文章目录
1. 特殊协议回调函数http_cb
在《mongoose V7.4核心篇之mgr管理用户请求套接字(五)》一文的2.4小节和《mongoose V7.4源码剖析之读取客户端数据(八)》一文的3.1小节中,有提到过http_cb()函数。它是mongoose服务为了实现HTTP(应用层)协议而在源码中实现的一个特殊回调函数,它在创建mongoose监听套接字以及其关联变量c时候(更多细节请阅读《mongoose V7.4之创建监听端口 (二)》一文的第3节内容),初始化其成员pfn,即c->pfn = http_cb()。
struct mg_connection *mg_http_listen(struct mg_mgr *mgr, const char *url,
mg_event_handler_t fn, void *fn_data) {
struct mg_connection *c = mg_listen(mgr, url, fn, fn_data);
// 初始化监听套接字fd关联的变量c中的成员pfn.
if (c != NULL) c->pfn = http_cb;
return c;
}
函数http_cb()函数负责的主要任务是解析客户端下发的HTTP报文,包括其请求行、首部和实体这3个主要部分(更多关于HTTP报文格式的知识请阅读《HTTP协议之报文格式》)。
之后便http_cb()回调函数便将所有解析的数据存储在struct mg_http_message数据类型所表示的变量中,这个变量能存储一个完整的HTTP请求/响应报文的所有数据内容信息。
2. 详聊 struct mg_http_message
现在,暂且先把注意力切回到mongoose,在前面反复提到过,它是一个轻量级的web服务器。在《HTTP权威指南》一书的5.1节中强调过:“web服务器会对HTTP请求进行处理并提供响应,它实现了HTTP和相关TCP连接处理。并负责管理web服务器提供的资源,以及对web服务器的配置、控制及扩展方面的管理。”mongoose作为一款web服务器,它必然具备这些特性。所以它在源码中声明了一个结构体数据类型(struct mg_http_message)用以存储客户端发送给mongoose服务器的请求报文,以及服务器响应给客户端的响应报文。而且这个结构体类型必须是清晰、简单、直观明了的。
下面是struct mg_http_message数据类型的声明:
struct mg_http_message {
struct mg_str method, uri, query, proto; // Request/response line
struct mg_http_header headers[MG_MAX_HTTP_HEADERS]; // Headers
struct mg_str body; // Body
struct mg_str head; // Request + headers
struct mg_str chunk; // Chunk for chunked encoding, or partial body
struct mg_str message; // Request + headers + body
};
成员method存储HTTP报文的请求方法(比如GET、HEAD、POST、PUT、TRACE,、OPTIONS和DELETE等); uri存储HTTP报文中的URL;proto成员存储HTTP版本号。
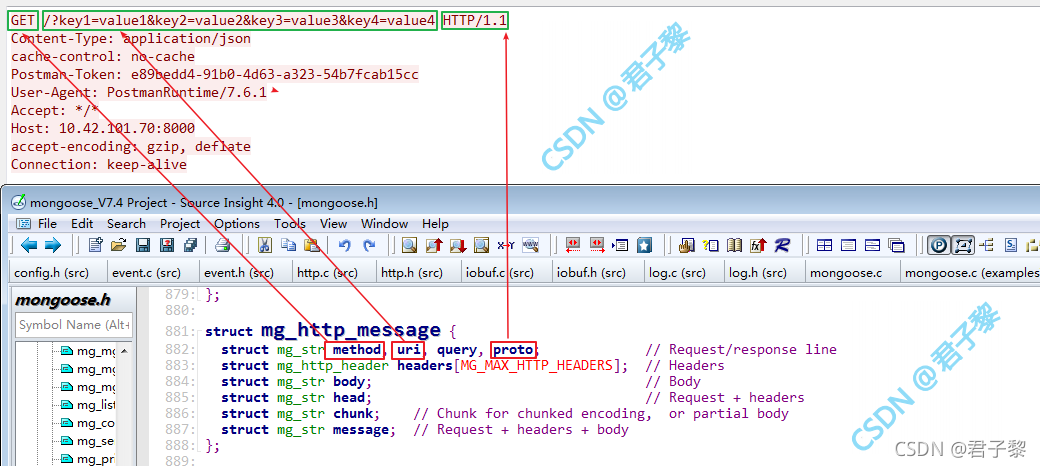
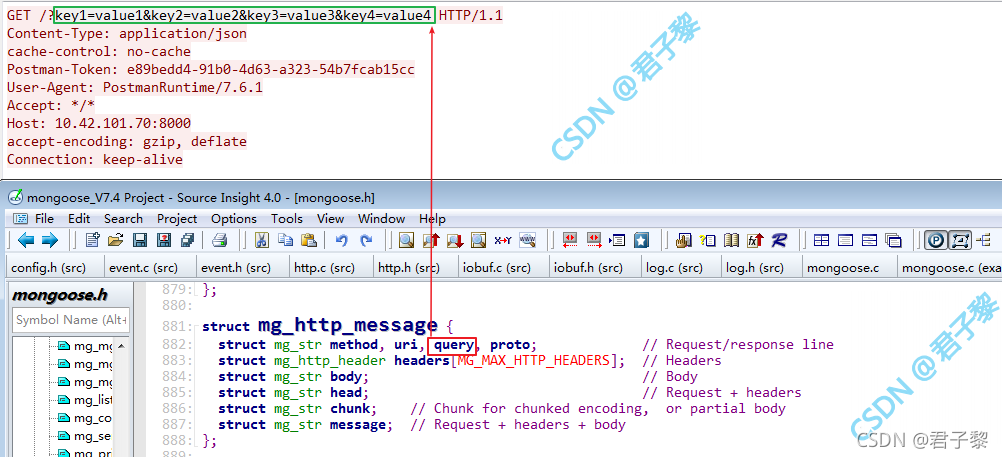
成员query用于存储HTTP报文URL中的(如果有)查询组件(即URL中存在“?”号,且在该“?”号后面的字符串。更多关于HTTP协议URL的知识请阅读《完全掌握URL》)。比如下发了一个GET请求,其完整URL是:/?key1=value1&key2=value2&key3=value3&key4=value4,由于该URL中存在“?”号,所有该问号(“?”)后面的字符串“key1=value1&key2=value2&key3=value3&key4=value4”是查询组件参数,将会被存储在struct mg_http_message数据类型的成员query中。
剩下的几个headers、body、head、chunk和message都将会在下面的内容中一一进行详细讲解。
3. 解析HTTP请求报文
3.1 获取“起始行+头部”的长度
HTTP协议报文格式中,GET方法没有“实体”部分,而对于POST,则存在实体部分。因此,我们首先需要通过函数mg_http_get_request_len()来获取到客户端下发的HTTP请求报文中“起始行 + 首部”的总长度。这样就可以将HTTP请求报文分为两部分,即“起始行 + 头部”是一部分;而实体又是另外一部分。通过“起始行 + 首部”的长度值,可以直接偏移到实体指针位置。
int mg_http_parse(const char *s, size_t len, struct mg_http_message *hm) {
// req_len值是客户端下发的HTTP请求报文中的: "请求行 + 首部"总长度.
// 对于GET方式, 没有实体部分; 而POST, 则由实体部分(这里的req_len不包括实体的长度在内).
int is_response, req_len = mg_http_get_request_len((unsigned char *) s, len);
. . . //省略
}
函数mg_http_get_request_len()的实现如下(注意,参数buf中的值来着《mongoose V7.4源码剖析之读取客户端数据(八)》)。在查找“起始行 + 首部”字符串的结束位置标记处时,我们将会对本次从客户端读取到的数据buf逐一字符进行检查、判断,若存在不可打印的非法字符(参考ASCII码表),则直接结束该函数的逻辑逻辑和流程。反之,则一直逐字符遍历字符串,直到指针位于首部结束符的位置。
// isprint: 检查所传的字符是否是可打印的. 可打印字符是非控制字符的字符.
// 可打印: true; 不可打印: false. 比如:'\t'是不可打印字符.
int mg_http_get_request_len(const unsigned char *buf, size_t buf_len) {
size_t i;
for (i = 0; i < buf_len; i++) {
if (!isprint(buf[i]) && buf[i] != '\r' && buf[i] != '\n' && buf[i] < 128)
return -1;
if ((i > 0 && buf[i] == '\n' && buf[i - 1] == '\n') ||
// 找到HTTP协议报文格式中的首部结束位置.
(i > 3 && buf[i] == '\n' && buf[i - 1] == '\r' && buf[i - 2] == '\n'))
// i + 1后,其长度包括了首部和实体间的CRLF(\r\n)中的“LF(\n)”字符的长度。
return (int) i + 1;
}
return 0;
}
当mg_http_get_request_len()函数运行结束且buf中的数据均满足规则,则该函数返回的长度包括“首部之后行终止序列符(CRLF,\r\n)”这两个字符的长度。
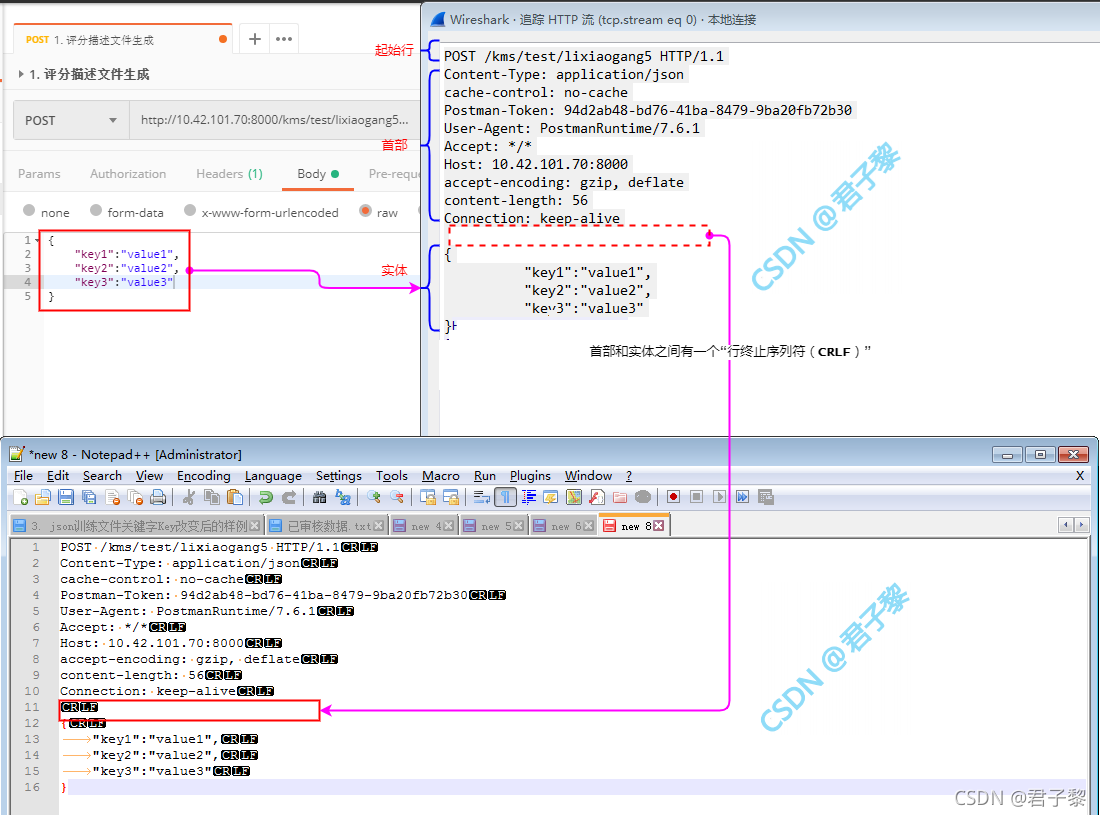
注意:在HTTP报文中,每行都是以一个由两个字符组成的行终止符序列作为结束。其中包括一个回车符(ASCII码0X0D, Carriage Return, 缩写为:CR('\r'))和一个换行符(ASCII码0x0A, Line Feed/New Line,缩写为:LF('\n')),因此,这个行终止序列可以写作CRLF。
如下图所示的POST方法请求报文中,首部和实体之间有一个行终止序列(CRLF)相隔开。通过借助Notepad++工具可以明显看到,当然也可以直接通过Wireshark查看。
3.2 初始化struct mg_http_message部分成员
通过调用函数mg_http_get_request_len(), 我们得到了HTTP协议报文中“起始行+首部”的长度,现在我们可以通过这个长度req_len来初始化struct mg_http_message数据类型中的一些相关成员。
如果变量req_len长度小于0,则说明这不是一个有效格式的HTTP报文,则结束mg_http_parse()函数的流程。
int mg_http_parse(const char *s, size_t len, struct mg_http_message *hm) {
. . . //省略
//如果HTTP请求报文有实体部分, 则end指针指向实体部分的起始位置处.
const char *end = s + req_len, *qs;
struct mg_str *cl;
memset(hm, 0, sizeof(*hm));
// 起始行 + 首部长度小于0, 说明buf中的数据不是一个有效的HTTP报文格式.
if (req_len <= 0) return req_len;
. . . //省略
}
反之,则初始化相关成员。在源码中,使成员message和head都指向buf(本次读取到的客户端下发的数据)缓冲区;成员body指向buf缓冲区中实体数据所在的起始位置;成员head中的len的值为req_len,因此,我们可以通过head.ptr + head.len得出HTTP请求报文中起始行+首部的实际数据; 成员chunk也指向buf缓存区中实体数据所在的起始偏移位置处;之后设置成员message中len以及body中的len的值为无穷大(因为此时还没有解析实体部分,暂时无法给出实际的具体值)。
int mg_http_parse(const char *s, size_t len, struct mg_http_message *hm) {
. . .
// 成员message和head都指向buf缓冲区的起始地址.
hm->message.ptr = hm->head.ptr = s;
// HTTP协议报文的实体部分起始位置处.
hm->body.ptr = end;
// 初始化成员变量head中成员len的值为req_len.
hm->head.len = (size_t) req_len;
// chunk指向实体部分
hm->chunk.ptr = end;
// 置message的len成员和body的len成员为无穷大.
hm->message.len = hm->body.len = (size_t) ~0; // Set body length to infinite
. . .
}
接下来将继续初始化 struct mg_http_message数据类型中的成员method、uri、query和proto。
3.3 获取HTTP请求方法、URL和版本
通过s(buf数据缓冲区)指针和end指针,我们可以得出HTTP报文中“起始行 + 首部”字符串位于缓冲区buf中的位置,即end - s所指向的内存缓冲区。如下图所示:
然后再根据HTTP报文格式特性,即起始行和首部都是ASCII文本,并且起始行中各部分都以空格分开,因此我们逐一遍历end - s 缓冲区区间的字符,并和空字符进行比较判断,即可得出各方法、URL和HTTP版本号的长度,这样就完成了 struct mg_http_message数据类型中的成员method、uri(如果URL中有符号“?”,则uri中成员len会被重新初始化)和proto的初始化操作。
int mg_http_parse(const char *s, size_t len, struct mg_http_message *hm) {
. . .
// Parse request line
s = skip(s, end, " ", &hm->method); //获取HTTP报文起始行的请求方式.
s = skip(s, end, " ", &hm->uri); //获取请求URL
s = skip(s, end, "\r\n", &hm->proto); //获取HTTP版本, eg: HTTP/1.1
. . .
}
skip()函数的实现如下:
// 函数skip()的具体实现
static const char *skip(const char *s, const char *e, const char *d,
struct mg_str *v) {
v->ptr = s;
while (s < e && *s != '\n' && strchr(d, *s) == NULL) s++;
/// 获取起始行中各属性的具体长度.
