链接,而不是直达
在之前《听说你很懂 DNS?》中我们分析过用户在浏览器里面输入 www.baidu.com 后,浏览器如何通过 DNS 解析拿到 IP 地址,然后请求该 IP 地址获取网站内容。
本文接着就讲讲浏览器端给目标主机(IP 地址)发送的数据在网络上如何历经千辛万苦到达目的地的。
我们现在所说的网络一般就是指因特网(Internet)。因特网是一种网络架构模式,世界上除了因特网还有其它网络架构如 ATM、帧中继等。现在地球上使用的互联网就是基于因特网架构。
在因特网中,每台联网设备都有一个全网唯一的身份标识叫 IP 地址(简称 IP),有了 IP 地址,两台主机(电脑、手机等联网设备)就能通过网络通信了:

上图我们在两台电脑之间直接拉了一条线缆,两端直通。如果土豆还想跟白菜通信,得再跟白菜拉一条线缆――也就是你的主机要分别跟百度、新浪、腾讯、阿里…各自拉一条线缆来通信,这显然不现实。
所以现实中主机间通信并不是直连的,而是通过很多个中转站来转发的。这就好比你在淘宝上买了袋饼干,人家快递公司不可能开着飞机从商家直接飞到你家楼下,而是通过各种中转站转发的,如先从商家所在的街道网点发往城区中转站,再从城区发往华北调度中心然后发往华中分发中心,进而分发给各区域网点,最后快递小哥骑着摩的送到你家。
所以,我们的网络看起来是这样:
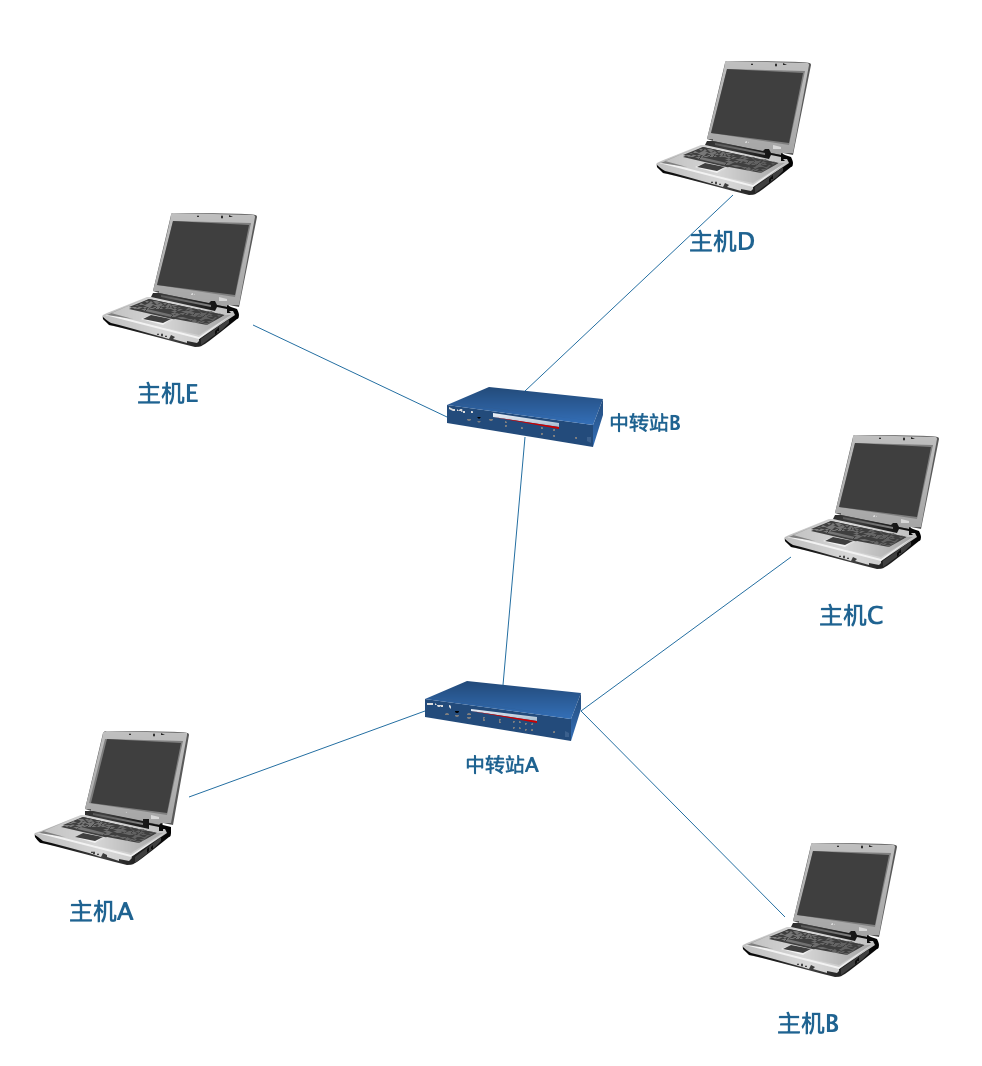
主机间并不是两两直连的,而是通过中转设备交换数据。这个中转设备我们叫它路由器(router)。
(路由:路指路径,由指从某地到某地、经过的意思,路由指经过某路径到达某地,该路径所经过的中转站叫路由器)
主机 A 要发数据给主机 B,需要通过路由器 A 中转;如果发给主机 D,则需要路由器 A 和路由器 B 做两次中转――这里需要几次中转,在计算机里面有个术语叫跳(hop,英文指单足蹦跳之意,从路由器这边”跳“到那边)。主机 A 到主机 B 需要 1 跳,到主机 D 需要 2 跳。
我们再看下主机 A 到主机 D 的路径,这条路径是通过路由器 A 和 路由器 B 链接起来的,整个路径就好像一根链子,所以称该路径上两两节点之间的线路叫链路,上面的路径由主机 A ― 路由器 A、路由器 A ― 路由器 B、路由器 B ― 主机 D 三条链路构成。
在继续深入细节之前,我们有必要先了解下网络的分层架构设计。
网络分层架构
一个现实的例子:
一般第一次坐飞机的人多少有点摸不着头脑(别问我是怎么知道的!),比如拉着手推车拖着一百来斤的行李横冲直撞,随便找个像门的地方(比如国内到达口?)溜进去,如入无人之地――然后很自然地就被安保摁倒在地。
像航线这种高逼格而又复杂的系统,比起公交有多得多的流程,你的一次航行流程大致是这样:
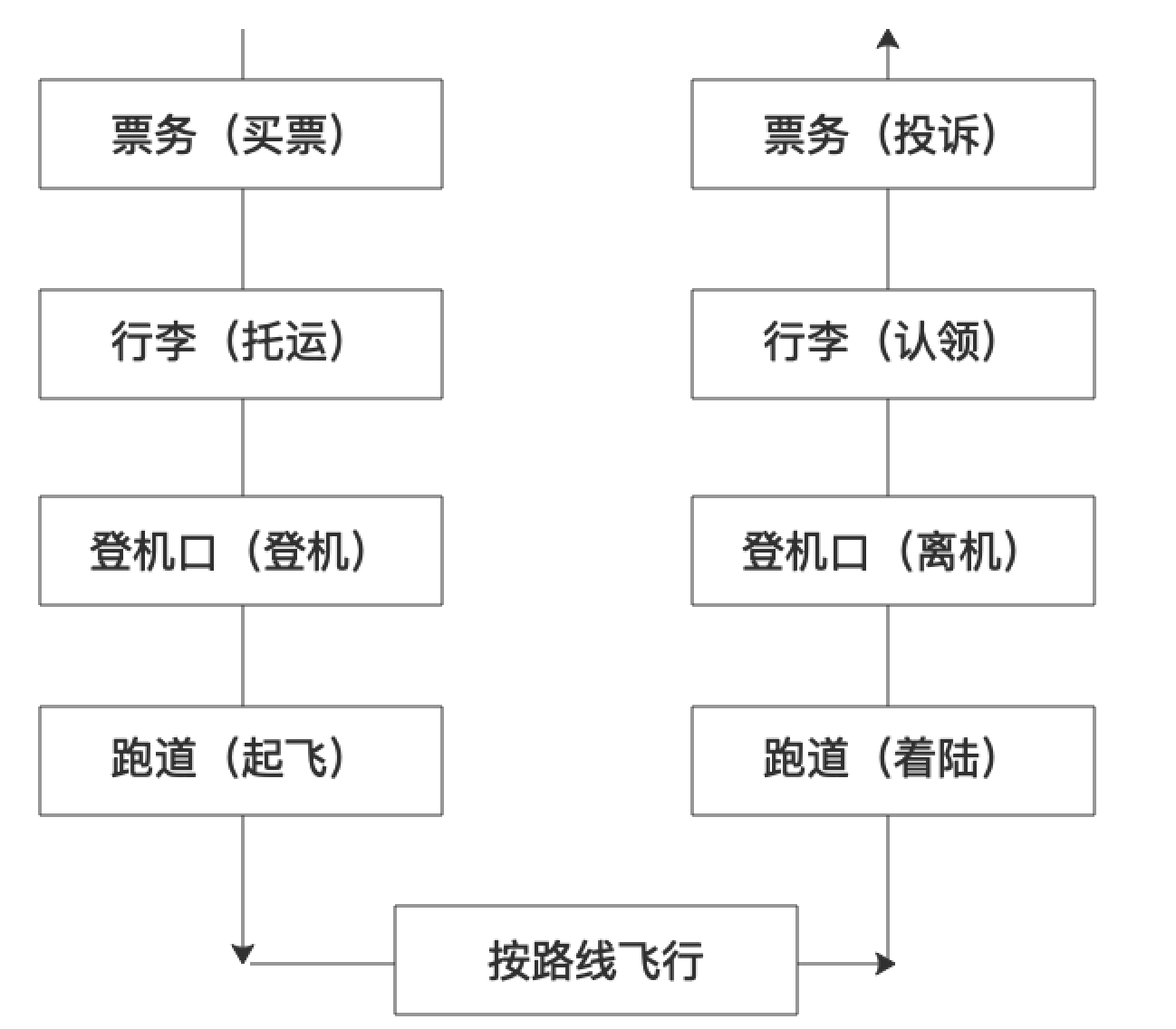
你不是在一个地方搞定所有的事情(票务、行李、登机等),而是在不同的办理点各搞定一部分,而且是按照上图箭头顺序依次执行,在入和出两个方向的办事点是相对应的(入口处最先做的事情在出口处是最后做的,入口处最后做的对应的是出口处最先做的),各个部分串在一起共同构成了你的这次航行。
互联网也是这样一个复杂系统,应用程序之间需要交互各种格式的数据,还要保证数据能够正确、及时、安全地传输到目的地,这过程中涉及到非常复杂的、异构的技术问题,也要采用这种分工的方式实现,具体的做法是在逻辑上分成几个层次,每层只处理特定的事情。
每层做事情的章法我们叫它协议(行李托运、登机、起飞等都有各自的规章制度),每层都有自己的协议集(可能不止一个协议,如不同的航站可能登机程序不同),所有层的协议在一起我们叫协议栈――之所以叫栈,你看下上面飞机航行的流程,两边各流程的对应关系正是后进先出,也就是整个操作满足栈的特性(比如上面左边出发流程的最后一道程序是跑到起飞,而右边到达流程的第一道程序是跑道着陆)。
OSI 模型和 TCP/IP 协议栈:
你在大学肯定学过著名的 OSI 七层模型:

然后你用 wireshark 等工具研究了半天,找不到会话层和表示层到底在哪里。
要知道的是这个 OSI 模型在设计的时候是针对所有(也就是抽象的)网络的,而不是针对因特网(其实在设计之初并没有考虑因特网)――所以这玩意对于我们来说理论意义大于实践意义。
因特网用的分层模型叫 TCP/IP 协议栈,它是个五层模型:
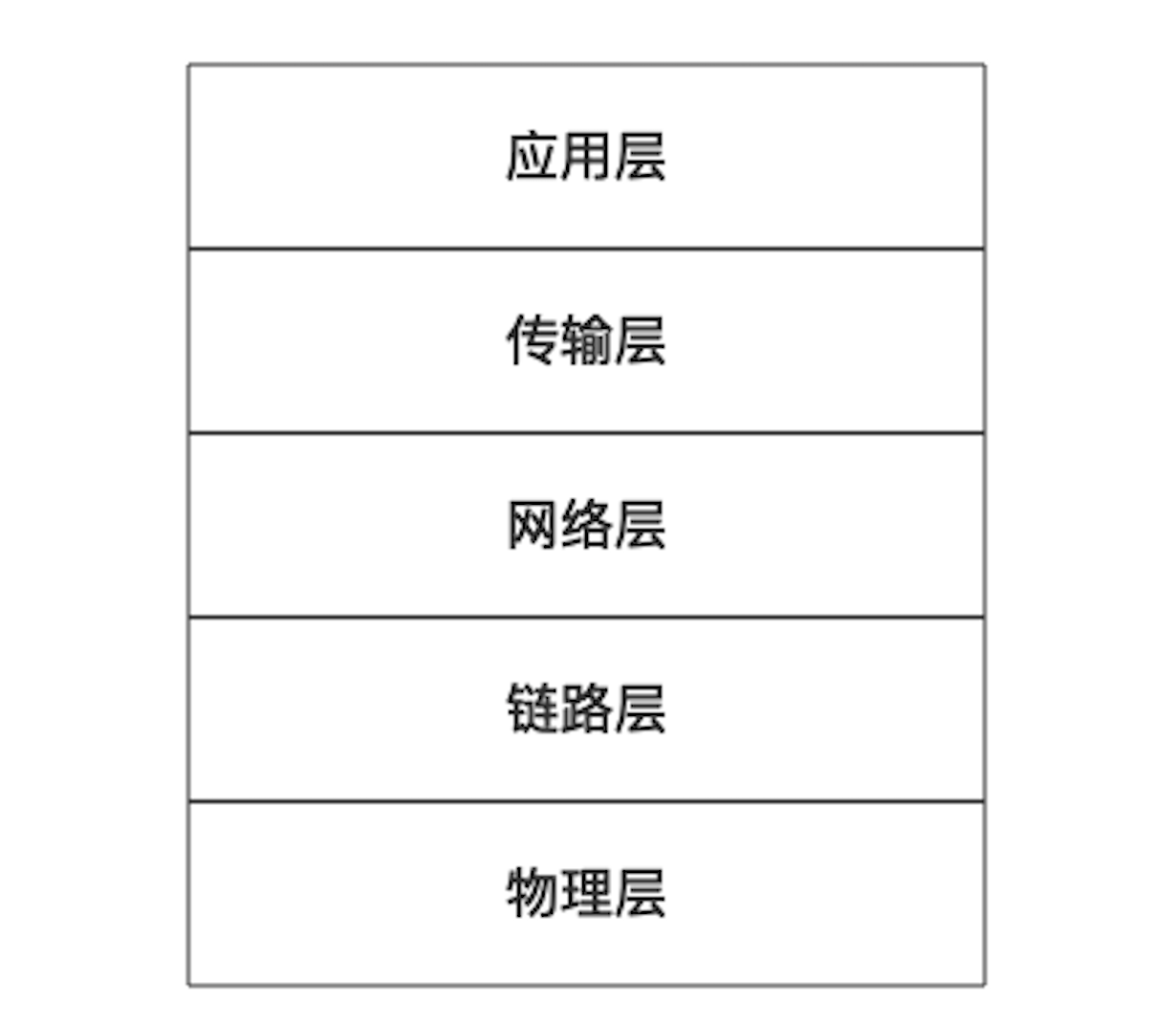
我们分析下这五层具体是干嘛的:
- 首先沟通的双方就具体的应用场景需要传递特定格式的数据,该数据格式是由应用层协议定的;
- 这些数据需要通过物理实体(光纤、铜线、网卡等)一步一步从源传给目的地。物理层关注的是这些比特的物理传输问题;
- 前面说过,源和目的之间并不是通过线缆直连的,而是通过一个个路由器转发的,那么两个节点之间(链路)如何传递数据则是链路层要处理的事情;
- 当数据通过链路层传递到中转站路由器时,路由器需要通过某种规则(协议)决定下一步发往哪条链路(走哪个出口),并完成转发――由网络层负责“寻路”的工作(具体的办事章程就是IP 协议和路由选择协议);
- 由前面的物理层(实际物理传输媒介)、链路层(两个节点间传输规则)和网络层(寻路)一起完成了数据的传输。然而,因特网的这三层虽然能传输数据,但并不是可靠的(其它网络模型如 ATM 的 CBR 模型能够在网络层保证数据的可靠传输,但因特网的设计原则是让网络本身更加简单,所以未在这三层提供可靠性保证),不能保证数据能准确、及时、安全地传递到目的地――比如路由器队列满了就会丢弃后续数据(而且不会给予通知)、TTL 跑完了(路由选择出问题了,数据在网络中迷路了)也会被丢弃。因特网的原则是保持网络本身的简单,将这种复杂的可靠性保证放在端系统(源和目的地主机)上实现。传输层就是用来做数据可靠性保证的(确保传递、流量控制)――当然如果应用本身为了性能考虑并不需要这层可靠性保证,那也可以不做。因特网传输层用到的协议是 TCP 和 UDP 协议。
可以看到,五层中的底下四层都是为了第五层数据的可靠传输设计的。下一层是在上一层的基础上工作的;底下三层工作在整个网络的每个节点(主机和路由器)和链路上,而传输层和应用层是工作在端系统(源和目的主机)上。
可能有人会问,因特网的五层协议没有 OSI 中的会话层和表示层,难道这两层不重要吗?
我们发现因特网的五层协议中,底下四层都是为数据传输服务的,所以整个模型我们可以归纳成两个大层:应用层与传输层(包含底下四层),然而在这两层之间其实还有很多事情要做:传输层很可能会对应用层数据做切分(数据过大无法一次性传输),所以在应用层接收到数据后不得不重新组装数据;应用层的数据在传输前可能需要压缩以降低网络流量占用,所以接收后需要解压;为了安全,应用层数据在网络上传输之前可能需要加密,所以接收后需要先解密;由于沟通双方系统的异构性,沟通双方需要就数据的某些方面做些约定,如多字节字符的编码、数值的大小端表示等。
因特网的回答是:这些杂碎的事情都让应用层自己去处理吧!
所以应用层协议一般会兼具会话和表示的功能,比如 HTTP 协议中的各种头部信息(里面包括字符编码、文本格式、是否压缩以及压缩策略、安全策略等),使得两边的 HTTP 客户端和服务器应用能够很好地理解数据的含义。
传输单元:
快递的运输单元叫包裹(packet),网络借鉴了这种说法。不过中文翻译过来不叫“包裹”,而叫分组(packet)(是不是瞬间逼格提升 n 倍)。
每一层的分组都有它自己的特定名字(否则每层都叫分组就很容易混淆了):
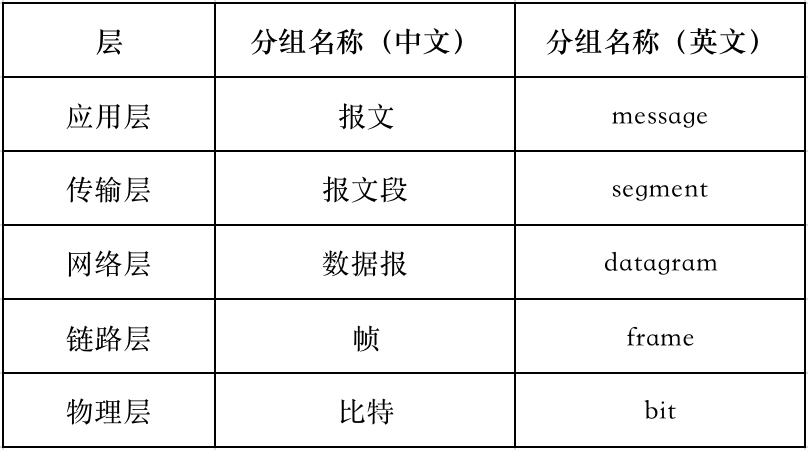
所以以后听到说“TCP 分组”和“TCP 报文段”不要再纠结它俩到底有啥区别了――压根就没区别。
网络分组和快递包裹有点不同的是,快递运输中往往是我们提供一个个小件包裹,然后快递公司装箱成大包裹――网络恰恰相反,网络上是应用层提供个大包裹(比如 HTTP 报文,可能有几十兆),传输层一次传不动,就会将它切分成一个个小的分组,这些分组在传给网络层、链路层后可能还会被切分成更小的分组。
一个分组由首部(Header)和有效载荷(payload)两部分构成。首部放一些元数据,比如协议的版本、加密算法、校验和、实际数据长度等;有效载荷也就是实际的数据:

整个网络分层体现在分组结构上就是俄罗斯套娃:下层(如网络层)拿到上层(如传输层)的分组(里面包含了上层的首部和有效载荷)后,在上面加上自己的首部,形成新的分组并交给自己的下层:

这样讲还是比较抽象,抓个包看看就明白了。
网络分层的运作过程:
我们抓一个 HTTP 包看看实际的数据包结构:
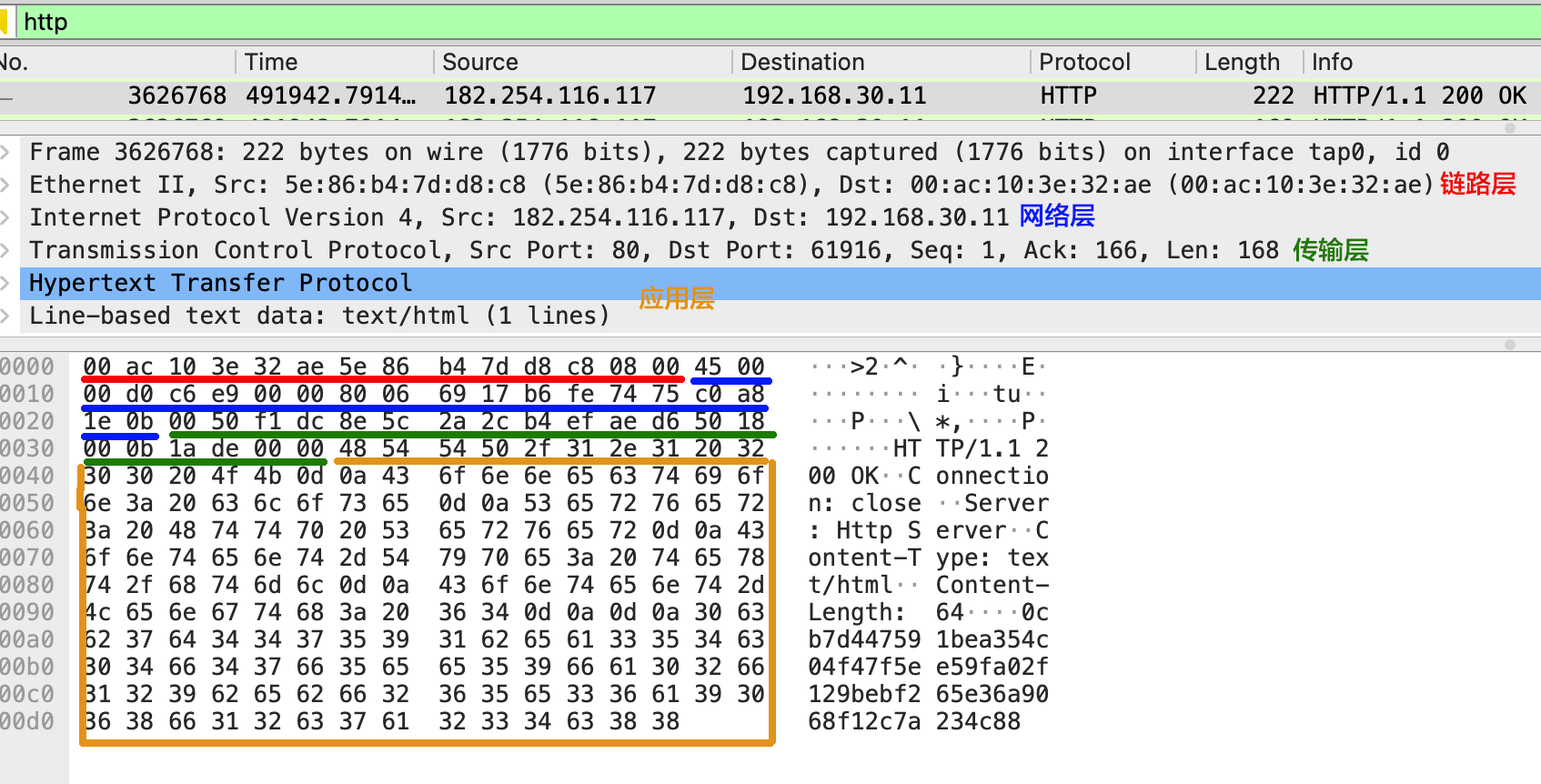
那么这样的数据包是如何生成和使用的呢?其中涉及到封包和解包的过程:
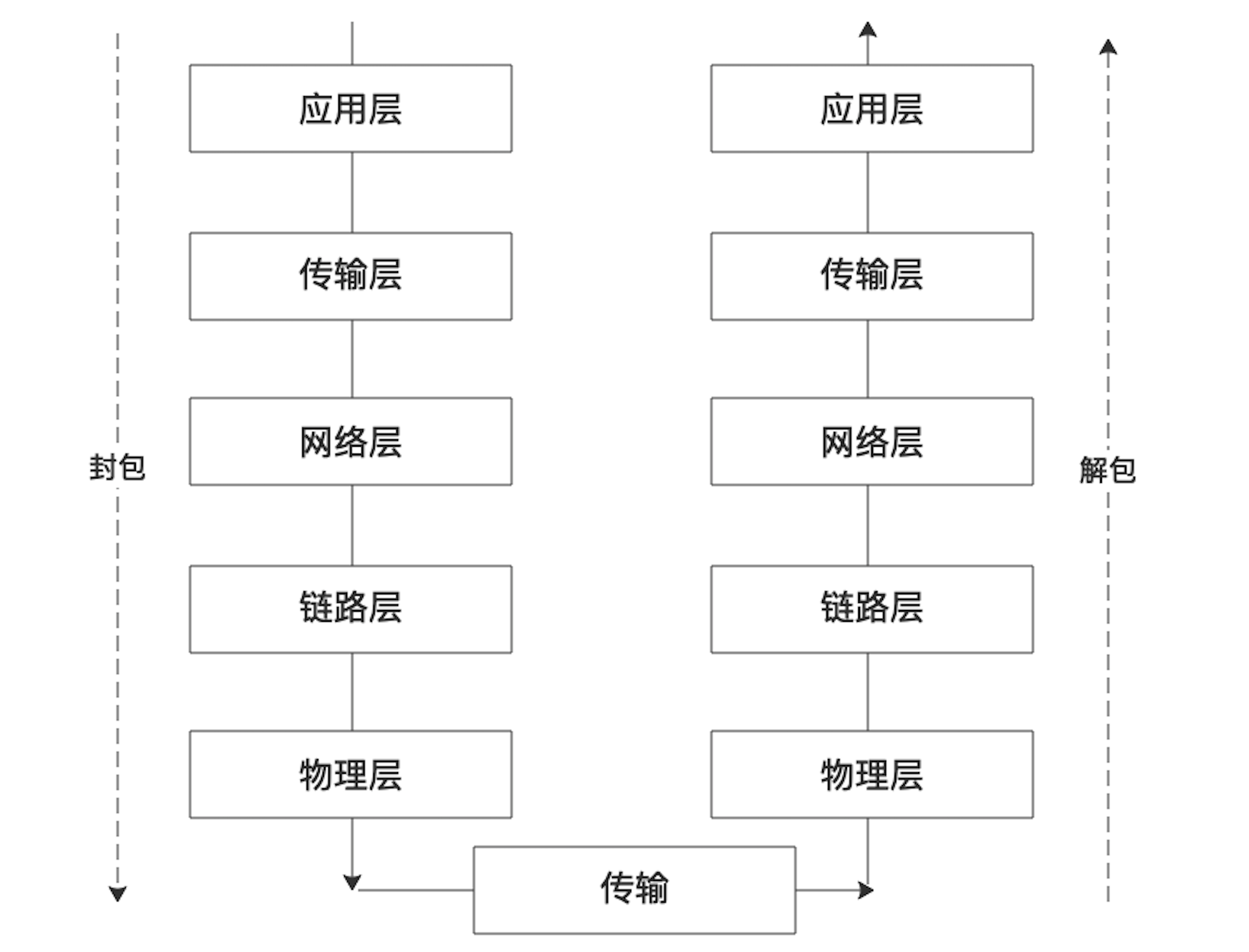
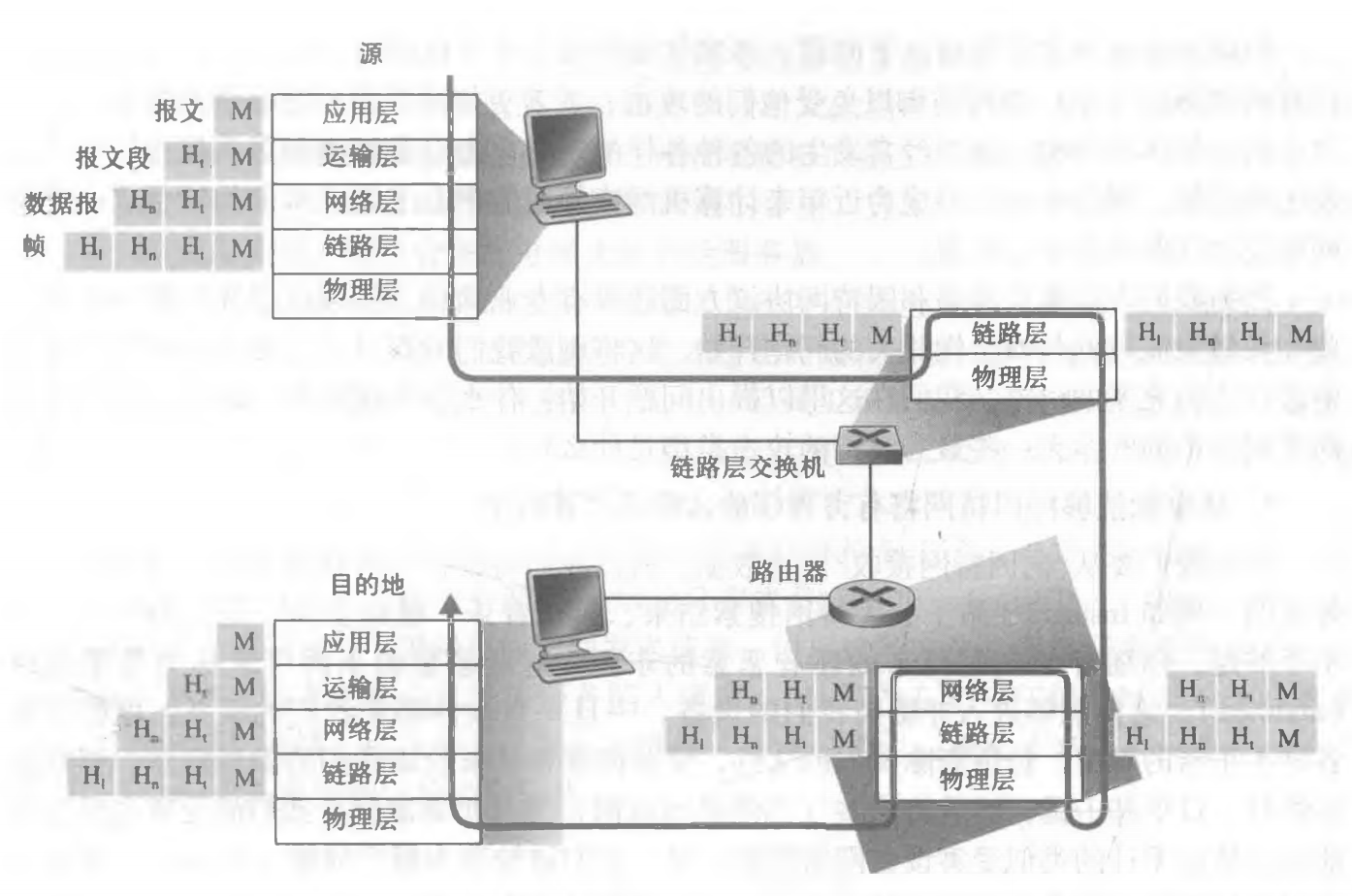
在发送端(源主机上),应用层将报文(前图橙色部分)传给传输层;传输层收到报文后附上传输层的首部(前图绿色部分,包括端口、序列号等信息),该首部和应用层传过来的报文一并构成传输层的报文段,继续传给网络层;网络层收到报文段后加上自己的首部(前图蓝色部分,包括 IP 地址等信息),构成网络层的数据报,传给链路层;链路层拿到传过来的数据后继续加上自己的首部(前图红色部分,包括 mac 地址等信息)构成链路层帧,最后交由物理层介质传输。
上面的过程是发送端的封包过程,当接收端(路由器或目标主机)收到数据后,需要执行逆向的解包。
根据设备工作的层不同,需要解包到的层次也不同。链路层设备(如链路层交换机)只需要从来源分组中取出链路层信息(mac 地址),根据此信息做分组转发――链路层以上的信息对它来说属于黑盒,无需关心;网络层设备(如路由器)需要取出网络层首部(IP 地址等信息),据此作出相应行为(如根据目标 IP 做转发)。目的主机需要对所有层解包,最终得到应用层报文,根据应用层协议做相应的处理。
注意,除了目标主机,其它的接收端(如路由器)同时也是发送端,因而这些设备除了在接收到分组后进行解包以获取必要的信息外,在转发分组前还要封包。比如路由器,它接收到分组后首先进行链路层解包,得到 mac 信息,发现其中的目标 mac 地址是自己后,再进行网络层解包(因为它是工作在网络层嘛)得到 IP 信息,根据其中的目标 IP 地址结合自己的路由转发表,决定要将分组转发到某个出网口。在转发前,它首先要修改该分组的网络层首部,将 TTL 的值减一(相应地校验和也要改变。如果它是一台 NAT 路由器,要做 NAT 转发的话,还要修改源 IP 和端口,这个后面再说);然后它还要修改链路层首部,更新 mac 地址(源 mac 改成自己,目标 mac 改成下一跳目标设备的)。
整个数据传输中的封包解包可参照下图:
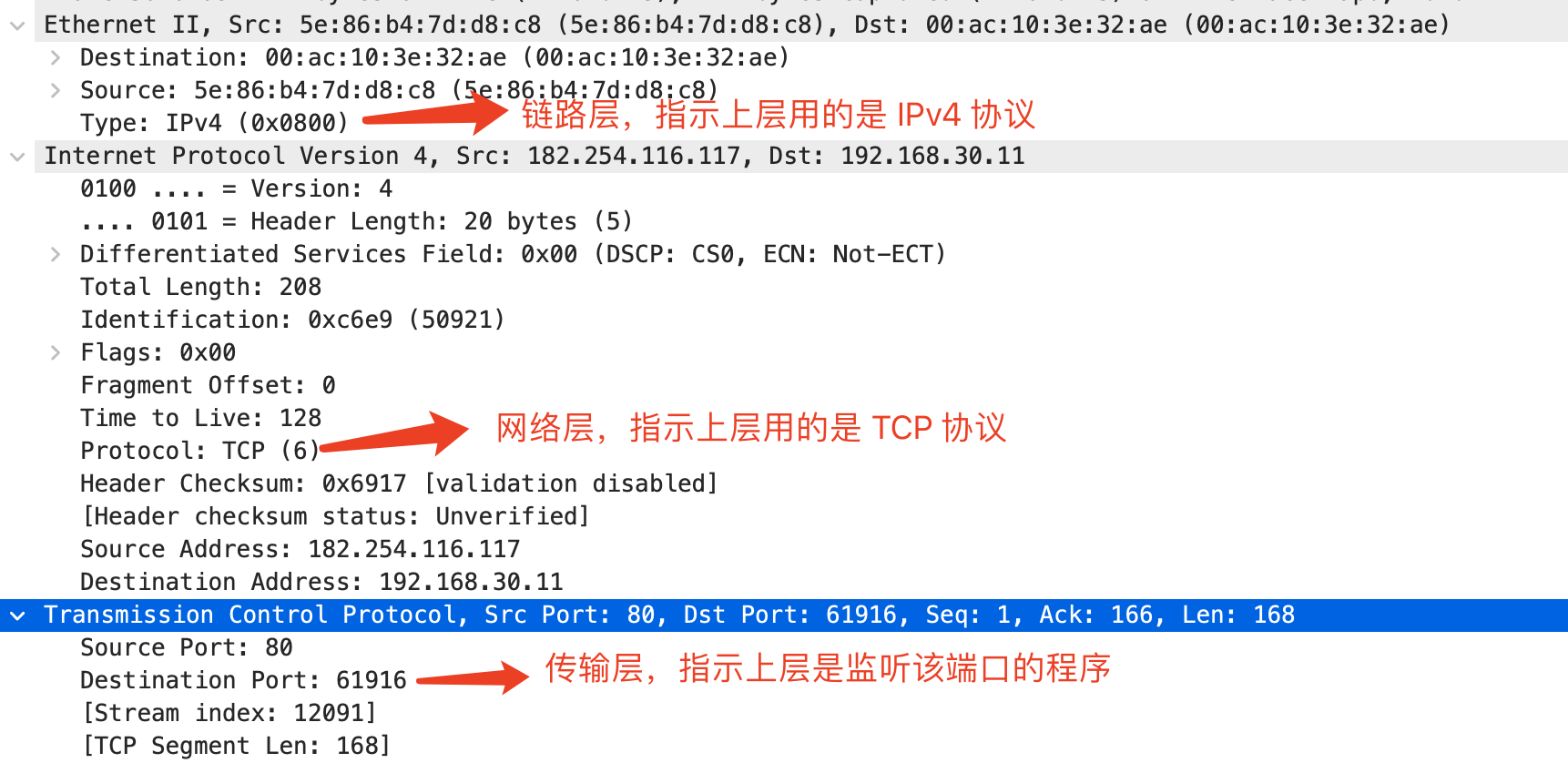
在结束网络分层架构的讨论之前,你可能还有个疑惑:在解包过程中,下层如何知道应该将分组交给上层哪个处理器处理呢?比如网络层如何知道应该将分组交给 TCP 处理器还是 UDP 处理器呢?
因而在各层协议的首部,都包含了指向上层协议的“指针”,如图:
讲完网络分层架构后,我们将目光聚焦到网络层上。
路由器
我们开头讲过,互联网上的主机间并不是直连的,而是通过很多路由器形成链状路径(也因此两节点之间的线路叫链路,负责两个节点间通信细节的叫链路层)。这里的核心设备是路由器。
路由器属于网络层分组交换机。所谓分组交换机,是指根据一定的路由规则对分组(如果现在你还对“分组”这个名字感到不适,那你就想象成快递包裹)执行转发的设备,让分组从一条链路走向另一条链路,最终到达目的地。交换机要执行转发,必定要依据来源分组的某些信息,并查找自己的转发表,以决定要将分组发往哪条出路――网络层分组交换机是指这个转发表(转发规则)是依据网络层信息制定的,具体来说就是 IP(请记住我们讨论的是因特网,其他网络模型就不一定是 IP 了)。
路由器做的核心的事情就是:根据来源分组的目标 IP 将其转发到合适的出链路。
路由器原理大致如下:
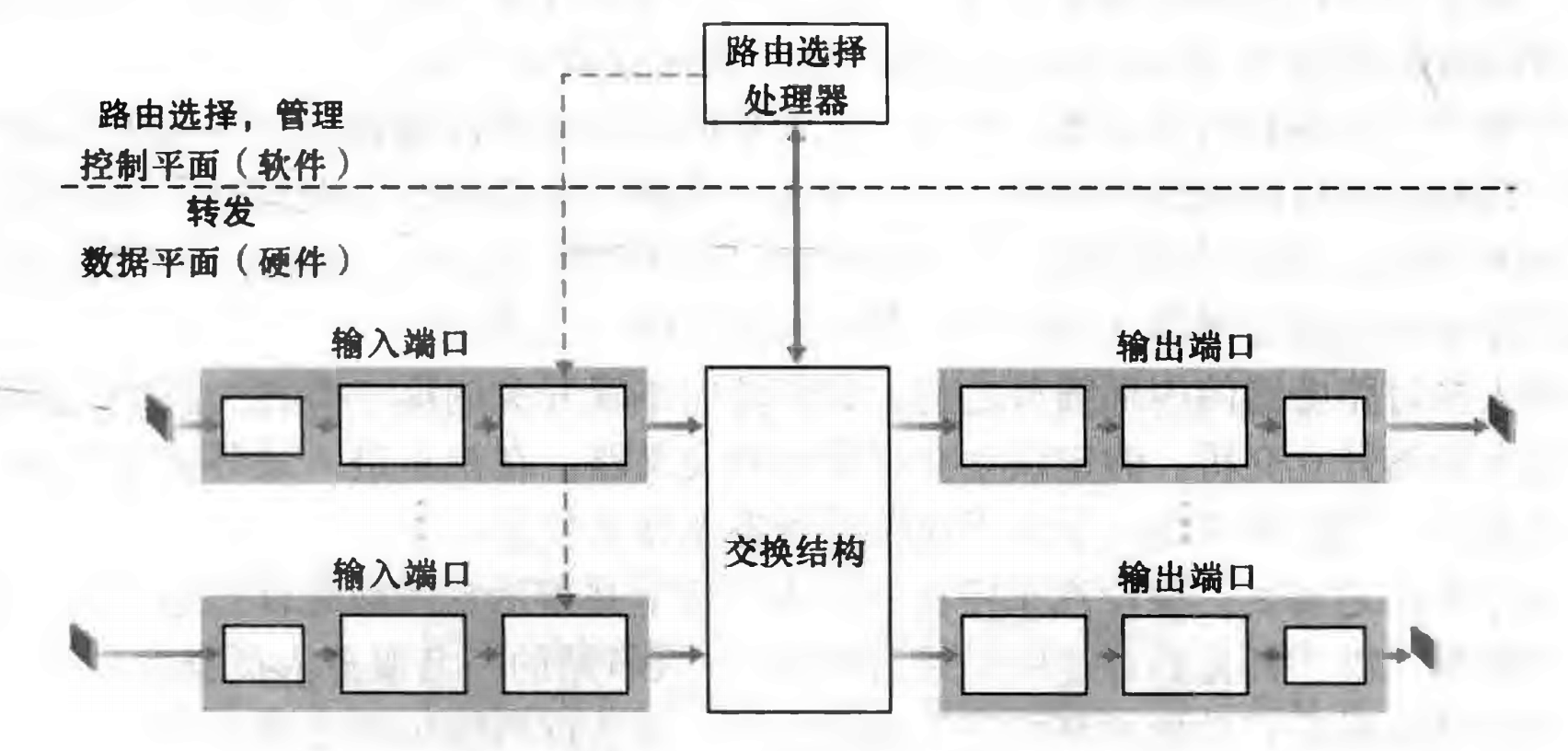
路由器主要由四部分构成:输入端口、输出端口、交换结构、路由选择处理器。
分组首先从输入端口进入,输入端口从中取出网络层首部,获取目的 IP,根据该 IP 查找自己的路由转发表,决定要将该分组交给哪个输出端口,然后将该分组放到交换结构的相应位置,由交换结构实际将分组发送给对应的输出端口。
上面提到的转发表是由路由选择处理器(一个普通的 CPU 加相关软件)计算的,该处理器根据相关路由选择算法计算本路由器的转发表并拷贝给各输入端口,输入端口便根据该表做分组转发。
一份转发表本质上就是 IP 到网口的映射,大致像这样(linux 用 route -n 查看,Mac 用 netstat -nr):
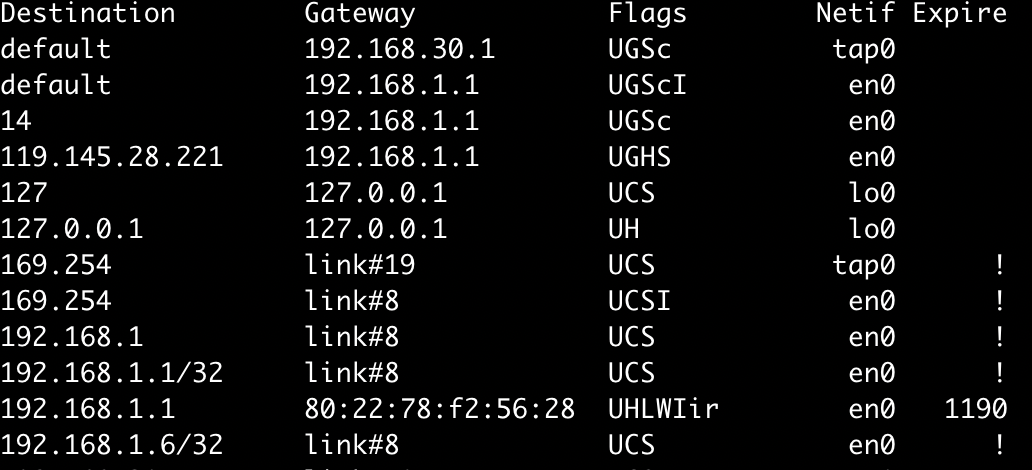
上面是我本机的路由转发表,有两个网卡(Netif 字段):en0(物理网卡)和tap0(虚拟网卡,用于跟公司做 VPN 连接)。你会发现,转发表的 IP 列(第一列)大部分不是完整的 IP,而是前缀,转发表的匹配策略是最长前缀匹配。上面定义了两个默认策略(所有 IP 前缀都匹配不上的时候走该策略),两个中优先走 tap0(也就是 VPN的)。按照上面的配置,在我访问绝大部分外网服务时都是走得 VPN 网络。上面有一条 14 的规则,说明以 14 开头的 IP 走的是 en0。
需要注意的是,路由器的处理单位是分组(数据报),而物理层数据是按比特传输的,一个数据报的所有比特一般不是同时到达路由器输入口的,此时路由器需要等待该分组的所有比特到达后才能开始处理该分组(而不是在第一个比特到来后就处理),这里就存在一个时延。另外路由器拆包、查找表、转发同样需要时间(虽然这些时间一般以纳秒计),所以数据每经过一个路由器便不可避免地产生网络时延――如何优化路由选择算法以减少数据包经过的路由器数量,以及优化路由器本身的处理性能是网络层需要处理的核心问题。
另外,如果路由器的处理性能跟不上,分组到来的速度大于路由器转发的速度,就会导致分组堆积到待处理队列中,队列堆满后,后面来的分组就会被丢弃,也就是我们常说的丢包。由于因特网的网络层并不提供可靠性保障,路由器会直接将分组丢弃而不会通知发送方,所以为了获得传输上的可靠性,必须在上层(如传输层)实现相关保障机制。
IP
IP 协议:
IPv4 数据报大致长这个样子:
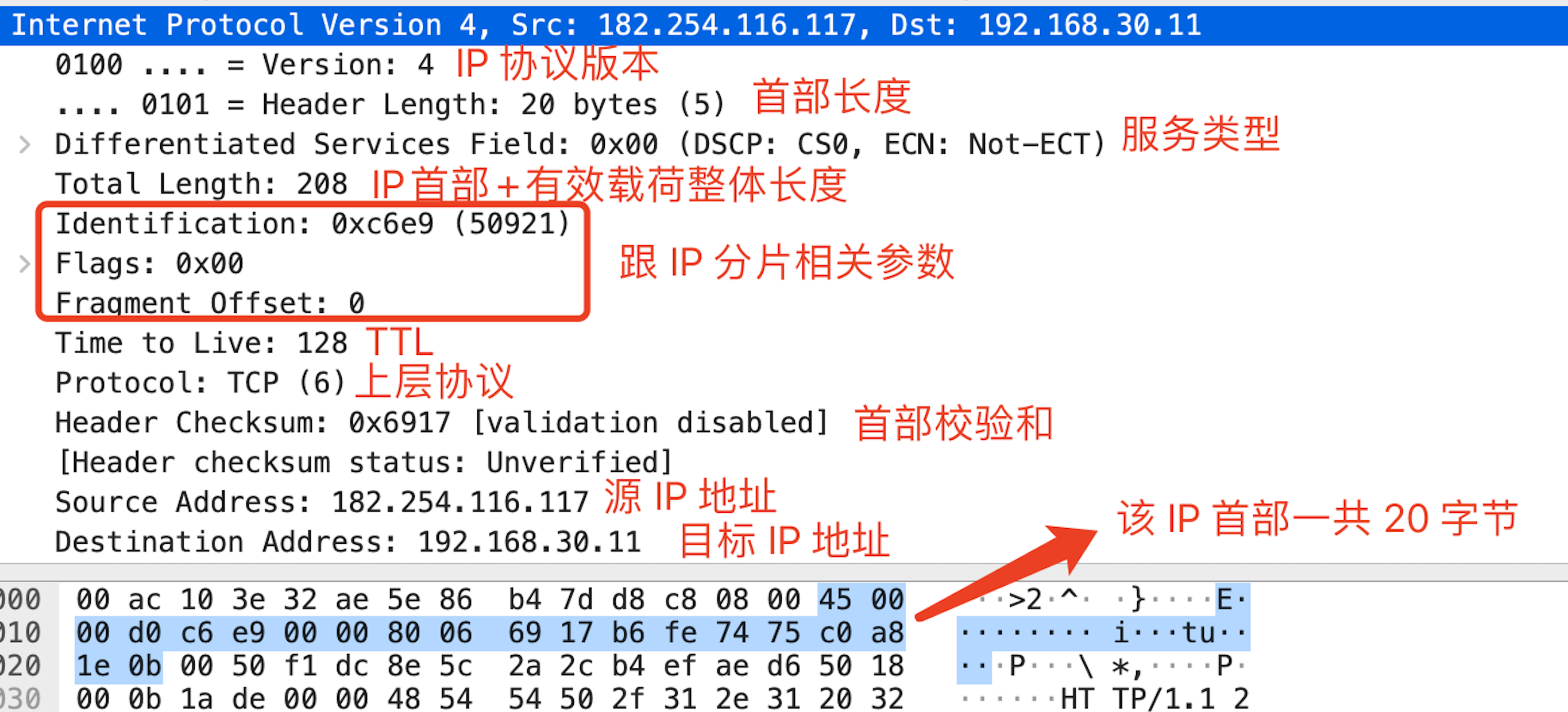
虽然只有20个字节,不过瞅瞅内容还是挺复杂的。
其中有 4 个比特记录首部长度――也就是说 IPv4 首部长度不是固定的!问题出在“服务类型”上,因为有些服务类型会有额外的 4 个字节扩展信息。
