什么是协议?
在计算机网络要做到有条不紊地交换数据,就必须遵守一些事先约定好的规则,比如交换数据的格式、是否需要发送一个应答信息。这些规则被称为网络协议。
网络协议是计算机之间为了实现网络通信而达成的一种“约定”或者”规则“,有了这种”约定“,不同厂商的生产设备,以及不同操作系统组成的计算机之间,就可以实现通信。
四层协议,五层协议和七层协议的关系如下:
- TCP/IP是一个四层的体系结构,主要包括:应用层、运输层、网际层和网络接口层。
- 五层协议的体系结构主要包括:应用层、运输层、网络层,数据链路层和物理层。
- OSI七层协议模型主要包括是:应用层(Application)、表示层(Presentation)、会话层(Session)、运输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
注:五层协议的体系结构只是为了介绍网络原理而设计的,实际应用还是 TCP/IP 四层体系结构。
应用层
应用层( application-layer )的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。
对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如域名系统 DNS,支持万维网应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。
运输层
运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。应用进程利用该服务传送应用层报文。
运输层主要使用一下两种协议
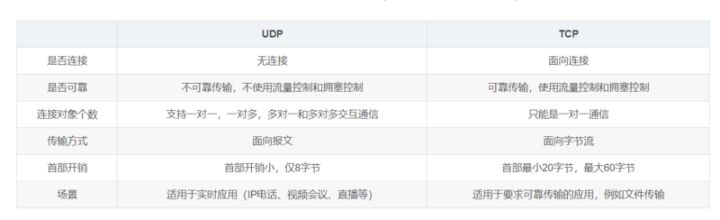
- 传输控制协议-TCP:提供面向连接的,可靠的数据传输服务。
- 用户数据协议-UDP:提供无连接的,尽最大努力的数据传输服务(不保证数据传输的可靠性)。
网络层
网络层的任务就是选择合适的网间路由和交换结点,确保计算机通信的数据及时传送。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报 ,简称数据报。
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Prococol)和许多路由选择协议,因此互联网的网络层也叫做网际层或 IP 层。
数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。
在两个相邻节点之间传送数据时,数据链路层将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。
一般的web应用的通信传输流是这样的:
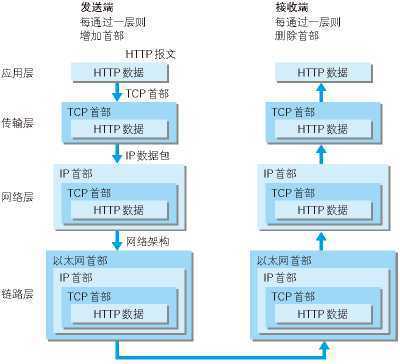
发送端在层与层之间传输数据时,每经过一层时会被打上一个该层所属的首部信息。反之,接收端在层与层之间传输数据时,每经过一层时会把对应的首部信息去除。
物理层
在物理层上所传送的数据单位是比特。 物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
TCP/IP 协议族
在互联网使用的各种协议中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的 TCP/IP 并不一定是单指 TCP 和 IP 这两个具体的协议,而往往是表示互联网所使用的整个 TCP/IP 协议族。因为该协定家族的两个核心协定:TCP(传输控制协议)和IP(网际协议) 是最先定义的两个核心协议,所以才统称为TCP/IP协议族

HTTP协议是什么?
