参考资料:刘超老师的《趣谈网络协议》、罗剑锋老师的《透析HTTP》、陶辉老师的《Web协议详解与抓包实战》、尚硅谷的《JavaWeb》、
题引开篇
HTTP概述
HyperText Transfer Protocol,超文本传输协议。我们倒着来拆解一下HTTP的名字。
定义
协议
协议不就是那老三样:语法、语义、顺序。
- HTTP的语法是经典的ABNF语法格式,体现在它的报文段上。HTTP的报文通常分为两类,请求报文与响应报文;
- HTTP的语义,两种报文上的语义稍微有点差别;
- HTTP的顺序,就是我们通常分开的那几部分:行、头、体还有里面具体的部分的顺序。
说完组成,再说说意义,这个就很简单了,这么烦杂的约定,不就是方便通信么。这跟你开发的时候与前端约定好接口就是一个道理的。
传输
传输,传输什么?传输超文本呀,还能传输什么。
那HTTP的传输有什么特点?――双向传输,也就是我们经常说的,有请求就有响应。所以这里可以看到HTTP的基于TCP的。
当然,后面会提到Google研发想要取代HTTP的,基于UDP的QUIC,后面再说。
超文本
这个最迷,什么是超文本?再拆一拆,看看什么是文本(Text)。普通人的眼里,文本不就是写在记事本里的那些字么。在计算机眼里,文本就是二进制,毕竟它自己就是二进制组成的,“眼界有限”好吧。“二进制”?生活中哪有什么二进制啊?确实,生活中是没有,但如果把生活中的东西放入计算机,就有了。比如说生活中有美景,你把美景拍个照片,照片的最底层的数据就是二进制数据,同理视频、音频…太多了,不说了。
所以再强调一遍,文本是什么,就是简单的字符文字。那超文本呢?不也是文本么,也是字符文字。不过这个“超”意味着超越了普通文本,被组织成其他形式的文件,比如图片.jpg,音频.mp3,视频.mp4,这些也能从记事本打开看到字符,但他们有其他形式的打开方式,因此被称为超文本。
超文本里还有一个很重要的东西――超链接,这个如果遇到相应情况在仔细谈谈,目前好像没什么好说的。
小结
所以HTTP是什么呢?就是用来在计算机网络中传输文字、图片、音频、视频等超文本数据的约定和规范。
谈论一个问题,首先从是什么开始,是什么除了定义以外,还有总结出来的特点,因此我们看看HTTP的特点。
特点
HTTP主要有7个比较明显的特点:
- 可靠
- 应用层协议
- 请求-应答
- 无状态
- 易于扩展
- 明文传输
- 不安全
可靠
可靠就比较明显,因为HTTP是基于TCP的,其实就是TCP的可参考传输。
应用层协议
这里具体来说应该是HTTP超文本的传输特性,因为传统的应用层协议,如FTP只能传文件、SMTP只能发送邮件、SSH只能远程登录,在通用的数据传输方面不如HTTP。
请求-应答
HTTP中规定报文必须是“一收一发”,这个其实是跟互联网架构有点关系的,现在互联网中比较传统的架构还是C-S以及B-S,而这些架构的通信都离不开应用层的HTTP。
无状态
关于无状态,我们先说说什么是状态吧。状态是通信过程中记录信息变化的标志,比如TCP的那几个状态值,0-CLOSED,2-ESTABLISHED。
那为什么说HTTP是无状态的呢?因为它只知道传个数据,其他什么也不知道。一个请求,把数据传过去之后,就拜拜了,有点类似“事了拂衣去,深藏功与名”。说到这是不是有点眼熟,UDP也是这样的,不过HTTP还是有目标的打击,因为HTTP是有连接的,但UDP是无连接也无状态,干脆直接往端口扔,也不管IP对不对得上号。
“无状态”有什么好处呢?
因为服务器没有“记忆能力”,所以就不需要额外的资源来记录状态信息,不仅实现上会简单一些,而且还能减轻服务器的负担,能够把更多的CPU和内存用来对外提供服务。
而且,“无状态”也表示服务器都是相同的,没有“状态”的差异,所以可以很容易地组成集群,让负载均衡把请求转发到任意一台服务器,不会因为状态不一致导致处理出错,使用“堆机器”的“笨办法”轻松实现高并发高可用。
那么,“无状态”又有什么坏处呢?
既然服务器没有“记忆能力”,它就无法支持需要连续多个步骤的“事务”操作。例如电商购物,首先要登录,然后添加购物车,再下单、结算、支付,这一系列操作都需要知道用户的身份才行,但“无状态”服务器是不知道这些请求是相互关联的,每次都得问一遍身份信息,不仅麻烦,而且还增加了不必要的数据传输量。
易于扩展
这个特性其实主要是HTTP的报文结构,待会会说到,它的报文只规定了行、头的格式。HTTP协议里的请求方法、URI、状态码、原因短语、头字段等每一个核心组成要素都没有被“写死”,允许开发者任意定制、扩充或解释,给予了浏览器和服务器最大程度的信任和自由,也正好符合了互联网“自由与平等”的精神――缺什么功能自己加个字段或者错误码什么的补上就是了。
“请勿跟踪”所使用的头字段DNT ( Do Not Track )就是一个很好的例子。它最早由Mozilla提出,用来保护用户隐私,防止网站监测追踪用户的偏好。不过可惜的是DNT从推出至今有差不多七八年的历史,但很多网站仍然选择“无视”DNT。虽然DNT基本失败了,但这也正说明HTTP协议是“灵活自由的”,不会受单方面势力的压制。
“灵活、易于扩展”的特性还表现在HTTP对“可靠传输”的定义上,它不限制具体的下层协议,不仅可以使用TCP、UNIX Domain Socket,还可以使用SSL/TLS,甚至是基于UDP的QUIC,下层可以随意变化,而上层的语义则始终保持稳定。
明文传输
“明文”意思就是协议里的报文(准确地说是header部分)不使用二进制数据,而是用简单可阅读的文本形式。
对比TCP、UDP这样的二进制协议,它的优点显而易见,不需要借助任何外部工具,用浏览器、Wireshark或者tcpdump抓包后,直接用肉眼就可以很容易地查看或者修改,为我们的开发调试工作带来极大的便利。
当然,明文的缺点也是一样显而易见,HTTP报文的所有信息都会暴露在“光天化日之下”,在漫长的传输链路的每一个环节上都毫无隐私可言,不怀好意的人只要侵入了这个链路里的某个设备,简单地“旁路”一下流量,就可以实现对通信的窥视。
不安全
安全有很多的方面,明文只是“机密”方面的一个缺点,在“身份认证”和“完整性校验”这两方面HTTP也是欠缺的。
“身份认证”简单来说就是“怎么证明你就是你”。在现实生活中比较好办,你可以拿出身份证、驾照或者护照,上面有照片和权威机构的盖章,能够证明你的身份。但在虚拟的网络世界里这却是个麻烦事。HTTP没有提供有效的手段来确认通信双方的真实身份。虽然协议里有一个基本的认证机制,但因为刚才所说的明文传输缺点,这个机制几乎可以说是“纸糊的”,非常容易被攻破。如果仅使用HTTP协议,很可能你会连到一个页面一模一样但却是个假冒的网站,然后再被“钓”走各种私人信息。
HTTP协议也不支持“完整性校验”,数据在传输过程中容易被窜改而无法验证真伪。比如,你收到了一条银行用HTTP发来的消息:“小明向你转账一百元”,你无法知道小明是否真的就只转了一百元,也许他转了一千元或者五十元,但被黑客窜改成了一百元,真实情况到底是什么样子HTTP协议没有办法给你答案。
虽然银行可以用MD5、SHA1等算法给报文加上数字摘要,但还是因为“明文”这个致命缺点,黑客可以连同摘要一同修改,最终还是判断不出报文是否被窜改。
为了解决HTTP不安全的缺点,所以就出现了HTTPS,这个我们以后再说。
Http请求
浏览器发起HTTP请求的典型场景

Http请求的准备
经过三次握手来建立连接。
Http请求的构建
请求报文的格式:
- 请求行
- 请求头
- 请求体


请求行
版本: Http 1.1
URL : 这部分比较怪,待会再说。
常用方法: GET POST PUT DELETE HEAD
还有几个不常用的方法 : HEAD CONNECT OPTIONS TRACE
GET,POST,DELETE,HEAD,见名知意,开发都常用,看看PUT,这个比较迷惑。
PUT
就是向指定资源位置上传最新内容。但是,HTTP 的服务器往往是不允许上传文件的,所以 PUT 和 POST 就都变成了要传给服务器东西的方法.
