“TCP/IP协议栈到底是内核态的好还是用户态的好?”
问题的根源在于,干嘛非要这么刻意地去区分什么内核态和用户态。
引子
为了不让本文成为干巴巴的说教,在文章开头,我以一个实例分析开始。
最近一段时间,我几乎每天深夜都在做一件事,对比mtcp,Linux内核协议栈的收包处理和TCP新建连接的性能,同时还了解了一下腾讯的F-Stack。这里指明,我的mtcp使用的是netmap作为底层支撑,而不是DPDK。
测试过程中,我确认了Linux内核协议栈的scalable问题并且确认了用户态协议栈是如何解决这个问题的。然而这并没有让我得出用户态协议栈就一定比内核态协议栈好这么一个明确的结论。具体怎么讲呢?先来看一张图,这张图大致描述了我的测试结论:
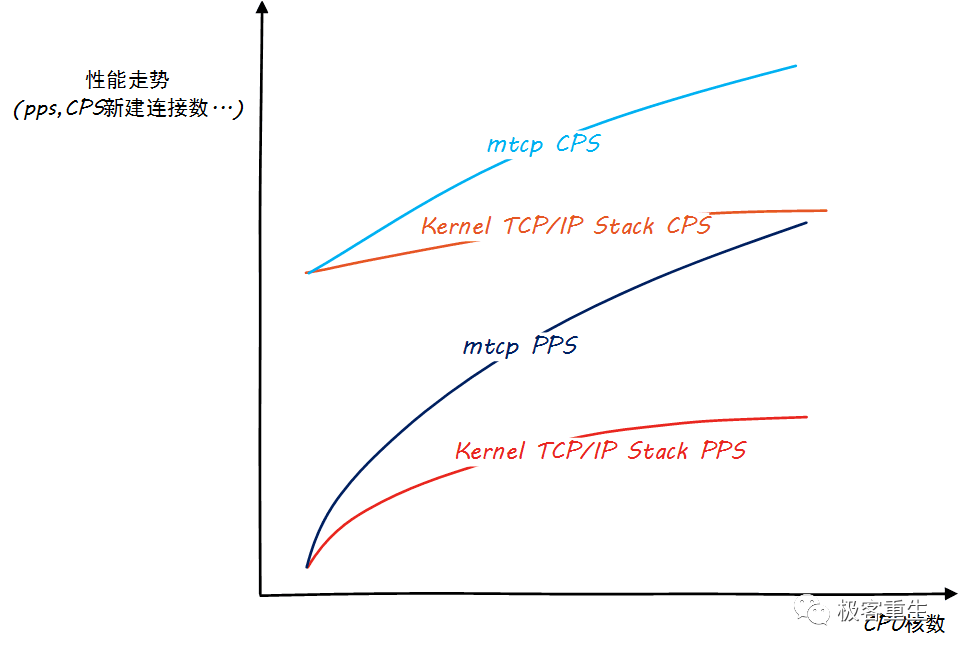
可以看出,Linux内核协议栈存在严重的scalable问题(可伸缩性),虽然我们看到用户态协议栈性能也并非完美地随着CPU核数的增加而线性扩展,但已经好太多了。看到这个结论,我们不禁要问,Why?两个问题:
为什么内核协议栈PPS曲线呈现严重上凸?
为什么内核协议栈的CPS(TCP每秒新建连接数)随着CPU核数的增加几乎没有什么变化?
第一个问题好回答,就像《人月神话》里说的一样,任何事情都不能完美线性扩展,因为沟通需要成本。好吧,当我巧妙绕开第一个问题后,我不得不深度解析第二个问题。
我们知道,Linux内核协议栈会将所有的Listener socket和已经建立连接的establish socket分别链接到两个全局的hash表中,这意味着每一个CPU核都有可能操作这两张hash表,作为抢占式SMP内核,Linux处理TCP新建连接时加锁是必须的。
好在如今的新内核的锁粒度已经细化到了hash slot,这大大提升了性能,然而面对hash到同一个slot的TCP syn请求来讲,还是歇菜!
