��Uncovering the structure of clinical EEG signals with
self-supervised learning��ԭ�ĵ�ַ
��ȡ��һ�͵ڶ�����(����RP����)�ķ���
����Ŀ¼
ժҪ
Ŀ��:�ලѧϰ��ʽͨ���ܵ����ñ�������������ơ������������ٴ���������������������,�����Ե�ͼ(EEG),��EEG��,��ǿ��ܻ���רҵ֪ʶ�����ദ��ʱ�䷽����۸߰������,�������ѧϰEEG���ݵ����ѧϰ��ϵ�ṹ���������dz��ģ��,�����ܳ������봫ͳ�Ļ��������ķ������ơ�Ȼ��,�ڴ���������,����δ��ǵ����ݿ��á�ͨ������Щδ��ǵ���������ȡ��Ϣ,���ܶԱ�ǩ�ķ�������,��ͨ�������������ܴﵽ���о�������������
����:�����о����Լලѧϰ(SSL),����һ����δ��������з��ֽṹ����ǰ;�ļ���,����ѧϰEEG�źŵı�ʾ��������˵,����̽������������ʱ��������Ԥ�������,�Լ������ٴ��������ĶԱ�Ԥ�����:����EEG��˯�߷��ںͲ������������������ӵ����ǧ����¼�Ĵ��������ݼ��Ͻ�����ʵ��,���봿�ල���ֹ���Ƶķ��������˻��߱Ƚϡ�
��Ҫ���:����SSLѧϰ����ѵ�������Է������ڵͱ������״̬��ʼ�����ڴ��ල���������,ͬʱ�����б�ǿ���ʱ�ﵽ��������������,ͨ��ÿ�ַ���ѧϰ��Ƕ��(embeddings)��ʾ�����������ٴ�����(������ЧӦ)��ص�����DZ�ڽṹ��
����:����չʾ�����Ҽලѧϰ�������Ե����ݵĺô������ǵ��о��������,SSL����Ϊ���Ե������ϸ��㷺��ʹ�����ѧϰģ����ƽ��·��
�ؼ���:�Լලѧϰ������ѧϰ������ѧϰ���Ե�ͼ��˯�߷��ڡ�������⡢�ٴ���ѧ
1 ����
�Ե�ͼ(EEG)�����������ź�ģʽ�Ѿ����ٴ���������ʵ��������Ӧ��,����,�о�˯��ģʽ�������[1], �������[2]����-���ӿ�[3]���ڹ�ȥ������,��Щ�豸�Ŀ����Ժͱ�Я����������,��Ч��ʵ����ʹ�õ�������,���ͷ��˶����������������Ӱ���DZ��[4,5]������,��ͥ˯�߷��ںͺ�����ͣ��⡢�������Ե�ͼ��⡢���ɼ���Ӧ��������ȫ����ʵ�֡�
��������Щ�����,���ģʽ�����Խ��Խ����Ҫ���͵����ݡ����,��Ҫ�ܹ����ࡢ��Ⲣ���ա����⡱�������ݵ�Ԥ��ģ�͡���ͳ��,�������͵Ľ�ģ��Ҫ�����ڼල����,�ڼල������,��Ҫ������ע�͵�ʾ�����ݼ���ѵ�����и����ܵ�ģ�͡�
Ȼ��,�����������ϻ��ȷ�ı�ע�����ǰ���ġ���ʱ�Ļ���������ܵ�������,ע��˯��¼��Ҫ������ѵ�ļ�����Ա���Ӿ���ʽ�鿴��Сʱ������,��������30��Ĵ���[6]���ٴ���¼,������������������˵ļ�¼,��������ҽ�����,���ǿ��ܲ������ǿ��õġ����㷺��˵,�����е���������Ȥ�Ĵ��Թ��̵ĸ����Ի�ʹ���ͺ�ע��EEG�źű������,��ᵼ��������֮��ĸ߶ȿɱ���,����ǩ����[7,8]������,��ijЩ�����,ȷ�˽����������֪��ѧʵ���е��뷨����Ϊ������һ����ս,��ʹ�ú��ѻ��ȷ�ı�ǩ������,������������,�����߿���û����ѭָʾ,�����о����̿������Կ�����(����ڤ�롢����)�����,һ�ֲ���Ҫ�����ڼලѧϰ���·�ʽ�������ô���δ��ע�ļ�¼��(���������������ɵļ�¼��)�DZ�Ҫ����Ȼ��,��ͳ���ලѧϰ����(������DZ������ģ��)�������ṩ��ȫ��������Ĵ�,��Ϊ���ǵ����ܲ����мල�ķ����������������ͽ�����
���Լලѧϰ��(SSL)��һ���ලѧϰ����,����δ��ǵ�������ѧϰ��ʾ,�������ݵĽṹ�ṩ�ල[9]��ͨ�����ලѧϰ�������¶���Ϊ�мලѧϰ����,SSL����ʹ�ñ��ġ�����������Ż����̡�SSL�������������͡����Ρ����������������û�ʵ�ʸ���Ȥ������,�����ע����û�б�ע����һ����,��������������������������,�Ա�ʹ�����Ƶı�ʾ��ִ��;��Ҫ����,�����ܹ�����ʹ��δ��ǵ�����Ϊ��������������ɱ�ע��
����,�ڼ�����Ӿ�������,����ʹ��ƴͼ����,��ͼ������ȡ����,�������,Ȼ������������,�����羭��ѵ���Իָ�������ԭʼ�ռ�˳��[10]����������ܹ��ܺõ������������,��ô��������,���Ѿ�ѧϰ����Ȼͼ���һЩ�ṹ,���Ҿ���ѵ������������ڽ�С��ģ���мලѧϰ����(��Ŀ��ʶ��)����������������ȡ��Ȩ�س�ʼ����
���˴ٽ����������/����ٱ�Ҫ�ı�עʾ����������,�Լල�����Է��ֱ���ר�żල������ѧϰ���ĸ��ձ顢���Ƚ�������[11]�����,���ǵ�SSL��DZ�ںô�,������������ǿEEG�ķ�����?