HTTP协议是超文本传输协议的缩写,英文是Hyper Text Transfer Protocol。它是从WEB服务器传输超文本标记语言(HTML)到本地浏览器的传送协议。
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
HTTP原理
HTTP是一个基于TCP/IP通信协议来传递数据的协议,传输的数据类型为HTML 文件,、图片文件, 查询结果等。
HTTP协议一般用于B/S架构()。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
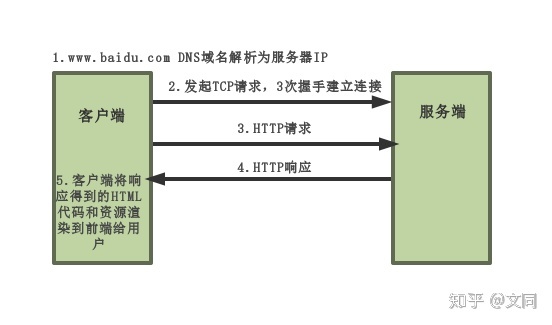
我们以访问百度为例:
三次握手
三次握手的本质是确认通信双方收发数据的能力
首先,我让信使运输一份信件给对方,对方收到了,那么他就知道了我的发件能力和他的收件能力是可以的。
于是他给我回信,我若收到了,我便知我的发件能力和他的收件能力是可以的,并且他的发件能力和我的收件能力是可以。
然而此时他还不知道他的发件能力和我的收件能力到底可不可以,于是我最后回馈一次**,他若收到了,他便清楚了他的发件能力和我的收件能力是可以的。**
这,就是三次握手。
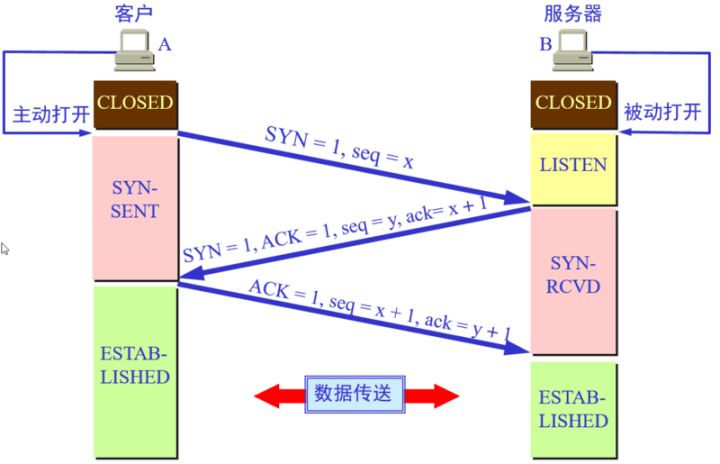
- 第一次握手:客户端要向服务端发起连接请求,首先客户端随机生成一个起始序列号ISN(比如是100),那客户端向服务端发送的报文段包含SYN标志位(也就是SYN=1),序列号seq=100。
- 第二次握手:服务端收到客户端发过来的报文后,发现SYN=1,知道这是一个连接请求,于是将客户端的起始序列号100存起来,并且随机生成一个服务端的起始序列号(比如是300)。然后给客户端回复一段报文,回复报文包含SYN和ACK标志(也就是SYN=1,ACK=1)、序列号seq=300、确认号ack=101(客户端发过来的序列号+1)。
- 第三次握手:客户端收到服务端的回复后发现ACK=1并且ack=101,于是知道服务端已经收到了序列号为100的那段报文;同时发现SYN=1,知道了服务端同意了这次连接,于是就将服务端的序列号300给存下来。然后客户端再回复一段报文给服务端,报文包含ACK标志位(ACK=1)、ack=301(服务端序列号+1)、seq=101(第一次握手时发送报文是占据一个序列号的,所以这次seq就从101开始,需要注意的是不携带数据的ACK报文是不占据序列号的,所以后面第一次正式发送数据时seq还是101)。当服务端收到报文后发现ACK=1并且ack=301,就知道客户端收到序列号为300的报文了,就这样客户端和服务端通过TCP建立了连接。
为什么要进行三次握手呢?两次握手不行吗
