逆向爬虫17 Scrapy中间件
在学习Scrapy之前,我们已经学了很多伪装防反爬的爬虫技术。
目标: 如何在Scrapy框架中也使用这些技术呢?这是本节要讨论的问题。本节要讨论的防反爬技术有
- 处理登录Cookies
- 处理UA
- 处理代理IP
- 结合Selenium进行浏览器环境伪装
- 利用Selenium获取Cookies
一、Scrapy处理登录Cookies问题
本节依然利用17k.com小说网来说明登录Cookies问题。
原理说明:
回忆一下之前的Cookies是如何添加的。

两种方式:
- 在浏览器中手动登录,从浏览器开发者工具中将cookies复制出来,放进HTTP请求头中。由于requests不会记住与服务器通信过程中的参数,每次通信时都是建立新的连接,因此每次都需要加上请求头。
- 使用requests.session()会话对象发送post请求模拟登录,无需复制Cookies,会话会记住与服务器通信过程中的参数,无需每次通信时都加上请求头,更方便。
在Scrapy中,同样也可以用这两种方式来解决登录Cookies问题。
再回顾一下Scrapy发起HTTP的流程:
在 爬虫 中指定start_urls,封装成request请求对象交给 调度器,引擎 从 调度器 中取出requests对象交给 下载器,下载器 去发起HTTP请求,并接收服务器返回的响应,封装成response响应对象交给 引擎,引擎 再转交给 爬虫,完成了一次HTTP请求。
Cookies本身属于请求头内部的参数,需要添加到request对象中,而request对象是在 爬虫 中生成的,因此这部分的功能需要在 爬虫 中来添加。 再回顾一下之前使用Scrapy的案例 ,每次我们都只需要指定start_urls,Scrapy会自动帮我们完成requests对象封装。当然Scrapy是不会知道我们要添加什么Cookies的,因此我们需要知道Scrapy是如何帮我们封装request对象的,这就需要一点看Scrapy源码的能力和面向对象的知识了。
已知的是,request对象是由 爬虫 模块完成的,而 爬虫 模块是继承了scrapy.Spider的一个对象,我们在子对象中指定了start_urls,却没有指定HTTP请求头,那么指定请求头的工作,多半是在父对象scrapy.Spider中完成了,因此去看一下scrapy.Spider的源码
scrapy.Spider类
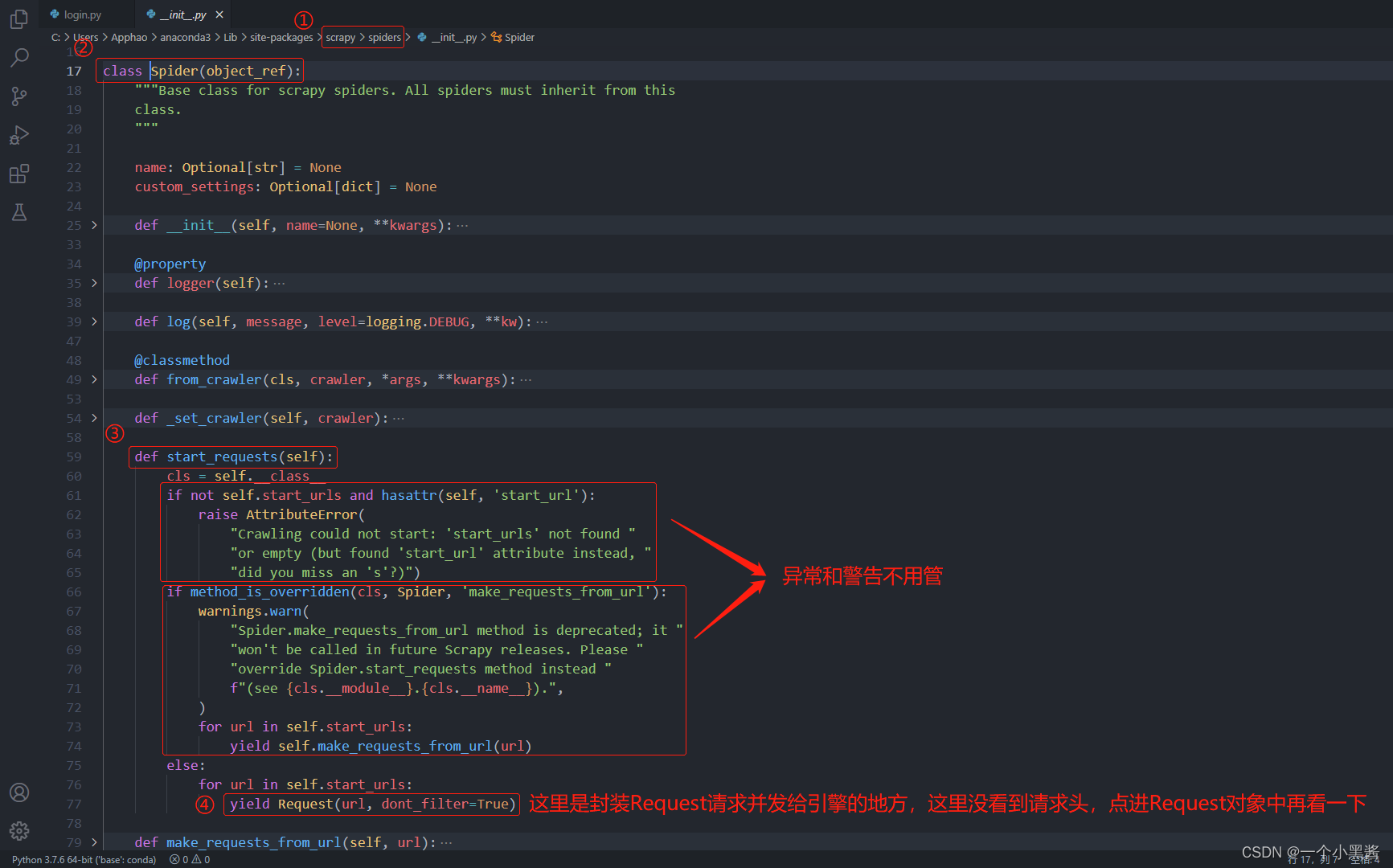
Request类

因此,通过阅读Scrapy源码,我们知道了 爬虫 默认继承的scrapy.Spider对象的start_requests函数是不会指定请求头参数的,如果我们需要自己指定请求头参数,就必须重写父类scrapy.Spider中的start_requests函数,这是面向对象的知识,应该是属于继承多态的特性。当父类的功能不满足子类的需求时,子类可以重写父类中的功能,然后利用面向对象中多态的特性,最后根据调用过程中传递的对象类型,来判断是调用父类的方法还是子类中重写的方法。
因此,我们就在 爬虫 模块中,重写一下start_requests函数。 这是方式1,在浏览器中登录成功后,复制Cookiess信息。
重写start_requests方法1(访问时带上Cookies)

下面再看一下方式2,模拟浏览器登录。
重写start_requests方法2(模拟浏览器登录)

有感而发
这部分内容又让我想起了之前考研时听过的一句话: 不要强求不可知,要从已知推未知。 回顾整个过程,虽然Scrapy本身是比较未知且陌生的东西,但是里面所用到的知识点,其实就是一些Scrapy工作流程,网络基础和面向对象中的内容。理论上即使没有老师带着走,我们依然应该能够通过过去学到的东西,自己一点一点地把整个过程推理出来。
login.py源码
import scrapy
class LoginSpider(scrapy.Spider): # 子类对父类提供的某个方法不满意了,不满足了,重写它即可
name = 'login'
allowed_domains = ['17k.com']
start_urls = ['https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919']
def parse_login(self, resp):
yield scrapy.Request(url=LoginSpider.start_urls[0], callback=self.parse)
def parse(self, resp):
print(resp.json())
"""
需要重新定义一下,scrapy原来对于start_urls的处理
只需要重写start_requests()方法即可
"""
def start_requests(self):
# 方法1: 直接从浏览器复制Cookies信息
# cookie_str = """
# GUID=36f0e84e-2313-43cd-b7dc-8e7f66188782; sajssdk_2015_cross_new_user=1; Hm_lvt_9793f42b498361373512340937deb2a0=1643851819; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E9%25BA%25BB%25E8%25BE%25A3%25E5%2587%25A0%25E4%25B8%259D%26e%3D1659404069%26s%3Df63a666b72b81b38; c_channel=0; c_csc=web; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%2217ebd34284cb6d-01ebf888572afe-f791539-1327104-17ebd34284ddfe%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%2236f0e84e-2313-43cd-b7dc-8e7f66188782%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1643852127
# """
# # 把Cookies保存成字典的形式(两种方法):
# # 1.传统方法
# # lst = cookie_str.split('; ')
# # dic = {}
# # for it in lst:
# # k, v = it.split('=')
# # dic[k.strip()] = v.strip()
# # 2.字典生成式(更简洁,推荐!)
# dic = {it.split('=')[0].strip(): it.split('=')[1].strip() for it in cookie_str.split('; ')}
# yield scrapy.Request(
# url=LoginSpider.start_urls[0],
# cookies=dic
# )
# 方法2: 走登录流程
url = 'https://passport.17k.com/ck/user/login'
username = '18614075987'
password = 'q6035945'
# 发送post请求(两种方法):
# 方法1: 不好用
# yield scrapy.Request(
# url=url,
# method='post',
# body=f"loginName={username}&password={password}",
# callback=self.parse_login
# )
# 方法2: 常用
yield scrapy.FormRequest(
url=url,
formdata={
'loginName': username,
'password': password
},
callback=self.parse_login
)
二、Scrapy的中间件
在说明如何处理后面几种防反爬技术前,需要先引入一下Scrapy的中间件。因为这些防反爬功能,都是写在Scrapy的下载器中间件中。
中间件的作用:负责处理 引擎 和 爬虫 以及 引擎 和 下载器 之间的请求和响应,主要是可以对request和response做预处理,为后面的操作做好充足的准备。在Scrapy中有两种中间件,分别是 下载器中间件 和 爬虫中间件 。
1. DownloaderMiddleware下载器中间件
下载器中间件位于 引擎 和 下载器 之间,引擎 在获取到request对象后,会交给 下载器 去下载,在这之间我们可以设置 下载器中间件 ,它的执行流程:
引擎 拿到request ==> 中间件1 (process_request) ==> 中间件2 (process_request) … ==> 下载器拿到request
引擎 拿到response <== 中间件1 (process_response) <== 中间件2 (process_response) … <== 下载器拿到response
下面是一个爬虫项目的中间件middlewares.py文件
from scrapy import signals
from itemadapter import is_item, ItemAdapter
class MidDownloaderMiddleware1:
def process_request(self, request, spider):
print("1, process_request")
return None
def process_response(self, request, response, spider):
print("1, process_response")
return response
class MidDownloaderMiddleware2:
def process_request(self, request, spider):
print("2, process_request")
return None
def process_response(self, request, response, spider):
print("2, process_response")
return response
设置中间件settings.py文件
DOWNLOADER_MIDDLEWARES = {
'mid.middlewares.MidDownloaderMiddleware1': 543,
'mid.middlewares.MidDownloaderMiddleware2': 544,
}
运行效果:
1, process_request
2, process_request
2, process_response
1, process_response
百度一下,你就知道
接下来说说这两个方法的返回值问题 (难点)
一、process_request函数:在每个请求达到下载器之前调用。
- return None 不拦截,把请求继续向后传递给权重低的中间件或者下载器。
- return request 请求被拦截,并将一个新的请求返回,后续中间件以及下载器收不到本次请求。
- return response 请求被拦截,下载器将获取不到请求,但是引擎是可以接收到本次响应的内容,也就是说在当前方法内就已经把响应内容获取到了。
二、process_response函数:每个请求从下载器出来调用。
- return response 通过引擎将响应内容继续传递给其他组件或传递给其他process_response()处理。
- return request 响应被拦截,将返回内容直接回馈给调度器 (通过引擎),后续process_response()接受不到响应内容。
OK,至此,中间件的含义算是完事儿了,在后面的案例中会充分的使用上述讲到的内容,这部分的内容感觉比较突兀,但是如何和第15篇笔记放到一起去理解记忆的话,就是将Scrapy的工作流程补充了一下,使得我们可以拿Scrapy做更多的事情。
1.1 动态随机设置UA
原理说明:
回忆一下之前的UA是如何添加的。
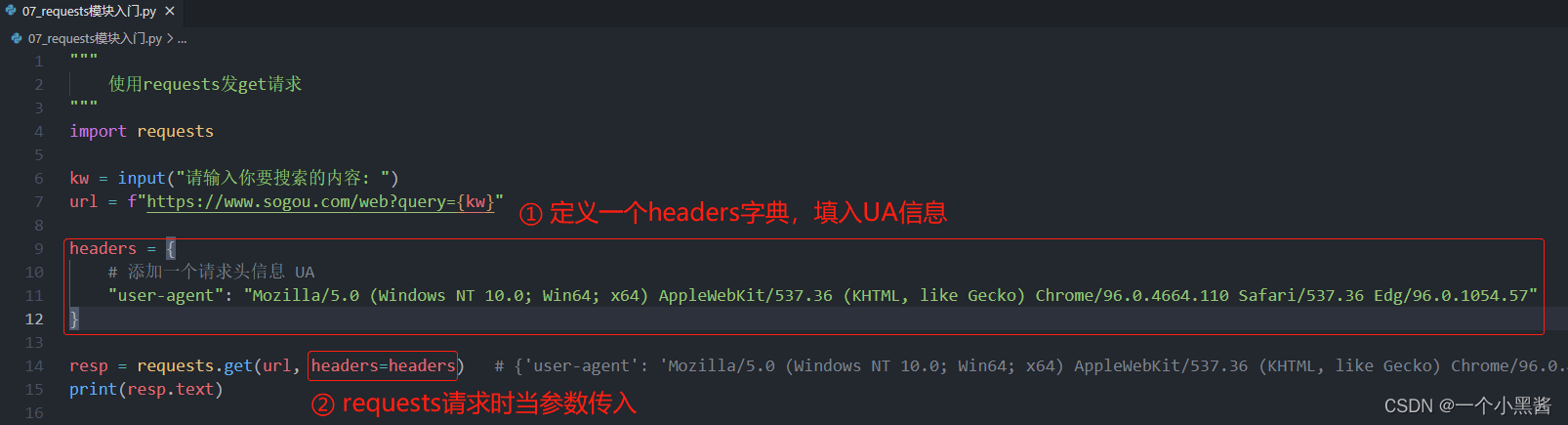
发现依然是在requests进行HTTP请求时,带上一个参数,即可加上UA伪装,和Cookies基本一样。因此这里依然可以用处理Cookies的方式来处理UA伪装,但这里我们打算在 下载器中间件 中加入UA伪装的功能。总之,只要在request对象被下载器拿到并发起HTTP请求之前,截获到request对象,并往里面加入UA,即可实现UA伪装功能。
开始动手:
# 新建一个douban项目 + 一个movie爬虫
scrapy startproject douban
cd douban
scrapy genspider movie douban.com
movie.py文件
import scrapy
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action=']
def parse(self, resp):
print(resp.xpath("//title/text()").extract_first())
settings.py文件修改
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
运行movie爬虫
scrapy crawl movie
发现什么也看不到。再一次修改settings.py文件,从浏览器中将UA复制添加进去
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
再一次运行movie爬虫,发现可以爬到数据了。但这只是利用Scrapy配置文件选项添加单一UA伪装,如果想要动态随机UA伪装,应该怎么办呢?
先写一个小爬虫到 http://useragentstring.com/pages/useragentstring.php?name=Chrome 网页中爬取不同的Chrome UA信息,再添加到settings.py文件中,并将前面配置的USER_AGENT注释掉。
USER_AGENT_LIST = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2919.83 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2866.71 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux i686 on x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2820.59 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2762.73 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2656.18 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
