Cilium 作为近两年最火的云原生网络方案,可谓是风头无两。作为第一个通过 ebpf 实现了 kube-proxy 所有功能的网络插件,它的神秘面纱究竟是怎样的呢?本系列文章将带大家一起来慢慢揭晓
作为《理解 Cilium系列文章》的第二篇,本文主要介绍 Cilium 网络相关知识点,为后续 Cilium 的深入了解做铺垫。了解 Cilium 是如何在网络流转的路径中做拦截处理的
之前的两篇文章【25 张图,一万字,拆解 Linux 网络包发送过程】和【图解Linux网络包接收过程】主要从源码层次介绍了 Linux 网络收发包的流程,感兴趣的同学可以看一下,读完上述两篇再看本篇将会更轻松 。
1. 网络分层的宏观视角
想必大家都应该准备过这样一道面试题 从输入 URL 到收到请求响应,中间发生了什么事情 。
这个问题如果往复杂了讲,恐怕讲个一天一夜也讲不完。此处咱们长话短说,简要描述下大体流程,先建立个宏观视角。
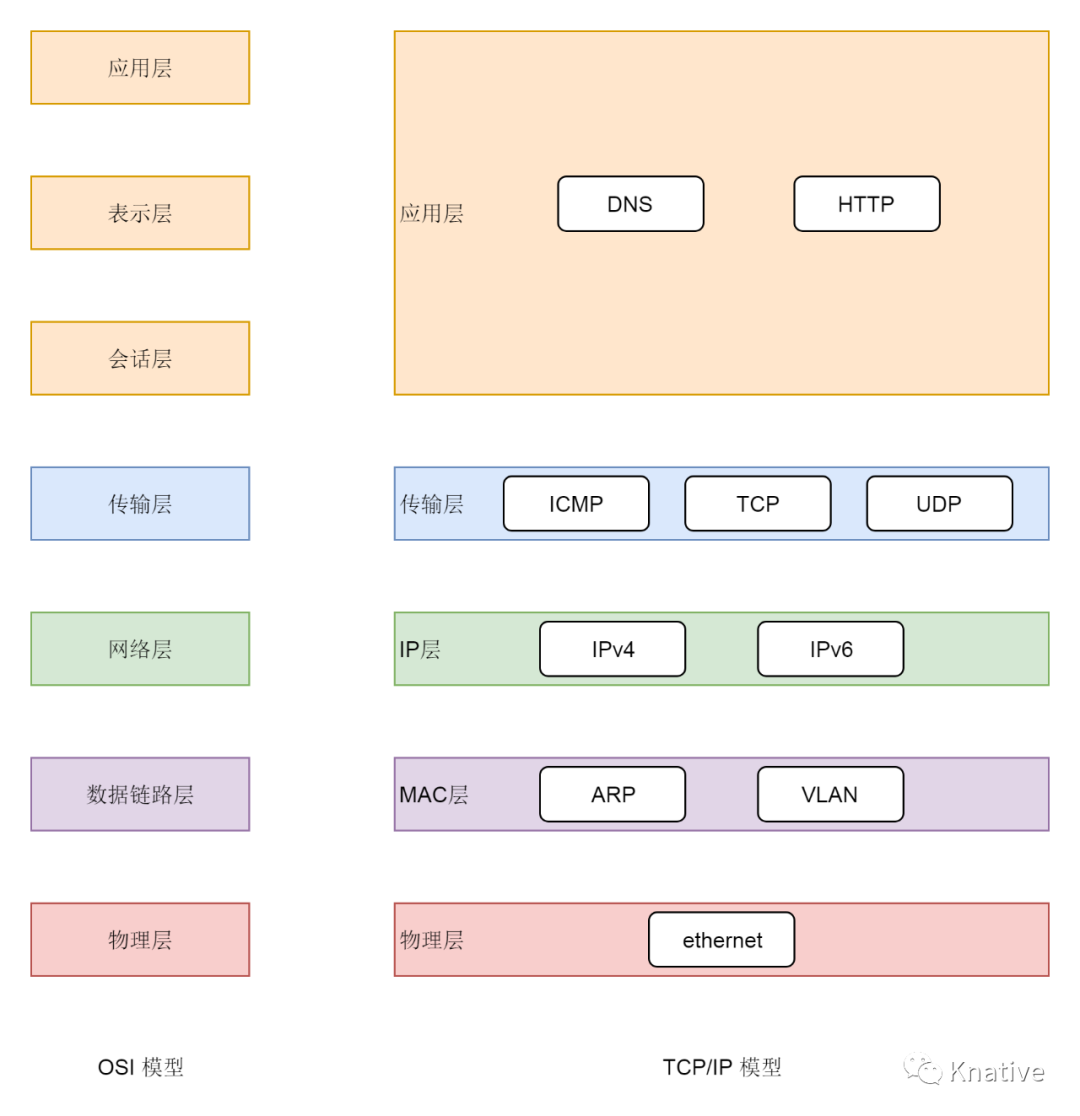
先复习下网络分层模型
如下 左图 为 OSI 的标准七层 网络模型,这套模型只是停留在概念上的,因为实现起来太复杂了。右边是业界标准的 TCP/IP 模型,Linux 系统中正是按照 TCP/IP 模型开发的网络协议栈。
接下来回到上文的问题 从输入 URL 到收到请求响应,中间发生了什么事情
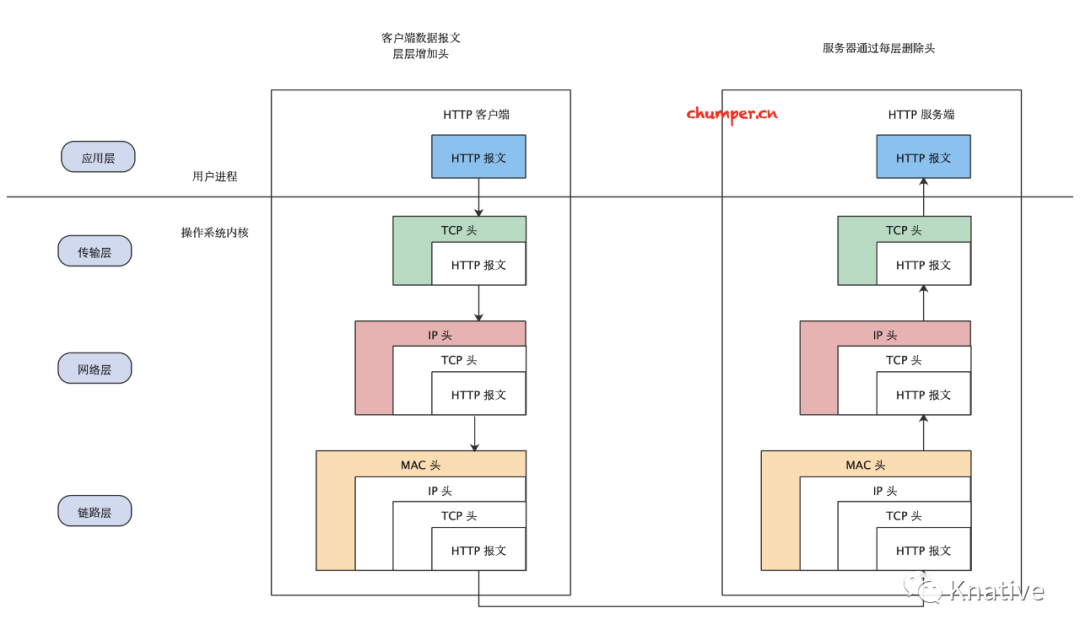
此处简要描述下流程,限于篇幅不一一展开了,当然如果小伙伴对其中某些知识点感兴趣的话,可以自行搜索相关材料继续深入研究。
-
客户端发起网络请求,
用户态的应用程序(浏览器)会生成 HTTP 请求报文、并通过 DNS 协议查找到对应的远端 IP 地址。 -
用户态的应用程序(浏览器) 会委托操作系统内核协议栈中的上半部分,也就是 TCP/UDP 协议发起连接请求。此处封装 TCP 头(或 UDP 头) -
然后经由协议栈下半部分的 IP 协议进行封装,然后交给下层协议。此处封装 IP 头
-
经过 MAC 层处理,找到接收方的目标 MAC 地址。此处封装 MAC 头。
-
最终数据包在经过网卡转化成电信号经过交换机、路由器发送到服务端,服务端经过处理拿到数据,再通过各种网络协议依次把封装的头解封装,把数据响应给客户端。
-
客户端拿到数据进行渲染。
2. Linux 网络协议栈
上面讲述了网络分层原理以及各层的封包解包流程,下面介绍下 Linux 网络协议栈,其实 Linux 网络协议栈就类似于 TCP/IP 的四层结构:
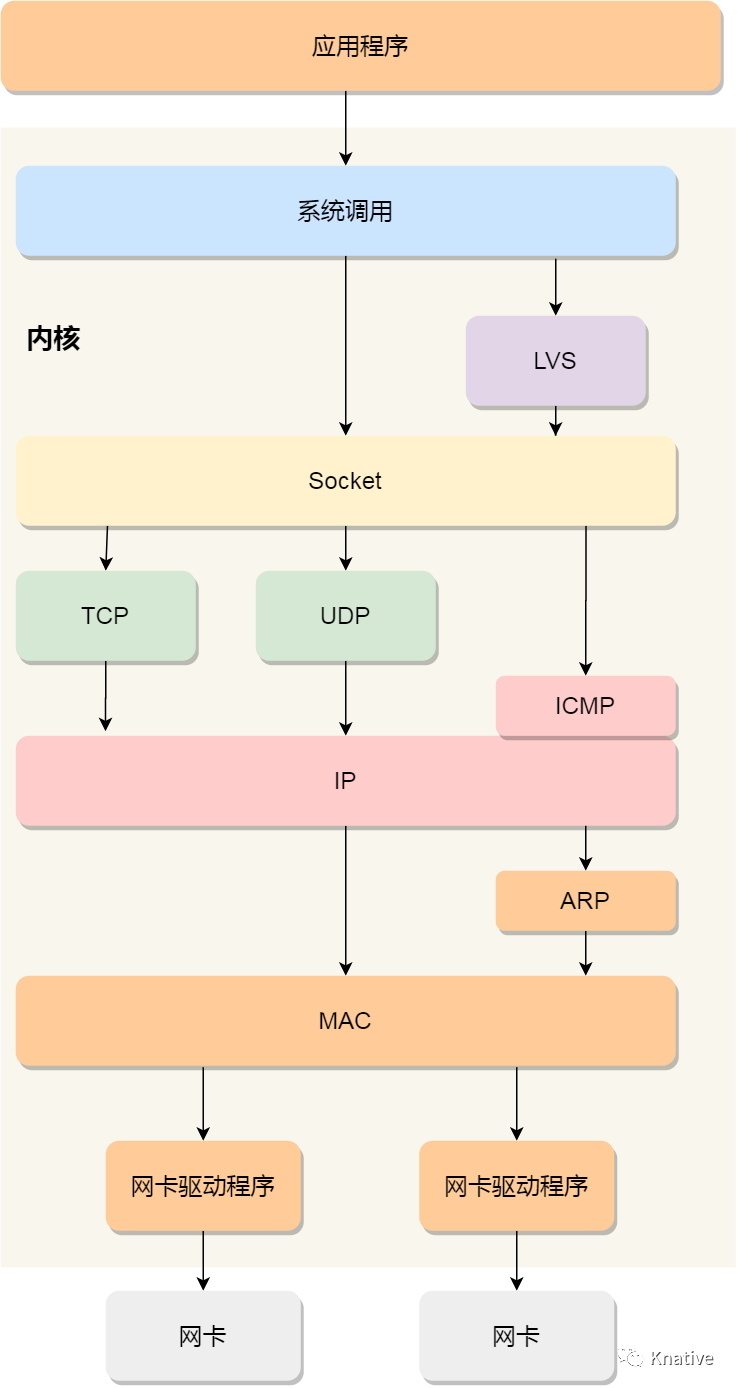
通过上图可以看到:
-
应用程序需要通过系统调用,来跟 Socket 层进行数据交互;
