上手就能用的Python爬虫,不香吗?
前言
【本人同样为学生,总结不一定对,这只是个人在学习过程中的记录,仅供参考。如果内容有问题的话,欢迎在评论区指出,谢谢正在阅读的您~】
身边还是有不少人不会或者嫌麻烦而不愿意迈出“学习爬虫”这对个人而言跨世纪的一步。
内容尽可能面向0基础人群、让不懂的人或者不是计算机专业的也能听懂
侧重功能实现而稍微忽略部分原理,直接复制代码+自己查找少部分内容即可实现简单爬虫用于完成作业或者应用
正文开始!
封装请求方法
# by-带刺儿玫瑰
import requests
def getResponseWithHeaders(sites: str, Headers:dict):
url = sites
headers = Headers
return requests.get(url, headers=headers) # 请求#Get方式获取网页数据
上述代码块为封装的用于发起请求的方法,接下来主要就是构造headers、找网址的构成规律
构造headers
通过代码访问与浏览器访问的区别?
用代码访问和人为通过浏览器访问肯定是不一样的, 每一个网页(或者说每一个网址)都和一个服务器(Server)相关联,在浏览器中输入网址后按下回车就是向Server发起一次请求,然后该Server把网页的内容通过网络发送给我们,所以简单来说,每次访问网页不光消耗我们访问的人(Client)的流量也会消耗服务器(Server)的流量。 服务器消耗的流量简单认为和所有客户端消耗流量的总和相同,但是分散到每个客户端也许只有1MB,但是若有1024个客户端,那服务器就要耗费1GB的流量,而且代码运行起来比人为操作快太多,所以可以简单理解为服务器的费用成本高。
因此服务器不会简单地让代码直接访问,需要为“访问的代码程序”嵌入一些“浏览器才具备的特征”,让服务器将代码发起的请求当作是浏览器发起的
Markdown将文本转换为 HTML。
headers的常用构造方法
下面为headers的常用构造方法,对大部分发布公共数据的网站基本就够用了,有些需要登录的…就肯定不行咯~那就需要进行更多的操作,让服务器“认可”、“许可”我们的访问并把资源通过网络发给我们。
def getHeaders():
headers = {
'Cookie': ''
, 'User-Agent': ''
}
上述代码其实很容易看懂,包含两个键值对,这两个就是需要我们人为查找、改改的内容。如何找呢?看下面的内容。
如何找headers的参数
打开任意一个浏览器(我常用的是Chrome或者Firefox,电脑里常备三个浏览器,Edge用于日常访问、Chrome和Firefox用于Web开发),按下F12打开开发者工具,可能会提示“是否要进入开发者模式”等等内容,就直接同意就好了。Chrome打开后的界面如下所示:
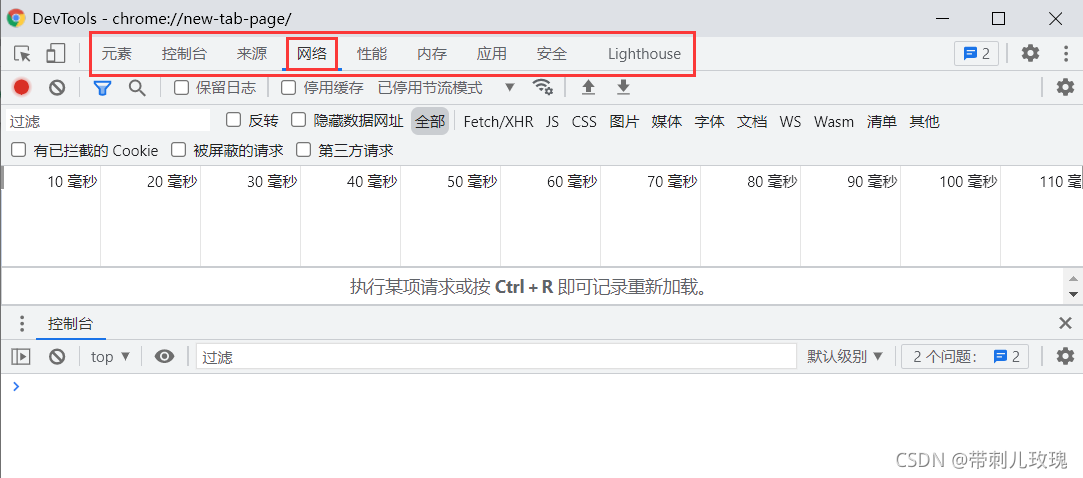
上图中最重要的是红框那一行的Tab,点击“网络”,然后关注下方有“毫秒”两字的区域,不出意外应该是空白或者每隔一段时间会新增一条记录。此时就在开发者工具界面按F5刷新网页(开发者工具和每一个网页是一一对应的, 不用回到网页,也可以刷新开发者工具对应的网页)
刷新后应该能观察到原来没有记录的区域会出现很多很多条记录,此时一般找第一个或者自己想要的资源所对应的那一条记录(如何找?看后续更新的博客吧!)