v->len = (size_t) (s - v->ptr);
/// 跳过起始行中各属性之间的空格符
while (s < e && strchr(d, *s) != NULL) s++;
return s;
}
初始化完成之后,再进行一次完整性检查。如果客户端下发的HTTP报文中,请求方法和URI变量中其成员len长度为0(间接表明相应变量为空),则不满足HTTP协议报文的格式要求,结束本次流程。注意:我们允许protocol(即请求报文中的HTTP版本号)和reason(响应报文中的原因短语)为空的情况出现。
// Sanity check. Allow protocol/reason to be empty
if (hm->method.len == 0 || hm->uri.len == 0) return -1;
至于成员query的初始化,我们需要进一步的进行判断。如果URL中包括“?”,那么说明该URL中存在查询参数(一个或多个key/value格式,且各之间用符号“&”隔开)。
因为现在已经知道了URL字符串值,所以我们仅在struct mg_http_message数据类型的成员uri中查找,这可以大量地节省CPU和内存的开销。借助memchr()函数,如果成员uri中存在符号“?”,则返回问号“?”所处缓冲区的偏移量位置。
// If URI contains '?' character, setup query string
// 如果qs不为空, 说明uri中包含符号“?”
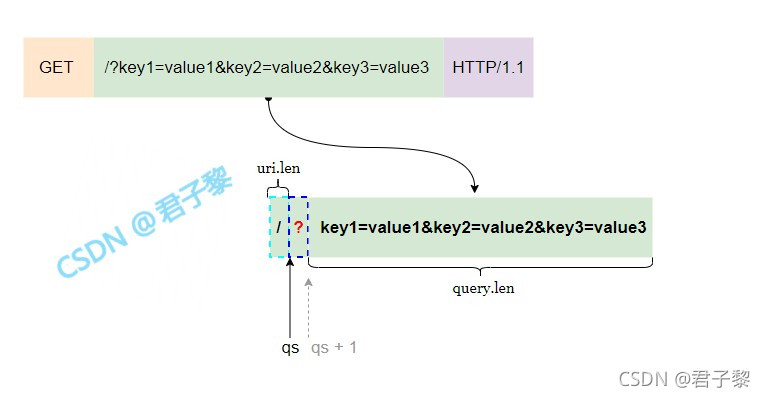
if ((qs = (const char *) memchr(hm->uri.ptr, '?', hm->uri.len)) != NULL) {
//qs + 1跳过问号“?”所处的缓冲区偏移量.
hm->query.ptr = qs + 1;
// 得到query的参数列表长度.
hm->query.len = (size_t) (&hm->uri.ptr[hm->uri.len] - (qs + 1));
// 计算uri的长度.
hm->uri.len = (size_t) (qs - hm->uri.ptr);
}
成员query中成员ptr、len,以及成员uri中成员len的值计算,如下图:
3.4 解析HTTP首部
HTTP报文中可以有零个或多个首部,每个首部都包含一个名字,后跟一个冒号(“:”),然后是一个可选的空格,接着是一个值,最后是一个CRLF,并且首部是以一个空行(CRLF)结束的(这个在本文的3.1节有讲过)。
接下来将详细讲解mongoose 7.4版本中,从读取到的客户端buf缓冲区数据中解析HTTP所有首部列表数量的内部处理逻辑。此部分功能主要由函数mg_http_parse_headers()负责完成。
3.4.1 moongoose 7.4最多支持首部个数
在mongoose 7.4版本中,所能够支持的首部数量最多不超过40个。由宏MG_MAX_HTTP_HEADERS进行限制,其声明如下:
#ifndef MG_MAX_HTTP_HEADERS
#define MG_MAX_HTTP_HEADERS 40
#endif
函数mg_http_parse_headers()的内部实现如下。这个首部字段的解析方式和前面描述的解析method、uri、proto等成员没有任何区别,我这里在代码中做了相关的解析逻辑说明。因此,将不再做过多的文字赘述。
void mg_http_parse_headers(const char *s, const char *end,
struct mg_http_header *h, int max_headers) {
int i;
for (i = 0; i < max_headers; i++) {
struct mg_str k, v, tmp;
// 跳过HTTP报文中的起始行.
const char *he = skip(s, end, "\n", &tmp);
// 内部通过strchr(": \r\n", *s)找到首部的key位置和长度
s = skip(s, he, ": \r\n", &k);
// 内部通过strchr("\r\n", *s)找到首部的key所对应的value位置和长度.
