TCP������ص�
�����Э����Ҫ������: TCPЭ���UDPЭ�顣TCPЭ�������UDPЭ����ص���:�������ӡ��ֽ����Ϳɿ����䡣
ʹ��TCPЭ��ͨ�ŵ�˫�������Ƚ�������,Ȼ����ܿ�ʼ���ݵĶ�д��˫��������Ϊ�����ӷ����Ҫ���ں���Դ,�Թ������ӵ�״̬�����������ݵĴ��䡣TCP������ȫ˫����,��˫�������ݶ�д����ͨ��һ�����ӽ��С�������ݽ���֮��,ͨ��˫��������Ͽ��������ͷ�ϵͳ��Դ��
TCPЭ�������������һ��һ��,���Ի��ڹ㲥�Ͷಥ(Ŀ���Ƕ��������ַ)��Ӧ�ó�����ʹ��TCP����������Э��UDP��dz��ʺ��ڹ㲥�Ͷಥ��
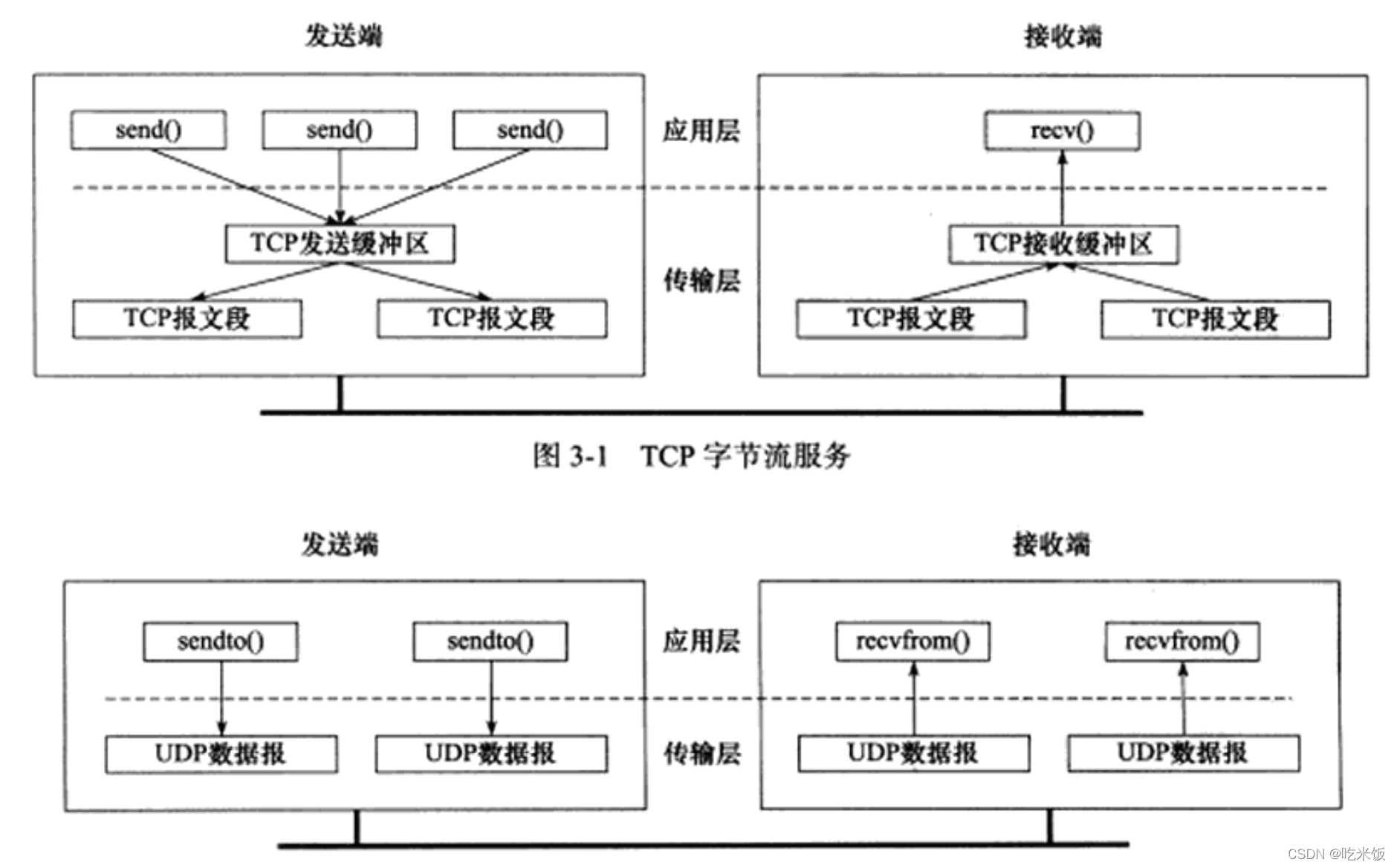
�ֽ�����������ݱ���������������Ӧ��ʵ�ʱ����,������Ϊͨ��˫���Ƿ����ִ����ͬ�����Ķ���д����(��Ȼ,��ֻ�DZ�����ʽ)�������Ͷ�Ӧ�ó�������ִ�ж��д����ʱ,TCPģ���Ƚ���Щ���ݷ���TCP���ͻ������С���TCPģ��������ʼ��������ʱ,���ͻ���������Щ�ȴ����͵����ݿ��ܱ���װ��һ������TCP���Ķη��������,TCPģ�鷢�ͳ���TCP���Ķεĸ�����Ӧ�ó���ִ�е�д��������֮��û�й̶���������ϵ��
�����ն��յ�һ������TCP���Ķκ�,TCPģ�齫����Я����Ӧ�ó������ݰ���TCP���Ķε����(������)���η���TCP���ջ�������,��֪ͨӦ�ó����ȡ���ݡ����ն�Ӧ�ó������һ���Խ�TCP���ջ������е�����ȫ������,Ҳ���Էֶ�ζ�ȡ,��ȡ�����û�ָ����Ӧ�ó�����������Ĵ�С�����,Ӧ�ó���ִ�еĶ�����������TCPģ����յ���TCP���Ķθ���֮��Ҳû�й̶���������ϵ��
��������,���Ͷ�ִ�е�д���������ͽ��ն�ִ�еĶ���������֮��û���κ�������ϵ,������ֽ����ĸ���:Ӧ�ó�������ݵķ��ͺͽ�����û�б߽����Ƶġ�UDP��Ȼ�����Ͷ�Ӧ�ó���ÿִ��һ��д����,UDPģ��ͽ����װ��-һ�� UDP���ݱ�������֮�����ն˱��뼰ʱ���ÿһ��UDP���ݱ�ִ�ж�����(ͨ��recvfromϵͳ����),����ͻᶪ��(�⾭�������ڽ����ķ�����,��)������,����û�û��ָ���㹻��Ӧ�ó���������ȡUDP����,��UDP���ݽ����ضϡ�
TCP�����ǿɿ��ġ�����,TCP Э����÷���Ӧ�����,�����Ͷ˷��͵�ÿ��TCP���Ķζ�����õ����շ���Ӧ��,����Ϊ���TCP���Ķδ���ɹ������,TCPЭ����ó�ʱ�ش�����,���Ͷ��ڷ��ͳ�һ��TCP���Ķ�֮��������ʱ��,����ڶ�ʱʱ����δ�յ�Ӧ��,�����ط��ñ��ĶΡ����,��ΪTCP���Ķ���������IP���ݱ����͵�,��IP���ݱ�������ն˿��������ظ�,����TCPЭ�黹��Խ��յ���TCP���Ķ����š�����,�ٽ�����Ӧ�ò㡣.UDPЭ�����IPЭ��һ��,�ṩ���ɿ��������Ƕ���Ҫ�ϲ�Э������������ȷ�Ϻͳ�ʱ�ش���
TCPͷ���ṹ
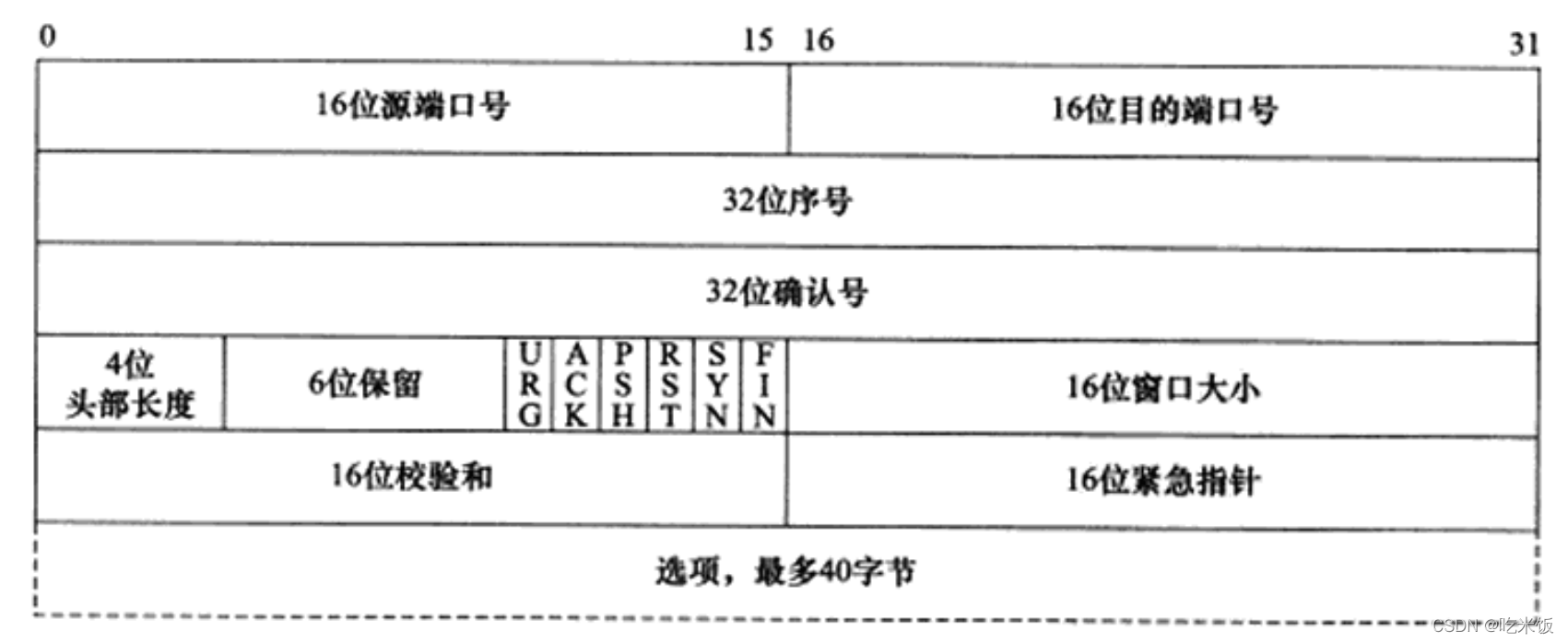
TCP�̶�ͷ���ṹ
-
16λ�˿ں�(port number):��֪�����ñ��Ķ�����������(Դ�˿�)�Լ������ĸ��ϲ�Э���Ӧ�ó���(Ŀ�Ķ˿�)�ġ�����TCPͨ��ʱ,�ͻ���ͨ��ʹ��ϵͳ�Զ�ѡ�����ʱ�˿ں�,����������ʹ��֪������˿ںš�1.3 �����ᵽ��,����֪������ʹ�õĶ˿ںŶ�������/etc/services�ļ��С�
-
32λ���( sequence number):һ��TCPͨ��(��TCP���ӽ������Ͽ�)������ijһ�����䷽���ϵ��ֽ�����ÿ���ֽڵı�š���������A������B����TCPͨ��,A����B�ĵ�һ��TCP���Ķ���,���ֵ��ϵͳ��ʼ��Ϊij�����ֵISN ( Initial Sequence Number,��ʼ���ֵ)����ô�ڸô��䷽����(��A��B),������TCP���Ķ������ֵ����ϵͳ���ó�ISN���ϸñ��Ķ���Я�����ݵĵ�һ���ֽ��������ֽ����е�ƫ�ơ�����,ij��TCP���Ķδ��͵��������ֽ����еĵ�1025~2048�ֽ�,��ô�ñ��Ķε����ֵ����ISN+1025.����һ�����䷽��(��B��A)��TCP���Ķε����ֵҲ������ͬ�ĺ��塣
