简单爬虫
安装第三方库
请求页面
解析网页
保存图片
安装第三方库
安装第三方请求库(requests)
pip install requests
请求页面
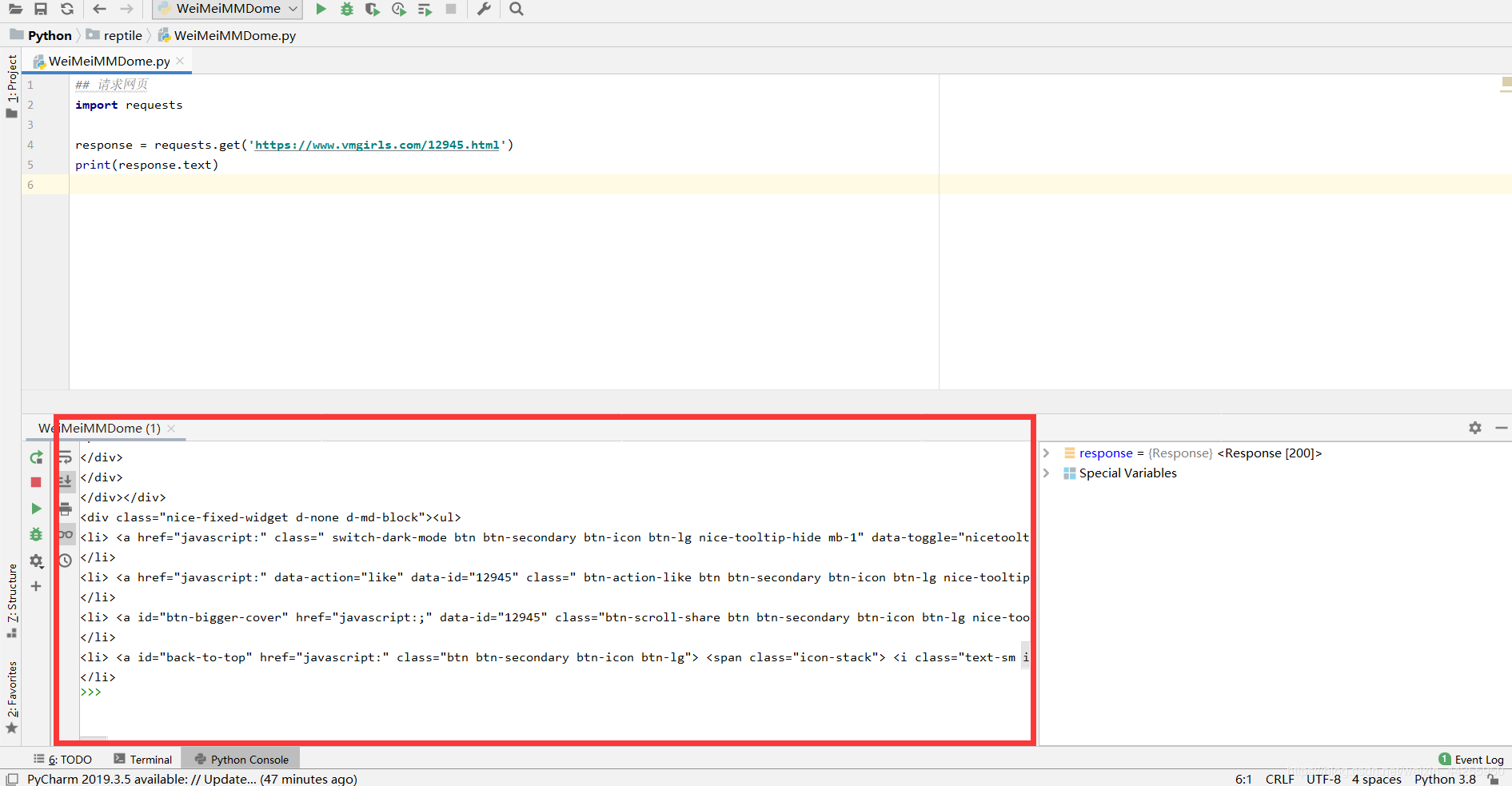
请求成功了
存在特殊情况:请求失败
原因八成是网页知道我们是Python过来的不给我们请求。
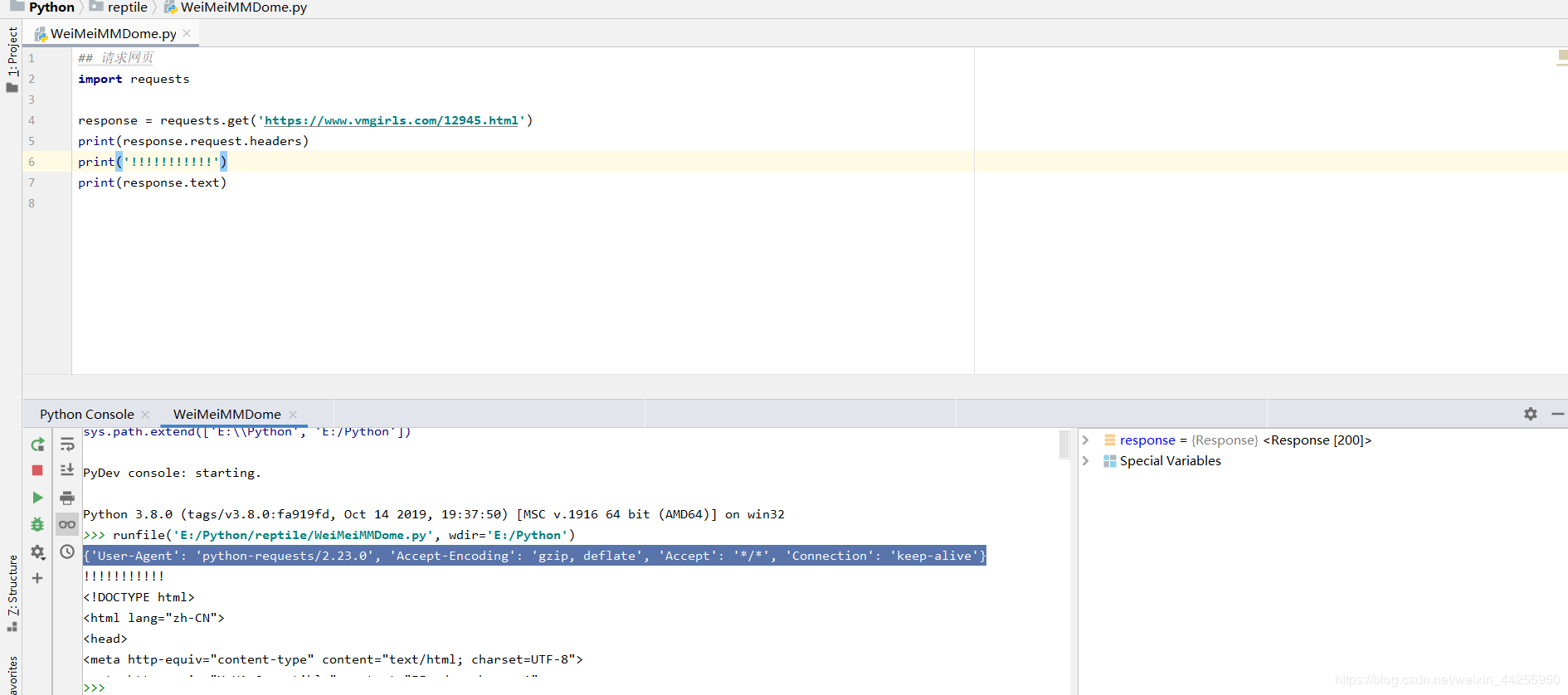
这里教各路神仙去解决这个User-Agent的尴尬问题:
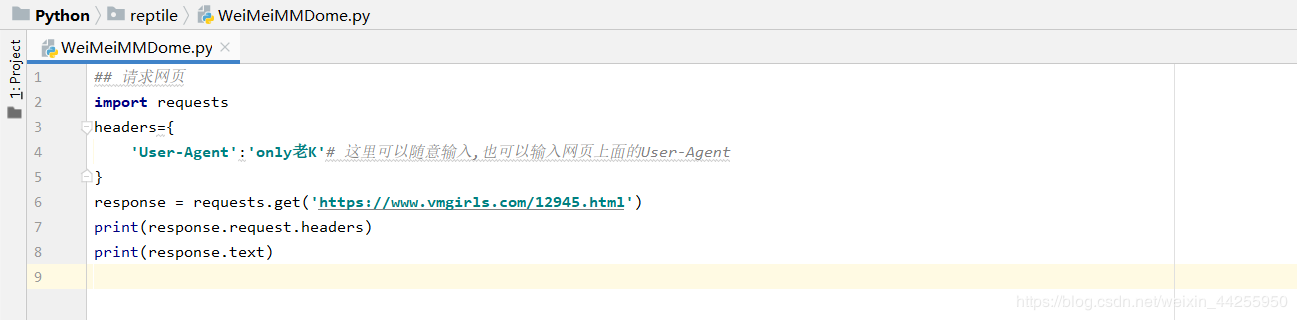
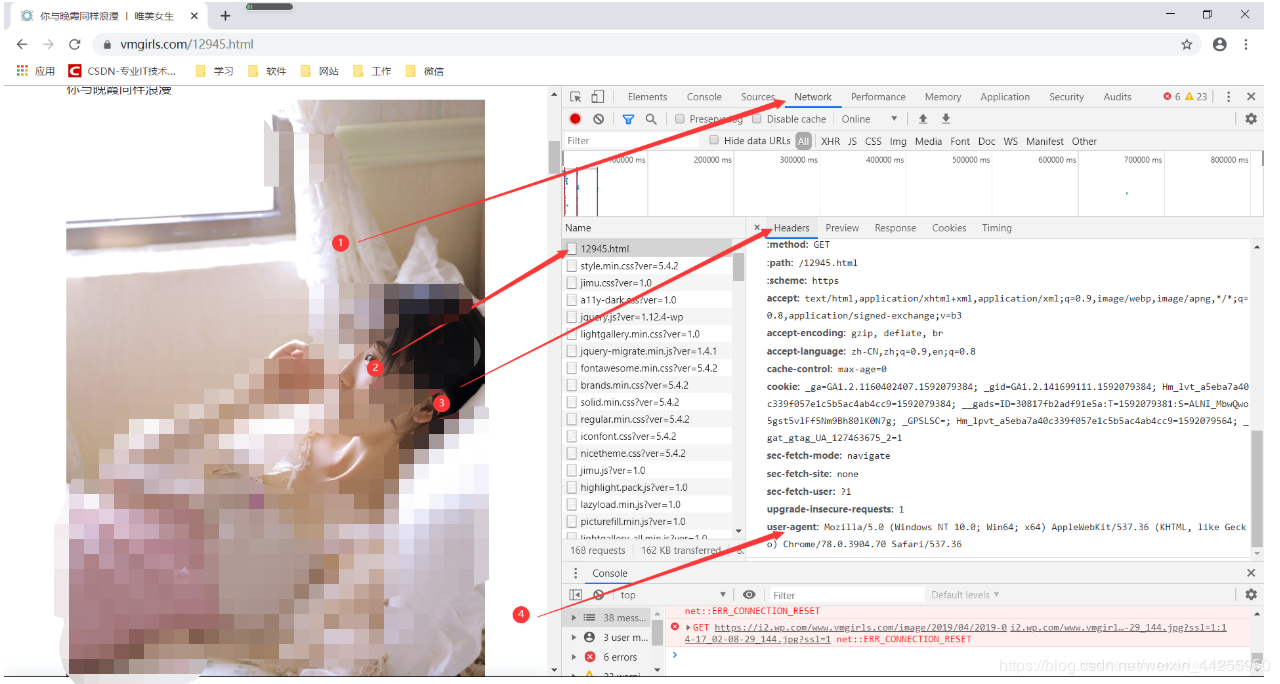
怎么看网页的了?
啊Sir。来了(只好打马赛克了)
## 请求网页
import requests
headers={
'User-Agent':'only老K'# 这里可以随意输入,也可以输入网页上面的User-Agent
}
response = requests.get('https://www.vmgirls.com/12945.html')