其中有三个部分跟分片有关――当出链路的 MTU(最大传输单元)不足以容纳整个分组的时候,会将分组分成多个小分组发送,那么因为最终还要把这些切分的分组整合成原来的大分组,所以要在这些分组里面记录额外信息(标识、分组偏移等)。
TTL 是该 IP 数据报的存活周期,该值在发送端设置,然后每经过一台路由器将其减 1,当值为 0 时直接丢弃――假如没有这玩意,如果一个分组在网络上迷路了,就变成孤魂野鬼整日在网络上游荡了(无限地转发)。
上层协议前面说过,表示该数据报到达目的主机后应交给上层哪个协议处理器处理,这里是要交给 TCP 处理。
首部校验和是为了防止这些首部信息被篡改而根据某种算法生成的值。由于每个路由器都要修改 TTL 的值,因而也必须重新计算校验和。
IPv4 的设计因其历史原因存在两大问题:
- 对路由器不友好。首先首部长度不是固定的,这就使得路由器无法就这块做性能优化,它必须从首部先获取长度,然后才能取出完整首部;然后里面有个校验和,而 TTL 是每经过一个路由器都会变化的,这就要求每个路由器得重新计算首部校验和。像路由器这种对性能要求极其苛刻的设备(不是说你家里那台仅服务两三个人的路由器,而是诸如骨干网上的那些路由器),做这些事情并不合适。
- IP 地址数量严重不足。IPv4 只有4 个字节,也就 40 多亿的地址,对于互联网爆炸的今天来说,少得可怜。
当然,我们不能对在上世纪 80 年代初那种网络流量按字节计、网络仅仅用于军事和科研的情景下设计出来的东西做事后诸葛亮般的评论,那时候的设计者或许压根没想到因特网会全球范围地民用化,相较于性能,他们考虑更多的可能是带宽(所以 IP 地址只有 4 字节,首部也是变长的,分组因受限于不同链路的 MTU 承载能力而不得不进一步切分)。
IPv6 针对这些问题做了优化,其设计原则是性能高于一切。
IPv6 采用 40 字节定长首部,这样路由器便可以做针对性地优化。
IPv6 也不支持分片,如果某段链路不支持这么大的分组,则直接给发送端返回错误,让发送更小的分组。
IPv6 也不计算校验和,数据正确性交由上层去保证。
这样在 IPv6 的 40 字节定长首部中,有 32 字节是源和目标 IP,仅有 8 字节是记录其他信息的。
分类编址与 CIDR:
IPv4 地址长度是 4 个字节,用十进制表示出来其范围是 0.0.0.0 到 255.255.255.255。IP 地址由网络地址+主机地址构成。在起初的设计中,IP 地址分为 A、B、C 等几大类,其中 A、B、C 三大类表示的是地址中哪些部分是网络地址,哪些部分是主机地址。 A 类地址规定 IP 的第一部分是网络地址,后面三个部分构成主机地址,而且第一部分的最高位必须是 0;B 类地址的前两部分是网络地址,后两部分是主机地址,而且最高两位必须是 10;C 类地址的前三部分是网络地址,后一部分是主机地址,而且最高三位必须是 110。如图:

将 IP 地址分成网络部分和主机部分是个不错的想法,它引入了子网的概念,使得路由选择具有层次化,路由器在计算转发策略时,只需要将分组转发到整个子网(具体是转发给子网的网关路由器),而不需要关心目的主机在子网的具体哪个地方;分组到达子网后,再由子网内部的路由器做近一步转发。
这就好比你想到深圳南山区大学城,你是先从北京坐飞机到深圳,然后再到南山区,最后才在南山区里面找大学城的位置,而不是一开始就锁定具体的位置。
然而,这种 IP 分类方式带来很大的问题,它会造成大量 IP 浪费。我们看看 A 类地址,它的网络部分一共有 2^7 - 2 = 126 个(之所以减 2 是因为全 0 和全 1的属于特殊地址),主机部分是 2^24 - 2 = 16,777,214 个。什么意思呢,A 类地址一共只能分配给 126 个机构,而每个机构可以拥有 1600 多万台主机!一般教科书会说“A 类地址一般用于拥有大量主机的大型网络”之类的废话,问题在于,这仅有的 126 个地址到底该分配给谁才合适?这不是一个技术问题,更可能是个政治问题。
我们再来看看 C 类,该类地址一共可有 2^21 - 2 = 2,097,150 个网络地址(200 多万),每个网络地址(网段)下只能有 2^8 - 2 = 254 个主机!你去大街上闭着眼睛指认一家公司很可能就超过这个数。当然,你可能认为 C 类的地址少没关系啊,玩内网撒,NAT 不香吗?问题是凭什么分配到 A 类的机构不能玩 NAT 呢?