-
Socket 层的下面就是传输层、网络层和网络接口层;
-
最下面的一层,则是网卡驱动程序和硬件网卡设备;
3. Linux 接收网络包的流程
同样的,先来个宏观视角,然后再一一介绍,避免一开始就陷入细节无法自拔
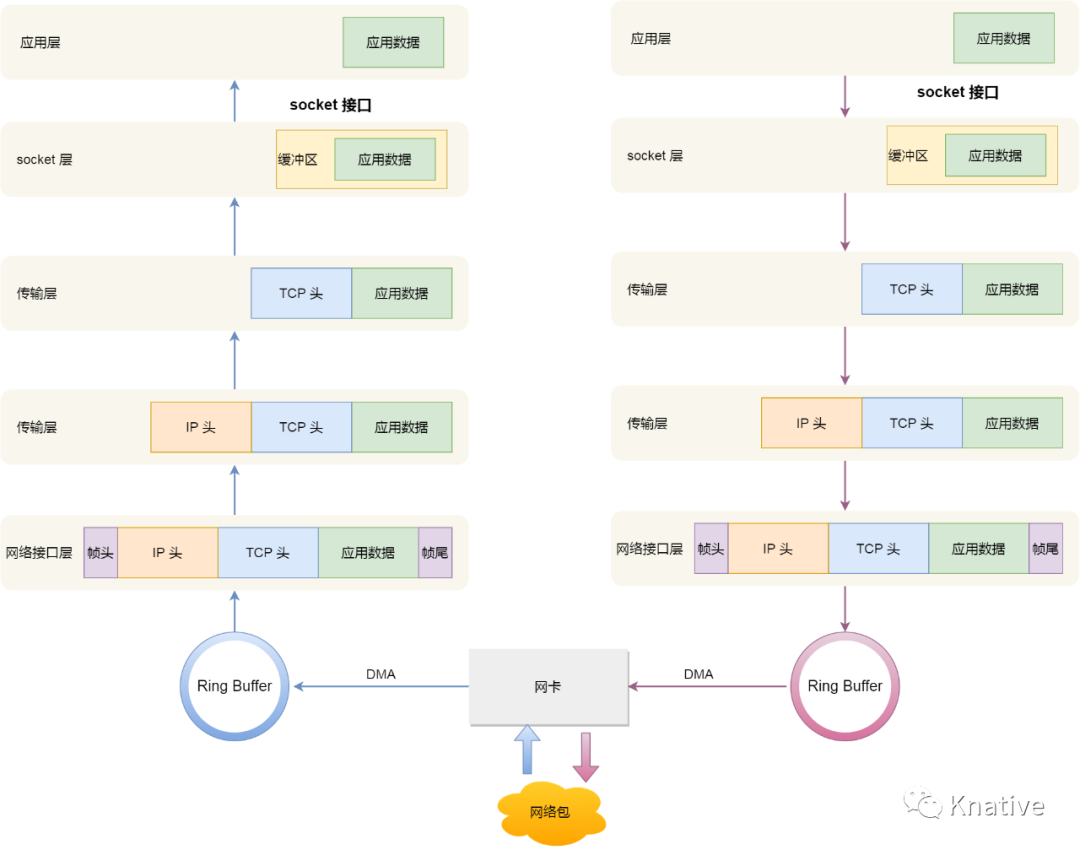
图片取自《你不好奇 Linux 网络发包过程吗?》[1]
可以看到上图比之前介绍的网络封包解包相比,多了下面网卡相关的内容。是的,因为咱们要介绍的是 Cilium 相关的网络基础,所以需要了解 数据包是如何穿过 network datapath 的:包括从硬件到 内核,再到用户空间。图中有 Cilium logo 的地方,都是 datapath 上 Cilium 重度使用 BPF 程序的地方。
参考 【[译] 深入理解 Cilium 的 eBPF 收发包路径(datapath)(KubeCon, 2019)】[2]
下面将分层 介绍:
3.1 L1 -> L2(物理层 -> 数据链路层)

网卡收包简要流程:
-
网卡驱动初始化。
-
网卡获得一块物理内存,作用收发包的缓冲区(ring-buffer)。这种方式称为 DMA(直接内存访问)。
-
驱动向内核 NAPI(New API)注册一个轮询(poll )方法。
-
网卡从网络中收到一个包,通过 DMA 方式将包放到 Ring Buffer,这是一个环形缓冲区。
-
如果此时 NAPI 没有在执行,网卡就会触发一个硬件中断(HW IRQ),告诉处理器 DMA 区域中有包等待处理。
-
收到硬中断信号后,处理器开始执行 NAPI。
-
NAPI 执行网卡注册的 poll 方法开始收包。
关于 NAPI poll 机制:
-
Linux 内核在 2.6 版本中引入了 NAPI 机制,它是混合「中断和轮询」的方式来接收网络包,它的核心概念就是不采用中断的方式读取数据,而是首先采用中断唤醒数据接收的服务程序,然后
poll的方法来轮询数据。 -
驱动注册的这个 poll 是一个主动式 poll(active poll),执行 poll 方法的是运行在某个或者所有 CPU 上的内核线程(kernel thread),一旦执行就会持续处理 ,直到没有数据可供处理,然后进入 idle 状态。
-
比如,当有网络包到达时,网卡发起硬件中断,于是会执行网卡硬件中断处理函数,中断处理函数处理完需要「暂时屏蔽中断」,然后唤醒「软中断」来轮询处理数据,不断从驱动的 DMA 区域内接收数据包直到没有新数据时才恢复中断,这样一次中断处理多个网络包,于是就可以降低网卡中断带来的性能开销。
-
之所以会有这种机制,是因为硬件中断代价太 高了,因为它们比系统上几乎所有东西的优先级都要高。