特别严重的是,如果用户态服务器仅仅侦听一个Nginx 80端口,那么这个机制就相当于一个全局的内核大锁!对于Listener的slot锁,那是为多个Listener而优化的(最多INET_LHTABLE_SIZE个bucket,即32个),对于仅有一个Listener的新建连接而言,不会起到任何作用。但是这个只是在频繁启停服务+reuseport的时候才会发生,无关我们描述的场景
对于TCP新建连接测试,很显然要频繁操作那张establish hash表,握手完成后加锁插入hash表,连接销毁时加锁从hash表删除!
问题已经描述清楚了,要揭示答案了。
对于TCP CPS测试而言,会有频繁的连接创建和链接销毁的过程在执行,映射到代码,那就是inet_hash和inet_unhash两个函数会频繁执行,我们看一下unhash:
void inet_unhash(struct sock *sk)
{
struct inet_hashinfo *hashinfo = sk->sk_prot->h.hashinfo;
spinlock_t *lock;
int done;
if (sk_unhashed(sk))
return;
if (sk->sk_state == TCP_LISTEN)
lock = &hashinfo->listening_hash[inet_sk_listen_hashfn(sk)].lock;
else // 多核SMP且高压力下,难免会有多个socket被hash到同一个slot
lock = inet_ehash_lockp(hashinfo, sk->sk_hash);
spin_lock_bh(lock); // 这里是问题的根源
done =__sk_nulls_del_node_init_rcu(sk);
if (done)
sock_prot_inuse_add(sock_net(sk), sk->sk_prot, -1);
spin_unlock_bh(lock);
}
关于hash的过程就不赘述了,同样会有一个spinlock的串行化过程。
这似乎解释了为什么内核协议栈的CPS如此之低,但依然没有解释为什么内核协议栈的CPS如此不scalable,换句话说,为何其曲线上凸。
从曲线上看,虚线的斜率随着CPU核数的增加而减小。而曲线的斜率和沟通成本是负相关的。这里的沟通成本就是冲突后的自旋!
不求完全定量化分析,我们只需要证明另外一件事即可,那就是随着CPU核数的增加,slot冲突将会加剧,从而导致spinlock更加频繁,即CPU核心和spinlock频度是正相关的!!
这是显然的,且这很容易理解。如果我们的hash函数是完美的,那么每一次hash都是不偏不倚的,最终的hash bucket分布将是概率均匀的。CPU核数的增加并不会改变这个结论:
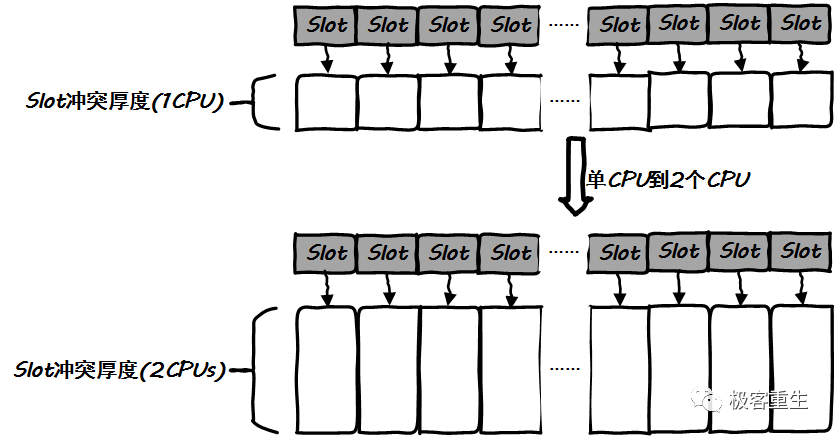
结论是,CPU核数的增加,只会加剧冲突,因此CPU核数越多,spinlock频度就越高,明显地二者正相关!spinlock随着CPU核数的增加而增加,CPU核数增加的收益被同样增加的spinlock成本完美抵消,所以说,随着CPU核数的增加,CPS几乎不会变化。
好了,这就是内核协议栈的缺陷,它能不能改进取决于你的决心,以上的描述没有任何细节证明在内核态实现协议栈是不好的,相反,它只是证明了Linux内核如此这般的实现方法存在问题,仅此而已。
