
- HTTP 1.0 ֮ǰ����ʷ
- HTTP 1.1 ����ʲô,�ô�,����
- HTTP 2.0 ��ʲô,�ô�,����
- HTTP 3.0 ��ʲô
- HTTPS
HTTP/0.9
HTTP �� 1990 ����������ʱ�� HTTP ��û����Ϊ��ʽ�ı��������� ���ڵ� HTTP ��ʵ���� HTTP1.0 ֮ǰ�汾����˼��
1990 �� 11 ��,CERN �ɹ��з��������ϵ�һ̨ Web �������� Web � ������������ 1992 �� 9 ��,�ձ���һ����վ����ҳ�����ˡ�
http://www.ibarakiken.gr.jp/www/
1990 ��,������ HTML1.0 �ݰ�����������,�� HTML1.0 �д��� �ദģ������IJ���,�ݰ���ֱ�ӷ����ˡ�
HTML1.0
http://www.w3.org/MarkUp/draft-ietf-iiir-html-01.txt
1993 �� 1 ��,�ִ������������ NCSA(National Center for Supercomputer Applications,�������ҳ��������Ӧ������)�з��� Mosaic �����ˡ����� in-line(����)����ʽ��ʾ HTML��ͼ��,�� ͼ�����ɫ�ı���ʹ��Ѹ�������緶Χ�����п����� ͬ������,Mosaic �� Windows ��� Macintosh ��������ʹ�� CGI ������ NCSA Web ��������NCSA HTTPd 1.0 Ҳ����������ʱ�ڳ��ֵġ�
NCSA Mosaic bounce page
http://archive.ncsa.illinois.edu/mosaic.html
The NCSA HTTPd Home Page(�浵)
http://web.archive.org/web/20090426182129/http://hoohoo.ncsa.illinois.edu/ (ԭַ��ʧЧ)
HTTP ��ʽ��Ϊ������������ 1996 ��� 5 ��,�汾������Ϊ HTTP/1.0,�������� RFC1945����˵�dz��ڱ�,����Э��������Ա��㷺ʹ���ڷ������ˡ�
RFC1945 - Hypertext Transfer Protocol �C HTTP/1.0
http://www.ietf.org/rfc/rfc1945.txt
1994 �� �� 12 ��,����ͨ�Ź�˾������ Netscape Navigator 1.0,1995 ������˾���� Internet Explorer 1.0 �� 2.0�� ����������������Ȼ��Ϊ Web ��������֮һ�� Apache,��ʱ���� Apache 0.2 ����̬������������ǰ���� HTMLҲ������ 2.0 �汾�� ��һ��,Web �����ķ�չͻ���ͽ��� ʱ����ת,�� 1995 ��������,����˾������ͨ�Ź�˾֮�䱬���� �������ս�������ҡ����ҹ�˾�����Զ� HTML������չ,���ǵ� ����д HTMLҳ��ʱ,���뿼�Ǽ����������ҹ�˾���������ʱ�� ����,�������������Щдǰ��ҳ��Ĺ���ʦ�е����֡� ���ⳡ�������Ӧ��֮��ľ�����,���Dz����Ե�ʱ��չ�еĸ��� Web �����Ӷ�����,���Ŵγ�����������û�ж�Ӧ˵���ĵ��������
2000 ��ǰ��,�ⳡ�����ս����������ͨ�Ź�˾��˥����ݸ�һ�� �䡣������ 2004 ��,Mozilla ����ᷢ���� Firefox �����,�ڶ����������ս�漴������ Internet Explorer ������İ汾�� 6 ���� 7 ǰ���� 5 ��ʱ�䡣֮��������ϵط����� 8��9��10 �汾������,Chrome��Opera��Safari �������Ҳ����ռ�г��ݶ
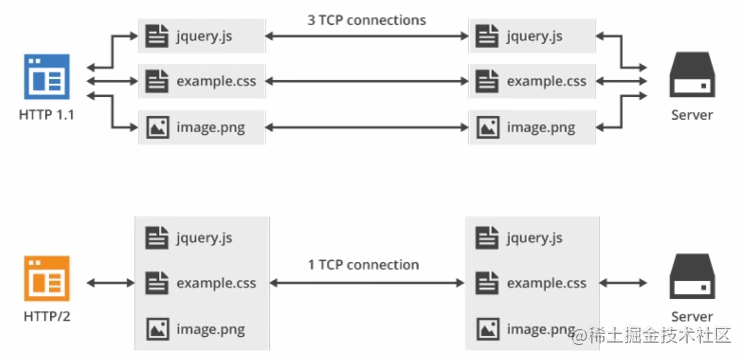
�ܽ�:ֻ��ʹ����һЩ��Ϊ����ҳ�Ϻ�����������,���ԱȽϼ�,ÿ������һ���µ�TCP����,�յ���Ӧ֮�������Ͽ����ӡ�
HTTP/1.1
1997 �� 1 �¹����� HTTP/1.1 ��Ŀǰ������ HTTP Э��汾�������ı��� RFC2068,֮�������� RFC2616 ���ǵ�ǰ�����°汾��
RFC2616 - Hypertext Transfer Protocol �C HTTP/1.1
http://www.ietf.org/rfc/rfc2616.txt
�ɼ�,��Ϊ Web �ĵ�����Э��� HTTP,���İ汾����û�и��¡���һ�� HTTP/2.0 �����ƶ���,��Ҫ�ﵽ�ϸߵ�ʹ�ø�����,�������ʱ�ա� ���� HTTP Э��ij�����Ҫ��Ϊ�˽���ı���������⡣����Э�鱾���dz���,�����ڴ˻����������˺ܶ�Ӧ�÷�����Ͷ����ʵ��ʹ �á����� HTTP Э���Ѿ������� Web �����ܵľ���,�����õ��� ���ֳ����
-
HTTP/1.1 �����˸���Ļ�����Ʋ���,��Entity tag,If-Unmodified-Since, If-Match, If-None-Match��
-
HTTP/1.1 ������Χ����,��������ͷ�м���
Rangeͷ�� -
HTTP/1.1 ��������Ϣ����Ӧ��Ϣ���������
Hostͷ��,������ͬһ�����������еIJ�ͬ�������������� -
HTTP/1.1 Ĭ�Ͽ����־�����,��һ��TCP�����Ͽ��Դ��Ͷ��HTTP�������Ӧ,�����˽����ر����ӵ����ĺ��ӳ١�
HTTP/1.1����������������Щ�仯?
