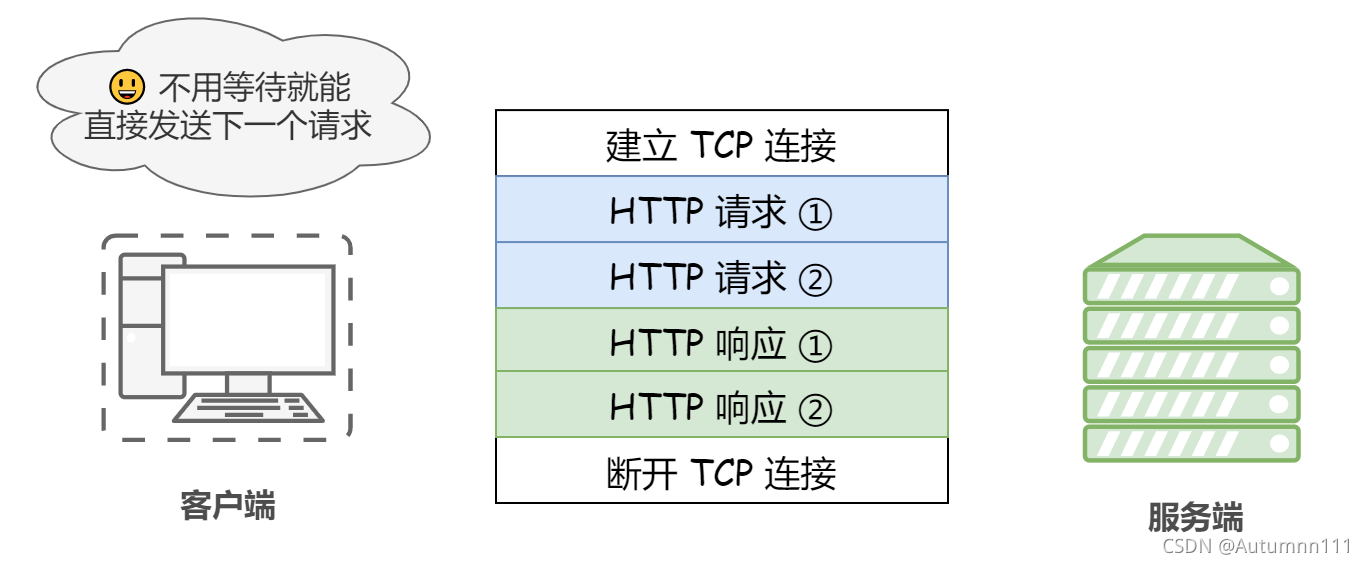
ЮозДЬЌЕФHTTPавщ
HTTPЪЧЮозДЬЌЕФавщ,МДЪЧЫЕЫќВЛЖджЎЧАЭъГЩЕФЧыЧѓКЭЯьгІНјааЙмРэ,ЫќЮоЗЈИљОнжЎЧАЕФзДЬЌЖдетИіЧыЧѓНјааДІРэЁЃ
етбљОЭЛсдьГЩвЛИіБзЖЫ,ШчЙћЮвУЧУПДЮдквЛИіЭјвГЩЯЗЂЦ№ЧыЧѓ,ЖМвЊжиаТЕЧТМвЛДЮ?етвВЬЋТщЗГСЫЁЃЖјЧвЗўЮёЦївЊМЧзЁЫљвдЕФПЭЛЇЖЫ,ЖдЗўЮёЦїадФмвВЛсгагАЯьЁЃ

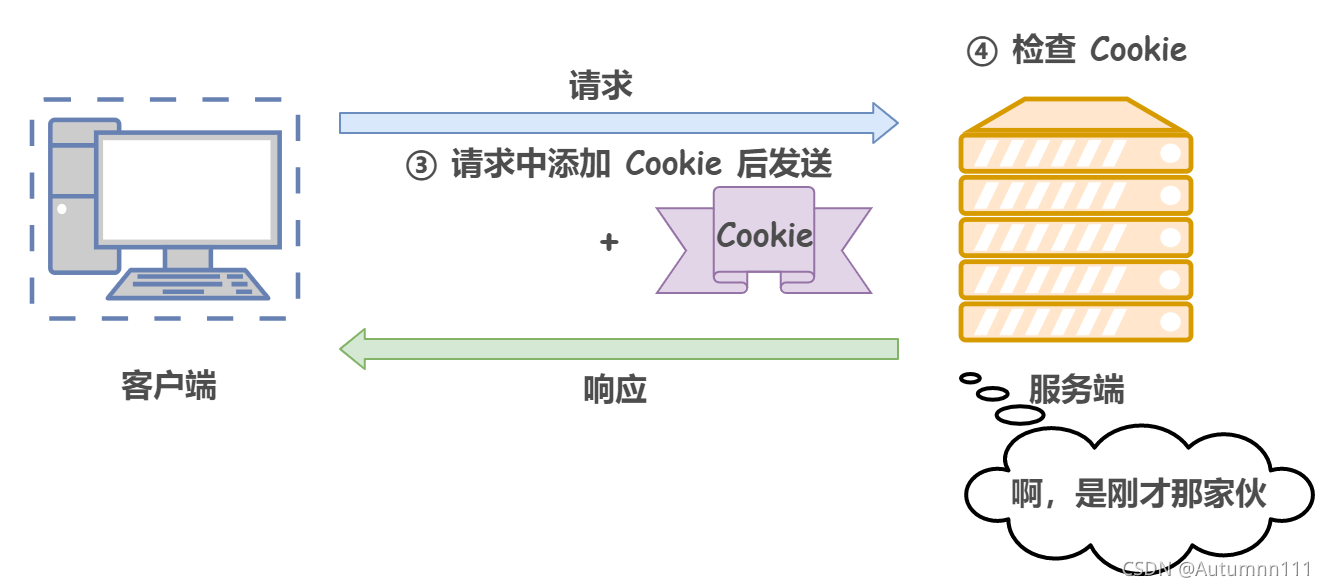
ЫљвдЮЊСЫБЃСєHTTPЮозДЬЌавщЫйЖШПьЕФгХЕу,НтОівГУцЬјзЊЕФБзЖЫ,в§ШыСЫCookieММЪѕ
1)ЕквЛДЮУЛгаCookieЕФЧыЧѓ
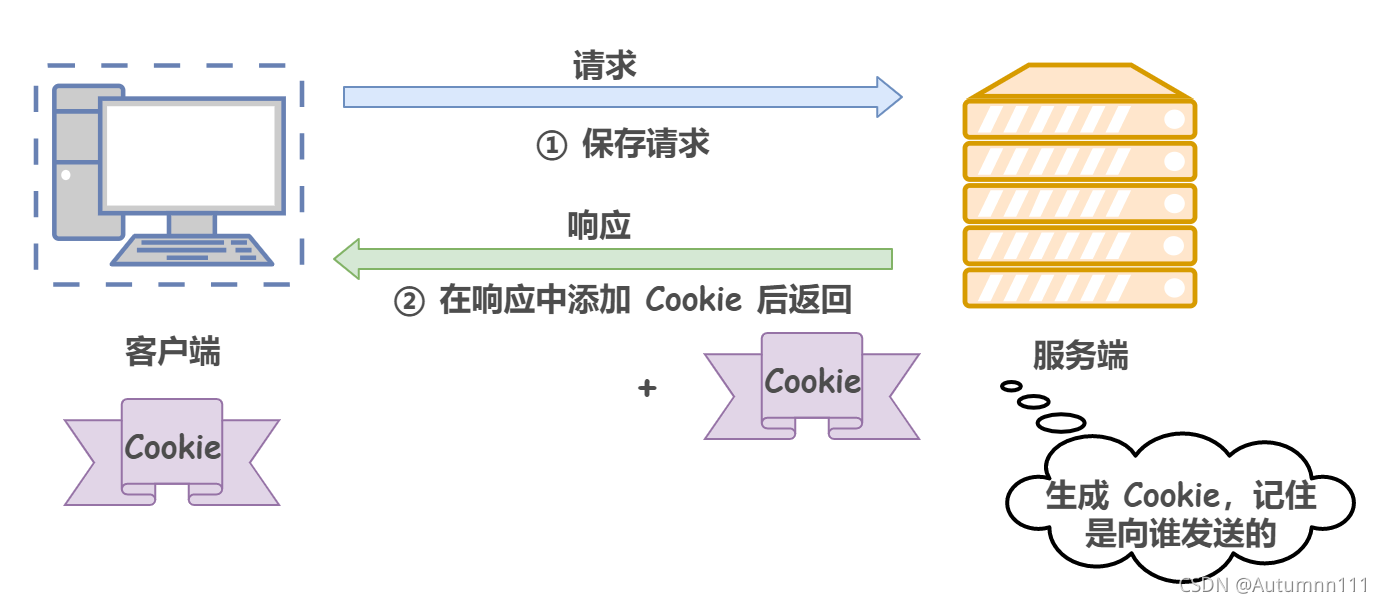
2)ЯТДЮЧыЧѓМгЩЯCookie
HTTPЖЯЕужиДЋ
ЖЯЕужиДЋЕФвтЫМЦфЪЕОЭЪЧЯТдиДЋЪфЮФМўЕФЪБКђПЩвджаЖЯ,ЯТДЮдйПЊЪМЯТдиЪБОЭДгжаЖЯЕФЕиЗНПЊЪМЯТ,ВЛгУжиаТПЊЪМ,етИіДѓМвгІИУОГЃгіЕНЁЃ
ЫќЕФдРэЦфЪЕвВЗЧГЃМђЕЅ,ОЭЪЧЧыЧѓЭЗжаЕФRangeзжЖЮКЭЯьгІЭЗЕФContent-RangeзжЖЮЕФХфКЯЪЙгУЁЃПЭЛЇЖЫвЛПщвЛПщЕФЧыЧѓЗўЮёЖЫЕФзЪдДЮФМў,ЗўЮёЖЫвВвЛПщвЛПщЕФЗЂЫЭЛиШЅЁЃ
ЕЋЪЧHTTPЦфЪЕгавЛаЉКмжТУќЕФЮЪЬт,ОЭЪЧЫќЕФАВШЋадЮЪЬт:
- ЭЈаХЪЙгУУїЮФДЋЪф,ФкШнПЩФмБЛЧдЬ§
- ВЛЬсЙЉбщжЄЛњжЦ,ЮоЗЈБцБ№ЧыЧѓЪЧПЭЛЇЖЫЛЙЪЧЙЅЛїепЗЂЦ№ЕФ
- ЮоЗЈБЃжЄЪ§ОнЕФЭъећад,ЫљвдгаПЩФмБЛДлИФ
ЮЊСЫБмУтЩЯУцЕФБзЖЫ,в§ШыСЫHTTPSавщ
ИќАВШЋЕФHTTPSавщ
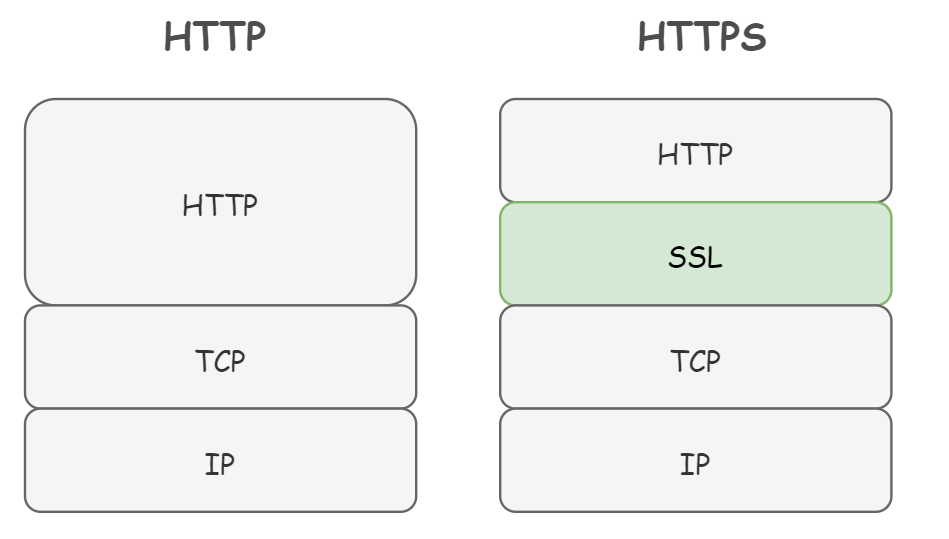