因为刚完成了与天气相关的大作业,所以直接就以“中国天气网”为例了。刷新该页面后,开发者工具显示的内容如下:
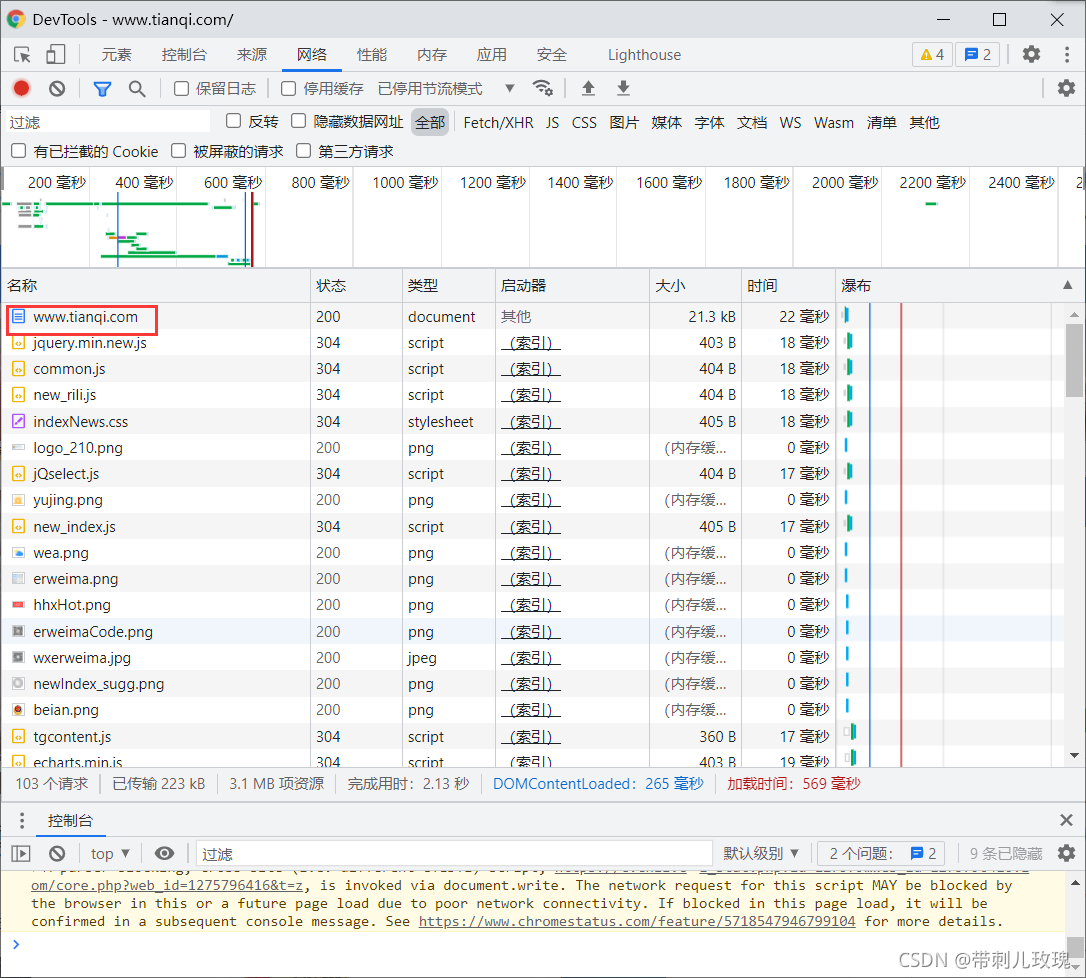
此时关注到第一条记录,名字就是网站的域名,嗯,所以应敏感地抓住这个特征,点击该条记录,在弹出的框内切换到“标头”这个Tab。如下所示:

“响应标头”可以简单理解为:是服务器(Server)给我们发资源的时候要先跟我们说清楚发的是什么东西以及格式啊之类的,以便我们接收到资源后浏览器可以进行检查之类的操作。
往下往下往下
