页面请求步骤
通过MDN上面的介绍,我大致了解到当通过浏览器访问网页时,服务器响应的步骤以及服务器响应后,资源加载的情况。
服务器响应
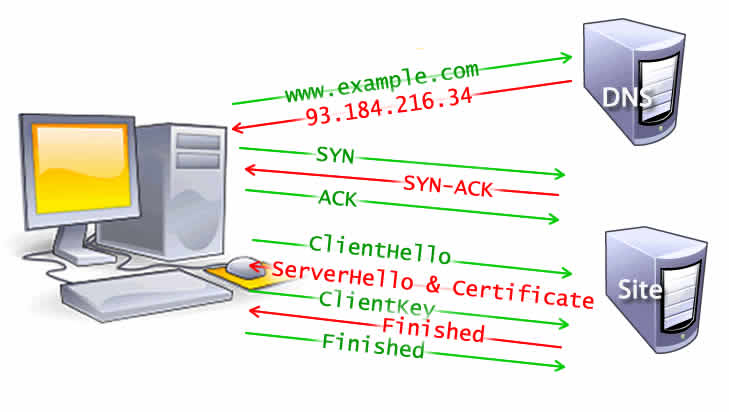
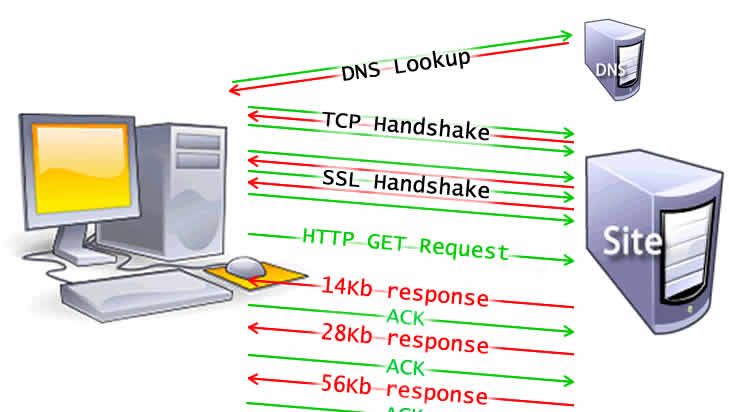
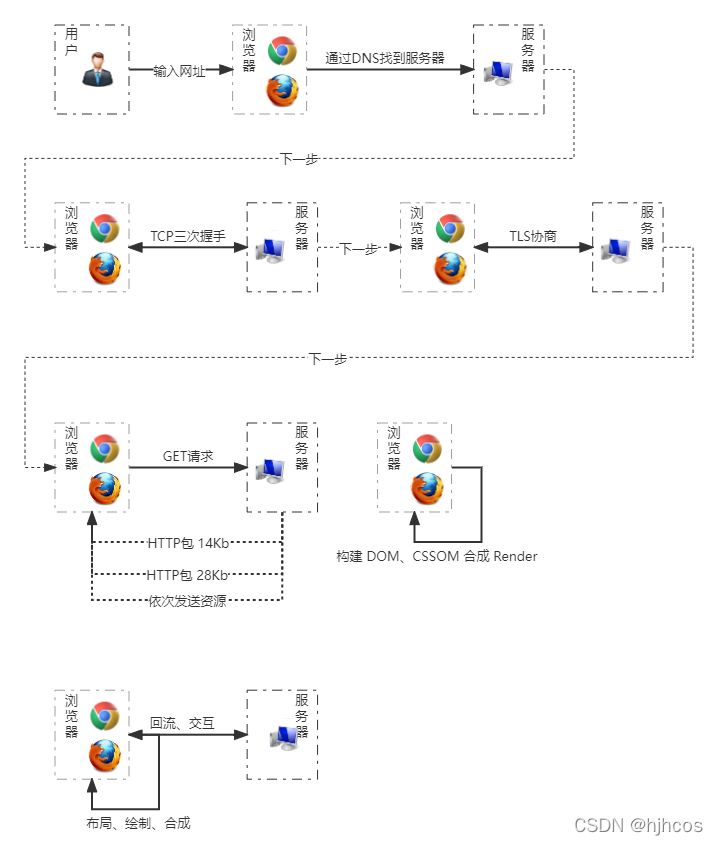
- 网址被DNS进行解析
- 浏览器与服务器进行三次TCP握手
- 浏览器与服务器进行TLS或SSL协商,创建安全连线
- 如果上面没有问题,那么浏览器与服务器正常连接
- 浏览器向服务端发送GET请求
- 服务端内部开始对请求进行处理并响应请求
页面加载显示
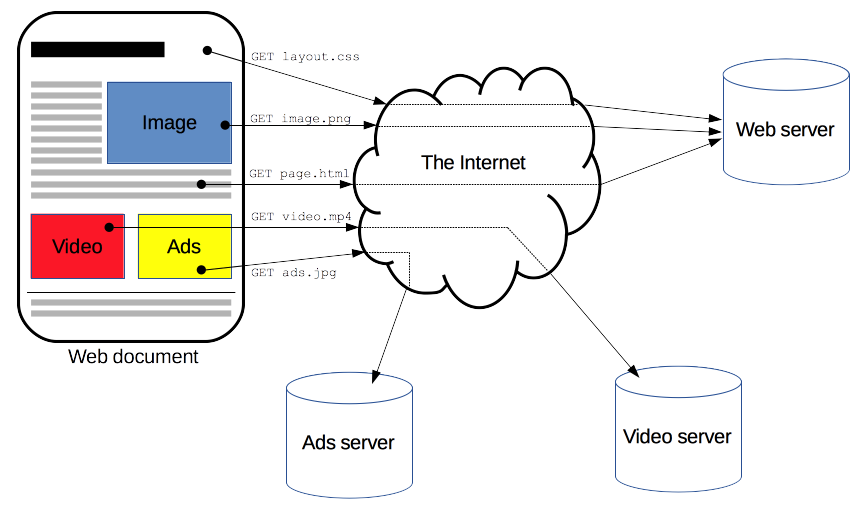
- 服务器初始响应后,浏览器接收数据包
- 浏览器解析数据,构建DOM树与CSSOM树
- 合成Render树,同时预加载扫描器开始工作
- 浏览器对页面的元素进行布局并进行绘制
- 如果资源在引用时没有加载出来,可能触发回流(即重新执行上面操作)
触发回流的几种情况
- 类似图片这种元素没有指定具体宽高
- 利用脚本生成的元素或资源
- 网络延时问题
怎么判断页面已经加载完毕,当执行window.onload命令时即表示页面已经基本加载完成。
爬虫访问页面的流程
爬虫访问方式和上面还是有一定区别的,大部分爬虫只会运行到【页面加载显示第一条】不会像浏览器通过预加载扫描器那样去加载页面内部的资源并进行引用,因此爬虫是不会自行运行页面引用的脚本,只会将源文件原封不动地返回给你。你自己再去通过某种方式运行这些脚本得到想要的数据。而且通过爬虫访问原始页面也并不是一件轻松的事,一部分网站会通过服务器限制爬虫的访问。下面我将与各位聊一聊对于爬虫限制的处理方式。
通过IP限制访问
通过单一的IP进行频繁访问时,可以根据【服务器响应第二条】中止当前IP与服务器的连接(一般可以通过Web服务器进行设置,拒绝同一IP短时间内的频繁访问)。这种方式的阻挡可以通过改变默认IP地址来解决问题。例如当使用爬虫框架快速频繁访问网站时,通过不断改变原本的IP地址进行不间断的访问。(我尝试用 requests 库去访问CSDN,正好爬虫框架可以进行访问,非常感谢CSDN!!)在我对CSDN网站依次进行50次、100次、1000次不间断频繁访问时,CSDN竟然没有限制我的IP地址,这就很难办了。只能另外找一个网站进行访问测试。【面试鸭!!大家关注一下】我非常崇拜鱼皮大哥
import requests
def getHtml(url):
try:
for i in range(100):
response = requests.get(url)
print("没有代理IP状态码: ", response.status_code, '\t'+str(i), end="\n")
except:
with open('data.txt', 'r', encoding='utf-8') as fd:
for i in range(100):
response = requests.get(url, proxies={'https': fd.readline().replace('\n', '')})
print("代理IP状态码: ", response.status_code, '\t'+str(i), end="\n")
fd.close()
getHtml('https://www.mianshiya.com/qd/54ad1eea61d460fa0308bff46de156a9')
// 同一IP多次访问 出现SSL错误 引起错误的原因是因为违反EOF规范