��ĿǰΪֹ,SSL�Ĵ����Ӧ�ö����������д�����ע���ݵ�����,�������Ӿ�[9]����Ȼ���Դ���[12,13]���ر����ڼ�����Ӿ���,�������ͨ����ͨ����ȫ�ල������(����,ImageNetԤѵ��)��ѵ���ġ������������,���㹻�ı�����ݿ���,�������������ֱ�Ӽලѧϰ�������Ѿ����о�����[14]��SSL�ڵͱ������ģʽ�ձ��Ҽලѧϰ����Ч����������,���������źź�EEG����,���и����DZ�����������,�����й���SSL�������źŵ��о���������Щ�о�Ҫôרע������������������ݼ�[15],Ҫô��EEG������ź��ϲ������ǵķ���[16]
���,�Լල�Ƿ�����������EEG�ı��ල�������д�֤��,���������,Ӧ��������ѷ�ʽ��ʲô��������˵,�����ܷ�ͨ���ԼලѧϰEEG��ͨ�ñ�ʾ,����������ʱ���ٶ���EEG��ע������?�������ѧϰ��ΪEEG�������ߵ������ռ�[17],�𰸿��ܻ��EEG��������ĵ�ǰʵ�������ش�Ӱ�졣��ʵ��,�������ѧϰ�����ݼ�������,��������ѧ�о��о��ֶ������ڵͱ����������,�����Ե�ͼ�о�:�����������ߵ��ٴ��о�ͨ������Ϊ�Ǵ�����,�����ģ�о����Ϊ����,ͨ����Դ���о�����[18,19,20,21]�����,����Ԥ�ڵ���,��������ѧϰ�Ե�ͼ�о�(ͨ���ڵͱ������״̬��)��������ܵ�ĿǰΪֹ��Ȼ����,����û���������ڴ�ͳ����[17]��ͨ������δ��ǵ�����,SSL������Ч�ش��������ʾ��,�Ӷ�ʹ���ѧϰ�ܹ����ɹ���Ӧ����EEG��
�ڱ�����,�����о����Լල��Ϊ���Ե�����ѧϰ������һ�㷽����ʹ�á���������֪,�����״���ϸ�����˶��������Ե�ͼ��¼��SSL�������ǵ�Ŀ���ǻش���������:
- ���Ե���������ؽṹ�ĺ�SSL������ʲô?
- �����η�����������,SSL�����������ල���мල�ķ���������?
- SSLѧϰ������������Щ�ص�?������˵,SSL�ܷ��δ��ǵ��Ե�ͼ�в��������ٴ���صĽṹ?
���ĵ����ಿ�ֽṹ���¡���2�ڸ�����SSL����,Ȼ�������������о��п��ǵIJ�ͬSSL�����ѧϰ���⡣���ǻ�����������ʵ����ʹ�õ��ṹ�����߷��������ݡ�������,��3�ڽ������������Ե�ͼ�ϵ�ʵ���������,���ǽ��ڵ�4�������۽����
2 ����
2.1 ���Ƚ����Լලѧϰ����
��Ȼ���Dz���������ô��Ϊ,��SSL�Ѿ���������������õ���Ӧ�á��ڼ�����Ӿ���,�ж��ַ��������,����������ͼ��Ŀռ�ṹ����Ƶ��ʱ��ṹ������,��[22]��,������Ԥ����������ͨ��Ԥ�����������ͼ��patch����ڵڶ���patch��λ��,��δ���ͼ���ϵ�������ȡ������ѵ����ʹ�����ַ��������������Ԥѵ��,���߱�������Pascal VOCĿ������ս��,�봿�ලģ�����,����������ߡ���Щ����״α���,�����ı�ע���ݿ���ʱ,�Լල��Ԥѵ�����������Ч�����Ƶ�,�����ᵽ��ƴͼ����[10]�����ͬһ���ݼ����������ܡ�����Ƶ��������,Ҳ����˻���ʱ��ṹ�ķ���:����,��[23]��,Ԥ����Ƶ֡����������Ļ�������ı�������������,��������ʶ�����������н��в��ԡ�����Ȥ�Ķ��߿�����[9]���ҵ�SSL��ͼ�������Ӧ�á�
���Ƶ�,�ִ���Ȼ���Դ���(NLP)����ͨ�������Լල��ѧϰ����Ƕ��,��������Ӧ�õĺ���[24]������,�����word2vecģ�;���ѵ��,����Ԥ�����Ĵ���Χ�Ĵʻ������Χ�Ĵ�Ԥ�����Ĵ�[12],Ȼ���ڸ��������������ظ�ʹ��[25]�����,һ��˫�����Լල����BERT��11��NLP����(���ʴ������ʵ��ʶ��)��ȡ�������Ƚ�������[13]�����ַ���ʵ�ֵĸ�����չʾ��SSL��ѧϰͨ�ñ�ʾ�����DZ����
���,���ձ�ĸ��������Լ��Ľ��ķ����Ѿ�������ǿ�����Ľ��,��Щ����Ѿ���ʼ�봿��ļල������⡣����,�Ա�Ԥ�����(CPC)��һ��DZ�ڿռ��е��Իع�Ԥ������,�ѳɹ�����ͼ���ı�������[11]������һ����������һ���Իع�ģ��,��������ڸ���������ڵ���������Ԥ��δ������(��ͼ����)�ı���������������ڸ������������ϸ�����һЩ�Ľ��Ľ��;�����о���һ������,����������������Խ�һ��������������,�������ڵͱ����������[26]�������Ա�(MoCo)�������һ���µĸ�������,���ǶԶԱ�����ĸĽ�,������������Ԥ����������������е��ĸ�����ʵ����[27,28]��ͨ���Ľ��Ա������и������ij���,MoCo���������SSL��ѵ��Ч���Լ���ѧ���������������Ƶ�,��[29]�з���,ʹ����ȷ��������ǿ�任(����,ͼ���ϵ�����ü�����ɫʧ��)�����������������������������ܡ�
����SSLѵ���������ܹ����Ե��ƹ㵽��������,����б�Ҫ��ϸ�о����ǵ�ͳ�ƽṹ��Hyv?rinen����[30,31]����������Զ������������ĽǶ���ʽȷ����һ���ձ�ġ��������и��ݵķ������������������,ʹ�ÿ���������Ƕ��۲�x,���븨������u(����,ʱ��ָ����segmentָ����������ʷ)���жԱȡ�������ͨ��ѧϰԤ��x�������Ӧ�ĸ�������u���,�������Ŷ�(���)����u���,����x�Խ��з��ࡣ��������ʾ��ij�ֽṹ(����,����ء���ƽ���ԡ��Ǹ�˹��)ʱ,�ڶԱ�������ѵ����Ƕ���߽�ִ�п�ʶ��ķ�����ICA[31]����ǰ����Ĵ����SSL������ͨ���ÿ�ܲ鿴���������Զ�������������ΪԤ������������ȡ�������Ե�����Ĺ㷺Ӧ��[32,33,34,35],�Է������������չ��һ����Ȼ�Ľ���,���������ڸĽ���ͳ�Ĵ���pipeline��
ֵ��ע�����,�������о���SSLӦ���������ź�,�������п������ô���δ������ݡ���[15]��,��word2vec����������һ����Ϊwave2vec��ģ��,���ڴ���EEG���ĵ�ͼ(ECG)ʱ��������ͨ����EEG�źŵ�ʱƵ��ʾ���˿�ͳ����Ϣ�Ĵ���Ԥ�����ڴ��ڵ�������ѧϰ��ʾ��Ȼ��,�÷������ڵ���EEG���ݼ��Ͻ����˲���,û������ȫ�ල�����ѧϰ������ר������������л����ԡ�SSL����Ӧ����ECG,��Ϊѧϰ��������ʶ������������һ�ַ���:��[16]��,ʹ����һ��ת��ʶ��������,ģ�ͱ���Ԥ����Щת��Ӧ����ԭʼ�źš���Ȼ��Щ�����ʾ�������ź����Ҽලѧϰ��DZ��,����Ҫ�����EEG��SSL���и��㷺�ķ���,Ϊʵ��Ӧ����ƽ��·��
2.2 �Ե�ͼ���Լලѧϰ��������
�ڱ�����,���ǽ����ܱ�����ʹ�õ�����SSL��������������Ӿ�������ͼ1��ʾ��

2.2.1 ��ض�λ(Relative Positioning)
Ϊ�˴Ӷ����ʱ������ S S S�в�������ǩ������,���ǽ�����ʱ�䴰�� ( x t , x t �� ) (x_t,x_{t^{'}}) (xt?,xt��?)���в���,����ÿ������ x t x_t xt?, x t �� x_{t^{'}} xt��?�� R C �� T R^{C��T} RC��T��ʾ, T T T��ÿ�����ڵij���ʱ��,�������� t t t��ʾ������ S S S��ʼ��ʱ����������һ������ x t x_t xt?����Ϊ��ê������(anchor window)�������ǵļ�����,���ݵ��ʵ���ʾӦ��ʱ�仺���ݱ�(����������������(SFA)[36,37]�������������),�����ʱ�䴰����ʱ���Ϲر�ʱӦ������ͬ�ı�ǩ��
����,��˯�߽�,ͨ������1��40����[38];���,�����Ĵ��ڿ�������ͬһ��˯�߽�,��Զ���Ĵ��ڿ������Բ�ͬ��˯�߽Ρ�
����
��
p
o
s
��_{pos}
��pos?��
N
N
N�� �������������ĵij���ʱ��,�Լ�
��
n
e
g
��_{neg}
��neg?��
N
N
N,��Ӧ��ÿ��������Χ�ĸ�������,���Dz���n����Ƕ�:
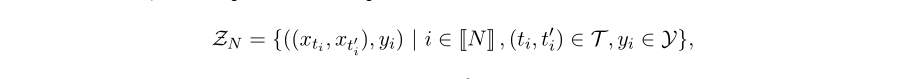
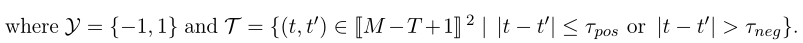
ֱ�۵�˵,������ʱ��ָ����
(
t
,
t
��
)
(t,t^{'})
(t,t��)�ļ���,���ԴӴ�СΪ
M
M
M��ʱ�������еĴ�СΪ
T
T
T�Ĵ��ڹ���,������
��
p
o
s
��_{pos}
��pos?��
��
n
e
g
��_{neg}
��neg?���ض�ѡ��ʩ�ӵij���ʱ��Լ��������
y
i
��
Y
y_i�� Y
yi?��Y�����������IJ���ָ��:
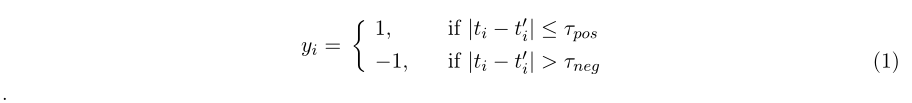

ͼ1 | ���о���ʹ�õ�����SSL����������Ӿ����͡���һ��˵������ÿ�����������л�ȡ�����ij������̡��ڶ���������ѵ������,����ʹ��������������ȡ��
h
��
h_��
h��?���ж˵���ѵ����
���Ǻ��� x t �� x_{t^{'}} xt��?����ê������ x t x_t xt?�������������еĴ��ڶԡ����仰˵,��ǩ��������ʱ�䴰����ʱ�����DZ� �� p o s ��_{pos} ��pos?�������DZ� �� n e g ��_{neg} ��neg?��Զ��ע���[22]���������ϵ,���ǽ��˸��������Ϊ����Զ�λ��(RP)��
Ϊ��ѧϰ�˵�����θ���ʱ�䴰�ڶԵ����λ������������,������������������ h �� h_�� h��?��gRP�� h �� : R C �� T �� R D h��:R^{C��T}�� R^D h��:RC��T��RD��һ�����в�������������ȡ��,�������� x x xӳ�䵽���������ռ��еı�ʾ������,�������� h �� h_�� h��?ѧϰԭʼ�Ե��������Ϣ��ʾ,��Щ��Ϣ�����ڲ�ͬ������������������Ȼ��ʹ���Ա�ģ�� g R P g_{RP} gRP?���ۺ�ÿ�����ڵ�������ʾ������RP����, g R P : R D �� R D �� R D g_{RP}:R^D��R^D�� R^D gRP?:RD��RD��RDͨ������Ԫ�ؼ����Բ���������ԳɶԴ��ڵı�ʾ,��|��|�������ʾ:
g R P ( h �� ( x ) , h �� ( x �� ) ) = �O h �� ( x ) ? h �� ( x �� ) �O �� R D g_{RP}(h_��(x),h_��(x^{'}))=|h��(x)? h��(x^{'})|�� R^D gRP?(h��?(x),h��?(x��))=�Oh��(x)?h��(x��)�O��RD��
g
R
P
g_{RP}
gRP?�������Ǿۺ�
h
��
h_��
h��?���������봰������ȡ����������,��ͻ�����ǵIJ���,�ԼԱ����������,������һ��ϵ��Ϊ
w
w
w�������������б�ģ��
w
w
w��
R
D
R_{D}
RD?��ƫ����
w
0
��
R
w_0�� R
w0?��R����Ԥ�����Ŀ��
y
y
y������
g
R
P
g_{RP}
gRP?Ԥ��Ķ�Ԫ����ʧ,���ǿ��Խ�������ʧ����
L
(
��
,
w
,
w
0
)
L(��,w,w_0)
L(��,w,w0?)�
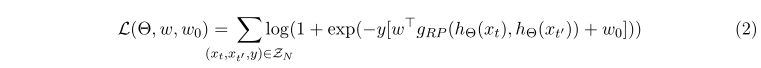
���Ǽ��������ڲ���
(
��
,
w
,
w
0
)
(��,w,w_0)
(��,w,w0?)����ȫ���ġ�����
y
y
y��Լ��,Ԥ��Ŀ����
w
T
g
(
h
��
(
x
t
)
,
h
��
(
x
t
��
)
)
+
w
0
w^Tg(h_��(x_t),h_��(x_t^{'}))+w_0
wTg(h��?(xt?),h��?(xt��?))+w0?�ķ�����
2.3 ��������
���ǶԻ��ڻ���ѧϰ���Ե�ͼ�����д�����ǰ��ս�������ٴ�����:˯���Ͳ���ɸ��,�����˻����Ե�ͼ�ľ�������ԡ��������ٴ�����ͨ���ᵼ�·�������,���ܷ���������ͬ,�������ɻ���Ҳ��ͬ:˯����������¼�(�¼�����)�й�,������ɸ������Ⱥ(��������)����뵥�������йء��������ٴ��������о����������൱��Ĺ�ע,����˴��������ݿ�Ĺ�����Ϊ�����мල�ķ������й�ƽ�Ƚ�,���Ƕ�2018����������ս[1,39]��TUH�쳣�Ե�ͼ[40]���ݼ���SSL�����˻����� ��
����,���ǿ�����˯�߷���,���ǵ���˯��������Ĺؼ���ɲ���,����Ϻ��о�˯���ϰ�(�������ͣ����˯֢)�Ĺؼ�[41]������(�����)ѧϰ����[42,43,17]��˯�߷��ڽ����˹㷺���о�(Լռ[17]�������ĵ�10%),����û�д�SSL�ĽǶȽ����о���ʵ����ȫ�Զ�����˯�߷��ڿ��ܻ���ٴ�ʵ�������ش�Ӱ��,��Ϊ
- ��������Ա֮���һ����ͨ������[7],
- ע���̺�ʱ������Ҫ���ֶ���[6]��
˯�߷���ͨ���ᵼ��5����������,���п��ܵ�Ԥ����W(����)��N1��N2��N3(��ͬ˯��ˮƽ)��R(�����۶�����)��������,�����������Ԥ���Ӧ��30��EEG���ڵ�˯�߽���
���,���ǽ�SSLӦ���ڲ������:EEG���ٴ������г�������ɸ�����ͳմ��������ĸ���[44,45]��Ȼ��,�ɹ��IJ��������Ҫ�߶�רҵ����ҽѧרҵ֪ʶ,������ȡ����ר�ҵ���ѵ�;��顣���,�Զ�����������ͨ���ٽ���ϵͳɸ����ٴ�ʵ�������ش�Ӱ�졣��Ͳ�����ѧ�Ʋ���ķ�������,���е���ս�Ǵ��Ե�ͼ��¼���ƶϻ��ߵ���ϻ�״������TUH���ݼ���,ҽѧר�ҽ���¼���Ϊ�����Ի�Dz�����,�ɴ˲����˶�Ԫ�������⡣��Ҫ����,��������ǩ��ӳ�˸߶������Ե����:������¼���ܷ�ӳ���ڸ���ҽ������������쳣,�����һ���൱���ӵ��������ɻ��ơ�ͬ��,�����ܼල�ķ���,����һЩ���������ܹ�,������[46,47,48]�н������һ����,����û��һ�ַ������������Ҽල��
����������ʵ����ʹ�õ�����ʱ,��2.6�ڽ���һ����������������
2.4 ���ѧϰ�ܹ�
�����ǵ�ʵ����,����ʹ�������ֲ�ͬ�����ѧϰ��ϵ�ṹ��ΪǶ���� h �� h_�� h��?(��ϸ������μ�ͼ2)�������ֽṹ�����ɿռ��ʱ���������ɵľ���������,�ֱ�ѧϰִ��EEG�����ܵ����͵Ŀռ��ʱ���˲�������
��һ��,���dz�֮ΪStagerNet,�Ǹ���֮ǰ����˯�߷��ڵĹ����ı������,��˯�߷��ڵĴ��ڷ�����,�����ֵúܺ�[42]��StagerNet��һ���������������,�Ż����ڴ���30��Ķ�ͨ��EEG���ڡ�������ļܹ��෴,
- ����ʹ����������ľ���ͨ��(16������8)
- ����������ʱ�������֮�������������淶��
- ����û�����ʱ�����
- ���ǽ�������ά����ΪD=100,����������(��ͼ2-1)��
��������ܹ�62307����ѵ��������
�ڶ���,Ƕ��ʽ�ܹ�ShallowNetֱ��ȡ��֮ǰ����TUH�쳣���ݼ�������[47,48]��ShallowNet������Ϊ��-���ӿ��г������˲����鹫���ռ�ģʽ(FBCSP)�����ܵ��IJ������汾,����һ����һ(�ָ�)������,Ȼ����ƽ�������ԡ�ƽ���ء����������Ժ���������㡣��ʱ�������֮��ʹ�������������ܼ�,����[48]����ʾ,����ϵ�ṹ��TUH�쳣���ݼ��IJ�����������еı��ּ��������ģ��һ���á����,���ǰ�ԭ��ʹ����,����������ά��,����Ҳ�������ΪD=100(��ͼ2-2)����������ܹ�170860����ѵ��������
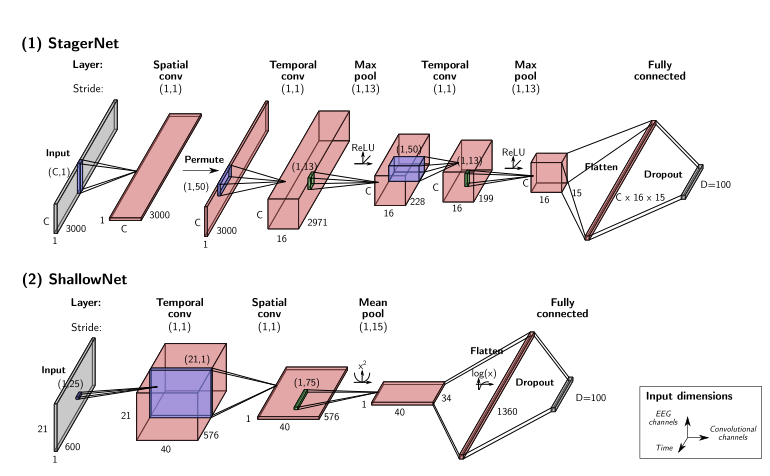
ͼ2 | ������ṹ����(1)˯���Ե�ͼ��(2)�������ʵ���Ƕ����
h
��
h_��
h��?��
����CPC����� g A R g_{AR} gAR?,����ʹ����һ�����ز��СΪ D A R = 100 D_{AR}=100 DAR?=100��GRU,�����������ݼ��ϵ�ʵ�顣
Adam�Ż���[50], �� 1 = 0.9 , �� 2 = 0.999 ��_1=0.9,��_2=0.999 ��1?=0.9,��2?=0.999,ѧϰ��Ϊ 5 �� 1 0 ? 4 5��10^{?4} 5��10?4����CPC����Ϊ32��,�������ģ�͵�batch��С������Ϊ256��ѵ��������150��ʱ��,��ֱ����֤��ʧֹͣ��������10��epoch(��CPC��6��epoch)����50%�����ʶ�ȫ���Ӳ�Ӧ��dropout,�����в�Ŀ�ѵ������Ӧ��0.001��Ȩ��˥�������,����������IJ�������ʹ��uniform He��ʼ�������ʼ����[51]��
2.5 ����(Baseline)
SSL������������������ֻ��߷��������˱Ƚ�:(1)���Ȩ��,(2)�����Զ�������,(3)���ලѧϰ��(4)�ֹ�������
���Ȩ�ػ���ʹ����һ��Ƕ����(embedder),��Ȩ���������ʼ�����ᡣ�Ա�����(AE)��һ�ָ������ı���ѧϰ����,�ɱ������ͽ�������ɵ�������ѧϰ��������֮�������ӳ��,����,���������ʧ[52]��������,����ʹ�� h �� h_�� h��?��Ϊ������,�������һ����������������ת h �� h_�� h��?�IJ��������ලģ��ֱ��������η����������ѵ��,�������Է��ʱ�ǵ����ݡ�Ϊ��,������Ƕ������������һ����������Է����,Ȼ��ʹ�ö��ཻ������ʧ������ģ�ͽ���ѵ����
���,���ǻ����������ֹ������Ĵ�ͳ����ѧϰ���ߡ�
����˯�߷���,������ȡ����������[42]:��ֵ�����ƫ�ȡ���ȡ���ƫ�Ƶ�ʶ������ʴ�(0.5��4.5��8.5��11.5��15.5��30)Hz֮��,�Լ����п��ܵ����ʡ����ֵ����˹��ָ���������غ�Hjorth���Ӷ������ÿ��EEGͨ����37������,��Щ���������ӳ�һ������������˹�α�����´������������е�ȱʧֵ,����ʹ����ѵ�������������ƽ��ֵ��������ʽ����ȱʧֵ��
���ڲ������,��[48]������,ʹ����������������,�ݱ���,�������߿ռ�����ѵ���ķ����Է�������TUH�쳣���ݼ����������ϴﵽ�˸߾��ȡ�����û��ƽ��ÿ����¼��Э�������,�Ա����������ڹ����ķ������й�ƽ�Ƚϡ����,�����Ե��Cͨ��,���������������ά�� C ( C + 1 ) / 2 C(C+1)/2 C(C+1)/2��
������������,ͨ��RP��TS��CPC��AEѧϰ������ʹ��L2������C=1���������ع����з���,���ֹ�������������ʹ�����ɭ�ַ��������з���,�÷���������300����,������Ϊ15��,ÿһ���������������Ϊ F \sqrt F F?(����F��������)��ƽ��ȷ��(bal acc)����Ϊÿ��ƽ��recall,�����������������ģ�����ܡ�����,��ѵ���ڼ�,��ʧ����Ȩ�Խ�������ʧ�⡣ʹ��braindecode[53]��MNE Python[54]��Pytork[55]��pyRiemann[56]��scikit learn[57]��������ģ�ͽ���ѵ�������,���ѧϰģ����1��2��Nvidia Tesla V100 GPU�Ͻ���ѵ��,ʱ��Ӽ����ӵ�7Сʱ����,����ȡ��������������ǰֹͣ��GPU���á�
2.6 ����
ʵ��������������EEG���ݼ��Ͻ���,���1�ͱ�2��ʾ��

2.6.1 Physionet Challenge 2018 dataset
����,������Physionet Challenge 2018(PC18)���ݼ�[1,39]�Ͻ�����˯�߷���ʵ�顣������ݼ��������һ����Դ�����ı����·�����,�þ���ּ�ڼ��˯��¼�еľ���,��ҹ����ݵ�����ʱ�̡���1983��(����)˯�ߺ�����ͣ���߽���ҹ����,���������ǵ�EEG��EOG���°�EMG������������Ѫ�����Ͷȡ��������,����10/20ϵͳ��6��EEGͨ����200 Hz�¼�¼:F3-M2��F4-M1��C3-M2��C4-M1��O1-M2��O2-M1��Ȼ��,7��������ѵ�ļƷ�Ա����AASM�ֲ�[58]����¼������ע�͵�˯�߽�(W��N1��N2��N3��R)������,��¼�л�������9�ֲ�ͬ���͵ľ��Ѻ�4�����͵�˯�ߺ�����ͣ�¼�������˯�߽α�ע���ڴ�Լһ��ļ�¼(�����ڼ�����ѵ����)�Ϲ���,���ǽ������ص������994�ż�¼�ϡ����ⲿ��������,ƽ������Ϊ55��(���18��,���93��),33%�IJ�����ΪŮ�� ��
2.6.2 TUH Abnormal EEG dataset
����ʹ����TUH�쳣�Ե�ͼ���ݼ�V2.0.0(TUHab)�����������Ե�ͼ���ʵ��[40]�������ݼ���[19]��һ���Ӽ�,����2329����ҽԺ�����ٴ��Ե�ͼ���IJ�ͬ���ߵ�2993��15���ӻ����ʱ��ļ�¼��������ϸ��ҽ������,ÿ����¼�����Ϊ��������(1385�μ�¼)���쳣��(998�μ�¼)���������¼�IJ���Ƶ��Ϊ250 Hz(������Щ��¼�IJ���Ƶ��Ϊ256��512 Hz),����27��36���缫������,���Ͽⱻ��Ϊһ��ѵ������һ��������,ÿ��ѵ�������������ֱ���2130�κ�253�μ�¼�����м�¼��ƽ������Ϊ49.3��(��С1��,���96��),53.5%�ļ�¼ΪŮ�Ի��ߡ�
2.6.3 ���ݲ�������
���ǽ�PC18��TUHab�Ŀ��ü�¼��Ϊѵ������֤�Ͳ��Լ�,�Ա�ÿ����¼�е�������������һ������(����3)��
����PC18,����ʹ����60-20-20%������ָ�,����ζ����ѵ������֤�Ͳ��Լ��зֱ���595��199��199�μ�¼������RP��TS,��ÿ�μ�¼�г�ȡ2000�Ի����Դ��ڡ�����CPC,��ÿ����¼����ȡ��batch������Ϊ�ü�¼�д�������0.05��;����,���ǽ�batch��С����Ϊ32��
����TUHab,����ʹ���ṩ����������Ϊ���Լ����������ļ�¼���ֳ�80-20%��ѵ��������֤�������,��������ѵ����֤�Ͳ��Լ���ʹ����2171��543��276�μ�¼������TUHab�ļ�¼�϶�,���������ȡ��400��RP�Ի�TS����̥,������ÿ����¼�е�2000��������ʹ������PC18��ͬ��CPC����������
2.6.4 ����Ԥ����
���������ݼ���EEG��¼Ԥ������ͬ��
��PC18��,����ʹ�ô��к�������30 Hz FIR��ͨ�˲�����ԭʼEEG�����˲�,�Ծܾ���˯�߷��ڲ���Ҫ�ĸ���Ƶ��[42,59]��Ȼ��EEGͨ���²�����100Hz,�Խ����������ݵ�ά��������ͬ����ԭ��,���ǽ������ص����ͨ��F3-M2��F4-M1�ϡ����,��ȡ��СΪ30��(3000 x 2)�ķ��ص����ڡ�
��TUHab��,ʹ������[48]���������Ƶij���ÿ�μ�¼�ĵ�һ���ӽ����ü�,��ɾ��¼�ƿ�ʼʱ���ֵ��������ݡ��������ļ�Ҳ���ü�,����ÿ��¼�����ʹ��20���ӡ�Ȼ��,ѡ��������¼�����е�21��Ƶ��(Fp1��Fp2��F7��F8��F3��Fz��F4��A1��T3��C3��Cz��C4��T4��A2��T5��P3��Pz��P4��T6��O1��O2)����EEGͨ���²�����100 Hz,���ڡ�800��V���ض�,�Լ���ԭʼ�����нϴ�αƫ���Ӱ�졣��ȡ���ص���6-s����,�õ���СΪ600��21�Ĵ��ڡ�
���,�������ݼ��з�ֵ���������1��V�Ĵ��ھ����ܾ������ര�ڰ�ͨ����������,ƽ��ֵ�͵�λ��ƫ��Ϊ�㡣
3 ����
�ܲ�������!!!!���̵�ַ
# ʹ��SSL-Relative Positioning��EEG�źŽ���˯�߷���
# Written By FelicityXu
# 20220226
import os
import numpy as np
import torch
from braindecode import EEGClassifier
from braindecode.datasets import SleepPhysionet, BaseConcatDataset
from braindecode.models import SleepStagerChambon2018
from braindecode.preprocessing import Preprocessor, scale, preprocess, create_windows_from_events
from braindecode.samplers import RelativePositioningSampler
from braindecode.util import set_random_seeds
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import balanced_accuracy_score, confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import scale as standard_scale, StandardScaler
from skorch.callbacks import Checkpoint, EarlyStopping, EpochScoring
from skorch.helper import predefined_split
from torch import nn
#
# import sys
#
# sys.setrecursionlimit(1000000)
from torch.utils.data import DataLoader
random_state = 87
n_jobs = 1
'''
����SleepPhysionet���ݼ�
'''
# crop_wake_mins:Number of minutes of wake time to keep before
# the first sleep event and after the last sleep event.
# Used to reduce the imbalance in this dataset. Default of 30 mins.
dataset = SleepPhysionet(
subject_ids=[0, 1, 2], recording_ids=[1], crop_wake_mins=30)
'''
����Ԥ����
'''
# ������,���Ƕ�ԭʼ���ݽ���Ԥ������
# ���ǽ�����ת��Ϊ����Ӧ�õ�ͨ�˲���������Sleep Physionet�����Ѿ��� 100 Hz ����,���Dz���ҪӦ�����²�����
high_cut_hz = 30
preprocessors = [
Preprocessor(scale, factor=1e6, apply_on_array=True),
Preprocessor('filter', l_freq=None, h_freq=high_cut_hz, n_jobs=n_jobs)
]
# ����Ԥ����
preprocess(dataset, preprocessors)
'''
��ȡ����
������ȡ 30 ��Ĵ��������ڸ�������������
����RP(��һ��� SSL)����Ҫ�������,��˿���ʹ��braindecode.datautil.windower.create_fixed_length_window().
Ȼ��,������,����Ϊ�˷���,����ֱ����ȡ��ǵĴ���,�Ա����ǿ������Ժ��˯�߷ֽ������������������ǡ�
'''
window_size_s = 30
sfreq = 100
window_size_samples = window_size_s * sfreq # �����ж��ٸ�������
mapping = { # We merge stages 3 and 4 following AASM standards.
'Sleep stage W': 0,
'Sleep stage 1': 1,
'Sleep stage 2': 2,
'Sleep stage 3': 3,
'Sleep stage 4': 3,
'Sleep stage R': 4,
}
windows_dataset = create_windows_from_events(
dataset, trial_start_offset_samples=0, trial_stop_offset_samples=0,
window_size_samples=window_size_samples,
window_stride_samples=window_size_samples, preload=True, mapping=mapping
)
# Ԥ�������� z-score��һ��
preprocess(windows_dataset, [Preprocessor(standard_scale, channel_wise=True)])
'''
���ݲ��Ϊѵ��������֤������Լ�
���ǽ���¼��subject����ֳ�ѵ��������֤���Ͳ��Լ���
���ǽ�һ��������һ���µ� Dataset ��,�����Խ���һ��������������Ӧ�Ĵ��ڡ�
�ڶԸ����������ѵ��������ʱ,�⽫�DZ���ġ�
'''
subjects = np.unique(windows_dataset.description['subject']) # ȥ�������е��ظ�����,��������֮�����
subj_train, subj_test = train_test_split(
subjects, test_size=0.4, random_state=random_state)
subj_valid, subj_test = train_test_split(
subjects, test_size=0.5, random_state=random_state)
class RelativePositioningDataset(BaseConcatDataset):
"""BaseConcatDataset with __getitem__ that expects 2 indices and a target.
"""
def __init__(self, list_of_ds):
super().__init__(list_of_ds) # ������������������,���ø����__init__����,��ʵ�������������������
self.return_pair = True
def __getitem__(self, index):
if self.return_pair:
ind1, ind2, y = index
return(super().__getitem__(ind1)[0],
super().__getitem__(ind2)[0]), y
else:
return super().__getitem__(index)
@property # ���η���,��������������һ������
def return_pair(self):
return self.return_pair
@return_pair.setter # @*.setter �����������@propertyװ�εĺ�����ֵ:
def return_pair(self, value):
self._return_pair = value
split_ids = {'train': subj_train, 'valid': subj_valid, 'test': subj_test}
splitted = dict()
for name, values in split_ids.items(): # name:"train" "valid" "test"
splitted[name] = RelativePositioningDataset(
[ds for ds in windows_dataset.datasets
if ds.description['subject'] in values])
'''
����������
������,������Ҫ��������������Щ��������������������ɶԵ�����,��ͨ���Լල��ѵ������֤���ǵ�ģ�͡�
RP ��������������Ҫ�ij�������tau_pos��tau_neg �ֱ� ���ơ������͡����������ĵĴ�С��
��С��tau_pos�����ָ��Ĵ��ڶԽ��������ǩ1,�������� tau_neg�����ָ��Ĵ��ڶԽ��������ǩ0��
������,����ʹ����1����ͬ��ֵ,��` tau_pos`= 1 ���Ӻ�` tau_neg`= 15 ���ӡ�
������������Ҫ�����Ķ���(ʹ�� n_examples����)��
������ֿ��Ժܴ�,�����淶��������ѵ��,����ÿ����¼ 2,000 ��
������,����ÿ�μ�¼ʹ�ý��ٵ� 250 ��������ѵ��ʱ�䡣
'''
tau_pos, tau_neg = int(sfreq * 60), int(sfreq * 15 * 60) # ���������IJ�����Ĵ�С
n_examples_train = 250 * len(splitted['train'].datasets)
n_examples_valid = 250 * len(splitted['valid'].datasets)
n_examples_test = 250 * len(splitted['test'].datasets)
train_sampler = RelativePositioningSampler(
splitted['train'].get_metadata(), tau_pos=tau_pos, tau_neg=tau_neg,
n_examples=n_examples_train, same_rec_neg=True, random_state=random_state)
valid_sampler = RelativePositioningSampler(
splitted['valid'].get_metadata(), tau_pos=tau_pos, tau_neg=tau_neg,
n_examples=n_examples_valid, same_rec_neg=True,
random_state=random_state).presample()
test_sampler = RelativePositioningSampler(
splitted['test'].get_metadata(), tau_pos=tau_pos, tau_neg=tau_neg,
n_examples=n_examples_test, same_rec_neg=True,
random_state=random_state).presample()
'''
�������ѧϰģ�͡�
ʹ��4�н��ܵ�˯�߷ּ��ܹ����İ汾����һ���IJ���������硪����Ϊ���ǵ�Ƕ������
���Ǹı����һ���ά���Ի�� 100 άǶ��,ʹ�� 16 ������ͨ�������� 8 ��,��������ʱ�������֮������������һ����
����ʹ�����涨��� # ContrastiveNet���һ����ģ�Ͱ�װ������ܹ�����ʹ�����ܹ��˵��˵�ѵ��������ȡ����
'''
# device = 'cuda' if torch.cuda.is_available() else 'cpu'
device = 'cpu'
# if device == 'cuda':
# torch.backends.cudnn.benchmark = True
set_random_seeds(seed=random_state, cuda=device == 'cuda')
# Extract number of channels and time steps from dataset
n_channels, input_size_samples = windows_dataset[0][0].shape
emb_size = 100
# ���� Chambon ���� 2018 ��˯�߷��ڼܹ���
emb = SleepStagerChambon2018(
n_channels,
sfreq,
n_classes=emb_size,
n_conv_chs=16,
input_size_s=input_size_samples / sfreq,
dropout=0,
apply_batch_norm=True
)
class ContrastiveNet(nn.Module):
"""Contrastive module with linear layer on top of siamese embedder.
Parameters
----------
emb : nn.Module
Embedder architecture.
emb_size : int
Output size of the embedder.
dropout : float
Dropout rate applied to the linear layer of the contrastive module.
"""
def __init__(self, emb, emb_size, dropout=0.5):
super().__init__()
self.emb = emb
self.clf = nn.Sequential(
nn.Dropout(dropout),
nn.Linear(emb_size, 1)
)
def forward(self, x):
x1, x2 = x
z1, z2 = self.emb(x1), self.emb(x2)
return self.clf(torch.abs(z1 - z2)).flatten()
model = ContrastiveNet(emb, emb_size).to(device)
'''
ѵ��
�������ڿ����ڸ���������ѵ�����ǵ����硣
����ʹ����1�����Ƶij�����,�������� epoch �������������ѧϰ��,�Խ���������Ľ�С���á�
'''
lr = 5e-3
batch_size = 512
n_epochs = 25
num_workers = 0 if n_jobs <= 1 else n_jobs
cp = Checkpoint(dirname='', f_criterion=None, f_optimizer=None, f_history=None)
early_stopping = EarlyStopping(patience=10)
train_acc = EpochScoring(
scoring='accuracy', on_train=True, name='train_acc', lower_is_better=False)
valid_acc = EpochScoring(
scoring='accuracy', on_train=False, name='valid_acc',
lower_is_better=False)
callbacks = [
('cp', cp),
('patience', early_stopping),
('train_acc', train_acc),
('valid_acc', valid_acc)
]
clf = EEGClassifier(
model,
criterion=torch.nn.BCEWithLogitsLoss,
optimizer=torch.optim.Adam,
max_epochs=n_epochs,
iterator_train__shuffle=False,
iterator_train__sampler=train_sampler,
iterator_valid__sampler=valid_sampler,
iterator_train__num_workers=num_workers,
iterator_valid__num_workers=num_workers,
train_split=predefined_split(splitted['valid']),
optimizer__lr=lr,
batch_size=batch_size,
callbacks=callbacks,
device=device
)
# Model training for a specified number of epochs. `y` is None as it is already
# supplied in the dataset.
clf.fit(splitted['train'], y=None)
clf.load_params(checkpoint=cp) # Load the model with the lowest valid_loss
os.remove('./params.pt') # Delete parameters file
'''
ʹ��ѧϰ�ı�ʾ����˯�߷���
�������ڿ���ʹ�þ���ѵ���ľ�����������Ϊ������ȡ����
����ʹ���������ع��������ѧϰ��������ʾ��ִ��˯�߽η��ࡣ
'''
# Extract features with the trained embedder
data = dict()
for name, split in splitted.items():
split.return_pair = False # Return single windows
loader = DataLoader(split, batch_size=batch_size, num_workers=num_workers)
with torch.no_grad():
feats = [emb(batch_x.to(device)).cpu().numpy()
for batch_x, _, _ in loader]
data[name] = (np.concatenate(feats), split.get_metadata()['target'].values)
# Initialize the logistic regression model
log_reg = LogisticRegression(
penalty='l2', C=1.0, class_weight='balanced', solver='lbfgs',
multi_class='multinomial', random_state=random_state)
clf_pipe = make_pipeline(StandardScaler(), log_reg)
# Fit and score the logistic regression
clf_pipe.fit(*data['train'])
train_y_pred = clf_pipe.predict(data['train'][0])
valid_y_pred = clf_pipe.predict(data['valid'][0])
test_y_pred = clf_pipe.predict(data['test'][0])
train_bal_acc = balanced_accuracy_score(data['train'][1], train_y_pred)
valid_bal_acc = balanced_accuracy_score(data['valid'][1], valid_y_pred)
test_bal_acc = balanced_accuracy_score(data['test'][1], test_y_pred)
print('Sleep staging performance with logistic regression:')
print(f'Train bal acc: {train_bal_acc:0.4f}')
print(f'Valid bal acc: {valid_bal_acc:0.4f}')
print(f'Test bal acc: {test_bal_acc:0.4f}')
print('Results on test set:')
print(confusion_matrix(data['test'][1], test_y_pred))
print(classification_report(data['test'][1], test_y_pred))