NAPI 驱动的 poll 机制将数据从 DMA 区域读取出来,对数据做一些准备工作,然后交给比 它更上一层的内核协议栈。
3.2 L2 数据链路层
此处不会过多展示驱动层做的事情,主要关注 Cilium 涉及到的流程,即 内核及以上的流程,主要包括
-
分配 socket buffers(skb)
-
BPF
-
iptables
-
将包送到网络栈(network stack)和用户空间
Step 1:NAPI poll

首先,NAPI poll 机制不断调用驱动实现的 poll 方法,后者处理 RX 队列内的包,并最终 将包送到正确的程序。也就是前面的公众号介绍的 XDP【Linux网络新技术基石――eBPF、XDP】。
Step 2:XDP 程序处理
XDP全称为eXpress Data Path,是Linux内核网络栈的最底层。**它只存在于RX(接收数据)路径上,**允许在网络设备驱动内部网络堆栈中数据来源最早的地方进行数据包处理,在特定模式下可以在操作系统分配内存(skb)之前就已经完成处理
插播一下 XDP 的工作模式
XDP 有三种工作模式,默认是
native(原生)模式,当讨论 XDP 时通常隐含的都是指这 种模式。
Native XDP
XDP 程序 hook 到网络设备的驱动上,它是XDP最原始的模式,因为还是先于操作系统进行数据处理,它的执行性能还是很高的,当然需要网卡驱动支持。大部分广泛使用的 10G 及更高速的网卡都已经支持这种模式 。
Offloaded XDP
XDP程序直接hook到可编程网卡硬件设备上,与其他两种模式相比,它的处理性能最强;由于处于数据链路的最前端,过滤效率也是最高的。如果需要使用这种模式,需要在加载程序时明确声明。
Generic XDP
对于还没有实现 native 或 offloaded XDP 的驱动,内核提供了一个 generic XDP 选 项,这是操作系统内核提供的通用 XDP兼容模式,它可以在没有硬件或驱动程序支持的主机上执行XDP程序。在这种模式下,XDP的执行是由操作系统本身来完成的,以模拟native模式执行。好处是,只要内核够高,人人都能玩XDP;缺点是由于是仿真执行,需要分配额外的套接字缓冲区(SKB),导致处理性能下降,跟native模式在10倍左右的差距。
对于在生产环境使用 XDP,推荐要么选择 native 要么选择 offloaded 模式。这两种模式需要网卡驱动的支持,对于那些不支持 XDP 的驱动,内核提供了 Generic XDP ,这是软件实现的 XDP,性能会低一些, 在实现上就是将 XDP 的执行上移到了核心网络栈
继续回来介绍 ,分两种情况:native/offloaded 模式、general 模式
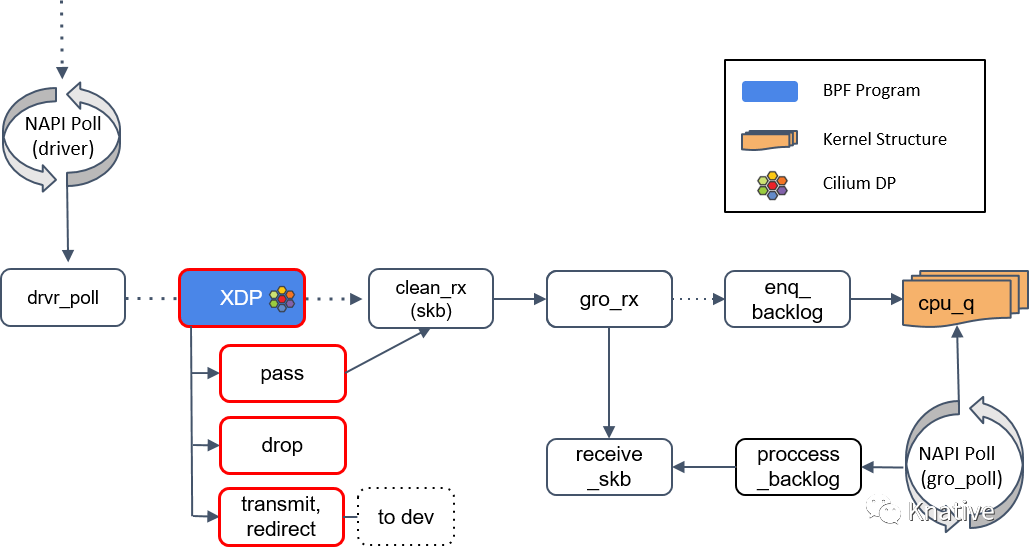