第三次握手是为了防止失效的连接请求到达服器,让服务器错误打开连接。客户端发送的连接请求如果在网络中滞留,那么就会隔很长一段时间才能收到服务器端发回的连接确认。客户端等待一个超时重传时间之后,就会重新请求连接。但是这个滞留的连接请求最后还是会到达服务器,如果不进行三次握手,那么服务器就会打开两个连接。如果有第三次握手,客户端会忽略服务器之后发送的对滞留连接请求的连接确认,不进行第三次握手,因此就不会再次打开连接。
四次挥手
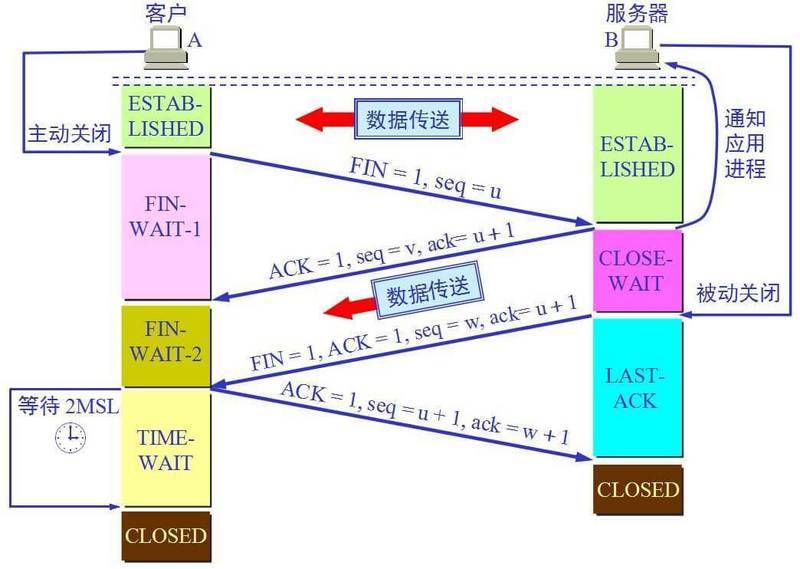
比如客户端初始化的序列号ISA=100,服务端初始化的序列号ISA=300。TCP连接成功后客户端总共发送了1000个字节的数据,服务端在客户端发FIN报文前总共回复了2000个字节的数据。
- 第一次挥手:当客户端的数据都传输完成后,客户端向服务端发出连接释放报文(当然数据没发完时也可以发送连接释放报文并停止发送数据),释放连接报文包含FIN标志位(FIN=1)、序列号seq=1101(100+1+1000,其中的1是建立连接时占的一个序列号)。==需要注意的是客户端发出FIN报文段后只是不能发数据了,但是还可以正常收数据;==另外FIN报文段即使不携带数据也要占据一个序列号。
- 第二次挥手:服务端收到客户端发的FIN报文后给客户端回复确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=1102(客户端FIN报文序列号1101+1)、序列号seq=2300(300+2000)。此时服务端处于关闭等待状态,而不是立马给客户端发FIN报文,这个状态还要持续一段时间,因为服务端可能还有数据没发完。
- 第三次挥手:服务端将最后数据(比如50个字节)发送完毕后就向客户端发出连接释放报文,报文包含FIN和ACK标志位(FIN=1,ACK=1)、确认号和第二次挥手一样ack=1102、序列号seq=2350(2300+50)。
- 第四次挥手:客户端收到服务端发的FIN报文后,向服务端发出确认报文,确认报文包含ACK标志位(ACK=1)、确认号ack=2351、序列号seq=1102。==注意客户端发出确认报文后不是立马释放TCP连接,而是要经过2MSL(最长报文段寿命的2倍时长)后才释放TCP连接。==而服务端一旦收到客户端发出的确认报文就会立马释放TCP连接,所以服务端结束TCP连接的时间要比客户端早一些。
为什么握手三次而挥手要四次呢?
因为服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送
FIN报文给客户端来表示同意现在关闭连接。从而比三次握手导致多了一次。
MSL:是Maximum Segment Lifetime英文的缩写,译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。2MSL即两倍的MSL
为什么 TIME_WAIT 等待的时间是 2MSL?