]
最后进入到middlewares.py文件
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from douban.settings import USER_AGENT_LIST # 导入setting.py中的UA列表
from random import choice # 每次访问时,利用random.choice函数随机选取一个
class DoubanDownloaderMiddleware:
def process_request(self, request, spider):
ua = choice(USER_AGENT_LIST)
request.headers['User-Agent'] = ua
return None # 不能返回任何东西
再一次运行movie爬虫,依然可以爬到数据,说明动态随机UA的功能,添加成功。
1.2 处理代理问题
原理说明:
回忆一下之前的代理是如何添加的。

原理上和前面的都差不多一样。
开始动手 (免费代理):
首先到快代理 https://www.kuaidaili.com/free/intr/ 免费代理IP中复制一些免费IP到settings.py文件中
PROXY_IP_LIST = [
"121.8.215.106:9797",
"47.92.113.71:80",
"222.173.194.112:38888",
"118.163.13.200:8080",
"117.186.112.42:9999",
"120.240.95.40:80",
"47.57.188.208:80",
"124.64.8.50:8000",
"211.136.128.154:53281",
"117.186.112.42:9999",
"47.92.113.71:80",
"124.64.8.50:8000",
"61.153.251.150:22222",
"47.92.113.71:80",
"223.70.126.84:3128"
]
然后到middlewares.py文件中添加一个免费代理中间件
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from douban.settings import USER_AGENT_LIST # 导入setting.py中的UA列表
from douban.settings import PROXY_IP_LIST # 导入setting.py中的代理列表
from random import choice # 每次访问时,利用random.choice函数随机选取一个
# 免费代理
class ProxyDownloaderMiddleware:
def process_request(self, request, spider):
ip = choice(PROXY_IP_LIST)
request.meta['proxy'] = "https://" + ip
return None # 放行
最后到settings.py中配置改中间件
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.DoubanDownloaderMiddleware': 543,
'douban.middlewares.ProxyDownloaderMiddleware': 544,
}
运行movie爬虫,发现速度明显变慢了,且有一定概率会失败。
开始动手 (收费隧道代理):
这部分内容由于我没有购买隧道代理,只是贴一下上课老师的代码,老师的代码也是从快代理官方文档中复制下来的,具体要使用收费代理时,都会有类似的文档,跟着教程做就行了。
到middlewares.py文件中添加收费代理的中间件
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from douban.settings import USER_AGENT_LIST # 导入setting.py中的UA列表
from douban.settings import PROXY_IP_LIST # 导入setting.py中的代理列表
from random import choice # 每次访问时,利用random.choice函数随机选取一个
from w3lib.http import basic_auth_header
# 收费隧道代理
class MoneyProxyDownloaderMiddleware:
def process_request(self, request, spider):
proxy = "tps138.kdlapi.com:15818"
request.meta['proxy'] = f"http://{proxy}"
# 用户名密码认证
request.headers['Proxy-Authorization'] = basic_auth_header('t12831993520578', 't72a13xu') # 白名单认证可注释此行
request.headers["Connection"] = "close"
到settings.py中配置改中间件
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.DoubanDownloaderMiddleware': 543,
'douban.middlewares.MoneyProxyDownloaderMiddleware': 544,
# 'douban.middlewares.ProxyDownloaderMiddleware': 544,
}
这样就可以运行了,相比于免费代理,速度更快,更稳定。
1.3 使用selenium完成数据抓取
老规矩,回忆一下,我们之前用selenium解决的是什么问题?之前我们用selenium解决了一个非常棘手的网站,BOSS直聘。BOSS直聘的所有页面都会进行不定次数的安全校验,通过后才会返回HTML代码。这个过程几乎无法通过传统的request发起HTTP请求来爬取到数据,因此引入了selenium模块来提供浏览器环境,解决抓取BOSS直聘这样的网站。除此之外,selenium因为提供了浏览器环境,还可以解决AJAX动态请求,JS加密等问题,很方便,除了慢之外,selenium几乎没有任何毛病。
因此这里我们需要将selenium和scrapy结合在一起,来解决BOSS直聘数据抓取的问题。
原理说明:
问题: Scrapy中的下载器和传统的requests模块类似,无法提供浏览器环境。
解决思路: 那么我们就应该改用selenium来对URL进行访问。在Scrapy中,URL通过 爬虫 模块来封装成request对象,通过引擎 转交到调度器 中,引擎 再从 调度器 中拿出request对象,扔进 下载器中间件,通过一系列中间件后交给 下载器,下载器 完成对URL的HTTP请求。为了阻止 下载器 拿到request对象,我们需要在 下载器中间件 上下功夫。
回顾一下前面介绍 下载器中间件 部分最后的难点内容:
一、process_request函数:在每个请求达到下载器之前调用。
1. return None 不拦截,把请求继续向后传递给权重低的中间件或者下载器。
2. return request 请求被拦截,并将一个新的请求返回,后续中间件以及下载器收不到本次请求。
3. return response 请求被拦截,下载器将获取不到请求,但是引擎是可以接收到本次响应的内容,也就是说在当前方法内就已经把响应内容获取到了。
我们只需要在 下载器中间件 的process_request函数这里,用selenium对网页进行访问,获取到网页源代码后,封装一个response对象返回,这样 下载器 的请求就被拦截了,由我们的selenium模块来执行。
开始动手:
# 新建一个boss项目 + 一个zhipin爬虫
scrapy startproject boss
cd boss
scrapy genspider zhipin zhipin.com
这部分内容比较复杂,还是用截图+文字的方式说明工作原理
首先到zhipin.py文件中

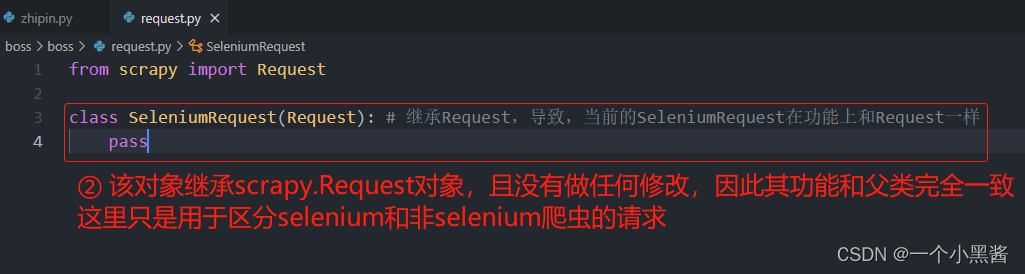
然后在middlewares.py的同级目录下新建一个request.py的文件,用于声明SeleniumRequest对象
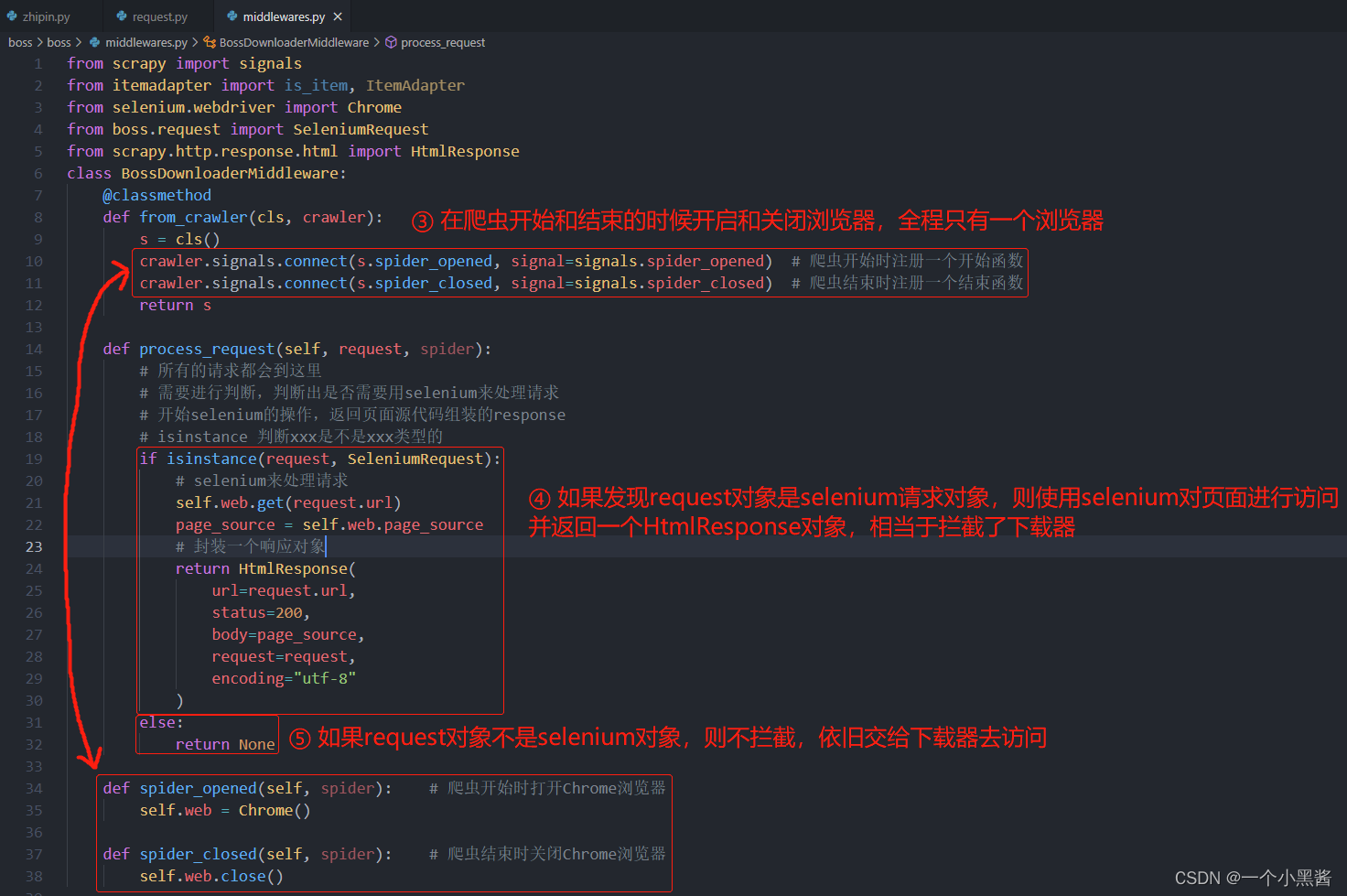
然后到middlewares.py添加如下内容
最后在settings.py文件中做如下配置

zhipin.py源码
import scrapy
from boss.request import SeleniumRequest
class ZhipinSpider(scrapy.Spider):
name = 'zhipin'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=']
def start_requests(self):
yield SeleniumRequest(
url=ZhipinSpider.start_urls[0],
callback=self.parse
)
def parse(self, resp):
print(resp.xpath("//title/text()").extract_first())
print(resp.text)
request.py源码
from scrapy import Request
class SeleniumRequest(Request): # 继承Request,导致,当前的SeleniumRequest在功能上和Request一样
pass
middlewares.py源码
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from selenium.webdriver import Chrome
from boss.request import SeleniumRequest
from scrapy.http.response.html import HtmlResponse
class BossDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) # 爬虫开始时注册一个开始函数
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed) # 爬虫结束时注册一个结束函数
return s
def process_request(self, request, spider):
# 所有的请求都会到这里
# 需要进行判断,判断出是否需要用selenium来处理请求
# 开始selenium的操作,返回页面源代码组装的response
# isinstance 判断xxx是不是xxx类型的
if isinstance(request, SeleniumRequest):
# selenium来处理请求
self.web.get(request.url)
page_source = self.web.page_source
# 封装一个响应对象
return HtmlResponse(
url=request.url,
status=200,
body=page_source,
request=request,
encoding="utf-8"
)
else:
return None
def spider_opened(self, spider): # 爬虫开始时打开Chrome浏览器
self.web = Chrome()
def spider_closed(self, spider): # 爬虫结束时关闭Chrome浏览器
self.web.close()
settings.py源码
BOT_NAME = 'boss'
SPIDER_MODULES = ['boss.spiders']
NEWSPIDER_MODULE = 'boss.spiders'
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
DOWNLOADER_MIDDLEWARES = {
'boss.middlewares.BossDownloaderMiddleware': 99,
}
1.4 用selenium模拟登陆后获取cookie
前面在 爬虫 模块中重写了start_requests函数来处理了登录cookies的问题,分别使用浏览器cookies复制和发post请求模拟登录两种方法来解决该问题。但是,当模拟登录需要用到人机验证码时,requests模拟发post的方法就比较麻烦了,需要先抓包将验证码图片爬下来,再使用超级鹰或图鉴识别,再进行登录。这个过程呢只需要做一次,因此用selenium来完成也不算太慢,且用selenium就比较简单了,因此我们可以考虑用selenium来完成模拟登录的过程,获取到cookies之后,再使用Scrapy的 下载器 来抓取目标网址的内容。