print(response.request.headers)
print(response.text)
解析网页
需要使用 re库来进行正则匹配
找到我们的图片的位置
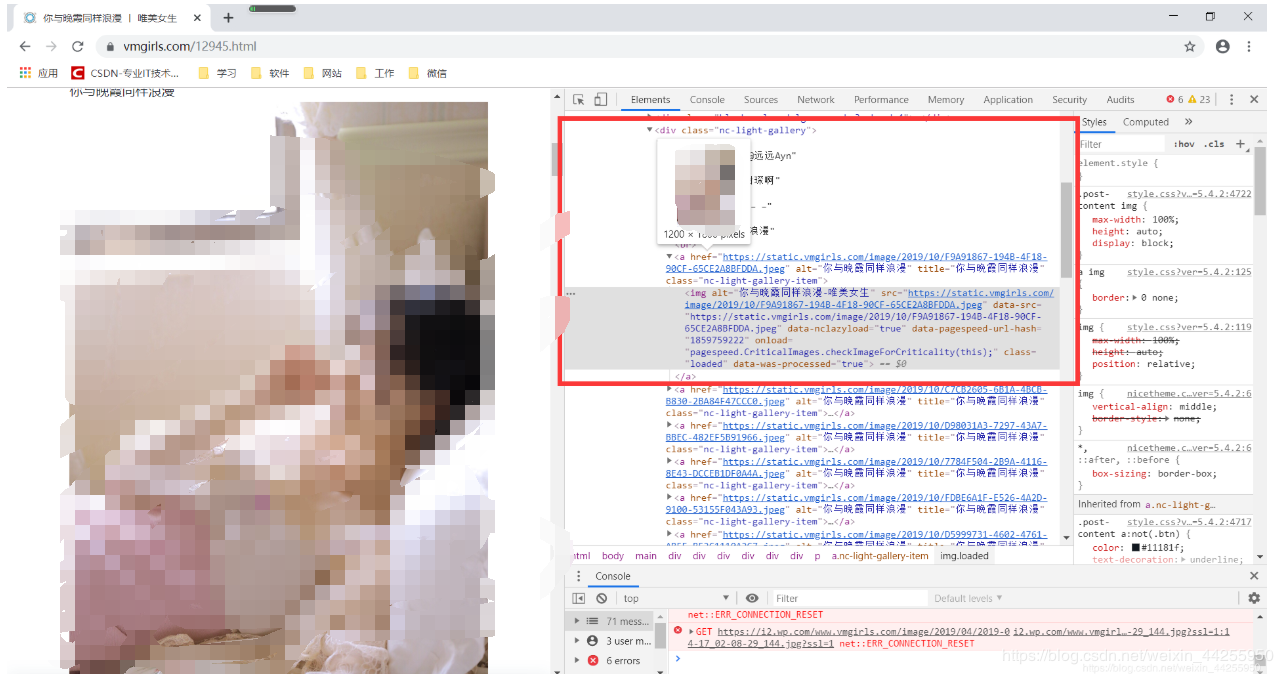
上面注意看匹配内容
然后进行解析(我们不是什么都需要匹配的,只是需要匹配href里面的内容)
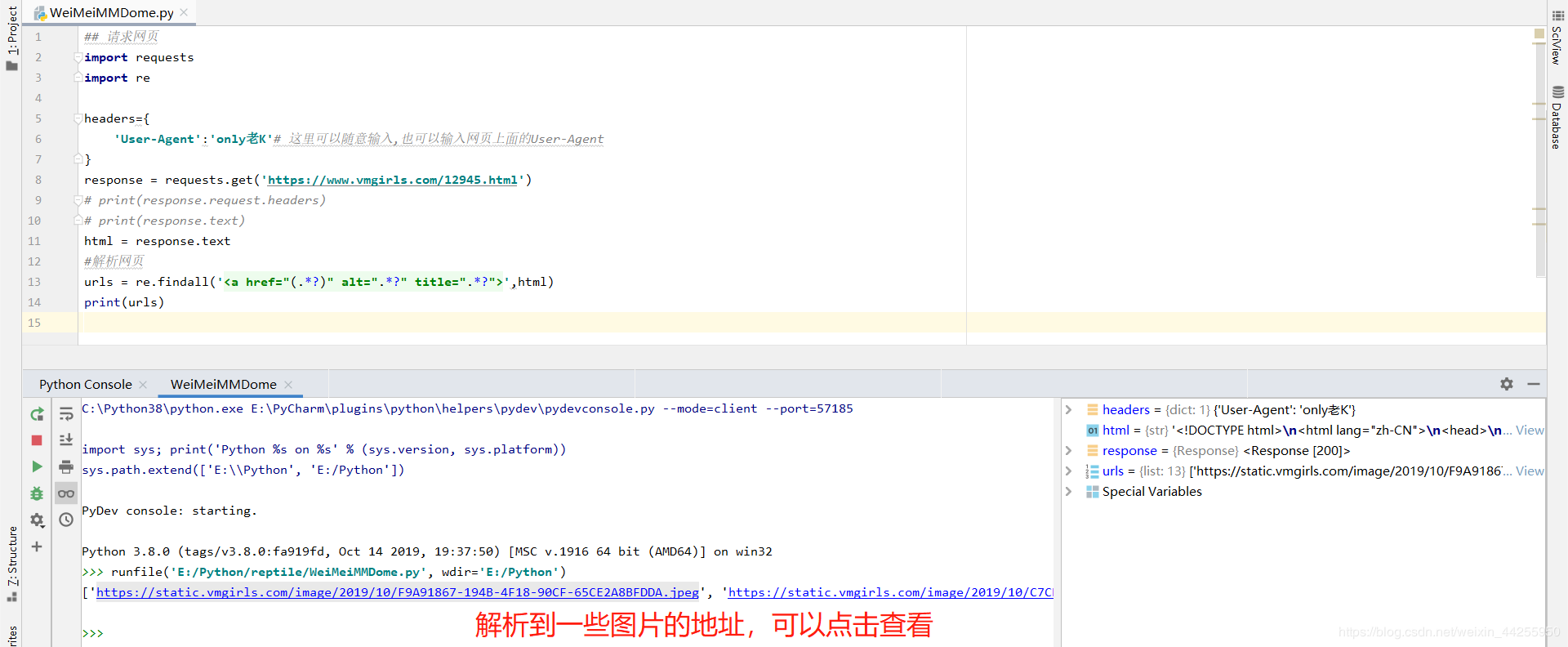
## 请求网页
import requests
import re
headers = {
'User-Agent':'only老K'# 这里可以随意输入,也可以输入网页上面的User-Agent
}
response = requests.get('https://www.vmgirls.com/12945.html')#然后这里就吧上面的headers放进去
#response = requests.get('https://www.vmgirls.com/12945.html',headers=headers)
# print(response.request.headers)
# print(response.text)
html = response.text
#解析网页
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html) # (.*?) 意思就是匹配这个数据
print(urls)
保存图片
第一版本:(文件存在在当前的文件夹,没有创建出来分类)
User-Agent:请求对象 AppleWebKit:请求内核 Chrome浏览器
## 请求网页
import requests
import re
import time
headers = {
'User-Agent':'only老K'# 这里可以随意输入,也可以输入网页上面的User-Agent
}
response = requests.get('https://www.vmgirls.com/12945.html')
# print(response.request.headers)
# print(response.text)
html = response.text
#解析网页
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html)
print(urls)
# 保存图片
for url in urls:
time.sleep(1) #睡眠一秒,别把别人网站查崩了
file_name = url.split('/')[-1]
response = requests.get(url) # 重新请求网站 图片地址就可以直接看了
with open(file_name,'wb') as f: #'wb':二进制 file_name:图片名称
f.write(response.content)
图片就有了…
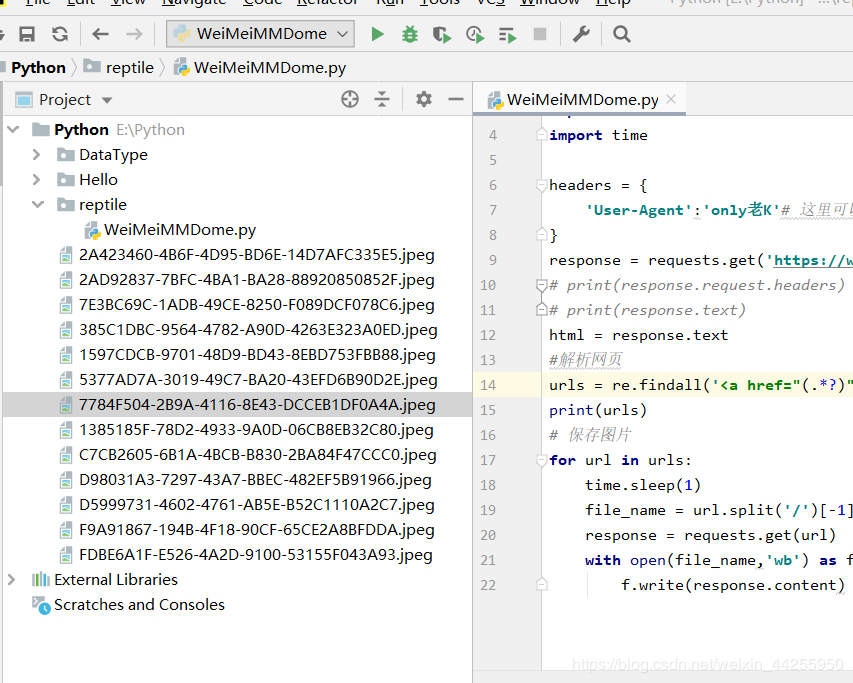
有问题?有点…不可能数据啥子的都放这里吧…
现在处理
## 请求网页
import requests
import re
import time
import os
headers = {
'User-Agent':'only老K'# 这里可以随意输入,也可以输入网页上面的User-Agent
}
response = requests.get('https://www.vmgirls.com/12945.html')
# print(response.request.headers)
# print(response.text)
html = response.text
#解析网页
dir_name = re.findall('<h1 class="post-title h3">(.*?)</h1>',html)[-1] #根据网页标题去做我们的文件夹名字
if not os.path.exists(dir_name):
os.mkdir(dir_name)
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html) # (.*?) 意思就是匹配这个数据
# print(urls)
# 保存图片
for url in urls:
time.sleep(1)
file_name = url.split('/')[-1]
response = requests.get(url)
with open(dir_name +'/' + file_name,'wb') as f: #'wb':二进制 file_name:图片名称
f.write(response.content)
网络觉得你的爬取速度…