- 为了保证客户端发送的最后一个ACK报文能够到达服务端,使服务端正常关闭连接。
如果客户端四次挥手的最后一个
ACK报文如果在网络中被丢失了,那么服务端会超时重传这个FIN+ACK报文段,客户端就能在2MSL时间内收到这个重传的FIN+ACK报文段。此时如果客户端TIME-WAIT过短或没有,则就直接进入了CLOSE状态了,那么服务端则会一直处在LASE-ACK状态。无法关闭连接
- 服务端没收到确认ack报文就会重发第三次挥手的报文,这样报文一去一回最长时间就是2MSL
HTTP特点
- http协议支持客户端/服务端模式,也是一种请求/响应模式的协议。
- 简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。
- 灵活:HTTP允许传输任意类型的数据对象。传输的类型由Content-Type加以标记。
- 无连接:限制每次连接只处理一个请求。服务器处理完请求,并收到客户的应答后,即断开连接,但是却不利于客户端与服务器保持会话连接,为了弥补这种不足,产生了两项记录http状态的技术,一个叫做Cookie,一个叫做Session。
- 无状态:无状态是指协议对于事务处理没有记忆,后续处理需要前面的信息,则必须重传。
URI和URL的区别
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
- URI:Uniform Resource Identifier 统一资源标识符
- URL:Uniform Resource Location 统一资源定位符
URI 是用来标示 一个具体的资源的,我们可以通过 URI 知道一个资源是什么。
URL 则是用来定位具体的资源的,标示了一个具体的资源位置。互联网上的每个文件都有一个唯一的URL。
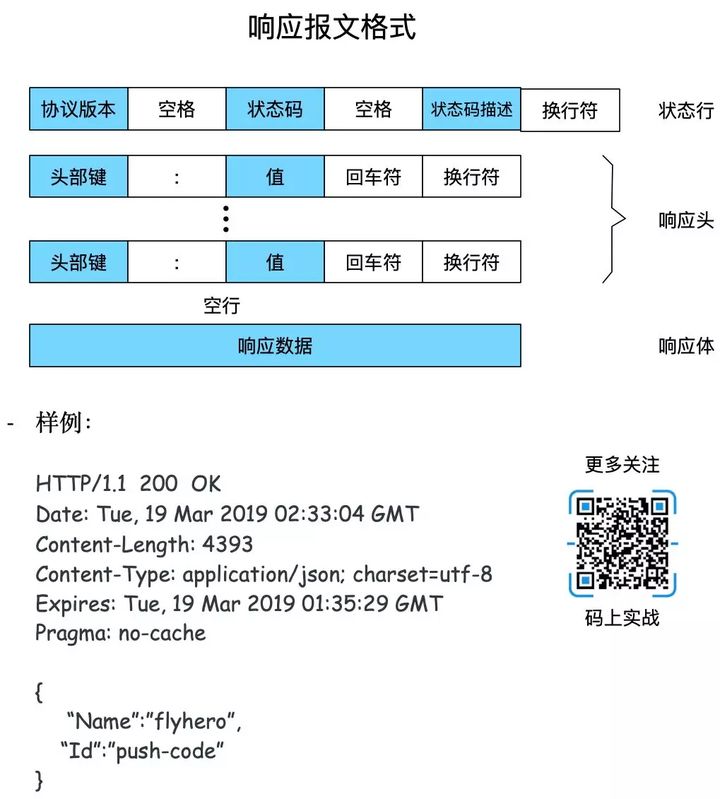
HTTP报文组成
请求报文构成
- 请求行:包括请求方法、URL、协议/版本
- 请求头(Request Header)
- 请求正文

响应报文构成
- 状态行
- 响应头
- 响应正文
常见请求方法
- HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头
- GET:从服务器上获取数据,也就是所谓的查,仅仅是获取服务器资源,不进行修改。
- POST:向服务器提交数据,这就涉及到了数据的更新,也就是更改服务器的数据。
- PUT:英文含义是放置,也就是向服务器新添加数据,就是所谓的增。
- DELETE:从字面意思也能看出,这种方式就是删除服务器数据的过程。
post和get的区别:
-
Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。 数据被放在body中。
-
Get请求提交的url中的数据是有限制的,这个限制是浏览器或者服务器给添加的,http协议并没有对url长度进行限制。具体的长度限制视浏览器而定。Post请求则没有大小限制。
-
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
响应状态码
访问一个网页时,浏览器会向web服务器发出请求。此网页所在的服务器会返回一个包含HTTP状态码的信息头用以响应浏览器的请求。
状态码分类:
- 1XX- 信息型,服务器收到请求,需要请求者继续操作。
- 2XX- 成功型,请求成功收到,理解并处理。
- 3XX - 重定向,需要进一步的操作以完成请求。
- 4XX - 客户端错误,请求包含语法错误或无法完成请求。
- 5XX - 服务器错误,服务器在处理请求的过程中发生了错误。
常见状态码:
- 200 OK - 客户端请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 302 - 临时跳转
- 400 Bad Request - 客户端请求有语法错误,不能被服务器所理解
- 401 Unauthorized - 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
- 404 - 请求资源不存在,可能是输入了错误的URL
- 500 - 服务器内部发生了不可预期的错误
- 503 Server Unavailable - 服务器当前不能处理客户端的请求,一段时间后可能恢复正常。