所以用现在的眼光看,IP 地址的这种分类是极不合理的,A、B 类会造成大量浪费而 C 类则远远不够用。
所以,这种分类编址法早早地就被送进博物馆了,现在世界上使用的是叫做无类别域间路由选择(Classless Interdomain Routing,CIDR)的分配策略。这个名字绕的很,着重强调了它是无类别分配法。简单地理解就是它仍然承袭了分类编制法的思想,即 IP 地址分成网络段和主机段两部分;不过,它不再限制只能根据点(.)来划分网络段和主机段,可以使用任意个比特表示网络段,而且主机段并不是只能挂主机,还可以进一步划分子网。
子网
看看下面这张图:
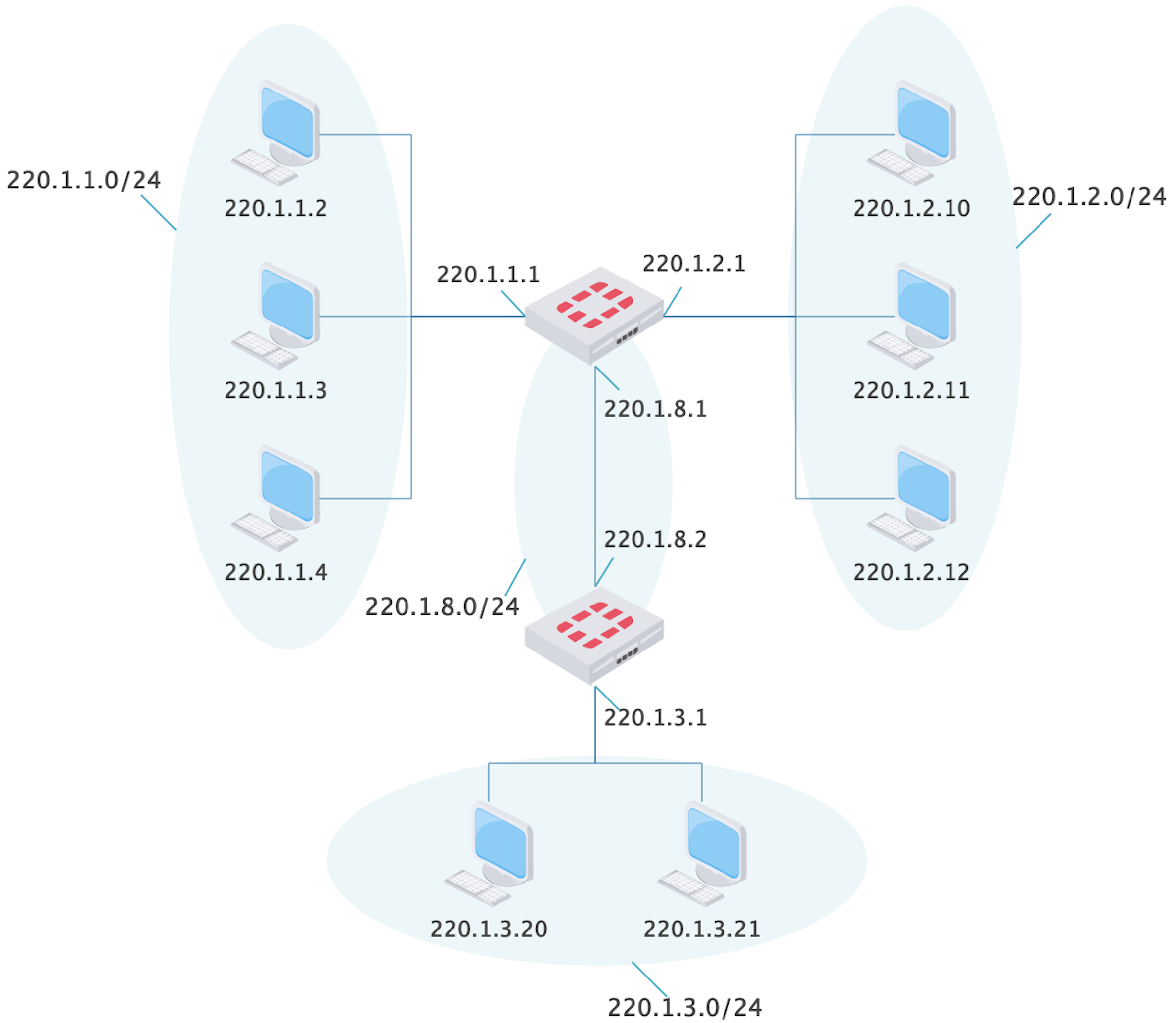
该图有两个路由器,将 8 台主机连接起来,而且路由器之间也有连接。
这张图一共有 4 个子网,它们使用适当的 IP 前缀作为子网标识。
最左边的三台主机都以 220.1.1 开头,我们记作 220.1.1.0/24,这里的 24 叫做子网掩码,它表示 IP 中的高位 24 比特表示该子网地址(网络段),子网中的所有主机的 IP 都是以该子网地址开头。同样,右边的子网地址是 220.1.2,下面两台的是 220.1.3。
上面那个路由器有三个网口,其中两个分别连到两个子网,第三个连到另一台路由器,而且这两个路由器也构成一个单独的子网 220.1.8.0/24。
现在我们看看主机 220.1.1.2(以下称主机 A) 如何给主机 220.1.3.20(以下称主机 B) 发消息。
从上面图可知,两台主机处于不同的子网中,而且中间经过了两台路由器(两跳)。首先主机 A 查找自己的路由表(其路由表中并不需要为网段 220.1.3.0/24 配单独的转发记录,直接走的默认网关路由器),发现要将分组发给自己的网关路由器 220.1.1.1(以下称为路由器 A)。
路由器 A 的转发表中会有一条类似下面的转发规则(假设路由器 A 通过网口 if1 和下面的路由器 B 相连):

路由器 A 拿到数据报首部中的目标 IP 信息并查找转发表后,将分组转发给网口 if1(IP 地址是 220.1.8.1),经该网口传给下方的路由器 B(具体是传给其网口 if2)。
路由器 B 拿到分组后,查找自己的转发表,发现需要转发到网口 if3(假设该路由器下方那个 220.1.3.1 对应的网口叫 if3),这样分组就进入了目标子网,然后再通过子网内部通信机制最终传送给目标主机 220.1.3.20。
现在有个问题,路由器 A 怎么知道 220.1.3.0/24 的分组需要通过网口 if1 转发给路由器 B 呢(即路由器 A 中的那条转发表记录是怎么写进去的)?
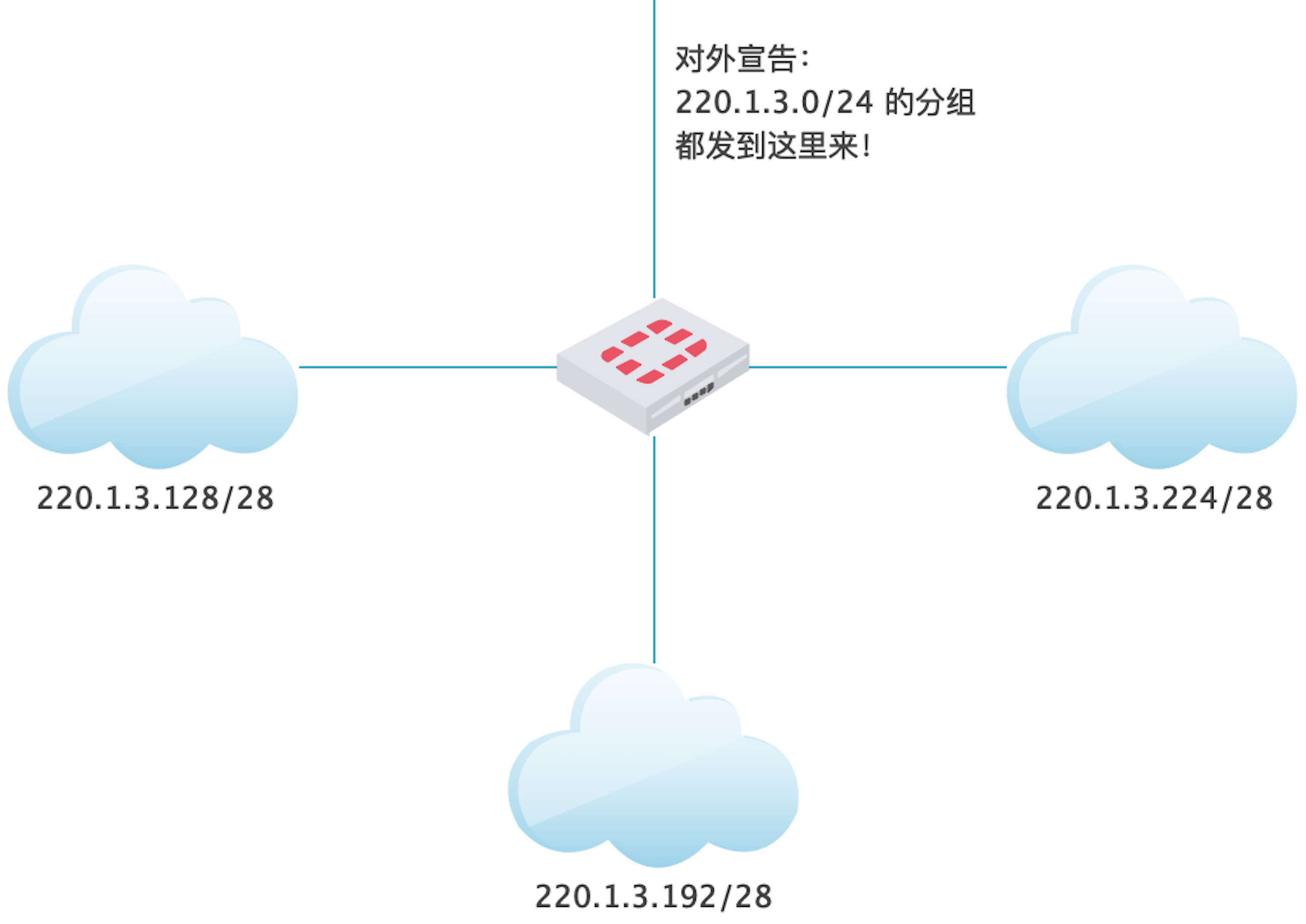
可以由网管手动写入,也可以由路由选择协议自动计算出来(还记得路由器里面有个路由选择处理器吗)。路由器 B 分管着子网 220.1.3.0/24,但别的路由器不知道这件事啊,所以路由器 B(通过网口 if2)得大声对外宣告:“所有 220.1.3.0/24 的数据报请发给我!”
子网分层与地址聚合:
你看上面的子网 220.1.3.0/24 是不是感觉它是个 C 类地址?
那如果是 120.1.3.0/24 呢?注意在分类编址中,120 属于 A 类地址啊(A 类的范围是 1 - 126),既然是 A 类地址,为何用 24 比特作为网络段呢?
前面说过,分类编址法早就躺在博物馆了,现在世界上用的是 CIDR,它是个无类别编址法,所以不要再去想什么 ABC 了。
另一个问题是,120.1.3.0/24 中的右 8 比特是不是一定只能用于主机呢?
答案是否定的。
子网是可以分层的。子网下面可以再划分子网。实际上 120.1.3.0/24 并不是一级网络,它归属于更大的子网如 120.1.0.0/16(具体怎么划分取决于 ISP 自己)。整个网络是如下的树形结构:
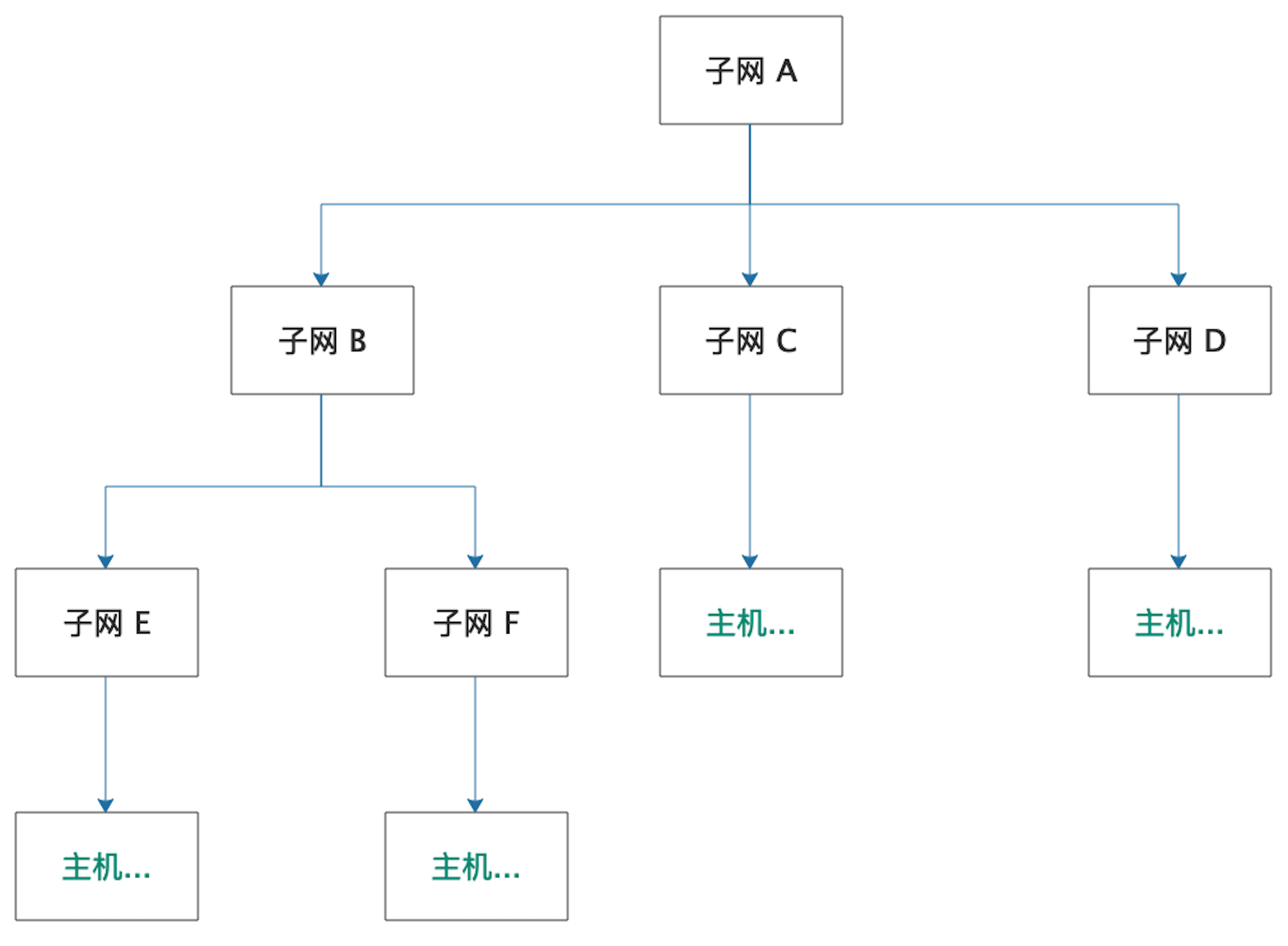
比如我们给 120.1.3.0/24 继续划分子网,将最后的 8 比特中前 4 比特作为子网地址,后 4 比特作为主机地址,这样的子网能容纳 2^4 - 2 = 14 台主机:
注意上面的 128(二进制:10000000)、192(二进制:11000000)和 224(二进制:11100000)都属于网络段。当然这些子网也可以通过多个路由器形成更复杂的网络拓扑。
这种子网分层使得一个路由器的出口不一定是指向某台主机,而是指向一个网段(该子网的网关路由器),这个网段(子网)是对一批 IP 地址的聚合。
自治系统(Autonomous System,AS)
有上百万上图那种子网分布在世界各地,要想让这些子网(其内部的主机)之间无障碍地通信,子网网关(路由器)需要进行复杂的路由计算,它必须记录到任何一个子网应该怎么走,这不但要求全世界所有的路由器都必须使用同样的路由选择算法,而且会导致路由器的转发表非常庞大。
就像公司会通过增加部门等组织结构来应对人员规模,因特网也通过对这些路由器本身进行组织化来应对规模复杂性。前面说同一个网段的主机可形成一个子网,这些主机之间可以直接通信,但无法直接跟子网外部通信,跟外部通信是通过网关路由器来实现的。类似地,我们将一群路由器(这些路由器一般属于同一个 ISP 或公司)组织在一起形成一个自治系统,这些路由器之间可直接通信,而且都知道自己到任何其他路由器的最短路径,但这些路由器不能跟自治系统外部的路由器通信,他们必须通过指定的一台或几台网关路由器和外面的路由器通信。同样,外面的那些路由器也是被组织进其它的自治系统中,所以这种通信实际上是自治系统之间的通信。
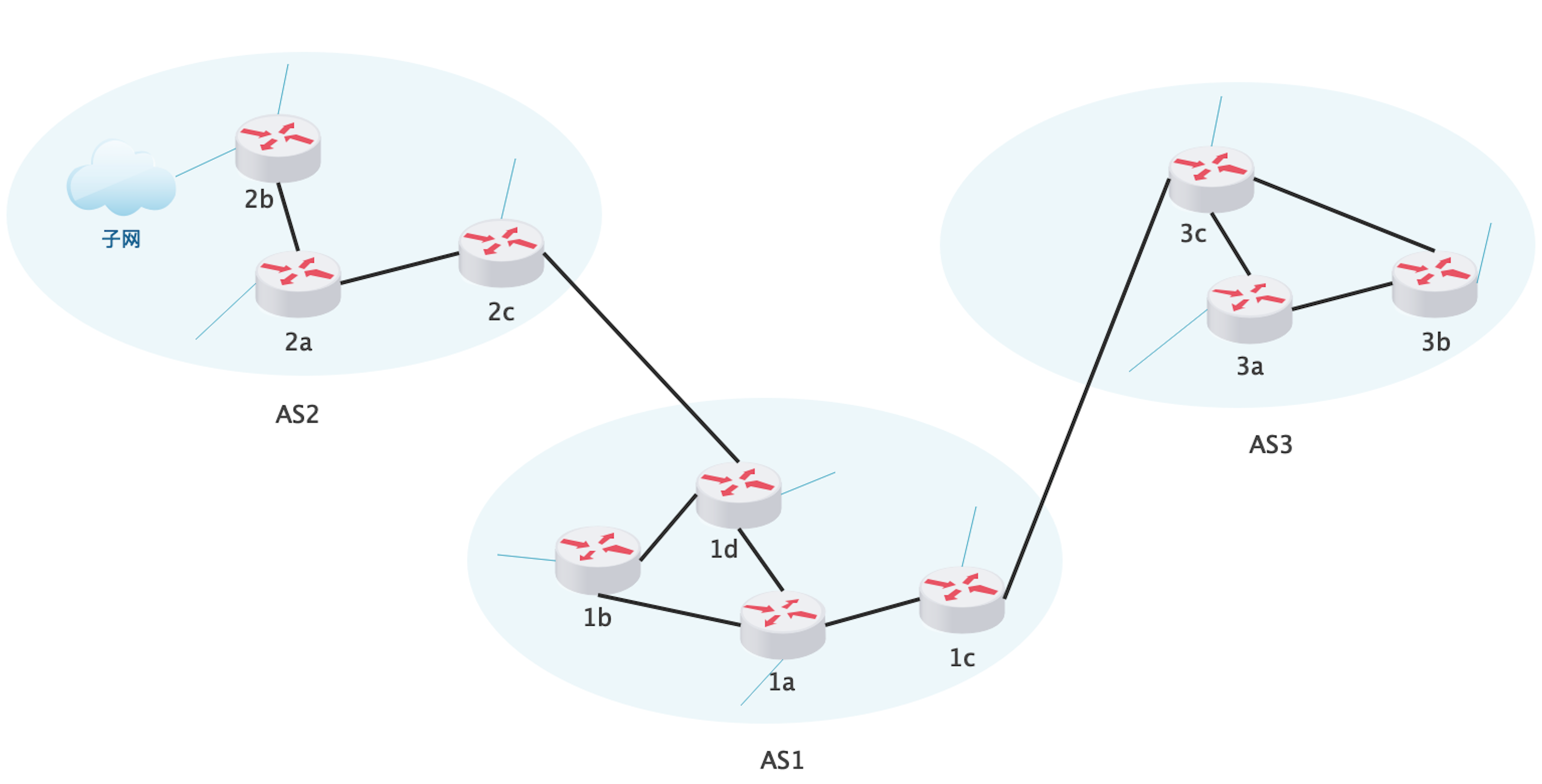
如图有 3 个自治系统,其中 AS1 有两个网关路由器 1d 和 1c,AS2 的网关路由器是 2c,AS3 的是 3c。自治系统内部的路由器之间直接或间接相连,都知道彼此通信的路径。现在假如 1b 子网的主机要和 3b子网的主机通信,则 1b 查找自己的路由表,发现目标在本 AS 外面,需要将分组交给网关路由器 1c,1c 查找自己的转发表后将分组发给 3c,最后由 3c 转给 3b。
这样 1b 就不用关心 3b 到底位于 AS3 中的哪个位置,直接把分组甩给网关,网关再甩给对面的网关就行了。
同样,如果 AS2 中的 2b 要和 AS3 中的 3b 通信,则需要通过 AS1 转发。
这里有个问题,AS1 有两个网关出口,上面说的 1b 怎么知道应该把分组转给网关 1c 而不是 1d 呢?
