��Һ�,����ǰ��᰷�,һö���߳��еij�����,������Ҫ����ҷ����������ıʼ�2021ǰ��������ϵ��:HTTP�����HTTP�������,�˷������������ǵĹ����г��õ�, Ҳ�����Թپ������ʵ�����,ϣ���������¶Դ������������
1. һ��������HTTP�������
�������
��������web������ĵ�ַ��������:www.baidu.com,���巢����ʲô?
- ��
www.baidu.com�����ַ����DNS��������,�õ���Ӧ��IP��ַ - �������IP,�ҵ���Ӧ�ķ�����,����TCP����������
- ����TCP���Ӻ���HTTP����
- ��������ӦHTTP����,������õ�html����
- ���������html����,������html�����е���Դ(��js��css��ͼƬ��)(�ȵõ�html����,����ȥ����Щ��Դ)
- �������ҳ�������Ⱦ���ָ��û�
- �������رչر�TCP����
ע:
- DNS��ô�ҵ�������?
DNS�����������õ��ǵݹ��ѯ�ķ�ʽ,������,��ȥ��DNS����->�����Ҳ�����ȥ�Ҹ�����������->�������ֻ�ȥ����һ��,�����ݹ����֮��,�ҵ���,�����ǵ�web�����
- ΪʲôHTTPЭ��Ҫ����TCP��ʵ��?
TCP��һ���˵��˵Ŀɿ����������ӵ�Э��,HTTP���ڴ����TCPЭ�鲻�õ������ݴ���ĸ�������(����������ʱ,���ش�)
- ���һ�����������ζ�ҳ�������Ⱦ��?
a)����html�ļ����� DOM��
b)����CSS�ļ�������Ⱦ��
c)�߽���,����Ⱦ
d)JS ���߳�����,JS�п�����DOM�ṹ,��ζ��JSִ�����ǰ,����������Դ��������û�б�Ҫ��,����JS�ǵ��߳�,������������Դ����
�����������ϸ��
DNS����(��������������)
- ���Ȼ����������������DNS����(����ʱ��Ƚ϶�,���ֻ��1����,��ֻ������1000������)
- �������������Ļ�������û���ҵ�,��ô�����������ϵͳ������DNS����
- �����û���ҵ�,��ô���Դ� hosts�ļ�����ȥ��
- ��ǰ���������̶�û��ȡ���������,�͵ݹ��ȥ����������ȥ����,�����������
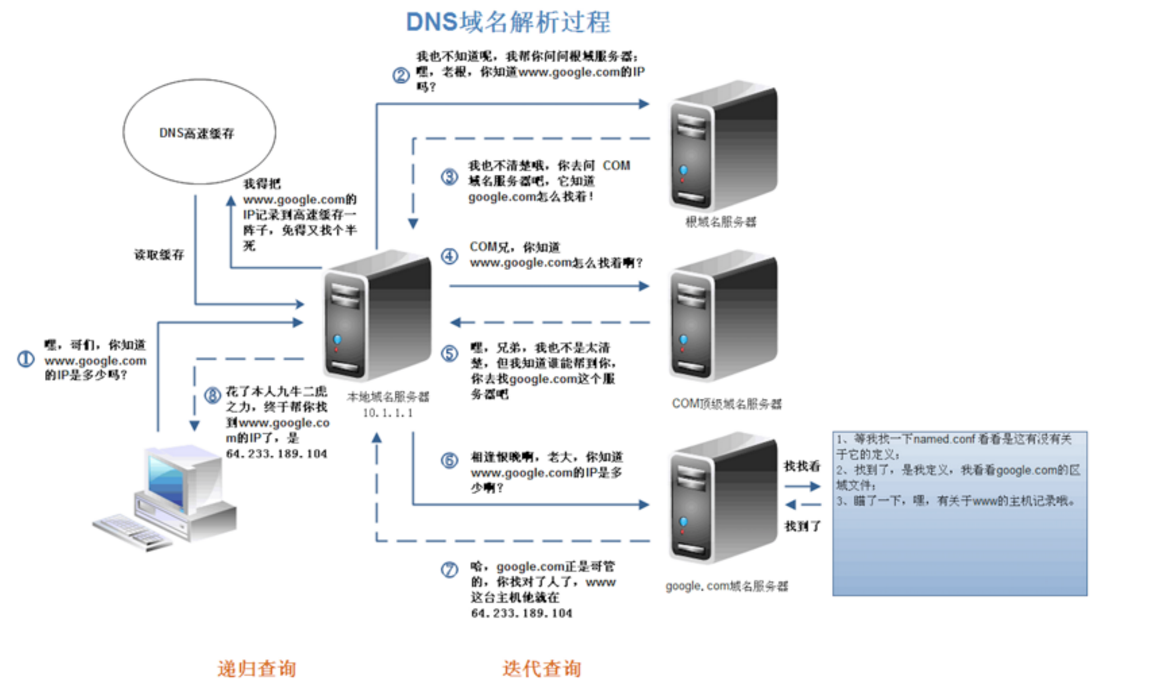
DNS�Ż���������:DNS���桢DNS���ؾ���
TCP���ӽ���(��������)
�õ�������Ӧ��IP��ַ֮��,User-Agent(һ��ָ�����)����һ������˿�(1024<�˿�<65535)���������WEB����(���õ���httpd,nginx)�ȵ�80�˿ڡ������������(ԭʼ��http����TCP/IP 4��ģ�͵IJ����)����������˺�(���м��и���·���豸,�������ڳ���),���뵽����,Ȼ���ǽ��뵽�ں˵�TCP/IPЭ��ջ(����ʶ����������,����,һ��һ��İ���),���п���Ҫ����Netfilter����ǽ(�����ں˵�ģ��)�Ĺ���,���մﵽWEB����,���ս�����TCP/IP�����ӡ�
����HTTP����(�������Ӻ�)
HTTP�����������������:������,����ͷ������ / ��������
**������:**���������ͻ��˵�����ʽ(GET/POST��),�������Դ����(URL)�Լ�ʹ�õ�HTTPЭ��İ汾��
**����ͷ:**���������ͻ���������̨��������˿�,�Լ��ͻ��˵�һЩ������Ϣ��
**����:**���о���\r\n (POST����ʱ����)
**��������:**��ʹ��POST�ȷ���ʱ,ͨ����Ҫ�ͻ�����������������ݡ���Щ���ݾʹ���������������(GET��ʽ�DZ�����url��ַ����,����ŵ�����)
����:
GET����
������������� http://localhost:8081/test?name=XXG&age=23��GET ����ʱ����������������:

���Կ���������������к�����ͷ�����֡������������а��� method(���� GET��POST)��URI(ͨһ��Դ��־��)��Э��汾������,��������֮���Կո�ֿ��������к�ÿ������ͷ��ռһ��,�Ի��з� CRLF(�� \r\n)�ָ
POST����
������������� http://localhost:8081/test �� POST ����ʱ����������������,��Ϣ���д��ϲ��� name=XXG&age=23
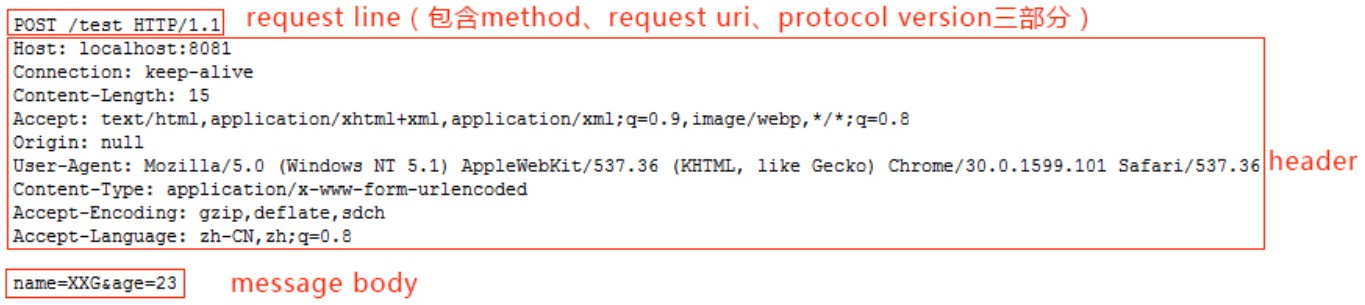
���Կ���,��������������������:�����С�����ͷ���ո�/��Ϣ��,��֮ǰ�� GET �������һ��������Ϣ,���� ����ͷ����Ϣ��֮����һ�����зָPOST ����IJ������� URL ��,��������Ϣ����,����ͷ�ж���һ�� Content-Length ���ڱ�ʾ��Ϣ����ֽ���,��������������֪�������Ƿ��ͽ�������Ҳ���� GET ����� POST �������Ҫ����
��ô��ʼ���е���������Щ����?
GET: ��������һ����Դ (����)
HEAD: ��������Ӧ�ײ�
POST:�ύ���� (����)
PUT: (webdav) �ϴ��ļ�(�����������֧�ָ÷���)
DELETE:(webdav) ɾ��
OPTIONS:�����������Դ��֧�ֵķ����ķ���
TRACE: ��һ����Դ�����м��������Ĵ���(�÷������������������)
��ʲô��URL��URI��URN?
URI Uniform Resource Identifier ͳһ��Դ��ʶ��
URL Uniform Resource Locator ͳһ��Դ��λ��
URN Uniform Resource Name ͳһ��Դ����
URL��URN ������ URI,Ϊ�˷���Ͱ�URL��URI��ʱ��ָͨһ������
��������Ӧhttp����,������õ�html����
HTTP��ӦҲ�����������:״̬��,��Ӧͷ,�ո�,��Ϣ��
״̬�а���:Э��汾��״̬�롢״̬������
**״̬��:**״̬�����ڱ�ʾ������������Ĵ������
1xx:ָʾ��Ϣ������ʾ�����Ѿ�����,��������
2xx:�ɹ�������ʾ�����Ѿ����ɹ����ա����⡢���ܡ�
3xx:�ض���Ҫ������������и���һ���IJ���
4xx:�ͻ��˴���������������������ʵ��
5xx:�������˴���������δ��ʵ�ֺϷ�������
�оټ��ֳ�����:
200(û������)
302(Ҫ��ȥ�ұ���)
304(Ҫ��ȥ�û���)
307(Ҫ��ȥ�û���)
403(�������Դ,����û�з���Ȩ��)
404(������û�������Դ)
500(���������������)
**��Ӧͷ:**��Ӧͷ���������������Ļ�����Ϣ,�Լ��ͻ�����δ�������
**�ո�:**CRLF(�� \r\n)�ָ�
**��Ϣ��:**���������ظ��ͻ��˵�����
��Ӧ��ʽ����ͼ
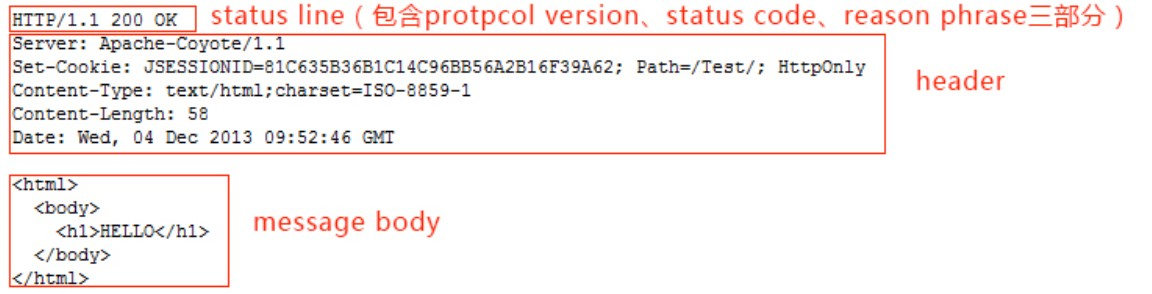
����� HTTP ��Ӧ��,��Ӧͷ�е� Content-Length ͬ�����ڱ�ʾ��Ϣ����ֽ�����Content-Type ��ʾ��Ϣ�������,ͨ�������ҳ��������HTML,��Ȼ��������������,����ͼƬ����Ƶ�ȡ�
���������html����,������html�����е���Դ
������õ�html�ļ���,�Ϳ�ʼ�������е�html����,����js/css/image�Ⱦ�̬��Դʱ,�����������ȥ��������(��ʹ�ö��߳�����,ÿ����������߳�����һ��),����ʱ������� keep-alive������,����һ��HTTP����,������������Դ,������Դ��˳����ǰ��մ��������˳��,��������ÿ����Դ��С��һ��,����������Ƕ��߳�����������Դ,����������ʾ��˳��һ���Ǵ��������˳��
�������ҳ�������Ⱦ���ָ��û�
���,����������Լ��ڲ��Ĺ�������,������ľ�̬��Դ��html���������Ⱦ,��Ⱦ֮����ָ��û�,�������һ���߽�������Ⱦ�Ĺ��̡�
�������������HTML�ļ�����DOM��,Ȼ�����CSS�ļ�������Ⱦ��,�ȵ���Ⱦ��������ɺ�,�������ʼ������Ⱦ����������Ƶ���Ļ�ϡ�
������̱Ƚϸ���,�漰����������: reflow(����)��repain(�ػ�)��
DOM�ڵ��еĸ���Ԫ�ض����Ժ�ģ�͵���ʽ����,��Щ����Ҫ�����ȥ������λ�úʹ�С��,������̳�Ϊrelow;����ģ�͵�λ��,��С�Լ���������,����ɫ,����,��ȷ������֮��,������㿪ʼ��������,������̳�Ϊrepain��
ҳ�����״μ���ʱ��Ȼ�ᾭ��reflow��repain��
reflow��repain�����Ƿdz��������ܵ�,���������ƶ��豸��,�����ƻ��û�����,��ʱ�����ҳ�濨�١���������Ӧ�þ������ٵļ���reflow��repain��
JS�Ľ�������������е�JS����������ɵġ�
JS�ǵ��߳�����,JS�п�����DOM�ṹ,��ζ��JSִ�����ǰ,����������Դ��������û�б�Ҫ��,����JS�ǵ��߳�,������������Դ���ء�
?
���������html��������ͼ
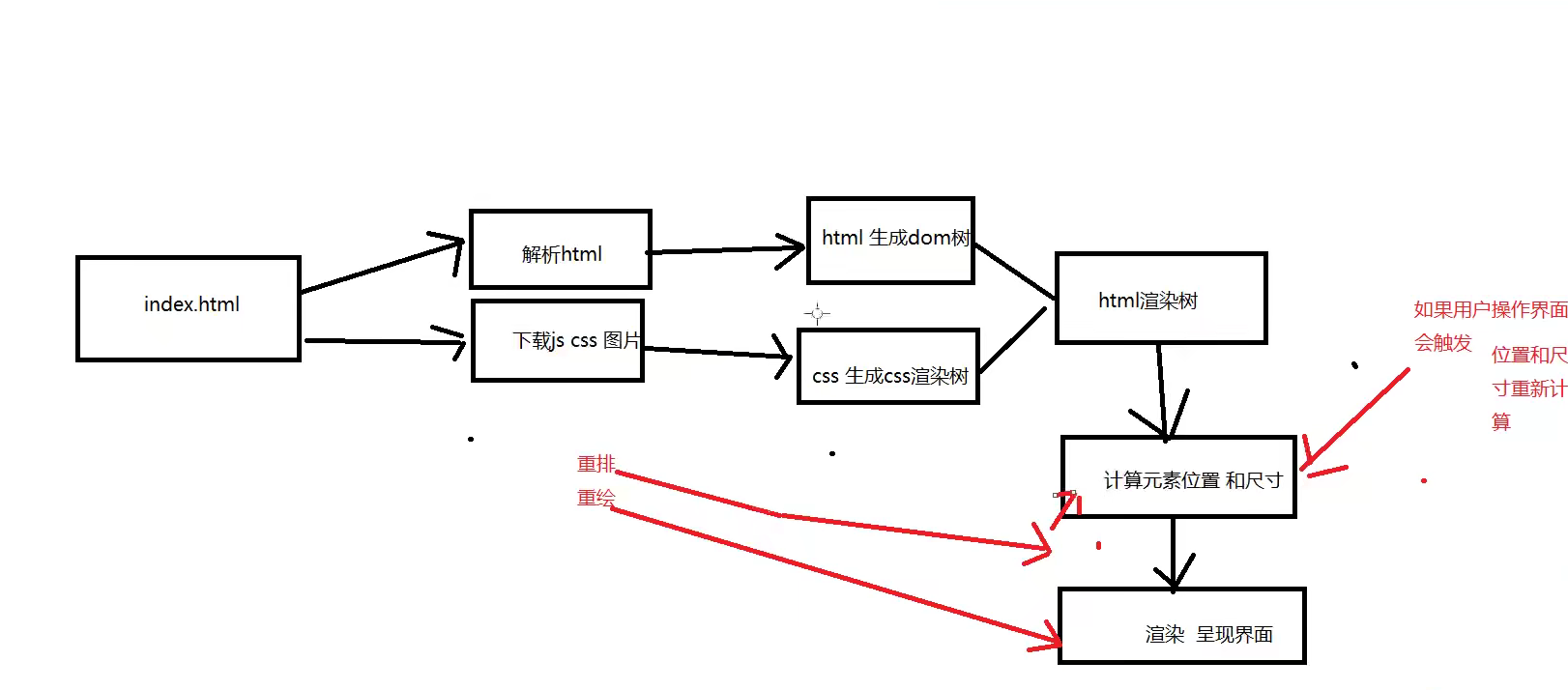
�������رչر�TCP����
һ�������,һ��Web���������������������������,����Ҫ�ر�TCP����,Ȼ�������������߷���������ͷ��Ϣ���������д���:
Connection:keep-alive
TCP�����ڷ��ͺ���Ȼ���ִ�״̬,����,��������Լ���ͨ����ͬ�����ӷ������������ӽ�ʡ��Ϊÿ�������������������ʱ��,����Լ�����������
�������̾���һ��������HTTP�������.
�������
- ��ַ������url��ʼ, ������ip�Ĺ���
- �õ�ip, ��ʼ����http����
- �õ�html֮������������Ⱦ����
�ش�˼·
��˵��url���õ�html�Ĺ���,Ȼ���ص����html����Ⱦ���̡�֮�����Թ��ٴ����ʵIJ��ػش�(��:����,�ػ桢tcp ���������Ĵλ���)��
�����չ
- tcp ���������Ĵλ���
2. http�������
�����������
Web ������¿��Է�Ϊ:���ݿ�桢�������˻���(�������������桢CDN ����)����������档
���������Ҳ�����ܶ�����: HTTP ���桢indexDB��cookie��localstorage �ȵȡ���������ֻ���� HTTP ����������ݡ�
�ھ����˽� HTTP ����֮ǰ������ȷ��������:
- ����������:�ӻ����еõ����ݵ��������������������ı��ʡ�����״̬��Խ��Խ�á�
- ��������:�������õ���Чʱ��,�����Ϊ���¾ɡ������ݡ�ͨ���������ݲ������ڻظ��ͻ��˵�����,����������Դ�����������µ����ݻ�����֤����������Ƿ���Ȼ����
- ��֤:��֤�����еĹ��������Ƿ���Ȼ��Ч,��֤ͨ���Ļ�ˢ�¹���ʱ�䡣
- ʧЧ:ʧЧ���ǰ����ݴӻ������Ƴ��������ݷ����ı�ʱ�ͱ����Ƴ�ʧЧ�����ݡ�
�����������Ҫ�� HTTP Э�鶨��Ļ�����ơ�HTML meta ��ǩ,����
������������������浱ǰҳ�档���Ǵ��������������� HTML ����,һ��Ӧ�ù㷺������ HTTP ͷ��Ϣ���ƻ��档
������������
����������Ϊǿ�����Э�̻���,���������һ��ҳ��ļ���������:
- ������ȸ��������Դ��httpͷ��Ϣ���ж��Ƿ�����ǿ���档���������ֱ�Ӽ��ڻ����е���Դ,�����Ὣ�����͵���������(ǿ����)
- ���δ����ǿ����,��������Ὣ��Դ���������͵������������������ж���������ػ����Ƿ�ʧЧ��������ʹ��,������������᷵����Դ��Ϣ,����������ӻ��������Դ��(Э�̻���)
- ���δ����Э�̻���,��������Ὣ��������Դ���ظ������,�������������Դ,�����»��档(�µ�����)
1. ǿ����
����ǿ����ʱ,����������Ὣ����������������Chrome�Ŀ����߹����п���http�ķ�������200,������Size�л���ʾΪ(from cache)��

ǿ����������http�ķ���ͷ�е�Expires����Cache-Control�����ֶ������Ƶ�,������ʾ��Դ�Ļ���ʱ�䡣
Expires
�������ʱ��,����ָ����Դ���ڵ�ʱ��,�Ƿ������˵ľ����ʱ��㡣Ҳ����˵,Expires=max-age + ����ʱ��,��Ҫ��Last-modified���ʹ�á��������������ᵽ��,cache-control�����ȼ����ߡ� Expires��Web��������Ӧ��Ϣͷ�ֶ�,����Ӧhttp����ʱ����������ڹ���ʱ��ǰ���������ֱ�Ӵ����������ȡ����,�������ٴ�����
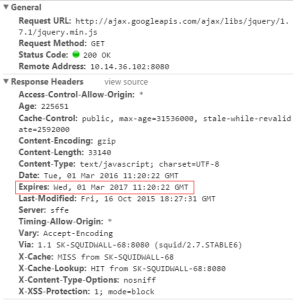
���ֶλ᷵��һ��ʱ��,����Expires:Thu,31 Dec 2037 23:59:59 GMT�����ʱ������������Դ��ʧЧʱ��,Ҳ����˵��2037��12��31��23��59��59��֮ǰ������Ч��,�����л��档���ַ�ʽ��һ�����Ե�ȱ��,����ʧЧʱ����һ������ʱ��,���Ե��ͻ��˱���ʱ�䱻���Ժ�,��������ͻ���ʱ��ƫ�����Ժ�,�ͻᵼ�»�����ҡ����Ƿ�չ����Cache-Control��
Cache-Control
Cache-Control��һ�����ʱ��,����Cache-Control:3600,��������Դ����Ч����3600�롣���������ʱ��,���Ҷ�����ͻ���ʱ��Ƚ�,���Է�������ͻ���ʱ��ƫ��Ҳ���ᵼ�����⡣
Cache-Control��Expires�����ڷ��������ͬʱ���û�����������һ��,ͬʱ���õ�ʱ��Cache-Control���ȼ��ߡ�
Cache-Control �����ɶ���ֶ���϶���,��Ҫ�����¼���ȡֵ:
- max-age ָ��һ��ʱ�䳤��,�����ʱ����ڻ�������Ч��,��λ��s���������� Cache-Control:max-age=31536000,Ҳ����˵������Ч��Ϊ(31536000 / 24 / 60 * 60)��,��һ�η��������Դ��ʱ��,��������Ҳ������ Expires �ֶ�,���ҹ���ʱ����һ���
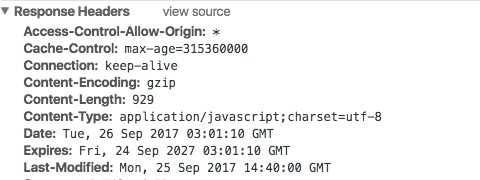
��û�н��û��沢��û�г�����Чʱ��������,�ٴη��������Դ�������˻���,�����������������Դ����ֱ�Ӵ������������ȡ��
��û�н��û��沢��û�г�����Чʱ��������,�ٴη��������Դ�������˻���,�����������������Դ����ֱ�Ӵ������������ȡ��
- s-maxage ͬ max-age,���� max-age��Expires,���������ڹ�������,��˽�л����б����ԡ�
- public ������Ӧ���Ա��κζ���(��������Ŀͻ��ˡ������������ȵ�)���档
- private ������Ӧֻ�ܱ������û�(�����Dz���ϵͳ�û���������û�)����,�Ƿǹ�����,���ܱ��������������档
- no-cache ǿ�����л����˸���Ӧ���û�,��ʹ���ѻ��������ǰ,���ʹ���֤������������������������˼�ϵIJ����档
- no-store ��ֹ����,ÿ������Ҫ����������»�ȡ���ݡ�
7.must-revalidateָ�����ҳ���ǹ��ڵ�,��ȥ���������л�ȡ�����ָ�������,�Ͳ�������������ˡ�
ǿ��������ͼ
2. Э�̻���
��δ����ǿ����,��������Ὣ��������������������������httpͷ��Ϣ�е�Last-Modify/If-Modify-Since��Etag/If-None-Match���ж��Ƿ�����Э�̻��档�������,��http������Ϊ304,������ӻ����м�����Դ��
Last-Modify/If-Modify-Since
�������һ������һ����Դ��ʱ��,���������ص�header�л����Last-Modify,Last-modify��һ��ʱ���ʶ����Դ�������ʱ��,����Last-Modify: Thu,31 Dec 2037 23:59:59 GMT��
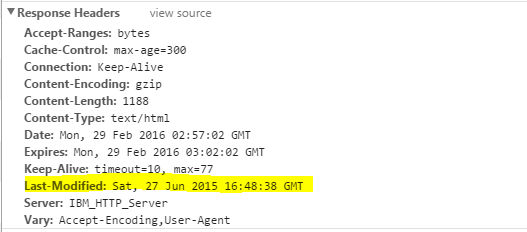
��������ٴ��������Դʱ,���͵�����ͷ�л����If-Modify-Since,��ֵΪ����֮ǰ���ص�Last-Modify���������յ�If-Modify-Since��,������Դ�������ʱ���ж��Ƿ����л��档
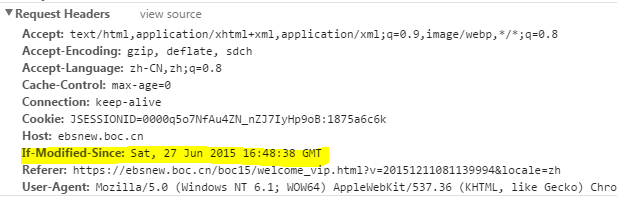
������л���,��http304,���Ҳ��᷵����Դ����,���Ҳ��᷵��Last-Modify�����ڶԱȵķ����ʱ��,���Կͻ���������ʱ����ᵼ�����⡣������ʱ��ͨ�������ʱ�����ж���Դ�Ƿ��Ļ��Dz�̫ȷ(��Դ�仯�������ʱ��Ҳ����һ��)�����dz�����ETag/If-None-Match��
ETag/If-None-Match
��Last-Modify/If-Modify-Since��ͬ����,Etag/If-None-Match���ص���һ��У����(ETag: entity tag)��ETag���Ա�֤ÿһ����Դ��Ψһ��,��Դ�仯���ᵼ��ETag�仯*��ETagֵ�ı����˵����Դ״̬�Ѿ����ġ�����������������Ϸ��͵�If-None-Matchֵ���ж��Ƿ����л��档
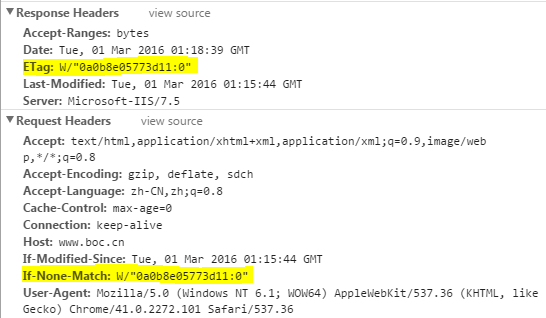
ETag��չ˵��
���Ƕ�ETag�������,ϣ��������ÿһ��url����Ψһ��ֵ,��Դ�仯ʱETagҲ�����仯�����ص�Etag��������ɵ���?��ApacheΪ��,ETag���ɿ����¼�������
- �ļ���i-node���,��i-node�DZ�iNode����Linux/Unix����ʶ���ļ��ı�š��ǵ�,ʶ���ļ��õIJ����ļ�����ʹ�����ls �CI�����Կ�����
- �ļ������ʱ��
- �ļ���С
����Etag��ʱ��,����ʹ������һ�ֻ�������,ʹ�ÿ���ײɢ�к��������ɡ�����,������ETagҲ�ǻ��ظ���,ֻ�Ǹ���С�����Ժ��ԡ�
����Last-Modified����Etag?
����ܻ����ʹ��Last-Modified�Ѿ������������֪�����صĻ��渱���Ƿ��㹻��,Ϊʲô����ҪEtag(ʵ���ʶ)��?HTTP1.1��Etag�ij�����Ҫ��Ϊ�˽������Last-Modified�Ƚ��ѽ��������:
- Last-Modified��ע�������ֻ�ܾ�ȷ���뼶,���ijЩ�ļ���1��������,���Ķ�εĻ�,��������ȷ��ע�ļ�����ʱ��
- ���ijЩ�ļ��ᱻ��������,����ʱ���ݲ�û���κα仯,��Last-Modifiedȴ�ı���,�����ļ�û��ʹ�û���
3.�п��ܴ��ڷ�����û��ȷ��ȡ�ļ���ʱ��,���������������ʱ�䲻һ�µ�����
Etag�Ƿ������Զ����ɻ����ɿ��������ɵĶ�Ӧ��Դ�ڷ������˵�Ψһ��ʶ��,�ܹ�����ȷ�Ŀ��ƻ��档Last-Modified��ETag�ǿ���һ��ʹ�õ�,��������������֤ETag,һ�µ������,�Ż�����ȶ�Last-Modified,���ž����Ƿ�304��
�������һ������
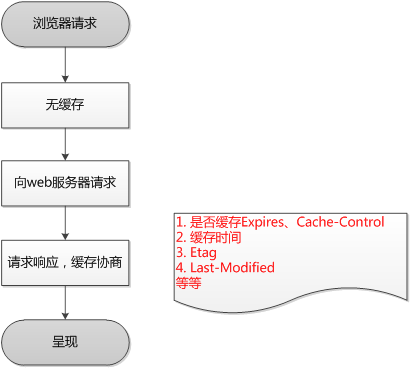
������ڶ�������
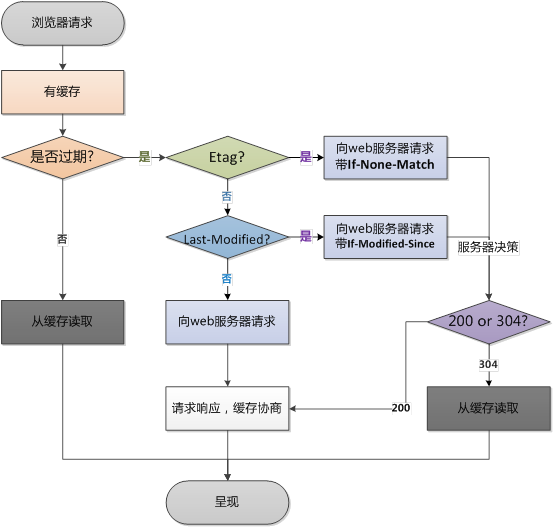
�������
- http�������÷�Χ
http�����ܹ�������������߲�������,�ܶ���Դ����Ҫ�ظ�����ֱ�Ӵ���������û���
- http�������
ǿ���� Э�̻���
- http����ʵ�ּ���
ǿ����: ͨ�� expires �� cache-control����
Э�̻���: ͨ�� last-Modify ��E-tag����
����:
-
Ϊʲô��expires ����Ҫcache-control
��Ϊexpires �и��������������ʱ�䲻ͬ�������� expires�Ǿ����¼� cache-control�����ʱ�� -
last-modify��Etag
last-modify ������������� ����
e-tag û�о������� ֻҪ�ļ��ı� e-tagֵ�ı�
�ش�˼·
���Ȼش�http��������÷�Χ, Ȼ����http������Ҫ��Ϊǿ�����Э�̻��档����ص����ǿ�����Э�̻��������ʵ�ֺ����http��Ӧͷ�ֶε��÷���
�����չ
-
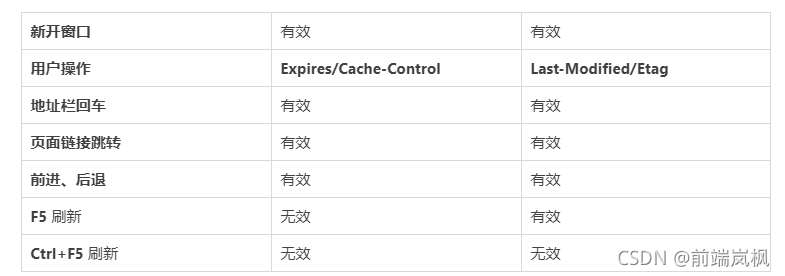
�û���Ϊ�뻺�� �����������Ϊ�����û�����Ϊ�й�!!!
-
�������˵Ļ��� CDN ��redis�����ݿ���
-
Nginx�¹��ڻ�������ֶ�cache-control������˵��
��ע���ں�:����Աʯ�� ��ȡ����ǰ��������