URL
我们看看URL怪在哪。有没有发现上面那个请求报文,请求行是没有URL的,那去哪了?在请求体HOST字段那里。
我们又会发现,虽然没有URL,但多了一个斜杠,那是干嘛的?我们来看看下面这个你就清楚了。

这里发现/后面有东西,多了个11-1,仔细一看,发现是URL里面的。
实际上,请求的域名,都会放在请求头的HOST字段,剩下的/xxx/xxx其实是资源路径,保留在请求行,如果是GET请求的话,请求的参数也会在请求行里;POST请求的参数在请求体里。看看下图,?后面就是参数,其中用&隔开,也就是说,这个请求有两个参数,一个是a=1,一个是b=2

请求头
全是key value的键值对格式,说一下常见的几个:
-
Accept:表示客户端可以理解的MIME type,比如
text/html,application/xhtml+xml,application/xml;,这里表示可以接收好多个类型,每个类型用,隔开,这里对应于响应头的Content-Type; -
Accept-Encoding:表示客户端可以接受的字符编码,通常是一个压缩算法中,比如
gzip, deflate, br,同样不同类型用,隔开,这里对应响应头的Content-Encoding; -
Accept-Charset:表示客户端可以接受的字符集,这里对应响应头的
Content-Type; -
Accept-Language:表示客户端可以理解的自然语言,比如
zh-CN,zh,这里对应响应头的Content-Language; -
Content-Type:指正文的格式,如
application/json; charset=UTF-8,这个最常用。 -
Cache-control:当客户端发送的请求中包含 max-age 指令时,如果判定缓存层中,资源的缓存时间数值比指定时间的数值小,那么客户端可以接受缓存的资源;当指定 max-age 值为 0,那么缓存层通常需要将请求转发给应用集群。

我们看看还有一个注意的地方,比如下面这个Accept字段,后面那些q=0.9,q=0.8是干嘛的?
accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
这是内容协商的质量值,q是“quality factor”的意思,最大是1,最小的0.01,默认是1,是用来表示权重设置优先级的,具体语法就是数据类型或语言代码;q = value,比如上面的那个意思就是,希望能优先接受text/html,application/xhtml+xml,application/xml;q=0.9或者application/signed-exchange;v=b3;q=0.9,因为他们的权重都是0.9。
这里容易被逗号误导,其实在ABNF的语法中逗号表示的意义跟我们在文档中的分号是一个意思,就是说ABNF的逗号和分号的用法跟我们平时的用法刚好反过来。
请求体
Http请求的发送
- 进程通过 stream 二进制流的方式将数据传给传输层
- 传输层会将二进制流变成报文段
- 经过协议栈流程到达对方的传输层
- 传输层将报文段变成stream二进制流,上交给应用层的进程
HTTP响应
Http响应的构建
HTTP1.1 响应报文的格式:
- 响应行
- 响应头
- 响应体

相应行
版本号:HTTP 1.1
状态码: 就是以代码的形式表示服务器对请求的处理结果,通常跟后面的那个“原因短语Reason”一起使用。
短路:指的是原因短语,就是那些OK,Not Found那些。
