ǰ��
����ͬ������һ�����������,��æ�������Ų�,�üһﲻ�鲻֪��,һ������֪����,��Ѷ�ƺͰ�����TCP�������־�Ȼ���в���,û���뵽�Ƴ�������Iass����ķ���,���в�ͬ�ı�~
��������
?�ͻ��ǰ��йܿͻ�,���Dz�������������Ƶ�nginx,nginx��ΪLB,���������N��java����,Java�������.������·����: �ͻ�������Java->������ nginx->������Java?�ӿͻ��������������Ƶ�nginx��ʱ��,�����˰�̫��,��ȡ��ʱ,��С,�������⡣�� ��������-��Ѷ�Ƶ�nginx->Java���� ����Ͱ�С��û�����⡣
���й�Java������־����: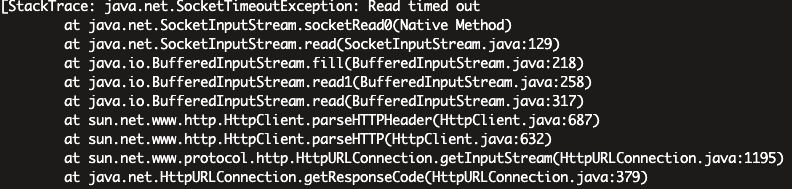
nginx��־����408
?������nginxҲ�������ͻ�����,û�г���408����,������ͻ�����?������־,��ԭ��������,����������ֱ��curl �����ƵĻ���Ҳ��ͬ��������,ͬ��������,curl��Ѷ�Ƶķ�����û������,ͬ�������ڿͻ���������,�ڱ����������ƵĻ���û�����⡣?����ά˵,��̨����������,�ͻ���ȥά��,���²���ͳ����������,ά��ǰû���������?������ֱ�Ӱ������������Ƶ�Java����,Ҳ��ͬ�������� �������C��������Java����?ѯ�ʿͻ�,ά���װ�˸�centosϵͳ,����������,����ʲô��û�ж�?ѯ����ά,ֻ�������,���ú���ǰһ��
nginx 408
ͨ������408�����������ط������ûᵼ��:client_body_timeout��client_header_timeout��
��������ʱʱ��Ĭ�϶���60s��
client_body_timeout:�����ȡ�ͻ����������ĵij�ʱ����ʱ��ָ�������ζ�����֮������ʱ����,��������������������ɴ�������ʱ�䡣����ͻ��������ʱ����û�д����κ�����,nginx������408 (Request Time-out)���ͻ��ˡ�
client_header_timeout:�����ȡ�ͻ�������ͷ���ij�ʱ������ͻ��������ʱ����û�д���������ͷ����nginx, nginx�����ش���408 (Request Time-out)���ͻ��ˡ�
���϶�˵��Ҫ������2������,��������ͬ������������,����Ѷ�Ƶ�nginx����û�������,��Ѷ��nginx�Ͱ����Ƶ�nginx�汾����������ȫ��һ�µġ����Բ�����nginx�������õ�����,����ֱ���Ͱ����Ƶ�Java����,Ҳ�Ƕ�ȡ��ʱ,���Ի����Ͽ����ų���nginx������
���ǿ��Կ���408���Ƕ�ȡ��ʱ,��ô������û�͵�nginx,������ǹؼ��㡣
���²���,����ץ��������
ץ��
?����ץ�� �������C��������nginx
������ץ��
tcpdump -i em1 host ali-nginx-ip -w btg.pcap
ali-nginxץ��
tcpdump -i eh1 host btg.ip -w ali-nginx.pcap
ʹ��wireshark����ץ���ļ�
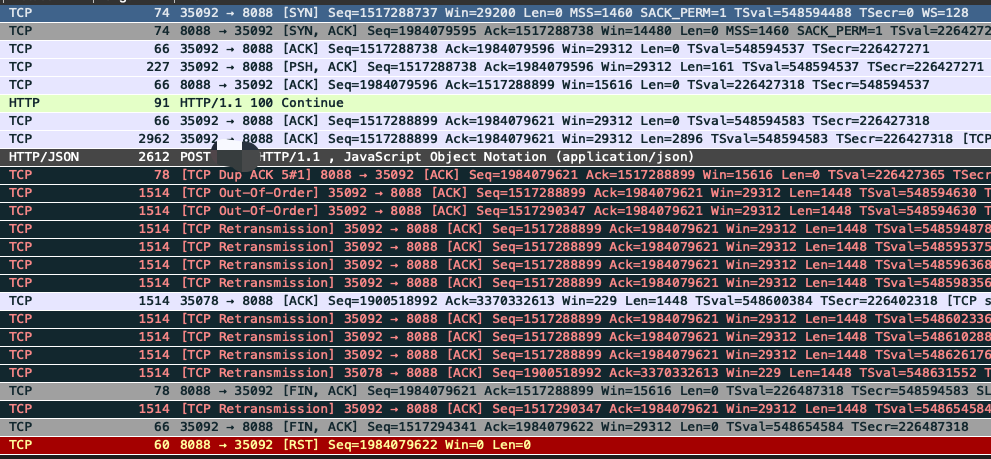
��ͼ�п��Կ������������dzɹ��˵�,�ڷ���http���ĵ�ʱ��,���������´���
?
TCP dup ack XXX#X��nginx�����������ص�,�����ظ�Ӧ��#ǰ�ı�ʾ���ĵ��ĸ���Ŷ�ʧ,#������DZ�ʾ�ڼ��ζ�ʧ
?
TCP Out_of_Order��ԭ�����:һ����˵������ӵ��,����˳����ִ�ʱ�䲻ͬ,��ʱ̫��,���߰���ʧ,��Ҫ����������ݵ�Ԫ,��Ϊ���ǿ������ɲ�ͬ��·��������ĵ������档
?
TCP Retransmissionԭ�����:������������ij�ʱ�����������ش�
?
nginx�ϵ�ץ����������

nginx��ץ��������,�������������͵�http����,��nginx�Ͼ�Ȼû�в���,�ѵ���żȻ��?Ȼ�����������˼���,��nginx�϶�û�в���������,����ȷ����,�������������Ƶ�������·������,���ֶ����ˡ�
���������·
?��ping�����Ƶ�nginx
ping aliyun-nginx-ip
û�з��ֶ���,������ȶ�
���뵽ֻ�а��ر��Ż������,������ping�ϼ��˲���
ping -s 4000 aliyun-nginx-ip
���ֵ���4000��ʱ��,ping�Ͷ�����,�Ʋ�������̫��,�ͻ��DZ����˰���������,��ϵ�ͻ�������,���мӰ�,����ping�������ˡ�
��������Ϊ�㶨��?�Ǿʹ��ˡ��ͻ��Ӱ�,ping��û��������,����http����һ��,����������һ��,�Ӳ��Ӱ�,���������û��ʲôӰ�졣
��������
��������˼·,ֻ������ͻ���������,������ͻ�������������,���ɱȽϴ�ѯ�ʿͻ�����,����ܹ�����ô���,���һ������֪��
ֻ�д���Ż��������,��ô�ܿ��ܺͷְ��й�ϵ,���ϲ鿴�ͻ�������Ϣ,����MTU��ֵ��1500,û�иĹ�,��������������,�ܲ���ֱ�Ӹ�MTU��ֵ��,��������һ������������ע�⡣
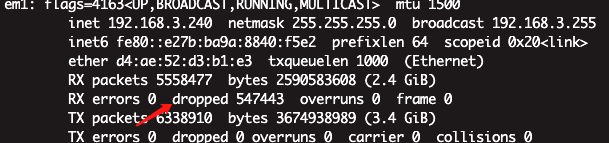 �����������Ϣ
�����������Ϣ
watch netstat --interfaces
�ǵ�,û�п���,dropped����һֱ�����ӡ�
RX==receive,����,�ӿ��������ڽ��շ�������,������������
TX==Transmit,����,�ӿ��������ڷ��ͷ�������,������������
������,���ǵ�����ҲӦ����TX,������RXһֱ�ڶ�����
�鿴������ring buffer
ethtool -g em1
Ring parameters for em1:
Pre-set maximums:
RX: 2040
RX Mini: 0
RX Jumbo: 8160
TX: 255
Current hardware settings:
RX: 2040
RX Mini: 0
RX Jumbo: 0
TX: 255
�Ѿ����������,���Բ���ring buffer�����⡣
����ͨ��linuxԴ��[1]����֪��,Linux֧�ֵ�Э�鶼�����ﶨ����,���Э�鲻��linux֧��,��ֱ��drop,��������������drop��һֱ�����ӡ�
ͨ���������linuxԴ������Կ���,���ǵ�tcp/ip�϶�����֧�ֵ�,����drop����������������ûʲô��ϵ��
�����һ��Ǻܺ���,��ʲôЭ�鵼����Linux�ں˲�֧��,���ǿ���ͨ�����·�ʽ�жϡ�
tcpdump -i em1 -e | grep -v -E 'ARP|IP|802.1Q|802.1ADP'
��ӡ������ether type,Ȼ����˵�����ϵͳ֧�ֵİ�,ʣ�µľ��Ƕ����İ�
listening on em1, link-type EN10MB (Ethernet), capture size 262144 bytes
17:31:55.517403 0c:38:3e:3f:aa:cf (oui Unknown) > 01:80:c2:00:00:0e (oui Unknown), ethertype LLDP (0x88cc), length 207: LLDP, length 193: X3SG
17:31:58.242948 0c:38:3e:3f:b1:31 (oui Unknown) > 01:80:c2:00:00:0e (oui Unknown), ethertype LLDP (0x88cc), length 207: LLDP, length 193: X3SG
17:31:58.318690 0c:38:3e:3f:b1:2f (oui Unknown) > 01:80:c2:00:00:0e (oui Unknown), ethertype LLDP (0x88cc), length 207: LLDP, length 193: X3SG
^C141 packets captured399 packets received by filter
������linux������һ��LLDPЭ��,���ֲ�û�С���ethertypes[2]�������Ķ�����������·��Э�顣���Խ���������ˡ�
�����������������ǰ���ᵽ�������ء�
��MTU
������,���ǵĻ��ɵ��ֻ��MTU��,ͨ��ping���ò������ְ����ֹ�̽��MTUֵ ��������
ping -s 1472 -M do aliyun-nginx-ip
1500-8(icmpͷ��)-20(ipͷ)=1472 ping��ͨ,�Լ���������������,��ok ��,��ô���ۺ�������,���ǿͻ��������м���·����С��1500��mtu�豸��
���������ֽ���,�ٽ����1465�ǿ���ͨ��,����1465�Ͳ��� ��ô��ѵ�mtu��ֵ,����=1465+8+20=1493
���������Ǹ��豸��MTUֵ���в�����
ifconfig em1 mtu 1493
ps:��ô��mtuֵ,ֻҪ��������,�ͻ�ʧЧ,Ҫ�о���mtu��ֵ
vim /etc/sysconfig/network-scripts/ifcfg-em1
������������
MTU="1493"
��������
service network restart
�������curl����,�����������Ƶ�nginx��û�������ˡ�
������������Ѿ������,�����и�����Ϊʲôû�и�mtuֵǰ,��Ѷ�Ŀ���,����IJ���?