(1) native/offloaded 模式:XDP 在内核收包函数 receive_skb() 之前
(2) Generic XDP 模式:XDP 在内核收包函数 receive_skb() 之后,
XDP 程序返回一个判决结果给驱动,可以是 PASS, TRANSMIT, 或 DROP
-
TRANSMIT 非常有用,有了这个功能,就可以用 XDP 实现一个 TCP/IP 负载均衡器。XDP 只适合对包进行较小修改,如果是大动作修改,那这样的 XDP 程序的性能 可能并不会很高,因为这些操作会降低 poll 函数处理 DMA ring-buffer 的能力。
-
如果返回的是 DROP,这个包就可以直接原地丢弃了,而 无需再穿越后面复杂的协议栈然后再在某个地方被丢弃,从而节省了大量资源。在业界最出名的一个应用场景就是 Facebook 基于 XDP 实现高效的防 DDoS 攻击,其本质上就是实现尽可能早地实现「丢包」,而不去消耗系统资源创建完整的网络栈链路,即「early drop」。
-
如果返回是 PASS,内核会继续沿着默认路径处理包,如果是 **native/offloaded 模式 ,**后续到达
clean_rx()方法;如果是 Generic XDP 模式,将导到check_taps()下面的 Step 6 继续讲解。
Step 3:clean_rx():创建 skb
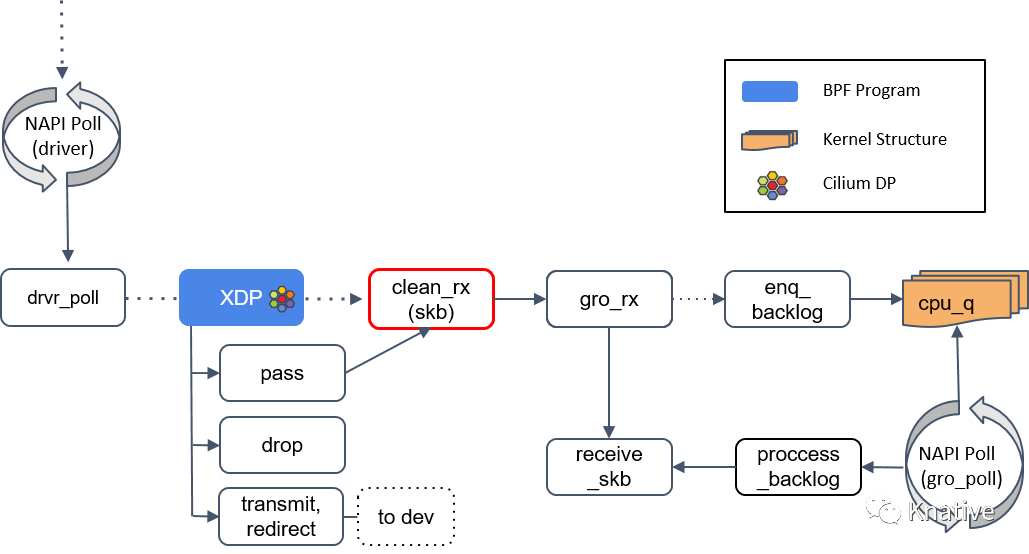
如果 XDP 返回是 PASS,内核会继续沿着默认路径处理包,到达 clean_rx() 方法。
这个方法创建一个 socket buffer(skb)对象,可能还会更新一些统计信息,对 skb 进行硬件校验和检查,然后将其交给 gro_receive() 方法。
Step 4:gro_receive()
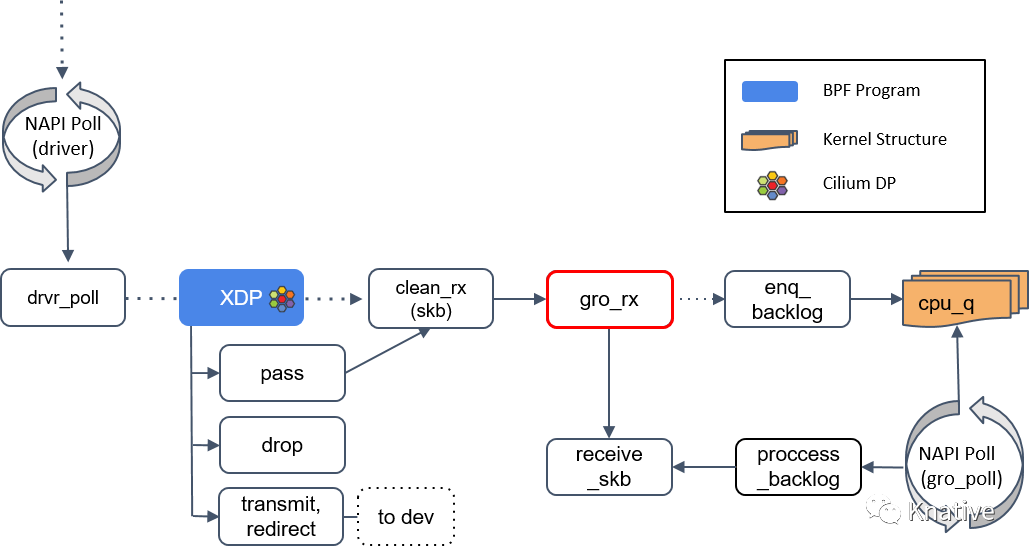
GRO[3] (Generic Receive Offload) 是一种硬件特性的软件实现,可以简单理解成:将包交给网络协议栈之前**,**把相关的小包合并成一个大包。目的是减少传送给网络栈的包数,这有助于减少 CPU 的使用量,提高吞吐量。
-
如果 GRO 的 buffer 相比于包太小了,它可能会选择什么都不做。
-
如果当前包属于某个更大包的一个分片,调用
enqueue_backlog将这个分片放到某个 CPU 的包队列。当包重组完成后,会交给receive_skb()方法处理。 -
如果当前包不是分片包,直接调用
receive_skb(),进行一些网络栈最底层的处理。
Step 5:receive_skb()

receive_skb() 之后会再次进入 XDP 程序点。