这里最重要的是状态码,我们来具体看看状态码。
状态码
目前RFC标准的状态码是3位数,就是000到999。不过其实没那么多,一般就五类:
- 1xx:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
- 2xx:成功处理,一般原因短路那里就返回“OK”;
- 3xx:表示发生重定向;
- 4xx:客户端错误;
- 5xx:服务器错误;

我们看看常见的状态码
常见状态码
2xx
最常见的200 OK,表示成功,每次看到都能松一口气;
还有一个是204 No Content,也是成功,不过响应体是没有数据的;
另外在断点续传或者分块下载里可以见到的,206 Partial Content,表明响应的资源不是全部,只是一部分。
3xx
301 Moved Permanently 这个表示资源真不在那个地方了,建议下次的请求链接改一下;
302 Found 这个说明只是临时不在。
4xx
400 Bad Request,就客户端的请求报文有问题;
403 Forbidden,这个要特别关注以下,因为这个不完全是客户端的问题,是服务器不让你访问了,具体原因可能有很多,比如信息敏感,法律禁止,还有我自己遇到的因为前后端日期转换的问题,它给了一个这样的原因:
由于被认为是客户端的错误(例如:畸形的请求语法、无效的请求信息帧或者虚拟的请求路由),服务器无法或不会处理当前请求。
还有经典的404 Not Found,找不到资源,这原因太多了,希望有时间能总结一下。我最经常遇到的就是请求地址给写错了。哈哈
5xx
最常见的是 500 Internal Server Error,就是纯纯的服务器出问题。
还有一个 503 Service Unavailable,通常表示服务器很忙,暂时没空搭理你,然后一会再来的意思。
响应头
全是key value的键值对格式
-
Content-Encoding:表示响应的编码,比如
gzip -
Content-Type:告诉客户端实际返回的内容的内容类型,比如
text/html; charset=UTF-8 -
Retry-After:告诉客户端应该在多长时间以后再次尝试一下
响应体
HTTP传输大文件的方法
其实就传统的传输大文件的方法,也就两种比较常用的:
- 压缩
- 分块
在HTTP里对应的就是数据压缩、文件分块。
数据压缩
这里报文段涉及的字段是请求头的Accept-Encoding,表示浏览器支持的压缩格式列表,比如gzip,defalte,br等,这样服务器就可以从中选择一种压缩算法,放入Content-Encoding响应头里,再把原数据压缩后放发给浏览器。
这里压缩的数据一般是文本文件,像图片、音频视频那些,本来就被压缩过的,效果不是很好。
关于多媒体数据的压缩,后面谈到流媒体协议的时候会具体讲到。
分块传输
HTTP里的数据块,称为chunk。响应报文头部会有Transfer-Encoding:chunked,就表示相应的数据不是一次性发过来,而是分了许多chunk。
这里有一个特别注意的地方,chunk除了主观性的使用以外,当传输长度不确定的数据时,也就是常说的“流式数据”,Content-Length是无法给出确切长度的,因此也是用chunk来传输。也就是说,Transfer-Encoding:chunked 与 Content-Length 是互斥字段,只能出现一个。
分块传输的编码规则