进入真正的形而上论述之前,扯点题外话。
首先推荐一个腾讯云的F-Stack,其github地址为:
https://github.com/F-Stack/f-stack

我们能从以下的链接看到它的全貌:
http://www.f-stack.org/
之所以推荐这个,是因为它是一个我们大家都能看得见摸得着便于深度交流的中文社区的用户态协议栈实现,并且是开源的。没有任何私心,但真心感觉不错。
其次聊一下第一代以太网的CSMA/CD。
这玩意儿相信几乎所有搞IT的听说过,一般学习网络的第一节课或者第二节课,老师都会提到这个,但也就仅仅这两节课,后面就再也不提了。我们都知道,如今的交换式以太网早就不用CSMA/CD那一套了…但无论如何,返璞归真总是会让人有所收获。
CSMA/CD是一个被动的抢占式协议,基于NAK而不是ACK,它具有典型的不联系就是没事,出事了我会联系你的90后特征。这个场景一般在爸妈送孩子上车的时候常见,“到了打电话啊”…但一般孩子们都会说,“有事再打电话,没事就不打了”,这种行为就是NAK。而ACK则完全相反。CSMA/CD就是NAK协议,有冲突就停等,没冲突继续发,但凡这种NAK协议都有一个致命的问题,即scalable问题,原因参见我上面关于hash概率均匀的论述。对于第一代以太网而言,如果网络上有越多的节点,就会出现越多的冲突,对于单个节点而言,其通信质量就会下降,这就是为什么第一代基于CSMA/CD协议的以太网的用户数/性能曲线呈现上凸趋势的原因。
现在回到Linux内核协议栈CPS问题的spinlock,其也是一个NAK协议,冲突了就等,直到等到,这是一种完全消极的被动应对方式。注定会失去scalable!!
Linux内核里充斥着大量的这种被动逻辑,但却没有办法去优化它们,因为一开始它们就这么存在着。典型的场景就是,TCP短链接加上nf_conntrack。二者全部都需要操作全局的spinlock,呜呼,悲哀!
最后说一下HTTP。搞底层协议的一般不会太关注HTTP,但是HTTP请求头里的Connection字段会对性能产生巨大的影响,如果你设置为close,那就意味着服务器在完成任务后就断开TCP连接,如果你设置为Keep-Alive,就意味着你可以在同一个TCP连接中请求多个HTTP。但这看起来也不是很有用。作为一个浏览器客户端,谁管你服务器能撑得住多少CPS啊!就算我个人将Connection设置为Keep-Alive,别人不从,又能把他们怎样?
ACK和NAK
一般认为NAK协议可以最大限度的节约空间,但是却浪费了时间,然而在带宽资源非常紧缺的TCP协议诞生伊始,多发一个字节都嫌多,为什么却选择了ACK而不是NAK?
答案正是空间换取scalable。后来的事实证明,TCP选择了ACK,这是一个正确的选择。
NAK表明你必须被动地等待坏消息,没有消息就是好消息,但是要等多久呢?不得而知。而ACK的主动报送则可以让你规划下一步的动作。
有没有深夜喝完酒和朋友分开的经历。我酒量还可以,所以一般都是担心朋友路上出点什么事情,一般我都会让朋友到家后发个微信表明自己到家了,这样我收到他的信息后就能安然入睡了。如果这个时候用NAK协议会怎样?对于一个本来就不可信的信道而言,就算他给我打了求救电话也有可能接不通,我要等到什么时候才能确保朋友已经安全到家?