3.3 L2 -> L3(数据链路层 -> 网络层)
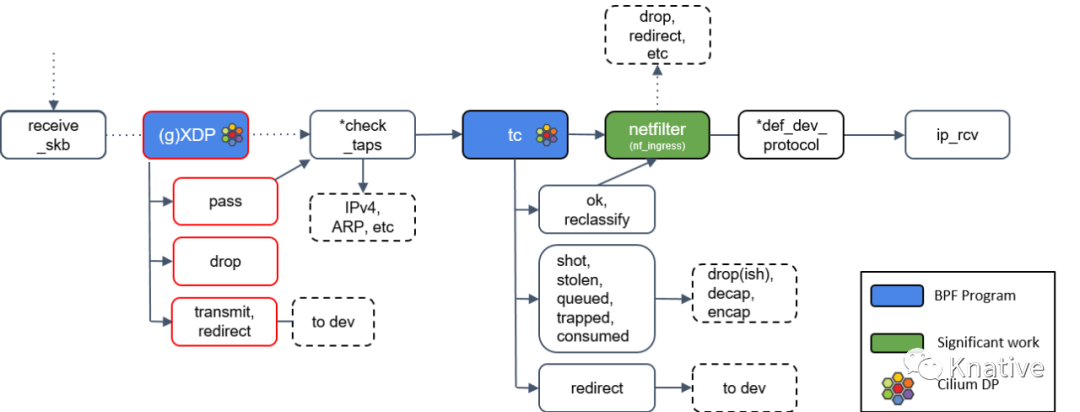
Step 6:通用 XDP 处理(gXDP)
上文说过,如果不支持 Native 或 Offloaded 模式的 XDP 的话,将通过 General XDP 来处理,就是此处的 (g)XDP。 此处 XDP 的行为 跟 Step 2 中一致,此处不再赘述。
Step 7:Tap 设备处理
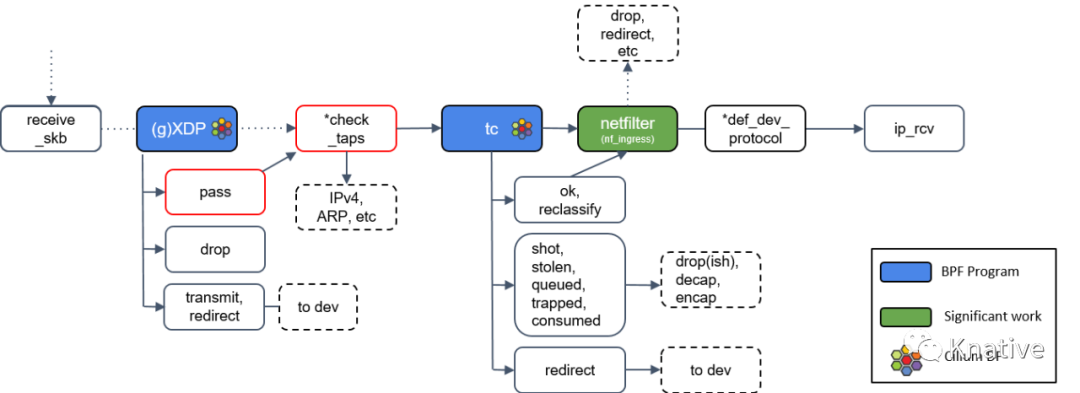
图中有个 *check_taps 框,但其实并没有这个方法:receive_skb() 会轮询所有的 socket tap,将包放到正确的 tap 设备的缓冲区。
tap 设备监听的是二层协议(L2 protocols)。如果 tap 设 备存在,它就可以操作这个 skb 了。
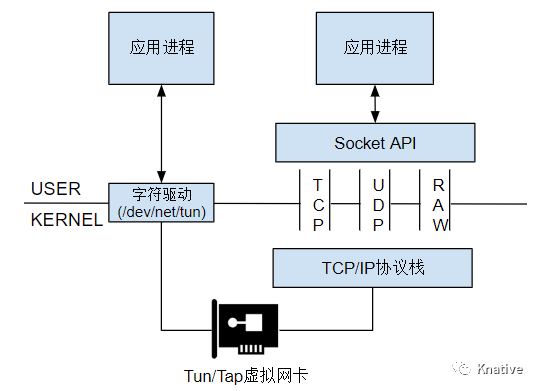
Tun/Tap 设备:
Tun 设备是一个三层设备,从/dev/net/tun字符设备上读取的是IP数据包,写入的也只能是IP数据包,因此不能进行二层操作,如发送ARP请求和以太网广播。
Tap设备是三层设备,处理的是二层 MAC 层数据帧,从/dev/net/tun字符设备上读取的是MAC 层数据帧,写入的也只能是 MAC 层数据帧。从这点来看,Tap虚拟设备和真实的物理网卡的能力更接近。
Step 8:tc(Traffic Control)处理
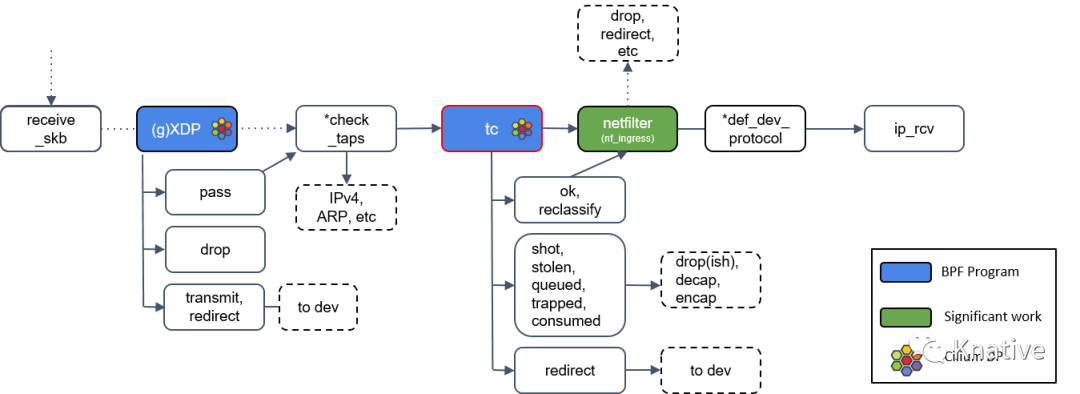
接下来是 TC (Traffic Control), 也就是流量控制,TC更专注于packet scheduler,所谓的网络包调度器,调度网络包的延迟、丢失、传输顺序和速度控制。和 XDP 一样,TC 的输出代表了数据包如何被处置的一种动作,最新的 Linux 内核中[4]定义的有 9 种动作:
#define?TC_ACT_OK??0
#define?TC_ACT_RECLASSIFY?1
#define?TC_ACT_SHOT??2
#define?TC_ACT_PIPE??3
#define?TC_ACT_STOLEN??4
#define?TC_ACT_QUEUED??5
#define?TC_ACT_REPEAT??6
#define?TC_ACT_REDIRECT??7
#define?TC_ACT_TRAP??8
注:Cilium 控制的网络设备,至少被加载了一个 tc eBPF 程序
Step 9:Netfilter 处理
如果 tc BPF 返回 OK,包会再次进入 Netfilter。
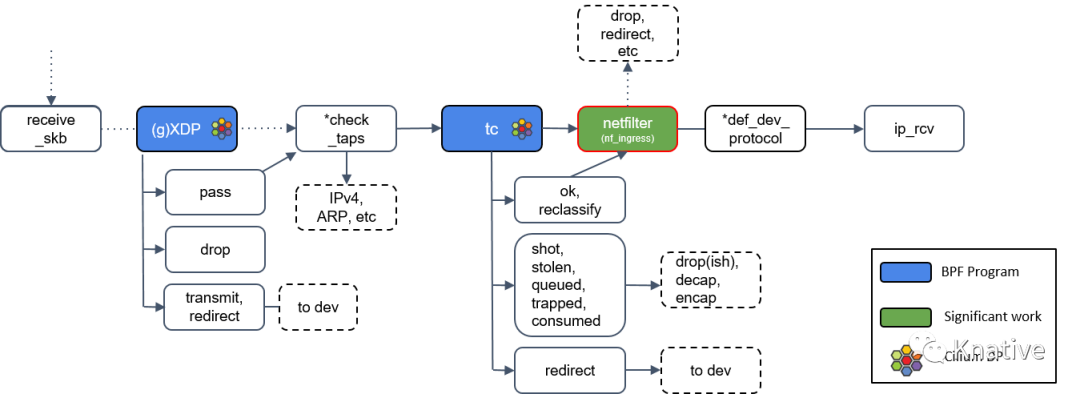