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.mianshiya.com', port=443): Max retries exceeded with url: /qd/54ad1eea61d460fa0308bff46de156a9 (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1129)')))
通过设置proxies参数修改IP代理进行访问,其实通过这个方法访问网站,不同的IP代理进行访问时所响应的时间也不相同,甚至可能断开连接出现类似于SSL报错、UDP报错等等。因此稳定的IP代理决定了爬虫的速度与访问主机之间的安全连接。
通过请求头限制访问
当你使用爬虫去访问每个页面时,根据【服务器响应第六条】服务器可以对你的请求进行筛别与阻挡(即可以对你的User-agent、cookie、referer等等进行检查,来限制部分爬虫的访问)。这种阻挡可以通过在请求头里面进行专门的参数设置得以解决。例如当使用某个爬虫框架去访问一个拒绝当前爬虫框架代理方式的网址时,可以通过改变它的代理方式即可解决问题。(前面有提到CSDN不检测代理方式,于是乎才找到某瓣。)
import requests
def getHtml(url):
response = requests.get(url)
print("没有设置代理方式", response.status_code, response.headers, end="\n")
response = requests.get(url, headers={'user-agent': 'Chrome'})
print("设置代理方式", response.status_code, response.headers, end="\n")
getHtml('https://www.douban.com/')
没有设置代理方式 418 {'Date': 'Sat, 22 Jan 2022 12:15:45 GMT', 'Content-Length': '0', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'Server': 'dae'}
设置代理方式 200 {'Date': 'Sat, 22 Jan 2022 12:15:45 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'X-Xss-Protection': '1; mode=block', 'X-Douban-Mobileapp': '0', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'Set-Cookie': 'll="118185"; path=/; domain=.douban.com; expires=Sun, 22-Jan-2023 12:15:45 GMT, bid=LMW4lRHfEhA; Expires=Sun, 22-Jan-23 12:15:45 GMT; Domain=.douban.com; Path=/', 'X-DAE-App': 'sns', 'X-DAE-Instance': 'home', 'X-DAE-Mountpoint': 'True', 'X-DOUBAN-NEWBID': 'LMW4lRHfEhA', 'Server': 'dae', 'X-Frame-Options': 'SAMEORIGIN', 'Strict-Transport-Security': 'max-age=15552000;', 'Content-Encoding': 'gzip'}
通过打印的结果可以清楚地看到,当你没有设置user-agent代理方式时,服务器就会返回418阻止爬虫访问。这种通过修改参数的形式进行反爬的机制,确实可以阻挡特定框架的爬虫进行访问。
通过脚本限制访问
根据【页面加载显示第五条】在目前爬虫框架中还无法实现回流效果,也就是不具有浏览器动态加载的特性。因此当有脚本操作元素时,爬虫是无法得知页面是否进行了改变。这也是为什么爬虫去访问一个动态页面时,body标签没有任何内容。虽然你可以访问但是没有数据。当遇到这种阻挡时,只需要让脚本运行起来便可以轻松解决问题。【面试鸭!!大家关注一下】我非常崇拜鱼皮大哥
import requests
def getHtml(url):
response = requests.get(url)
print('页面数据: ', response.text)
getHtml('https://www.mianshiya.com/')
<div id="root">
<style>...</style>
<div>
<div class="page-loading-warp">
<div class="ant-spin ant-spin-lg ant-spin-spinning">
<span class="ant-spin-dot ant-spin-dot-spin">
<i class="ant-spin-dot-item"></i>
<i class="ant-spin-dot-item"></i>
<i class="ant-spin-dot-item"></i>
<i class="ant-spin-dot-item"></i>
</span>
</div>
</div>
</div>
</div>
<script src="https://cdn.mianshiya.com/umi.1f886f75.js"></script>
当你用上面的方法去访问【面试鸭】的时候,body部分只会返回非主要数据给你,真正具有意义的数据这不会请求到。通过上面的返回不难看出,爬虫需要的数据应该是在id="root"的节点里面,该节点里面的内容是通过umi.1f886f75.js加载出来的。因此需要将该脚本运行起来,从而解决内容没有加载出来的问题。
import requests_html
session = requests_html.HTMLSession()
def getHtml(url):
response = session.get(url)
response.html.render()
print('页面数据: ', response.html.html)
getHtml('https://www.mianshiya.com/')
<div id="root">
<div style="display: flex; height: 100%; align-items: center; justify-content: center;">
<div class="ant-spin ant-spin-lg ant-spin-spinning">
<span class="ant-spin-dot ant-spin-dot-spin">
<i class="ant-spin-dot-item"></i>
<i class="ant-spin-dot-item"></i>
<i class="ant-spin-dot-item"></i>
<i class="ant-spin-dot-item"></i>
</span>
</div>
</div>
</div>
为什么数据没有加载出来,这也是因为回流的问题,虽然JS脚本是可以运行了(可以观察两者标签可以看出不同),但是对于通过JS利用POST请求的数据并不能通过这个脚本请求到。这就是另一种限制访问,也符合【页面加载显示第五条】。具体方法就是通过控制台【网络】去查看他的请求地址,在通过这个请求地址去访问它。
请不要拿本文的内容去做大量爬取或非法爬取,请遵循ROBOTS协议
如果你是无意刷到这篇文章并看到这里,希望你给我的文章来一个赞赞👍👍。如果你不同意其中的内容或有什么问题都可以在下方评论区留下你的想法或疑惑,谢谢你的支持!!😀😀