找到**“请求标头”**。与“响应标头”类似,这个标头会和我们的请求操作一同发送给服务器(Server),表示我们要什么东西和我们的身份,方便服务器识别我们的身份和明白我们要什么东西。
再找到“请求标头”里的“User-Agent”和“Cookie”两栏,如下红框内的所示:
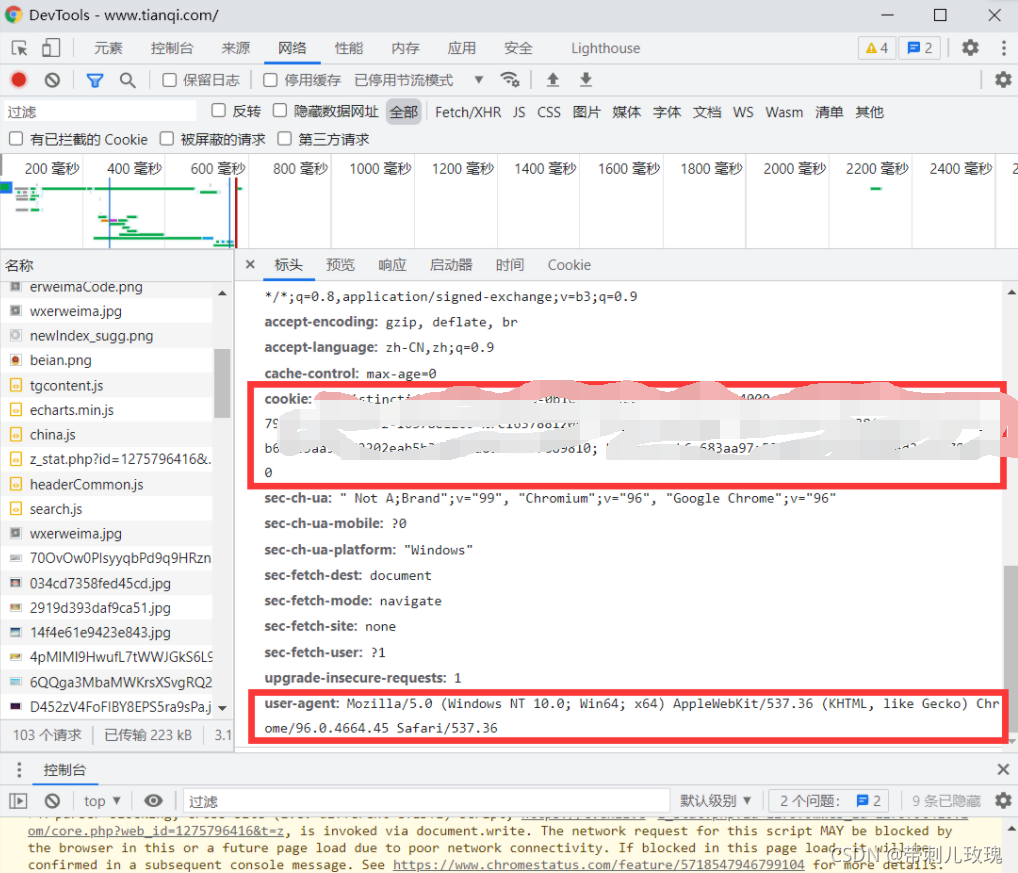
然后,把“User-Agent”和“Cookie”字段后面对应的值(也就是内容),复制到构造headers的代码里,就行了。
headers构造完毕!
构造网址
不更了, 未完待续…