Netfilter 也会对入向的包进行处理,这里包括 nftables 和 iptables 模块。
*def_dev_protocol 框是二层过滤器(L2 net filter),由于 Cilium 没有用到任何 L2 filter,此处就不展开了。
Step 10:L3 协议层处理:ip_rcv()
最后,如果包没有被前面丢弃,就会通过网络设备的 ip_rcv() 方法进入协议栈的三层( L3)―― 即 IP 层 ―― 进行处理。
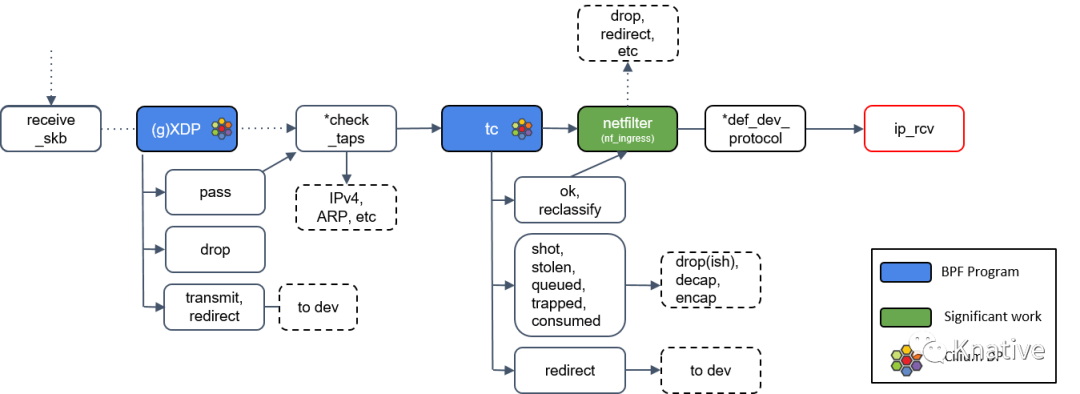
接下来看ip_rcv()(但这里需要提醒大家的是,Linux 内核也支持除了 IP 之 外的其他三层协议,它们的 datapath 会与此有些不同)。
3.3 L3 -> L4(网络层 -> 传输层)
Step 11:Netfilter L4 处理
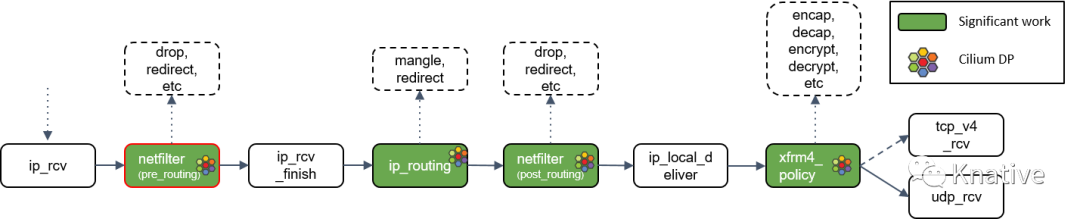
ip_rcv() 做的第一件事情是再次执行 Netfilter 过滤,因为我们现在是从四层(L4)的 视角来处理 socket buffer。因此,这里会执行 Netfilter 中的任何四层规则(L4 rules )
Step 12:ip_rcv_finish() 处理
Netfilter 执行完成后,调用回调函数 ip_rcv_finish()。
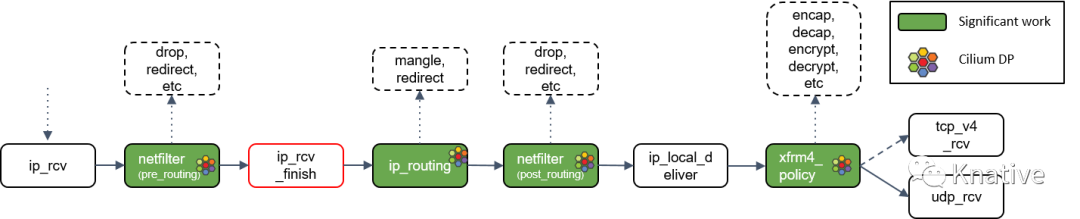
ip_rcv_finish() 立即调用 ip_routing() 对包进行路由判断。
Step 13:ip_routing() 处理
ip_routing() 对包进行路由判断,例如看它是否是在 lookback 设备上,是否能 路由出去(egress),或者能否被路由,能否被 unmangle 到其他设备等等。
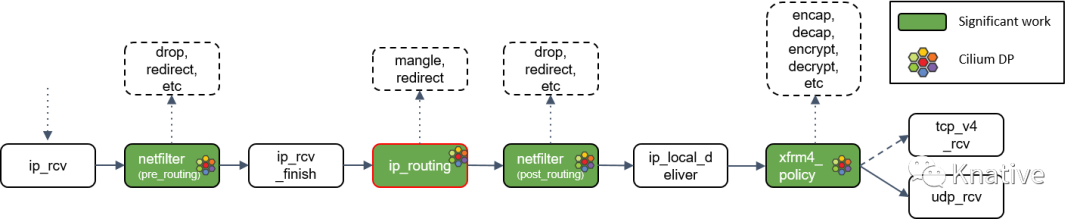
在 Cilium 中,如果没有使用隧道模式(tunneling),那就会用到这里的路由功能。相比 隧道模式,路由模式会的 datapath 路径更短,因此性能更高。
Step 14:目的是本机:ip_local_deliver() 处理
根据路由判断的结果,如果包的目的端是本机,会调用 ip_local_deliver() 方法。
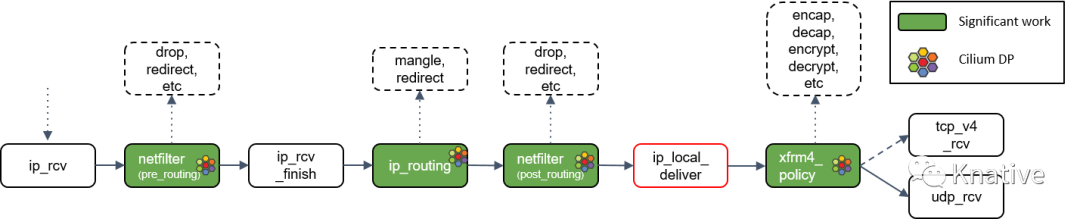
ip_local_deliver() 会调用 xfrm4_policy()。
Step 15:xfrm4_policy() 处理
xfrm4_policy() 完成对包的封装、解封装、加解密等工作。例如,IPSec 就是在这里完成的。

最后,根据四层协议的不同,ip_local_deliver() 会将最终的包送到 TCP 或 UDP 协议 栈。这里必须是这两种协议之一,否则设备会给源 IP 地址回一个 ICMP destination unreachable 消息。
此处拿 UDP 协议作为例子,因为 TCP 状态机太复杂了,不适合这里用于理解 datapath 和数据流。但不是说 TCP 不重要,Linux TCP 状态机还是非常值得好好学习的。
3.4 L4(传输层,以 UDP 为例)
Step 16:udp_rcv() 处理

udp_rcv() 对包的合法性进行验证,检查 UDP 校验和。然后,再次将包送到 xfrm4_policy() 进行处理。
Step 17:xfrm4_policy() 再次处理
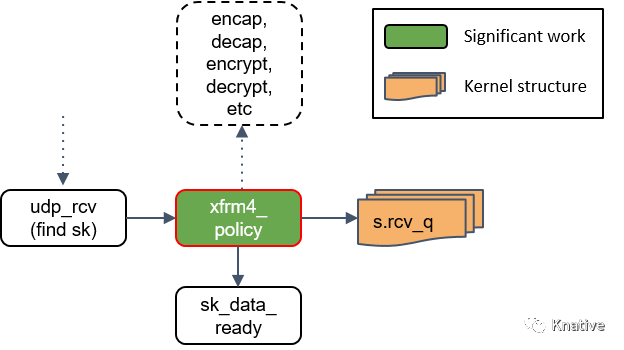
这里再次对包执行 transform policies 是因为,某些规则能指定具体的四层协议,所以只 有到了协议层之后才能执行这些策略。
Step 18:将包放入 socket_receive_queue
这一步会拿端口(port)查找相应的 socket,然后将 skb 放到一个名为 socket_receive_queue 的链表。
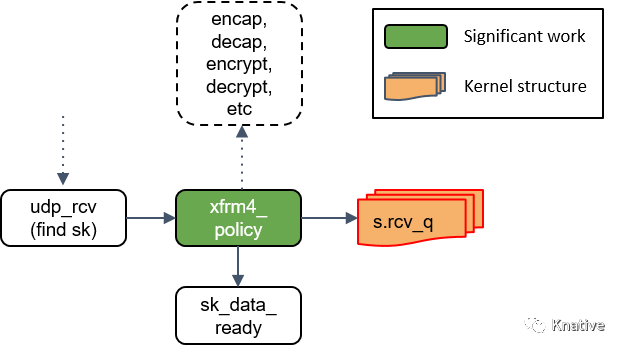
Step 19:通知 socket 收数据:sk_data_ready()
最后,udp_rcv() 调用 sk_data_ready() 方法,标记这个 socket 有数据待收。
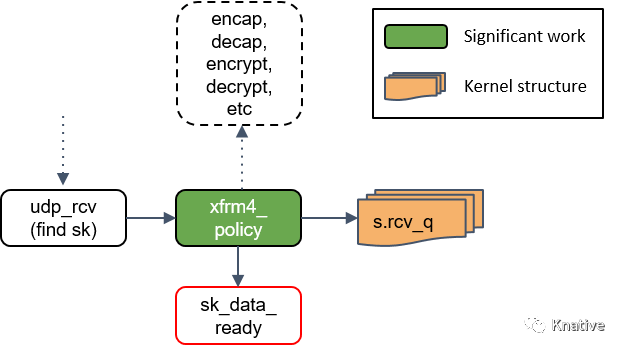
本质上,一个 socket 就是 Linux 中的一个文件描述符,这个描述符有一组相关的文件操 作抽象,例如 read、write 等等。
网络栈下半部分小结
以上 Step 1~19 就是 Linux 网络栈下半部分的全部内容。
接下来介绍几个内核函数,都是与进程上下文相关的。
3.5 L4 User Space
下图左边是一段 socket listening 程序,这里省略了错误检查,而且 epoll 本质上也 是不需要的,因为 UDP 的 recv 方法已经在执行 poll 操作了。

事实上当我们调 用 recvmsg() 方法时,内核所做的事情就和上面这段代码差不多。对照右边的图:
-
首先初始化一个 epoll 实例和一个 UDP socket,然后告诉 epoll 实例我们想 监听这个 socket 上的 receive 事件,然后等着事件到来。
-
当 socket buffer 收到数据时,其 wait queue 会被上一节的
sk_data_ready()方法置位(标记)。 -