��Ѷ�Ͱ��� tcp�������ֵ�����
��������,����Ѷ������������������ץ�˸���,���Ͱ����ƵĽ��жԱȡ�����ץ���ļ�,����MTUΪ1500��Ϊ��
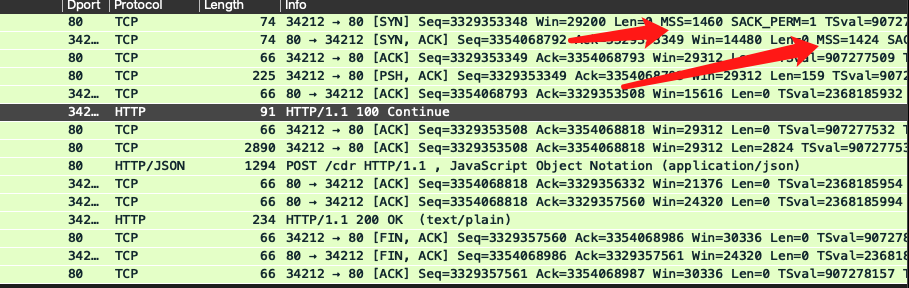 ������Ѷ�Ƶ�SYN������,MSSֵΪ1460=(1500-20(tcpͷ���ֽ�)-20(ipͷ���ֽ�))1460��ʵ��һ��Ĭ�ϵĹ淶 ����Ѷ�ص�SYN,ACK������,MSSֵΪ1424,�ȳ����1460,��16���ֽ�,��Ȼ��16���ֽ��Ǽ��˸�ɶ,��Ҳ��֪����
������Ѷ�Ƶ�SYN������,MSSֵΪ1460=(1500-20(tcpͷ���ֽ�)-20(ipͷ���ֽ�))1460��ʵ��һ��Ĭ�ϵĹ淶 ����Ѷ�ص�SYN,ACK������,MSSֵΪ1424,�ȳ����1460,��16���ֽ�,��Ȼ��16���ֽ��Ǽ��˸�ɶ,��Ҳ��֪����
�ص�����,����˵�м���·���豸MTU��ֵ����1500,����Ϊ1493. 1493-20-20=1453,1453��Ӧ������������MSSֵ,�������1460��1453��,�ᵼ�¶���,������1424����,����û������ġ�
���е�һ�ж��ܽ��͵�ͨ�ˡ�
��Ѷ�ƵĻ���MTUֵ����Ĭ�ϵ�1500��?
��,������Ĭ�ϵ�1500,��1424�����϶�����������Ѷ�����ӵ�,Ϊ��ȷ���������,��������Ѷ���Ͻ�����ץ��,���ڻ�����NAT����,��Ѷ�Ʋ�û�а���ip,����ץ�İ�Ϊnginx���������java�������������
 ���Կ���,nginxȥ��java�������ӵ�ʱ��ʹ�õ���1460,Ҳ����˵,1424������ڽ����������ǰ�����ġ��������java����,�ص���1460,˵���ڳ�ȥ��ʱ��,��ѶҲ��mss��Ϊ1424�ˡ�
���Կ���,nginxȥ��java�������ӵ�ʱ��ʹ�õ���1460,Ҳ����˵,1424������ڽ����������ǰ�����ġ��������java����,�ص���1460,˵���ڳ�ȥ��ʱ��,��ѶҲ��mss��Ϊ1424�ˡ�
������,�����Ͻ�������ǵ��������ʡ�
����
�����ںͿͻ�������,��ͨ����1493�������DZ����õ�,����û�иĹ�,��ǰ�����õ�����������ǵ���ά˵Ҳû�Ĺ����Ǿ������~
��ͨ��,�ͻ�����������mtuֵΪ1560,˵������ֵ,����ʵ��������1500��,���Dz����ҵġ�
References
[1]?linuxԴ��:?https://elixir.bootlin.com/linux/v3.10/source/include/uapi/linux/if_ether.h
[2]?ethertypes:?https://github.com/openbsd/src/blob/master/sys/net/ethertypes.h#L305