һ����������������
�����Э��Ϊ�����ڲ�ͬ�����ϵ�Ӧ�ý���֮���ṩ����ͨ������,���ý���ʹ��������ṩ����ͨ�Ź��ܱ˴˷��ͱ���,�����迼�dz�����Щ���ĵ�����������ʩ��ϸ�ڡ�

��ͼ��ʾ,�����Э�����ڶ�ϵͳ�ж�������·������ʵ�ֵġ�
1:������������Ĺ�ϵ
������ṩ������֮�����ͨ��,�������Ϊ�����ڲ�ͬ�����ϵĽ���֮���ṩ��ͨ�š�
��������������һ��������������ϵ,�����������Ҳ���ᴩ��ƪ���µĺ��ġ�
������������ͥ,һ��λ�ں�����,һ��λ�ں��ϡ�ÿ�Ҷ���ʮ�������ӡ���������ͥ�ĺ������Ǻ��ϼ�ͥ�����ǵ����ֵܽ��á���������ͥ�ĺ�����ϲ���˴�ͨ��,ÿ����ÿ����Ҫ����дһ����,ÿ���Ŷ��õ������ŷ�ͨ����ͳ�����������͡����,ÿ����ͥÿ����Ҫ����һ�ҷ���144���š�ÿ����ͥ����һ�����Ӹ����շ��ʼ�,��������ͥ�ǽ��������ϼ�ͥ�ǰ�ΰ��ÿ���ڽ���ȥ�����е��ֵܽ��������ռ��ż�,������Щ�ż�����ÿ�쵽���ſ��������������ϡ����ż����������ʱ,����Ҳ�����ż��ַ��������ֵܽ������С�ͬ��λ�ں��ϵİ�ΰҲ�������ƵĹ�����
�ɴ����
Ӧ�ò㱨�� = �ŷ��ϵ�����
���� = ���ֵܽ���
���� = ��ͥ
�����Э�� = �����Ͱ�ΰ
�����Э�� = ��������(�����ʳ�)
����ij�찢ΰ���߽���������,����һ�������ð��ĺͽ������������ǵĹ���,���������������̫С,û�о���,������ʱ��ᷢ���ʼ����߶�ʧ�ʼ����������,�����������Ҳ�ж�������Э��,ÿ��Э��ΪӦ�ó����ṩ��ͬ�ķ���ģ�͡�
2:��������������
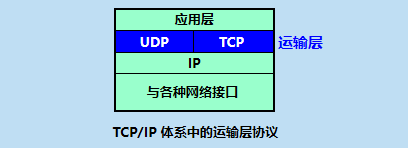
������ΪӦ�ó����ṩ�����ֽ�Ȼ��ͬ�Ŀ��������Э�顣һ����UDP(�û����ݱ�Э��),��Ϊ��������Ӧ�ó����ṩ��һ�ֲ��ɿ��ġ������ӵķ�����һ����TCP(�������Э��),��Ϊ��������Ӧ�ó����ṩ��һ�ֿɿ��ġ��������ӵķ���Ӧ�ó���Ŀ�����Ա����������ʱ����ָ����ѡ��UDP����TCP��
Ϊ������,���ǽ����������Ϊ���Ķ�(segment),Ҳ����TCP��UDP�ķ���ͳ��Ϊ���ĶΡ�
��ѧϰUDP��TCP֮ǰ,������Ҫ�ȼ�Ҫ�˽�һ��������IPЭ��,IP�ķ���ģ����������Ϊ������������ζ��IP�������Ŭ����ͨ������֮�佻�����Ķ�,�����������κ�ȷ�����ر���,����ȷ�����ĶεĽ���,����֤���Ķεİ���,����֤���Ķ��е����������ԡ�������Щԭ��,IP����Ϊ���ɿ��������ڴ�����Ҫǿ��,ÿ̨��������Ҫ��һ��������ַ,����ν��IP��ַ����������١����ֵİ�����֪ʶ����:ÿ̨���������ж��IP��ַ,��ΪIP��ַ���DZ�ʶ����������ڵ�λ��,������������ڲ�ͬ�ľ�������,����IP��ַҲ������ͬ,����ÿ̨����ֻ����һ��MAC��ַ������ÿ̨������Ψһ��ʶ��IP��ַ�������Ϊһ���˵��ջ���ַ,��MAC��ַ��������˵����֡�
�˽�IP��ַ��,�����ܽ�һ��UDP��TCP���ṩ����ģ��,UDP��TCP�������������,��������ϵͳ��IP�Ľ���������չΪ�����ڶ�ϵͳ�ϵ���������֮��Ľ������������佻����չ�����̼佻������Ϊ��������·����(multiplexing)����·�ֽ�(demultiplexing)
UDP��TCP������ͨ�����䱨�Ķ��ײ��м���������ֶζ��ṩ�����Լ�顣���̵����̵����ݽ�����������ʱ��������ȵ���������,Ҳ��UDP�����ṩ�Ľ��е����ַ���TCP�ڴ˻����ϻ��ṩ�ɿ����ݴ�����ӵ����������
������·���úͶ�·�ֽ�
��Ŀ������,�����ӽ������µ��������ձ��ĶΡ�����㸺����Щ���Ķ��е����ݽ����������������е��ʵ�Ӧ�ó�����̡�
��һ��������ͬʱ�кü�������ʱ,���������������Ӧ�÷����Ǹ�������?
����֪��,һ������(��Ϊ����Ӧ�õ�һ����)��һ����������(socket),���൱�ڴ���������̴������ݺʹӽ��������紫�����ݵ��Ż�������ͼ��ʾ,�ڽ��������������ʵ���ϲ�û�н�����ע�⽻��������,���ǽ����ݽ������м��һ�����֡���������һʱ��,�ڽ��������Ͽ����в�ֹһ������,����ÿ�����ֶ���Ψһ�ı�ʶ����

������㱨�Ķ��е����ݽ�������ȷ�����ֵĹ�����Ϊ��·�ֽ⡣��Դ�����Ӳ�ͬ���������ռ����ݿ�,��Ϊÿ�����ݿ��װ���ײ���Ϣ�Ӷ����ɱ��Ķ�,Ȼ���Ķδ��ݵ������,���е���Щ����������·���á�
���:
�������ֵܽ��������ռ��ż� �C ��·����
�������ֵܽ��÷ַ��ż� �C ��·�ֽ�
��·���õ�Ҫ��:
-
������Ψһ�ı�ʶ��;
���:���ڽ��շ�ÿ�����Ӷ����Լ�Ψһ������
-
ÿ�����Ķ��������ֶ���ָʾ�ñ��Ķ���Ҫ������������;
���:���ڷ��ͷ���˵,Ҫ��ÿ���ż���д��������
Դ�˿ں�(Source Port)
Ŀ�Ķ˿ں�(Destination Port)


�������ڿ���һ��Ӧ�ó���ʱ���DZ���ҪΪ�����һ���˿ںš�
��������Ӧ����������������ʵ�ֶ�·�ֽ����:�������ϵ�ÿ�������ܹ�����һ���˿ں�,�����Ķ��ʹ������ʱ,������鱨�Ķε�Ŀ�Ķ˿ں�,�����䶨����Ӧ�����֡�
1:�����ӵĶ�·�������·�ֽ�

һ��UDP��������һ����Ԫ��ȫ���ʶ��,�ö�Ԫ�����һ��Ŀ��IP��ַ��һ��Ŀ�Ķ˿ڡ�
���,�������UDP���Ķ��в�ͬ��ԴIP��ַ������Դ�˿ں�,��������ͬ��Ŀ��IP��ַ��Ŀ�Ķ˿�,��ô���������Ķν�ͨ����ͬ��Ŀ�����ֱ�������ͬ�Ľ���
�ٸ�🌰

p3�Ķ˿���6428,p2��p1������ͬ�Ľ��������Ҫ��p3����UDP����,��Ҫ�����Լ���Դ�˿ںź�Ŀ�Ķ˿ںš�
��ôԴ�˿ںŵ��ô���ʲô��?��Ҫ��������Ϊ ���ص�ַ,Ҳ����p2��������p1 �� p3������
2:�������ӵĶ�·�������·�ֽ�
TCP��UDP��һ��ϸ�IJ�����:TCP��������һ����Ԫ��(ԴIP��ַ,Դ�˿ں�, Ŀ��IP��ַ,Ŀ�Ķ˿ں�)����ʶ�ġ�

�ر���UDP��ͬ����,�������в�ͬԴIP��ַ��Դ�˿ںŵ���TCP���Ķν�������������ͬ������
�ٸ�🌰

����C��Ϊ������,����A���佨����һ��HTTP�Ự,����B���佨��������HTTP�Ự,��̨�������������Լ�Ψһ��IP��ַ������A������B��Դ�˿ں�����ͬ��,�ⲻ������,��ΪB����IP��ַ�ܹ��ֱ档
3:web��������TCP
�������ܹ�����ԴIP��ַ��Դ�˿ں����������Բ�ͬ�ͻ��ı��Ķ�
����ͼʾ�Dz�ͬ���߳̽�����TCP����

4:�����������ҪЭ�����
�û����ݱ�Э�� UDP (User Datagram Protocol)
��������� TCP (Transmission Control Protocol)
�����Ե�����ʵ����ͨ��ʱ���͵����ݵ�λ��������Э�����ݵ�Ԫ TPDU (Transport Protocol Data Unit)��TCP ���͵����ݵ�λЭ���� TCP ���Ķ�(segment),��UDP ���͵����ݵ�λЭ���� UDP ���Ļ��û����ݱ���

��������������:UDP
1:UDP����
UDP(�û����ݱ�Э��,User Datagram Protocol),��ֻ�����������Э���ܹ��������ٹ���,���˶�·���úͶ�·�ֽ⼰һЩ��������,������û�����κζ��������Ӧ�ó���ʹ�õ������Э����UDP,��Ӧ�ó�����ֱ����IP���ġ�
ͬʱ,UDPҲ��һ�������ӵ������Э��,��Ϊ��ʹ��UDPʱ,�ڷ��ͱ��Ķ�֮ǰ,���ͷ��ͽ��շ��������ʵ��֮��û�н�������,��ν������,���Ƿ��ͷ��ͽ��շ�ͨ������һЩ�ض��ı��Ķ�������ȷ��,�Ӷ�Ϊ����������
UDPΪ��������Ϻ�Ӧ�ò������ṩ��һ���Ľӿڡ�UDPֻ�ṩ���ݵIJ��ɿ�����,��һ����Ӧ�ó������������ݷ��ͳ�ȥ,�Ͳ��������ݱ���(����UDP�Dz��ɿ������ݱ�Э��),Ҳ��Ҫ����շ��ظ����ճɹ�ȷ��,Ҳ�����ط�����,���ṩ��������,�����ṩӵ�����ơ�UDP��IP���ݱ���ͷ�����������˸��ú�����У��(�ֶ�)
��Ҫ�ص�:
- ������, ��������֮ǰ����Ҫ��������,��˼����˿����ͷ�������֮ǰ��ʱ�ӡ�
- ʹ�þ����Ŭ������, ������֤�ɿ�����,�����������Ҫά�ָ��ӵ�����״̬����
- ������, UDP ��Ӧ�ò㽻�����ı���,�Ȳ��ϲ�,Ҳ�����,���DZ�����Щ���ĵı߽硣UDP һ�ν���һ�������ı��ġ�
- û��ӵ������, ���������ֵ�ӵ������ʹԴ�����ķ������ʽ��͡����ijЩʵʱӦ���Ǻ���Ҫ�ġ����ʺ϶�ý��ͨ�ŵ�Ҫ��
- ֧��һ��һ��һ�Զࡢ���һ�Ͷ�Զ�Ľ���ͨ����
- �ײ�����С, ֻ�� 8 ���ֽ�,�� TCP �� 20 ���ֽڵ��ײ�Ҫ�̡�
���е�������Ӧ�ü�������������Э��:
| Ӧ�� | ҽ�ò�Э�� | ���������Э�� |
|---|---|---|
| �����ʼ� | SMTP | TCP |
| Զ���ն˷��� | Telnet | TCP |
| Web | HTTP | TCP |
| �ļ����� | FTP | TCP |
| Զ���ļ������� | NFS | ͨ��UDP |
| ��ʽ��ý�� | ͨ��ר�� | UDP��TCP |
| �������绰 | ͨ��ר�� | UDP��TCP |
| ������� | SNMP | ͨ��UDP |
| ����ת�� | DNS | ͨ��UDP |
ʹ��UDP��Ӧ��Ҳ����ͨ������ȷ�����ش�������ʵ�ֿɿ����ݴ��䡣
2:UDP���Ķνṹ
����ͼ���Կ���,UDP�ײ�ֻ��4���ֶ�,ÿ���ֶ��������ֽ����,һ��8�ֽڴ�С��
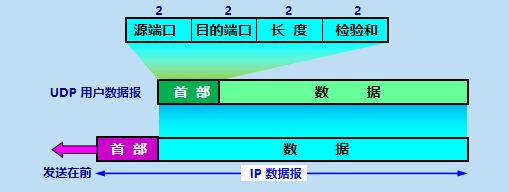
- Դ�˿ں��DZ���(�ͻ���)��Ӧ�ó������������Ӧ�Ķ˿ں�,�������˿����ô˶˿ں���ͻ��˷������ݡ�
- Ŀ�Ķ˿ں��Ƿ�����ϵ�Ӧ�ý��̵���������Ӧ�Ķ˿ں�,����HTTP��������80�˿ڡ�
- ����ָ�����ײ������ݲ��ֵ�UDP���Ķε��ܳ���,��λΪ�ֽ�,���ײ�+���ݡ�
- ������ṩ�˲������,�����������ȷ����UDP���Ķδ�Դ����Ŀ��ʱ,���еı����Ƿ����˸ı䡣��ʵ��,��������ʱ,����UDP���Ķ����껹ʹ����IP�ײ���һЩ�ֶΡ�ע��,��ֻ�ܼ�һ�����Ķη����˴���,�������ܾ����������
3:UDP�����
�ٸ�🌰
���������� 3 �� 16 ���ص���,�ֱ�����
0110011001100000
0101010101010101
1000111100001100
��һ��:�� 3 �� 16 ���ص����������
0110 0110 0110 0000 + 0101 0101 0101 0101 + 1000 1111 0000 1100 = 0100 1010 1100 0010 1
ע��,�����һ�μӷ��Ĺ�����,�����˻ؾ�(��ν ���ؾ��� ���ǵ����� 16 ���صļӷ������ʱ��,�����λ�� 17λ,�� 17 λ�ͺ� 16 λ���мӷ�������),������,���˵� 17 λ,Ҫ������ 17 λ

����������ӵõ�

��ʱ��
1 + 0100 1010 1100 0001 = 0100 1010 1100 0010
�ڶ���:�Ժͽ��з�������
0100 1010 1100 0010 �ķ��� 1011 0101 0011 1101
������:�����ֵ����У�����
���IJ�:�ڽ��շ���,��ȫ���� 4 �� 16���ص���(������У���)����һ��,û�в���Ļ�,���� 1111 1111 1111 1111
4:UDP������
1��Ӧ�ò��ܸ��÷�����Ҫ���͵����ݺͷ���ʱ�䡣
Ϊʲô����UDP��Ӧ�ò��ܸ��õؿ��Ʒ��͵����ݺ�ʱ����?��ΪUDPֻ�ṩ����������ٵķ���,���Ե�����Ӧ�ý��������ݴ��ݸ�UDPʱ,UDP���ϾͻὫ�����ݴ����UDP���Ķ�,�����������������,�Ӷ������ݷ��ͳ�ȥ���෴,����TCP�ṩ�˸��ֵĻ���,�ر���ӵ������,�Ա���Դ��Ŀ���������һ���������·��÷dz�ӵ��ʱ,���������TCP���ͷ�,�Ӷ����������绰����Ƶ����֮���ʵʱӦ�����ܱ�úܲ����,TCP��������ط����ݱ��Ķ�ֱ��Ŀ�������յ��˱��IJ�����ȷ��,������ ���ܿɿ��Ľ�����Ҫ����ʱ�䡣TCP����Щ����,����һЩʵʱӦ����˵ͨ���Dz��ʺϵ�,��Ϊ����ͨ��Ҫ�������ķ������ʷ�������,��������ֵ��ӳٱ��ĵĴ���,��������������һЩ���ݶ�ʧ,����û�ñ�Ҫʹ��TCP,ʹ��TCP�������Ӷ���ĸ�����
2���������ӽ���
������������,UDP��һ�������ӵ������Э��,��TCP�ڿ�ʼ���ݴ���֮ǰҪ�����������֡�UDP��������һ�������ӵ�Э��,���Կ��Բ���Ҫ�κ������ɽ������ݴ���,������������뽨�����ӵ�ʱ�ӡ�����DNS������UDP֮�϶�����TCP֮��,��Ϊ���DNS������TCP֮��,�������Ҫ������������Ӷ���������������ʱ,�Ӷ���DNS���еú�����
3��������״̬
TCP�������ṩ���ֿɿ�����ķ���,��Ҫ�ڶ�ϵͳ��ά������״̬��������״̬�������պͷ��ͻ��桢ӵ�����Ʋ����������ȷ����ŵȲ�������UDP��ά������״̬,Ҳ��������Щ���������,ʹ��UDP�ķ�������֧�ָ���Ļ�ͻ�����
4�������ײ�����С
����UDP�ṩ�ķ�����,ֻ�ṩ��·�ֽ�Ͷ�·���ú�У�鹦��,�������ײ��ֶ���,ֻ��8���ֽ�,��TCP���ײ���20���ֽڡ�
�ġ��ɿ����ݴ���ԭ��
�ɿ����ݴ���:Ϊ�ϲ�ʵ���ṩһ���ɿ����ŵ����д���,�����������ŵ�,�������ݱ��ز����ܵ�����ʧ,���������ݶ��ǰ���˳����н�����
IP�������ṩ���Dz��ɿ��Ĵ���:
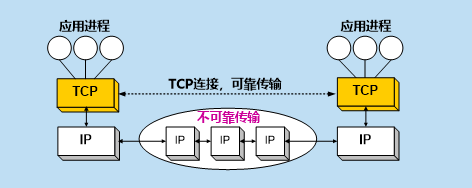
����Ĵ��������ص�:
- �����ŵ������������
- ���ܷ��ͷ��Զ����ٶȷ�������,���շ��������ü������յ������ݡ�
�����������봫��������,����Ҫ��ȡ�κδ�ʩ���ܹ�ʵ�ֿɿ����䡣Ȼ��ʵ�ʵ����綼���߱�����������������,����ʹ��һЩ�ɿ����ݴ���Э��(reliable data transfer protocol),�ڲ��ɿ��Ĵ����ŵ�ʵ�ֿɿ����䡣
1:ֹͣ�ȴ�Э��
��ֹͣ�ȴ�������ÿ������һ�������ֹͣ����,�ȴ��Է���ȷ�ϡ����յ�ȷ�Ϻ��ٷ�����һ�����顣ȫ˫��ͨ�ŵ�˫�����Ƿ��ͷ�Ҳ�ǽ��շ���
1.������

2.���ֲ��
�ڽ��շ� B ������������:
-
B ���� M1 ʱ�����˲��,�Ͷ��� M1,����ʲôҲ����(��֪ͨ A �յ��в���ķ���)��
-
M1 �ڴ�������ж�ʧ��,��ʱ B ��Ȼʲô����֪��,Ҳʲô��������
�������������,B �����ᷢ���κ���Ϣ,��A�������ط�����,ֱ��B��ȷ����Ϊֹ,��������ʵ�ֿɿ�ͨ�š�
A���֪�� B �Ƿ���ȷ�յ��� M1 ��?
�������:��ʱ�ش� A Ϊÿһ���ѷ��͵ķ��鶼������һ����ʱ��ʱ����AֻҪ�ڳ�ʱ��ʱ������֮ǰ�յ�����Ӧ��ȷ��,�ͳ����ó�ʱ��ʱ��,����������һ������ M2,��A�ڳ�ʱ��ʱ���涨ʱ����û���յ�B��ȷ��,����Ϊ��������ʧ,���ط��÷��顣
����:��������ȷ����B,��B���͵�ȷ�϶�ʧ���ӳ���,Aδ�յ�B��ȷ��,�ᳬʱ�ط���B ���ܻ��յ��ظ��� M1��B���֪���յ����ظ��ķ���,��Ҫ������?
�������:���
AΪÿһ�����͵ķ��鶼���б�š���B�յ��˱����ͬ�ķ���,����Ϊ�յ����ظ�����,���ظ��ķ���,������ȷ�ϡ�
BΪ���͵�ȷ��Ҳ���б��,ָʾ��ȷ���Ƕ���һ�������ȷ�ϡ�A����ȷ�ϼ�����,����ȷ�����Ƕ���һ�������ȷ��,�����ط����͡���Ϊ�ظ���ȷ��,���䶪����

- ȷ�϶�ʧ��ȷ�ϳٵ�
ȷ�϶�ʧ:
�� B �����͵Ķ� M1 ��ȷ�϶�ʧ��,��ô A ���趨�ij�ʱ�ش�ʱ���ڲ����յ�ȷ��,�� A
����֪��:���Լ����͵ķ����������ʧ��,���� �� B ���͵�ȷ�϶�ʧ�ˡ���� A �ڳ�ʱ��ʱ�����ں��Ҫ�ش� M1��
�ٶ� B���յ����ش��ķ��� M1����ʱ B Ӧ��ȡ�����ж�:
��һ,��������ظ��ķ��� M1,�����ϲ㽻����
�ڶ�,�� A����ȷ�ϡ�������Ϊ�Ѿ�����ȷ�ϾͲ��ٷ���,��Ϊ A ֮�����ش� M1 �ͱ�ʾ A û���յ��� M1 ��ȷ�ϡ�
ȷ�ϳٵ�:
���������û�г��ֲ��,�� B �Է��� M1 ��ȷ�ϳٵ��ˡ�A ���յ��ظ���ȷ�ϡ����ظ���ȷ�ϵĴ����ܼ�:���º�Ͷ�����B ��Ȼ���յ��ظ��� M1,����ͬ��Ҫ�����ظ��� M1,���ش�ȷ�Ϸ��顣

2:��ˮ�߿ɿ����ݴ���Э��
������ʱ�� RTT Զ���ڷ��鷢��ʱ�� TD ʱ,�ŵ��������ʾͻ�dz��͡��������ش�,��Դ������õ�������Ϣ��˵,�ŵ��������ʾͻ�Ҫ���͡�
Ϊ����ߴ���Ч��,���ͷ����Բ�ʹ�õ�Ч�ʵ�ֹͣ�ȴ�Э��,���Dz�����ˮ�ߴ��䡣
��ˮ�ߴ���:���Ƿ��ͷ����������Ͷ������,����ÿ����һ�������ͣ�������ȴ��Է���ȷ�ϡ�������ʹ�ŵ���һֱ�����ݲ���ϵش��͡������ŵ���һֱ�����ݲ���ϵش���,���ִ��䷽ʽ�ɻ�úܸߵ��ŵ������ʡ�

��ˮ��:���Ե�ͣ��ʽ����,�������ͷ����Ͷ�����������ȴ�ȷ�ϡ�����������Ӱ�졣
- ������ŷ�Χ,ÿ����һ����š�
- ���ͷ��ͽ��շ���Ҫ���������顣
- ������ʧ�����ӳٵ����ݷ���:����N��(Go Back N,GBN)����ѡ���ش�(Selective Repeat,SR)��
3:����N��
��ˮ����δȷ�ϵķ��������ó���N����N����Ϊ���ڳ��ȡ�GBNЭ��Ҳ������������Э��
- �����(base):Ϊ�����δȷ�Ϸ������š�
- ��һ���(nextseqnum):Ϊ��С��δʹ�õ����(����һ��������������)

����ͼ��ʾ����ŷ�Χ��Ϊ4�Ρ���[0,base-1]���ڵ���Ŷ�Ӧ���Ѿ����Ͳ���ȷ�ϵķ��顣[base,nextseqnum-1]���ڵ���Ŷ�Ӧ���Ѿ����͵�δ��ȷ�ϵķ��顣[nextseqnum,base+N-1]���ڵ������������ЩҪ���������͵ķ���,��������������ϲ�Ļ��������ڻ����base+N������Dz���ʹ�õ�,ֱ����ǰ��ˮ����δ��ȷ�ϵķ����ѵõ�ȷ��Ϊֹ��
GBN���ͷ�������Ӧ�������͵��¼�:
- �ϲ�ĵ���:���ϲ����rdt_send()ʱ,Ҫ��ⷢ�ʹ����Ƿ����������δ��,����һ�����鷢�͡��������,�������ݸ��ϲ�,Ȼ���ϲ���ܹ�һ������ԡ�
- �յ�һ��ACK����GBNЭ����,�����Ϊn�ķ����ȷ�ϲ�ȡ�ۻ�ȷ��(cumulative
acknowledgment)�ķ�ʽ,�������շ�����ȷ�յ����Ϊn����ǰ�Ұ���n���ڵ����з��顣 - ��ʱʱ�䡣������ֳ�ʱ,���ͷ��ش������ѷ��͵���δ��ȷ�ϵķ��顣
GNB���շ�������ܷ���,������������÷��顣

4:ѡ���ش�
��GBN��,��������IJ���ܹ�����GBN�ش��������顣
ѡ���ش�(SR)Э��ͨ���÷��ͷ����ش���Щ�������ڽ��շ������ķ�������ⲻ��Ҫ���ش���

5:����������
��������Э��Ƚϸ���,�� TCP Э��ľ������ڡ����ͷ�ά�ֵķ��ʹ���,����������:λ�ڷ��ʹ����ڵķ��鶼���������ͳ�ȥ,������Ҫ�ȴ��Է���ȷ�ϡ�����,�ŵ������ʾ�����ˡ����� ARQ Э��涨,���ͷ�ÿ�յ�һ��ȷ��,�Ͱѷ��ʹ�����ǰ����һ�������λ�á�
- ���ͷ��ͽ��շ��ֱ�ά�ַ��ʹ��ںͽ��մ���,
- ���ͷ����ͺ�,���յ�ȷ��ǰ,���ʹ��ڻ��С,
- ���ܷ����յķ�����ȷʱ,��ǰ�������մ���
- ���ͷ��յ�ȷ�Ϻ�,��ǰ�������ʹ���,���ڱ��

6:����ARQ��
���ͷ�һ�ο��Է���������顣ʹ�û�������Э����Ʒ��ͷ��ͽ��շ����ܷ��ͺͽ��յķ���������ͱ��,ÿ�յ�һ��ȷ��,���ͷ��Ͱѷ��ʹ�����ǰ������

���շ�һ������ۻ�ȷ�ϵķ�ʽ,���û���N(Go-Back-N)���������ش���
�ۻ�ȷ��:
���շ�һ������ۻ�ȷ�ϵķ�ʽ�������ض��յ��ķ����������ȷ��,���Ƕ�������һ�����鷢��ȷ��,�����ͱ�ʾ:���������Ϊֹ�����з��鶼����ȷ�յ��ˡ�
�ŵ�:����ʵ��,��ʹȷ�϶�ʧҲ�����ش���
ȱ��:�������ͷ���ӳ�����շ��Ѿ���ȷ�յ������з������Ϣ��

���� ARQ Э����ֹͣ�ȴ�Э��:

7:�ɿ�������Ƽ�����;���ܽ�
| ���� | ��;��˵�� |
|---|---|
| ����� | ���ڼ��һ����������еı��ش��� |
| ��ʱ�� | ���ڳ�ʱ/�ش�һ������ |
| ��� | ���ڶԴӷ��ͷ�������շ������ݷ��鰴˳����,�����ý��շ�������ʧ������ķ��� |
| ȷ�� | ���ܷ����ڸ��߷��ͷ�һ�������һ������ѱ���ȷ�ؽ��յ��� |
| ��ȷ�� | ���շ����߷��ͷ�ij������δ�������ؽ���,ͨ�����Ÿ÷������� |
| ���ڡ���ˮ�� | ���ڽ����ͷ��������ݱ���Χ����һ����Χ�ڵķ���,��ˮ���������ӷ��ͷ��ŵ������� |
�塢�������ӵ�����:TCP
TCP���������������������ӵĿɿ�������Э�顣
1:TCP��Ҫ�ص�
- TCP���������ӵ�(connection-oriented),������Ϊ��һ��Ӧ�ý��̿��Կ�ʼ����һ��Ӧ�ý��̷�������֮ǰ,���������̱�����������֡��������DZ��������ijЩԤ�����Ķ�,�Խ���ȷ�����ݴ���IJ�����
- TCP�����ṩ����ȫ˫������(full-duplex service):��ͨ��˫���������շ���Ϣ��
- TCP�����ǵ�Ե�(point-to-point)��,���ڵ������ͷ��뵥�����շ�֮������ӡ���ν�ಥ,����һ�η��Ͳ�����,��һ�����շ������ݴ���������շ�,���������TCP��˵�Dz����ܵġ�
- TCP�Ὣ���������������ӵ�TCP����(sender buffer)��,֮��ͻ�ʱ��ʱ�شӻ�����ȡһ�����ݷ��͡�
- TCP���Դӷ��ͻ���ȡ�������뱨�Ķ��е�������������������ij���(Maximum Segment Size,MSS)��MSS���ݱ����������͵������·��֡����(������䵥Ԫ(Maximum Transmission Unit,MTU))���á�
- TCP�����ֽ���,��ȻӦ�ó���� TCP �Ľ�����һ��һ�����ݿ�,�� TCP ��Ӧ�ó������������ݿ��ɽ�����һ�����ṹ���ֽ���
2:TCP����
TCP ��������Ϊ������ij���,ÿһ�� TCP �����������˵㡣TCP ���ӵĶ˵㲻������,����������IP ��ַ,����Ӧ�ý���,Ҳ����������Э��˿�,�����ӵĶ˵�������� (socket) ���ڡ�

����(socket):�ɶ˿ں�ƴ�ӵ� (contatenated with) IP ��ַ����
����:���� socket = (192.169.1.20 : 2028) ÿһ�� TCP
����Ψһ�ر�ͨ�����˵������˵�(����������)��ȷ������:
TCP ���Ӿ�����Э���������ṩ��һ�ֳ���,�����ӵĶ˵��Ǹ��ܳ��������,��(IP ��ַ:�˿ں�)��ͬһ�� IP ��ַ�����ж����ͬ��
TCP ����,ͬһ���˿ں�Ҳ���Գ����ڶ����ͬ�� TCP �����С�


Socket �ж��ֲ�ͬ����˼:
- Ӧ�ñ�̽ӿ� API ��Ϊ socket API, ���Ϊ socket��
- socket API ��ʹ�õ�һ��������Ҳ���� socket��
- ���� socket �����Ķ˵��Ϊ socket��
- ���� socket ����ʱ�䷵��ֵ��Ϊ socket ������,�ɼ��Ϊ socket��
- �ڲ���ϵͳ�ں�������Э��� Berkeley ʵ��,��Ϊ socket ʵ�֡�
3:TCP���Ķνṹ

| �ֶ��� | ռλ��С | ���� |
|---|---|---|
| Դ�˿ں�Ŀ�Ķ˿��ֶ� | ��ռ2�ֽ� | �˿����������Ӧ�ò�ķ���ӿ�,�����ĸ��úͷ��ù��ܶ�Ҫͨ���˿ڲ���ʵ�֡� |
| ����ֶ� | ռ 4 �ֽ� | TCP �����д��͵��������е�ÿһ���ֽڶ�����һ�����,����ֶε�ֵ��ָ���DZ����Ķ������͵����ݵĵ�һ���ֽڵ���š� |
| ȷ�Ϻ��ֶ� | ռ 4 �ֽ� | �������յ��Է�����һ�����Ķε����ݵĵ�һ���ֽڵ���� |
| ����ƫ��(���ײ�����) | ռ 4 λ | ָ�� TCP ���Ķε�������ʼ������ TCP ���Ķε���ʼ���ж�Զ��������ƫ�ơ��ĵ�λ�� 32 λ��(�� 4 �ֽ�Ϊ���㵥λ) |
| �����ֶ� | ռ 6 λ | ����Ϊ���ʹ��,��ĿǰӦ��Ϊ 0 |
| ���� URG | ռ1λ | �� URG Ϊ 1 ʱ,��������ָ���ֶ���Ч��������ϵͳ�˱��Ķ����н�������,Ӧ���촫�� |
| ȷ�� ACK | ռ1λ | ֻ�е� ACK =1 ʱȷ�Ϻ��ֶβ���Ч���� ACK =0 ʱ,ȷ�Ϻ���Ч |
| ���� PSH | ռ1λ | ���� TCP �յ� PSH = 1 �ı��Ķ�,�;���ؽ�������Ӧ�ý���,�����ٵȵ��������涼�����˺������Ͻ��� |
| ��λ RST | ռ1λ | �� RST=1 ʱ,���� TCP �����г������ز��(��������������������ԭ��),�����ͷ�����,Ȼ�������½����������ӡ� |
| ͬ�� SYN | ռ1λ | ͬ�� SYN = 1 ��ʾ����һ��������������ӽ��ܱ��� |
| ��ֹ FIN | ռ1λ | �����ͷ�һ�����ӡ�FIN=1 �����˱��Ķεķ��Ͷ˵������ѷ������,��Ҫ���ͷ��������� |
| �����ֶ� | ռ 2 �ֽ� | �����öԷ����÷��ʹ��ڵ�����,��λΪ�ֽ� |
| ����� | ռ 2 �ֽ� | ������ֶμ���ķ�Χ�����ײ��������������֡��ڼ�������ʱ,Ҫ�� TCP ���Ķε�ǰ����� 12 �ֽڵ�α�ײ� |
| ����ָ���ֶ� | ռ 16 λ | ָ���ڱ����Ķ��н������ݹ��ж��ٸ��ֽ�(�������ݷ��ڱ����Ķ����ݵ���ǰ��) |
| ѡ���ֶ� | ���ȿɱ� | TCP ���ֻ�涨��һ��ѡ��,������Ķγ��� MSS��MSS ���߶Է� TCP:���ҵĻ������ܽ��յı��Ķε������ֶε������ MSS ���ֽڡ� |
| ��������ѡ�� | ռ 3 �ֽ� | ������һ���ֽڱ�ʾ��λֵ S���µĴ���ֵ���� TCP �ײ��еĴ���λ������ (16 + S),�൱�ڰѴ���ֵ�����ƶ� S λ����ʵ�ʵĴ��ڴ�С�� |
| ʱ���ѡ�� | ռ 10 �ֽ� | ����Ҫ���ֶ�ʱ���ֵ�ֶ�(4 �ֽ�)��ʱ������ͻش��ֶ�(4 �ֽ�) |
| ѡ��ȷ��ѡ�� | ||
| ����ֶ� | ��ȷ������ | ����Ϊ��ʹ�����ײ������� 4 �ֽڵ������� |
MSS (Maximum Segment Size)�� TCP ���Ķ��е������ֶε���ȡ������ֶμ��� TCP �ײ��ŵ��������� TCP ���Ķ�,����,MSS�ǡ�TCP ���Ķγ��ȼ�ȥ TCP �ײ����ȡ���
4:����ʱ��Ĺ����볬ʱ
TCP���ó�ʱ/�ش��������������ĶεĶ�ʧ���⡣��˳�ʱ���������ڸ����ӵ�����ʱ��(RTT)��
��������ʱ��
-
TCPʹ��������������ʱ�䡣���Ķε�����RTT(��ʾΪSampleRTT)���Ǵ�ij���Ķα��������Ըñ��Ķε�ȷ�ϱ��յ�֮���ʱ����������TCP����Ϊ���ش��ı��Ķμ���SampleRTT��
-
TCPά��һ��SampleRTT��ֵ(��ΪEstimatedRTT)���Կ�·������ӵ���Ͷ�ϵͳ���صı仯��
EstimatedRTT = ( 1 ? �� )? EstimatedRTT + �� �� SampleRTTEstimatedRTT
����ƽ��ͨ��Ϊ��Ϊָ����Ȩ�ƶ�ƽ��(Exponential Weighted Moving Average,EWMA)����������Ľ���ֵΪ0.125��
-
���˹���RTT,����RTT�ı仯Ҳ���м�ֵ��,RTT���DecRTT����,�� ���Ƽ�ֵΪ0.25��
DevRTT = ( 1 ? �� )? DevRTT + �� ? �O SampleRTT ? EstimatedRTT �O
���ú�����ʱ�ش���ʱ���
- ��ʱ���TimeoutIntervalΪ
TimeoutInterval = EstimatedRTT + 4 ? DevRTT
5:�ɿ����ݴ���
-
TCP��IP���ɿ��ľ�����Ϊ�ķ���֮�ϴ�����һ���ɿ����ݴ������(reliable data transfer service)��ȷ��һ�����̴�����ܻ����ж���������������������������ࡢ������������������ֽ��������ӵ���һ����ϵͳ���ͳ����ֽ�������ȫ��ͬ�ġ�
-
TCP�������뷢�ͺ��ش��йص���Ҫ�¼�:
- ���ϲ�Ӧ�ó����������:һ�����յ�����,TCP�����ݷ�װ��һ��������,������IP��
- ��ʱ:TCPͨ���ش�����ʱ�ı�������Ӧ��ʱʱ��,��������ʱ����
- �յ�ACK:TCP�Ὣ�յ���ACK������SendBase(����δ��ȷ�ϵ��ֽ����)���бȽ�,��������Ӧ�Ķ�����
-
TCPÿ���ش����Ὣ��һ�εij�ʱ���TimeoutInterval����Ϊ֮ǰ������,������֮ǰ�о�ֵ��ƫ������Ĺ�ʽ.
-
TCPʹ������ACK(duplicate ACK)�����ٴ�ȷ��ij�����Ķε�ACK,�����ͷ���ǰ�Ѿ��յ��Ըñ��Ķε�ȷ��,���Ǻ��������ݿ��ܶ�ʧ,���Ҫ�ٴη��͡�
-
TCP�IJ���ָ������ǻ���N��GBN��ѡ���ش�SR�Ļ���塣
5.1���ֽ�Ϊ��λ�Ļ�������
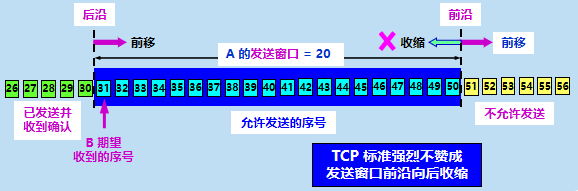
TCP ʹ����ˮ�ߴ���ͻ�������Э��ʵ�ָ�Ч���ɿ��Ĵ���,TCP �Ļ������������ֽ�Ϊ��λ�ġ�
���ͷ� A �ͽ��շ� B �ֱ�ά��һ�����ʹ��ں�һ�����մ��ڡ����ʹ��ڱ�ʾ:��û���յ�ȷ�ϵ������,���������Ѵ����ڵ�����ȫ�����ͳ�ȥ�����մ��ڱ�ʾ:ֻ�����������봰���ڵ����ݡ�
���� B �����Ĵ���ֵ,A ������Լ��ķ��ʹ��ڡ�
���ʹ��ڱ�ʾ:��û���յ� B ��ȷ�ϵ������,A ���������Ѵ����ڵ����ݶ����ͳ�ȥ��
���ʹ����������ű�ʾ�������͵���š�
��Ȼ,����Խ��,���ͷ��Ϳ������յ��Է�ȷ��֮ǰ���������������,������ܻ�ø��ߵĴ���Ч�ʡ�




���ͻ���:

���ջ���:

���ͻ�������ջ��������:
- ���ͻ���������ʱ��ŷ���Ӧ�ó��������ͷ� TCP �����͵����ݺ�TCP �ѷ��ͳ�����δ�յ�ȷ�ϵ����ݡ�
- ���ջ���������ʱ���:����ġ�����δ������Ӧ�ó����ȡ�����ݺͲ���������ݡ�
5.2��ʱ�ش�ʱ��ѡ��
�ش������� TCP ������Ҫ����ӵ�����֮һ��TCP ÿ����һ�����Ķ�,�Ͷ�������Ķ�����һ�μ�ʱ��,ֻҪ��ʱ�����õ��ش�ʱ�䵽����û���յ�ȷ��,��Ҫ�ش���һ���ĶΡ��ش�ʱ���ѡ���� TCP ��ӵ�����֮һ��
����ʱ�ӵķ���ܴ�:
 TCP ��ʱ�ش�ʱ������:
TCP ��ʱ�ش�ʱ������:
- ����ѳ�ʱ�ش�ʱ�����õ�̫��,�ͻ�����ܶ౨�ĶεIJ���Ҫ���ش�,ʹ���縺������
- �����ѳ�ʱ�ش�ʱ�����õù���,����ʹ����Ŀ���ʱ������,�����˴���Ч�ʡ�
- TCP ������һ������Ӧ�㷨,����¼һ�����Ķη�����ʱ��,�Լ��յ���Ӧ��ȷ�ϵ�ʱ�䡣������ʱ��֮����DZ��Ķε�����ʱ�� RTT��
��Ȩƽ������ʱ��:
TCP������RTT��һ����Ȩƽ������ʱ��RTTS(���ֳ�Ϊƽ��������ʱ��)�� ��һ�β����� RTT ����ʱ,RTTSֵ��ȡΪ���������� RTT ����ֵ���Ժ�ÿ������һ���µ� RTT ����,�Ͱ���ʽ���¼���һ�� RTTS:
ʽ��,0 �ܦ� �� 1���� �� �ܽӽ�����,��ʾ RTT ֵ���½�������ѡ�� ? �ӽ��� 1,���ʾ RTT ֵ���½Ͽ졣 RFC 6298
�Ƽ��� �� ֵΪ 1/8,�� 0.125��

��ʱ�ش�ʱ��RTO
RTO (Retransmission Time-Out) Ӧ�Դ�������ó��ļ�Ȩƽ������ʱ�� RTTS�� RFC6298 ����ʹ����ʽ���� RTO:
RTTD �� RTT ��ƫ��ļ�Ȩƽ��ֵ�� RFC 6298 ������������RTTD ����һ�β���ʱ, RTTD ֵȡΪ�������� RTT ����ֵ��һ�롣���Ժ�IJ�����,��ʹ����ʽ�����Ȩƽ���� RTTD :
���Ǹ�С�� 1 ��ϵ��,���Ƽ�ֵ�� 1/4,�� 0.25��
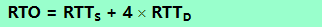
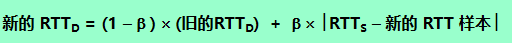
����ʱ�� (RTT) �IJ����൱����
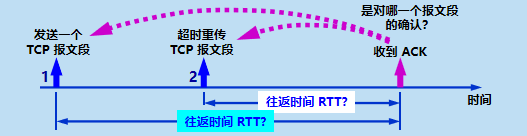
TCP ���Ķ� 1 û���յ�ȷ�ϡ��ش�(�����Ķ� 2)��,�յ���ȷ�ϱ��Ķ� ACK��
����ж���ȷ�ϱ��Ķ��Ƕ�ԭ���ı��Ķ� 1 ��ȷ��,���Ƕ��ش��ı��Ķ� 2 ��ȷ��?
Karn �㷨: �ڼ���ƽ������ʱ�� RTT ʱ,ֻҪ���Ķ��ش���,�Ͳ�����������ʱ�������������ó��ļ�Ȩƽ��ƽ������ʱ�� RTTS�ͳ�ʱ�ش�ʱ�� RTO�ͽ�ȷ������,���������µ����⡣�����Ķε�ʱ��ͻȻ�����˺ܶ�ʱ,��ԭ���ó����ش�ʱ����,�����յ�ȷ�ϱ��ĶΡ����Ǿ��ش����ĶΡ�������Karn �㷨,�������ش��ı��Ķε�����ʱ������������,��ʱ�ش�ʱ��������¡� ������ Karn �㷨: ���Ķ�ÿ�ش�һ��,�Ͱ� RTO����һЩ:
ϵ�� �� �ĵ���ֵ�� 2 �������ٷ������Ķε��ش�ʱ,�Ÿ��ݱ��Ķε�����ʱ�Ӹ���ƽ������ʱ�� RTT �ͳ�ʱ�ش�ʱ�� RTO����ֵ��ʵ��֤��,���ֲ��Խ�Ϊ������
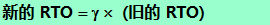
5.3ѡ��ȷ��ACK
����:���յ��ı��Ķ����,ֻ��δ�����,�м仹ȱ��һЩ��ŵ�����,��ô�ܷ��跨ֻ����ȱ�ٵ����ݶ����ش��Ѿ���ȷ������շ�������?���ǿ��Եġ�ѡ��ȷ�� SACK (Selective ACK) ����һ�ֿ��еĴ���������
���յ����ֽ�����Ų�����
TCP �Ľ��շ��ڽ��նԷ��������������ֽ�������Ų�����,������γ���һЩ���������ֽڿ顣
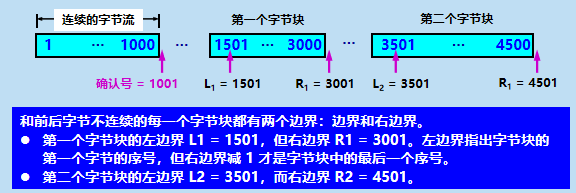
6:��������
- ���ڽ��շ�����һ�����ϴ�TCP�����ȡ����,�����շ����һֱ������,����ɽ��ջ��������
- TCPΪ����Ӧ�ó����ṩ���������Ʒ���(flow-control service)��������������Ŀ����ԡ�
- TCPͨ���÷��ͷ�ά��һ����Ϊ���մ���(congestion control)�ı������ṩ��������,ָ�����շ����ж��ٿ��õĻ���ռ䡣����TCP��ȫ˫��ͨ�ŵ�,����˫���Ķ�����ά��һ�����մ��ڡ�
- �����մ���ֵΪ0ʱ,���ͷ��Իᷢ��һ��ֻ��һ�ֽڵı��Ķ�,���ջᱻ���շ�ȷ��,���ջ��潫��ʼ���,���ҷ���һ����0�Ľ��մ���ֵ��
���ÿɱ䴰�ڽ����������ƾ��� A �� B �������ݡ������ӽ���ʱ,B ���� A:���ҵĽ��մ��� rwnd = 400(�ֽ�)����
���������ͼƬ����
���ܷ������� :
B �� A �������㴰�ڵı��Ķκ�,B �Ľ��ջ���������һЩ�洢�ռ䡣���� B �� A ������ rwnd = 400�ı��ĶΡ� ��������Ķ��ڴ������ж�ʧ�ˡ�A һֱ�ȴ��յ� B ���͵ķ��㴰�ڵ�֪ͨ,�� B Ҳһֱ�ȴ� A ���͵����ݡ�
���û��������ʩ,���ֻ���ȴ����������潫һֱ������ȥ�� Ϊ�˽���������, TCP Ϊÿһ����������һ��������ʱ��(persistence timer) �� ֻҪ TCP ���ӵ�һ���յ��Է����㴰��֪ͨ,�������ó�����ʱ����
��������ʱ�����õ�ʱ�䵽��,�ͷ���һ���㴰��̽�ⱨ�Ķ�(��Я�� 1 �ֽڵ�����),���Է�����ȷ�����̽�ⱨ�Ķ�ʱ���������ڵĴ���ֵ��
��������Ȼ����,���յ�������Ķε�һ�����������ó�����ʱ����
�����ڲ�����,�������Ľ��־Ϳ��Դ����ˡ�

7:TCP���ӹ���
��������
TCP �������ӵĹ��̽������֡�������Ҫ�ڿͻ��ͷ�����֮�佻������ TCP ���Ķ�,��֮Ϊ�������֡�����������������Ҫ��Ϊ�˷�ֹ��ʧЧ�����������Ķ�ͻȻ�ִ��͵���,�����������

- ��ͼ������B�� TCP �����������ȴ���������ƿ�TCB,�����ܿͻ����̵���������
- ����A �� TCP �� ����B �������������Ķ�,���ײ��е�ͬ��λ SYN = 1,��ѡ����� seq = x,������������ʱ�ĵ�һ�������ֽڵ������ x��
- ����B �� TCP �յ����������Ķκ�,��ͬ��,��ȷ�ϡ�����B ��ȷ�ϱ��Ķ���Ӧʹ SYN = 1,ʹ ACK = 1,��ȷ�Ϻ�ack = x + 1,�Լ�ѡ������ seq = y��
- ����A �յ��˱��Ķκ��� ����B ����ȷ��,�� ACK = 1,ȷ�Ϻ� ack = y + 1������A �� TCP֪ͨ�ϲ�Ӧ�ý���,�����Ѿ�������
- ����B �� TCP �յ����� A ��ȷ�Ϻ�,Ҳ֪ͨ���ϲ�Ӧ�ý���:TCP �����Ѿ�������
�ܽ��������ֵ�Ŀ�ľ���ȷ��ͨ��˫������������״̬,����֪���Է�������״̬��
������ɢ����ϯ,����TCP����Ҳ����ˡ�����һ��TCP���ӵ����������е��κ�һ��������ֹ�����ӡ������ӽ�����,�����еġ���Դ�������ͷš�
�Ĵλ���
TCP �����ͷŹ��̱Ƚϸ��ӡ����ݴ��������,ͨ�ŵ�˫�������ͷ�����,TCP �����ͷŹ������Ĵλ��֡�

- ���ݴ��������,ͨ�ŵ�˫�������ͷ����ӡ����� ����A ��Ӧ�ý��������� TCP ���������ͷű��Ķ�,��ֹͣ�ٷ�������,�����ر� TCP���ӡ�����A �������ͷű��Ķ��ײ���FIN = 1,�����seq = u,�ȴ� B ��ȷ�ϡ�
- ����B ����ȷ��,ȷ�Ϻ� ack = u+1,��������Ķ��Լ������ seq = v��TCP ����������֪ͨ�߲�Ӧ�ý��̡��� ����A ������B �����������Ӿ��ͷ���,TCP ���Ӵ��ڰ�ر�״̬������B ����������,����A ��Ҫ���ա�
- �� ����B �Ѿ�û��Ҫ�� ����A ���͵�����,��Ӧ�ý��̾�֪ͨ TCP �ͷ����ӡ�
- ����A �յ������ͷű��Ķκ�,���뷢��ȷ�ϡ� ��ȷ�ϱ��Ķ���ACK = 1,ȷ�Ϻ� ack = w + 1,�Լ������ seq = u +1��
�ܽ��Ĵλ��ֵ�Ŀ����ȷ��˫�����Ѿ��Ͽ����Ӳ��Ҹ��Ի����е����ݶ�������ϡ�
����A����ȴ� 2MSL ��ʱ��:
��һ,Ϊ�˱�֤ ����A ���͵����һ�� ACK ���Ķ��ܹ����� ����B
�ڶ�,��ֹ ����ʧЧ�����������ĶΡ������ڱ�������
�����ʱ��:
������ֹ��TCP���ӳ��ֳ�ʱ�ڵĿ��С������ʱ�� ͨ������Ϊ2Сʱ ��������������2Сʱ��û���յ��ͻ�����Ϣ,���ͷ���̽�ⱨ�ĶΡ���������10��̽�ⱨ�Ķ�(ÿһ�����75��)��û����Ӧ,�ͼٶ��ͻ����˹���,�������ֹ�����ӡ�
����ӵ������ԭ��
1:ӵ�����Ƶ�һ��ԭ��
��ij��ʱ��,����������ij��Դ�������˸���Դ�����ṩ�Ŀ��ò���,��������ܾ�Ҫ�仵�����������Ϊӵ�� (congestion)������:ϵͳ������
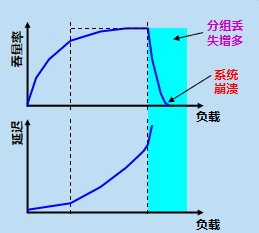
ӵ���������������Ƶ�����:

2:ӵ��ԭ�������
- �Ŷ�ʱ��:��������ĵ������ʽӽ���·����ʱ,���龭������Ŷ�ʱ�ӡ�
- �����ش�:�����ͷ���������ʱ��ʱ�����еIJ���Ҫ�ش�������·������������·������ת������Ҫ�ķ��鸱����
- �������:����һ��������һ��·��������ʱ,ÿ������·��������ת���÷��鵽�����÷����ʹ�õĴ����������ձ��˷ѵ��ˡ�
3:ӵ�����Ʒ���
-
�˵���ӵ������ :��ʹ�����д���ӵ��,��ϵͳҲ����ͨ����������Ϊ�Ĺ۲�(����鶪ʧ��ʱ��)���ƶ������Ƿ����ӵ���������û��Ϊ�����ӵ�������ṩ��ʾ֧�֡�
-
���縨����ӵ������:����㹹��(��·����)���ͷ��ṩ����������ӵ��״̬����ʾ������Ϣ�����ַ������Լ���һ����������ʾ��
���縨����ӵ�������ַ�Ϊ����
1.������·�����������ͷ���
2.·������ǻ���´ӷ��ͷ�������շ��ķ����е�ij���ֶ���ָʾӵ���IJ�����

�ߡ�TCPӵ������
�����Ѿ�֪��TCPΪ�����ڲ�ͬ�����ϵ���������֮���ṩ�˿ɿ��������TCP����һ���ؼ����־���ӵ�����ƻ��ơ�TCP����ʹ�ö˵���ӵ�����ƶ�����ʹ�����縨����ӵ������,��ΪIP�㲻���ϵͳ�ṩ��ʽ������ӵ������
TCP�����õķ�������ÿ�����ͷ���������֪��������ӵ���̶����������������ӷ������������ʡ����һ��TCP���ͷ���֪������Ŀ�ĵ�֮���·����û��ʲôӵ��,��TCP���ͷ������䷢������;������ͷ���֪���Ÿ�·����ӵ��,���ͷ��ͻή���䷢�����ʡ��������ַ����������������:
������1��һ��TCP���ͷ�����������������ӷ�������������?
- ͨ������ӵ������cwnd��ֵ��(cwnd��ӵ������(congestion window)�ǽ��շ�TCP����ʣ��Ŀռ�,rwnd�ǻ�������,�Ƿ��ͷ������������ڻ���N����ѡ���ش����Ǹ����ڡ�)
������2�� һ��TCP���ͷ���θ�֪�����д���ӵ��?
- �� �������¼��� ����ΪҪô���ֳ�ʱ,Ҫô�յ����������ACK��
- ���ֶ����¼�,���ͷ�����Ϊ·���ϳ�����ӵ����ָʾ��
������3�� �����ͷ���֪���˵��˵�ӵ��ʱ,�ú����㷨�ı��䷢��������?
- TCPӵ�������㷨(TCP congestion control algorithm)
TCPӵ�������㷨���������������֡�������������ӵ������IJ���������cwnd�ij����ϡ����ٻظ����Ƽ����֡���ά��һ����ֵthreshold,������С����ֵʱʹ��������,������ֵʱʹ��ӵ�����⡣
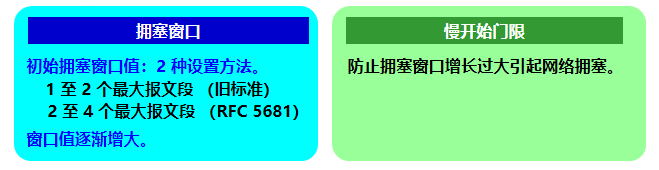
(1)����ʼ
����ʼ (Slow start)
Ŀ��:����ȷ������ĸ���������ӵ���̶ȡ�
�㷨��˼·:��С����������ӵ��������ֵ��
��������:
ӵ������ cwnd ���Ʒ���:��ÿ�յ�һ�����µı��Ķε�ȷ�Ϻ�,����ӵ�������������һ�� SMSS ����ֵ��
���� N ��ԭ��δ��ȷ�ϵġ������ڱ����յ���ȷ�ϱ��Ķ���ȷ�ϵ��ֽ����� ���ѿ���,�� N < SMSS ʱ,ӵ������ÿ�ε�������ҪС��SMSS�� �������ķ����������ͷ���ӵ������ cwnd,����ʹ����ע�뵽��������ʸ��Ӻ�����
���ͷ�ÿ�յ�һ�����±��Ķε�ȷ��(�ش��IJ�������)��ʹ cwnd �� 1��
ÿ����һ�������ִ�,ӵ�����ھͼӱ������ڴ�С��ָ������,����!
�����ִ�
ʹ������ʼ�㷨��,ÿ����һ�������ִ� (transmission round),ӵ������ cwnd �ͼӱ��� һ�������ִ���������ʱ����ʵ��������ʱ�� RTT�� ��������ʼ����״̬���� ssthresh,
����ʼ���� ssthresh ���÷�����:
- �� cwnd < ssthresh ʱ,ʹ������ʼ�㷨��
- �� cwnd > ssthresh ʱ,ֹͣʹ������ʼ�㷨������ӵ�������㷨��
- �� cwnd = ssthresh ʱ,�ȿ�ʹ������ʼ�㷨,Ҳ��ʹ��ӵ�������㷨��



(2)ӵ������
ӵ�������㷨(congestion avoidance) ˼·:
��ӵ������ cwnd ����������,�������ӵ����
ÿ����һ�������ִ�,ӵ������ cwnd = cwnd + 1��
ʹӵ������ cwnd �����Թ��ɻ���������
��ӵ�������,���С��ӷ����� (Additive Increase) ���ص㡣
�ڳ�ʱ֮ǰ,ÿ����һ�������ִξ�ʹ cwnd �� 1��
���������ӵ��ʱ:
����������ʼ�λ�����ӵ�������,ֻҪ���ͷ��ж��������ӵ��(�ش���ʱ����ʱ):
ssthresh = max(cwnd/2,2)
cwnd = 1 ִ������ʼ�㷨
Ŀ��:Ѹ�ټ����������͵������еķ�����,ʹ�÷���ӵ����·�������㹻ʱ��Ѷ����л�ѹ�ķ��鴦����ϡ�

(3)���ش�
���ش� (fast retransmit)
���ͷ�ֻҪһ���յ������ظ�ȷ��,��֪�����շ�ȷʵû���յ����Ķ�,���Ӧ�����������ش�(�������ش���),�����Ͳ�����ֳ�ʱ,���ͷ�Ҳ���ͻ�����Ϊ����������ӵ����
ʹ�ÿ��ش�����ʹ������������������Լ20%��
���ѿ���,���ش�����ȡ���ش���ʱ��,������ijЩ����¿��Ը����(�����)�ش���ʧ�ı��ĶΡ�
���ÿ��ش� FR (Fast Retransmission) �㷨�����÷��ͷ�����֪�������˸����ĶεĶ�ʧ��
���ش��㷨����Ҫ����շ���Ҫ�ȴ��Լ���������ʱ�Ž����Ӵ�ȷ��,����Ҫ��������ȷ��,��ʹ�յ���ʧ��ı��Ķ�ҲҪ�������������յ��ı��Ķε��ظ�ȷ�ϡ�

(4)��ָ�
��ָ� (fast recovery)
�����Ͷ��յ����������ظ���ȷ��ʱ,���ڷ��ͷ�������Ϊ����ܿ���û�з���ӵ��,������ڲ�ִ������ʼ�㷨,����ִ�п�ָ��㷨 FR (Fast Recovery) �㷨:
����ʼ���� ssthresh = ��ǰӵ������ cwnd / 2 ;
��ӵ������ cwnd = ����ʼ����ssthresh ;
��ʼִ��ӵ�������㷨,ʹӵ�����ڻ�������������
����ʼ��ӵ�������㷨��ʵ�־���:
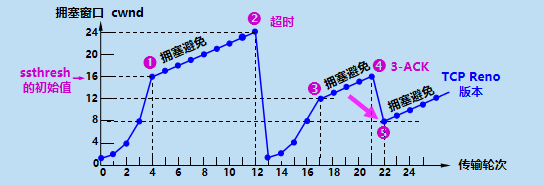
���,��ͼ�ĵ�4,���ͷ�֪������ֻ�Ƕ�ʧ�˸���ı��ĶΡ����Dz���������ʼ,����ִ�п�ָ��㷨����ʱ,���ͷ���������ֵ ssthresh = cwnd / 2 = 8,ͬʱ����ӵ������ cwnd = ssthresh = 8(��ͼ�еĵ�5),����ʼִ��ӵ�������㷨��
�ӷ�����,�˷���С (AIMD)
���Կ���,��ӵ�������,ӵ�������ǰ������Թ�������ġ��ⳣ��Ϊ���ӷ����� AI (Additive Increase)��
�����ֳ�ʱ��3���ظ���ȷ��ʱ,��Ҫ������ֵ����Ϊ��ǰӵ������ֵ��һ��,������Сӵ�����ڵ���ֵ���ⳣ��Ϊ���˷���С��MD (Multiplicative Decrease),���ߺ���һ�������ν�� AIMD �㷨��
TCPӵ����������ͼ

���ͷ��ķ��ʹ��ڵ�����ֵӦ��ȡΪ���շ����� rwnd ��ӵ������ cwnd �����������н�С��һ��,��Ӧ�����¹�ʽȷ��:

- �� rwnd < cwnd ʱ,�ǽ��շ��Ľ����������Ʒ��ʹ��ڵ����ֵ��
- �� cwnd < rwnd ʱ,���������ӵ�����Ʒ��ʹ��ڵ����ֵ��
- Ҳ����˵,rwnd �� cwnd ����ֵ��С��һ��,�����˷��ͷ��������ݵ����ʡ�
�ˡ�TCP������״̬��
��ͷ�Աߵ���,�����������ֱ�Ǩ��ԭ��,���������״̬��Ǩ���ֳ���ʲô����,ͼ�������ֲ�ͬ�ļ�ͷ��
- ��ʵ��ͷ��ʾ�Կͻ����̵�������Ǩ��
- ������ͷ��ʾ�Է��������̵�������Ǩ��
- ϸ��ͷ��ʾ�쳣��Ǩ��
