����������ܽ�
����:Ernest
ȫ�Ľϳ�,�����ղ�
����Ŀ¼
- ����������ܽ�
- @[toc]
- ��һ����:�����
-
- �ڶ�����:Ӧ�ò�(HTTP)
- 1. URL��URI��URN ��������
- 2. HTTP ���������Ӧ����
-
- ��������:�����
-
����Ŀ¼
- ����������ܽ�
- @[toc]
- ��һ����:�����
- �ڶ�����:Ӧ�ò�(HTTP)
- 1. URL��URI��URN ��������
- 2. HTTP ���������Ӧ����
- ��������:�����
��һ����:�����
1. OSI �߲�ģ�͡�TCP/IP �IJ�ģ�͡����Э��
![[����ͼƬng)]](https://img-blog.csdnimg.cn/466eb44546d9424993af583947ad3825.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyo56yUIw==,size_20,color_FFFFFF,t_70,g_se,x_16)
1. �����
1.1. Ӧ�ò�
? �ṩ�û��ӿ�,��ָ�ܹ��������������ij���,����QQ��web�������web�������ȡ����ݵ�λΪ���ġ�
1.2. �����
? �ṩ�������̼���ͨ�����ݴ������,����Ӧ�ò�Э��ܶ�,����ͨ�õ������Э��Ϳ���֧�ֲ��������Ӧ�ò�Э�顣�������Ҫ����:
- �������Э�� TCP,�ṩ�������ӡ��ɿ������ݴ������,���ݵ�λΪ���Ķ�
- �û����ݱ�Э�� UDP,�ṩ�����ӡ������Ŭ�������ݴ������,���ݵ�λΪ�û����ݱ�
- TCP ��Ҫ�ṩ�����Է���,UDP ��Ҫ�ṩ��ʱ�Է���
1.3. �����
? �ṩ���������������ݴ������(�������Ϊ�����еĽ����ṩ����),����������㴫�������ı��Ķλ����û����ݱ���װ�ɷ���(����ѡ�����·���滮 IP ��ַ)��
? ·�����鿴���ݱ�Ŀ�� IP ��ַ,����·�ɱ�Ϊ���ݱ�ѡ��·����·�ɱ��е���Ŀ�����˹�����(��̬·��),Ҳ���Զ�̬����(��̬·��)��
1.4. ������·��
? ��ͬ����������,�������ݵĻ��Ʋ�ͬ,������·����ǽ����ݰ���װ���ܹ��ڲ�ͬ�����紫���֡,�ܹ����в������,��������,����������֡��
- ֡�Ŀ�ʼ�ͽ����������䡢���У��
1.5. ������
? ����������������Ӹ��ּ�����Ĵ���ý���ϴ������ݱ�����,������ָ����Ĵ���ý��,���������Ҫ��������Ϊ:ȷ���봫��ý��ӿڵ�һЩ����,��:
- ��е����:�ӿ���״����С,������Ŀ��
- ��������:��ѹ��Χ��
- ��������:�涨 -5V ��ʾ0,+5V ��ʾ1��
- ��������:Ҳ�й������,�涨��������ʱ������ز����Ĺ�������
2. ISO �߲�ģ���б�ʾ��ͻỰ�㹦����ʲô
- ��ʾ��:����ѹ���������Լ���������,��ʹ��Ӧ�ó��ص����ڸ�̨�����б�ʾ���洢���ڲ���ʽ(�����ơ�ASCII,��������)��ͬ������
- �Ự��:�����Ự,�� session ��֤���ϵ�������ͨ�ŵ�Ӧ�ó���֮�佨����ά�����ͷ������û������ӡ�ͨ�ŵ�Ӧ�ó���֮�佨���Ự,��Ҫ����㽨��1����������
- ˵��:���Э��û�б�ʾ��ͻỰ��,���ǽ���Щ��������Ӧ�ó����ߴ���
3. �����ڸ���֮��Ĵ��ݹ���
? �����µĹ�����,��Ҫ�����²�Э������Ҫ���ײ�����β��,�������ϵĹ����в��ϲ��ײ���β����

- ·����ֻ����ͼ�е���������Э��,��Ϊ·����λ�����������,����ҪΪ���̻���Ӧ�ó����ṩ����,���Ҳ�Ͳ���Ҫ������Ӧ�ò�
- ������ֻ����ͼ�е���������Э��
4. TCP/IP �IJ�ģ��
? TCP/IP ģ��ֻ���IJ�,�൱�����Э���н�������·���������ϲ�Ϊ����ӿڲ㡣
? ���ڵ� TCP/IP ��ϵ�ṹ���ϸ���ѭ OSI �ֲ����,Ӧ�ò���ܻ�ֱ��ʹ�� IP ���������ӿڲ�,����ͼ���� TCP/IP ��ϵ�ṹ����һ�ֱ�ʾ����:
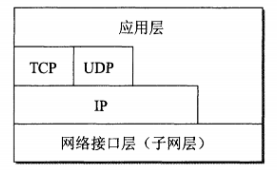
? TCP/IP Э������һ��ɳ©��״,�м�С���ߴ�,IP Э��������ռ������Ҫ�ĵ�λ:

2. TCP ��ͷ��ʽ�� UDP ��ͷ��ʽ
? �����ֻ�ѷ��鷢�͵�Ŀ������,������ͨ�ŵIJ������������������еĽ���,������ṩ�˽��̼����ͨ��,�������߲��û����������������ĺ���ϸ��,ʹӦ�ó����������������������ʵ��֮����һ���˵��˵���ͨ���ŵ���
1. UDP �� TCP ���ص�
- **�û����ݰ�Э�� UDP(User Datagram Protocol):**�������ӵ�,�������ܽ���,û��ӵ������,������(����Ӧ�ó��������ı��IJ��ϲ�Ҳ�����,ֻ������ UDP �ײ�),֧��һ��һ��һ�Զࡢ���һ�Ͷ�Զ�Ľ���ͨ��,����:��Ƶ���䡢ʵʱͨ��
- **�������Э�� TCP(Transmission Control Protocol):**���������ӵ�,�ṩ�ɿ�����,���������ơ�ӵ�����ơ��ṩȫ˫��ͨ��,�����ֽ���(��Ӧ�ò㴫�����ı��Ŀ����ֽ���,���ֽ�����֯�ɴ�С���ȵ����ݿ�),ÿһ�� TCP ����ֻ���ǵ�Ե�(һ��һ)�ġ�
2. UDP �ײ���ʽ

? �ײ��ֶ�ֻ��8�ֽ�,����Դ�˿ڡ�Ŀ�Ķ˿ڡ����ȡ�����͡�12�ֽڵ�α�ײ���Ϊ�˼���������ʱ���ӵġ�
3. TCP �ײ���ʽ

-
**��� seq:**���ڶ��ֽ������б��,�������Ϊ 301,��ʾ��һ���ֽڵı��Ϊ 301,���Я�������ݳ���Ϊ 100 �ֽ�,��ô��һ�����Ķε����ӦΪ 401 ��
-
**ȷ�Ϻ� ack:**�����յ�����һ�����Ķε���š����� B ��ȷ�յ� A ��������һ�����Ķ�,���Ϊ 501,Я�������ݳ���Ϊ 200 �ֽ�,��� B ������һ�����Ķε����Ϊ 701,B ���� A ��ȷ�ϱ��Ķ���ȷ�Ϻž�Ϊ 701��
-
����ƫ��: ָ�������ݲ��־��뱨�Ķ���ʼ����ƫ����,ʵ����ָ�����ײ��ij��ȡ�
-
ȷ�� ACK: �� ACK=1 ʱȷ�Ϻ��ֶ���Ч,������Ч��TCP �涨,�����ӽ��������д��͵ı��Ķζ������ ACK �� 1��
-
ͬ�� SYN: �����ӽ���ʱ����ͬ����š��� SYN=1,ACK=0 ʱ��ʾ����һ�����������ĶΡ����Է�ͬ�⽨������,����Ӧ������ SYN=1,ACK=1��
-
��ֹ FIN: �����ͷ�һ������,�� FIN=1 ʱ,��ʾ�˱��Ķεķ��ͷ��������ѷ������,��Ҫ���ͷ����ӡ�
-
����: ����ֵ��Ϊ���շ��÷��ͷ������䷢�ʹ��ڵ����ݡ�֮����Ҫ���������,����Ϊ���շ������ݻ���ռ������ġ�
3. TCP �����������Ĵλ���
1. ��������

���� A Ϊ�ͻ���,B Ϊ�������ˡ�
- ���� B ���� LISTEN(����)״̬,�ȴ��ͻ�����������
- A �� B �������������Ķ�,SYN=1,ACK=0,ѡ��һ����ʼ����� seq = x��
- B �յ����������Ķ�,���ͬ�⽨������,���� A ��������ȷ�ϱ��Ķ�,SYN=1,ACK=1,ȷ�Ϻ�Ϊ x+1,ͬʱҲѡ��һ����ʼ����� seq = y��
- A �յ� B ������ȷ�ϱ��Ķκ�,��Ҫ�� B ����ȷ��,ȷ�Ϻ�Ϊ ack = y+1,���Ϊ seq = x+1��
- A �� TCP ֪ͨ�ϲ�Ӧ�ý���,�����Ѿ�������
- B �յ� A ��ȷ�Ϻ�,���ӽ�����
- B �� TCP �յ����� A ��ȷ�Ϻ�,Ҳ֪ͨ���ϲ�Ӧ�ý���:TCP �����Ѿ�������
2. Ϊʲô TCP ������Ҫ��������,���β�����,Ϊʲô
? Ϊ�˷�ֹ��ʧЧ�����������Ķ�ͻȻ�ִ��͵��˷����,ռ�÷�������Դ��
? ���ڼٶ�һ���쳣���,�� A(�ͻ���)�����ĵ�һ�����������Ķβ�û�ж�ʧ,������ijЩ����ڵ㳤ʱ��������,�������������ͷ��Ժ��ij��ʱ��ŵ� B(�����)����������һ���Ѿ�ʧЧ�ı��Ķ�,���� B �յ���ʧЧ�����������Ķκ�,����Ϊ A �ַ���һ���µ�����,���Ǿ��� A ����ȷ�ϱ��Ķ�,ͬ�⽨������,�ٶ���������������,��ôֻҪ B ����ȷ��,�µ����Ӿͽ����ˡ�
? �������� A ��û�з����������ӵ�����,��˲������� B ��ȷ��,Ҳ������ B ��������,�� B ��Ϊ�µ����������Ѿ�������,��һֱ�ȴ� A ��������,B ��������Դ���������ˡ�
? �����������ֿ��Է�ֹ��������ķ���,�����ڸղŵ������,A ������ B ��ȷ�Ϸ���ȷ��,B �����ղ���ȷ��,��֪�� A ��û��Ҫ��������,Ҳ�Ͳ����ת�ˡ�
3. �Ĵλ���

? ���ݴ��������,ͨ�ŵ�˫�������ͷ����ӡ����� A ��Ӧ�ý��������� TCP ���������ͷű��Ķ�,��ֹͣ�ٷ�������,�����ر� TCP���ӡ�
- A �������ͷű��Ķ��ײ��� FIN = 1,����� seq = u,�ȴ� B ��ȷ�ϡ�
- B ����ȷ��,ȷ�Ϻ� ack = u+1,��������Ķ��Լ������ seq = v��(TCP ����������֪ͨ�߲�Ӧ�ý���)
- �� A �� B �����������Ӿ��ͷ���,TCP ���Ӵ��ڰ�ر�״̬��A ������ B ��������;B ����������,A ��Ҫ���ա�
- �� B ������Ҫ����ʱ,���������ͷ������Ķ�,FIN=1��
- A �յ���ȷ��,���� TIME-WAIT ״̬,�ȴ� 2 MSL(2*2 = 4 mins)ʱ����ͷ����ӡ�
- B �յ� A ��ȷ�Ϻ��ͷ����ӡ�
4. �Ĵλ��ֵ�ԭ��
? �ͻ��˷����� FIN �����ͷű���֮��,�������յ����������,�ͽ����� CLOSE-WAIT ״̬,���״̬��Ϊ���÷������˷��ͻ�δ������ϵ�����,�������֮��,�������ᷢ�� FIN �����ͷű��ġ�
5. TIME_WAIT
MSL ��Ӣ�ĵ��� Maximum Segment Lifetime ����д,�������������ʱ��,�����κα����������ϴ��ڵ��ʱ��,�������ʱ�䱨�Ľ�������,2MSL = 2*2mins = 4mins.
? �ͻ��˽��յ��������˵� FIN ���ĺ�����״̬,��� B û���յ� A ��������ȷ�ϱ��Ķ�,��ô�ͻ����·��������ͷ������Ķ�,A �ȴ�һ��ʱ�����Ϊ�˴�����������ķ�����
? �ȴ�һ��ʱ����Ϊ���ñ����ӳ���ʱ�����������ĵı��Ķζ�����������ʧ,ʹ����һ���µ����Ӳ�����־ɵ����������ĶΡ�
6. ��α�֤�ɿ�����
- Ӧ�����ݱ�ָ�� TCP ��Ϊ���ʺϷ��͵����ݿ�
- ��ʱ�ش�:�� TCP ����һ���κ�,������һ����ʱ��,�ȴ�Ŀ�Ķ�ȷ���յ�������Ķ�,������ܼ�ʱ�յ�һ��ȷ��,���ط�������Ķ�
- TCP �����͵�ÿһ�������б��,���շ������ݰ���������,���������ݴ���Ӧ�ò�
- У���:TCP ���������ײ������ݵ�У���,����һ���˵��˵ļ����,Ŀ���Ǽ�������ڴ�������е��κα仯,����յ��εļ�����в��,TCP ������������ĶκͲ�ȷ���յ��˱��Ķ�
- TCP �Ľ��ն˻ᶪ���ظ�������
- ��������:TCP ���ӵ�ÿһ�����й̶���С�Ļ���ռ�,TCP �Ľ��ն�ֻ�������Ͷ˷��ͽ��ն˻������ܽ��ɵ�����,�����շ��������������ͷ�������,����ʾ���ͷ����ͷ��͵�����,��ֹ����ʧ��TCP ʹ�õ���������Э���ǿɱ��С�Ļ�������Э��
- ӵ������:������ӵ��ʱ,�������ݵķ���
7. TCP ����״̬
- CLOSED:��ʼ״̬��
- LISTEN:���������ڼ���״̬��
- SYN_SEND:�ͻ���socketִ��CONNECT����,����SYN��,�����״̬��
- SYN_RECV:������յ�SYN�������ͷ����SYN��,�����״̬��
- ESTABLISH:��ʾ���ӽ������ͻ��˷��������һ��ACK��������״̬,����˽��յ�ACK��������״̬��
- FIN_WAIT_1:��ֹ���ӵ�һ��(ͨ���ǿͻ���)������FIN���ĺ���롣�ȴ��Է�FIN��
- CLOSE_WAIT:(���������)���յ��ͻ���FIN��֮��ȴ��رյĽΡ��ڽ��յ��Է���FIN��֮��,��Ȼ����Ҫ�����ظ�ACK����,��ʾ�Ѿ�֪���Ͽ������DZ����Ƿ������Ͽ�����(����FIN��)ȡ�����Ƿ���������Ҫ�����ͻ���,����,���ڷ���FIN��֮ǰ��Ϊ��״̬��
- FIN_WAIT_2:��ʱ�ǰ�����״̬,����һ��Ҫ��ر�����,�ȴ���һ���رա��ͻ��˽��յ���������ACK��,����û���������յ�����˵�FIN��,����FIN_WAIT_2״̬��
- LAST_ACK:����˷�������FIN��,�ȴ����Ŀͻ���ACK��Ӧ,�����״̬��
- TIME_WAIT:�ͻ����յ�����˵�FIN��,����������ACK��������ȷ��,�ڴ�֮���2MSLʱ���ΪTIME_WAIT״̬��
8. TCP �� HTTP

4. TCP ����������ϵ���ô��(TCP ����)
? ��TCP����A��B���������Ӻ�,���һ�˰ε������߰ε���Դ,��ô��һ���ܹ��յ�֪ͨ��?
? ���Dz�����
ԭ�����
? TCP ��һ�������ӵ�Э��,������Ӳ�����˵��һ��ʵ�ʵĵ�·,����һ������ġ����ϵ����ӡ�TCP �������ӺͶϿ����Ӷ���ͨ����������ʵ�ֵ�,Ҳ��������˵���������֡��Ĵλ���,TCP ���˸��Ա�����һ�����ݵ�״̬,������������,TCP ����֮���·���豸ֻ�ǽ�����ת����Ŀ�ĵ�,����֪����Щ���ݴ���ʲô����,Ҳ�������������ı����κ�״̬��Ϣ,Ҳ����˵��Ϊ�м����·���豸������û�� �����ӡ� �������,ֻ�ǽ�����ת����Ŀ�ĵ�,ֻ�����ݵķ����ߺͽ�������������֪����������ݴ���һ�� ���ϵ����� ��
? ���˵����һ��,�������������,��ô�����Ͽ����������� ,��������µ� TCP ��һ�� A ������ socket�� close ���߽��̽���,����ϵͳ�ͻᰴ�� TCP Э�鷢�� FIN���ݱ���,B ���յ���ͻ�Ͽ�����,���ǵ����ֶϵ���߰������������ʱ,B �������յ��Ͽ����ӵ������,���� ���ӻ�һֱ����,����ʵ���� A �Ѿ������� ,���������·���豸��,��������֪����ʱ A �Ѿ�������,�������Dz���֪�� �����ӡ� �Ĵ���,Ҳ�Ͳ�������ν��֪ͨ B �ˡ�
�������
? ֻ��Ҫ�����ӵ�˫��ʱ��ȥ�������һ��״̬�Ϳ���,���ķ����ܼ�,ֻҪ�� B ������ͨ����������� A �˼����������ݼ��� ,�������ݵĹ�����,·�����϶��᷵�ظ� B һ��Ŀ�IJ��ɴ���Ϣ,��ʱ B ��֪�������Ѿ��Ͽ���,���ֱ���ʱ�̼��ķ����ͽ� TCP ����,�� KEEP_ALIVE ��
? TCPЭ�鱾�����ṩ��һ�������Ļ�����̽��Զ˵Ĵ�TCPЭ����һ��KEEP_LIVE����,ֻҪ��������ؾͻᶨʱ����һЩ���ݳ���Ϊ���̽��������,���͵�Ƶ�ʺʹ�������������,����ķ�������������tcp keepalive����,�����кܶ�����,���ﲻ������
Ӧ�ò�����
? ����ʹ�� TCP �����ı���ػ���,��������Ӧ�ò����������������ݰ�,����ߵ���������:
- Ӧ�ò���������ݰ���ռ�ø���Ĵ���,��Ϊ TCP Э��ı�����Ʒ��͵������ݳ���Ϊ0���������ݰ�,��Ӧ�ò㷢�͵��������ݰ����ݳ��ȱ�Ȼ����0
- Ӧ�ò���������ݰ�����Я��һЩ����,���ɳ���Ա����,�� TCP Э��ı�����������Ӧ�ò���,��Я������
? Ҫע�����,��������һ����˫������,�����˶��ᷢ����̽�������ݰ�,�����ʧȥ�����塣
5. TCP �� UDP ������,��θĽ� TCP
��������
- UDP �������ӵ�,��������֮ǰ����Ҫ��������,�� TCP ���������ӵ������Э��
- UDP ʹ�þ����Ŭ������,������֤�ɿ�����,ͬʱҲ��ʹ��ӵ������,�� TCP ���ṩ�ɿ������,��ӵ������
- UDP �������ĵ�,û��ӵ������,�ʺ϶�ý��ͨ�ŵ�����,�� TCP �������ֽ�����,�ṩȫ˫��ͨ��
- UDP ֧��һ��һ��һ�Զࡢ���һ����Զ�ͨ��,TCP ����ֻ���������˵�,��һ��һ
- UDP �ײ�����С,ֻ�� 8 �ֽ�,TCP �ײ���Ͷ��� 20 �ֽ�
6. TCP ��������

? �����ǻ����һ����,������ʱ����ֽ��������ͷ��ͽ��շ�����һ������,���շ�ͨ�� TCP ���Ķ��еĴ����ֶθ��߷��ͷ��Լ��Ĵ��ڴ�С,���ͷ��������ֵ��������Ϣ�����Լ��Ĵ��ڴ�С��
? ���ʹ����ڵ��ֽڶ�����������,���մ����ڵ��ֽڶ����������ա�������ʹ������ֽ��Ѿ����Ͳ����յ���ȷ��,��ô�ͽ����ʹ������һ���һ������,ֱ����һ���ֽڲ����ѷ��Ͳ�����ȷ�ϵ�״̬;���մ��ڵĻ�������,���մ������ֽ��Ѿ�����ȷ�ϲ���������,�����һ������մ��ڡ�
? ���մ���ֻ��Դ��������һ��������ֽڽ���ȷ��,������մ����Ѿ��յ����ֽ�Ϊ {31, 34, 35},���� {31} ����,�� {32, 33} �Ͳ���,���ֻ���ֽ� 31 ����ȷ�ϡ����ͷ��õ�һ���ֽڵ�ȷ��֮��,��֪������ֽ�֮ǰ�������ֽڶ��Ѿ������ա�
���½��л�������ģ��
? �� TCP ��,����������Ϊ��ʵ����������������Է��������ݹ���,���շ�������������,���շ�����Ҫͨ��Է�,�������ݵķ��͡�

- ���ͷ����յ��˶Է������ı��� ack = 33, win = 10,֪���Է��յ��� 33 ��ǰ������,������������ [33, 43) �����ݡ����ͷ����������� 4 �����Ķμ���Ϊ A, B, C, D, �ֱ�Я�� [33, 35), [35, 36), [36, 38), [38, 41) �����ݡ�
- ���շ����յ��˱��Ķ� A, C,����û�յ� B �� D,Ҳ����ֻ�յ��� [33, 35) �� [36, 38) �����ݡ����շ����ͻضԱ��Ķ� A ��ȷ��:ack = 35, win = 10��
- ���ͷ��յ��� ack = 35, win = 10,�Է��������� [35, 45) �����ݡ����ŷ�����һ�����Ķ� E,��Я���� [41, 44) �����ݡ�
- ���շ����յ��˱��Ķ� B: [35, 36), D:[38, 41),���շ����Ͷ� D ��ȷ��:ack = 41, win = 10. (����һ���ۻ�ȷ��)
- ���ͷ��յ��� ack = 41, win = 10,�Է��������� [41, 51) �����ݡ�
- ����
- ��Ҫע�����,���շ����� tcp ���ĵ�˳���Dz�ȷ����,������һ�����յ� 35 ���յ� 36,Ҳ���������յ� 36,37,���յ� 35.
7. TCP ��������
? ����������Ϊ�˿��Ʒ��ͷ��ķ�������,������շ����ü�����,���շ����͵�ȷ�ϱ����д����ֶο����������Ʒ��ͷ����ڵĴ�С,�Ӷ�Ӱ�췢�ͷ��ķ�������,�������ֶ�����Ϊ0,���ͷ����ܷ������ݡ�
8. TCP ӵ������
ӵ�����Ƶ�һ��ԭ��
- ��ij��ʱ��,����������ij��Դ�������˸���Դ�����ṩ�Ŀ��ò���,��������ܾ�Ҫ�仵��������ӵ��(congestion)��
- ������Դӵ��������:����Դ������ܺ� > ������Դ
- ����������������Դͬʱ����ӵ��,��������ܾ�Ҫ���Ա仵,����������������������븺�ɵ�������½���
? ����������ӵ��,���齫�ᶪʧ,��ʱ���ͷ�������ش�,�Ӷ���������ӵ���̶ȸ��ߡ���˵�����ӵ��ʱ,Ӧ�����Ʒ��ͷ������ʡ���һ����������ƺ���,���dz����㲻ͬ������������Ϊ���ý��շ������ü�����,��ӵ��������Ϊ�˽������������ӵ���̶ȡ�

? TCP ��Ҫͨ�������㷨������ӵ������:����ʼ��ӵ�����⡢���ش�����ָ���
? ���ͷ���Ҫά��һ������ӵ������(cwnd)��״̬����,ע��ӵ�������뷢�ͷ����ڵ�����:ӵ������ֻ��һ��״̬����,ʵ�ʾ������ͷ��ܷ��Ͷ������ݵ��Ƿ��ͷ����ڡ�
? Ϊ�˱�������,�����¼���:
- ���շ����㹻��Ľ��ջ���,��˲��ᷢ����������;
- ��Ȼ TCP �Ĵ��ڻ����ֽ�,���������贰�ڵĴ�С��λΪ���ĶΡ�

1. ����ʼ��ӵ������
���͵����ִ������ʼ,�� cwnd=1,���ͷ�ֻ�ܷ��� 1 �����Ķ�;���յ�ȷ�Ϻ�,�� cwnd �ӱ�,���֮���ͷ��ܹ����͵ı��Ķ�����Ϊ:2��4��8 ��
ע�����ʼÿ���ִζ��� cwnd �ӱ�,�������� cwnd �����ٶȷdz���,�Ӷ�ʹ�÷��ͷ����͵��ٶ������ٶȹ���,����ӵ���Ŀ���Ҳ���ߡ�����һ����������ֵ ssthresh,�� cwnd >= ssthresh ʱ,����ӵ������,ÿ���ִ�ֻ�� cwnd �� 1��
��������˳�ʱ,���� ssthresh = cwnd/2,Ȼ������ִ������ʼ��
2. ���ش����ָ�
�ڽ��շ�,Ҫ��ÿ�ν��յ����Ķζ�Ӧ�ö����һ�����յ��������Ķν���ȷ�ϡ������Ѿ����յ� M1 �� M2,��ʱ�յ� M4,Ӧ�����Ͷ� M2 ��ȷ�ϡ�
�ڷ��ͷ�,����յ������ظ�ȷ��,��ô����֪����һ�����Ķζ�ʧ,��ʱִ�п��ش�,�����ش���һ�����ĶΡ������յ����� M2,�� M3 ��ʧ,�����ش� M3��
�����������,ֻ�Ƕ�ʧ�����Ķ�,����������ӵ�������ִ�п�ָ�,�� ssthresh = cwnd/2 ,cwnd = ssthresh,ע���ʱֱ�ӽ���ӵ�����⡣����ʼ�Ϳ�ָ��Ŀ���ָ���� cwnd ���趨ֵ,������ cwnd ���������ʡ�����ʼ cwnd �趨Ϊ 1,����ָ� cwnd �趨Ϊ ssthresh��

3. ���ʹ��ڵ�����ֵ
���ͷ��ķ��ʹ��ڵ�����ֵӦ��ȡΪ���շ����� rwnd ��ӵ������ cwnd �����������н�С��һ��,��Ӧ�����¹�ʽȷ��:
- ���ʹ��ڵ�����ֵ = Min {rwnd, cwnd}
- �� rwnd < cwnd ʱ,�ǽ��շ��Ľ����������Ʒ��ʹ��ڵ����ֵ��
- �� cwnd < rwnd ʱ,���������ӵ�����Ʒ��ʹ��ڵ����ֵ��
9. ��������������ӵ������
- ӵ��������Ҫ���Ķ���һ��ǰ��,���������ܹ��������е����縺��
- ӵ��������һ��ȫ���ԵĹ���,�漰�����е�������·����,�Լ��뽵�����紫�������йص���������
- ������������ָ�ڸ����ķ��Ͷ˺ͽ��ն�֮��ĵ�Ե�ͨ�����Ŀ���
- ����������Ҫ���ľ������Ʒ��Ͷ˷������ݵ�����,�Ա�ʹ���ն����ü�����
- ������������ͨ��˫��Э��,ӵ�������漰ͨ����·ȫ��
- ����������Ҫͨ��˫����ά��һ�����͡����մ���,������һ��,���մ���С����������,���ʹ���С�ɽ��շ���Ӧ��TCP���Ķ��д���ֵȷ��;ӵ�����Ƶ�ӵ�����ڴ�С�仯����̽�Է���һ������������̽������״���������Ӧ������
- ʵ�����շ��ʹ��� = min {�������Ʒ��ʹ���,ӵ������}
10. ���� RTO,RTT �ͳ�ʱ�ش�
- ��ʱ�ش�: ���Ͷ˷��ͱ��ĺ�����ʱ��δ�յ�ȷ�ϵı���,����Ҫ�ط��ñ���,�����¼������:
- ���͵�����û������ն�,���ԶԷ�û��Ӧ
- ���ն��ܵ�����,���� ACK �����ڷ��ع����ж�ʧ
- ���ն˾ܾ���������
- RTO: ����һ�η�������,��Ϊ����û�н��յ� ACK ��Ӧ,����һ���ط�֮���ʱ��,�����ش����
- ͨ��ÿ���ش� RTO ��ǰһ���ش����������,������λͨ���� RTT,���� 1RTT,2RTT,4RTT����
- �ش�������������֮��ֹͣ�ش�
- RTT: ���ݱ��ӷ��ͳ�ȥ�����յ��Է���Ӧ,���м��ʱ����,�����ݱ���������һ��������ʱ,��С���ȶ�
11. ��������ַ�����ҳ��������������
-
��ѯ DNS
- ��������������� DNS ����
- ��������ϵͳ�� DNS ����,���� host �ļ���ѯ
- ��� DNS �����������ǵ�������ͬһ��������,ϵͳ�ᰴ�� ARP ���̶� DNS ���������� ARP ��ѯ
- ��� DNS �����������ǵ���������ͬһ������,ϵͳ�ᰴ�� ARP ���̶�Ĭ�����ؽ��в�ѯ
-
��������������Ӧ�� IP ��ַ��,���� HTTP ����������
-
TCP/IP ���ӽ�����,������Ϳ�������������� HTTP ������
-
TLS ����
- �ͻ��˷���һ��
ClientHello��Ϣ����������,��Ϣ��ͬʱ���������� TLS �汾�����õļ����㷨��ѹ���㷨 - ����������ͻ��˷���һ��
ServerHello��Ϣ,��Ϣ�а����˷������˵� TLS �汾����������ѡ��ļ��ܺ�ѹ���㷨,�Լ�������֤����(CA)ǩ���ķ���������֤��,�����а�����Կ,�ͻ��˻�ʹ�������Կ���ܽ����������ֹ���,ֱ��Э������һ���µĶԳ���Կ - �ͻ��˸����Լ������� CA �б�,��֤�������˵�֤���Ƿ����,�������,����һ��α�����,ʹ�÷������Ĺ�Կ������,�������������������µĶԳ���Կ
- ��������ʹ���Լ���˽Կ������������,Ȼ��ʹ�������������Լ��ĶԳ�����Կ
- �ͻ��˷���һ��
Finished��Ϣ����������,ʹ�öԳ���Կ�������ͨѶ��һ��ɢ��ֵ - �������������Լ���
hashֵ,Ȼ����ܿͻ��˷�������Ϣ,���������ֵ�Ƿ��Ӧ,�����Ӧ,����ͻ��˷���һ��Finished��Ϣ,Ҳʹ��Э�̺õĶԳ���Կ - �����ڿ�ʼ,���������� TLS �Ự��ʹ�öԳ���Կ���м���,����Ӧ�ò�(�� HTTP)������
- �ͻ��˷���һ��
-
HTTP ������������
HTTPD(HTTP Daemon)�ڷ������˴�������/��Ӧ,����� HTTPD �� Linux �ϳ��õ� Apache �� Nginx,�Լ� Windows �ϵ� IIS��
-
HTTPD ��������
-
��������������Ϊ���¼�������
HTTP ����(
GET,POST,HEAD,PUT,DELETE,CONNECT,OPTIONS, ����TRACE)��ֱ���ڵ�ַ�������� URL ���������,ʹ�õ��� GET ��������:google.com����·��/ҳ��:/ (����û������google.com�µ�ָ����ҳ��,��� / ��Ĭ�ϵ�·��) -
��������֤�����Ѿ������� google.com ����������
-
��������֤ google.com ���� GET ����
-
��������֤���û�����ʹ�� GET ����(���� IP ��ַ,������Ϣ��)
-
�����������װ�� URL ��дģ��(���� Apache �� mod_rewrite),�������᳢��ƥ����д����,���ƥ��ɹ��Ļ�����д����
-
����������������Ϣ��ȡ��Ӧ����Ӧ����,������������ڷ���·���� ��/�� ,�������ҳ�ļ�
-
��������ʹ��ָ���Ĵ������������������ļ�,�������������ظ�������
-
-
���������յ��������,����·������,������˵�һЩ�������� HTML ҳ����뷵�ظ������
-
������õ������� HTML ���뿪ʼ������Ⱦ,������������ⲿ�� .js .css ����Դ,ͬ��Ҳ��һ������ HTTP ����,�ظ��������
-
����������õ�����Դ��ҳ�������Ⱦ,���հ�һ��������ҳ����ָ��û�
��ϸ�汾�뿴:what-happens-when-zh_CN
�ڶ�����:Ӧ�ò�(HTTP)
1. URL��URI��URN ��������
- URI:Uniform Resource Identifier,ͳһ��Դ��ʶ��,�� web ��������Դ������,����:index.html index.js
- URL:Uniform Resource Locator,ͳһ��Դ��λ��,����������
- URN:Uniform Resource Name,ͳһ��Դ����,����:urn:isbn:0-486
URI ���� URL �� URN,Ŀǰ web ֻ�� URL �Ƚ�����,�����Ļ������� URL��
2. HTTP ���������Ӧ����
1. ������


2. ��Ӧ����



3. HTTP ״̬
���������ص� ��Ӧ���� �е�һ��Ϊ״̬��,������״̬���Լ�ԭ�����,������֪�ͻ�������Ľ����
| ״̬�� | ��� | ԭ����� |
|---|---|---|
| 1XX | Informational(��Ϣ��״̬��) | ���յ��������ڴ��� |
| 2XX | Success(�ɹ�״̬��) | ��������������� |
| 3XX | Redirection(�ض���״̬��) | ��Ҫ���и��Ӳ������������ |
| 4XX | Client Error(�ͻ��˴���״̬��) | ���������������� |
| 5XX | Server Error(����������״̬��) | ����������������� |
1XX ��Ϣ
- 100 Continue :������ĿǰΪֹ��������,�ͻ��˿��Լ�������������ߺ��������Ӧ��
2XX �ɹ�
- 200 OK
- 204 No Content :�����Ѿ��ɹ�����,���Ƿ��ص���Ӧ���IJ�����ʵ������岿�֡�һ����ֻ��Ҫ�ӿͻ�����������������Ϣ,������Ҫ��������ʱʹ�á�
- 206 Partial Content :��ʾ�ͻ��˽����˷�Χ������Ӧ���İ����� Content-Range ָ����Χ��ʵ�����ݡ�
3XX �ض���
- 301 Moved Permanently :�������ض���
- 302 Found :��ʱ���ض���
- 303 See Other :�� 302 ������ͬ�Ĺ���,���� 303 ��ȷҪ��ͻ���Ӧ�ò��� GET ������ȡ��Դ��
- ע:��Ȼ HTTP Э��涨 301��302 ״̬���ض���ʱ�������� POST �����ij� GET ����,���Ǵ��������������� 301��302 �� 303 ״̬�µ��ض���� POST �����ij� GET ������
- 304 Not Modified :����������ײ�����һЩ����,����:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,�������������,��������᷵�� 304 ״̬�롣
- 307 Temporary Redirect :��ʱ�ض���,�� 302 �ĺ�������,���� 307 Ҫ�������������ض�������� POST �����ij� GET ������
4XX �ͻ��˴���
- 400 Bad Request :��������������
- 401 Unauthorized :��״̬���ʾ���͵�������Ҫ����֤��Ϣ(BASIC ��֤��DIGEST ��֤)�����֮ǰ�ѽ��й�һ������,���ʾ�û���֤ʧ�ܡ�
- 403 Forbidden :���ܾ�,��������û�б�Ҫ�����ܾ�����ϸ���ɡ�
- 404 Not Found
5XX ����������
- 500 Internal Server Error :����������ִ������ʱ��������
- 503 Service Unavailable :��������ʱ���ڳ����ػ����ڽ���ͣ��ά��,��������������
4. HTTP ����
? �ͻ��˷��͵� ������ ��һ��Ϊ������,�����˷����ֶΡ�
(1)GET
��ȡ��Դ
? ��ǰ����������,����ʹ�õ��� GET ������
(2)HEAD
��ȡ�����ײ�
? �� GET ����һ��,���Dz����ر���ʵ�����岿�֡�
? ��Ҫ����ȷ�� URL ����Ч���Լ���Դ���µ�����ʱ��ȡ�
(3)POST
����ʵ������
? POST ��Ҫ������������,�� GET ��Ҫ������ȡ��Դ��
? ���� POST �� GET �ıȽ�����ڰ��¡�
(4)PUT
�ϴ��ļ�
? ��������������֤����,�κ��˶������ϴ��ļ�,��˴��ڰ�ȫ������,һ�㲻ʹ�ø÷�����
PUT /new.html HTTP/1.1
Host: example.com
Content-type: text/html
Content-length: 16
<p>New File</p>
(5)PATCH
����Դ���в�����
? PUT Ҳ������������Դ,����ֻ����ȫ���ԭʼ��Դ,PATCH ���������ġ�
PATCH /file.txt HTTP/1.1
Host: www.example.com
Content-Type: application/example
If-Match: "e0023aa4e"
Content-Length: 100
[description of changes]
(6)DELETE
ɾ���ļ�
? �� PUT �����෴,����ͬ��������֤���ơ�
DELETE /file.html HTTP/1.1
(7)OPTIONS
��ѯ֧�ֵķ���
? ��ѯָ���� URL �ܹ�֧�ֵķ�����
? �᷵�� Allow: GET, POST, HEAD, OPTIONS ���������ݡ�
(8)CONNECT
Ҫ���������������ͨ��ʱ��������
? ʹ�� SSL(Secure Sockets Layer,��ȫ�Ӳ�)�� TLS(Transport Layer Security,����㰲ȫ)Э���ͨ�����ݼ��ܺ������������䡣
CONNECT www.example.com:443 HTTP/1.1

(9)TRACE
��·��
? �������Ὣͨ��·�����ظ��ͻ��ˡ�
? ��������ʱ,�� Max-Forwards �ײ��ֶ���������ֵ,ÿ����һ���������ͻ�� 1,����ֵΪ 0 ʱ��ֹͣ���䡣
? ͨ������ʹ�� TRACE,�����������ܵ� XST ����(Cross-Site Tracing,��վ��)��
5. GET �� POST ������
- GET ��������ǿ��֧��
- ������� URL ����������,���� GET �����ܴ��� POST �����ʹ�������
- GET ���������ݸ�С
- GET �����Dz���ȫ��
- GET �������ݵȵ�,��ζ�Ŷ�ͬһ URL �Ķ������Ӧ�÷���ͬ���Ľ��
- POST �����ܱ�����
- POST ������� GET �����ǰ�ȫ��,�����ȫ����ָ���Ƿ�����Ϣ
- GET ������Ϣ��ȡ,���Ұ�ȫ�ĺ����ݵȵ�,��ν��ȫ����ζ�Ÿò������ڻ�ȡ��Ϣ��������Ϣ,���仰˵,GET ����һ�㲻Ӧ����������,����˵,�������ǻ�ȡ��Դ��Ϣ,�������ݿ�IJ�ѯһ��,�����ġ���������,����Ӱ����Դ��״̬
- POST �����ķ������ϵ���Դ������
- ���Ͱ���δ֪�ַ����û�����ʱ,POST �� GET ���ȶ�Ҳ���ɿ�
����һ��,�ӱ����Ͽ������ߵ�����
- GET�Ǵӷ������ϻ�ȡ����,POST����������������ݡ� GET�� POSTֻ��һ�ִ������ݵķ�ʽ,GETҲ�������ݴ���������,���ǵı��ʶ��Ƿ�������ͽ��ս����ֻ����֯��ʽ�������������в��,httpЭ�������н���
- GET�ǰѲ������ݶ��мӵ��ύ������ACTION������ָ��URL��,ֵ�ͱ����ڸ����ֶ�һһ��Ӧ,��URL�п��Կ�����POST��ͨ��HTTP POST����,�������ڸ����ֶ��������ݷ�����HTML HEADER��һ���͵�ACTION������ָ��URL��ַ���û�������������̡� ��ΪGET��Ƴɴ���С����,��������Dz��ķ�����������,���������һ�㶼�ڵ�ַ��������Կ���,��POSTһ�㶼�������ݴ�����,��Ƚ���˽������,�����ڵ�ַ��������,�ܲ��ܿ�������Э��涨,��������涨�ġ�
- ����GET��ʽ,����������Request.QueryString��ȡ������ֵ,����POST��ʽ,����������Request.Form��ȡ�ύ�����ݡ� û����,��ô��ñ�������ķ������й�,��GET��POST��,������������Щ�������˷�װ
- GET���͵���������С,���ܴ���2KB��POST���͵��������ϴ�,һ�㱻Ĭ��Ϊ�������ơ���������,IIS4�������Ϊ80KB,IIS5��Ϊ100KB�� POST����û������,�����Ҷ��ϴ����ļ�,������POST��ʽ�ġ�ֻ����Ҫ��form������Ǹ�type����
- GET��ȫ�Էdz���,POST��ȫ�Խϸߡ� ���û�м���,���ǰ�ȫ������һ����,���һ�����������������е����ݼ�������
6. ������� HTTP Э������״̬��
? HTTPЭ������״̬��(stateless),ָ����Э�����������û�м�������,��������֪���ͻ�����ʲô״̬��Ҳ����˵,��һ���������ϵ���ҳ����һ�δ�����������ϵ���ҳ֮��û���κ���ϵ��HTTP��һ����״̬���������ӵ�Э��,��״̬������HTTP���ܱ���TCP����,�����ܴ���HTTPʹ�õ���UDPЭ��(������)��
? ȱ��״̬��ζ���������������Ҫǰ�����Ϣ,���������ش�,�������ܵ���ÿ�����Ӵ��͵�������������һ����,�ڷ���������Ҫ��ǰ��Ϣʱ����Ӧ��ͽϿ졣
7. ʲô�Ƕ����Ӻͳ�����
? �� HTTP/1.0 ��Ĭ��ʹ�ö�����,Ҳ����˵�ͻ��˺ͷ�����ÿ����һ�� HTTP ����,�ͽ���һ������,����������ж����ӡ����ͻ�����������ʵ�ij�� HTML ���������͵� WEB ҳ���а�����������Դ(���� JS �ļ���ͼ���ļ���CSS �ļ�),ÿ��������һ�� WEB ��Դ,������ͻ����½���һ�� HTTP �Ự��
? ���� HTTP/1.1 ��,Ĭ��ʹ�ó�����,����Ӧͷ����һ�д���:Connection:keep-alive ,��ʹ�ó����ӵ������,һ����ҳ��ͻ��˺ͷ�����֮�����ڴ��� HTTP ���ݵ� TCP ���Ӳ����,���Ҳ��������˵�� tcp ����,��Ϊ HTTP Э��ij�������ʵ���Ͼ��� TCP Э��ij������ӡ�
8. Cookie
? HTTP Э������״̬��,��Ҫ��Ϊ���� HTTP Э�龡���ܼ�,ʹ�����ܹ�������������HTTP/1.1 ���� Cookie ������״̬��Ϣ��
? Cookie �Ƿ��������͵��û�������������ڱ��ص�һС������,������������´���ͬһ�������ٷ�������ʱ��Я�������͵��������ϡ������ڸ�֪��������������Ƿ�����ͬһ�����,�������û��ĵ�¼״̬��
1. ��;
- �Ự״̬����(���û���¼״̬�����ﳵ����Ϸ������������Ҫ��¼����Ϣ)
- ���Ի�����(���û��Զ������á������)
- �������Ϊ����(����ٷ����û���Ϊ��)
? Cookie ��һ�����ڿͻ������ݵĴ洢,��Ϊ��ʱ��û���������ʵĴ洢�취����ΪΨһ�Ĵ洢�ֶ�,�����������ִ��������ʼ֧�ָ��ָ����Ĵ洢��ʽ,Cookie ��������̭�����ڷ�����ָ�� Cookie ��,�������ÿ������Я�� Cookie ����,�������������ܿ���(���������ƶ�������)���µ������ API �Ѿ�����������ֱ�ӽ����ݴ洢������,��ʹ�� Web storage API (���ش洢�ͻỰ�洢)�� IndexedDB��
2. ��������
���������͵���Ӧ���İ��� Set-Cookie �ײ��ֶ�,�ͻ��˵õ���Ӧ���ĺ�� Cookie ���ݱ��浽������С�
HTTP/1.0 200 OK
Content-type: text/html
Set-Cookie: yummy_cookie=choco
Set-Cookie: tasty_cookie=strawberry
[page content]
�ͻ���֮���ͬһ����������������ʱ,���������ж��� Cookie ��Ϣͨ�� Cookie �����ײ��ֶη�����������
GET /sample_page.html HTTP/1.1
Host: www.example.org
Cookie: yummy_cookie=choco; tasty_cookie=strawberry
3. ����
- �Ự�� Cookie:������ر�֮�����ᱻ�Զ�ɾ��,Ҳ����˵�����ڻỰ������Ч��
- �־��� Cookie:ָ��һ���ض��Ĺ���ʱ��(Expires)����Ч��(max-age)֮��ͳ�Ϊ�˳־��Ե� Cookie��
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2021 07:28:00 GMT;
4. �� JavaScript ��ȡ Cookie
? ͨ�� Document.cookie ���Կɴ����µ� Cookie,Ҳ��ͨ�������Է��ʷ� HttpOnly ��ǵ� Cookie��
document.cookie = "yummy_cookie=choco";
document.cookie = "tasty_cookie=strawberry";
console.log(document.cookie);
5. Secure �� HttpOnly
? ���Ϊ Secure �� Cookie ֻӦͨ���� HTTPS Э����ܹ�������������ˡ������������� Secure ���,������ϢҲ��Ӧ��ͨ�� Cookie ����,��Ϊ Cookie ������еIJ���ȫ��,Secure ���Ҳ���ṩȷʵ�İ�ȫ���ϡ�
? ���Ϊ HttpOnly �� Cookie ���ܱ� JavaScript �ű����á���Ϊ����ű� (XSS) ��������ʹ�� JavaScript �� Document.cookieAPI ��ȡ�û��� Cookie ��Ϣ,���ʹ�� HttpOnly ��ǿ�����һ���̶��ϱ��� XSS ������
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
6. ������
? Domain ��ʶָ������Щ�������Խ��� Cookie�������ָ��,Ĭ��Ϊ��ǰ�ĵ�������(������������)�����ָ���� Domain,��һ�����������������,������� Domain=mozilla.org,�� Cookie Ҳ��������������(�� developer.mozilla.org)��
? Path ��ʶָ���������µ���Щ·�����Խ��� Cookie(�� URL ·��������������� URL ��)�����ַ� %x2F ("/") ��Ϊ·���ָ���,��·��Ҳ�ᱻƥ�䡣����,���� Path=/docs,�����µ�ַ����ƥ��:
- /docs
- /docs/Web/
- /docs/Web/HTTP
9. Session
? ���˿��Խ��û���Ϣͨ�� Cookie �洢���û��������,Ҳ�������� Session �洢�ڷ�������,�洢�ڷ������˵���Ϣ���Ӱ�ȫ��
? Session ���Դ洢�ڷ������ϵ��ļ������ݿ�����ڴ���,����������ǽ� Session �洢���ڴ������ݿ���,���� Redis��
? ʹ�� Session ά���û���¼�Ĺ�������:
- �û����е�¼ʱ,�û��ύ�����û���������ı���,���� HTTP ��������;
- ��������֤���û���������;
- �����ȷ����û���Ϣ�洢�� Redis ��,���� Redis �е� ID ��Ϊ Session ID;
- ���������ص���Ӧ���ĵ� Set-Cookie �ײ��ֶΰ�������� Session ID,�ͻ����յ���Ӧ����֮�� Cookie ֵ�����������;
- �ͻ���֮���ͬһ����������������ʱ������� Cookie ֵ,�������յ�֮����ȡ�� Session ID,�� Redis ��ȡ���û���Ϣ,����֮���ҵ�������
? Ӧ��ע�� Session ID �İ�ȫ������,���������������������ȡ,��ô�Ͳ��ܲ���һ�����ױ��µ��� Session ID ֵ������,����Ҫ������������ Session ID���ڶ�ȫ��Ҫ�ߵij�����,����ת�˵Ȳ���,����ʹ�� Session �����û�״̬֮��,����Ҫ���û�����������֤,����������������,����ʹ�ö�����֤��ȷ�ʽ��

10. ��������� Cookie
? ��ʱ��ʹ�� Cookie �������û���Ϣ,ֻ��ʹ�� Session������֮��,�����ٽ� Session ID ��ŵ� Cookie ��,����ʹ�� URL ��д����,�� Session ID ��Ϊ URL �IJ������д��ݡ�
11. Cookie �� Session ѡ��
- Cookie ֻ�ܴ洢 ASCII ���ַ���,�� Session ����Դ�ȡ�κ����͵�����,����ڿ������ݸ�����ʱ��ѡ Session;
- Cookie �洢���������,���ױ�����鿴�������Ҫ��һЩ��˽���ݴ��� Cookie ��,���Խ� Cookie ֵ���м���,Ȼ���ڷ��������н���;
- ���ڴ�����վ,����û����е���Ϣ���洢�� Session ��,��ô�����Ƿdz����,��˲����齫���е��û���Ϣ���洢�� Session �С�
12. HTTPS ��ȫ��
? HTTP �����°�ȫ������:
- ʹ�����Ľ���ͨ��,���ݿ��ܻᱻ����;
- ����֤ͨ�ŷ�������,ͨ�ŷ��������п�������αװ;
- ��֤�����ĵ�������,�����п�����۸ġ�
? HTTPs(Hyper Text Transfer Protocol over Secure Socket Layer),����ȫΪĿ���HTTPͨ��,����HTTP�İ�ȫ�档
? HTTPs ��������Э��,������ HTTP �Ⱥ� SSL(Secure Sockets Layer)ͨ��,���� SSL �� TCP ͨ�š�Ҳ����˵ HTTPs ʹ������������ͨ�š�
? ͨ��ʹ�� SSL,HTTPs �����˼���(������)����֤(��αװ)�������Ա���(���۸�)��
1. �Գ���Կ����
? �Գ���Կ����(Symmetric-Key Encryption),���ܺͽ���ʹ��ͬһ��Կ��
- �ŵ�:�����ٶȿ�;
- ȱ��:����ȫ�ؽ���Կ�����ͨ�ŷ���
2. �ǶԳ���Կ����
? �ǶԳ���Կ����,�ֳƹ�����Կ����(Public-Key Encryption),���ܺͽ���ʹ�ò�ͬ����Կ��
? ������Կ�����˶����Ի��,ͨ�ŷ��ͷ���ý��շ��Ĺ�����Կ֮��,�Ϳ���ʹ�ù�����Կ���м���,���շ��յ�ͨ�����ݺ�ʹ��˽����Կ���ܡ�
? �ǶԳ���Կ������������,��������������ǩ������Ϊ˽����Կ���������˻�ȡ,���ͨ�ŷ��ͷ�ʹ����˽����Կ����ǩ��,ͨ�Ž��շ�ʹ�÷��ͷ��Ĺ�����Կ��ǩ�����н���,�����ж����ǩ���Ƿ���ȷ��
- �ŵ�:���Ը���ȫ�ؽ�������Կ�����ͨ�ŷ��ͷ�;
- ȱ��:�����ٶ�����
3. HTTPS ���õļ��ܷ�ʽ
? HTTPS ���û�ϵļ��ܻ���,ʹ�÷ǶԳ���Կ�������ڴ���ĶԳ���Կ����֤��ȫ��,֮��ʹ�öԳ���Կ���ܽ���ͨ������֤Ч�ʡ�
13. SSL/TLS Э������ֹ���
? ����֪��,HTTP Э�鶼�����Ĵ�������,������ֻչʾ��̬����ʱû�����⡣�����Ż������Ŀ��ٷ�չ,���Ƕ������紫�䰲ȫ�Ե�Ҫ��ҲԽ��Խ��,HTTPS Э����˳��֡�����ͼ��ʾ,�� HTTPS ���������������õ���ʵ�� SSL/TLS Э�顣SSL/TLS Э�������� HTTP Э��֮��,�����ϲ�Ӧ����˵,ԭ���ķ��ͽ����������̲���,��ͺܺõؼ������ϵ� HTTP Э��,��Ҳ�����������зֲ�ʵ�ֵ����֡�
SSL (Secure Socket Layer,��ȫ���ֲ�)
? SSLΪNetscape���з�,���Ա�����Internet�����ݴ���֮��ȫ,�������ݼ���(Encryption)����,��ȷ��������������֮��������в��ᱻ��ȡ,��ǰΪ3.0�汾��
? SSLЭ��ɷ�Ϊ����: SSL��¼Э��(SSL Record Protocol):�������ڿɿ��Ĵ���Э��(��TCP)֮��,Ϊ�߲�Э���ṩ���ݷ�װ��ѹ�������ܵȻ������ܵ�֧�֡� SSL����Э��(SSL Handshake Protocol):��������SSL��¼Э��֮��,������ʵ�ʵ����ݴ��俪ʼǰ,ͨѶ˫������������֤��Э�̼����㷨������������Կ�ȡ�
TLS (Transport Layer Security,����㰲ȫЭ��)
? ��������Ӧ�ó���֮���ṩ�����Ժ����������ԡ� TLS 1.0��IETF(Internet Engineering Task Force,Internet����������)�ƶ���һ���µ�Э��,��������SSL 3.0Э��淶֮��,��SSL 3.0�ĺ����汾,��������ΪSSL 3.1,����д���� RFC �ġ���Э�����������: TLS ��¼Э��(TLS Record)�� TLS ����Э��(TLS Handshake)���ϵ͵IJ�Ϊ TLS ��¼Э��,λ��ij���ɿ��Ĵ���Э��(���� TCP)���档
? SSL/TLS ������Ϊ����ȫ��Э�̳�һ���ԳƼ�������Կ,������̺�����˼,��������һ�����˽�һ�¡�

(1)client hello
? ���ֵ�һ���ǿͻ��������˷��� Client Hello ��Ϣ,�����Ϣ�������һ���ͻ������ɵ������ Random1���ͻ���֧�ֵ�������(Support Ciphers)�� SSL Version ����Ϣ��
(2)server hello
? �ڶ����Ƿ������ͻ��˷��� Server Hello ��Ϣ,�����Ϣ��� Client Hello �������� Support Ciphers ��ȷ��һ�ݼ�����,����������˺������ܺ�����ժҪʱ����ʹ����Щ�㷨,���������һ������� Random2��ע��,���˿ͻ��˺ͷ���˶�ӵ�������������(Random1+ Random2),��������������ں������ɶԳ���Կʱ�õ���
(3)server certificate
? ��һ���Ƿ���˽��Լ���֤���·����ͻ���,�ÿͻ�����֤�Լ�������,�ͻ�����֤ͨ����ȡ��֤���еĹ�Կ��
(4)Server Hello Done
? Server Hello Done ֪ͨ�ͻ��� Server Hello ���̽�����
(5)Client Key Exchange
? ����ͻ��˸��ݷ����������Ĺ�Կ������ PreMaster Key,Client Key Exchange ���ǽ���� key ���������,����������Լ���˽Կ������ PreMaster Key �õ��ͻ������ɵ� Random3������,�ͻ��˺ͷ���˶�ӵ�� Random1 + Random2 + Random3,�����ٸ���ͬ�����㷨�Ϳ�������һ����Կ,���ֽ������Ӧ�ò����ݶ���ʹ�������Կ���жԳƼ��ܡ�
? ΪʲôҪʹ�������������?������Ϊ SSL/TLS ���ֹ��̵����ݶ������Ĵ����,���Ҷ�������������������Կ�����ױ������ƽ������
(6)Change Cipher Spec(Client)
? ��һ���ǿͻ���֪ͨ����˺����ٷ��͵���Ϣ����ʹ��ǰ��Э�̳�������Կ������,��һ���¼���Ϣ��
(7)Finished(Client)
? �ͻ��˷���Finished���ġ��ñ��İ�����������ȫ�����ĵ�����У��ֵ���������Э���Ƿ��ܳɹ�,Ҫ�Է������Ƿ��ܹ���ȷ���ܸñ�����Ϊ�ж�����
(8)Change Cipher Spec(Server)
? ������ͬ������Change Cipher Spec���ĸ��ͻ���
(9)Finished(Server)
? ������ͬ������Finished���ĸ��ͻ���
(10-11)Application Data
? ������,˫���Ѱ�ȫ��Э�̳���ͬһ����Կ,���е�Ӧ�ò����ݶ����������Կ���ܺ���ͨ�� TCP ���пɿ����䡣
(12)Alert:warning, close notify
? ����ɿͻ��˶Ͽ����ӡ��Ͽ�����ʱ,����close_notify���ġ���ͼ����һЩʡ��,���ⲽ֮���ٷ���һ�ֽ���MAC(Message Authentication Code)�ı���ժҪ��MAC�ܹ���֪�����Ƿ���۸�,�Ӷ��������ĵ������ԡ�
14. ����ǩ��������֤�顢SSL��HTTPS ��ʲô��ϵ
����
? ����ѧ�еġ����롱��������վ��¼ʱ�õ�����(password)�Dz�һ���ĸ���,password ���������ʵ�ǡ����,����������֤��;��һ���ı��ַ�����
? ������ѧ�е�����(cipher)��һ���㷨(algorithm),�����㷨���ڶ���Ϣ���м��ܺͽ���,�����ĵ����ĵĹ��̳�֮Ϊ����,���ķ������������ij�֮Ϊ����,�����㷨������㷨����һ���Ϊ�����㷨��
��Կ
? ��Կ(key)����ʹ�������㷨�����������һ�β�����ͬһ����������ͬ�������㷨�Ͳ�ͬ����Կ�����»������ͬ�����ġ��ܶ�֪���������㷨���ǹ�����,��Կ���Ǿ��������Ƿ�ȫ����Ҫ����,ͨ����ԿԽ��,�ƽ���Ѷ�Խ��,����һ��8λ����Կ�����256�����,ʹ����ٷ�,�ܷdz������ƽ⡣������Կ��ʹ�÷���,����ɷ�Ϊ�ԳƼ��ܺ�Կ���ܡ�
�ԳƼ���
? �Գ���Կ(Symmetric-key algorithm)�ֳ�Ϊ������Կ����,���ܺͽ���ʹ����ͬ����Կ�������ĶԳƼ����㷨��DES��3DES��AES��RC5��RC6���Գ���Կ���ŵ��Ǽ����ٶȿ�,��������ȱ��,��������Ҫ�����߸�֪��Կ���ܽ���,�����Կ��ΰ�ȫ�ķ��������߳�Ϊ��һ�����⡣
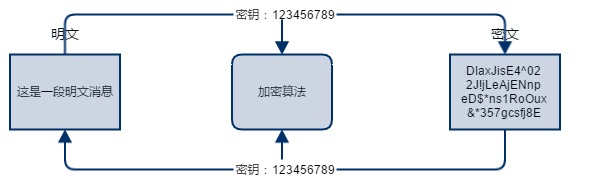
? Alice �� Bob ��������ʱ,�������öԳƼ��ܺ��� Bob,�����������ڶ����ݽ����˼���,��˼�ʹ������ȡ������Ҳû���ƽ�,��Ϊ����֪����Կ��ʲô������ͬ���������� Bob �յ����ݺ�Ҳһ��Īչ,��Ϊ��Ҳ��֪����Կ��ʲô,��ô Alice �Dz��ǿ������ݺ���Կһͬ���� Bob �ء���Ȼ����,һ������Կ����Կһ���͵Ļ�,�Ǿ���������ûʲô������,��Ϊһ�����˰���Կ������ͬʱ��ȡ��,���ľ��ƽ��ˡ����ԶԳƼ��ܵ���Կ���Ǹ����⡣��ν����,��Կ������һ���취��
��Կ����(�ǶԳƼ���)
? ������Կ����(public-key cryptography)��ƹ�Կ����,���������㷨������Ե���Կ��,��Ϊ������Կ�ͽ�����Կ���������ü�����Կ���м���,�������ý�����Կ���н��ܡ�������Կ�ǹ�����,�κ��˶����Ի�ȡ,��˼�����Կ�ֳ�Ϊ��Կ(public key),������Կ���ܹ���,ֻ���Լ�ʹ��,������ֳ�Ϊ˽Կ(private key)�������Ĺ�Կ�����㷨�� RSA��
? ������Alice �� Bob ��������Ϊ��,��Կ�����㷨�ɽ����� Bob ����
- Bob ���ɹ�Կ��˽Կ��,˽Կ�Լ�����,����¶���κ��ˡ�
- Bob �ѹ�Կ���� Alice,�������м�ʹ������ȡҲû��ϵ
- Alice �ù�Կ�����ݽ��м���,������ Bob,�������б�����ȡ��ͬ��û��ϵ,��Ϊû����Ե�˽Կ���н�����û���ƽ��
- Bob ����Ե�˽Կ���ܡ�
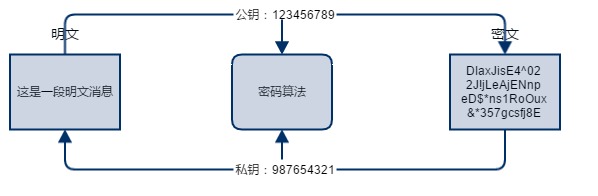
? ��Ȼ��Կ���ܽ������Կ���͵�����,������û��ȷ�Ϲ�Կ�Dz��ǺϷ���,Bob ���͵Ĺ�Կ�㲻�ܿ϶������ Bob ����,��ΪҲ�п����� Bob �ѹ�Կ���� Alice �Ĺ����г����м��˹���,����ʵ�Ĺ�Կ�����滻�������� Alice ��˵��ȫ��֪������һ��ȱ�������������ٶȱȶԳƼ������ܶࡣ
��ϢժҪ
? ��ϢժҪ(message digest)������һ�������ж����������Ե��㷨,Ҳ��Ϊɢ�к������ϣ����,�������ص�ֵ��ɢ��ֵ,ɢ��ֵ�ֳ�Ϊ��ϢժҪ����ָ��(fingerprint)�������㷨��һ����������㷨,�����û��ͨ����ϢժҪ�����Ƶ�����Ϣ��ʲô��������Ҳ��Ϊ����ɢ�к�������������ʱ���ȷ���ǹٷ��ṩ����������,������м�������������Ƕ���˲���,��Ҳ���ö�֪���������ǿ���ʹ��ɢ�к�������Ϣ��������,����ɢ��ֵ,ͨ�������ṩ����ͬʱ�ṩ���������ص�ַ��������ɢ��ֵ,�û����������غ��ڱ�������ͬ��ɢ���㷨�����ɢ��ֵ,��ٷ��ṩ��ɢ��ֵ�Ա�,�����ͬ,˵������������ɵ�,������DZ����Ĺ��ˡ����õ�ɢ���㷨��MD5��SHA��
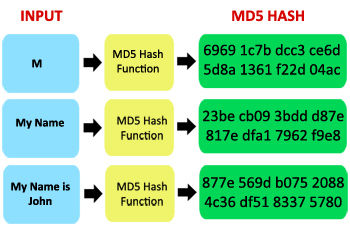
? ���� Eclipse ʱ,�ٷ���վͬʱ�ṩ��������ַ����ϢժҪ
? ɢ�к������Ա�֤���ݵ�������,ʶ��������Ƿ۸�,����������ʶ��������Dz���αװ��,��Ϊ�м��˿������ݺ���ϢժҪͬʱ�滻,������Ȼ��������,����ʵ���ݱ�������,�������յ��IJ����Ƿ����߷���,�����м��˵ġ���Ϣ��֤�ǽ��������ʵ�Եİ취����֤ʹ�õļ�������Ϣ��֤�������ǩ����
��Ϣ��֤��
? ��Ϣ��֤��(message authentication code)��һ�ֿ���ȷ����Ϣ�����Բ�������֤(��Ϣ��֤��ָȷ����Ϣ������ȷ�ķ�����)�ļ���,��� MAC����Ϣ��֤����Լ�����Ϊһ������Կ��صĵ���ɢ�к�����
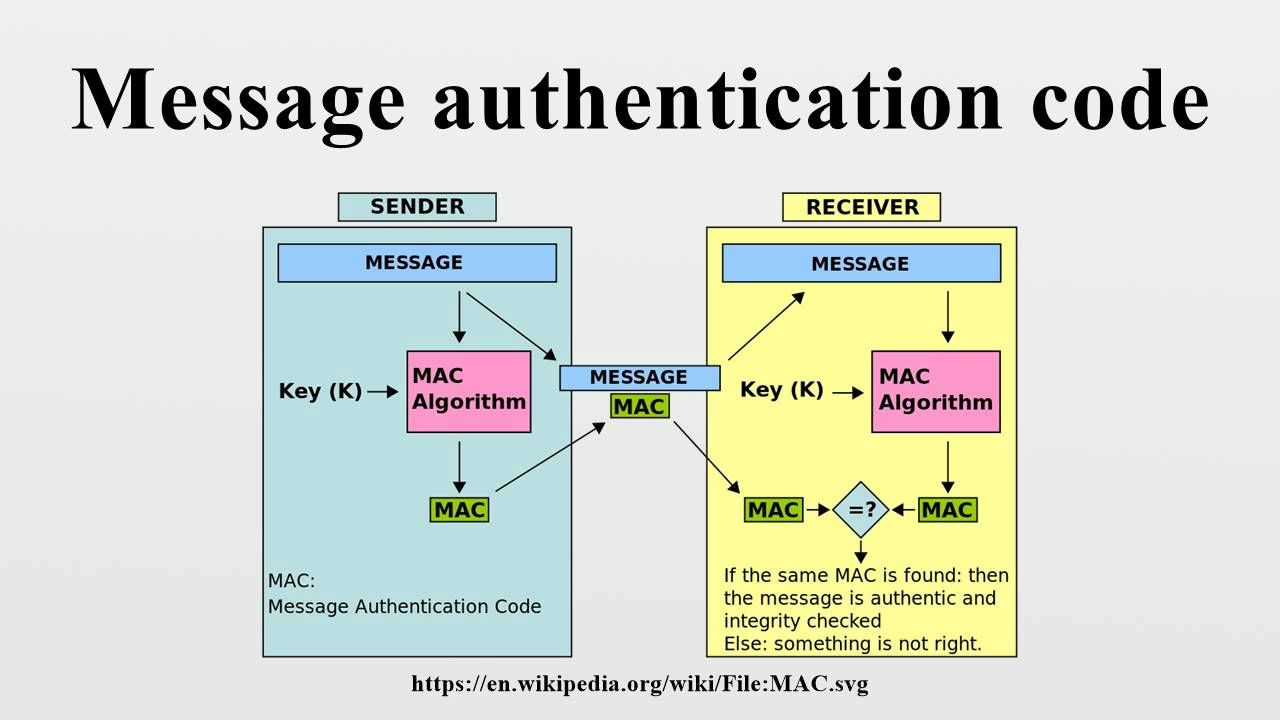
? Alice �� Bob ������Ϣǰ,�Ȱѹ�����Կ(key)���� Bob,Alice ����Ϣ����� MAC ֵ,��ͬ��Ϣһ���� Bob,Bob ���յ���Ϣ�� MAC ֵ��,�뱾�ؼ���õ� MAC ֵ�Ա�,���������ͬ,��˵����Ϣ��������,���ҿ���ȷ���� Alice ���͵�,û���м���α�졣����,��Ϣ��֤��ͬ���������ԳƼ��ܵ���Կ��������,��˽����Կ���������Ҫ���ù�Կ���ܵķ�ʽ��
? ����,��Ϣ��֤�뻹��һ�������������,Bob ��Ȼ����ʶ�����Ϣ�Ĵ۸ĺ�αװ,���� Alice ���Է���˵:����û����Ϣ,Ӧ���� Bob ����Կ�� Attacker ��ȡ��,���� Attacker ���İɡ���Alice ��ô˵�㻹��ûʲô���Է�����,��ô��η�ֹ Alice ��������,����ǩ������ʵ�֡�
����ǩ��
? Alice ���ʼ��� Bob ��1��Ǯ,��Ϊ�ʼ����Ա��˴۸�(�ij�10��),Ҳ���Ա�α��(Alice ������û���ʼ�,���� Attacker α�� Alice �ڷ��ʼ�),Alice ����Ǯ֮���Բ�����(�����ҽ��,��û��ǩ����)��
? ��Ϣ��֤�����Խ���۸ĺ�α�������,Alice �������Լ�����Ǯʱ,Bob ȥ�ҵ���������������,��ʹ����,������Ҳû���ж� Alice ��û����Ľ�Ǯ,��Ϊ��������������Կ,Ҳ����˵���������Լ������ȷ�� MAC ֵ,Bob ˵:�������㷢����Ϣ�� MAC ֵ�����Լ����ɵ� MAC ֵһ��,�϶����㷢����Ϣ��,Alice ˵:�������Կ¶����������,���������ʼ�,������ȥ�ɡ���Alice ʸ�ڷ��ϡ�
? ����ǩ��(Digital Signature)�Ϳ��Խ�����ϵ�����,������Ϣʱ,Alice �� Bob ʹ�ò�ͬ����Կ,�ѹ�Կ�����㷨������ʹ��,������ Alice ʹ��˽Կ����Ϣ����ǩ��,����ֻ����ӵ��˽Կ�� Alice ���Զ���Ϣǩ��,Bob ����ԵĹ�Կȥ��֤ǩ��,����������Ҳ�����ù�Կ��֤ǩ��,�����֤ͨ��,˵����Ϣһ���� Alice ���͵�,����Ҳ����,��Ϊ��ֻ�� Alice ��������ǩ������ͷ�ֹ�˷��ϵ����⡣

? ����������:
? ��һ��:������ Alice ����Ϣ��ϣ��������������ϢժҪ,ժҪ��Ϣʹ��˽Կ����֮������ǩ��,��ͬ��Ϣһ���������� Bob��
? �ڶ���:���ݾ������紫��,Bob�յ����ݺ�,��ǩ������Ϣ�ֱ���ȡ������
? ������:��ǩ��������֤,��֤�Ĺ������Ȱ���Ϣ��ȡ������ͬ����Hash����,�õ���ϢժҪ,���� Alice ��������ǩ���ù�Կ����,����������,�ͱ�ʾǩ����֤�ɹ�,������֤ʧ��,��ʾ���� Alice���ġ�

��Կ֤��
? ��Կ����������ǩ������������ݾ������صĽ�ɫ,������α�֤��Կ�ǺϷ�����,�������м��˹���,������ô��?���ʱ��Կ��Ӧ�ý���һ��������Ȩ������������,�������������֤����(Certification Authority)CA,CA ���û�����������֯�������ַ�ȸ�����Ϣ�ռ�����,���д��˵Ĺ�Կ,���� CA �ṩ����ǩ�����ɹ�Կ֤��(Public-Key Certificate)PKC,���֤�顣
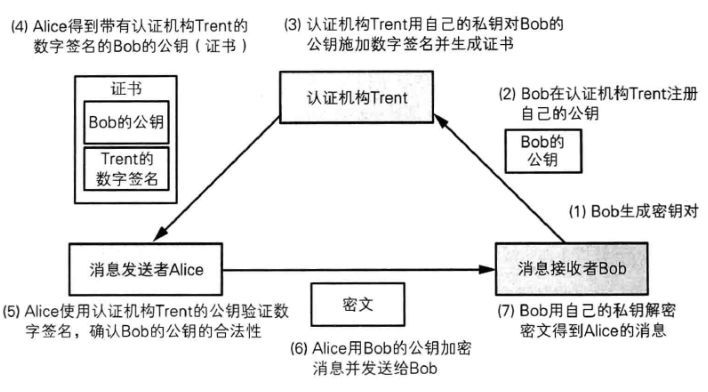
? Alice �� Bob ������Ϣʱ,��ͨ�� Bob �ṩ�Ĺ�Կ���ܺ������,�� Alice ��ȡ�Ĺ�Կ�������� Bob ֱ�Ӹ���,������ί��һ�������εĵ������������ġ�
- Bob ������Կ��,˽Կ�Լ�����,��Կ������֤���� Trent��
- Trent ����һϵ���ϸ�ļ��ȷ�Ϲ�Կ�� Bob ���˵�
- Trent ����Ҳ�����Լ���һ����Կ��,���Լ���˽Կ�� Bob �Ĺ�Կ��������ǩ������������֤�顣֤���а����� Bob �Ĺ�Կ����Կ�������Dz���Ҫ���ܵ�,��Ϊ�κ��˻�ȡ Bob �Ĺ�Կ��û��,ֻҪȷ���� Bob �Ĺ�Կ���С�
- Alice ��ȡ Trent �ṩ��֤�顣
- Alice �� Trent �ṩ�Ĺ�Կ��֤�����ǩ����֤,ǩ����֤�ɹ��ͱ�ʾ֤���еĹ�Կ�� Bob �ġ�
- ���� Alice �Ϳ����� Bob �ṩ�Ĺ�Կ����Ϣ���ܺ��� Bob��
- Bob �յ����ĺ�,����֮��Ե�˽Կ���н��ܡ�
? ����,һ�ױȽ����Ƶ����ݴ��䷽��������ˡ�HTTPS(SSL/TLS)����������һ�����̻���֮�Ͻ��������ġ�
15. HTTP �� HTTPS ������
- http �� HTTP Э�������� TCP ֮�ϡ����д�������ݶ�������,�ͻ��˺ͷ������˶�����֤�Է������ݡ�
- https �� HTTP ������ SSL/TLS ֮��,SSL/TLS ������ TCP ֮�ϡ����д�������ݶ���������,���ܲ��öԳƼ���,���ԳƼ��ܵ���Կ�÷���������֤������˷ǶԳƼ��ܡ�����ͻ��˿�����֤�������˵�����,��������˿ͻ�����֤,��������Ҳ������֤�ͻ��˵����ݡ�
- https Э����Ҫ�� ca ����֤��,һ�����֤�����,��Ҫ���ѡ�
- http �dz��ı�����Э��,��Ϣ�����Ĵ���,https ���Ǿ��а�ȫ�Ե� ssl ���ܴ���Э��
- http �� https ʹ�õ�����ȫ��ͬ�����ӷ�ʽ�õĶ˿�Ҳ��һ��,ǰ���� 80,������ 443��
- http �����Ӻܼ�,����״̬��
- HTTPS Э������ SSL+HTTP Э�鹹���Ŀɽ��м��ܴ��䡢������֤������Э��Ҫ�� http Э�鰲ȫ
16. HTTP 2.0 ����
? HTTP/2 ͨ��֧����������Ӧ�Ķ�·�����������ӳ�,ͨ��ѹ��HTTP�ײ��ֶν�Э�鿪���������,ͬʱ���Ӷ��������ȼ��ͷ����������͵�֧�֡�
(1)�����Ʒ�֡
? �������⼸������:
? ֡:HTTP/2 ����ͨ�ŵ���С��λ��Ϣ:ָ HTTP/2 �����ϵ� HTTP ��Ϣ�������������Ӧ��,��Ϣ��һ������֡��ɡ�
? ��:�����������е�һ������ͨ���������Գ���˫����Ϣ,ÿ��������һ��Ψһ������ID��
? HTTP/2 ���ö����Ƹ�ʽ��������,���� HTTP 1.x ���ı���ʽ,������Э�������������Ч�� HTTP/1 ���������Ӧ����,��������ʼ��,�ײ���ʵ������(��ѡ)���,������֮�����ı����з��ָ���HTTP/2 ���������Ӧ���ݷָ�Ϊ��С��֡,�������Dz��ö����Ʊ��롣
? **HTTP/2 ��,ͬ����������ͨ�Ŷ��ڵ������������,�����ӿ��Գ�������������˫����������**ÿ��������������Ϣ����ʽ����,����Ϣ����һ������֡��ɡ����֮֡�����������,����֡�ײ�������ʶ����������װ��
(2)��·����
? ��·����,����ԭ�������к��������ơ����о�������Ķ���ͨ��һ�� TCP���Ӳ�����ɡ� HTTP 1.x ��,����벢���������,����ʹ�ö�� TCP ����,�������Ϊ�˿�����Դ,����Ե��������� 6-8����TCP������������,����ͼ,��ɫȦ������������������������ѳ�������,��������ȴ���һ��ʱ�䡣
[����ͼƬת���С�(img-QoaxZ4qR-1646124628794)]
? �� HTTP/2 ��,���˶����Ʒ�֮֡��,HTTP /2 �������� TCP ����ȥʵ�ֶ���������,�� HTTP/2��:
- ͬ����������ͨ�Ŷ��ڵ�����������ɡ�
- �������ӿ��Գ�������������˫����������
- ����������Ϣ����ʽ����,����Ϣ����һ������֡���,���֮֡�����������,��Ϊ����֡�ײ�������ʶ����������װ��
? ��һ����,ʹ�������˼�������:
- ͬ������ֻ��Ҫռ��һ�� TCP ����,���������� TCP ���Ӷ���������ʱ���ڴ����ġ�
- ���������Ͽ��Բ��н������������Ӧ,֮�以�����š�
- ��HTTP/2��,ÿ�������Դ�һ��31bit������ֵ,0��ʾ������ȼ�, ��ֵԽ�����ȼ�Խ�͡������������ֵ,�ͻ��˺ͷ������Ϳ����ڴ�����ͬ����ʱ��ȡ��ͬ�IJ���,�����ŵķ�ʽ����������Ϣ��֡��
(3)����������
? ����˿����ڷ���ҳ��HTMLʱ��������������Դ,�����õȵ��������������Ӧλ��,������������Ӧ���������˿���������JS��CSS�ļ������ͻ���,������Ҫ�ͻ��˽���HTMLʱ�ٷ�����Щ����
? ����˿�����������,�ͻ���Ҳ��Ȩ��ѡ���Ƿ���ա������������͵���Դ�Ѿ�������������,���������ͨ������RST_STREAM֡�����ա���������Ҳ����ͬԴ����,����������������͵�������Դ���ͻ��ˡ�
(4)ͷ��ѹ��
? HTTP 1.1����Ĵ�С���Խ��Խ��,��ʱ���������TCP���ڵij�ʼ��С,��Ϊ������Ҫ�ȴ�����ACK����Ӧ�����Ժ���ܼ��������͡�HTTP/2����Ϣͷ����HPACK(רΪhttp/2ͷ����Ƶ�ѹ����ʽ)����ѹ������,�ܹ���ʡ��Ϣͷռ�õ��������������HTTP/1.xÿ������,����Я����������ͷ��Ϣ,�˷��˺ܶ������Դ��
��������:�����
1. mac �� ip ��ôת��
ARP��:
? ��IP��ַͨ���㲥Ŀ��MAC��ַ�� FF-FF-FF-FF-FF-FF ����Ŀ�� IP ��ַ�� MAC ��ַ,ɨ�豾����MAC��ַ��
DHCP��:
? DHCP��Լ���̾���DHCP�ͻ�����̬��ȡIP��ַ�Ĺ��̡�
? DHCP��Լ���̷�Ϊ4��:
- �ͻ�������IP(�ͻ�����DHCPDISCOVER�㲥��);
- ��������Ӧ(��������DHCPOFFER�㲥��);
- �ͻ���ѡ��IP(�ͻ�����DHCPREQUEST�㲥��);
- ������ȷ����Լ(��������DHCPACK/DHCPNAK�㲥��)��
�����:
2. IP��ַ��������
| ������ | ʮ���� |
|---|---|
| 1 | 1 |
| 10 | 2 |
| 100 | 4 |
| 1000 | 8 |
| 10000 | 16 |
| 100000 | 32 |
| 1000000 | 64 |
| 10000000 | 128 |
| 10000000 | 128 |
| 11000000 | 192 |
| 11100000 | 224 |
| 11110000 | 240 |
| 11111000 | 248 |
| 11111100 | 252 |
| 11111110 | 254 |
| 11111111 | 255 |

IP����
���е�ַ:
IP���� ȱʡ����
A 1-127 /8
B 128-191 /16
C 192-223 /24
D 224-239 �鲥��ַ
E 240-247 ������ַ
˽�е�ַ:
A:10.0.0.0 - 10.255.255.255
B: 172.16.0.0 - 172.31.255.255
C: 192.168.0.0 - 192.168.255.255
�жϺϷ�������(IP)��ַ:
192.168.10.240/24 �Ϸ�
192.168.10.0/24 ���Ϸ�,����λȫΪ0,�����ַ
192.168.10.255/24 ���Ϸ�,����λȫΪ1,�����㲥��ַ
255.255.255.255 ���Ϸ�,���������λȫΪ1,ȫ���㲥��ַ
127.x.x.x/8 ���Ϸ�,���ػ��ص�ַ
172.16.3.5/24 �Ϸ�
192.168.5.240/32 �Ϸ�
224.10.10.10.1 ���Ϸ�,�鲥��ַ
300.2.4.200/24 ���Ϸ�
- IP�����ַ
- ���ػ��ص�ַ:127.0.0.0 �C 127.255.255.255,��������TCP/IPЭ��ջ�Ƿ�װ��ȷ��
- ������·��ַ:169.254.0.0 �C 169.254.255.255,�Զ���ַ����ȡʱϵͳ�Զ�����ռλ��
- ���㲥��ַ:255.255.255.255,���������ַ�����ݲ��ܿ�Խ�����豸,���������������е����������Խ��յ�����
- �����:
- 4internetLayer
- IP��ַ���������� - ����Ĺ���Ӱ - ����
- [ZenCloud2/13-�������.md at a78722799508a7ac3fc7d055ff8d2d88edd0b595 �� destinyplan/ZenCloud2](ZenCloud2/13-�������.md at a78722799508a7ac3fc7d055ff8d2d88edd0b595 �� destinyplan/ZenCloud2 )
3. ��ַ����Э��ARP
4. ��������·����������
- ·�������Ը���ľ������Զ����� IP,���Ⲧ��,����һ����ͨ����,ָ������ĵ��Ը�������,���Լ����ò�����ô���ˡ�������ֻ�����������������ݵġ�
- ·�����������,·��������IP��ַѰַ,·�������Դ��� TCP/IP Э��,�����������ԡ�
- ���������м̲�,���������� MAC ��ַѰַ��·��������һ�� IP ������ܶ������ʹ��,��Щ��������ֻ���ֳ�һ�� IP�����������Ѻܶ�����������,��Щ����������и��� IP��
- ·�����ṩ����ǽ�ķ���,�����������ṩ�ù��ܡ����������������������˿���չ��,�������������(ͨ��������̫��)�Ľ����,Ҳ�������þ�������������������ĵ��ԡ�·��������������������,Ҳ�����������Ӳ�ͬ�����硣
? ������������������ַ����˵ MAC ��ַ��ȷ��ת�����ݵ�Ŀ�ĵ�ַ����·�����������ò�ͬ����� ID ��(�� IP ��ַ)��ȷ������ת���ĵ�ַ��IP ��ַ����������ʵ�ֵ�,���������豸���ڵ�����,��ʱ��Щ������ĵ�ַҲ��ΪЭ���ַ���������ַ��MAC ��ַͨ����Ӳ���Դ���,�������������������,�����Ѿ��̻�����������ȥ,һ����˵�Dz��ɸ��ĵġ��� IP ��ַ��ͨ�����������Ա��ϵͳ�Զ����䡣
? ·�����ͽ�����������һ:��������һ����������,���Ǵ�������Ƿֱ�,����ʹ���Լ��Ŀ���,�������û��Ӱ�졣��·�����Ƚ���������һ�����Ⲧ�Ź���,ͨ��ͬһ̨·���������ĵ����ǹ���һ�������˺�,�������Ҫ�Ӱ�졣
? ·�����ͽ������������:�������������м̲�,���������� MAC ��ַѰַ��·���������������,����IP��ַѰַ,·�������Դ��� TCP/IP Э��,�������������ԡ�
? ·�����ͽ�������������:����������ʹ�������Ķ�̨������ɾ�����,������д����������Ļ�������ʵ��ͬʱ�������ܶ��Ҿ��������е����ǹ������Ĵ������ʵ�,���ǽ�����û��·�������Զ�ʶ�����ݰ����ͺ͵����ַ�Ĺ��ܡ�·���������Զ�ʶ�����ݰ����ͺ͵���ĵ�ַ,·�����൱����·�ϵľ���,����ͨ�赼��ָ·�ġ�
? ·�����ͽ�������������:�ټ�������,·������С�ʾ�,��һ����ַ(IP),����һ���ط����շ�(���˵���,ij��������,�����������Ҫ�������),��������ʡ��Ĵ���������,������һ����ַ������С�ط�����ϵ����˵·����ר������,������ֻ������,·��·�ɾ��Ǹ�����·����������,������ֻ������,����������Ҫû��·�������ϲ������ġ�
? ·�����ͽ�������������:·�����ṩ�˷���ǽ�ķ���·��������ת���ض���ַ�����ݰ�,�����Ͳ�֧��·��Э������ݰ����ͺ�δ֪Ŀ���������ݰ��Ĵ���,�Ӷ����Է�ֹ�㲥�籩��
5. �������������
? ������192.168.1.199��ǰ�����������,��һ����������,�����������255.255.255.0
? ����Ҫ˵������:����ij��IP������ź������ž�������������ʲô,�����������������ij��IP��ַ�����������������ʲô,IP��ַ��Ҫ������������ʹ�õġ�����������������������192.168.1.199��ǰ����192.168.1�������,���һ��199�������š�
? �������������������������,�Ⱦٸ�����,�����ϵ��������Ҷ��������ӳ�,ÿ�����Ҷ�������ǵij���,��������ô֪�����ǵijӵ�����?�ܼ�,��ȥ��һ�� 1KG �Ĺ���ǧ��ԭ��,���ŵ����ǵij��ϲ���,����ӵIJ���ֵ��1KG,����ѳӾ�����,������������þ��൱�������ҹ��ϵĹ���ǧ��ԭ��,�����Dz�������IP�Ƿ�����ͬһ�����ε�һ������(Ӧ��˵������֪��ij��IP��ַ��������������ŷֱ���ʲô) ��
? ��������ж�һ��IP��ַ:192.168.1.199������ź������ŷֱ���ʲô?
? ��������ô�ж�?��ƾʲô˵192.168.1�������?199��������?��ʲô������?
? ��������Ҹ���һ��IP��ַ������(����������)��ʽ��:
? IP:192.168.1.199
? ��������:255.255.255.0
? ��ô���ݴ�ҹ��ϵĹ���,��Ϳ��Եó����IP������ź���������,��ô����?
? ��������ij��Ⱥ�IP��ַһ��Ҳ��һ��32λ�Ķ���������,ֻ����Ϊ����Ŀɶ��Ժͼ����Եķ���,ͨ��ʹ��ʮ������������ʾ,����������IP��ַ���������붼ת������Ӧ�Ķ����ƾ�������������:
**ʮ����** **������**
? IP ��ַ:192.168.1.199 �\>11000000.10101000.00000001.11000111
? ��������:255.255.255.0 �\>11111111.11111111.11111111.00000000
? ʮ���Ƶ���ʾ��ʽ�Ǹ��˿���,�����Ƶ���ʾ��ʽ�Ǹ���������ġ�����
? ������������������λ,�ö��������֡�1����ʾ,1����Ŀ��������λ�ij���;�ұ�������λ,�ö��������֡�0����ʾ,0����Ŀ��������λ�ij��ȡ�
? �����������������255.255.255.0�� ��1���ĸ��������24λ,���ӦIP��ַ��ߵ�λ��Ҳ��24λ;
**ʮ����** **������**
? IP ��ַ:192.168.1.199 �\>11000000.10101000.00000001.11000111
? ��������:255.255.255.0 �\>11111111.11111111.11111111.00000000
? �����IP��ַ������ž���11000000.10101000.00000001 ,ת����ʮ���ƾ��� 192.168.1,������255.255.255.0�� ��0���ĸ������ұ�8λ,�����IP��ַ�������ž���11000111,ת����ʮ���ƾ���199.