二、爬虫实战一(requests模块)
1.需求:
- 爬取搜狗指定词条对应的搜索结果页面(简易网页采集器)
- 在搜索栏中录入关键词,将关键词对应的页面进行一个查询
- UA检测(反爬机制)
- UA伪装(反反爬策略)
2. 实战
(1)初步代码(不完整)
import requests
# 'https://www.sogou.com/web?query=MFC'
# 1 指定url
url = 'https://www.sogou.com/web'
# 处理url携带的参数:封装到字典中
kw = input('enter a keyword: ')
param = {
'query': kw
}
# 2 发起get请求
# 对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url = url, params = param)
# 3 获得数据
page_text = response.text
filename = kw + '.html'
# 4 持久化存储
with open(filename, 'w', encoding = 'utf-8') as fp:
fp.write(page_text)
print(filename, '保存成功')
(2)引出一种反反爬策略――UA伪装
a. UA伪装对应的反爬机制――称为UA检测
UA:User-Agent (请求头信息――请求载体的身份标识)
# 如果我们用浏览器对应的一个网址发送请求的话,当前的一个url它所对应的一个请求载体是当前的浏览器
# 我们利用requests模块的get方法也可以发送请求,但是这个url所对应的请求的这个载体的身份标识就不再是浏览器了,而是我们当前的爬虫程序
- 所以UA检测指的就是:门户网站的服务器会检测对应请求的载体的身份标识,如果检测到请求的载体身份标识为某一款浏览器,就说明该请求是一个正常的请求(用户通过浏览器发起的请求),服务器一定不会拒绝这个正常的请求。但是,如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示该请求为不正常的请求(爬虫),则服务器端就很有可能拒绝该次请求(就拿不到服务器端对应的页面数据)。这就是UA伪装对应的一种反爬机制。
- 一个正常用户发起的请求,请求载体的身份标识:(win10操作系统上的Chrome浏览器)
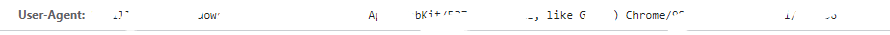
- 所以为了让我们的请求成功,我们编写的爬虫程序需要进行UA伪装
b. 反反爬策略:UA伪装
UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
- 代码如下:(key 'User-Agent’的value值替换一下 可以自己搜索一个东西,Chrome就按F12 打开控制台,点击network,查看响应头信息中的User-Agent)
# headers 字典中,key 'User-Agent'对应的value值,可以自己'伪装'
import requests
# UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla。。。' # 此处需要替换
}
# 'https://www.sogou.com/web?query=MFC'
# 1 指定url
url = 'https://www.sogou.com/web'
# 处理url携带的参数:封装到字典中
kw = input('enter a keyword: ')
param = {
'query': kw
}
# 2 发起get请求
# 对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url = url, params = param, headers = headers) # 头信息
# 3 获得数据
page_text = response.text
filename = kw + '.html'
# 4 持久化存储
with open(filename, 'w', encoding = 'utf-8') as fp:
fp.write(page_text)
print(filename, '保存成功')
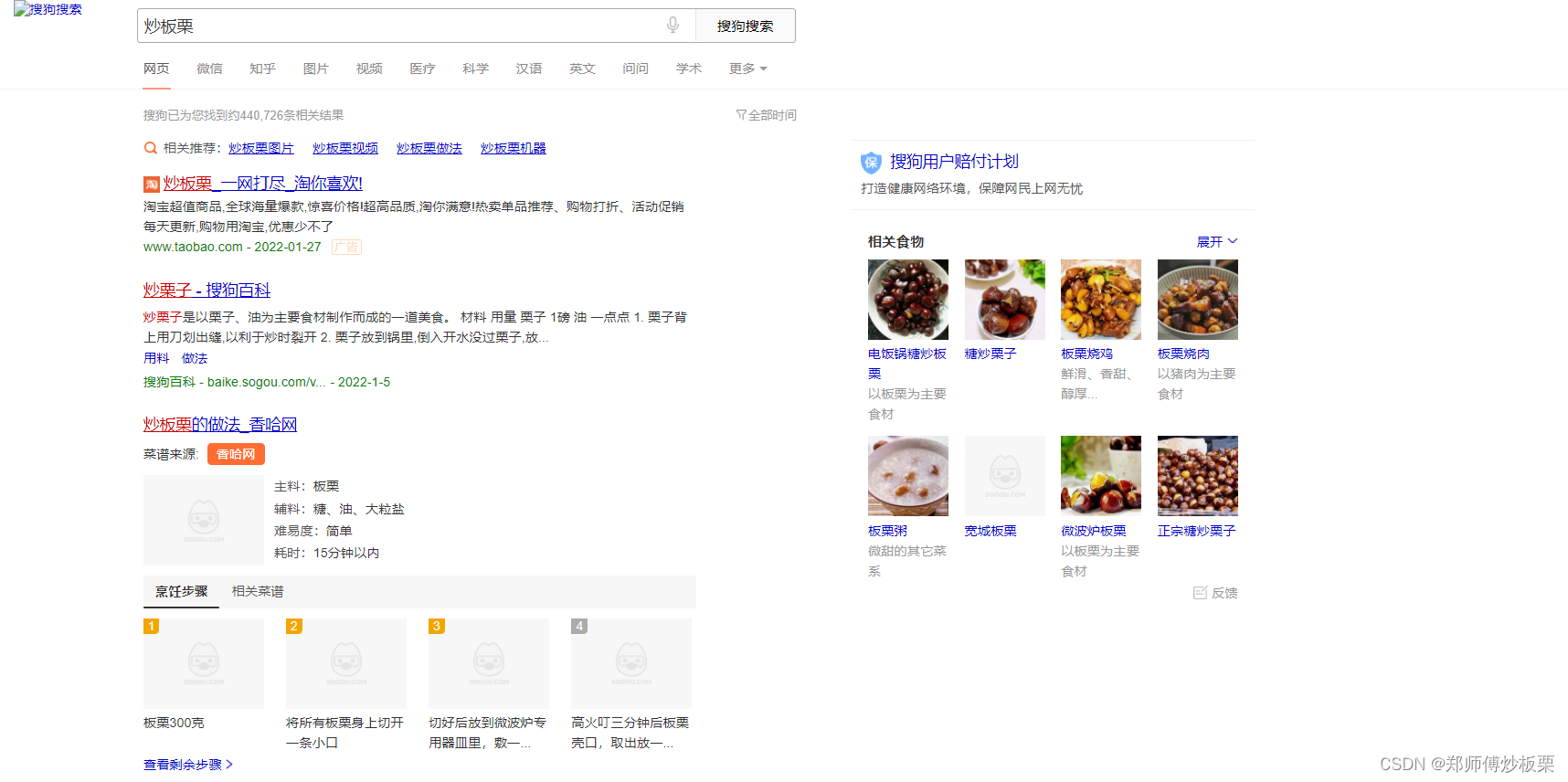
- 运行后的结果大致如下: