1.网络分层
- 七层OSI
- 应用层、表示层、会话层、传输层、网络层、数据链路层、物理层
- 五层协议(主要)
- 应用层、传输层、网络层、数据链路层、物理层
- 四层协议TCP/IP
- 应用层、传输层、网际层、网络接口层
2.各层的功能
- 应用层
- 为应用程序提供交互服务。如:HTTP、HTTPS、DNS、SMTP、FTP
- 表示层
- 主要负责数据格式的转换。如:加密解密、压缩解压缩。
- 会话层
- 负责在网络中的两节点之间建立、维持、终止通信。如:服务器验证用户登录
- 运输层/传输层
- 向主机进程提供通用的数据传输服务。如:TCP、UDP
- 网络层
- 路由选择和转发。如:IP
- 数据链路层
- 封装成帧。
- 物理层
- 比特流透明传输。
3.传输层
3.0TCP的组成
- 源端口、目的端口、序号seq、确认号ack、窗口
- 控制位:ACK、FIN、SYN
3.1TCP和UDP的区别
- TCP
- 面向连接的,可靠的,面向字节流的,主要是一对一连接。
- 场景:FTP文件传输、SMTP邮件发送、远程登陆、HTTP网络请求
- UDP
- 无连接的,不可靠的,尽最大努力交付的,面向报文段的,包含一对一、一对多、多对多连接。
- 场景:QQ直播、QQ语音、QQ视频
3.2TCP的可靠性体现
- 1.确认应答机制
- 每次请求都会根据seq序列号进行“重排、丢掉重复的”,然后发送ACK报文,包含ack确认号。
- 2.重传机制
- 超时重传:对于发送的报文,如果在RTO(超时重传时间)>RTT(往返时延),没有收到ACK确认报文,则需要重新发送这个报文段。--------基于时间
- 快重传:对于发送的报文,如果在一定时间内,连续收到对于同一个报文的确认,说明下一个报文丢失,直接重传下一个报文。---------基于数据
- 3.流量控制
- 局部的思想,主要保证是接受方来限制发送方的发送效率,使得自己来得及接受,在TCP的报文段的窗口来设置。
- 4.滑动窗口
- 不再局限于之前的发送一个报文,应答一个报文;而是可以发送多个报文,接受多个报文;并且只需要对最后一个进行应答即可,这是累计确认,是有一个缓存机制的。
- 发送方窗口组成:已经发送并收到确认的报文、已经发送未收到确认、还未发送的但可以发送的、不可以发送的;
- 发送方窗口大小 = 已经发送未收到确认 + 还未发送的但可以发送的
- 接收方窗口组成:已经接受并发送确认的报文、可以接受还未发送确认的、不可以接受的;
- 接受方窗口大小 = 可以接受还未发送确认的
- 5.拥塞控制
- 基于全局的思想,防止一段时间可能由于需求大于提供而导致的性能变差。
- 变量:拥塞窗口cwnd、慢开始门限ssthresh
- 慢开始
- cwnd = 1;每一个RTT后,cwnd = cwnd*2
- 拥塞避免
- cwnd>ssthrensh,cwnd = cwnd +1
如果出现网络拥塞:cwnd = 1,ssthresh = cwnd/2 - 快重传