规则super easy,每一个块都是 “数据 + 长度”。长度是16进制,数据和长度都用CRLF(也就是常说的\r\n)结尾。然后注意一下结尾,用长度0来表示结束分块。

范围请求
有没有想过,视频进度条拖动的话,数据是如何请求的?
这是为了满足需求,Web服务器扩展了一个功能――范围请求。
HTTP协议为了满足这样的需求,允许客户端在请求头里使用Accept-Ranges:bytes来告诉客户端支持范围请求,设置成Accept-Ranges:node就是不支持。
HTTP里的实现是用偏移量实现的,具体我还不太懂,先放放。
范围请求的出现其实是对分块传输的一个优化,这样做的好处有很多:
- 比如看视频可以根据时间点计算出文件的Range(偏移量),不用传输整个文件,直接精确获取片段所在的数据内容;
- 比如说我们下载时的多段下载、断点续传都是基于范围请求实现的:
- 先发个HEAD,看服务器是否支持范围请求,同时获取文件的大小;
- 开N个线程,每个线程使用Range字段划分出各自负责下载的片段,发请求传数据;
- 下载意外中断也不怕,不必重头再来一遍,只要根据上次的下载记录,用Range请求剩下的那一部分就可以了。
具体的我也不是很懂,以后学了再说。
多段数据
范围请求,一次拿某个段,其实还能拿多个段,看看下面这张图:

先留个坑,以后用到再回来深入了解一下。
HTTP的连接管理
在http1.1之前,是用短连接的,然后1.1之后才开始使用长连接,不过这长连接还有很多种叫法,比如“持久连接”、“连接保活”、“连接复用”。
长短连接
首先谈谈经典的短连接与长链接,因为HTTP是基于TCP的,所以要经过三次握手与四次挥手的过程。所以短连接是不可能短连接的,这辈子都不可能短连接的。

关于连接的头字段
HTTP1.1是默认开启长连接的,当然也可以在请求头里设置Connection:keep-alive来显示开启,不然其实没什么用好吧,都说了默认开启了。
这个字段主要用在关闭连接的时候,也就是设置成Connection:close来告诉服务器,这次通信之后就关闭连接。服务器看到后也会在响应报文加上Connection字段。
服务端通常不会主动关闭连接,除非是设置了一些策略,这里可以看看Nginx的两种策略:
- 使用“keepalive_timeout”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。
- 使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成1000,那么当Nginx在这个连接上处理了1000个请求后,也会主动断开连接。
队首阻塞
我们在讲“请求-应答”特性的时候提到HTTP报文必须是“一收一发”,因此容易出现阻塞的情况。最简单的解决方案就是开多线程并发了,不过如果用户数量多,用户数*并发数将会是一个天文数字,会将服务器弄炸的。
因此有一种从服务器端解决的方法,将域名分片,这是著名的domain sharding技术,后面将DNS的时候会详细谈到。主要的做法是开多个域名指向同一主域名。
以后遇到再补充更详细的资料。
重定向与跳转
这个基本过程在Java Web开发中已经学过了,贴两张图:


我们说说转发forward与重定向redirect的特点。
重定向与转发的特点
- forward
- 浏览器地址没有改变
- 多少次转发都只有一个请求
- 共享Request域的数据
- 可以转发到WEB-INF目录下
- 不可以访问工程以外的资源
- redirect
- 浏览器地址会发生变化
- 两次请求
- 不共享request域的数据