HTTPSавщВЂВЛЪЧгІгУВуЩЯЕФвЛИіаТЕФавщ,жЛВЛЙ§ЪЧдкHTTPавщЕФЭЈаХНгПкВПЗжЪЙгУSSL(Secure Socket Layer)авщКЭTLS(Transport Layer Security)авщНјааАВШЋадБЃжЄЖјвбЁЃ
МђЕЅЕФЫЕ,HTTPавщЪЧжБНгКЭTCPавщНјааЭЈаХЕФ,ЖјHTTPSавщдђЪЧHTTPавщЯШКЭSSLавщЭЈаХ,SSLдйКЭTCPавщЭЈаХЁЃ
гаСЫSSLавщжЎКѓ,HTTPавщОЭОпгаСЫМгУм,бщжЄЛњжЦКЭЭъећадБЃЛЄЕФЙІФмСЫ,ете§КУНтОіСЫЩЯЪіГіЯжЕФЮЪЬтЁЃ
(Tips:SSLавщЪЧвЛИіЖРСЂЕФавщ,ЫљвдЫљгагІгУВуЕФавщЖМПЩвдКЭSSLХфКЯЪЙгУ)
ЯТУцЮвУЧРДЯъНтSSLЕФУПИіЙІФмЪЧШчКЮЙЄзїЕФЁЃ
МгУм
HTTPдкДЋЪфЙ§ГЬжаЪЧУїЮФДЋЪфЕФ,ЮоЗЈБЃжЄВЛБЛЧдШЁ,МШШЛЮвВЛФмЗРжЙБЛЧдЬ§,ЮвОЭИјДЋЪфЕФЪ§ОнМгУмпТЁЃ(ОЭКУЯёвдЧАеНељЪБЦк,ЬиЙЄУЧЪЙгУФІЫЙУмТыНјааНЛСї,ЧдЬ§ЕФШЫВЛеЦЮеНтУмЕФЗНЗЈЪЧУЛгагУЕФ)
МгУмЕФЗНЪНгаШ§жж,ЗжБ№ЪЧЖдГЦУмдПМгУм,ЗЧЖдГЦУмдПМгУм,ЛьКЯУмдПМгУм
ЖдГЦУидПМгУм
МђЕЅРДЫЕ,ОЭЪЧЗўЮёЦїгавЛАбЙЋдПA1,ЗўЮёЦїАбЙЋдПЗЂЫЭИјПЭЛЇЖЫ,ШЛКѓПЭЛЇЖЫдйЗЂЦ№ЧыЧѓЪБОЭЪЙгУA1НјааМгУм,ЗўЮёЦїЪеЕНЪ§ОнНјааНтУмМДПЩЁЃ
ЕЋЪЧетДцдквЛИіЮЪЬт,ШчЙћдкЗЂЫЭA1ЕФЙ§ГЬжаБЛЙЅЛїепЧдШЁСЫ,КЭУїЮФДЋЪфвВУЛВюБ№
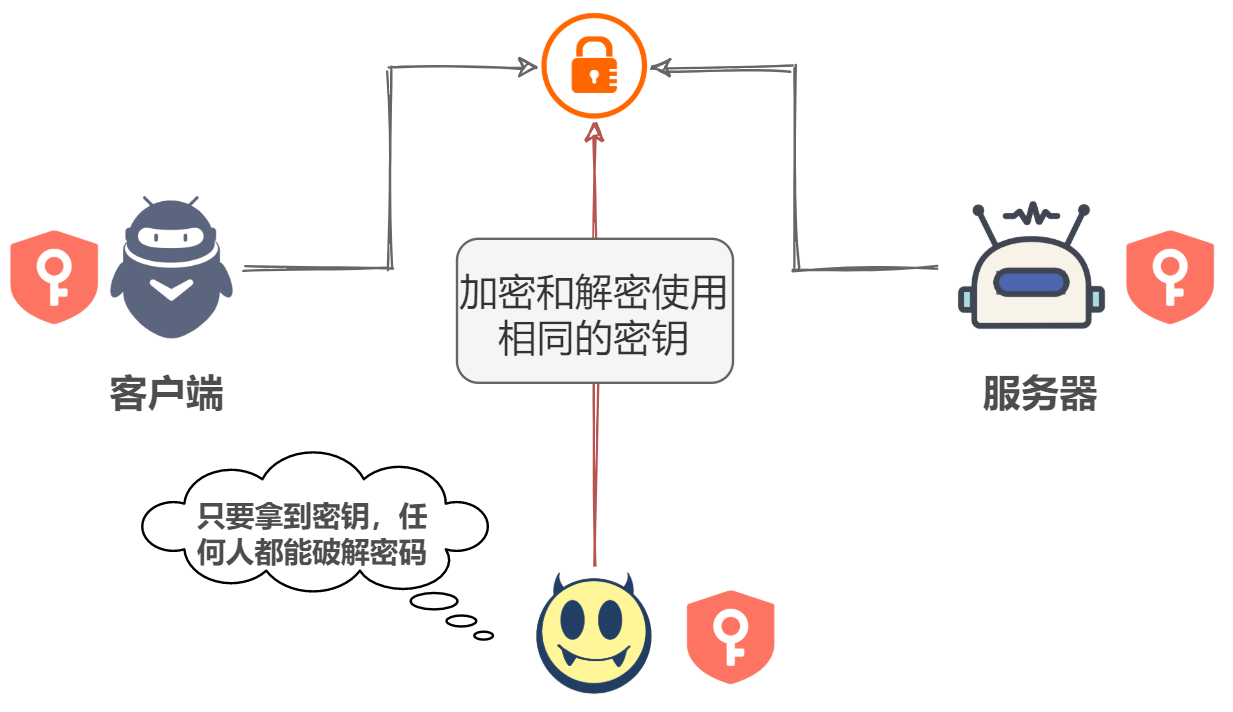
ЫљвдвЊШчКЮНтОіетИіЮЪЬтФи?ЮвУЧЭљЯТПД
ЗЧЖдГЦУмдПМгУм
ЗўЮёЦїгавЛАбЙЋдПA1КЭЫНдПB1,ЙЋдПЪЧЫЖМПЩвдгЕгаЕФ,ЫНдПЪЧжЛФмздМКГжга,етСНИіУмдПЪЧГЩЖдГіЯжЕФЁЃ
ЪзЯШЗўЮёЦїНЋЙЋдПЗЂЫЭИјПЭЛЇЖЫ,ПЭЛЇЖЫФУЕНжЎКѓЪЙгУA1ЖдЪ§ОнНјааМгУм,ЗўЮёЦїЪеЕНКѓдйЪЙгУB1НтУмМДПЩ,ДЫЪБФФХТA1БЛЙЅЛїепЧдШЁвВУЛЪТ,ЫћУЛгаB1вВЮоЗЈНтУмЪ§ОнЁЃ
ЛьКЯМгУмЗНЪН
ЕЋЪЧЩЯЪіЕФЗЧЖдГЦУмдПМгУмЫфШЛАВШЋадБЃжЄСЫ,ЕЋЪЧДІРэЫйЖШЯТНЕВЛЩй,ФЧУДгаУЛгаЪВУДЗНЗЈПЩвдЭЌЪБгЕгаЫйЖШПьКЭАВШЋадЕФБЃжЄФи?ФЧУДЛьКЯМгУмЗНЪНОЭВЛхиЖрШУСЫ
ЛьКЯМгУмЦфЪЕОЭЪЧгУЙЋдПЖдЙВЯэУмдПНјааМгУм,ОйИіР§зг
- ЗўЮёЦїгаЗЧЖдГЦУмдПЁЊЙЋдПA1,ЫНдПB1
- ЗўЮёЦїАбA1ЗЂЫЭИјПЭЛЇЖЫ
- ПЭЛЇЖЫЫцЛњЩњГЩвЛИіЙВЯэУмдПX,ЪЙгУA1МгУмжЎКѓЗЕЛиИјЗўЮёЦї
- ЗўЮёЦїНтУмКѓШЁЕУX,КѓУцЫЋЗНОЭПЩвдЪЙгУXНјааЙВЯэМгУмЕФЗНЪНДЋЪфЪ§ОнСЫЁЃ
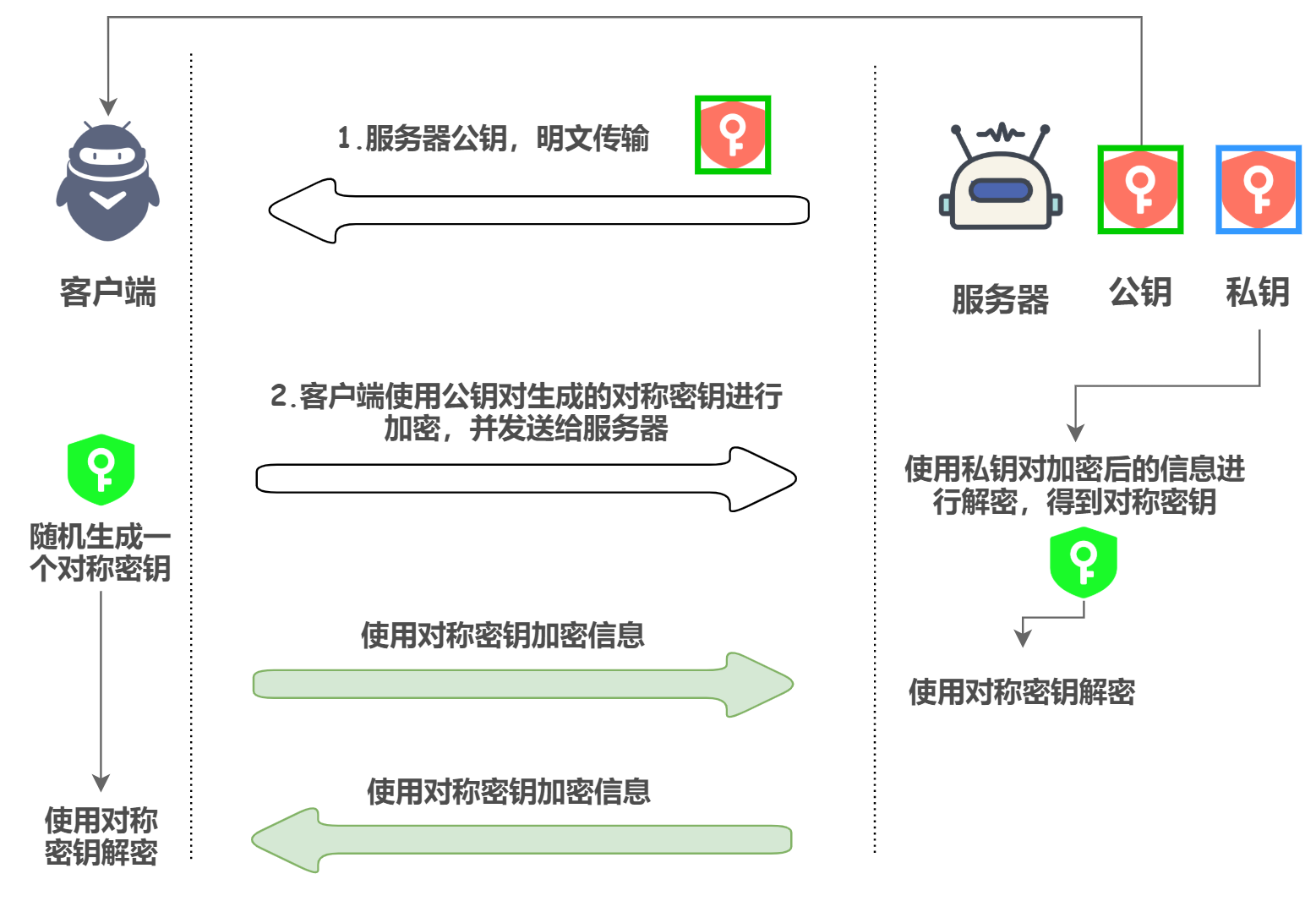
ЕЋЪЧЛьКЯУмдПЕФЗНЗЈЛЙЪЧгавЛИіБзЖЫЕФ,ЮвУЧРДЯъЯИНтЮі - ЗўЮёЦїгаЙЋдПA1,ЫНдПB1
- ПЭЛЇЖЫЗЂЦ№ЧыЧѓКѓ,ЗўЮёЦїдкЯьгІБЈЮФжаМгШыЙЋдПA1
- ДЫЪБетИіЯьгІБЈЮФБЛРЙНи,ЙЅЛїепгЕгаЙЋдПA2,ЫНдПB2
- ЙЅЛїепдкетИіЯьгІБЈЮФжаАбA1ЧдШЁ,ВЂЧвЛЛГЩA2
- ПЭЛЇЖЫЪеЕНКѓ,ЩњГЩвЛИіЙВЯэУмдПX,ШЛКѓЩЕКѕКѕЕФЪЙгУA2НјааМгУм
- ЙЅЛїепдйАбетИіБЈЮФРЙНиЯТРД,ЪЙгУB2НјааНтУмКѓЛёЕУX,ШЛКѓдйгУНиШЁЕФA1ЖдXМгУмЗЂЫЭИјЗўЮёЦї
- ЗўЮёЦїНтУмКѓЕУЕНУмдПX,ЕЋЪЧДЫЪБПЭЛЇЖЫЁЂЙЅЛїепЁЂЗўЮёЦїЖМгЕгаX,АВШЋадвВОЭЮоашдйЫЕСЫЁЃ
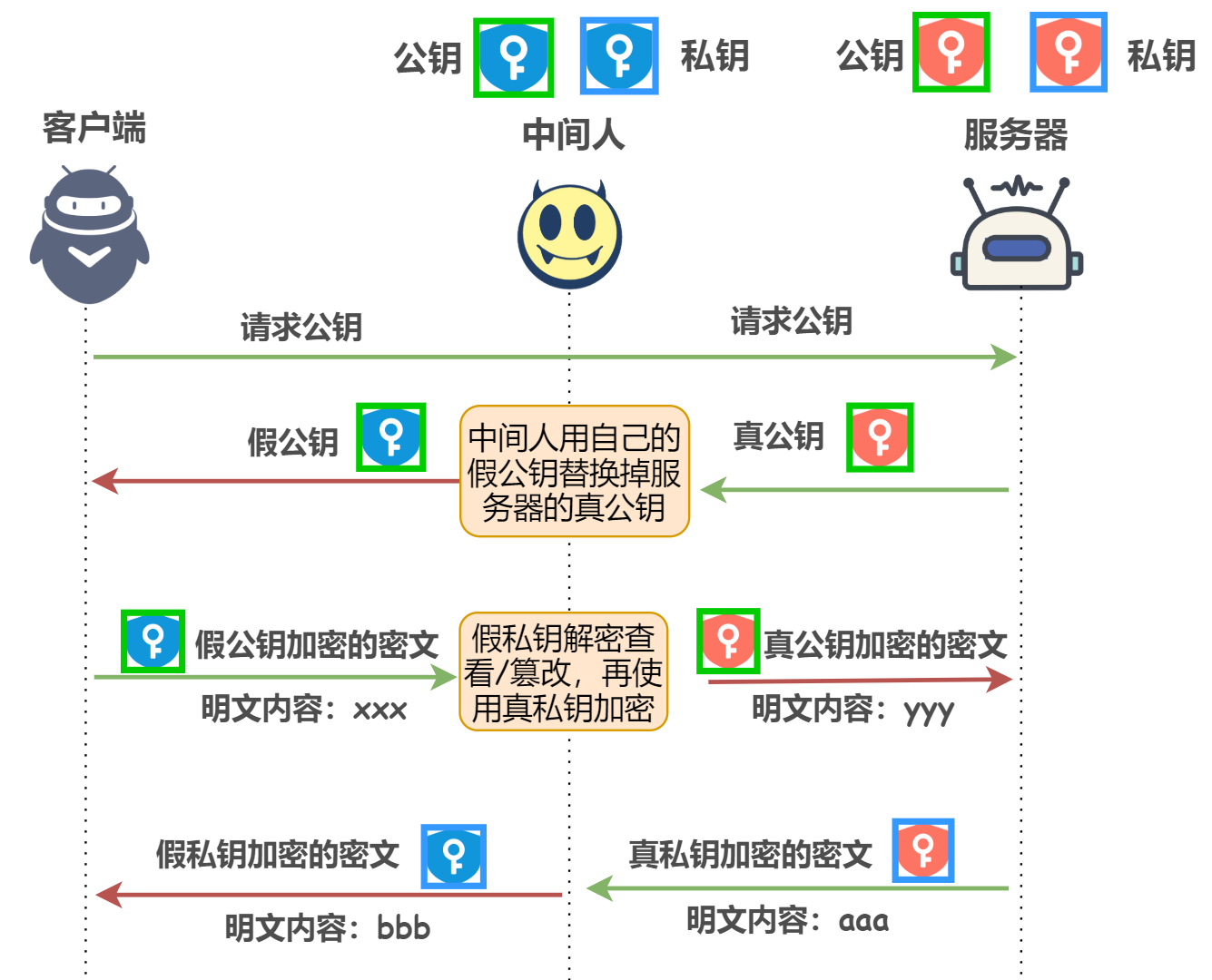
ЫљвдЩЯУцЕФМгУмЙ§ГЬЬхЯжСЫвЛИіЮЪЬт,ОЭЪЧПЭЛЇЖЫдѕУДжЊЕРЗЂЫЭЙ§РДЕФУмдПОЭЪЧЗўЮёЦїЕФУмдПФи?етЪБКђОЭашвЊЩэЗнбщжЄ!
Ъ§зжжЄЪщ+Ъ§зжЧЉУћЁЊЁЊЩэЗнбщжЄЕФБЃеЯ
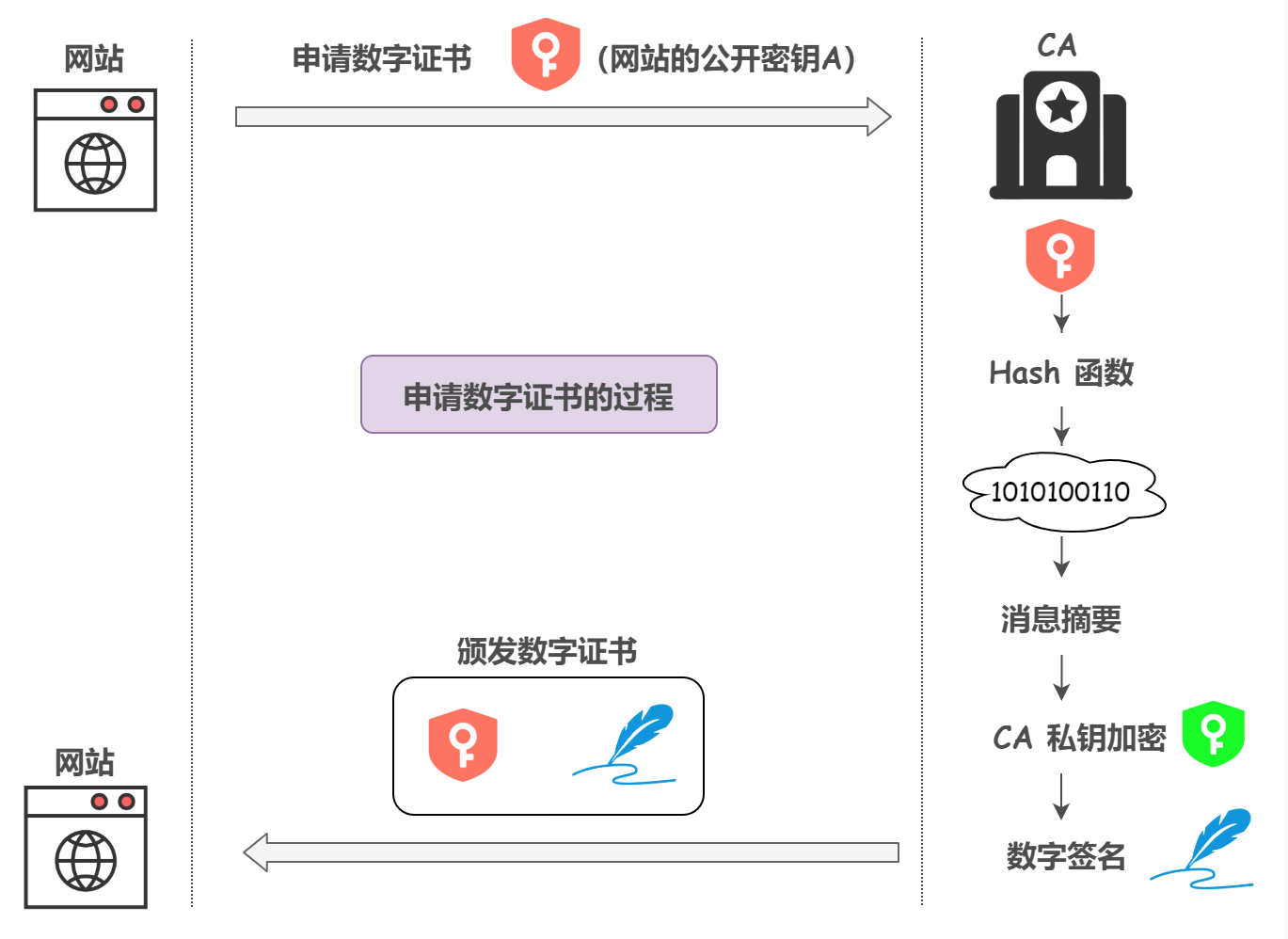
ЮвУЧШеГЃЩњЛюжа,МйШчашвЊжЄУїЮвЕФЩэЗн,ЪЧВЛЪЧФУГіЮвЕФЩэЗнжЄОЭПЩвдСЫ,ЩэЗнжЄЪЧгЩОпгаЙЋаХСІЕФеўИЎАфЗЂЕФ;ФЧУДдкЛЅСЊЭјжа,вВгаРрЫЦЕФетУДвЛИіЛњЙЙЈCЪ§зжжЄЪщШЯжЄЛњЙЙ Certificate Authority, CA,CAАфЗЂЕФЪ§зжжЄЪщОЭЪЧРрЫЦЩэЗнжЄвЛбљЕФЖЋЮїЁЃФЧУДЛЙгавЛИіЮЪЬт,дѕУДжЄУїетИіжЄЪщВЛЪЧМйУАЮБСгВњЦЗ,ОЭЪЧвРППЕФЪ§зжЧЉУћ
ЮвУЧРДЯъЯИНВЪіCAАфЗЂжЄЪщЕФЙ§ГЬ
- CAгаЙЋдПC1КЭЫНдПC2
- ЗўЮёЦїЯђCAЩъЧыЪ§зжжЄЪщ,ВЂЗЂЫЭздМКЕФЙЋдПA1
- CAЖдA1Нјааhash,ЕУЕНеЊТМаХЯЂMIC
- ЖдMICЪЙгУздМКЕФЫНдПНјааМгУм,ЕУЕНЪ§зжЧЉУћ
- НЋЪ§зжЧЉУћКЭЗўЮёЦїЕФA1вЛЦ№ЗХНјЪ§зжжЄЪщЗЕЛиИјЗўЮёЦї
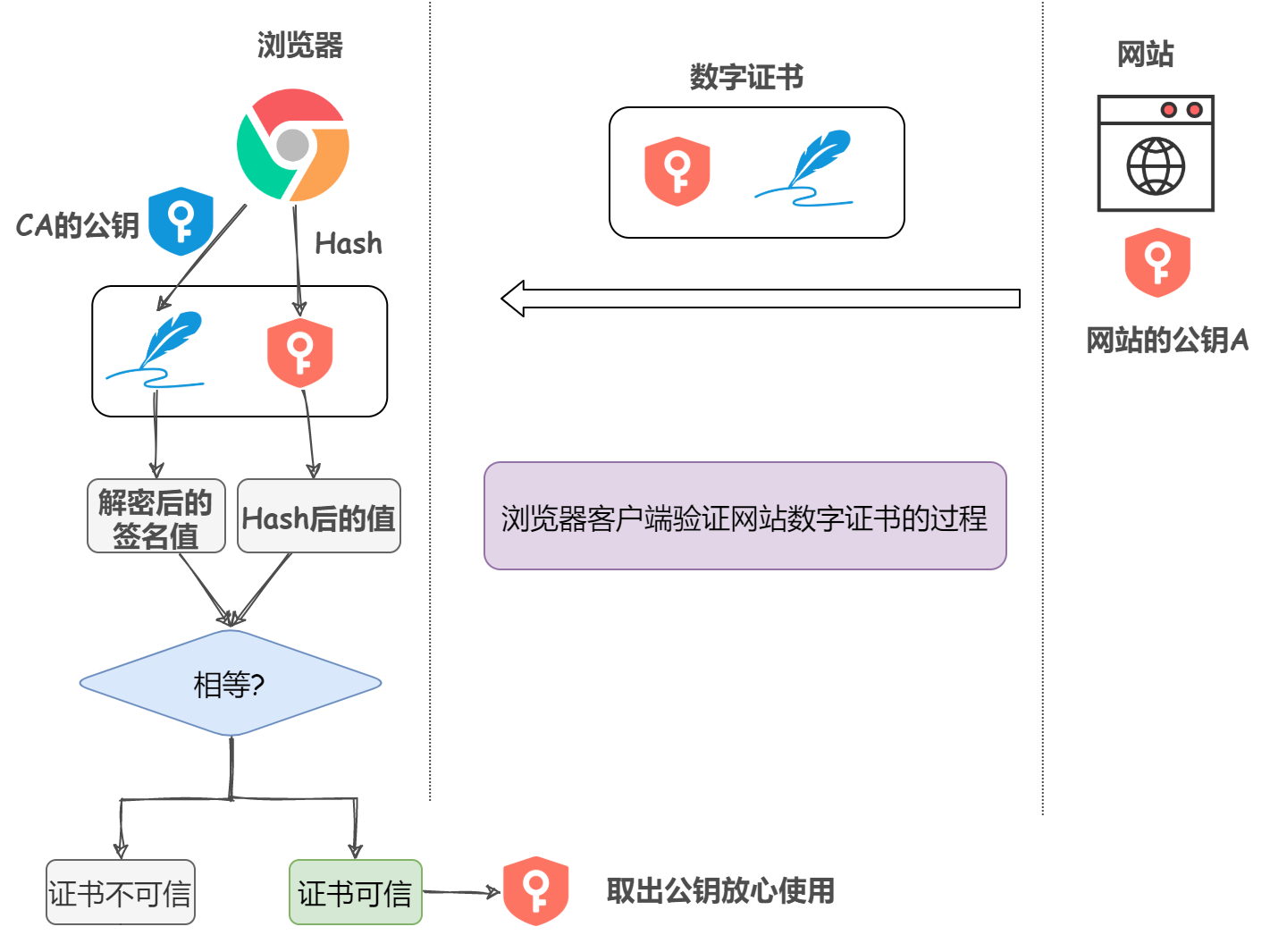
ШЛКѓОЭЪЧПЭЛЇЖЫбщжЄЪ§зжжЄЪщЕФЙ§ГЬСЫ
- ПЭЛЇЖЫЪеЕНЗўЮёЦїЗЂЫЭЕФЪ§зжжЄЪщ,ЕУЕНЙЋдПA1КЭЪ§зжЧЉУћS1
- ПЭЛЇЖЫЪЙгУЪТЯШжВШыЕФCAЙЋдПC1ЖдS1НјааНтУм,ЕУЕНS2
- гУЪ§зжжЄЪщАќКЌЕФЫуЗЈЖдA1Нјааhash,ЕУЕНA2
- ПДA2ЪЧЗёЕШгкS2,ШчЙћЯрЕШ,ДњБэЗўЮёЦїе§ГЃ,ВЛЪЧЙЅЛїеп,ЖдA1ПЩвдЗХаФЪЙгУ
ЮЊЪВУДHTTPSетУДАВШЋУЛгаШЋУцЪЙгУЁЊЁЊЙѓ
вдЩЯ,TCP/IPЮхВуФЃаЭЕФУПвЛВуЖМвбОЯъЯИзмНсЭъГЩ,ЯТУцдйВЙГфзюКѓвЛЕу,ЭјТчI/OЁЃ
ИпадФмЭјТчI/O
ВЮПМзджЊКѕ-ЧкРЭЕФаЁЪж
ЙЋжкКХ-ЮвЪЧГЬађдБаЁМњ
1.зшШћI/O
ЮвУЧдкЕїгУФГИіКЏЪ§ЕФЪБКђ,ТэЩЯЛсЗЕЛиЯргІЕФНсЙћ,ШЛКѓЯТУцЕФвЕЮёТпМОЭИљОнетИіЗЕЛижЕНјааКѓајВйзї,ШчЙћНсЙћЛЙУЛгаЗЕЛиОЭвЛжБЕШД§ЁЃ
зшШћI/OЦфЪЕОЭЪЧетИідРэ:ЕБНјГЬдкЕШД§ФГИіЪ§ОнЪБ,ШчЙћетИіЪ§ОнУЛгазМБИКУ,етИіНјГЬОЭЛсвЛжБзшШћжБЕНЪ§ОнзМБИЭъГЩЁЃДЫЪБCPUОЭЛсЗжХфИјЦфЫћЕФНјГЬ,дкгУЛЇНЧЖШПД,етИіНјГЬОЭКУЯёПЈзЁСЫЁЃ
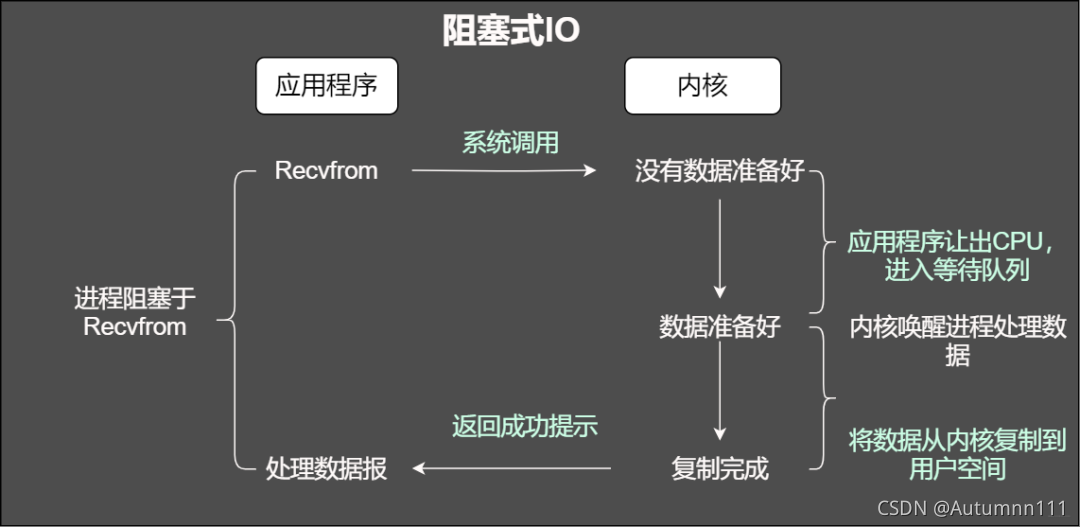
ДЋЭГзшШћI/OФЃаЭ
ЬиЕу:
- ЭЈЙ§зшШћЪНI/OЛёШЁЪфШыЪ§Он
- УПИіЧыЧѓЖМВЩгУЕЅЖРЕФЯпГЬНјааЪ§ОнЖСШЁ,вЕЮёВйзївдМАЪ§ОнЗЕЛиЕШВйзї
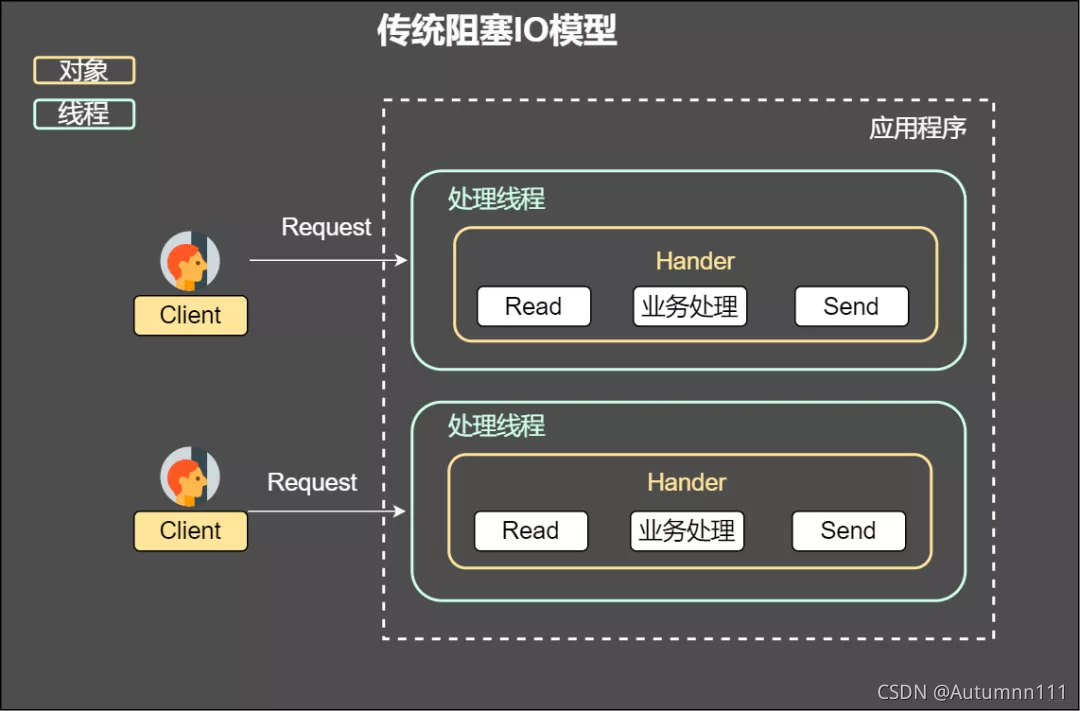
ЗЧзшШћI/O
ЗЧзшШћI/OКЭзшШћI/OЯрБШ,ЦфЪЕОЭдкгкЗЧзшШћI/OдкЪ§ОнУЛгазМБИКУЪБ,ВЛЛсзшШћЯпГЬ,ЖјЪЧТэЩЯЗЕЛиЁЃ
гУзЈвЕЪѕгяРДЫЕ:ЗЧзшШћI/OрЧгУRecvfromКЏЪ§ЖСШЁЪ§ОнЪБ,ШчЙћДЫЪБФкДцжаЪ§ОнУЛгазМБИКУ,ОЭЛсЗЕЛивЛИіEWOULDBLOCKДэЮѓ,ВЛЛсШУЯпГЬвЛжБЕШД§,ШЛКѓЯпГЬОЭЛсВЛЖЯЕФТжбЏ,ВщПДЪ§ОнЪЧЗёзМБИЭъБЯЁЃ
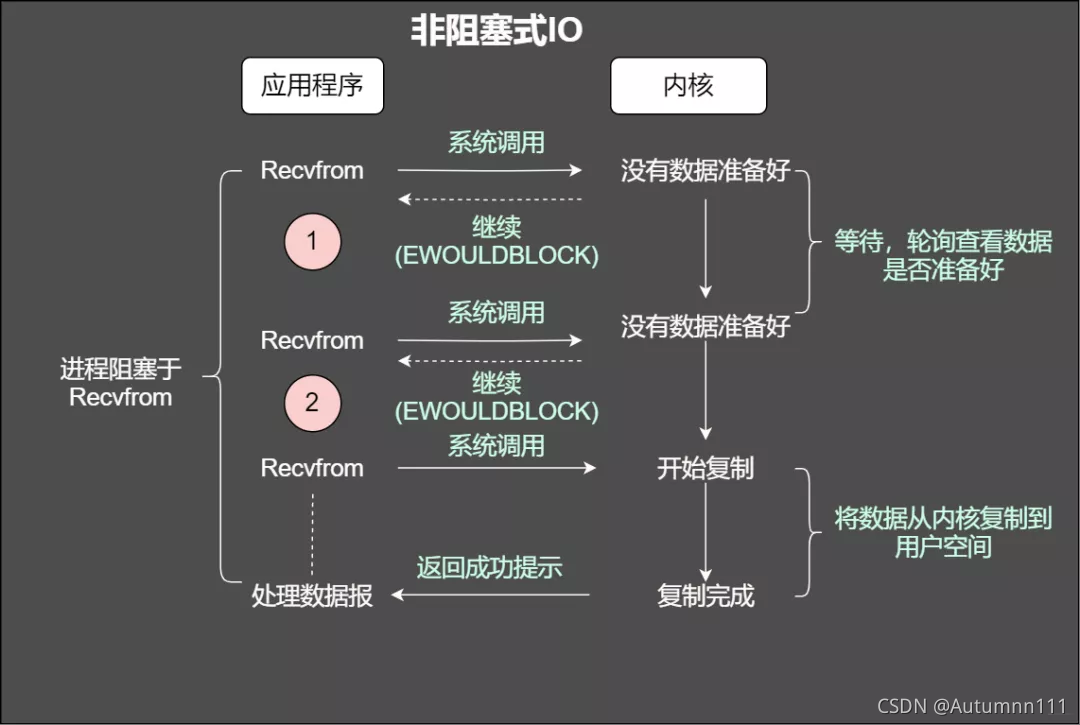
ОпЬхСїГЬ:
- ЯпГЬЯђФкКЫЕїгУRecvfromКЏЪ§ЖСШЁЪ§Он
- Ъ§ОнЮДзМБИКУ,ЗЕЛиEWOULDBLOCKДэЮѓ
- ЯпГЬТжбЏ,МЬајЯђФкКЫЕїгУRecvfromКЏЪ§
- Ъ§ОнзМБИКУ,НјааЯТвЛВН(ЗёдђШдШЛЗЕЛиДэЮѓ)
- НЋЪ§ОнДгФкКЫИДжЦЕНгУЛЇПеМф
- ЭъГЩВйзї,ЗЕЛиНсЙћ
ЖСВйзїКЭаДВйзї
- 1)ЖСВйзї
ЮвУЧжЊЕРУПИіЬзНгзжSocketЖМгавЛИіНгЪеЛКГхЧј,ШчЙћЛКГхЧјЮЊПе,зшШћIOЛсжБНгзшШћжБЕНЪ§ОнПЩЖС,ЗЧзшШћIOдђЛсЗЕЛивЛИіEWOULDBLOCKзДЬЌ,ДЅЗЂТжбЏ - 2)аДВйзї
ЩЯЪіЕФЖСВйзїЪЧЛљгкНгЪеЛКГхЧј,ФЧУДаДВйзїПЯЖЈвВгавЛИіЗЂЫЭЛКГхЧј,ЕБЗЂЫЭЛКГхЧјПеЯаЪБ,зшШћIOЛсНЋЫљгаЪ§ОнЖМаДШыЗЂЫЭЛКГхЧјВХЗЕЛи,ЗёдђОЭзшШћ,жБЕНЪ§ОнШЋВПаДШы,ЖјЗЧзшШћIOдђЪЧОЁПЩФмЖрЕФаДШы,ЕБЛКГхЧјаДТњжЎКѓ,ЗЕЛивЛИіжЕИцЫпЯпГЬЛЙЪЃЖрЩйЪ§ОнашвЊЯТДЮПеЯаЪБаДШыЁЃ

ФЧУД(ЗЧ)зшШћI/OФЃаЭДцдкЪВУДЮЪЬтФи?
- ИпВЂЗЂГЁОАЯТ,ЖрИігУЛЇЗЂЦ№ЧыЧѓ,ашвЊДДНЈДѓСПЕФЯпГЬДІРэетаЉЧыЧѓ,ЯћКФДѓСПЯЕЭГзЪдДЁЃ
- ЕБЪ§ОнУЛгазМБИКУЪБ,ДѓСПЕФЯпГЬЪВУДЖМВЛИЩ,БЛзшШћдкReadВйзї(ЗЧзшШћОЭвЛжБТжбЏ,ЯрЕБгкCPUПезЊ),ЯпГЬзЪдДРЫЗбЁЃ
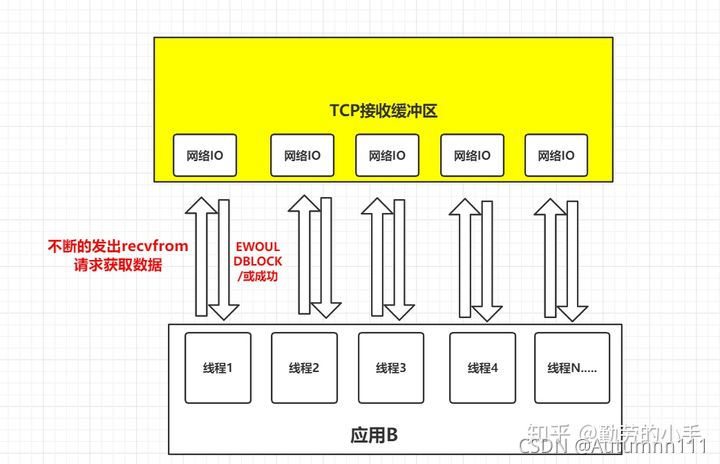
ЮвУЧжЊЕРЯпГЬЪЧгаЯоЕФ,ЮвУЧКФЗбетУДЖрзЪдДдкбЏЮЪЪ§ОнзДЬЌЩЯ,ЪЧЗёгааЉЬЋРЫЗбСЫ?етЪБКђ,I/OЖрТЗИДгУФЃаЭГіЯжСЫЁЃ
2.I/OЖрТЗИДгУФЃаЭ
I/OЖрТЗИДгУЕФЪЕжЪЁЊДДНЈвЛИіЯпГЬРДМрПиЖрИіЭјТчЧыЧѓfd(LinuxНЋЭјТчЧыЧѓгУfdРДУшЪі),етбљОЭПЩвдгУвЛИіЛђМИИіЯпГЬЭъГЩЪ§ОнзДЬЌбЏЮЪЕФВйзї,ЕБгаЪ§ОнзМБИКУСЫ,дйШЅЛНабЖдгІЕФЯпГЬНјааКѓајВйзїЁЃетбљОЭПЩвдНкЪЁДѓСПЕФЯпГЬзЪдДСЫЁЃ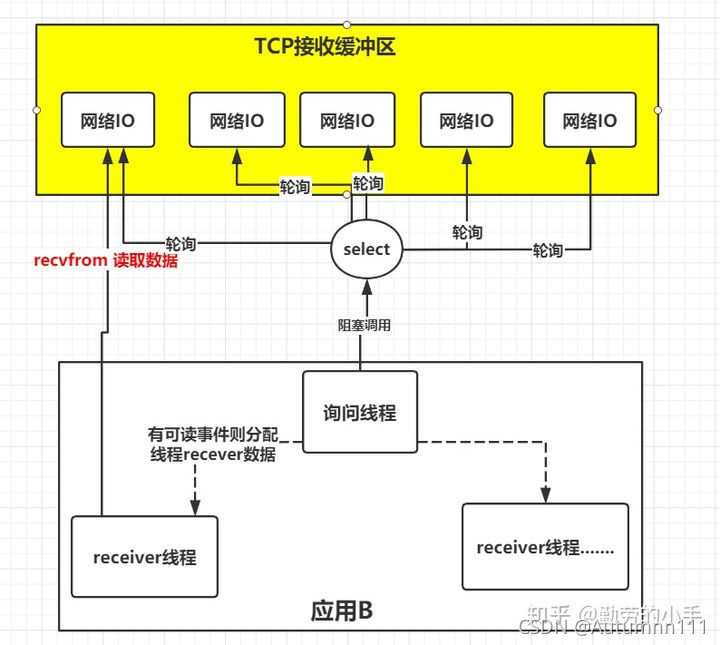
ШчЩЯЭМЫљЪО,IOЖрТЗИДгУФЃаЭЬсЙЉСЫвЛИіКЏЪ§ШЅМрПиЖрИіЭјТчЧыЧѓfdЕФЪ§ОнзДЬЌ,ЕБЪ§ОнзМБИКУКѓетИіКЏЪ§ОЭЛсЗЕЛиПЩЖСзДЬЌ,ЖдгІЕФЯпГЬБЛЛНабНјааКѓајВйзї,етИіКЏЪ§ОЭЪЧЮвУЧГЃЫЕЕФselect,pollКЭepollКЏЪ§ЁЃ
Ъѕгя:НјГЬНЋвЛИіЛђЖрИіЭјТчЧыЧѓfdДЋЕнИјselectКЏЪ§,ЕБЪ§ОнЮДзМБИКУЪБ,НізшШћselectВйзї,гЩselectАяжњЮвУЧМрЪгfdзДЬЌ,ЕБгаfdзМБИОЭаїЪБ,selectЗЕЛиПЩЖСзДЬЌ,ЯпГЬЕїгУRecvfromКЏЪ§ЖСШЁЪ§Он
selectКЏЪ§
ЕБЪЙгУselectКЏЪ§ЪБ,ЯШЭЈжЊФкКЫЙвЦ№ЕБЧАНјГЬ,ШЛКѓЕБвЛИіЛђЖрИіIOЪТМўЗЂЩњЪБ,ПижЦШЈНЋЗЕЛиИјНјГЬ,гЩНјГЬДІРэIOЁЃ
IOЪТМўАќРЈ:
1.ЭјТчЧыЧѓfdПЩЖС
2.ЬзНгзжSocketзМБИКУПЩвдаД
3.ШчЙћвЛИіIOЪТМўЕШД§ГЌЙ§10s,ЗЂЩњГЌЪБ
selectЪЙгУЗНЗЈ:
int select(int maxfdp, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);
- maxdpВЮЪ§:ЕШД§ДІРэЕФfdЛљЪ§,ОЭЯрЕБгкзюДѓЕФfdЪ§СПМг1,БШШчЫЕЮвУЧЯждкЕФЭјТчЧыЧѓfdга{0,1,2},ФЧУДmaxdp=3+1=4
- readset:ЖСМЏКЯ,гаЪ§ОнПЩЖСЪБЭЈжЊФкКЫ
- writeset:аДМЏКЯ,гаЪ§ОнПЩаДЪБЭЈжЊФкКЫ
- exceptset:вьГЃМЏКЯ,вьГЃЗЂЩњЪБИцЫпФкКЫ
ЕЋЪЧselectКЏЪ§гавЛИіШБЕу,ОЭЪЧ**ЫќжЇГжЕФЮФМўУшЪіЗћ/ЭјТчЧыЧѓ(fd)ЪЧгаЯоЕФ,ФЌШЯЮЊ1024Иі,**Ыљвдв§ШыСЫpollКЏЪ§
pollКЏЪ§
selectФЌШЯжЇГж1024Иіfd,Ъ§СПгаЯо,гУpollНтОіетИіЮЪЬт
ЮвУЧПДвЛЯТpollКЏЪ§ЕФЪЙгУЗНЗЈ
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
ЮвУЧПДвЛЯТstruct pollfdЪЧЪВУДНсЙЙ
struct pollfd {
int fd; /* ЮФМўУшЪіЗћ */
short events; /* УшЪіЗћД§МьВтЕФЪТМў */
short revents; /* returned events */
};
- pollfdАќРЈСЫЮФМўУшЪіЗћfdКЭfdЖдгІЕФЪТМў,ЦфжаЪТМўгЩЖўНјжЦИёЪНБэЪО,БШШчЫЕPOLLINЪЧЖСЪТМў,POLLOUTЪЧаДЪТМўЁЃ
#define POLLIN 0x0001 /* any readable data available */
#define POLLPRI 0x0002 /* OOB/Urgent readable data */
#define POLLOUT 0x0004 /* file descriptor is writeable */
- ФЧУДГ§СЫfdКЭevents,ЛЙгавЛИіreventsЪТМў,етИіВЮЪ§БэЪОЖдЪТМўЕФБИЗн,ЯрЕБгкpollКЏЪ§ЛсНЋУПИіfdЕФЪТМўМьВтНсЙћБЃСєдкrevents,ВЛгУУПДЮЖМДгЭЗЕНЮВМьВтвЛБщЁЃ(ЯрЕБгкБЃДцУПИіfdМАЦфЪТМўЕФзДЬЌ)
ФЧУДpollКЏЪ§ЕФЗЕЛижЕгаФФаЉФи?
- ПЩЖС,ФкКЫЛсЭЈжЊНјГЬПЩНјааЖСВйзї
- ПЩаД,ФкКЫЛсЭЈжЊНјГЬПЩНјаааДВйзї
- аЁгк0:БэЪОЪТМўЗЂЩњжЎЧАвЛжБЕШД§
- -1:ЗЂЩњДэЮѓ
- 0:дкЙцЖЈЕФЪБМфФкУЛгаШЮКЮЪТМўЗЂЩњ(ГЌЪБ)
ФЧУДpollКЏЪ§ЪЧШчКЮИФНјselectКЏЪ§жЇГжЮФМўУшЪіЗћгаЯоЕФФи?
ОЭЪЧЭЈЙ§ПижЦpollfdЕФДѓаЁРДИФБфжЇГжfdЕФЪ§СПЁЃ
epollКЏЪ§
ЮвУЧРДПДвЛЯТУцЖдВЛЭЌЪ§СПЕФfd,select,pollКЭepollКЏЪ§ЕФадФмВювь

ПЩвдЗЂЯжselectКЭpollЕФадФмВюВЛЖр,ЖјepollдкЪ§ОнСПдђдЖГЌЧАУцСНеп,ЫќЪЧШчКЮзіЕНЕФ?
epollЭЈЙ§МрПизЂВсЖрИіУшЪізжНјааIOЪТМўЕФЗжЗЂЁЃВЛЭЌpollЕФЪЧ,epollВЛНіЬсЙЉФЌШЯЕФlevel-triggerЛњжЦЛЙЬсЙЉСЫБпдЕДЅЗЂЛњжЦЁЃ
аХКХЧ§ЖЏIOФЃаЭ
ИДгУIOФЃаЭНтОіСЫвЛИіЯпГЬМрПивЛИіfdЕФЮЪЬт,ЕЋЪЧselectетаЉКЏЪ§ВЩгУТжбЏЕФЗНЪНРДМрПиЖрИіfd,ЕБТжбЏЕНзДЬЌПЩЖС/ПЩаДдйНјааЯТвЛВНВйзї;ЮвУЧЛсОѕЕУетжжЗНЪНгаЕуЬЋБЉСІСЫ,вђЮЊДѓВПЗжЧщПіЯТЕФТжбЏЖМЪЧЮоаЇЕФЁЃгкЪЧгаШЫЬсГіЁЊФмВЛФмВЛвЊЮвШЅбЏЮЪЪ§ОнЪЧЗёзМБИКУ,ЖјЪЧФузМБИКУЪ§ОнжЎКѓРДИцЫпЮвФи?ЁЊЁЊаХКХЧ§ЖЏIOФЃаЭгІдЫЖјЩњЁЃ
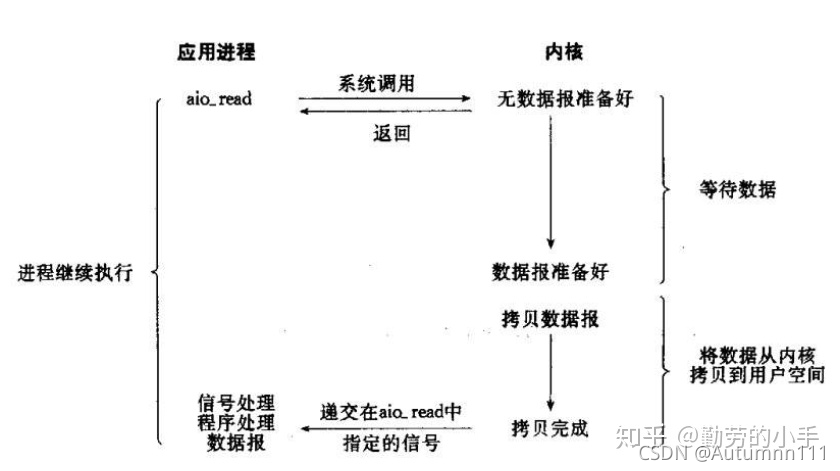
**аХКХЧ§ЖЏIOВЛЪЧгУТжбЏЕФЗНЪНШЅМрПиfdзДЬЌ,ЖјЪЧЕїгУsignificationЪБНЈСЂвЛИіSIGIOаХКХСЊЯЕ,ЕБФкКЫжаЕФЪ§ОнзМБИЭъБЯКѓ,дйЭЈЙ§SIGIOаХКХЭЈжЊЯпГЬЪ§ОнПЩЖС,ЕБЯпГЬНгЪеЕНаХКХКѓ,ЕїгУrecvfromКЏЪ§ЖСШЁЪ§Он,НјааКѓајВйзїЁЃ**вђЮЊаХКХЧ§ЖЏIOФЃаЭЯТЕФгІгУЯпГЬдкЯЕЭГЕїгУsignificationКѓМДПЩЗЕЛи,ВЛЛсзшШћ,ЫљвдвЛИібЏЮЪЯпГЬОЭПЩвдМрПиЖрИіfdзДЬЌЁЃ
Ъѕгя:ЪзЯШПЊЦєЬзНгзжжаЕФаХКХЧ§ЖЏIOЙІФм,ВЂЭЈЙ§ЯЕЭГЕїгУsignificationжДаавЛИіаХКХДІРэКЏЪ§,ДЫЪБЧыЧѓСЂМДЗЕЛи;ЕБЪ§ОнзМБИЭъБЯКѓ,ЩњГЩЖдгІНјГЬЕФSIGIOаХКХ,ЭЈЙ§аХКХЛиЕїЭЈжЊгІгУЯпГЬЕїгУrecvfromКЏЪ§
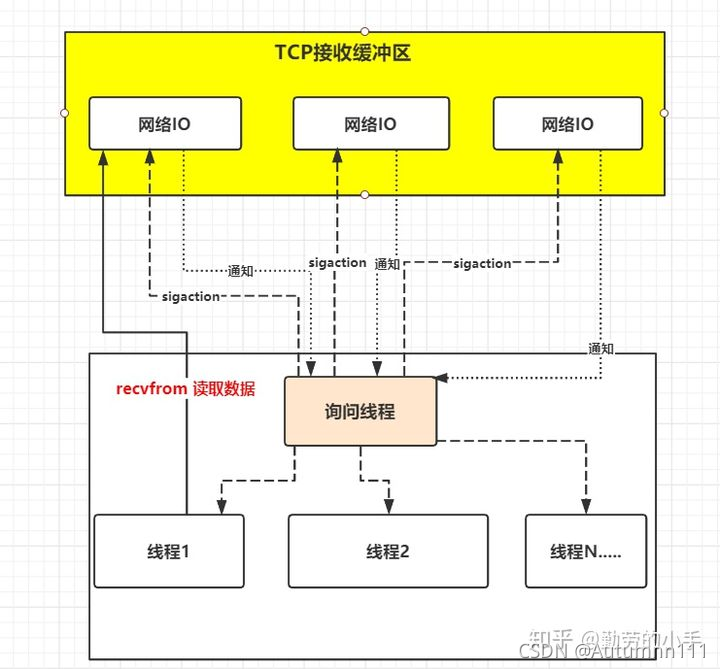

IOЖрТЗИДгУЕФselectКЏЪ§,ЪЕжЪЪЧВЛЖЯЕФЭЈЙ§ТжбЏРДМрПиfdЕФзДЬЌ,ЖјДѓЖрЪ§ЪБКђЕФТжбЏЦфЪЕЪЧУЛгавтвхЕФ,ЖјаХКХIOЧ§ЖЏФЃаЭЭЈЙ§НЈСЂаХКХЙиСЊЕФФЃЪН,ЪЕЯжСЫЗЂГіЧыЧѓКѓжЛашвЊЕШД§Ъ§ОнзМБИЭъГЩЕФЭЈжЊМДПЩ,БмУтСЫДѓСПЮовтвхЕФТжбЏВйзїЁЃ
вьВНIO
ЮвУЧПЩвдЗЂЯж,ВЛЙмЪЧЖрТЗИДгУЛЙЪЧаХКХЧ§ЖЏ,ЖМжСЩйашвЊСНЖЮЕФВйзї,ЪзЯШЭЈЙ§selectТжбЏЛђепНЈСЂаХКХСЊЯЕМрПизДЬЌ,ШЛКѓЯпГЬдйЕїгУrecvfromКЏЪ§ЖСШЁЪ§ОнЁЃ
ЫљвдетОЭв§Ц№СЫШЫУЧЕФЫМПМ,ЮвУЧЮЊЪВУДВЛФмИцЫпФкКЫЮвУЧашвЊетжжЪ§Он,ФкКЫзМБИКУжЎКѓжБНгЗЂИјЮвЁЃвЛВНЕНЮЛЁЃ
ЫљвдгаДѓРаЩшМЦСЫвЛИіЗНАИ:гІгУНјГЬЯђФкКЫЗЂЫЭвЛИіreadЧыЧѓ,ИцЫпФкКЫЫќашвЊЪВУДЪ§ОнжЎКѓСЂМДЗЕЛи;ФкКЫЪеЕНreadЧыЧѓКѓЛсгыНјГЬНЈСЂвЛИіаХКХСЊЯЕ,ЕБЪ§ОнзМБИОЭаїКѓ,ФкКЫЛсАбЪ§ОнжїЖЏИДжЦЕНгУЛЇПеМф,ЕБетаЉВйзїЭъГЩКѓ,ФкКЫЩњГЩвЛИіЭЈжЊИцЫпгІгУНјГЬЁЃетжжЗНЪНОЭНазівьВНIOФЃаЭ
Ъѕгя:гІгУИцжЊФкКЫЦєЖЏФГИіВйзї,ВЂШУФкКЫдйЭъГЩетИіВйзїКѓЭЈжЊгІгУЁЃКЭаХКХЧ§ЖЏIOЕФЧјБ№дкгк,аХКХЧ§ЖЏдкЪеЕНЭЈжЊКѓЛЙвЊЕїгУrecvfromКЏЪ§ШЅЖСШЁЪ§Он,ЖјвьВНIOЪЧСЌЖСЪ§ОнЖМгЩФкКЫЭъГЩ,вЛВНЕНЮЛЁЃ
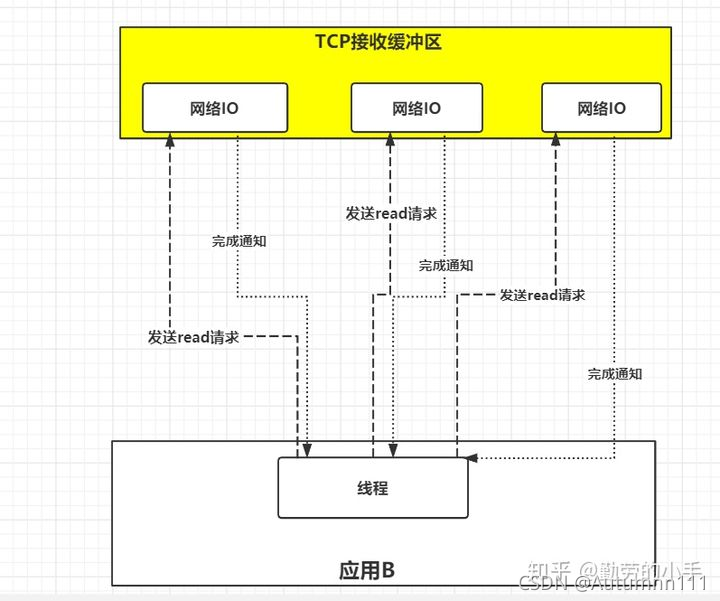
вьВНIOНтОіСЫIOЖрТЗИДгУКЭаХКХЧ§ЖЏIOЕФБзЖЫ,ЮоашдкбЏЮЪЪ§ОнзДЬЌжЎКѓдйШЅЖСШЁ,ЖјЪЧдкЪ§ОнЖСШЁЭъГЩКѓЭЈжЊгІгУЁЃгІгУжЛашвЊЯђФкКЫЗЂЦ№вЛДЮЧыЧѓМДПЩЁЃ
змНс
- зшШћIO:ЮвШЅТђвТЗў,ЕъдБИцЫпЮввТЗўЛЙУЛЕНЛѕ,ЮвОЭвЛжБдкЕъРяЕШ,ЕШЕНЕНЛѕСЫдйШЅзіБ№ЕФЪТЧщ
- **ЗЧзшШћIO:**ЛЙЪЧШЅТђвТЗў,вТЗўУЛЕНЛѕ,ЮвЯШШЅзіБ№ЕФЪТЧщ,БШШчЫЕДђРКЧђ,ГдЗЙЕШЕШ,зіЭъетаЉЪТЧщКѓдйРДбЏЮЪвТЗўЕНЛѕУЛга,ЕНСЫОЭТђЯТРД,УЛЕНЛѕОЭМЬајзіБ№ЕФЪТЧщ
- IOЖрТЗИДгУ:ШЅТђвТЗў,ЛЙЪЧУЛЕНЛѕ,етДЮбЇДЯУїСЫ,ЧыСЫИіаЁЕмдкФЧАяЮвЮЪ,УПИєвЛЗжжгОЭШЅЮЪвЛДЮ,ШчЙћУЛЕНЛѕОЭЕШвЛЗжжгдйЮЪ,ШчЙћЮЪЕНСЫТэЩЯЭЈжЊЮвЙ§РДТђ
- аХКХЧ§ЖЏIO:ЩЯДЮЧыЕФаЁЕмЫЕЮвКкаФ,УЛБивЊИєвЛЗжжгЮЪвЛДЮ,ЛљБОЖМЪЧУЛгавтвхЕФЮЪ,ЫљвдЮвТђЭЈСЫЕъдБ,ШУЫќвЛЕНЛѕОЭЭЈжЊЮвЙ§РДТђвТЗў
- вьВНIO:ЮвЗЂВЦСЫ,жБНгЛЈШ§БЖМлЧЎ,ШУЕъГЄдквТЗўЕНЕФЪБКђИјЮвЫЭЕНМвРя,БЯОЙгаЧЎЫцБуВйзїЁЃ