- 对于发送的报文,如果在一定时间内,连续收到对于同一个报文的确认,说明下一个报文丢失,直接重传下一个报文。
- cwnd = cwnd/2;ssthresh = cwnd-3;
- 快恢复
- cwnd = ssthresh + 3,重新走到拥塞避免。
3.3TCP的三次握手
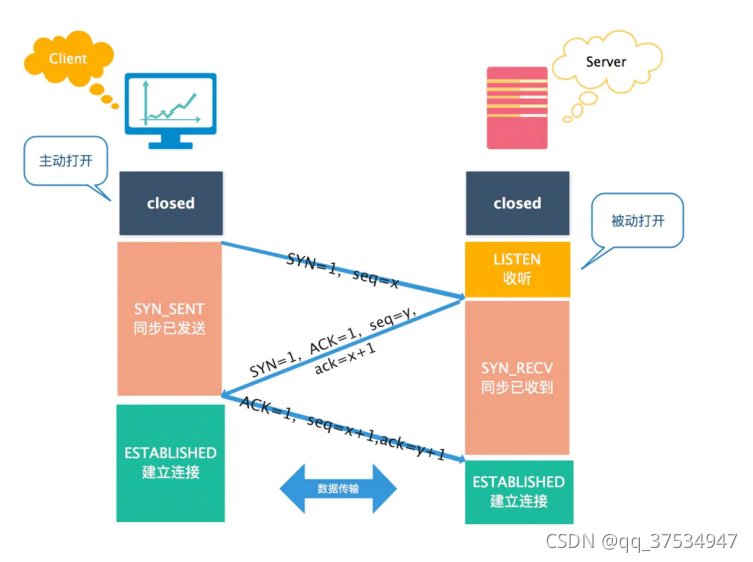
- 过程:确保通信双方都能发送和接收数据
- 1.发送方发送SYN = 1,seq = x,发送方进入SYN-SENT
这里的初始序列号最好是随机的,因为如果有第三方知道双方端口和ip地址,推测出序列号就会产生一定的危害。 - 2.接收方收到请求,发送ACK = 1,SYN =1,seq = y,ack = x+1,接收方进入SYN-RECV
- 3.发送方接收到请求,建立连接;发送ACK = 1,seq= y,ack =y+1
此时如果接收方没有收到第三次握手,则第二次会继续发送
补充:
1.四次握手可以吗?
- 当然可以,但是没有意义,因为四次握手要完成的事情,三次握手已经完成了
2.二次握手呢?
- 不可以,如果仅仅两次握手,假设第一次握手的请求因为网络原因,没有及时到达接收方,此时发送方重传,接受方建立连接,但是如果之前的请求再次到达,就会再次建立一个新的请求;而三次握手,在第二次握手的时候,会适当的抛弃。
3.SYN泛洪攻击(DOS_Denial of Service)
- 大量发送SYN=1的请求,导致服务器方,很多连接处于半连接队列中,从而导致半连接队列满,而正常的请求被抛弃。
- 解决:对于攻击的ip进行设置,拒绝访问;及时清空半连接队列的请求连接。
4.DDOS(Distributed Denial of Service)
- 分布式攻击的泛洪攻击,没什么区别
- 解决:减少SYN的timeout时间;减少SYN的连接数量。
5.三次连接可以发送数据吗?
- 第一次和第二次不可以:就是防止SYN攻击的时候,有大量的数据发送,导致服务器崩溃。
- 第三次可以:此时客户端处于建立状态,并且知道服务器可以发送和接受数据。
6.第三次握手丢失?
- 重传机制,RTO>RTT的时候,服务端继续重新发送数据,时间指数倍增长。
3.4TCP的四次挥手
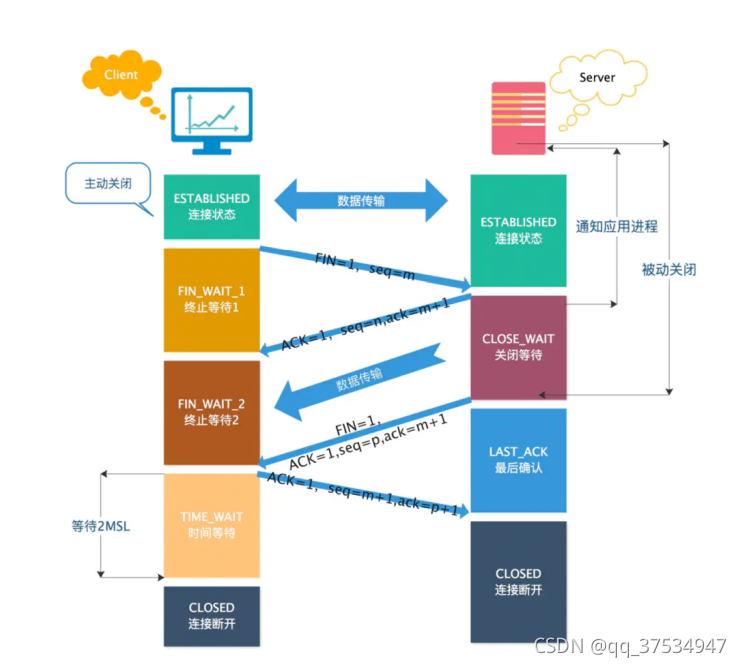
- 过程:通信双方发送完数据,来断开连接。
- 发送方断开连接
- 1.发送方发送FIN = 1,ACK、seq、ack;发送方进入FIN_WAIT1
- 2.接收方收到请求,发送ACK 、seq、ack,接收方进入close_wait,发送方进入FIN_WAIT2
- 接收方断开连接
- 3.接收方数据接收完,请求断开连接;发送FIN=1,ACK ,seq,ack;进入Last_Ack
- 4.发送方接受到请求,发送ACK、seq,ack,进入TIME_WAIT阶段
补充:
1.为什么需要四次?