epoll 监听在 wait queue,因此 epoll 收到事件通知后,提取事件内容,返回给用户空间。
-
用户空间程序调用
recv方法,它接着调用udp_recv_msg方法,后者又会 调用 cgroup eBPF 程序 ―― 这是本文出现的第三种 BPF 程序。Cilium 利用 cgroup eBPF 实现 socket level 负载均衡:
-
一般的客户端负载均衡对客户端并不是透明的,即,客户端应用必须将负载均衡逻辑内置到应用里。
-
有了 cgroup BPF,客户端根本感知不到负载均衡的存在。
-
本文介绍的最后一种 BPF 程序是 sock_ops BPF,用于 socket level 整流(traffic shaping ),这对某些功能至关重要,例如客户端级别的限速(rate limiting)。
-
最后,我们有一个用户空间缓冲区,存放收到的数据。
以上就是 Cilium 涉及到网络数据包在内核流转的过程, 实际上内核 datapath 要远比这里讲的要复杂。
-
前面只是非常简单地介绍了协议栈每个位置(Netfilter、iptables、eBPF、XDP)能执行的动作。
-
这些位置提供的处理能力是不同的。例如
-
XDP 可能是能力最受限的,因为它只是设计用来做快速丢包(fast dropping)和 非本地重定向(non-local redirecting);但另一方面,它又是最快的程序,因为 它在整个 datapath 的最前面,具备对整个 datapath 进行短路处理(short circuit the entire datapath)的能力。
-
tc 和 iptables 程序能方便地 mangle 数据包,而不会对原来的转发流程产生显著影响。
关于 Cilium 与 Linux 内核更多的知识点,就留给感兴趣的读者自行深入研究吧~
参考资料
[1]
你不好奇 Linux 网络发包过程吗: https://xie.infoq.cn/article/6ba14b756c3019cc737ed48a6
[2]
【[译] 深入理解 Cilium 的 eBPF 收发包路径(datapath)(KubeCon, 2019)】: http://arthurchiao.art/blog/understanding-ebpf-datapath-in-cilium-zh
[3]
GRO: https://zhuanlan.zhihu.com/p/44683790
[4]
Linux 内核: https://elixir.bootlin.com/linux/v5.14-rc7/source/include/uapi/linux/pkt_cls.h#L60
推荐阅读
【理解 Cilium 系列文章】(一) 初识 Cilium

扫描二维码 | 加入技术交流群