- 不能访问WEB-INF下的资源
- 可以访问工程以外的资源
我们主要研究一下重定向的使用场景。
重定向的使用场景
之前说过重定向一般常用的有两种,301 永久重定向 与 302 临时重定向。
先说一下为什么要用重定向,主要有两个常见的原因:
- 资源不可用
- 避免重复
资源不可用的情况太多了,域名变更、服务器变更…说不完,不说了;
避免重复主要是有的网站申请多个类似的域名,然后访问这些域名后,就重定向到主站上。
那301 和 302 什么时候用?
301比较常用的地方是搜索引擎优化(SEO),原来的URI可能因为换了新域名、服务器切换到新机房、网站目录重构…等原因导致不能用了,必须通知浏览器和搜索引擎更新到新地址。
302常用的场景一般是故障维护的时候,或者双十一“服务降级”,暂时把流引开,有点类似围魏救赵的策略吧。
重定向的相关问题
重定向主要有两个问题:
- 一个是性能损耗,因为比转发多发了一个请求。
- 另一个比较麻烦,循环跳转。因此HTTP协议特别规定浏览器必须具有检测“循环跳转”的能力。具体情况以后遇到再研究。
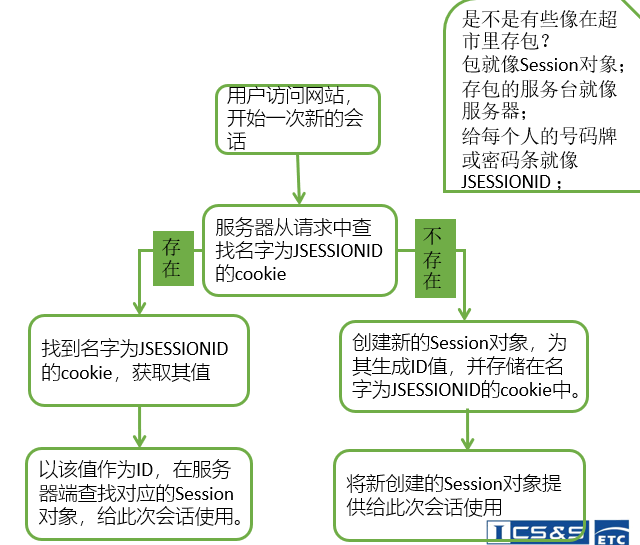
Cookie机制
首先看看Cookie的使用过程。
Cookie的使用过程
这要用到两个字段:响应头字段Set-Cookie和请求头字段Cookie。
当用户通过浏览器第一次访问服务器的时候,服务器肯定是不知道他的身份的。所以,就要创建一个独特的身份标识数据,格式是“key=value”,然后放进Set-Cookie字段里,随着响应报文一同发给浏览器。
浏览器收到响应报文,看到里面有Set-Cookie,知道这是服务器给的身份标识,于是就保存起来,下次再请求的时候就自动把这个值放进Cookie字段里发给服务器。
因为第二次请求里面有了Cookie字段,服务器就知道这个用户不是新人,之前来过,就可以拿出Cookie里的值,识别出用户的身份,然后提供个性化的服务。

Cookie里有两点是要注意的:
- Cookie是存在浏览器的,而不是放在操作系统本地,伴随着浏览器的关闭就消亡了;
- Cookie的语法不是HTTP那种,所以
;就是用来分开不同字段的。
Cookie的属性
贴一张以前学JavaWeb的图,是关于JavaWeb开发用到的属性:

还有几个关于安全性的属性:
- HttpOnly:只能通过HTTP协议传输
- SameSite
- 设置成
SameSite=Strict可以严格限定cookie不能随着跳转链接跨站发送 - 设置成
SameSite=Lax松一些,允许GET/HEAD等安全方法,但不允许POST跨站发送
- 设置成
- Secure:表示Cookie只能通过HTTPS协议加密传输,明文的HTTP协议会禁止发送。
Cookie的应用
比较常用的就是“身份识别”了,就是网站登录账号密码那些,这里主要是用Seesion,本质上是Cookie,后面可能会说到。
还有一个是广告跟踪,这个打开浏览器应该会经常看到,你上网的时候肯定看过很多的广告图片,这些图片背后都是广告商网站(例如Google ),它会“偷偷地”给你贴上Cookie小纸条,这样你上其他的网站,别的广告就能用Cookie读出你的身份,然后做行为分析,再推给你广告。
这种Cookie不是由访问的主站存储的,所以又叫“第三方Cookie”( third-party cookie )。如果广告商势力很大,广告到处都是,那么就比较“恐怖”了,无论你走到哪里它都会通过Cookiei认出你来,实现广告“精准打击”。