这就涉及到自治系统之间的路由选择。全世界所有自治系统间都运行同样的路由选择算法 BGP(Broder Gateway Protocol,边界网关协议), 通过该算法,全世界的自治系统之间就能知道如何到达任何一个其他自治系统了,BGP 算法本身很复杂,大致意思是这样的:
-
AS3 告诉邻居 AS1:通过我可以到 220.1.0.0/16(这个地址段就是 AS3 管理的);
-
AS1 的网关路由器收到消息后,广播给本 AS 内部所有路由器:通过我(AS1 的网关 1c)可以到 220.1.0.0/16;
-
于是这些路由器便在自己的转发表里面记录一条转发策略,我们拿 1b 为例:假设 1b 到 1c 的最短路径是 1b -> 1a -> 1c(这是通过 AS 内部路由选择算法算出来的),其下一跳是 1a,假设 1b 通过网口 if1 和 1a 相连,则 1b 会在其转发表中记录:
220.1.0.0/16 -> if1
-
AS1 的另一个网关路由器 1d 当然也收到了这条消息,它在自己的转发表中记录一条转发策略后,还会将这条消息告诉其邻居 AS2:通过我(AS1)可以到达 220.1.0.0/16;
-
于是 AS2 内部也重复上面的步骤;
当然实际算法会复杂很多,比如如何选择 AS3 间的最短路径等。
一个 ISP(如中国移动) 或公司(如阿里云)往往会有多个自治系统,每个自治系统需要向相关注册机构(中国是 CNNIC)申请自治号(ASN),在 AS 间路由选择算法中需要用到自治号。
可以从https://tools.ipip.net/as.php查看某个 IP 所属的自治系统信息,比如我们看看 36.152.44.96:
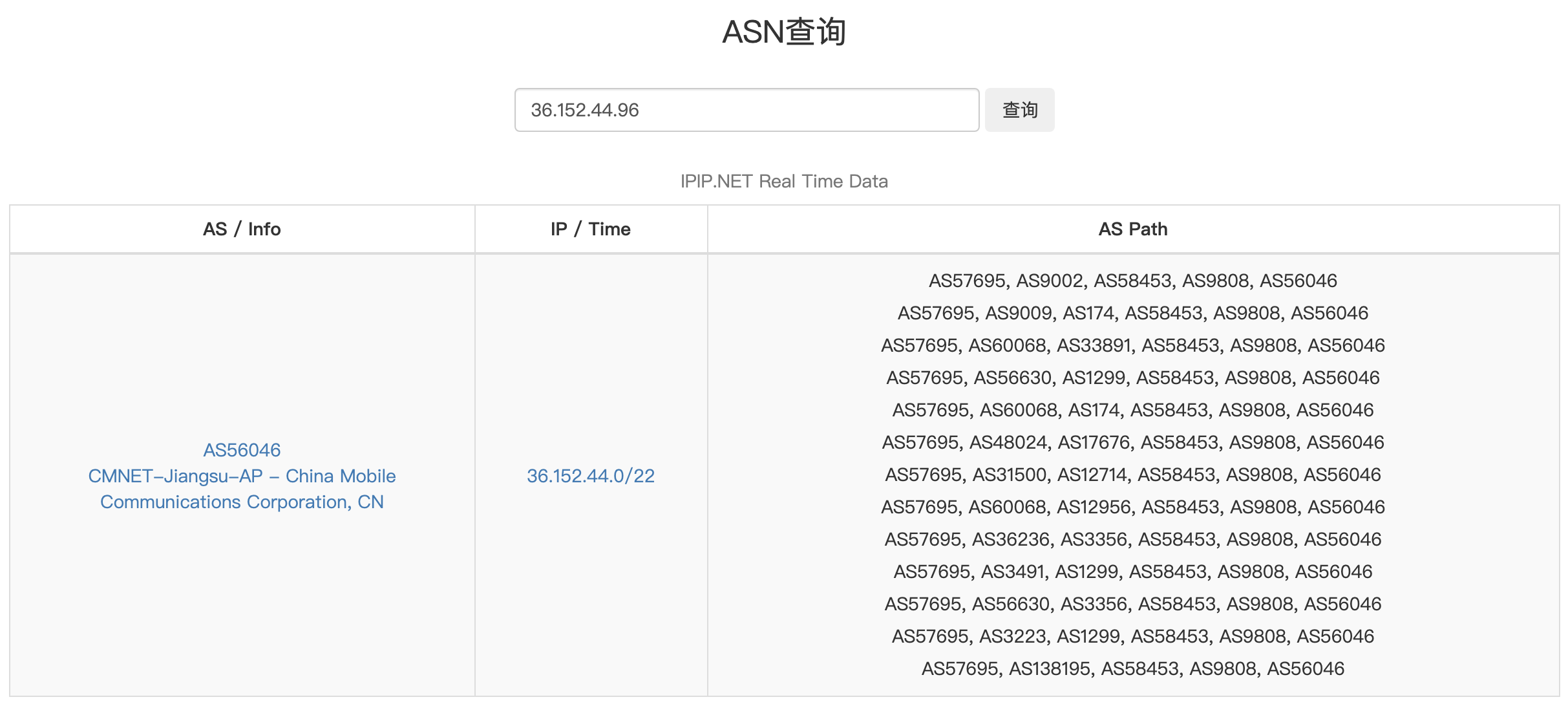
这个 IP 属于中国移动江苏分公司的自治系统 AS56046 管理,该自治系统对外宣告的 IP 段是 36.152.44.0/22。注意看右侧的 AS Path,它表示自治系统的“36.152.44.0/22都发给我”这条消息向外传给了哪些其它自治系统(从右往左看)。我们看看第一条的详情:

该消息从中移江苏的自治系统传播到中移总部的 AS9808,然后传播到中移香港,再到英国,最后到美国。
我们再通过 https://whois.ipip.net/AS56046 看看这个 AS 详情:
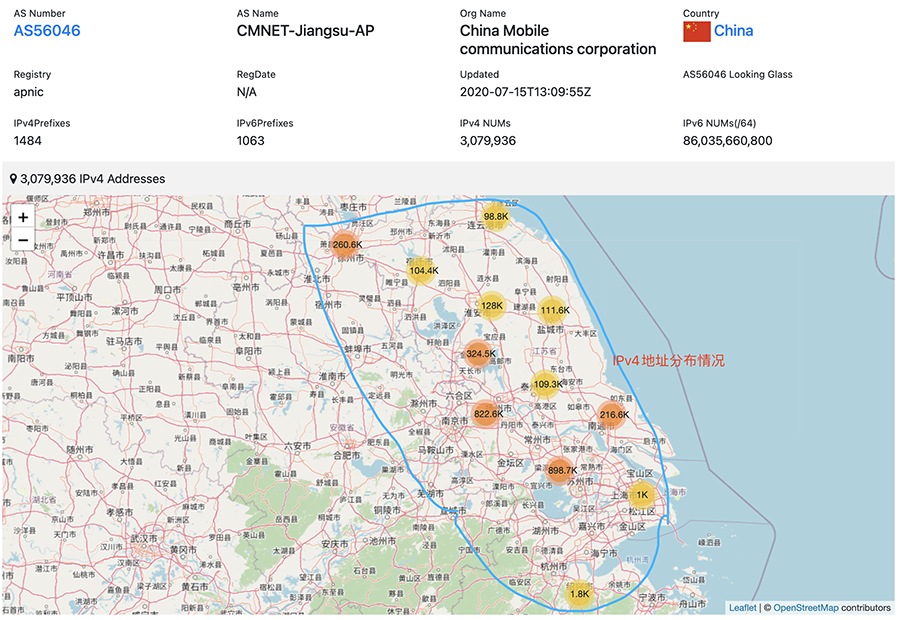
该自治系统是在 APNIC(亚太互联网信息中心,属于区域注册机构,CNNIC 是其下属的国家注册机构。中国移动的 IP 也是由 APNIC 分配的)注册的,虽然这个 AS 是用于江苏地区,但注册公司是中国移动(而不是江苏分公司)。该 AS 一共持有 1484 个 IPv4 前缀,一共有 300 多万个 IP 地址(注意其持有的 IPv6 有多达 860 多亿!)。途中蓝色圈圈中是这些 IPv4 地址的使用分布情况。
这些是 1484 个 IPv4 前缀中的一小部分:
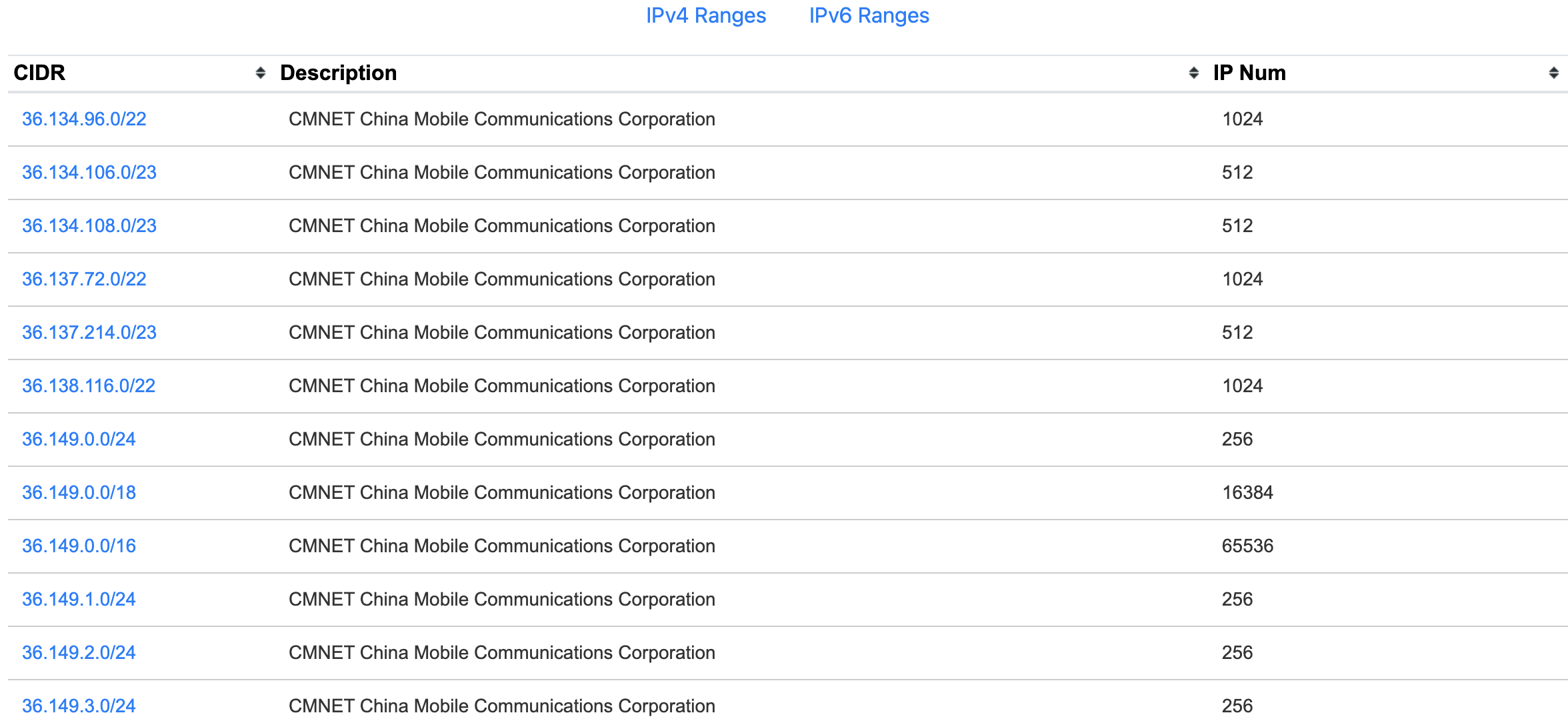
需要注意的是,自治系统内部以及自治系统之间的路由选择策略是不同的。自治系统内部的路径选择一般着重考虑性能,而自治系统之间的策略可能更多考虑的是商业和政治等经济、社会因素。比如联通用户访问移动网络中的服务器,只会经过联通和移动的自治系统,不可能经过电信的自治系统中转,哪怕从技术上来说这样路径更短。
IP 地址的分配
在《听说你很懂 DNS?》一文中我们已经提过,全世界的 IP 地址都是由 ICANN(Internet Corporation for Assigned Names and Numbers,互联网名称与数字地址分配机构)管理和分配的(具体是其下设机构 IANA),ICANN 将地址分配给各区域注册机构(比如亚太的 APNIC),区域注册机构再分配给国家/地区注册机构(如中国的 CNNIC),区域注册机构也可以直接分配给一些大型 ISP(如中国移动)。
目前 IANA 在全球设立五大区域注册机构:

其中 APNIC 分管亚太地区。
以下是 IANA 的地址分配情况(部分):
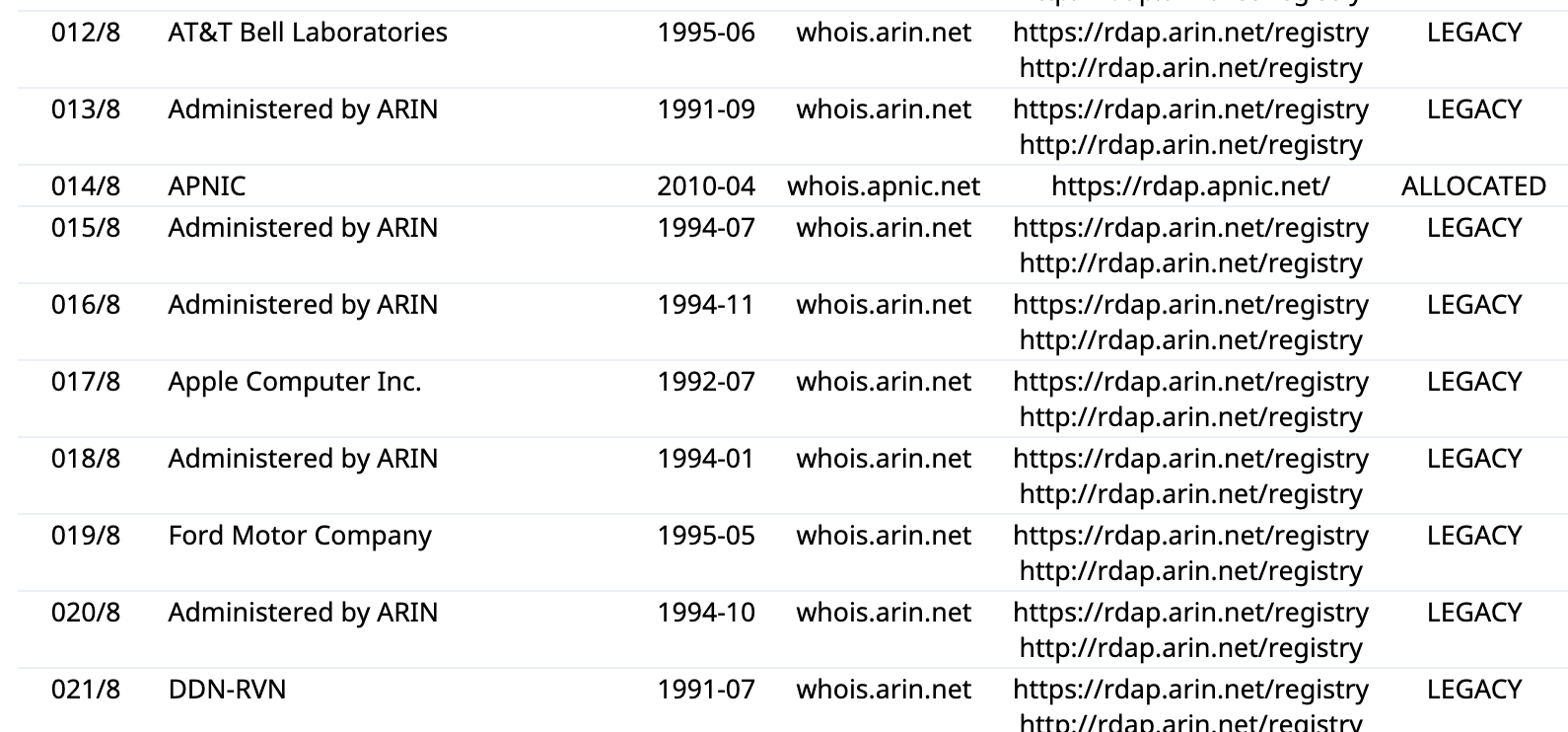
我们发现,IANA 的分配都是以 8 作为子网掩码,属于粗粒度分配,各区域拿到这些地址段后,会更细粒度地分配给国家/地区的注册中心。比如上面将 014/8 分配给了亚太,亚太可以再将 14.192/10 分配给中国的 CNNIC,CNNIC 再将 14.240/12 分配给阿里云等公司。
上面有个 012/8 是分配给美国贝尔实验室了,017/8 分配给苹果了,019/8 给福特了。前面说过,历史上 IP 地址曾采用分类编址法,这里面这些 8 位掩码的都属于 A 类地址(1-126 的都属于 A 类),按照当时的想法,这类地址是分配给一些大型公司的(当然也都是美国的),比如 IBM、AT&T、苹果、福特、通用等,后面很快发现这种搞法行不通,所以废弃了分类编址法,去官网看下会发现目前绝大部分的“A 类”地址还是分配给了区域注册机构。
当然所谓的“分配”并不是免费的,比如阿里云从 CNNIC 申请了 1000 多万的 IP 资源,每年需要交一笔不菲的年费给 CNNIC。跟域名一样,这也是一块肥水。
另外我们特别看下 47.106.193.19 这个 IP 地址,看其 47 开头,查找 IANA 官网发现它归属北美的 ARIN,但查一下该 IP 的 whois 信息发现该 IP 是阿里巴巴(阿里云)的――难道阿里云不是从 CNNIC 申请地址,跑到美国找 ARIN 了?
我们看下 whois:
$ whois 47.106.193.19
......
refer: whois.arin.net
inetnum: 47.0.0.0 - 47.255.255.255
organisation: Administered by ARIN
status: LEGACY
whois: whois.arin.net
changed: 1991-01
source: IANA
# whois.arin.net
NetRange: 47.98.0.0 - 47.112.255.255
CIDR: 47.104.0.0/13, 47.112.0.0/16, 47.100.0.0/14, 47.98.0.0/15
NetName: APNIC
......
Organization: Asia Pacific Network Information Centre (APNIC)
RegDate: 2015-04-01
......
% Abuse contact for '47.104.0.0 - 47.111.255.255' is 'ipas@cnnic.cn'
inetnum: 47.104.0.0 - 47.111.255.255
netname: ALISOFT
descr: Aliyun Computing Co., LTD
......
source: APNIC
irt: IRT-CNNIC-CN
......
% Information related to '47.104.0.0/13AS37963'
route: 47.104.0.0/13
descr: Hangzhou Alibaba Advertising Co.,Ltd.
country: CN
origin: AS37963
......
信息很长,做了截取。可以看出,在 1991 年 IANA 将 47/8 分配给了 ARIN,ARIN 在 2015 年将其中的网段 47.104.0.0/13, 47.112.0.0/16, 47.100.0.0/14, 47.98.0.0/15 转给了 APNIC,APNIC 将其中的某些网段分配给了 CNNIC,阿里云从 CNNIC 申请了 47.104.0.0/13 这段地址。
内网与 NAT 技术
IPv4 面临的一个严峻问题是地址资源枯竭,虽然上世纪 90 年代 IETF 就开始研发 IPv6,但由于网络层设施涉及到整个网络的所有结点(而不仅仅是端系统),其升级替换的工程量浩大,至今仍未普及。
一个替代方案是采用可复用的私有 IP。和公有 IP 全球唯一性不同,私有 IP 仅在某个范围(局域网)内是唯一的,出了这个范围,不能保证其唯一性。
ICANN 为A、B、C 三类地址各保留了一个私有 IP 段,分别是:10.0.0.0/8、172.16.0.0/12、192.168.0.0/16。
注意到 172/8 号段在 1993 年分配给 ARIN(美国互联网号码注册中心) 了,而 172.16 私网是在 1996 年的RFC1918中定义的,也就是说这段号码是后面从 ARIN 中收回的。
我们现在无论是在家庭还是公司中基本都是用的私有 IP,大致是这样:
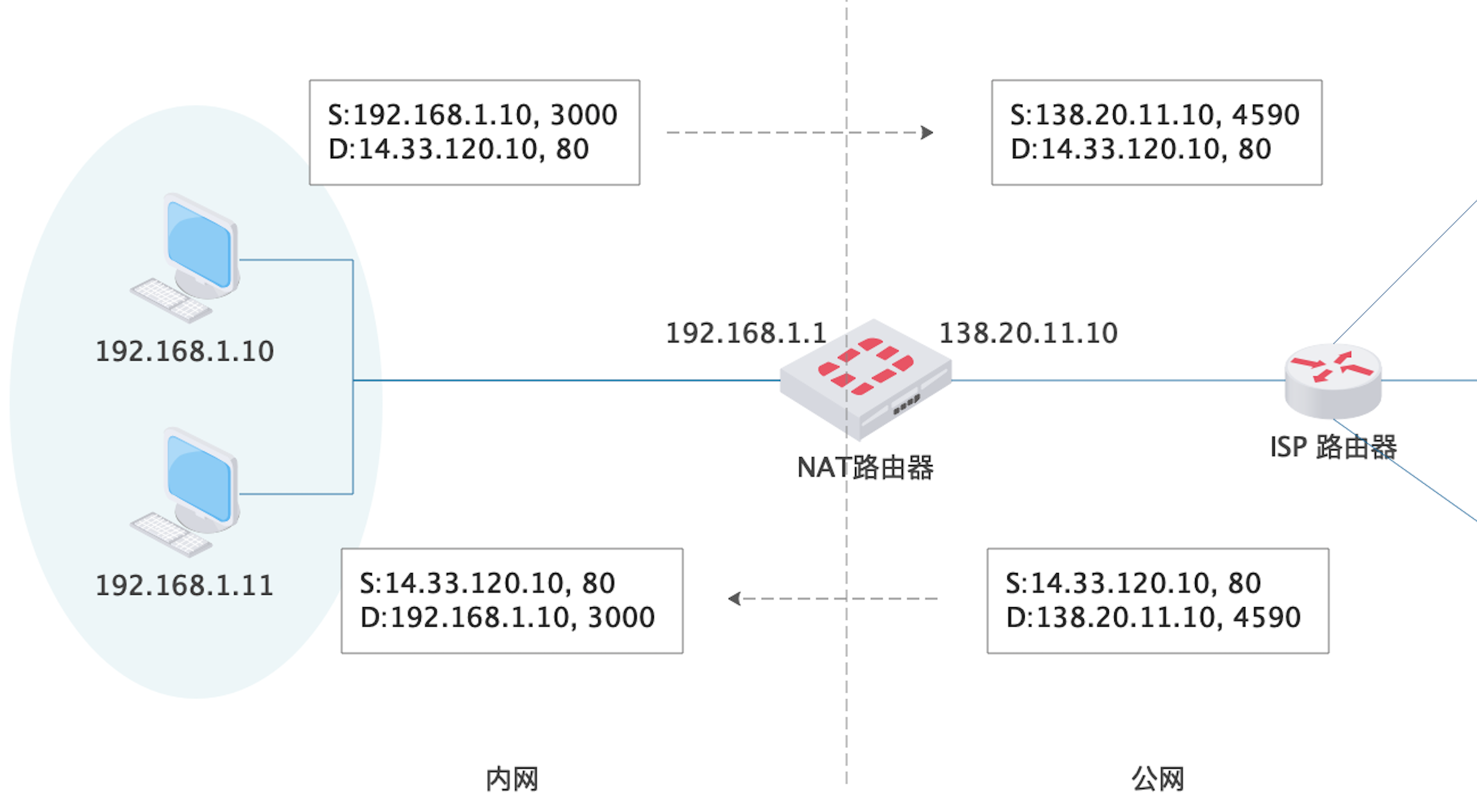
一个问题是,既然内网的 IP 地址不是全球唯一的,无法在公网上使用,那当我通过浏览器在内网访问百度服务器,百度服务器的数据是怎么找到我的内网这台电脑的呢?