- 不同于三次握手,因为要涉及到通信双方的数据
2.为什么最后要等待2MSL?
- MSL:报文段最大存活时间,保证了如果最后一次挥手没有丢失,第三次挥手的报文段重新接受;并且保证了下一次的连接中,不会有上次的存留的报文段
3.四次挥手的首次请求方一定是客户端吗?
- 不一定
- 让服务端先退出,然后我们用netstat观察端口的状态,此时我们发现四次挥手过程中服务器和客户端的状态颠倒了, 也就是说,服务端和客户端的进程那个先向对方发送FIN 字段报文,那么哪个就先进入FIN_WAIT2状态。
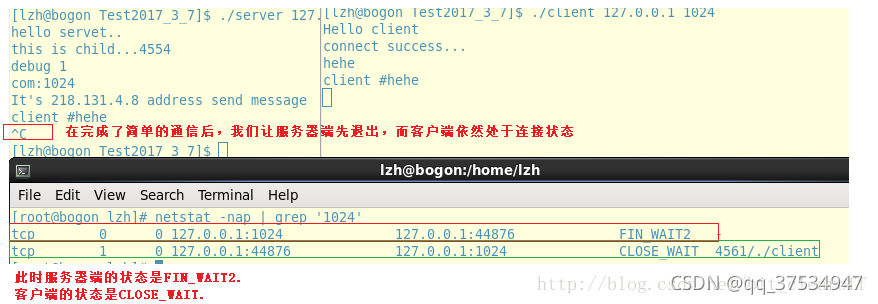
- 但是下一步:客户端往服务端发送数据就不一样?
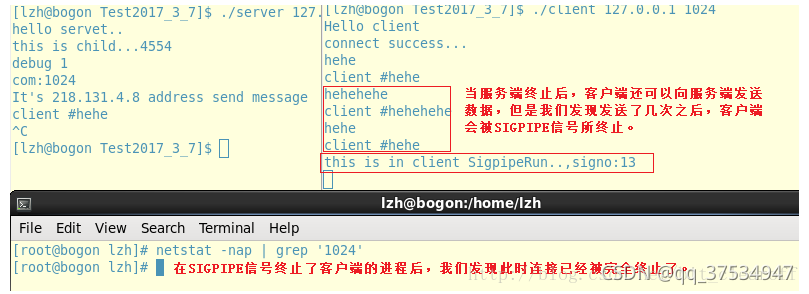
- 原因:当服务器进程被终止时,会关闭其打开的所有文件描述符,此时就会向客户端发送一个FIN 的报文,客户端则响应一个ACK 报文,但是这样只完成了“四次挥手”的前两次挥手,也就是说这样只实现了半关闭,客户端仍然可以向服务器写入数据。但是当客户端向服务器写入数据时,由于服务器端的套接字进程已经终止,此时连接的状态已经异常了,所以服务端进程不会向客户端发送ACK 报文,而是发送了一个RST 报文请求将处于异常状态的连接复位; 如果客户端此时还要向服务端发送数据,将诱发服务端TCP向服务端发送SIGPIPE信号,因为向接收到RST的套接口写数据都会收到此信号.