Session
Session,会话,底层通过Cookie实现,可以看看下面这两张图:

HTTP的缓存控制
Http2.0
2.0的特性:
- 首部压缩
- 二进制分帧
- 流量控制
- 多路复用
- 请求优先级
- 服务器推送
首部压缩
首部复用性
HTTP 1.1 在应用层以纯文本的形式进行通信。每次通信都要带完整的 HTTP 的头来描述资源属性。但首部可能存在相同的描述字段,重复发送会影响性能。
工作过程
为了解决这些问题,HTTP 2.0 会对 HTTP 的头进行一定的压缩,将原来每次都要携带的大量 key value 在两端建立一个索引表,对相同的头只发送索引表中的索引。
请求与响应首部的定义在HTTP2.0中基本没有变,只是所有首部键必须全部小写,而且要求行要独立为:method:、:scheme:、:host:、:path:这些键值对。
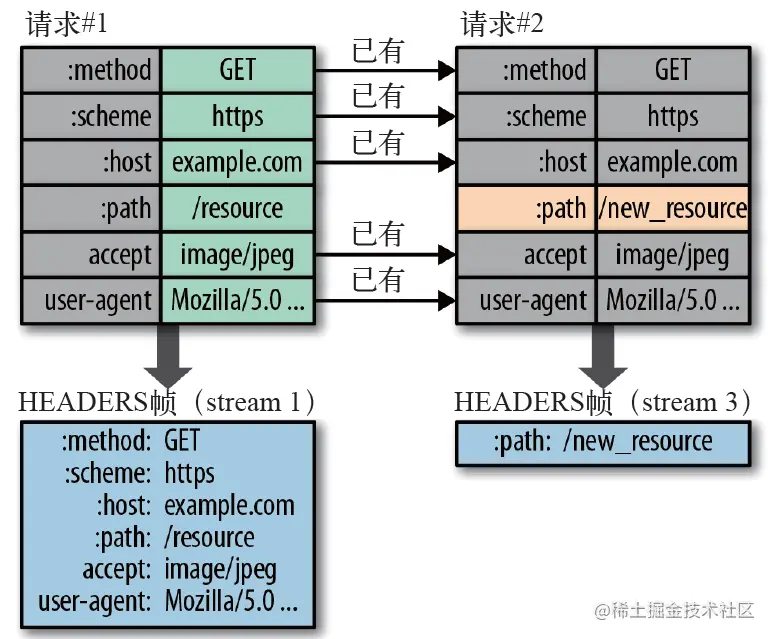
二进制分帧
通信单位
- 帧:HTTP2.0通信的最小单位
- 消息:比帧大的通讯单位,是指逻辑上的HTTP消息,比如请求、响应等。由一个或多个帧组成
- 流:比消息大的通讯单位。是TCP连接中的一个虚拟通道,可以承载双向的消息。
工作过程
HTTP 2.0 将所有的传输信息分割为更小的消息和帧,并对它们采用二进制格式的编码将其封装,如:
- Header 帧:用于传输 Header 内容(请求头),并且会开启一个新的流。
- Data 帧:用来传输正文实体(请求体)。多个 Data 帧属于同一个流。
流量控制
多路复用
基于二进制分帧层,HTTP2.0可以在共享TCP链接的基础上同时发送请求和响应。
HTTP 2.0 协议将一个 TCP 的连接中,切分成多个流,每个流都有自己的 ID,而且流可以是客户端发往服务端,也可以是服务端发往客户端。
它其实只是一个虚拟的通道。
HTTP消息被分解为独立的帧,而不破坏消息本身的语义。这些帧可以乱序发送,然后根据每个帧首部的流标识符重新组装。
请求优先级
把HTTP消息分为很多独立帧之后,就可以通过优化这些帧的交错和传输顺序进一步优化性能。
每个流都可以带有一个31bit的优先值:0表示最高优先级;2的31次方-1表示最低优先级。
工作过程
客户端明确指定优先级,服务端可以根据这个优先级作为交互数据的依据,比如客户端优先设置为.css>.js>.jpg。服务端按此顺序返回结果更加有利于高效利用底层连接,提高用户体验。然而,在使用请求优先级时应注意服务端是否支持请求优先级,是否会引起队首阻塞问题,比如高优先级的慢响应请求会阻塞其他资源的交互。
服务器推送
案例分析
假设我们的一个页面要发送三个独立的请求,一个获取css,一个获取js,一个获取图片jpg。如果使用HTTP 1.1就是串行的,但是如果使用HTTP 2.0,就可以在一个连接里,客户端和服务端都可以同时发送多个请求或回应,而且不用按照顺序一对一对应。
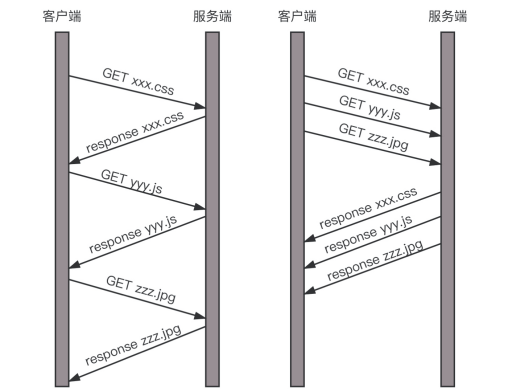
HTTP 2.0其实是将三个请求变成三个流,将数据分成帧,乱序发送到一个TCP 连接中。
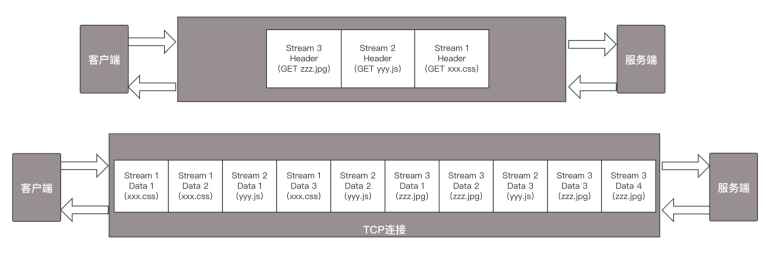
缺点
- 乱序不符合TCP协议
因为 HTTP 2.0 也是基于 TCP 协议的,TCP 协议在处理包时是有严格顺序的。当其中一个数据包遇到问题,TCP 连接需要等待这个包完成重传之后才能继续进行。虽然 HTTP 2.0 通过多个 stream,使得逻辑上一个 TCP 连接上的并行内容,进行多路数据的传输,然而这中间并没有关联的数据。一前一后,前面 stream 2 的帧没有收到,后面 stream 1 的帧也会因此阻塞。