开始动手:
# 新建一个chaojiying项目 + 一个login爬虫
scrapy startproject chaojiying
cd chaojiying
scrapy genspider login chaojiying.com
然用截图+文字的方式说明
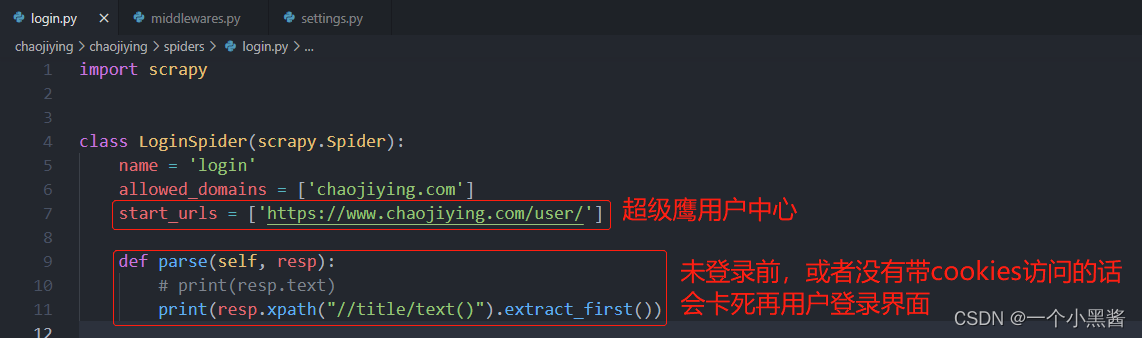
login.py文件
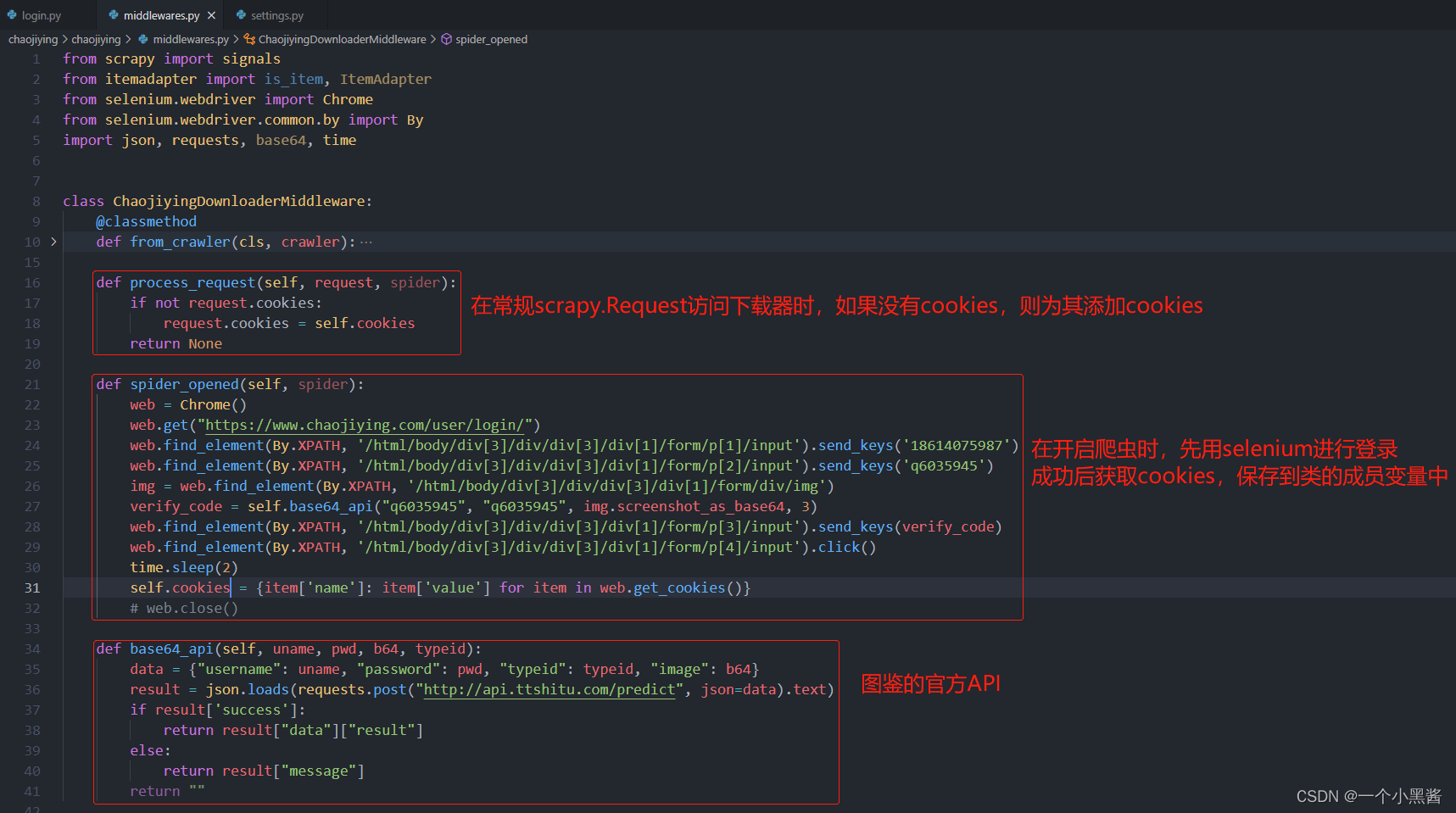
middlewares.py文件
最后在settings.py文件中做相应配置,这里就不截图了
login.py源码
import scrapy
class LoginSpider(scrapy.Spider):
name = 'login'
allowed_domains = ['chaojiying.com']
start_urls = ['https://www.chaojiying.com/user/']
def parse(self, resp):
# print(resp.text)
print(resp.xpath("//title/text()").extract_first())
middlewares.py源码
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import json, requests, base64, time
class ChaojiyingDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
if not request.cookies:
request.cookies = self.cookies
return None
def spider_opened(self, spider):
web = Chrome()
web.get("https://www.chaojiying.com/user/login/")
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys('18614075987')
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys('q6035945')
img = web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img')
verify_code = self.base64_api("xxxxxx", "xxxxxx", img.screenshot_as_base64, 3)
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(verify_code)
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
time.sleep(2)
self.cookies = {item['name']: item['value'] for item in web.get_cookies()}
# web.close()
def base64_api(self, uname, pwd, b64, typeid):
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
return result["message"]
return ""
settings.py源码
BOT_NAME = 'chaojiying'
SPIDER_MODULES = ['chaojiying.spiders']
NEWSPIDER_MODULE = 'chaojiying.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = "WARNING"
DOWNLOADER_MIDDLEWARES = {
'chaojiying.middlewares.ChaojiyingDownloaderMiddleware': 543,
}
三、感慨一下
这节课的内容实在是太丰富了,记这篇笔记花了我整整一天,干货太多了,希望以后要用的时候通过回顾这篇笔记可以快速回忆起来。
借用冬泳怪哥的一句名言激励一下自己: 成功不在于你力量多少!而在于你能坚持多久!加油,奥里给!!!