- 所以说,这就是为什么我们主动关闭服务端后,用客户端向服务端写数据,还必须是写两次后连接才会关闭的原因。
- 注:感觉有点问题,不太理解?只需要记住不同于正常关闭即可,并且传输数据会进行两次写,但不成功!
参考链接:
https://blog.csdn.net/bit_clearoff/article/details/60884905
4.Time-wait过多怎么办?
- 对于服务器来说,则会严重损耗服务器的资源,导致部分客户端连接不上。
- 解决:设置参数SO_REUSEADDR套接字选项来避免time-wait,进行端口重用
- 对于客户端来说,会导致客户端端口被占用,65536,导致无法创建新的连接
- 解决:发送RST包,直接越过Time-wait,进入closed,这就像上面的服务端主动关闭导致的一样。
3.5TCP的心跳机制
- 很多应用层协议都有HeartBeat机制,通常是客户端每隔一小段时间向服务器发送一个数据包,通知服务器自己仍然在线,并传输一些可能必要的数据。使用心跳包的典型协议是IM,比如QQ/MSN/飞信等协议。
- 心跳包之所以叫心跳包是因为:它像心跳一样每隔固定时间发一次,以此来告诉服务器,这个客户端还活着。事实上这是为了保持长连接,至于这个包的内容,是没有什么特别规定的,不过一般都是很小的包,或者只包含包头的一个空包。
- 总的来说,心跳包主要也就是用于长连接的保活和断线处理。一般的应用下,判定时间在30-40秒比较不错。如果实在要求高,那就在6-9秒。
- 实现步骤:TCP的KeepAlive保活机制?
- 1:客户端每隔一个时间间隔发生一个探测包给服务器
- 2:客户端发包时启动一个超时定时器
- 3:服务器端接收到检测包,应该回应一个包
- 4:如果客户机收到服务器的应答包,则说明服务器正常,删除超时定时器
- 5:如果客户端的超时定时器超时,依然没有收到应答包,则说明服务器挂了
参考链接:
https://blog.csdn.net/qq_33314107/article/details/80574137
3.6TCP的粘包和拆包
- 问题: TCP报文段传输的时候也会出现报文段分段的现象(主要是报文段太大),类似于网络层的ip分组。
- 现象: 两个包合在一起发送、一个包的前一部分和另一个包一起发送、一个包的后部分单独发送
- 原因: 1.报文段太大,大于MSS(最大分段长度)、2.发送方发送的数据大于发送缓冲区剩余数据的大小、3.发送方发送的数据小于接收方缓冲区空间的大小,多次将数据发送到网络
- 解决: 1.对于报文段固定相同的长度,不足进行填充;2.对于每个报文段进行定界符的填充来进行区分;3.在报文段的首部添加表示报文段长度的标识。
3.7UDP会发生粘包和拆包吗?
- 不会,因为其报文段发送的,而TCP是按字节流,并且UDP的首部指示了报文段的长度。
3.8UDP怎么实现可靠的?