QUIC协议
Quick UDP Internet Connection,基于UDP协议,打算替代 TCP 成为 HTTP/3 的数据传输层协议,主要有4个机制:
- 自定义连接:以随机数代替四元组标识
- 自定义重传:一次性序号解决RTT计算不准的问题
- 无阻塞多路复用:
- 自定义流量控制:
自定义连接机制
我们都知道,一条 TCP 连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口.一旦一个元素发生变化时,就需要断开重连,重新连接。
在移动互联情况下,当手机信号不稳定或者在 WIFI 和 移动网络切换时,都会导致重连,从而进行再次的三次握手,导致一定的时延。
这在 TCP 是没有办法的,但是基于 UDP,就可以在 QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
自定义重传机制
在 TCP 里面超时的采样存在不准确的问题。QUIC 也有个序列号,是递增的。任何一个序列号的包只发送一次,下次就要加一了。例如,发送一个包,序号是 100,发现没有返回;再次发送的时候,序号就是 101 了;如果返回的 ACK 100,就是对第一个包的响应。如果返回 ACK 101 就是对第二个包的响应,RTT 计算相对准确。但是这里有一个问题,就是怎么知道包 100 和包 101 发送的是同样的内容呢?
QUIC 定义了一个 offset 概念。QUIC 既然是面向连接的,也就像 TCP 一样,是一个数据流,发送的数据在这个数据流里面有个偏移量 offset,可以通过 offset 查看数据发送到了哪里,这样只要这个 offset 的包没有来,就要重发;如果来了,按照 offset 拼接,还是能够拼成一个流。
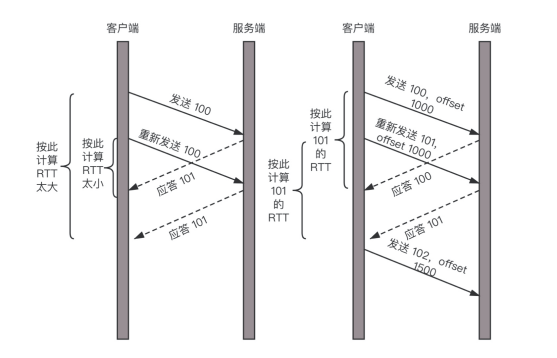
无阻塞的多路复用
同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
自定义流量控制
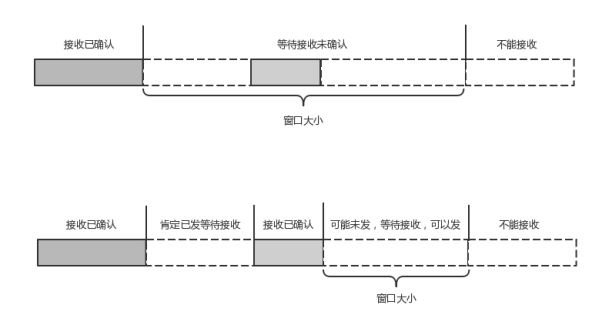
QUIC 的流量控制也是通过 window_update,来告诉对端它可以接受的字节数。但是 QUIC 的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个 stream 控制窗口。
还记得吗?在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
QUIC 的 ACK 是基于 offset 的,每个 offset 的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空档会等待到来或者重发即可,而窗口的起始位置为当前收到的最大 offset,从这个 offset 到当前的 stream 所能容纳的最大缓存,是真正的窗口大小。显然,这样更加准确。
小结
HTTP协议虽然很常用,也很复杂,重点记住GET、POST、PUT、DELETE这几个方法,以及重要的首部字段;
HTTP2.0通过头压缩、分帧、二进制编码、多路复用等技术提升性能;
QUIC协议通过基于UDP自定义的类似TCP的连接、重试、多路复用、流量控制技术,进一步提升性能。