爬虫笔记(一)
什么是爬虫
请求网络并提取数据的自动化程序
爬虫流程
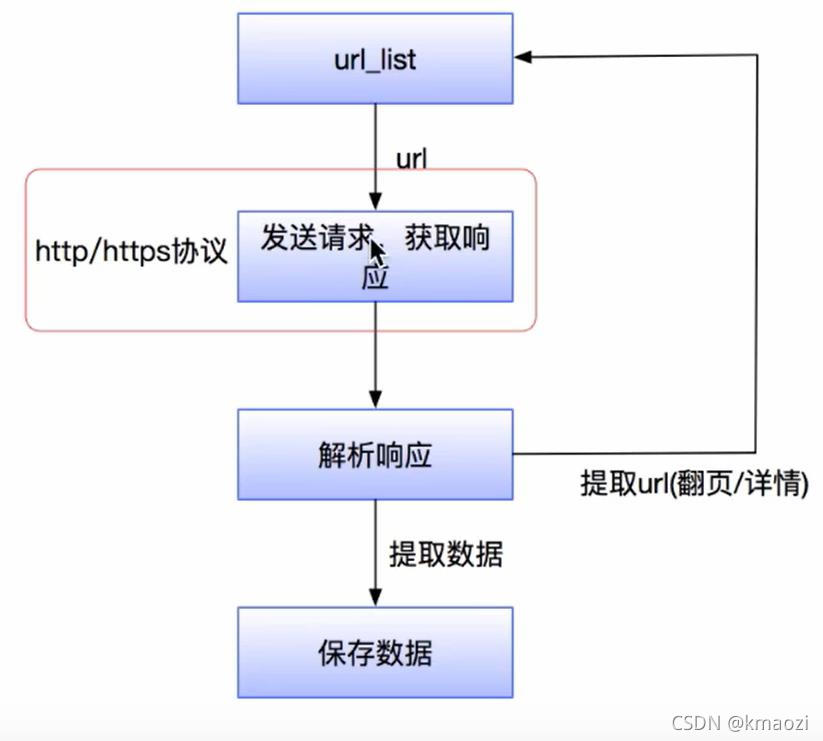
1、对url向服务器发起request请求
2、服务器返回一个respond响应,respond中的内容即为获取页面的内容
3、解析网页内容,若是url则进行爬取,若是数据则保存在数据库中
4、重复以上操作直至满足设置的停止条件或者没有url可爬取为止
request的常用属性
1、请求方式:
| get | 请求指定的页面信息,并返回实体主体 |
|---|---|
| post | 向指定资源提交数据 |
| head | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| put | 从客户端向服务器传送的数据取代指定的文档的内容 |
| delete | 请求服务器删除指定的页面 |
| options | 允许客户端查看服务器的性能 |
'''
get和post的区别
get用于向服务器获取资源,参数保存在url中,post用于向服务器提交数据(比如提交from表单),
数据是隐藏的保存在请求体中,因此post比get安全。
'''
import requests
url = "https://www.baidu.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
data = {'wq': "dog"}
response = requests.get( # get用于向服务器获取资源,访问百度成功
url=url,
headers=headers,
params=data,
timeout=3) # 向服务器发送请求后,若超过3秒没有得到响应则抛出异常
'''
response1 = requests.post( # post请求用于向服务器提交数据,比如登录页面的form表单,访问百度失败
url=url,
headers=headers,
data=data)
'''
with open("baidu.com", "wb")as f:
f.write(response.content)
2、请求头包含的主要信息
| User-Agent | 用户代理 |
|---|---|
| Referer | 页面跳转处 |
| Cookie | 保存登录信息 |
| Connection | 链接类型 |
| Upgrade-Insecure-Requests | 升级为Https请求 |
| Authorization | 用于表示HTTP协议中需要认证资格的认证信息 |
3、请求体:请求时额外携带的数据,如表单提交时的表单数据
Response的常用属性
1、响应状态:
2、响应头:如内容类型、内容长度、服务器信息、设置Cookie等
爬虫只关注Set-Cookie这一个响应头
3、响应体:请求资源的内容如网页、图片、二进制数据
# response的基本属性
import requests
url = "https://www.baidu.com/"
response = requests.get(url) # 向服务器发送request请求并接收返回的Response对象
'''
response.content:以字节码形式存储返回的网页内容
response.text:以某种猜测的编码方式将返回的网页内容编码成字符串
若是网页内容为中文,则需要utf-8、GBK,GB2312来编码,否则会出现中文乱码问题
共同点:皆是存储的网页内容
不同点:网页内容的存储形式不一样
联系:response.text=response.content.decode("推测的编码方式")
'''
# print(response.text) # 出现中文乱码问题
print(response.content.decode('utf-8')) # 解决中文乱码问题:网络传输的字符串都是Byte类型的,response.content是存储Byte类型的响应源码
print(response.url) # 响应url
print(response.status_code) # 响应状态码
print(response.request.headers) # 响应对应请求的请求头
print(response.headers) # 响应头
print(response.cookies.get_dict) # 响应的cookies
print(response.request) # 返回请求方式
print(response.history) # 返回请求(URL)历史的响应对象列表
爬取的数据的类型
1、网页
2、图片
3、视频
4、其他
解析方式
1、直接处理
2、Json解析
3、正则表达式
4、PyQuery
5、BeautifulSoup
6、XPath
怎样解决Javascript渲染问题
1、分析Ajax请求
2、Selenium/WebDriver
首发文章,如若有错,望指教。