http��Ӧ�ò��Э��, Ӧ�ó���֮�����ݸ�ʽ��Լ��ͳһ��ʽ, �ɳ���Ա���Լ�Լ��
Э��������Զ���Э��Ҳ���������еġ������֪����Э��.
httpЭ����Ǵ�����Ū�õ���Ե���Ӧ�õ�֪����nb��Э��.(Ӧ�ò��֪����Э�黹��: http ���ı�����Э��,https ���ܵ�http, ftp �ļ�����Э��, smtp �ʼ�����Э��, dns ��������Э��)
�Զ���Э��: ���ǿ����Լ���㶨��ʹ�õ����ݸ�ʽ,? ����Ҫ��Ч�͵ÿ���: ���л�,�����л��Ĵ������ܺͽ�����������. ���л���Ķ���������Խ�̴�������Խ��, ���л��ͷ����л��Ĺ���Խ��������Խ��. ͨ��ʹ�ýṹ��Ķ��������л��������ܷdz��� (ͨ�����ǽṹ�������,�Գ�Ա�����ĸ�ֵ����ʵ���������ڴ��е����л�.) ���ǽṹ�巽ʽ�����л�����ȱ��: ��ͬƽ̨ λ�ε�ʹ�á��ֽڶ��� ��ͬ.
httpЭ����Ӧ�ò�Э��,�ڴ�����õ�tcpЭ��.Ҳ����˵http������Ҳ����tcp������.?httpЭ���Ǹ�������-��ӦЭ��,һ������һ����Ӧ. http�������ַ�������Э��(2.0�汾ǰ), ��Э����֯��������Ӧ���������ܿ��ö���.
http�����ʽ:
��������, ͷ���ֶ�, ����, �����ĸ�����
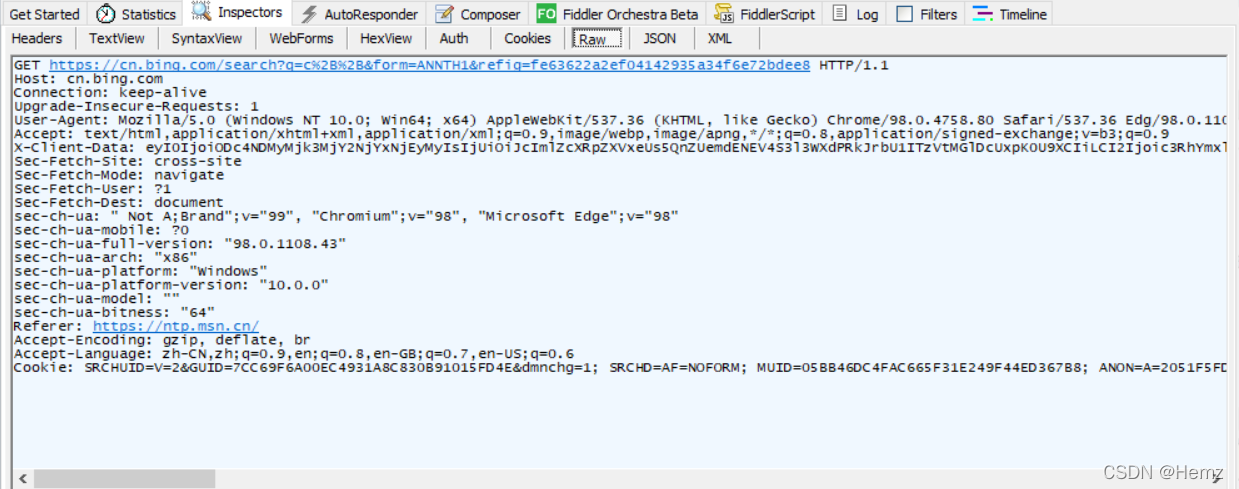
����:
���о����������еĵ�һ��, ��������Ҫ��: method url version\r\n, ����Ҫ��֮���ÿո���.
һ�����������о�����:?
GET http://www.baidu.com:9090/path?key=val&key=val#ch HTTP/1.1\r\n
(\r\n�ǻ�����һ������, ����һ���ַ�������˼)
method: ����.
������������������Ŀ��, �����ǻ�ȡ���ݻ����ύ���ݻ�����������, ɾ������. ���͵���:
GET: ��ȡ����, û������, Ҳ�����ύ��������, �ύ��������url��,�а�ȫ��������Ҳ������.
POST: �ύ����, �ύ��������������, ����������.
HEAD: ��GET����,����Ӧ��Ҫ��������,ֻҪͷ������.
URL: ͳһ��Դ��λ��, �׳���ַ.??
��Ϊ������URL��ʽ:
Э�鷽������://�û���:����@������IP��ַ:�˿�/��Դ·��?��ѯ�ַ���#Ƭ�α�ʶ��
Э�鷽������: ����ͨ������Э��.
�û���:���� :�����Ѿ���������,��Ϊ֮����û��������������ַ���Dz���ȫ��.
������ip��ַ: �������ı���, �����˼����(����baidu.com), ͨ�����������õ�������ip��ַ.
�˿�: ����(��ip��ַ)�Ͷ˿ڶ�λ�����������е�ijһ̨�����ϵ�ij������, httpĬ��80�˿�,https-443�˿�
/��Դ·��: ����ָ��·���µ�ij��ʵ����Դ(����), / �Ƿ����������Ը�Ŀ¼. ����(��ip��ַ)+�˿�+/��Դ·��,�;����˿ͻ�������������������ָ�������ϵ�ָ����Դ, ������������ĸ����̴���. ����: http://cn.bing.com/search, ��Ӧ�������IJ�ѯ����.http://cn.bing.com/login, ��Ӧ�������ĵ�¼
��ѯ�ַ���:?�ͻ����ύ������˵���������, ��ʽΪ(��ֵ��): key=val&key=val ...
Ϊ�˷�ֹ�ύ���������������ַ�(��ĸ����ַ�)����? ����������ַ���url�еļ������������, ���������ַ���Ҫ����ת��, ��url����,urlencode.
urlencode: ���������ַ�����ÿ���ֽ�ת��Ϊ16���Ƶ������ַ�, ������������c++���������е�url�еIJ�ѯ�ַ����е� ' + ' ��ת��ascii��ʮ�����Ƶ�2B. ����ת����Ϊ�˱�ʾ���������ַ�,��ǰ��ʶ%,����c++תΪc%2B%2B
urlencode: url����,��url���������ݽ���, ����%,��%��������ַ���16����asciiֵת��Ϊ�������.
Ƭ�α�ʶ��:?html��ҳ�еı�ǩid,����Ƭ�α�ʶ����������ҳֱ�ӻ�����ָ��λ��.
version: httpЭ��汾��
Э��汾��� \r\n ����ת������,����,����س����е���һ������.
0.9�汾: ���ɳ���İ汾, ֻ��GET�ķ���,Э���ʽ������.
1.0�汾: �淶��Э���ʽ, ����HEAD,POST,GET����, ֧���˶�ý������������.
1.1�汾: ֧�ָ���������ͷ���ֶ�, ���˳����ӹ����ͻ������.
2.0�汾: ����httpЭ��ӷ��,���½��������,�е��Ʒ��ؽ���ά��, �����һЩ����,���ܵ�����.
1.0���0.9: ��Ҫ�淶��Э���ʽ, ֧���˸�����ܺ����ݴ��䷽ʽ..
1.1���1.0: ��Ҫ�������ϸĽ�.�������: һЩ��Դ��û�иı�����Ҫ�����ٴδ���.?
�����ӵĸĽ�: ������: һ������ֻ����һ������, ����������,��������,�õ���Ӧ,�Ͽ�����. ���´�(ÿ��)������ٴ��½�һ������.? ������: һ�������п��Խ��ж������. ����������ڶ����ӽ�ʡ�˴����������ӽ���ʱ��
1.1�汾�ij������ǹ���˼��, 2.0�汾�ij������Ƕ�·����˼��.
����:����ڴ�ͳ������,������������ͬʱ����,��ʡ����ʱ��,������Ӧ
ȱ��:��Ӧ����������˳��һ��,���ڶ�ͷ��������
��ͷ����:�����һ����Դ����ʱ�䳤,�����ߵ���Դ������Ҳ������Ӧ
2.0�汾�еij����Ӷ�·����: ����˶�ͷ��������,ÿ����Ӧ�а�����Ӧ����������,����ĸ���Դ�����˾Ϳ���ֱ����Ӧ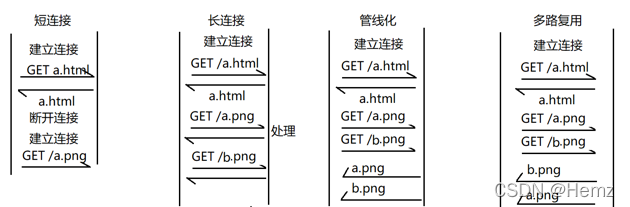
2.0���1.1:
1.�������ַ��������Ϊ�����ƴ���
��֧�ַ��������������������(��ǰ��һ������һ����Ӧ),һ������,������Ӧ�������
3.��·��������Ӧͷ��������������Ϣ,���ð�����Ӧ,�����ͷ��������
4.������ǰ������û�г��ֵ�ͷ���ֶ�,��ͬ��ͷ���ֶβ�ͬÿ�ζ����´�����
ͷ��:
ͷ���ֶ��� key: val ��ɵĶ����ֵ���ֶ����(valǰ�пո�), ÿ����ֵ����\r\n��β, �ǹ�����������ĵĹؼ�������Ϣ. key���ֶ�������, key: val��ֵ�Ծ��� ѧУ: ijijij��ѧ ����,val����key, �������ֶ���:
Host: �������������ַ��Ϣ.
Connection: �������ӵĹ���.(Connection: keep-alive��ʾ������,Connection: close��ʾ������)
User-Agent: ���߷���� �ͻ��˵�������汾�Լ�ϵͳ�汾��Ϣ(���ݰ汾����˻���Ӧ��ͬ����Ⱦҳ���..)
Accept: ���߷���˿ͻ����Լ��ܹ�����ʲô������Ӧ����
Referer:?val�а���һ������,��ʾ���ǵ�ǰ�������Դҳ������(����ٶȸ�ij��վ����, ����վ����ͨ��refererͳ�ƴӰٶȵ����ӽ���������,���������ֵ��ֵ��..)
Content-Length:?��������,���������ж
���������Ӧ�����������ܴ���,�������ͻ���: ����������Ӧ��������,�ͻ����ճ������(����������ӵ�һ��������ÿ�����ݵ���ʼ�ͽ�β, ȡ���Ϳ��ܰ���һ�����ŵİ�������ͷ����ʲôҲ����ǰһ����������.ȡ�̾�ȡ���˿�). ����ֶξ������ڽ��httpճ������, ���ݸ�ʽ��ȡ��ͷ��,����ͷ���е�content-length�ֶ�ȷ�����ij���Ȼ��ȡ��ָ����������,���ճ��
Content-Type: ������������,�����˶Զ���δ�����������
?
����:
���о���\r\n��ռһ��, ���ڼ��ͷ��������. ��ͷ���Զ����ȡ��,��ij���ֶ�ֻ��\r\nʱ,���ʾͷ������. Ҳ��������Ϊͷ�����һ���ֶν�βΪ\r\n\r\n.
����:
�ύ������˵�����, GETû���ⲿ��.POST�ύ�����ݾͷ���������.(GET��url��)
һ����http����:

http��Ӧ��ʽ:

����:
Ҳ��������Ҫ��: Э��汾 ��Ӧ״̬�� ״̬������? ? Ҳ���Կո�Ϊ���.����ж�\r\n
Э��汾: �����ϱ�˵��0.9/ 1.0/?1.1/ 2.0
��Ӧ״̬��: һ����λ��������, ÿ�����ִ�����ͬ��������
1xx: 1��ͷ����Ӧ״̬��, ������Ϣ����Э���л�Э��, ����101��Э���л���Ӧ, ������ͬ��ͻ��˵��л�Э������ͻ���Ӧ101
2xx: ��������ɹ�����, ����200��Ӧ��״̬����������OK
3xx: �ض���,?��һ����Դ���ӷ����ı�,���DZ���ԭ������Ȼ������ԭ�����ض����µ�����,��Locationͷ���ֶδ���, �ͻ��˿���3xx����Ӧ,����������Location�ֶ��е���ַ.
301-����-�´�����ʱֱ������������;? ? ? 302-��ʱ-�´�����ʱ��Ȼ����ԭ����
4xx: �����ͻ��˴���, 400-�����ʽ����,? 404-�������Դ������.
5xx: ��������˴���, 500-�������ڲ�����;? 502-��������������; 504-��������ʱ
״̬������: ��״̬��ļ�����, ��һЩӢ�ĵ���,���� 200 OK,OK���Ƕ�200�����Ӧ״̬��ļ�����. ������õ�����Ӧ���,����ɹ��˾���OK.? 404 NOT FOUND.? ״̬���������������,�����Լ�д��Ӧʱ,�����״̬��������״̬��Բ���Ҳ���ᱨ��.
ͷ��:
Ҳ���ɶ�� key: val ��ֵ�����, ÿ����ֵ����\r\n��β, Ҳ�������������Ļ���Ӧ��Ϣ.
Ҳ��Connection-Length: ���ij���,Connection-Type: ��������. ֮���ͷ���ֶ�.
Location: ��3xx����Ӧ�����ʹ��, val��һ���ض����������.
Set-Cookie: �������Cookieͷ���ֶδ���ʹ��, ����ʵ��http��cookie����.
cookie����:
http��һ����״̬��Э��, ���ڰ汾�ж�����,һ��ͨ�����Ӿͻ�Ͽ�,��������Э��ķ�չ, �ͻ��˵ı�ʶ״̬Խ��Խ��Ҫ,���繺��U��¼����߶Է��ͻ��˵�������Ϣ,���ǵ��㱾��ͨ��������ӾͶϿ���,�´�������ʱ����Ȼ��Ҫ���½������ӷ��Ϳͻ�����֤��Ϣ.
��˾���cookie����,����˽��ͻ��˵�һЩ״̬��Ϣͨ��Set-Cookie�ֶη����ͻ���,�ͻ��˽���Щ��Ϣ���浽cookie�ļ���,���´������������ʱ��cookie��Ϣ��cookie�ļ��ж�ȡ����,ͨ��Cookie�ֶη���������,�������յ�֮��,�����˽�ͻ��˵�����״̬��Ϣ�ˡ�����,֮��ÿ�δ���ҳ��Ͳ���Ҫÿ�ζ�Ҫ�����˺ź�������
cookie����������httpЭ���г���ά���ͻ���ͨ��״̬�Ļ���

session����:
���ͻ��˷�����֤��Ϣ��������,��������Ϊÿ���ͻ��˴���һ���Ự,�Ự��Ϣ�а����пͻ��˵������Լ�����״̬��Ϣ,Ȼ���������ڷ��������ݿ���,ÿ���Ự����һ��ΨһID,Ȼ��session_id��ΪSet-Cookie���ֶ�ֵ������ͻ���,�ͻ������´�������������ʱ��Ͱ�session_id����������,������ͨ��session_id���������ݿ����ҵ��Ự��Ϣ������ȡ���ͻ��˵�״̬��Ϣ, �����ͻ��˵�������Ϣ�Ͳ����������ϳ���������.
cookie�ǿͻ���״̬��Ϣ�����ڿͻ��˵�, session�ǿͻ���״̬��Ϣ�����ڷ����
?
����:
\r\n, һ��, ���ڼ��ͷ��������
����:
��Ӧ���ͻ��˵�����,? һ������Ӧ��ʾ��:?

HTTP������ʵ��:
����ʹ������֮ǰд��tcp������, ��ѡ���˶��̰߳��, ����С��ֻ��Ҫ������:

?
?��:?

?ץ������ץ����: �±���������Ӧ
�������Ӧ�ij�302 FOUND:

��ֱ�������ٶȵ�ҳ��.?

?�����Ӧ����404:?
�Լ�Ū��404ҳ��, ���ﰳ������������:
HTTPS��:
https�����ϻ���httpЭ��, ����������һ�����: SSL����. �����tcpЭ���.
��ͬ��: 1.�����˵�Ȼ��ȫ�Ը�����. 2.httpʹ��80�˿�, httpsʹ��443�˿�.
httpsЭ��ļ�������:
httpsЭ��ļ�����ʵ����SSL����, ���ܷ�Ϊ��������: ������֤�����ݼ���
������֤:
˫����֤: ����һ��˫�������εĵ�����Ȩ������,������˫�������εĻ���,˫����Ȩ�������䷢һ������֤��,��ͨ��ǰ��֤�鷢���Է��Է�����֤���е���Ϣ(����˭,������䷢��֤��,��Ч�ڡ���.)���ж϶Է�������,����ȥ������Ȩ������������֤ͨ������������֤�ɹ���Ȼ���ٽ���ͨ��
������ƽʱ�����������ֻ��������֤: �ͻ�����֤������
���ݼ���:
�ԳƼ���:
˫��ʹ����ͬ����Կ���м��ܽ��ܽжԳƼ���.
ͨ��ǰ����Կ�����Է�,�Լ�ʹ����Կ�������ݼ���,�Է�ʹ����ͬ��Կ�������ݽ��ܡ�����һֱʹ��ij����Կ,�����ױ��ƽ�(�����ƽ�),��ÿ��ͨ��ǰ��̬Э��Ҳ���ڰ�ȫ����, ��ΪЭ����ԿҲ���ױ��ٳ�;
�ô�: ���ܽ���ͨ��Ч�ʱȽϸ�.? ȱ��:?��ȫ�ȵ�
�ǶԳƼ���:
����, ���ܵ���Կ��ͬ�зǶԳƼ���.
����һ����Կ(��Կ��˽Կ),���й�Կ���ڽ������ݼ���,˽Կ���ڶԹ�Կ���ܵ����ݽ��н���(��Կ���ܵ�����ʹ�ù�Կ�������ܵ�),���ͨ��ǰ,����Կ���ݸ��Է�,�Է�ʹ�ù�Կ�������ݼ���,���ݵ�����Լ�ʹ��˽Կ���н���,�õ�����
��ȫ�ȷdz���: ���¹�Կ���ٳ�;? ? ����Ҳ��ȱ��:���ܽ���Ч�ʺܵ�
��ϼ���:
�Ƚ��зǶԳƼ���,ͨ��ǰ,����Կ�����Է�,�Է��ù�Կ���ܶԳ���Կ��Э�̹���,�����Գ���Կ�������ٳ���,Э�����֮��,ʹ��Э�̳��ĶԳ���Կ����ͨ�š�ͨ�����ַ�ʽ����֤�˰�ȫ,Ҳ��֤��Ч�ʡ�
?
SSL��������:
1.������(��Ҫ����֤���ݵ�һ��),���ɡ�����Կ(��Կ��˽Կ)
��.���������Ź�Կ,ȥȨ����������һ��֤��(����˭,Ȩ��������˭,��Ч��....��Կ)
3.ͨ��ʱ,��tcp�������ӳɹ���,��֤�����ȷ����ͻ���
4.�ͻ����յ�֤��,���н���,�õ���������,Ȼ��Ȩ���������з�����������֤
5.��֤�ɹ�,ʹ�ù�Կ�����Լ���֧�ֵĶԳƼ����㷨�б��Լ�һ�����������������
6.�������յ���Կ���ܵ���Ϣ��,ʹ��˽Կ���н���,�õ��˿ͻ���֧�ֵ��㷨�б��Լ������
7.���������Լ�֧�ֵ��㷨�б��Լ�һ������������ͻ���, �ⲽ����Ҫ����,��Ϊ�ٳ���Ҳû��
8.�ͻ�������������Ը����㷨�б��Լ��Լ��ͶԷ������������һ���Գ���Կ9.����ͨ��ʹ�öԳ���Կ���м���ͨ�š