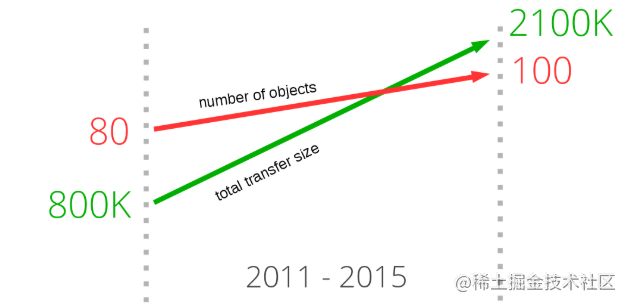
�����ϸ�۲����Щ�����е���վ��ҳ����Ҫ���ص���Դ�Ļ�,�ᷢ��һ���dz����Ե����ơ� ������������վ��ҳ��Ҫ�����ص���������������,���Ѿ�������2100K�������������Ǹ�Ӧ�ù��ĵ���:ƽ��ÿ��ҳ��Ϊ�������ʾ����Ⱦ����Ҫ���ص���Դ���Ѿ�������100������2011������,�������ݴ�С��ƽ��������Դ�������ϳ�������,��û�м����ļ���ͼ������ɫֱ��չʾ�˴������ݴ�С������,��ɫֱ��չʾ��ƽ��������Դ������������
HTTP/1.1�Դ�1997�귢������,�����Ѿ�ʹ��HTTP/1.x �൱��һ��ʱ����,�������Ž�ʮ�껥�����ı�ըʽ��չ,�ӵ�����ҳ�������ı�Ϊ��,�������Ը�ý��(��ͼƬ����������Ƶ)Ϊ��,���Ҷ�ҳ������ʵʱ�Ը�Ҫ���Ӧ��Խ��Խ��(�������졢��Ƶֱ��),���ǵ�ʱЭ��涨��ijЩ����,�Ѿ��������ִ�����������ˡ�
HTTP/1.1��ȱ��
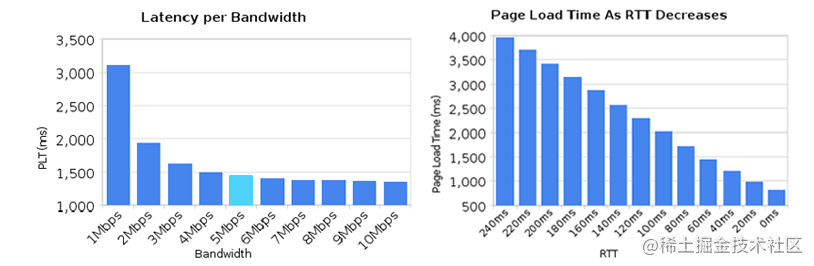
���ӳ٨C����ҳ������ٶȵĽ���
��Ȼ��������������������dz���,Ȼ������ȴ��û�п��������ӳ��ж�Ӧ�̶ȵĽ��͡������ӳ�������Ҫ���ڶ�ͷ����(Head-Of-Line Blocking),���´����������������
��ͷ������ָ��˳���͵����������е�һ��������Ϊij��ԭ������ʱ,�ں����Ŷӵ���������Ҳһ��������,�ᵼ�¿ͻ��˳ٳ��ղ������ݡ���Զ�ͷ����,���dz��Թ����°취�����:
- ��ͬһҳ�����Դ��ɢ����ͬ������,�����������ޡ� Chrome�и�����,����ͬһ������,Ĭ������ͬʱ���� 6 �� TCP�־�����,ʹ�ó־�����ʱ,��Ȼ�ܹ���һ��TCP�ܵ�,������һ���ܵ���ͬһʱ��ֻ�ܴ���һ������,�ڵ�ǰ������û�н���֮ǰ,����������ֻ�ܴ�������״̬�����������ͬһ��������ͬʱ��10��������,��ô����4�����������Ŷӵȴ�״̬,ֱ�������е�������ɡ�
- Spriting�ϲ�����СͼΪһ�Ŵ�ͼ,����JavaScript����CSS��Сͼ���¡��и�����ļ�����
- ����(Inlining)������һ�ַ�ֹ���ͺܶ�Сͼ����ļ���,��ͼƬ��ԭʼ����Ƕ����CSS�ļ������URL��,�����������������
.icon1 {
background: url(data:image/png;base64,<data>) no-repeat;
}
.icon2 {
background: url(data:image/png;base64,<data>) no-repeat;
}
- ƴ��(Concatenation)����������С��JavaScriptʹ��webpack�ȹ��ߴ����1����������JavaScript�ļ�,���������1���ļ��ĸĶ��ͻᵼ�´������ݱ��������ض���ļ���
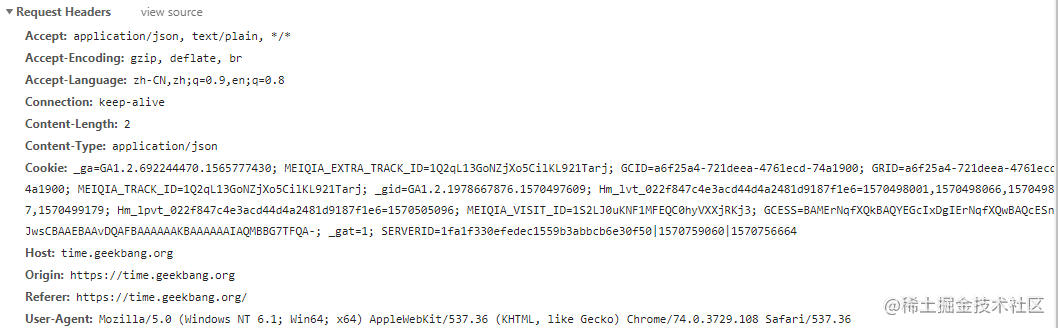
��״̬���ԨC�����ľ�HTTPͷ��
���ڱ���Headerһ���Я��"User Agent"��Cookie����Accept��"Server"������̶���ͷ�ֶ�(����ͼ),��X���ֽ�������ǧ�ֽ�,��Bodyȴ����ֻ�м�ʮ�ֽ�(����GET���� 204/301/304��Ӧ),���˲��۲��۵ġ���ͷ���ӡ���Header��Я�������ݹ���,��һ���̶��������˴���ijɱ�����Ҫ������,��ǧ�����������Ӧ�������кܶ��ֶ�ֵ�����ظ���,�dz��˷ѡ�
���Ĵ���C�����IJ���ȫ��
HTTP/1.1�ڴ�������ʱ,���д�������ݶ�������,�ͻ��˺ͷ������˶�����֤�Է�������,����һ���̶�������֤���ݵİ�ȫ�ԡ�
����û����˵��"���WiFi���塱֮���������? �ڿ;���������HTTP���Ĵ����ȱ��,�ڹ�����������һ��WiFi�ȵ㿪ʼ�����㡱,��ƭ����������һ�������������WiFi�ȵ�,���е��������ᱻ�ػ�,������������п��š���վ�����������Ϣ�Ļ��Ǿ�Σ����,�ڿ��õ�����Щ���ݾͿ���ð����Ϊ����Ϊ��
��֧�ַ�����������Ϣ
SPDY ��
SPDY ��
���������ᵽ,����HTTP/1.x��ȱ��,���ǻ�����ѩ��ͼ����Сͼ������ʹ�ö�������ȵȵķ�ʽ��������ܡ�������Щ�Ż����ƿ���Э��,ֱ��2009��,�ȸ蹫���������з��� SPDY Э��,��Ҫ���HTTP/1.1Ч�ʲ��ߵ����⡣�ȸ��Ƴ�SPDY,��������ʽ����HTTPЭ�鱾���������ӳ�,ѹ��header�ȵ�,SPDY��ʵ��֤������Щ�Ż���Ч��,Ҳ���մ���HTTP/2�ĵ�����
��Ҫͨ��֡����·���á��������ȼ���HTTP��ͷѹ������������������С�������ӳ�,���������ٶ�,�Ż��û�������ʹ�����顣
ԭ������SSL��������һ��SPDY�Ự��,����һ��TCP������ʵ�ֲ�������ͨ����HTTP GET��POST��ʽ��Ȼ��һ����,Ȼ��SPDYΪ����ʹ������������һ���µ�֡��ʽ����Ϊ����˫���,���Կ����ڿͻ��˺ͷ����������

HTTP/1.1��������Ҫ��ȱ��:��ȫ��������ܲ���,���ڱ����� HTTP/1.x �Ӵ����ʷ����,����Э�����,����������Ҫ���ǵ�Ŀ��,����ͻ��ƻ����������������е��ʲ�������ͼ��ʾ, SPDYλ��HTTP֮��,TCP��SSL֮��,�����������ɼ����ϰ汾��HTTPЭ��(��HTTP1.x�����ݷ�װ��һ���µ�frame��ʽ),ͬʱ����ʹ�����е�SSL���ܡ�
SPDY Э����Chrome�������֤�������Ժ�,�ͱ����� HTTP/2 �Ļ���,��Ҫ���Զ��� HTTP/2 ֮�еõ��̳С�
HTTP/2 ���
2015��,HTTP/2 ������HTTP/2������HTTPЭ��(HTTP/1.x)�����,����������д,HTTP����/״̬��/���嶼��HTTP/1.xһ����HTTP/2����SPDY,רע������,����һ��Ŀ�������û�����վ��ֻ��һ������(connection)����Ŀǰ���������,������һЩ������ǰ��վ�������ʵ����HTTP/2�IJ���,ʹ��HTTP/2�ܴ���20%~60%��Ч��������
HTTP/2�������淶(Specification)���:
- Hypertext Transfer Protocol version 2 - RFC7540
- HPACK - Header Compression for HTTP/2 - RFC7541
HTTP/2 ������
HTTP/2�����������Ĵ������,��Ҫ������ԭ��:�Զ����Ʒ�ʽ�����Header ѹ����
�� HTTP/2 ��,�������dz���Ҫ�ĸ���,�ֱ���֡(frame)����(stream),�������������������������·���õ�ǰ�ᡣ ֡�������ݴ������С�ĵ�λ,ÿ��֡�������б�ʶ������֡�����ĸ���,��Ҳ���Ƕ��֡��ɵ�������,ÿ������ʾһ������
�����ƴ���
HTTP/2 ���ö����Ƹ�ʽ��������,����HTTP/1.x �﴿�ı���ʽ�ı��ġ������ı�Э��Ľ���������Ȼȱ��,�ı��ı�����ʽ�ж�����,Ҫ����ȫ���Կ��ǵij�����Ȼ�ܶࡣ������Э�������������Ч��ֻʶ��0��1����ϡ� HTTP/2 ���������Ӧ���ݷָ�Ϊ��С��֡,�������Dz��ö����Ʊ�����
����TCPЭ��IJ�������Ų����Ӧ�ò�,��ԭ����"Header+Body"����Ϣ"��ɢ"Ϊ����СƬ�Ķ�����"֡"(Frame),��"HEADERS"֡���ͷ���ݡ���DATA"֡���ʵ�����ݡ�HTTP/2���ݷ�֡��"Header+Body"�ı��Ľṹ����ȫ��ʧ��,Э�鿴����ֻ��һ������"��Ƭ����
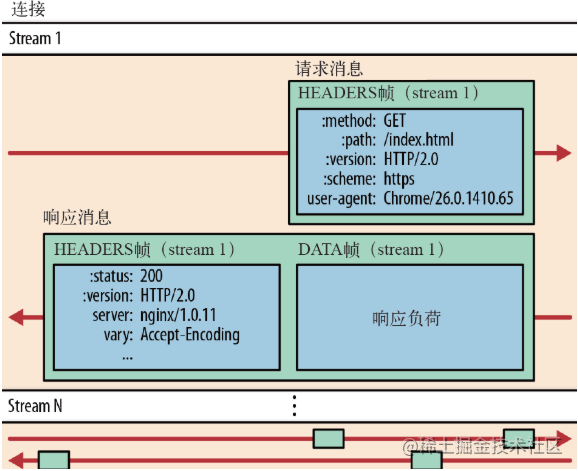
HTTP/2 ��,ͬ����������ͨ�Ŷ��ڵ������������,�����ӿ��Գ�������������˫����������ÿ��������������Ϣ����ʽ����,����Ϣ����һ������֡��ɡ����֮֡�����������,����֡�ײ�������ʶ����������װ��
�����װ�ɶ��ڵı���:
-
��ν������,ֵ���Dz�ͬID��Stream�������,����ͬһ��Stream ID��֡�ǰ�˳����ġ�
-
���շ��յ�������֡��,����ͬ��Stream ID��װ�������������ĺ���Ӧ���ġ�
-
������֡����һЩ�ֶ�,������
���ȼ������������ȹ���,�����ӵĻ�,�Ϳ�����������֡�����ȼ�,�÷�����������Ҫ��Դ,�Ż��û����顣
Header ѹ��
HTTP/2��û��ʹ�ô�ͳ��ѹ���㷨,���ǿ�����ר�ŵ�"HPACK���㷨,�ڿͻ��˺ͷ��������˽������ֵ䡱,�������ű�ʾ�ظ����ַ���,�����ù�����������ѹ���������ַ���,���Դﵽ50%~90%�ĸ�ѹ���ʡ�
HPACK�㷨
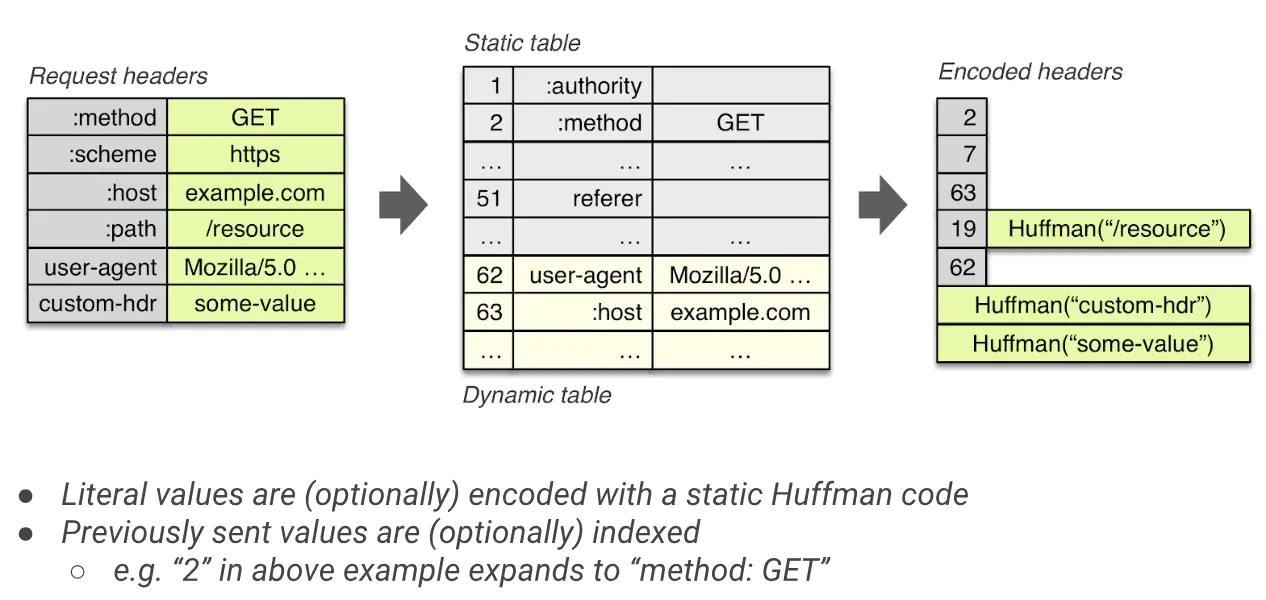
�����濴,���ǿ��Կ���������������,ÿ����������Ӧһ��ֵ,��������Ϊ2��Ӧͷ���е�methodͷ����Ϣ,�����ӵĻ�,�ڴ����ʱ��,�����Ǵ����Ӧ��ͷ����Ϣ��,���Ǵ�������,����֮ǰ���ֹ���ͷ����Ϣ,ֻ��Ҫ��**��������**(����1,2,��)�����Է�����,�Է��õ�������������ˡ�
����**����������**�ķ�ʽ,����˵������ͷ�ֶεõ�����̶ȵľ�����á�
������˵:
- �ڿͻ��˺ͷ�������ʹ�á��ײ����������ٺʹ洢֮ǰ���͵ļ�-ֵ��,������ͬ������,����ͨ��ÿ���������Ӧ����;
- �ײ�����HTTP/2�����Ӵ�������ʼ�մ���,�ɿͻ��˺ͷ�������ͬ�����ظ���;
- ÿ���µ��ײ���-ֵ��Ҫô���ӵ���ǰ����ĩβ,Ҫô�滻����֮ǰ��ֵ
������ͼ�е���������, ����һ���������е�ͷ���ֶ�,�ڶ���������ֻ��Ҫ���Ͳ�������,�������Լ�����������,���Ϳ��� 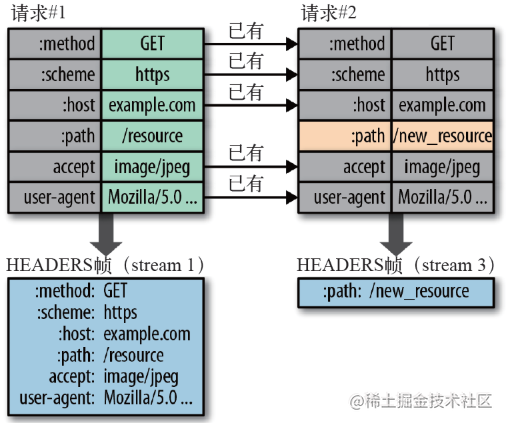
��·����
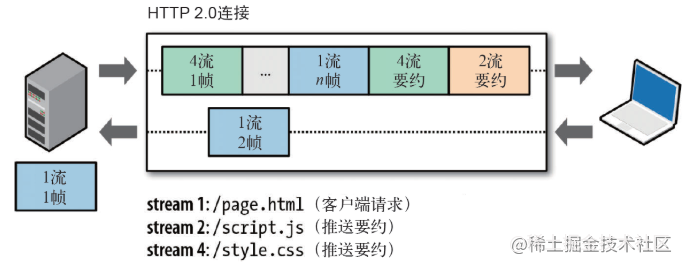
HTTP/2.0֧�ֶ�·����,����HTTP/1.1�־����ӵ������档��·����,������һ�� TCP �����п��Դ��ڶ�����,Ҳ���ǿ��Է��Ͷ������,����������ͨ��֡�еı�ʶ֪����֡�����ĸ���(������),ͨ����������ԭ����·�������������ķ���������,ÿ�������������Ӧ����Ҫ�ȴ��������������Ӧ,��������ͷ�������⡣����ij�����������ʱ����,����Ӱ�쵽�������ӵ�����ִ��,�������ߴ������ܡ�
��ҿ���ͨ�� ������ ֱ�۸����� HTTP/2 �� HTTP/1 �����˶��١�  �� HTTP/2 ��,���˶����Ʒ�֮֡��,HTTP /2 �������� TCP ����ȥʵ�ֶ���������,�� HTTP/2��,
�� HTTP/2 ��,���˶����Ʒ�֮֡��,HTTP /2 �������� TCP ����ȥʵ�ֶ���������,�� HTTP/2��,
- ͬ����������ͨ�Ŷ��ڵ�����������ɡ�
- �������ӿ��Գ�������������˫����������
- ����������Ϣ����ʽ����,����Ϣ����һ������֡���,���֮֡�����������,��Ϊ����֡�ײ�������ʶ����������װ��
��һ����,ʹ�������˼�������:
- ͬ������ֻ��Ҫռ��һ�� TCP ����,ʹ��һ�����Ӳ��з��Ͷ���������Ӧ,��������ҳ����Դ�����ع���ֻ��Ҫһ��������,ͬʱҲ�����˶��TCP���Ӿ������������������⡣
- ���н����ط��Ͷ������/��Ӧ,����/��Ӧ֮�以��Ӱ�졣
- ��HTTP/2��,ÿ�������Դ�һ��31bit������ֵ,0��ʾ������ȼ�, ��ֵԽ�����ȼ�Խ�͡������������ֵ,�ͻ��˺ͷ������Ϳ����ڴ�����ͬ����ʱ��ȡ��ͬ�IJ���,�����ŵķ�ʽ����������Ϣ��֡��
 ����ͼ��ʾ,��·���õļ�������ֻͨ��һ�� TCP ���ӾͿ��Դ������е��������ݡ�
����ͼ��ʾ,��·���õļ�������ֻͨ��һ�� TCP ���ӾͿ��Դ������е��������ݡ�
Server Push
HTTP2����һ���̶��ϸı��˴�ͳ�ġ�����-Ӧ�𡱹���ģʽ,��������������ȫ��������Ӧ����,Ҳ�����½�������������ͻ��˷�����Ϣ������,�������������HTML��ʱ�����ǰ�ѿ��ܻ��õ���JS��CSS�ļ������ͻ���,���ٵȴ����ӳ�,�ⱻ��Ϊ"����������"( Server Push,Ҳ�� Cache push)
������ͼ��ʾ,�����������JS��CSS�ļ������ͻ���,������Ҫ�ͻ��˽���HTMLʱ�ٷ�����Щ����
������Ҫ�������,����˿�����������,�ͻ���Ҳ��Ȩ��ѡ���Ƿ���ա������������͵���Դ�Ѿ�������������,���������ͨ������RST_STREAM֡�����ա���������Ҳ����ͬԴ����,���仰˵,������������㽫��������Դ�����ͻ���,�������Ǿ���˫��ȷ�ϲ��С�
��߰�ȫ��
���ڼ��ݵĿ���,HTTP/2������HTTP/1�ġ����ġ��ص�,��������ǰһ��ʹ�����Ĵ�������,��ǿ��ʹ�ü���ͨ��,������ʽ���Ƕ�����,ֻ�Dz���Ҫ���ܡ�
������HTTPS�Ѿ��Ǵ�������,���������������Chrome��Firefox�ȶ���������ֻ֧�ּ��ܵ�HTTP/2,���ԡ���ʵ�ϡ���HTTP/2�Ǽ��ܵ���Ҳ����˵,��������ͨ�����ܼ�����HTTP/2����ʹ��"https��Э����,����TLS���档HTTP/2Э�鶨���������ַ�����ʶ��:��h2"��ʾ���ܵ�HTTP/2,��h2c����ʾ���ĵ�HTTP/2��
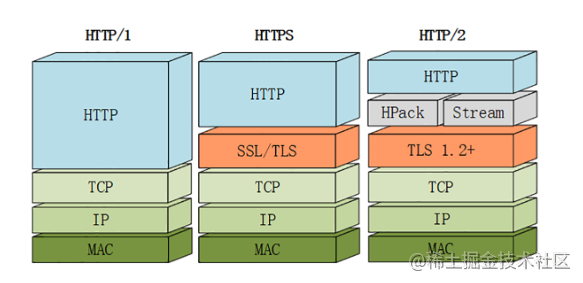
SPDY �� HTTP2 ������
- ͷ��ѹ���㷨,SPDY��ͨ�õ�
deflate�㷨,HTTP2��ר��Ϊѹ��ͷ����Ƶ�HPACK�㷨 - SPDY������
TLS������,HTTP2����TCP��ֱ��ʹ��,��Ϊ������HTTP1.1��Upgrade���� - SPDY�������Ƶ�Э�����ֺ�ȷ������
- SPDY�������Ƶ�Server Push����
- SPDY���ӿ���֡������,����֡�ĸ�ʽ���ǵĸ�ϸ��
HTTP1 �� HTTP2
- HTTP2��һ��
������Э��,HTTP1�����ı�Э��,��������ݶ�����һ���� - HTTP2��ͷѹ��,����ʹ��HPACK����
ͷ��ѹ��,HTTP1����ʲô���ᷢ�� - HTTP2
���������(Server push),����������Ԥ�Ƚ���ҳ����Ҫ����Դpush����������ڴ浱�� - HTTP2��ѭ
��·����,����ͬһ�����µ�����,ֻ����һ������,HTTP1.x����,��������6~8���������� - HTTP2����
����������֡�����ĸ���,����֡�����ݽ���˳���ʶ,����������յ�����֮��,�Ϳ��������ж����ݽ��кϲ�,��������ֺϲ������ݴ��ҵ����,ͬ������Ϊ��������,�������Ϳ��Բ��еĴ�������,����������������顣HTTP2��ͬһ���������������ǻ�������,Ҳ����˵ͬһ�����²��ܷ��ʶ����ļ�,ֻ����һ�����ӡ�
HTTP/3 ������
HTTP/2 ��ȱ��
��Ȼ HTTP/2 ����˺ܶ�֮ǰ�ɰ汾������,���������Ǵ���һ���������,��Ҫ�ǵײ�֧�ŵ� TCP Э����ɵ���HTTP/2��ȱ����Ҫ�����¼���:
- TCP �Լ� TCP+TLS�������ӵ���ʱ
HTTP/2ʹ��TCPЭ���������,�����ʹ��HTTPS�Ļ�,����Ҫʹ��TLSЭ����а�ȫ����,��ʹ��TLSҲ��Ҫһ�����ֹ���,��������Ҫ�����������ӳٹ���:
���ڽ���TCP���ӵ�ʱ��,��Ҫ�ͷ�������������������ȷ�����ӳɹ�,Ҳ����˵��Ҫ��������1.5��RTT֮����ܽ������ݴ��䡣
�ڽ���TLS����,TLS�������汾����TLS1.2��TLS1.3,ÿ���汾��������������ʱ�䲻ͬ,��������Ҫ1~2��RTT��
��֮,�ڴ�������֮ǰ,������Ҫ���� 3~4 �� RTT��
- TCP�Ķ�ͷ������û�г����
���������ᵽ��HTTP/2��,�������������һ��TCP�ܵ��еġ����������˶���ʱ,HTTP/2 �ı��ַ������� HTTP/1 �ˡ���ΪTCPΪ�˱�֤�ɿ�����,�и��ر�ġ������ش�������,��ʧ�İ�����Ҫ�ȴ����´���ȷ��,HTTP/2���ֶ���ʱ,���� TCP ��Ҫ��ʼ�ȴ��ش�,��ô�ͻ�������TCP�����е���������(����ͼ)�������� HTTP/1.1 ��˵,���Կ������ TCP ����,���������������ֻ��Ӱ������һ������,ʣ��� TCP ���ӻ����������������ݡ�
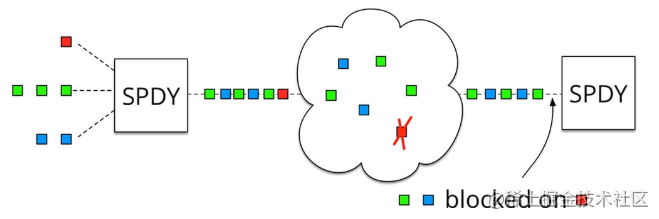
Ϊʲô��ֱ��ȥ�� TCP Э��?��ʵ���Ѿ���һ����������ɵ������ˡ���Ϊ TCP ���ڵ�ʱ��ʵ��̫��,�Ѿ�����ڸ����豸��,�������Э�����ɲ���ϵͳʵ�ֵ�,��������������ʵ��
HTTP/3���
Google ����SPDY��ʱ����Ѿ���ʶ������Щ����,���Ǿ�����¯�����һ������ UDP Э��ġ�QUIC��Э��,��HTTP����QUIC�϶�����TCP�ϡ� �������HTTP over QUIC������HTTPЭ�����һ����汾,HTTP/3������HTTP/2�Ļ�������ʵ�����ʵķ�Ծ,�������������ؽ���ˡ���ͷ���������⡣
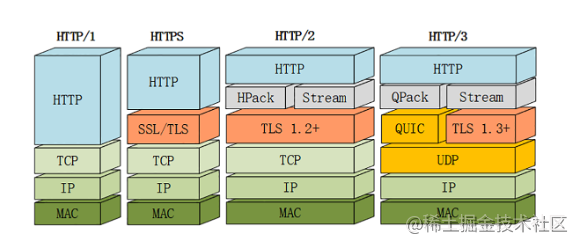
QUIC�¹���
���������ᵽQUIC����UDP,��UDP�ǡ������ӡ���,�����Ͳ���Ҫ�����֡��͡����֡�,���Ծͱ�TCP���ÿ졣����QUICҲʵ���˿ɿ�����,��֤����һ���ܹ��ִ�Ŀ�ĵء���������������HTTP/2�ġ������͡���·���á�,��������"�������,���ܻ���Ϊ����������,�����������������ܵ�Ӱ�졣������˵QUICЭ���������ص�:
-
�ڴ����ֱ�Ӹɵ�TCP,��
UDP��� -
ʵ����һ���µ�
ӵ�������㷨,�����TCP�ж�ͷ���������� -
ʵ��������TCP���������ơ�����ɿ��ԵĹ��ܡ���ȻUDP���ṩ�ɿ��ԵĴ���,��QUIC��UDP�Ļ���֮��������һ������֤���ݿɿ��Դ��䡣���ṩ�����ݰ��ش���ӵ�������Լ�����һЩTCP�д��ڵ����ԡ�
-
ʵ���˿������ֹ��ܡ�����QUIC�ǻ���UDP��,����QUIC����ʵ��ʹ��0-RTT����1-RTT����������,����ζ��QUIC�����������ٶ������ͺͽ�������,�������Դ�������״δ�ҳ����ٶȡ�0RTT ��������˵�� QUIC ��� HTTP2 ��������������
-
������TLS���ܹ��ܡ�ĿǰQUICʹ�õ���TLS1.3,��������ڰ汾TLS1.3�и�����ŵ�,��������Ҫ��һ���Ǽ��������������ѵ�RTT������
-
��·����,�����TCP�ж�ͷ����������
��TCP��ͬ,QUICʵ������ͬһ���������Ͽ����ж����������������(����ͼ)��ʵ�����������ĵ�������,�ͽ����TCP�ж�ͷ���������⡣
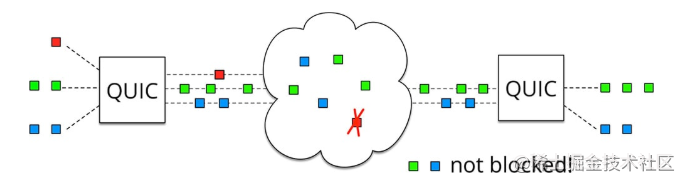
�ܽ�
- HTTP/1.1��������Ҫ��ȱ��:��ȫ��������ܲ��ߡ�
- HTTP/2��ȫ����HTTP/1,�ǡ�����ȫ��HTTP�������HTTPS",ͷ��ѹ������·���õȼ������Գ�����ô���,�����ӳ�,�Ӷ�����������������;
- QUIC ���� UDP ʵ��,�� HTTP/3 �еĵײ�֧��Э��,��Э����� UDP,��ȡ�� TCP �еľ���,ʵ���˼����ֿɿ���Э��
HTTPS
HTTPS��������
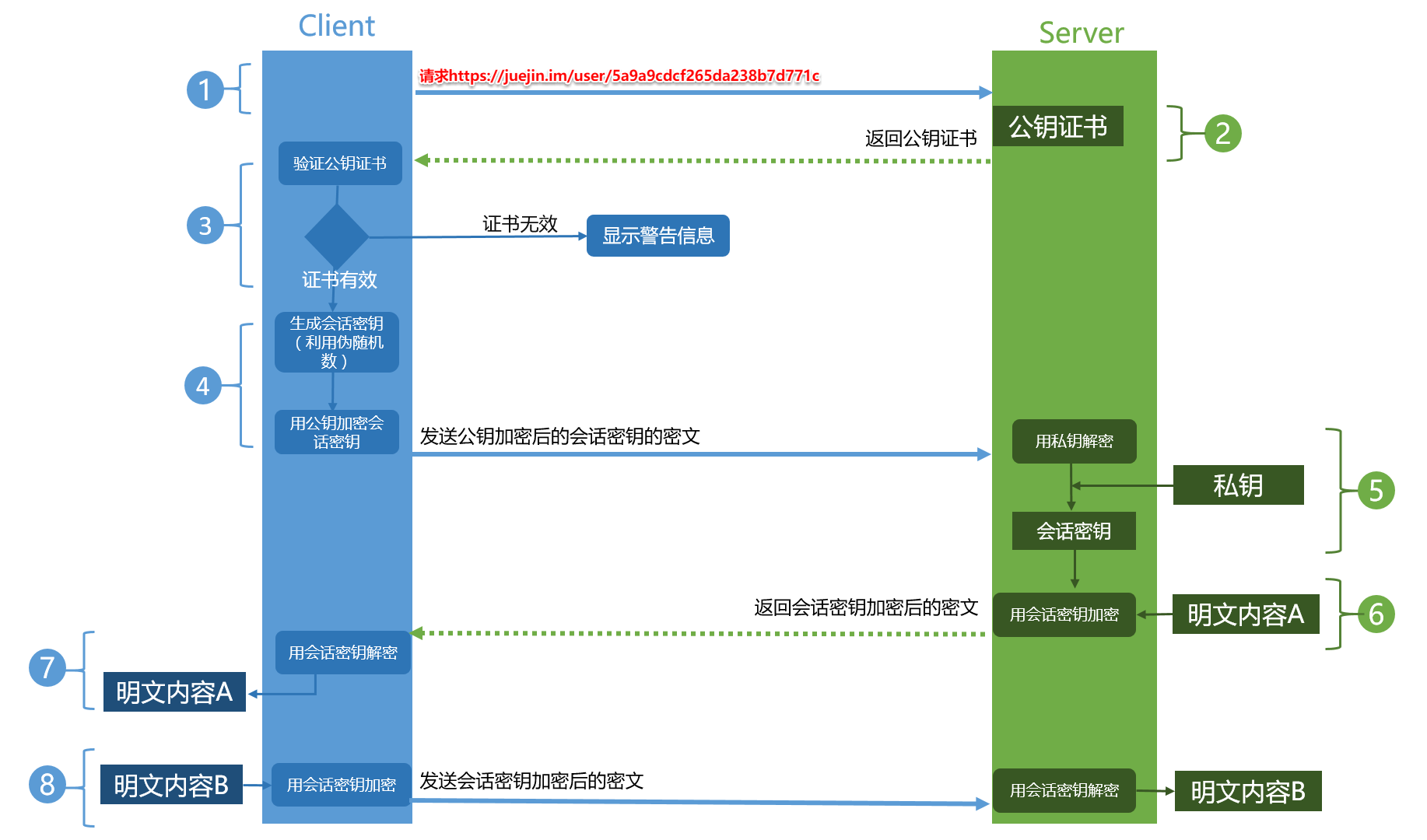
-
HTTPS��Ҫʹ��һ��CA����֤��,֤���ڻḽ��һ����ԿPub,��֮��Ӧ��˽ԿPrivate�����ڷ���˲�����
-
�û������������HTTPS����,Ĭ��ʹ�÷���˵�443�˿ڽ�������
-
������յ�����,�������úõİ�����ԿPub��CA����֤�����ͻ���
-
�ͻ����յ�֤��,У��Ϸ���,��Ҫ�����Ƿ�����Ч���ڡ�֤�������������������Ƿ�ƥ��,��һ��֤���Ƿ���Ч(�ݹ��ж�,ֱ���жϵ�ϵͳ���û���������úõĸ�֤��),�����ͨ��,����ʾHTTPS������Ϣ,���ͨ�������
-
�ͻ�������һ�����ڶԳƼ��ܵ����Key,����֤���ڵ���ԿPub���м���,���������
-
������յ����Key������,ʹ������ԿPub��Ե�˽ԿPrivate���н���,�õ��ͻ��������뷢�͵����Key
-
�����ʹ�ÿͻ��˷����������Key��Ҫ�����HTTP���ݽ��жԳƼ���,�����ķ��ؿͻ���
-
�ͻ���ʹ�����Key�Գƽ�������,�õ�HTTP��������
-
����HTTPS����ʹ��֮ǰ�����õ����Key���жԳƼӽ���
�Գ���Կ���ܺͷǶԳ���Կ���ܵ�����
**�ԳƼ���:**�ӽ����õĶ�����ͬ����Կ���ӽ���Ч�ʺܿ�,������ȫ,��������õ��������Կ��˭�����Խ��н����ˡ�
**�ǶԳ���Կ����:**�ǶԳ���Կ����������Կ,һ����˽Կ,ֻ���Լ�����;һ���ǹ�Կ,���Է������κ��ˡ����Ҽ��ܵ�����ֻ����ƥ�����Կ���ܽ⡣�ܱ�֤����������ǰ�ȫ��,����ǹ�Կ���ܵ�����,�����������ȡ������û�ж�Ӧ��˽ԿҲ�ƽⲻ�ˡ�����,��Կ��Ϊ�ǹ�����,˭�������õ�,���������ͨ��˽Կ���ܵĻ�,��ӵ�ж�Ӧ��Կ�ĺڿ;Ϳ����������Կ�����н��ܵõ��������Ϣ����Կ�ﲢû�а�������������Ϣ,Ҳ���Dz�����ȷ�����������ݵĺϷ��ԡ��ǶԳƼ��ܵ�ʱ��Ҫ����һ����ʱ��,���������ݵĴ���Ч�ʡ�
��ϼ��ܻ���
��ϼ��ܻ��ƾ��ǽ����߽���������Ǹ��Ե��ŵ������м��ܴ��䡣��Ȼ�Գ���Կ���ŵ��Ǽӽ���Ч�ʿ�,��ô�ڿͻ���������ȷ��������֮��Ϳ������������м��ܴ��䡣����ǰ���ǵý��˫�����ܰ�ȫ���õ���ѶԳ���Կ����ʱ��Ϳ������÷ǶԳ���Կ������������ѶԳ���Կ������֤�˶Գ���Կ����˫��֮�䰲ȫ�Ĵ���,����ʹ�öԳƼ��ܷ�ʽ����ͨ��,��ȵ�����ʹ�÷ǶԳƼ���ͨ�ſ��˺ܶࡣ�Դ��������HTTP�����ݿ��ܱ����������⡣��ϼ�����Ҫ��Ϊ�˽��HTTP�����ݿ��ܱ����������⡣�����������ܱ�֤���ݵ�������,Ҳ����˵�ڴ����ʱ���������п��ܱ��������۸ĵ�,������ȫ�滻��,����˵��������У�����ݵ������ԡ������Ҫ������һ�����Ҫʹ�õ�����ǩ����
����ǩ��
Ϊ�˽��HTTP�����ݿ��ܱ��۸ĵ�����,��У�����ݵ������ԡ�����ȷ����Ϣ�Ƿ��ͷ���������,��Ϊ�������һ����֤����ǩ���Ĺ���,�����Ǽ�ð���˷��ͷ���ǩ���ġ�
����ǩ���IJ���
- ��ԭ���� Hash ��������һ������ϢժҪ�Ķ���
- �÷��ͷ���˽Կ�������ϢժҪ���н��м��ܡ���������Ķ����ͽ�������ǩ��,��һ�����ԭ��һ���������ߡ�
��֤����ǩ��
- ���ȷ��ͷ��Ὣԭ��������ǩ��(Ҳ���Ǽ��ܺ��ժҪ)һ�������շ�
- ���շ�����յ�����������,��ԭ�ĺ�����ǩ��
- ���շ���Hash��������ԭ�Ļ�õ�һ����ϢժҪ
- ͬʱ�÷��ͷ��Ĺ�Կ��������ǩ��Ҳ��õ�һ����ϢժҪ
- ֻҪ�Ƚ���������ϢժҪ�Ƿ���ȾͿ�����֤��������û�б��۸���
��Ȼ����ؼ���һ������Ҫ��֤���ͷ����ݹ����Ĺ�Կ�ǿ�������,��ʱ��͵��õ�����֤���ˡ�
����֤��
����֤��Ҳ�й�Կ֤��,�����֤�顣����Ҫ��Ϊ�˽��ͨ�ŷ�������αװ������,Ҳ������֤ͨ�ŷ������ݡ�
��Ϊ����֪����HTTPS����Ȼ���˻�ϼ��ܻ��Ʊ�֤���ݲ�������,��������ǩ��У�����ݵ�������,��������ǩ��У���ǰ�������õ����ͷ��Ĺ�Կ,���ұ�֤�����Կ�ǿ�������,���Ծ���Ҫ����֤�顣
������˵��ʵ����һЩȨ����������֤�����䷢����������һ���ļ���������֤�������CA,���ǿͻ��˺ͷ���˶����εĵ������������䷢֤�������,��Ҫ��Ϊ:
- ����������Ӫ��Ա������֤�����ύ�Լ��Ĺ�Կ����֯��Ϣ��������Ϣ�Ȳ�������֤
- ����֤�������õ���Щ��Ϣ���ͨ�����ϡ����¸���;����֤�������ύ��Ϣ����ʵ��
- ��ȷ������ʵ�Ժ�,��֤��������Щ��Ϣ(�����ߵĹ�Կ,��֯��Ϣ,������Ϣ�Լ���֤�����Լ�����Ϣ��),���Ǽ��Ϊ������Ϣ,��������ǩ��,����Ҳ����ǩ���ᵽ������ǩ���IJ���:
- ͨ��Hash��������������Ϣ����һ����ϢժҪ
- ������֤�����Լ���˽Կ����ϢժҪ���м��ܴ�����ͨ���������������ɵ��ļ��ͽ�����ǩ����
- ֮��Ὣ������Ϣ������ǩ����϶��ɵ�֤��䷢��������,Ҳ���Ƿ�������
Ϊʲô˵����֤����ܶ�ͨ�ŷ������ݽ�����֤
��Ϊ�ڿͻ��˵�һ�θ�����˷���HTTPS�����ʱ��,����˻Ὣ���Լ���֤��������������Ϣ(����server_random�� server_params����Ҫʹ�õļ������ȶ���)һ���ͻ��ˡ�
�ͻ������յ�֮�����Ȼ���֤���֤��,ֻ����֤ͨ��֮��Ż��к�������������֤�Ĺ�����ʵҲ��������ǩ������֤����:
- ǰ��˵����,֤����ʵ����������Ϣ(�����ߵĹ�Կ,��֯��Ϣ,������Ϣ�Լ���֤�����Լ�����Ϣ��)�����������Ϣ������ǩ����ɵġ�
- �ͻ��˻���Hash��������������Ϣ����һ����ϢժҪ
- Ȼ������������������ϵ�CA�Ĺ�Կ������֤���������ǩ��,�õ�һ����ϢժҪ����Ϊ����֪��֤��ʵ������CA�䷢����������,�������������ǩ��Ҳ���õ�CA��˽Կ���ܵ�,����ֻ��CA�Ĺ�Կ���ܽ⡣
- ����ٽ�������ϢժҪ���жԱ�,����һ�����ܱ�֤ͨ�ŷ�����������ȷ�ġ�
��ʵ��֤֤��Ĺ��̲�����������ǩ������֤,�ͻ��˻�����֤֤����ص�������Ϣ,��Чʱ��,�Dz�����CRL�����б���,�Լ�������һ���Ƿ���Ч�ȵȡ�
����ǰ��˵��,ֻ������CA�Ĺ�Կ���ܵ�����ǩ������ͨ������֤��֤�������Ч��,��Ϊ֤����CA�䲼�ġ���Ҳ�ͱ�֤�˿ͻ����յ��ķ����������Ĺ�Կ����ʵ���õ�(��Ϊ��Կ��֤���������Ϣ��)��
��Ϊ��������Լ�û�б��֤���Ƿ�Ϸ�������,���Ͱ����½���CAȥ��,CA�����εĹ��Ļ���,��ֻҪ���Լ��Ĺ�Կ��Ƕ���������,������������CA��Կ����֤�����ǩ���Ϳ����ˡ���֤���ǩ��Ҳ�Ǿ���CA��˽Կ�������ɵ�,ֻ��CA�Ĺ�Կ�ܽ�,�����Ĺ�Կ�ֲ�����������õ���,ֻ�и�����������̲���,�������������֤�����֤����
����:
�����֤��һ������Ч��
����һ���ݹ�Ĺ���,ֱ����֤����֤��Ҳ���Dz���ϵͳ���õ�Root֤�������������õ�Root֤��Ϊֹ
TLS1.2 ����
��HTTPS���ܴ�����,ʵ�����漰�� SSL/TLS Э��,��������һ��TSL���ֵĹ��̡����ڴ�ͳ��TLS����Ҳ����RSA�����ҾͲ�������,��Ҫ��˵һ������������TLS1.2�汾������,Ҳ����ECDHE���֡�
���Ĺ��̴�����˵��������:
- �ͻ����ڵ�һ�η���HTTPS�����ʱ��,��� client_random��TSL�汾�š��������б�����������
- �������ڽ��յ�֮��ȷ��TSL�İ汾��,ͬʱ���� server_random��server_params����Ҫʹ�õļ��������Լ��Լ���֤����ͻ���
- �ͻ������յ���Щ��Ϣ֮��,�����ǻ�Է�������֤�������֤,������֤�ɹ���ᴫ��һ�� client_params ��������
- ���ͬʱ�ͻ��˻�ͨ��ECDHE�㷨�����һ��pre_random,�����Ǵ�������������,һ���� client_params,��һ���� server_params��(Ҳ����˵:ECDHE(client_params, server_params) = per_random)
- ��ʱ��ͻ��˾�ͬʱӵ���� client_random��server_random��pre_random,���Ὣ����������ͨ��һ��α�����������ó����յ�secret,���secret�������Ǻ���ͨ����Ҫ�õĶԳ���Կ��
- ���ڿͻ���������secret֮��,�������������һ����β��Ϣ,���߷�����֮��Ҫ�öԳƼ���,�ҶԳƼ��ܵ��㷨���õ�һ��Լ���õġ�
- ���������ڽ��յ��ոմ��ݹ�����client_params֮��,Ҳ��ʹ�úͿͻ���һ���ķ�ʽ����secret,����Ҳ�ᷢ��һ����β��Ϣ���ͻ��ˡ�
- ��˫�����յ���β��Ϣ����֤�ɹ�֮��,���־ͽ����ˡ����濪ʼ�����secret�Գ���Կ���ܱ��Ľ��д��䡣
(ECDHE������Բ������ɢ����,�������������Ҳ��������Բ���ߵĹ�Կ)

����RSA����
- �ͻ������ȷ��� client_random��TLS�汾�š��������б���������
- �������ڽ��յ�֮��ȷ��TLS�汾��,ͬʱ����server_random����Ҫʹ�õļ��������Լ���֤����ͻ���
- �ͻ������յ���Щ��Ϣ֮��,�����ǻ�Է�������֤�������֤,������֤�ɹ������RSA�㷨����һ��pre_random,���÷������Ĺ�Կ(��֤����)����pre_random������������
- ��ʱ,�ͻ������� client_random��server_random��pre_random,���Ὣ����������ͨ��һ��α�����������ó����յ�secret,���secret�������Ǻ���ͨ����Ҫ�õĶԳ���Կ��
- ���������յ��˸ո����Լ���Կ���ܵ�pre_random֮��,���Լ���˽Կ���н���,�õ������ pre_random,�úͿͻ���һ���ķ�ʽ����secret��
- ֮�������� secret�Գ���Կ���ܱ��Ĵ��䡣

ECDHE���ֺ�RSA��������
���ǵ�������Ҫ��:
- ����secret(�Գ���Կ)�Ĺ��̲�ͬ��RSA����ʹ��RSA�㷨����һ��pre_random���÷������Ĺ�Կ��pre_random����������,Ȼ�������α�������������ͬ��secret�Գ���Կ;����ECDHE������,��û���õ�RSA�㷨,������ECDHE�㷨���ɵ�pre_random,����������б�RSA����client_params��server_params����������
- ��������secret֮��,ECDHE�����ڿͻ��˷�������β��Ϣ�������ǰ
����,ֱ�ӷ��� HTTP ����,��ʡ��һ�� RTT,���صȵ���β��Ϣ���������,Ȼ��ȷ�����������β��Ϣ���Լ�,ֱ�ӿ�ʼ��������Ҳ��TLS False Start�� - ����Ҫ��:RSA���߱���ǰ��ȫ��,ECDHE��
(��ǰ��ȫ��:һ���ƽⲢ��Ӱ����ʷ��Ϣ�����ʾ�����ǰ��ȫ��)
��ǰ��ȫ��
һ�仰����:һ���ƽⲢ��Ӱ����ʷ��Ϣ�����ʾ�����ǰ��ȫ�ԡ�
������RSA���ֵĹ�����,�ͻ����õ��˷���˵Ĺ�Կ,Ȼ���ô˹�Կ����pre_random������ˡ������ʱ�е������з���˵�˽Կ,���ҽػ���֮ǰ���б��ĵ�ʱ��,��ô���Ϳ����ƽ�������IJ��õ�pre_random��client_random��server_random�����ݶ�Ӧ��α�����������secret,���õ�������ͨ�ŵĶԳ���Կ,ÿһ����ʷ���Ķ���ͨ�������ķ�ʽ�����ƽ⡣���Ͳ�������ǰ��ȫ�ԡ�
����ECDHE��ÿ�����ֵ�ʱ�����һ����ʱ����Կ��(Ҳ����client_params��server_params),��ʹ����������˽Կ���ƽ�,���Ƕ�֮ǰ����ʷ���IJ�û��Ӱ�졣���;�����ǰ��ȫ�ԡ�
TSL1.3�汾��TSL1.2������Щ�Ľ�
TSL1.3�汾��2018���Ƴ��ġ�����TSL1.2��Ҫ���������¸Ľ�:
- ǿ����ȫ
�ϳ��˺ܶ�ļ����㷨,ֻ������5������������������Ҫ���Ƿ�����RSA,��Ϊ��2015�귢����PRAEK����,���Ѿ����˷�����RSA��©���ܽ����ƽ�;����RSA���߱���ǰ��ȫ�ԡ�
- �������
ͬʱ���ûỰ���ý�ʡ������������Կ��ʱ��,���� PSK ������0-RTT���ӡ�
�����:
https://juejin.cn/post/6844903968380813325
https://juejin.cn/post/6844903844216832007
https://juejin.cn/post/6994629873985650696