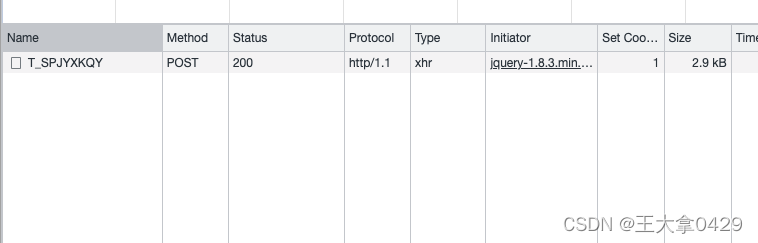
http1.1 如上
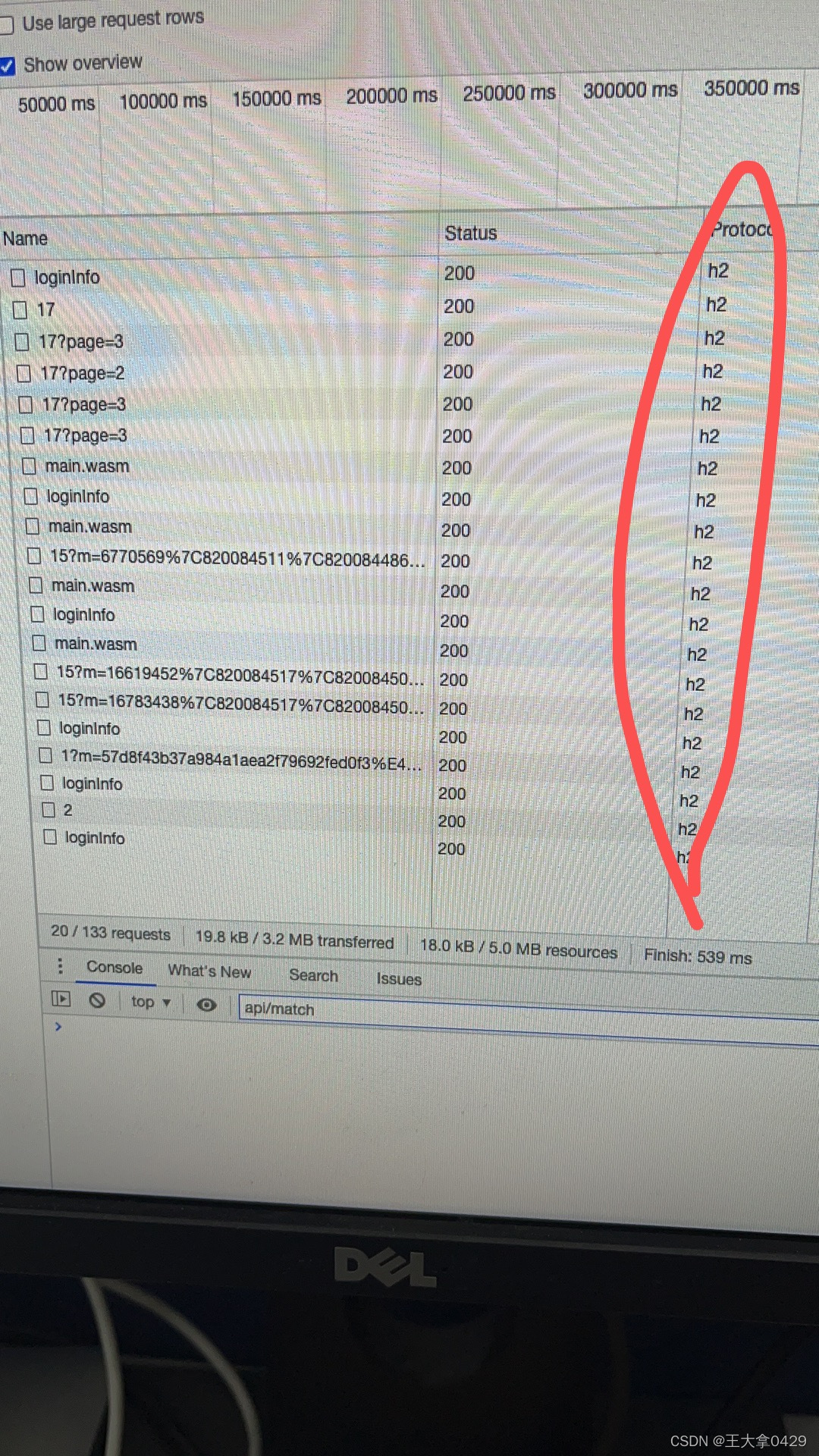
http2.0如上
chrome中通过查看protocol,可以看出使用的http版本。
通过查看protocol,发现所有题目的数据接口都是使用http2.0的。
那为什么我在其他题目中使用requests进行http1.1的请求也能成功访问到?
答:
http2.0兼容http1.x,所以浏览器使用2.0一样可以访问,其他题目也并没有在接收请求时验证http版本
而只有17题在后台规定了要使用http2.0(应该是在进行验证请求的时候,判断http版本,如果不是2.0则返回error),
而其他题目没有。猿人学网站要求浏览器统一使用http2.0进行获取数据。
所以以后做爬虫时候还要注意到请求的http版本,有些网站会对此做判断
python中用http2.0的话需要安装httpx(pip3 install httpx),用法在代码里
安装httpx时,还要安装pip3 install h2,httpx库中用到http2的时候提示安装的命令不对。
import httpx
client = httpx.Client(http2=True)
'''
'''
headers = {
'authority': 'match.yuanrenxue.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="96", "Google Chrome";v="96"',
'accept': 'application/json, text/javascript, */*; q=0.01',
'x-requested-with': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'user-agent': 'yuanrenxue.project',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://match.yuanrenxue.com/match/17',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cookie': 'sessionid=6gyxplyr65qflo1sjcp1kefoggtmfucr; qpfccr=true; Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1640075874,1640148370; Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1640075857,1640148368,1640165643; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1640165643; no-alert3=true',
}
result = 0
for page in range(1,6):
response = client.get(f'https://match.yuanrenxue.com/api/match/17?page={str(page)}', headers=headers)
for i in response.json()['data']:
result += i['value']
print(result)