- 其实现不了,主要在应用层实现的,就像QQ的QICQ,其实现了TCP的各种可靠机制。
4.应用层
4.1:http常见的状态码
- 100:Continue
- 200:OK、206:部分请求
- 301:永久重定向、302:临时重定向
- 永久:代表访问某个a,会自动跳转到b,url为b;临时:访问a,url不变,但是内容渲染的是b
- 400:客户端语法错误、403:服务器拒绝提供服务(不为请求提供服务,或您没有连接到此站点的权限时)、404:页面没有找到
- 500:服务器内部执行错误,无法完成请求、503:服务器正在维护
4.2:http的请求报文、响应报文
- 请求报文组成:
- 请求行、请求头、请求体(其中请求行和请求体之间有空格来区分),如:
- Post /from/login?xxx HTTP1.1
- Host:www.baidu.com Connection:keep-alive
- name = swz & age =37
- 响应报文组成:
- 响应行、响应头、响应体(响应行和响应体之间有空格),如:
- 200 OK HTTP1.1
- Data:xxxx Content-length:360
- < h1 > hello,world!< h1 >
4.3:Get、Post(前两个为主)、Delete、Put
-
Get:主要用于获取资源;参数传递通过请求行url,所以相对不是安全,并且长度限制;但是从整体上看,其主要是有幂等性的,这个说明多次请求效果一样,保证了对数据库的安全;
-
Post:主要用于传输实体内容;参数传递在请求体中,所以相对安全,长度足够;主要是用于修改数据库内容,无法保证对数据库的安全;
注:其实Post、Get这是两种规定,完全可以不按照走,但是处不处理就不一定了;并且相比较而言,Post是比Get有一些好处,但是Get请求,我们的浏览器可以进行缓存,所以多次请求的时候会加快速度。
-
Delete:删除文件
-
Put:上传文件
4.4:Http1.0和Http1.1的区别
- 1.前者是短连接,后者是长连接
- 当请求一次连接的时候,如果是短连接的话,对于页面中的其他资源,如:js、image都会建立一次新的连接,而长连接可以共用一个。
- 2.后者增加了很多新的状态码,如206:部分请求
- 3.后者对于网络资源的处理更加优化,如允许部分请求
- 4.后者在请求头中增加了Host字段,之前认为是一台主机一个IP,而因为虚拟机等的出现,多个主机公用一个ip
4.5:Http1.1和Http2.0的区别?
- 后者维护一个头部字段表,这样就不用在客户端和服务器端来回传输,只需要每次有修改的东西,传过去即可
- 后者支持自动发送,不需要必须请求,而是在一定的时候,进行自动的推动数据
- 后者利用了多路复用的基础,实现了服务器可以响应多个请求,实现了一条连接不同请求进行复用(这一部分具体实现我也不太懂----)
- 并且2.0是基于二进制格式的,实现方便。
