һ������
�������ڴ�����������·��֮��,����Ҫ������ʵ����������ϵͳ֮�������������,�������·��ѡ��,ӵ�����������ʻ����ȡ������������������֮��ͨ�ŵ���ײ�,�����ݴ�������·�������������ݴ����ͨ����,����һ���м�ͨ�����������á���ͬ�������Ų�ͬ�������Э��͵�ַ�淶,���һ�������е��û�����ʶ�����������ͨ��Э��͵�ַ�淶,��ô����������֮��Ͳ��ܽ�������ͨ��,�ͺñȲ�ͬ�������Ų�ͬ�Ľ�ͨ����,���ڲ�ͬ�Ľ���ϵͳ����,��������������������һ������ͬ����Ҳ�в�ͬ����ƹ淶,���ڲ�ͬ����֯������,����ͨ����Ȩ,����ר�ŵ�Э��������������ͨ�š����ֻ��ͬһ�������ڵĸ��������֮���ͨ��,�����������������·��Ϳ��Խ���ͨ����·����û��������ͨ��,��Ҫ����Ӧ�÷�Χ,���Ӳ�ͬ�ľ�������,����Ҫ��������㴦����������������Э��,�Ӷ����м���������绥��,�����������TCP/IPЭ����ϵ�н����ʻ����㡣
��һ��ĸ�������,�����绥����������Ҫʹ��һЩ�м��豸�������м��豸���ڵIJ��,�������������ֲ�ͬ���м��豸:
(1)������ʹ�õ��м��豸��ת����(repeater)
(2)������·��ʹ�õ��м��豸�������Ż����Ž���(bridge)
(3)�����ʹ�õ��м��豸����·����(router)
(4)�����������ʹ�õ��м��豸��������(gateway)���������������������ݵ�ϵͳ��Ҫ�ڸ߲����Э��ת����
1:ת����·��ѡ��
���������ôӱ����Ͽ������ܼ��������һ̨���������ƶ���һ̨������������Ҫ���ֹ���:
- ת��:��һ�����鵽��·������һ��������·ʱ,·�������뽫�÷����ƶ����ʵ��������·��
- ·��ѡ��:����ӷ��ͷ�������շ�ʱ,�������������Щ������õ�·�ɻ�·��,������Щ·�����㷨��·��ѡ���㷨(routing algorithm)��
ת����·�������ض���,��Ҫ��Ӳ����ʵ�֡�·��ѡ�������緶Χ����,��Ҫ��������ʵ�֡����翪���ӱ������Ϻ�,ת���൱����ij��·��ѡ��ijһ����·,·��ѡ���൱�ڹ滮�ӱ������Ϻ�������·�Ĺ���
ÿ̨·�ɶ���һ��ת������·�����������ײ��ֶ�ֵ(������Ŀ�ĵ�ַ����������,�������Э��)��ת������,ʹ�ø�ֵ��ת����������ѯ����ֵָ���˸÷��齫��ת����·���������·�ӿڡ�
ת����������:
- ��ͳ����:�����������Աֱ������,��һ��˵����ת����·��ѡ���ܵ�����Ͳ�ͬĿ��,����������²���Ҫ�κ�·��ѡ��Э��(������·,ÿ��һ����·������·�ߵ��˵�Ŀ�ĵ���Ҫ���ĸ�������)����Ȼ��Щ�������Ա����Ҫ�˴˽���,��ȷ����ת������������ʹ���鵽��������Ҫ��Ŀ�ĵء�
- SDN(������������)����
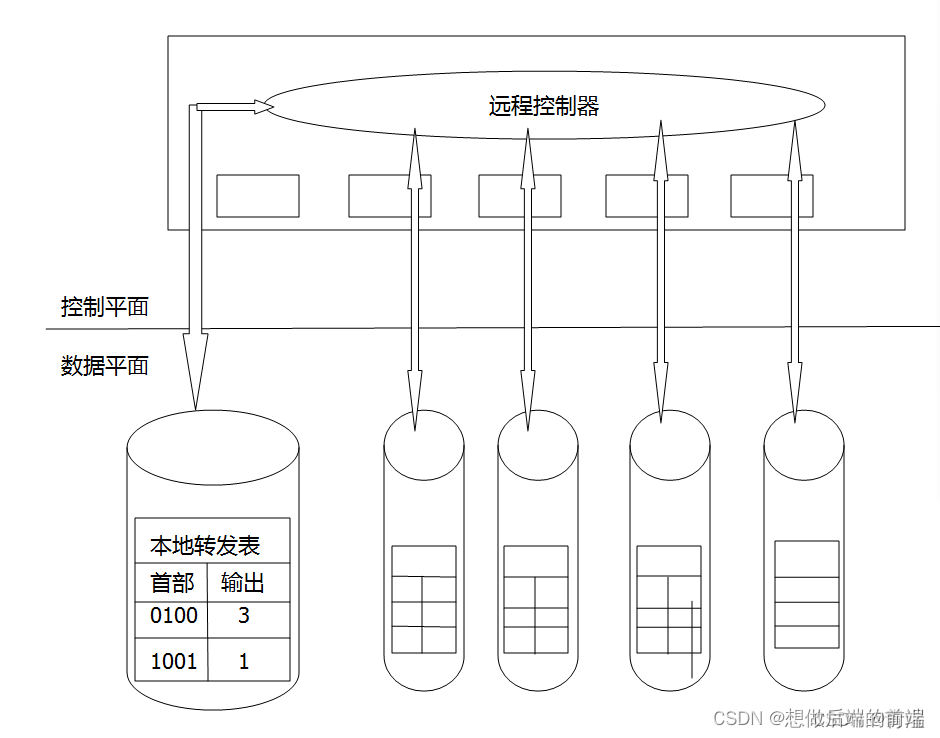
��ͼ��ʾ:Զ�̿���������ͷַ�ת�����Թ�ÿ̨·����ʹ��,����ƽ��·��ѡ������������·���Ƿ����,��·��ѡ���豸����ִ��ת��,��Զ�̿��������㲢�ַ�ת����,Զ�̿���������ʵ���ھ��и߿ɿ��Ժ������Ե��������Ļ���ISP��ijЩ����������
2:�������ģ��
�����˷����ڷ�������ն�ϵͳ֮��Ķ˵����������ԡ�
��λ�ڷ��������������������㴫�����ʱҪ��Ե�һϵ������:
- �������ָ������㽫���齻����Ŀ�ĵ���?
- �����Ͷ������ʱ,���ǻᰴ����˳�����������������������?
- �����������������ʱ��������յ������������ʱ������ͬ��?
- �������ṩ����������ӵ����������Ϣ��?
- �ڷ���������������������������ͨ���ij�����ͼ��ʲô?
���������ṩ�ķ���(ע��IP��û����Щ����!):
- �����������㴫�ݷ���ʱ:
- ȷ������
- ����ʱ���Ͻ��ȷ������
- Ϊ����Դ��Ŀ�ĵ�֮��ķ������ṩ����:
- ������齻��
- ȷ����С����:ģ�·��ͷ��ͽ��շ�֮��һ���ض������ʴ�����·����Ϊ���������ʵ��ڸ�����,���鲻�ᶪʧ,�һ���Ԥ��ʱ���ڵ���
- ȷ�����ʱ�Ӷ���:ȷ�����ͷ�������̷���֮���ʱ�� = Ŀ�ĵؽ��յ�����֮���ʱ��
��ȫ�Է���:ʹ�ý���Դ��Ŀ�ĵ�����֪������Կ,�������ݱ�,Դ����,Ŀ���������ܡ���������������Ժ�Դ�������
�������������IPЭ���ṩ��һ����,������Ϊ����,������֤,������֤,��˳��֤,����ʱ,��ӵ��ָʾ��
����·��������ԭ��
1:��ɲ���
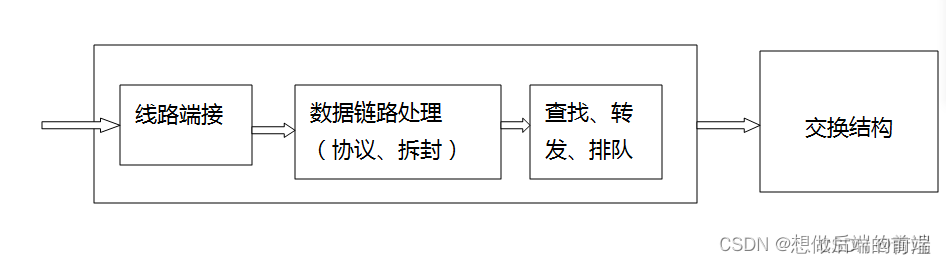
(1)����˿�:
- ִ�н�һ�������������·��·���������ӵ������㹦��
- ִ����λ������·Զ�˵�������·�㽻����������·�㹦��
- ���ҹ���,��ѯת��������·����������˿�,������ת��������˿�
(2)�����ṹ
- ��·����������˿�������˿�����
- ����ͨ�������ṹת��������˿�
(3)����˿�
- �洢�ӽ����ṹ���յķ���,ִ�б�Ҫ����·��������㹦����������·�ϴ�����Щ���顣
- ����·��˫���ʱ,����˿�������˿���ͬһ��·���ɶԳ���
(4)·��ѡ������
- ִ��·��ѡ��Э��
- ά��·��ѡ��������ӵ���·״̬��Ϣ,Ϊ·��������ת����
- �������
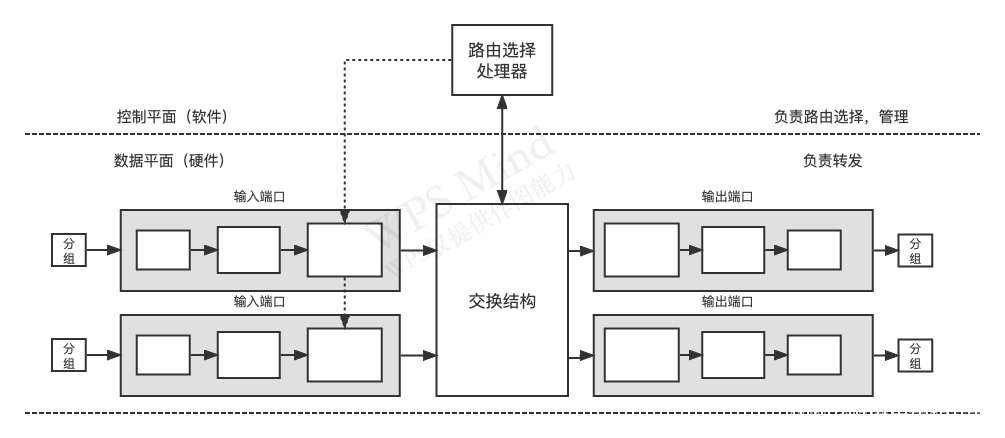
·��ת��ƽ�� :һ̨·����������˿ڡ�����˿ںͽ����ṹ��ͬʵ����ת������,������Ӳ��ʵ��(����̫��,��������ʱ��߶�����)
·�ɿ���ƽ��:·�����Ŀ��ƹ���(ִ��·��ѡ��Э�顢��������������·������Ӧ����������),�ں���ʱ��߶�������,������ʵ�ֲ���ѡ��������ִ��(һ��cpu)
2:����˿�
(1)��·�˽�
(2)������·����(Э�顢���)
(3)����
- ���ұ��������뼶��ִ��,����Ҫ��Ӳ��ִ�в���,����Ҫ�Դ���ת����ʹ�ÿ��ٲ����㷨,������Ҫ������ڴ�����ٶ�(DRAM��SRAM)��
- ��̬���ݿ�Ѱַ�洢��TCAM�������ڲ��ҡ�ʹ��TCAM,һ��32bit��IP��ַ�����ڴ�,TCAM�ڻ�������ʱ���ڷ���ת����������
(4)ת��
- ת������·��ѡ�������������,��·��ѡ�����������������߸��Ƶ�(����)��·��
- ����ת��������,ת����������ÿ������˿ڱ�������,�������·��ѡ������,���⼯��ʽ����
(5)�Ŷ�
- ����ȷ����ij��������˿�,������ܷ��ͽ��뽻���ṹ��һ���������ķ������������˿ڴ��Ŷ�
3:�����ṹ
�����ṹλ��һ̨·�����ĺ��IJ�λ,����ͨ�����ֽ����ṹ,ͨ�������ṹ,�������ʵ�ʵش�һ������˿ڽ���(ת��)��һ������˿��С�
���ֽ�����ʽ:
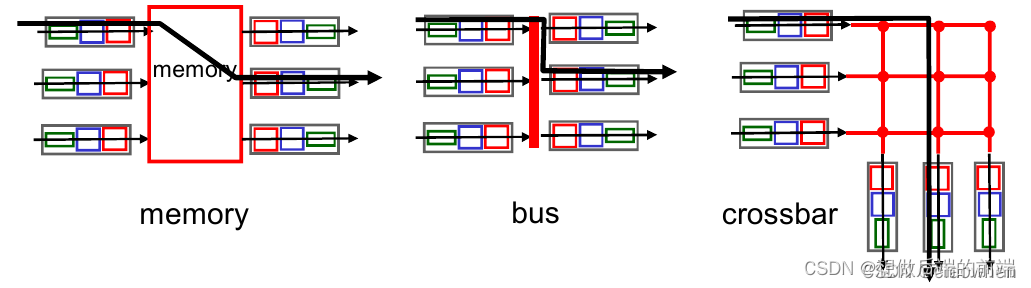
(1)���ڴ潻��
- һ�����鵽������˿�ʱ,�ö˿ڻ���ͨ���жϷ�ʽ��·��ѡ�����������ź�
- ���������˿ڸ��Ƶ��������ڴ���(�ִ�·�������ҽ������ڴ�,����������·��������)
- ����·��ѡ���������ײ���ȡĿ�ĵ�ַ,��ת������������˿�,�����鸴�Ƶ�����˿�
(2)�����߽���
- ����˿ھ�һ���������߽�����ֱ�Ӵ��͵�����˿�,����·��ѡ�������ĸ�Ԥ
- ·�����Ľ���������������������
(3)���������罻��
- �ݺ�ʽ������,2N�������������,����N������˿ں�N������˿�
- ÿ����ֱ��������ÿ��ˮƽ�����߽���,�����ͨ�������ṹ�����������պ�
- ij���鵽��˿�A,��Ҫת����Y,�������������պ�����A��Y�Ľ����,A���������Ϸ��ͷ���,����Y����;ͬʱBҲ�ܷ����鵽X,��Ϊû�й������ߡ��ݺ�ʽ�����ܲ���ת���������
4:����˿�

ȡ���Ѿ����������˿��ڴ��еķ��鲢���䷢�͵������·�ϡ�
5:��ʱ�����Ŷ�
- ���롢����˿ڶ����γɷ������,ȡ�����������ء������ṹ�����������ܵȴ���������������ںͳ��ڡ�
- ���Ŷ�������,·��������ռ��ľ�,���ֶ���(�����������ж�ʧ,������·��������)
- ��Ҫ·�������������������ز���,��Ҫ���ٻ���?
- ����TCP��:RTT * C(��·����)
- ����TCP��:RTT* C/ (N^1/2)
(1)�����Ŷ�
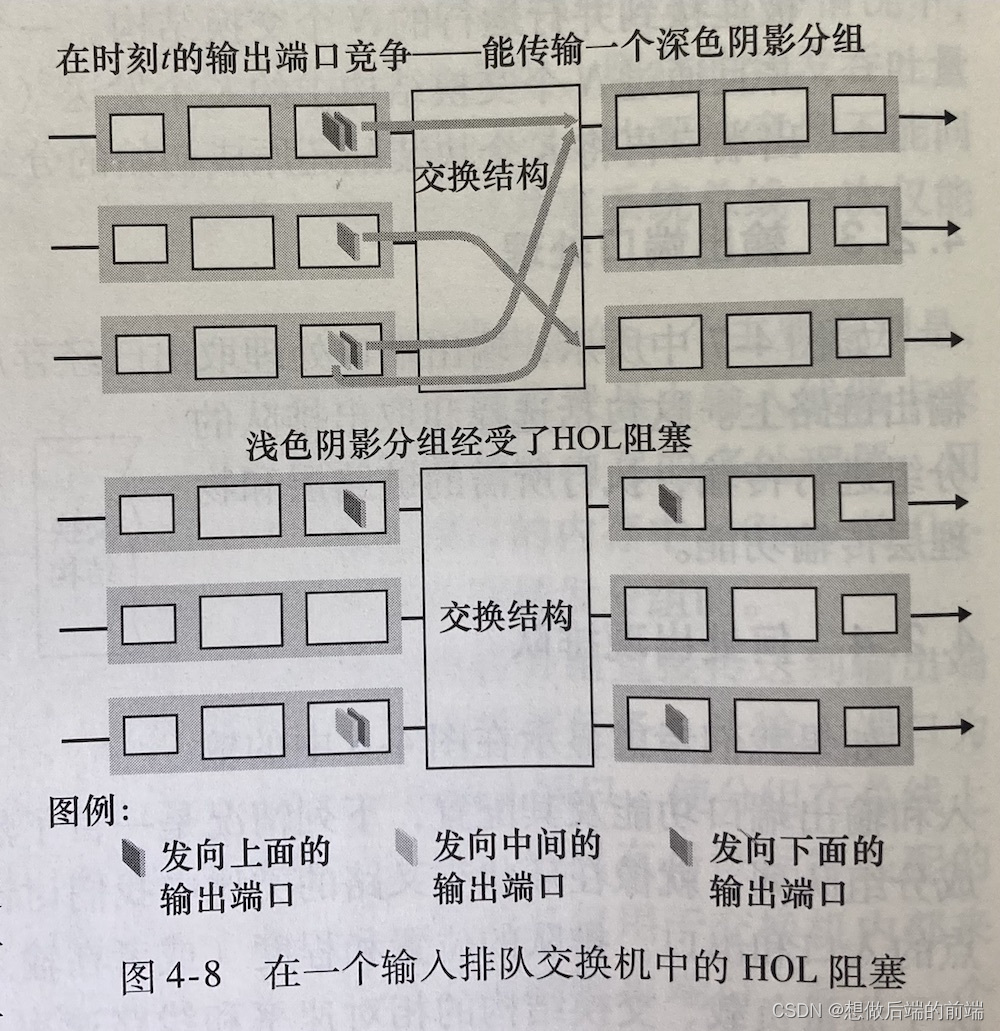
��ͼ��ʾ,�������������ǰ�˵���������(����ɫ��Ӱ)Ҫ����ͬһ�����Ͻǵ�����˿ڡ��ٶ��ý����ṹ�����������ϽǶ���ǰ�˷��顣�����������,���½Ƕ����е���ɫ��Ӱ�������ȴ����������÷���Ҫ�ȴ�,���½Ƕ��������ڸ÷�������dzɫ��Ӱ����ҲҪ�ȴ�,��ʹ���в�����˿�������������������������Ŷӽ������е���·ǰ������(Head-Of-the-Line,HOL)������һ������������Ŷӵķ������ȴ�ͨ�������ṹ����(��ʹ����˿��ǿ��е�),��Ϊ����λ����·ǰ�˵���һ��������������
(2)����Ŷ�
���������������㹻��ʱ,�ľ�����˿ڵĿ����ڴ�,�ͱ�����������:Ҫô��������ķ���(����һ����β�IJ���),Ҫôɾ��һ���������Ŷӵķ���Ϊ�����ķ����ڳ��ռ䡣��ijЩ�����,�ڻ�������֮ǰ�㶪��һ�������������������,��������ͷ��ṩһ��ӵ���źš��Ѿ�����ͷ�����������鶪���ͱ�Dz���,��Щ����ͳ��Ϊ�������й���(Active Queue Manager,AQM).
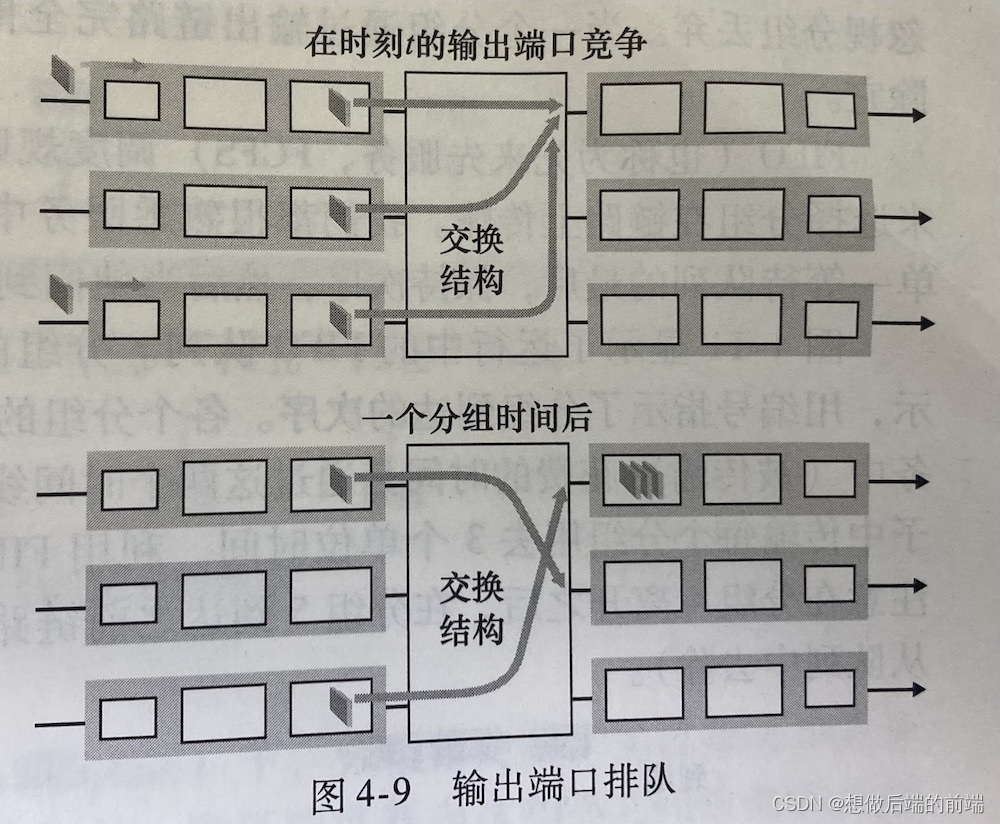
��ͼ��ʾ������˿ڵ��Ŷ��������tʱ��,ÿ������˿ڶ�������һ������,ÿ�����鶼�Ƿ������ϲ������˿ڡ��ٶ���·�ٶ���ͬ,��������3������·�ٶȵ��ٶ�����,һ��ʱ�䵥λ�Ժ�,����������ʼ���鶼�����͵�����˿�,���Ŷӵȴ����䡣����һʱ�䵥λ��,�����������е�һ����ͨ�������·���ͳ�ȥ�������������,�������������ѵ��サ�������;��Щ����֮һҪ�������ϲ������˿ڡ������ĺ����,����˿ڵ��������(packet scheduler)����Щ�Ŷӷ�����ѡ��һ�����������䡣
6:�������
���Ŷӵķ�������ξ������·����ġ�
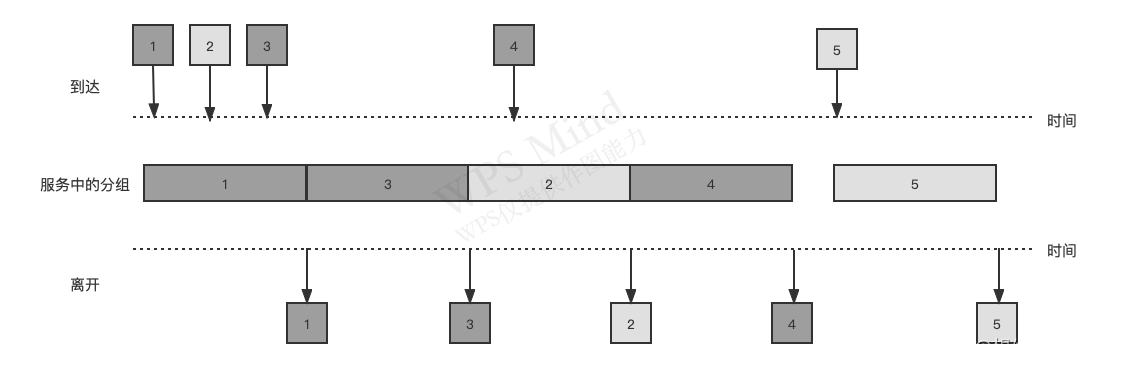
(1)�Ƚ��ȳ�(First-In-First-Out,FIFO)
���շ��鵽�������·���еĴ�����ѡ���������·�ϴ���
�Ŷӳ���:
�����еĶ���:
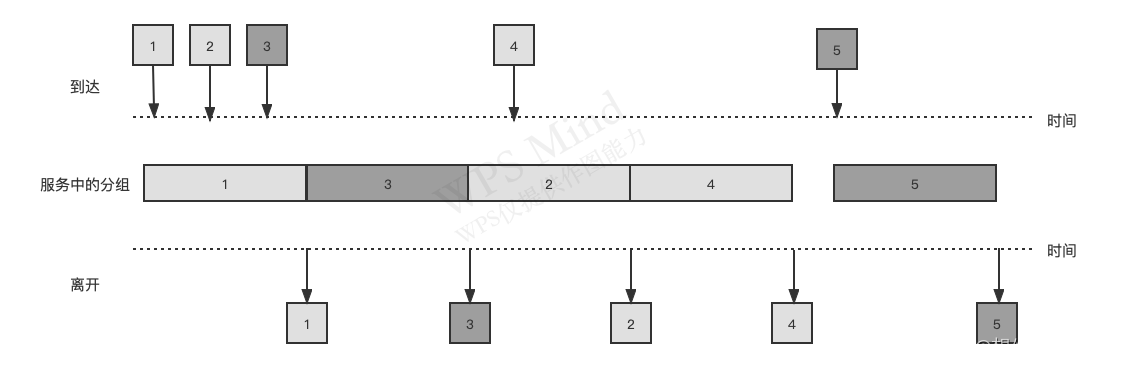
(2)����Ȩ�Ŷ�(Priority Queuing)
���������·�ķ��鱻���������������е�����Ȩ����,ÿ������Ȩ���һ������,�ȴ�������Ȩ�����еķ���,���������Ȩ����еķ��顣�ڷ���ռʽ����Ȩ�Ŷ���,һ�����鿪ʼ����Ͳ����Ա���ϡ�
�Ŷӳ���: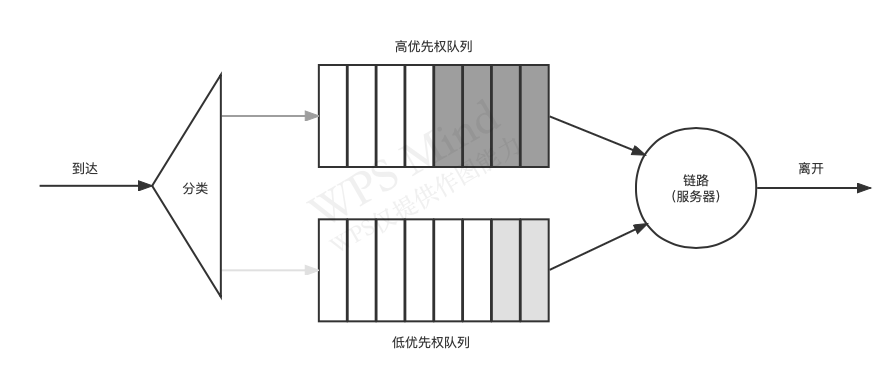
�����еĶ���:
(3)ѭ���ͼ�Ȩ��ƽ�Ŷ�(round robin queuing discipline)
��ѭ���Ŷӹ�����,����������Ȩ�Ŷ�����������,Ȼ��,����֮�䲻�����ϸ�����ȷ���Ȩ,ѭ������������Щ��֮�������ṩ�����������ʽ��ѭ��������,��1�ķ��鱻����,��������2�ķ���,����������1�ķ���,Ȼ��������2�ķ���,�ȵȡ�һ����ν�ı��ֹ����Ŷӹ�������(�κ����)�����Ŷӵȴ�����ʱ,��������·���ֿ��С���Ѱ�Ҹ�����ķ��鵫��û���ҵ�ʱ,���ֹ�����ѭ�������������ѭ�������е���һ���ࡣ
�Ŷӳ���: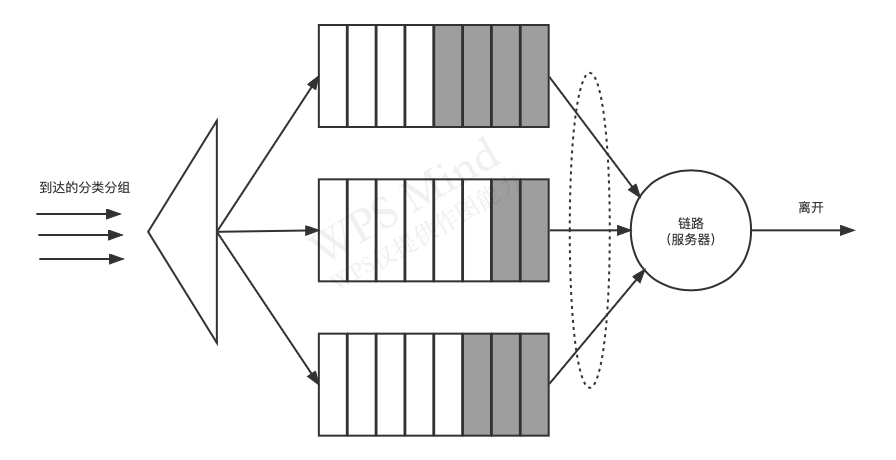
�����еĶ���:
��Ȩ��ƽ�Ŷ�(WFQ)��һ��ͨ�õ�ѭ���Ŷӡ���ѭ���ŶӲ�ͬ����,����ÿ�������κ�ʱ�����ڿ��յ��в�ͬ�����ķ���
����IPv4
1:IPv4���ݱ���ʽ
�������鱻��Ϊ���ݱ�,��ͼ��IPV4���ݱ���ʽ��һ��IP���ݱ����ܳ�Ϊ20�ֽڵ��ײ�,������ݱ�����һ��TCP���Ķ�,��ÿ�����ݱ�������40���ֽڵ��ײ��Լ�Ӧ�ò㱨��

| �ؼ��� | ���� |
|---|---|
| �汾 | ��4���ع涨�����ݱ���IPЭ��汾,ͨ���汾��·��������ȷ����ν���IP���ݱ�����ͬIP�汾ʹ�ò�ͬ�����ݱ���ʽ�� |
| �ײ����� | IPV4���ݱ�������һЩ�ɱ�������ѡ��,��������4������ȷ��IP���ݰ��е��غ�ʵ�ʿ�ʼ�ĵط��� |
| ��������(TOS) | �Ա�ʹ��ͬ���͵�IP���ݰ��ܹ����������:ʵʱ���ݰ��ͷ�ʵʱ���ݰ��� |
| ���ݰ����� | IP���ݰ����ܳ��ȡ����ֶ�16����,���������65535 |
| ��ʶ����־��Ƭƫ�� | �������ֶ�����ν��IP��Ƭ�йء� |
| ���� | ����ȷ�����ݱ���Զ������������ѭ����ÿ��һ̨·������·���ݱ�ʱ��,���ֶ�-1,ֱ��TTL�ֶ�Ϊ0,���������ݱ��� |
| Э�� | ָʾ��IP���ݱ������ݲ���Ӧ�ý������Ǹ��ض��������Э�顣ֵΪ6������TCP,Ϊ17������UDP�� |
| �ײ�У��� | �ײ�У������ڰ���·��������յ���IP���ݱ��еı��ش���,�ײ�У��ͼ��㷽��:���ײ���ÿ�����ֽڵ���һ����,�÷�����������Щ����͡�����ײ���Я����У��ͺͼ������У��Ͳ�һ�����������,һ��ᶪ�����������ݱ��� |
| Դ��Ŀ�ĵ�ַ | ��ԴIP�ֶβ���ԴIP��ַ,��Ŀ��IP�ֶβ���Ŀ��IP��ַ�� |
| ѡ�� | ����IP�ײ�����չ,���п��ޡ� |
| ���� | ��Ч�غ�,���ݱ���ŵĵط��� |
2:IPv4���ݱ���Ƭ
����䵥Ԫ(MTU):������������·�㶼�ܳ�����ͬ���ȵ��������顣�е�Э���ܳ��ش����ݱ�,���е�Э��ֻ�ܳ���С���顣���һ����·��֡�ܳ��ص������������������䵥Ԫ����Ϊÿ��IP���ݱ���װ����·��֡��һ̨·����������һ̨·����,������·��Э���MTU�ϸ�����IP���ݱ��ij��ȡ���ͬ��·��Э���е�MTU��ͬ��
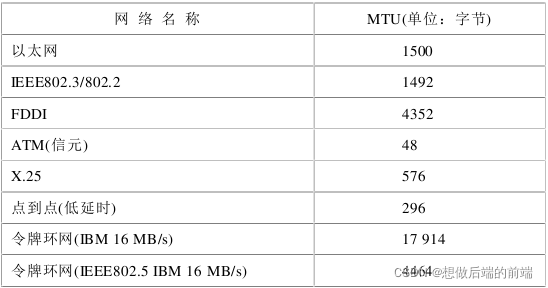
��Ƭ:�����·��MTU��IP���ݱ�����С,��ô��IP���ݱ��е����ݷ�Ƭ���������߶����С��IP���ݱ�,�õ�������·��֡��װ��Щ��С�����ݱ�,Ȼ���͡���Щ��С�����ݱ���ΪƬ���ڵ���Ŀ�ĵ�ʱ�������װ��
IPv4������߽���ʶ����־��Ƭƫ�Ʒ���IP���ݱ���,������Ƭ��
- ��ʶ:��Щ��Ƭ�Ƿ�����һ��������ݱ�,��������ͳһ���ݱ��ķ�Ƭ�ı�ʶ��һ���ġ�
- ��־:
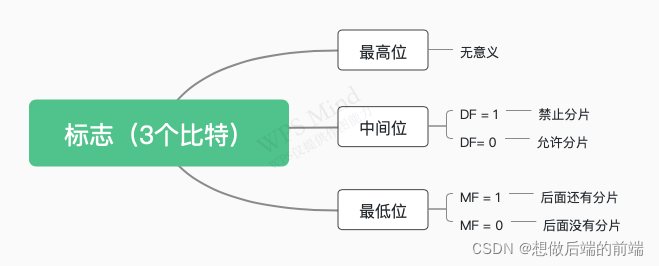
- Ƭƫ��:ָ����Ƭ��,ijƬ��ԭ�����е����λ��,��8BΪ��λ,�������һƬ,ÿ����Ƭһ����8B����������
�ٸ�🌰:
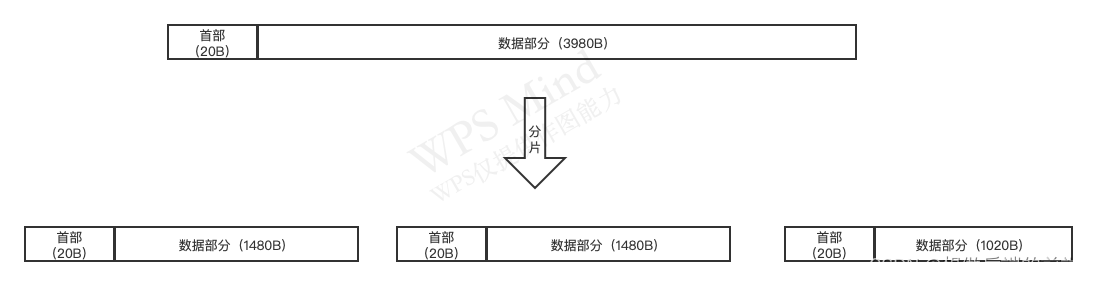
4000�ֽ����ݱ�:20�ֽ�ͷ��,3980�ֽ�����,MTU = 1500�ֽ�
��һƬ:20�ֽ�ͷ�� + 1480�ֽ�����(1480�ֽ�Ӧ������),ƫ����:0
�ڶ�Ƭ:20�ֽ�ͷ�� + 1480�ֽ�����(1480�ֽ�Ӧ������),ƫ����:1480 / 8 = 185(Ϊ�˷������,��8���ֽ�Ϊ��λ)
����Ƭ:20�ֽ�ͷ�� + 1020�ֽ�����(Ӧ������),ƫ����:2960 / 8 = 370
| �ܳ��� | ��ʶ | MF | DF | Ƭƫ�� | |
|---|---|---|---|---|---|
| ԭʼ���ݱ� | 40000 | 12345 | 0 | 0 | 0 |
| ���ݱ�Ƭ1 | 1500 | 12345 | 1 | 0 | 0 |
| ���ݱ�Ƭ2 | 1500 | 12345 | 1 | 0 | 185 |
| ���ݱ�Ƭ2 | 1040 | 12345 | 0 | 0 | 370 |
3:IPv4��ַ
������IP����֮ǰ,������Ҫ����һ��·�������뻥�����ķ���:һ̨����ͨ��ֻ��һ����·��������;�������е�IP�뷢��һ�����ݱ�ʱ,�����ڸ���·�Ϸ��͡�������������·֮��ı߽�����ӿڡ� ��Ϊ·�����������Ǵ���·�Ͻ������ݲ���ijЩ��·ת����ȥ,����·��������ӵ����������������·��������,���һ̨·�����ж���ӿ�,IPҪ��ÿ̨������·���������Լ���IP��ַ,���һ��IP��ַʵ��������ÿһ���ӿ�������ġ�
ÿ��IP��ַ����32bit(4�ֽ�),�ܹ�2^32�����ܵ�IP��ַ,Լ40�ڸ�,���õ��ʮ���Ʊ�ʶ,��:193.32.216.9����ȫ���������е�ÿ̨������·�����ϵ�ÿ���ӿ�,��������һ��ȫ��Ψһ��IP��ַ(��NAT����Ľӿڳ���)��Ȼ��,��Щ��ַ�����������ѡ��һ���ӿڵ�IP��ַ��һ������Ҫ�������ӵ�������������
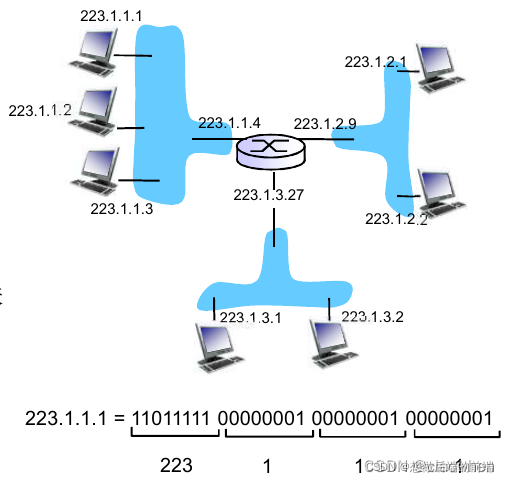
����ͼ��ʾ,һ̨·����(���������ӿ�)���ڻ���7̨������ע�����ϲ��3̨�����Լ��������ǵ�·�����ӿ�,����һ������223.1.1.xxx��IP��ַ�������˵,�����ǵ�IP��ַ��,������24��������ͬ�ġ���4���ӿ�Ҳͨ����������·���������绥������,�����������һ����̫��LAN����,�ڴ������,��Щ�ӿڽ�ͨ��һ̨��̫������������,����ͨ��һ�����߽���㻥�������Ǵ�ʱ��������·����������Щ�����������ʾΪһ���ơ���IP��������˵,����������������һ���ӿڵ������γ�һ��������
IP��ַΪ�����������һ����ַ223.1.1.0/24,����/24�Ƿ�,��ʱ��Ϊ��������(network mask),ָʾ32�����������24���ض�����������ַ,�κ�����Ҫ���ӵ�223.1.1.0/24������������Ҫ�����ַ����223.1.1.xxx����ʽ��
�������ĵ�ַ�������:
(1)��������·��ѡ��(Classless Interdomain Routing,CIDR)
CIDR������Ѱַ�ĸ���һ�㻯�ˡ���ʹ������ʱ,32���ص�IP��ַ������Ϊ������,���Ҿ��е��ʮ��������ʽa.b.c.d/x,����xָʾ�˵�ַ�ĵ�һ�����еı�������x����ʾ�����ַ�ı�����,���Ҿ�������Ϊ�õ�ַ��ǰ��һ����֯ͨ��������һ�������ĵ�ַ,��������ͬǰ��һ�ε�ַ��ʣ���32-x���ؿ���Ϊ���������ָ���֯�ڲ��豸,���������豸������ͬ������ǧ�֡�
(2)������ַ(classful addressing)
��CIDR������ǰ,IP��ַ�����粿�ֱ�����Ϊ����Ϊ8,16,24����,����һ�ֳ�Ϊ�����ַ�ı�ַ������
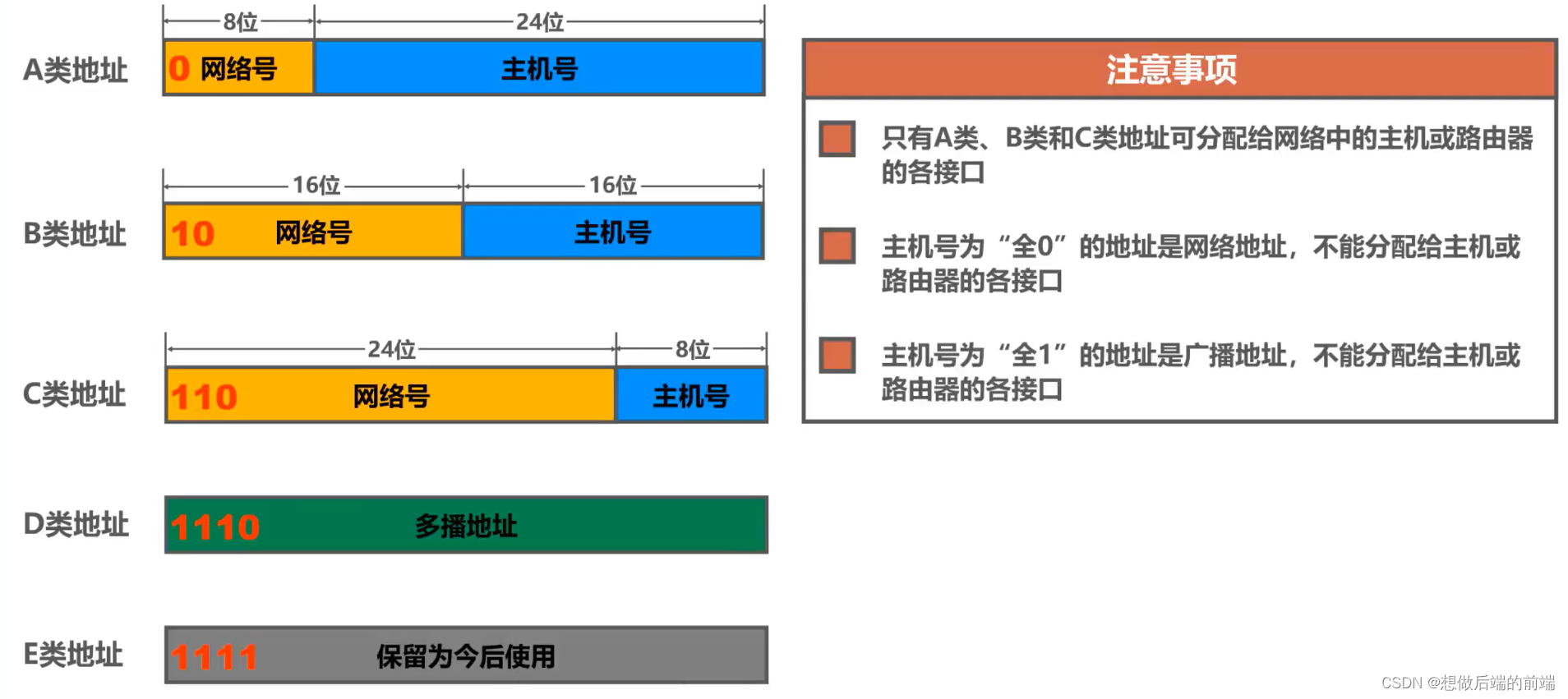
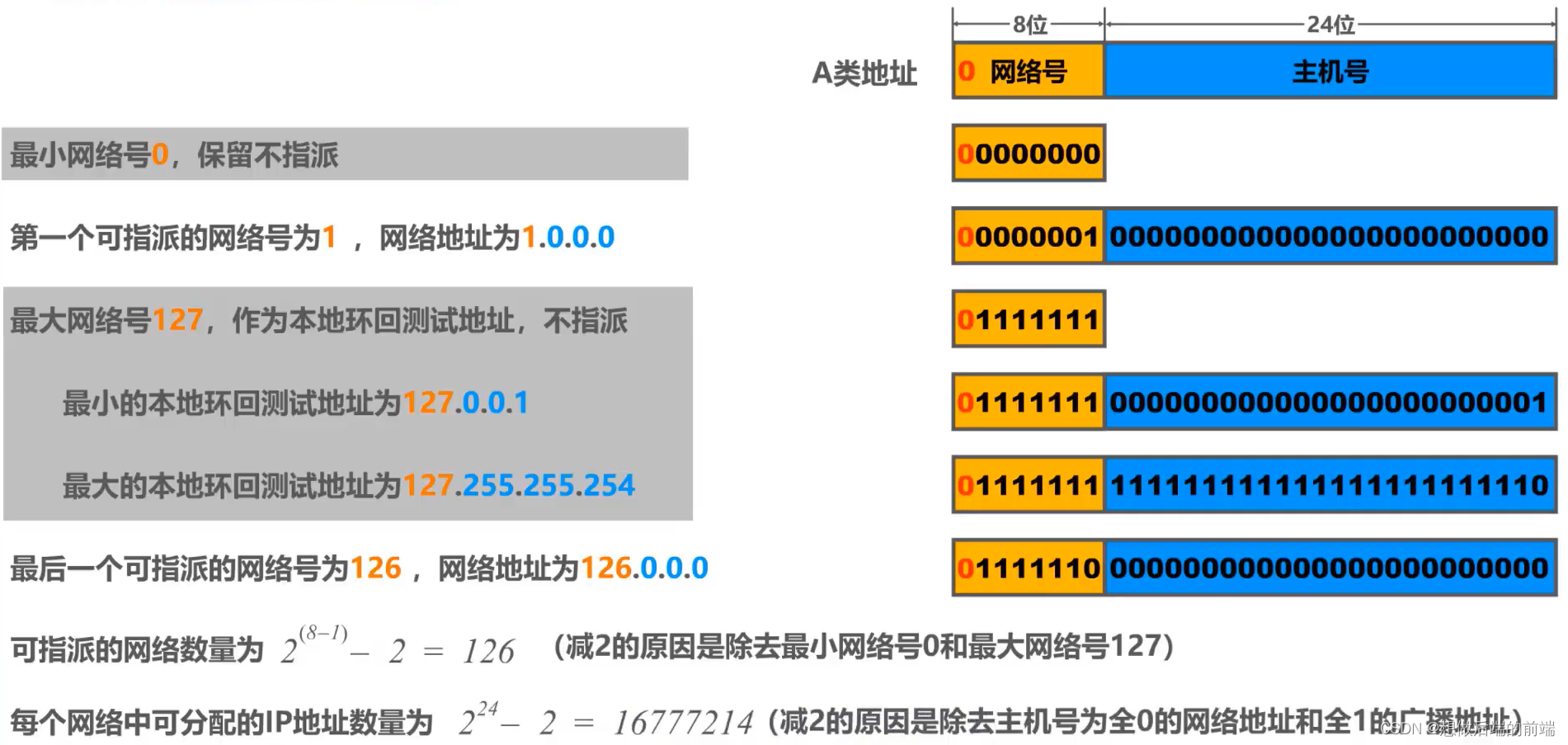
A���ַ:
B���ַ:

C���ַ:

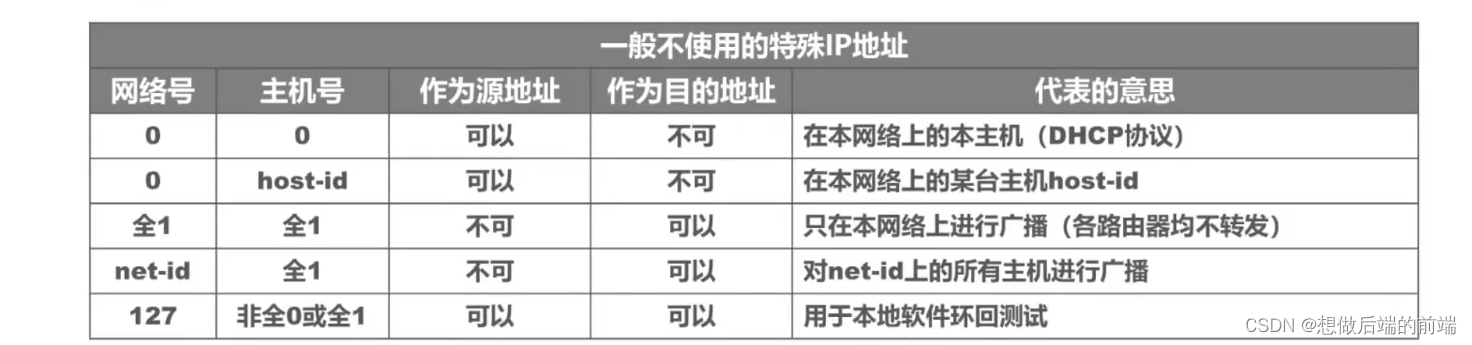
һ�㲻ʹ�õ�����IP��ַ:
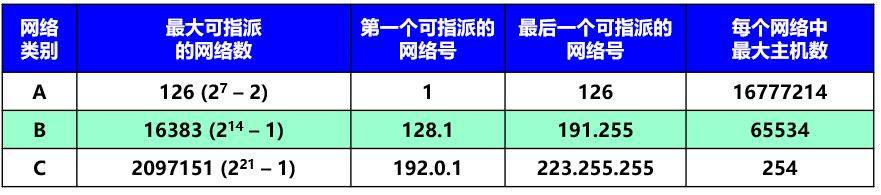
�ܽ�:
(3)IP�㲥��ַ
��һ̨��������Ŀ�ĵ�ַΪ255.255.255.255�����ݱ�ʱ,���Ļύ����ͬһ���������������,·����Ҳ����ѡ������ڽ�������ת���ñ���(��Ȼ����ͨ����������)��
�ġ�Ѱַ
1:��ȡ��ַ�������ַ
(1)��ȡһ���ַ
- ������ȡIP��ַ:��ISP��������ַ�з���
- ISP��ȡIP��ַ:IP��ַ�����������ֺͱ�ŷ������ICANN����(Ҳ����DNS����������AS��ʶ��)��ICANN��������������ע����������ַ,�����������ڵĵ�ַ����/����
(2)��ȡ������ַ
- ��֯���һ���ַ,�Ϳ�Ϊ��֯�ڵ�������·�����ӿ��������IP��ַ
- ������ַ���ֶ�����,Ҳ���Զ�����,����̬��������Э��DHCP
(3)��̬��������Э��(Dynamic Host Configuration Protocol, DHCP)
DHCP���������Զ���ȡһ��IP��ַ���������ԱҲ������DHCP,��ʹij��������ÿ������������ʱ���ܵõ�һ����ͬ��IP��ַ,����ij������������һ����ʱ��IP��ַ,ÿ������������ʱ�õ�ַҲ���Dz�ͬ�ġ���������IP��ַ��,DHCP������һ̨������֪������Ϣ,���������������롢���ĵ�һ��·����λ��(����ΪĬ������)�����ı���DNS��������ַ��
DHCP�ܽ��������ӽ�һ��������Զ�����,������Ϊ���弴��Э��(plug-and-play protocol)����������(zeroconf)Э�顣
DHCP��һ���ͻ�-������Э�顣����������Ҫ�����ʹ�õ�IP��ַ������������Ϣ:
- ÿ����������һ̨DHCP������
- ������û��DHCP������,����һ��·������DHCP�м̴���,�ô���֪���������DHCP��������ַ
����������ʱ,DHCPЭ����ĸ�����:
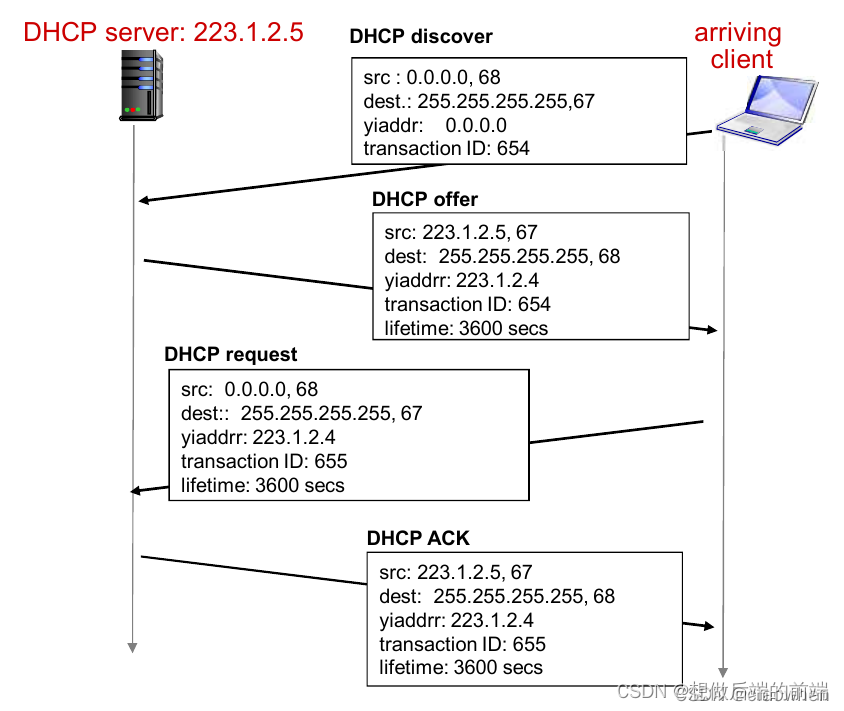
- DHCP����������(�����㲥):һ̨�µ������������Ҫ�����Ƿ���һ��Ҫ���佻����DHCP�����������ͨ��ʹ��DHCP���ֱ�������ɡ��ͻ���UDP��������˿�67���ñ��ġ�����������ݱ�Ӧ�÷���˭��?����������֪���������������IP��ַ,������˵���ڸ������DHCP��������ַ�������������,DHCP�ͻ���������DHCP���ֱ��ĵ�IP���ݱ�,����ʹ�ù㲥Ŀ�ĵ�ַ255.255.255.255����ʹ�ñ�����ԴIP��ַ0.0.0.0��DHCP�ͻ��������ݱ����ݸ���·��,��·��Ȼ��֡�㲥���������������ӵĽڵ㡣
- DHCP�������ṩ:DHCP�������յ�һ��DHCP������,��DHCP�ṩ����(DHCP offer message)��ͻ�������Ӧ����Ȼʹ�ù㲥��ַ,�����ж�̨DHCP������,ÿ̨�������ṩ�ı�����,����ͻ������Ƽ���IP��ַ�����������Լ�IP��ַ������(һ�㼸���Сʱ)����Ϊ��ʱ�¿ͻ���û��IP��ַ��
- DHCP����:�µ���Ŀͻ���һ�������������ṩ��ѡ��һ��,����ѡ�еķ������ṩ��DHCP������(DHCP request message)������Ӧ,�������õIJ�����
- DHCP ACK����������DHCP ACK����(DHCP ACK message)��DHCP�����Ľ�����Ӧ,֤ʵ��Ҫ��IJ�����
�ͻ��յ�ACK��,�������,��������ʹ��DHCP�����IP��ַ��DHCP�ṩ�˻��������ͻ����¶�һ��IP��ַ������
2:�����ַת��(Network Address Translate, NAT)
��ISP�Ѿ�ΪSOHO(Small Office,Home Office)���統ǰ��ַ��Χ�����һ��������ַ,��SOHO������Խ��Ҳ��ʱ,��Ҫ�õ�NAT(������Ÿ���ҷ���һ����̬IP��ַ,����Ҫ�ü�̨�ֻ�����������һ��IP��ַ,��Ҫ��NAT)��
(1) NATʹ��·����
NAT·���������������һ�����е�һIP��ַ�ĵ�һ�豸������,������һ��NATʹ��·����,��IP��ַ138.76.29.7,�ҽ�����뿪��ͥ�ı��Ķ���ͬ���ĸõ�ַ���ӱ�������˵,NATʹ��·�������������˼�ͥ�����ϸ�ڡ�NAT·������ISP��DHCP�������õ����ĵ�ַ,����·��������һ��DHCP������,Ϊλ��NAT-DHCP·�������Ƶļ�ͥ�����ַ�ռ��е������ṩ��ַ
(2)NATת����
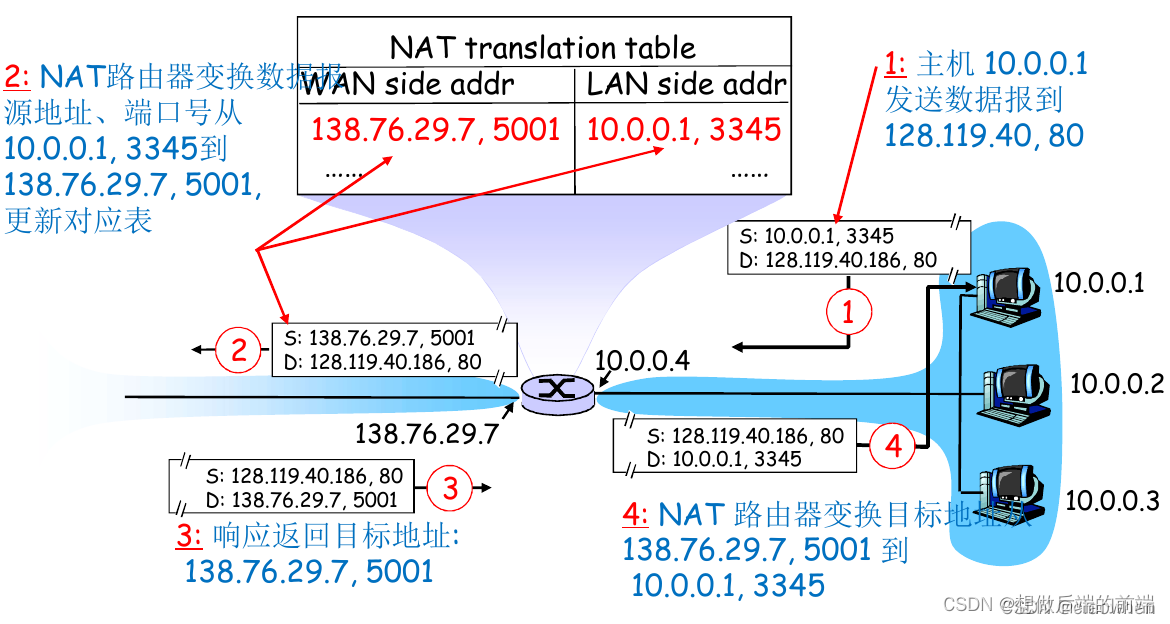
����ӹ�����WAN����NAT·�������������ݱ���������ͬ��Ŀ��IP��ַ,��ô·����Ӧ������֪������ij������ת�����Ǹ��ڲ�������?���ɾ���ʹ��NAT·�����ϵ�һ��NATת����(NAT translation table)��
(3)NAT��Ҫ����
- Υ������ԭ��,Ӧ����IPv6���Ľ�
- ����P2PӦ�ó���,����P2P������������һ���Եȷ���NAT����,���ܳ䵱������������TCP����,�����취�����ӷ�ת
- NAT��Խ:�������Ŀͻ�����Ҫ���������ķ�����ʱ,�ᷢ��NAT��Խ�����
(4)NAT�������
����һ:��̬����NAT,ת�������ĶԷ������ض��˿���������
e.g:123.76.29.7, port 2500 ����ת����10.0.0.1 port 25000
������:ͨ�ü��弴��(Universal Plug and Play, UPnP)
- ��֪����Ĺ��� IP ��ַ(138.76.29.7)
- �оٴ��ڵĶ˿�ӳ��
- ��/ɾ�˿�ӳ�� (������ʱ����)
������: �м� (usedin Skype)
- NAT ����ķ������������м̵�����
- �ⲿ�Ŀͻ������ӵ��м�
- �м���2������֮���Ž�
�塢IPv6
��20����90�������,����������������Ϳ�ʼ�����ڿ���һ�ִ���IPv4��Э��,��Ŭ������Ҫ������������ʵ:�����µ�������IP�ڵ��Ծ��˵�������������������(��������Ψһ��IP��ַ),32���ص�IP��ַ�������þ���
1:IPv6���ݱ���ʽ
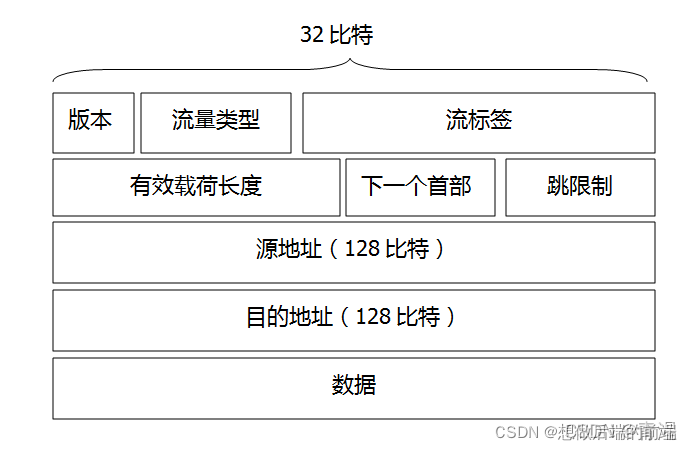
| �ؼ��� | ���� |
|---|---|
| ����ǩ | ��20�������ڸ��������ķ�����ϱ�ǩ,��������һ�ַ�Ĭ�Ϸ�����������Ҫʵʱ���������������Ƶ�� |
| �汾 | ��4�����ֶ����ڱ�ʾIP�汾�� |
| �������� | ��8�����ֶ���������IPV4�п�����TOS �ֶ����� |
| ��Ч�غɳ��� | ��16������Ϊһ����������,������IPV6���ݱ��и��ڶ���40�ֽ����ݱ�����ֽ����� |
| ��һ���ײ� | ���ֶα�ʶ���ݱ��е����ݽ������ĸ�Э��(UDP����TCP),��IPV4��Э���ֶ���ͬ |
| ������ | ת�����ݱ���ÿ̨·�������Ը�ֵ��һ,��ֵΪ0ʱ,���������ݱ� |
| Դ��ַ��Ŀ�ĵ�ַ | IPv6 128���ص�ַ�ĸ��ָ�ʽ��RFC 4291�н����˲��� |
| ���� | IPV6��Ч�غɲ��� |
2:��IPv4�ĸ�ʽ�Ա�
| ���� | ԭ�� |
|---|---|
| ��Ƭ/������װ | IPv6���������м�·�����Ͻ��з�Ƭ��װ�����ֲ���ֻ����Դ��Ŀ�ĵ�ִ�С����·�����յ���IPv6���ݱ�̫����,��·����ֻ�趪�������ݱ�,�����ͷ�����һ��������̫��ICMP������� |
| �ײ������ | ��Ϊ�������е�������������·��Э��ִ���˼������,���Ծͱ�ȥ���� |
| ѡ�� | ѡ���ֶβ����DZ�IP�ײ���һ������,������û����ʧ,���ǿ��ܳ�����IPv6�ײ����ɡ���һ�ײ���ָ����λ���� |
3:��IPv4��IPv6��Ǩ��
��Ȼ���͵�IPv6�ܹ�������,���ܷ���,·�ɺͽ���IPv4���ݱ�,���Ѿ�����ľ���IPv4������ϵͳȴ���ܹ�����IPv6���ݱ���
������ʵ�����Ѿ��õ��㷺Ӧ�õ�IPv4��IPv6��Ǩ�Ʒ���������������
�ٶ�����IPV6·�����ͨѶ�м��и�IPV4��·����,���ǽ���̨IPV6�м��IPV4��·�������ϳ�Ϊһ������,�������Ͷ˵�IPV6�ڵ���Խ�����IPV6�����ݱ���װ��һ��IPV4�����ݱ���,��IPV4�ĵ�ַָ���������ն˵�IPV6�ڵ�,�������ն˵�IPV6���ս��ܵ���IPV4�����ݱ�����ͼ

����·��ѡ���㷨
��Ŀ���Ǵӷ��ͷ������շ��Ĺ�����ȷ��һ��ͨ��·��������ĺõ�·����ͨ����ָ������͵�·����
1:����
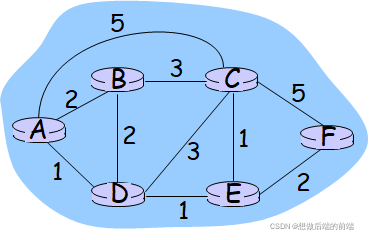
(1)ͼ(graph)
���ǿ�����ͼ������·��ѡ�����⡣
G = (N,E)
���� N ָ�ڵ�,Eָ��,G�����ǵļ��ϡ�
ѡ·�㷨��ͼ�۳���: ͼ�еĽڵ���·���� ͼ�еı���������·
(2)����
һ������һ��ֵ��ʾ���Ŀ���
c(x,y)= n
���� x,y ��ʾ�����ڵ�,n ��ʾ����
(3)·��
ͼ G = (N,E)�е�һ��·��(path)��һ���ڵ�����(x1, x2, ��, xp)
�����ܺ���:c(x1,x2)+ c(x2,x3)+ �� + c(xp-1,xp)
ͨ���ڵ�֮��������·��,ÿ��·������һ��������
(4)��Ϳ���·��/���·��
- ��Ϳ���·��(least-cost path):��Щ·����һ���������ϵ�·��������͡�
- ���·��(shortest path):��ͼ�����б߾�����ͬ�Ŀ���,����Ϳ���·���������·����
2:����
(1)���շֲ������֡�������Ҫ
- ����ʽ·��ѡ���㷨(centralized routing algorithm):ȫ�ֵġ�ÿ��·������������·����������ȫ�����ˡ���·������Ϣ������ȫ��״̬��Ϣ���㷨��������·״̬�㷨(Link State,LS)
- ��ɢʽ·��ѡ���㷨(centralized routing algorithm):��ɢ�ġ�·������������ֱ��������·�Ŀ�����Ϣ,Ȼ��ͨ���������ֲ�ʽ�ķ�ʽ���ڽڵ㽻����Ϣ,���������Ϳ���·��������Ҳ����Ϊ���������㷨(Distance-Vector,DV)
(2)���ն�/��̬������
- ��̬·��ѡ���㷨(static routing algorithm):·����ʱ��仯�dz�����,ͨ�����˹����е���(��:�˹��༭һ����·����)
- ��̬·��ѡ���㷨(dynamic routing algorithm):���������������ػ����˷����仯���ı�·��ѡ��·����
(3)���ո���������
- ���������㷨(load-sensitive algorithm):��·�����ᶯ̬�ı仯��ӳ���ײ���·�ĵ�ǰӵ��ˮƽ��
- ���سٶ�(load-insensitive):������ȷ��Ӧӵ��ˮƽ��Ŀǰʹ��:RIP��OSPF��BGP��
3:��·״̬·��ѡ���㷨
����·״̬�㷨��,�������˺�������·�Ŀ���������֪��,Ҳ����˵������LS�㷨�����롣ʵ��������ͨ����ÿ���ڵ������������������ڵ�㲥��·״̬��������ɵ�,����ÿ����·״̬��������������ӵ���·��ʶ�Ϳ�����
��·״̬·��ѡ���㷨һ����� Dijsktra �㷨:
(1)c(x,y):�ӽڵ�x��y����·����; = �� �������ֱ���ھ�
(2)D(v):��Դ��Ŀ�ĵ�v·�����õĵ�ǰֵ
(3)p(v):��Դ��v��·����ǰ�νڵ�
(4)N��:��֪����С����·���еĽڵ㼯��
���:
1 Initialization
2 N' = {u}
3 for all nodes v:
4 if v is a neighbor of u
5 then D(v) = c(u,v)
6 else D(v) = ��
7
8 Loop
9 find w not in N' such that D(w) is a minimum
10 add w to N'
11 update D(v) for each neighbor v of w and not in N'
12 D(v) = min( D(v), D(w) + c(w,v) )
13 /*new cost to v is either old cost to v or known
least path cost to w plus cost from w to v*/
15 until N' = N
�ٸ�🌰:
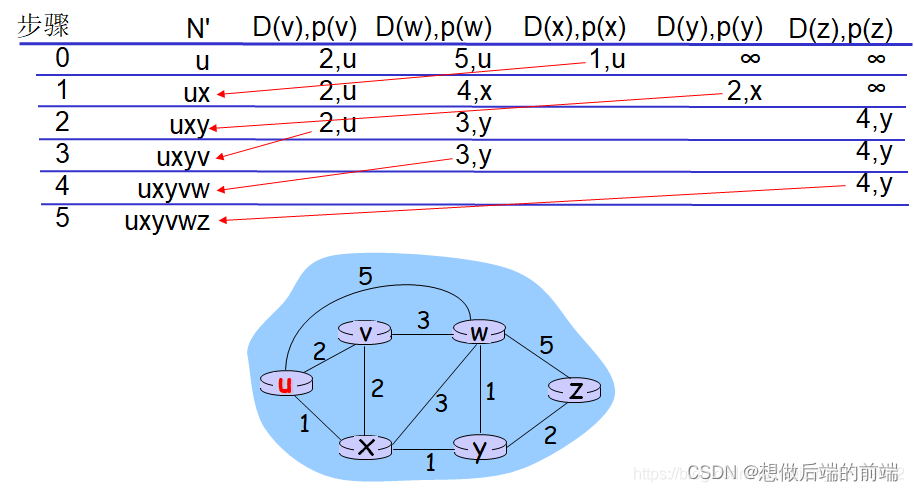
��LS�㷨��ֹʱ,����ÿ���ڵ�,���Ƕ��ܵõ���Դ�ڵ�����������Ϳ���·����ǰһ�ڵ㡣����ÿ��ǰһ�ڵ�,����������ǰһ�ڵ�,���ε������ǿ��Թ�����Դ�ڵ㵽����Ŀ�Ľڵ������·����
4:��������·��ѡ���㷨
���������㷨��һ�ֵ����ġ��첽�ĺͷֲ�ʽ���㷨,��LS�㷨��һ��ʹ��ȫ����Ϣ���㷨��˵���Ƿֲ�ʽ��,����Ϊÿ���ڵ㶼Ҫ��һ������ֱ�������ھӽ���ijЩ��Ϣ,ִ�м���,Ȼ��������������ھӡ�˵���ǵ�����,����Ϊ�˹���һֱҪ�������ھ�֮��������Ϣ����Ϊֹ��˵�����첽��,����Ϊ����Ҫ�����нڵ���䲽��һ�µز�����
�����Ǹ���DV�㷨֮ǰ,�б�Ҫ����һ�´�������Ϳ���·���Ŀ���֮���һ����Ҫ��ϵ����
Dx(y)�Ǵӽڵ�x���ڵ�y����Ϳ���·���Ŀ����������Ϳ�����������Bellman-Ford(BF)�������,��
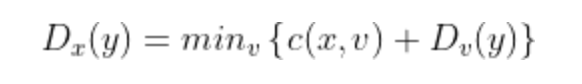
�����е�minv�Ƕ���x�������ھӵġ�
��������·��ѡ���㷨һ����� Bellman-Ford�㷨:
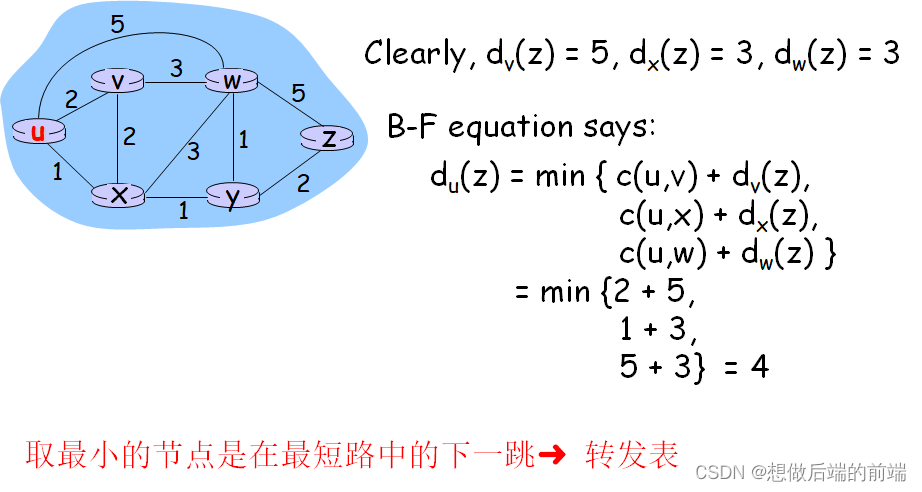
(1)c(x,v):�ڵ� x ���ڽڵ� v �Ŀ���
(2)Dv(y):�ڽڵ� v ��Ŀ�ĵ� y ����С����
(3)Dx(y):�ڽڵ� x ��Ŀ�ĵ� y ����С����
���:
1 Initialization
2 for all destinations y in N:
3 Dx(y) = c(x,y) /*if y is not a neighbor then c(x,y) = �� */
4 for each neighbor w
5 Dw(y) = ?for all destionations y in N
6 for each neighbor w
7 send distance vector Dx = [Dx(y): y in N] to w
8 Loop
9 wait(until I see a link cost change to some neighbor w or until I receive a distance vector from some neighbor w)
10 for each y in N
11 Dx(y) = minv{c(x,y) + Dv(y)}
12 if Dx(y) changed for any destination y
13 send distance vector Dx = [Dx(y) : y in N] to all neighbor
14 forever
�ٸ�🌰:
4:���������㷨:��·���ϺͶ�����ת
(1)��·����:�γɻ�·
������ͼ������
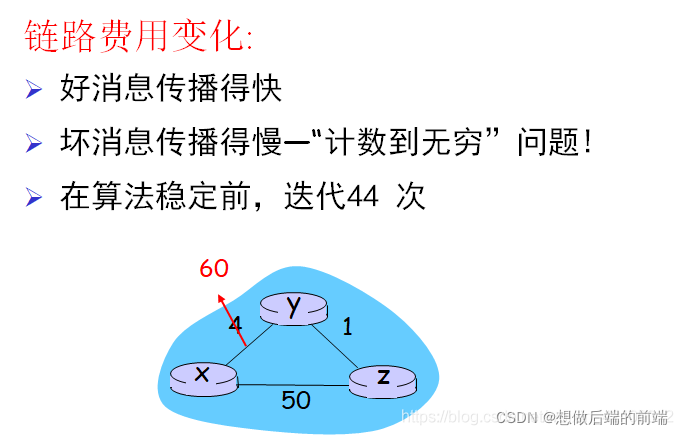
ijʱ�� x<�C>y �Ŀ����� 4 ��Ϊ 60,y ��Ҫ֪ͨ�����ڵ�ı俪��,���� y Ҫ���ȸı��� x �Ŀ�����Ҫ���� x,ͨ���㷨 y Ҫ���� z ���� x,���� z û�������·��,���� y ���� x ֻ��Ҫ 5,��� y �� z Ȼ�� y,������ 5 ��Ϊ 6,���ǻ���С�� 60,һֱ�� 5 ���������� 50 �Ž�������Ҫ���� 44 �Ρ�
(2)������ת
������γɻ�·���������ͨ��������ת�����⡣
�취:���� dz(x) = ��,y ��ʼֱ�ӻ�ѡ�� 60 �� x,���º�������ת������
����:ֻ�ܽ�������ڵ�֮�������,һ���ڵ����ͬ�����ܽ�����⡣
5:LS��DV�㷨�Ƚ�
N�ǽڵ�(·����)�ļ���,��E�DZ�(��·)�ļ��ϡ�
(1)���ĸ�����
- LS:��N���ڵ�,E����·, ����O(|N||E|) ����
- DV:�����ھ�֮�佻��
(2)�����ٶ�
- LS:O(N2) �㷨Ҫ�� O(NE)����
- DV:��������,��������ʱ������·��ѡ��·����������������������⡣
(3)��׳��:�����һ̨·��������,������ʲô����
LS:�ڵ����ͨ�治��ȷ����·���á�ÿ���ڵ���������Լ��ı��������ζ��,·����������ij�̶ֳ����Ƿ����,�ṩ��һ���̶ȵĽ�׳�ԡ�
DV:һ���ڵ���������������Ŀ�Ľڵ�ͨ���䲻��ȷ����Ϳ���·��,һ������ȷ�Ľڵ�������ɢ���������硣
�ߡ�������������ϵͳ�ڲ���·��ѡ��:OSPF
ĿǰΪֹ,���ǽ�����ֻ����һ������·�����ļ��ϡ�������·����ִ����ͬ��·��ѡ���㷨�Լ��㴩Խ���������·��ѡ��·������������˵,һ̨·��������ͬ��һ̨·�����������������Ļ�����·����������úܴ�,�漰·��ѡ����Ϣ��ͨ��,����ʹ洢�Ŀ������ߵIJ���ʵ�֡���������ISP������,����ÿ��ISP�������Լ���·�������硣ISPͨ��ϣ�����Լ�����Ը����·����,����ⲿ������������ڲ���֯��ò�������������,һ����֯Ӧ���ܹ������Լ�����Ը���к���������,��Ҫ�ܽ��������������ⲿ��������������
���������ⶼ����ͨ��·������֯������ϵͳ(Autonomous System, AS)�����������ÿ��AS��һ��ͨ��������ͬ���������µ�·������ɡ�
����ͬAS�е�·������������ͬ��·��ѡ���㷨�����б˴˵���Ϣ����һ����������ϵͳ�����е�·��ѡ���㷨��������ϵͳ�ڲ�·��ѡ��Э��(intra-autonomous system routing protocol)
1:�������·����(OSPF)
�������·����(OSPF):OSPF��һ����·״̬Э��,��ʹ�ú鷺��·״̬��Ϣ��Dijkstra�㷨��ʹ��OSPF,һ̨·����������һ��������������ϵͳ����������ͼ��ÿ̨·�����ڱ�������Dijkstra�㷨��ȷ��һ��������Ϊ���ڵ㵽�������������·������ʹ��OSFPʱ·����������ϵͳ(AS)����������·�����㲥·��ѡ��Э��,ÿ��һ����·״̬�����仯ʱ��,·�����ͻ�㲥��·״̬��Ϣ����ʹ״̬δ�����仯Ҳ��ÿ��30min�㲥һ��״̬��
�ŵ�:
- ��ȫ��:�ܹ�����OSPF·����֮��Ľ�����ʹ�ü�����������ε�·��������һ��AS�ڵ�OSPFЭ��,��˿��Է�ֹ���������߽�����ȷ����Ϣע��·�������ڡ�һ���OSPF������Ա�α��,���Լ�����MD5���б�����
- ������ͬ������·��:������ijĿ�ĵؾ�����ͬ�Ŀ���·��ʱ,OFPS����ʹ�ö���·����
- �Ե�����ಥ·��ѡ����ۺ�֧��:�ಥ��OFPS�ļ���չ,�Ա��ṩ�ಥ·��ѡ��
- ֧���ڵ���AS�еIJ�νṹ:һ��OSPF����ϵͳ�ܹ���λ������ö������,ÿ�����������Լ���OSPF��·״̬��·ѡ���㷨,�����ڵ�ÿ̨·��������������ڵ���������·�����㲥����·״̬��һ̨���̨���·�����������������������ķ����ṩ·��ѡ��,�����AS��ֻ��һ��OSPF�������ó���������,Ϊ��AS����������֮��������ṩ·��ѡ��
�ˡ�������������ϵͳ֮���·��ѡ��:BGP
�߽�����Э��(Broder Gateway Protocol��BGP):һ��������AS֮���·��ѡ��Э�顣��Э����������������Ƶ�ISP��OSPF��һ��AS�ڲ���·��ѡ��Э�顣
1:BGP������
��BGP��,���鲢����·�ɵ�һ���ض���Ŀ�ĵ�ַ,�෴��·�ɵ�CIDR����ǰ������ÿ��ǰ��ʾһ��������һ�������ļ��ϡ���BGP��������,һ��Ŀ�ĵؿ��Բ���138.16.68/22����ʽ,�������������˵����1024��IP��ַ��
��Ϊһ��AS���·��ѡ��Э��,BGPΪÿ̨·�����ṩ��һ���������������ֶ�:
- ���ھ�AS���ǰ�Ŀɴ�����Ϣ:BGP����ÿ�������������������ಿ��ͨ�����Ĵ��ڡ�
- ȷ����ǰ�����·��:һ��·��������֪��һ�����߶����ض�ǰ�IJ�ͬ·��,Ϊ��ȷ����õ�·��,·��������������һ��BGP·��ѡ����̡�
2:ͨ��BGP·����Ϣ
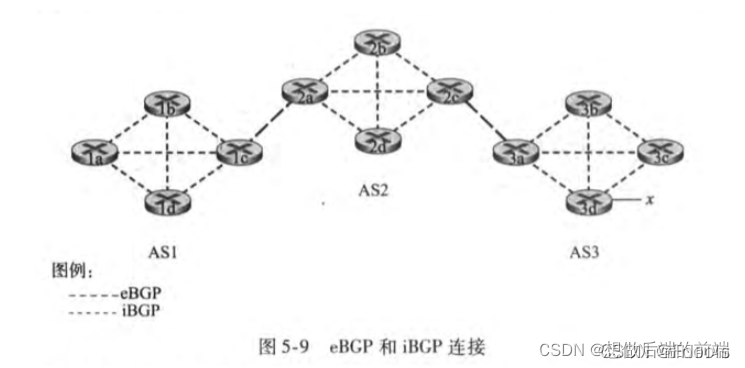
����ͼ��ʾ,��������������������ϵͳAS1��AS2��AS3������ʾ������,AS3����һ������ǰx������������ÿ��AS,ÿ̨·����Ҫô��һ̨����·����(gateway router),Ҫô��һ̨�ڲ�·����(interal router)����·������һ̨λ��AS��Ե��·����,��ֱ�����ӵ�����AS�е�һ̨���߶�̨·�������ڲ�·�������������Լ�AS�е�������·��������Խ����AS�����ӳ�Ϊ�ⲿBGP����,������ͬAS�е���̨·����֮���BGP�Ự��Ϊ�ڲ�BGP���ӡ���AS1��·����1c������·����,·����1a��1b��1d�����ڲ�·������
�ٸ�🌰
��ͼ��ʾ������·��������ǰx�Ŀɴ���Ϣ:����AS3��AS2����һ��BGP����,��֪x���ڲ���λ��AS3��;���ǽ��ñ��ı�ʾΪ��AS3 x����Ȼ��AS2��AS1����һ��BGP����,��֪x���ڲ����ܹ���ͨ��AS2Ȼ�����AS3��������x;���ǽ��ñ��ı�ʾΪ��AS2 AS3 x���������ַ�ʽ,ÿ������ϵͳ����֪��x����,����֪��ͨ��x������ϵͳ��·����
��BGP��,ÿ��·����ͨ��ʹ��179�˿ڵİ�����TCP���ӽ���·��ѡ����Ϣ��ÿ��ֱ�������Լ�����ͨ�������ӷ��͵�BGP����,��ΪBGP����(BGP connection)������,��Խ����AS��BGP���ӳ�Ϊ�ⲿBGP(eBGP)����,������ͬAS�е���̨·����֮���BGP�Ự��Ϊ�ڲ�BGP(iBGP)���ӡ�
�ٸ�🌰
��ʹ����iBGP��eBGP��,����·����3a��������·����2c����һ��eBGP���ġ�AS3 x��������·����2cȻ����AS2�е���������·����(��������·����2a)����iBGP���ġ�AS3 x��������·����2a������������·����1c����һ��eBGP���ġ�AS2 AS3 x�������,����·����1cʹ��iBGP��AS1�е�����·�������͡�AS2 AS3 x���������������ɺ�,��AS1��AS2�е�ÿ��·������֪����x�Ĵ��ڲ���֪����ͨ��x��AS·����
3:ȷ����õ�·��
����ʵ������,��һ��������·������һ��Ŀ�����������ж���·��,������Ǿ�Ҫȷ����õ�·�ɡ�
�ڴ����������֮ǰ,������Ҫ�˽�һЩBGP������:
- AS-PATH:������ͨ���Ѿ�ͨ����AS���б�,��ǰ���🌰��,Ϊ������AS-PATH��ֵ,��һ��ǰͨ��ijASʱ,��AS��ASn���뵽AS-PATH���б��С�BGP·������ʹ��AS-PATH���������ͷ�ֹͨ�滷·;�ر���,���һ̨·������·���б��п���������������AS,�����ܾ���ͨ�档
- NEXT-HOP:��AS���AS�ڲ�·��ѡ��Э��֮���ṩ�ؼ���·��NEXT- HOP��AS-PATH��ʼ·�����Ľӿڵ�ַ��
(1)������·��ѡ��:����·����1b,�����ܿ�ؽ����鷢�ͳ���AS(��Ϳ���),����������AS�ⲿ��Ŀ�ĵص����²��ֿ�����
(2)·����ѡ���㷨:
1.·������ָ��һ������ƫ��ֵ��Ϊ������֮һ��һ��·�ɵı���ƫ�ÿ����ɸ�·�������û����������ͬAS�е���һ̨·����ѧϰ��������ƫ�����Ե�ֵ��һ�ֲ��Ծ���,����ȫȥ�����ڸ�AS������Ա��������߱���ƫ�õ�·�ɽ���ѡ��
2.������б���ƫ��ֵ����ͬ,��ôѡ����̵�AS-PATH��·�ɡ�
3.���1��2����ͬ,��ôʹ��������·��ѡ��,ѡ����� NEXT-HOP��·����·�ɡ�
4:IP�β�
BGP��������IP�β�����,�÷�������DNS�С�IP�β���DNSϵͳ�㷺���ڽ�DNS�����ָ������ĸ�DNS��������
�š�SDN(������������)����ƽ��
SDN����ƽ�漴���Ʒ����������SDNʹ���豸��ת�������緶Χ��,�Լ���Щ�豸�ĺ����ǵķ�������������,������ת���豸��Ϊ���齻���������������Դ/Ŀ�ĵ�ַ����·��Դ/Ŀ�ĵ�ַ�Լ�����㡢��������·���еķ����ײ�����ת��������
SDN��ϵ�ṹ���������ĸ�����:
- ��������ת��:SDN���ƵĽ���������ת������,�ܹ���������㡢����������·���ײ��������������ײ��ֶ�ֵ���С�����ת������ȷ�涨�ڽ�������������,SDN����ƽ�湤���Ǽ��㡢�����Ͱ�װ�������罻�����е������
- ����ƽ��Ϳ���ƽ�����:����ƽ�������罻�������,����������Լ��豸,���豸�����ǵ�������ִ��ƥ��Ӷ����Ĺ���,����ƽ���ɷ������Լ���������������������������
- ������ƹ���:λ������ƽ�潻�����ⲿ������ƽ��������������:һ����SDN������(�������ϵͳ),һ�����������Ӧ�ó�������ά��ȷ������״̬��Ϣ,Ϊ�������������ƽ���Ӧ�ó����ṩ��Ϣ�ͷ�����Ӧ�ó���ͨ����Щ���������м��ӡ���̺Ϳ�������������豸��
- �ɱ�̵�����:ͨ�������ڿ���ƽ���е��������Ӧ�ó���,�������ǿɱ�̵ġ�ʹ������SDN�ṩ��API������Ϳ��������豸�е�����ƽ�档
1.SDN����ƽ��:SDN��������ADN�������Ӧ�ó���
��ͼ��SDN�����������
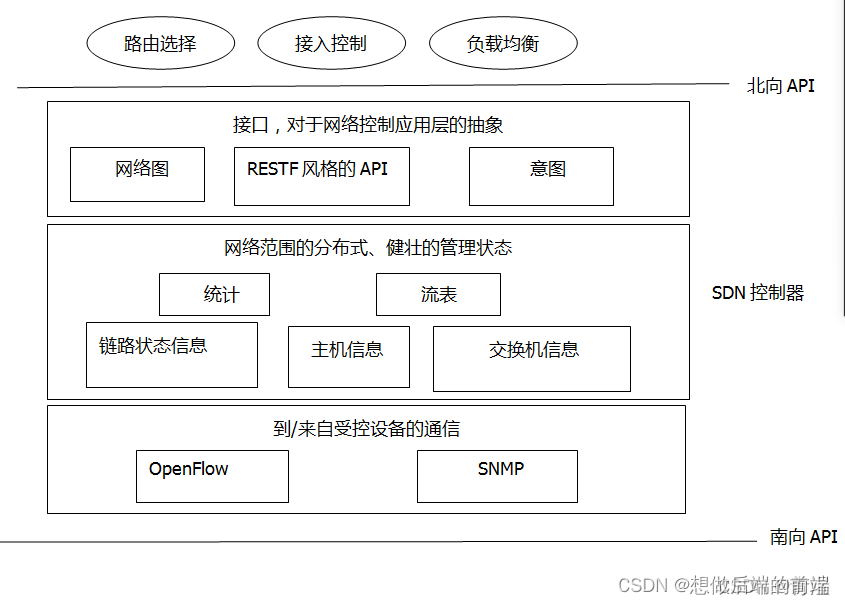
ͨ�Ų�:SDN���������ܿ��������豸֮���ͨ��,���SDN������Ҫ����Զ��SDNʹ�ܽ������������������豸������,��Ҫһ��Э�������Ϳ���������Щ�豸֮�����Ϣ�������豸������SDN���������ͱ��ع۲쵽���¼�,��Щ�¼���SDN�������ṩ����״̬��������ͼ�����Э�鹹���˿�������ϵ�ṹ����ײ㡣���Э����ͼ�е�����API��
���緶Χ״̬������:��SDN����ƽ�������������տ��ƾ���,��Ҫ������������й��������������·��������������SDN�����豸������״̬��Ϣ����Ȼ����ƽ����ռ�Ŀ�������ڿ����豸������,��ô������Ҳ����ά����Щ���Ŀ�������Щ��Ϣ����������SDN������ά�������緶Χ״̬�����ӡ�
�����������Ӧ�ó����Ľӿ�:������ͨ������ӿ����������Ӧ�ó�������API�����������Ӧ�ó�����״̬������֮���/д����״̬������,��״̬�ı��¼�����ʱӦ�ó����ܹ�ע�����ͨ�档
2.OpenFlow��
OpenFlow��һ�����罻��ģ��,OpenFlow��������FlowTable(����)��SecureChannel(��ȫͨ��)��OpenFlowProtocol(Э��)��������ɡ�OpenFlow������������OpenFlow����ĺ��IJ���,��Ҫ�������ݲ��ת������������TCP֮��Ĭ�϶˿�6653��
�ӿ��������ܿؽ�������������Ҫ������:
- ����:�ñ���������������ѯ�����ý����������ò�����
- �IJ���:�ɿ���������/ɾ�����Ľ����������еı���,�����ý������˿����ԡ�
- ��״̬:���������ڴӽ������������Ͷ˿��ռ�ͳ�����ݺͼ�������ֵ��
- ���ͷ���:�������������ܿؽ��������ض��Ķ˿ڷ���һ���ض��ı���
- ��ɾ��:�ñ���֪ͨ�������Ѿ�ɾ��һ�������
- �˿�״̬:�������֪ͨ�˿ڱ仯��
- ������:�����鷢����������
3.ICMP:���������Ʊ���Э��
ICMP:��������·���������˴˹�ͨ�������Ϣ,ICMP������;�Dz�����档����http�����粻�ɴ�����Ĵ��档ICMP����ϵ�ṹ�Ͻ�λ��IP֮��,��ΪICMP�����dz�����IP�����еġ�ͬ��IP���ݱ����Էֽ�����ݱ����ݸ�ICMP��ICMP��һ�������ֶκ�һ�������ֶ�,���������ICMP�����״����ɵ�IP���ݱ����ײ���ǰ8���ֽڡ�������֪����ping������Ƿ�����һ��ICMP����8����0�ı��ĵ�ָ������,Ȼ��������,Ŀ����������һ��ICMP����0����0��ICMP���Իش�
ICMP�������ͱ�ͼ����:
| ICMP���� | ���� | ���� |
|---|---|---|
| 0 | 0 | ���Իش�(��ping�Ļش�) |
| 3 | 0 | Ŀ�����粻�ɴ� |
| 3 | 1 | Ŀ���������ɴ� |
| 3 | 2 | Ŀ��Э�鲻�ɴ� |
| 3 | 3 | Ŀ�Ķ˿ڲ��ɴ� |
| 3 | 6 | Ŀ������δ֪ |
| 3 | 7 | Ŀ������δ֪ |
| 4 | 0 | Դ����(ӵ������) |
| 8 | 0 | �������� |
| 9 | 0 | ·����ͨ�� |
| 10 | 0 | ·�������� |
| 11 | 0 | TTL���� |
| 12 | 0 | IP�ײ��� |
4.���������SNMP
�������:�����������Ӳ��������������Ԫ�ص����á��ۺϺ�Э��,�Լ��ӡ����ԡ���ѯ�����á����������ۺͿ��������Լ���Ԫ��Դ,�ú����ijɱ�����ʵʱ�ԡ���Ӫ�Ժͷ�������������
����������:
����������:����һ��Ӧ�ó���,ͨ�����˲���,��������������Ӫ����(NOC)�ļ���ʽ�������վ��,����ִ�����������ĵط�,���������������Ϣ���ռ�����������������ʾ���������������Ϊ�Ķ�����
�����豸:����װ����һ����,λ�ڱ�������������,������һ̨������·�������������������豸����Щ�����豸ʵ�ʱ��ܶ������豸�е�Ӳ�����ֺ�Ӳ������������ɲ��֡�
������Ϣ��(MIB):һ�������豸�е�ÿ�����ܶ���Ĺ�����Ϣ�ռ��ء���Щ��Ϣ�ɱ�������Ϣ���������á�
�����������:�����ڱ����豸�е�һ������,�ý��������������ͨ��,�ڹ���������������Ϳ������ڱ����豸�в�ȡ���ض�����
�������Э��:��������������������ͱ����豸֮��,������������ѯ�����豸��״̬,������������ӵ�����Щ�豸�ϲ�ȡ������
SNMP:�����������:
����һ��Ӧ�ò�Э��,���ڹ����������ʹ�������������ִ�еĴ���֮�䴫������������ƺ���Ϣ���ġ�SNNP��õ���������Ӧģʽ,����SNMPP������������SNMP ��������һ������,�����յ�����֮��ִ��ıЩ������Ȼ���������һ���ش�����ͨ�����ڲ�ѯ����ij�������豸������MIB����ֵ������һ����;�Ǵ������������������һ�ַ������ĸñ��ij�Ϊ�ݽ�����,����֪ͨ�������������쳣�������MIB����ֵ�Ѹı䡣
����,Խ������Խд����ȥ��,�ȸ�����,�Ժ��ٲ�ȫ��!