TCP的ACK机制作为时钟驱动其发送引擎源源不断地发送数据,最终可以适应各种网络环境,也正为如此,30多年前的TCP到现在还依然安好(PS:这里并不能让我释怀,因为我讨厌TCP。我在这里说TCP的好话,仅仅是因为它选择了ACK而不是NAK这件事是正确的,仅此而已)。
鄙视链
把内核态和用户态做了一个界限分明的区分,于是一条鄙视链就形成了,或者说反过来就是是一条膜拜链。在内核态写代码的鄙视写应用程序的,写用户态代码的膜拜搞内核的(然后把Java和C都扯进来,搞C的鄙视搞Java的?)。
先不谈鄙视链,也不谈膜拜链。只要区分了内核态和用户态,那么想要实现一个功能的时候,就必然面临一个选择,即在什么态实现它。紧接着而来的就是一场论战,随便举几个例子。
Linux 2.4内核中有个小型的WEB服务器,结果被鄙视了
现如今Facebook搞了个KTLS,旨在把SSL过程放在内核里以支持高性能HTTPS
我自己把OpenVPN数据通道移植进内核,见人就拿这事跟人家炫耀
腾讯F-Stack把BSD协议栈嫁接在用户态,美其名曰高效,灵活
mtcp貌似也做了同样的事
Telira的销售不厌其烦告诉我用户态的DPI是多么高效
微软的很多网络服务都实现在内核态
无论怎么搞,套路基本就是原来在内核态实现的,现在移到用户态,原来在用户态实现的,现在移到内核态,就这么搞来搞去,其中有的很成功,有的就很失败,所谓的成功是因为这个移植解决了特定场景下的特定问题,比如用户态协议栈的mmap+Polling模式就解决了协议栈收包PPS吞吐率低的问题,然而很多移植都失败了,这些失败的案例很多都是为了移植而移植,故意捣腾的。
请注意,不要被什么用户态协议栈所误导,世界上没有万金油!
正文
很多人混淆了原因和结果,正如混淆目标和手段一样常见。
我们都知道,Linux内核协议栈收包吞吐低,然而当你问起Linux内核协议栈为什么这样时,回答大多是“切换开销大”,“内存拷贝太多”,“cache miss太高”,“中断太频繁”…但是注意,作为使用协议栈的业务方没人会关注这些,实际上这些都是原因而不是结果,业务关注的就是收包吞吐低这个事实,为什么吞吐低这正是内核工程人员要查明并搞定的,上面那些关于切换,拷贝,cache miss,中断之类的描述,其实都是造成收包吞吐低的原因而不是问题本身。同时,优化掉这些问题并不是目的,目的只有一个,就是提高收包吞吐,优化掉这些问题全部是达到目的的手段。
手段和目的混淆非常常见,这也是为什么很难有手机卖过苹果手机的原因。看看苹果的广告宣传的是什么,是产品本身,而很多安卓机的广告都是在拼数据,大肆宣传什么CPU,内存等硬件采用了什么先进的技术,但是那些买手机拍视频的网红懂这些吗?关注这些吗?
回到协议栈话题。现在,我们优化的目标只有一个,那就是提高收包吞吐,我们的优化目标并不是什么避免切换,降低cache miss,避免频繁中断这些,这些只是达到目标的手段,如果有更好地手段,我们大可不关注这些。
同样的,把协议栈移来移去的,并不是目标,没有什么公司会把“将协议栈移植到用户态”,“在内核态实现HTTP协议”这种作为KPI,这些都是手段而已,把协议栈在内核态用户态移来移去除了能展示自己高超的水平之外,对整体目标是没有帮助的。那么很显然,如果不用移植,能就地解决问题,那岂不更好?如果我有点石成金的本事,我干嘛还要通过辛勤地工作来让我的老婆和女儿崇拜我?
接下来就要评估到底是用移植的手段还是就地解决的手段来解决协议栈收包吞吐低的问题。在评估之前,首先我们要明确问题的原因到底出在哪里。嗯,上面已经列举了一些了,切换开销大,内存拷贝昂贵,cache miss高,中断太频繁…
原因知道了,自然就能对症下药了,现在的问题是,需要评估用户态和内核态搞定这些问题的可行性,成本以及难度,来决定到底在什么态来解决问题,最终其实会发现用户态实现一套协议栈是更容易的。换句话说,如果能在内核态协议栈通过patch的方式解决这些问题,谁也不会去搞用户态协议栈了。
不是内核态实现协议栈不好,而是内核态解决多核下的收包扩展性问题很难,因为Linux内核设计之初并没有考虑多核扩展性。一旦面对多核,以下的问题是积重难返的:
任务切换
内存拷贝
CPU跳跃
锁和中断
内核,至少是Linux内核没有提供任何基础设施来完美解决上述问题,随着CPU核数越来越多,为了应对上述很多问题将会导致越来越多的trick加入内核,内核将会变得越来越重。
简而言之,如果能在内核态实现一个稳定的内核线程高效收包,那也并不是不可以,而不是说必须要搞在用户态。然而,在内核态实现这个确实不易,正是因为用户态完成同样的工作更加简单,才会出现大量的用户态协议栈。
中断和轮询
现在来看一下中断和轮询背后的哲学。
中断本质上是一种节约的思维影响下的产物,典型的“好莱坞法则”之实例。这是让系统被动接收通知的方式,虽然在主观上,这种方式可以让系统“在没有收到通知时干点别的”,但是在客观现实看来,这段时间任何系统都没法一心一意地去做所谓的“别的”。
都面试过吧,如果你不是什么太牛的人,那么一般很难拿到招聘方人员的联系方式,面试完后一句“回去等通知吧”会让多少人能平常心态等通知的同时还能继续自己的当前工作?(我之前不能,但现在确实可以了,我除外)这个时候,很多人都会想,如果能问一下就好了,然而并不能。
此外,有没有这样的经历,当你专注地想做一件事时,最烦人的就是手机响。此时很多人都会手机静音且扔远一点,等事情做完了再去看一下。
对,这就是中断和轮询的特征。中断是外界强加给你的信号,你必须被动应对,而轮询则是你主动地在处理事情。对于中断而言,其最大的影响就是打断你当前工作的连续性,而轮询则不会,完全在你自己的掌控之中。对于我自己而言,我的手机基本上是常静音的,微信则是全部“消息免打扰”,我会选择在自己idle的时候主动去看手机消息,以此轮询的方式治疗严重的电话恐惧症。
那么如何来治疗Linux内核收包的电话恐惧症呢?答案是暂时没有办法。因为如果想中断变轮询,那就必然得有一个内核线程去主动poll网卡,而这种行为与当前的Linux内核协议栈是不相容的,这意味着你要重新在内核实现一套全新的协议栈,面临着没完没了的panic,oops风险。虽然Linux已经支持socket的busy polling模式,但这也只是缓解,而非根治!相反,完全在用户态实现poll,则是一个非常干净的方案。
关于内存拷贝,任务切换以及cache miss,试着用上面的思路去分析,最终的结论依然是在用户态重新实现一个自主的处理进程,将会比修改内核协议栈的方式来的更加干净。
几乎所有的评估结论表明,用户态协议栈是一个干净的方案,但却并不是唯一正确的方案,更没有证据说用户态协议栈是最好的方案。选择在用户态实现协议栈解决收包吞吐低的问题,完全是因为它比在内核态解决同样的问题更加容易,仅此而已。
意义
这里聊一个哲学问题。
有人说内核就应该只负责控制平面,数据平面的操作全部应该交给用户态。
好吧,这里又一个柏拉图式的分类,实际上依然毫无意义。当然,引出类似概念的人肯定有十足的理由去说服别人相信他的分类是客观的,有依据的,但那仍然不过是一种主观的臆断。继续说下去的话,也许最终的结论将是,只有微内核体系的操作系统才是最完美的操作系统。但事实上,我们都在用的几乎所有操作系统,没有一个是完全的微内核操作系统,微软的Windows不是,而Linux更是一个宏内核系统,没有微内核系统。
看来似乎只有一个说法能解释这种矛盾,那就是完美的东西本来就是不存在的,我们看到的世界上所有的东西,都是柏拉图眼中的影子,而完美则代表了抽象的本质,那是上帝的范畴,我们甚至无力去仰望!从小的时候,我们就被老师告知,世界上不存在完美的球形。
因此,如果微内核,宏内核根本就不存在,那么凭什么内核态就只能处理控制平面呢?如果内核态处理网络协议栈这种做法是错误的,那为什么UNIX/Linux的内核网络协议栈却存在了40多年呢?嗯,存在的即是合理的。
世界是进化而来的,而不是设计而来的,即便是存在设计者,也是一个蹩脚的设计者,你看,我们人体本身不就存在很多bug吗?因此,即便是上帝那里,存在的也是柏拉图眼里的影子。
原文链接:https://blog.csdn.net/dog250/article/details/80532754
- END -
看完一键三连在看,转发,点赞
是对文章最大的赞赏,极客重生感谢你
推荐阅读
图解Linux 内核TCP/IP 协议栈实现|Linux网络硬核系列