-
32λȷ�Ϻ�(acknowledgement number):��������һ����������TCP���Ķε���Ӧ����ֵ���յ���TCP���Ķε����ֵ��1.��������A������B����TCPͨ��,��ôA���ͳ���TCP���Ķβ���Я���Լ������,���Ұ�����B��������TCP���Ķε�ȷ�Ϻš���֮,B���ͳ���TCP���Ķ�ҲͬʱЯ���Լ�����źͶ�A�������ı��Ķε�ȷ�Ϻš�
-
4λͷ������(header length):��ʶ��TCPͷ���ж��ٸ�32bit��(4�ֽ�)����Ϊ4λ����ܱ�ʾ15,����TCPͷ�����60�ֽڡ�
-
6λ��־λ�������¼���:
- URG��־,��ʾ����ָ��(urgent pointer)�Ƿ���Ч��
- ACK��־,��ʾȷ�Ϻ��Ƿ���Ч�����dz�Я��ACK��־��TCP���Ķ�Ϊȷ�ϱ��ĶΡ�
- PSH��־,��ʾ���ն�Ӧ�ó���Ӧ��������TCP���ջ������ж�������,Ϊ���պ�
�������ڳ��ռ�(���Ӧ�ó������յ������ݶ���,���Ǿͻ�Cֱͣ����TCP���ջ�������)�� - RST��־,��ʾҪ��Է����½������ӡ����dz�Я��RST��־��TCP���Ķ�Ϊ��λ���ĶΡ�
- SYN��־,��ʾ������-һ�����ӡ����dz�Я��SYN��־��TCP���Ķ�Ϊͬ�����ĶΡ�
- FIN��־,��ʾ֪ͨ�Է�����Ҫ�ر������ˡ����dz�Я��FIN��־��TCP���Ķ�Ϊ�������ĶΡ�
-
16λ���ڴ�С( window size):��TCP�������Ƶ�-һ���ֶΡ�����˵�Ĵ���,ָ���ǽ���ͨ�洰��(Receiver Window, RWND)�������߶Է����˵�TCP���ջ������������ɶ����ֽڵ�����,�����Է��Ϳ��Կ��Ʒ������ݵ��ٶȡ�
-
16λУ���(TCP checksum):�ɷ��Ͷ����,���ն˶�TCP���Ķ�ִ��CRC�㷨�Լ���TCP���Ķ��ڴ���������Ƿ���ע��,���У�鲻������TCPͷ��,Ҳ�������ݲ��֡���Ҳ��TCP�ɿ������-һ����Ҫ���ϡ�
-
16λ����ָ��(urgent pointer):��-һ������ƫ��������������ֶε�ֵ��ӱ�ʾ���һ���������ݵ���һ-�ֽڵ���š����,ȷ�е�˵,����ֶ��ǽ���ָ����Ե�ǰ��ŵ�ƫ��,������֮Ϊ����ƫ�ơ�TCP �Ľ���ָ���Ƿ��Ͷ�����ն˷��ͽ������ݵķ�����
TCPͷ��ѡ��
TCPͷ�������-һ��ѡ���ֶ�(options) �ǿɱ䳤�Ŀ�ѡ��Ϣ���ⲿ��������40�ֽ�,��ΪTCPͷ�����60�ֽ�(���л�����ǰ�����۵�20�ֽڵĹ̶�����)�����͵�TCPͷ��ѡ��ṹ��ͼ��ʾ��

ѡ��ĵ�һ���ֶ�kind˵��ѡ������͡��е�TCPѡ��û�к��������ֶ�,������1�ֽڵ�kind�ֶΡ��ڶ����ֶ�length ( ����еĻ�)ָ����ѡ����ܳ���,�ó��Ȱ���kind�ֶκ�length�ֶ�ռ�ݵ�2�ֽڡ��������ֶ�info (����еĻ�)��ѡ��ľ�����Ϣ��������TCPѡ����7��,��ͼ��ʾ��
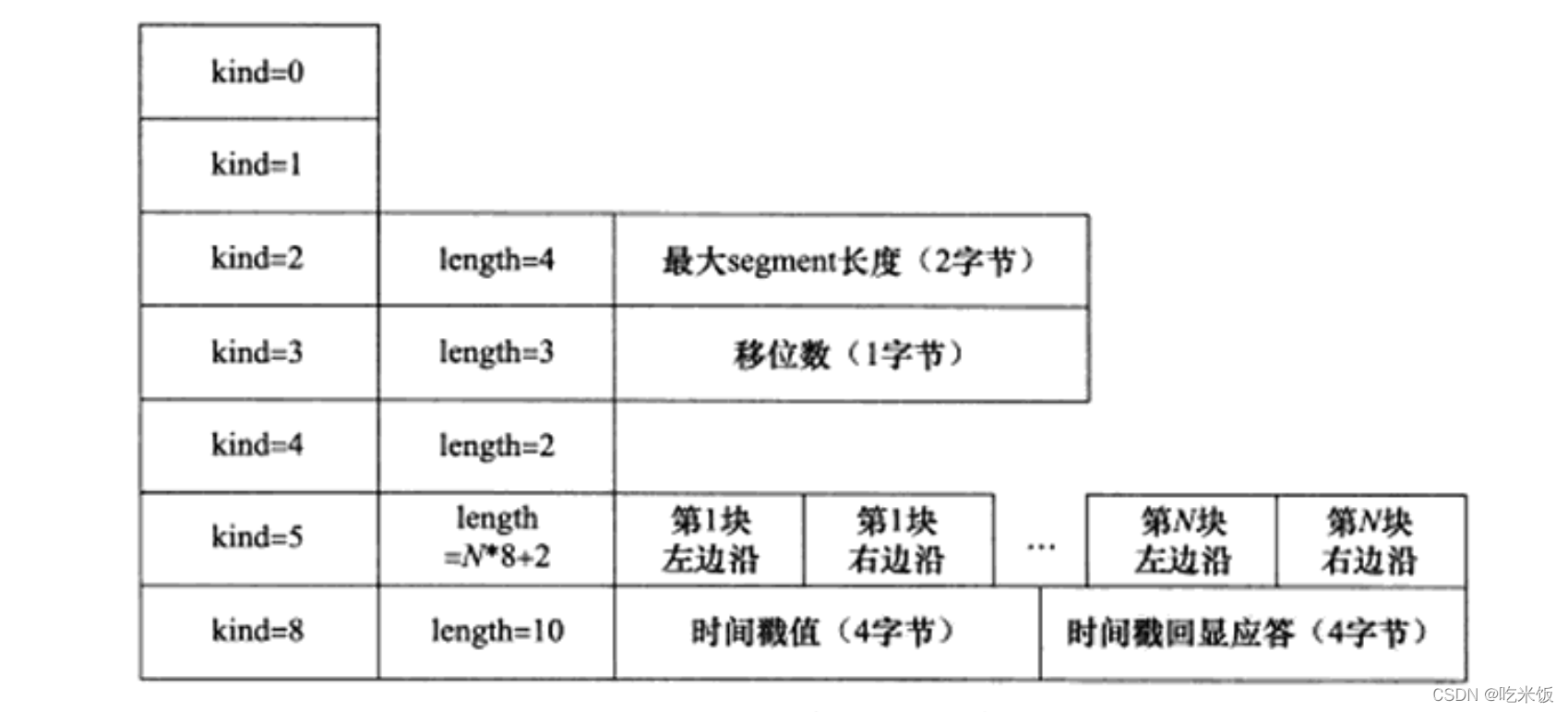
- kind=0��ѡ�������ѡ�
- kind=1�ǿղ���(nop)ѡ��,û�����⺬��,һ�����ڽ�TCPѡ����ܳ������Ϊ4�ֽڵ���������
- kind =2������Ķγ���ѡ�TCP���ӳ�ʼ��ʱ,ͨ��˫��ʹ�ø�ѡ����Э������Ķγ���(Max Segment Size, MSS)�� TCPģ��ͨ����MSS����Ϊ(MTU-40) �ֽ�(��������40�ֽڰ���20�ֽڵ�TCPͷ����20�ֽڵ�IPͷ��)������Я��TCP���Ķε�IP���ݱ��ij��ȾͲ��ᳬ��MTU (����TCPͷ����IPͷ����������ѡ���ֶ�,������Ҳ��һ�����),�Ӷ����Ȿ������IP��Ƭ������̫������,MSSֵ��1460 (1500 -40)�ֽڡ�
- kind=3�Ǵ�����������ѡ�TCP���ӳ�ʼ��ʱ,ͨ��˫��ʹ�ø�ѡ����Э�̽���ͨ�洰�ڵ��������ӡ���TCP��ͷ����,����ͨ�洰�ڴ�С����16λ��ʾ��,�����Ϊ65535�ֽ�,��ʵ����TCPģ�������Ľ���ͨ�洰�ڴ�СԶ��ֹ�����(Ϊ�����TCPͨ�ŵ�������)�������������ӽ����������⡣����TCPͷ���еĽ���ͨ�洰�ڴ�С��N,������������(��λ��)��M,��ôTCP���Ķε�ʵ�ʽ���ͨ�洰�ڴ�С��N��2^M,����˵N����Mλ��ע��,M��ȡֵ��Χ��0~14�����ǿ���ͨ����/proc/sys/net/ipv4/tcp_window_scaling�ں˱��������û�رմ�����������ѡ�
��MSSѡ��-��,������������ѡ��ֻ�ܳ�����ͬ�����Ķ���,�������ԡ���ͬ�����Ķα�����ִ�д����������,��ͬ�����Ķ�ͷ���Ľ���ͨ�洰�ڴ�С���Ǹ�TCP���Ķε�ʵ�ʽ���ͨ�洰�ڴ�С�������ӽ�����֮��,ÿ�����ݴ��䷽��Ĵ����������Ӿ̶������ˡ�
- kind=4��ѡ����ȷ��( Selective Acknowledgment, SACK) ѡ�TCPͨ��ʱ,���ij��TCP���Ķζ�ʧ,��TCPģ����ش����ȷ�ϵ�TCP���Ķκ��������б��Ķ�,����ԭ���Ѿ���ȷ�����TCP���Ķ�Ҳ�����ظ�����,�Ӷ�������TCP���ܡ�SACK��������Ϊ�������������������,��ʹTCPģ��ֻ���·��Ͷ�ʧ��TCP���Ķ�,���÷�������δ��ȷ�ϵ�TCP���ĶΡ�ѡ����ȷ��ѡ���������ӳ�ʼ��ʱ,��ʾ�Ƿ�֧��SACK���������ǿ���ͨ����/proc/sys/net/ipv4/tcp_ sack�ں˱��������û�ر�ѡ����ȷ��ѡ�
- kind=5��SACKʵ�ʹ�����ѡ���ѡ��IJ������߷��ͷ������Ѿ��յ�������IJ����������ݿ�,�Ӷ��÷��Ͷ˿��Ծݴ˼�鲢�ط���ʧ�����ݿ顣ÿ�������(edge of block)��������һ��4�ֽڵ���š����п�����ر�ʾ��������ĵ�һ�����ݵ����, �����ұ������ʾ������������һ�����ݵ���ŵ���һ����š�����һ�Բ���(������غͿ��ұ���)֮���������û���յ��ġ���Ϊһ������Ϣռ��8�ֽ�,����TCPͷ��ѡ����ʵ������������4�������IJ��������ݿ�(����ѡ�����ͺͳ���ռ�õ�2�ֽ�)��kind=8��ʱ���ѡ���ѡ���ṩ�˽�Ϊȷ�ļ���ͨ��˫��֮��Ļ�·ʱ��( Round Trip Time, RTT)�ķ���,�Ӷ�ΪTCP���������ṩ��Ҫ��Ϣ�����ǿ���ͨ����/proc/sys/net/ipv4/tcp_ timestamps �ں˱��������û�ر�ʱ���ѡ�
TCP���ӵĽ����ر�
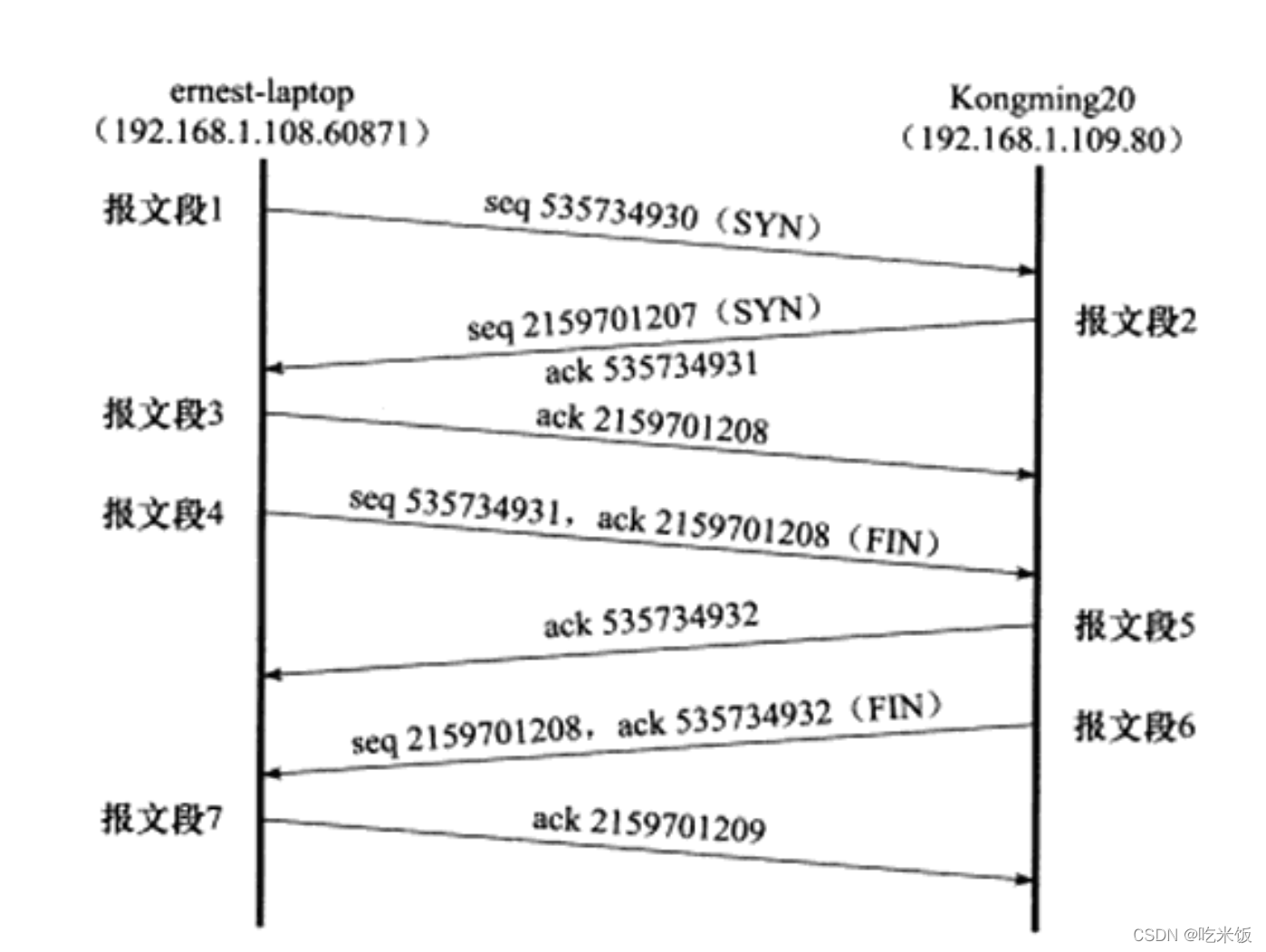
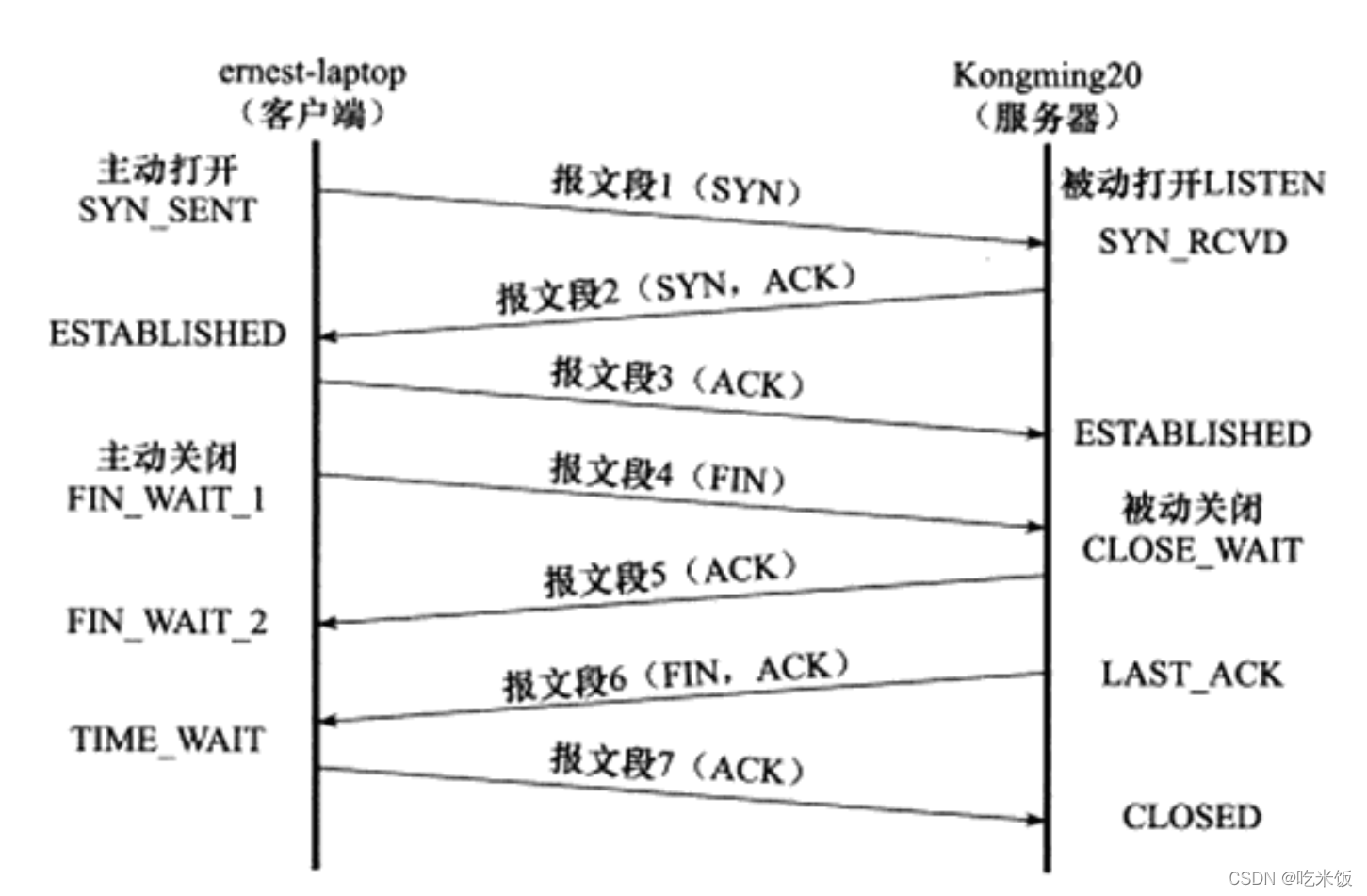
��1��TCP���Ķΰ���SYN��־,�������һ��ͬ�����Ķ�,��ernest-laptop (�ͻ���)��Kongming20 (������)������������ͬʱ,��ͬ�����Ķΰ���һ��ISNֵ535734930���ֺš�
��2��TCP���Ķ�Ҳ��ͬ�����Ķ�,��ʾKongming20ͬ����ernest-laptop�������ӡ�ͬʱ�������Լ���ISNֵΪ2159701207�����,���Ե�1��ͬ�����Ķν���ȷ�ϡ�ȷ��ֵ��535734931,����1��ͬ�����Ķε����ֵ��1,���ֵ��������ʶTCP�������е�ÿһ�ֽڵġ���ͬ�����ĶαȽ�����,��ʹ����û��Я���κ�Ӧ�ó�������,��ҲҪռ��һ�����ֵ��
��3��TCP���Ķ���ernest- laptop�Ե�2��ͬ�����Ķε�ȷ�ϡ�����,TCP���Ӿͽ��������ˡ�����TCP���ӵ���3�����豻��ΪTCP�������֡�
����4��TCP���Ķ��ǹر����ӵĹ��̡���4��TCP���Ķΰ���FIN��־,�������-���������Ķ�,��ermestlaptopҪ��ر����ӡ��������Ķκ�ͬ�����Ķ�һ��, ҲҪռ��һ�����ֵ��Kongming20 ��TCP���Ķ�5��ȷ�ϸý������ĶΡ�������Kongming20�����Լ��Ľ������Ķ�6, ernest-laptop ����TCP���Ķ�7����ȷ�ϡ�ʵ����,������ȷ��Ŀ�ĵ�ȷ�ϱ��Ķ�5�ǿ���ʡ�Ե�,��Ϊ�������Ķ�6ҲЯ���˸�ȷ����Ϣ��ȷ�ϱ��Ķ�5�Ƿ���������ӶϿ��Ĺ�����,ȡ����TCP���ӳ�ȷ�����ԡ�
�����ӵĹرչ�����,��Ϊermest-laptop�ȷ��ͽ������Ķ�,�ʳ�ernest-laptopִ�������ر�,����Kongming20ִ�б����رա�
һ�����,TCP�������ɿͻ��˷���,��ͨ���������ֽ���(�����������νͬʱ�ġ�TCP���ӵĹرչ�����Ը���һЩ�������ǿͻ���ִ�������ر�,����ǰ�������;Ҳ�����Ƿ�����ִ�������ر�,��������������ж϶�ǿ�ƹر�����;��������ͬʱ�ر�(��ͬʱ��һ��,�dz��ټ�)��
��ر�״̬
TCP������ȫ˫����,����������������������ݴ��䱻�����رա�����֮,ͨ�ŵ�һ�˿��Է��ͽ������Ķθ��Է�,�����������Ѿ���������ݵķ���,�����������������ԶԷ�������,ֱ���Է�Ҳ���ͽ������Ķ��Թر����ӡ�TCP���ӵ�����״̬��Ϊ��ر�( half close)״̬,��ͼ��ʾ��
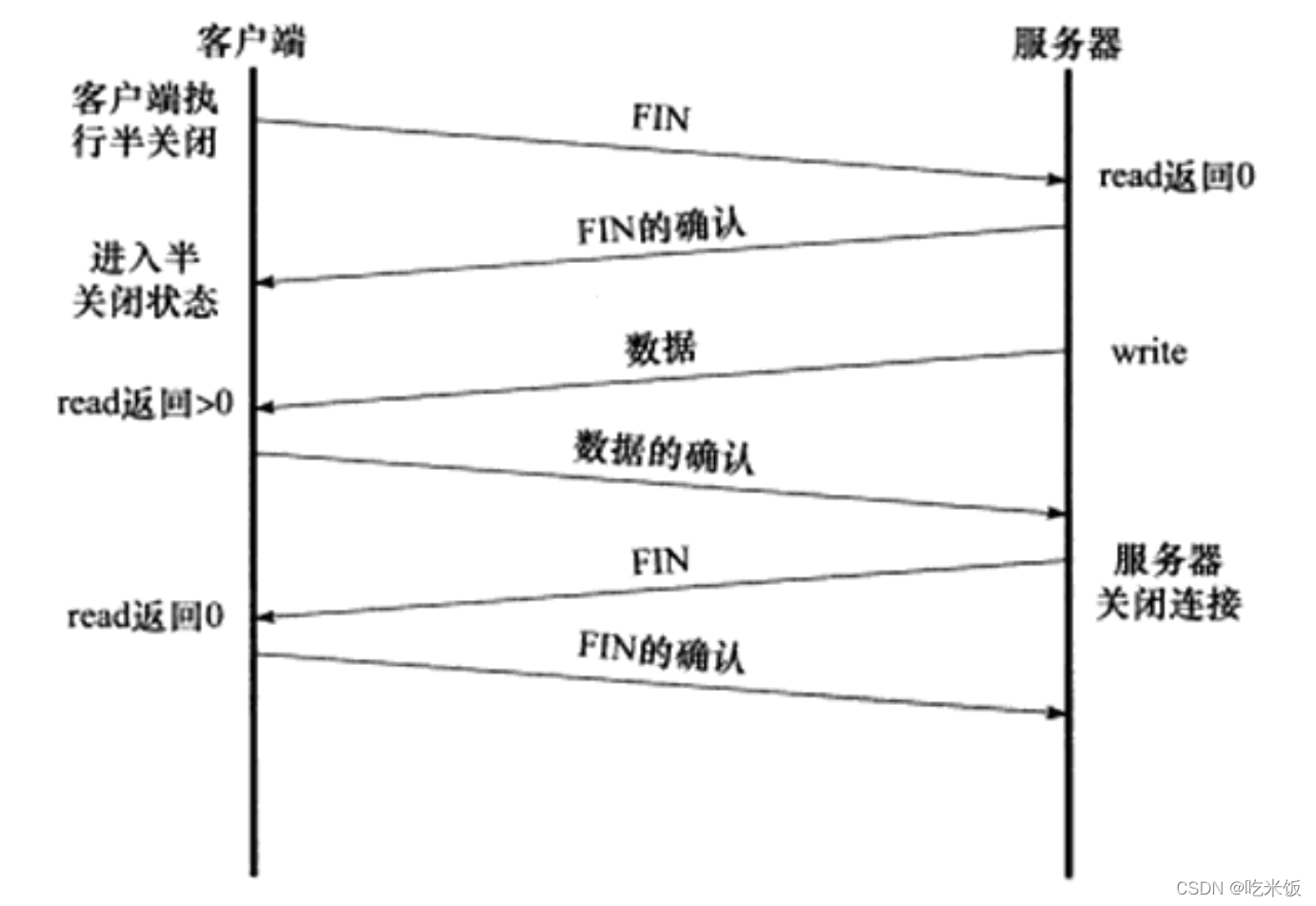
��ע��,��ͼ��,�������Ϳͻ���Ӧ�ó����ж϶Է��Ƿ��Ѿ��ر����ӵķ�����:readϵͳ���÷���0 (�յ��������Ķ�)����Ȼ,Linux ���ṩ������������ǷԷ��رյķ���,socket�����̽ӿ�ͨ��shutdown�����ṩ�˶�رյ�֧�֡�
���ӳ�ʱ
����ͻ��˷���һ�������Զ�ķ�����,�����������緱æ,���·��������ڿͻ��˷��͵�ͬ�����Ķ�û��Ӧ��TCPģ������һ��5����������,������/proc/sys/net/ipv4/tcp. syn, retries �ں˱���������ġ�ÿ�������ij�ʱʱ�䶼����һ-������5��������ʧ�ܵ������,TCPģ��������Ӳ�֪ͨӦ�ó���
TCP״̬ת��
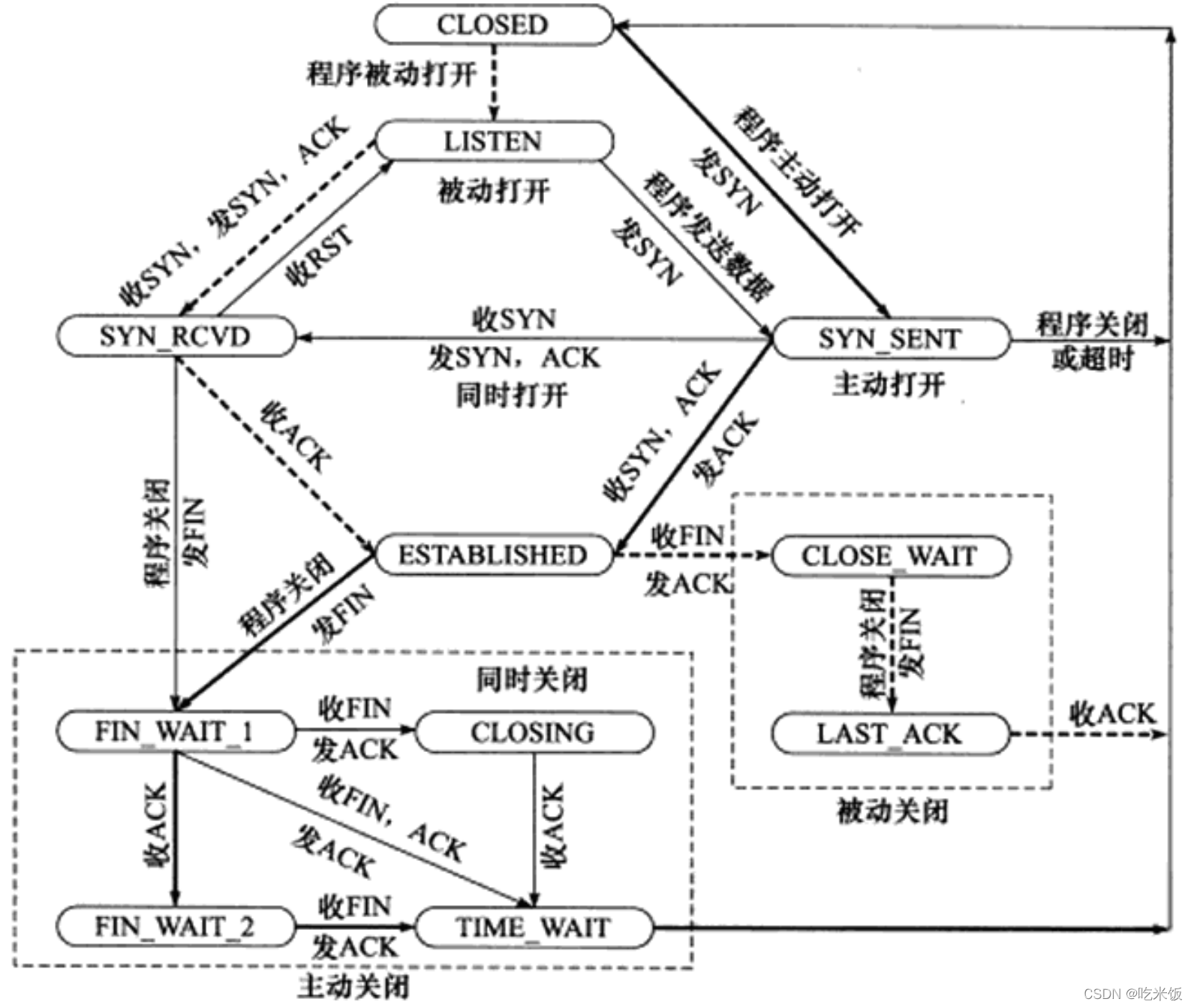
����˵�״̬
������ͨ��listenϵͳ���ý���LISTEN״̬,�����ȴ��ͻ�������,���ִ�е�����ν�ı�����������- -��������ij����������(�յ�ͬ�����Ķ�),�ͽ������ӷ����ں˵ȴ�������,����ͻ��˷��ʹ�SYN��־��ȷ�ϱ��ĶΡ���ʱ�����Ӵ���SYN_RCVD״̬������������ɹ��ؽ��յ��ͻ��˷��ͻص�ȷ�ϱ��Ķ�,�������ת�Ƶ�ESTABLISHED״̬��ESTABLISHED״̬������˫���ܹ�����˫�����ݴ����
״̬��
���ͻ��������ر�����ʱ(ͨ��close��shutdownϵͳ��������������ͽ������Ķ�),������ͨ������ȷ�ϱ��Ķ�ʹ���ӽ���CLOSE_ WAIT״̬�����״̬�ĺ������ȷ:�ȴ�������Ӧ�ó���ر����ӡ�ͨ��,���������ͻ��˹ر����Ӻ�,Ҳ���������ͻ��˷���һ���������Ķ����ر����ӡ��⽫ʹ����ת�Ƶ�LAST_ _ACK״̬,�Եȴ��ͻ��˶Խ������Ķε����һ��ȷ�ϡ�һ��ȷ�����,���Ӿͳ��ر��ˡ�
�ͻ���״̬
�ͻ���ͨ��connctϵͳ����������������������ӡ�connect ϵͳ�������ȸ�����������һ��ͬ�����Ķ�,ʹ����ת�Ƶ�SYN, _SENT״̬���˺�,connect ϵͳ���ÿ�����Ϊ��������ԭ��ʧ�ܷ���:
- ���connect���ӵ�Ŀ��˿ڲ�����(δ���κν��̼���),���߸ö˿��Ա�����TIME WAIT״̬��������ռ��(������),������������ͻ��˷���-һ���� λ���Ķ�,connect ����ʧ�ܡ�
- ���Ŀ��˿ڴ���,��connect�ڳ�ʱʱ����δ�յ���������ȷ�ϱ��Ķ�,��connect����ʧ�ܡ�
connect����ʧ�ܽ�ʹ�����������ص���ʼ��CLOSED״̬������ͻ��˳ɹ��յ���������ͬ�����Ķκ�ȷ��,��connect���óɹ�����,����ת����ESTABLISHED״̬�����ͻ���ִ�������ر�ʱ,��������������һ���������Ķ�,ͬʱ���ӽ���FIN_WAIT_1״̬������ʱ�ͻ����յ�������ר������ȷ��Ŀ�ĵ�ȷ�ϱ��Ķ�,������ת����FIN_ WAIT_ 2״̬�����ͻ��˴���FIN_ WAIT_ 2״̬ʱ,����������CLOSEWAIT״̬,��һ��״̬�ǿ��ܷ�����رյ�״̬����ʱ���������Ҳ�ر�����(���ͽ������Ķ�),��ͻ��˽�����ȷ�ϲ�����TIME _WAIT״̬��
ͼ�������˿ͻ��˴�FIN_ WAIT_ 1״ֱ̬�ӽ���TME WAIT״̬��һ����·(������FINWAIT2״̬),ǰ���Ǵ���FIN__WAIT_1״̬�ķ�����ֱ���յ���ȷ����Ϣ�Ľ������Ķ�(���������յ�ȷ�ϱ��Ķ�,���յ��������Ķ�)������FIN_WAIT2״̬�Ŀͻ�����Ҫ�ȴ����������ͽ������Ķ�,����ת����TIME_ WAIT״̬,��������һֱͣ �������״̬���������Ϊ���ڰ�ر�״̬�¼�����������,���ӳ�ʱ���ͣ����FIN_ WAIT 2״̬�����洦������ͣ����FIN_ WAIT_ 2״̬��������ܷ�����:�ͻ���ִ�а�رպ�,δ�ȷ������ر����Ӿ�ǿ���˳��ˡ���ʱ�ͻ����������ں����ӹ�,�ɳ�֮Ϊ�¶�����(�¶���������)��Linux Ϊ�˷�ֹ�¶����ӳ�ʱ��������ں���,�����������ں˱���: /proc/sys/netipv4/tcp_ max_orphans ��/proc/sys/net/ipv4/tcp_ fin_ timeout�� ǰ��ָ���ں��ܽӹܵŶ�������Ŀ,����ָ���¶��������ں��������ʱ�䡣
TIME_WAIT״̬
��ͼ����,�ͻ����������յ��������Ľ������Ķ�(TCP���Ķ�6)֮��,��û��ֱ�ӽ���CLOSED״̬,����ת�Ƶ�TIME_ WAIT״̬�������״̬,�ͻ�������Ҫ�ȴ�һ�� ��Ϊ2MSL (Maximum Segment Life,���Ķ��������ʱ��)��ʱ��,������ȫ�رա�MSL��TCP���Ķ��������е��������ʱ��,���ĵ�RFC 1122�Ľ���ֵ��2 min.TIME_ WAIT״̬���ڵ�ԭ��������:
- �ɿ�����ֹTCP���ӡ�
- ��֤�ó�����TCP���Ķ����㹻��ʱ�䱻ʶ������
��һ��ԭ��ܺ����⡣����ͼ������ȷ�Ϸ������������Ķ�6��TCP���Ķ�7�Gʧ,��ô���������ط��������ĶΡ���˿ͻ�����Ҫͣ����ij��״̬�Դ����ظ��յ��Ľ������Ķ�(�������������ȷ�ϱ��Ķ�)������,�ͻ��˽��Ը�λ���Ķ�����Ӧ������,����������Ϊ����-һ������,��Ϊ����������һ����TCP���Ķ�7������ȷ�ϱ��ĶΡ���Linuxϵͳ��,һ��TCP�˿ڲ��ܱ�ͬʱ���(���μ�����)����һ��TCP���Ӵ���TIME_ WAIT״̬ʱ,���ǽ�������ʹ�ø�����ռ���ŵĶ˿�������һ�������ӡ�������˼��,���������TIME_ WAIT״̬,��Ӧ�ó����ܹ���������-һ���չرյ��������Ƶ�����(����˵������,��ָ���Ǿ�����ͬ��IP��ַ�Ͷ˿ں�)������µġ���ԭ�����Ƶ����ӱ���Ϊԭ�������ӵĻ���( incarnation)���µĻ������ܽ��յ�����ԭ�������ӵġ�Я��Ӧ�ó������ݵ�TCP���Ķ�(�ٵ��ı��Ķ�),����Ȼ�Dz�Ӧ�÷����ġ������TIME_WAIT״̬���ڵĵڶ���ԭ��
����,��ΪTCP���Ķε��������ʱ����MSL,���Լ��2MSLʱ���TIME WAIT״̬�ܹ�ȷ���������������䷽������δ�����յ��ġ��ٵ���TCP���Ķζ��Ѿ���ʧ(����ת·��������)�����,һ�����ӵ��µĻ���������2MSLʱ��֮��ȫ�ؽ���,�����Բ�����յ�����ԭ�����ӵ�Ӧ�ó�������,�����TIME_WAIT״̬Ҫ����2MSLʱ���ԭ��
��ʱ������ϣ������TIME__WAIT״̬,��Ϊ�������˳���,����ϣ���ܹ������������������ڴ���TIME_ WAIT״̬�����ӻ�ռ���Ŷ˿�,����������(ֱ��2MSL��ʱʱ�����)��
������Ƿ����������ر����Ӻ��쳣��ֹ,����Ϊ������ʹ��ͬ- -��֪������˿ں�,�������ӵ�TIME WAIT״̬��������������������������,���ǿ���ͨ��socketѡ��so_REUSEADDR��ǿ�ƽ�������ʹ�ô���TIME _WAIT״̬������ռ�õĶ˿ڡ�
��λ���Ķ�
��ijЩ����������,TCP���ӵ�һ�˻�����һ�˷���Я��RST��־�ı��Ķ�,����λ���Ķ�,��֪ͨ�Է��ر����ӻ����½������ӡ�
���ʲ����ڵĶ˿�
������һ�������ڵĶ˿�ʱ,����Ӧһ����λ���ĶΡ���Ϊ��λ���ĶεĽ���ͨ�洰�ڴ�СΪ0,���Կ���Ԥ��:�յ���λ���Ķε�һ��Ӧ�ùر����ӻ�����������,�����ܻ�Ӧ�����λ���ĶΡ�ʵ����,���ͻ��˳������������ij���˿ڷ�������,���ö˿��Ա�����TIMEWAIT״̬��������ռ��ʱ,�ͻ��˳���Ҳ���յ���λ���ĶΡ�
�쳣��ֹ����
TCP�ṩ���쳣��ֹһ�����ӵķ���,�����Է�����- -����λ���ĶΡ�һ�������˸�λ���Ķ�,���Ͷ������Ŷӵȴ����͵����ݶ�����������Ӧ�ó������ʹ��socketѡ��sO_ LINGER������λ���Ķ�,���쳣��ֹ-һ�����ӡ����ǽ��ڵ�5������SO_ LINGERѡ�
�����������
������������:������(��ͻ���)�رջ����쳣��ֹ������,���Է�û�н��յ��������Ķ�(���緢�����������),��ʱ,�ͻ���(�������)��ά����ԭ��������,��������(��ͻ���)��ʹ����,Ҳ�Ѿ�û�и����ӵ��κ���Ϣ�ˡ����ǽ�����״̬��Ϊ���״̬,��������״̬�����ӳ�Ϊ������ӡ�����ͻ���(�������)�����ڰ��״̬������д������,��Է�����Ӧ-һ����λ���ĶΡ�
TCP����������
TCP���Ķ���Я����Ӧ�ó������ݰ��ճ��ȷ�Ϊ����:�������ݺͳɿ����ݡ��������ݽ��������ٵ��ֽڡ�ʹ�ý������ݵ�Ӧ�ó���( ��Э��)��ʵʱ��Ҫ���,����telnet��ssh .�ȡ��ɿ����ݵij�����ͨ��ΪTCP���Ķ�������������ݳ��ȡ�ʹ�óɿ����ݵ�Ӧ�ó���(��Э��)�Դ���Ч��Ҫ���,����ftp.�����������۽�����������
��һ��telnet������,�ͻ�����Է��������ص����������͵�ȷ�ϱ��Ķζ����s���κ�Ӧ�ó�������(����Ϊ0),��������ÿ�η��͵�ȷ�ϱ��Ķζ���������Ҫ���͵�Ӧ�ó������ݡ������������ִ�����ʽ��Ϊ�ӳ�ȷ��,����������ȷ���ϴ��յ�������,������һ���ӳ�ʱ���鿴�����Ƿ���������Ҫ����,�����,���ȷ����Ϣ-һ������Ϊ�������Կͻ��������úܿ�,����������ȷ�ϱ��Ķε�ʱ������������һ-���͡� �ӳ�ȷ�Ͽ��Լ��ٷ���TCP���Ķε��������������û��������ٶ��������ڿͻ��˳���Ĵ����ٶ�,���Կͻ��˵�ȷ�ϱ��Ķ����Dz�Я���κ�Ӧ�ó������ݡ�ǰ�����ᵽ,��TCP���ӵĽ����ͶϿ�������,Ҳ���ܷ����ӳ�ȷ�ϡ�
�������ڱ��ػ�·���еĽ��,�ھ�������Ҳ�ܵõ�������ͬ�Ľ��,���ڹ�������δ������ˡ��������ϵĽ������������ܾ��ܴܺ���ӳ�,����,�s���������ݵ�СTCP���Ķ�����һ��ܶ�(һ���������˾͵���һ��TCP���Ķ�),��Щ���ض����ܵ���ӵ������������������-һ������Ч�ķ�����ʹ��Nagle�㷨��
Nagle�㷨Ҫ��һ��TCP���ӵ�ͨ��˫��������ʱ�̶����ֻ�ܷ���һ��δ��ȷ�ϵ�TCP���Ķ�,�ڸ�TCP���Ķε�ȷ�ϵ���֮ǰ���ܷ�������TCP���ĶΡ���һ����,���ͷ��ڵȴ�ȷ�ϵ�ͬʱ�ռ�������Ҫ���͵�������,����ȷ�ϵ���ʱ��һ��TCP���Ķν�����ȫ�������������ͼ���ؼ����������ϵ�СTCP���Ķε����������㷨����-һ���ŵ�����������Ӧ��:ȷ�ϵ����Խ��,����Ҳ�ͷ��͵�Խ�졣
TCP�ɿ�������
���������������ݵ�ʱ��,���ͷ����������Ͷ��TCP���Ķ�,���շ�����һ��ȷ��������Щ���ĶΡ���ô���ͷ����յ���һ��ȷ�Ϻ�,���������Ͷ��ٸ�TCP���Ķ���?�����ɽ���ͨ�洰��(����Ҫ����ӵ������)�Ĵ�С�����ġ�
����һ��ֵ��ע��ĵط���,������ÿ����4��TCP���Ķξʹ���һ��PSH��־���ͻ���,��֪ͨ�ͻ��˵�Ӧ�ó����ȡ���ݡ�������Է�������˵��Ȼ���DZ����,��Ϊ��֪���ͻ��˵�TCP���ջ������л��п��пռ�(����ͨ�洰�ڴ�С��Ϊ0)��
��������
��Щ�����Э����д���(Out Of Band, 0OB)���ݵĸ���,����Ѹ��ͨ��Է����˷�������Ҫ�¼������,�������ݱ���ͨ����(Ҳ��Ϊ��������)�и��ߵ����ȼ�,��Ӧ����������������,�����۷��ͻ��������Ƿ����Ŷӵȴ����͵���ͨ���ݡ��������ݵĴ������ʹ��һ�������Ĵ��������,Ҳ����ӳ�䵽������ͨ���ݵ������С�ʵ��Ӧ����,�������ݵ�ʹ�ú��ټ�,��֪�Ľ���telnet�� ftp ��Զ�̷ǻ�Ծ����
UDPû��ʵ�ִ������ݴ���,TCPҲû�������Ĵ������ݡ�����TCP������ͷ���еĽ���ָ���־�ͽ���ָ�������ֶ�,��Ӧ�ó����ṩ��һ�ֽ�����ʽ��TCP�Ľ�����ʽ���ô�����ͨ���ݵ�����������������ݡ����ֽ������ݵĺ���ʹ�����������,��˺���Ҳ��TCP�������ݳ�Ϊ�������ݡ�
������������TCP���ʹ������ݵĹ��̡�����һ�������� ����ij��TCP���ӵķ��ͻ�������д����N�ֽڵ���ͨ����,���ȴ��䷢�͡������ݱ�����ǰ,�ý��������������д����3�ֽڵĴ������ݡ�abc"����ʱ,�����͵�TCP���Ķε�ͷ����������URG��־,���ҽ���ָ�뱻����Ϊָ�����һ���������ݵ���һ�ֽ�(��һ����ȥ��ǰTCP���Ķε����ֵ�õ���ͷ���еĽ���ƫ��ֵ),��ͼ��ʾ��
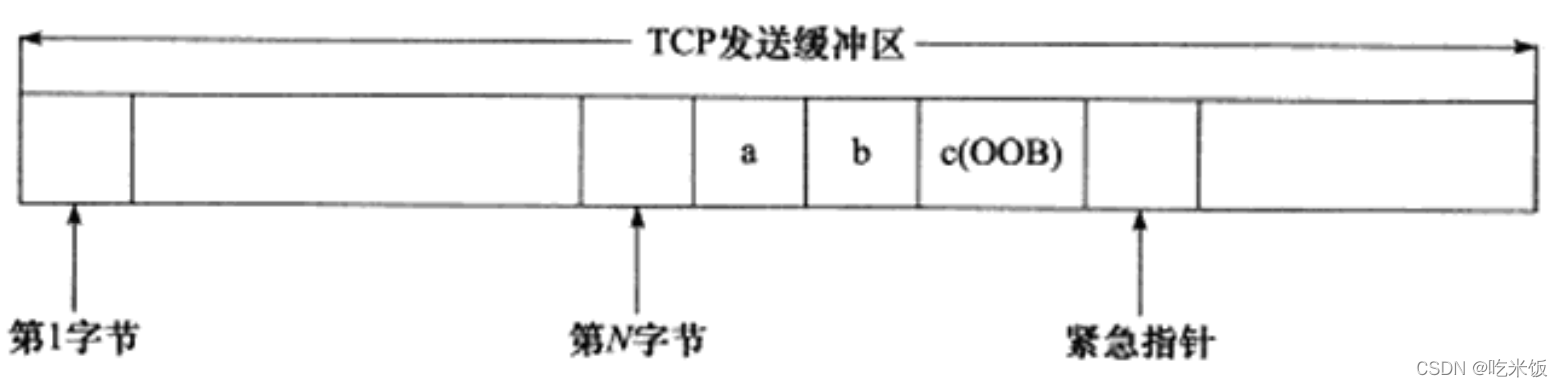
��ͼ�ɼ�,���Ͷ�һ�η��͵Ķ��ֽڵĴ���������ֻ�����C�ֽڱ�������������(��ĸc),����������(��ĸa��b)����������ͨ���ݡ����TCPģ���Զ��TCP���Ķ�������ͼ��ʾTCP���ͻ������е�����,��ÿ��TCP���Ķζ�������URG��־,�������ǵĽ���ָ��ָ��ͬһ��λ��( �������д������ݵ���һ��λ��),��ֻ��-һ��TCP���Ķ������s���������ݡ�
���ڿ���TCP���մ������ݵĹ��̡�TCP���ն�ֻ���ڽ��յ�����ָ���־ʱ�ż�����ָ��,Ȼ����ݽ���ָ����ָ��λ��ȷ���������ݵ�λ��,����������һ������Ļ����С��������ֻ��1�ֽ�,��Ϊ����档����ϲ�Ӧ�ó���û�м�ʱ���������ݴӴ�����ж���,������Ĵ�������( ����еĻ�)����������
ǰ�����۵Ĵ������ݵĽ��չ�����TCPģ����մ������ݵ�Ĭ�Ϸ�ʽ��������Ǹ�TCP����������SO_OOBINLINEѡ��,��������ݽ�����ͨ����һ����TCPģ������TCP���ջ������С���ʱӦ�ó�����Ҫ���ȡ��ͨ����һ������ȡ�������ݡ���ô���������������ִ������ݺ���ͨ������?��Ȼ,����ָ���������ָ���������ݵ�λ��,socket��̽ӿ�Ҳ�ṩ��ϵͳ������ʶ��������ݡ�
TCP��ʱ�ش�
TCP��������ܹ��ش���ʱʱ����δ�յ�ȷ�ϵ�TCP���ĶΡ�Ϊ��,TCPģ��Ϊÿ��TCP���Ķζ�ά��-һ���ش���ʱ��,�ö�ʱ����TCP���Ķε�һ�α�����ʱ�����������ʱʱ����δ�յ����շ���Ӧ��,TCPģ�齫�ش�TCP���Ķβ����ö�ʱ���������´��ش��ij�ʱʱ�����ѡ��,�Լ����ִ�ж��ٴ��ش�,����TCP���ش����ԡ�
Linux��������Ҫ���ں˲�����TCP��ʱ�ش����: /proc/sys/net/ipv4/tcp_retries1 ��/proc/sys/net/ipv4/tcp_retries2�� ǰ��ָ���ڵײ�IP�ӹ�֮ǰTCP����ִ�е��ش�����,Ĭ��ֵ��3������ָ�����ӷ���ǰTCP������ִ�е��ش�����,Ĭ��ֵ��15(һ���Ӧ13 ~ 30 min)��
ӵ������
TCPģ�黹��һһ����Ҫ������,�����������������,���Ͷ�����,����֤������Դ��ÿ���������Ĺ�ƽ�ԡ��������ν��ӵ�����ơ�
TCPӵ�����Ƶ��ĸ�����:������(slow start)��ӵ������(congestion avoidance).�����ش�(fast retransmit)�Ϳ��ٻָ�(fast recovery).ӵ�������㷨��Linux���ж���ʵ��,����reno�㷨��vegas �㷨��cubic�㷨
�ȡ����ǻ��߲��ֻ���ȫ��ʵ���������ĸ����֡�/pos/s/s/tipv4/epo._congestion_control �ļ�ָʾ������ǰ��ʹ�õ�ӵ�������㷨��
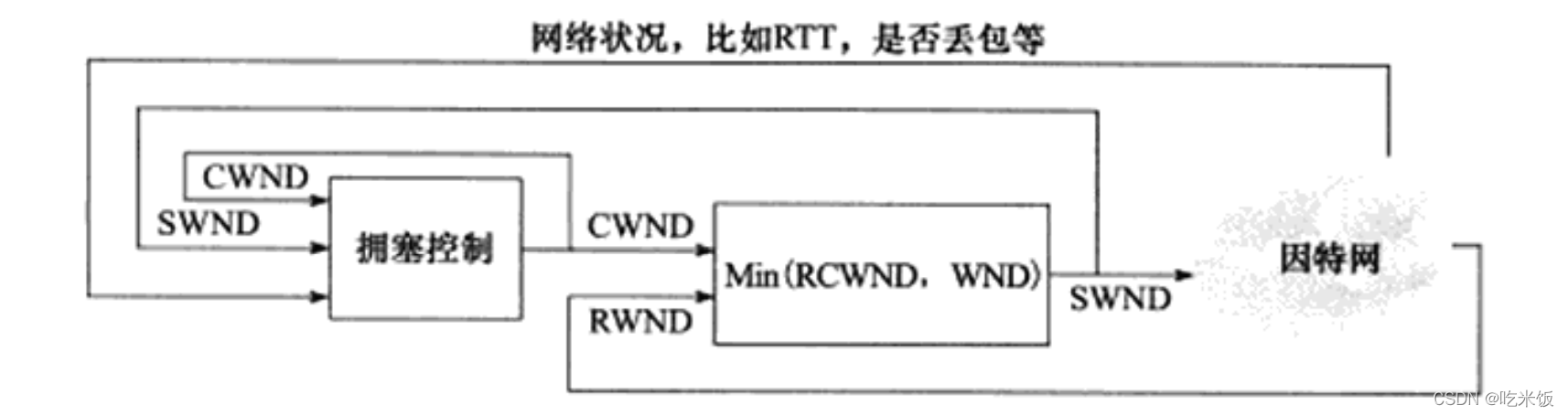
ӵ�����Ƶ������ܿر����Ƿ��Ͷ�������-������д�� (�յ����е�- -�����ݵ�ȷ��֮ǰ)��������,���dz�ΪSWND (Send Window,���ʹ�����)������,���Ͷ�������TCP���Ķ�����������,����SWND���˷��Ͷ����������͵�TCP���Ķ���������ЩTCP���Ķε����(��ָ���ݲ���)��ΪSMSS (Sender Maximum Segment Size,���������δ�С),��ֵһ�����MSS.