认证
我们知道, http协议本身是一种无状态的协议,而这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,那么下一次请求时,用户还要再一次进行用户认证才行,因为根据http协议,我们并不能知道是哪个用户发出的请求,所以为了让我们的应用能识别是哪个用户发出的请求,我们只能在服务器存储一份用户登录的信息,这份登录信息会在响应时传递给浏览器,告诉其保存为cookie ,以便下次请求时发送给我们的应用,这样我们的应用就能识别请求来自哪个用户了,这就是传统的基于session认证。

什么是cookie
cookie是由Web服务器保存在用户浏览器上的小文件(key-value格式),包含用户相关的信息。客户端向服务器发起请求,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户身份。
什么是session
session 是浏览器和服务器会话过程中,服务器分配的一块储存空间。服务器默认为浏览器在cookie中设置 sessionid,浏览器在向服务器请求过程中传输 cookie 包含 sessionid ,服务器根据 sessionid 获取出会话中存储的信息,然后确定会话的身份信息。
session是依赖Cookie实现的。session是服务器端对象
session的暴露的问题
-
每个用户经过我们的应用认证之后,我们的应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开销会明显增大
-
用户认证之后,服务端做认证记录,如果认证的记录被保存在内存中的话,这意味着用户下次请求还必须要请求在这台服务器上这样才能拿到授权的资源。
解决思路:所有服务器共享一份session,或所有服务器的session需要同步处理,即每台服务器上的session相同.
- 因为是基于cookie来进行用户识别的,cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击
cookie与session区别
- 存储位置与安全性:cookie数据存放在客户端上,安全性较差,session数据放在服务器上,安全性相对更高;
- 存储空间:单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie,session无此限制
- 占用服务器资源:session一定时间内保存在服务器上,当访问增多,占用服务器性能,考虑到服务器性能方面,应当使用cookie。
什么是Token
Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位
session与token区别
- session机制存在服务器压力增大,CSRF跨站伪造请求攻击,扩展性不强等问题;
- session存储在服务器端,token存储在客户端
- token提供认证和授权功能,作为身份认证,token安全性比session好;
- session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上,token适用于项目级的前后端分离(前后端代码运行在不同的服务器下)
一般http中存在如下问题:
- 请求信息明文传输,容易被窃听截取。
- 数据的完整性未校验,容易被篡改
- 没有验证对方身份,存在冒充危险
由于我们在传输数据时信息都是明文的,因此很容易出现数据被监听和窃取的情况。示意图如下:

另外,传输的数据还有可能被一些别有用心的人篡改,导致浏览器与网站收发的内容不一致。示意图如下:

也就是说,使用http传输数据至少存在着数据被监听以及数据被篡改这两大风险,因此http是一种不安全的传输协议。
为了解决上述HTTP存在的问题,就用到了HTTPS。事实上实际使用中,绝大数的网站现在也都采用的是https协议,这也是未来互联网发展的趋势。
HTTPS
既然数据以明文的形式在网络上传输是不安全的,那么我们显然要对数据进行加密才行。加密方式主要有两种,对称加密和非对称加密。
HTTPS 协议(HyperText Transfer Protocol over Secure Socket Layer):一般理解为HTTP+SSL/TLS,通过 SSL证书来验证服务器的身份,并为浏览器和服务器之间的通信进行加密。
那么SSL又是什么?