4.6:Http3.0和Http2.0的区别?
- 这一部分问的少,加分项吧(一般c++可能会问,之后补充吧)
4.7:Cookie和Session和Token的区别?
1.Cookie、Session的区别?
- 一般我们会问到Cookie和Session的区别,但是对于Token,可能有些面生
- Cookie:主要用于客户端,存储在本机上,所以相对不安全
- Session:主要用于服务器端,相比是安全的,一般两者结合使用,是为了应对http请求的无状态,其实现主要是:在服务器端保存一个SeeionID和Seesion,用来表示每一个会话,以及存储相应的内容,将sessionid及对应的session分别作为key和value保存到缓存中,也可以持久化到数据库中,然后将SessionId返回给客户端,然后每次请求的时候在Cookie中将SessionID传过来,进行用户的跟踪。
- 中途为了保证Cookie的一些信息,我们可以在Cookie进行加密,然后在服务器端进行解密即可。
- 如果浏览器禁用了Cookie,那怎么办?
- 这时候,我们可以通过在url发送的形式,将SessionID进行发送,当然为了安全,可以进行加密。
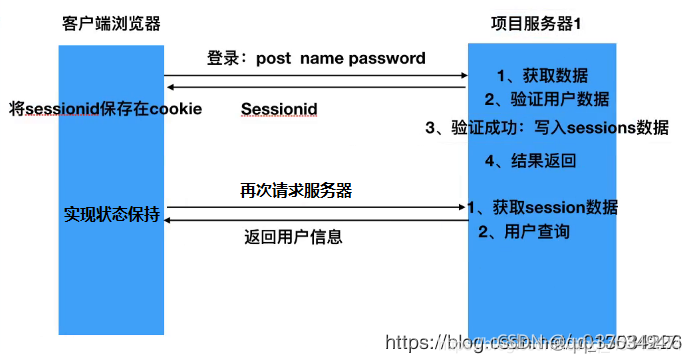
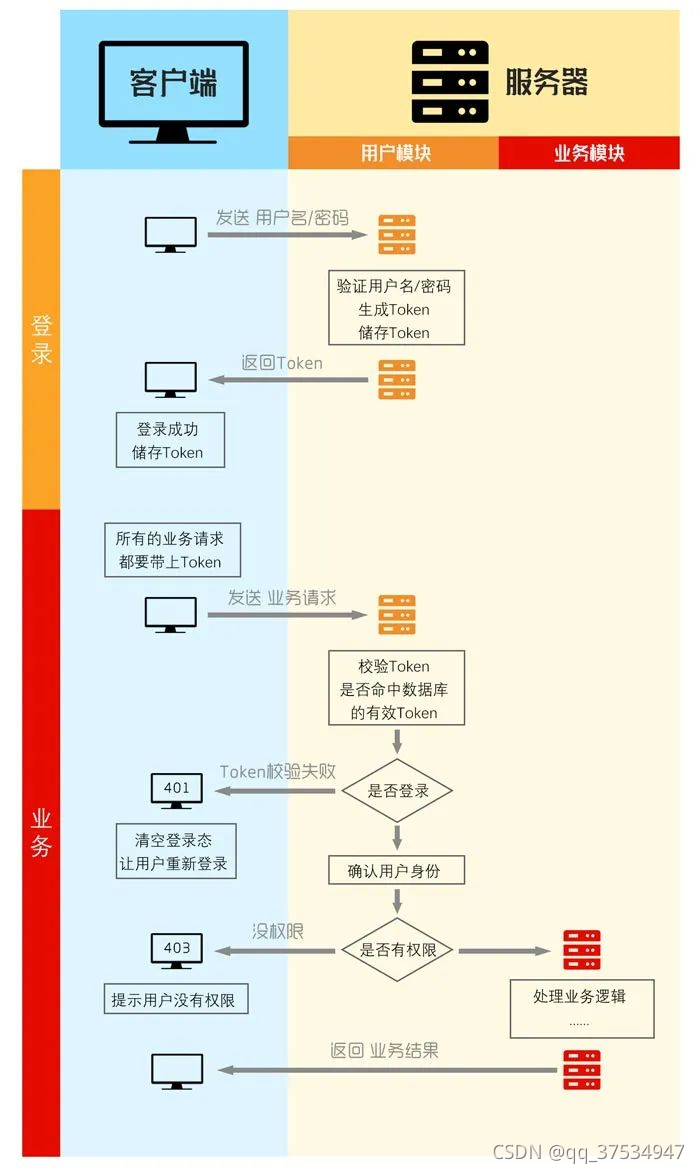
2.Session和Token的区别
- Token 出现主要是解决Session本身会占用空间来说的
- 流程:对用户id + 数据 进行签名操作,生成token,发送给客户端,下次客户端再次请求的时候,将token也传过来,然后再次使用相同的算法+密钥进行签名,比较两者的token是否相等,如果相等,则认为是同一个用户。
- 区别:
- Session可以说是空间换时间,而Cookie可以说是时间换空间。
3.无状态协议
- 由于HTTP是一种没有状态的协议,它并不知道是谁访问了我们的应用。
- 这里把用户看成是客户端,客户端使用用户名还有密码通过了身份验证,不过下次这个客户端再发送请求时候,还得再验证一下。所以上面的session和token是解决这个问题的(之前一直以为是为了保存数据的,我giao!)
4.分布式Session
这里在补充下分布式Session的解决方案:
- 共享Session,单独有一个服务器存储Session,然后每台服务器进行响应的读取
- 同步Session,说白了就是每台服务器都要存储一份,实时更新
- hash(ip),这是负载均衡的一个算法,实现一个客户端之后访问对应的服务器,直接就解决了
5.负载均衡
在补充下负载均衡算法
- 随机
- 轮询
- 加权轮询
- hash(ip)
6.签名
简单说一下:主要是对数据通过哈希算法进行第一步处理,然后利用私钥进行加密生成数字签名
- CA证书:签名 + 服务器的公钥
4.8:Https和Http的区别?
