1.1 最简单的爬虫
@ 我的老师:Jack Cui
PS:我是通过 看 Jack Cui 老师的文章 学习的爬虫,也为我之后的 爬虫打开了大门。
1.1.1 URL 是什么?
在学习 爬虫之前,我们必须知道 我们 平常 所说的网址,实际上 叫做 URL。
即:统一资源定位符(Uniform Resource Locator)
它的格式通常都是:
协议://主机名[:端口]/资源路径/参数
但是我们知道的是,一般我们看到的网址,好像都不是这么全。好像是 隐藏了 什么似的。对!没错,就是隐藏了点儿 东西。(可以用 谷歌浏览器的 NetWork 进行抓包,把所有的数据通通抓到。)
举个例子:http://www.baidu.com
实际上 它隐藏了一个 很明显的东西,就是 端口!http 协议默认的端口是 80,而 https 协议 默认的端口是 443。
http://www.baidu.com:80
https://www.baidu.com:443
那么 讲到这里,我们要 回归主题了。我们 说了 URL ,但是 URL 和网络 爬虫有啥关系呢?
答:关系非常非常的大!我们的网络爬虫 是为了 爬网络上的数据的!得到 我们可以利用的数据!而 网络上的数据 最直接的途径 就是 网页。也就是 一个一个 反馈给我们的 资源文件。如果 我们 要得到 这些反馈,就必须 在 浏览器里 输入 这个 URL。
这就类似于 你得到了 地址(URL),然后 我们 根据这个地址 去找 资源文件,找到后,我们 才能够 读取数据!甚至进行 相关的网页操作。
1.1.2 数据在哪里?
我们都知道,每次访问一个网页,得到了反馈后,数据就在眼前。但是 总觉得 缺点儿 什么。
学过 前端知识的人 应该知道,网页所呈现给我们的效果,是浏览器 渲染出来!
其实本质上 它们也都是代码。。。
即使是 没有学过 前端的人其实 也能发现这个秘密。那就是 我们右键 网页,然后点击 查看源代码。
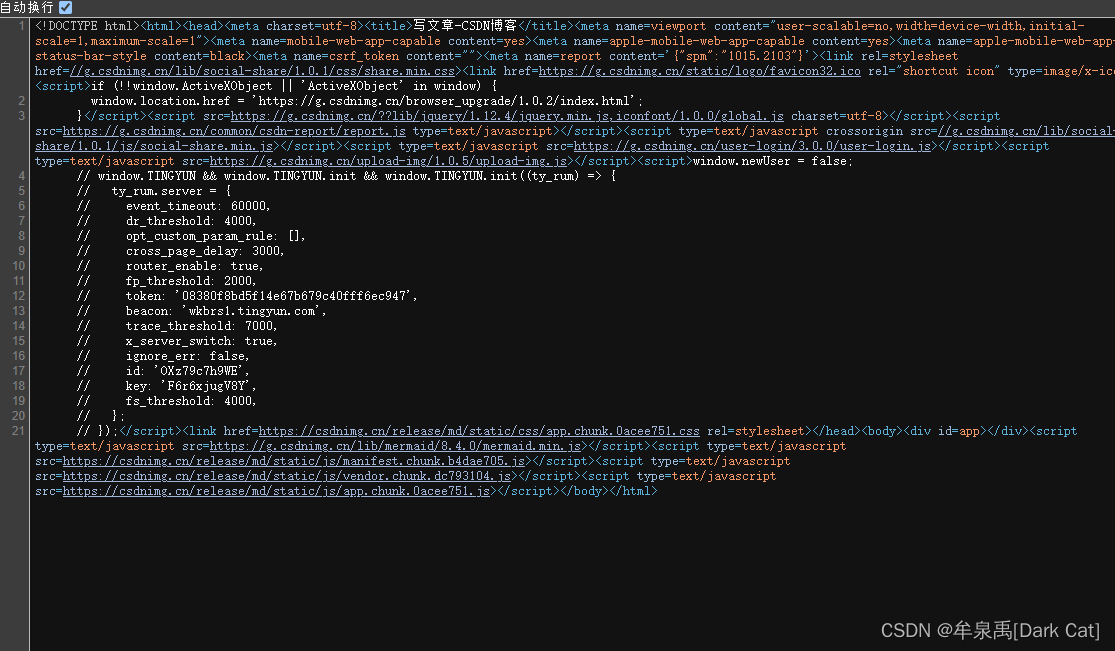
我们就会 看到 一个 以代码的形式。 突然,在我们面前 出现了。
所以 我才说,数据就在眼前,可是总觉得缺点儿什么。这主要的 原因就是 渲染的太好了。让你无法 直接的 通过某种方式 获取。才会觉得 要得到了,却又 很难。。。
那么 这样的 显示代码的 样子 还有点儿丑,而且 不结构化。我们 怎么解决呢?