s = skip(s, he, "\r\n", &v);
if (k.len == tmp.len) continue;
// 移除首部key所对应的value字符串中的空格字符
while (v.len > 0 && v.ptr[v.len - 1] == ' ') v.len--; // Trim spaces
// 如果首部key的长度为0,则说明解析失败,间接说明HTTP报文不正确.
if (k.len == 0) break;
// LOG(LL_INFO, ("--HH [%.*s] [%.*s] [%.*s]", (int) tmp.len - 1, tmp.ptr,
//(int) k.len, k.ptr, (int) v.len, v.ptr));
h[i].name = k;
h[i].value = v;
}
}
3.5 解析首部Content-Length
在HTTP协议中,只有POST、PUT方法定义了实体部分(Entity Body)。因此,如果没有指定Conten-Length,并且方法不是POST或PUT,则将body的长度设置为0。
在mongoose 7.4源码中,尝试通过函数mg_http_get_header()来获取首部“Content-Length”。该函数内部工作原理和逻辑大致描述就是遍历struct mg_http_message数据类型中数组成员headers中的每一个元素,然后使用指针变量k和v分别指向headers数据中的每一个成员的内存地址。之后将其和“Content-Length”变量进行长度、字符串大小写进行比较。如果发现指针k指向的数组元素长度和“Content-Length”字符串长度形同,而且大小写匹配,则说明找到了该首部。此时,返回该数组成员中的v(v指向了首部value的值地址和长度信息)。代码如下:
/ mg_http_get_header(hm, "Content-Length"))
struct mg_str *mg_http_get_header(struct mg_http_message *h, const char *name) {
// n等于待获取首部的key长度,比如: n = strlen("Content-Length");
size_t i, n = strlen(name), max = sizeof(h->headers) / sizeof(h->headers[0]);
// 获取struct mg_http_message数据类型中成员headers的数组大小. 然后遍历
// headers成员中的每一个key值.
for (i = 0; i < max && h->headers[i].name.len > 0; i++) {
// 使指针遍历k和v分别指向成员headers数组中的每一个元素的地址.
struct mg_str *k = &h->headers[i].name, *v = &h->headers[i].value;
// 如果该成员key的长度和“Content-Length”长度相等,其大小写同时相等. 则说明
// 找到了首部“Conten-Length”, 返回指向该成员的Value的字符串地址.
if (n == k->len && mg_ncasecmp(k->ptr, name, n) == 0) return v;
}
return NULL;
}
如果找到了首部“Content-Length”,则用其value的值来初始化该HTTP报文中的实体数据的长度的,以及整个HTTP报文的长度。(注:body和message的长度在本文的3.2小节中先初始化了无穷大。当时也做了解释说明,是因为那时候还没有判断该HTTP报文是否有首部“Content-Length”)
if ((cl = mg_http_get_header(hm, "Content-Length")) != NULL) {
// 用HTTP报文中首部“Content-Length”的对应value的值来初始化body中成员len
hm->body.len = (size_t) mg_to64(*cl);
// 这个message报文的长度是: req_len(起始行 + 所有首部 + 空行) + 实体的长度。
hm->message.len = (size_t) req_len + hm->body.len;
}
注意:函数mg_http_parse()用于解析HTTP请求报文和HTTP响应报文。所以如果HTTP响应报文中没有设置“Content-Length”,则读取body(实体)直到socket关闭,即body.len = ~0(body.len为无穷大)。
我们通过判断数据类型struct mg_http_message中成员method的值,来知晓本次的HTTP报文是请求还是响应。
is_response = mg_ncasecmp(hm->method.ptr, "HTTP/", 5) == 0;
// 如果body.len值为无穷大且不是响应报文,同时也不是POST、PUT方法,那么则设置body.len = 0,
// 则表明没有实体数据,因此整个HTTP报文(即message成员)的长度即为:“起始行 + 首部 + 一个空行”
// 的总大小
if (hm->body.len == (size_t) ~0 && !is_response &&
mg_vcasecmp(&hm->method, "PUT") != 0 &&
mg_vcasecmp(&hm->method, "POST") != 0) {
hm->body.len = 0;
hm->message.len = (size_t) req_len;
}
如果method是以HTTP开头,则说明是响应报文;反之,则是请求报文。
如果body.len值为无穷大且不是响应报文,同时也不是POST、PUT方法,那么则设置body.len = 0,则表明没有实体数据。因此整个HTTP报文(即message成员)的长度即为:“起始行 + 首部 + 一个空行”的总大小。
此外,对于204响应码(没有实体),其实体长度len成员也是0。
// The 204 (No content) responses also have 0 body length
if (hm->body.len == (size_t) ~0 && is_response &&
mg_vcasecmp(&hm->uri, "204") == 0) {
hm->body.len = 0;
hm->message.len = (size_t) req_len;
}
到这里时,从客户端套接字缓冲区中读取的buf数据,已经全部解析完成。并且初始化了struct mg_http_message数据类型中的所有成员。接下来的工作就是对这些客户端下发的数据所想要表达的动作,做一个处理,然后及时响应给客户端HTTP报文。
4. 将mongoose事件状态置为 MG_EV_HTTP_MSG
通过函数mg_is_chunked()判断该HTTP报文是否为chunked。该函数实现如下:
static bool mg_is_chunked(struct mg_http_message *hm) {
struct mg_str needle = mg_str_n("chunked", 7);
struct mg_str *te = mg_http_get_header(hm, "Transfer-Encoding");
return te != NULL && mg_strstr(*te, needle) != NULL;
}
如果是chunked,则对该chunked实体中的每个chunked都触发walkchunks()函数处理分支。更多有关HTTP协议中chunked的知识,请求阅读《HTTP权威指南》。这里不作为本文的讲解重点,因此,我们只是简单略过。
bool is_chunked = n > 0 && mg_is_chunked(&hm);
if (ev == MG_EV_CLOSE) {
hm.message.len = c->recv.len;
hm.body.len = hm.message.len - (size_t) (hm.body.ptr - hm.message.ptr);
} else if (is_chunked && n > 0) {
walkchunks(c, &hm, (size_t) n);
}
如果mg_http_parse()函数的返回值小于0,即HTTP报文的“起始行 + 首部的 + 一个空行”的长度为0,同时mongoose此刻的事件状态是MG_EV_READ,则说明buf缓冲区中读取到的数据不是一个满足规则/或更不不是HTTP的报文。因此,打印“HTTP parse: ”解析出错的日志信息(包括buf缓冲区长度和值),并同时关闭掉该套接字连接。
static void http_cb(struct mg_connection *c, int ev, void *evd, void *fnd) {
. . .
if (n < 0 && ev == MG_EV_READ) {
mg_error(c, "HTTP parse:\n%.*s", (int) c->recv.len, c->recv.buf);
break;
}
. . . //省略
}
反之,若读取到了HTTP报文的起始行+首部信息,则将mongoose事件状态置为MG_EV_HTTP_MSG,并调用mg_call()函数。换言之,这里的MG_EV_HTTP_MSG事件状态,主要是给用户自定义的普通函数使用,因为http_cb()中并不处理MG_EV_HTTP_MSG状态。
static void http_cb(struct mg_connection *c, int ev, void *evd, void *fnd) {
. . .
} else if (n > 0 && (size_t) c->recv.len >= hm.message.len) {
mg_call(c, MG_EV_HTTP_MSG, &hm);
mg_iobuf_del(&c->recv, 0, hm.message.len);
}
. . . //省略
}
其次,我们注意到,当mg_call()函数调用结束之后,还调用了mg_iobuf_del()函数。该函数的实现如下:
size_t mg_iobuf_del(struct mg_iobuf *io, size_t ofs, size_t len) {
if (ofs > io->len) ofs = io->len;
if (ofs + len > io->len) len = io->len - ofs;
memmove(io->buf + ofs, io->buf + ofs + len, io->len - ofs - len);
zeromem(io->buf + io->len - len, len);
io->len -= len;
return len;
}
它的主要作用是将已处理了的buf缓冲区数据给移除掉,节省内存空间。到这里时,关于mongoose 7.4版本的特殊协议回调函数http_cb()已经讲解结束。如果你想对学的这些知识印象更加深刻,那么强烈建议你亲自下载编译运行该mongoose服务,通过阅读源码结合实战的方式,将会学的更快、更深。