- 简单来说:就是在http和tcp之间,加一层ssl/tls协议。
- 最新版本的TLS 1.0是IETF(工程任务组)制定的一种新的协议,它建立在SSL 3.0协议规范之上,是SSL 3.0的后续版本。两者差别极小,可以理解为SSL 3.1,它是写入了RFC的。
注:RFC面试问过,但是不会,有兴趣的可以去了解。 - 主要包含三个方面:
- 1.防窃听
- 解决:加密(对称加密(加密解密一个密钥)和非对称加密(公钥解密,私钥解密))
- 过程:首先服务器将公钥传给来,然后客户端将对称加密的密钥利用公钥加密进行传输,服务器获取到利用私钥解密,之后两者利用客户端的公钥进行对称加密传输。
- 分析:因为对称加密相比于非对称加密是更快的,而对称加密本身无法安全的将其传给服务器端,所以最后是两者结合了。
- 2.防伪装
- 解决:CA证书
- 步骤:证书机构,如下面的安信。服务器端将自己的公钥传给CA,然后CA进行hash+私钥加密,生成数字签名,然后数字签名+服务器公钥 = CA证书;客户端获取服务器的证书,并获取CA的公钥,进行数字签名的解密,然后比较相等,则认证成功,获取服务端的公钥,下面的就一样了。
- 分析:因为在上一步中可能会出现一些第三方中途截取的过程,它获取服务器端的公钥,然后把自己的公钥传给客户端,客户端将自己的公钥加密传给第三方,第三方私钥获取,然后利用服务器公钥加密发送给服务器,这样神不知鬼不觉就获到了。

- 3.防篡改
- 前面两个步骤很好的解决了。
4.9:Https这么好,为什么不常用?
- 1.CA证书有点贵
- 2.因为多了处理,所以比较慢
- 3.还是会有安全问题(怎么个问题?不知道)
5.一些相关协议、过程
5.1ARP请求协议
- 这是网络层的一个协议,其主要完成了从ip地址到mac地址的一个映射。
- 每个主机都会有一个ARP高速缓存,就是目的ip地址的mac地址的一个映射表
- 步骤:
- 1.查询Arp高速缓存,有,获得mac地址;没有,则广播发送ARP请求包
- 2.ARP响应包,单播传回到A
- 3.将mac地址写到Arp高速缓存中
5.2DNS协议
-
这是应用层的协议,其主要功能:完成url到ip地址的映射
-
主要分为递归查询和迭代查询
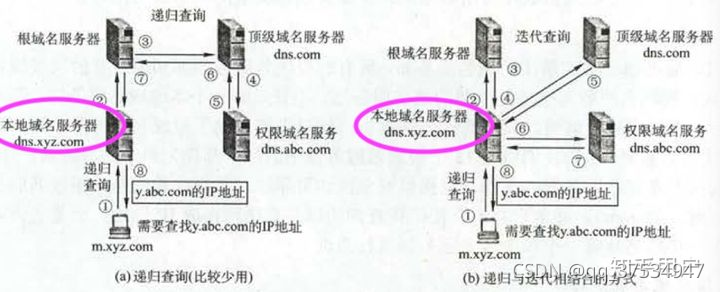
-
步骤:(递归+迭代组合查询)
-
1.递归查询
搜索浏览器本身的缓存、os的缓存,然后向本地域名服务器进行查找
本地域名服务器:

-
2.迭代查询
本地域名服务器向根域名服务器进行查询,返回顶级域名的地址
本地域名服务器向顶级域名服务器进行查询,返回权限域名服务器的地址
本地域名服务器向权限域名服务器进行查询,返回ip地址 -
3.缓存
将url-ip的映射保存到os、浏览器缓存中即可。
5.3URL过程
- 1.url-ip地址的解析(DNS协议,见上面)
- 2.TCP三次握手(见上面)
- 3.ARP协议(见上面)
- 4.数据传输(数据发送过程)
- 5.页面渲染:将数据从报文拿出来进行页面的渲染。
- 6.四次挥手(见上面)
6.网络层的一些简单了解(笔试题)
1.有类网
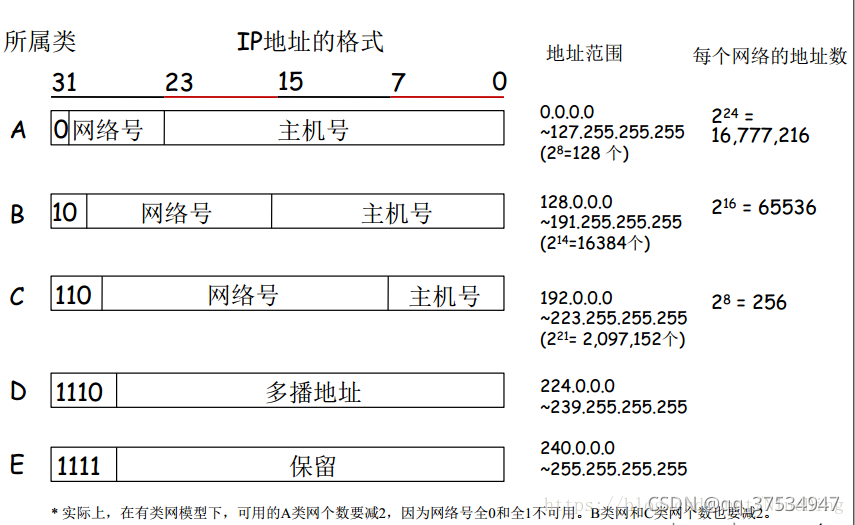
- 相关问题:
- 1.下面的IP地址中A类、B类、C类地址分别有几个?
92.168.1.100、129.32.123.54、223.89.201.145、220.18.255.254、124.254.200.254
191.64.220.8、66.254.1.100、92.1.100.1、202.15.200.12
答:
A类:第一位确定为0,范围为:0~127,所以:92.168.1.100 124.254.200.254 66.254.1.100三个属于A类网;B类:前两位确定为10,范围为:128~191,所以:129.32.123.54 191.64.220.8两个属于B类网;C类:前三位确定为110,范围为:192~223,所以:223.89.201.145 220.18.255.254 192.1.100.1 202.15.200.12四个属于C类网 - 2.有类地址191.168.1.2的网络号和主机号分别是什么?
答:
因为为191开头,所以为B类地址,前16位为网络号,后16位为主机号,所以网络号为191.168.0.0,主机号为0.0.1.2 - 3.一个C类网可用的IP地址有多少个?
答:
根据问题,可知是一个确定的C类网,IP地址为可用主机个数,2^8-2=254个。
- 1.下面的IP地址中A类、B类、C类地址分别有几个?
2.子网划分
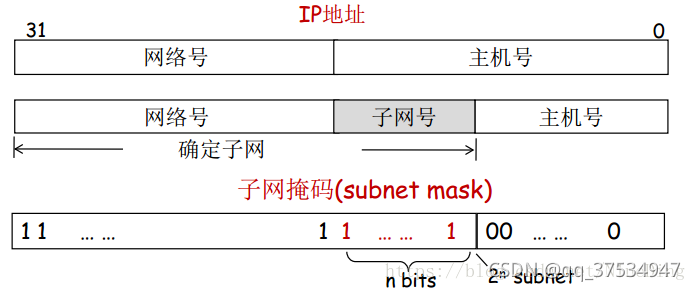
C类网192.168.1.0划分为四个子网的子网掩码为255.255.255.192,子网号分别为00、 01、 10、 11。
- 主机号为全1或全0的地址被保留,不能使用。
- 子网号为全0或全1的子网现在都可以使用(以前规定不可使用)。
- 子网掩码即将主机号的前n位拿出来作子网号,主机号的剩余部分作主机号。
将子网掩码与ip地址作与运算,便可以得到网络地址,将取反后的子网掩码与ip地址作与运算,便可以得到主机地址。
- 相关问题:假设有一个 I P 地址: 192.168.0.1,子网掩码为: 255.255.255.0,求网络地址和主机地址?
- 步骤:
- 化为二进制为: I P 地址 11000000.10101000.00000000.00000001,子网掩码 11111111.11111111.11111111.00000000,将两者做 ’ 与 ’ 运算得: 11000000.10101000.00000000.00000000
将其化为十进制得: 192.168.0.0,这便是上面 IP 的网络地址,主机地址以此类推。
参考链接:
https://blog.csdn.net/N1neDing/article/details/80740701