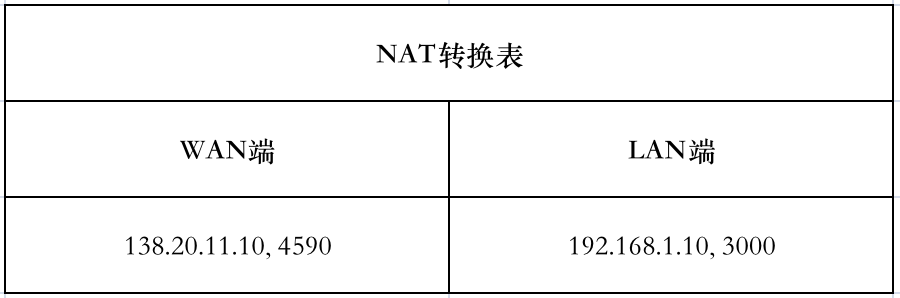
内网和公网的通信需要用到叫做 NAT(Network Address Translation,网络地址转换)的技术。NAT 的原理是,NAT 路由器的两块网卡,一块连接内网,使用内网 IP,一块连接外网,使用外网 IP。路由器接收到内网主机发送的分组后,取出分组首部的 IP 信息,将其中的源 IP(内网 IP,上面的 192.168.1.10)替换成自己的外网 IP(138.20.11.10),并且生成一个该路由器尚未使用的新端口号(上面的 4590)替换掉源端口号(3000),用这个新的 IP 和端口号替换掉分组中的源 IP 和端口,然后转发出去。同时,路由器将内网的 IP+端口号与新的外网 IP+端口号的映射关系记录到 NAT 转发表中。
目标服务器(如百度)接收到分组后,取出首部一看,该分组是 138.20.11.10 发来的,即它认为是那个路由器发的,而不知道其实是路由器后面的局域网主机发的。服务器返回的分组的目标 IP 和端口自然是 138.20.11.10 和 4590,该分组自然会被上面那个 NAT 路由器收到。NAT 路由器从外网收到分组后,拿到目标 IP 和端口号,去 NAT 转换表查,发现对应的内网 IP 和端口是 192.168.1.10 和 3000,于是修改分组的首部,最后通过局域网发送给目标主机。
看到这样的骚操作你是不是不由得竖起大拇指?人类的大脑终究还是聪明的,自己挖的坑自己"完美"地填平了。
别急,还有更骚的操作。
我家中使用无线路由上网,分配的局域网 IP 是 192.168.1.6,网关是 192.168.1.1。网关路由器的出口接到中国移动的路由器,我们看看那边分配的 IP:
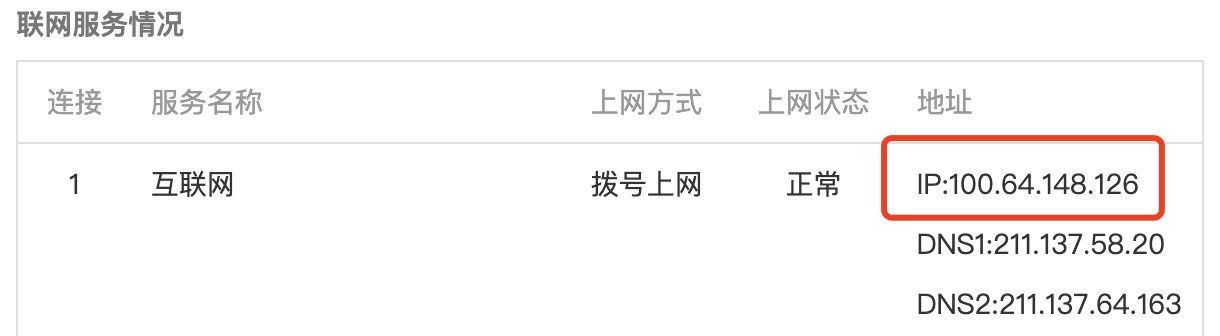
说我的“外网” IP 是 100.64.148.126。处于好奇,我用 ip138 查了下这个 IP 的详情:

纳尼?这也是个局域网 IP?在三个私有 IP 段没见过 100 开头的啊?
于是赶紧跑到 IANA 官网查一下,在底下脚注看到这么句话:
100.64.0.0/10 reserved for Shared Address Space [RFC6598].
说是在 RFC6598 中将其定义为共享地址空间,翻开该 RFC,有这么一段话:
This document requests the allocation of an IPv4 /10 address block to be used as Shared Address Space to accommodate the needs of Carrier Grade NAT (CGN) devices. It is anticipated that Service Providers will use this Shared Address Space to number the interfaces that connect CGN devices to Customer Premises Equipment (CPE).
Shared Address Space is distinct from RFC 1918 private address space because it is intended for use on Service Provider networks.However, it may be used in a manner similar to RFC 1918 private address space on routing equipment that is able to do address translation across router interfaces when the addresses are identical on two different interfaces. Details are provided in the text of this document.
如果你跟我一样英文不好,就不要去钻研上面这么一大段话了,大致意思是 100.64.0.0/10 这个网段是专门给网络服务提供商(ISP)用的私有 IP。因为 ISP 的客户(家庭、公司)已经在使用 RFC1918 定义的三个私有 IP 段了(就是10、172.16、192.168),所以 ISP 就不能使用这三个网段做私有 IP 了――否则当你家的路由器遇到目标 IP 是 192.168.1.10 它到底是要转给内部呢还是转给 ISP 呢?
ISP 为啥也要玩局域网呢?还不是因为 IP 不够用嘛!你想中国移动、中国电信有多少客户(家庭、公司),得要多少公网 IP 才能玩得转?所以他们在局域网外再套一层局域网,于是我们和外网的通信就变成这样子:
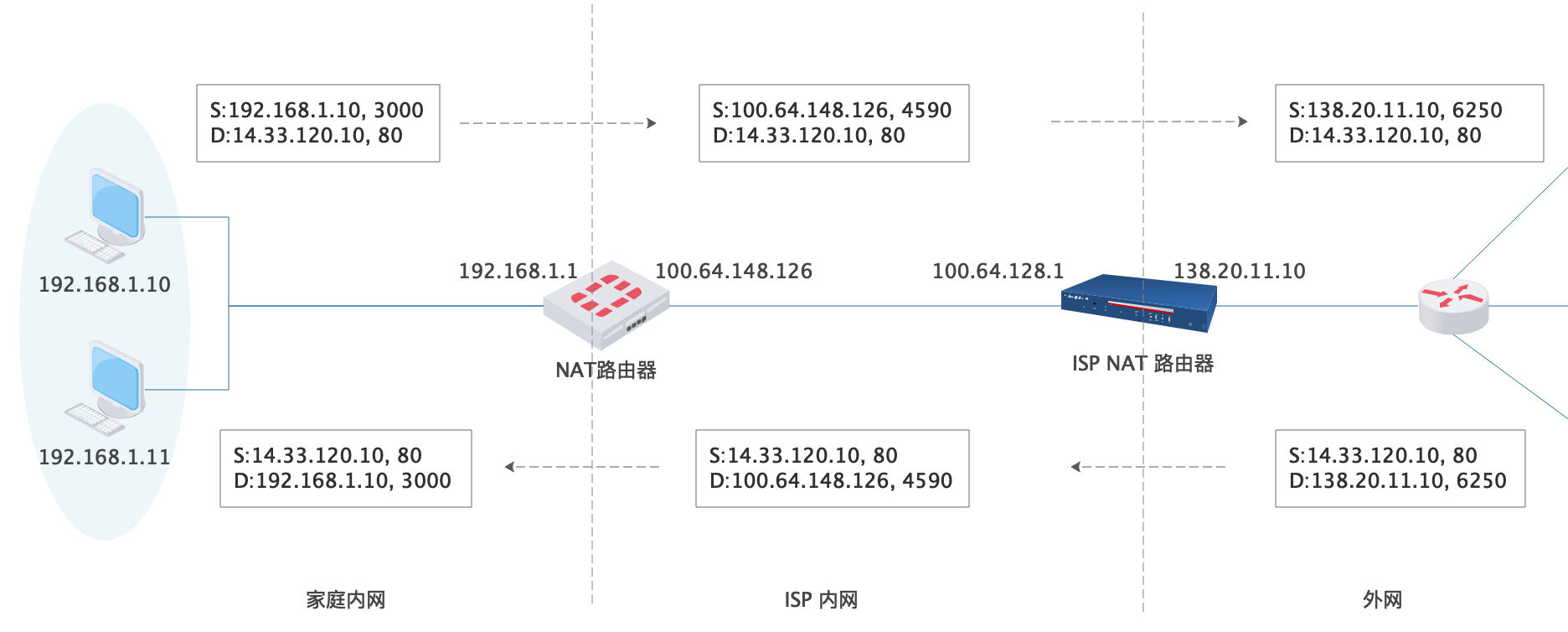
然而,NAT 并不是一项完美的技术。
从上面图就能看出来,NAT 路由器要去修改分组首部,并维护 NAT 转换表,这多少会带来些许的网络时延,特别是在两层 NAT “加持”下。
路由器本来属于网络层设备,而端口号是放在传输层的――意味着这个网络层设备需要取出并修改传输层首部,这在设计上违背了分层原则。
局域网主机用的私有 IP,这导致它无法直接对外提供服务(想想外面的主机怎样去寻址 192.168.1.10?),因而无法直接实现 P2P。要想在这种情况下实现 P2P,需使用 NAT 穿越技术(此处不详细讨论这种技术,感兴趣的可自行百度)。另外 NAT 也限制了物联网的发展,比如你家有一台美的的电暖气,该电暖气能够联网控制,但由于电暖气位于局域网,用的是私有 IP,它无法直接和你的手机相连,必须通过美的的中央服务器中继。
可能更大的影响是,NAT 技术限制了 IPv6 的普及速度。试想如果没有 NAT 技术,每台主机想要联网就必须持有外网 IP,这种情况下全世界的 IPv4 地址早已枯竭,逼迫各大运营商和公司去实施 IPv6。而现在有了 NAT,公司可以玩内网,运营商也可以玩 NAT,钱照赚不误的情况下,谁会有动力花大财力去升级设备?公司(ISP 当然属于公司)是以盈利导向的,在当前大有盈利的情况下,傻子才去做那种短期看不到回报的大手笔投资。所以世界上 IPv6 的推进非常缓慢,即便中国在很早(上世纪 90 年代末)就开始关注 IPv6 了,但至今仍未普及。
现实中的网络
想想你家里是怎么接入互联网的。
首先你要打电话找一家电信运营商(接入 ISP,比如中国移动),他们会就近网点派人上门给你拉光纤,装个一体化路由器(光猫和路由器一体化设备),设置或者不设置一个 IP(一般是通过 ISP 的 DHCP 服务器自动获取),然后你交了钱,就能上网了。
假如你现在访问 www.baidu.com,电脑通过 DNS 查询获取 IP 后,请求是如何在网络上一路狂奔走到百度的某个机房的呢?
这取决于 DNS 返回的 IP 归属情况。目前大公司的权威 DNS 都有智能解析的能力,假如你是在武汉,用的移动网络,如果百度在武汉有数据中心,而且还跟移动有合作,那它多半会返回武汉移动的 IP 给你,此时你的请求不需要出城,也不需要跨运营商网络,请求进入接入 ISP (就是给你办宽带的那家)网络后,经过武汉移动的某个自治系统可能就直接到达目的地了。
假如百度在武汉没有移动数据中心,那他可能会返回一个其它城市的移动 IP 给你,比如江苏南京的移动 IP。此时你的请求进入接入 ISP 网络后,很可能通过城域网而后交换进入骨干网,然后跑到南京。具体怎么走取决于中国移动的网络基础设施的架构。
但如果返回的是百度在武汉的联通数据中心 IP 呢?此时数据报能直接从武汉移动网络进入武汉联通网络吗?很可能不能。移动和联通属于两家 ISP,如果他俩在武汉没有实现互联互通的话,数据就必须出城跑到能互联互通的那个城市(假如是广州),然后在那个城市进入联通网络,然后再跑回武汉百度的数据中心。这就是为啥 CDN 会尽量选择和客户在同一家网络的结点返回――不同家的网络,即使客户和服务器面对面站着,数据报也有可能要跑遍大半个中国。
假如我们要访问美国的某个网站呢(虽然大部分访问不了)?这就比较复杂了。首先你的数据报进入接入 ISP 的自治系统后,几番路由,进入中国移动的骨干网,然后通过某个核心节点(每家骨干网一般会在一些省会城市建设核心节点,其中一些核心节点能够通往国外)经由海底光缆传输到美国的某家运营商的核心节点(具体取决于目标 IP 归属),而后一层一层逐步路由到目的地。
整个网络从逻辑上大致是下面的等级关系:
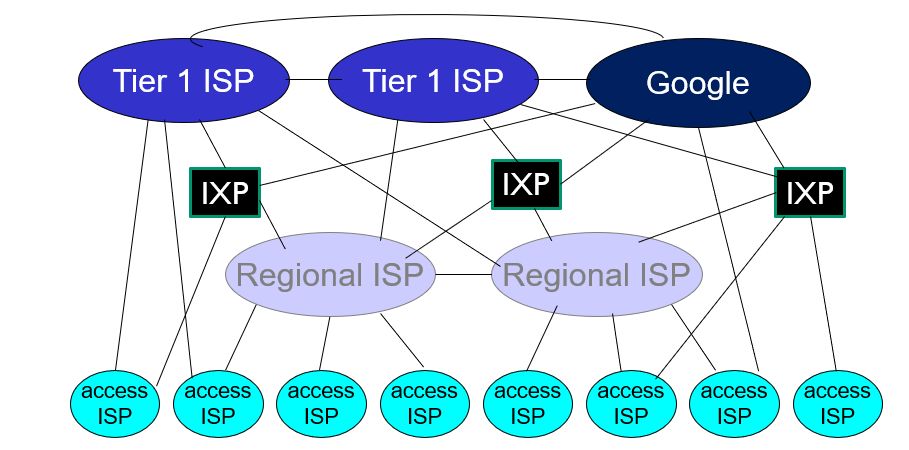
最接近用户的是接入 ISP 网络(一般就是给你办宽带的那家),接入 ISP 会连入区域 ISP 网络,区域 ISP 网络进一步接入到第一层 ISP。区域 ISP 之间、第一层 ISP 之间一般会互联。区域 ISP 一般也会接入到多家第一层 ISP。
不过这个理论图你了解下就行了,实际中关系和概念可能都不同,每家运营商网络架构可能都不同,比如有些运营商会采用城域网-省网-骨干网的层次架构,有些则直接采用城域网-骨干网架构。
这里面有个 IXP,中文叫互联网交换中心(Internet Exchange Point),目的是让多家运营商(网络接入商 ISP、内容提供商 ICP)在这里交换数据,而不用为了从一个服务商网络进入另一个服务商网络就要绕地球大半圈――因为现实中不同运营商之间一般都是只在顶层(骨干网)互联互通。IXP 是本地化交换中心,什么意思呢,刚才说假如移动和联通在武汉没有实现互联互通,那么移动用户想要访问同一个城市的联通网络上的服务器,就得跑到遥远的地方(意味着要经过很多个路由,而每个路由转发都会带来额外时延)跨网后再跑回来,大部分时间都是在浪费生命,而采用 IXP 方案的话就是在武汉建立一个本地交换中心,各运营商之间都可以在这里直接互通。IXP 在欧美很火,但在中国一直发展不起来。和欧美 ISP 百花齐放不同,中国主要就三座大山(后面广电也进入了),各有各的利益考虑。打个比方,假如移动的网络设施比电信少很多(实际上就是少),大部分移动用户访问的网络服务都要经过电信的网络,这时候移动是要给电信钱的。搞了 IXP 后,虽然能同城跨网访问了,但 IXP 国际惯例是双方免费互通,电信愿意?所以这种事情就跟中国的携号转网一样,往往是剃头的挑子一头热,甚至两头都不热。中国曾经在政府主导下搞了北上广三个国家级交换中心,但没搞起来。这些大佬基本是通过顶层直连的方式互通。
我是林子,欢迎关注公众号“编码胡同”获取更多精彩文章。