RPC(Remote Procedure Call)远程过程调用,一个RPC框架应该是帮我们屏蔽网络编程的细节,实现远程调用就跟本地调用一样的体验。总的来说,RPC的作用就是体现在这样两个方面:
- 屏蔽远程调用跟本地调用的区别,让我们感觉就是调用项目内的方法;
- 隐藏底层网络通信的复杂性,让我们更专注于业务逻辑。
0x01 核心原理
为什么需要RPC?或如果没有 RPC 会怎样?
所有的代码堆砌在一个项目中,开发过程中可能就会遇到,在只需要改一行代码, 编译却需要花很长时间。如果是团队开发项目,别人把接口定义改了的话,我们连编译通过的机会都没有。这就导致团队开发效率低下
因此,我们需要将服务进行拆分,实现分而治之的思想。这时 RPC 就可以帮我们解决服务拆分后的调用(通信)问题,能让我们像拆分前调本地方法一样的方式实现远程方法调用。此时,应用就由 “单体” 演化成了 “微服务化”。这解决了开发过程中的效率低下的问题,还有效的使系统进行了解耦,使得应用框架更为清晰、健壮,并且易于运维。
一个完整的RPC涉及到哪些步骤
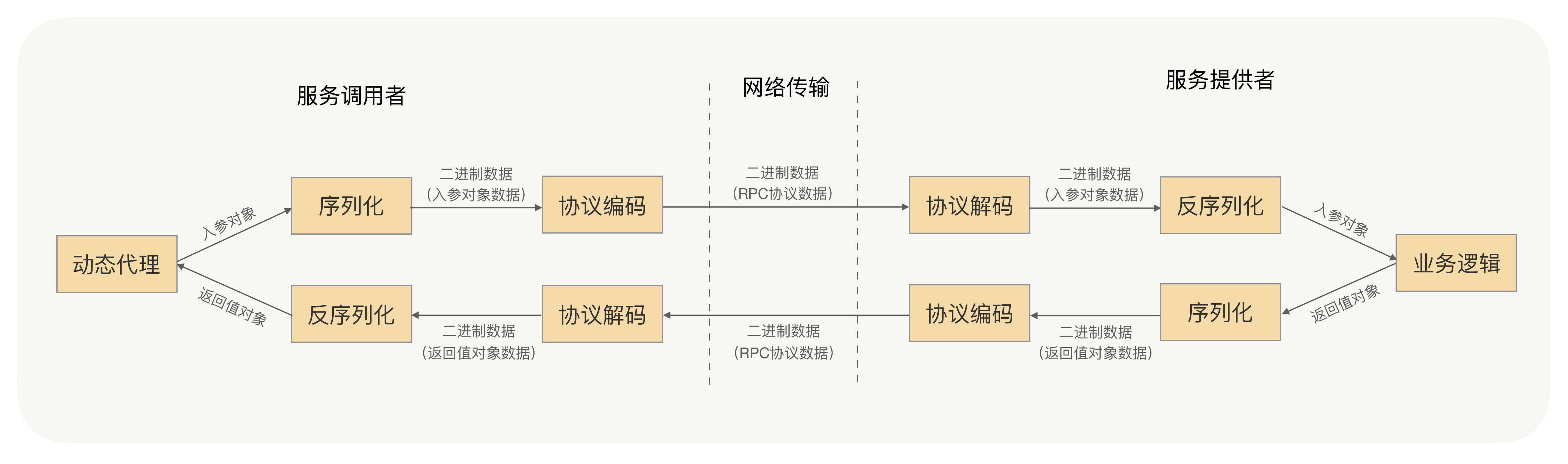
- 传输协议:RPC 为了保证可靠性,默认使用TCP作为传输协议。
- 序列化与反序列化:
- 在网络传输中的数据必须是二进制,因此需要将应用层的内容(对象)转成二进制,并且这一过程必须是可逆的。(这个将对象转换为二进制格式的过程就是序列化)
- 在网络传输中可以在消息头中加入对消息体的定义,这样服务提供方就可以根据协议格式,服务提供方就可以正确地从二进制数据中分割出不同的请求来,同时根据请求类型和序列化类型,把二进制的消息体逆向还原成请求对象。这个过程叫作“反序列化”。
- 服务提供方本地调用:服务提供方再根据反序列化出来的请求对象找到对应的实现类,完成真正的方法调用
- 返回结果:把执行结果序列化后,回写到对应的TCP通道里面。调用方获取到应答的数据包后,再反序列化成应答对象,这样调用方就完成了一次RPC调用。
上面的过程还缺乏很多的细节,比如,如何构造请求,调用序列化,网络调用的实现,等等。那么如何才能屏蔽 RPC 的细节,让使用方像调用本地接口一样实现远程调用?
Spring 中的 AOP 技术,核心是采用动态代理技术,通过字节码增强对方法的拦截增强,以便于实现增加额外的逻辑。这一技术就可以应用到 RPC 场景来解决
由服务提供者给出业务接口声明,在调用方的程序里面,RPC框架根据调用的服务接口提前生成动态代理实现类,并通过依赖注入等技术注入到声明了该接口的相关业务逻辑里面。该代理实现类会拦截所有的方法调用,在提供的方法处理逻辑里面完成一整套的远程调用,并把远程调用结果返回给调用方,这样调用方在调用远程方法的时候就获得了像调用本地接口一样的体验。
0x02 RPC 协议
前面提到,数据需要使用二进制在网络中传输,那么如何从一串二进制数据中,正确识别出请求所对应的部分并解析出来呢?这就需要协议来进行约定。
为什么不用 现有的 HTTP 协议?
相对于HTTP的用处,RPC更多的是负责应用间的通信,所以性能要求相对更高。但HTTP协议的数据包大小相对请求数据本身要大很多,又需要加入很多无用的内容,比如换行符号、回车符等;还有一个更重要的原因是,HTTP协议属于无状态协议,客户端无法对请求和响应进行关联,每次请求都需要重新建立连接,响应完成后再关闭连接。因此,对于要求高性能的RPC来说,HTTP协议基本很难满足需求
由于 RPC 的每次调用请求包大小是不固定的,并且还有可能进行拆包与组包(对相同目的地址)。
这时我们就可以先在请求头部固定一个长度来存放该条请求的数据大小。此时我们就可以从数据包中提取出一次请求对应的二进制字符串,但如何将其反序列化成对象呢? 这就需要在头部再固定一个长度来存放序列化方式。当然除了上面的两种,还会存放一些诸如:消息ID,消息类型等参数。
此时,一个协议就被拆分成了协议头和协议体。协议头是由一堆固定的长度参数组成;协议体根据请求接口和参数构造的,一般只放请求接口方法、请求的业务参数值和一些扩展属性,长度属于可变的。
那么这样的设计是否合理呢?似乎失去了请求头的拓展性,那么可以在加两个固定位――一个记录协议总长度,一个记录消息头长度,剩下那个记录消息体长度。