SSL/TLS(Secure Socket Layer,安全套接字层):SSL 协议位于 TCP/IP 协议与各种应用层协议之间,为数据通讯提供安全支持。广泛地用于Web浏览器与服务器之间的身份认证和加密数据传输。
SSL为Netscape所研发,用以保障在Internet上数据传输之安全,利用数据加密技术,可确保数据在网络上之传输过程中不会被截取及窃听。一般通用之规格为40 bit之安全标准,美国则已推出128 bit之更高安全标准,但限制出境。
对称加密与非对称加密
- 对称加密:就是客户端和服务器共用同一个密钥,该密钥可以用于加密一段内容,同时也可以用于解密这段内容。
对称加密的优点:加解密效率高,而我们在网络上传输数据是非常讲究效率的。但是在安全性方面可能存在一些问题,因为密钥存放在客户端有被窃取的风险。对称加密的代表算法有:AES、DES等。
- 非对称加密:它将密钥分成了两种:公钥和私钥。公钥通常存放在客户端,私钥通常存放在服务器。使用公钥加密的数据只有用私钥才能解密,反过来使用私钥加密的数据也只有用公钥才能解密。(公钥可以随意发布,但私钥只有自己知道。)
非对称加密的优点:安全性更高,因为客户端发送给服务器的加密信息只有用服务器的私钥才能解密,因此不用担心被别人破解,但缺点是加解密的效率相比于对称加密要差很多。非对称加密的代表算法有:RSA、ElGamal等。
对称加密。示意图如下:

可以看到,由于我们在网络上传输的数据都是密文,所以不怕被监听者获取到,因为他们无法得知原文是什么。而浏览器收到密文之后,只需要使用和网站相同的密钥来对数据进行解密就可以了。
这种工作机制看上去好像确实保证了数据传输的安全性,但是却存在一个巨大的漏洞:浏览器和网站怎样商定使用什么密钥呢?
这绝对是一个计算机界的难题,浏览器和网站要使用相同的密钥才能正常对数据进行加解密,但是如何让这个密钥只让它们俩知晓,而不被任何监听者知晓呢?你会发现不管怎么商定,浏览器和网站的首次通信过程必定是明文的。这就意味着,按照上述的工作流程,我们始终无法创建一个安全的对称加密密钥。
所以,只使用对称加密看来是永远无法解决这个问题了,这个时候我们需要将非对称加密引入进来,协助解决无法安全创建对称加密密钥的问题。
那么为什么非对称加密就可以解决这个问题呢?我们还是通过示意图的方式来理解一下:

可以看到,如果我们想要安全地创建一个对称加密的密钥,可以让浏览器这边来随机生成,但是生成出来的密钥不能直接在网络上传输,而是要用网站提供的公钥对其进行非对称加密。由于公钥加密后的数据只能使用私钥来解密,因此这段数据在网络上传输是绝对安全的。而网站在收到消息之后,只需要使用私钥对其解密,就获取到浏览器生成的密钥了。(公钥是公开的,所有人都可以拿到,但没有私钥是无法解密的,因此只有网站可以解密拿到密钥A)
另外,使用这种方式,只有在浏览器和网站首次商定密钥的时候需要使用非对称加密,一旦网站收到了浏览器随机生成的密钥之后,双方就可以都使用对称加密来进行通信了,因此工作效率是非常高的。
那么,上述的工作机制你认为已经非常完善了吗?其实并没有,因为我们还是差了非常关键的一步,浏览器该怎样才能获取到网站的公钥呢?虽然公钥是属于公开的数据,在网络上传输不怕被别人监听,但是如果公钥被别人篡改了怎么办?示意图如下:

也就是说,只要我们从网络上去获取任何网站的公钥,就必然存在着公钥被篡改的风险。而一旦你使用了假的公钥来对数据进行加密,那么就可以被别人以假的私钥进行解密,后果不堪设想。方案设计到这里好像已经进入了死胡同,因为无论如何我们都无法安全地获取到一个网站的公钥。
这个时候,就必须引入一个新的概念来打破僵局了:CA机构。
CA机构
CA机构专门用于给各个网站签发数字证书,从而保证浏览器可以安全地获得各个网站的公钥。那么CA机构是如何完成这个艰巨的任务的呢?下面开始一步步解析。
首先,我们作为一个网站的管理员需要向CA机构进行申请,将自己的公钥提交给CA机构。CA机构则会使用我们提交的公钥,再加上一系列其他的信息,如网站域名、有效时长等,来制作证书。
证书制作完成后,CA机构会使用自己的私钥对其加密,并将加密后的数据返回给我们,我们只需要将获得的加密数据配置到网站服务器上即可。
然后,每当有浏览器请求我们的网站时,首先会将这段加密数据返回给浏览器,此时浏览器会用CA机构的公钥来对这段数据解密。
如果能解密成功,就可以得到CA机构给我们网站颁发的证书了,其中当然也包括了我们网站的公钥。你可以在浏览器的地址栏上,点击网址左侧的小锁图标来查看证书的详细信息,如下图所示。

得到了公钥之后,接下来的流程就和刚才示意图中所描述的一样了。
而如果无法解密成功,则说明此段加密数据并不是由一个合法的CA机构使用私钥加密而来的,有可能是被篡改了,于是会在浏览器上显示一个著名的异常界面,如下图所示。

但是即使使用CA机构的公钥能够正常解密出数据,目前的流程也还是存在问题的。因为每一家CA机构都会给成千上万的网站制作证书,假如攻击者知道abc.com使用的是某家CA机构的证书,那么他也可以同样去这家CA机构申请一个合法的证书,然后在浏览器请求abc.com时对返回的加密证书数据进行替换。示意图如下:

可以看到,由于攻击者申请的证书也是由正规CA机构制作的,因此这段加密数据当然可以成功被解密。
也正是因为这个原因,所有CA机构在制作的证书时除了网站的公钥外,还要包含许多其他数据,用来辅助进行校验,比如说网站的域名就是其中一项重要的数据。
同样是刚才的例子,如果证书中加入了网站的域名,那么攻击者就只能无功而返了。因为,即使加密数据可以被成功解密,但是最终解密出来的证书中包含的域名和浏览器正在请求的域名对不上,那么此时浏览器仍然会显示异常界面。示意图如下:

好了,方案设计到这里,其实我们的网络传输就已经做到足够的安全了。当然,这其实也就是https的工作原理。
HTTPS的缺点
- HTTPS协议多次握手,导致页面的载时间延长近50%;
- HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗;
- 申请SSL证书需要钱,功能越强大的证书费用越高。
- SSL涉及到的安全算法会消耗 CPU 资源,对服务器资源消耗较大。
总结HTTPS和HTTP的区别
- HTTPS是HTTP协议的安全版本,HTTP协议的数据传输是明文的,是不安全的,HTTPS使用了SSL/TLS协议进行了加密处理。
- http和https使用连接方式不同,默认端口也不一样,http是80,https是443。