答:右键 点击检查
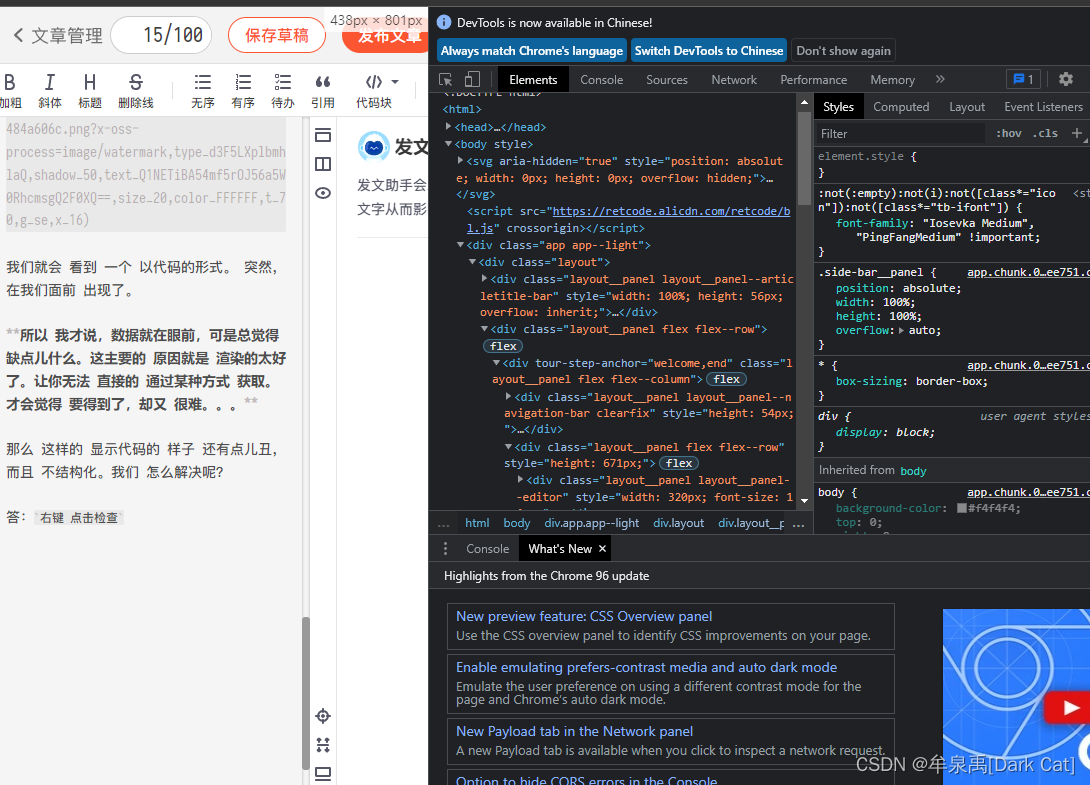
就会出现 这样的 好看的 工具栏,这个工具栏 里 包括了 很多工具。其中 第一个 工具 就是用来 查看 代码的。而且是 结构化的 查询。还能直接 对网页 进行 相关的更改。只要你 懂 前端代码。。
1.1.3 requests 库
在 cmd 中,使用如下指令安装 requests :
pip install requests
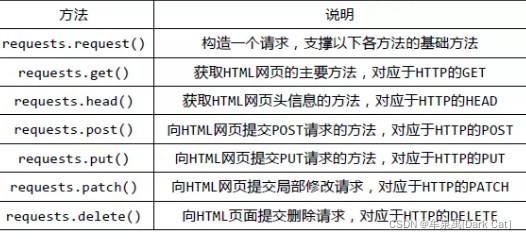
既然我们已经知道了,它的所有数据 其实 都在 源代码里。那么我们就应该 想办法 获取到 这个 源代码。
即 安装 requests 库,利用 get 方式进行 网页的访问,访问后,它 会 自动的把 源代码 装在 text 这个属性里。
import requests
req = requests.get("http://www.baidu.com")
req.encoding = 'utf-8'
print(req.text)
utf-8 是万国码 编码,可以对 几乎 大多数国家的 语言 进行 编码。
如果你不用这个编码,你可能会发现 你读的源代码 很多 地方 都是乱码的。
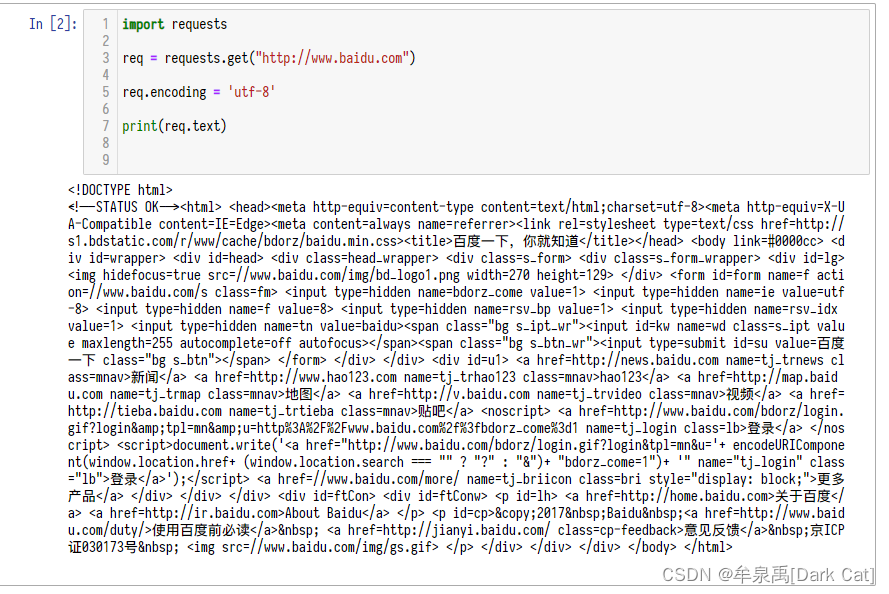
这样 我们就把 我们需要的 源代码 爬取下来了。
这个过程其实就是 最简单那的 爬虫。因为 源代码 爬取下来后,我们只要 对 其 进行 re 正则的定位,和 字符串 相关的 处理。得到 准确的 数据。就是 爬虫了。。。