���Ͷ���Ҫ������ѡ��SWND�Ĵ�С�����SWND̫С,���������Ե������ӳ�;��֮,���SWND ̫��,������������ӵ����ǰ���ᵽ,���շ���ͨ�������ͨ�洰��(RWND)�����Ʒ��Ͷ˵�SWND.������Ȼ����,���Է��Ͷ�������һ����Ϊӵ������(Congestion Window, CWND)��״̬������ʵ�ʵ�SWNDֵ��RWND��CWND�еĽ�С�ߡ�ͼ����ʾ��ӵ�����Ƶ����˺����(�ɼ�,����-һ���ջ���������)��
��������ӵ������
TCP���ӽ�����֮��,CWND�������óɳ�ʼֵIW (Initial Window),���СΪ2~ 4��SMSS�����µ�Linux�ں�����˸ó�ʼֵ,�Լ�С�����ͺ�ʱ���Ͷ�����ܷ���Iw�ֽڵ����ݡ��˺��Ͷ�ÿ�յ����ն˵�һ��ȷ��,��CWND�Ͱ�����ʽ����:
CWND+= min (N,SMSS)
����N�Ǵ˴�ȷ���а�����֮ǰδ��ȷ�ϵ��ֽ����������C��,CWND������ָ����;ʽ����,�������ν�����������������㷨��������,TCPģ��տ�ʼ��������ʱ����֪�������ʵ�����,��Ҫ��һ����̽�ķ�ʽƽ��������CWND�Ĵ�С��
���������ʩ�������ֶ�,��������Ȼʹ��CWND�ܿ�����(�ɼ���������ʵ����)�����յ�������ӵ�������TCPӵ�������ж�������һ����Ҫ��״̬����:����������,(slow start threshold size, ssthresh)�� ��CWND�Ĵ�С������ֵʱ,TCP ӵ�����ƽ�����ӵ������Ρ�
ӵ�������㷨ʹ��CWND�������Է�ʽ����,�Ӷ�����������RFC 5681���ᵽ����������ʵ�ַ�ʽ:
- ÿ��RTTʱ���ڰ�����ʽ �����µ�CWND,�����۸�RTTʱ���ڷ��Ͷ��յ����ٸ�ȷ�ϡ�
- ÿ�յ�һ���������ݵ�ȷ�ϱ��Ķ�,�Ͱ�����ʽ������CWND.
CWND+= SMSS* SMSS/CWND
ͼ�д��Ե���������������ӵ�����ⷢ����ʱ�������𡣸�ͼ��,������SMSSΪ��λ����ʾCWND (ʵ�����������ֽ�Ϊ��λ��),�Դ���Ϊ��λ����ʾRTT,��ֻ��Ϊ�˷����������⡣����,���Ǽ��赱ǰ��ssthresh��16SMSS��С(��Ȼ,ʵ�ʵ�ssthresh ��ȻԶ��ֹ��ô��)��
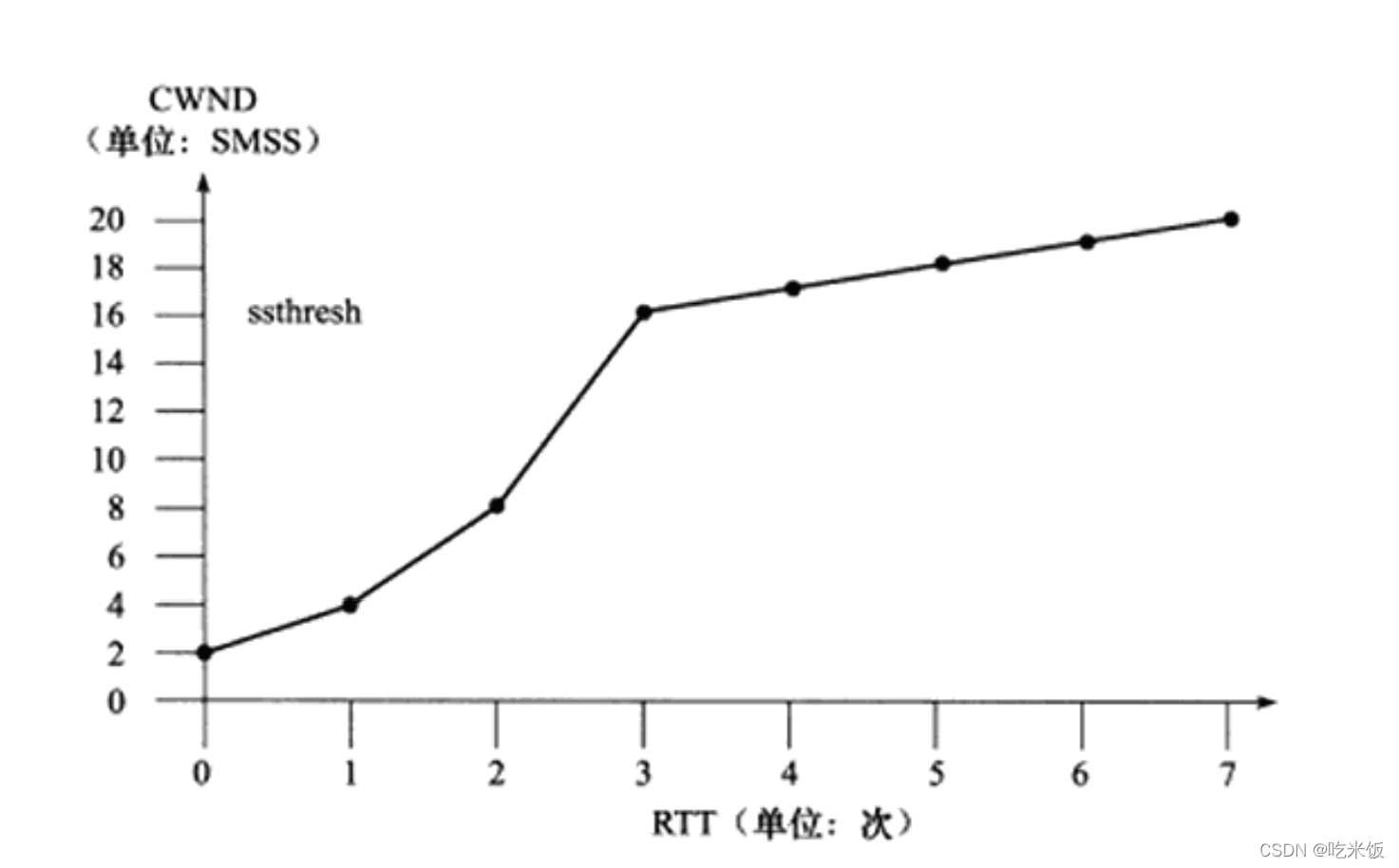
�������������˷��Ͷ���δ��ӵ��ʱ�����õĻ�������ӵ���ķ���������������ӵ������ʱ(���ܷ������������λ���ӵ�������)ӵ�����Ƶ���Ϊ������������Ҫ��������Ͷ�������ж�ӵ���Ѿ������ġ����Ͷ��ж�ӵ����������������������:
- ���䳬ʱ,����˵TCP�ش���ʱ�������
- ���յ��ظ���ȷ�ϱ��ĶΡ�
ӵ�����ƶ�����������в�ͬ�Ĵ�����ʽ���Ե�һ�������Ȼ ʹ����������ӵ�����⡣�Եڶ��������ʹ�ÿ����ش��Ϳ��ٻָ�(�������ķ���ӵ���Ļ�)��ע��,�ڶ����������������ش���ʱ�����֮��,��Ҳ��ӵ�����Ƶ��ɵ�һ��������Դ���������Ͷ˼�ӵ�����������ڴ��䳬ʱ,��������һ�����,��ô����ִ���ش��������µ���:
ssthresh=max ( FlightSize/2,2*SMSS)
CWMD<=SMSS
����FlightSize���Ѿ����͵�δ�յ�ȷ�ϵ��ֽ�������������֮��,CWMD��С��SMSS,��ôҲ��ȻС���µ�����������ֵssthresh (��Ϊ������ʽ, ��һ����С��SMSS��2��),�ʶ�ӵ�������ٴν����������Ρ�
�����ش��Ϳ��ٻָ�
�ںܶ������,���Ͷ˶����ܽ��յ��ظ���ȷ�ϱ��Ķ�,����TCP���Ķζ�ʧ,���߽��ն��յ�����TCP���Ķβ�����֮�ȡ�ӵ�������㷨��Ҫ�жϵ��յ��ظ���ȷ�ϱ��Ķ�ʱ,�����Ƿ���ķ�����ӵ��,����˵TCP���Ķ��Ƿ���Ķ�ʧ�ˡ�����������:���Ͷ���������յ�3���ظ���ȷ�ϱ��Ķ�,����Ϊ��ӵ�������ˡ�Ȼ�������ÿ����ش��Ϳ��ٻָ��㷨������ӵ��,��������:
- ���յ���3���ظ���ȷ�ϱ��Ķ�ʱ,������ʽ����shresh,Ȼ�������ش���ʧ�ı��Ķ�,��������ʽ ����CWND.
CWND=ssthresh+3*SMSS
- ÿ���յ�1���ظ���ȷ��ʱ,����CWND=CWND+SMSS.��ʱ���Ͷ˿��Է����µ�TCP���Ķ�(����µ�CWND�����Ļ�)��
- ���յ������ݵ�ȷ��ʱ,����CWND=ssthresh (ssthresh ���µ�����������ֵ,�ɵ�һ������õ�)��